Download to read offline




















![http://www.budapestopenaccessinitiative.org/read
… an unprecedented public good. …
… completely free and unrestricted access to [peer-
reviewed literature] by all scientists, scholars, teachers,
students, and other curious minds. …
…Removing access barriers to this literature will
accelerate research, enrich education, share the
learning of the rich with the poor and the poor with
the rich, make this literature as useful as it can be, and
lay the foundation for uniting humanity in a common
intellectual conversation and quest for knowledge.
(BOAI, 2003)](https://image.slidesharecdn.com/ebi-140515051540-phpapp02-151124231117-lva1-app6891/75/Open-Knowledge-and-University-of-Cambridge-European-Bioinformatics-Institute-33-2048.jpg)








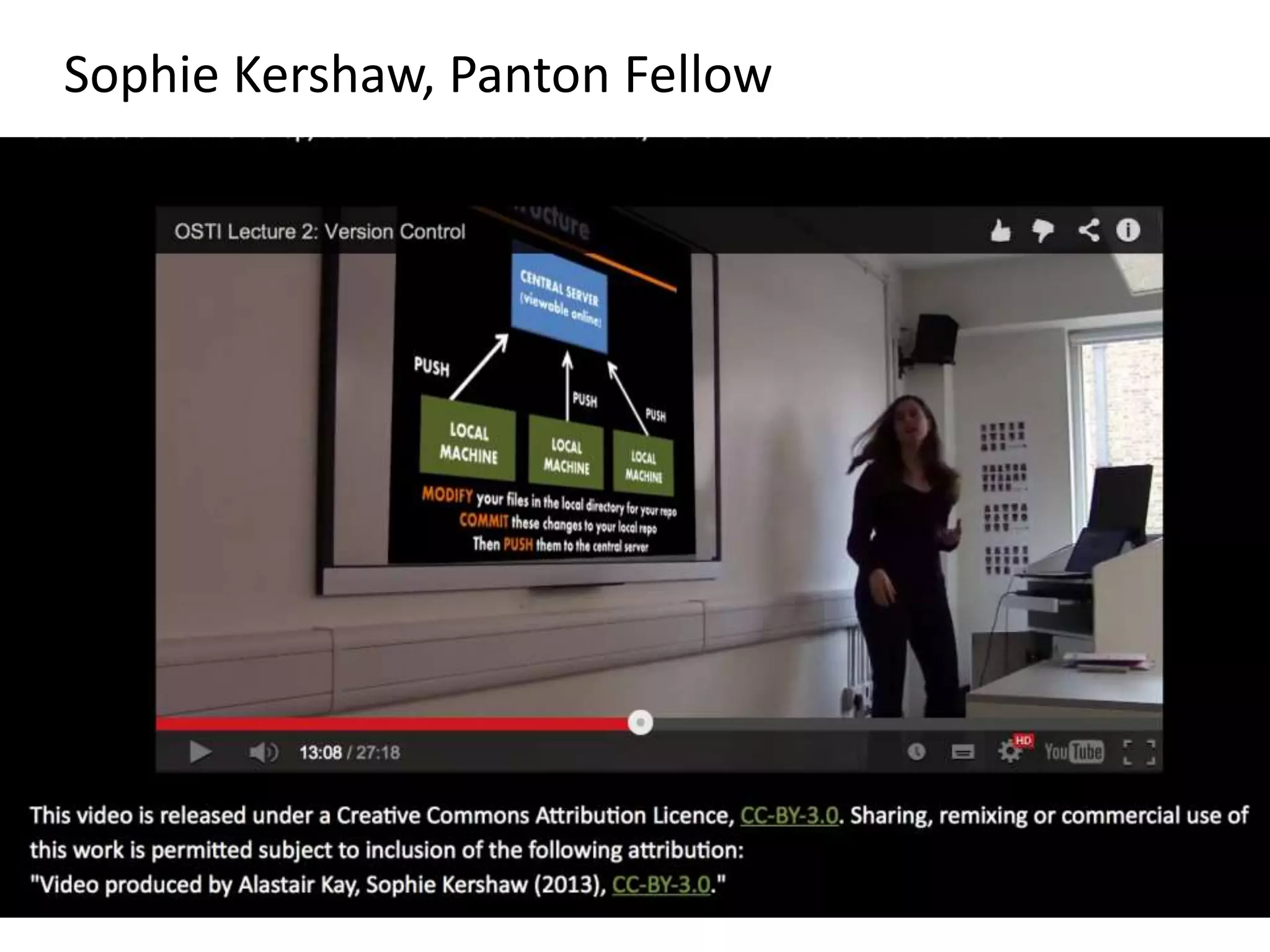



![Ross Mounce (Bath), Panton Fellow
• Sharing research data:
http://www.slideshare.net/rossmounce
• How to figures from PLOS/One [link]:
Ross shows how to bring figures to life:
• PLOSOne at http://bit.ly/PLOStrees
• PLOS at http://bit.ly/phylofigs (demo)](https://image.slidesharecdn.com/ebi-140515051540-phpapp02-151124231117-lva1-app6891/75/Open-Knowledge-and-University-of-Cambridge-European-Bioinformatics-Institute-51-2048.jpg)



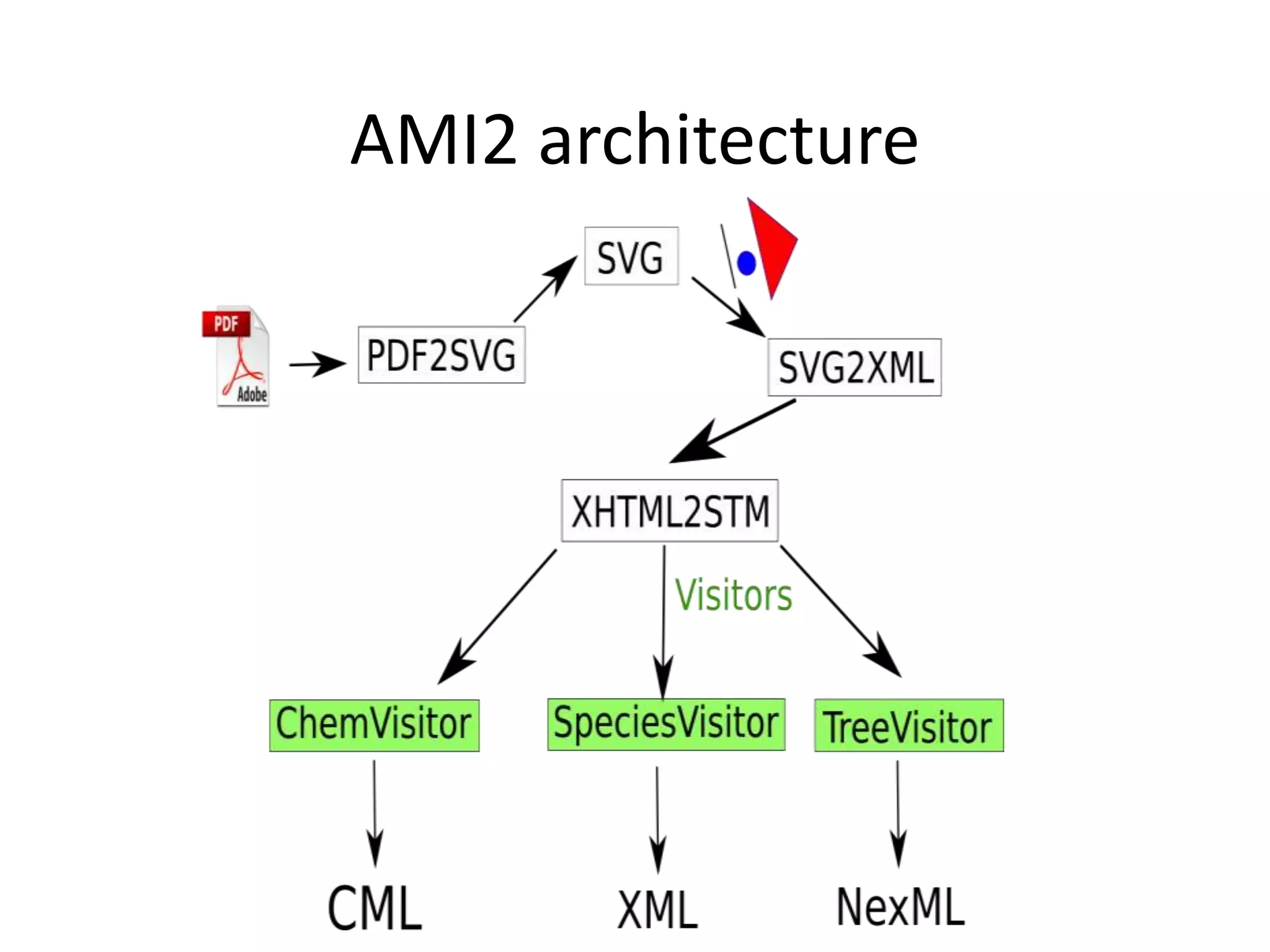

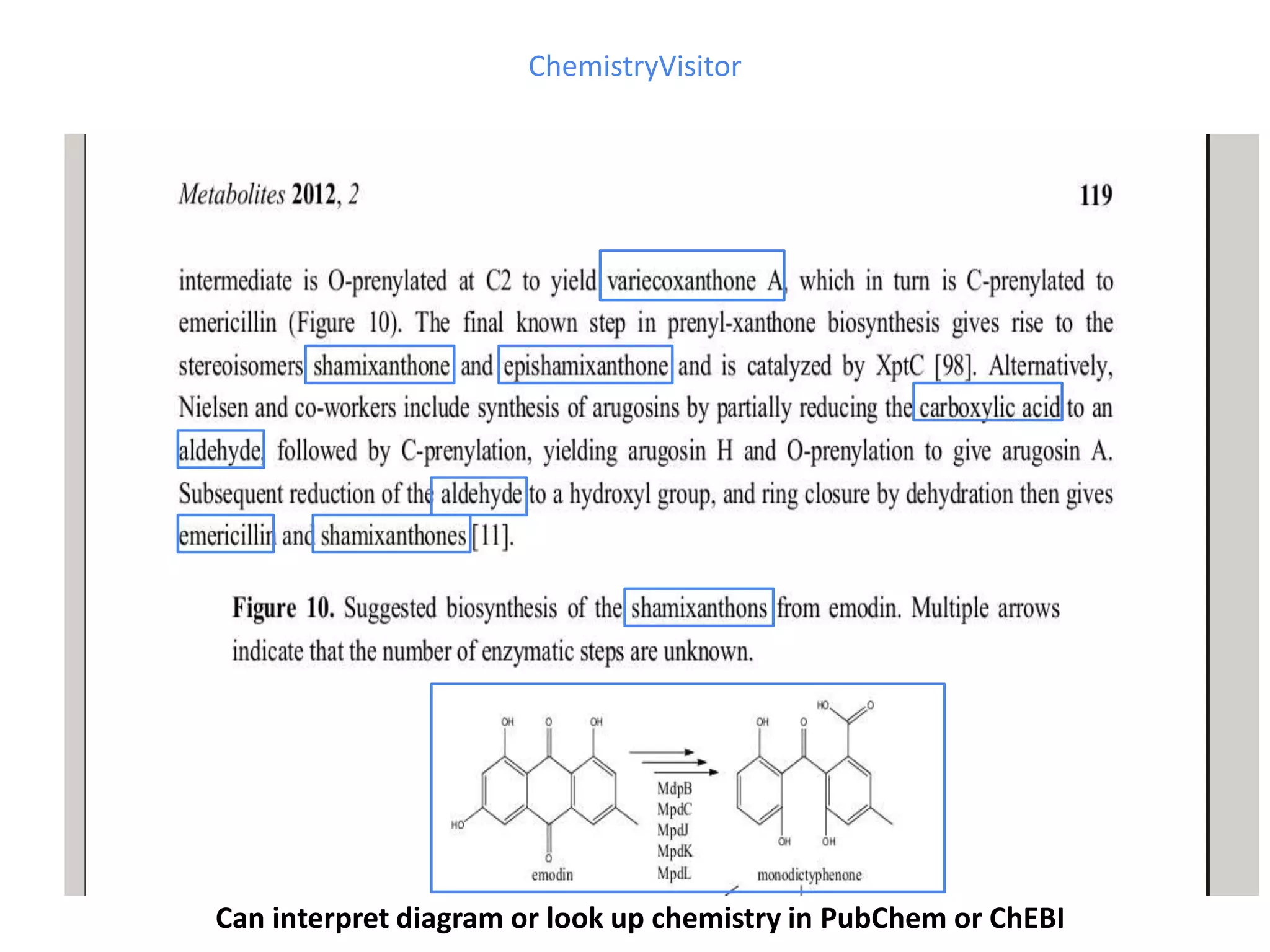

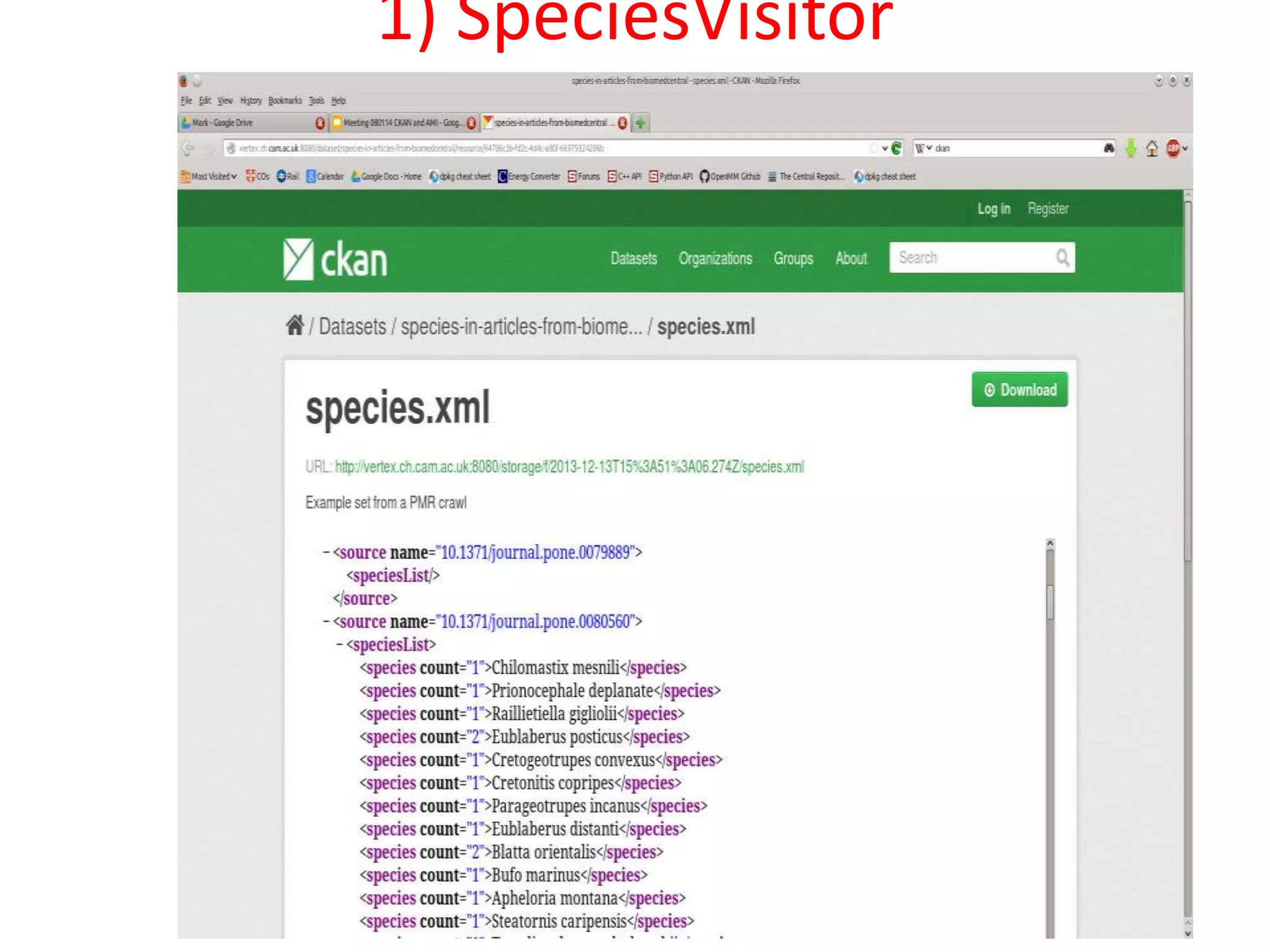
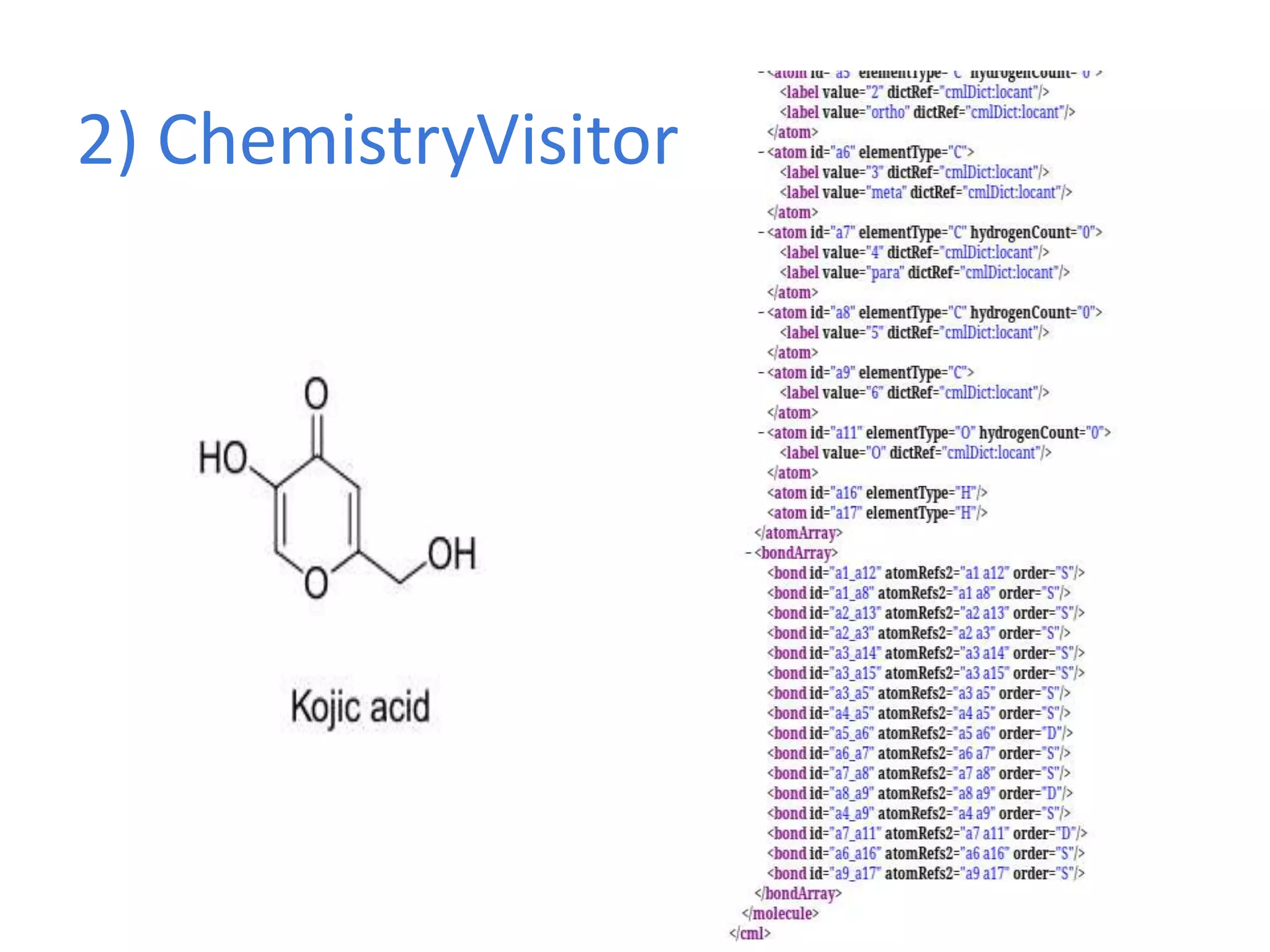
