Download to read offline


![Advanced Computing: An International Journal ( ACIJ ), Vol.3, No.6, November 2012
31
2. RELATED WORK
Distributed Data Mining in Peer-to-Peer Networks (P2P) [1] offers an overview of
distributed data-mining applications and algorithms for peer-to-peer environments. It describes
both exact and approximate distributed data-mining algorithms that work in a decentralized
manner. It illustrates these approaches for the problem of computing and monitoring clusters in
the data residing at the different nodes of a peer-to-peer network. This paper focuses on an
emerging branch of distributed data mining called peer-to-peer data mining. It also offers a
sample of exact and approximate P2P algorithms for clustering in such distributed
environments.
Web Service-based approach for data mining in distributed environments [2] presents an
approach to develop a data mining system in distributed environments. This paper presents a
web service-based approach to solve these problems. The system is built using this approach
offers a uniform presentation and storage mechanism, platform independent interface, and a
dynamically extensible architecture. The proposed approach in this paper allows users to
classify new incoming data by selecting one of the previously learnt models.
Architecture for data mining in distributed environments [3] describes system architecture for
scalable and portable distributed data mining applications. This approach presents a document
metaphor called emph{Living Documents} for accessing and searching for digital documents
in modern distributed information systems. The paper describes a corpus linguistic analysis of
large text corpora based on colocations with the aim of extracting semantic relations from
unstructured text.
Distributed Data Mining of Large Classifier Ensembles [4] presents a new classifier
combination strategy that scales up efficiently and achieves both high predictive accuracy and
tractability of problems with high complexity. It induces a global model by learning from the
averages of the local classifiers output. The effective combination of large number of classifiers
is achieved this way.
Multi Agent-Based Distributed Data Mining [5] is the integration of multi-agent system and
distributed data mining (MADM), also known as multi-agent based distributed data mining. The
perspective here is in terms of significance, system overview, existing systems, and research
trends. This paper presents an overview of MADM systems that are prominently in use. It also
defines the common components between systems and gives a description of their strategies and
architecture.
Preserving Privacy and Sharing the Data in Distributed Environment using Cryptographic
Technique on Perturbed data [6] proposes a framework that allows systematic transformation of
original data using randomized data perturbation technique. The modified data is then submitted
to the system through cryptographic approach. This technique is applicable in distributed
environments where each data owner has his own data and wants to share this with the other
data owners. At the same time, this data owner wants to preserve the privacy of sensitive data in
the records.
Distributed anonymous data perturbation method for privacy-preserving data mining [7]
discusses a light-weight anonymous data perturbation method for efficient privacy preserving in
distributed data mining. Two protocols are proposed to address these constraints and to protect
data statistics and the randomization process against collusion attacks.An Algorithm for
Frequent Pattern Mining Based on Apriori[8] proposes three different frequent pattern mining
approaches (Record filter, Intersection and the Proposed Algorithm) based on classical Apriori
algorithm. This paper performs a comparative study of all three approaches on a data-set of](https://image.slidesharecdn.com/3612acij04-181221070229/75/MAP-REDUCE-DESIGN-AND-IMPLEMENTATION-OF-APRIORIALGORITHM-FOR-HANDLING-VOLUMINOUS-DATA-SETS-3-2048.jpg)
![Advanced Computing: An International Journal ( ACIJ ), Vol.3, No.6, November 2012
32
2000 transactions. This paper surveys the list of existing association rule mining techniques and
compares the algorithms with their modified approach.
Using Apriori-like algorithms for Spatio-Temporal Pattern Queries [9] presents a way to
construct Apriori-like algorithms for mining spatio-temporal patterns. This paper addresses
problems of the different types of comparing functions that can be used to mine frequent
patterns.Map-Reduce for Machine Learning on Multi core [10] discusses ways to develop a
broadly applicable parallel programming paradigm that is applicable to different learning
algorithms. By taking advantage of the summation form in a map-reduce framework, this paper
tries to parallelize a wide range of machine learning algorithms and achieve a significant speed-
up on a dual processor cores.
Using Spot Instances for MapReduce Work flows [11] describes new techniques to improve the
runtime of MapReducejobs. This paper presents Spot Instances (SI) as a means of attaining
performance gains at low monetary cost.
