Download as PDF, PPTX



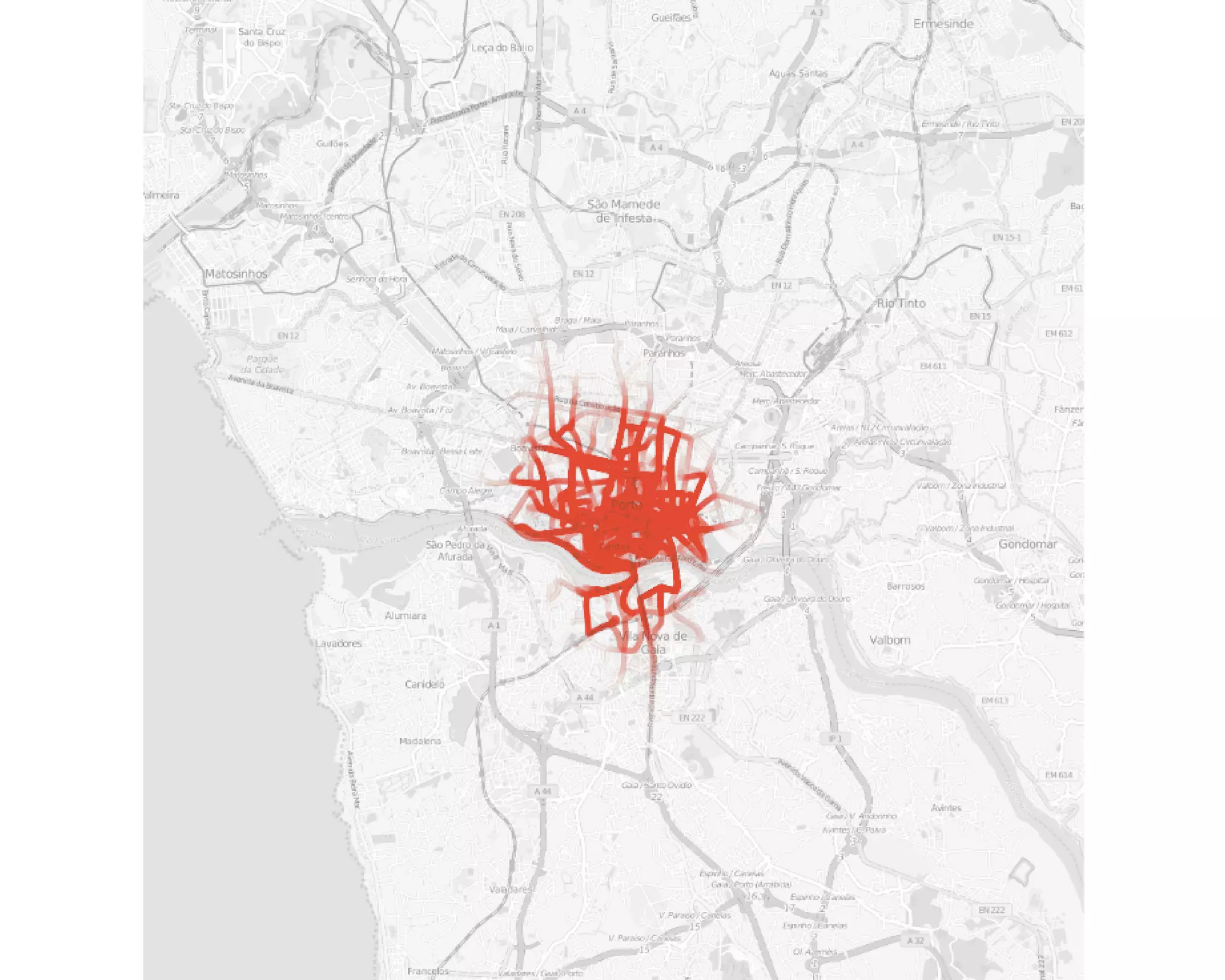
![How taxis navigate the city of Porto [1.7m trips] (K et.al., 2016).](https://image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-5-2048.jpg)




