Download as PDF, PPTX















![Spark - MLlib
spark.mllib - DataTypes
Local vector
integer-typed and 0-based indices and double-typed values
dv2 = [1.0, 0.0, 3.0]
Labeled point
a local vector, either dense or sparse, associated with a label/response
pos = LabeledPoint(1.0, [1.0, 0.0, 3.0])
Matrices:
Local matrix
Distributed matrix
RowMatrix
IndexedRowMatrix
CoordinateMatrix
BlockMatrix](https://image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/75/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-32-2048.jpg)










![Spark - MLlib
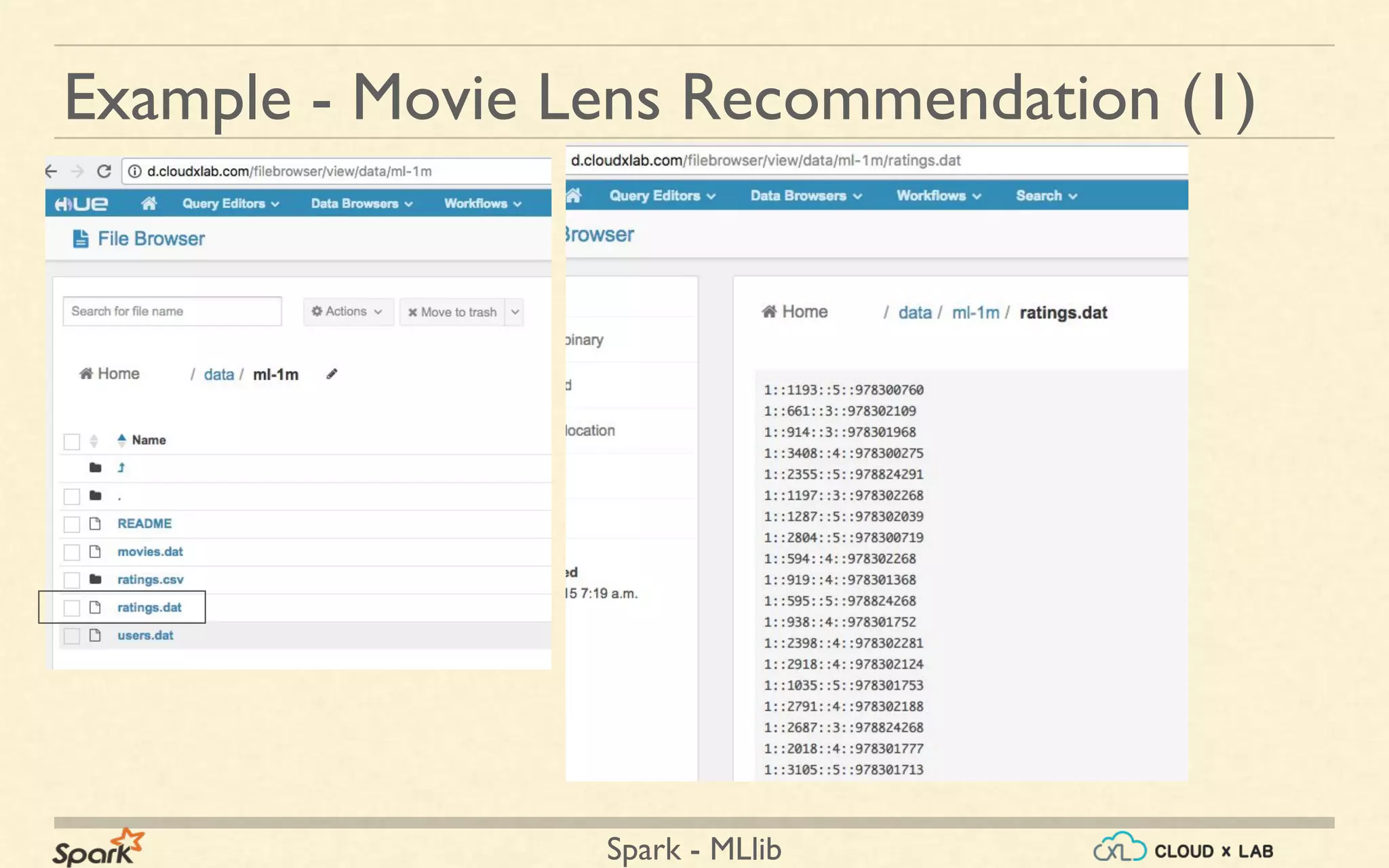
import org.apache.spark.mllib.recommendation._
var raw = sc.textFile("/data/ml-1m/ratings.dat")
var mydata = [(2, 0.01), ....]
