Download as PDF, PPTX


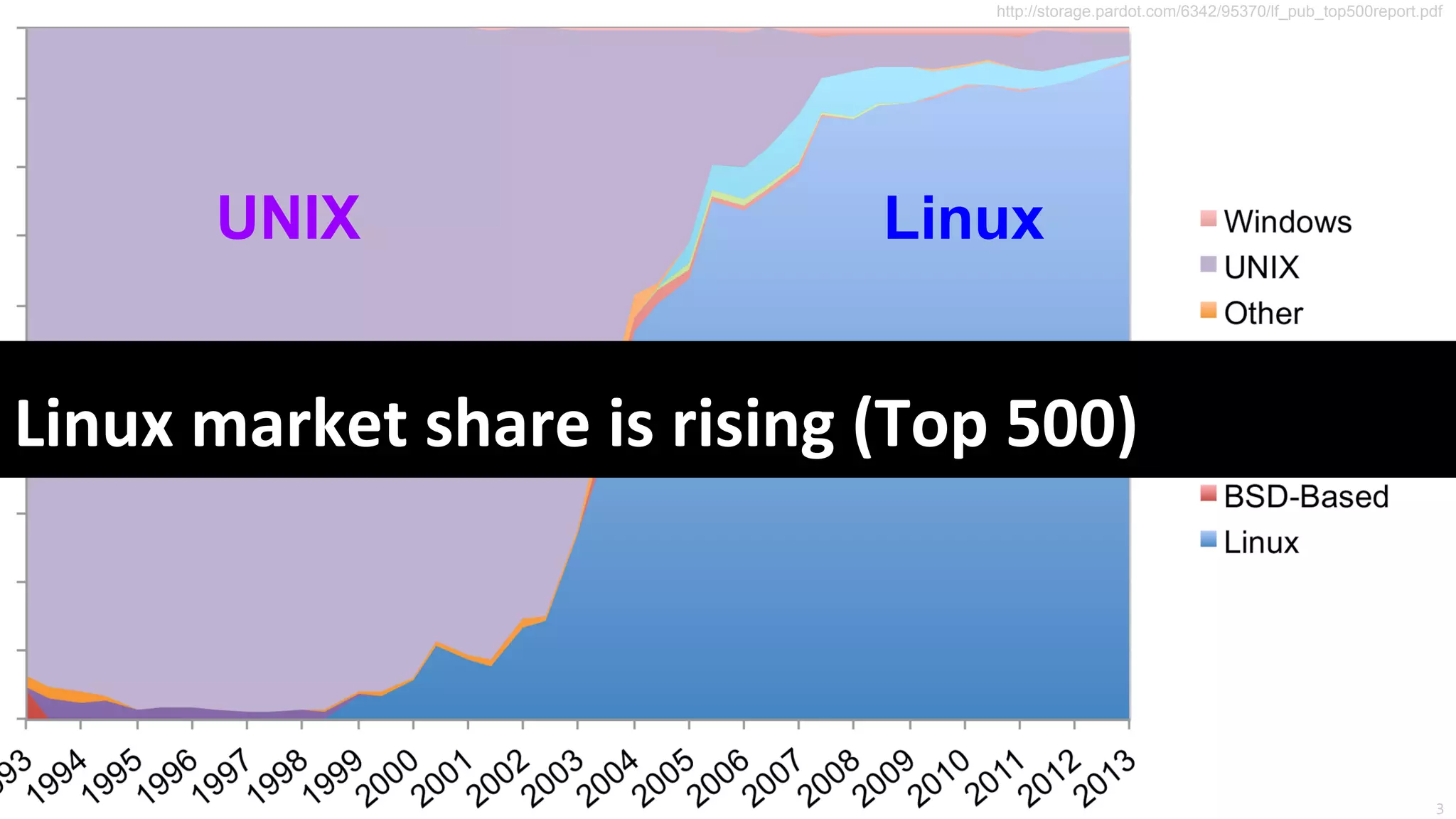


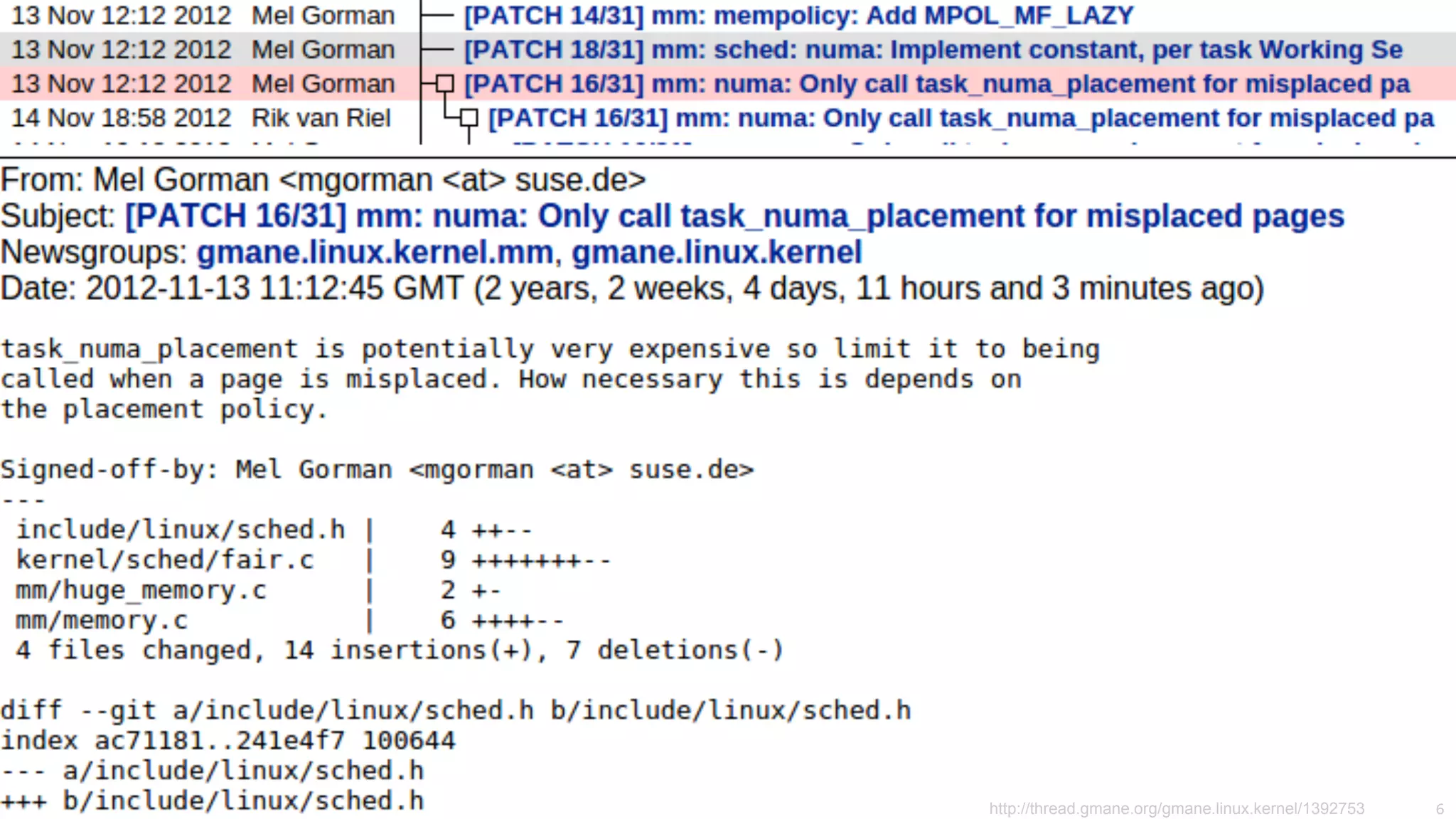



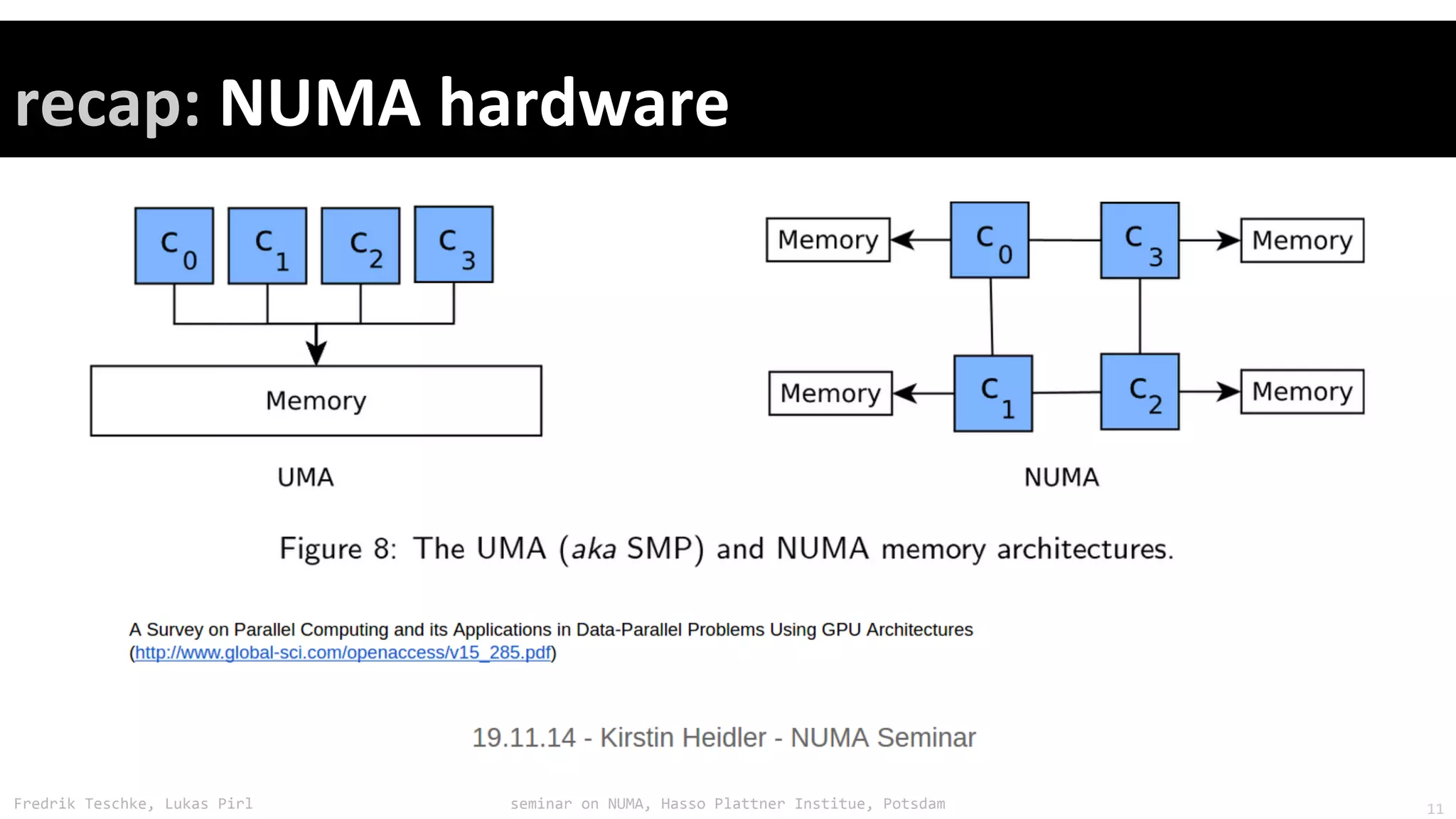












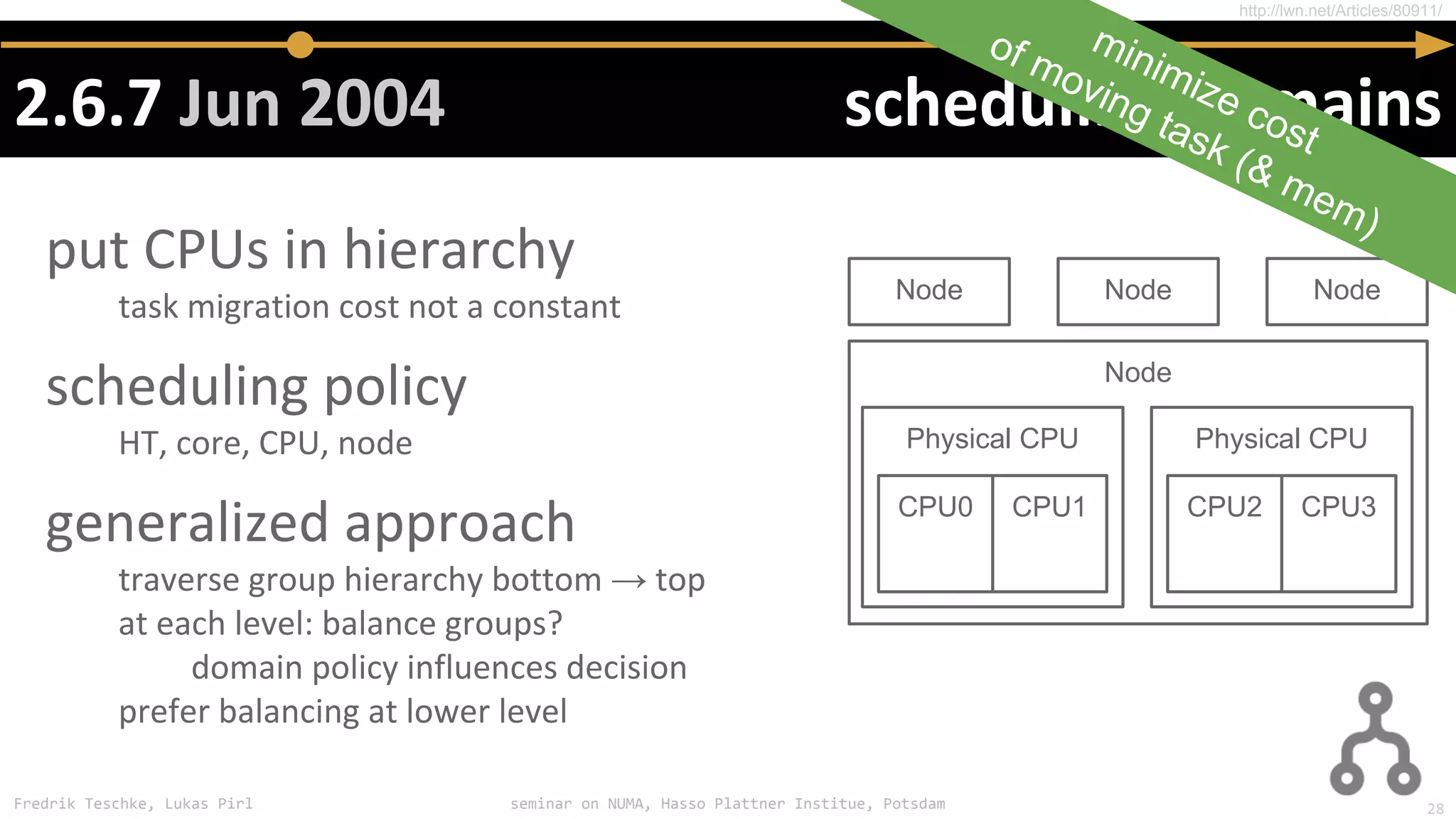