3. DESIGN AND IMPLEMENTATION
3.1 Experimental Setup
The experimental setup has three nodes connected to managed switch linked to private
LAN. One of these nodes is configured as Hadoop Master or as the namenode which
controls the data distribution over the Hadoop cluster. All the nodes are identical in
terms of the system configuration i.e., all the nodes have identical processor - Intel
Core2 Duo and assembled by standard manufacturer. As investigative
effort,configuration made to understand Hadoop will have three nodes in fully
distributed mode. The intention is to scale the number of nodes by using standard
cluster management software that can easily add new nodes to Hadoop rather than
installing Hadoop in every node. The visualization of this setup is shown in the figure 2.
Figure 2: Experimental Setup for Hadoop Multi-node
3.1.1 Special Configuration Setup for Hadoop
Focus here is on Hadoop setup with multi-node configuration. The prerequisite for
Hadoop installation is mentioned below -](https://image.slidesharecdn.com/3612acij04-181221070229/75/MAP-REDUCE-DESIGN-AND-IMPLEMENTATION-OF-APRIORIALGORITHM-FOR-HANDLING-VOLUMINOUS-DATA-SETS-4-2048.jpg)




![Advanced Computing: An International Journal ( ACIJ ), Vol.3, No.6, November 2012
38
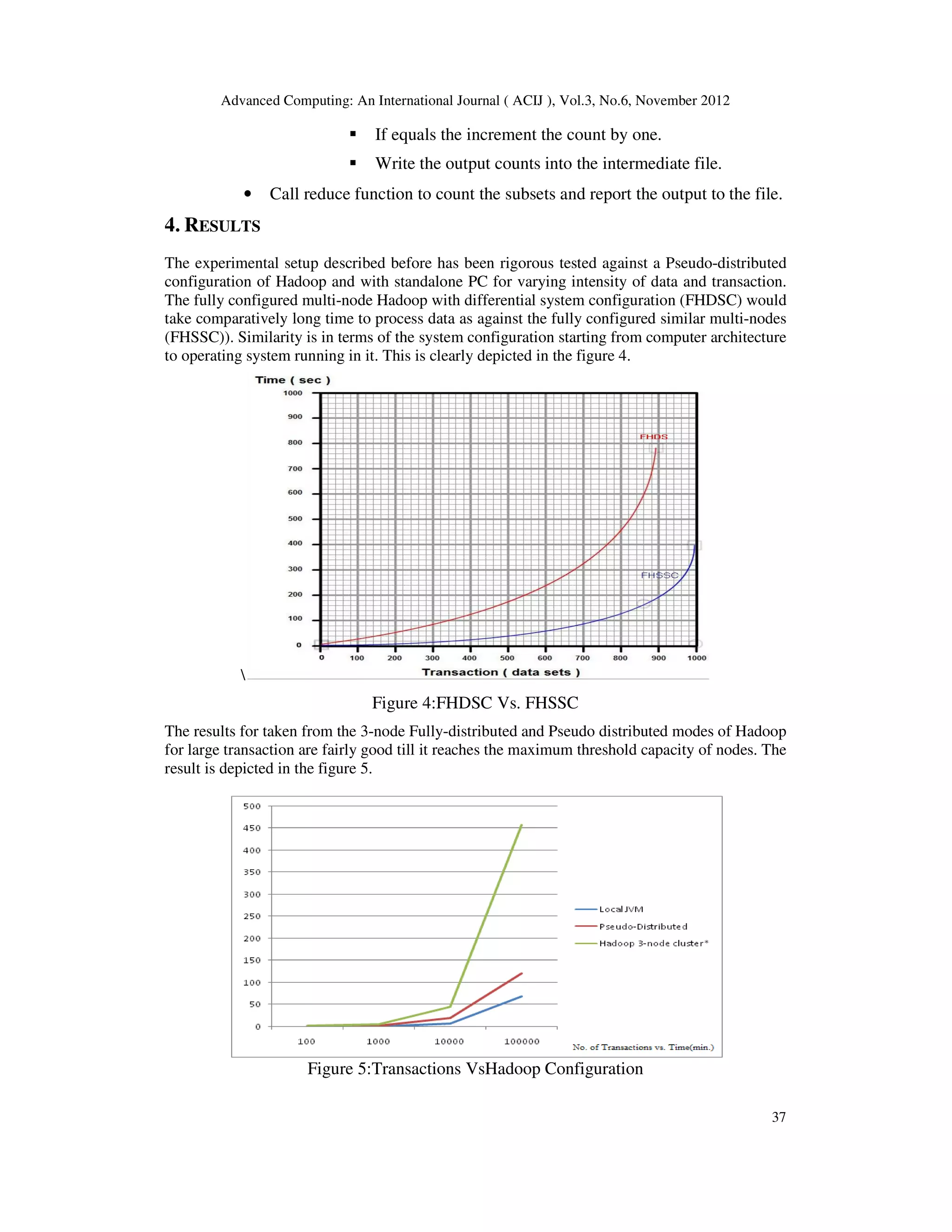
Looking the graph, there is large variance in time seen at threshold of 12,000 transactions.