var mydatardd = mydata.parallelize().map(x => Ratings(0, x._1, x._2))
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat)
}
val ratings = raw.map(parseRating)
totalratings = ratings.union(mydatardd)
val model = ALS.train(totalratings, 8, 5, 1)
var products = model.recommendProducts(1, 10)
//load data from movies , join it and display the names ordered by ratings
Example - Movie Lens Reco (ver 2.0)](https://image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/75/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-48-2048.jpg)



![Spark - MLlib
MLlib - k-means Example
from pyspark.mllib.clustering import KMeans, KMeansModel
from numpy import array
from math import sqrt
# Load and parse the data
data = sc.textFile("/data/spark/mllib/kmeans_data.txt")
parsedData = data.map(lambda line: array([float(x) for x in line.split(' ')]))
# Build the model (cluster the data)
clusters = KMeans.train(parsedData, 2, maxIterations=10, runs=10,
initializationMode="random")](https://image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/75/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-53-2048.jpg)
![Spark - MLlib
MLlib - k-means Example
# Evaluate clustering by computing Within Set Sum of Squared Errors
def error(point):
center = clusters.centers[clusters.predict(point)]
return sqrt(sum([x**2 for x in (point - center)]))
WSSSE = parsedData.map(lambda point: error(point)).reduce(lambda x, y: x +
y)
print("Within Set Sum of Squared Error = " + str(WSSSE))
# Save and load model
clusters.save(sc, "myModelPath")
sameModel = KMeansModel.load(sc, "myModelPath")](https://image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/75/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-54-2048.jpg)































![Spark - MLlib
spark.mllib - DataTypes
Local vector
integer-typed and 0-based indices and double-typed values
dv2 = [1.0, 0.0, 3.0]
Labeled point
a local vector, either dense or sparse, associated with a label/response