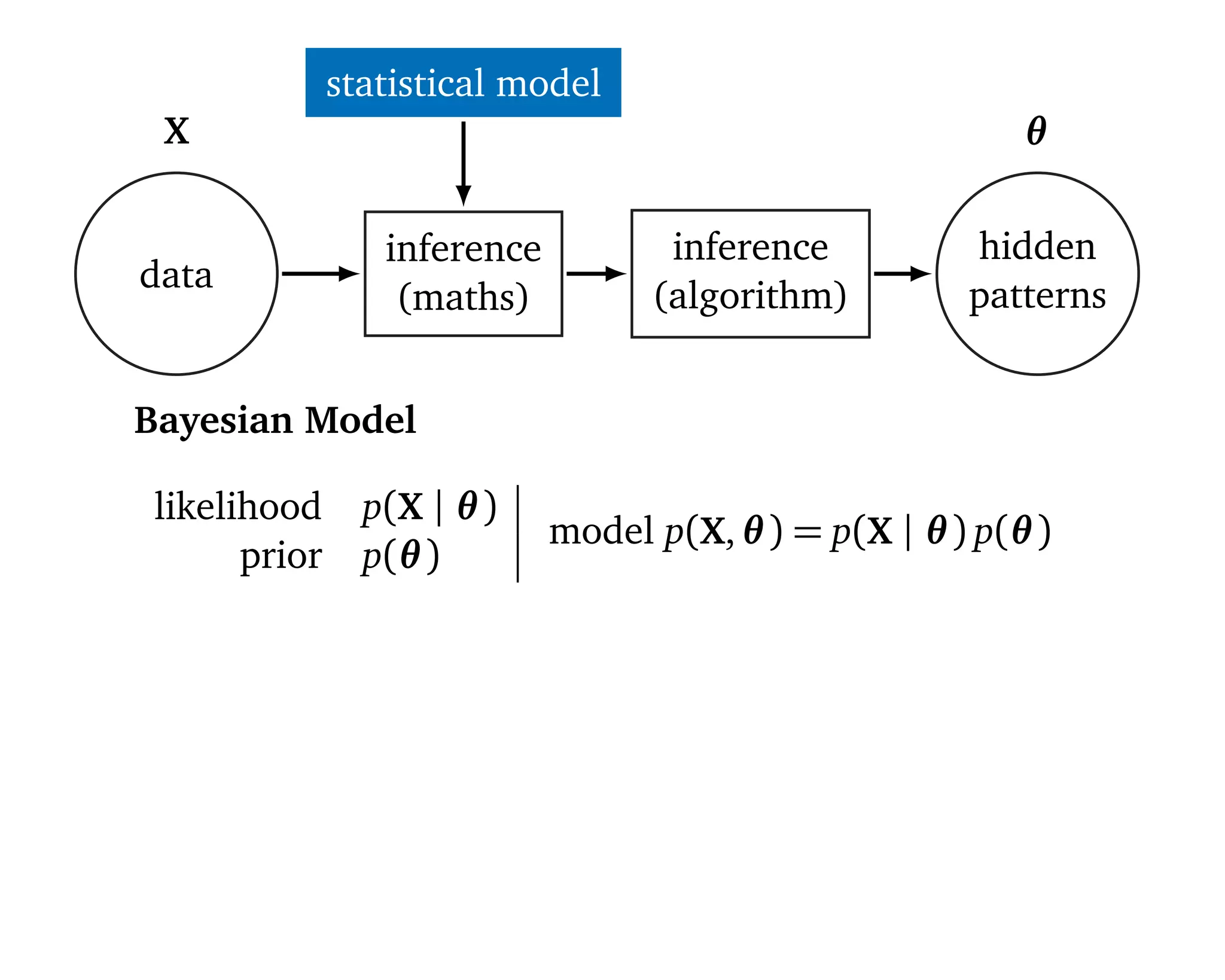
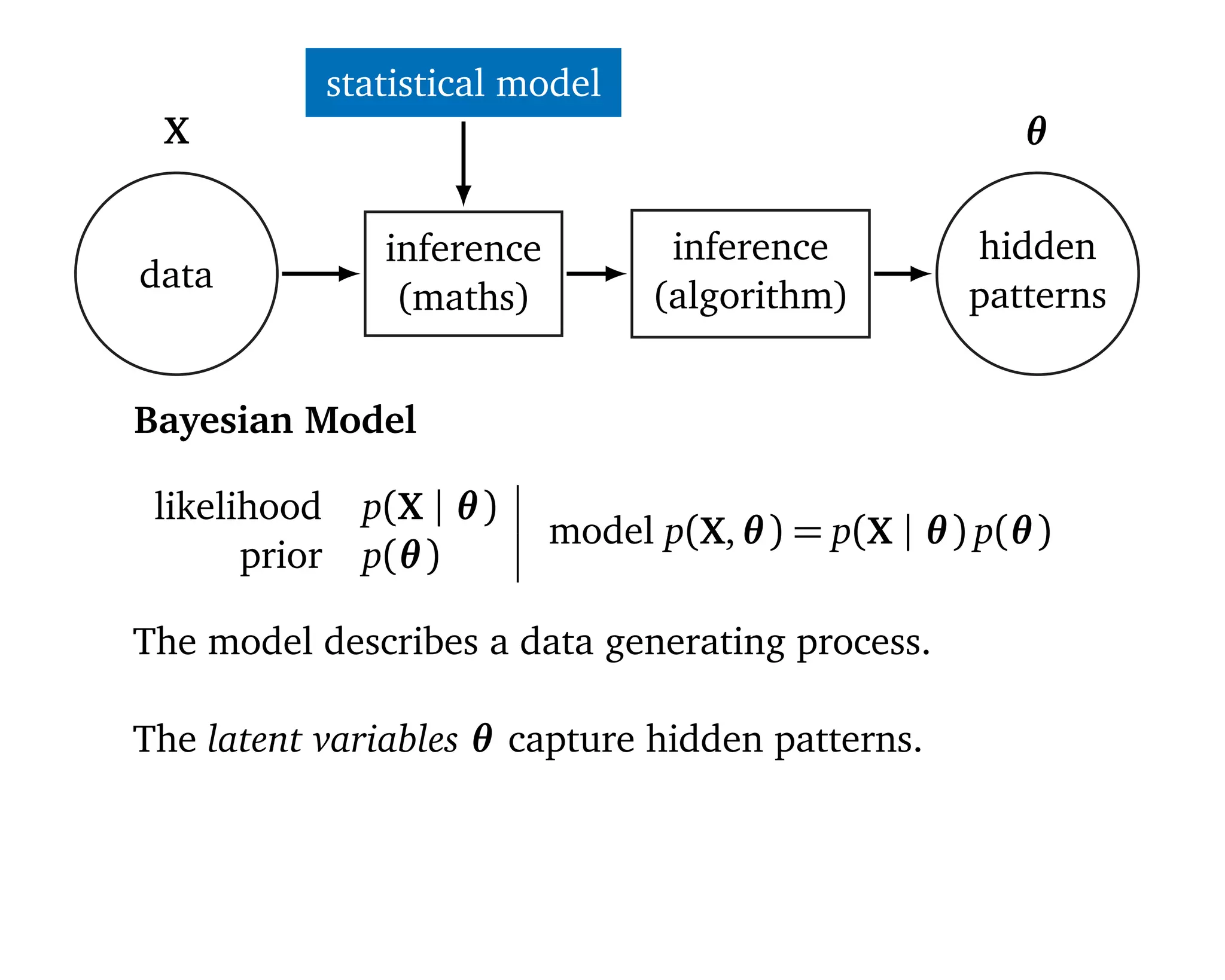
![statistical model
data
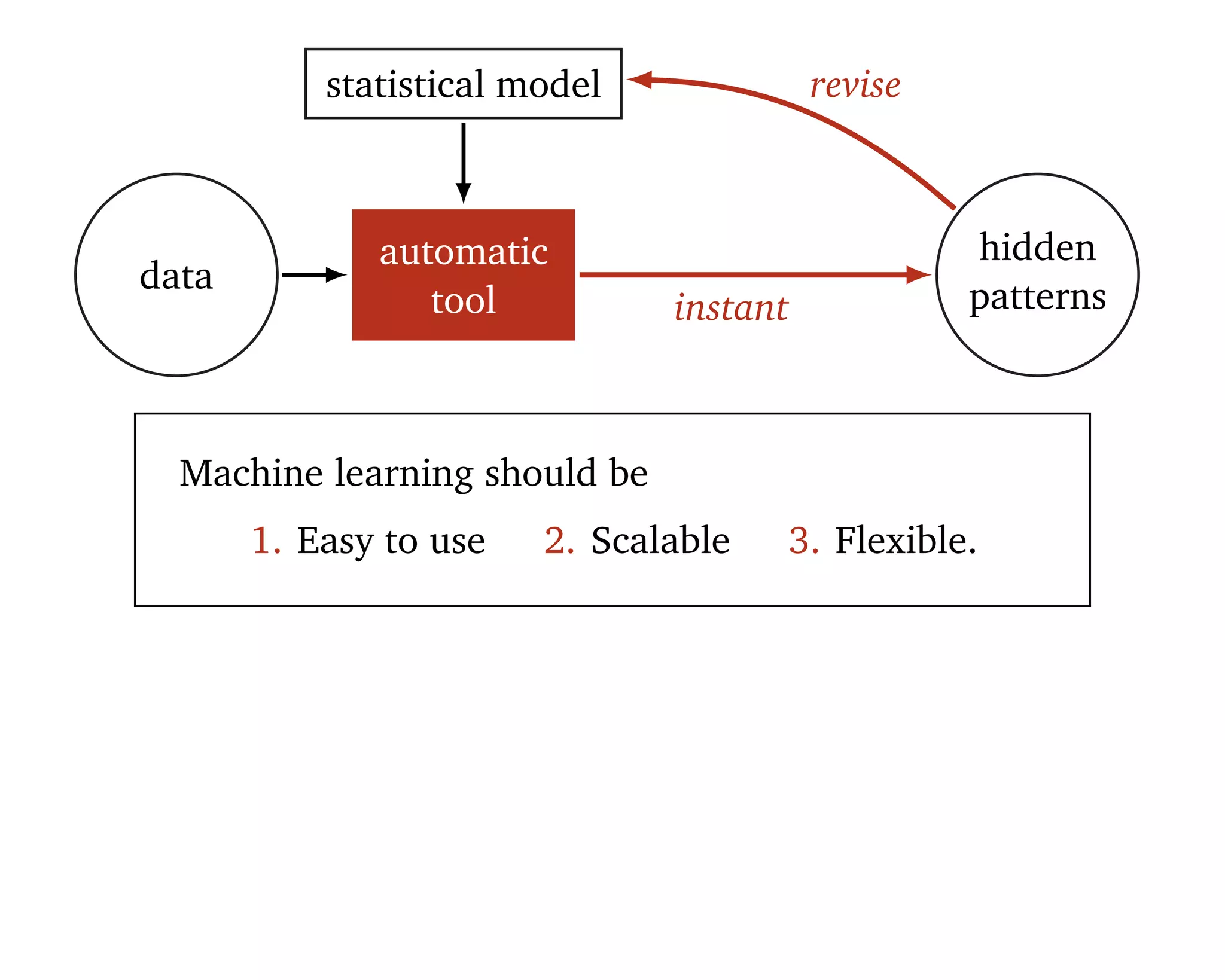
automatic
tool
hidden
patternsinstant
revise
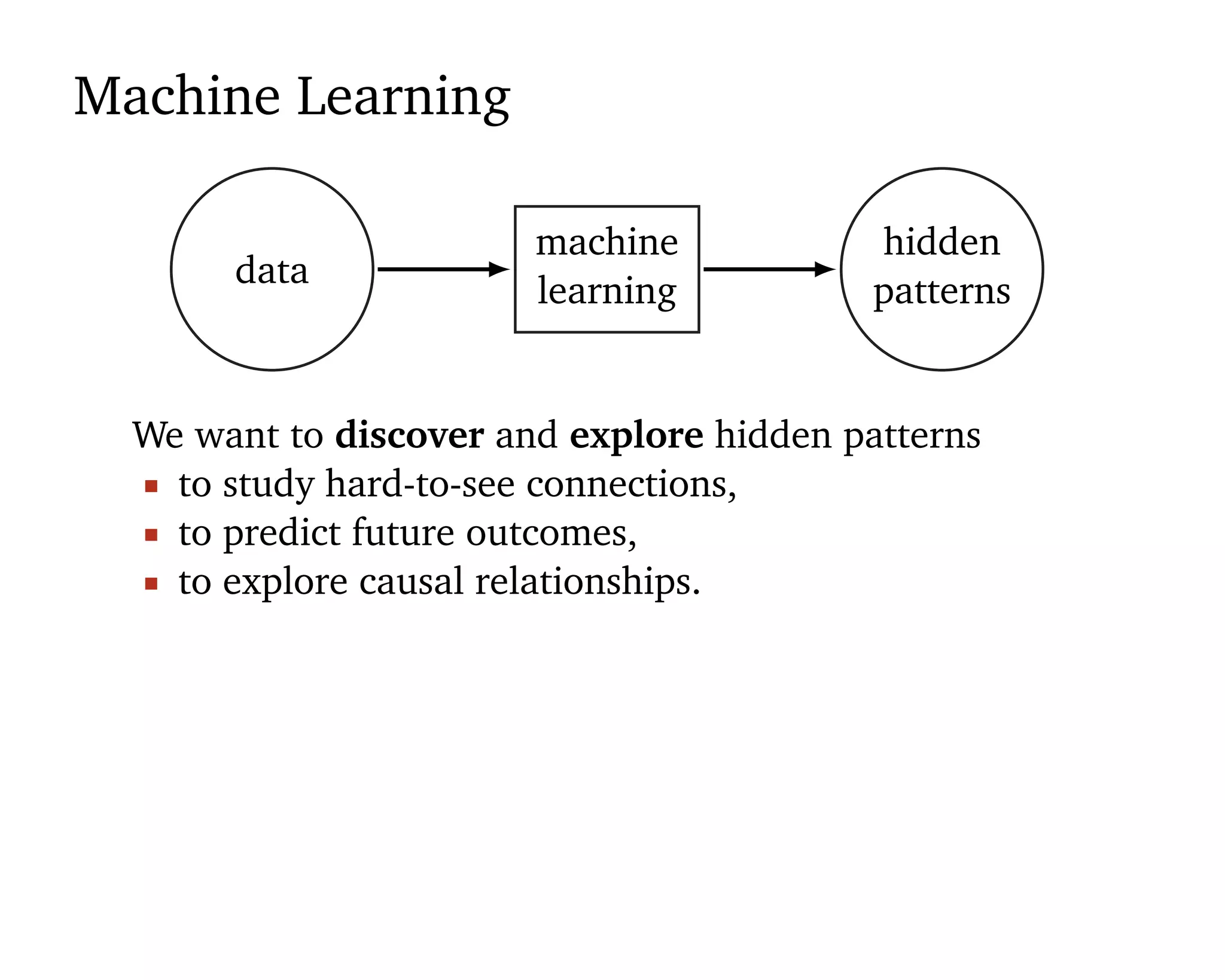
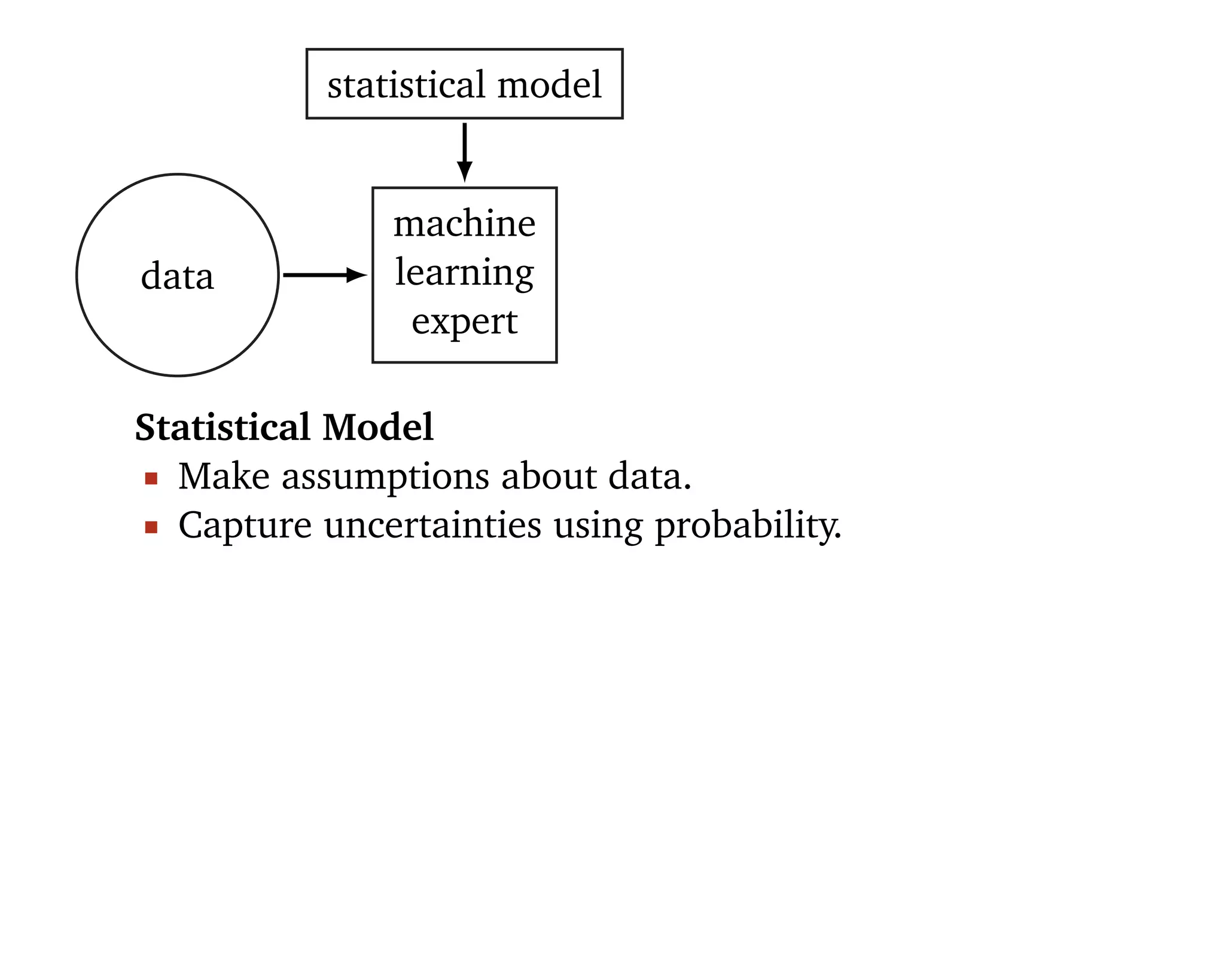
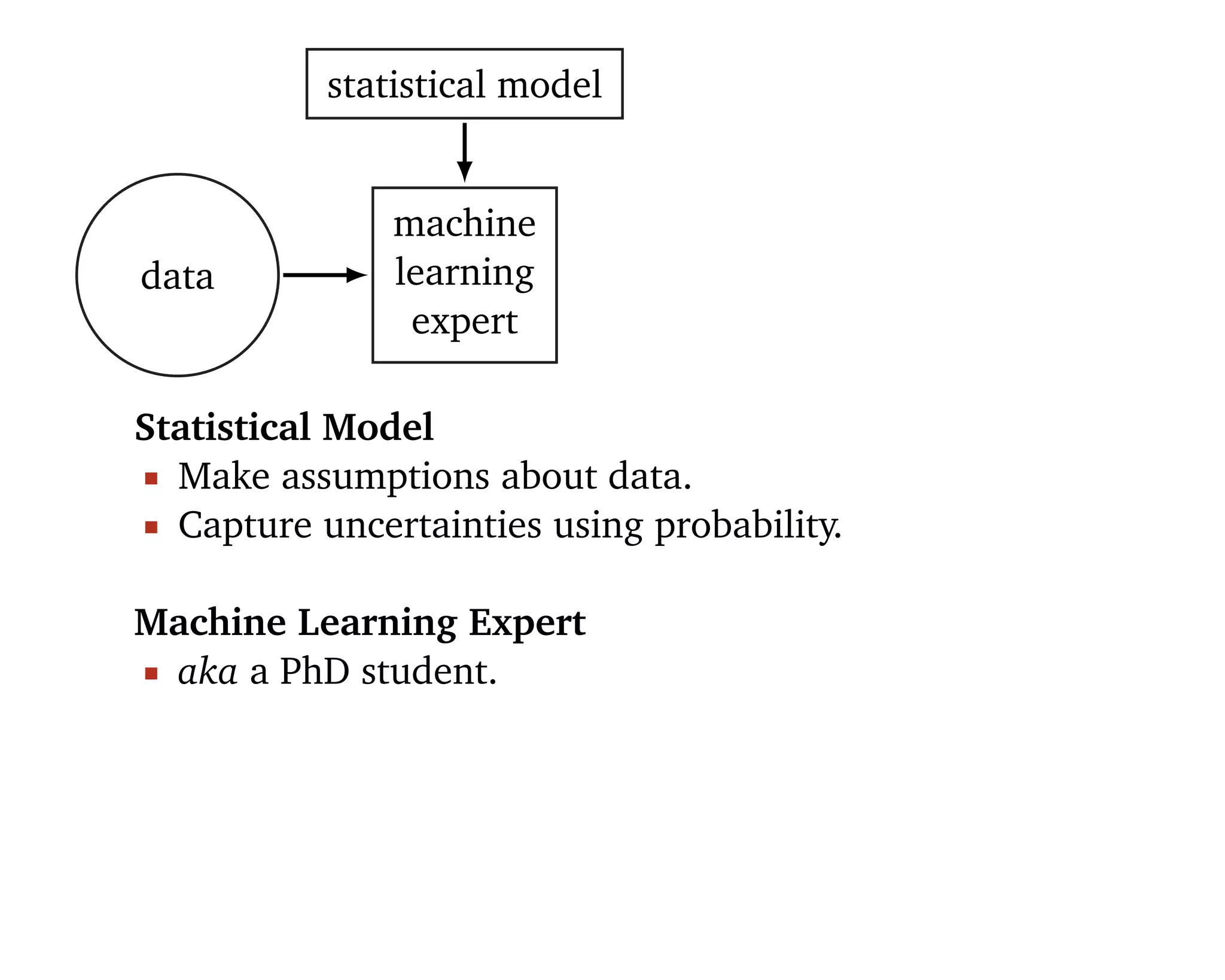
