Downloaded 637 times




![What does CSSD do?
CSSD monitors and evicts nodes
• Monitors nodes using 2 communication channels:
– Private Interconnect Network Heartbeat
– Voting Disk based communication Disk Heartbeat
• Evicts (forcibly removes nodes from a cluster)
nodes dependent on heartbeat feedback (failures)
CSSD “Ping” CSSD
“Ping”
Network Heartbeat
Interconnect basics
• Each node in the cluster is “pinged” every second
• Nodes must respond in css_misscount time (defaults to 30 secs.)
– Reducing the css_misscount time is generally not supported
• Network heartbeat failures will lead to node evictions
– CSSD-log: [date / time] [CSSD][1111902528]clssnmPollingThread: node
mynodename (5) at 75% heartbeat fatal, removal in 6.770 seconds
CSSD “Ping” CSSD](https://image.slidesharecdn.com/oracleclusterwarenodemanagementandvotingdisks-13255655561301-phpapp01-120102224312-phpapp01/75/Oracle-Clusterware-Node-Management-and-Voting-Disks-5-2048.jpg)
![Disk Heartbeat
Voting Disk basics – Part 1
• Each node in the cluster “pings” (r/w) the Voting Disk(s) every second
• Nodes must receive a response in (long / short) diskTimeout time
– I/O errors indicate clear accessibility problems timeout is irrelevant
• Disk heartbeat failures will lead to node evictions
– CSSD-log: … [CSSD] [1115699552] >TRACE: clssnmReadDskHeartbeat:
node(2) is down. rcfg(1) wrtcnt(1) LATS(63436584) Disk lastSeqNo(1)
CSSD CSSD
“Ping”
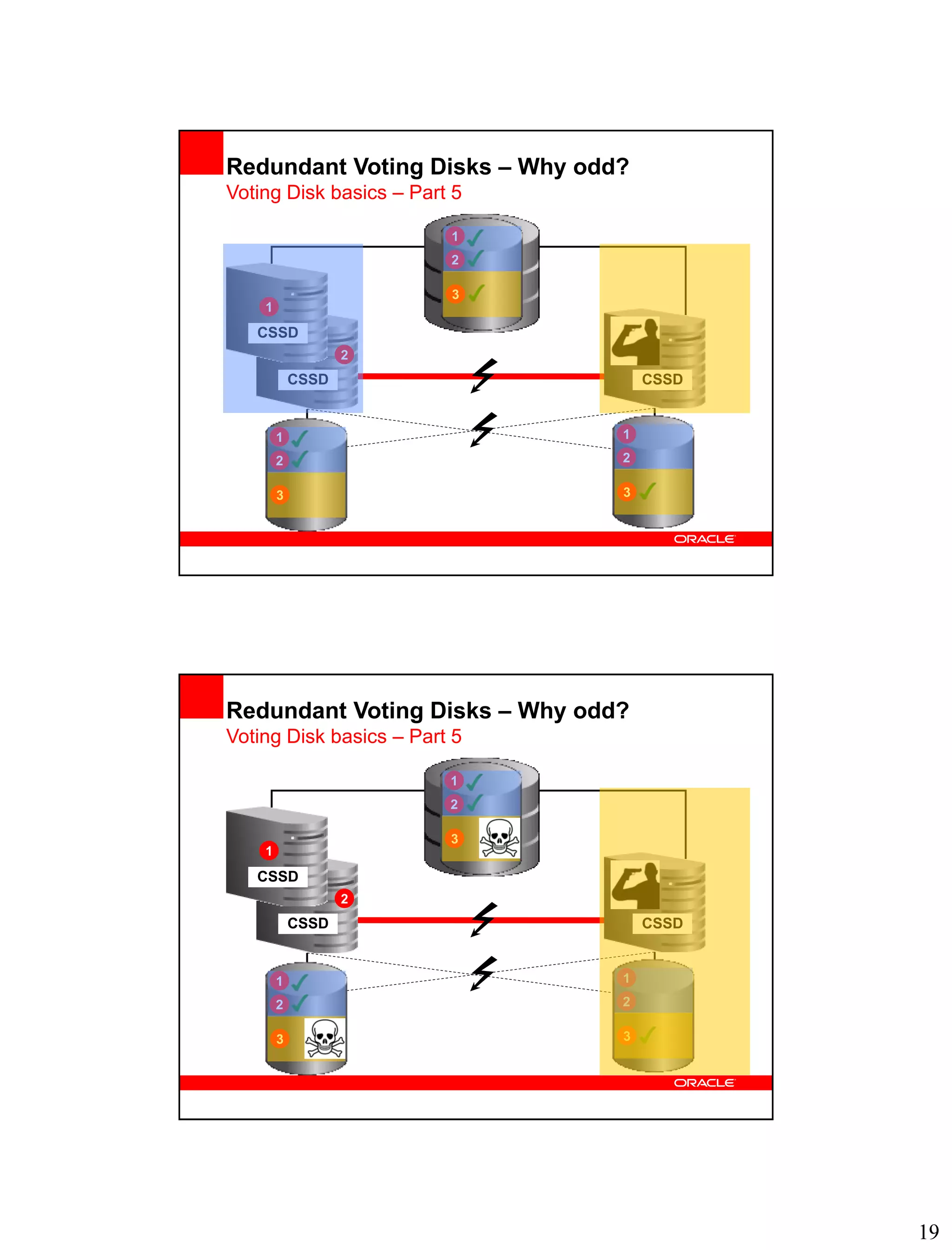
Voting Disk Structure
Voting Disk basics – Part 2
• Voting Disks contain dynamic and static data:
– Dynamic data: disk heartbeat logging
– Static data: information about the nodes in the cluster
• With 11.2.0.1 Voting Disks got an “identity”:
– E.g. Voting Disk serial number: [GRID]> crsctl query css votedisk
1. 2 1212f9d6e85c4ff7bf80cc9e3f533cc1 (/dev/sdd5) [DATA]
• Voting Disks must therefore not be copied using “dd” or “cp” anymore
Node information Disk Heartbeat Logging](https://image.slidesharecdn.com/oracleclusterwarenodemanagementandvotingdisks-13255655561301-phpapp01-120102224312-phpapp01/75/Oracle-Clusterware-Node-Management-and-Voting-Disks-6-2048.jpg)

