Download to read offline





![1/24/2018 Dan Elton, P.W. Chung Group Meeting 14
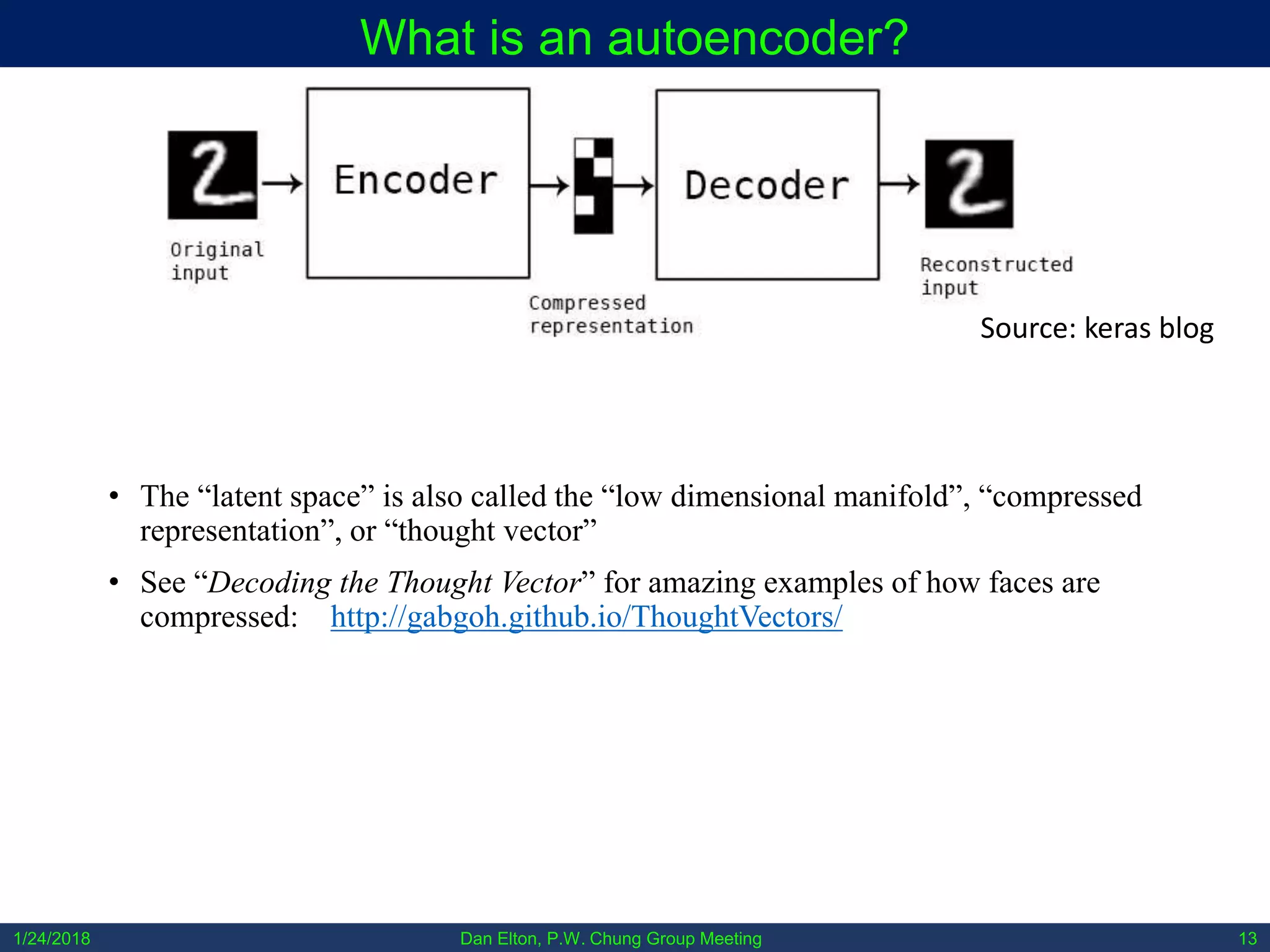
What is a variational autoencoder?
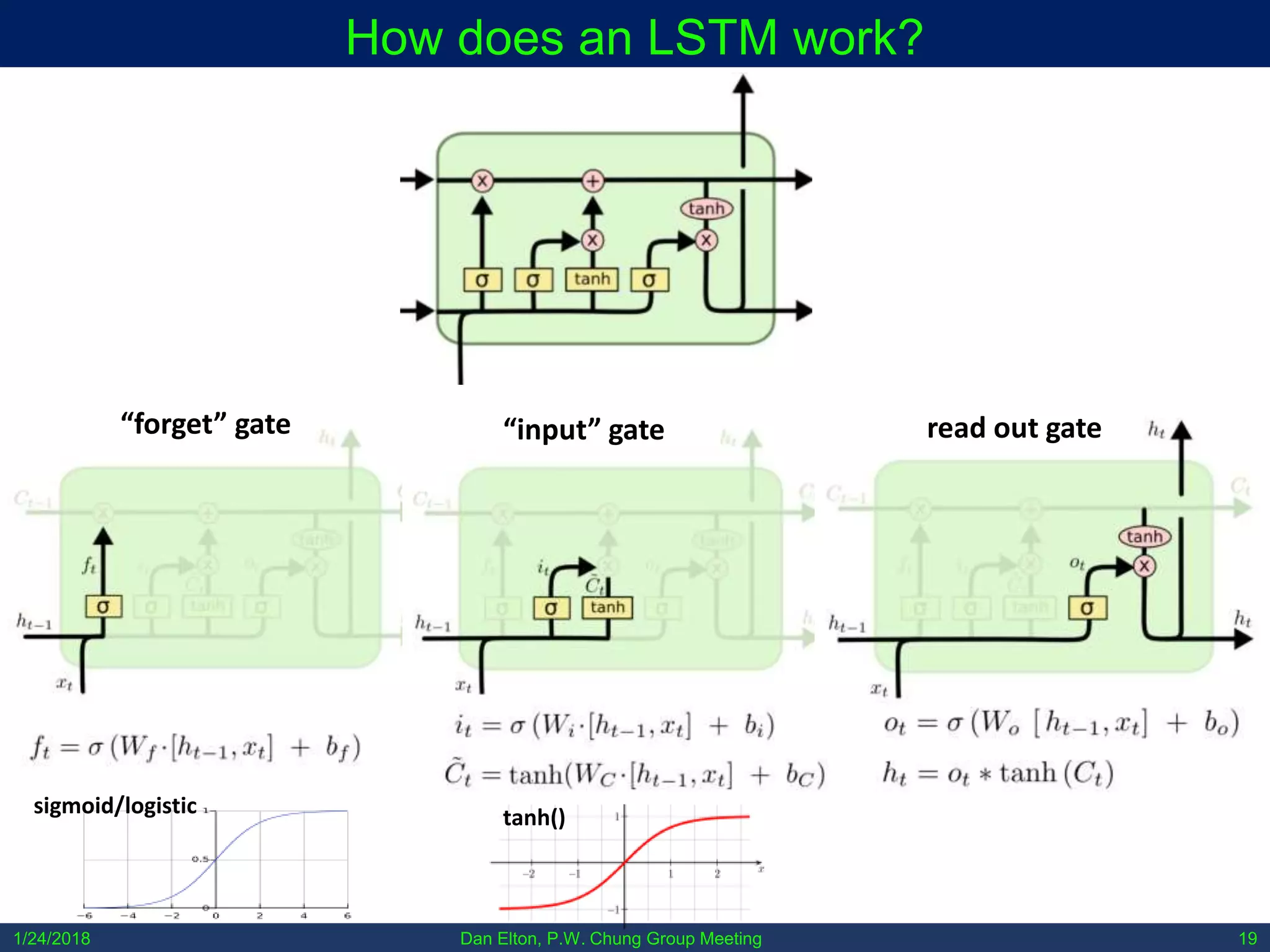
• During training, the output is sampled from the enforced
distribution as mean + random_noise * variance, during testing
the output is the mean.
• Minimize Kullback–Leibler divergence
D.P. Kingma, M. Welling