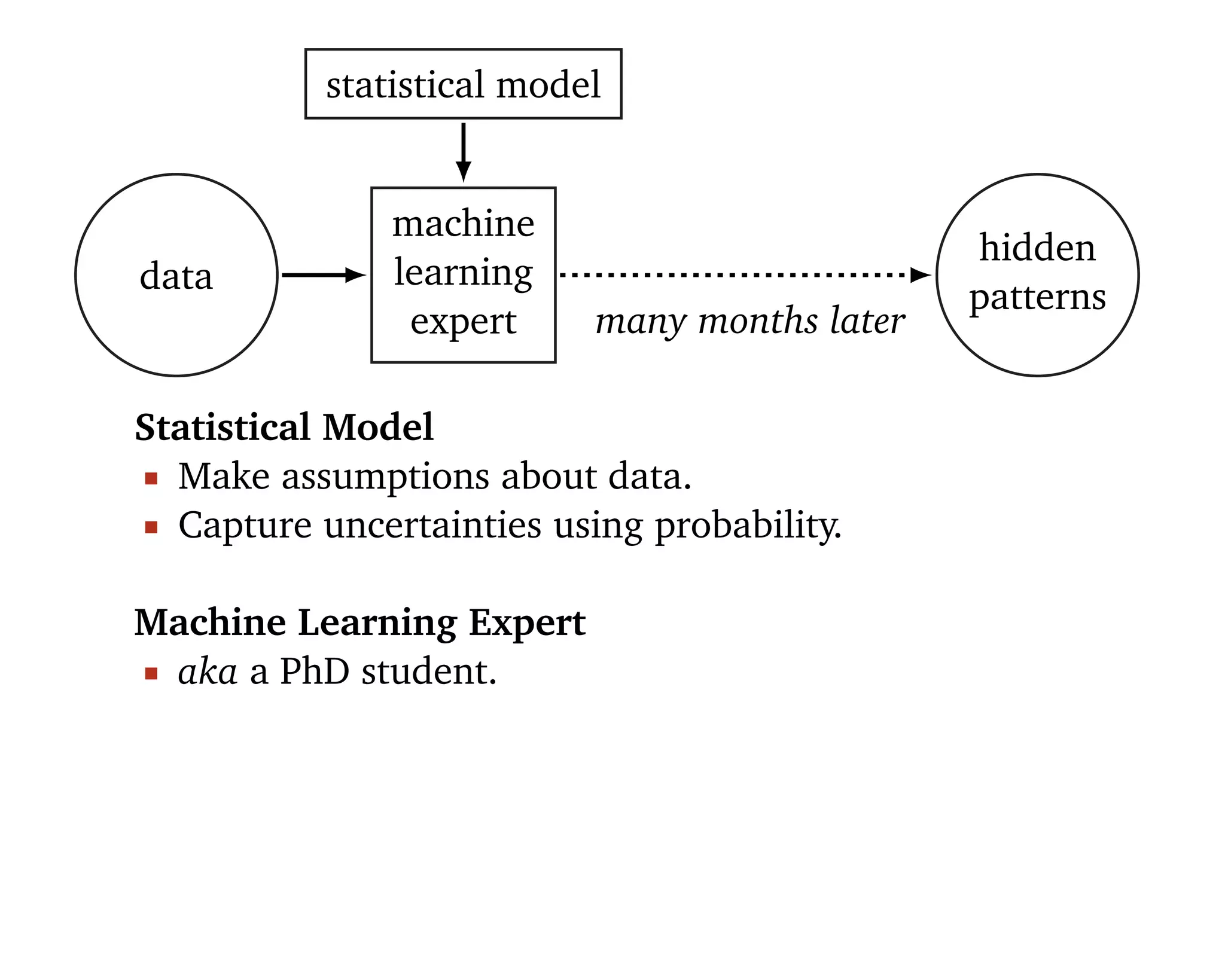
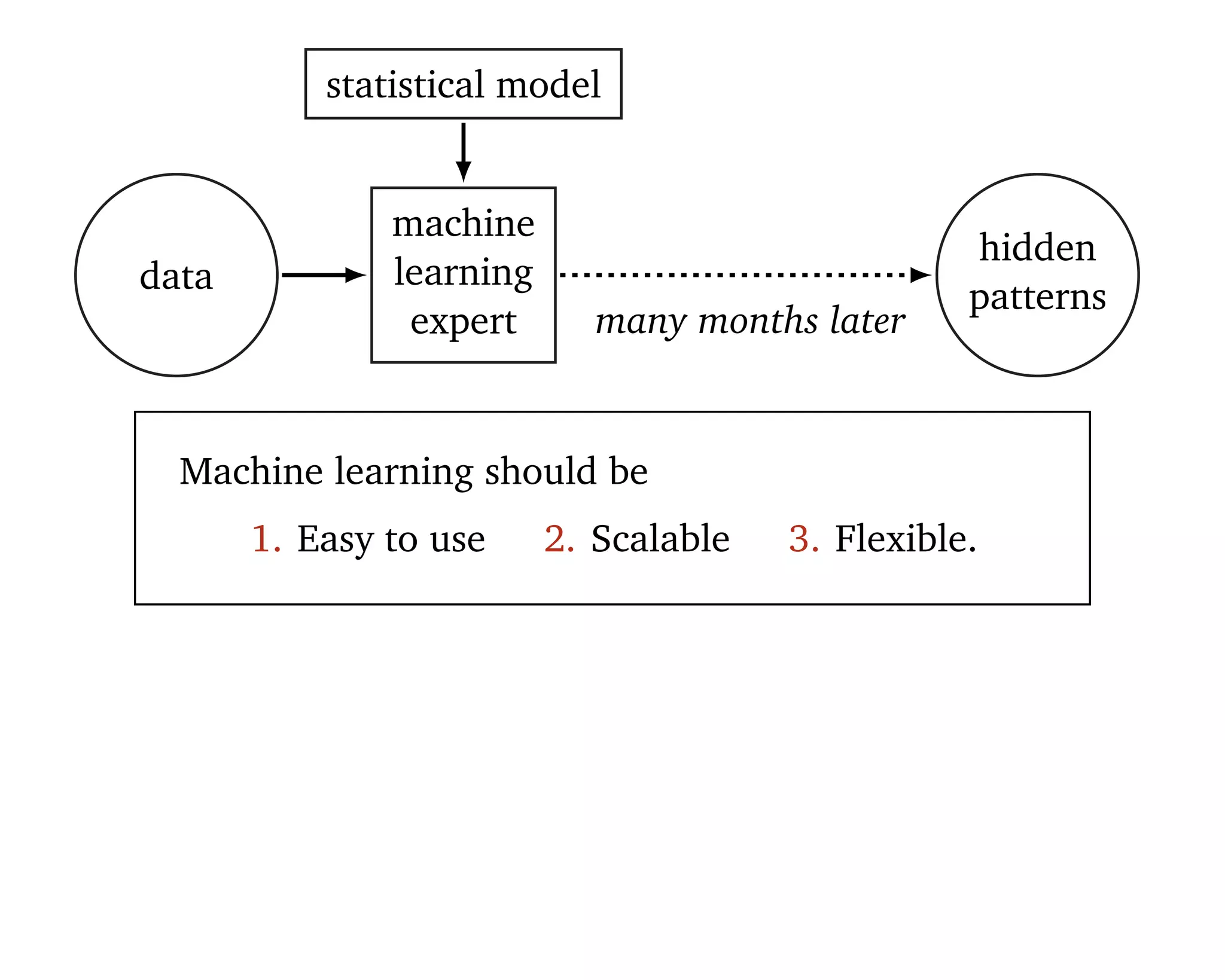
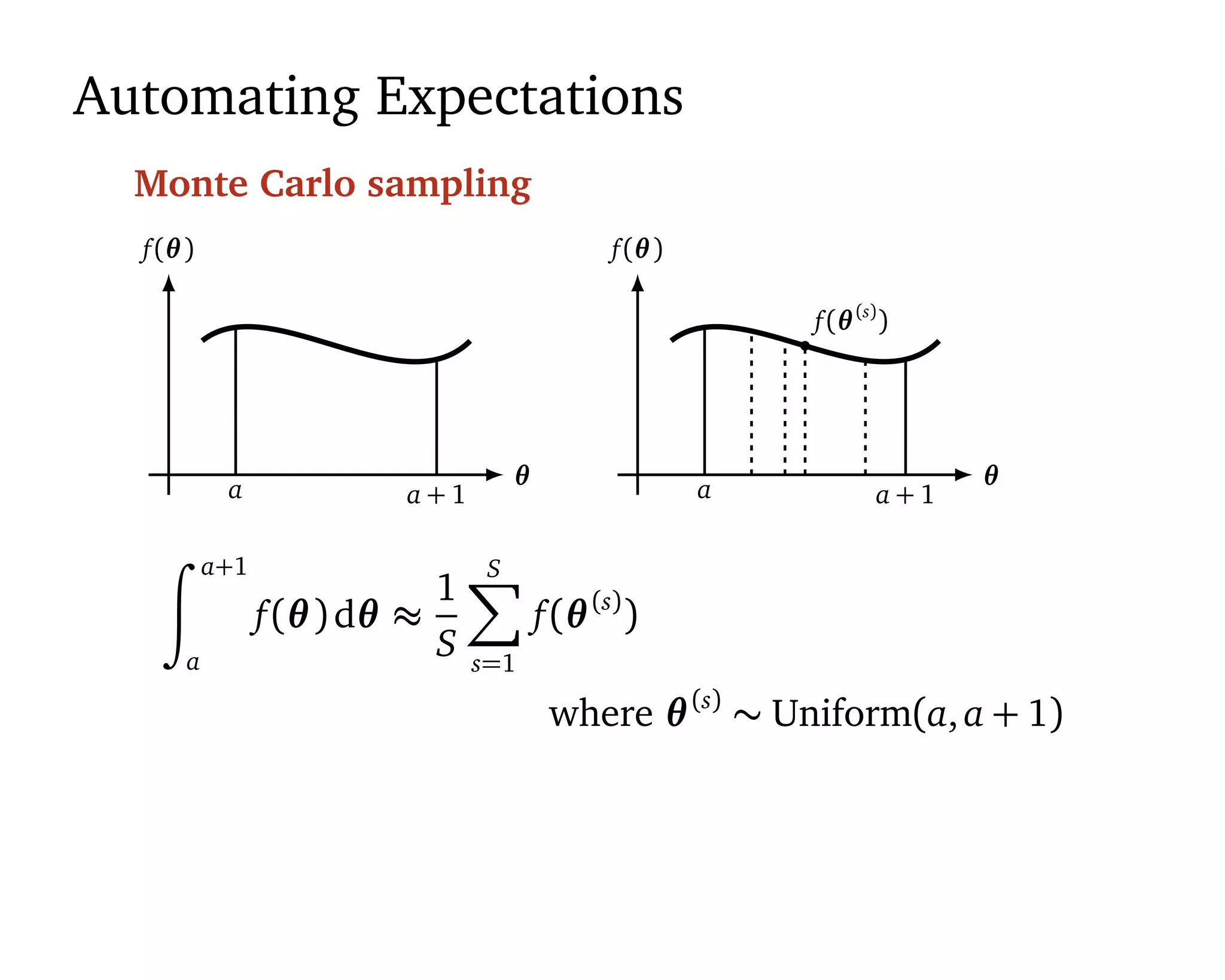
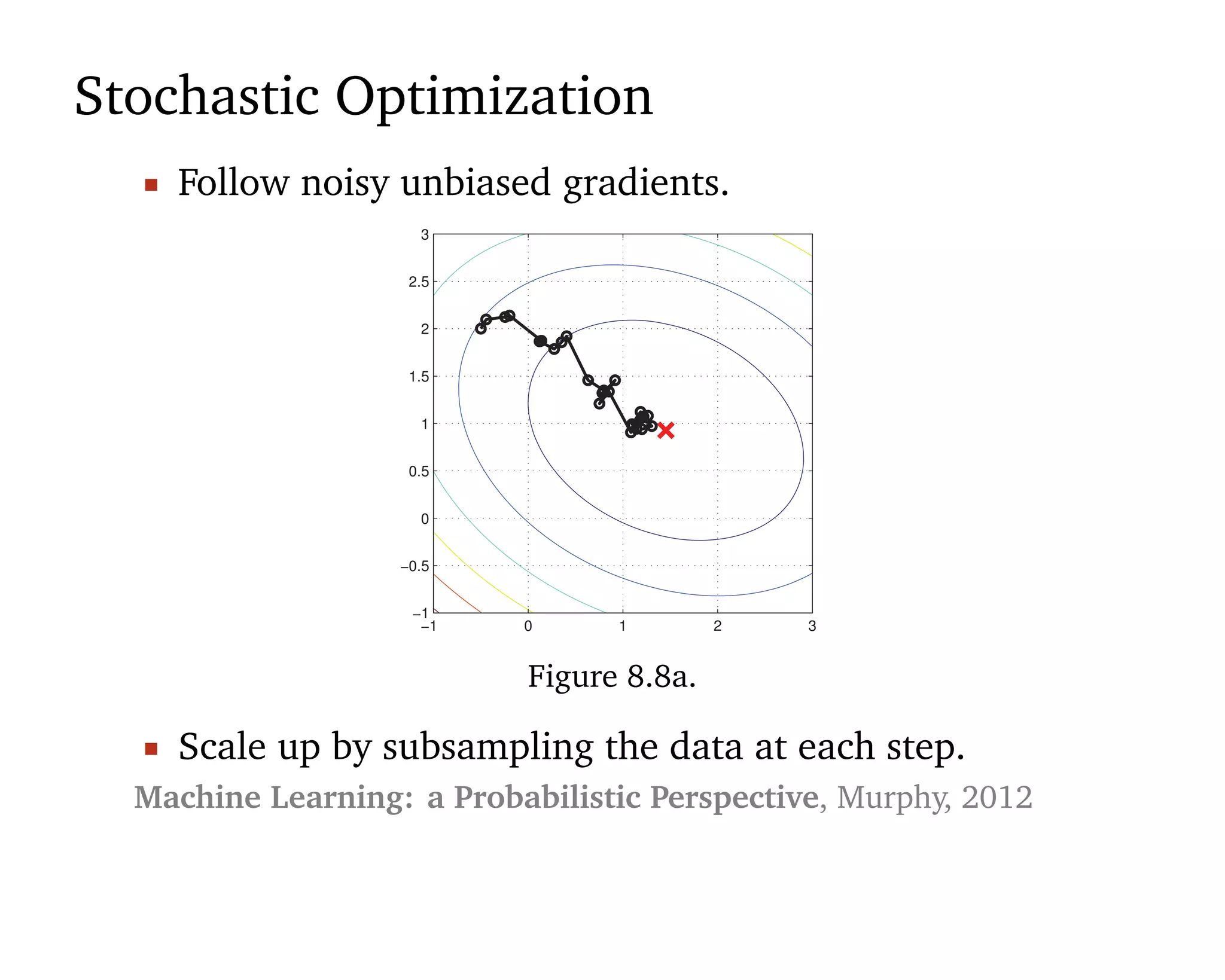
Machine learning should be
1. Easy to use 2. Scalable 3. Flexible.
“[Statistical] models are developed iteratively: we build a
