
Downloaded 36 times














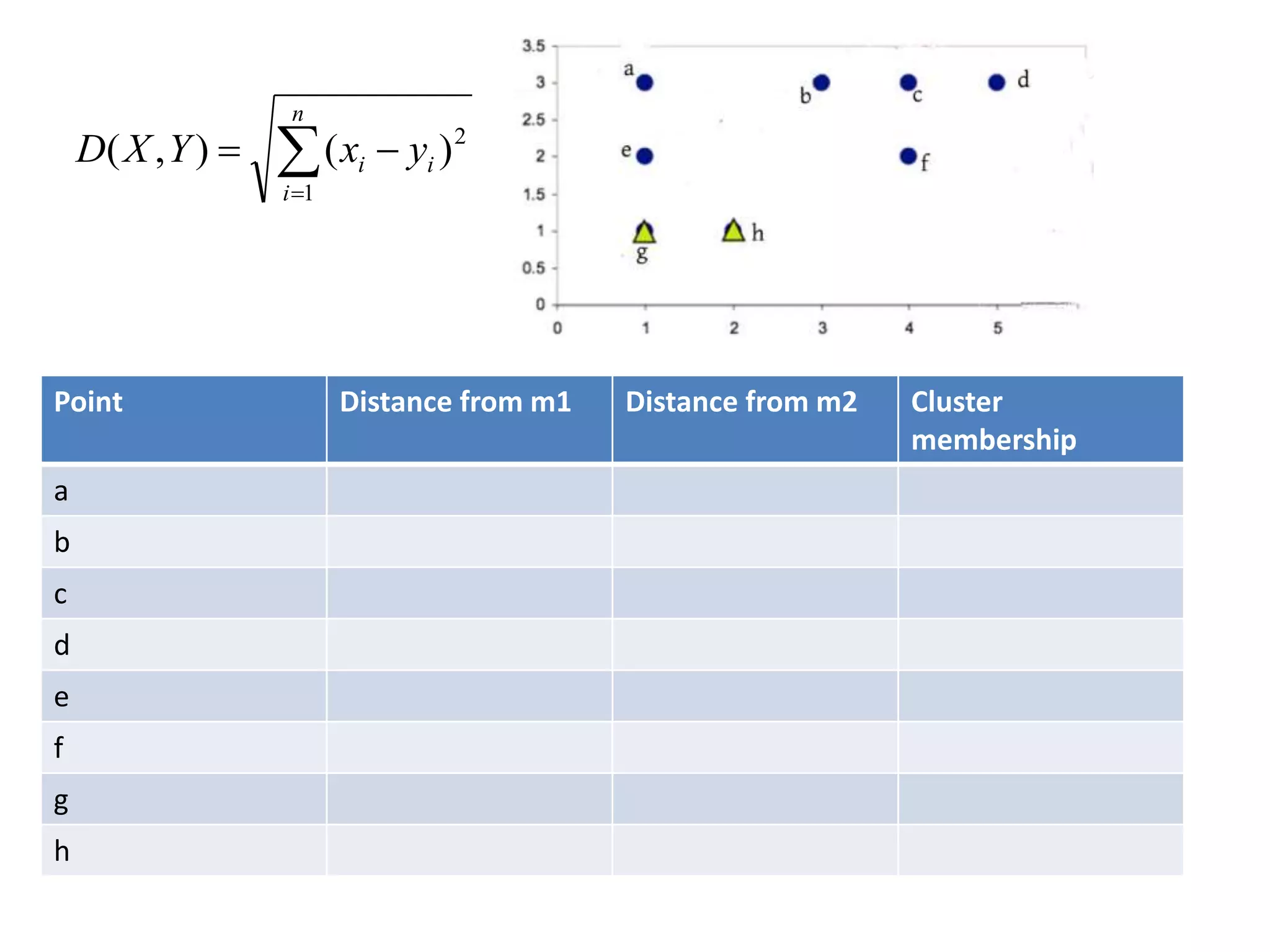
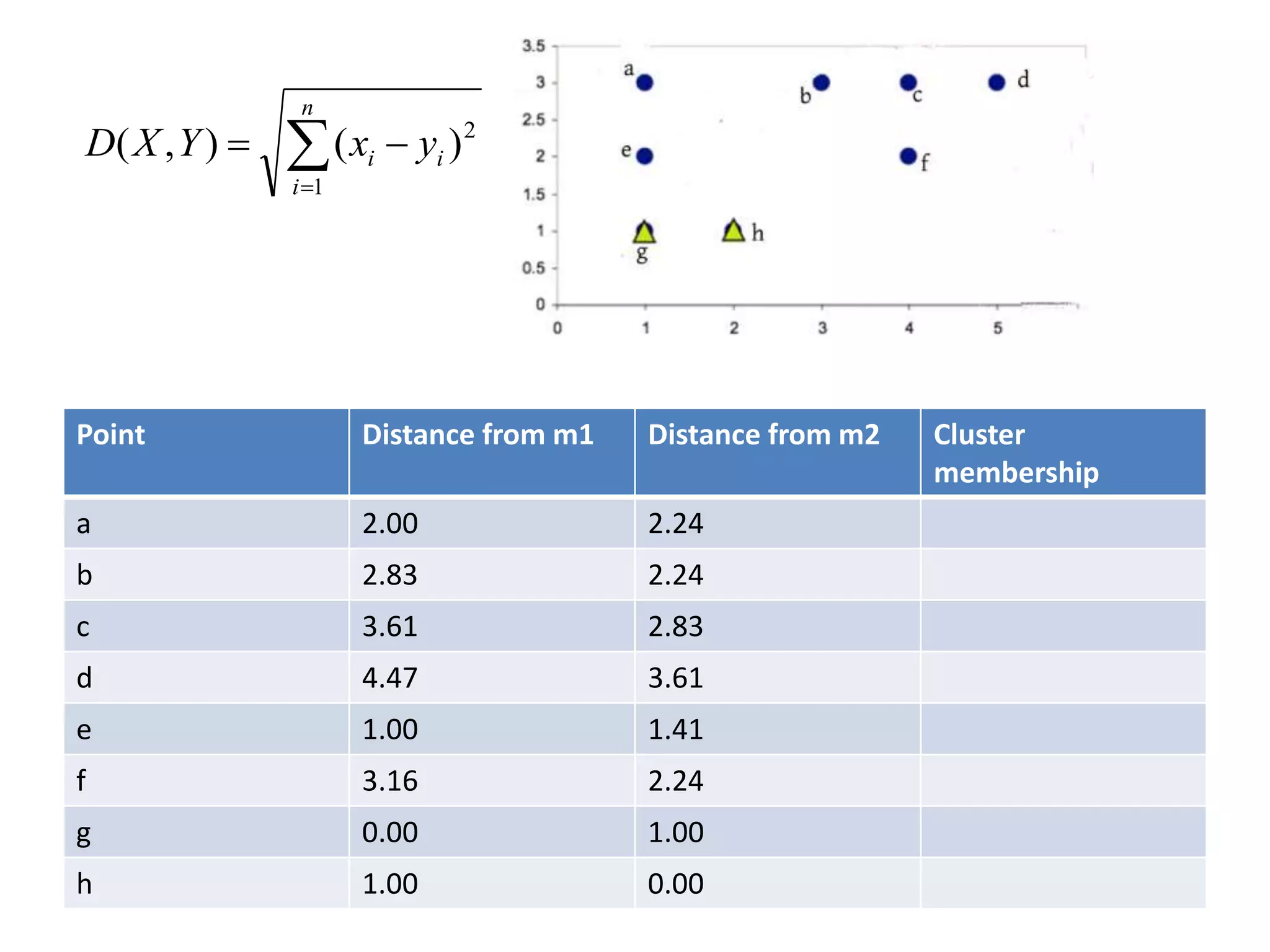
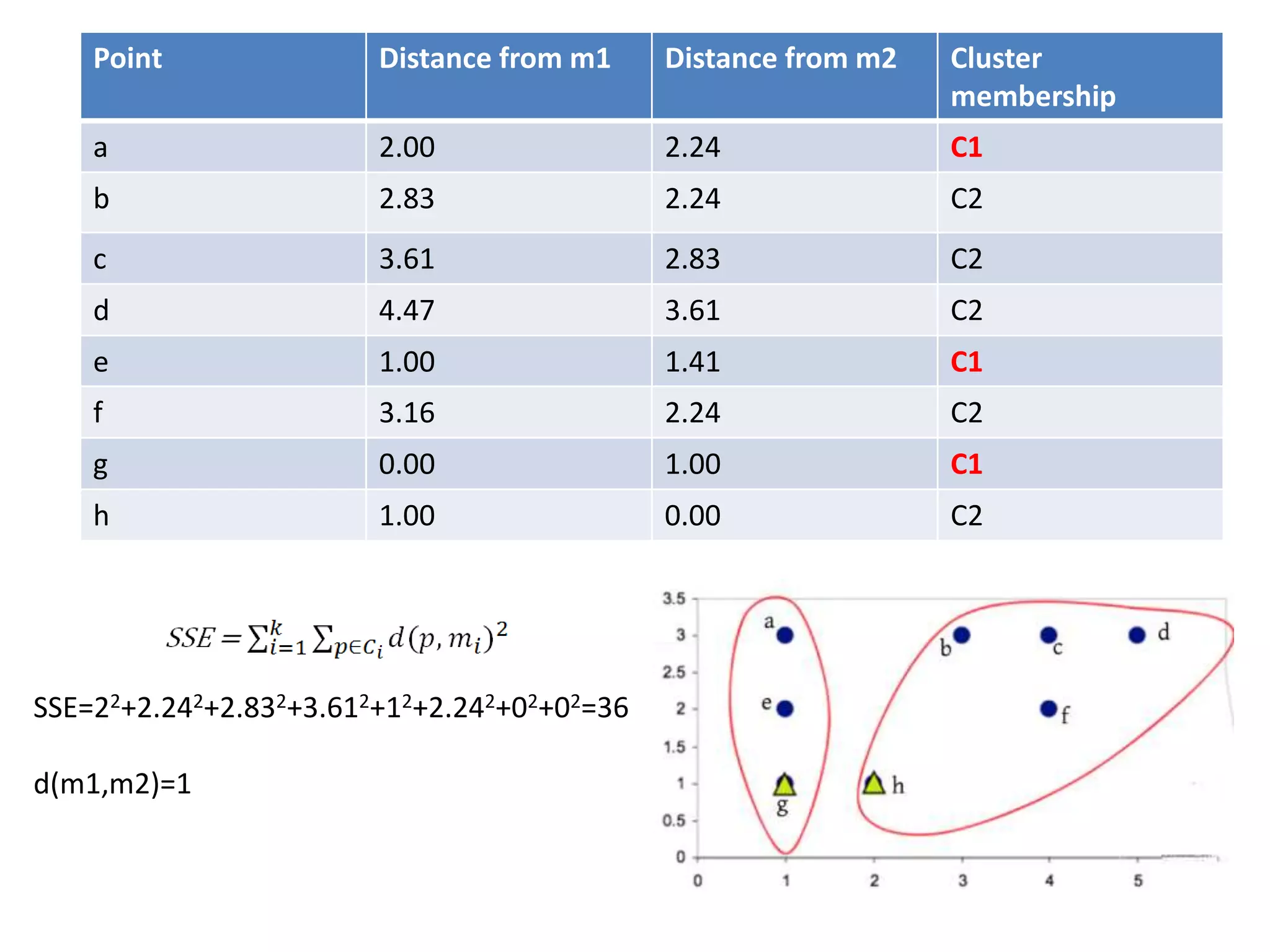
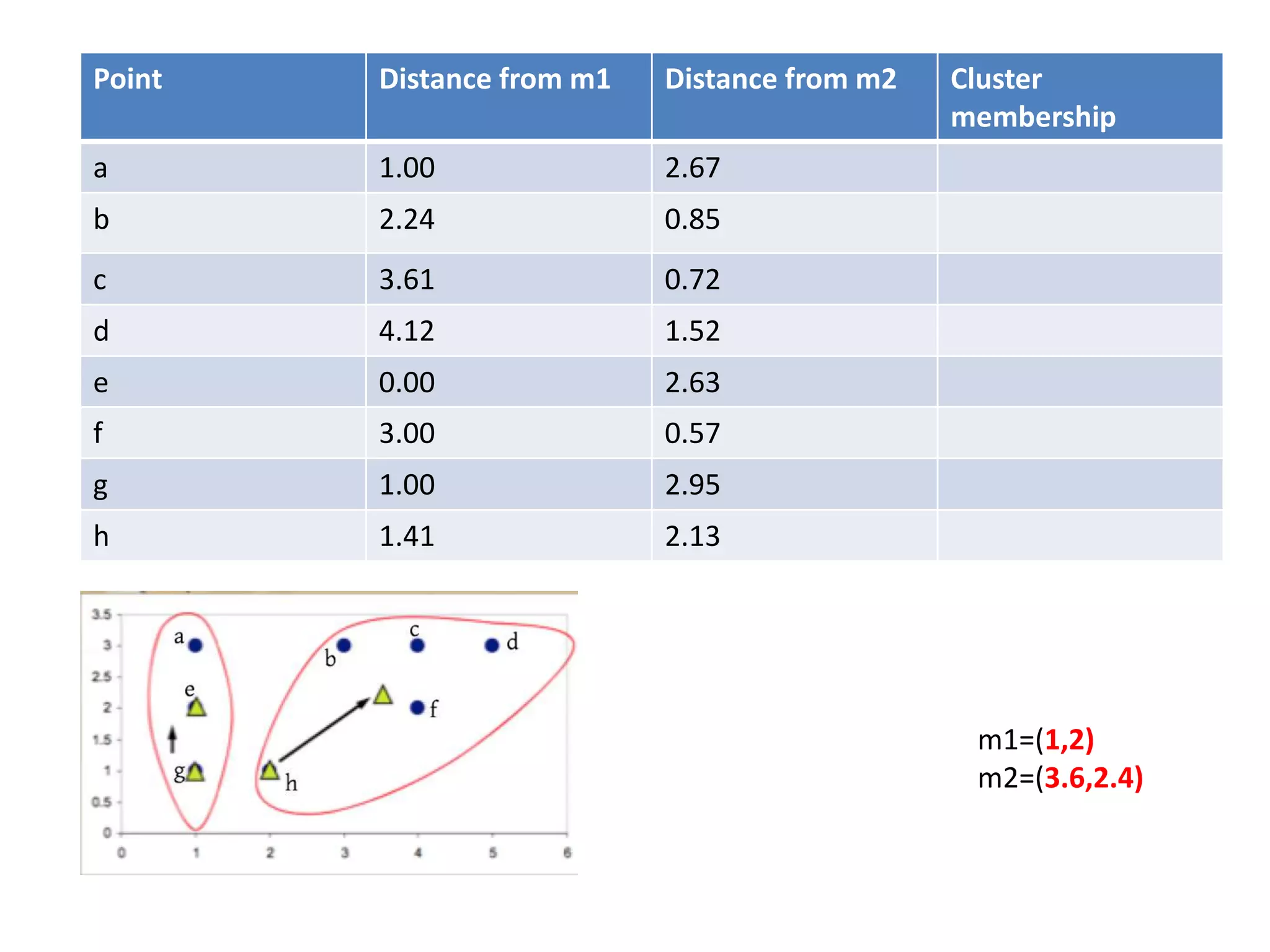
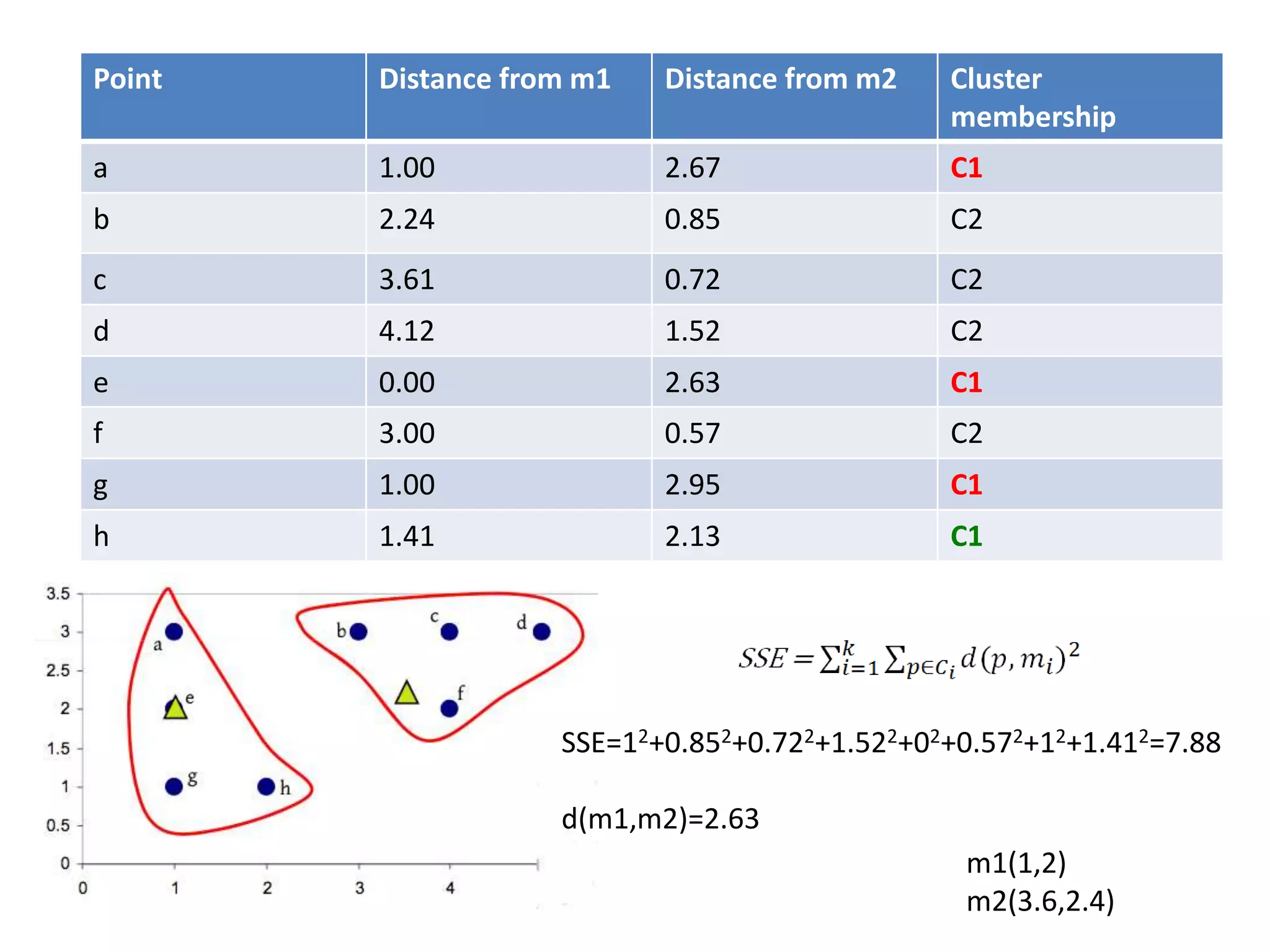
![Centroid of the cluster 1 is
[(1+1+1)/3,(3+2+1)/3]
=(1,2)
Centroid of the cluster 2 is