Beyond which the time is in exponential. This is because of the computer architecture and
limited storage capacity of 80GB per Node. Hence the superset transaction generation will take
longer time to compute and the miner for frequent item-set.
The performance is expressed in the lateral comparison between FHDSC and FHSSC as given
below-
ࣁ ൌ
ࡲࡴࡰࡿ
ࡲࡴࡿࡿ
FHDSC = FHSSC = loge N
Where N is the number of nodes installed in the cluster.
5. CONCLUSIONS AND FUTURE ENHANCEMENTS
The paper presents a novel approach of design algorithms for clustered environment. This is
applicable to scenarios when there data-intensive computation is required. Such setup give a
broad avenue for investigation and research in Data mining. Looking the demand for such
algorithm there is urgent need to focus and explore more about clustered environment specially
for this domain.
The future works concentrates about building a framework that deals with unstructured data
analysis and complex Data mining algorithms. Also to look at integrating one of the following
parallel computing infrastructure with Map/Reduce to utilize computing power for complex
calculation on data especially in case of the classifiers under supervised learning-
• MPJ express is Java based parallel computing toolkit that can be integrated with
distributed environment.
• AtejiPX parallel programming toolkit with Hadoop.
ACKNOWLEDGEMENTS
Prof. Anjan K would like to thanks Late Dr. V.K Ananthashayana, Erstwhile Head,
Department of Computer Science and Engineering, M.S.Ramaiah Institute of
Technology, Bangalore, for igniting the passion for research.Authors would also like to
thank Late. Prof. Harish G for his consistent effort and encouragement throughout this
research project.
REFERENCES
[1]SouptikDatta, KanishkaBhaduri, Chris Giannella, Ran Wolff, and HillolKargupta, Distributed Data
Mining in Peer-to-Peer Networks, Universityof Maryland, Baltimore County, Baltimore, MD, USA,
Journal IEEEInternet Computing archive Volume 10 Issue 4, Pages 18 - 26, July 2006.
[2]Ning Chen, Nuno C. Marques, and NarasimhaBolloju, A Web Servicebasedapproach for data mining
in distributed environments, Departmentof Information Systems, City University of Hong Kong, 2005.
[3] MafruzZamanAshrafi, David Taniar, and Kate A. Smith, A Data MiningArchitecture for Distributed
Environments, pages 27-34, Springer-VerlagLondon, UK, 2007.](https://image.slidesharecdn.com/3612acij04-181221070229/75/MAP-REDUCE-DESIGN-AND-IMPLEMENTATION-OF-APRIORIALGORITHM-FOR-HANDLING-VOLUMINOUS-DATA-SETS-10-2048.jpg)
![Advanced Computing: An International Journal ( ACIJ ), Vol.3, No.6, November 2012
39
[4] GrigoriosTsoumakas and IoannisVlahavas, Distributed Data Mining ofLarge Classifier Ensembles,
SETN-2008, Thessaloniki, Greece, Proceedings,Companion Volume, pp. 249-256, 11-12 April 2008.
[5] VudaSreenivasaRao, Multi Agent-Based Distributed Data Mining: AnOver View, International
Journal of Reviews in computing, pages 83-92,2009.
[6] P.Kamakshi, A.VinayaBabu, Preserving Privacy and Sharing the Datain Distributed Environment
using Cryptographic Technique on Perturbeddata, Journal Of Computing, Volume 2, Issue 4, ISSN
21519617, April2010.
[7] Feng LI, Jin MA, Jian-hua LI, Distributed anonymous data perturbationmethod for privacy-preserving
data mining, Journal of Zhejiang UniversitySCIENCE A ISSN 1862-1775, pages 952-963, 2008.
[8] Goswami D.N. et. al., An Algorithm for Frequent Pattern Mining BasedOn Apriori (IJCSE)
International Journal on Computer Science andEngineering Vol. 02, No. 04, 942-947, 2010.
[9] MarcinGorawski and PawelJureczek, Using Apriori-like Algorithmsfor Spatio-Temporal Pattern
Queries, Silesian University of Technology,Institute of Computer Science, Akademicka 16, Poland, 2010.