model, use it to analyze data, assess how it succeeds and
fails, revise it, and repeat.” (Box, 1960; Blei, 2014)](https://image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-15-2048.jpg)









![How taxis navigate the city of Porto [1.7m trips] (K et.al., 2016).](https://image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-33-2048.jpg)


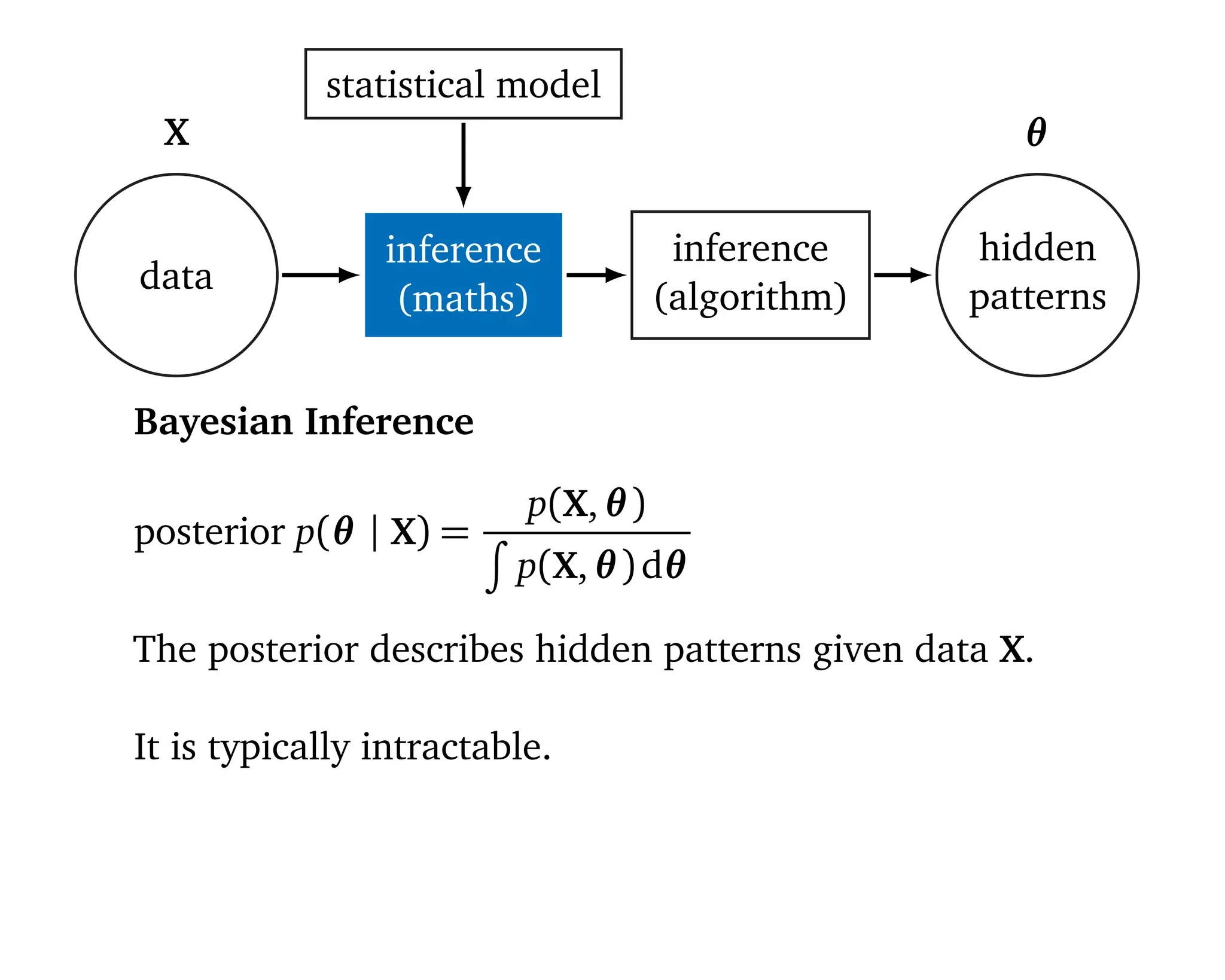
![Kullback Leibler Divergence
KL(q(θ) p(θ | X)) =
θ
q(θ)log
q(θ)
p(θ | X)
dθ
= q(θ) log
q(θ)
p(θ | X)
= q(θ) [logq(θ) − logp(θ | X)]](https://image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-39-2048.jpg)