[(3+4+5+4+2)/5,(3+3+3+2+1)/5]
=(3.6,2.4)](https://image.slidesharecdn.com/clusterkmean-160904075141/75/kmean-clustering-26-2048.jpg)
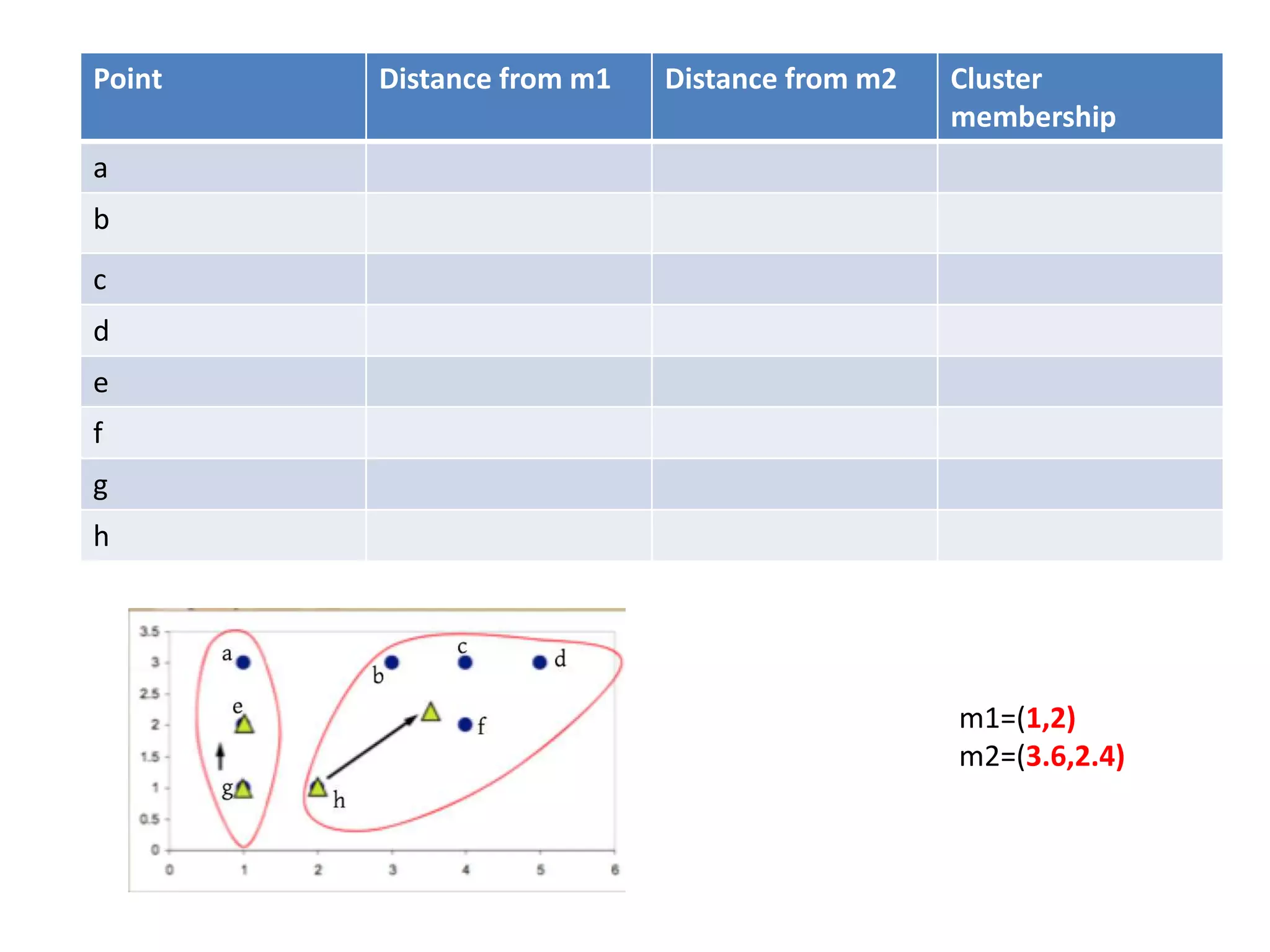
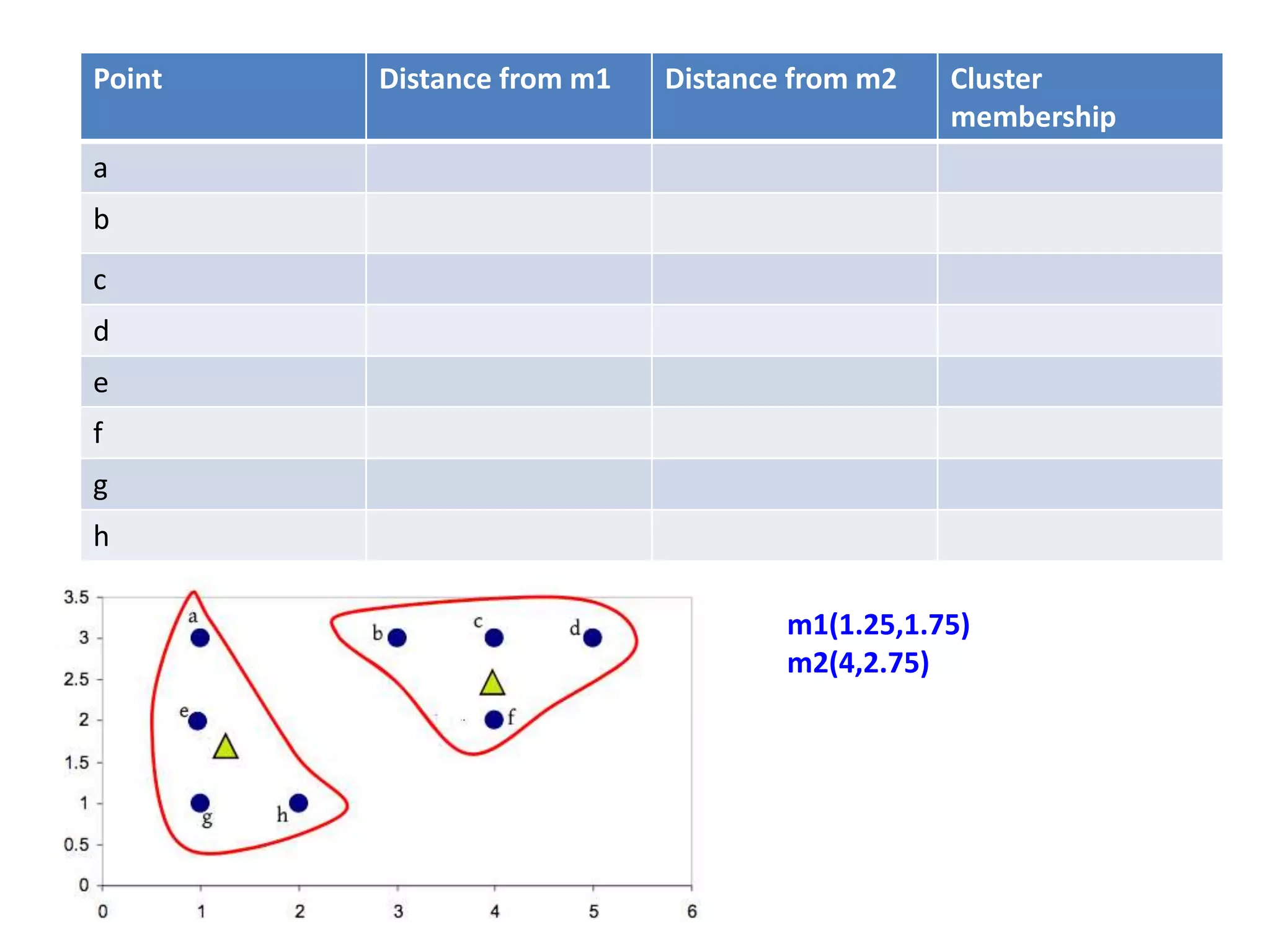
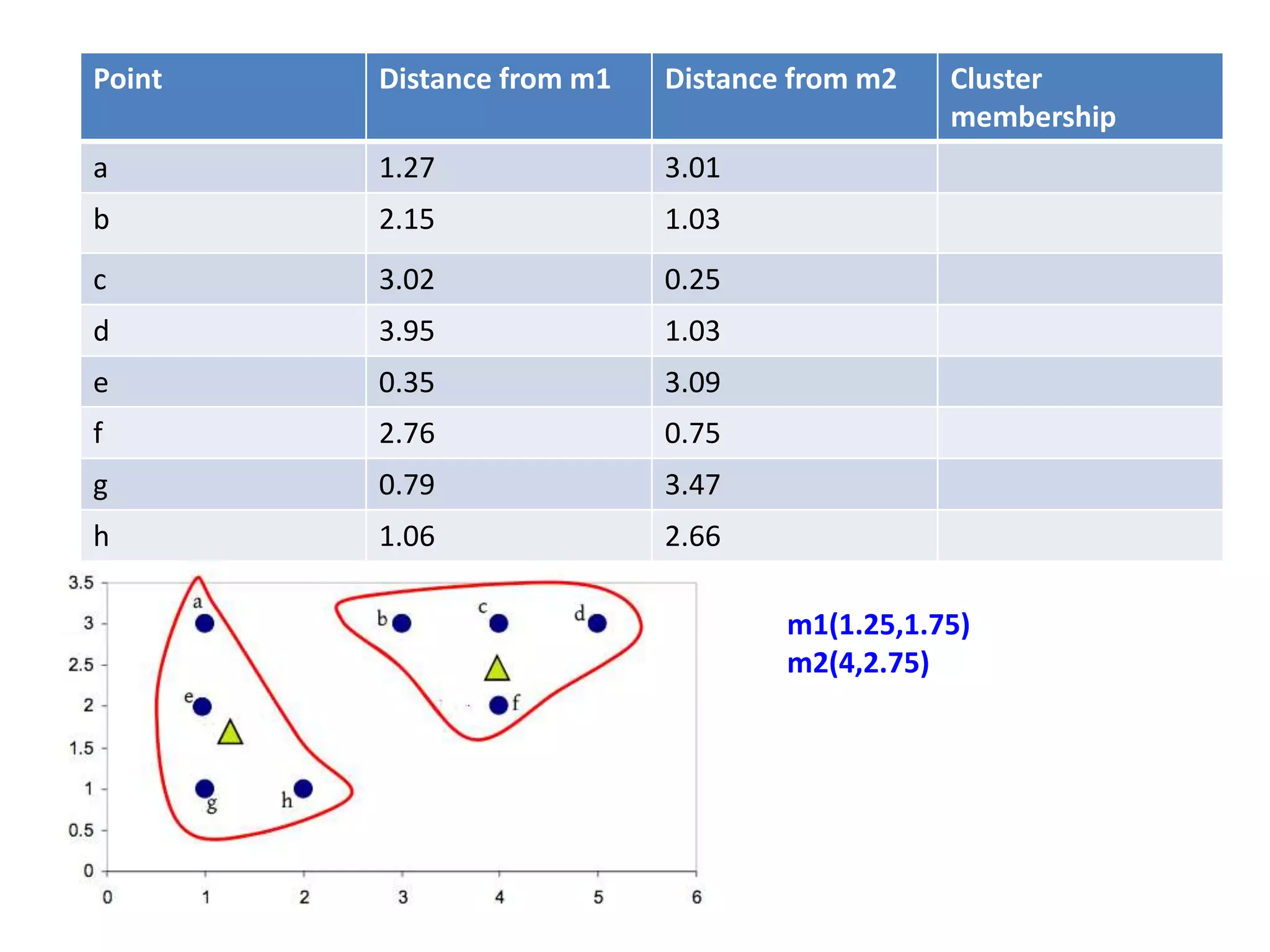
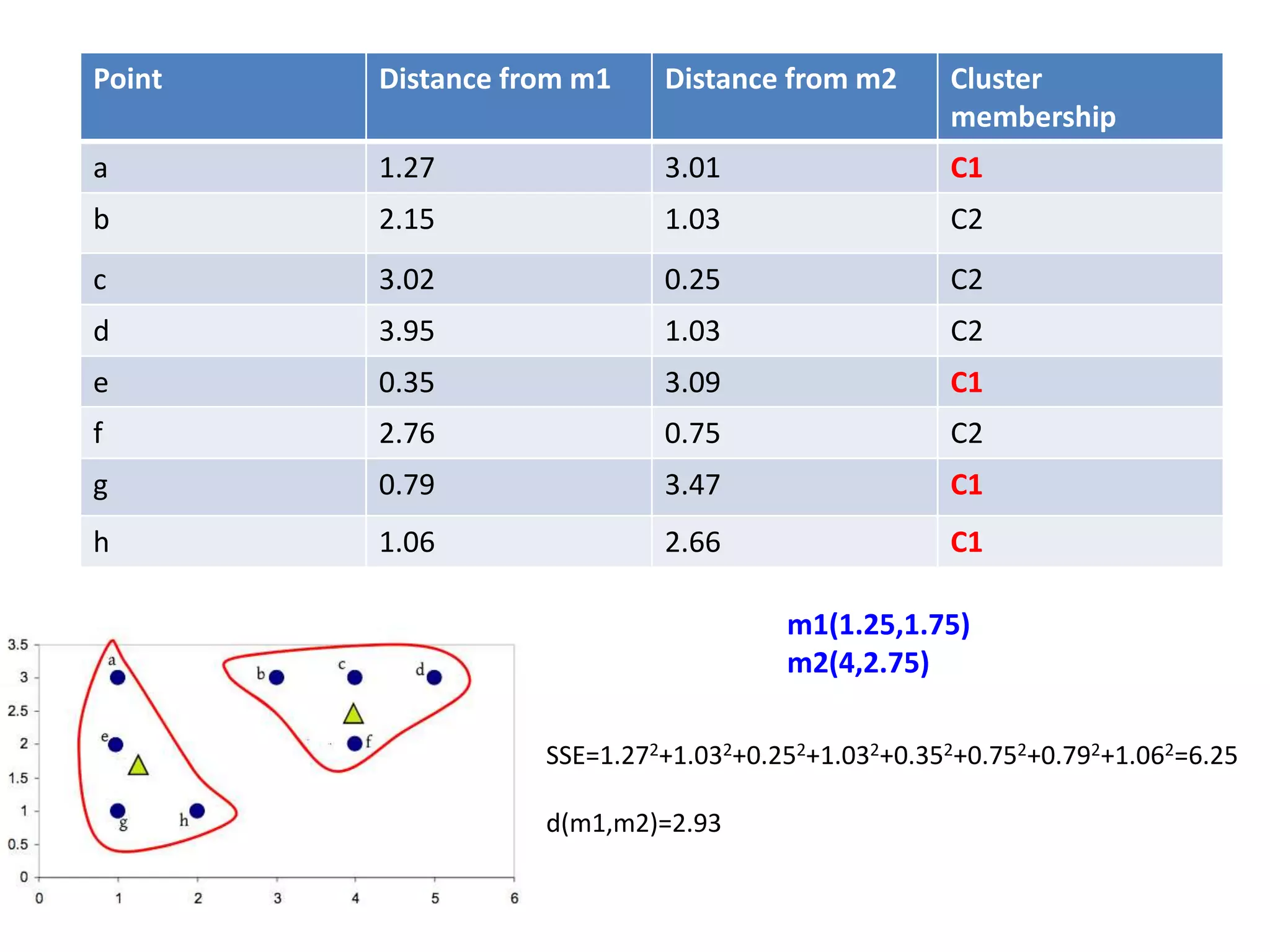
