Download as PDF, PPTX






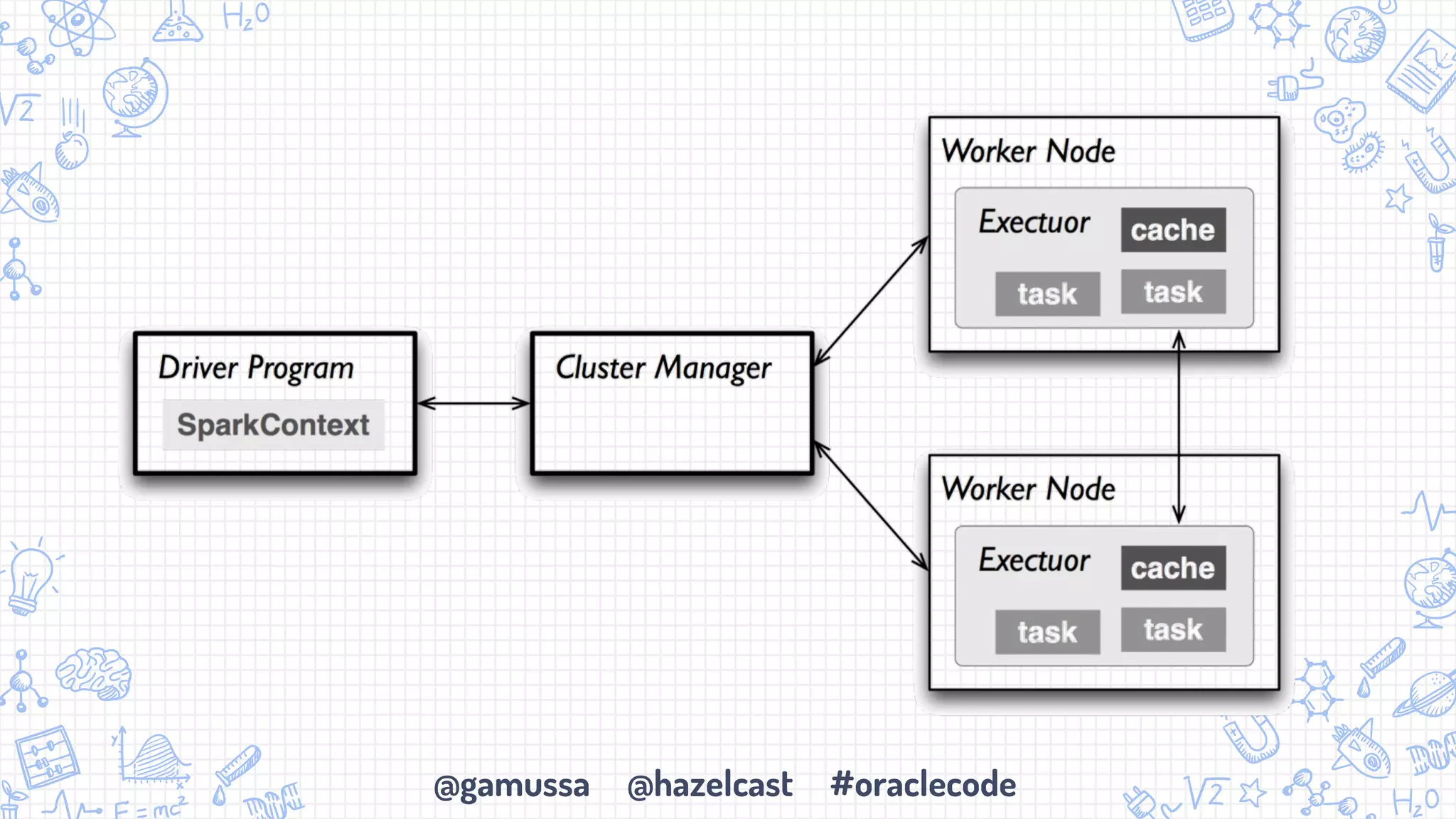


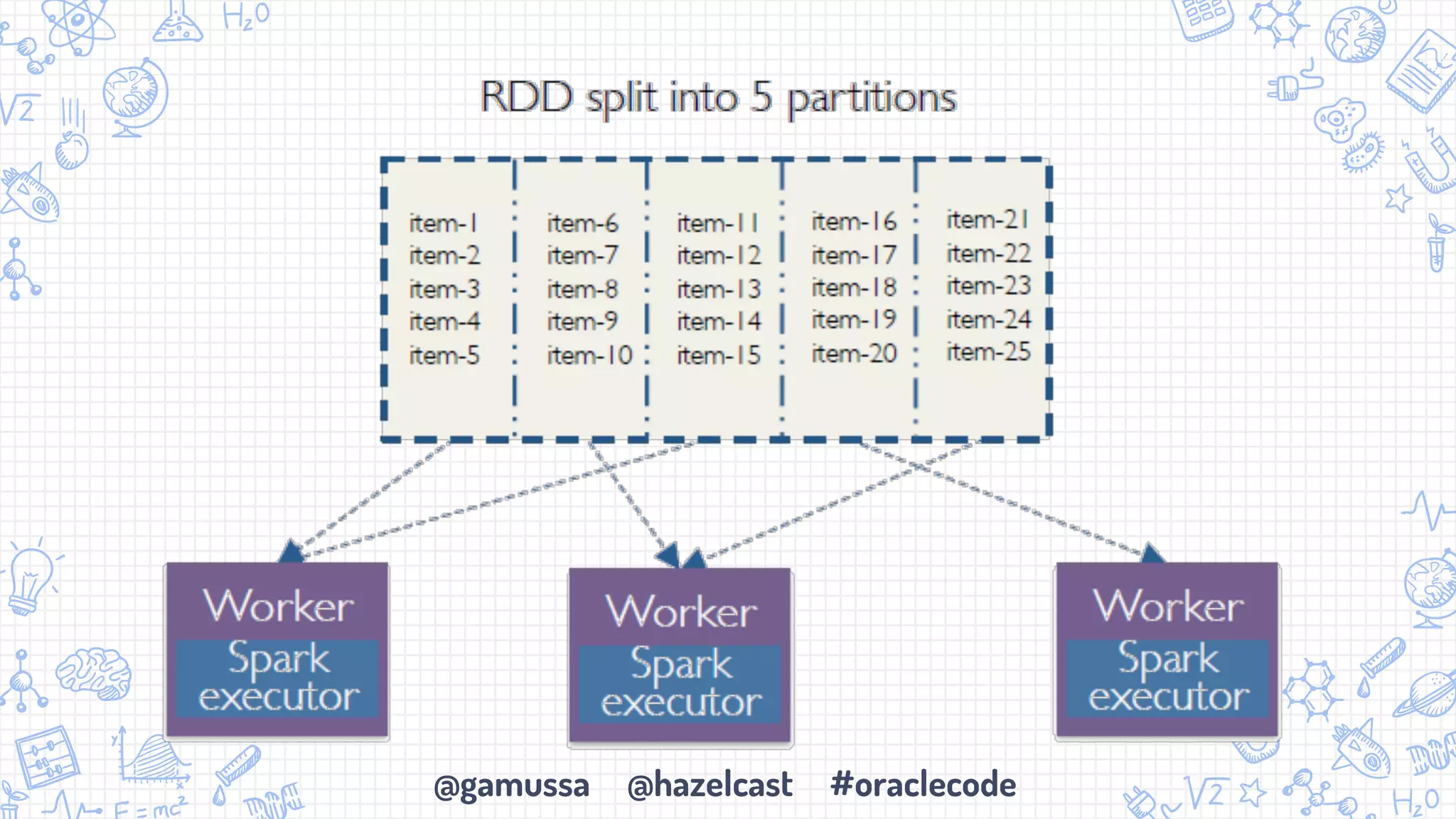

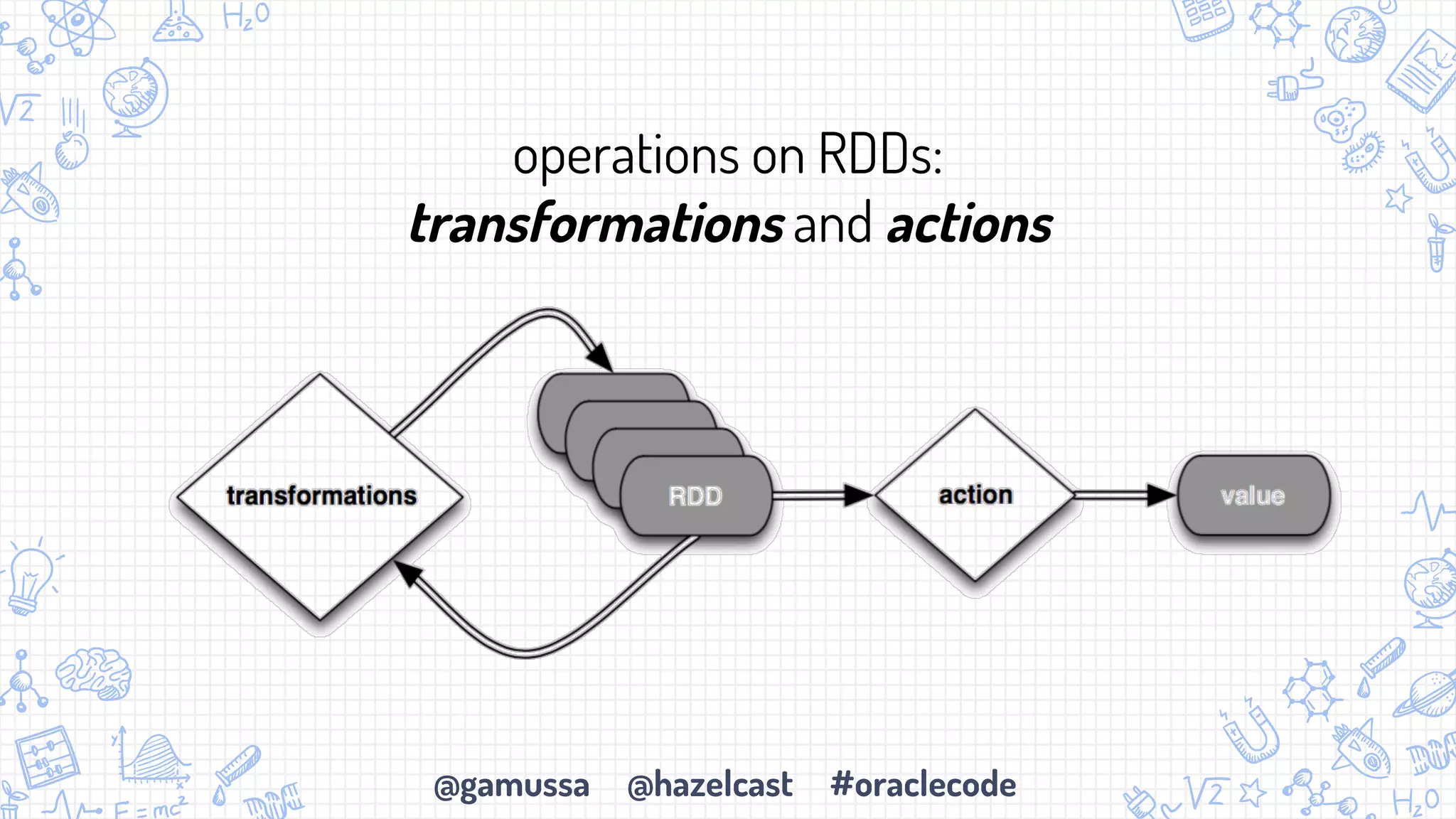





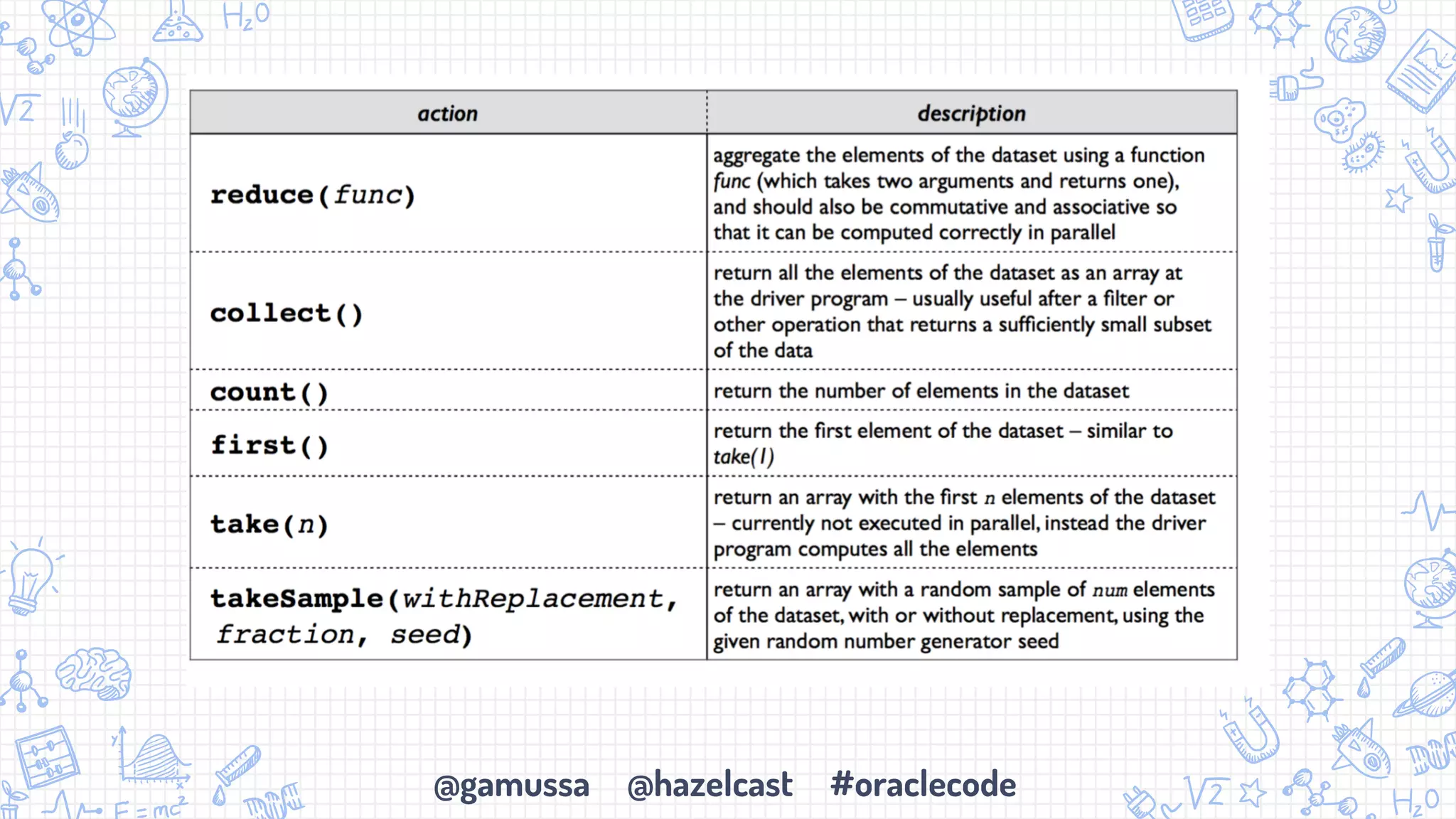








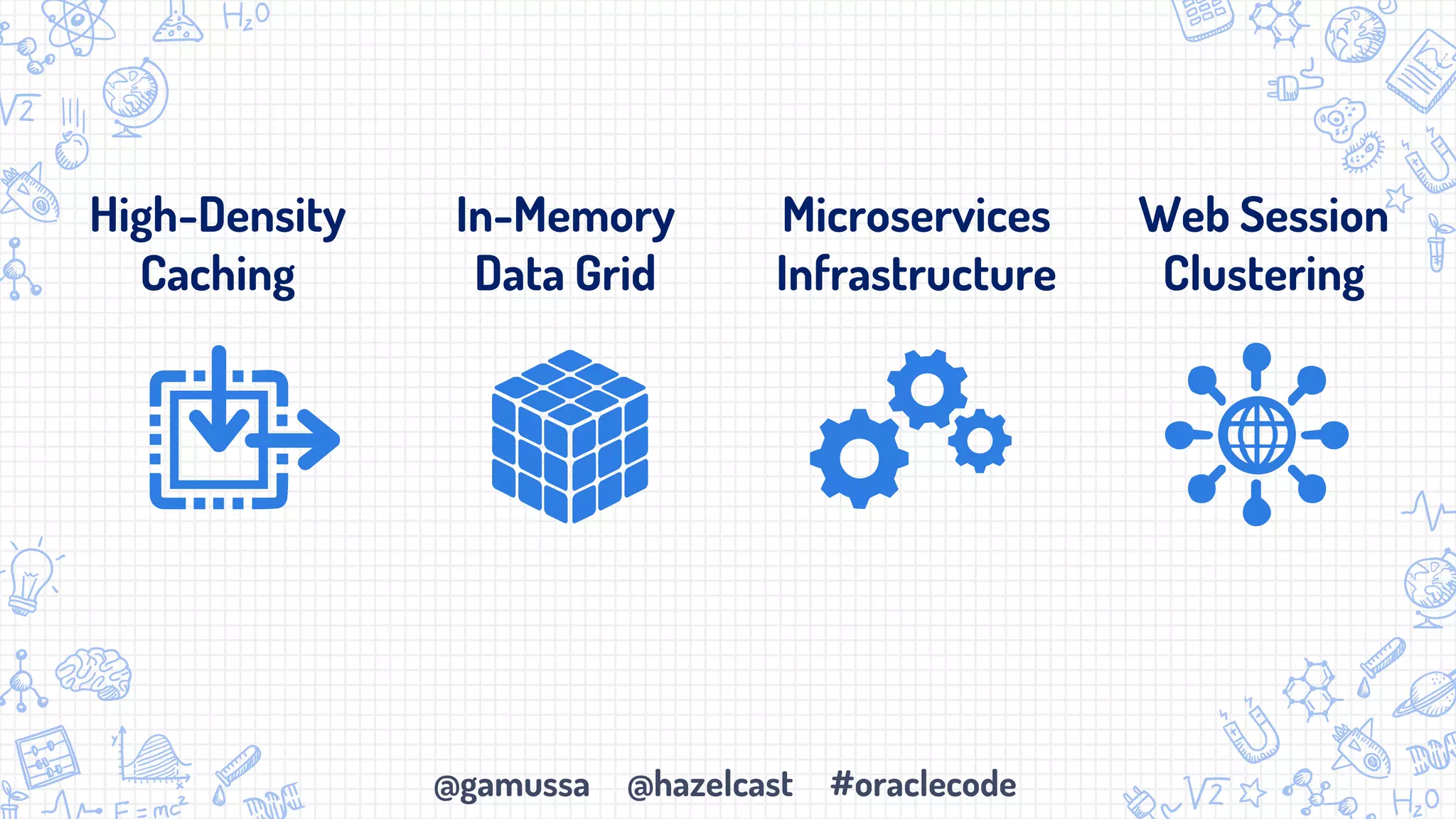

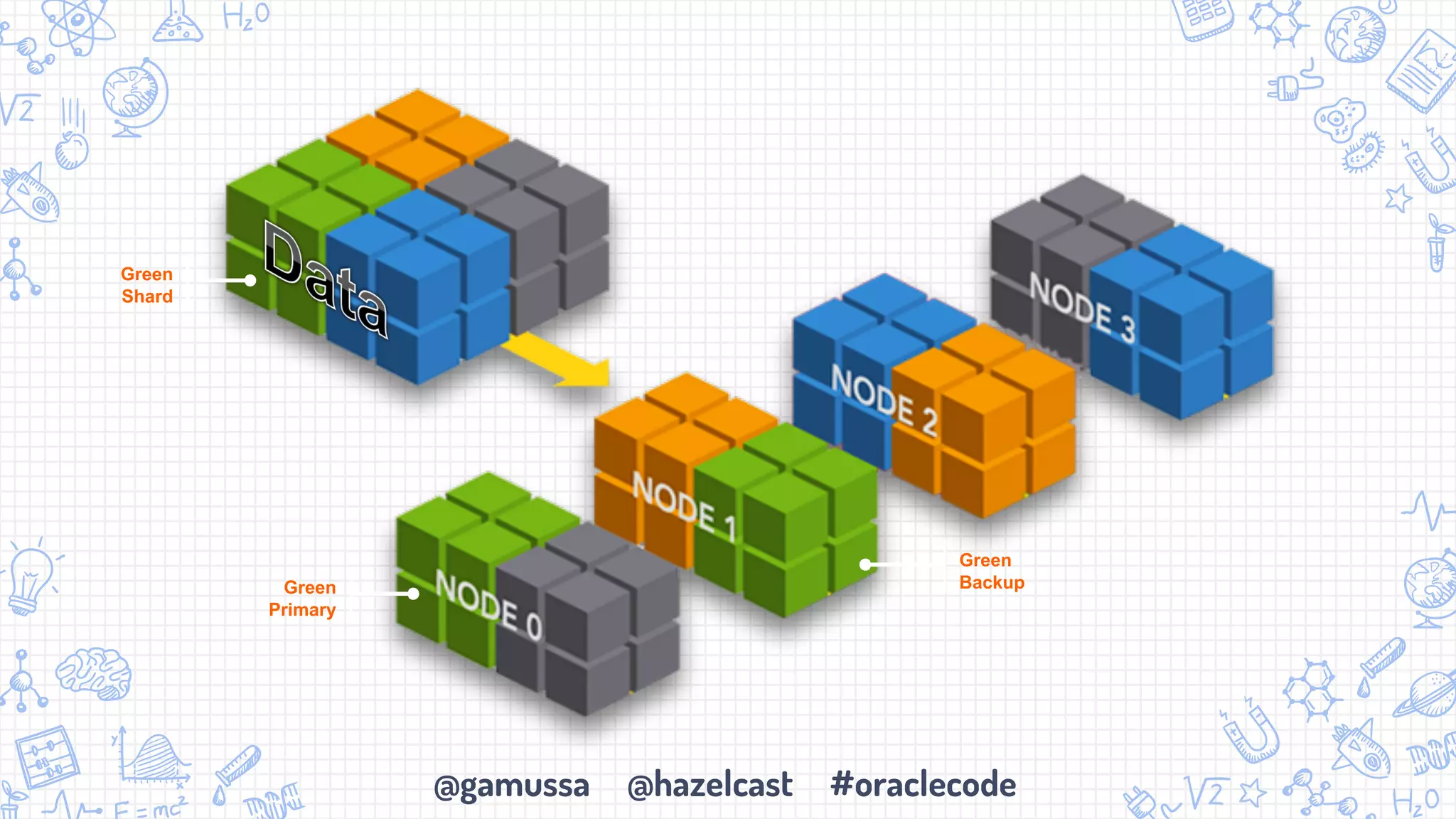
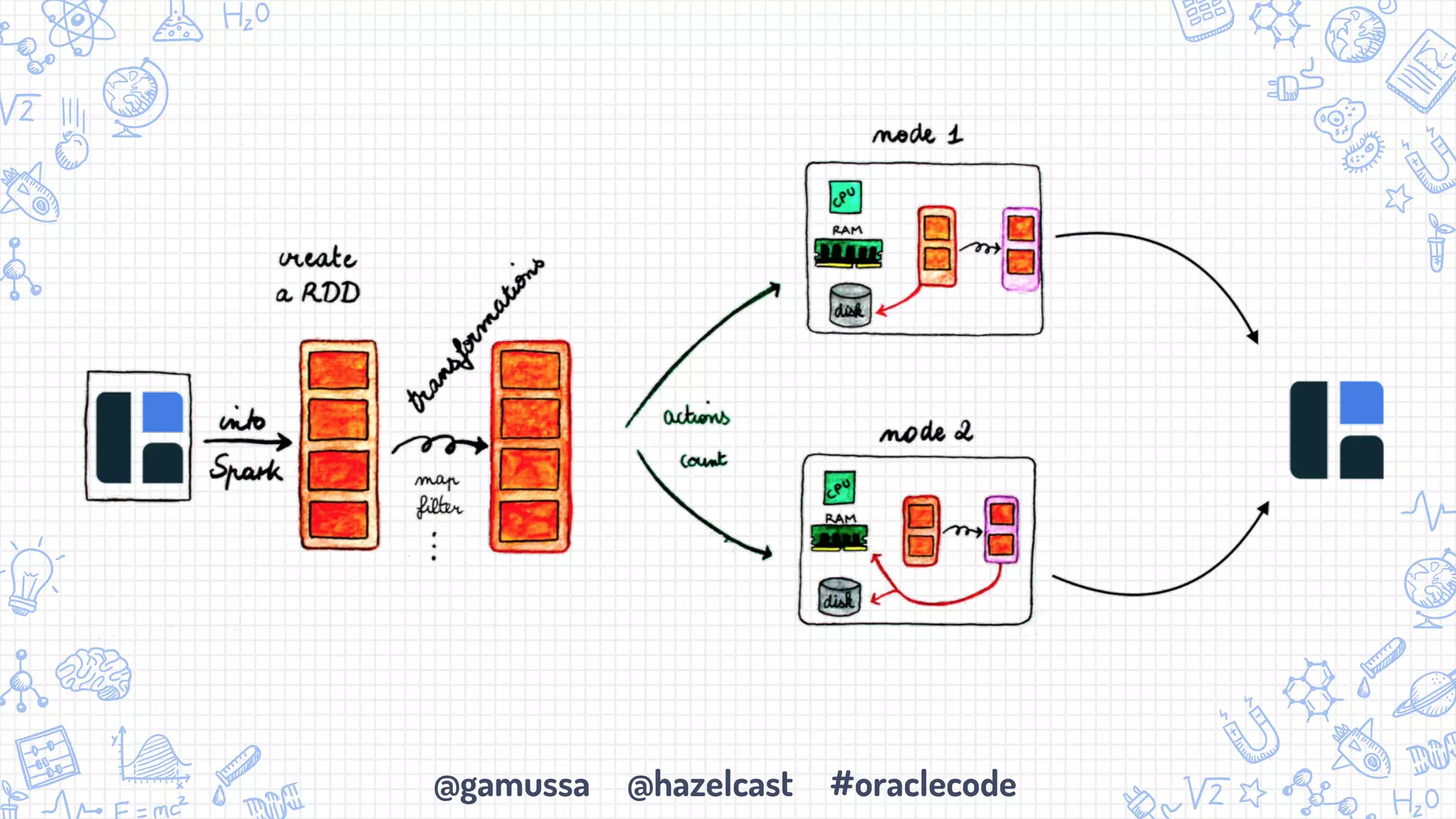























































