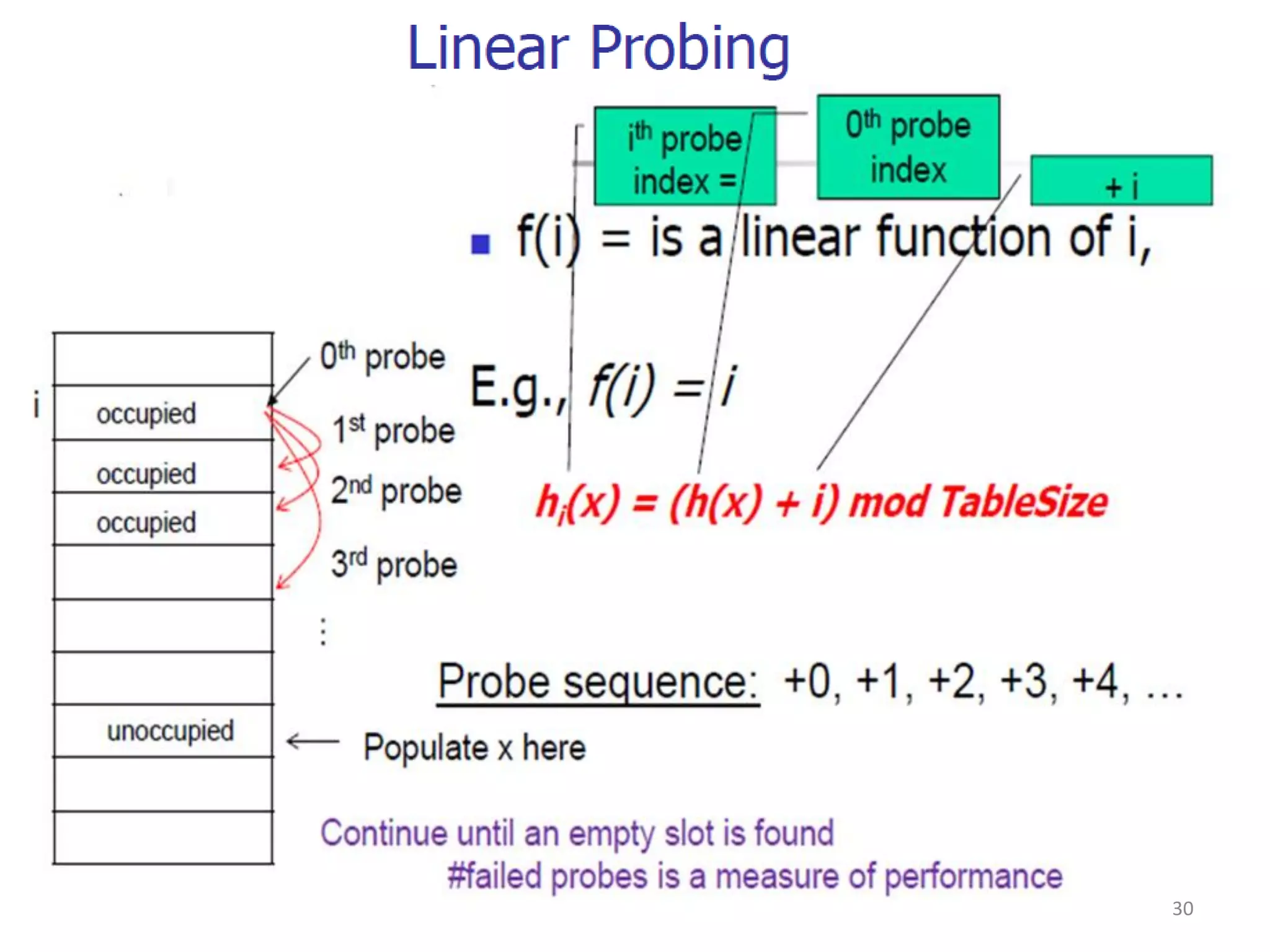
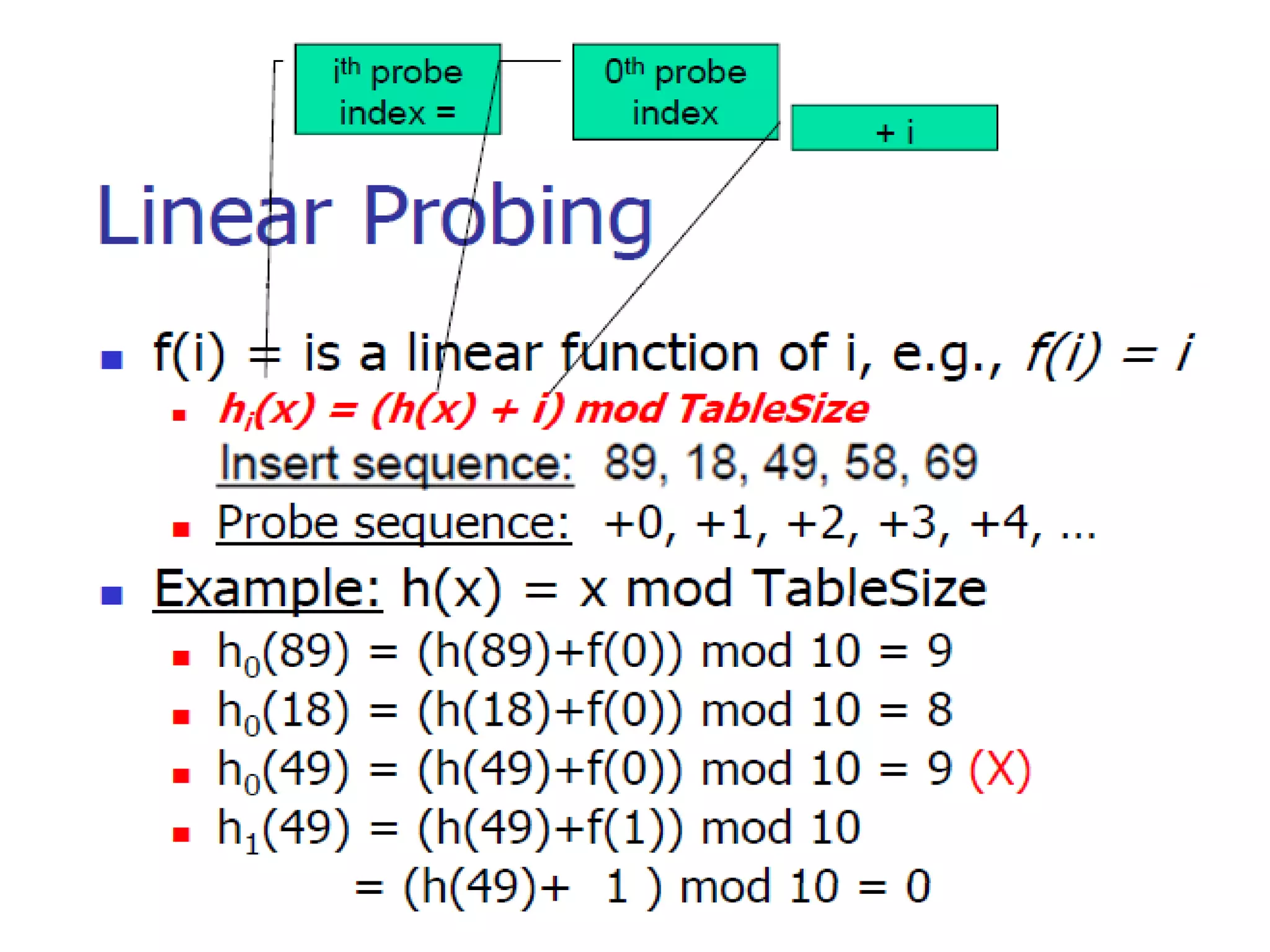
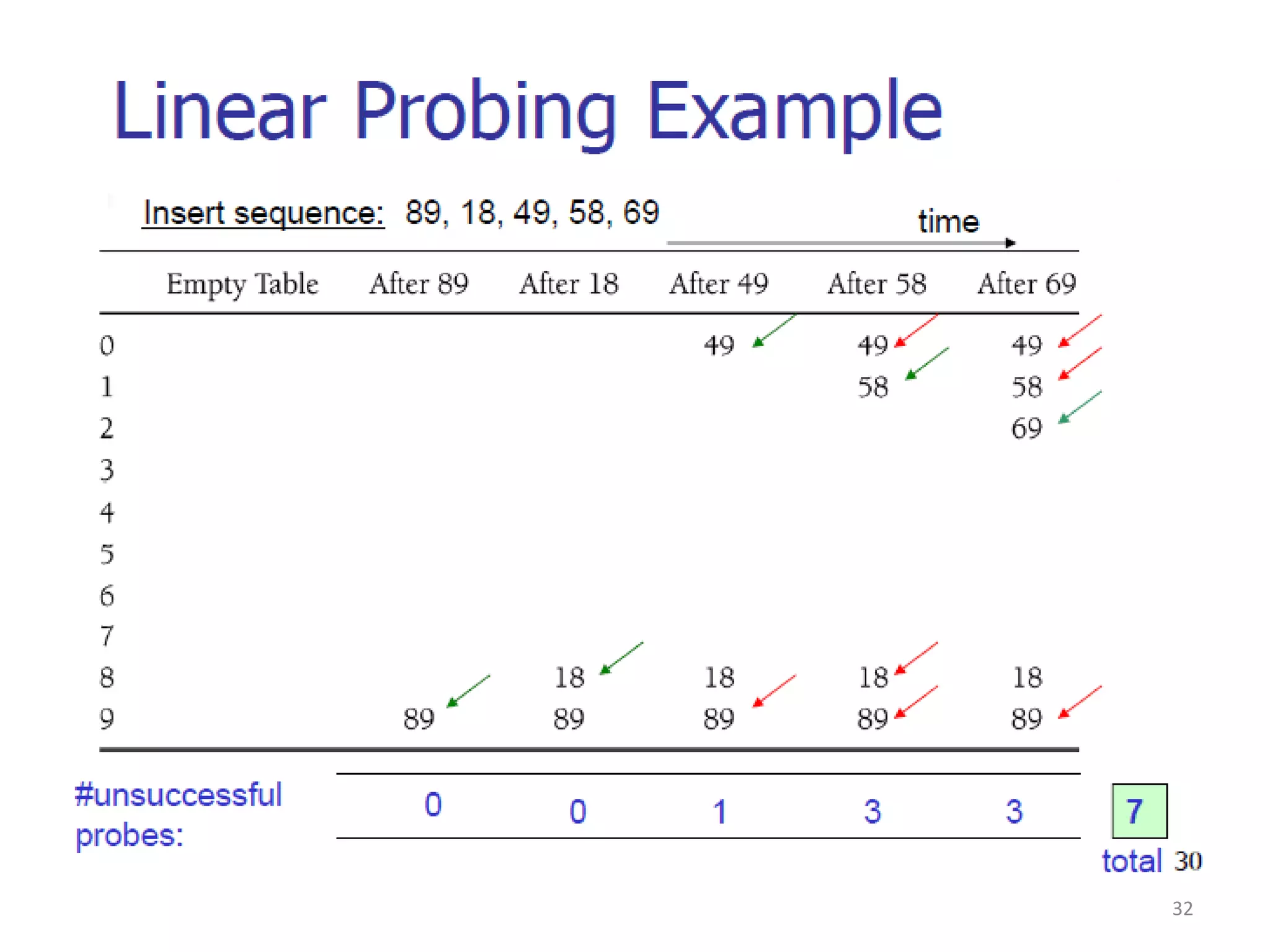
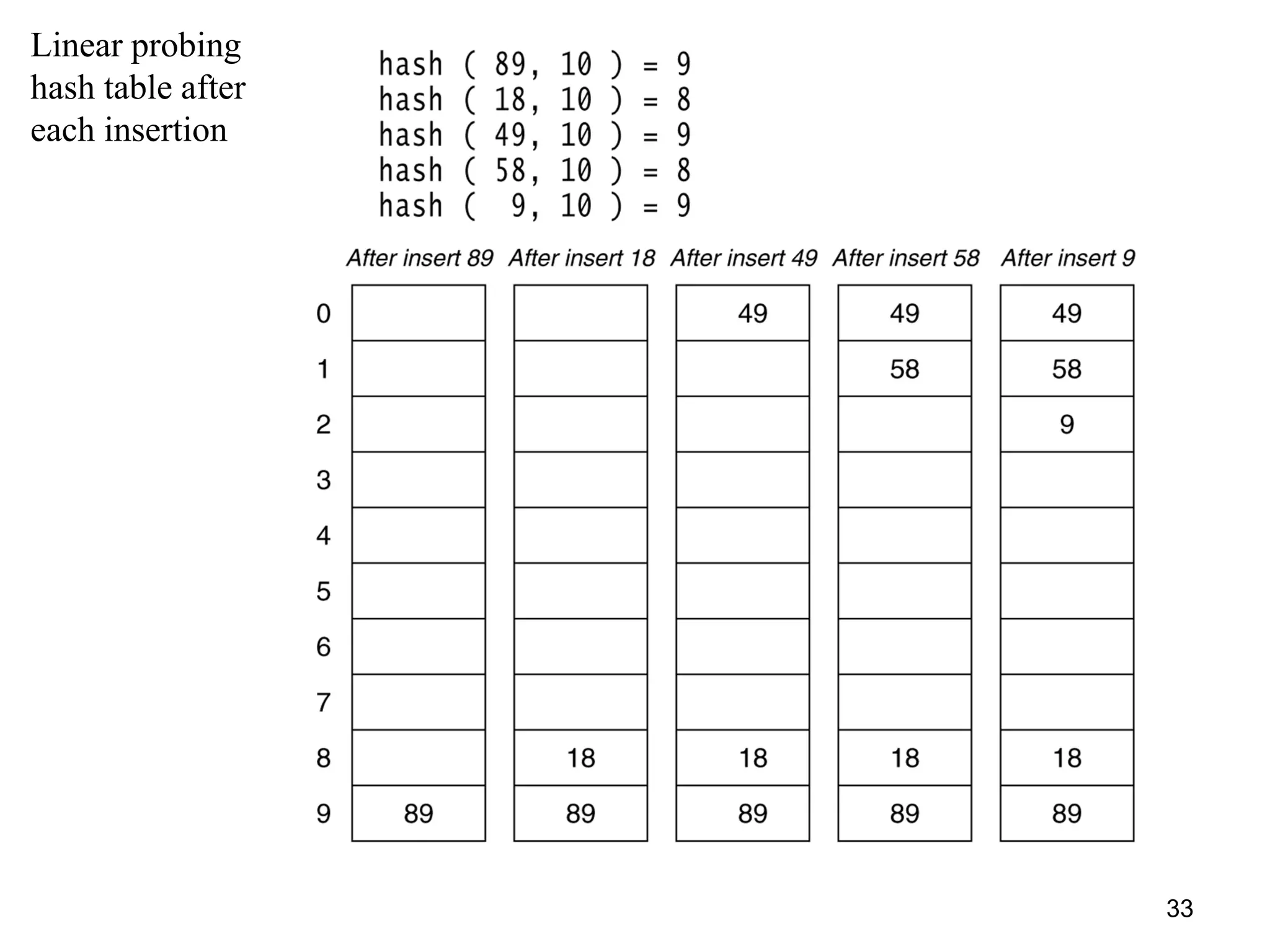
