Downloaded 20 times
















![Nested Data
• Nested data is becoming prevalent
– JSON, BSON, XML, Protocol Buffers, Avro, etc.
– The data source may or may not be aware
• MongoDB supports nested data natively
• A single HBase value could be a JSON document
(compound nested type)
– Google Dremel’s innovation was efficient columnar
storage and querying of nested data
• Flattening nested data is error-prone and often
impossible
– Think about repeated and optional fields at every
level…
• Apache Drill supports nested data
– Extensions to ANSI SQL:2003
enum Gender {
MALE, FEMALE
}
record User {
string name;
Gender gender;
long followers;
}
{
"name": "Homer",
"gender": "Male",
"followers": 100
children: [
{name: "Bart"},
{name: "Lisa”}
]
}
JSON
Avro](https://image.slidesharecdn.com/nosqlandsql-openanalyticssummit7-130618083120-phpapp02/75/No-sql-and-sql-open-analytics-summit-26-2048.jpg)



























![Nested Data
• Nested data is becoming prevalent
– JSON, BSON, XML, Protocol Buffers, Avro, etc.
– The data source may or may not be aware
• MongoDB supports nested data natively
• A single HBase value could be a JSON document
(compound nested type)
– Google Dremel’s innovation was efficient columnar
storage and querying of nested data
• Flattening nested data is error-prone and often
impossible
– Think about repeated and optional fields at every
level…
• Apache Drill supports nested data