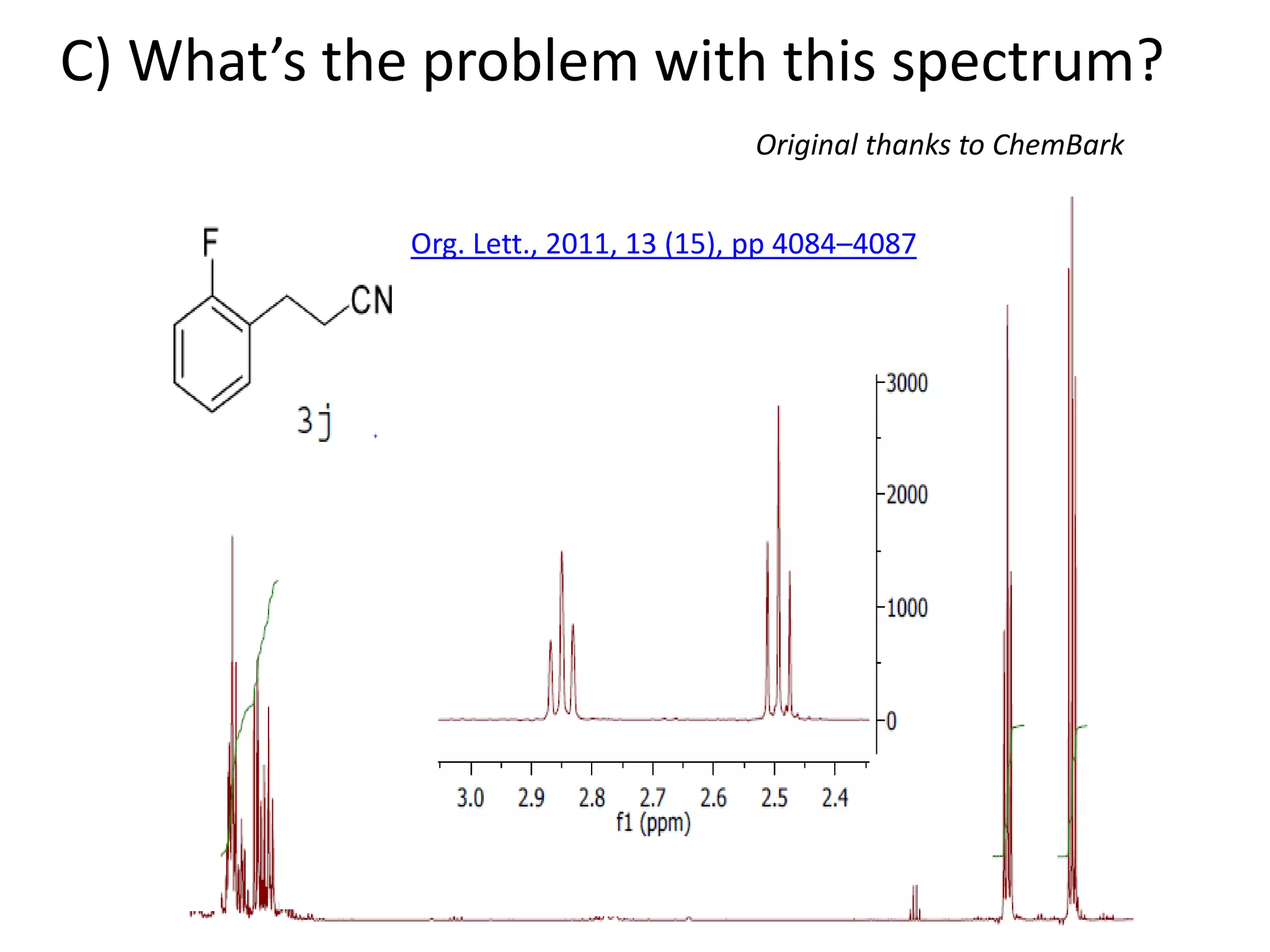
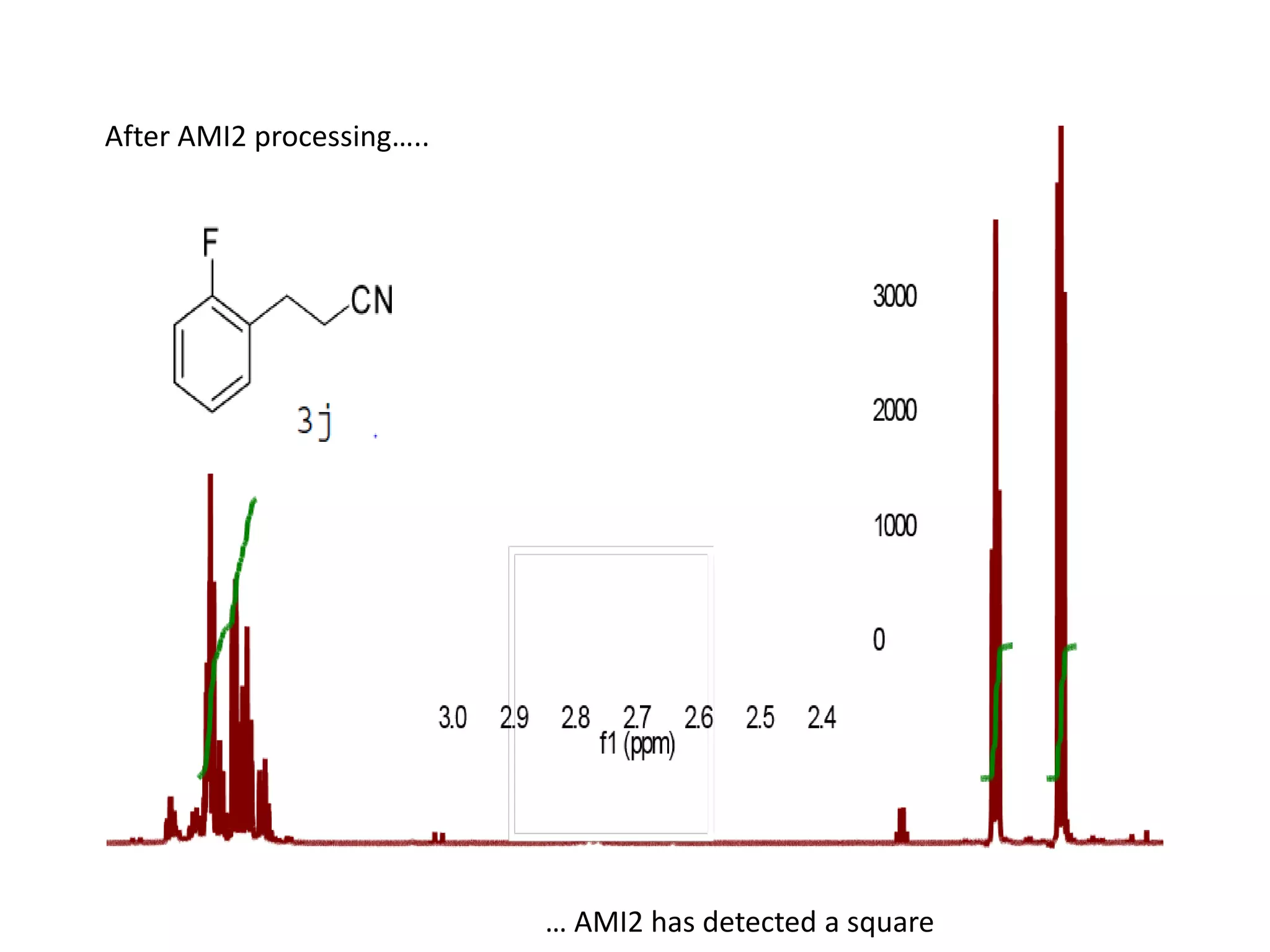
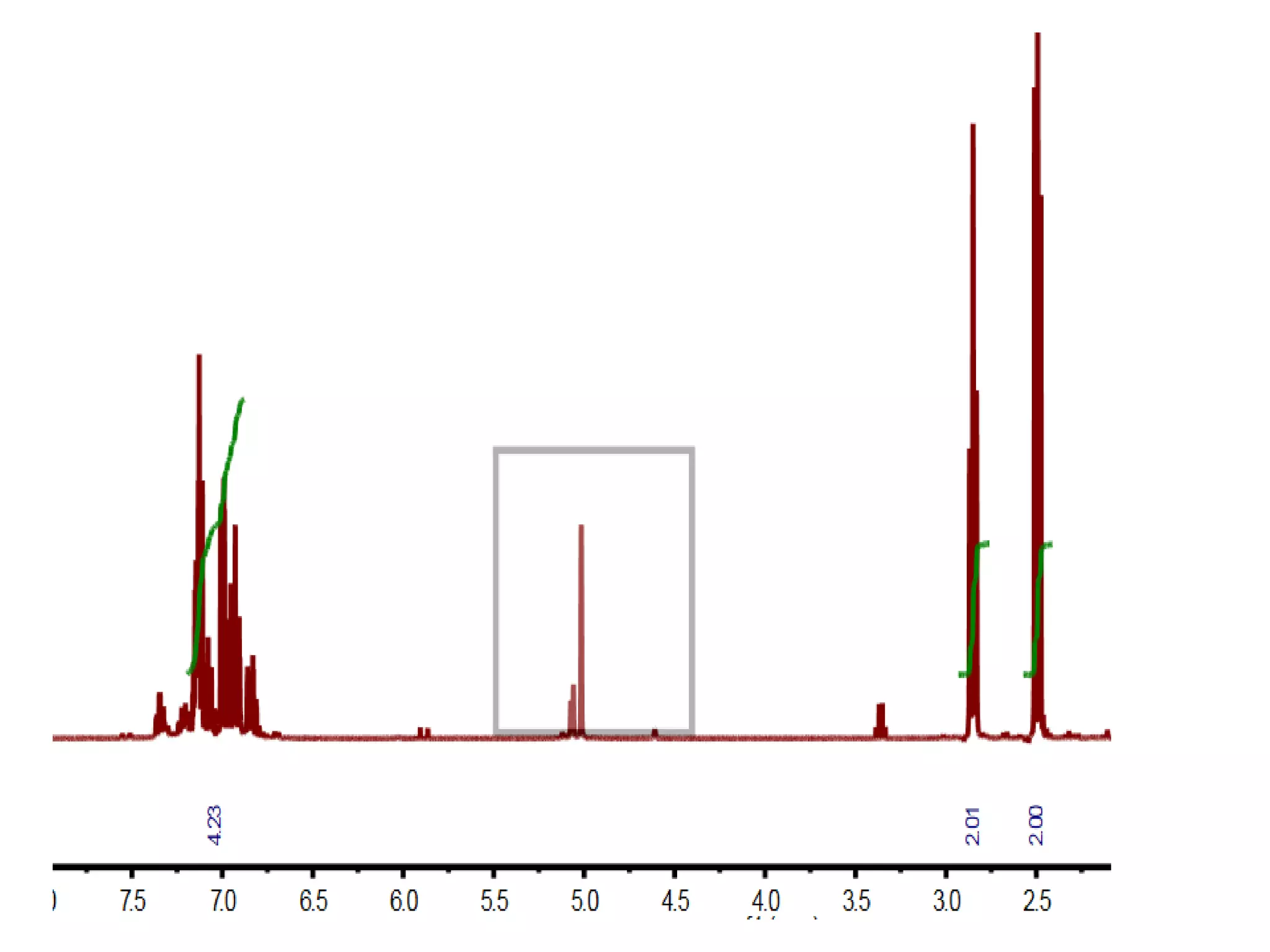




































![http://www.budapestopenaccessinitiative.org/read
… an unprecedented public good. …
… completely free and unrestricted access to [peer-
reviewed literature] by all scientists, scholars, teachers,
students, and other curious minds. …
…Removing access barriers to this literature will
accelerate research, enrich education, share the
learning of the rich with the poor and the poor with
the rich, make this literature as useful as it can be, and
lay the foundation for uniting humanity in a common
intellectual conversation and quest for knowledge.