Auto-Encoding Variational Bayes
The International Conference on Learning Representations (ICLR), Banff, 2014
[arXiv preprint].](https://image.slidesharecdn.com/molecularautoencoder-180124155905/75/Molecular-autoencoder-14-2048.jpg)
![1/24/2018 Dan Elton, P.W. Chung Group Meeting 21
What are SMILES strings?
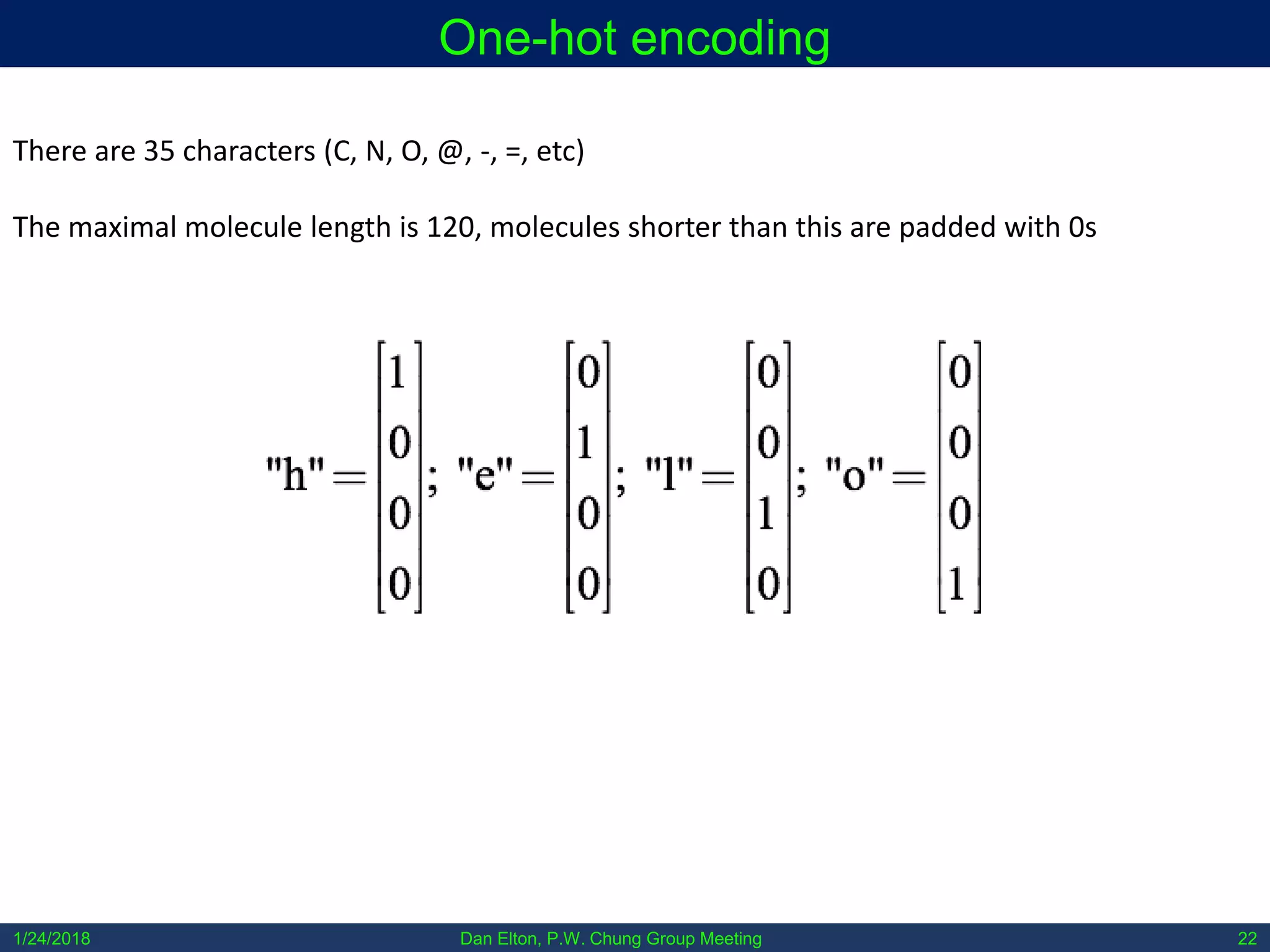
SMILES (simplified molecular-input line-entry system) encode 2D molecular graphs into 1D.