pos = LabeledPoint(1.0, [1.0, 0.0, 3.0])
Matrices:
Local matrix
Distributed matrix
RowMatrix
IndexedRowMatrix
CoordinateMatrix
BlockMatrix](https://crownmelresort.com/image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/75/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-32-2048.jpg)















![Spark - MLlib
import org.apache.spark.mllib.recommendation._
var raw = sc.textFile("/data/ml-1m/ratings.dat")
var mydata = [(2, 0.01), ....]
var mydatardd = mydata.parallelize().map(x => Ratings(0, x._1, x._2))
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat)
}
val ratings = raw.map(parseRating)
totalratings = ratings.union(mydatardd)
val model = ALS.train(totalratings, 8, 5, 1)
var products = model.recommendProducts(1, 10)
//load data from movies , join it and display the names ordered by ratings
Example - Movie Lens Reco (ver 2.0)](https://crownmelresort.com/image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/75/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-48-2048.jpg)




![Spark - MLlib
MLlib - k-means Example
from pyspark.mllib.clustering import KMeans, KMeansModel
from numpy import array
from math import sqrt
# Load and parse the data
data = sc.textFile("/data/spark/mllib/kmeans_data.txt")
parsedData = data.map(lambda line: array([float(x) for x in line.split(' ')]))
# Build the model (cluster the data)
clusters = KMeans.train(parsedData, 2, maxIterations=10, runs=10,
initializationMode="random")](https://crownmelresort.com/image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/75/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-53-2048.jpg)
![Spark - MLlib
MLlib - k-means Example
# Evaluate clustering by computing Within Set Sum of Squared Errors
def error(point):
center = clusters.centers[clusters.predict(point)]
return sqrt(sum([x**2 for x in (point - center)]))
WSSSE = parsedData.map(lambda point: error(point)).reduce(lambda x, y: x +
y)
print("Within Set Sum of Squared Error = " + str(WSSSE))
