Download as PDF, PPTX

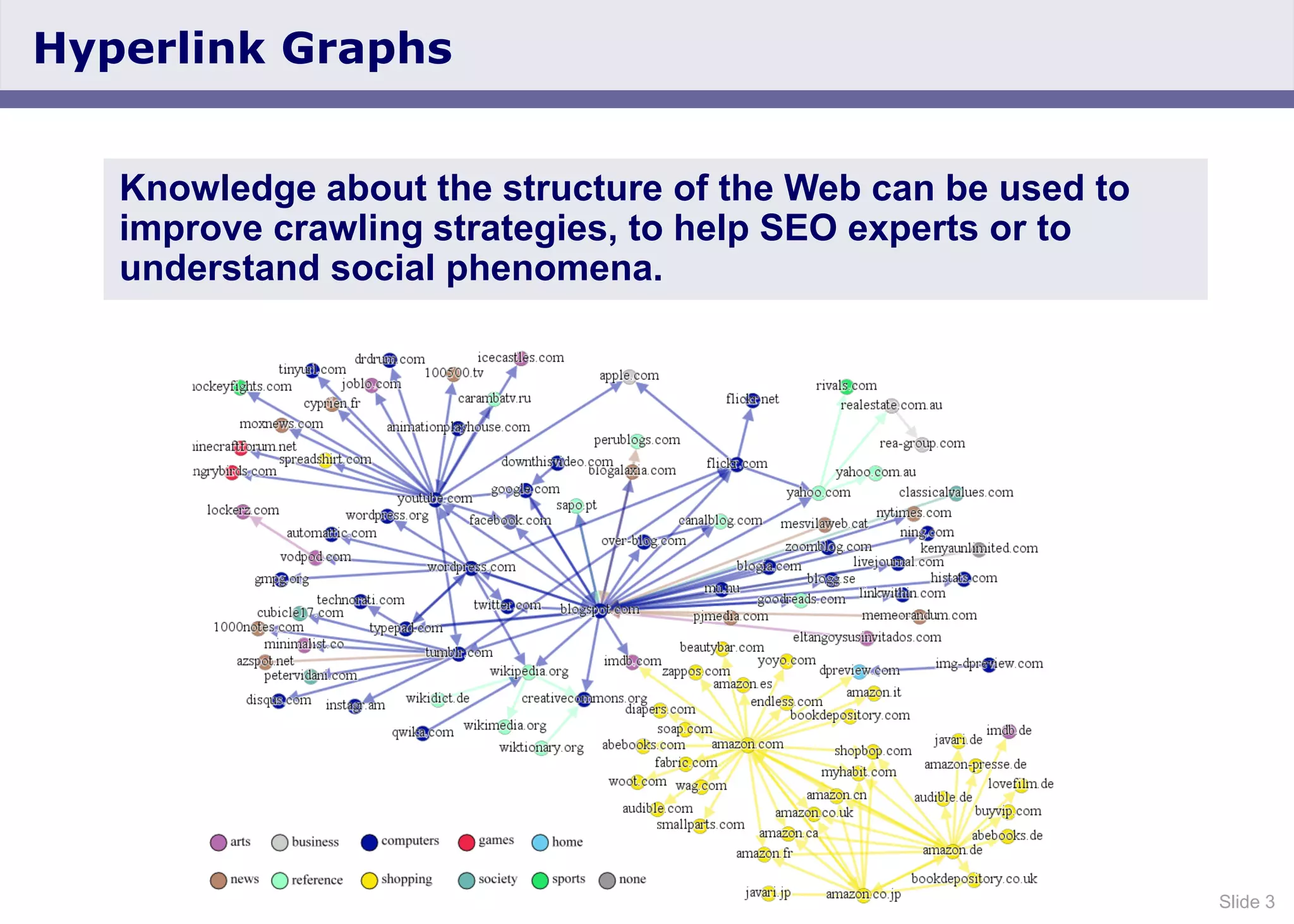

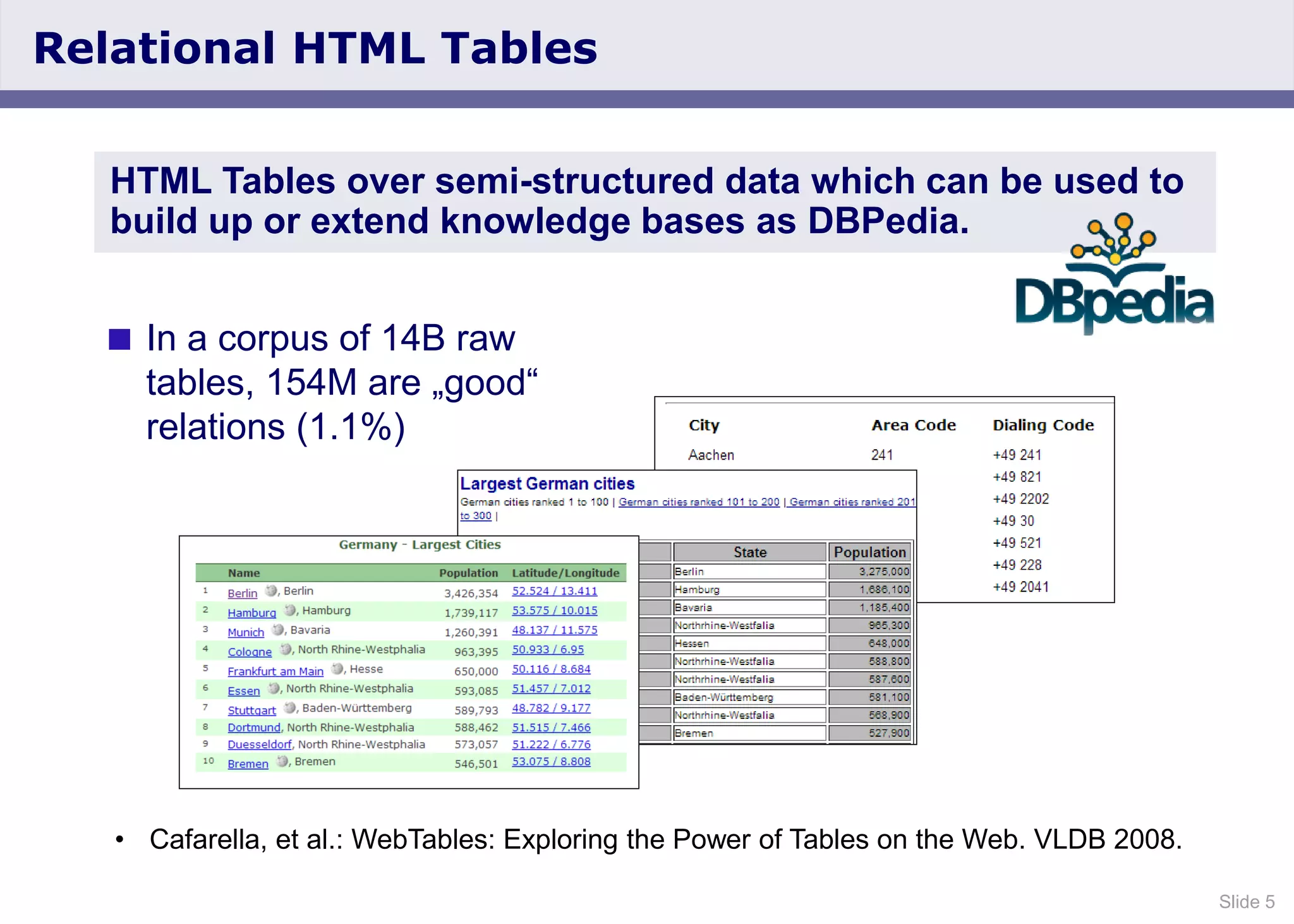

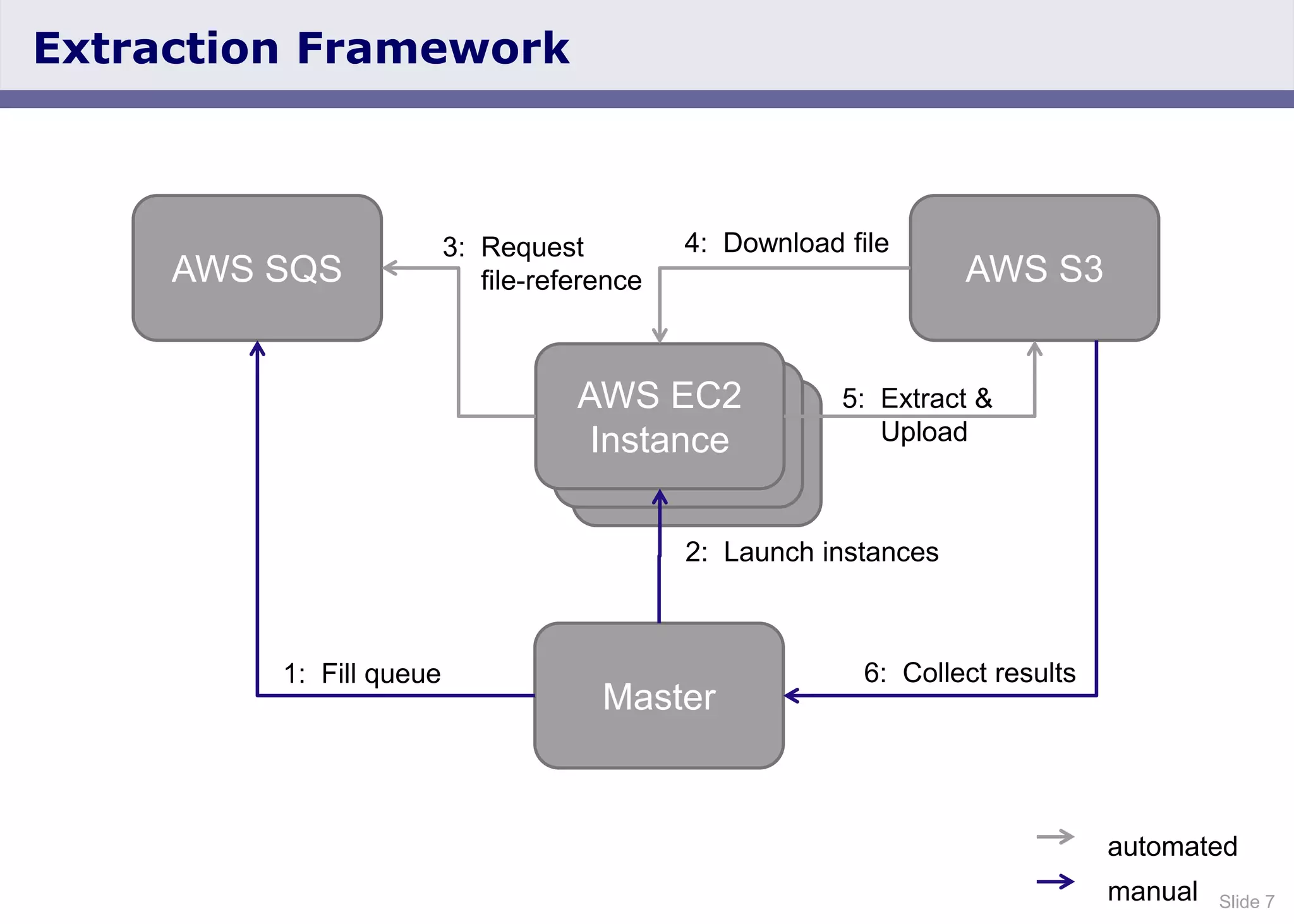
