Download to read offline
![CONFIDENTIAL
Quantization and Training of
Neural Networks for Efficient
Integer-Arithmetic-Only Inference
[Jacob et al. from Google 2017]
Ryo Takahashi](https://image.slidesharecdn.com/1712-200119081902/75/Quantization-and-Training-of-Neural-Networks-for-Efficient-Integer-Arithmetic-Only-Inference-1-2048.jpg)

![3
Approaches to CNN deployment on mobile platform
● Approach 1: computation/memory-efficient network architecture
l e.g. MobileNet[arXiv:1704.04861], SqueezeNet[arXiv:1602.07360]
● Approach 2: quantization (Today’s topic)
l definition: quantize weights and activations from float into lower bit-depth format
l benefit: save memory/power use, speed up inference
Existing works Issues
• Ternary weight networks [arXiv:1605.04711]
• Binary Neural networks [arXiv:1602.02505]
• Their baseline architectures are over-parameterized
- fat architectures (e.g. VGG) are easy to compress
- it’s still unclear that their schemes are applicable
to modern light-weight architectures (e.g. MobileNet)
- they are verified only in classification tasks, which
are tolerant to quantization errors unlike regression
• NOT efficient on common hardware (e.g. CPU)
- bit-shifts/counts based conv. provides
benefit only on custom hardware (e.g. FPGA, ASIC)these works can approximate conv. by bit-shifts/counts](https://image.slidesharecdn.com/1712-200119081902/75/Quantization-and-Training-of-Neural-Networks-for-Efficient-Integer-Arithmetic-Only-Inference-3-2048.jpg)