[10] Cheng-Tao Chu et. al., Map-Reduce for Machine Learning on Multicore,CS Department, Stanford
University, Stanford, CA, 2006.
[11] NavrajChohanet. al., See Spot Run: Using Spot Instances for Map-Reduce Workflows, Computer
Science Department, University of California,2005.
AUTHORS PROFILE
Anjan K Koundinya has received his B.E degree from Visveswariah
Technological University, Belgaum, India in 2007 And his master degree from
Department of Computer Science and Engineering, M.S. Ramaiah Institute of
Technology, Bangalore, India. He has been awarded Best Performer PG 2010
and rank holder for his academic excellence. His areas of research includes
Network Security and Cryptology, Adhoc Networks, Mobile Computing, Agile
Software Engineering and Advanced Computing Infrastructure. He is currently
working as Assistant Professor in Dept. of Computer Science and Engineering, R
V College of Engineering.
Srinath N K has his M.E degree in Systems Engineering and Operations
Research from Roorkee University, in 1986 and PhD degree from
AvinashLingum University, India in 2009. His areas of research interests include
Operations Research, Parallel and Distributed Computing, DBMS,
Microprocessor.His is working as Professor and Head, Dept of Computer
Science and Engineering, R V College of Engineering.](https://image.slidesharecdn.com/3612acij04-181221070229/75/MAP-REDUCE-DESIGN-AND-IMPLEMENTATION-OF-APRIORIALGORITHM-FOR-HANDLING-VOLUMINOUS-DATA-SETS-11-2048.jpg)


![Advanced Computing: An International Journal ( ACIJ ), Vol.3, No.6, November 2012
31
2. RELATED WORK
Distributed Data Mining in Peer-to-Peer Networks (P2P) [1] offers an overview of
distributed data-mining applications and algorithms for peer-to-peer environments. It describes
both exact and approximate distributed data-mining algorithms that work in a decentralized
manner. It illustrates these approaches for the problem of computing and monitoring clusters in
the data residing at the different nodes of a peer-to-peer network. This paper focuses on an
emerging branch of distributed data mining called peer-to-peer data mining. It also offers a
sample of exact and approximate P2P algorithms for clustering in such distributed
environments.
Web Service-based approach for data mining in distributed environments [2] presents an
approach to develop a data mining system in distributed environments. This paper presents a
web service-based approach to solve these problems. The system is built using this approach
offers a uniform presentation and storage mechanism, platform independent interface, and a
dynamically extensible architecture. The proposed approach in this paper allows users to
classify new incoming data by selecting one of the previously learnt models.
Architecture for data mining in distributed environments [3] describes system architecture for
scalable and portable distributed data mining applications. This approach presents a document
metaphor called emph{Living Documents} for accessing and searching for digital documents
in modern distributed information systems. The paper describes a corpus linguistic analysis of
large text corpora based on colocations with the aim of extracting semantic relations from
unstructured text.
Distributed Data Mining of Large Classifier Ensembles [4] presents a new classifier
combination strategy that scales up efficiently and achieves both high predictive accuracy and
tractability of problems with high complexity. It induces a global model by learning from the
averages of the local classifiers output. The effective combination of large number of classifiers
is achieved this way.
Multi Agent-Based Distributed Data Mining [5] is the integration of multi-agent system and
distributed data mining (MADM), also known as multi-agent based distributed data mining. The
perspective here is in terms of significance, system overview, existing systems, and research
trends. This paper presents an overview of MADM systems that are prominently in use. It also
defines the common components between systems and gives a description of their strategies and
architecture.
Preserving Privacy and Sharing the Data in Distributed Environment using Cryptographic
Technique on Perturbed data [6] proposes a framework that allows systematic transformation of
original data using randomized data perturbation technique. The modified data is then submitted
to the system through cryptographic approach. This technique is applicable in distributed
environments where each data owner has his own data and wants to share this with the other
data owners. At the same time, this data owner wants to preserve the privacy of sensitive data in
the records.