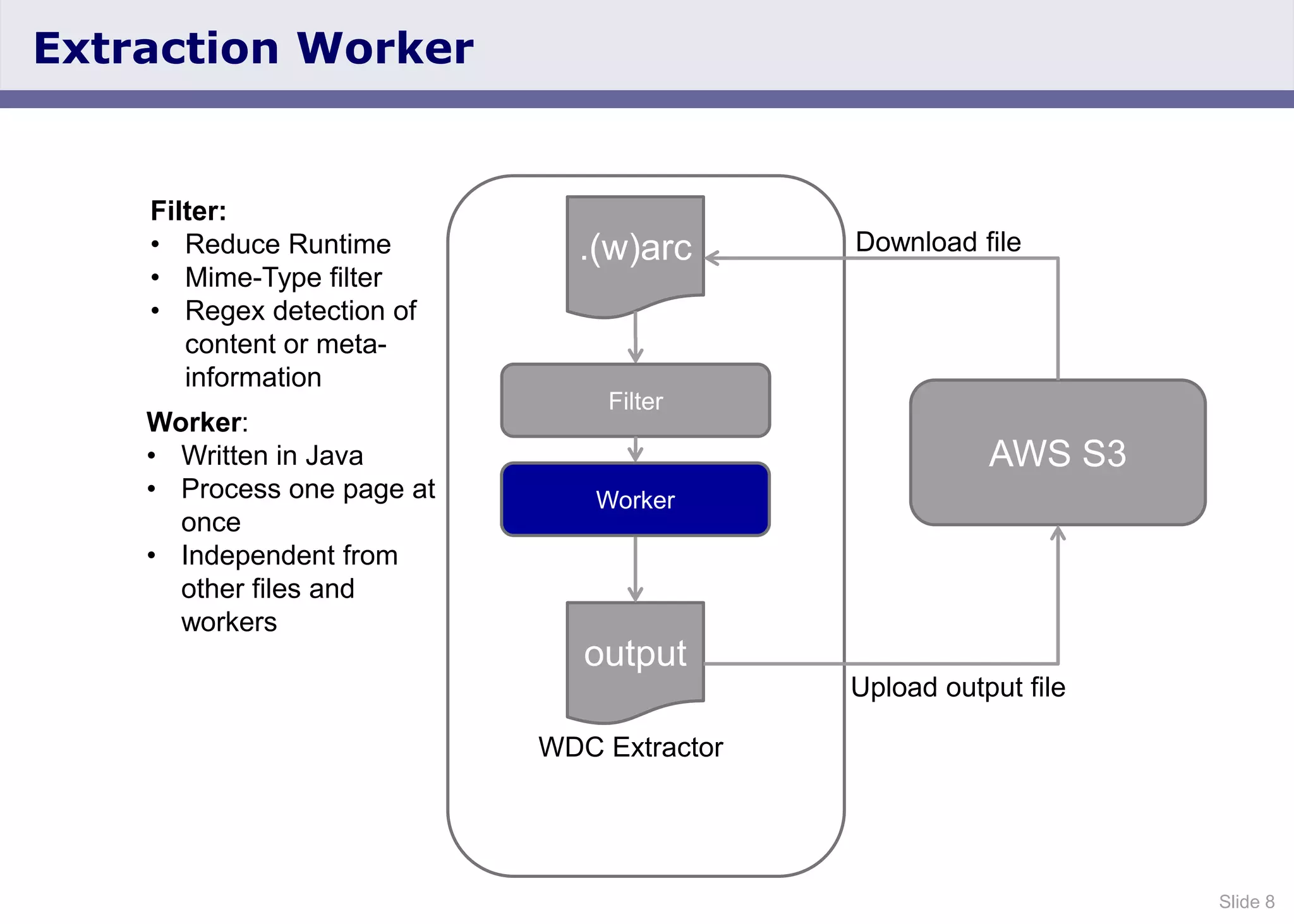

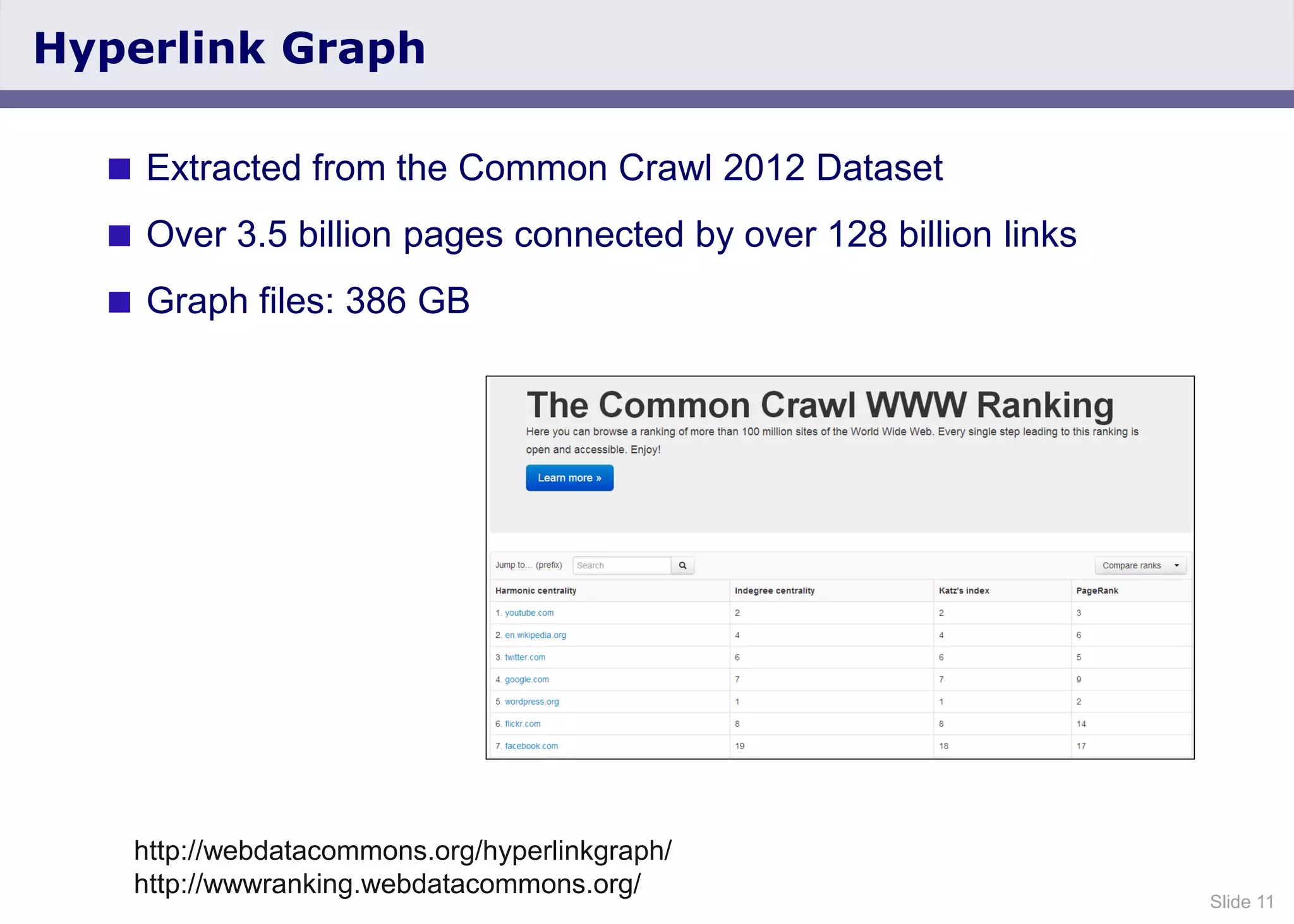
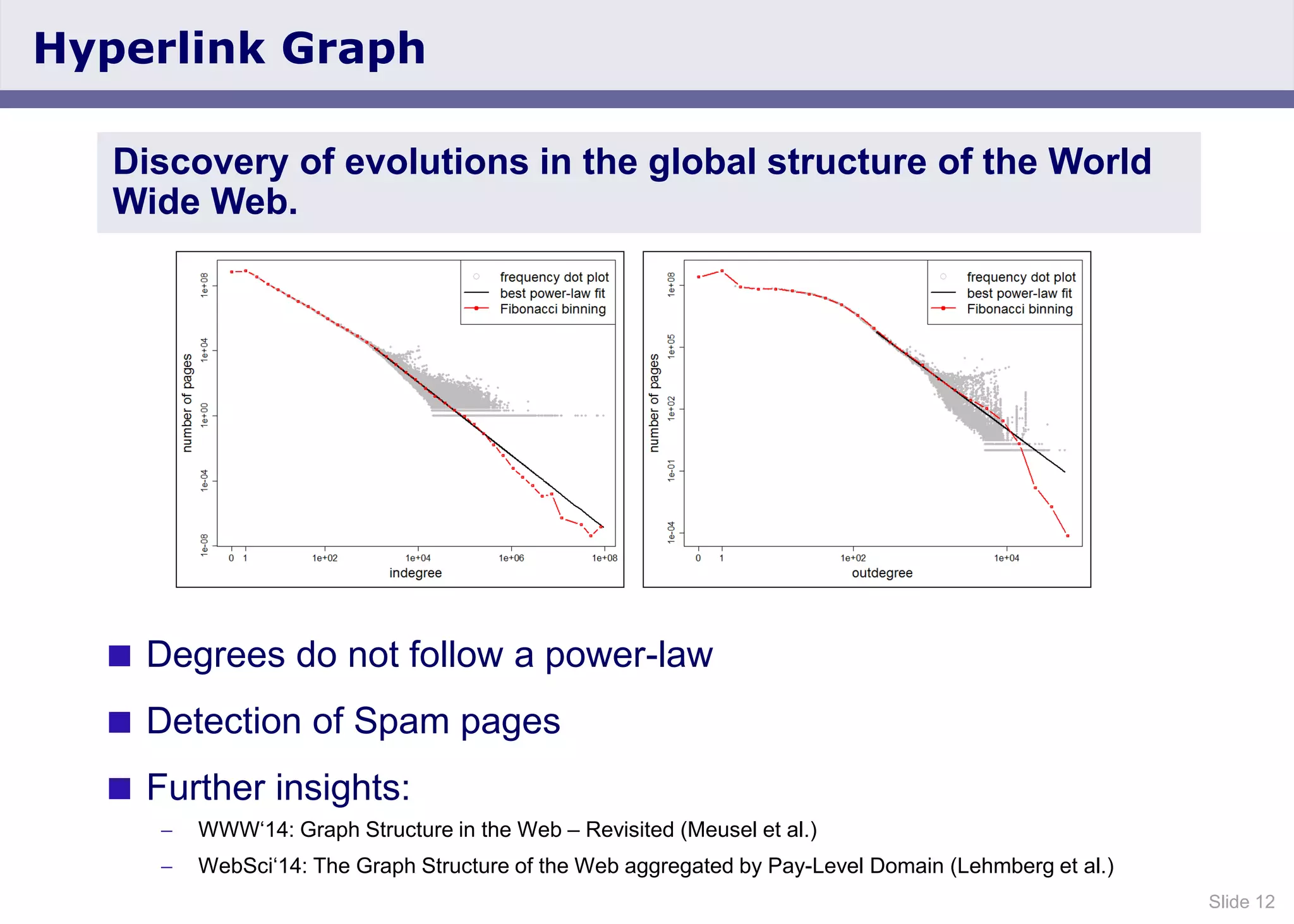
