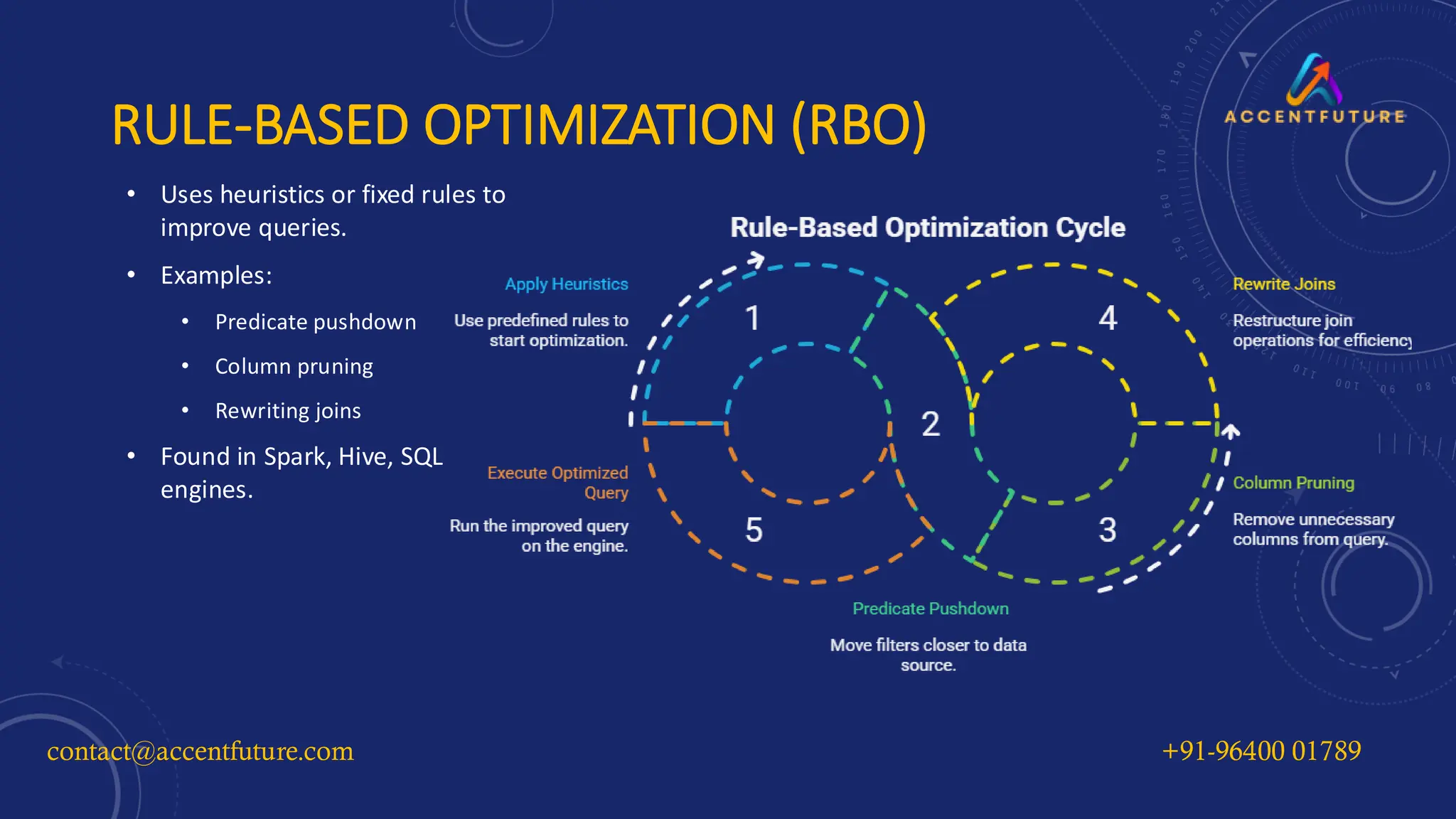
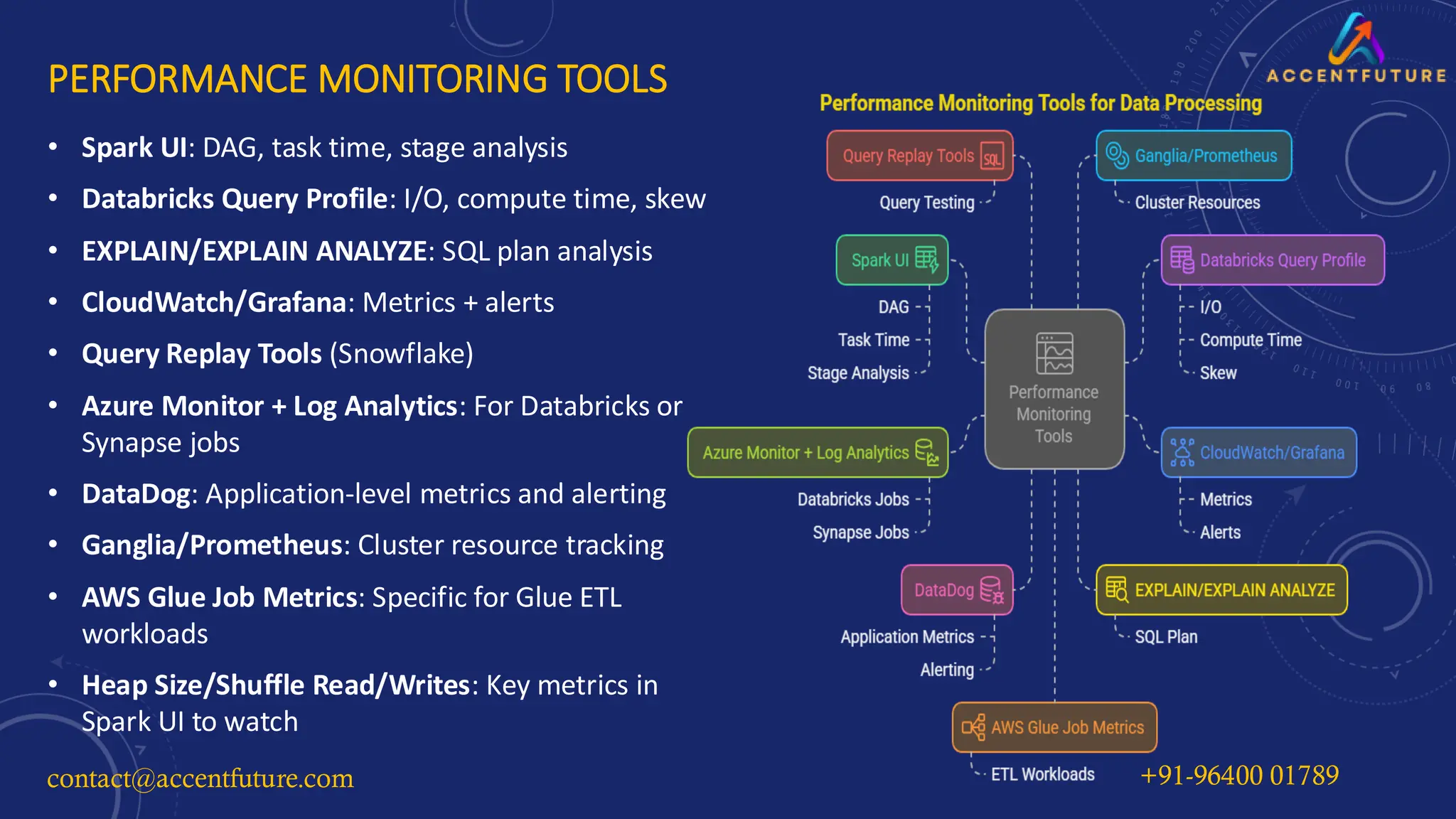
Unlock the full potential of your data pipelines with our in-depth guide to Query Optimization Techniques. This presentation dives deep into performance tuning strategies across platforms like Apache Spark, Databricks, Snowflake, and BigQuery. Learn the key differences between rule-based and cost-based optimization, avoid common pitfalls, and implement advanced Spark strategies like AQE, Z-Ordering, and Broadcast Joins.