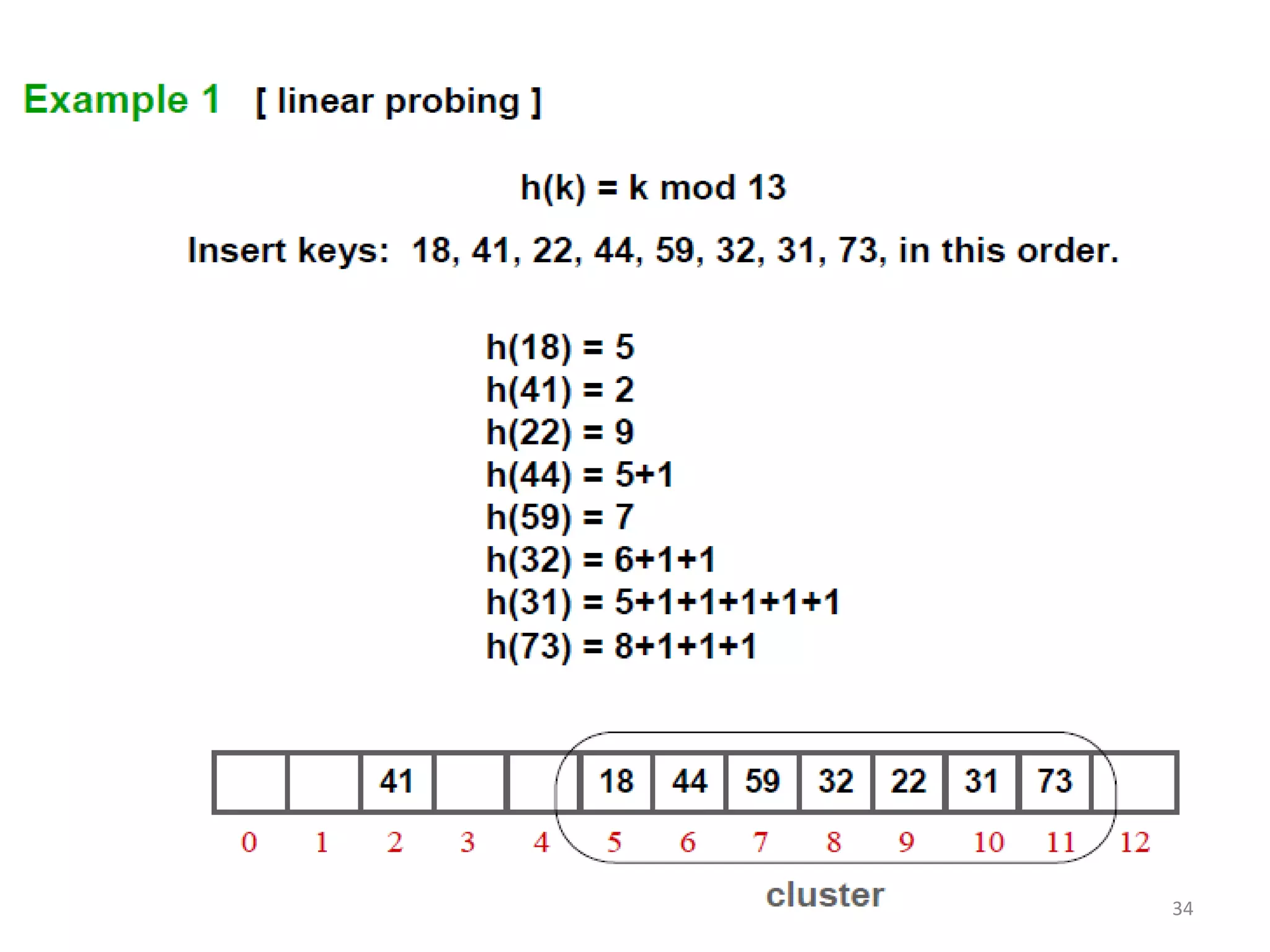
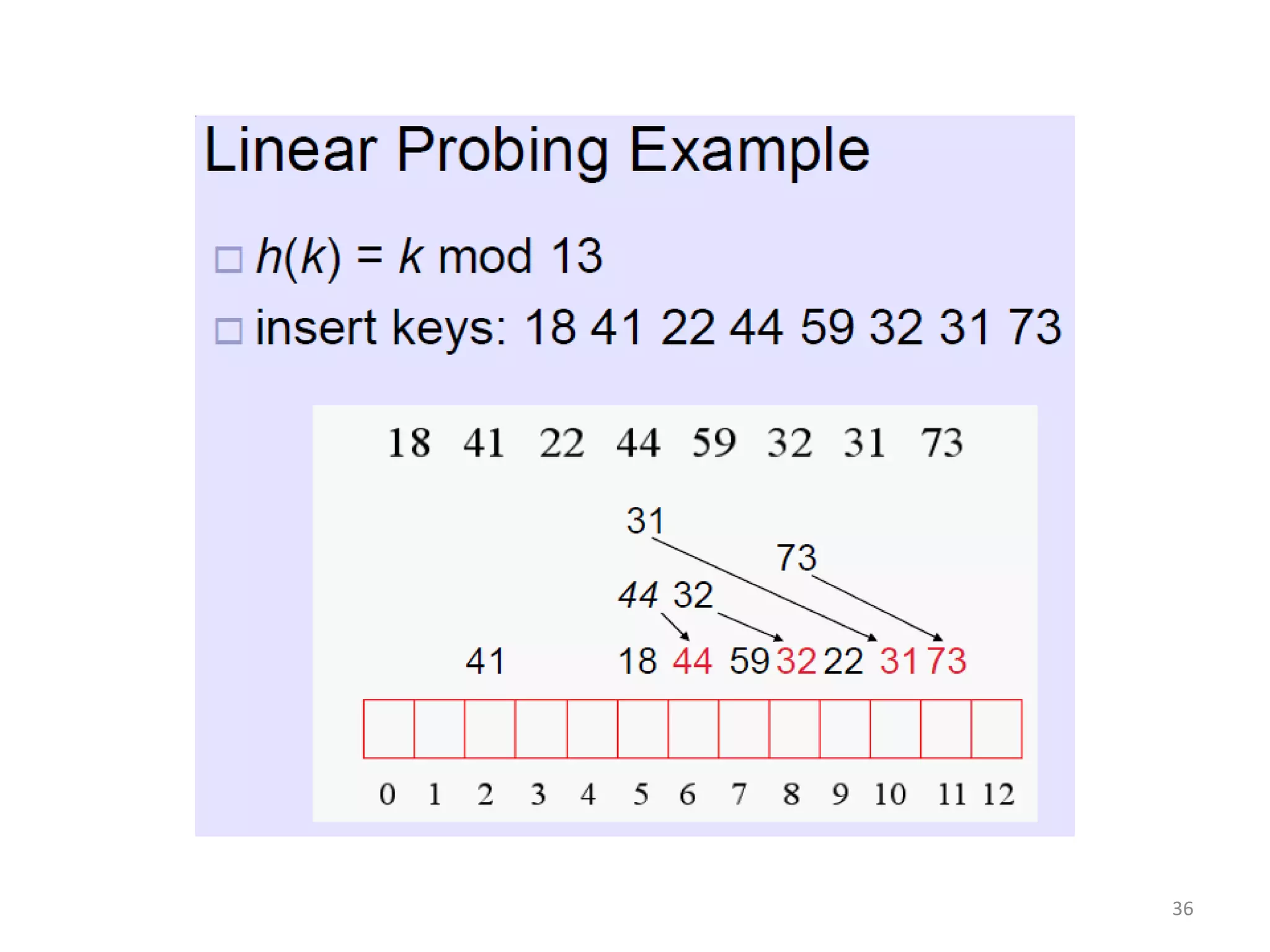
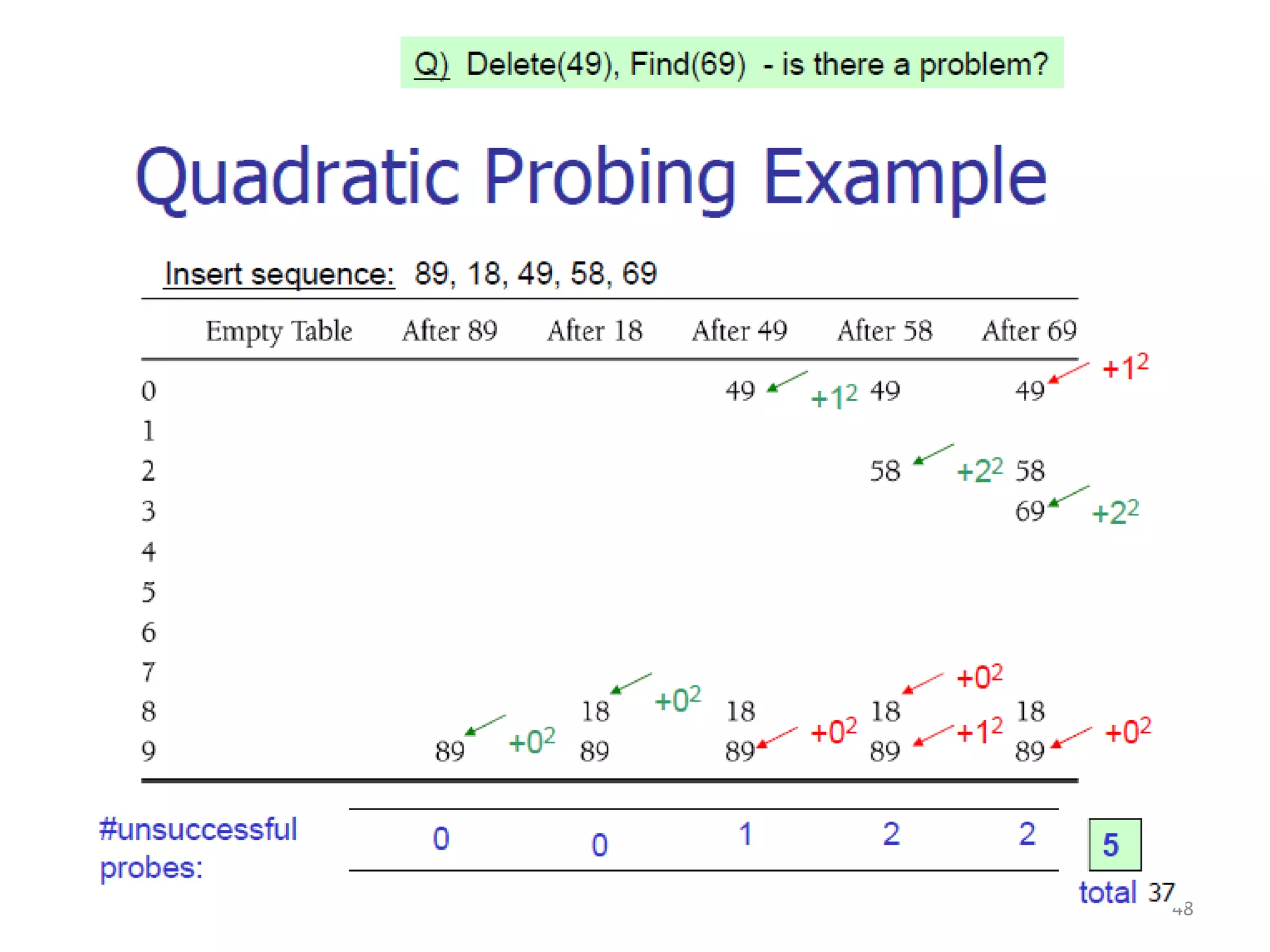