(BOAI, 2003)](https://crownmelresort.com/image.slidesharecdn.com/ebi-140515051540-phpapp02-151124231117-lva1-app6891/75/Open-Knowledge-and-University-of-Cambridge-European-Bioinformatics-Institute-33-2048.jpg)

















![Ross Mounce (Bath), Panton Fellow
• Sharing research data:
http://www.slideshare.net/rossmounce
• How to figures from PLOS/One [link]:
Ross shows how to bring figures to life:
• PLOSOne at http://bit.ly/PLOStrees
• PLOS at http://bit.ly/phylofigs (demo)](https://crownmelresort.com/image.slidesharecdn.com/ebi-140515051540-phpapp02-151124231117-lva1-app6891/75/Open-Knowledge-and-University-of-Cambridge-European-Bioinformatics-Institute-51-2048.jpg)





















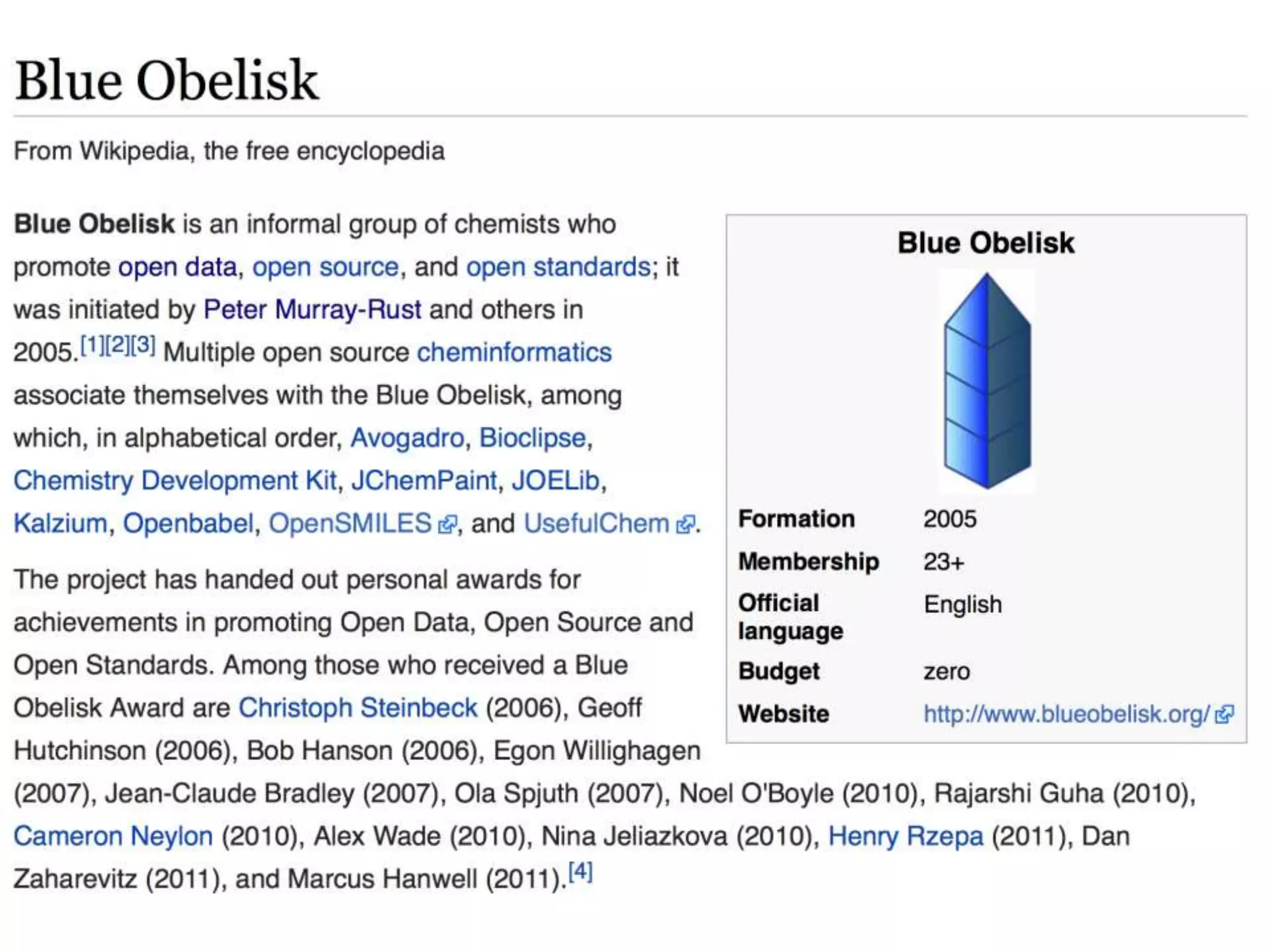