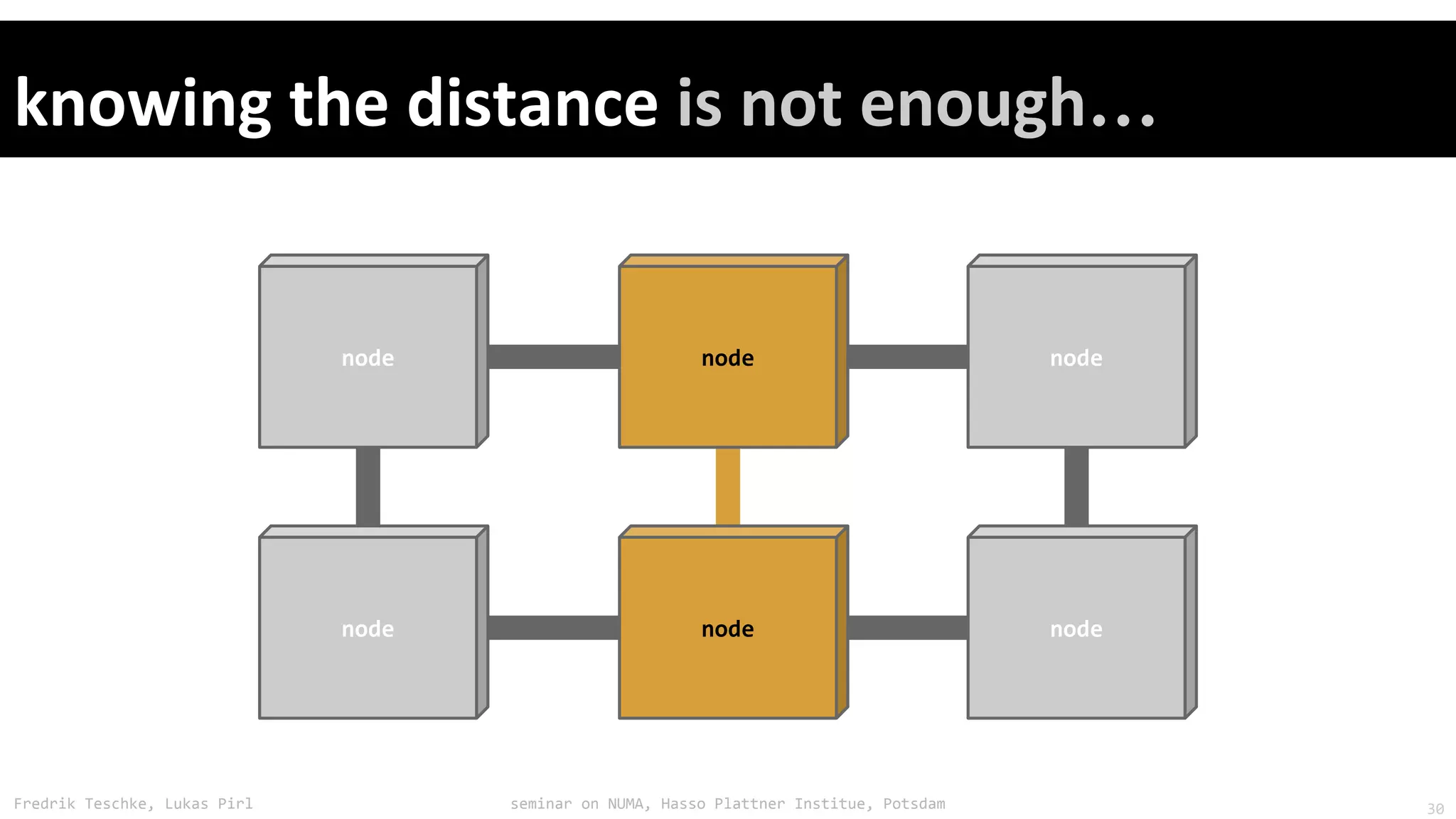
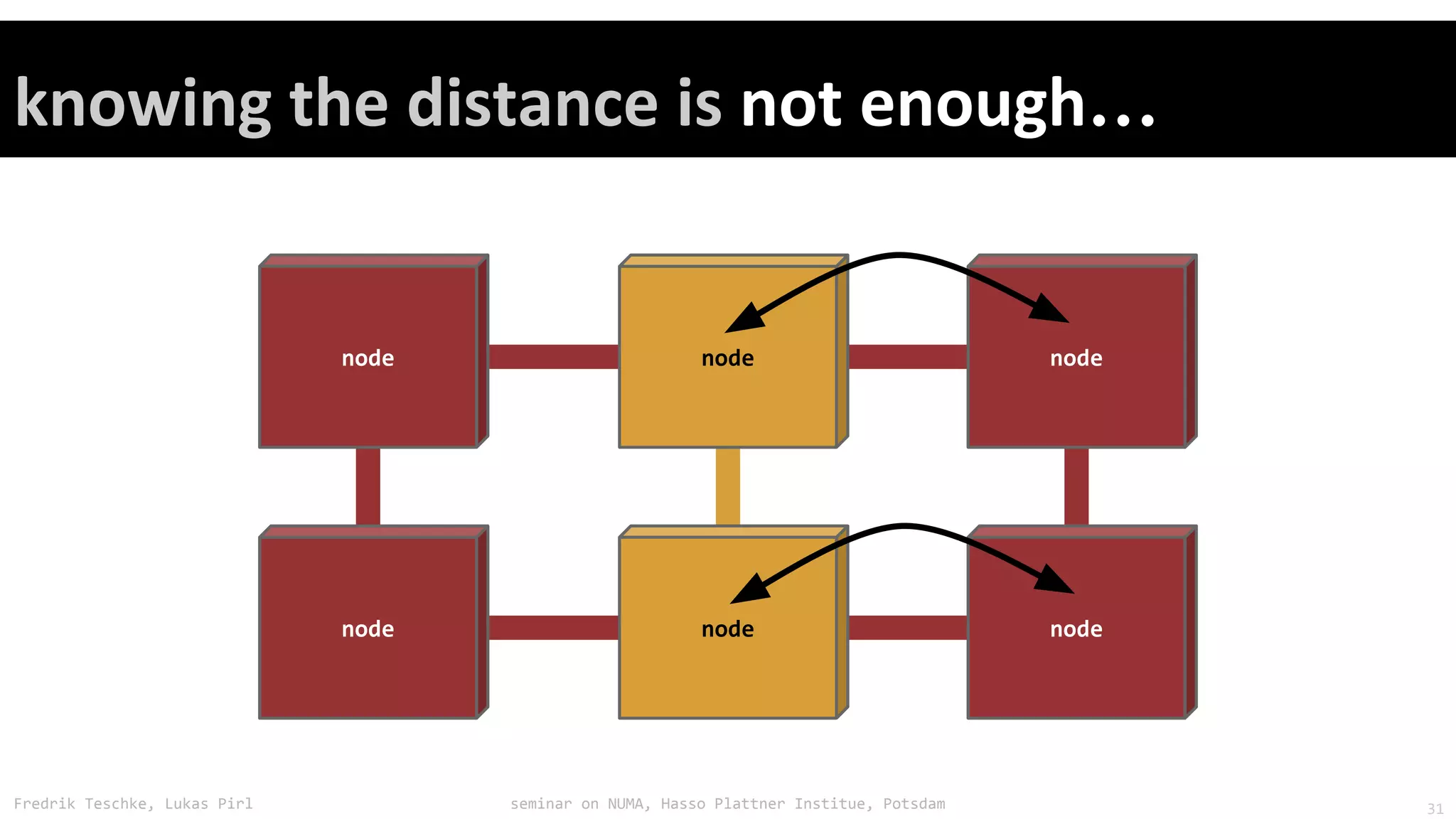
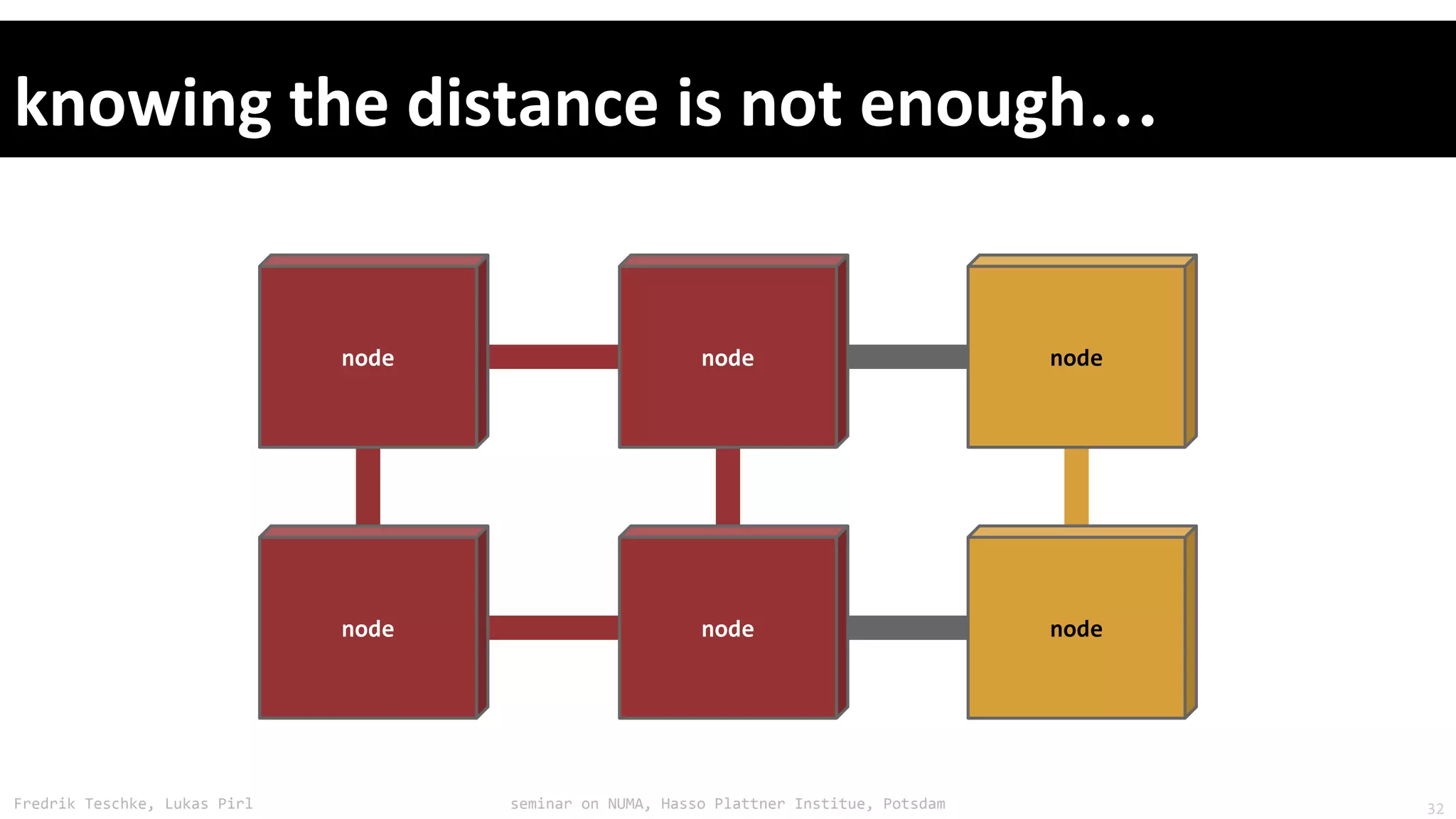

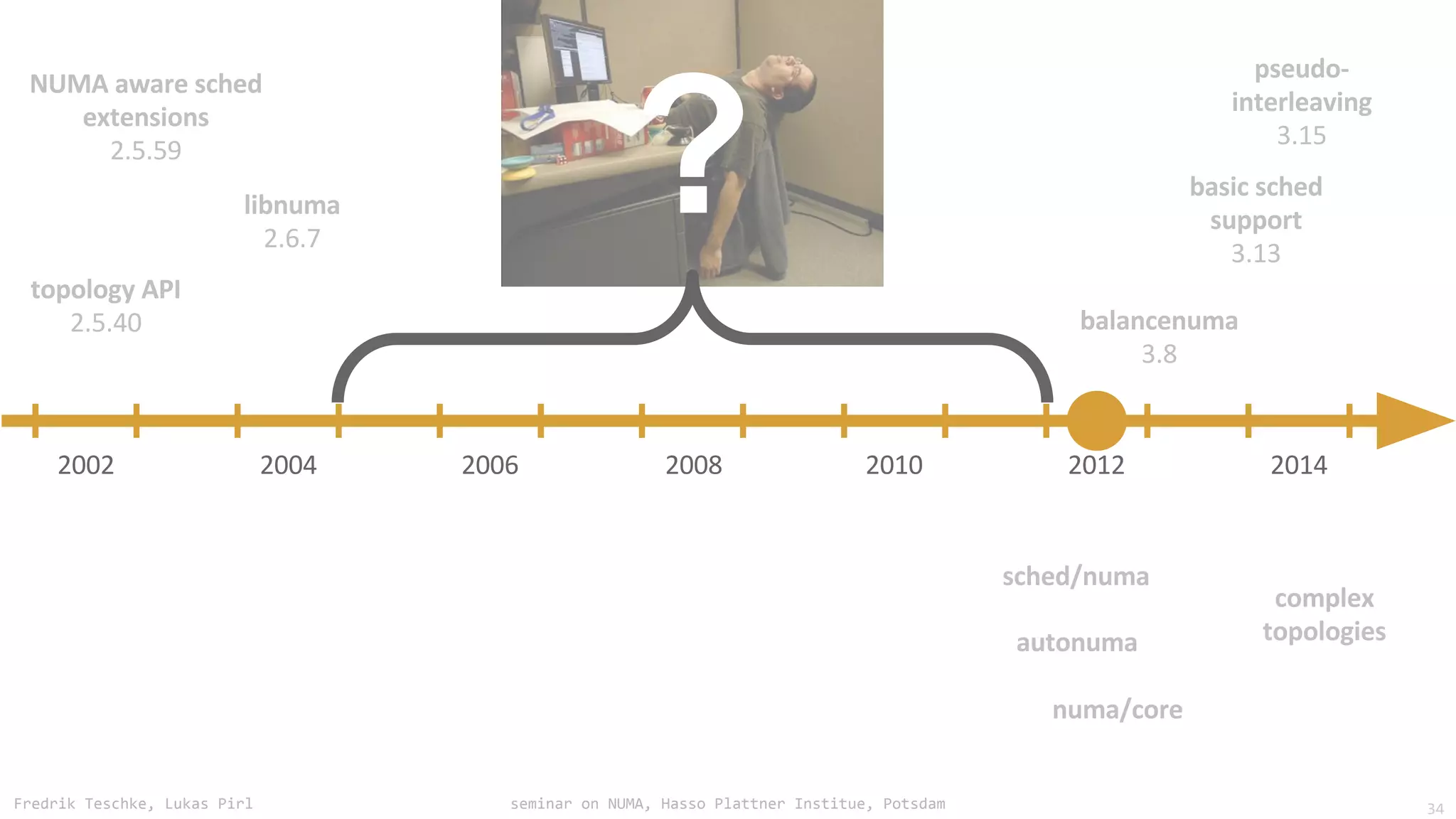
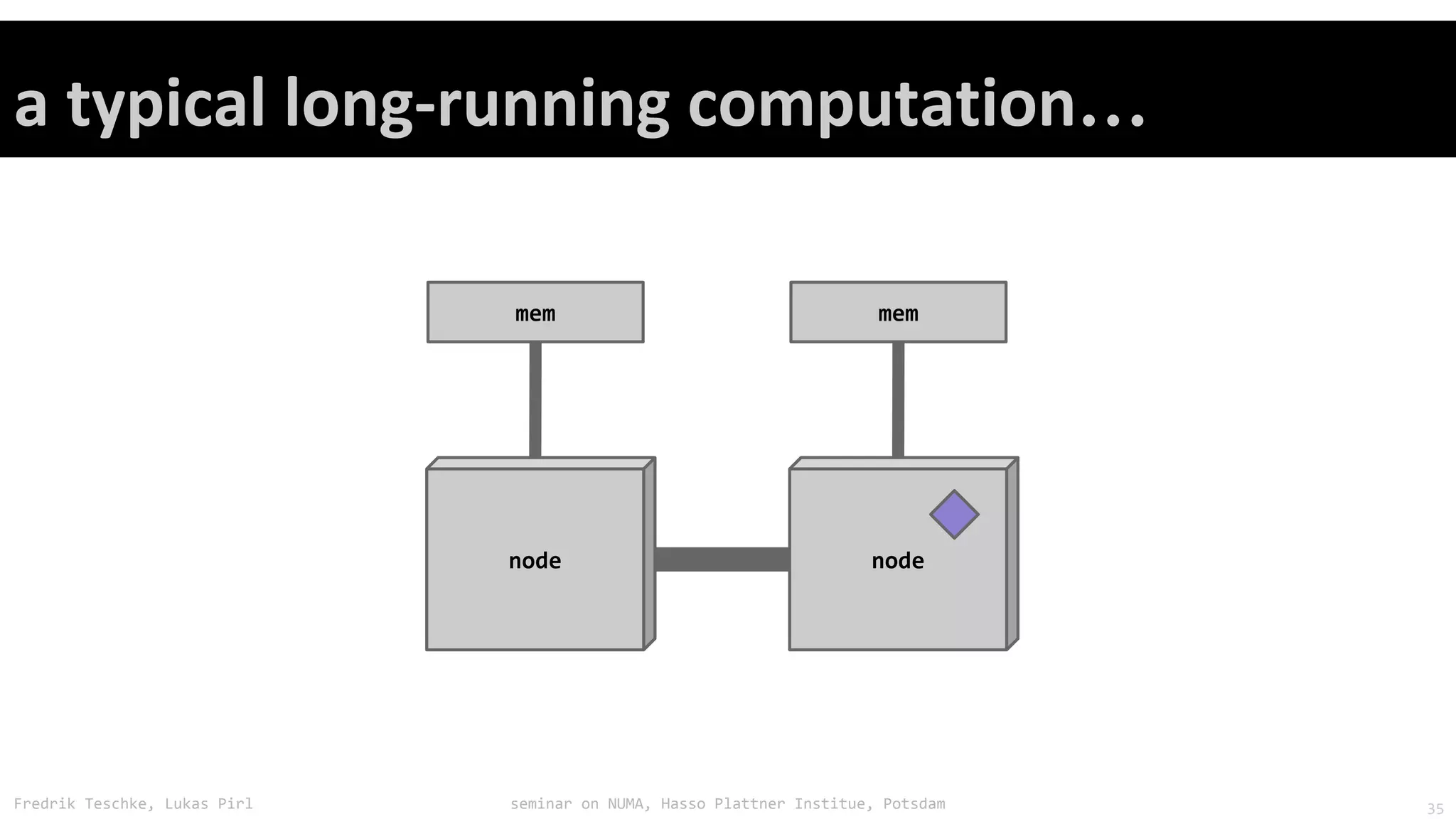