The document discusses the integration of Apache Spark with Hazelcast's in-memory data grid, highlighting the speed advantages of Spark and its fault-tolerance with resilient distributed datasets (RDDs). It provides code examples for configuration and uses cases, emphasizing parallel processing and operational benefits. Additionally, it mentions limitations regarding data updates while reading from Spark, suggesting potential issues like cursor inaccuracies.


![[OracleCode - SF] Distributed caching for your next node.js project](https://cdn.slidesharecdn.com/ss_thumbnails/distributedcachingforyournextnode-170302181006-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[Jfokus] Riding the Jet Streams](https://cdn.slidesharecdn.com/ss_thumbnails/ridingthejetstreams-jfokus-02-08-2017-170208120631-thumbnail.jpg?width=640&height=640&fit=bounds)







![[NYJavaSig] Riding the Distributed Streams - Feb 2nd, 2017](https://cdn.slidesharecdn.com/ss_thumbnails/ridingdistributedstreams-nyjavasig-02-02-2017-170203005616-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Codemash] Caching Made "Bootiful"!](https://cdn.slidesharecdn.com/ss_thumbnails/cachingmadebootifulcodemash11217-170112212321-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JokerConf] Верхом на реактивных стримах, 10/13/2016](https://cdn.slidesharecdn.com/ss_thumbnails/ridingthejetstreams-jokerconf-10-13-2016-161014221528-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[JBreak] Блеск И Нищета Распределенных Стримов - 04-04-2017](https://cdn.slidesharecdn.com/ss_thumbnails/gamov-jbreak-04-04-2017-170404164301-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DataSciCon] Divide, distribute and conquer stream v. batch](https://cdn.slidesharecdn.com/ss_thumbnails/dividedistributeandconquer-streamv-171201225205-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Philly ETE] Java Puzzlers NG](https://cdn.slidesharecdn.com/ss_thumbnails/javapuzzlerss02-phillyete-170418150118-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Philly JUG] Divide, Distribute and Conquer: Stream v. Batch](https://cdn.slidesharecdn.com/ss_thumbnails/dividedistributeandconquer-streamv-170920171540-thumbnail.jpg?width=640&height=640&fit=bounds)













![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)