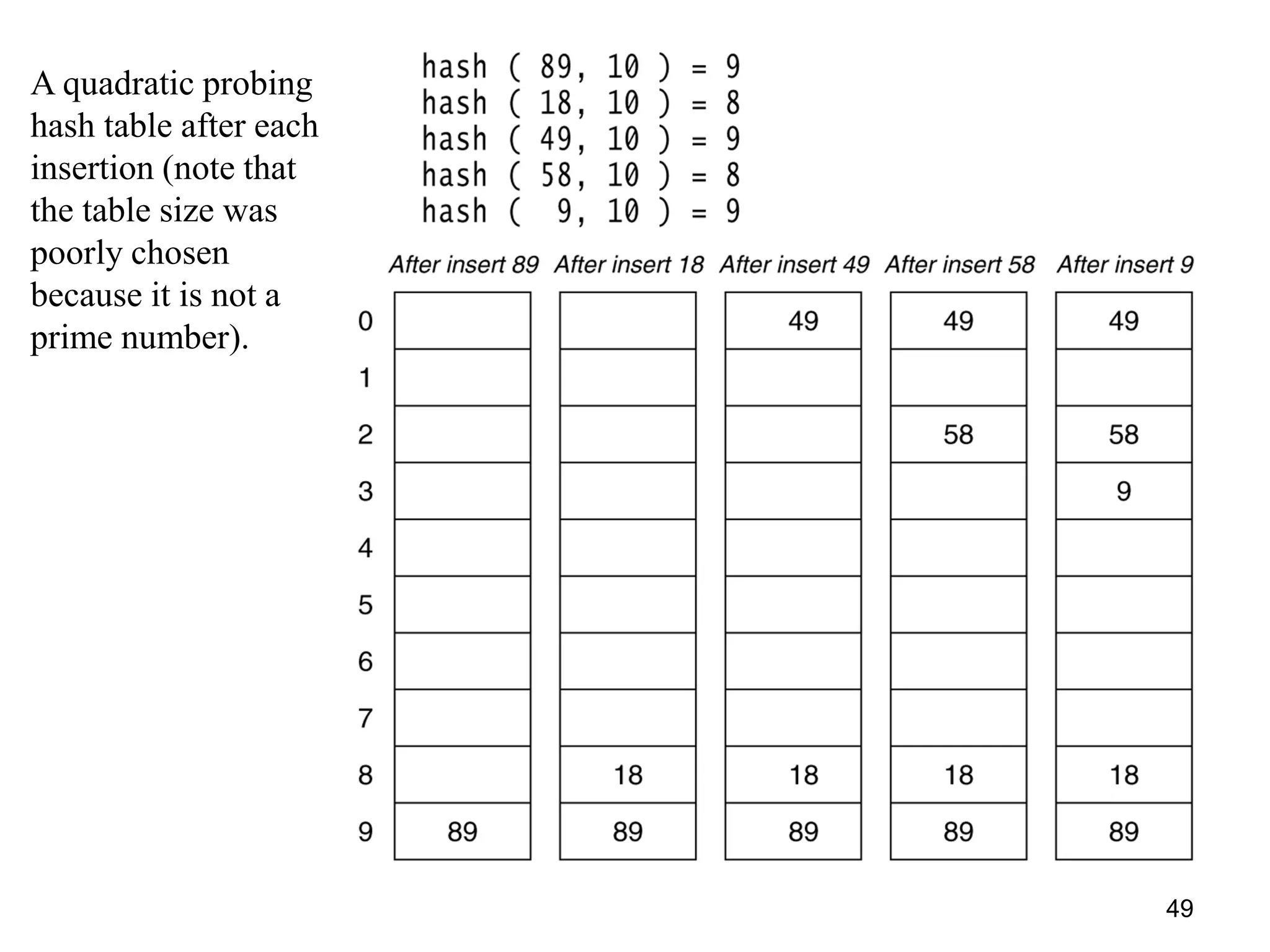
The document discusses different hashing techniques used to store and retrieve data in hash tables. It begins by motivating the need for hashing through the limitations of linear and binary search. It then defines hashing as a process to map keys of arbitrary size to fixed size values. Popular hash functions discussed include division, folding, and mid-square methods. The document also covers collision resolution techniques for hash tables, including open addressing methods like linear probing, quadratic probing and double hashing as well as separate chaining using linked lists.


