# Save and load model
clusters.save(sc, "myModelPath")
sameModel = KMeansModel.load(sc, "myModelPath")](https://crownmelresort.com/image.slidesharecdn.com/machinelearningwithmllib-spark-180514105332/75/Machine-learning-with-Apache-Spark-MLlib-Big-Data-Hadoop-Spark-Tutorial-CloudxLab-54-2048.jpg)


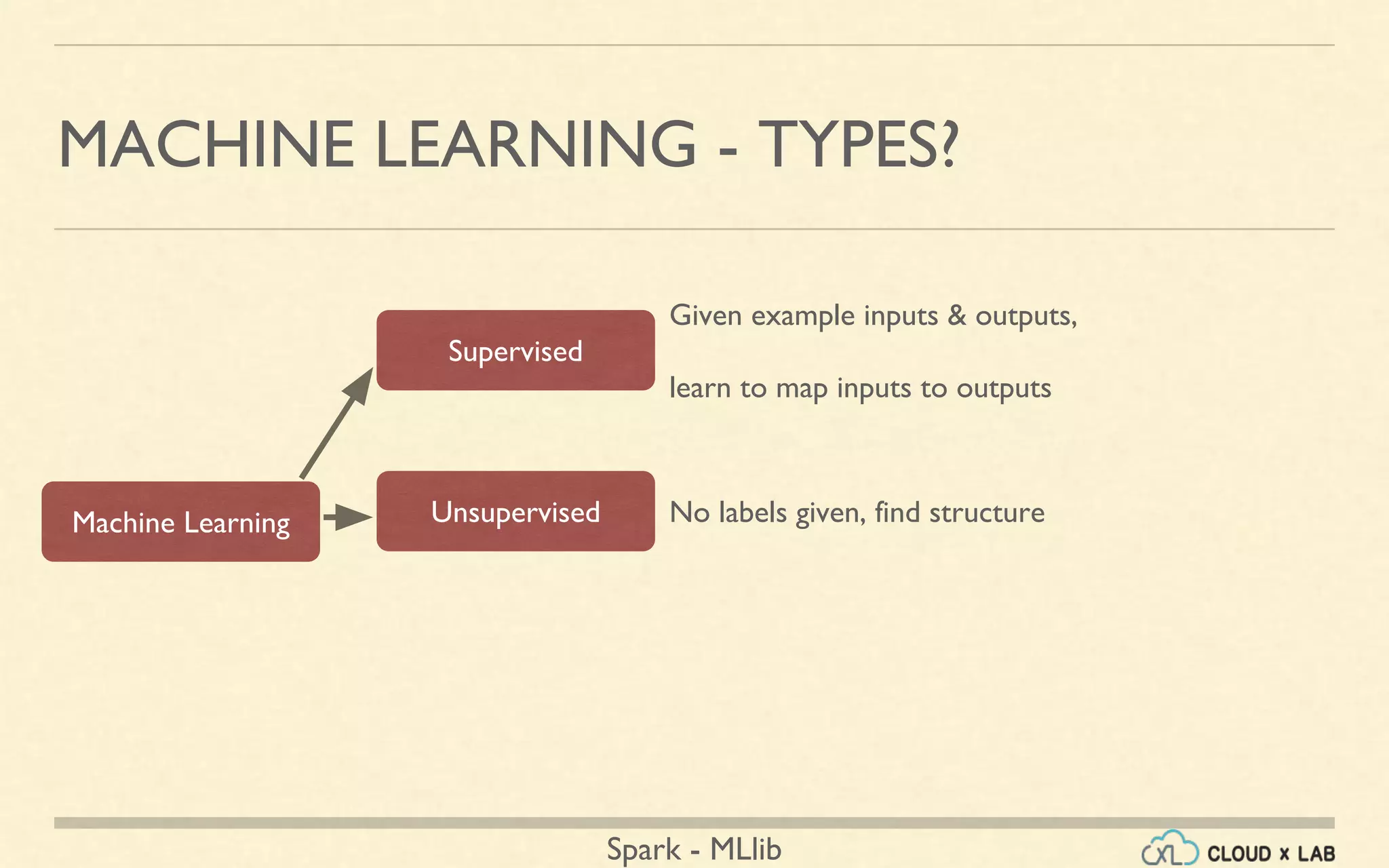
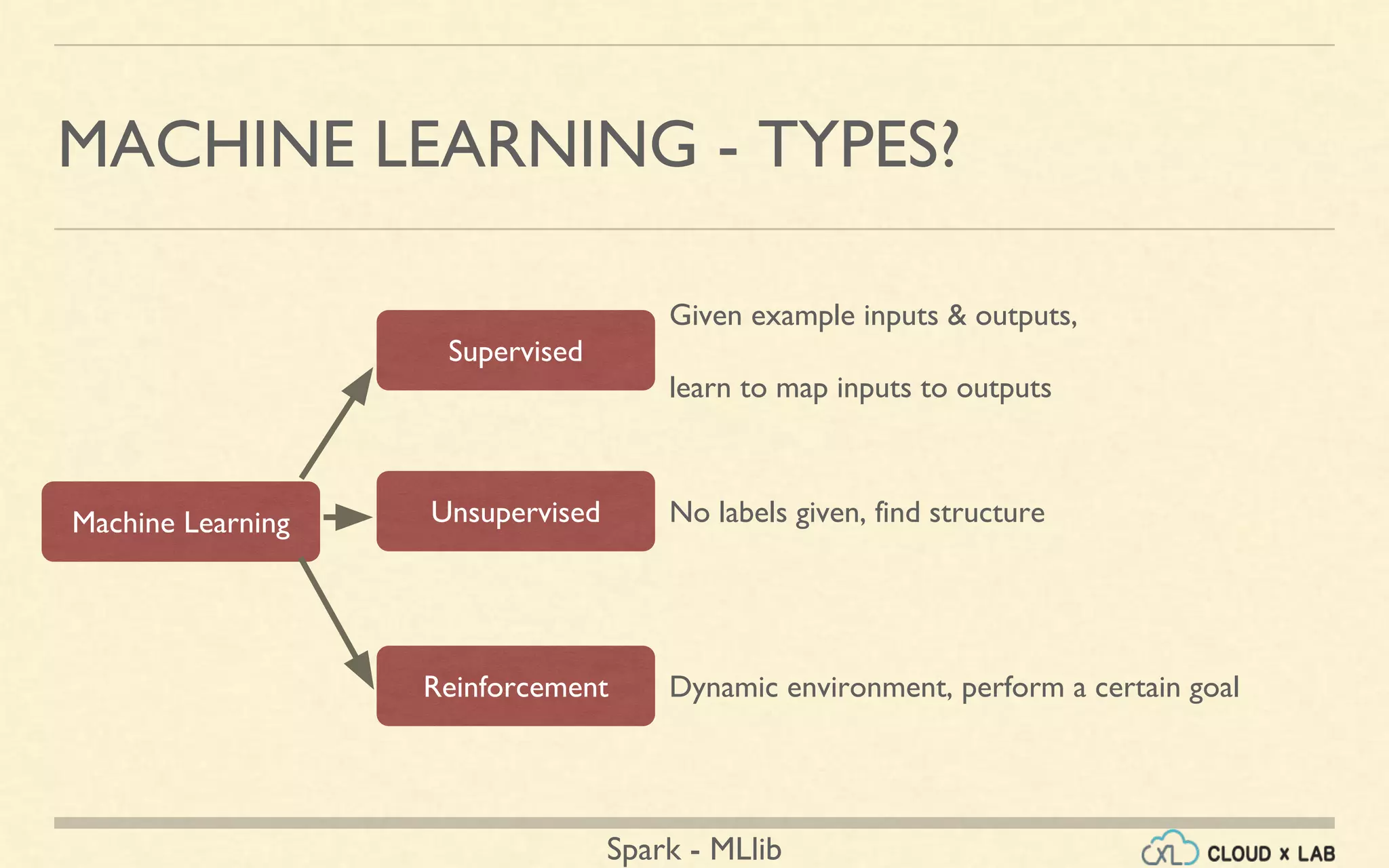
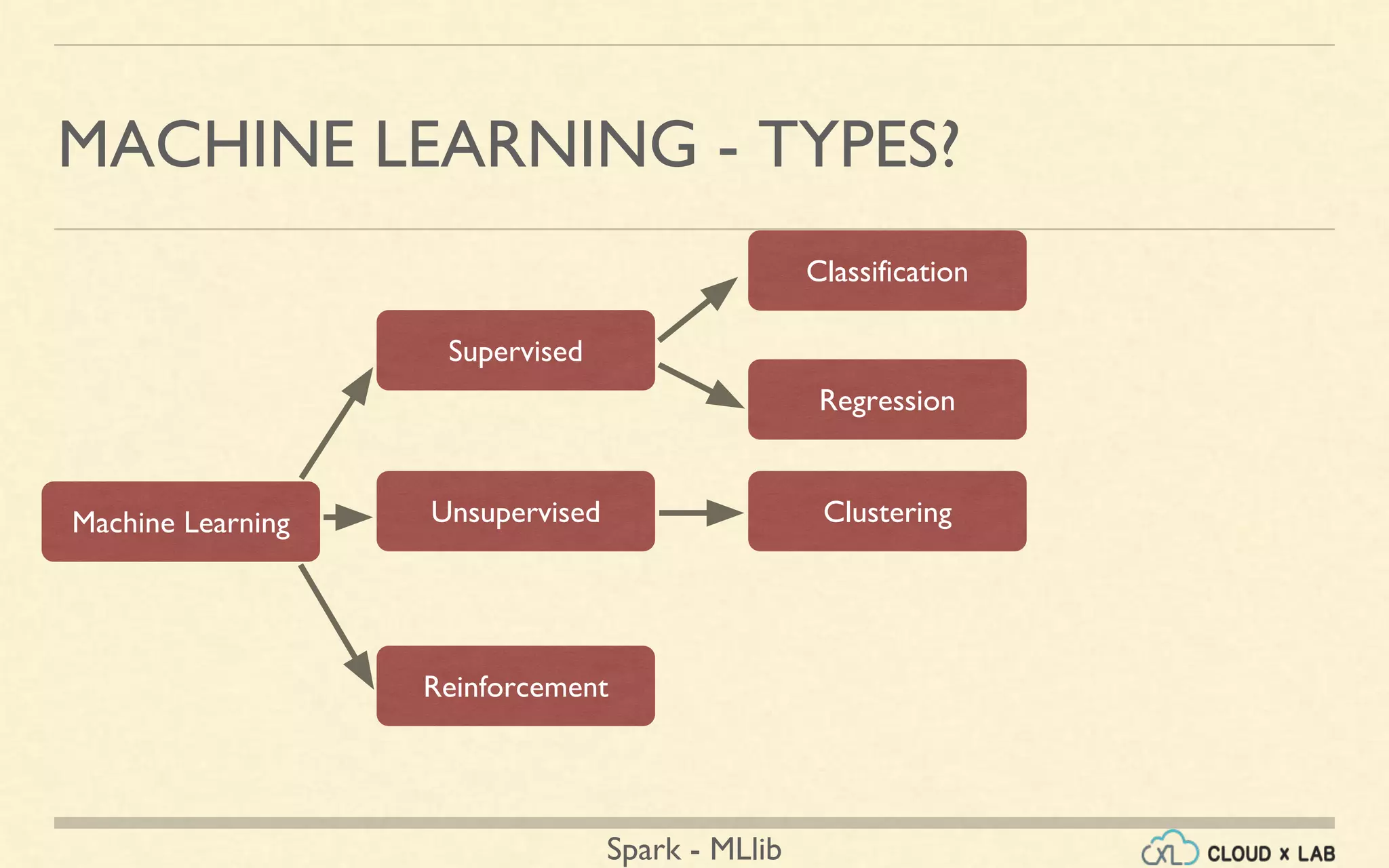
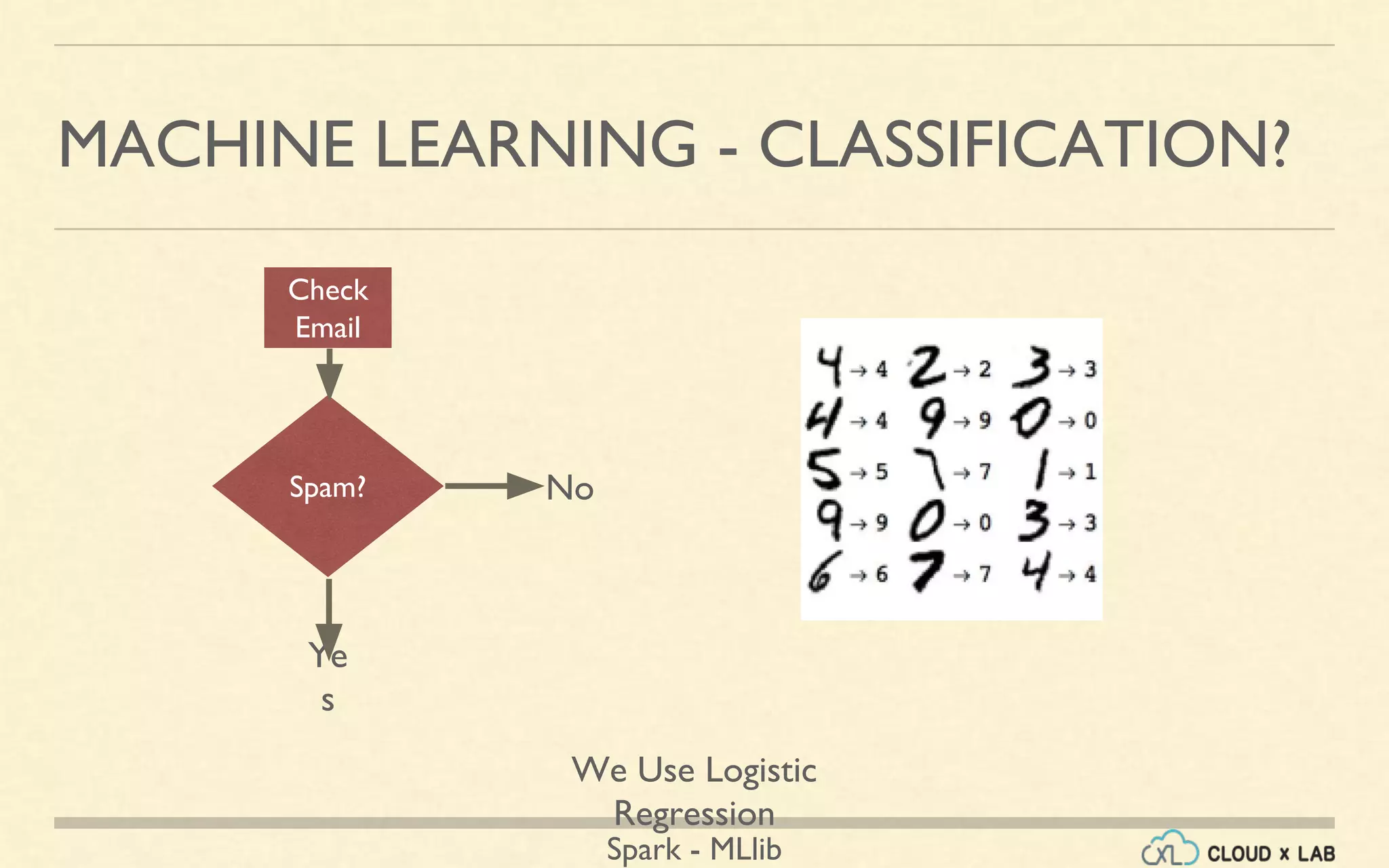
The document provides an overview of machine learning, focusing on the Spark MLlib framework. It covers types of machine learning such as supervised, unsupervised, and reinforcement learning, along with various applications and algorithms including classification, regression, and clustering. Additionally, it discusses the MLlib library's capabilities, usage, and examples like collaborative filtering and k-means clustering.























































































