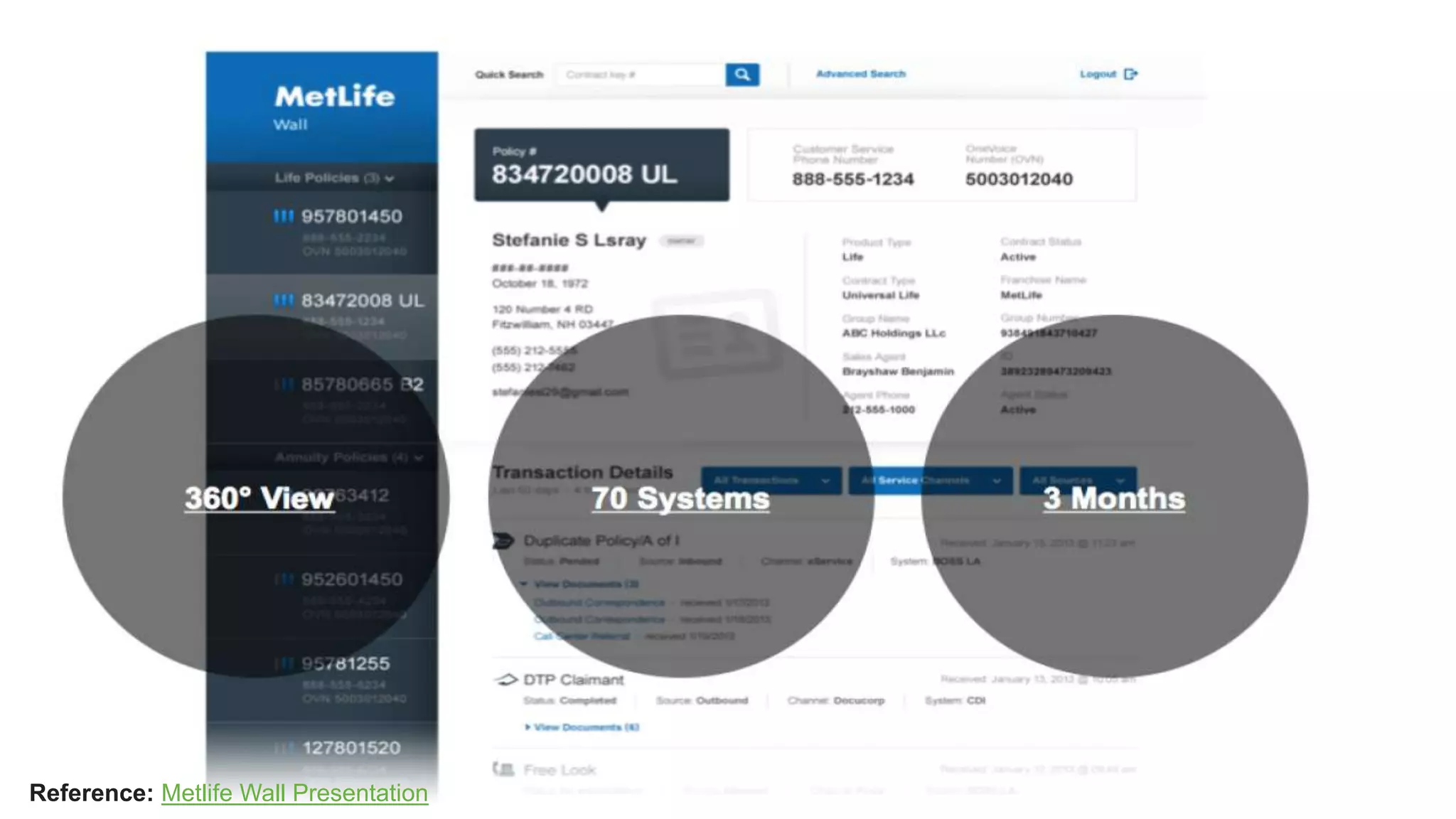
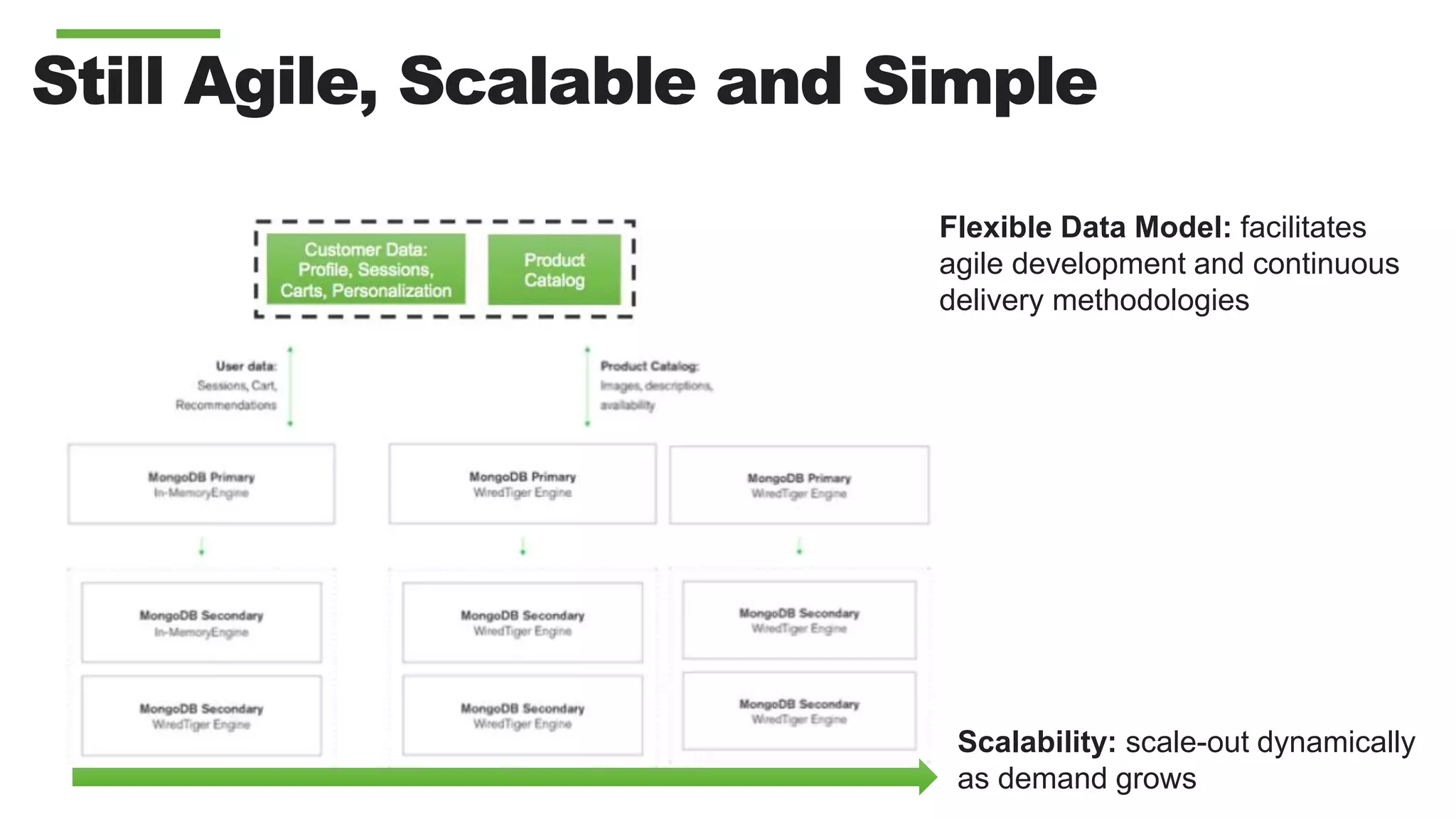
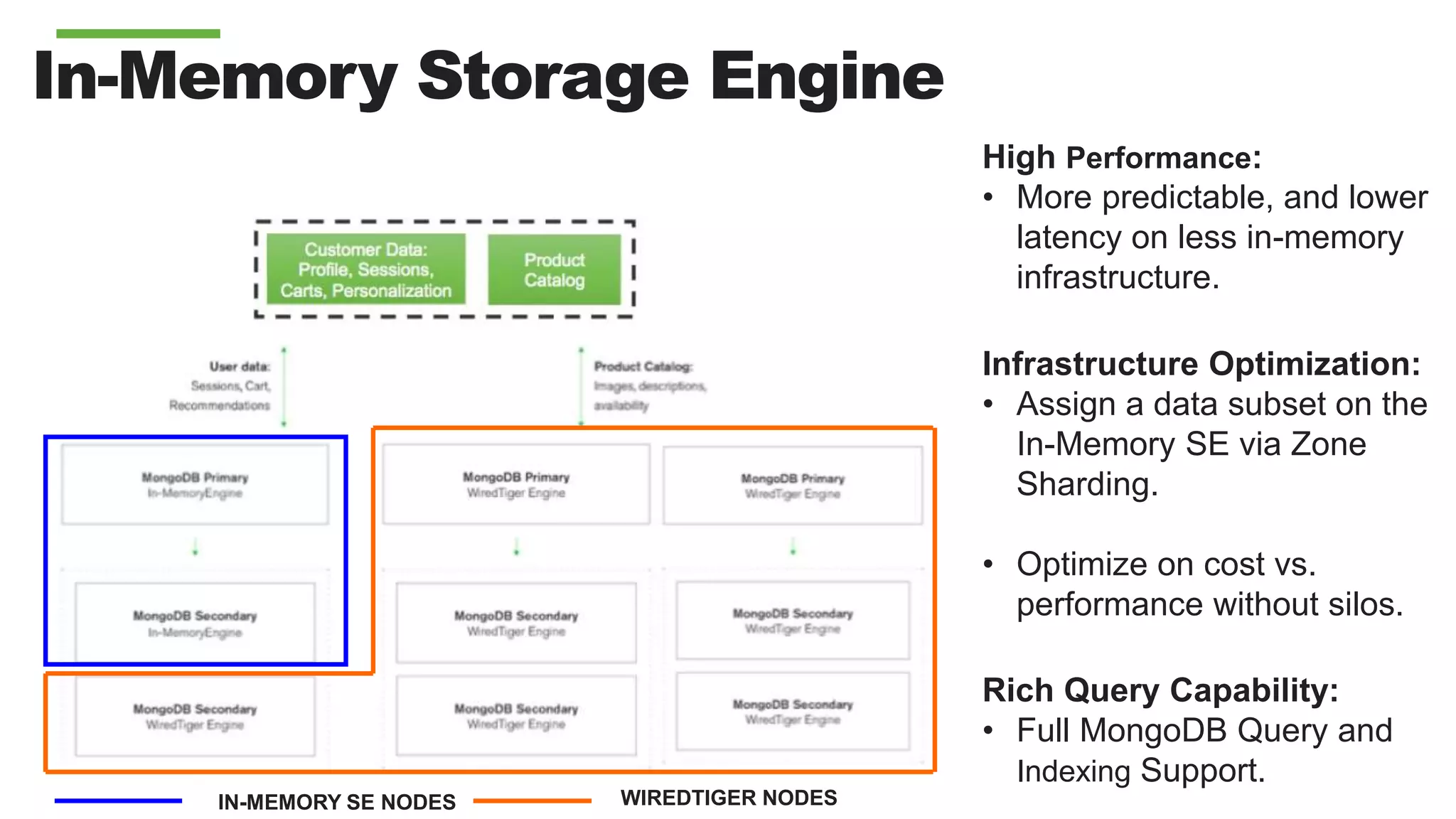
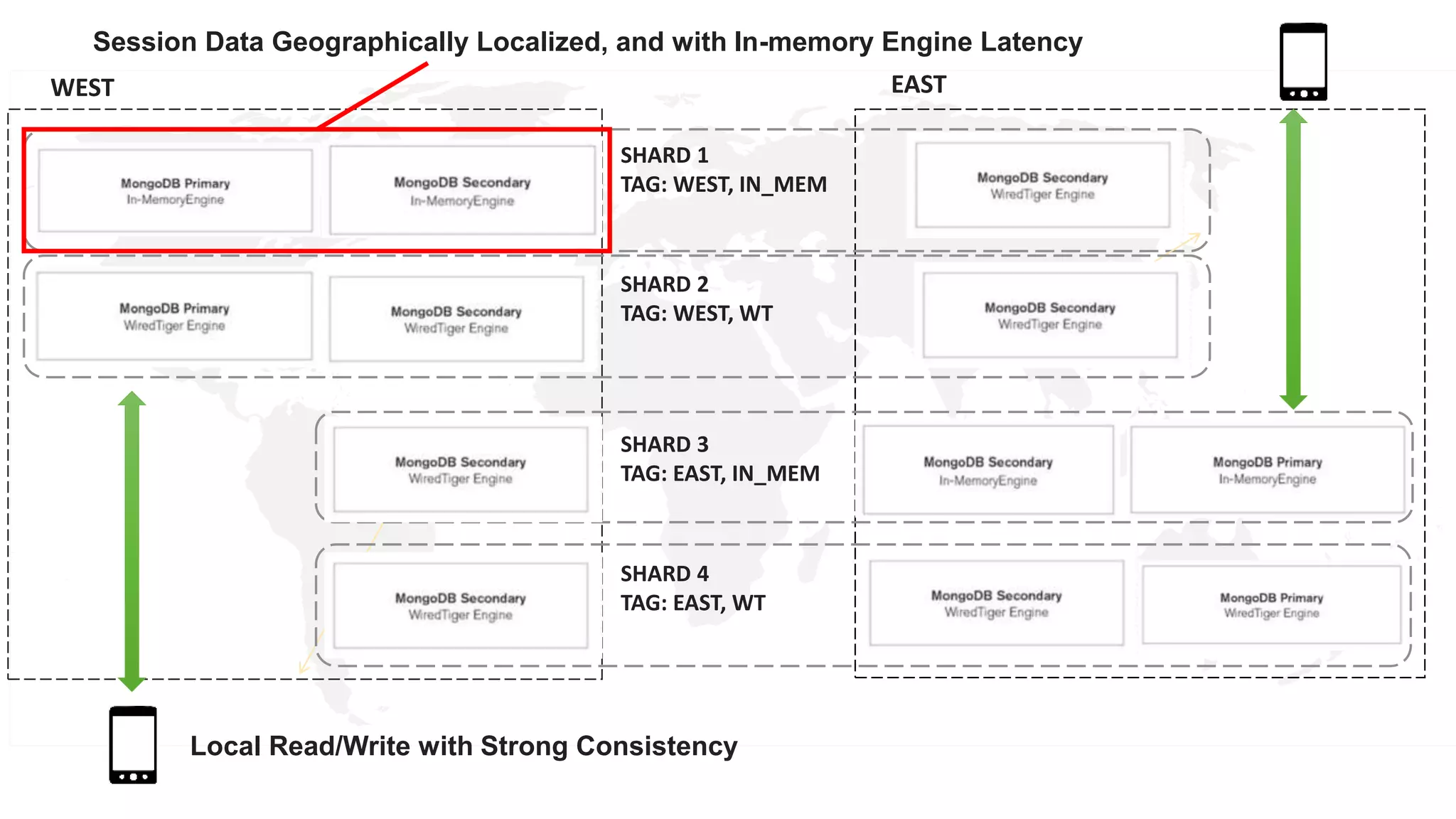
Downloaded 16 times


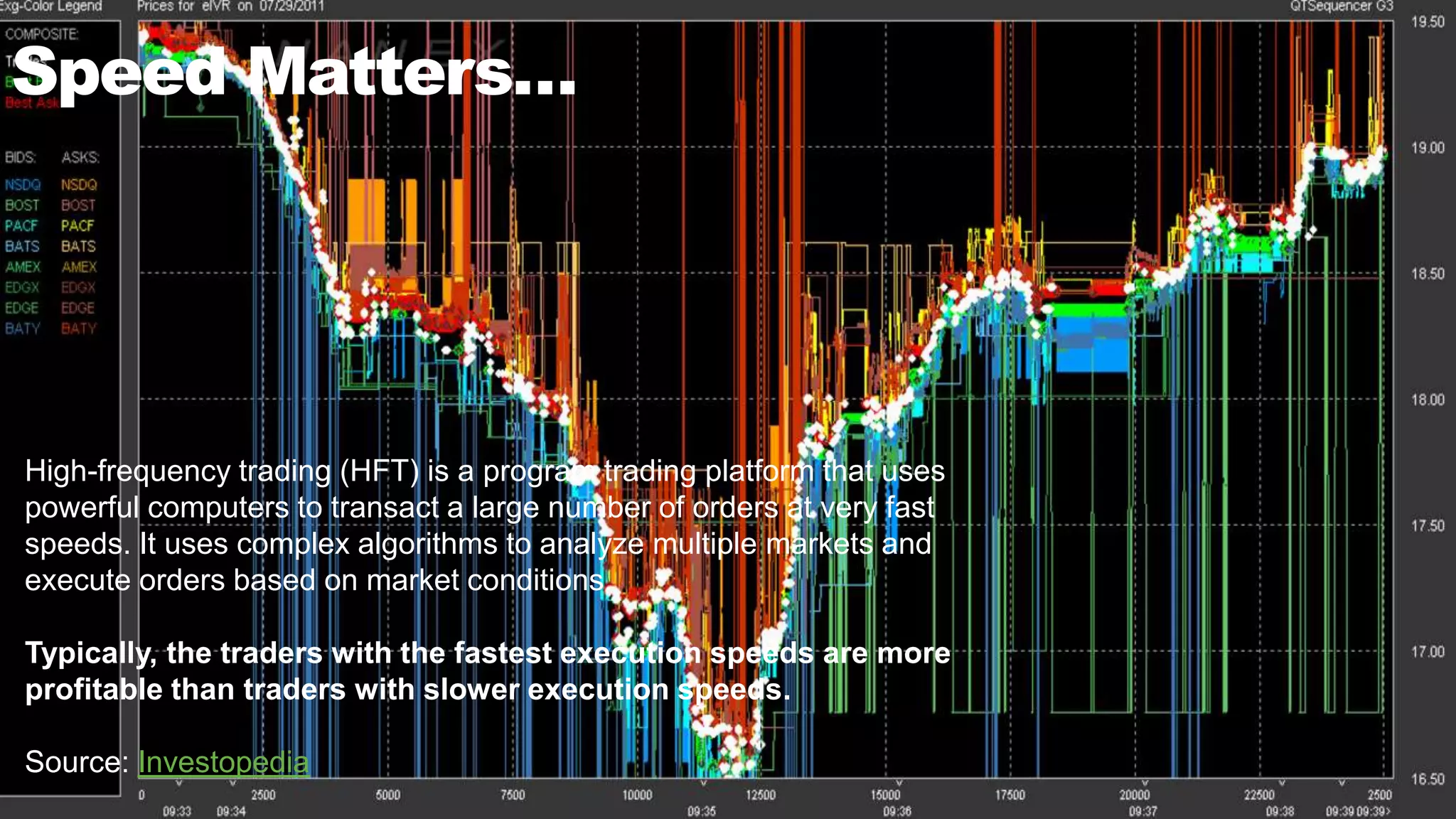
![Speed Matters…
Amazon found that it increased revenue by 1% for every 100ms of
improvement [source: Amazon]
A 1-second delay in page load time equals 11% fewer page views,
a 16% decrease in customer satisfaction, and 7% loss in
conversions. [Source: Aberdeen Group]
A study found that 27% of the participants who did mobile shopping
were dissatisfied due to the experience being too slow. [Source:
Forrester Consulting]](https://image.slidesharecdn.com/mongodbimcwebinar-final-160810224231/75/MongoDB-and-In-Memory-Computing-4-2048.jpg)









![{
product_name: ‘Acme Paint’,
color: [‘Red’, ‘Green’],
size_oz: [8, 32],
finish: [‘satin’, ‘eggshell’]
}
{
product_name: ‘T-shirt’,
size: [‘S’, ‘M’, ‘L’, ‘XL’],
color: [‘Heather Gray’ … ],
material: ‘100% cotton’,
wash: ‘cold’,
dry: ‘tumble dry low’
}
{
product_name: ‘Mountain Bike’,
brake_style: ‘mechanical disc’,
color: ‘grey’,
frame_material: ‘aluminum’,
no_speeds: 21,
package_height: ‘7.5x32.9x55’,
weight_lbs: 44.05,
suspension_type: ‘dual’,
wheel_size_in: 26
}
Documents in the same product catalog collection in MongoDB
Dynamic Schema](https://image.slidesharecdn.com/mongodbimcwebinar-final-160810224231/75/MongoDB-and-In-Memory-Computing-22-2048.jpg)

![BI Connector
BI Connector
db.orders.aggregate( [
{
$group: {
_id: null,
total: { $sum:
"$price" }
}
}
] )
SELECT SUM(price)
AS total
FROM orders](https://image.slidesharecdn.com/mongodbimcwebinar-final-160810224231/75/MongoDB-and-In-Memory-Computing-34-2048.jpg)






![Speed Matters…
Amazon found that it increased revenue by 1% for every 100ms of
improvement [source: Amazon]
A 1-second delay in page load time equals 11% fewer page views,
a 16% decrease in customer satisfaction, and 7% loss in
conversions. [Source: Aberdeen Group]