– Extensions to ANSI SQL:2003
enum Gender {
MALE, FEMALE
}
record User {
string name;
Gender gender;
long followers;
}
{
"name": "Homer",
"gender": "Male",
"followers": 100
children: [
{name: "Bart"},
{name: "Lisa”}
]
}
JSON
Avro](https://crownmelresort.com/image.slidesharecdn.com/nosqlandsql-openanalyticssummit7-130618083120-phpapp02/75/No-sql-and-sql-open-analytics-summit-26-2048.jpg)



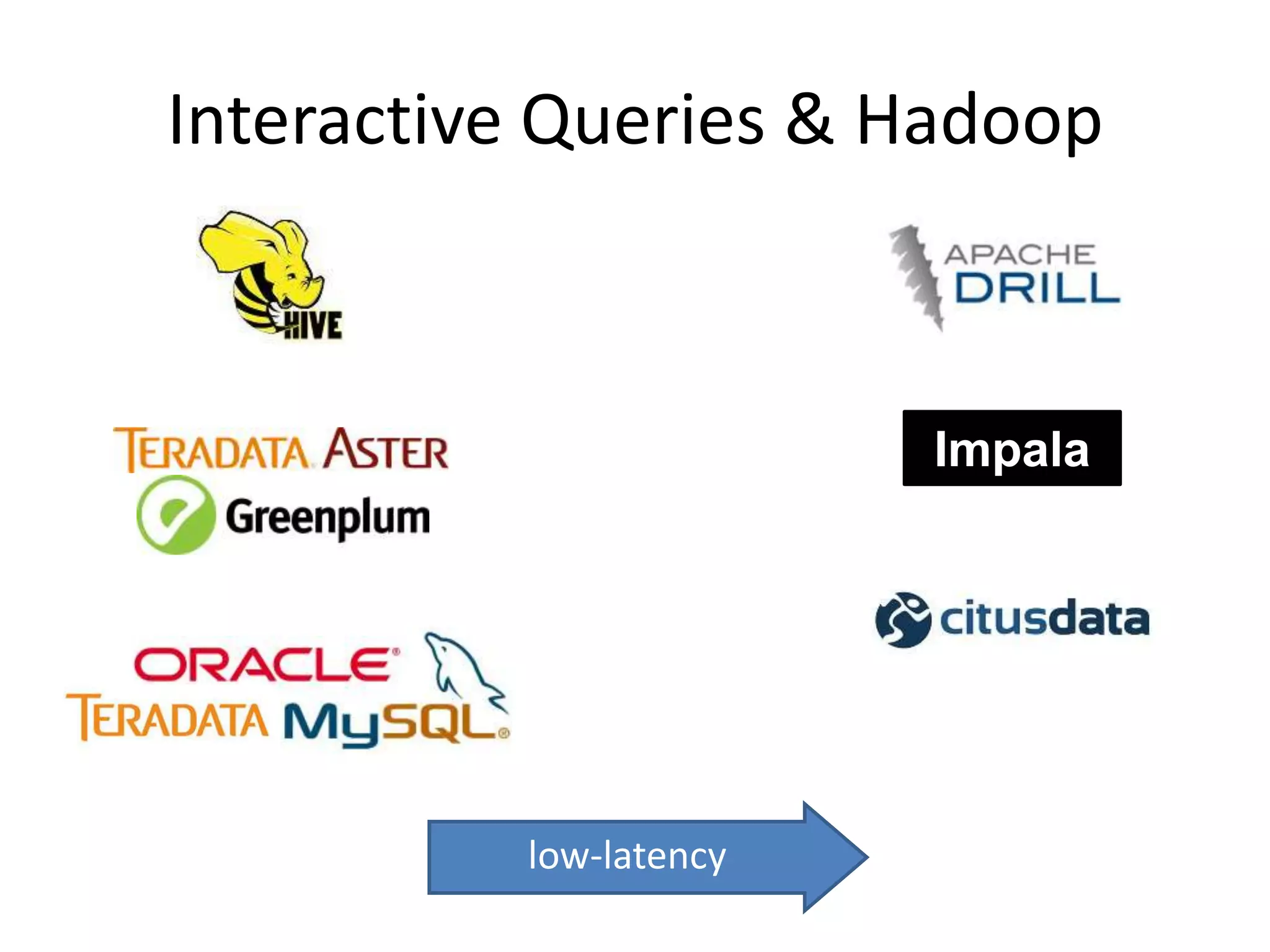
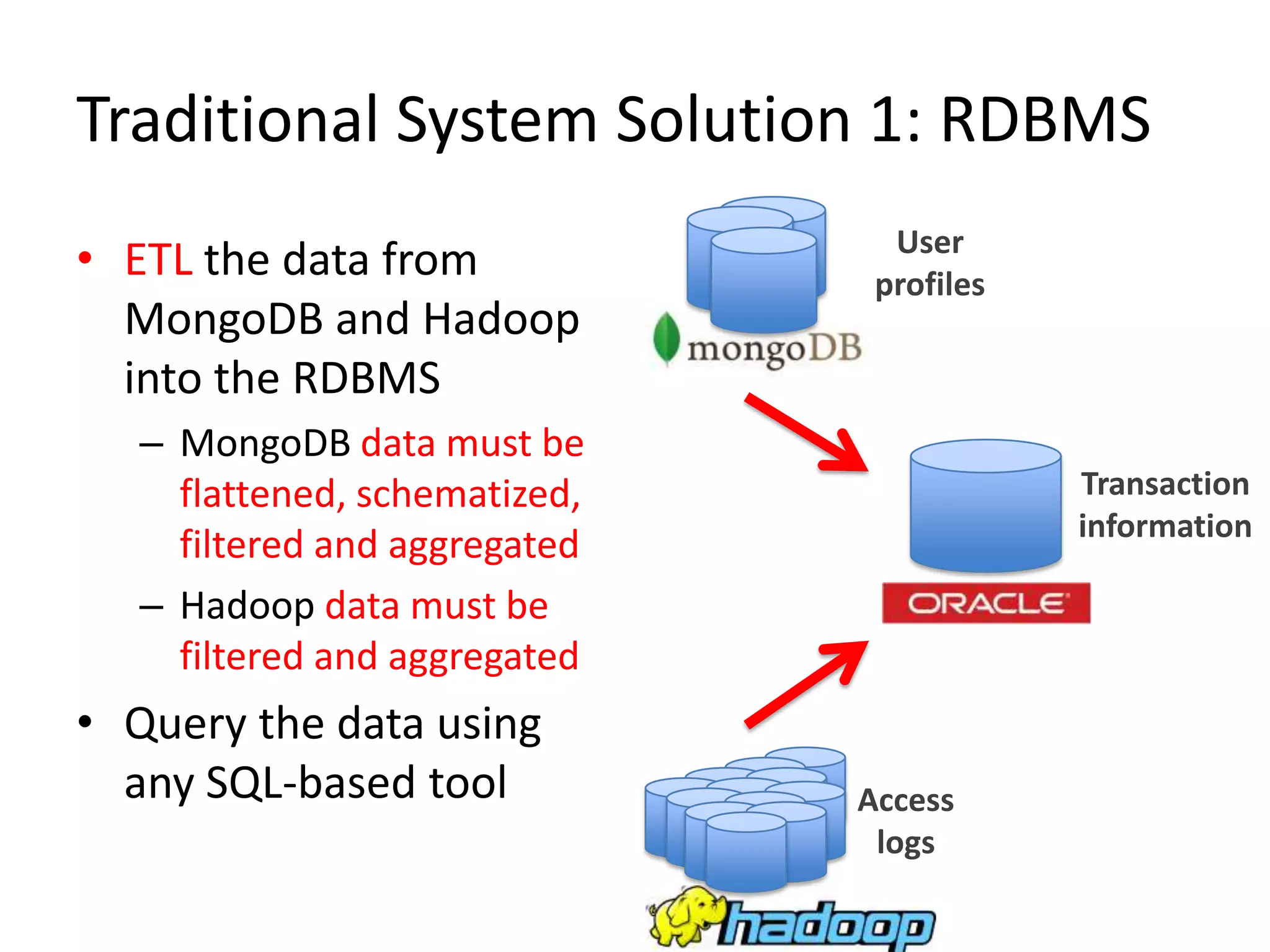
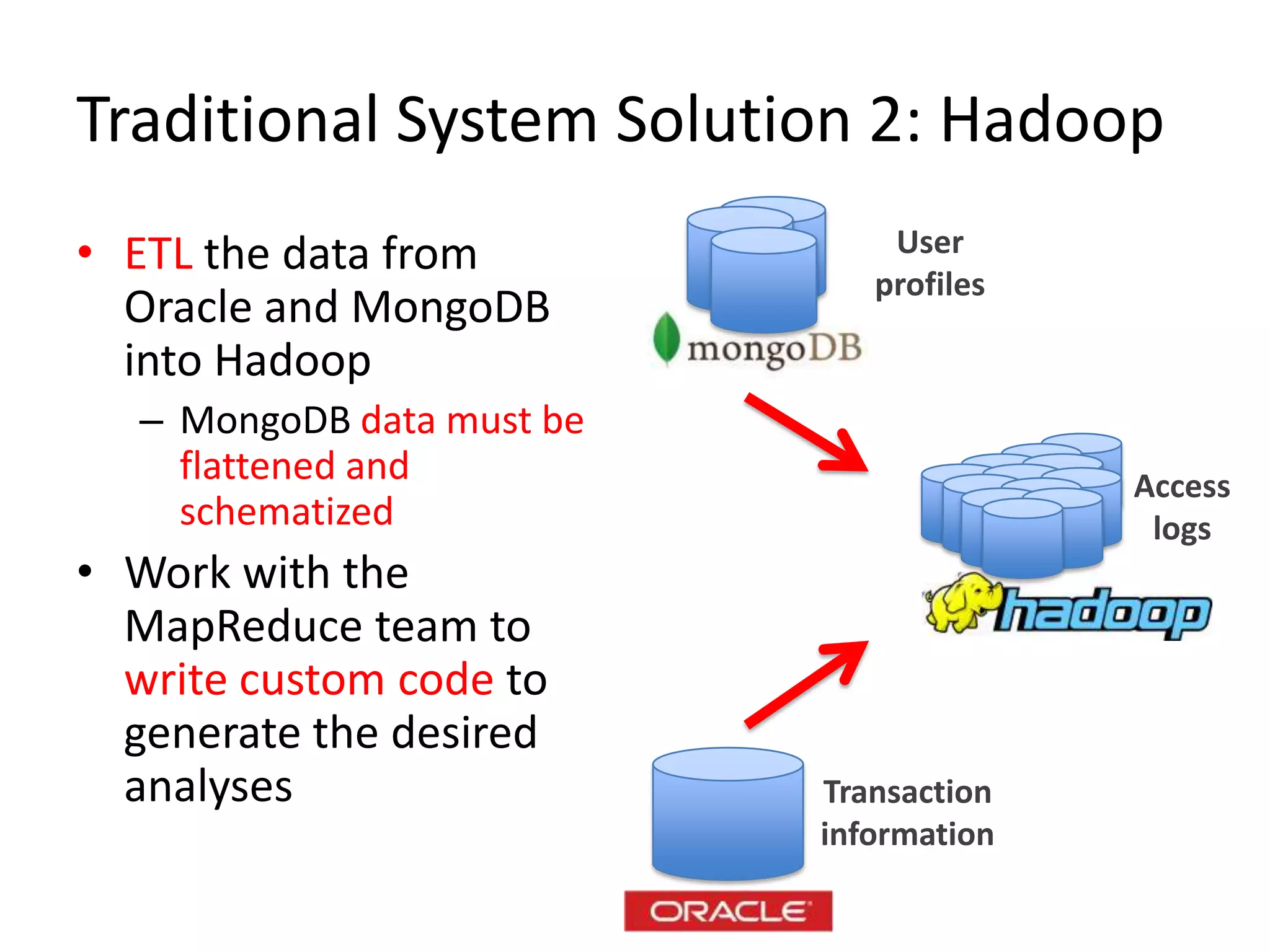
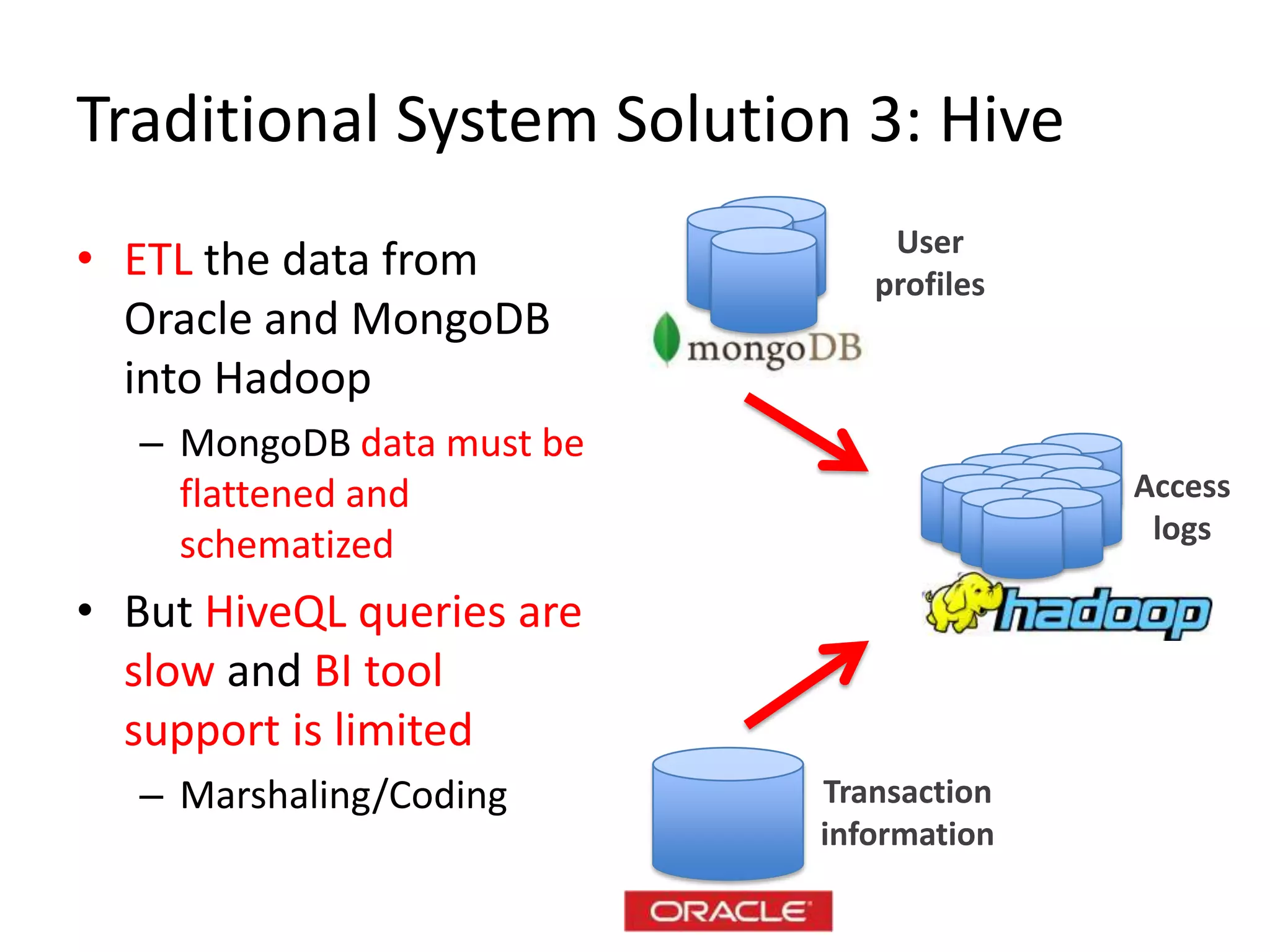
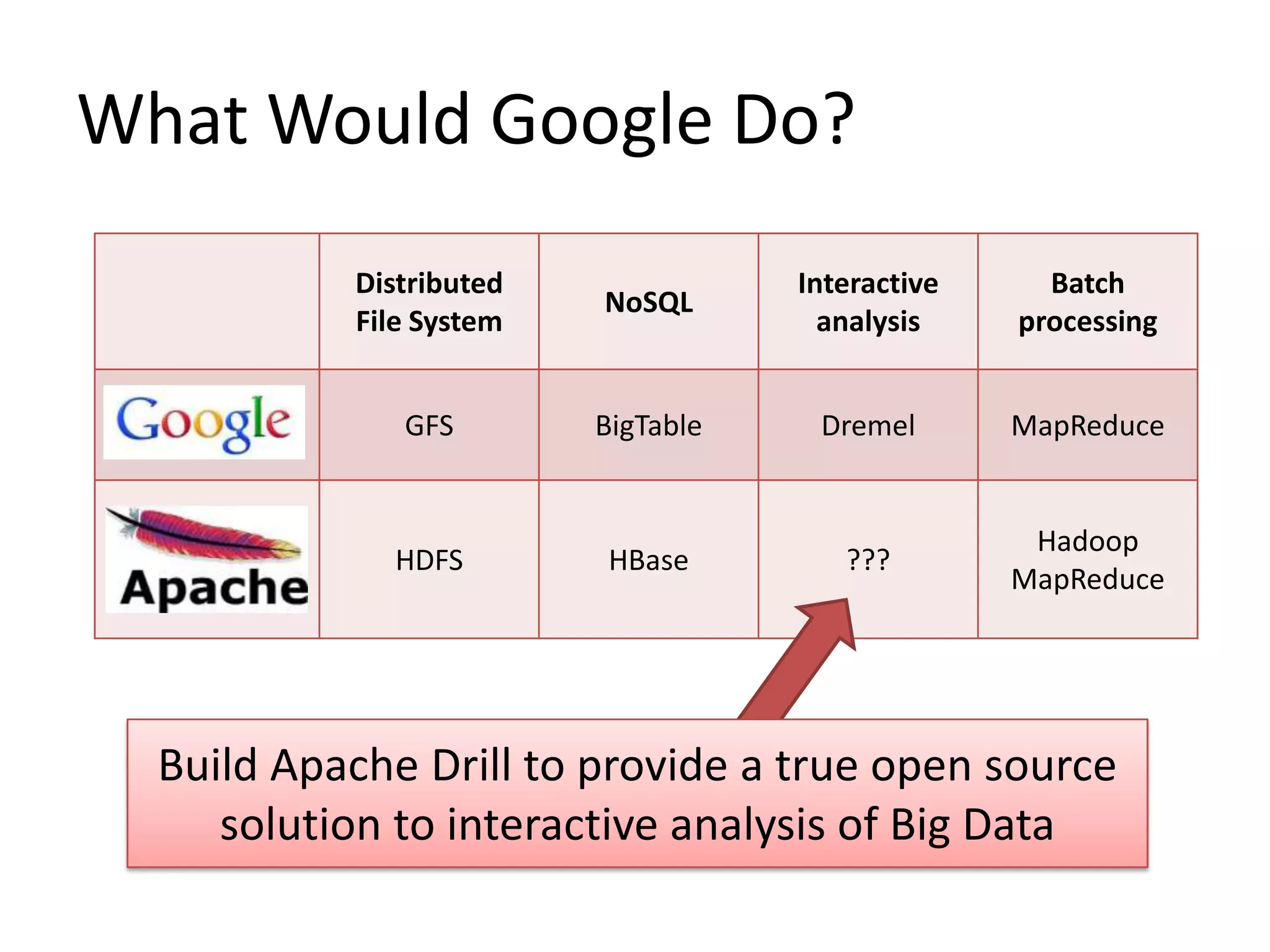
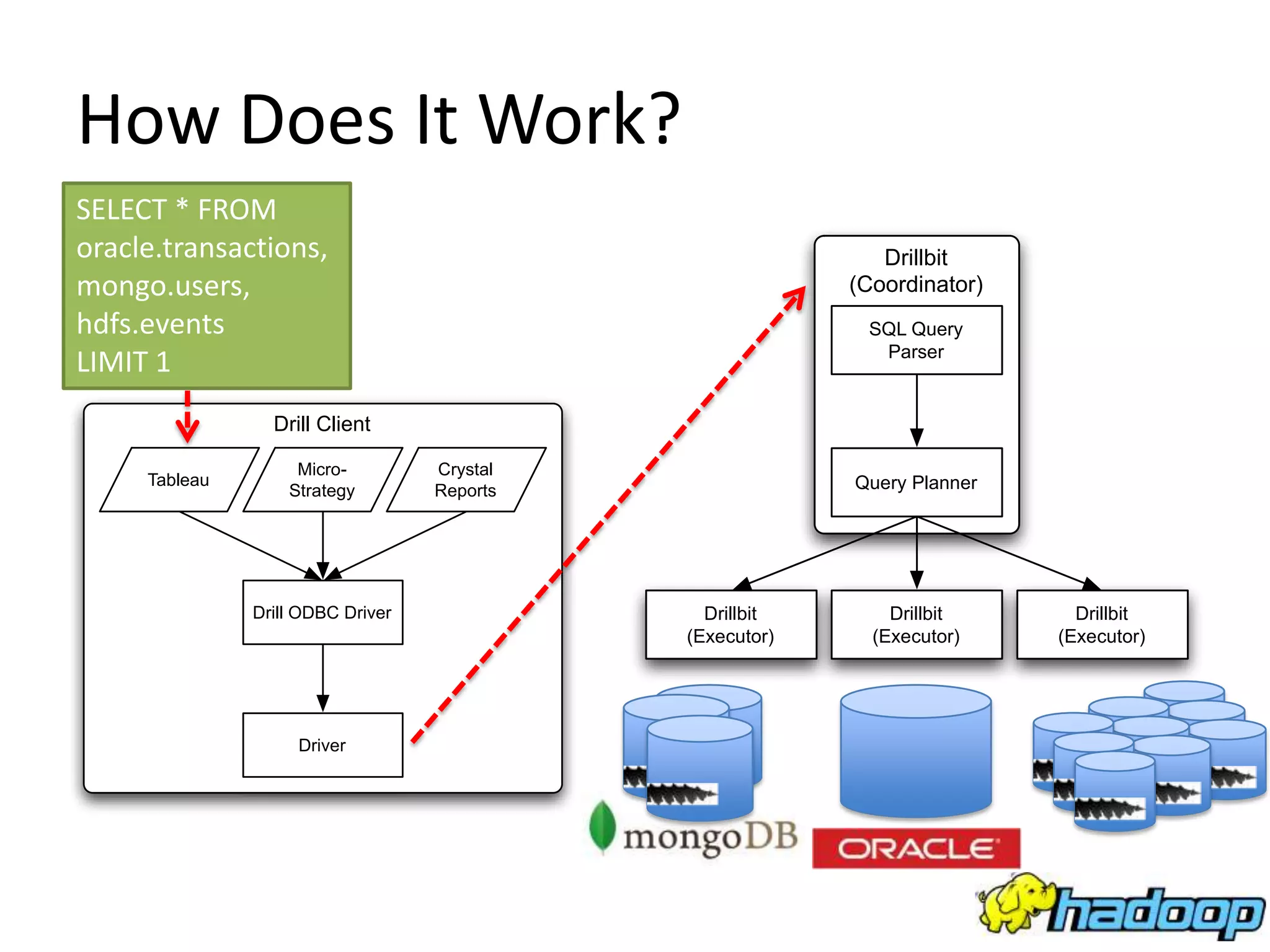
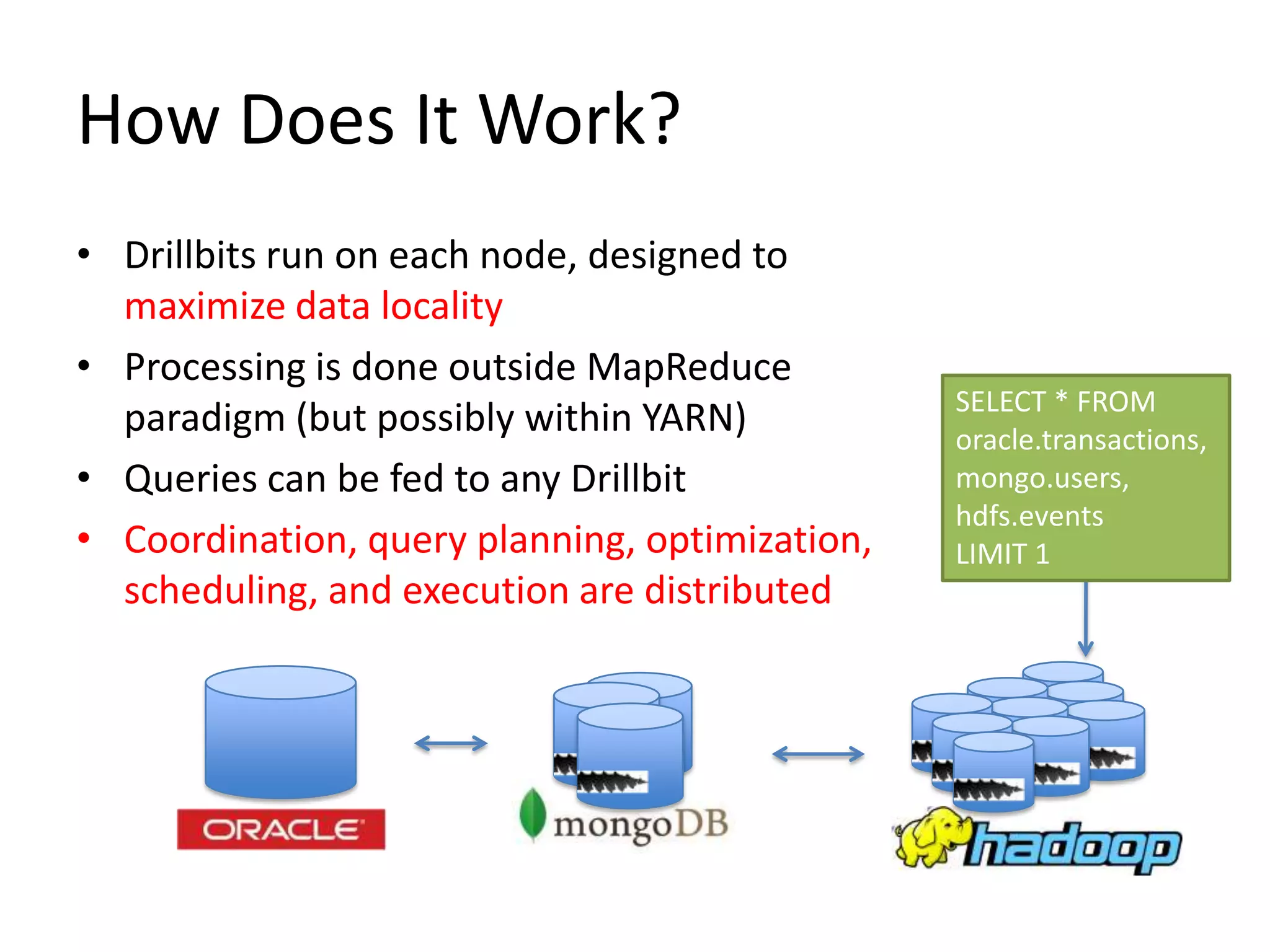
