


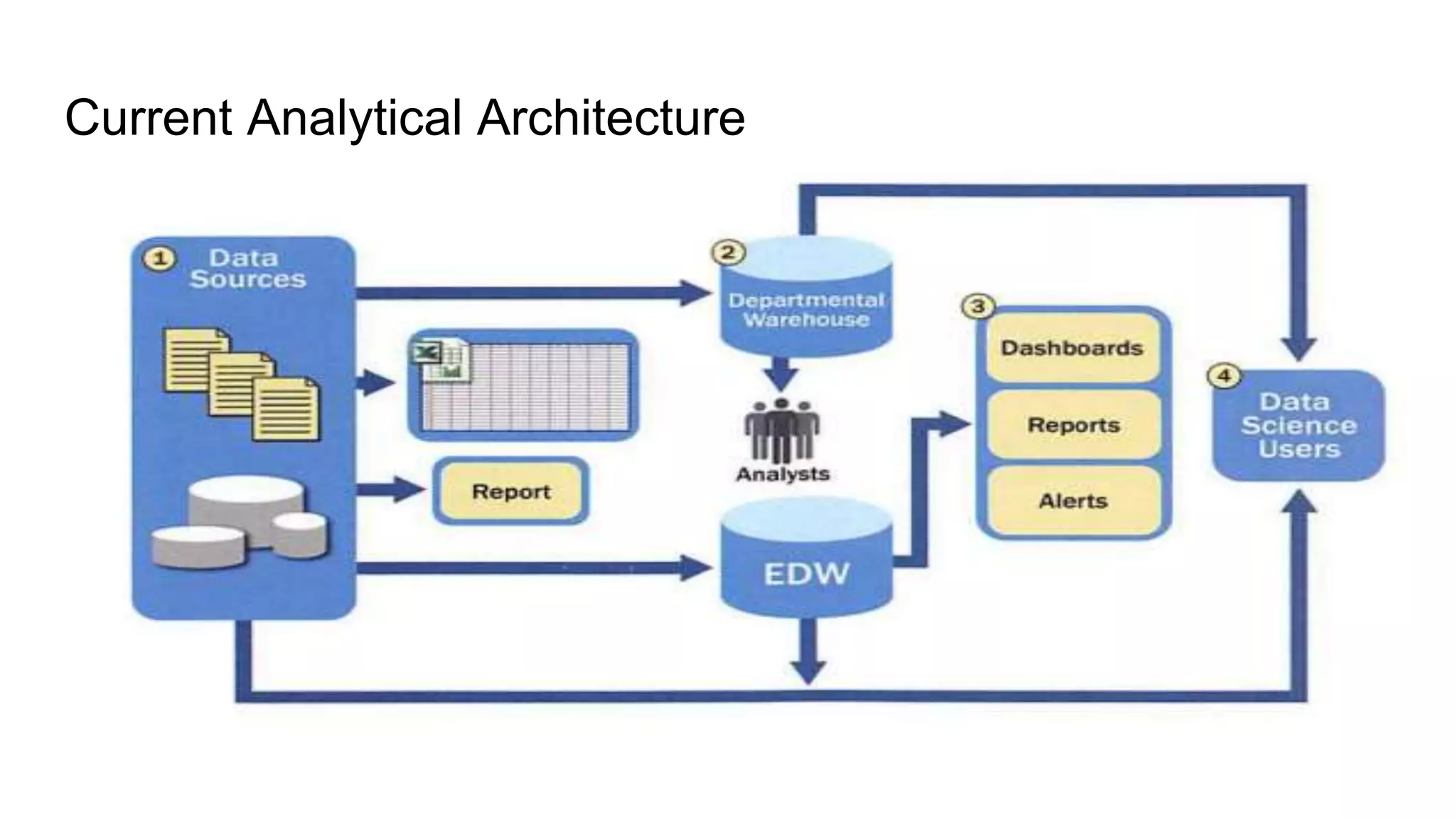


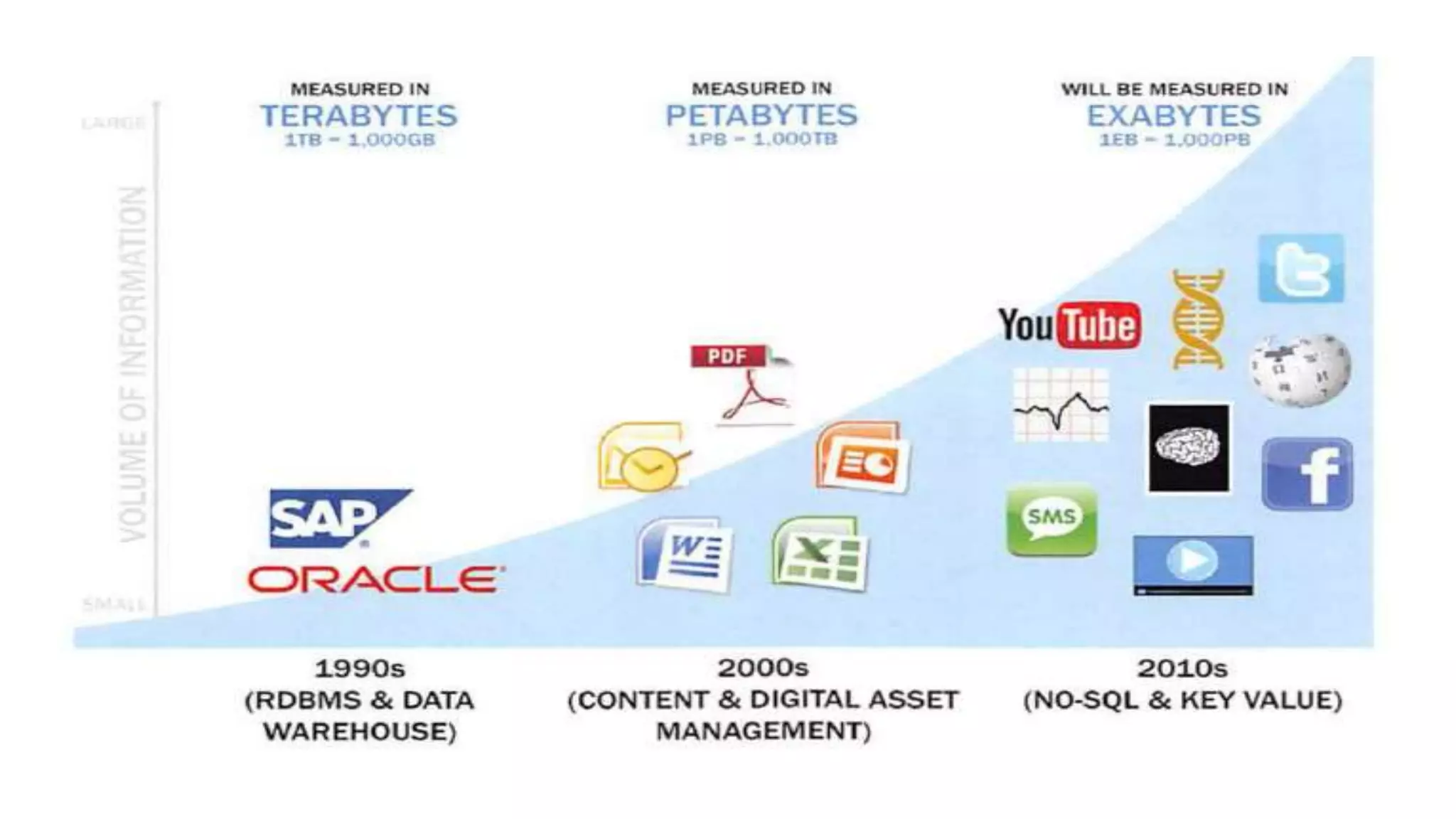
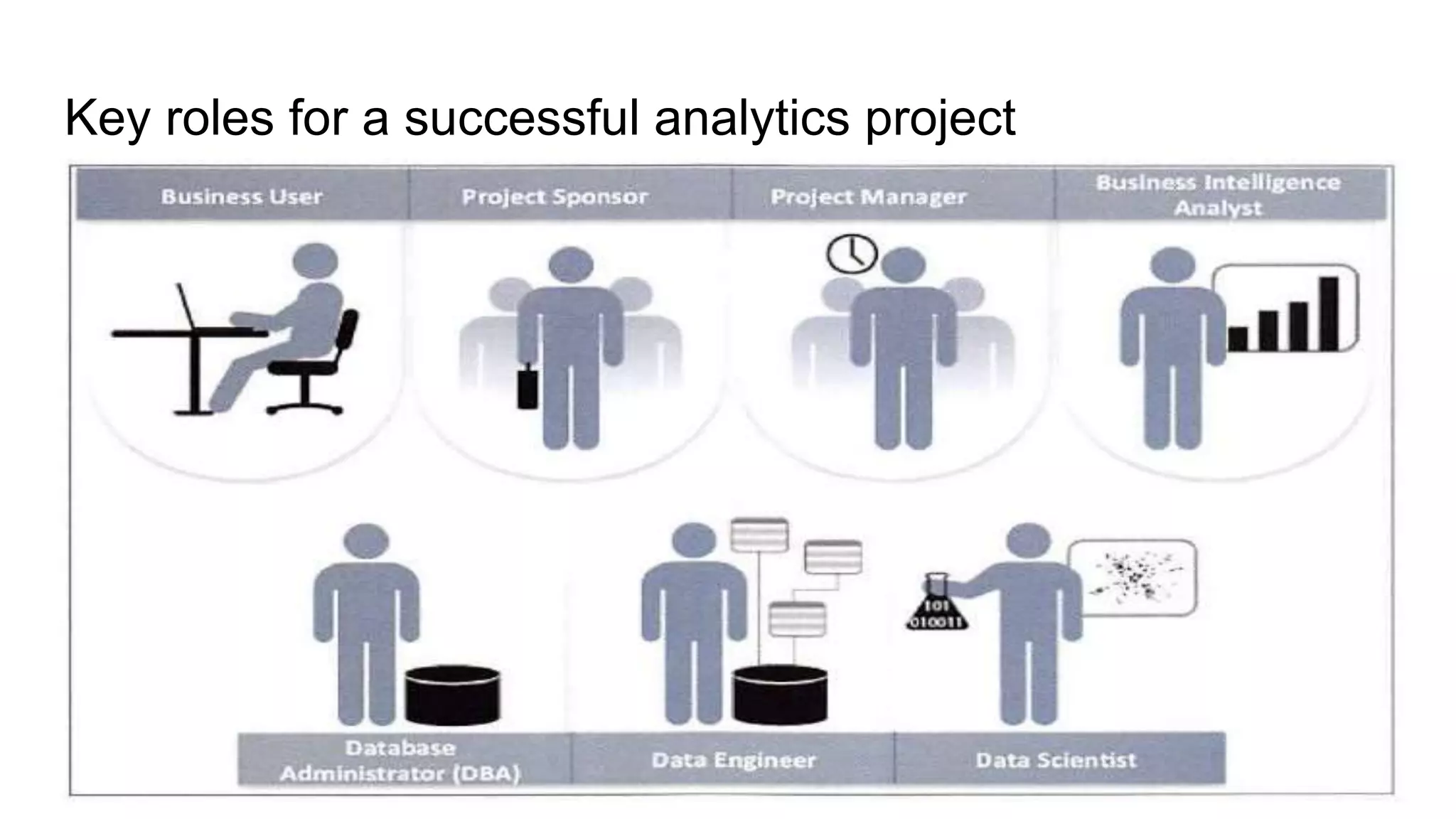





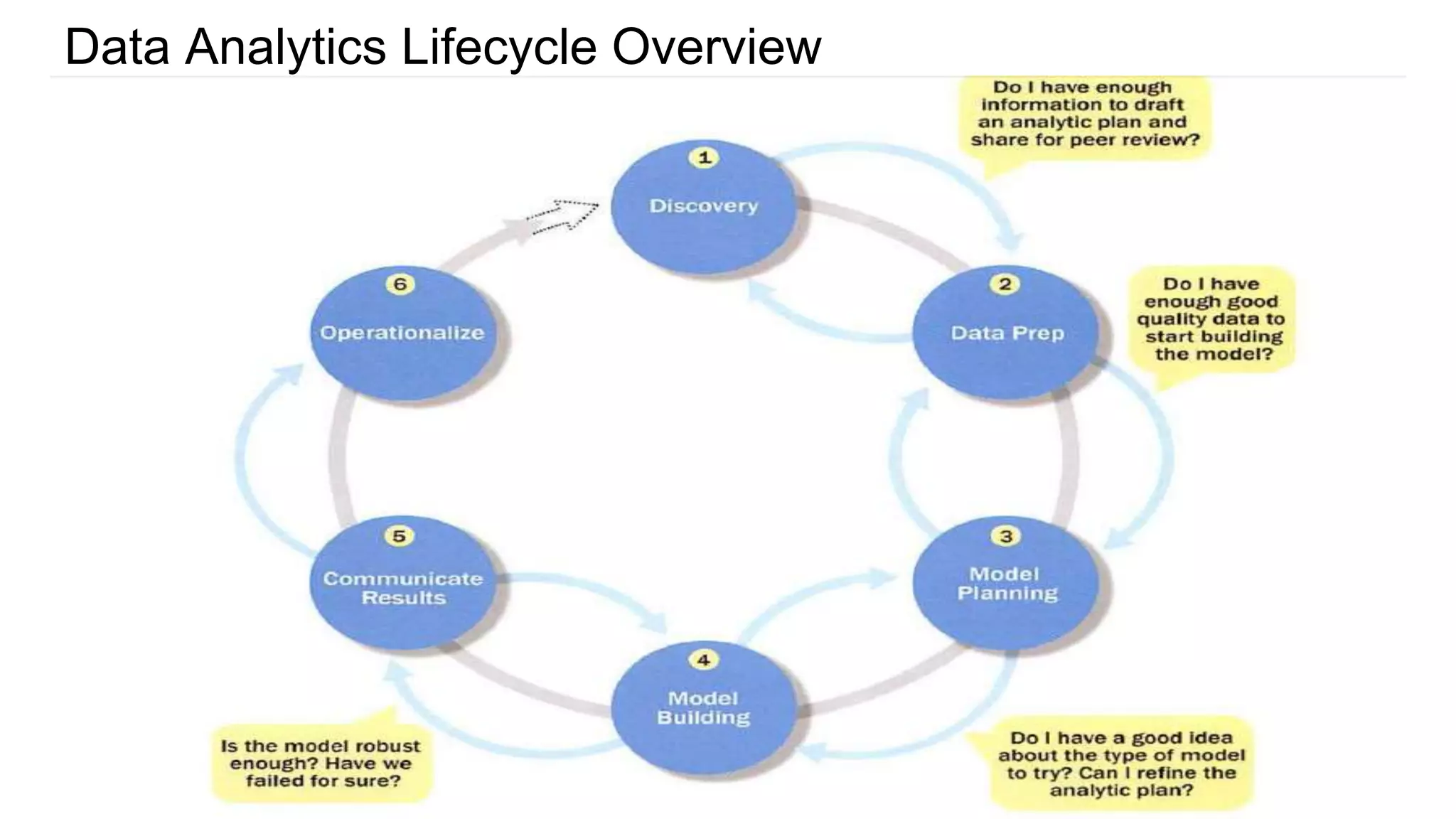










































































































The document provides an overview of the data analytics lifecycle and its key phases. It discusses the 6 phases: discovery, data preparation, model planning, model building, communicating results, and operationalizing. For each phase, it describes the main activities and considerations. It also discusses roles, tools, and best practices for ensuring a successful analytics project.
































![Data Analytics Life Cycle [EMC² - Data Science and Big data analytics]](https://cdn.slidesharecdn.com/ss_thumbnails/bdalifecycle-slideshare-211028070344-thumbnail.jpg?width=640&height=640&fit=bounds)






















