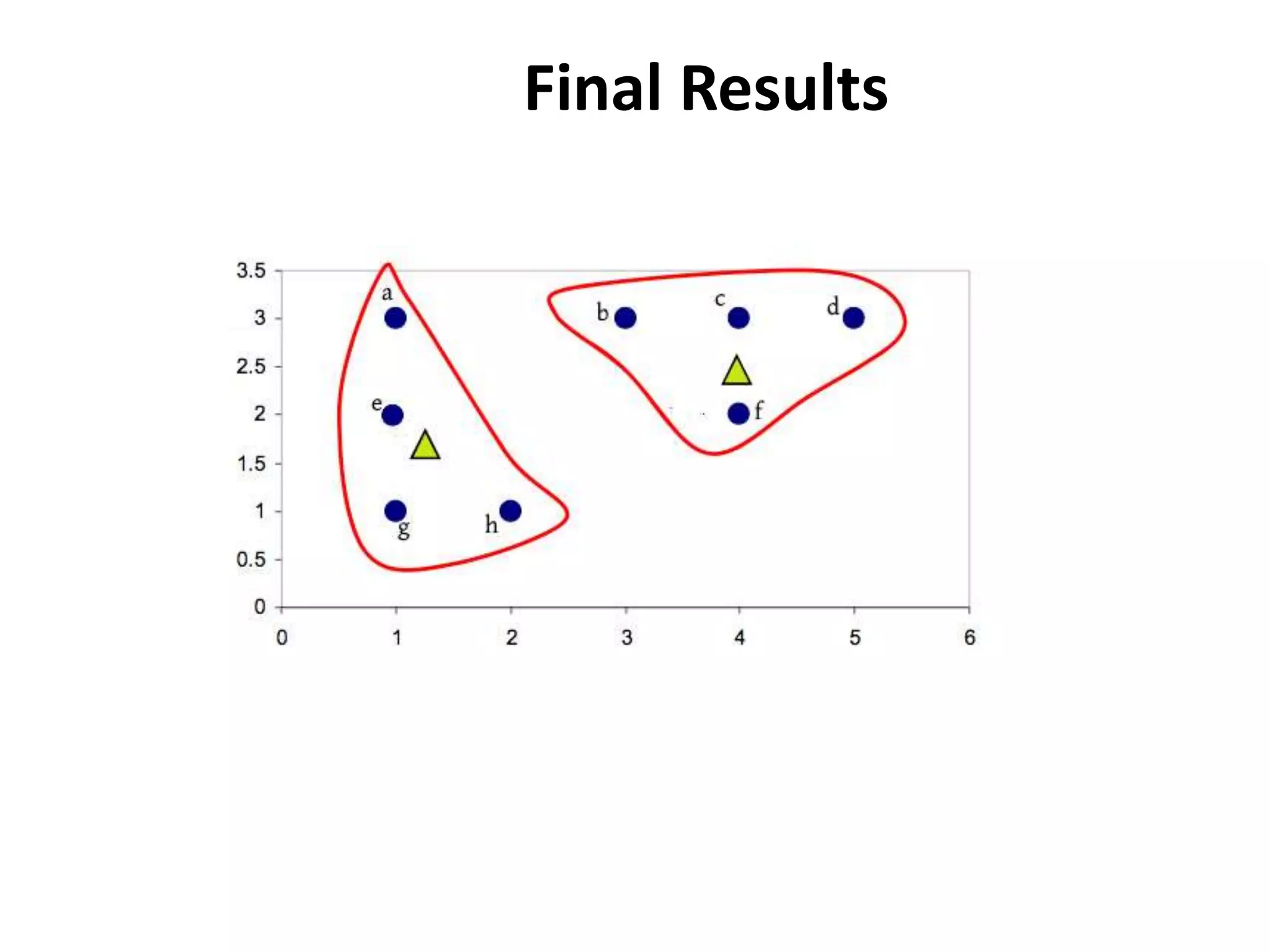
![Centroid of the cluster 1 is
[(1+1+1+2)/4,(3+2+1+1)/4]
=(1.25,1.75)
Centroid of the cluster 2 is
[(3+4+5+4)/4,(3+3+3+2)/4]
=(4,2.75)](https://image.slidesharecdn.com/clusterkmean-160904075141/75/kmean-clustering-30-2048.jpg)






























![Centroid of the cluster 1 is