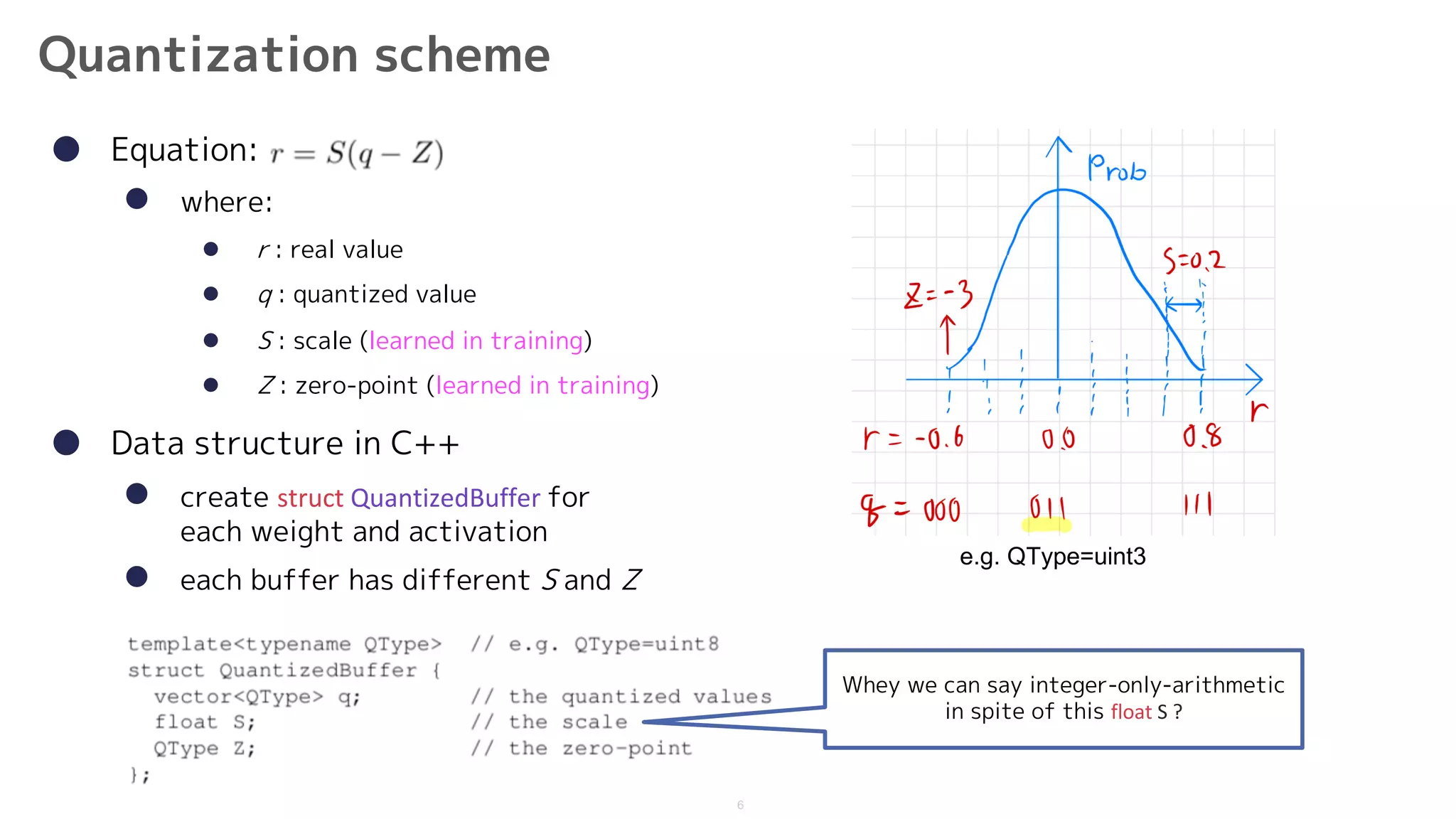

![8
Implementation of a typical fused layer
(1) Accumulate products in
• quantize bias-vectors by not uint8 but int32
- reason: quantization errors in bias-vectors tend to be overall errors
because their elements are added to many output activations
(2) Scale down int32_t to uint8
a. multiplying the fixed-point value 𝑀)
b. 𝑛 bit-shift
c. saturating cast to [0, 255]
(3) Apply activation functions
• mere clamp uint8_t because MobileNets use only ReLU and ReLU6
(2) (1) (3)](https://image.slidesharecdn.com/1712-200119081902/75/Quantization-and-Training-of-Neural-Networks-for-Efficient-Integer-Arithmetic-Only-Inference-8-2048.jpg)
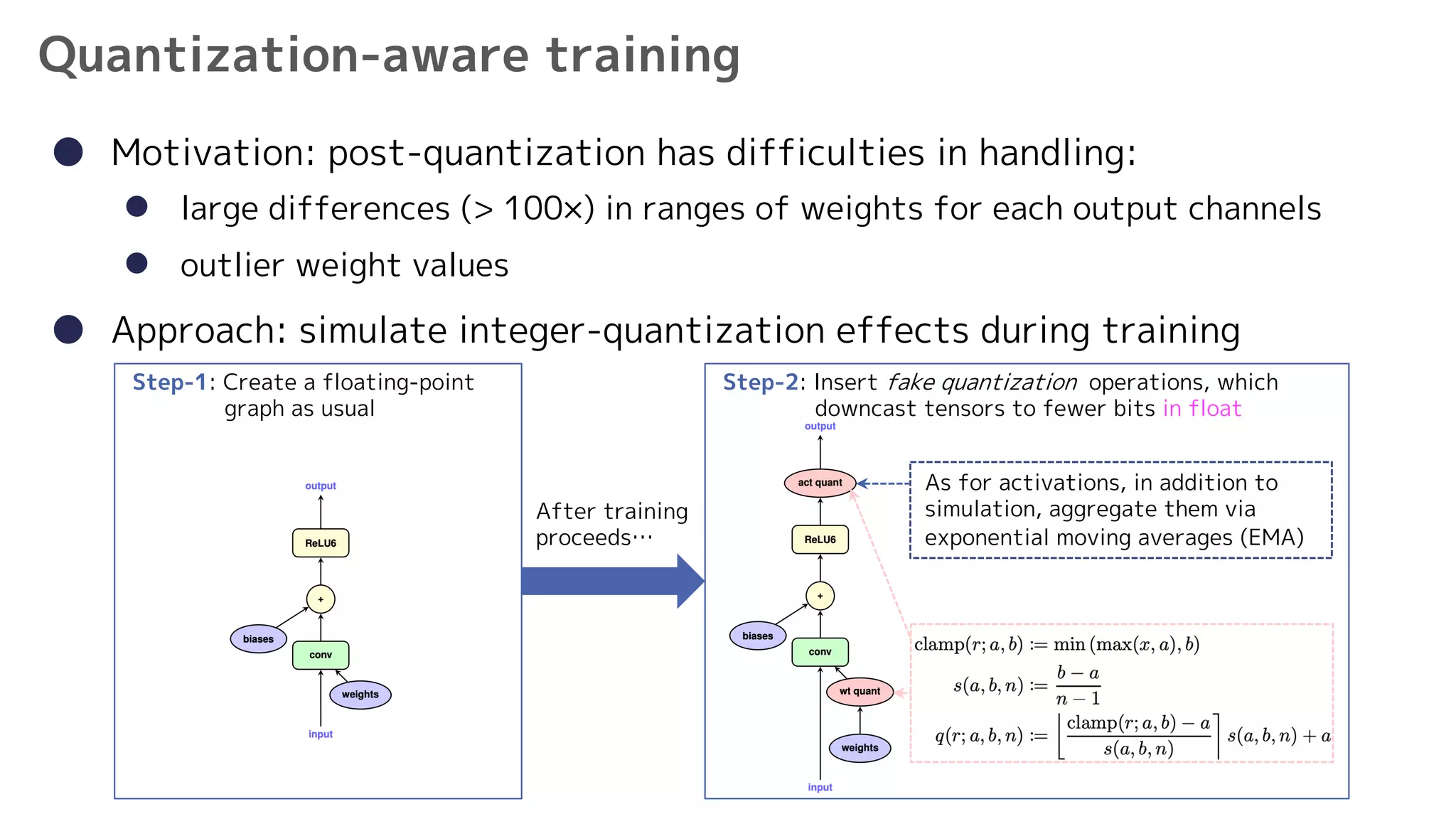
![10
Experiments with MobileNets
● CPU: Snapdragon 835
l march: ARM big.LITTLE [Cortex-(A73|A53)]
l optimize by ARM NEON
ImageNet:
• in the LITTLE core, the accuracy gap at 33ms (30FPS)
is quite substantial (~10%)
COCO:
• MobileNet SSD was used
• up to a 50% reduction in inference time
with a minimal loss in accuracy (−1.8% relative)
• The INT8 quantization deals well with regression
tasks
big LITTLE](https://image.slidesharecdn.com/1712-200119081902/75/Quantization-and-Training-of-Neural-Networks-for-Efficient-Integer-Arithmetic-Only-Inference-10-2048.jpg)