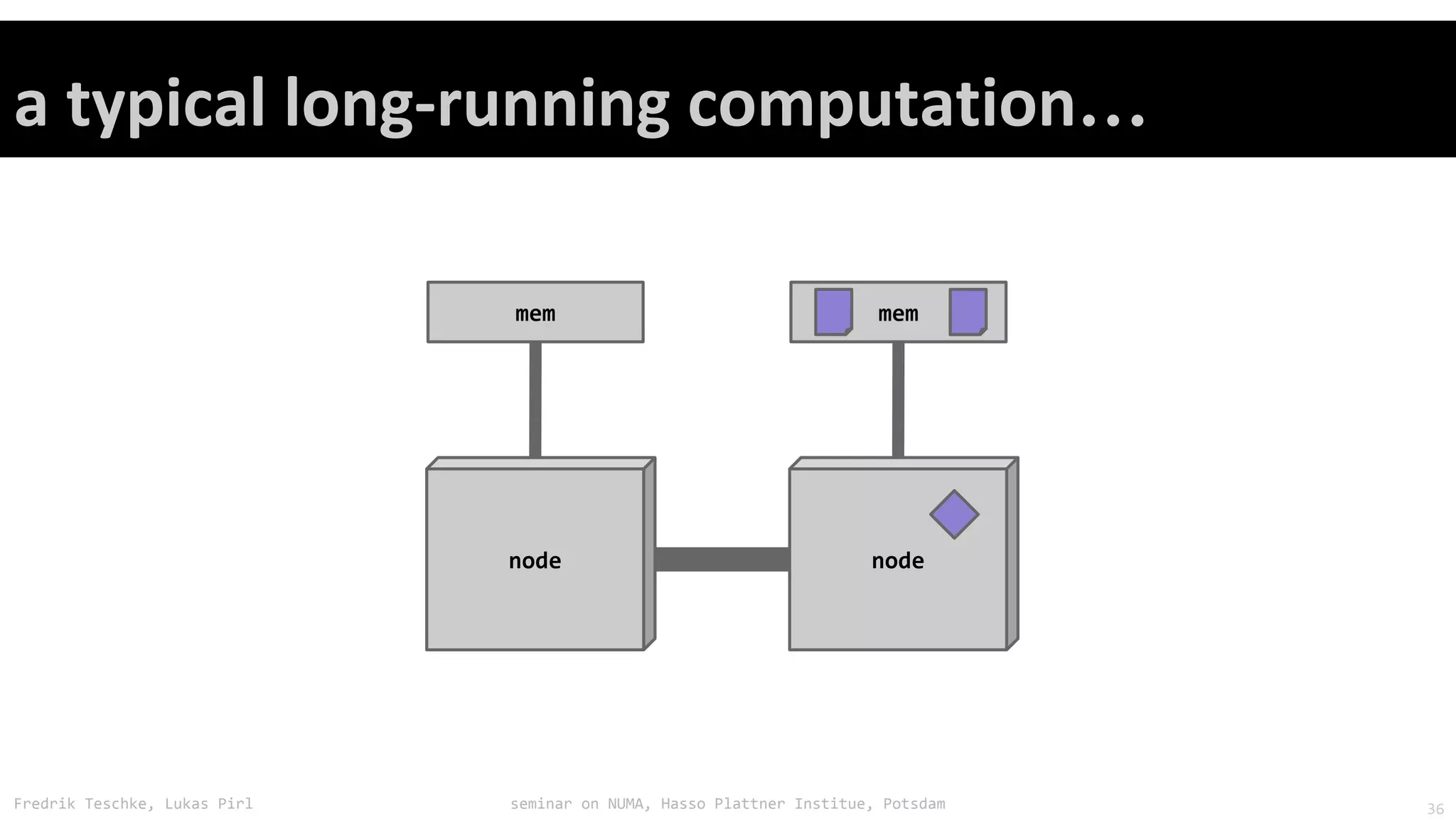
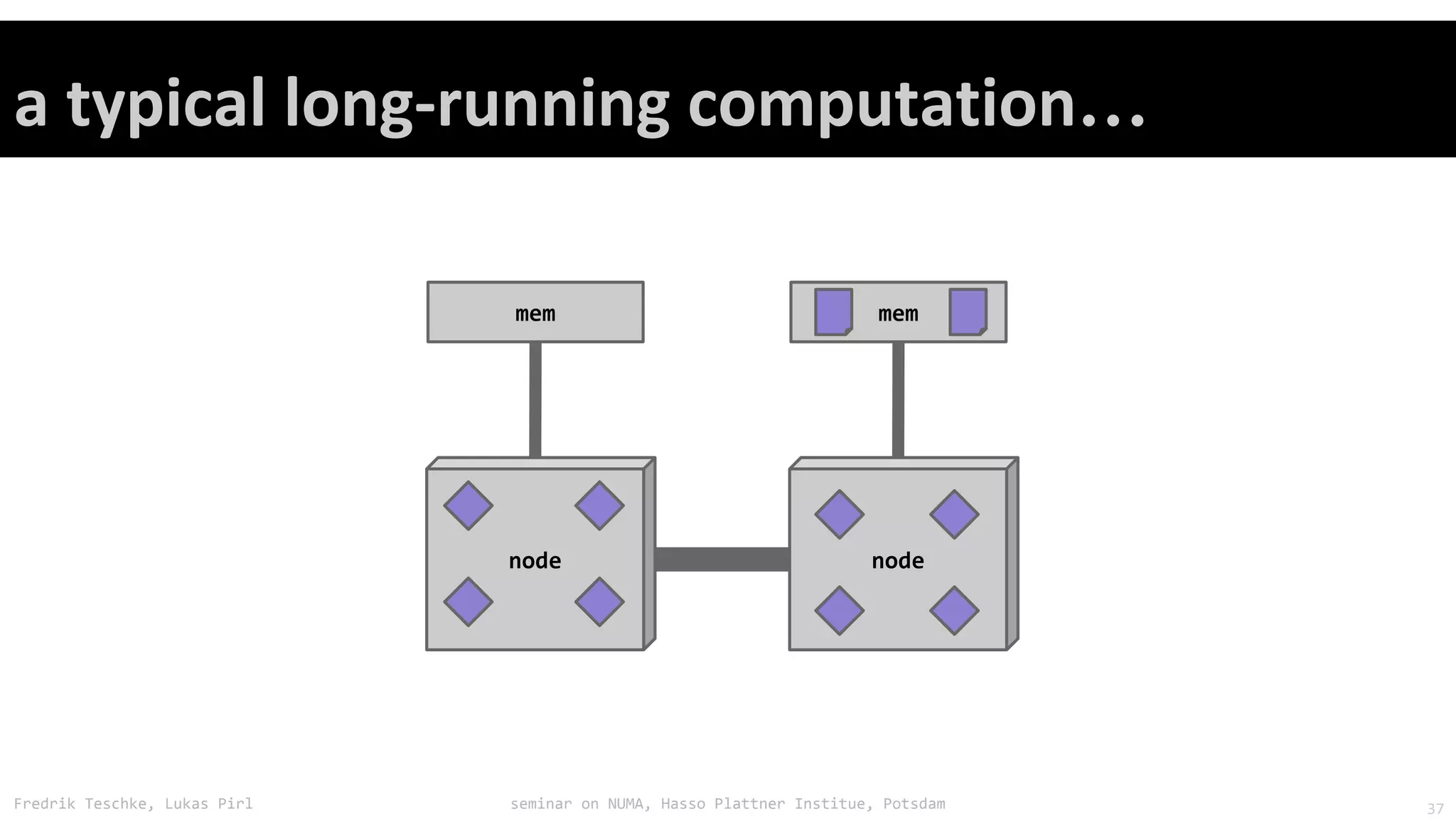
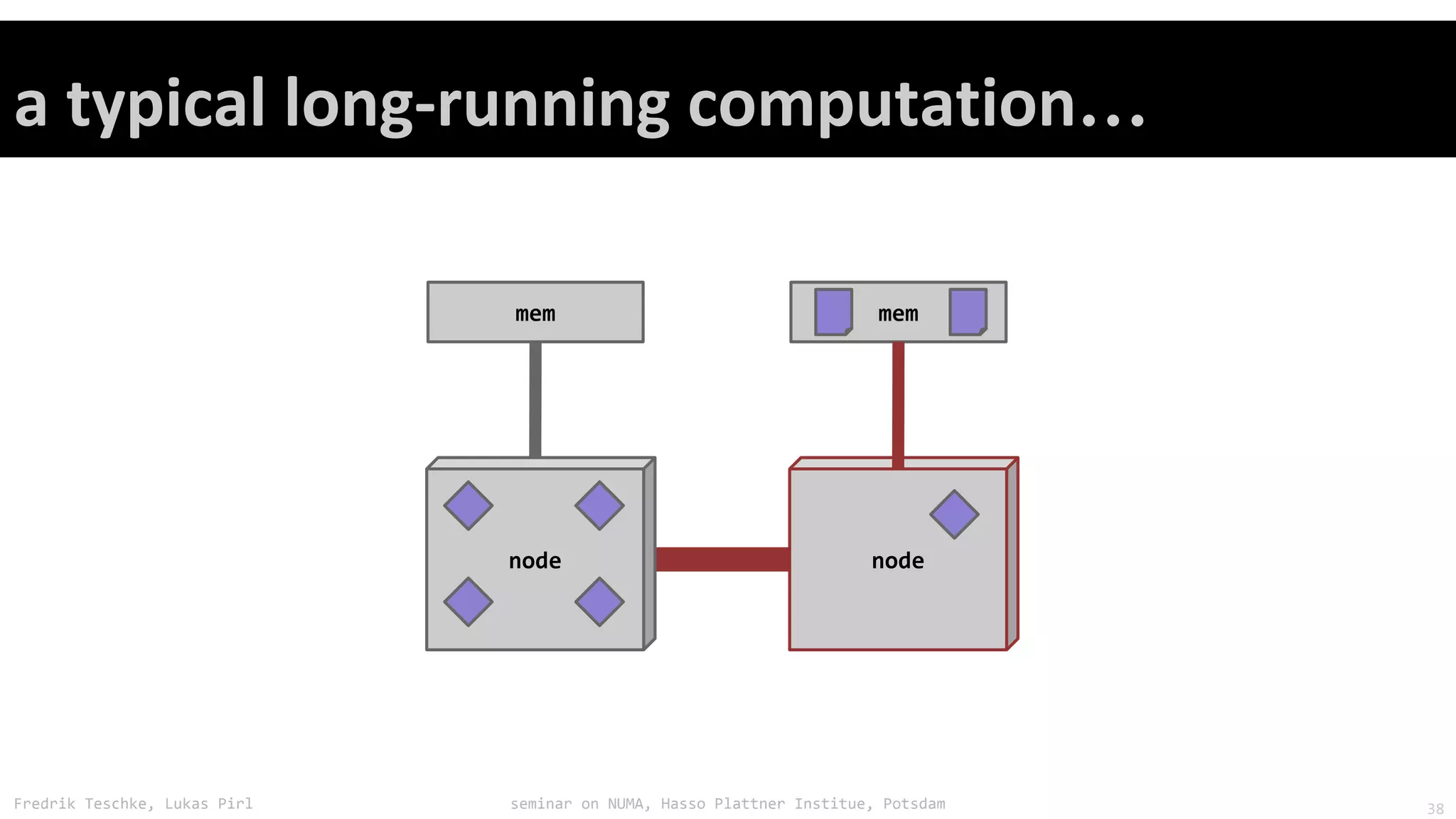
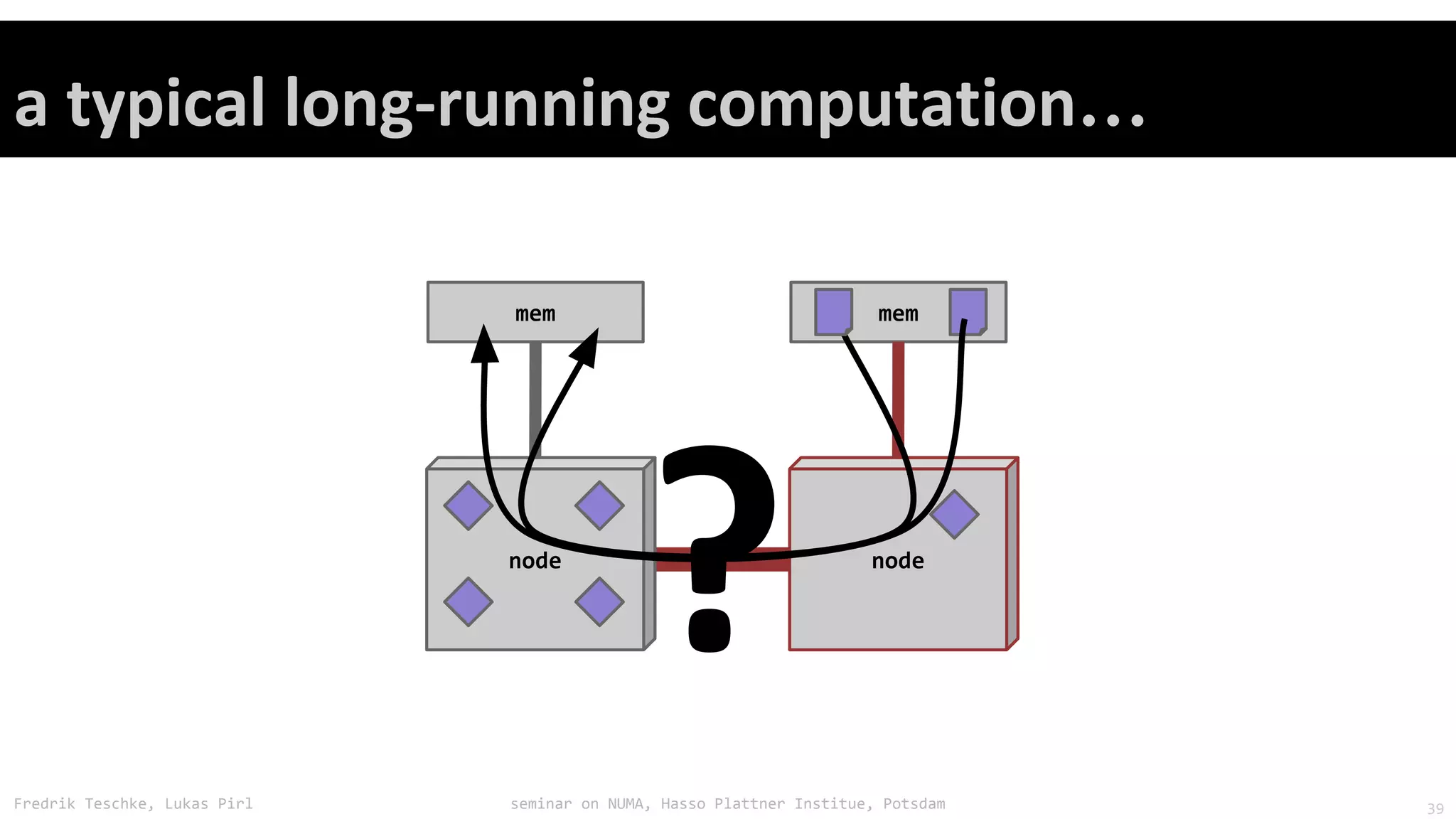
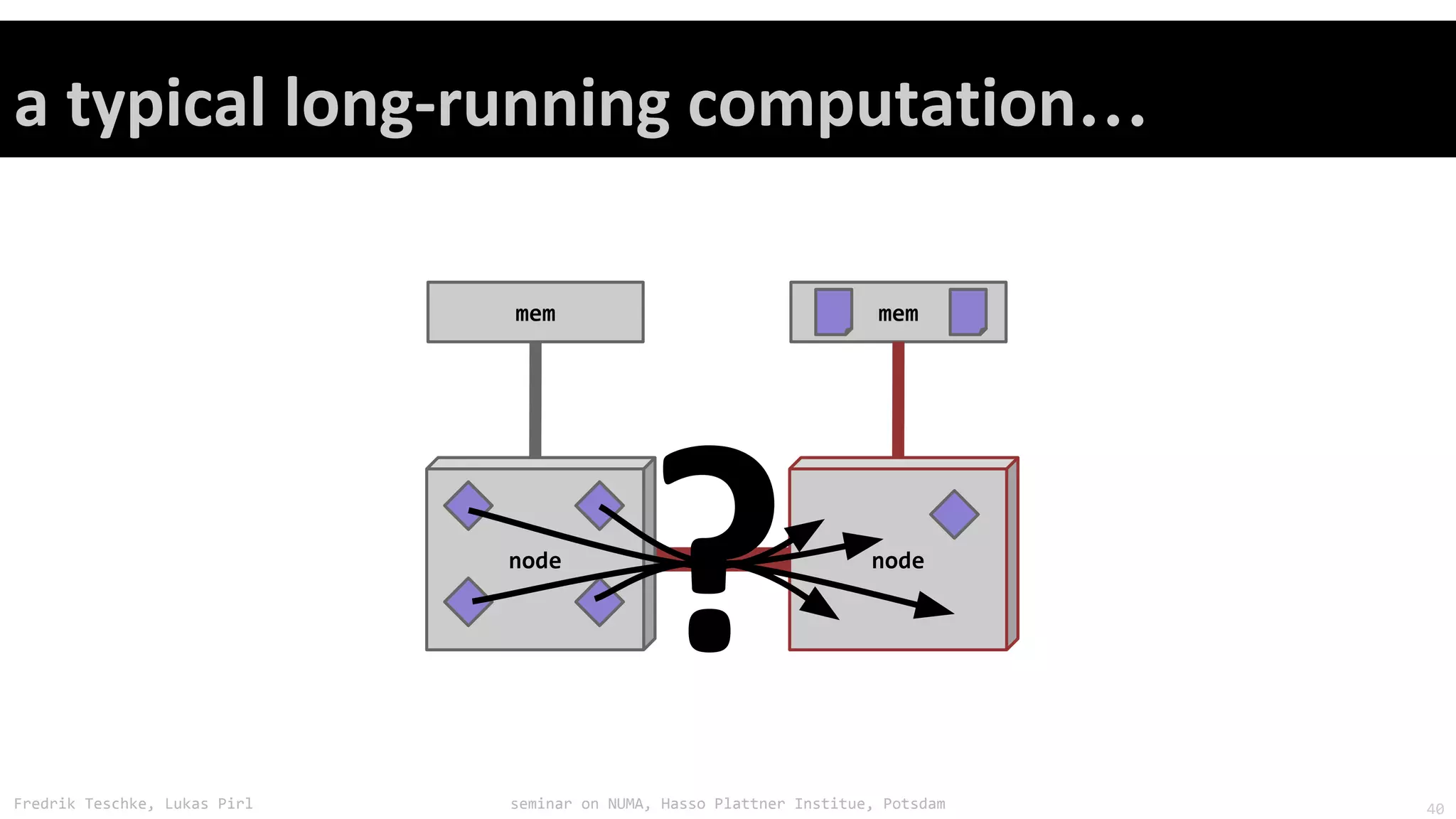