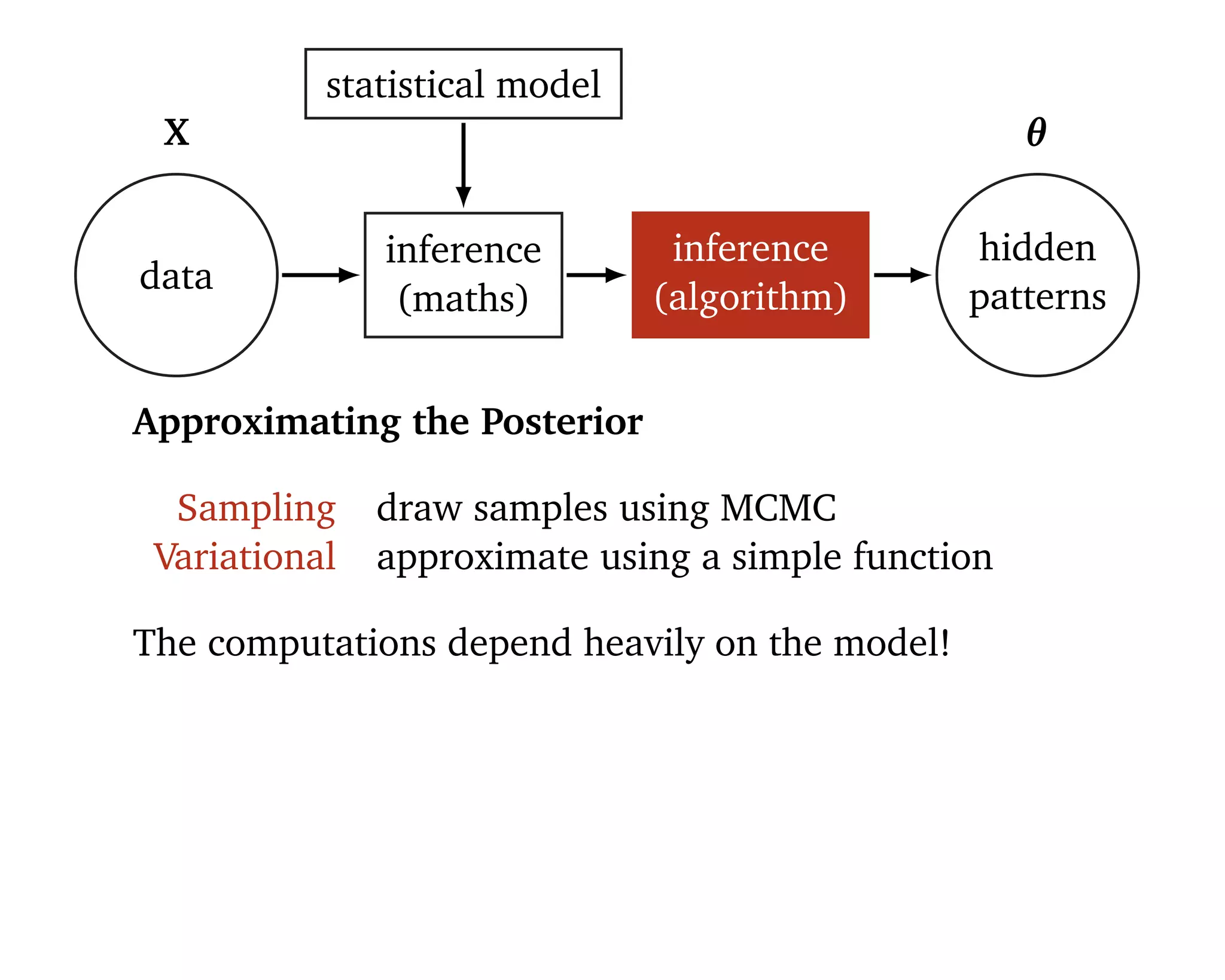
![Related Objective Function
(φ) = logp(X) − KL(q(θ) p(θ | X))
= logp(X) − q(θ) [logq(θ) − logp(θ | X)]
= logp(X) + q(θ) [logp(X | θ)] − q(θ) [logq(θ)]
= q(θ) [logp(θ,X)] − q(θ) [logq(θ)]
= q(θ ;φ) logp(X,θ)
cross-entropy
− q(θ ;φ) logq(θ ; φ)
entropy](https://image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-40-2048.jpg)




![How taxis navigate the city of Porto [1.7m trips] (K et.al., 2016).](https://crownmelresort.com/image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-5-2048.jpg)