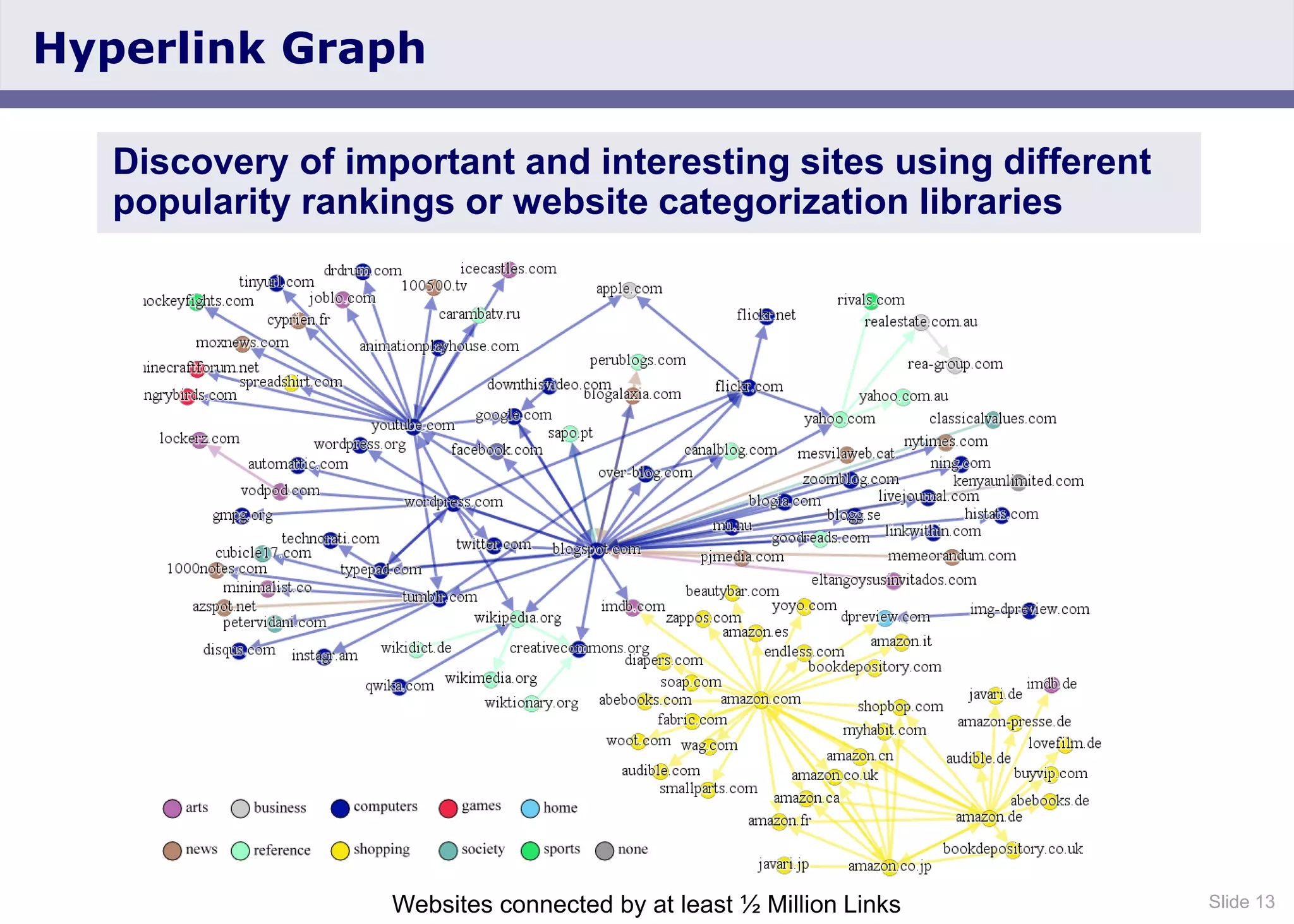


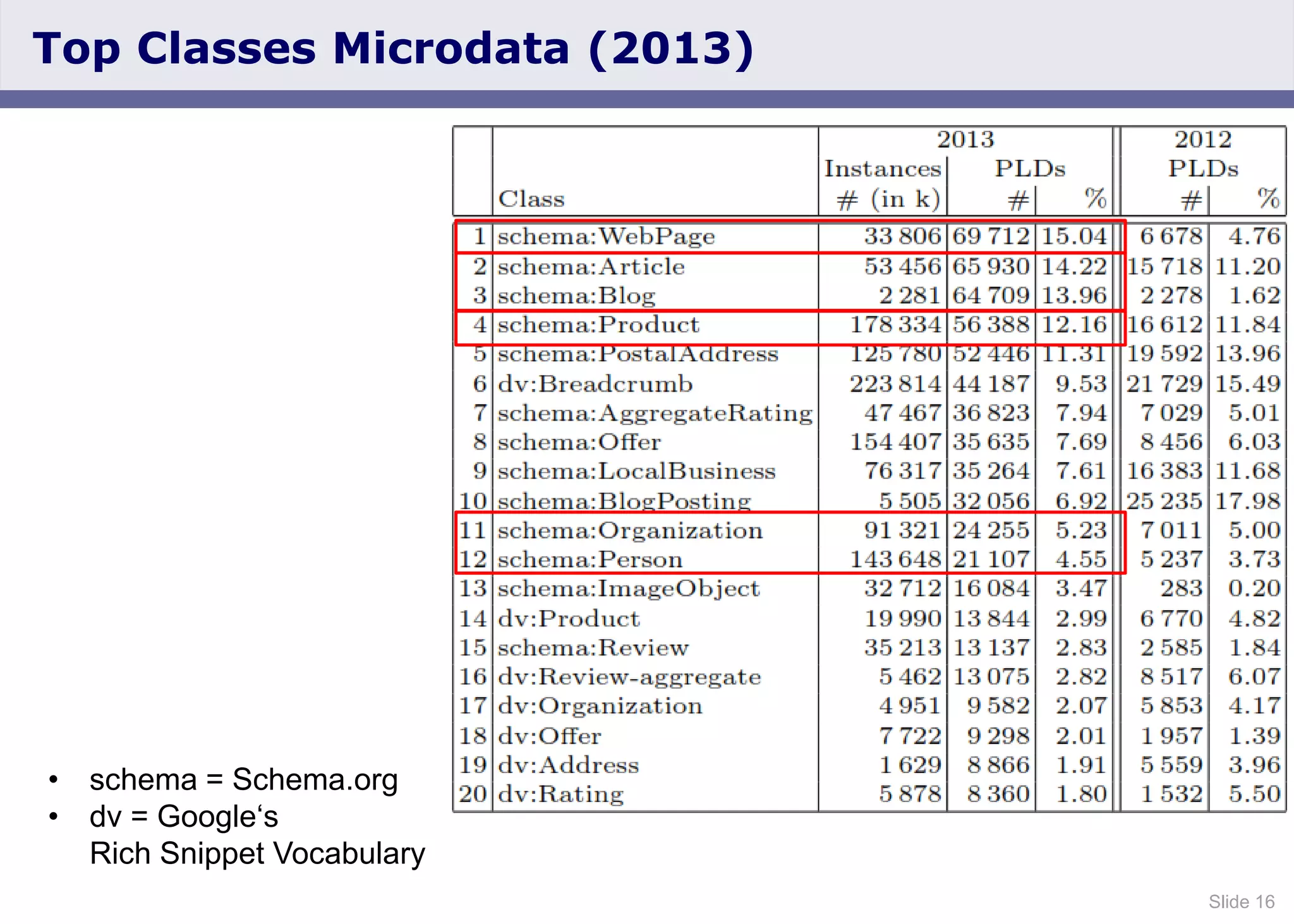
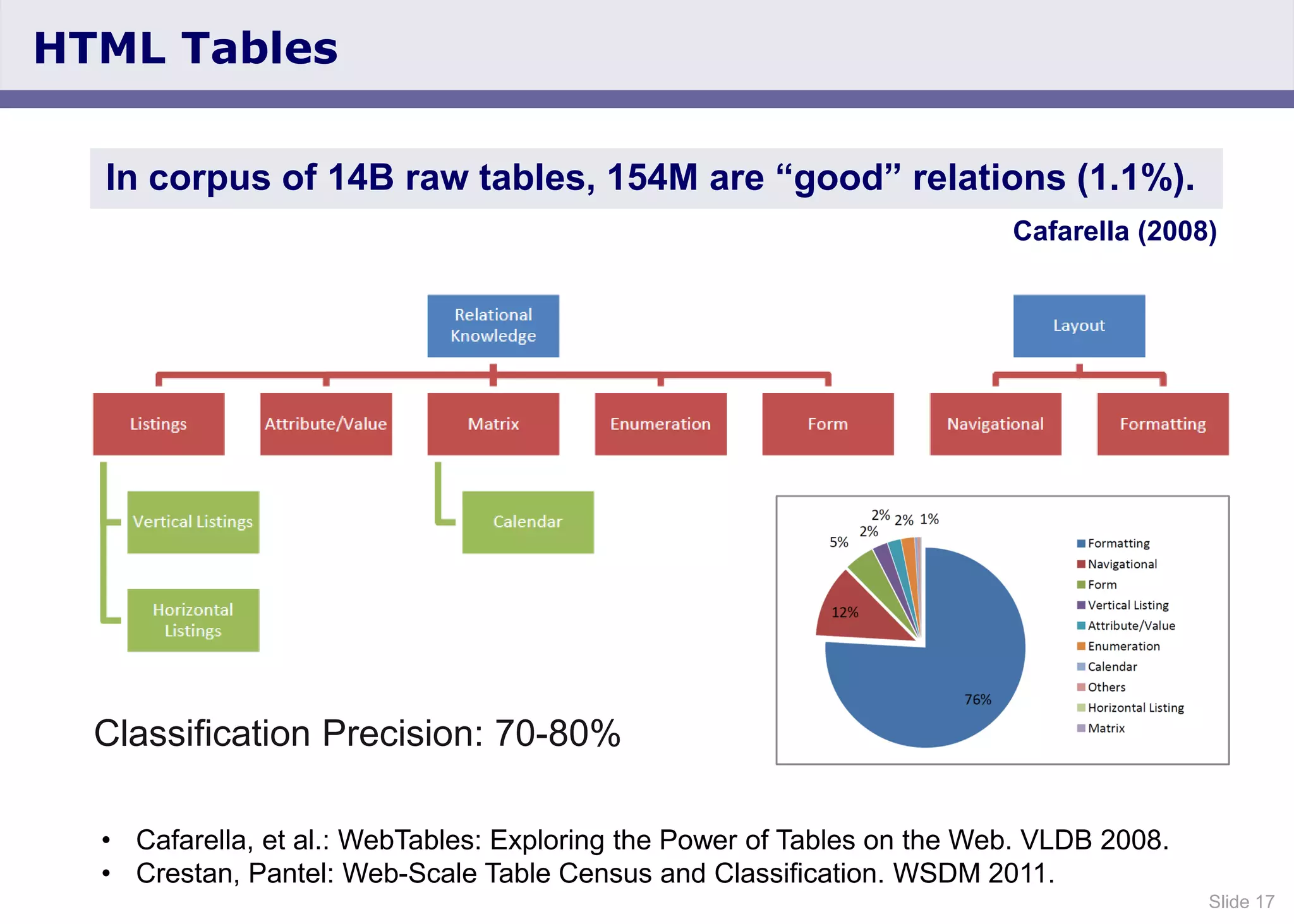