[(1+1+1)/3,(3+2+1)/3]
=(1,2)
Centroid of the cluster 2 is
[(3+4+5+4+2)/5,(3+3+3+2+1)/5]
=(3.6,2.4)](https://crownmelresort.com/image.slidesharecdn.com/clusterkmean-160904075141/75/kmean-clustering-26-2048.jpg)



![Centroid of the cluster 1 is
[(1+1+1+2)/4,(3+2+1+1)/4]
=(1.25,1.75)
Centroid of the cluster 2 is
[(3+4+5+4)/4,(3+3+3+2)/4]
=(4,2.75)](https://crownmelresort.com/image.slidesharecdn.com/clusterkmean-160904075141/75/kmean-clustering-30-2048.jpg)














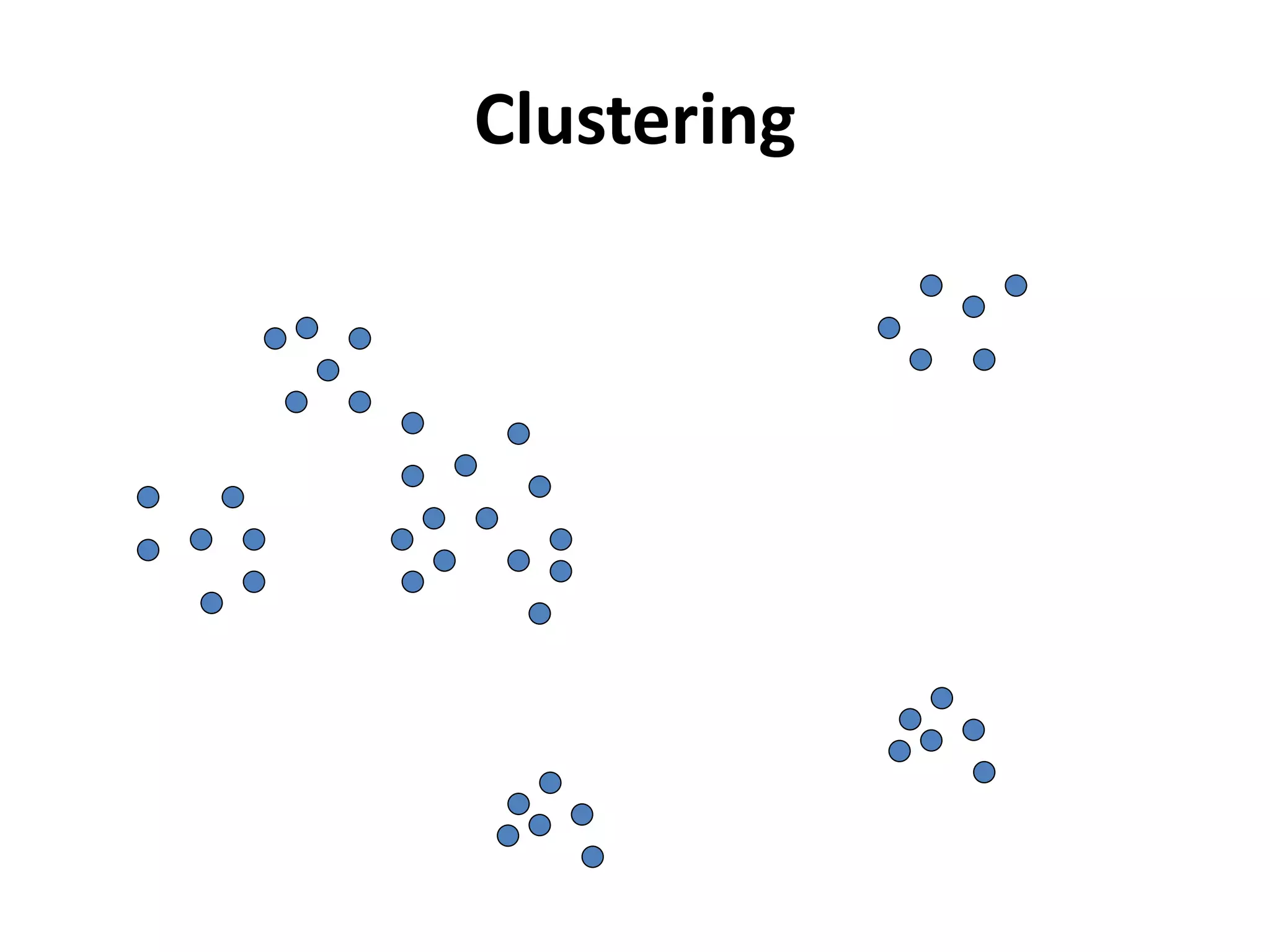
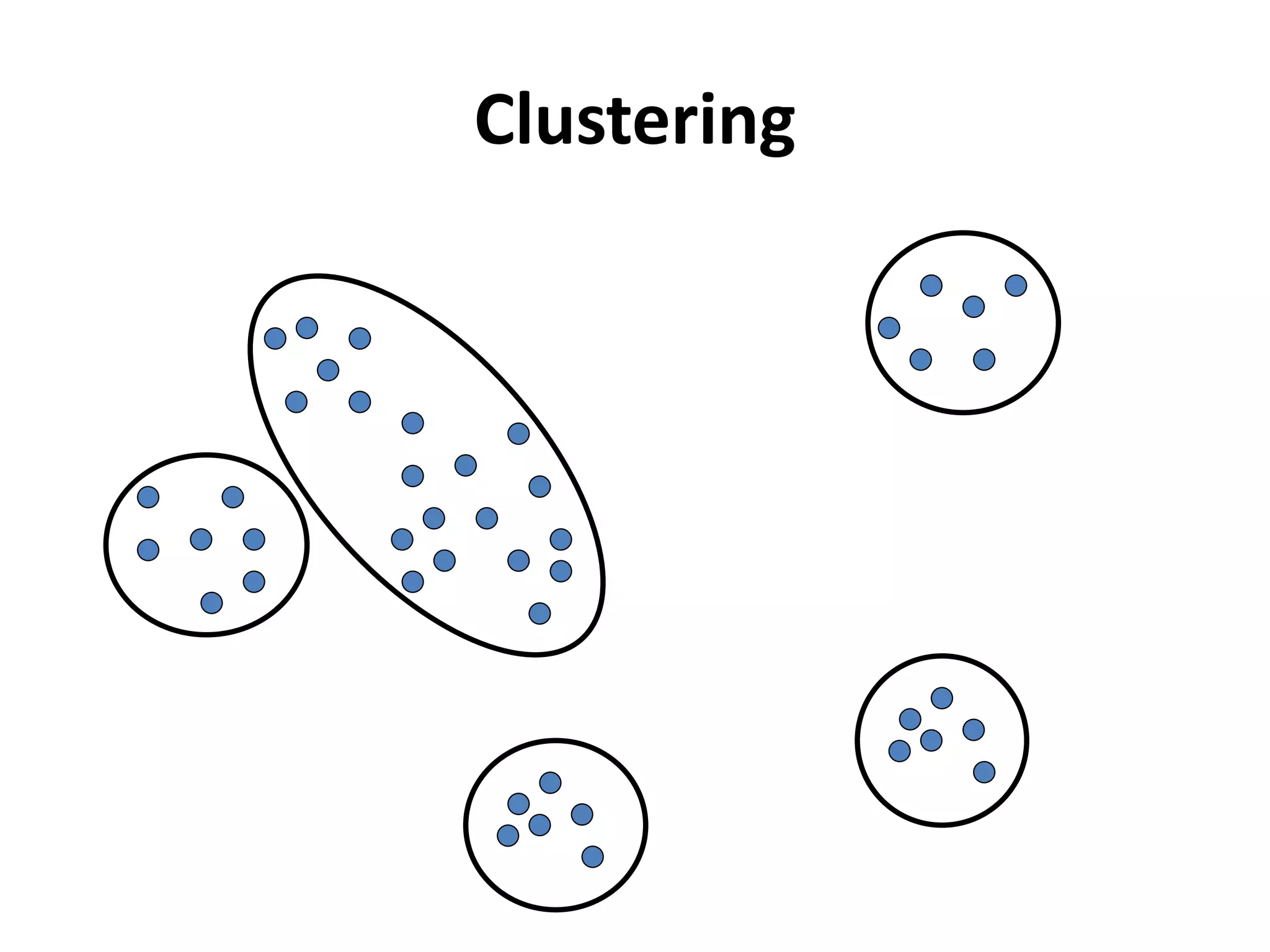
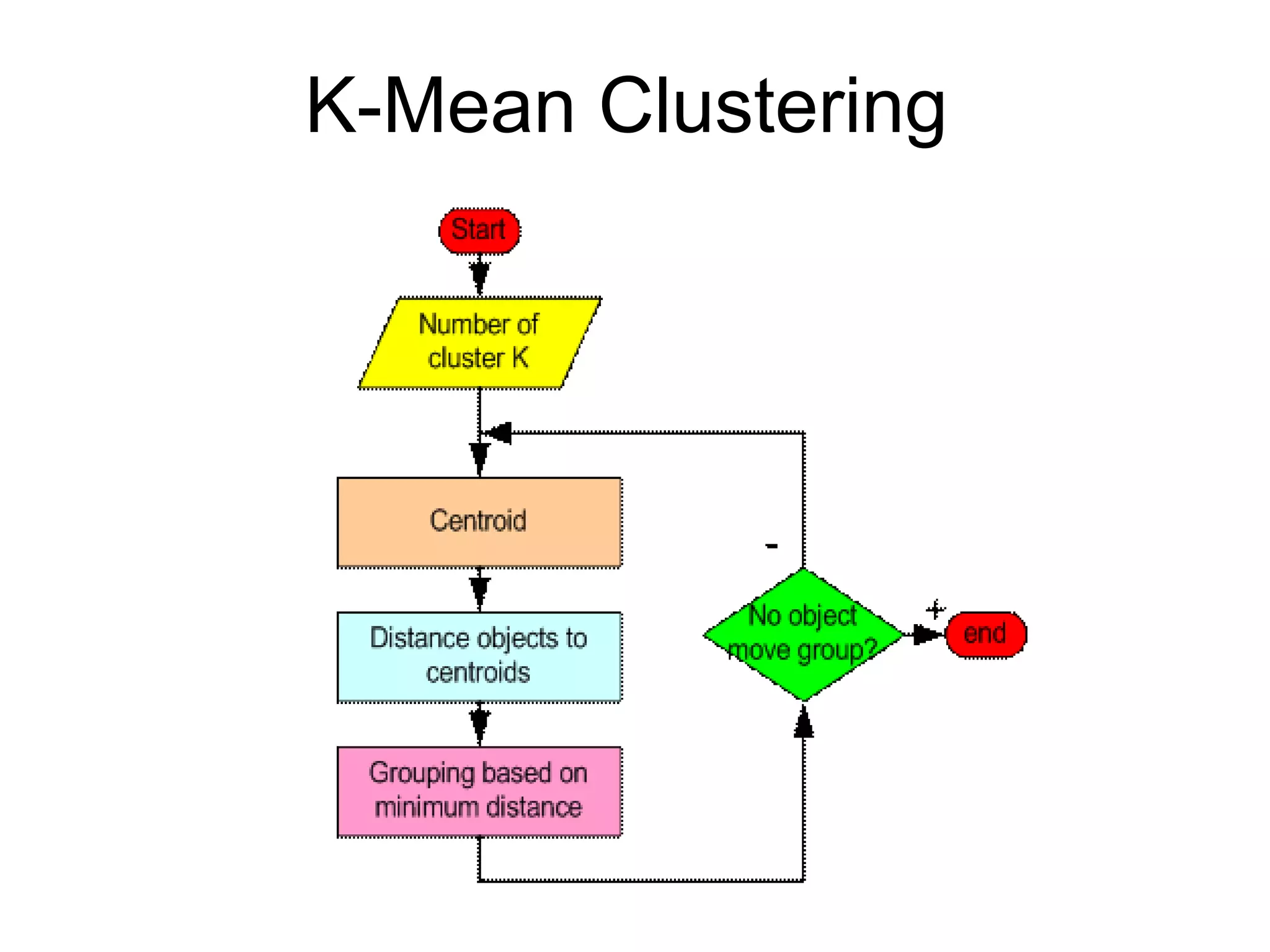
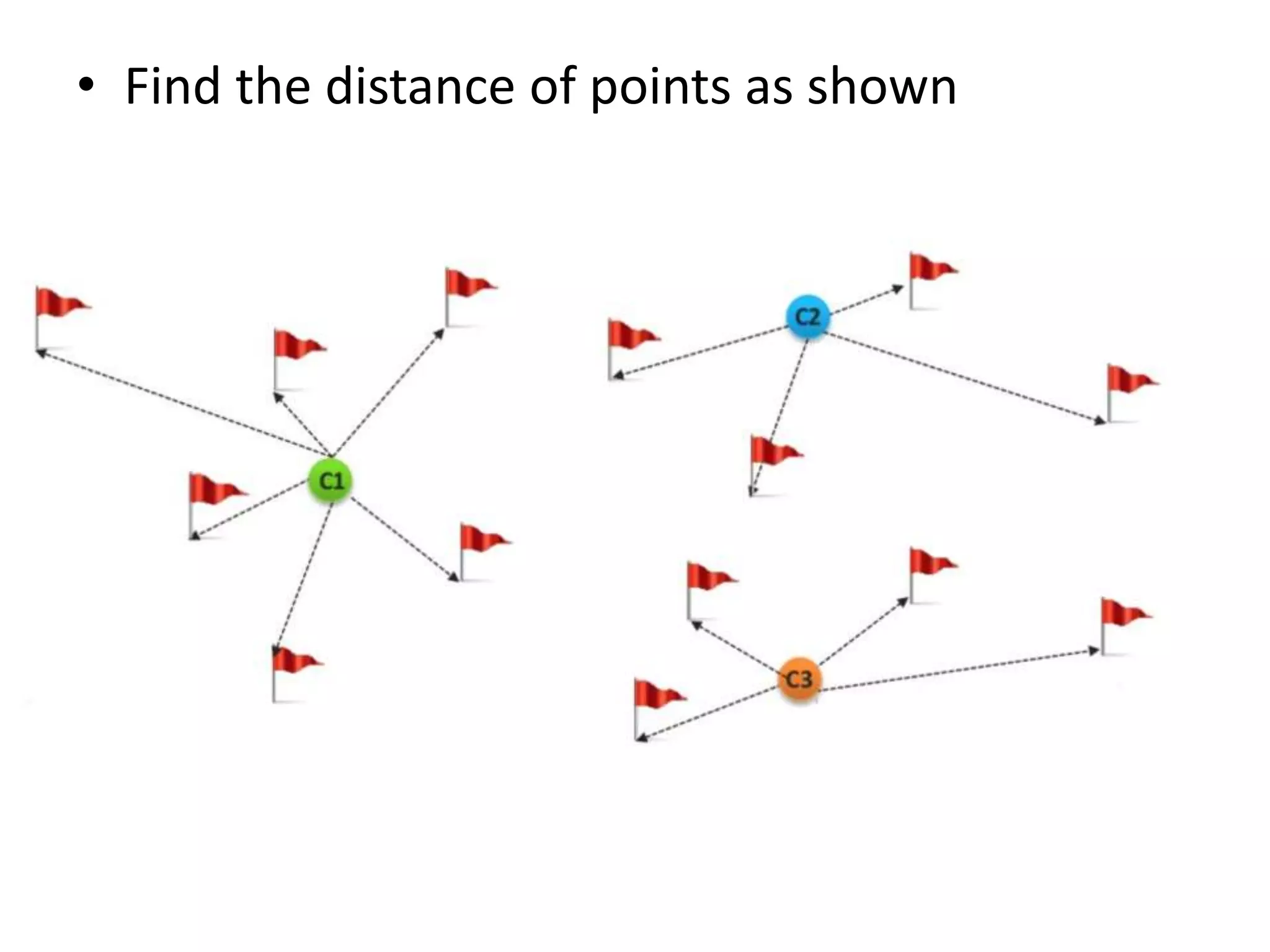