Distributed anonymous data perturbation method for privacy-preserving data mining [7]
discusses a light-weight anonymous data perturbation method for efficient privacy preserving in
distributed data mining. Two protocols are proposed to address these constraints and to protect
data statistics and the randomization process against collusion attacks.An Algorithm for
Frequent Pattern Mining Based on Apriori[8] proposes three different frequent pattern mining
approaches (Record filter, Intersection and the Proposed Algorithm) based on classical Apriori
algorithm. This paper performs a comparative study of all three approaches on a data-set of](https://crownmelresort.com/image.slidesharecdn.com/3612acij04-181221070229/75/MAP-REDUCE-DESIGN-AND-IMPLEMENTATION-OF-APRIORIALGORITHM-FOR-HANDLING-VOLUMINOUS-DATA-SETS-3-2048.jpg)
![Advanced Computing: An International Journal ( ACIJ ), Vol.3, No.6, November 2012
32
2000 transactions. This paper surveys the list of existing association rule mining techniques and
compares the algorithms with their modified approach.
Using Apriori-like algorithms for Spatio-Temporal Pattern Queries [9] presents a way to
construct Apriori-like algorithms for mining spatio-temporal patterns. This paper addresses
problems of the different types of comparing functions that can be used to mine frequent
patterns.Map-Reduce for Machine Learning on Multi core [10] discusses ways to develop a
broadly applicable parallel programming paradigm that is applicable to different learning
algorithms. By taking advantage of the summation form in a map-reduce framework, this paper
tries to parallelize a wide range of machine learning algorithms and achieve a significant speed-
up on a dual processor cores.
Using Spot Instances for MapReduce Work flows [11] describes new techniques to improve the
runtime of MapReducejobs. This paper presents Spot Instances (SI) as a means of attaining
performance gains at low monetary cost.
3. DESIGN AND IMPLEMENTATION
3.1 Experimental Setup
The experimental setup has three nodes connected to managed switch linked to private
LAN. One of these nodes is configured as Hadoop Master or as the namenode which
controls the data distribution over the Hadoop cluster. All the nodes are identical in
terms of the system configuration i.e., all the nodes have identical processor - Intel
Core2 Duo and assembled by standard manufacturer. As investigative
effort,configuration made to understand Hadoop will have three nodes in fully
distributed mode. The intention is to scale the number of nodes by using standard
cluster management software that can easily add new nodes to Hadoop rather than
installing Hadoop in every node. The visualization of this setup is shown in the figure 2.
Figure 2: Experimental Setup for Hadoop Multi-node
3.1.1 Special Configuration Setup for Hadoop
Focus here is on Hadoop setup with multi-node configuration. The prerequisite for
Hadoop installation is mentioned below -](https://crownmelresort.com/image.slidesharecdn.com/3612acij04-181221070229/75/MAP-REDUCE-DESIGN-AND-IMPLEMENTATION-OF-APRIORIALGORITHM-FOR-HANDLING-VOLUMINOUS-DATA-SETS-4-2048.jpg)





![Advanced Computing: An International Journal ( ACIJ ), Vol.3, No.6, November 2012
38
Looking the graph, there is large variance in time seen at threshold of 12,000 transactions.
Beyond which the time is in exponential. This is because of the computer architecture and
limited storage capacity of 80GB per Node. Hence the superset transaction generation will take
longer time to compute and the miner for frequent item-set.
The performance is expressed in the lateral comparison between FHDSC and FHSSC as given
below-
ࣁ ൌ
ࡲࡴࡰࡿ
ࡲࡴࡿࡿ
FHDSC = FHSSC = loge N
Where N is the number of nodes installed in the cluster.
5. CONCLUSIONS AND FUTURE ENHANCEMENTS
The paper presents a novel approach of design algorithms for clustered environment. This is
applicable to scenarios when there data-intensive computation is required. Such setup give a
broad avenue for investigation and research in Data mining. Looking the demand for such
algorithm there is urgent need to focus and explore more about clustered environment specially
for this domain.
The future works concentrates about building a framework that deals with unstructured data
analysis and complex Data mining algorithms. Also to look at integrating one of the following
parallel computing infrastructure with Map/Reduce to utilize computing power for complex
calculation on data especially in case of the classifiers under supervised learning-
• MPJ express is Java based parallel computing toolkit that can be integrated with
distributed environment.
• AtejiPX parallel programming toolkit with Hadoop.
ACKNOWLEDGEMENTS
Prof. Anjan K would like to thanks Late Dr. V.K Ananthashayana, Erstwhile Head,
Department of Computer Science and Engineering, M.S.Ramaiah Institute of
Technology, Bangalore, for igniting the passion for research.Authors would also like to
thank Late. Prof. Harish G for his consistent effort and encouragement throughout this
research project.
REFERENCES
[1]SouptikDatta, KanishkaBhaduri, Chris Giannella, Ran Wolff, and HillolKargupta, Distributed Data
Mining in Peer-to-Peer Networks, Universityof Maryland, Baltimore County, Baltimore, MD, USA,
Journal IEEEInternet Computing archive Volume 10 Issue 4, Pages 18 - 26, July 2006.