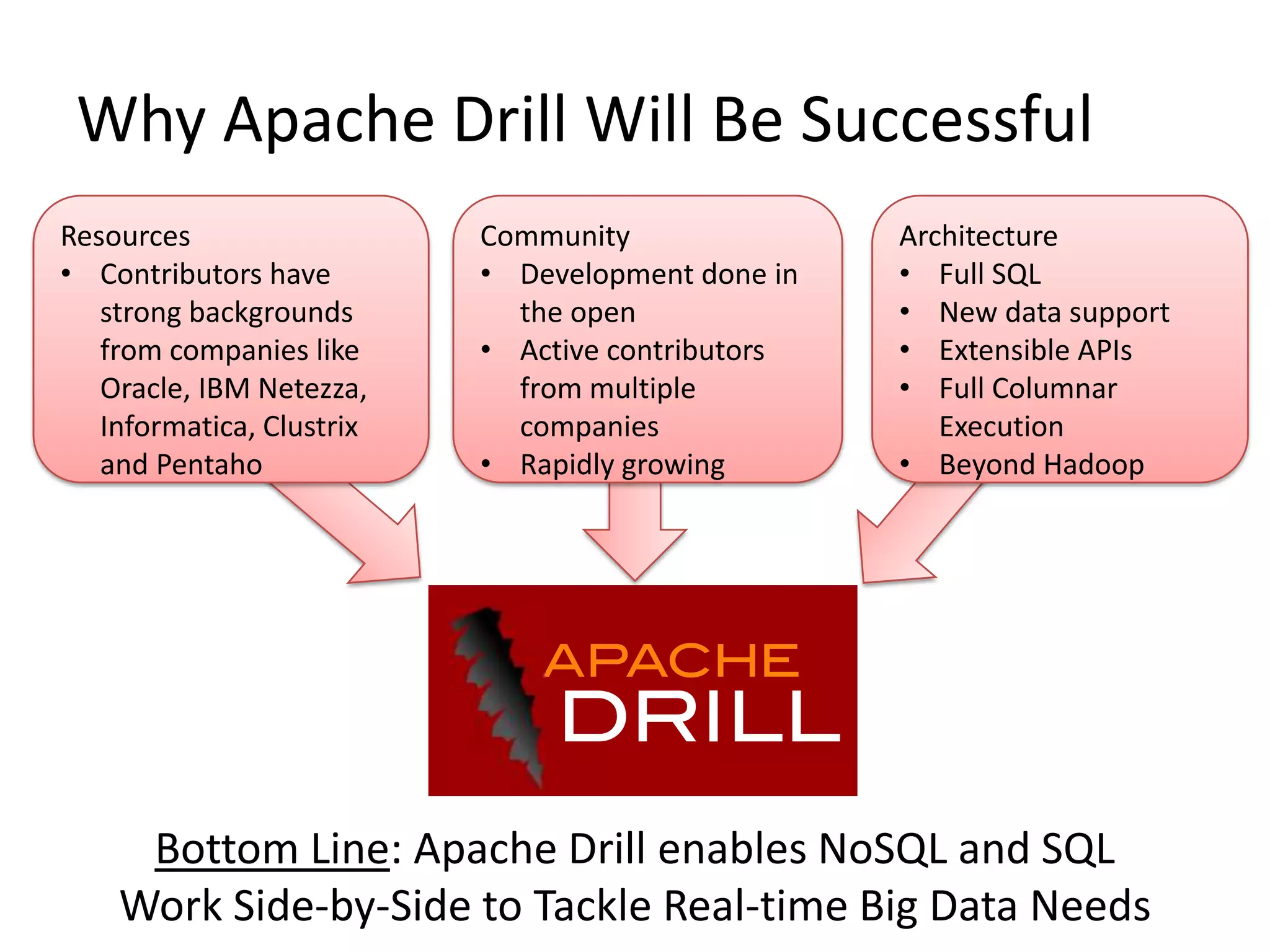
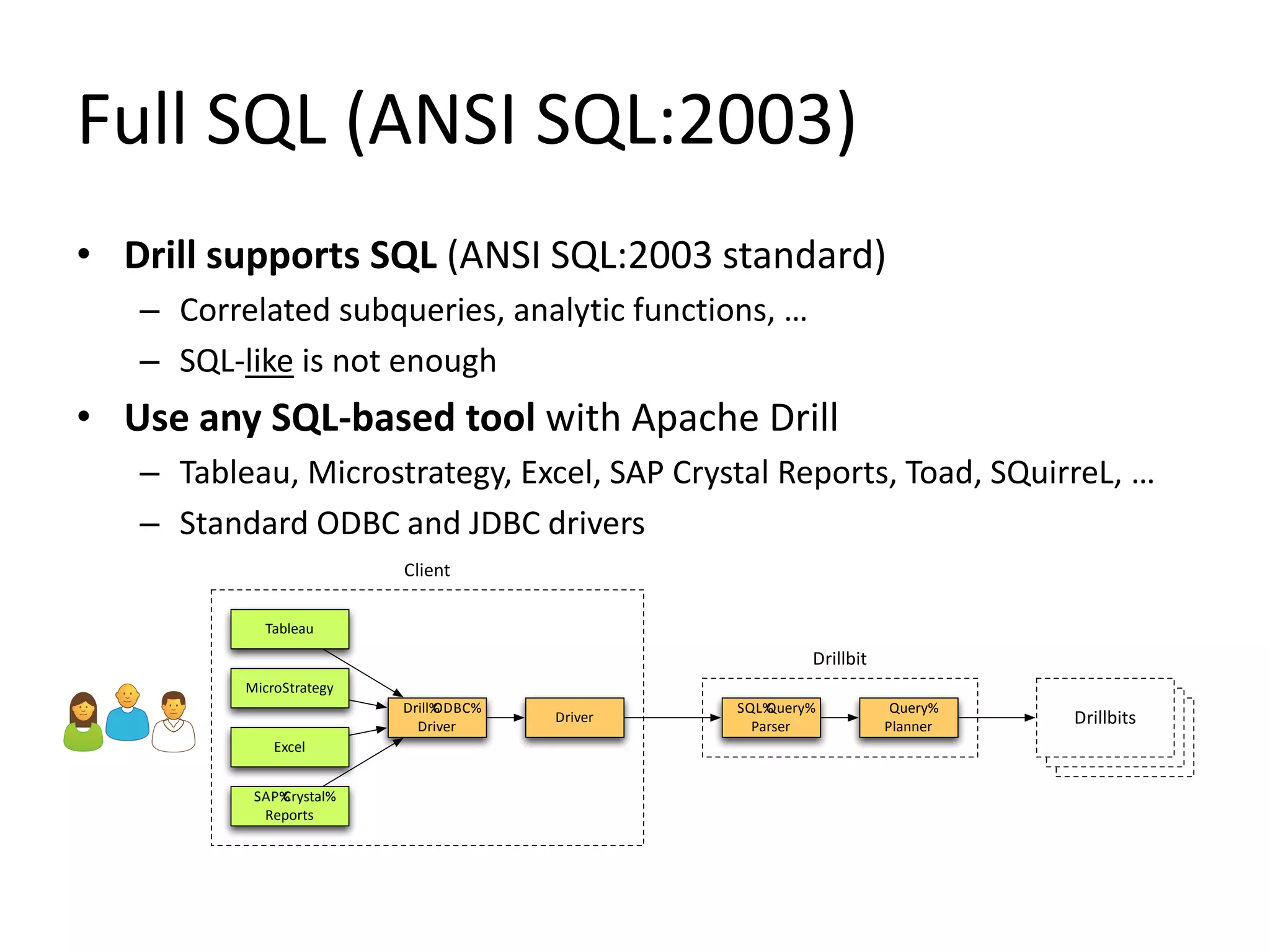
NoSQL and SQL databases can work together to handle real-time big data needs. Apache Drill is an open source tool that allows interactive analysis of big data using standard SQL queries across NoSQL, Hadoop, and relational data sources. It provides low-latency queries, full ANSI SQL support, and flexibility to handle rapidly evolving schemas and data in different systems. By enabling analysis of all data together using a common interface, it helps tackle challenges of combining operational and decision support systems on big, diverse datasets.























































