![statistical model
data
automatic
tool
hidden
patternsinstant
revise
Machine learning should be
1. Easy to use 2. Scalable 3. Flexible.
“[Statistical] models are developed iteratively: we build a
model, use it to analyze data, assess how it succeeds and
fails, revise it, and repeat.” (Box, 1960; Blei, 2014)](https://crownmelresort.com/image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-15-2048.jpg)

















![How taxis navigate the city of Porto [1.7m trips] (K et.al., 2016).](https://crownmelresort.com/image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-33-2048.jpg)





![Kullback Leibler Divergence
KL(q(θ) p(θ | X)) =
θ
q(θ)log
q(θ)
p(θ | X)
dθ
= q(θ) log
q(θ)
p(θ | X)
= q(θ) [logq(θ) − logp(θ | X)]](https://crownmelresort.com/image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-39-2048.jpg)
![Related Objective Function
(φ) = logp(X) − KL(q(θ) p(θ | X))
= logp(X) − q(θ) [logq(θ) − logp(θ | X)]
= logp(X) + q(θ) [logp(X | θ)] − q(θ) [logq(θ)]
= q(θ) [logp(θ,X)] − q(θ) [logq(θ)]
= q(θ ;φ) logp(X,θ)
cross-entropy
− q(θ ;φ) logq(θ ; φ)
entropy](https://crownmelresort.com/image.slidesharecdn.com/rstatsnyc-160511214053/75/One-Algorithm-to-Rule-Them-All-How-to-Automate-Statistical-Computation-40-2048.jpg)

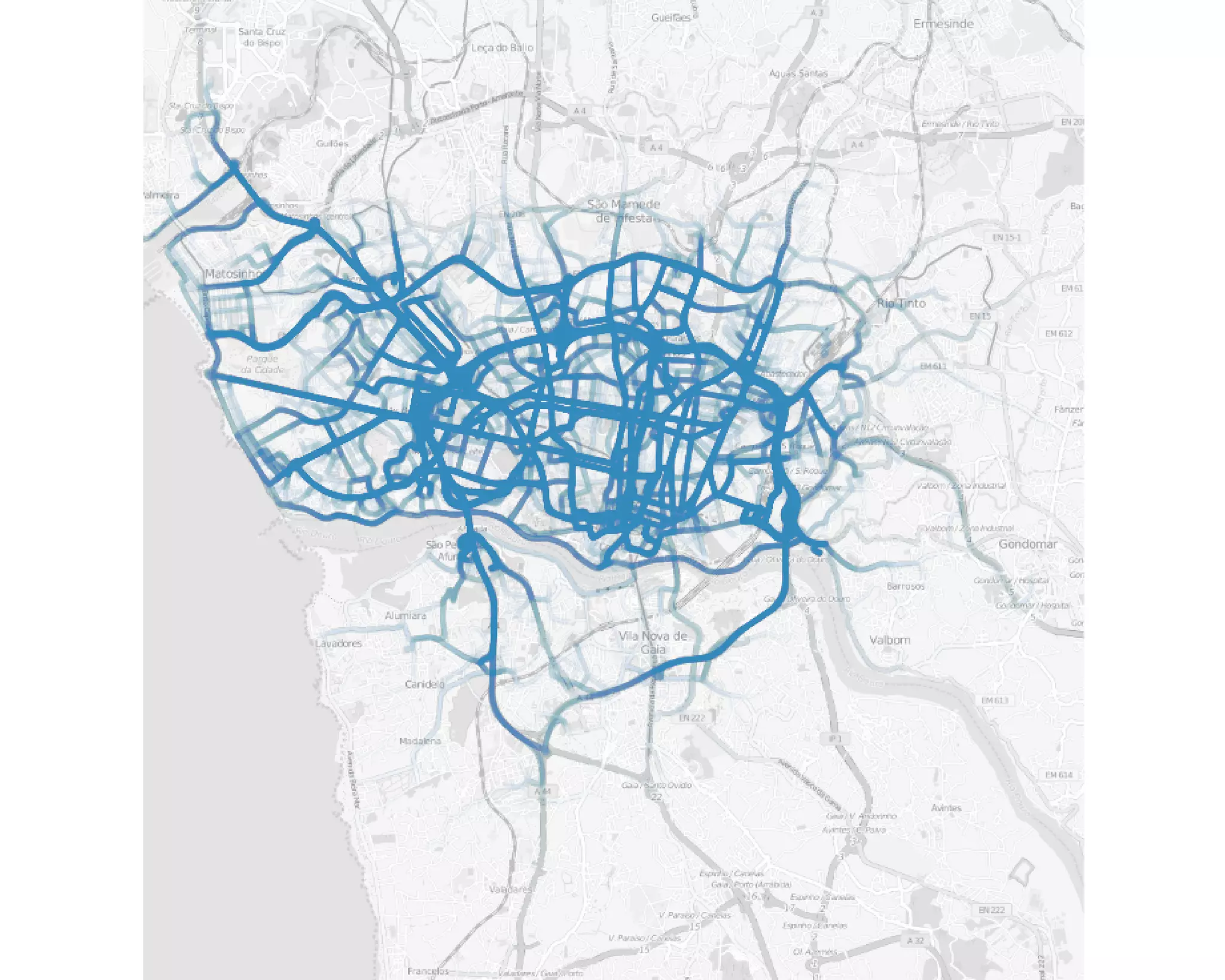
The document discusses the capabilities and limitations of automating statistical computations through machine learning algorithms. It emphasizes the need for models to be easy to use, scalable, and flexible while detailing techniques such as Monte Carlo sampling and automatic differentiation to enhance statistical analysis. The application of these methods is illustrated with examples like analyzing large datasets of taxi rides to extract hidden patterns efficiently.






























































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)