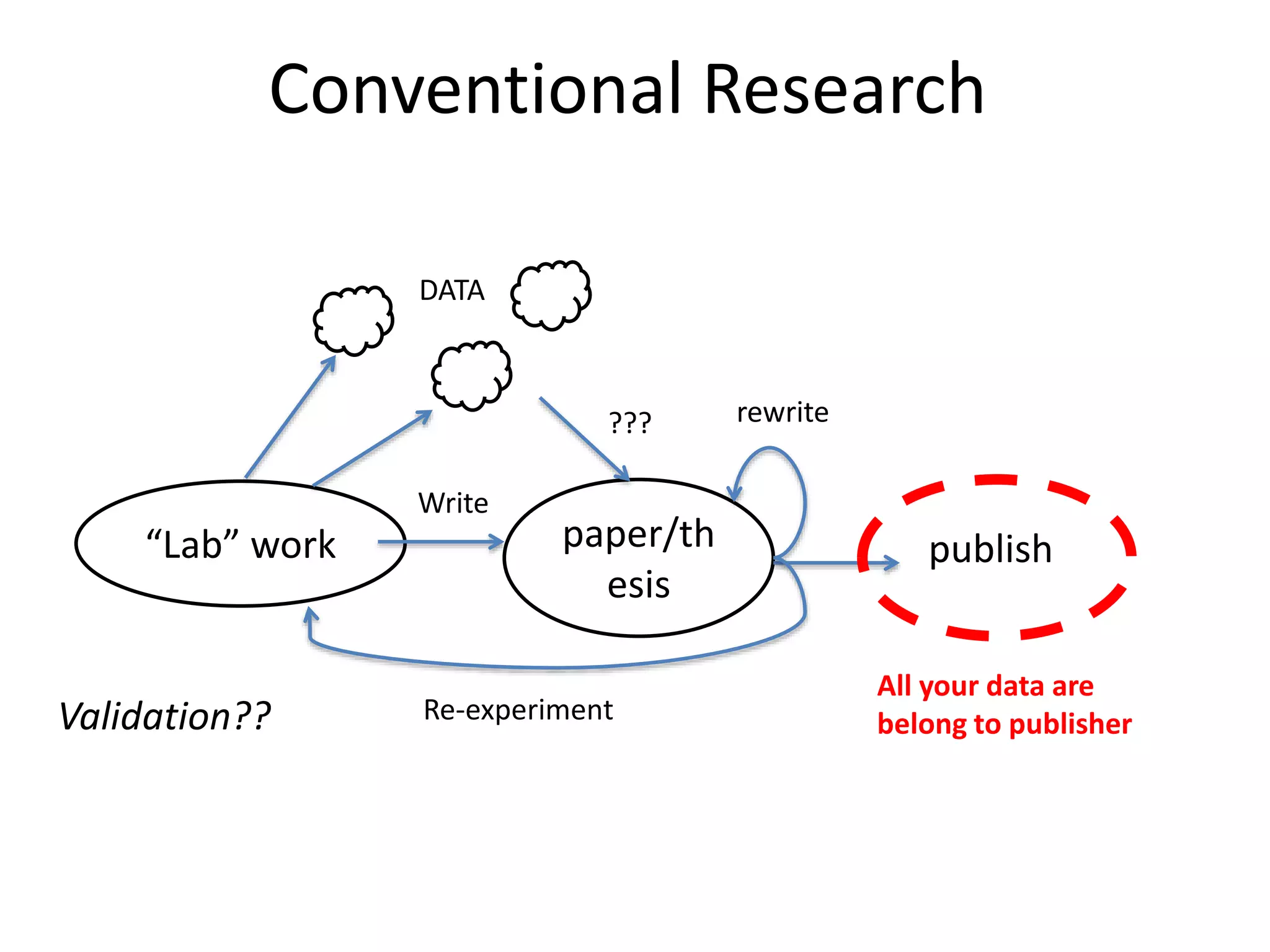
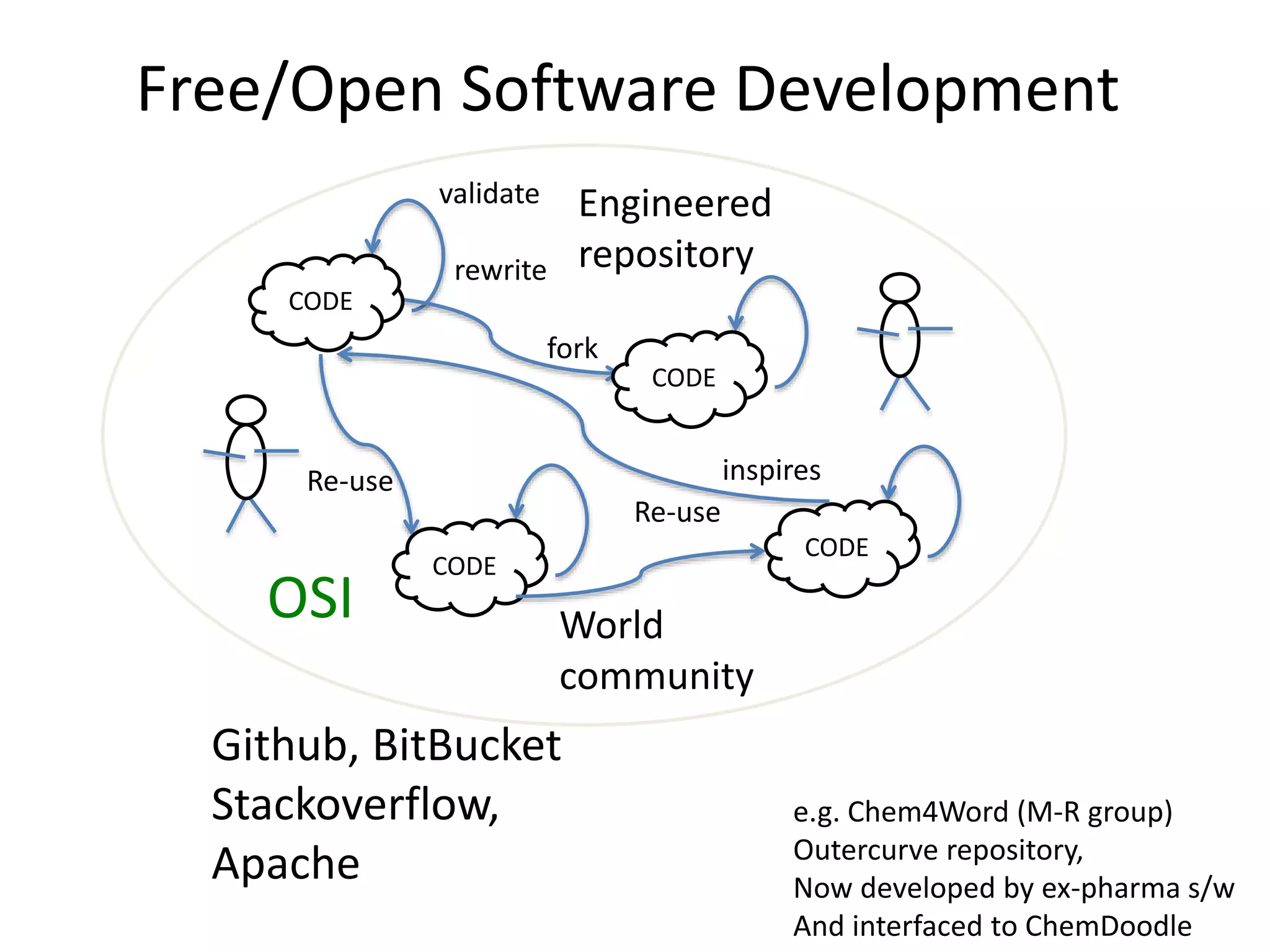
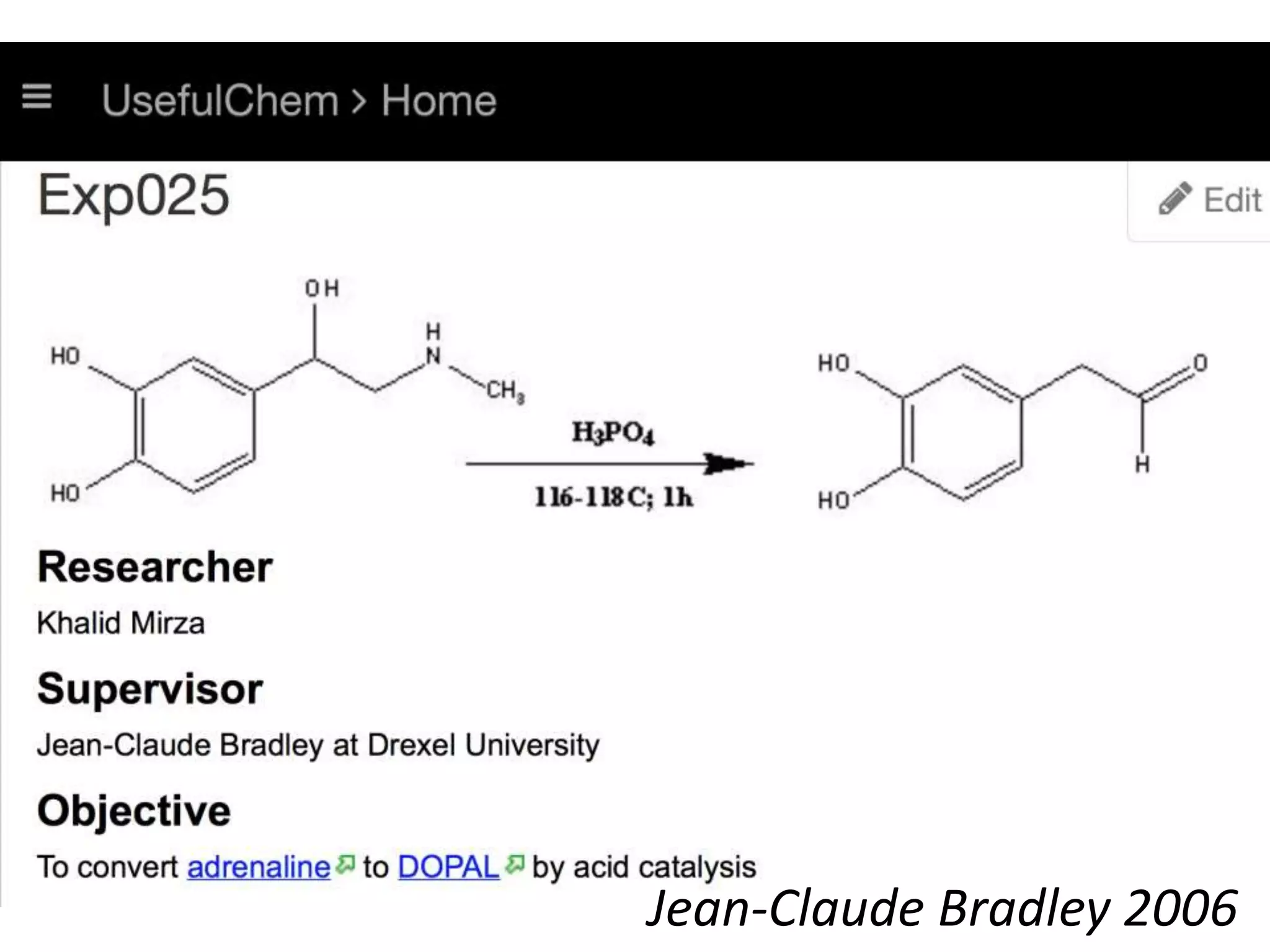
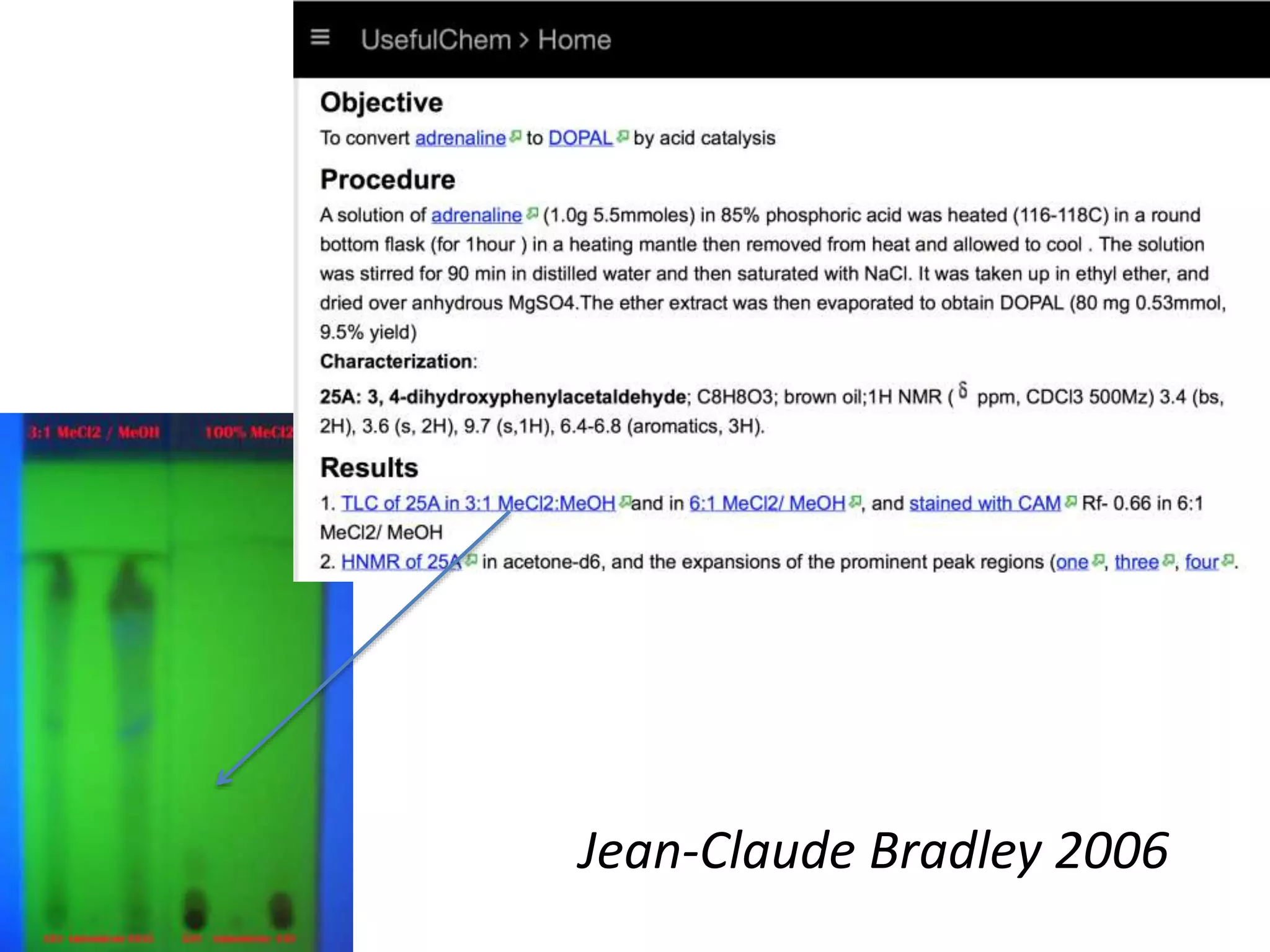
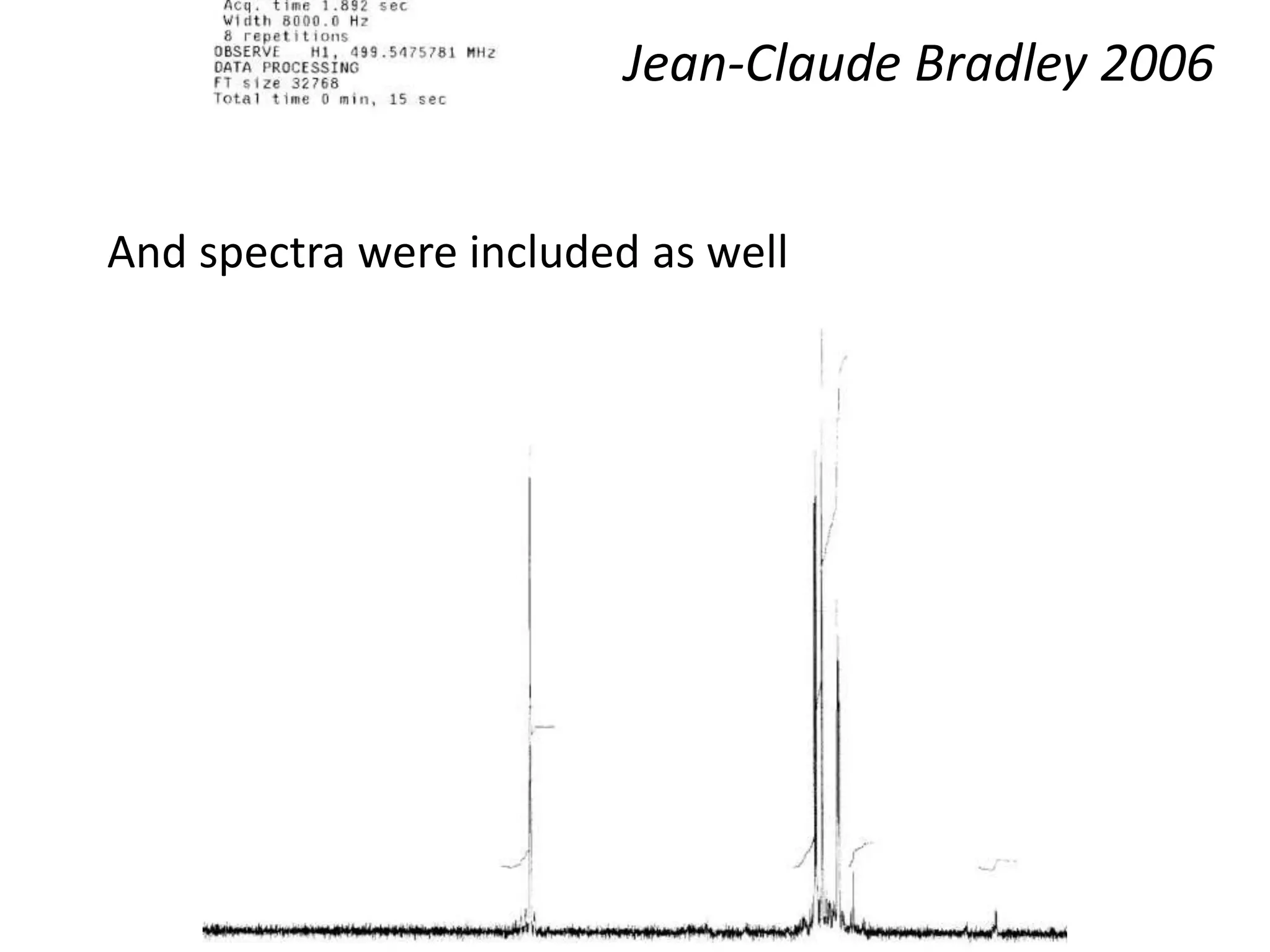
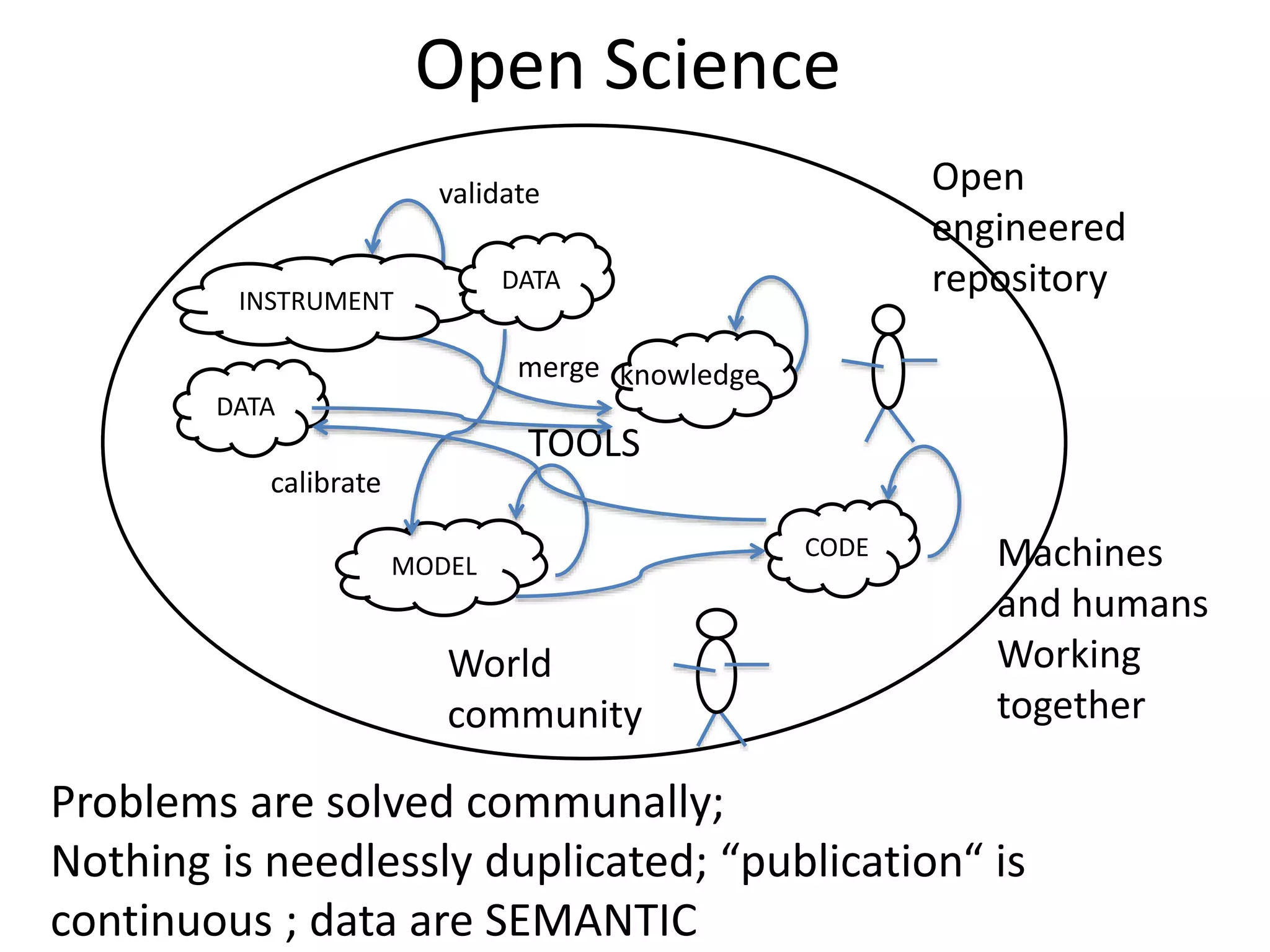
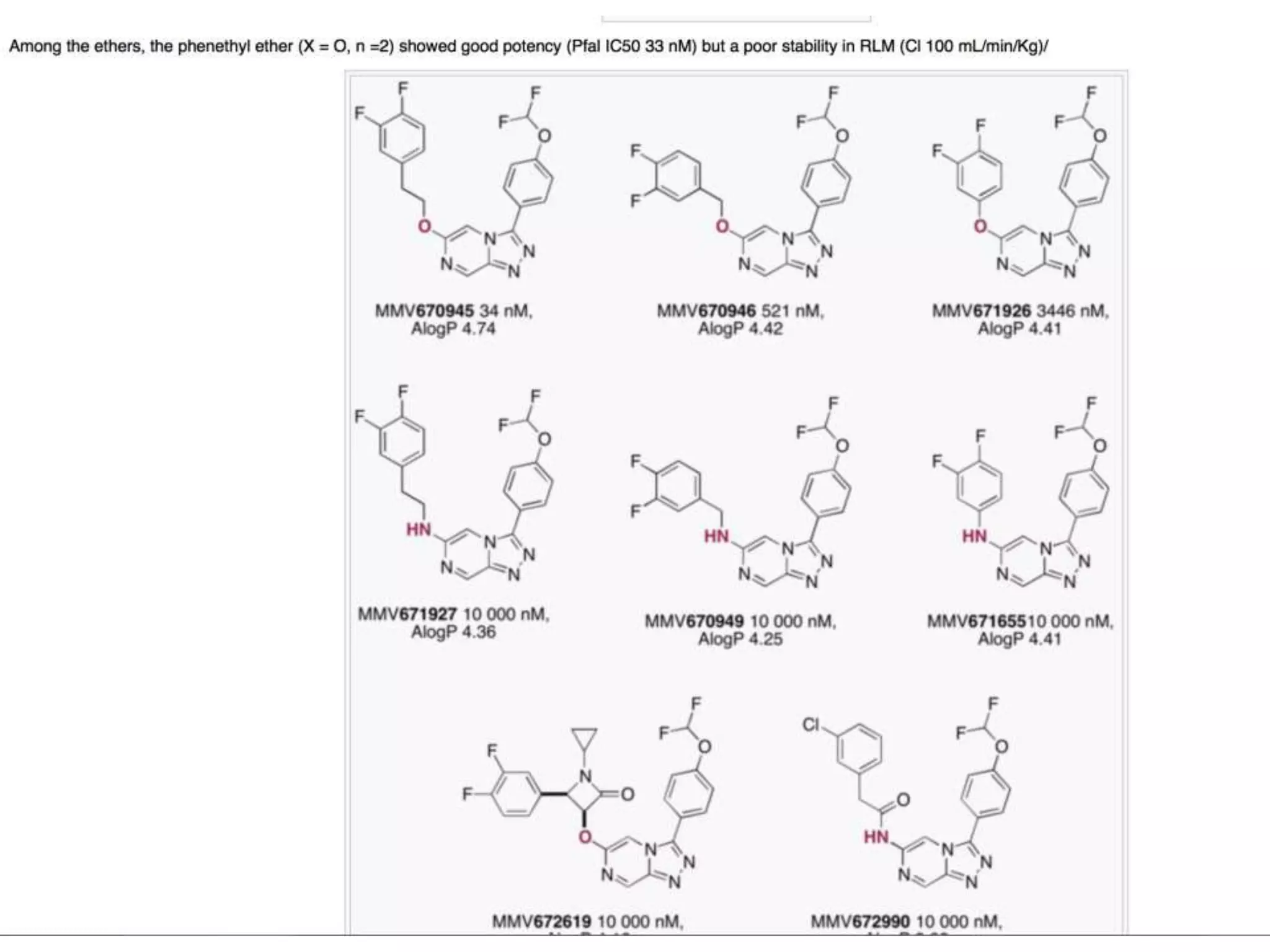
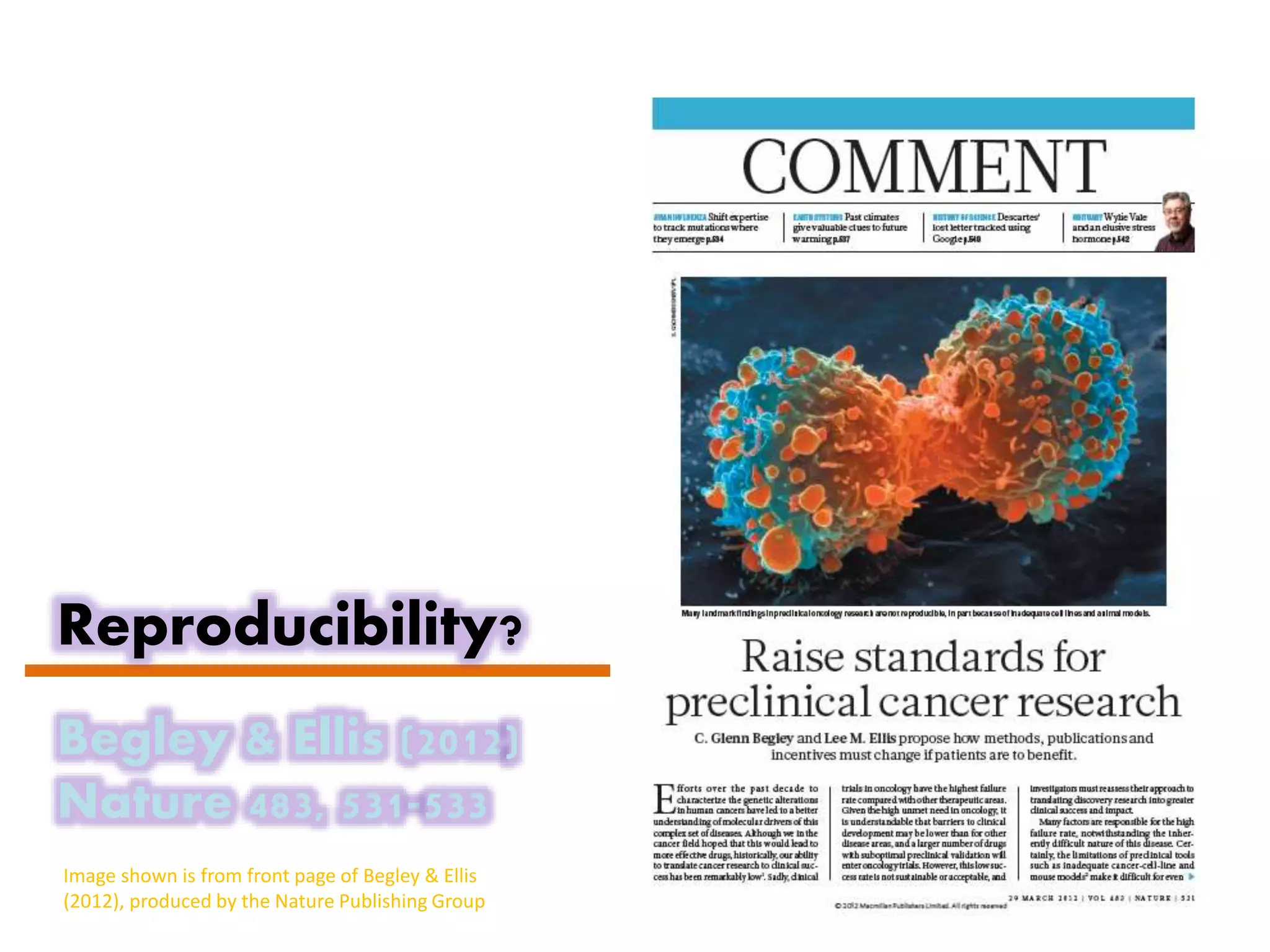
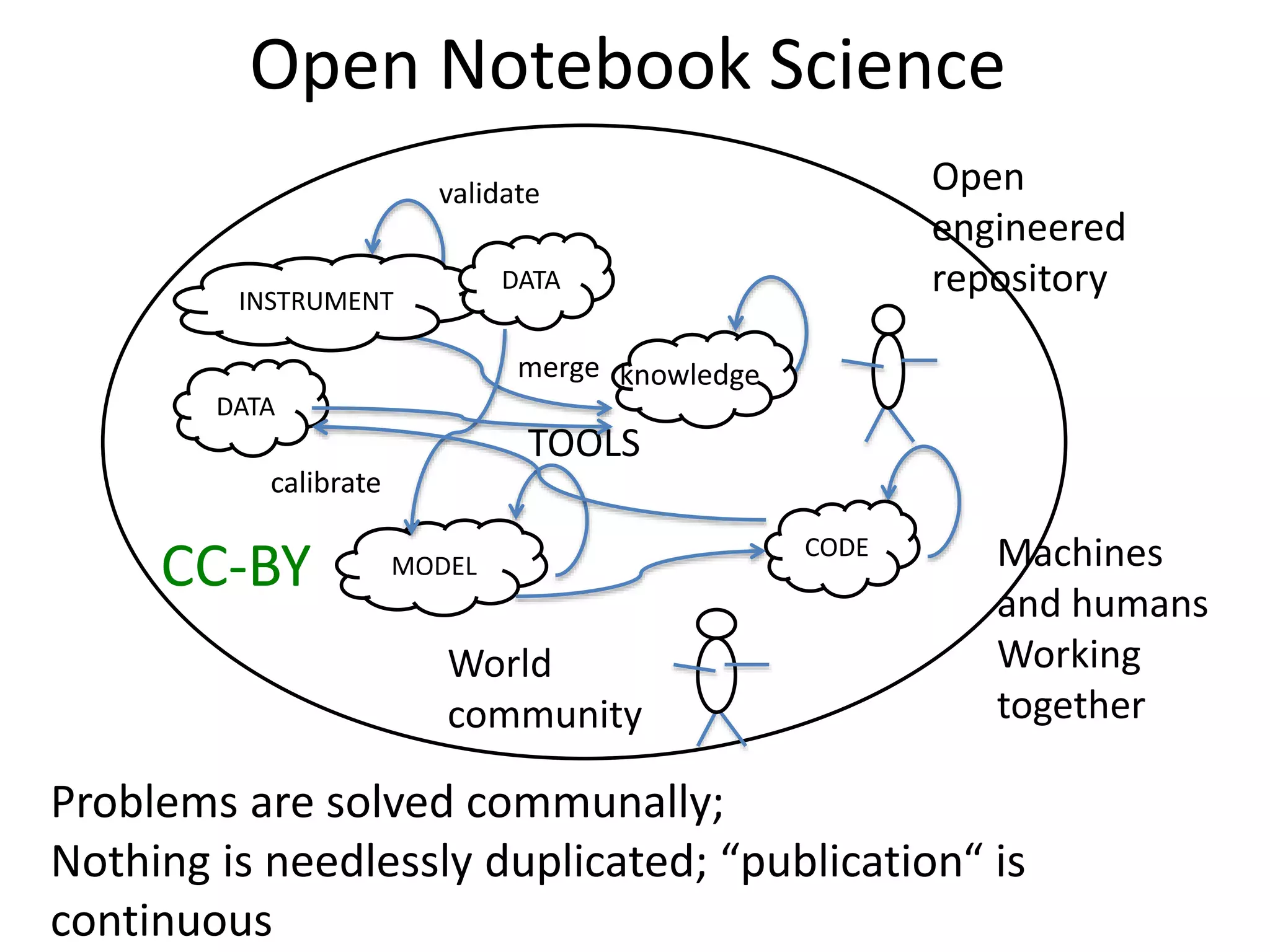