A study found that 27% of the participants who did mobile shopping
were dissatisfied due to the experience being too slow. [Source:
Forrester Consulting]](https://crownmelresort.com/image.slidesharecdn.com/mongodbimcwebinar-final-160810224231/75/MongoDB-and-In-Memory-Computing-4-2048.jpg)

















![{
product_name: ‘Acme Paint’,
color: [‘Red’, ‘Green’],
size_oz: [8, 32],
finish: [‘satin’, ‘eggshell’]
}
{
product_name: ‘T-shirt’,
size: [‘S’, ‘M’, ‘L’, ‘XL’],
color: [‘Heather Gray’ … ],
material: ‘100% cotton’,
wash: ‘cold’,
dry: ‘tumble dry low’
}
{
product_name: ‘Mountain Bike’,
brake_style: ‘mechanical disc’,
color: ‘grey’,
frame_material: ‘aluminum’,
no_speeds: 21,
package_height: ‘7.5x32.9x55’,
weight_lbs: 44.05,
suspension_type: ‘dual’,
wheel_size_in: 26
}
Documents in the same product catalog collection in MongoDB
Dynamic Schema](https://crownmelresort.com/image.slidesharecdn.com/mongodbimcwebinar-final-160810224231/75/MongoDB-and-In-Memory-Computing-22-2048.jpg)











![BI Connector
BI Connector
db.orders.aggregate( [
{
$group: {
_id: null,
total: { $sum:
"$price" }
}
}
] )
SELECT SUM(price)
AS total
FROM orders](https://crownmelresort.com/image.slidesharecdn.com/mongodbimcwebinar-final-160810224231/75/MongoDB-and-In-Memory-Computing-34-2048.jpg)




The document discusses enhancing enterprise architecture through in-memory computing to achieve faster data processing, citing examples from high-frequency trading and major companies like Amazon. It highlights challenges such as cost, scalability, and durability while exploring the potential of in-memory storage solutions alongside dynamic schemas for better performance and integration. The document emphasizes the benefits of speed and simplicity in using in-memory architecture with tools like MongoDB and Spark for optimizing real-time data analytics and improving customer experiences.











































