![CONFIDENTIAL
Quantization and Training of
Neural Networks for Efficient
Integer-Arithmetic-Only Inference
[Jacob et al. from Google 2017]
Ryo Takahashi](https://crownmelresort.com/image.slidesharecdn.com/1712-200119081902/75/Quantization-and-Training-of-Neural-Networks-for-Efficient-Integer-Arithmetic-Only-Inference-1-2048.jpg)

![3
Approaches to CNN deployment on mobile platform
● Approach 1: computation/memory-efficient network architecture
l e.g. MobileNet[arXiv:1704.04861], SqueezeNet[arXiv:1602.07360]
● Approach 2: quantization (Today’s topic)
l definition: quantize weights and activations from float into lower bit-depth format
l benefit: save memory/power use, speed up inference
Existing works Issues
• Ternary weight networks [arXiv:1605.04711]
• Binary Neural networks [arXiv:1602.02505]
• Their baseline architectures are over-parameterized
- fat architectures (e.g. VGG) are easy to compress
- it’s still unclear that their schemes are applicable
to modern light-weight architectures (e.g. MobileNet)
- they are verified only in classification tasks, which
are tolerant to quantization errors unlike regression
• NOT efficient on common hardware (e.g. CPU)
- bit-shifts/counts based conv. provides
benefit only on custom hardware (e.g. FPGA, ASIC)these works can approximate conv. by bit-shifts/counts](https://crownmelresort.com/image.slidesharecdn.com/1712-200119081902/75/Quantization-and-Training-of-Neural-Networks-for-Efficient-Integer-Arithmetic-Only-Inference-3-2048.jpg)




![8
Implementation of a typical fused layer
(1) Accumulate products in
• quantize bias-vectors by not uint8 but int32
- reason: quantization errors in bias-vectors tend to be overall errors
because their elements are added to many output activations
(2) Scale down int32_t to uint8
a. multiplying the fixed-point value 𝑀)
b. 𝑛 bit-shift
c. saturating cast to [0, 255]
(3) Apply activation functions
• mere clamp uint8_t because MobileNets use only ReLU and ReLU6
(2) (1) (3)](https://crownmelresort.com/image.slidesharecdn.com/1712-200119081902/75/Quantization-and-Training-of-Neural-Networks-for-Efficient-Integer-Arithmetic-Only-Inference-8-2048.jpg)

![10
Experiments with MobileNets
● CPU: Snapdragon 835
l march: ARM big.LITTLE [Cortex-(A73|A53)]
l optimize by ARM NEON
ImageNet:
• in the LITTLE core, the accuracy gap at 33ms (30FPS)
is quite substantial (~10%)
COCO:
• MobileNet SSD was used
• up to a 50% reduction in inference time
with a minimal loss in accuracy (−1.8% relative)
• The INT8 quantization deals well with regression
tasks
big LITTLE](https://crownmelresort.com/image.slidesharecdn.com/1712-200119081902/75/Quantization-and-Training-of-Neural-Networks-for-Efficient-Integer-Arithmetic-Only-Inference-10-2048.jpg)


This document proposes an approach for quantizing neural networks to integer values only in order to enable efficient inference on common hardware like CPUs. It involves: (1) Quantizing weights and activations to unsigned 8-bit integers during both training and inference, while keeping biases in 32-bit. (2) Performing "quantization-aware training" where the model is trained with quantization simulated to help handle outlier values. Experiments on MobileNets for ImageNet classification and COCO object detection showed up to 50% faster inference with minimal accuracy loss using this integer-only quantization approach.








![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)














![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)









































