This document discusses parallelism and its goals of increasing computational speed and throughput. It describes two types of parallelism: instruction level parallelism and processor level parallelism. Instruction level parallelism techniques include pipelining and superscalar processing to allow multiple instructions to execute simultaneously. Processor level parallelism involves multiple independent processors working concurrently through approaches like array computers and multi-processors.
Goals of Parallelism
The purpose of parallel processing is to speedup the computer processing
capability or in words, it increases the computational speed.
Increases throughput, i.e. amount of processing that can be accomplished
during a given interval of time.
Improves the performance of the computer for a given clock speed.
Two or more ALUs in CPU can work concurrently to increase throughput.
The system may have two or more processors operating concurrently.
5.
Exploitation of Concurrency
Techniquesof Concurrency:
Overlap : execution of multiple operations by heterogeneous functional units.
Parallelism : execution of multiple operations by homogenous functional units.
Throughput Enhancement:
Internal Micro-operations: performed inside the hardware functional units
such as the processor, memory, I/O etc.
Transfer of information: between different functional hardware units for
Instruction fetch, operand fetch, I/O operation etc.
1. Instruction LevelParallelism (ILP)
Instruction-level parallelism (ILP) is a measure of
how many operations in a computer program can
be performed "in-parallel" at the same time.
8.
ILP TECHNIQUES
An instructionpipeline is a technique used in the design of modern
microprocessors, microcontrollers and CPUs to increase their instruction
throughput (the number of instructions that can be executed in a unit of time).
For example, the RISC pipeline is broken
into five stages with a set of flip flops
between each stage as follow:
9.
ILP TECHNIQUES
A superscalarCPU architecture implements ILP inside a single processor
which allows faster CPU throughput at the same clock rate
Simple superscalar pipeline. By fetching
and dispatching two instructions at a time,
a maximum of two instructions per cycle
can be completed.
10.
2. Processor LevelParallelism
Instruction-level parallelism (pipelining and superscalar operation) rarely win more than
a factor of five or ten in processor speed.
To get gains of 50, 100, or more, the only way is to design computers with multiple CPUS
We will consider three alternative architectures:
–Array Computers
–Multi-processors
11.
Array Computer
Anarray processor consists of a large number of identical processors that perform the same
sequence of instructions on different sets of data.
A vector processor is efficient at executing a sequence of operations on pairs of Data elements;
all of the addition in a single, heavily-pipelined adder.
12.
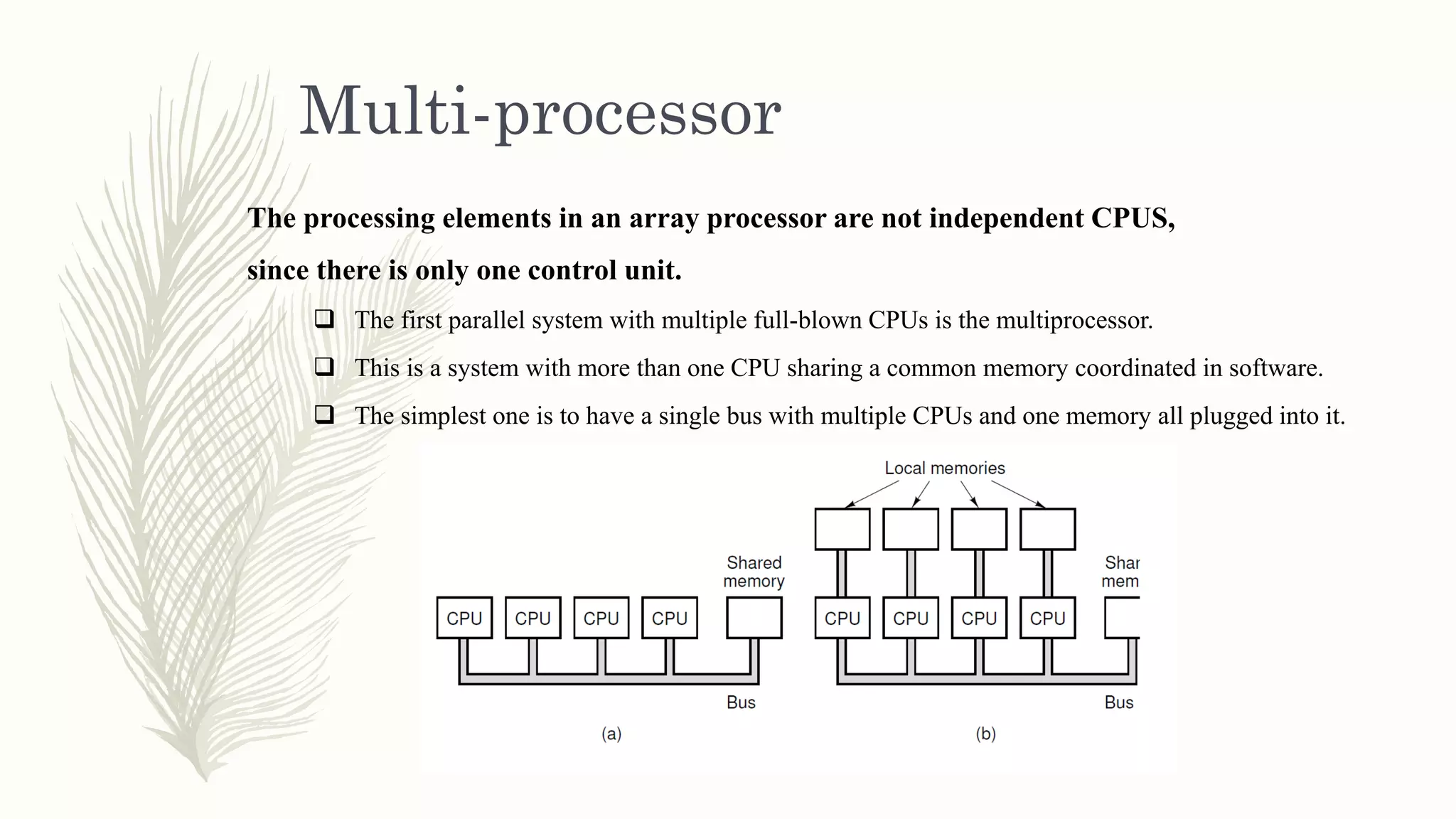
Multi-processor
The processing elementsin an array processor are not independent CPUS,
since there is only one control unit.
The first parallel system with multiple full-blown CPUs is the multiprocessor.
This is a system with more than one CPU sharing a common memory coordinated in software.
The simplest one is to have a single bus with multiple CPUs and one memory all plugged into it.