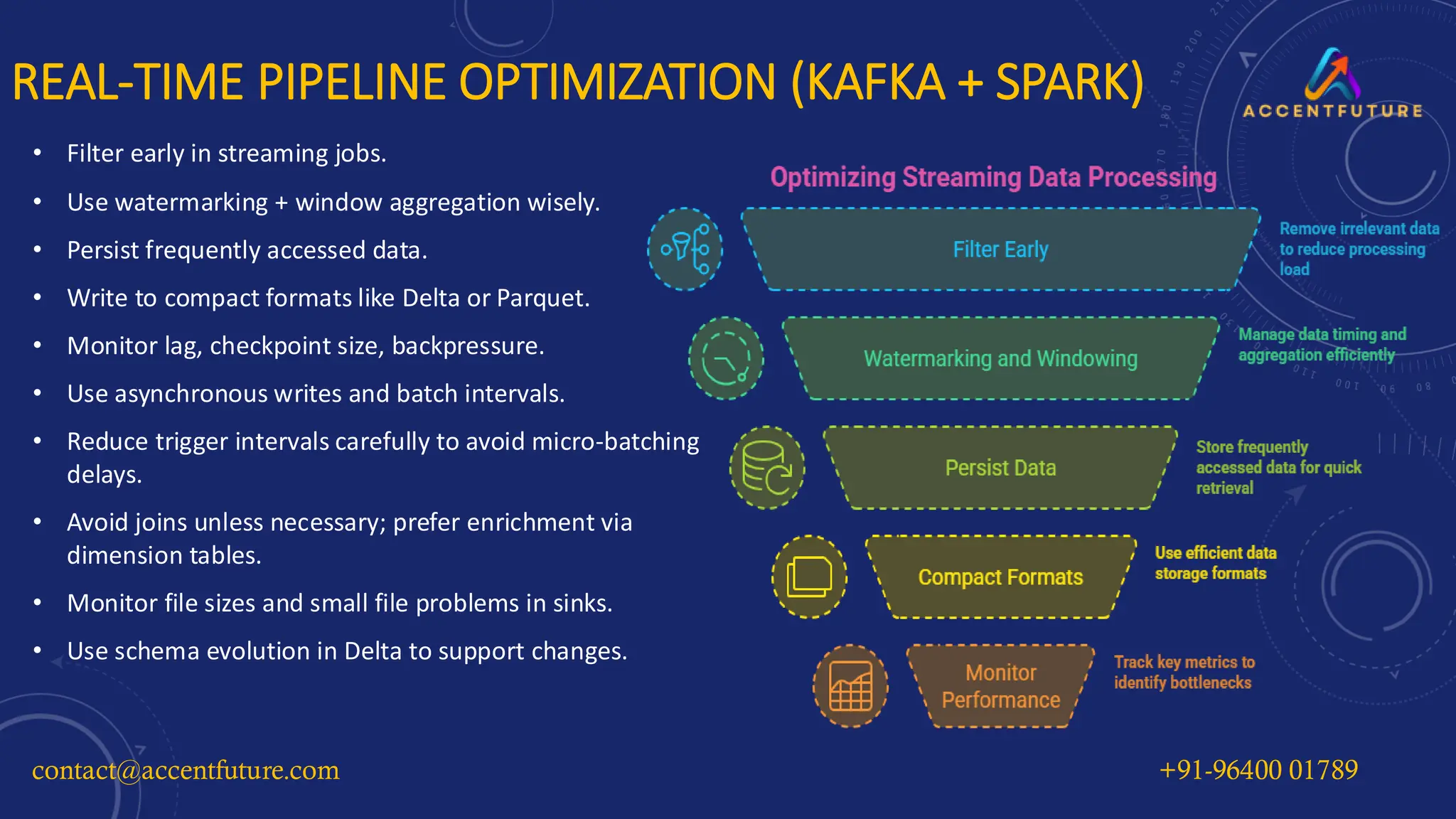
Get interview-ready with expert Q&A and explore real-world tips for optimizing real-time data pipelines with Kafka + Spark. Perfect for data engineers looking to boost performance, scalability, and cost-efficiency in production systems.
🎯 Includes tools, examples, and case-based learning from AccentFuture's expert-led training.