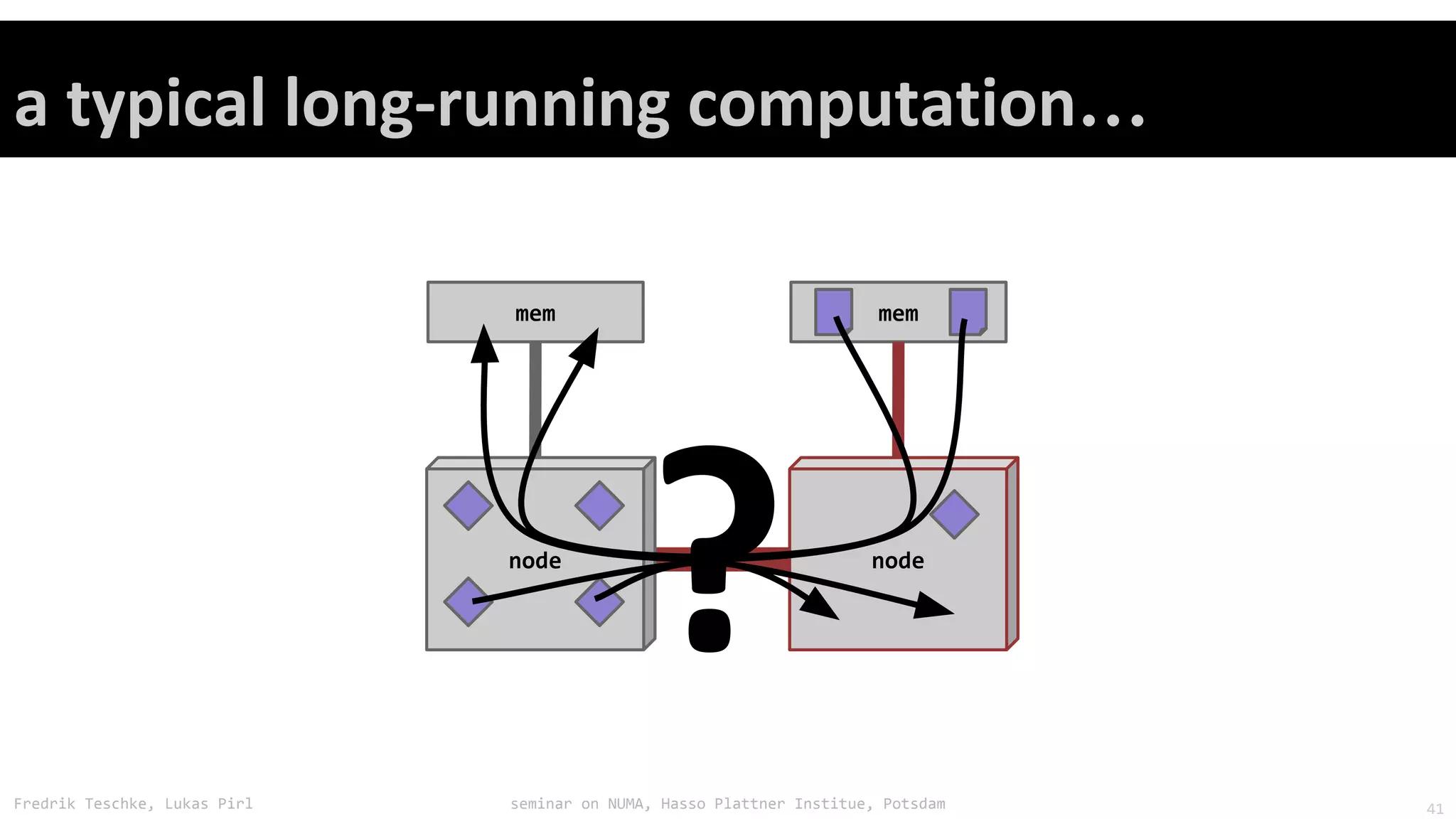






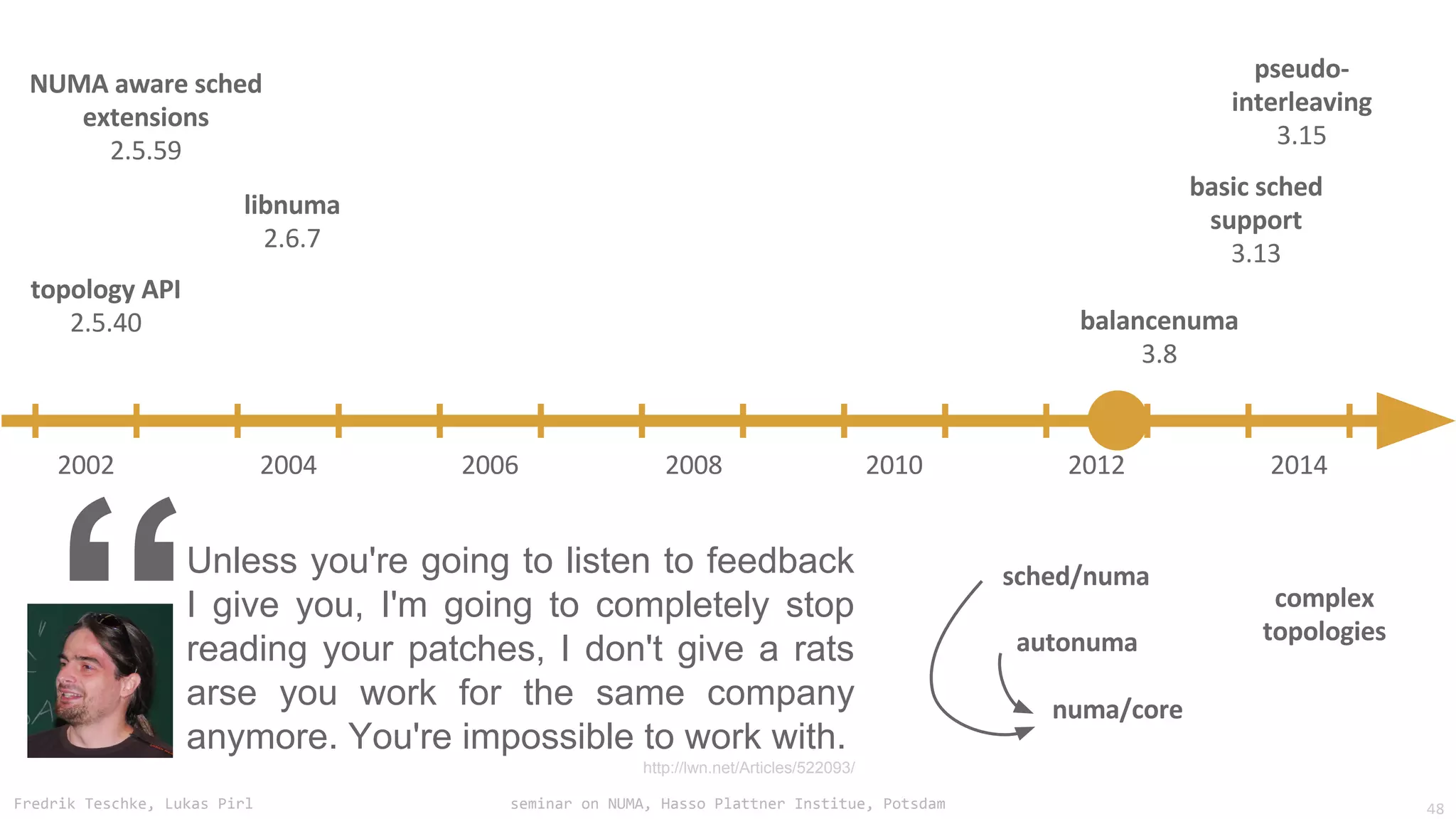

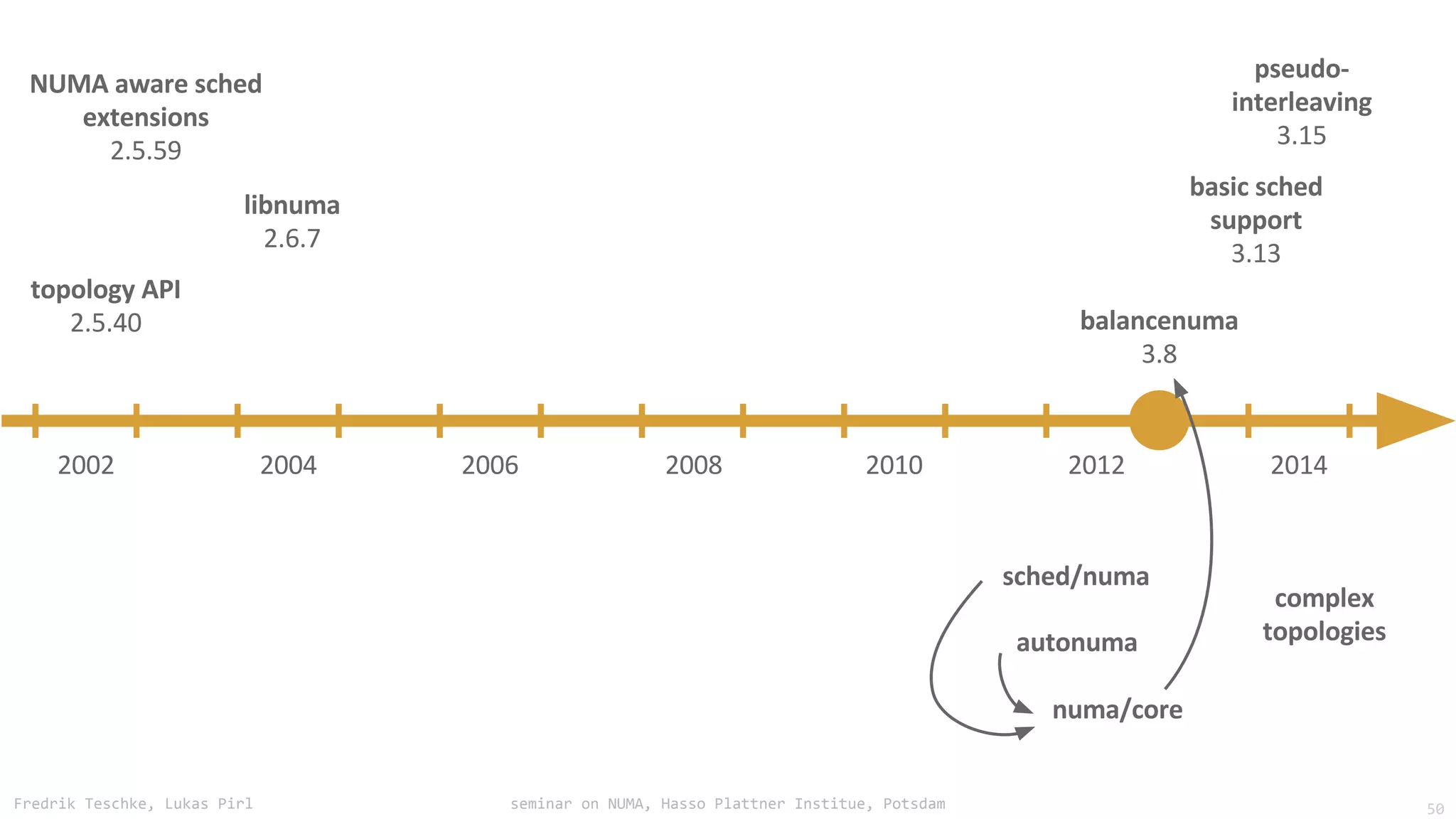


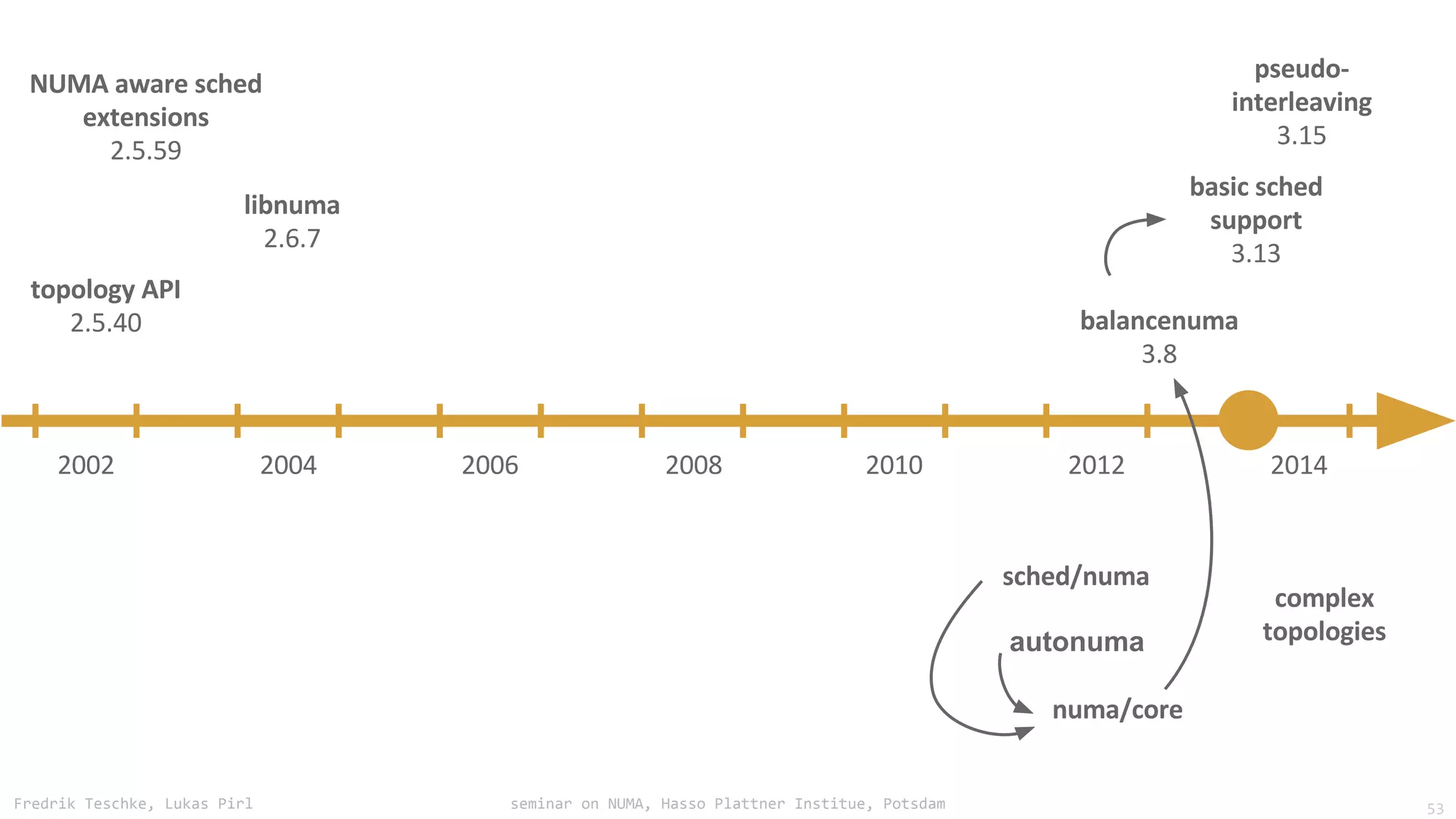

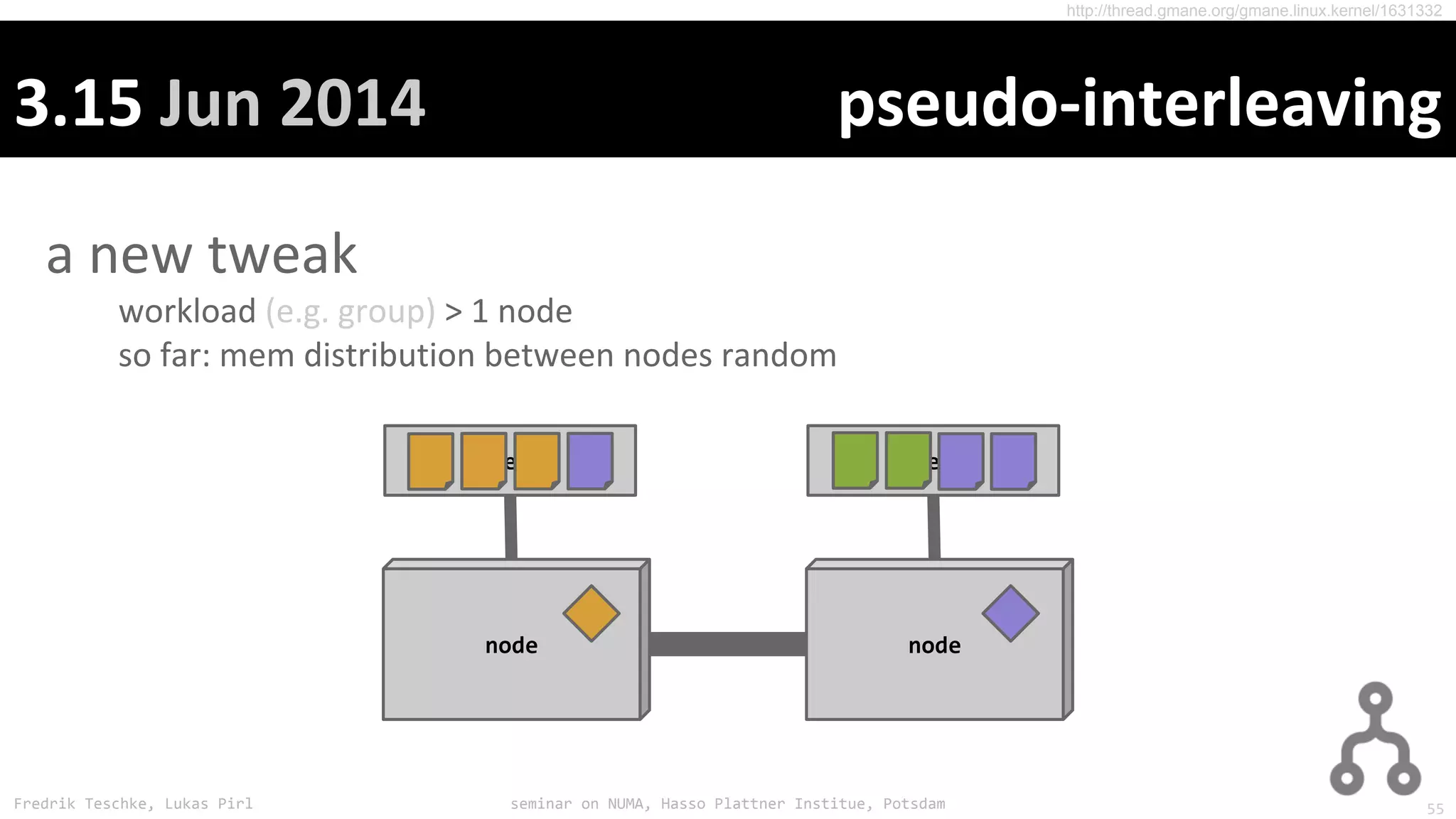