![22
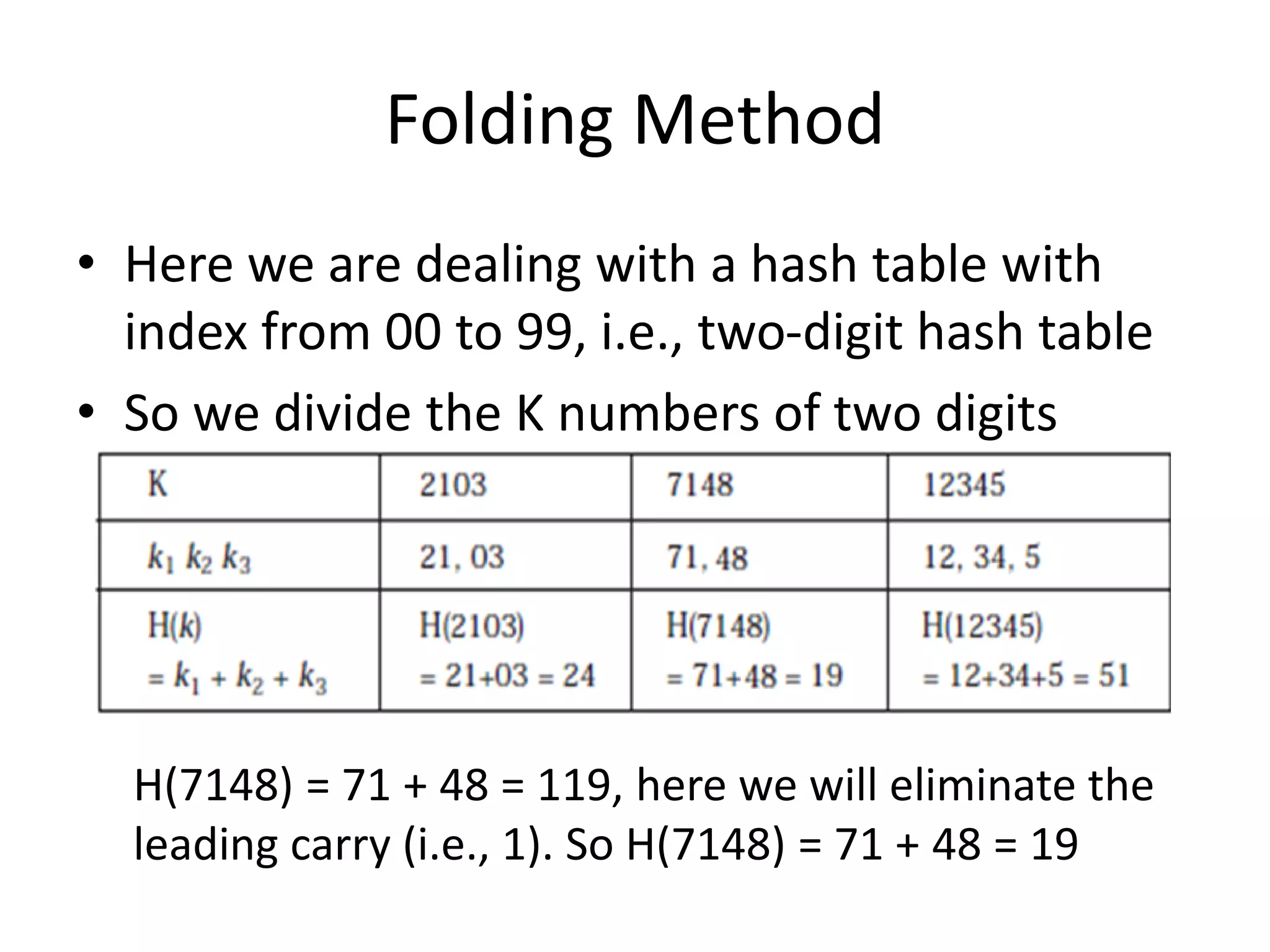
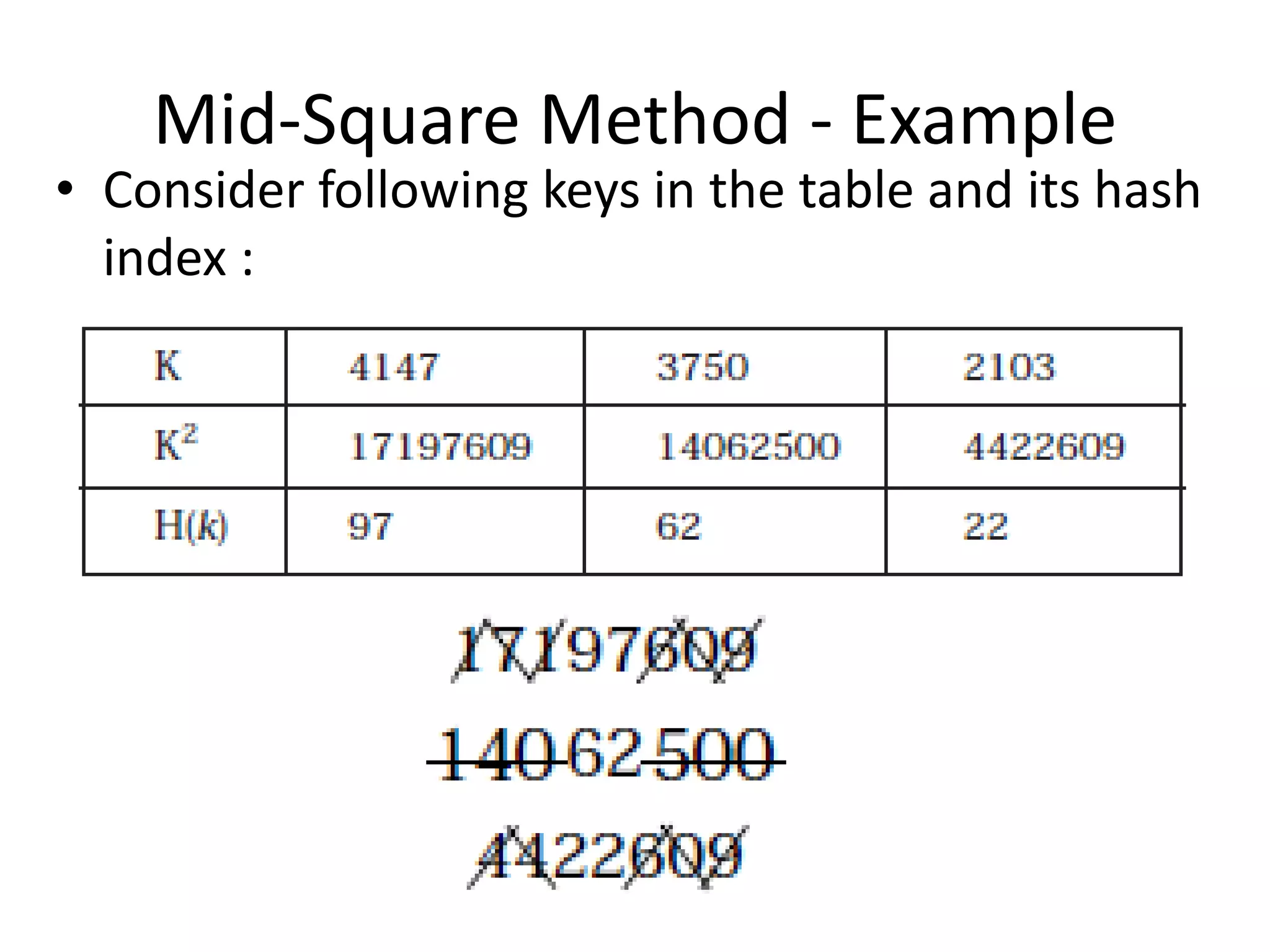
•Table size [0..99]
•A..Z ---> 1,2, ...26
•0..9 ----> 27,...36
•Key: CS1 --->3+19+28 (concatenate) = 31,928
•(31,928)2 = 1,019,397,184 → 10 digits
•Extract middle 2 digits (5th and 6th) as table size
is 0..99.
•Get 39, so: H(CS1) = 39.
Hashing a string key](https://image.slidesharecdn.com/lect1011-dsalgohashing-220407193337/75/LECT-10-11-DSALGO-Hashing-pdf-22-2048.jpg)


















































![22
•Table size [0..99]
•A..Z ---> 1,2, ...26
•0..9 ----> 27,...36
•Key: CS1 --->3+19+28 (concatenate) = 31,928
•(31,928)2 = 1,019,397,184 → 10 digits
•Extract middle 2 digits (5th and 6th) as table size
is 0..99.
•Get 39, so: H(CS1) = 39.
Hashing a string key](https://crownmelresort.com/image.slidesharecdn.com/lect1011-dsalgohashing-220407193337/75/LECT-10-11-DSALGO-Hashing-pdf-22-2048.jpg)


















































































































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)