[2]Ning Chen, Nuno C. Marques, and NarasimhaBolloju, A Web Servicebasedapproach for data mining
in distributed environments, Departmentof Information Systems, City University of Hong Kong, 2005.
[3] MafruzZamanAshrafi, David Taniar, and Kate A. Smith, A Data MiningArchitecture for Distributed
Environments, pages 27-34, Springer-VerlagLondon, UK, 2007.](https://crownmelresort.com/image.slidesharecdn.com/3612acij04-181221070229/75/MAP-REDUCE-DESIGN-AND-IMPLEMENTATION-OF-APRIORIALGORITHM-FOR-HANDLING-VOLUMINOUS-DATA-SETS-10-2048.jpg)
![Advanced Computing: An International Journal ( ACIJ ), Vol.3, No.6, November 2012
39
[4] GrigoriosTsoumakas and IoannisVlahavas, Distributed Data Mining ofLarge Classifier Ensembles,
SETN-2008, Thessaloniki, Greece, Proceedings,Companion Volume, pp. 249-256, 11-12 April 2008.
[5] VudaSreenivasaRao, Multi Agent-Based Distributed Data Mining: AnOver View, International
Journal of Reviews in computing, pages 83-92,2009.
[6] P.Kamakshi, A.VinayaBabu, Preserving Privacy and Sharing the Datain Distributed Environment
using Cryptographic Technique on Perturbeddata, Journal Of Computing, Volume 2, Issue 4, ISSN
21519617, April2010.
[7] Feng LI, Jin MA, Jian-hua LI, Distributed anonymous data perturbationmethod for privacy-preserving
data mining, Journal of Zhejiang UniversitySCIENCE A ISSN 1862-1775, pages 952-963, 2008.
[8] Goswami D.N. et. al., An Algorithm for Frequent Pattern Mining BasedOn Apriori (IJCSE)
International Journal on Computer Science andEngineering Vol. 02, No. 04, 942-947, 2010.
[9] MarcinGorawski and PawelJureczek, Using Apriori-like Algorithmsfor Spatio-Temporal Pattern
Queries, Silesian University of Technology,Institute of Computer Science, Akademicka 16, Poland, 2010.
[10] Cheng-Tao Chu et. al., Map-Reduce for Machine Learning on Multicore,CS Department, Stanford
University, Stanford, CA, 2006.
[11] NavrajChohanet. al., See Spot Run: Using Spot Instances for Map-Reduce Workflows, Computer
Science Department, University of California,2005.
AUTHORS PROFILE
Anjan K Koundinya has received his B.E degree from Visveswariah
Technological University, Belgaum, India in 2007 And his master degree from
Department of Computer Science and Engineering, M.S. Ramaiah Institute of
Technology, Bangalore, India. He has been awarded Best Performer PG 2010
and rank holder for his academic excellence. His areas of research includes
Network Security and Cryptology, Adhoc Networks, Mobile Computing, Agile
Software Engineering and Advanced Computing Infrastructure. He is currently
working as Assistant Professor in Dept. of Computer Science and Engineering, R
V College of Engineering.
Srinath N K has his M.E degree in Systems Engineering and Operations
Research from Roorkee University, in 1986 and PhD degree from
AvinashLingum University, India in 2009. His areas of research interests include
Operations Research, Parallel and Distributed Computing, DBMS,
Microprocessor.His is working as Professor and Head, Dept of Computer
Science and Engineering, R V College of Engineering.](https://crownmelresort.com/image.slidesharecdn.com/3612acij04-181221070229/75/MAP-REDUCE-DESIGN-AND-IMPLEMENTATION-OF-APRIORIALGORITHM-FOR-HANDLING-VOLUMINOUS-DATA-SETS-11-2048.jpg)

The paper discusses the design and implementation of the Apriori algorithm using Map/Reduce in a Hadoop distributed computing environment for analyzing voluminous structured data. It highlights the efficiency of processing large data sets using clustered nodes and provides an overview of related work in distributed data mining. The experimental setup, configuration, and results are detailed, showcasing the algorithm's effectiveness in handling complex data analytics tasks.





















































