Example
CC(=O)NCCC1=CNc2c1cc(OC)cc2 CN1CCC[C@H]1C2=CN=CC=C2
The only ambiguity in SMILES strings:
• They do not capture 3D structure. However for small molecules and most application
areas this doesn’t matter much as molecules generally only have one conformation, so it
is implicitly contained. It only would matter in something like proteins, which might fold
into more than one conformation, or if the molecules are interacting with something like
an interface.
FC(F)FCCC(=O)O](https://image.slidesharecdn.com/molecularautoencoder-180124155905/75/Molecular-autoencoder-21-2048.jpg)

















![1/24/2018 Dan Elton, P.W. Chung Group Meeting 14
What is a variational autoencoder?
• During training, the output is sampled from the enforced
distribution as mean + random_noise * variance, during testing
the output is the mean.
• Minimize Kullback–Leibler divergence
D.P. Kingma, M. Welling
Auto-Encoding Variational Bayes
The International Conference on Learning Representations (ICLR), Banff, 2014
[arXiv preprint].](https://crownmelresort.com/image.slidesharecdn.com/molecularautoencoder-180124155905/75/Molecular-autoencoder-14-2048.jpg)






![1/24/2018 Dan Elton, P.W. Chung Group Meeting 21
What are SMILES strings?
SMILES (simplified molecular-input line-entry system) encode 2D molecular graphs into 1D.
Example
CC(=O)NCCC1=CNc2c1cc(OC)cc2 CN1CCC[C@H]1C2=CN=CC=C2
The only ambiguity in SMILES strings:
• They do not capture 3D structure. However for small molecules and most application
