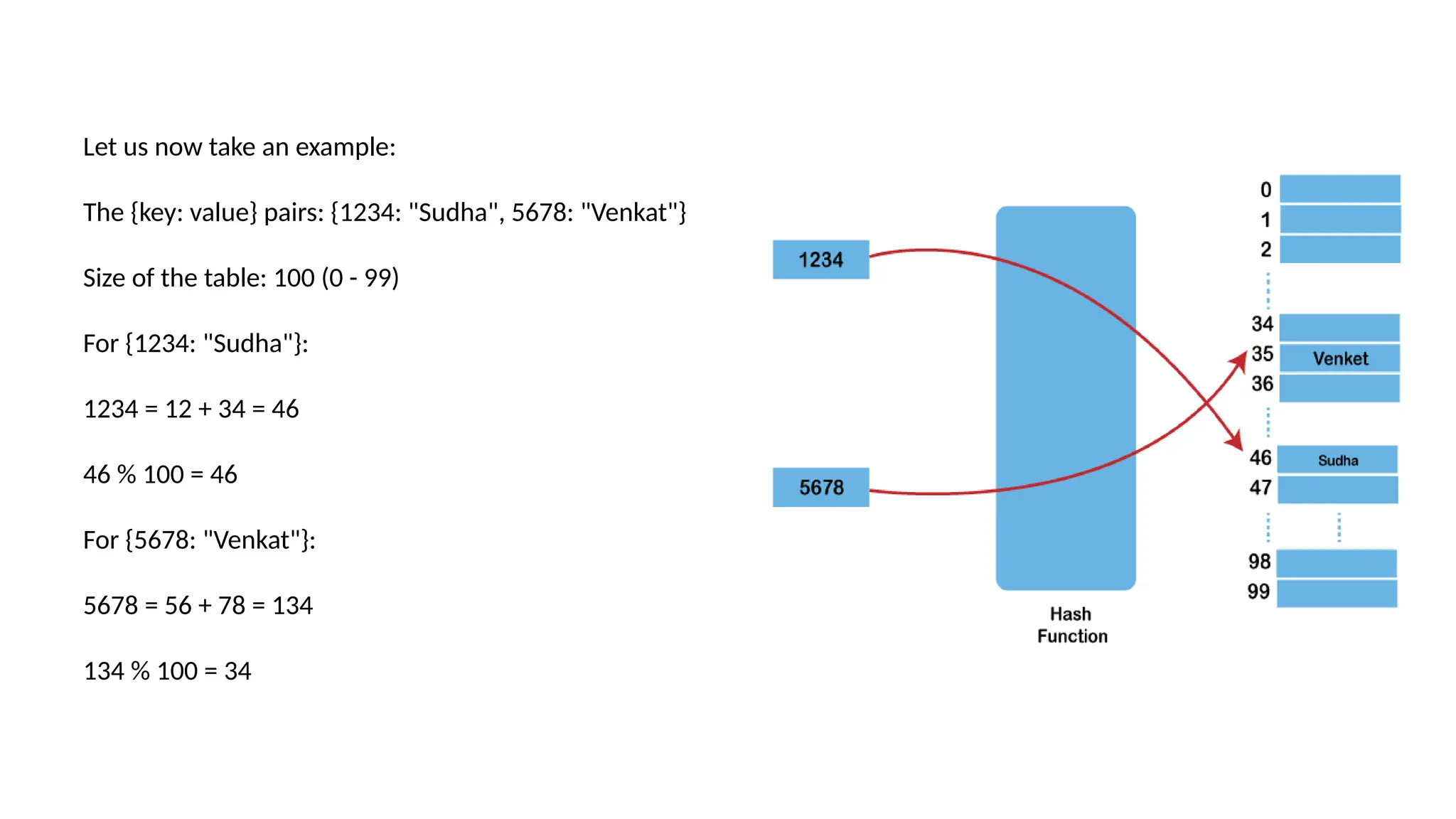
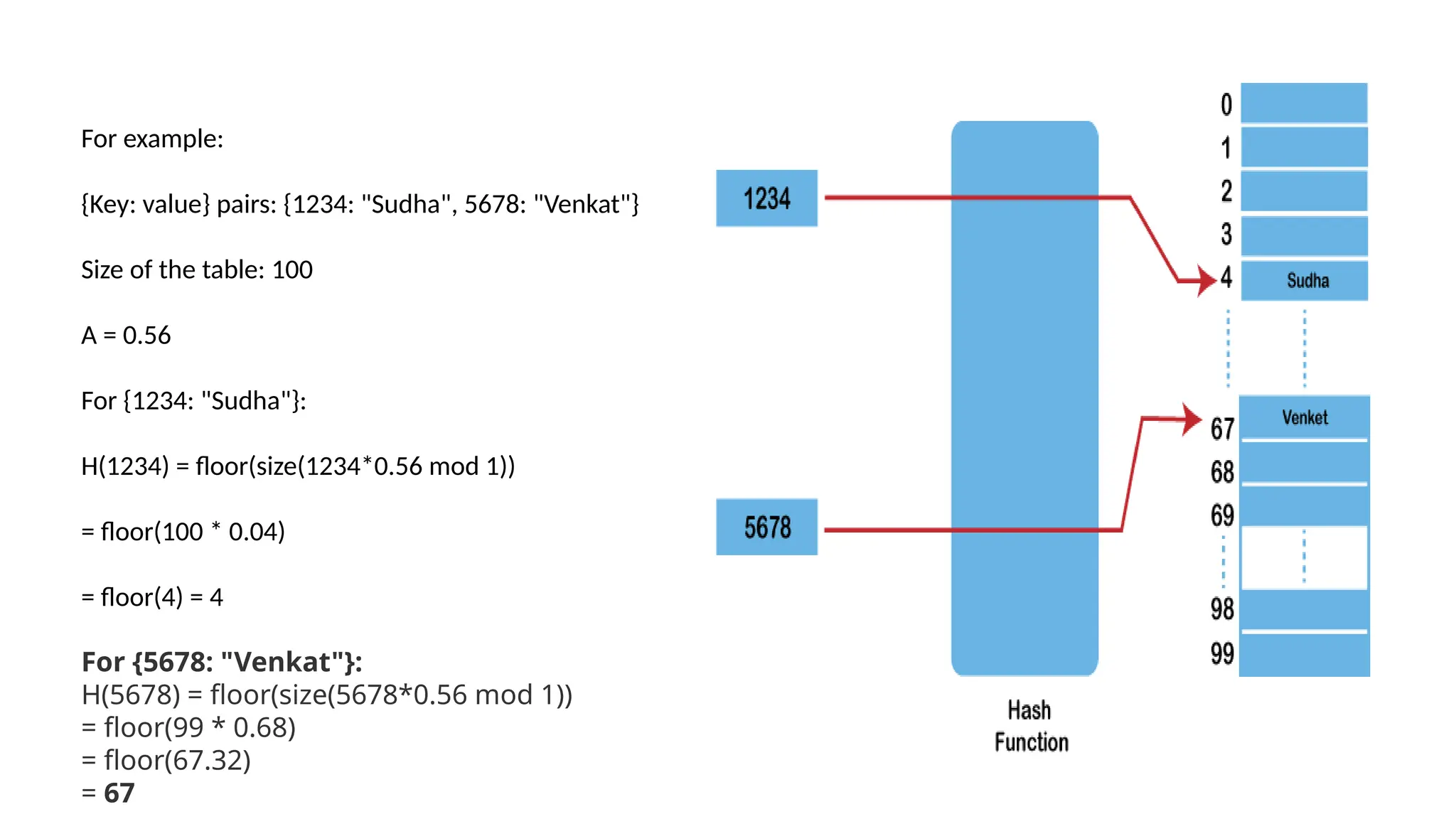
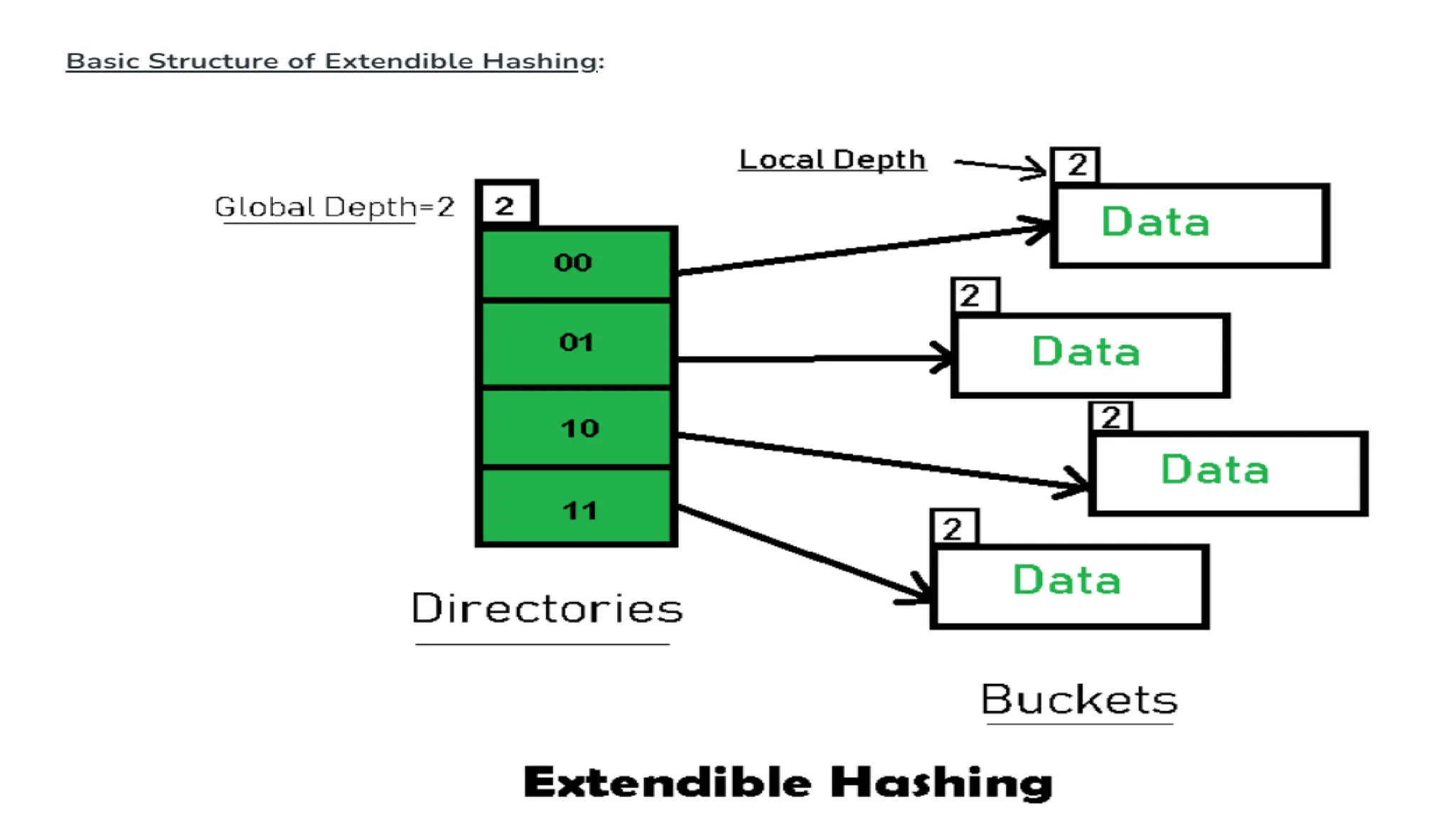
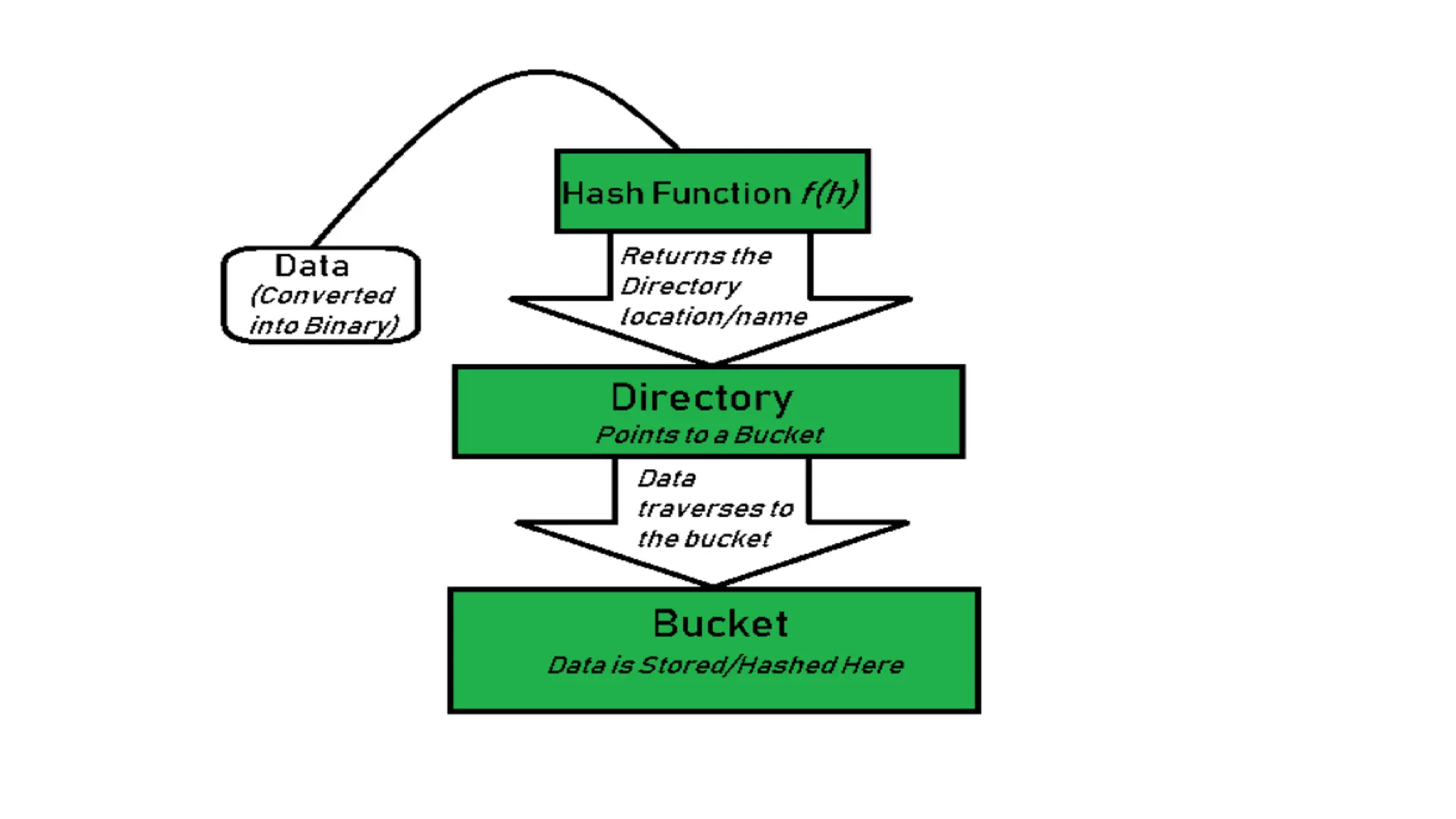
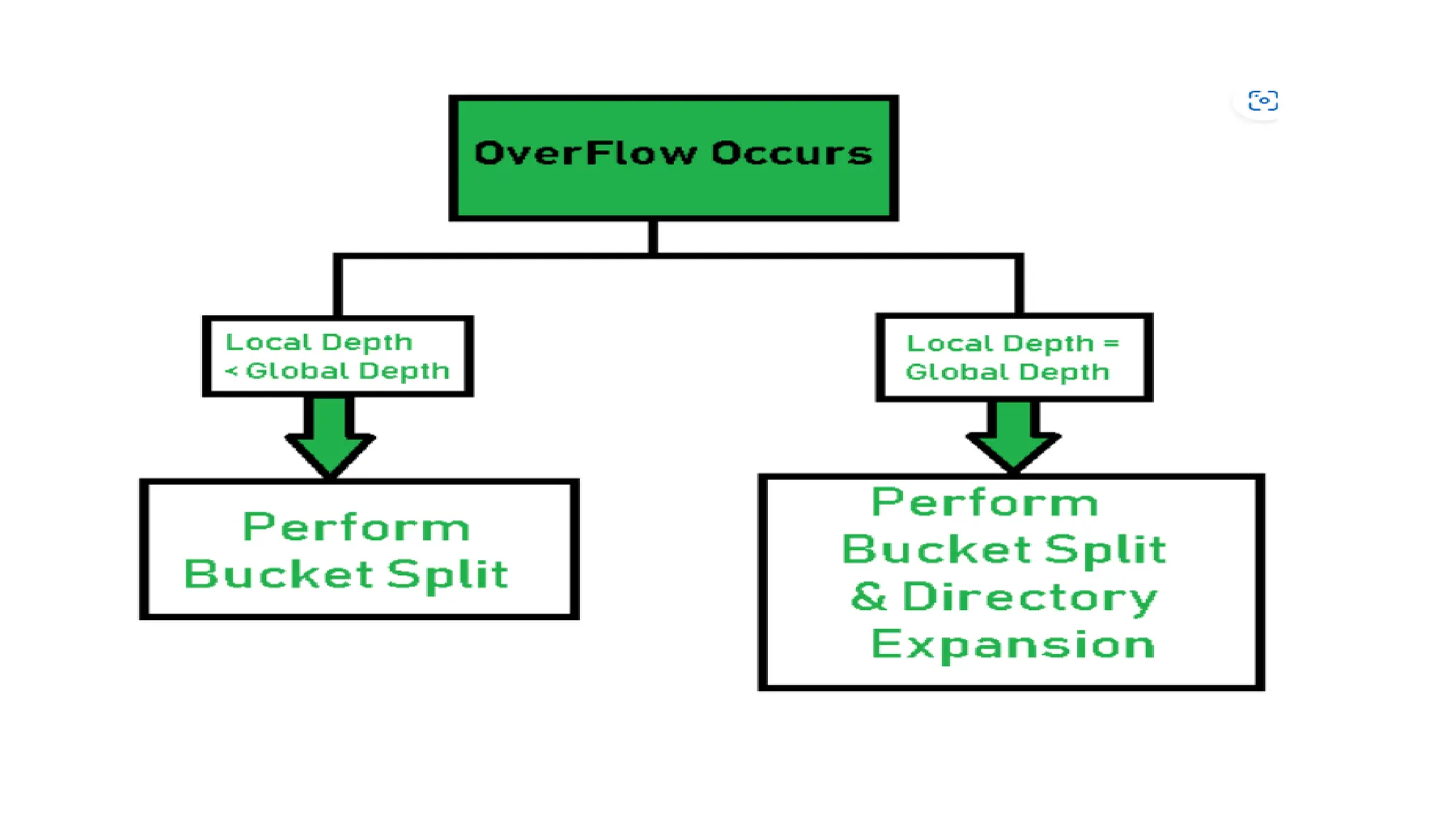
The document provides a comprehensive overview of hashing, a data structure that facilitates efficient data storage and retrieval by mapping large datasets to fixed-length values. It covers various hashing techniques, including static and dynamic hashing, and collision resolution methods such as separate chaining and open addressing. The document also explains different hash functions like division, mid square, folding, and multiplication methods, along with their applications and potential drawbacks.




























































![Data Structures - Lecture 9 [Stack & Queue using Linked List]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-9stackqueueusinglinkedlist-150219032411-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



























