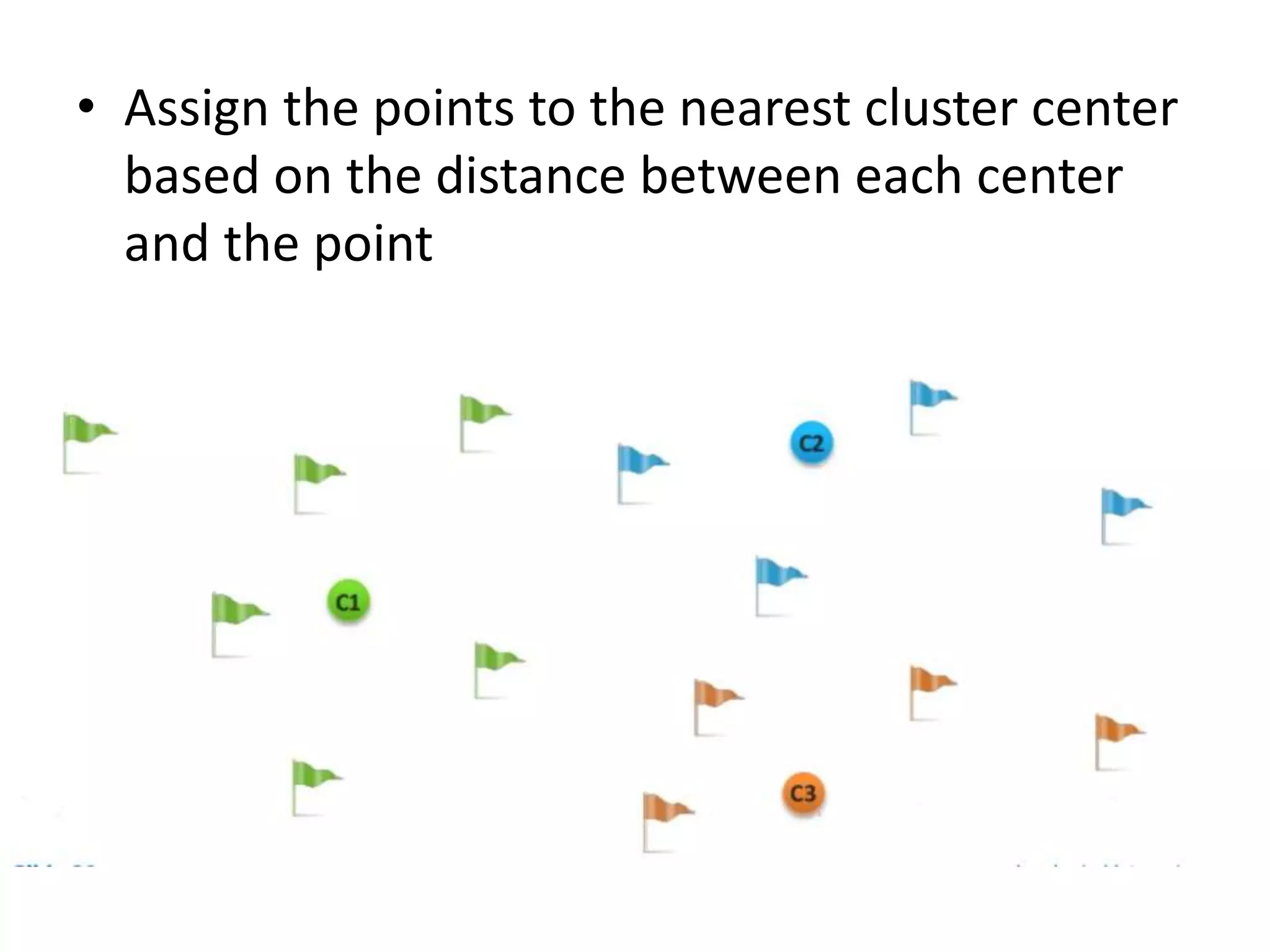
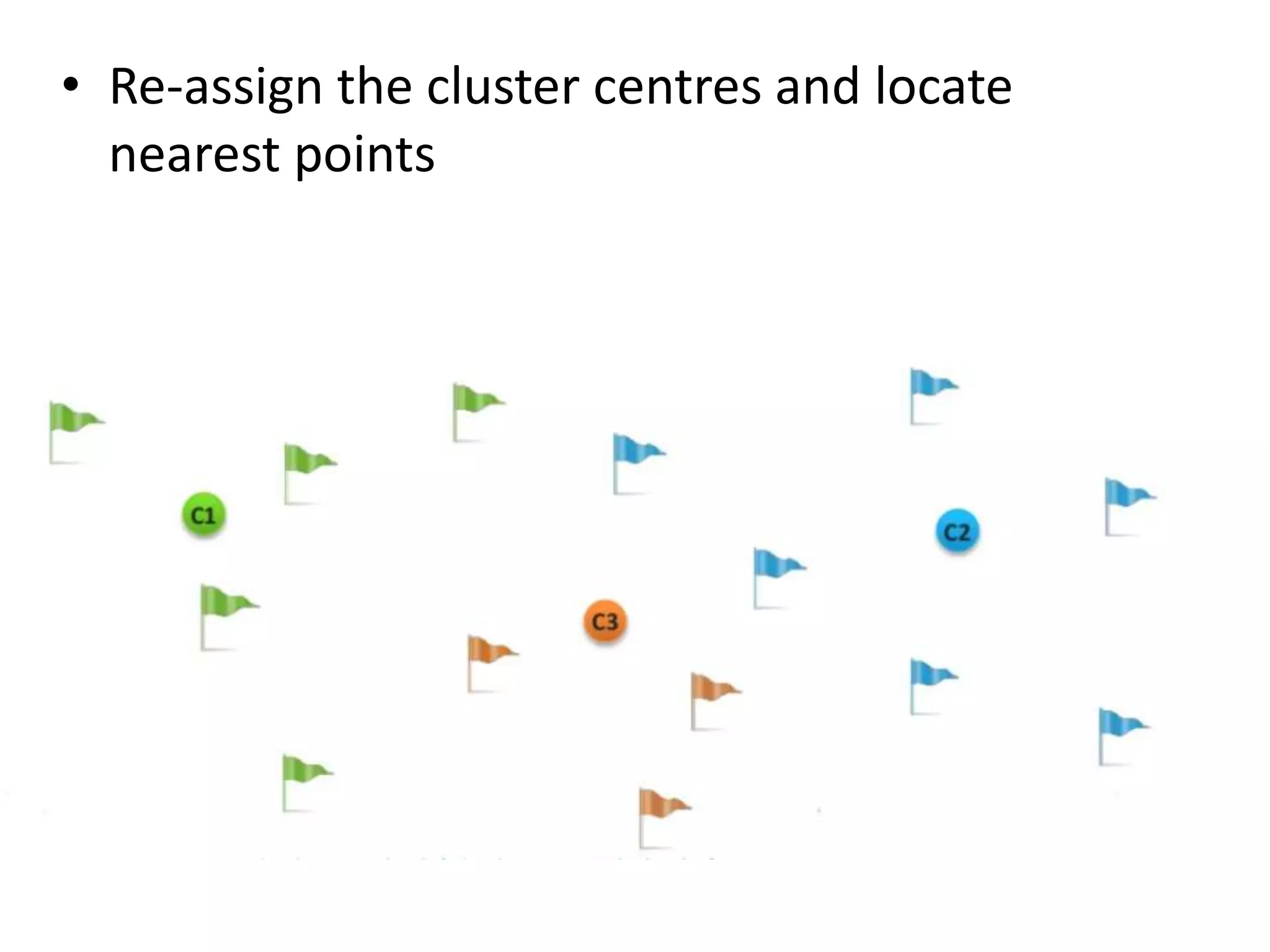
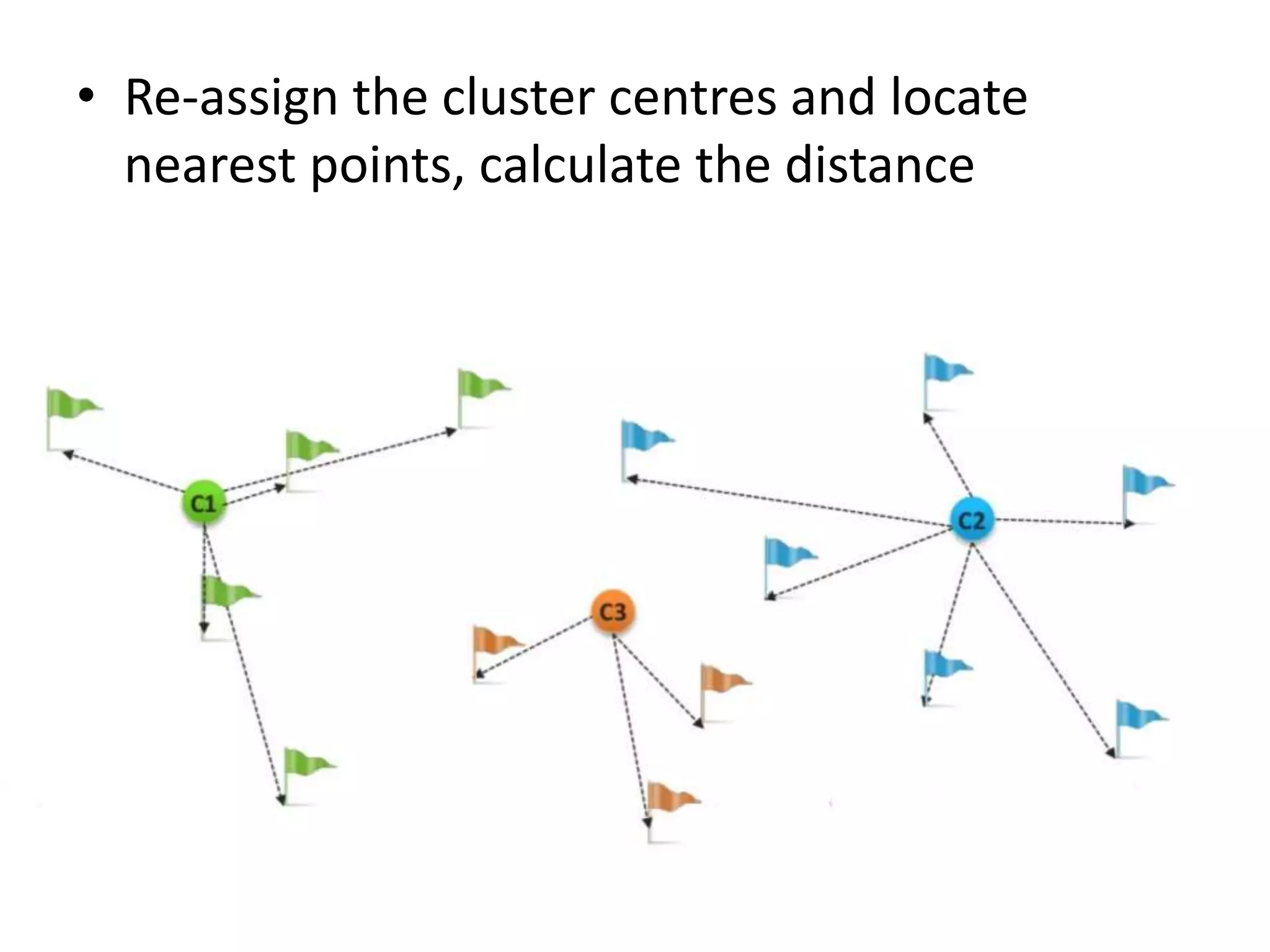
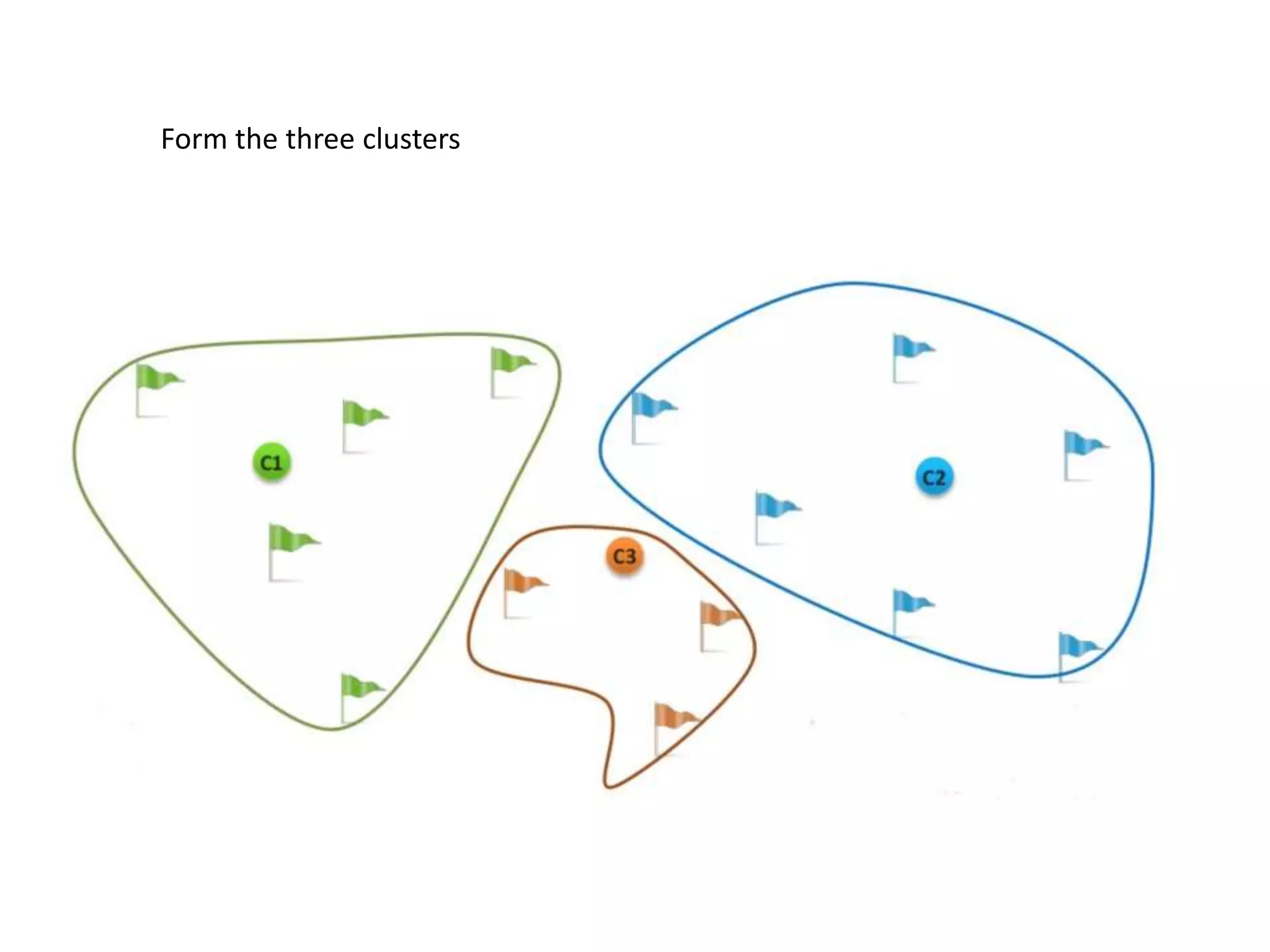
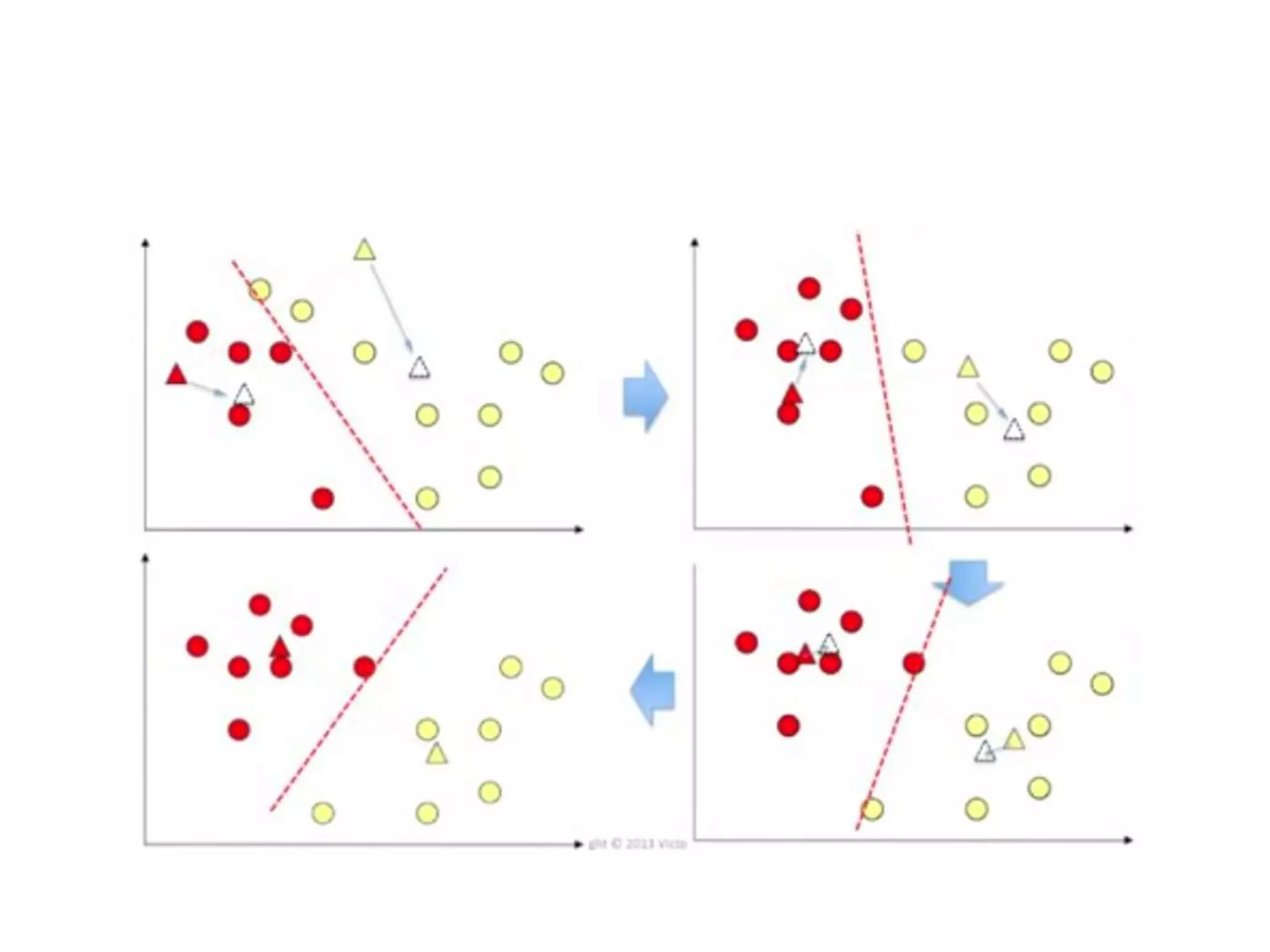
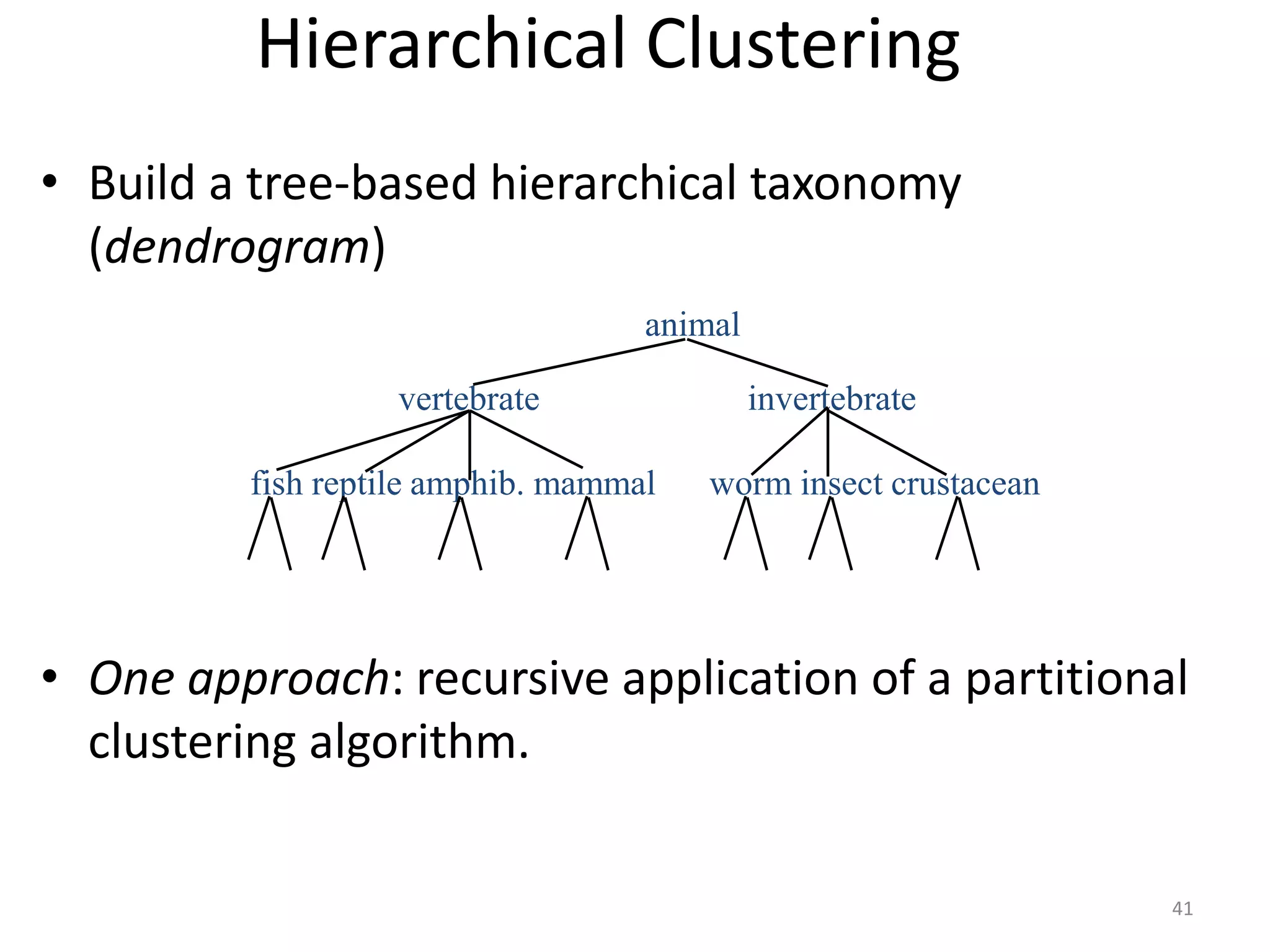
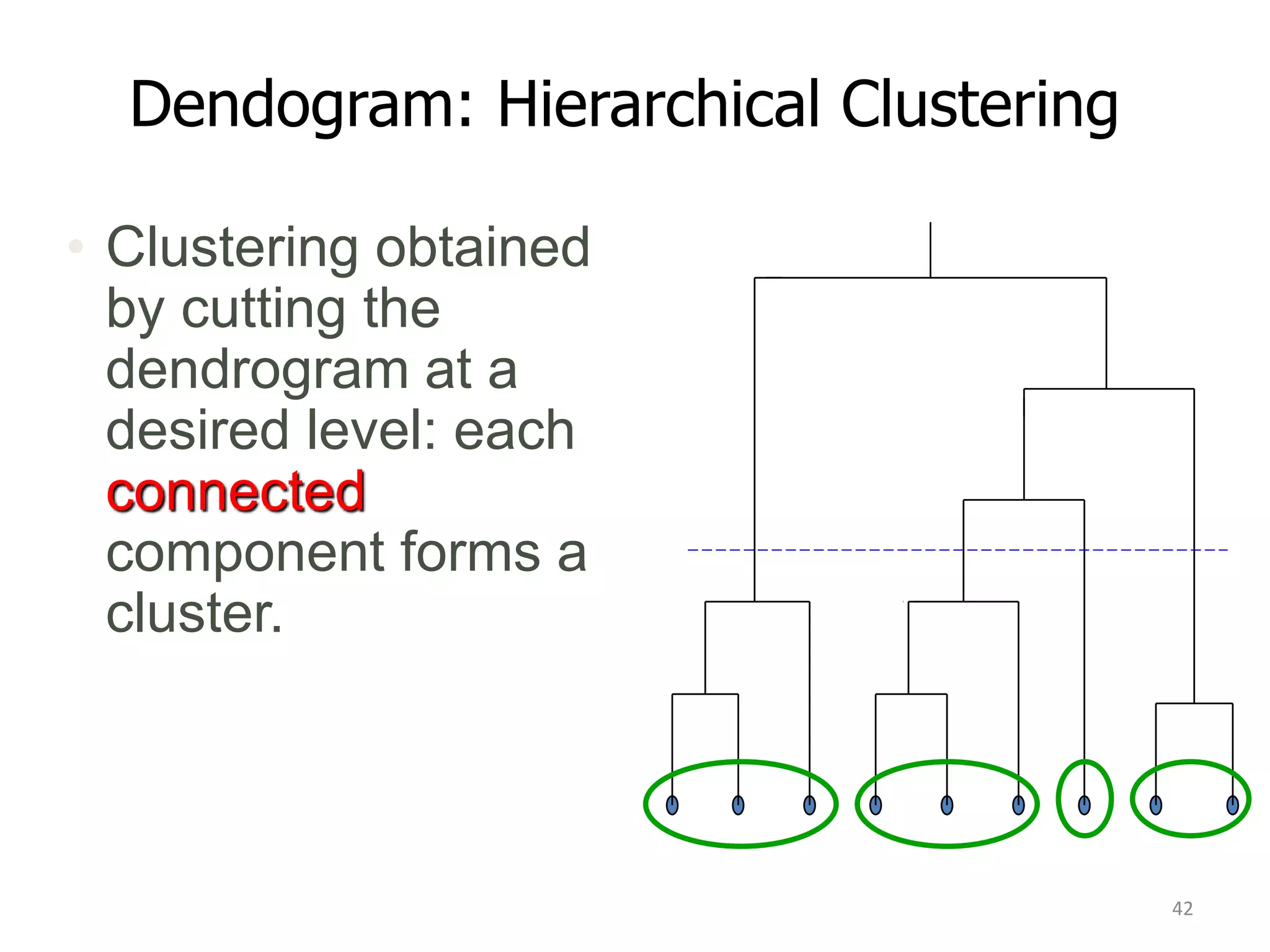
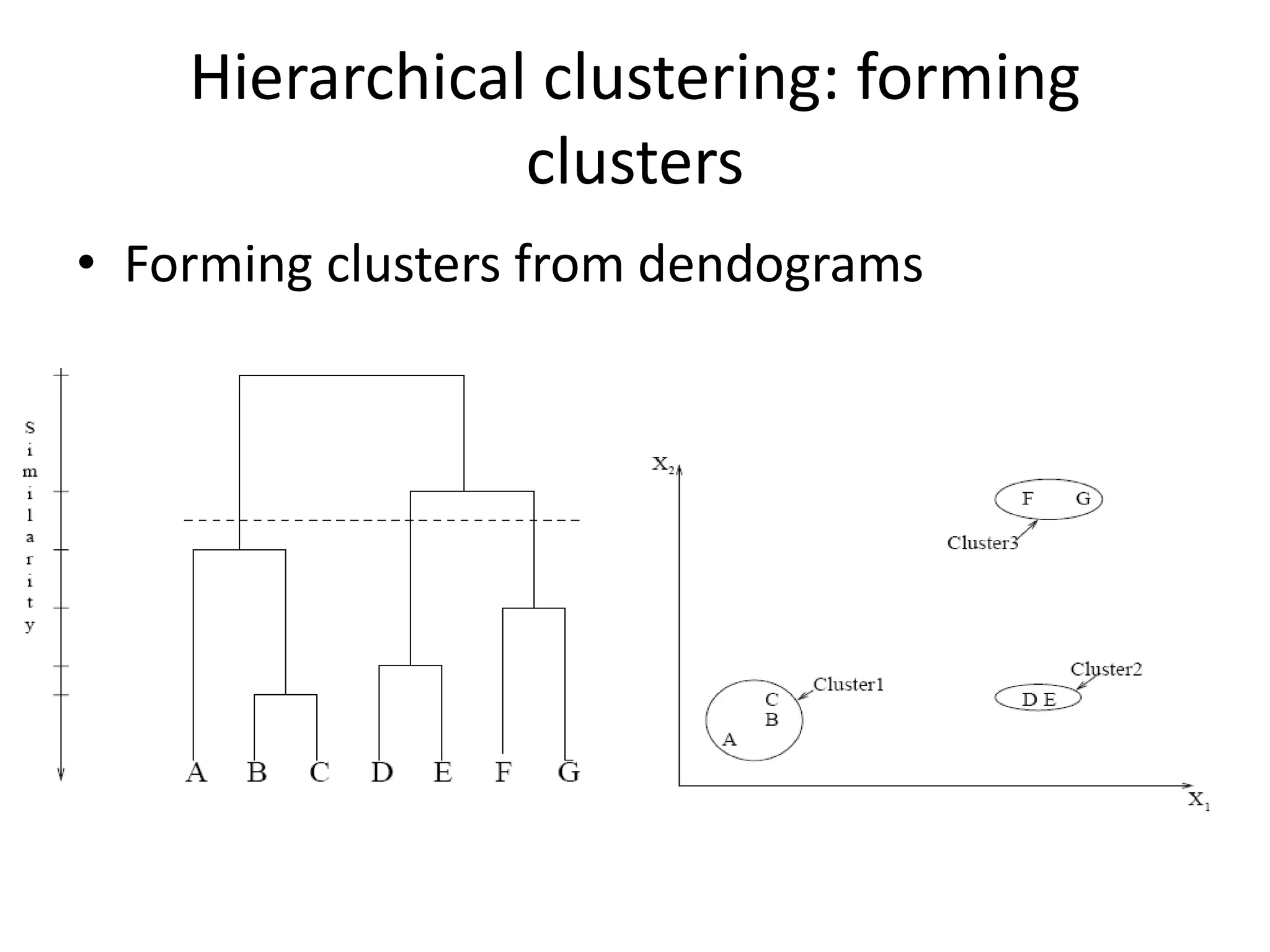
K-means clustering groups data points into k clusters by minimizing the distance between points and cluster centroids. It works by randomly assigning points to initial centroids and then iteratively reassigning points to centroids until clusters are stable. Hierarchical clustering builds a dendrogram showing the relationship between clusters by either recursively merging or splitting clusters. Both are unsupervised learning techniques that group similar data points together without labels.



















































































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)