![Insertion 2: Voting Disk in Oracle ASM
The way of storing Voting Disks doesn’t change its use
[GRID]> crsctl query css votedisk
1. 2 1212f9d6e85c4ff7bf80cc9e3f533cc1 (/dev/sdd5) [DATA]
2. 2 aafab95f9ef84f03bf6e26adc2a3b0e8 (/dev/sde5) [DATA]
3. 2 28dd4128f4a74f73bf8653dabd88c737 (/dev/sdd6) [DATA]
Located 3 voting disk(s).
• Oracle ASM auto creates 1/3/5 Voting Files
– Based on Ext/Normal/High redundancy
and on Failure Groups in the Disk Group
– Per default there is one failure group per disk
– ASM will enforce the required number of disks
– New failure group type: Quorum Failgroup
<Insert Picture Here>
Node Eviction Basics](https://image.slidesharecdn.com/oracleclusterwarenodemanagementandvotingdisks-13255655561301-phpapp01-120102224312-phpapp01/75/Oracle-Clusterware-Node-Management-and-Voting-Disks-8-2048.jpg)




















![What does CSSD do?
CSSD monitors and evicts nodes
• Monitors nodes using 2 communication channels:
– Private Interconnect Network Heartbeat
– Voting Disk based communication Disk Heartbeat
• Evicts (forcibly removes nodes from a cluster)
nodes dependent on heartbeat feedback (failures)
CSSD “Ping” CSSD
“Ping”
Network Heartbeat
Interconnect basics
• Each node in the cluster is “pinged” every second
• Nodes must respond in css_misscount time (defaults to 30 secs.)
– Reducing the css_misscount time is generally not supported
• Network heartbeat failures will lead to node evictions
– CSSD-log: [date / time] [CSSD][1111902528]clssnmPollingThread: node
mynodename (5) at 75% heartbeat fatal, removal in 6.770 seconds
CSSD “Ping” CSSD](https://crownmelresort.com/image.slidesharecdn.com/oracleclusterwarenodemanagementandvotingdisks-13255655561301-phpapp01-120102224312-phpapp01/75/Oracle-Clusterware-Node-Management-and-Voting-Disks-5-2048.jpg)
![Disk Heartbeat
Voting Disk basics – Part 1
• Each node in the cluster “pings” (r/w) the Voting Disk(s) every second
• Nodes must receive a response in (long / short) diskTimeout time
– I/O errors indicate clear accessibility problems timeout is irrelevant
• Disk heartbeat failures will lead to node evictions
– CSSD-log: … [CSSD] [1115699552] >TRACE: clssnmReadDskHeartbeat:
node(2) is down. rcfg(1) wrtcnt(1) LATS(63436584) Disk lastSeqNo(1)
CSSD CSSD
“Ping”
Voting Disk Structure
Voting Disk basics – Part 2
• Voting Disks contain dynamic and static data:
– Dynamic data: disk heartbeat logging
– Static data: information about the nodes in the cluster
• With 11.2.0.1 Voting Disks got an “identity”:
– E.g. Voting Disk serial number: [GRID]> crsctl query css votedisk
1. 2 1212f9d6e85c4ff7bf80cc9e3f533cc1 (/dev/sdd5) [DATA]
• Voting Disks must therefore not be copied using “dd” or “cp” anymore
Node information Disk Heartbeat Logging](https://crownmelresort.com/image.slidesharecdn.com/oracleclusterwarenodemanagementandvotingdisks-13255655561301-phpapp01-120102224312-phpapp01/75/Oracle-Clusterware-Node-Management-and-Voting-Disks-6-2048.jpg)

![Insertion 2: Voting Disk in Oracle ASM
The way of storing Voting Disks doesn’t change its use
[GRID]> crsctl query css votedisk
1. 2 1212f9d6e85c4ff7bf80cc9e3f533cc1 (/dev/sdd5) [DATA]
2. 2 aafab95f9ef84f03bf6e26adc2a3b0e8 (/dev/sde5) [DATA]
3. 2 28dd4128f4a74f73bf8653dabd88c737 (/dev/sdd6) [DATA]
Located 3 voting disk(s).
• Oracle ASM auto creates 1/3/5 Voting Files
– Based on Ext/Normal/High redundancy
and on Failure Groups in the Disk Group
– Per default there is one failure group per disk
– ASM will enforce the required number of disks
– New failure group type: Quorum Failgroup
<Insert Picture Here>
Node Eviction Basics](https://crownmelresort.com/image.slidesharecdn.com/oracleclusterwarenodemanagementandvotingdisks-13255655561301-phpapp01-120102224312-phpapp01/75/Oracle-Clusterware-Node-Management-and-Voting-Disks-8-2048.jpg)


















Node management in Oracle Clusterware involves monitoring nodes and evicting nodes if necessary to prevent split-brain situations. The CSSD process monitors nodes through network heartbeats over the private interconnect and disk heartbeats using the voting disks. If a node fails to respond within the configured time limits for either heartbeat, it will be evicted from the cluster. Eviction involves sending a "kill request" to the node over the remaining communication channels to forcibly remove it. With Oracle Clusterware 11.2.0.2, reboots of nodes can be avoided by gracefully shutting down the Oracle Clusterware stack instead of an immediate reboot when fencing a node.


















![Understanding Oracle RAC 12c Internals OOW13 [CON8806]](https://cdn.slidesharecdn.com/ss_thumbnails/understandingoraclerac12cinternalsoow13con8806-131001010807-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





















































