areas this doesn’t matter much as molecules generally only have one conformation, so it
is implicitly contained. It only would matter in something like proteins, which might fold
into more than one conformation, or if the molecules are interacting with something like
an interface.
FC(F)FCCC(=O)O](https://crownmelresort.com/image.slidesharecdn.com/molecularautoencoder-180124155905/75/Molecular-autoencoder-21-2048.jpg)










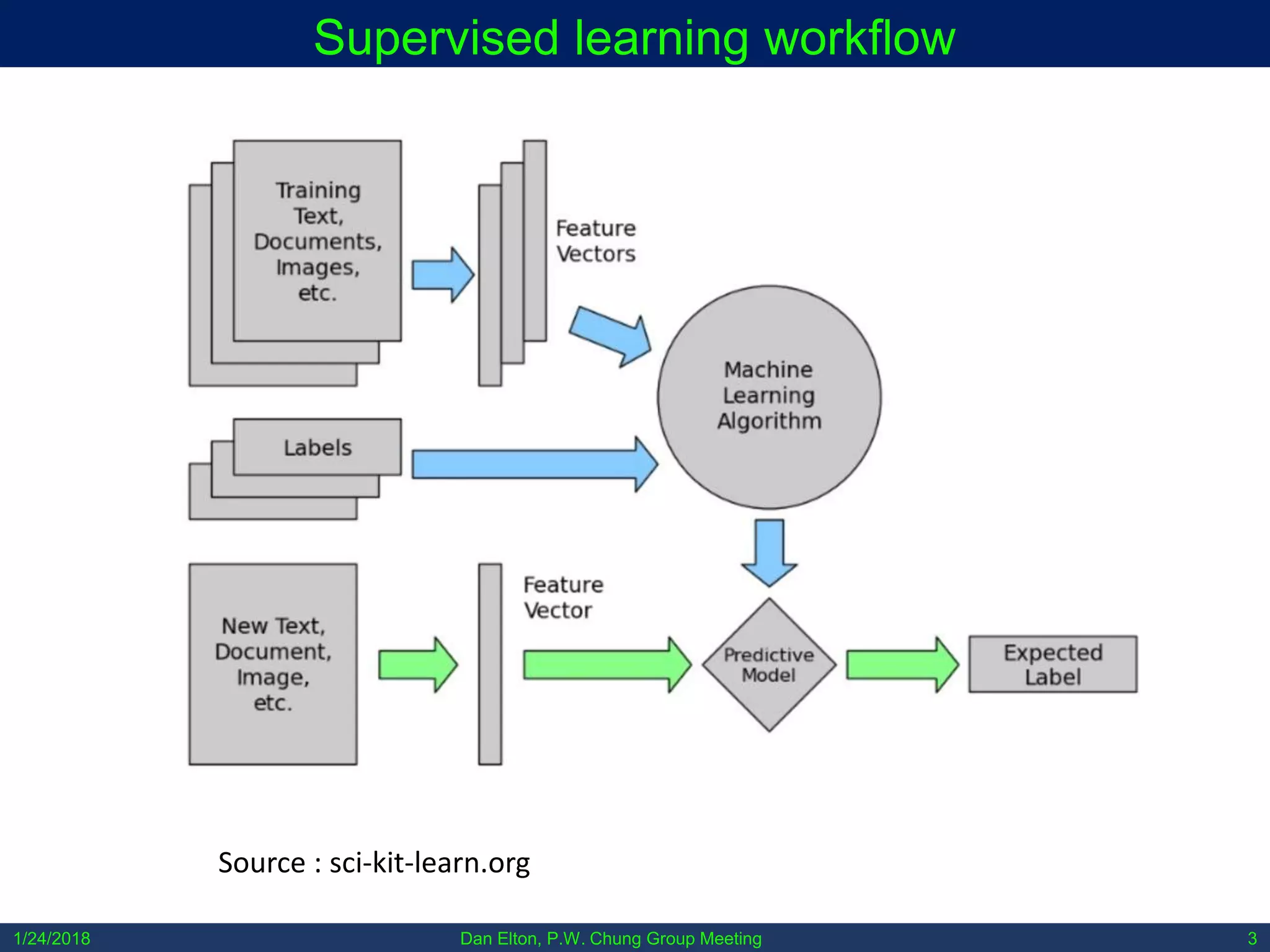
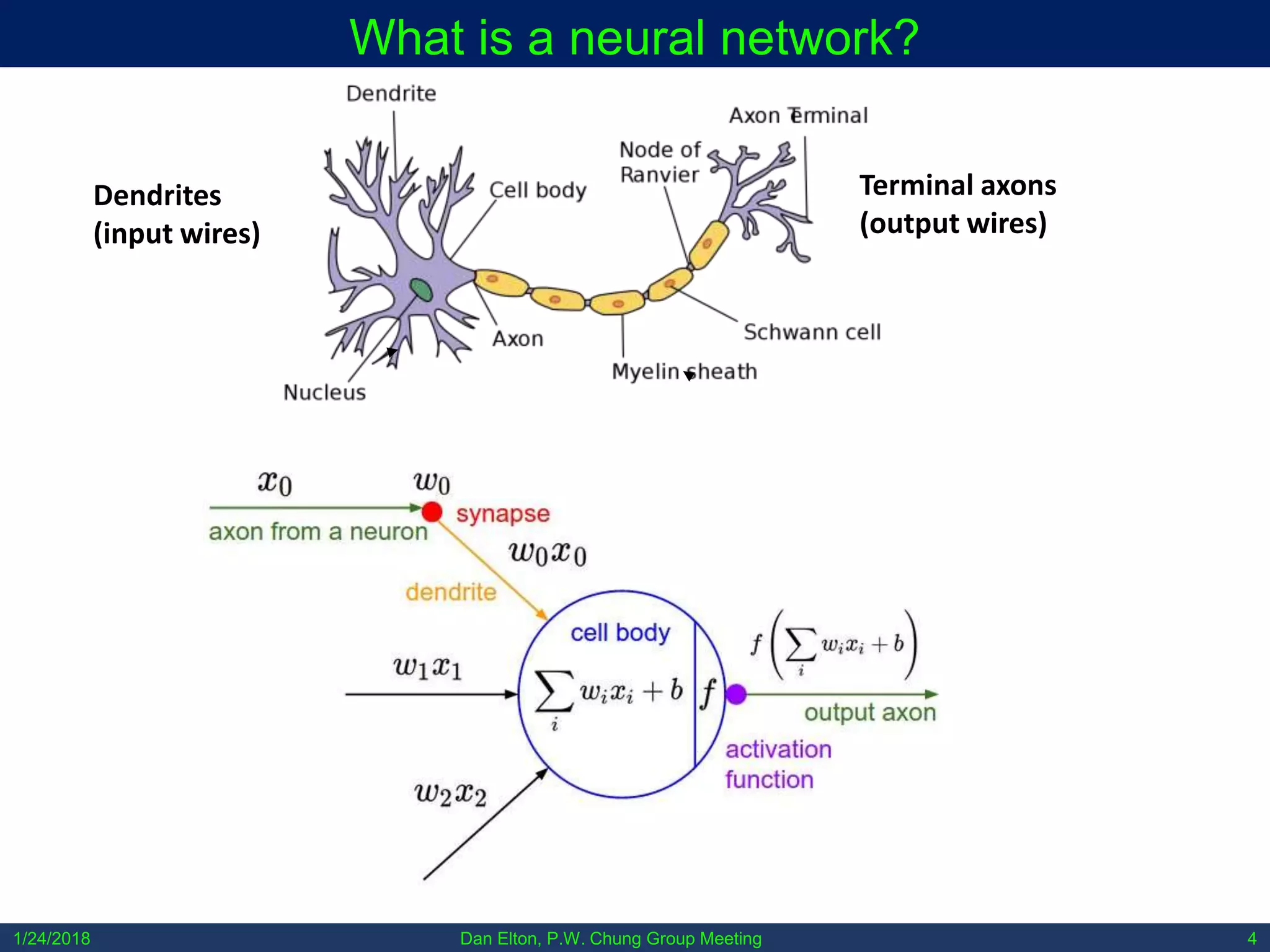
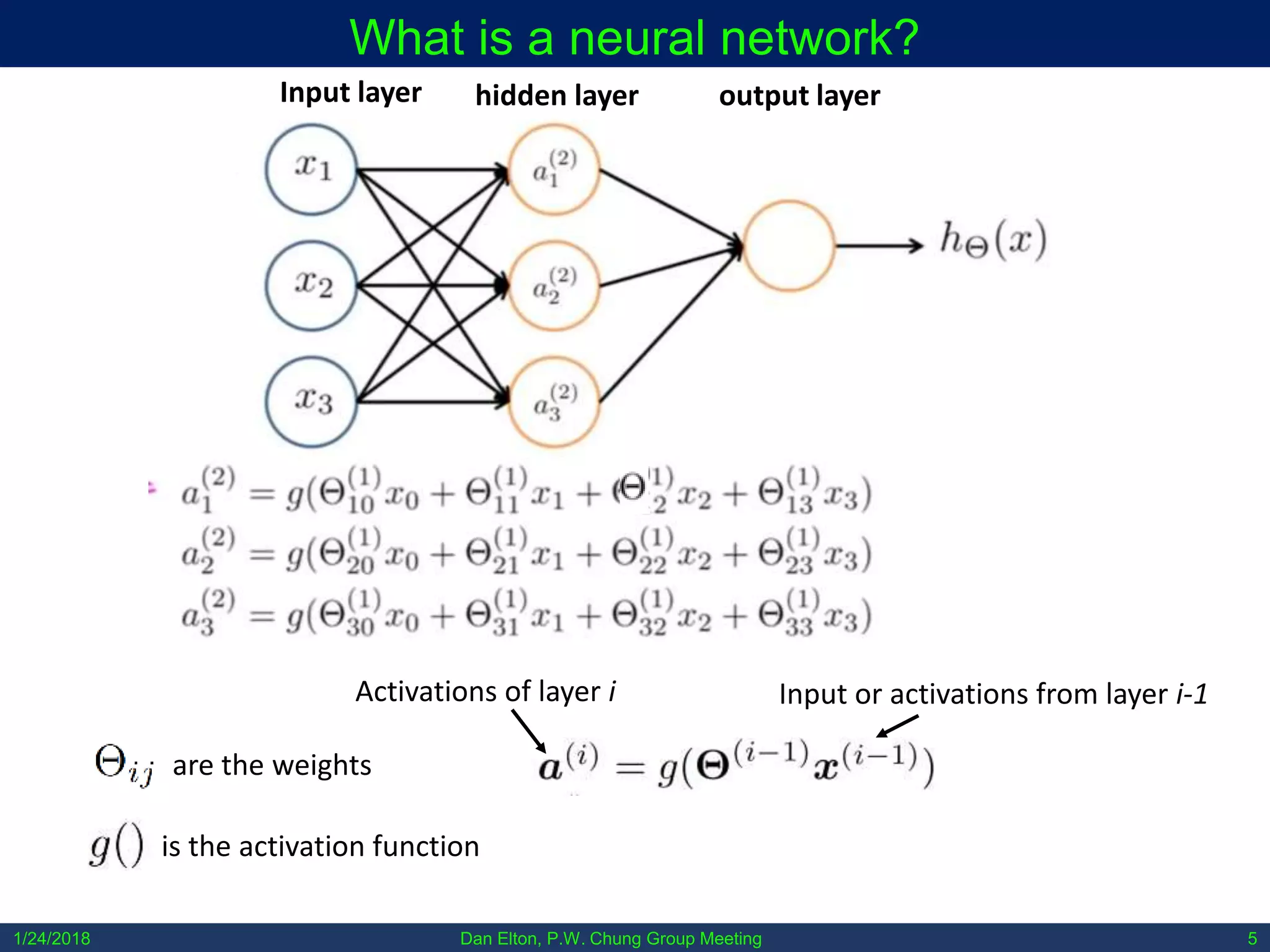
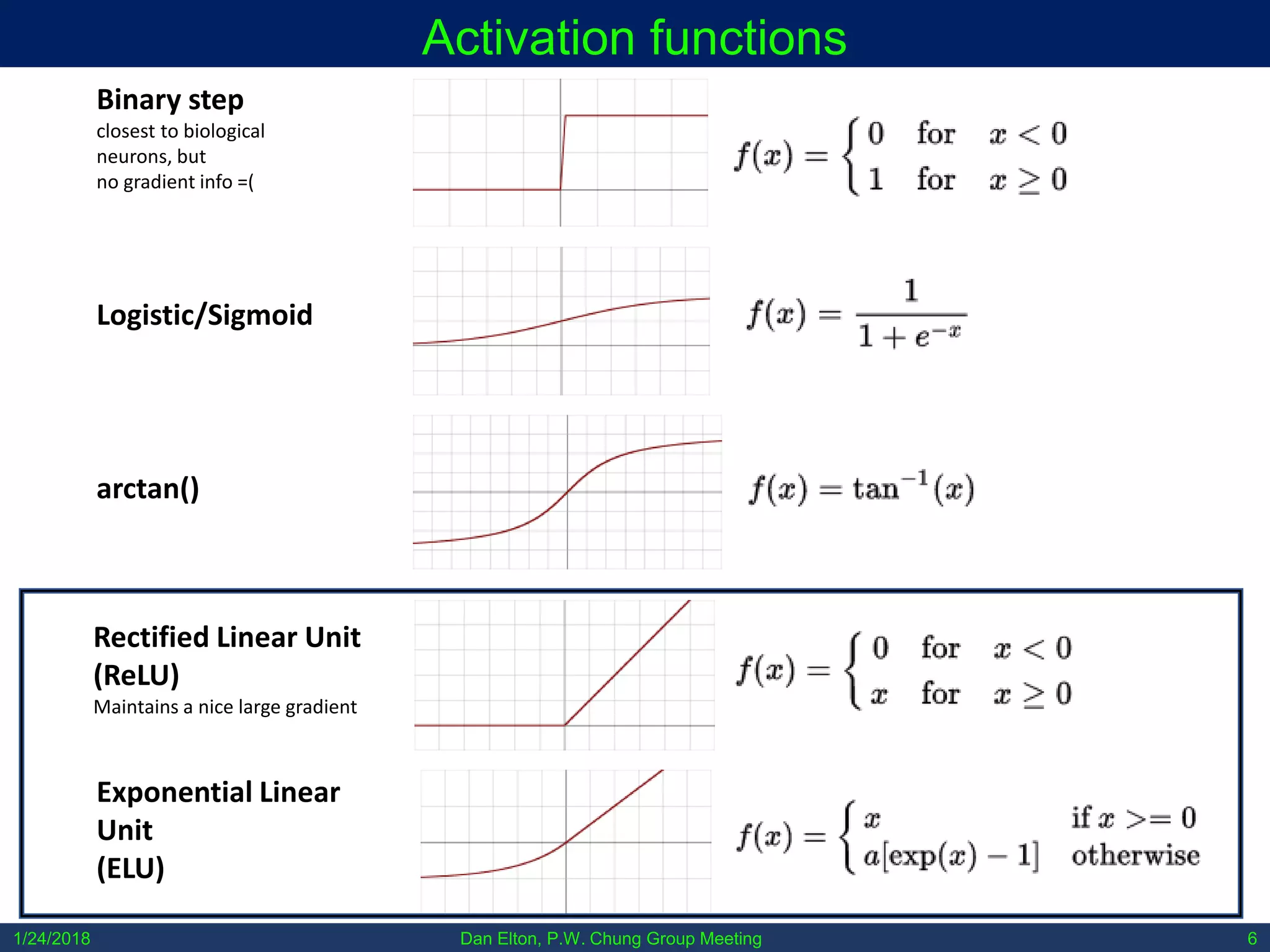
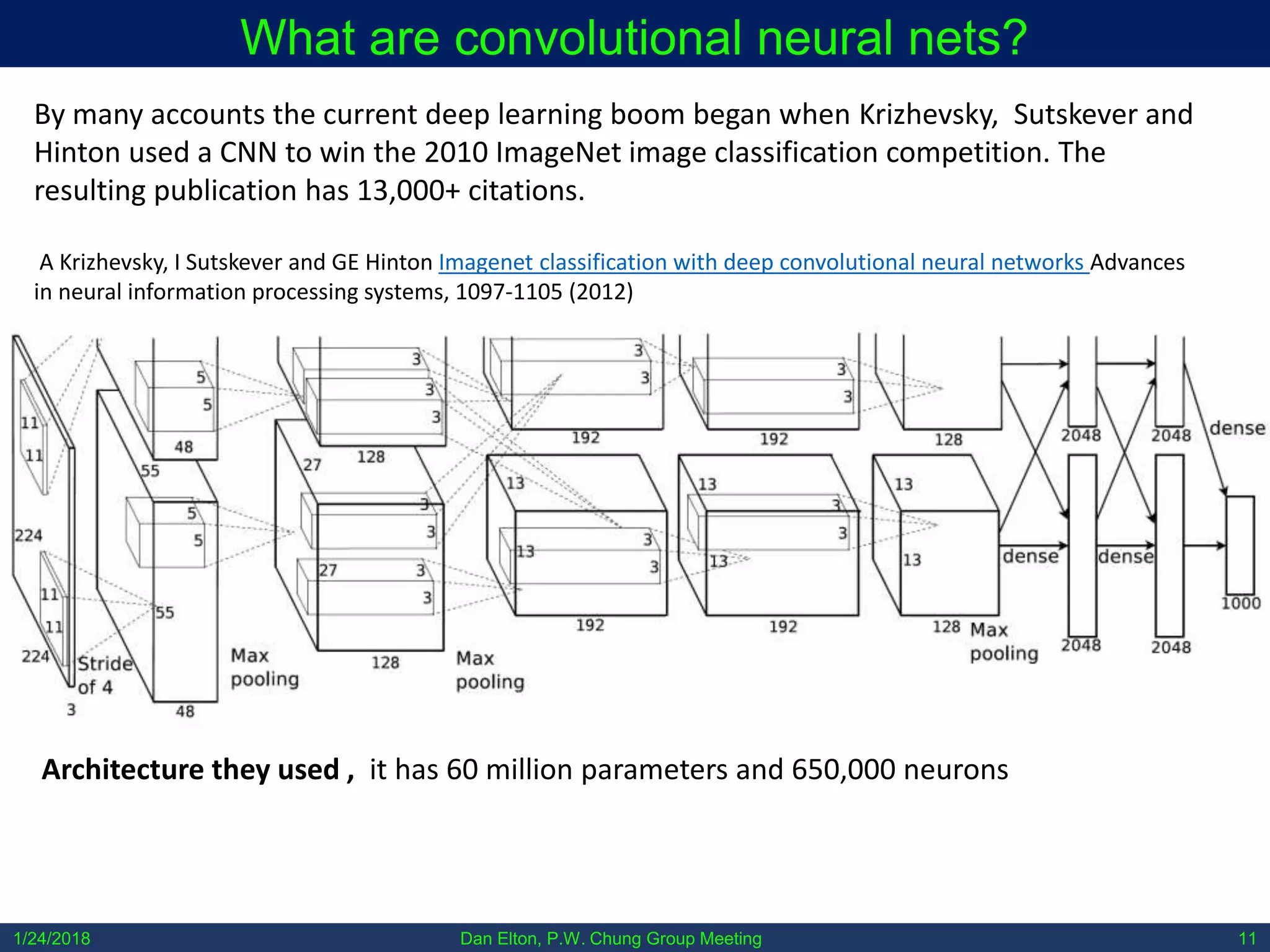
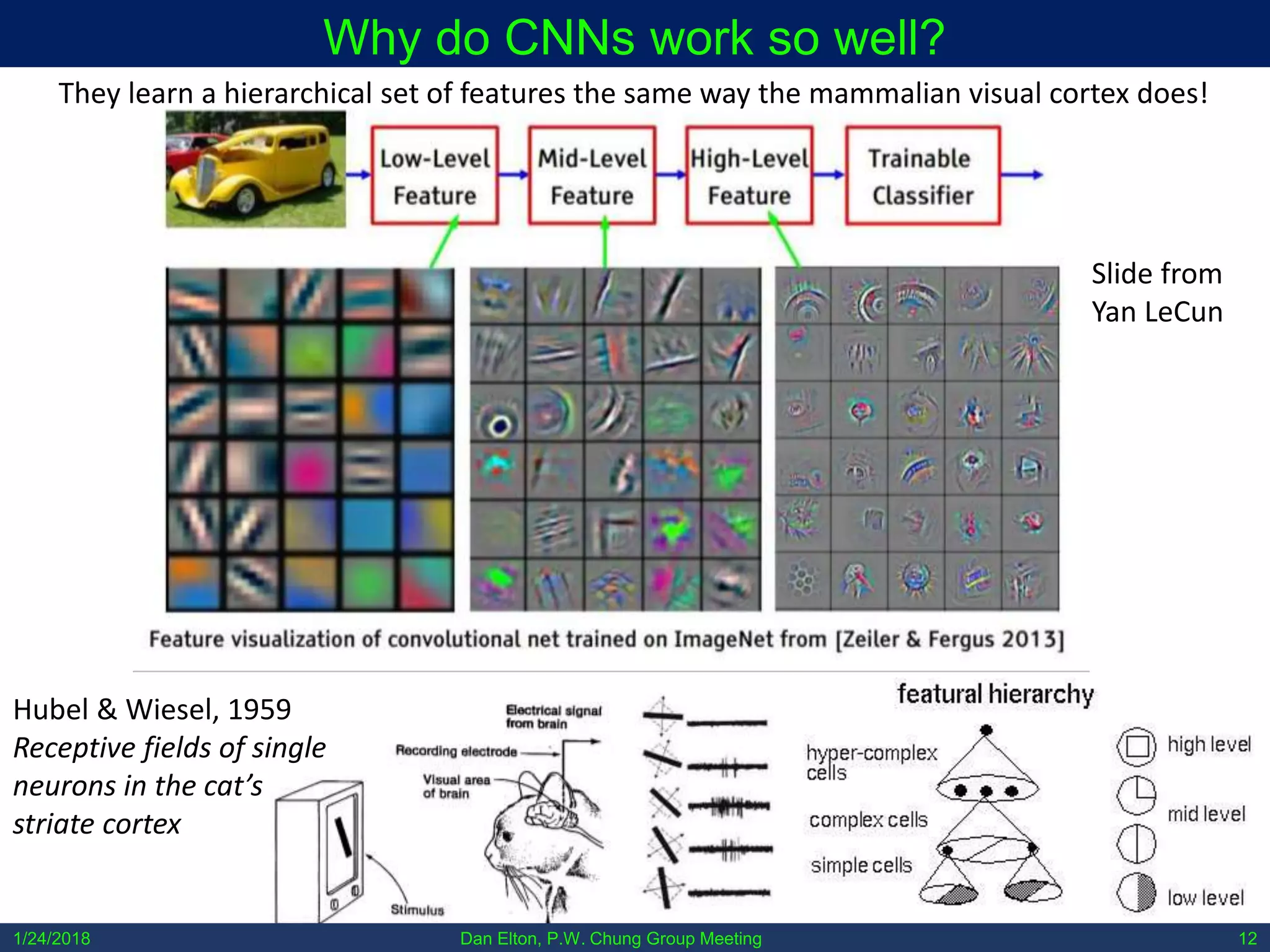
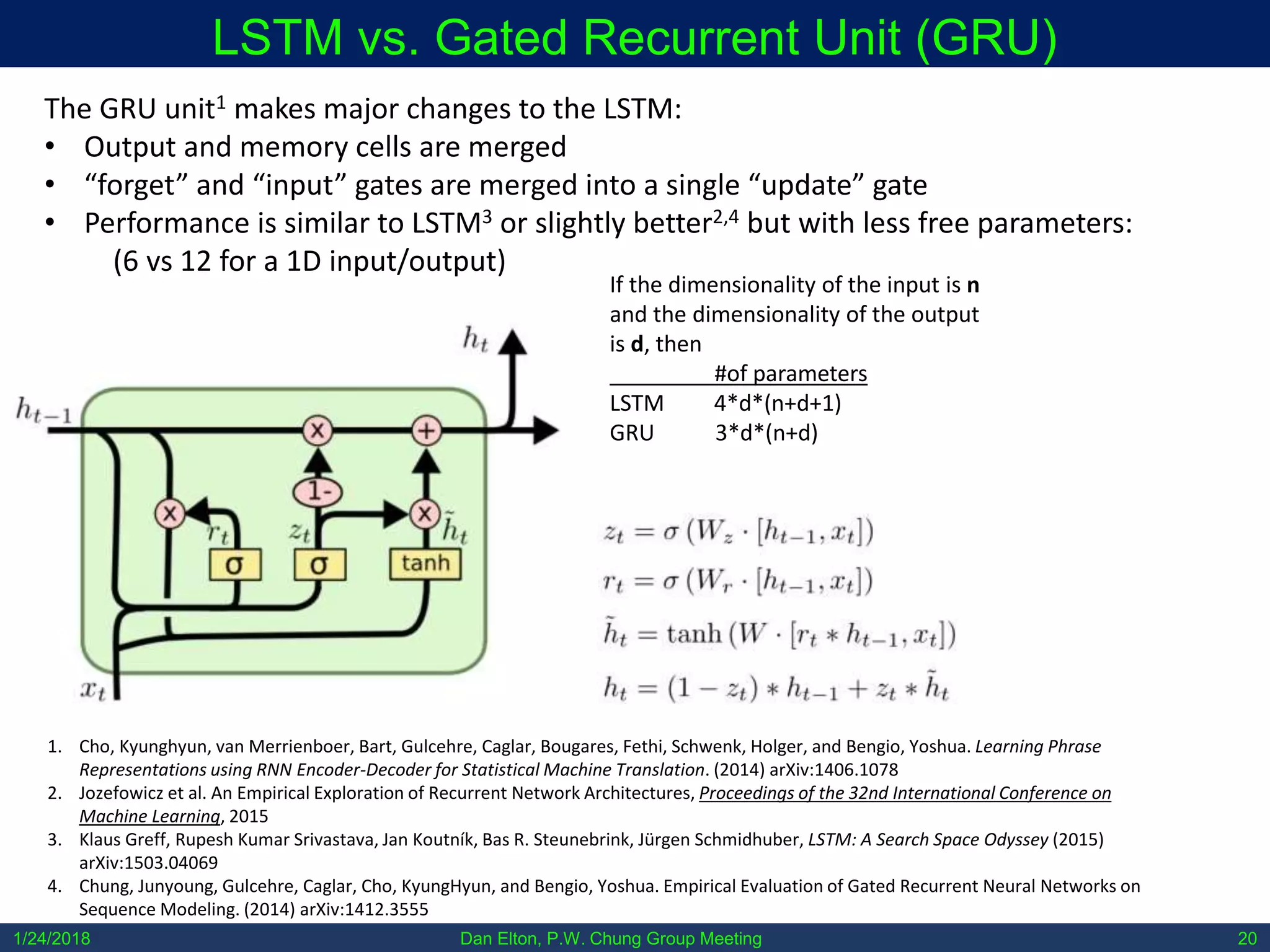
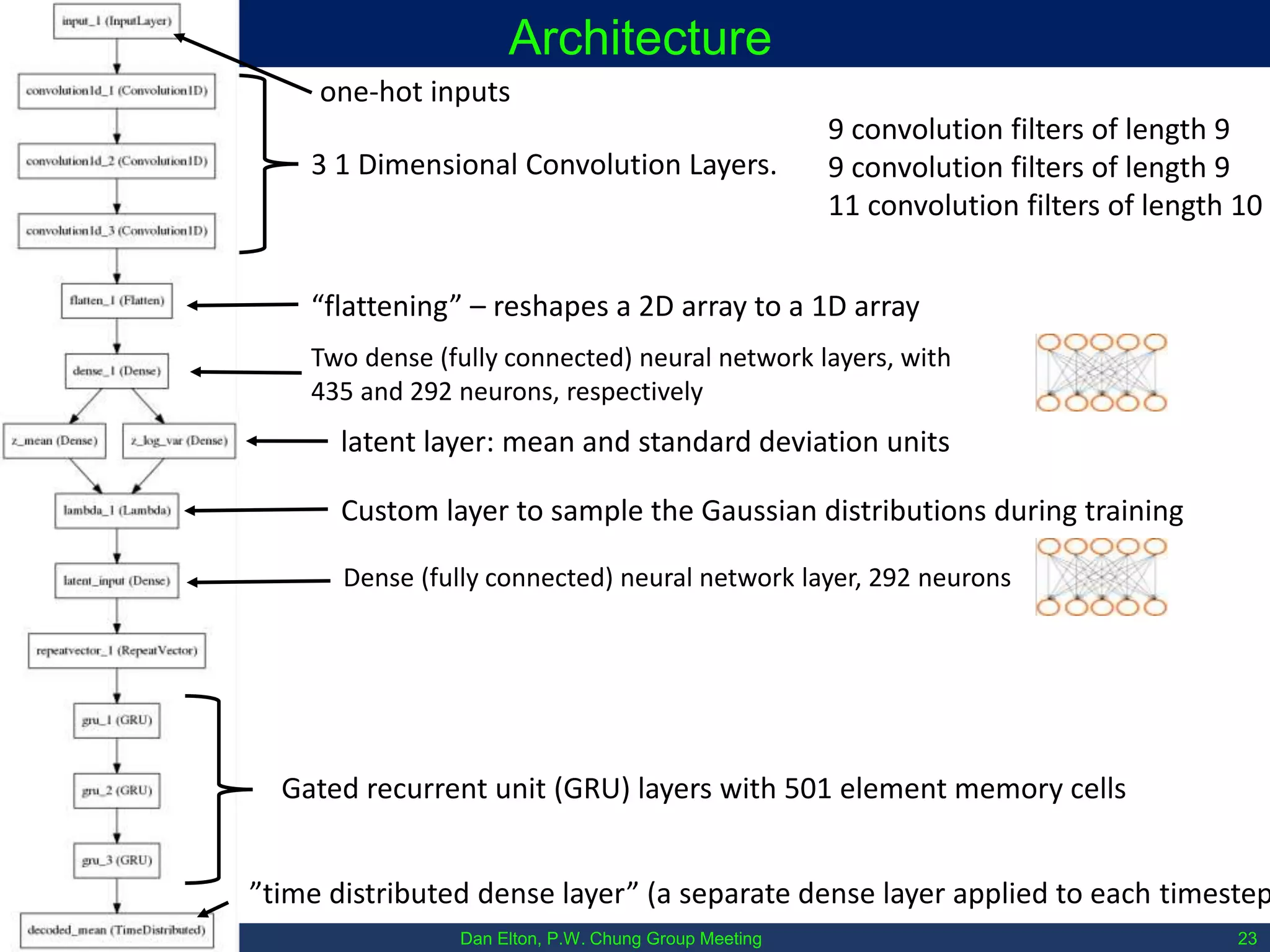
The document discusses various machine learning concepts, focusing on different types of learning such as supervised, unsupervised, and reinforcement learning, along with neural network architectures including convolutional and recursive neural networks. It highlights the architecture and functionality of autoencoders, variational autoencoders, and gated recurrent units (GRUs), as well as applications in molecular studies and drug discovery. The presentation emphasizes the complexity of defining hyperparameters and architectural design in deep learning models.








































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