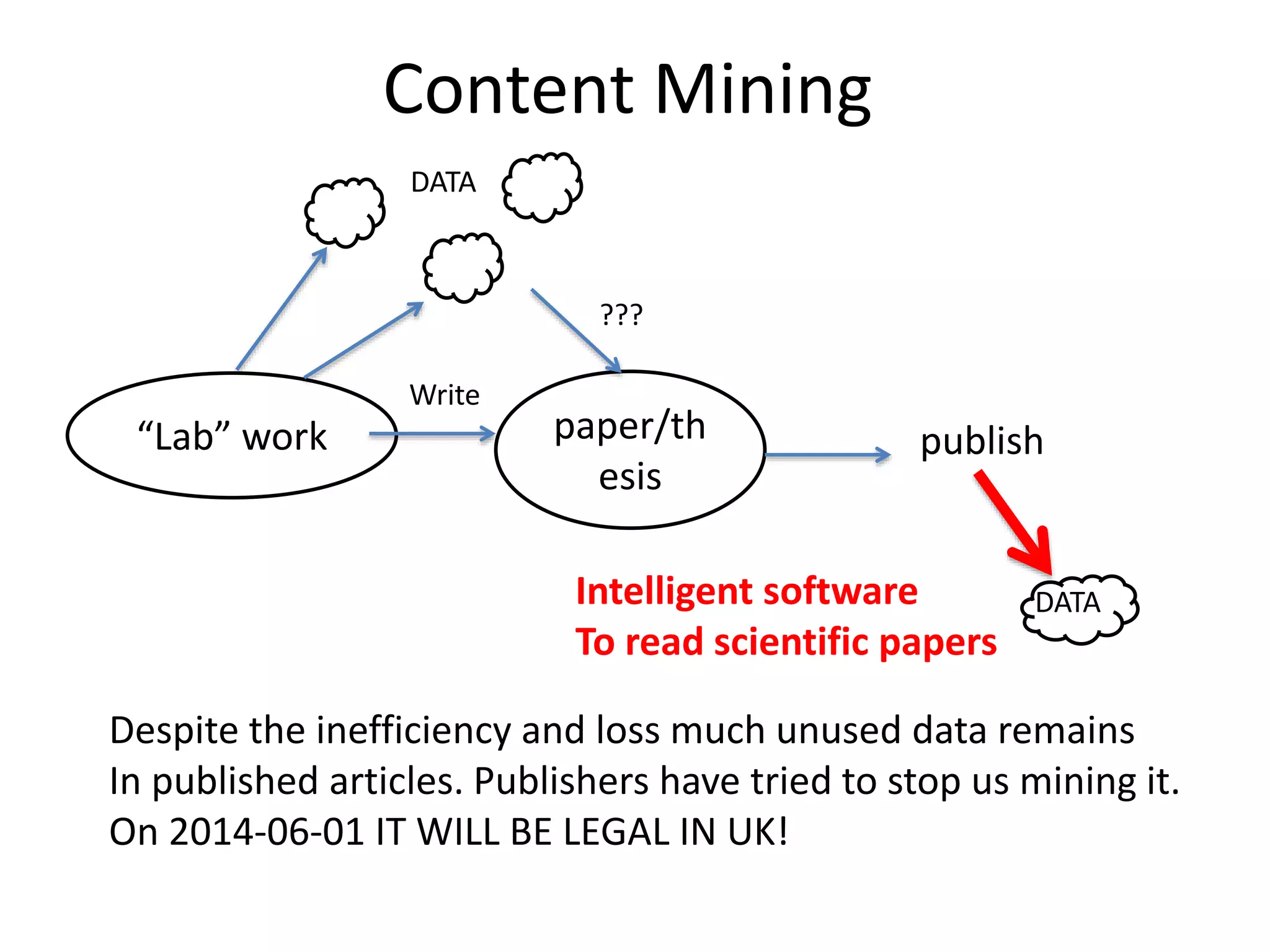
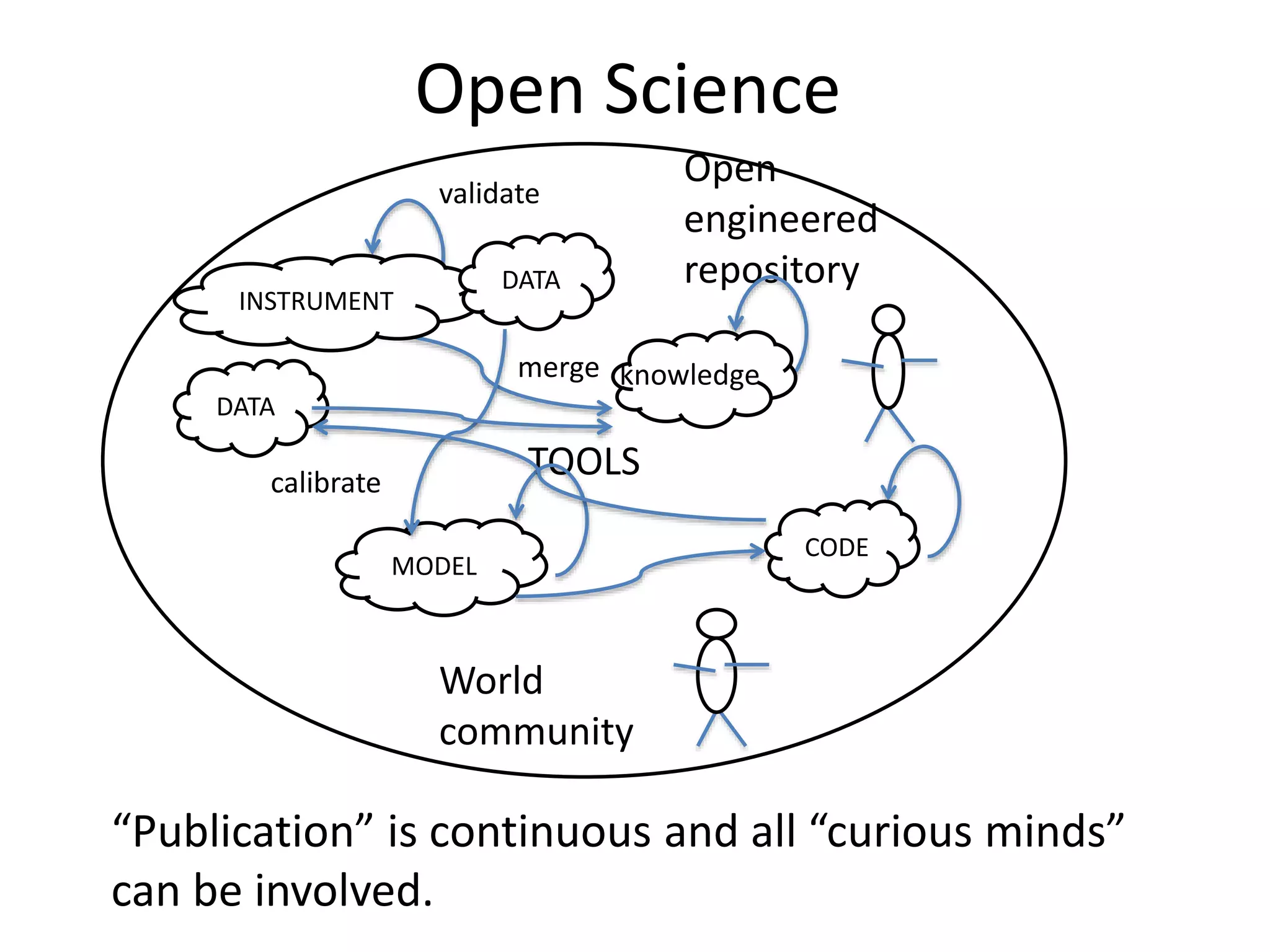
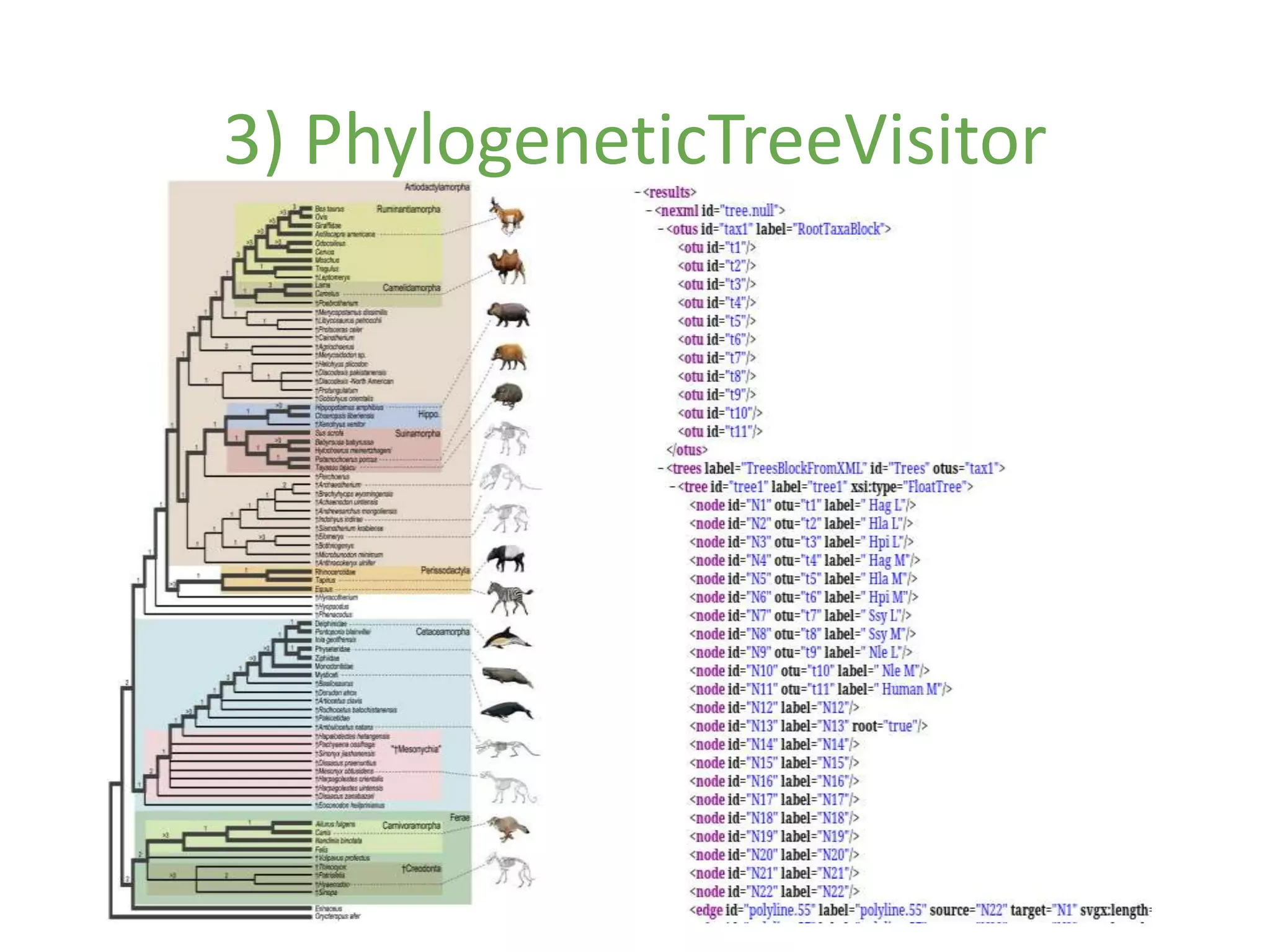
This document discusses open data and open science. It highlights Jean-Claude Bradley as a pioneer of open notebook science and open data who believed closed data means people die. It describes tools like ContentMine that can automatically extract data like chemical reactions, phylogenetic trees and clinical trial results from papers. Visitors can extract specific types of data while repositories can solve problems communally with continuous publication and validation.

















































































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)

