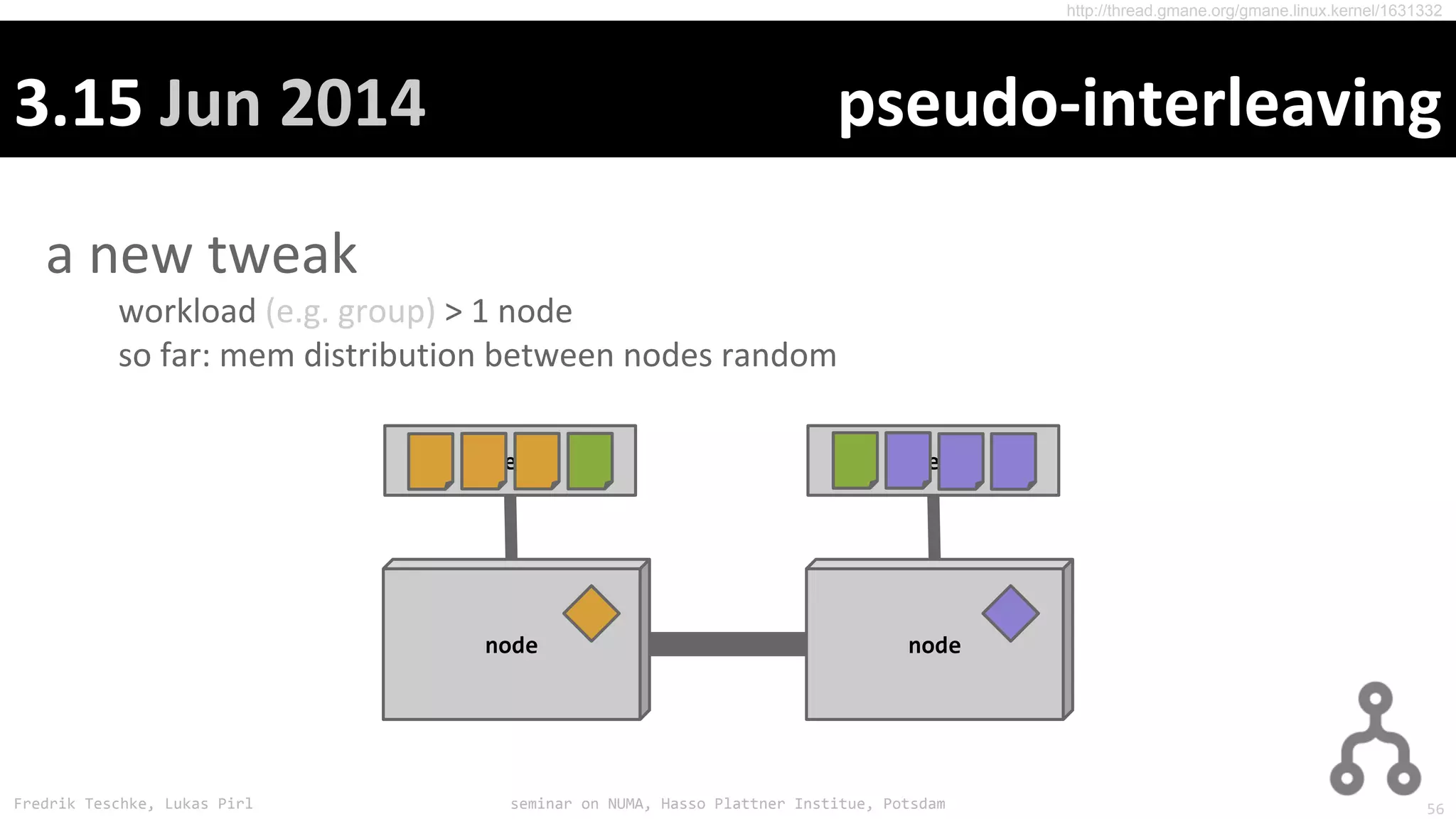




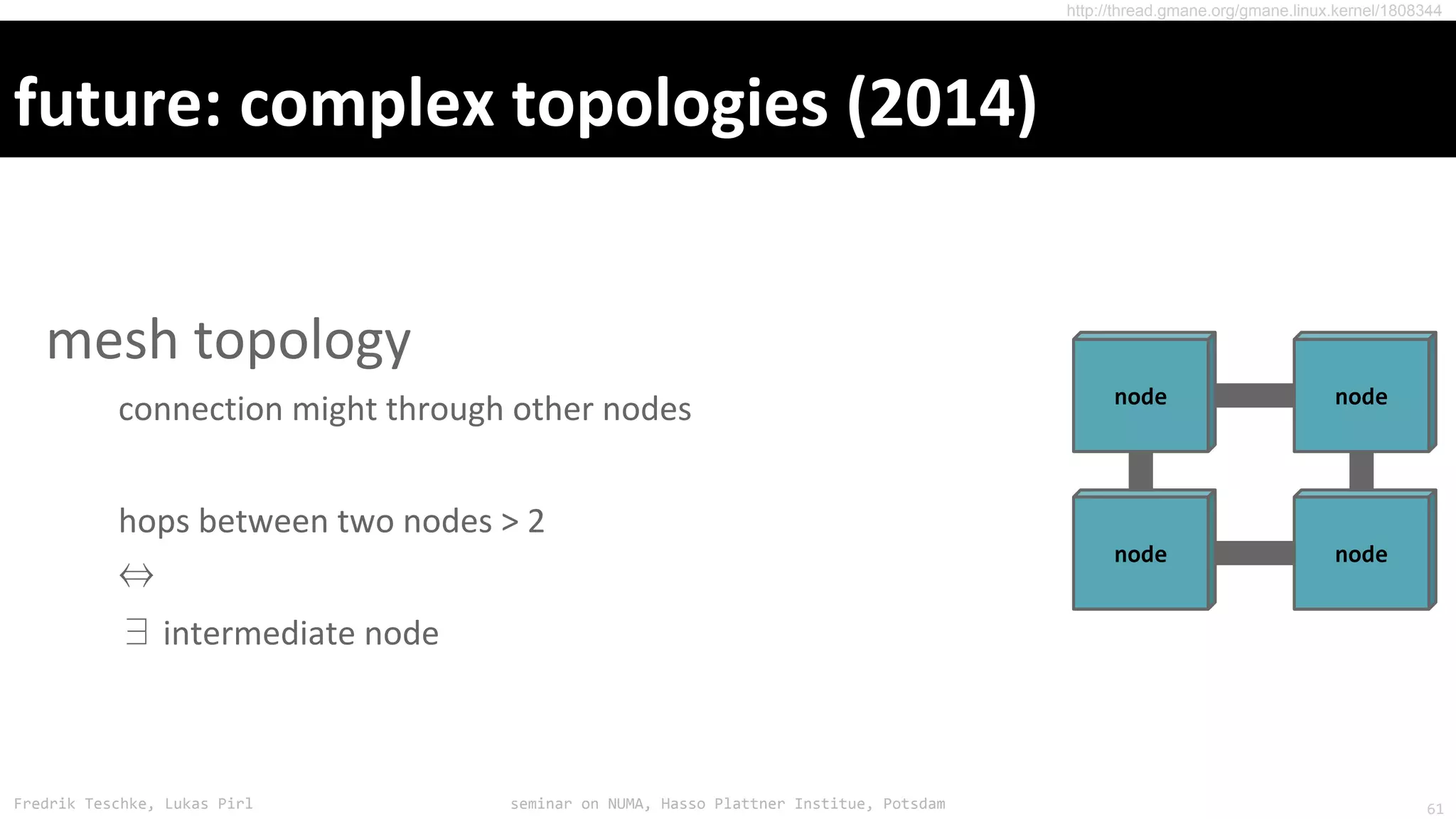




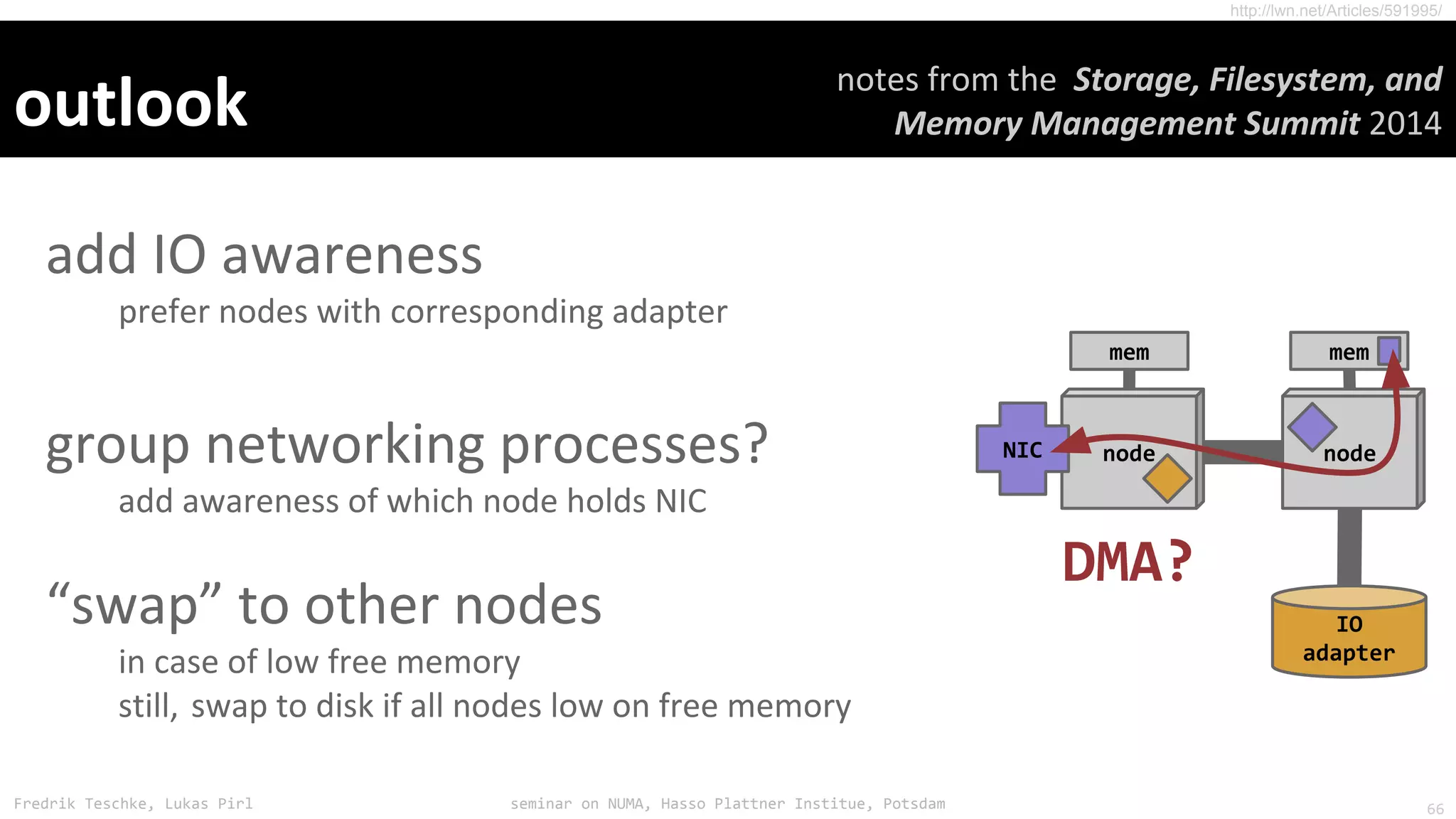



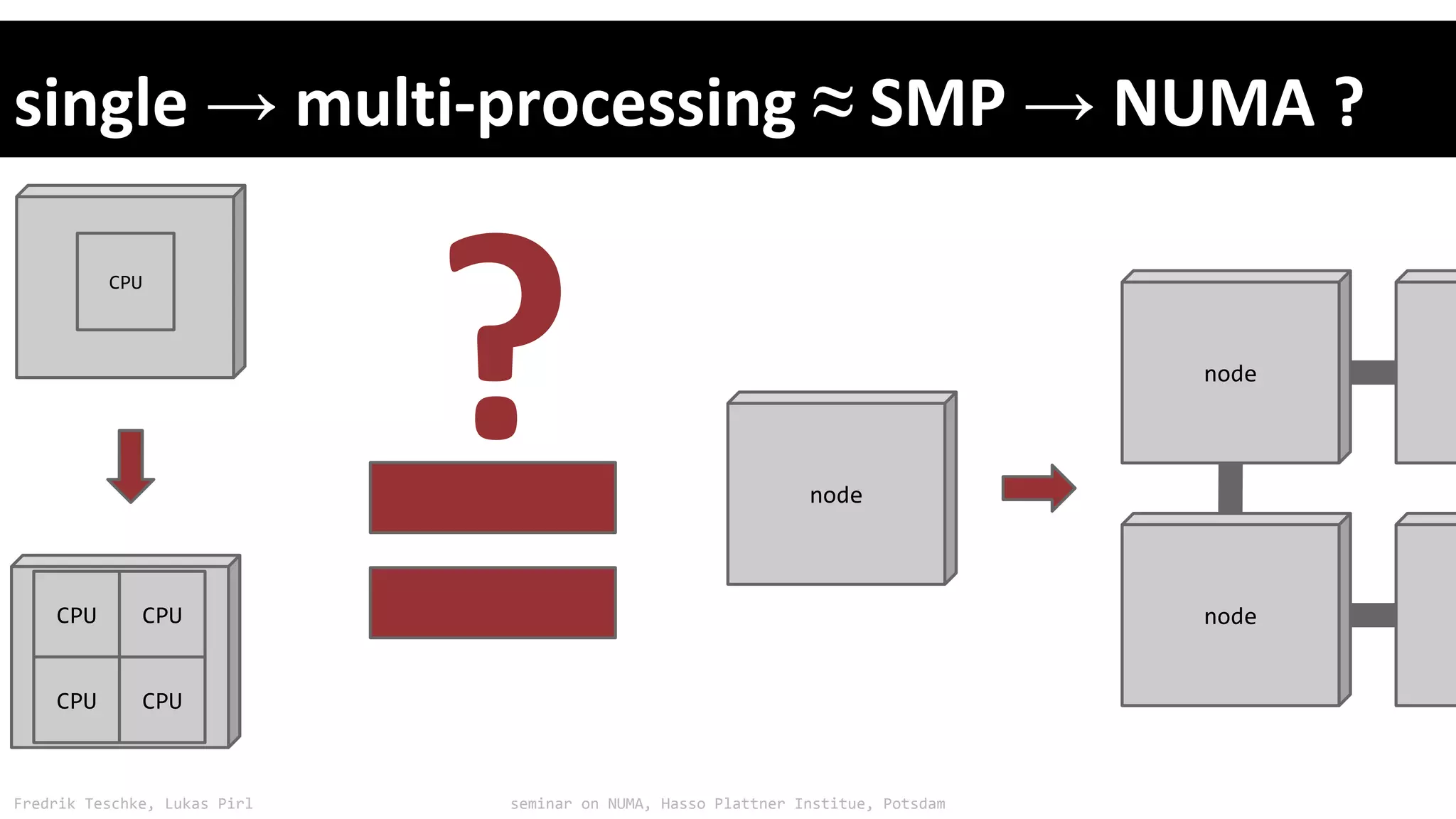







































































The document outlines notes and slides from a seminar given by Fredrik Teschke and Lukas Pirl on NUMA (Non-Uniform Memory Access) architecture at the Hasso Plattner Institute in Potsdam. The seminar covered topics including NUMA scheduling and load balancing challenges, memory allocation policies, and the Linux kernel APIs and mechanisms for managing NUMA systems. A number of links are provided to Linux kernel documentation and LWN articles discussing the history and ongoing development of NUMA support in Linux.












