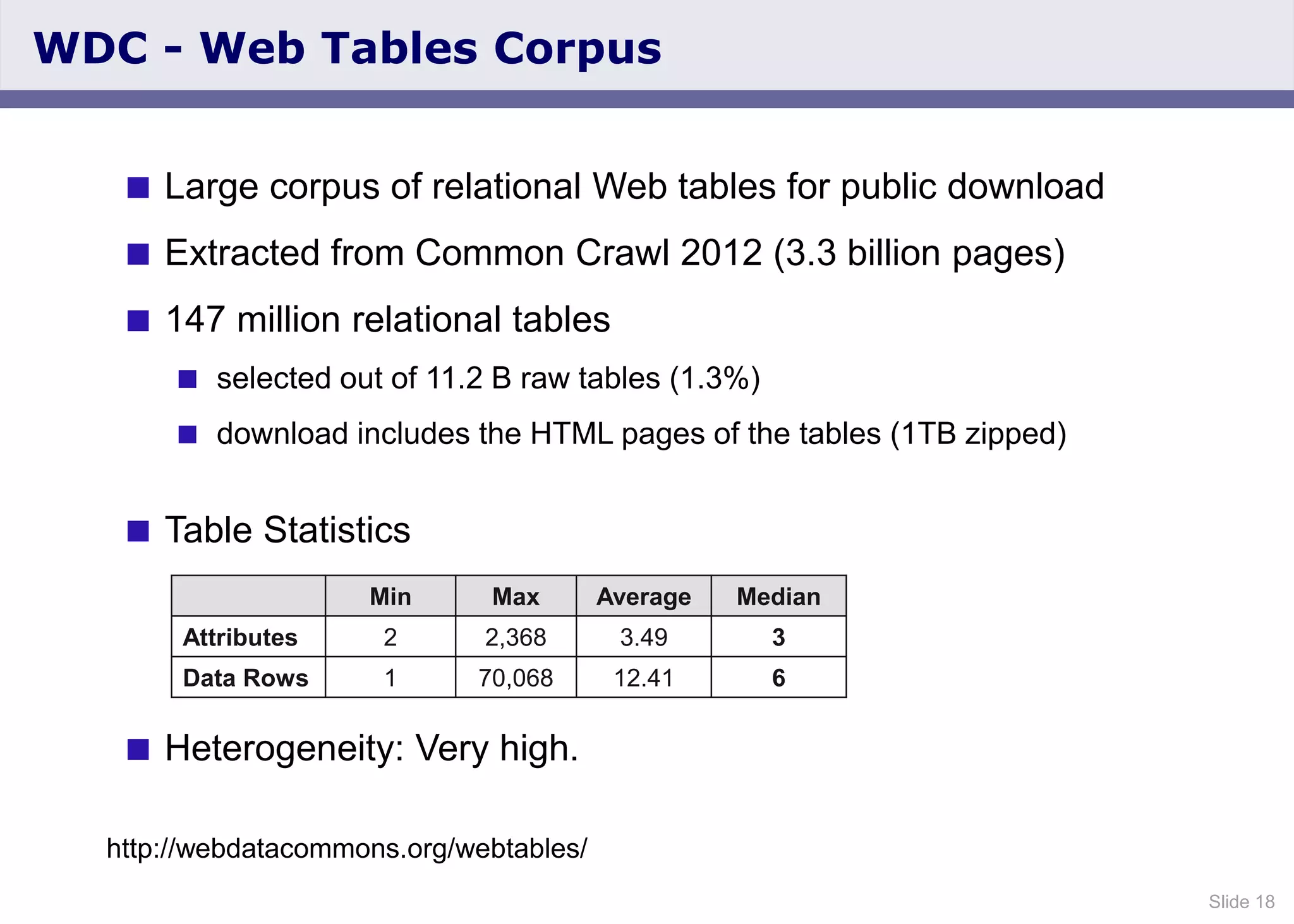
























The document discusses the Web Data Commons project, which provides a framework for extracting and analyzing data from large web crawls, specifically the Common Crawl. It highlights various data types that can be extracted, including hyperlink graphs, HTML-embedded data, and relational HTML tables, and outlines the infrastructure used for this extraction process. Additionally, it notes the increasing prevalence of structured data on the web and provides access to extracted datasets for public use.













































































