Download to read offline

















![Logging, turn it on
● Default is to stderr only
● In PG:
logging_collector = on
log_filename = strftime-patterned filename
[log_destination = [stderr|syslog|csvlog] ]
log_statement = [none|ddl|mod|all] // all
log_min_error_statement = ERROR
log_line_prefix = '%t %c %u ' # time sessionid user](https://image.slidesharecdn.com/jddpostgres-161108111308/75/JDD-2016-Tomasz-Borek-DB-for-next-project-Why-Postgres-of-course-22-2048.jpg)
























































![Logging, turn it on
● Default is to stderr only
● In PG:
logging_collector = on
log_filename = strftime-patterned filename
[log_destination = [stderr|syslog|csvlog] ]
log_statement = [none|ddl|mod|all] // all
log_min_error_statement = ERROR
log_line_prefix = '%t %c %u ' # time sessionid user](https://crownmelresort.com/image.slidesharecdn.com/jddpostgres-161108111308/75/JDD-2016-Tomasz-Borek-DB-for-next-project-Why-Postgres-of-course-22-2048.jpg)













































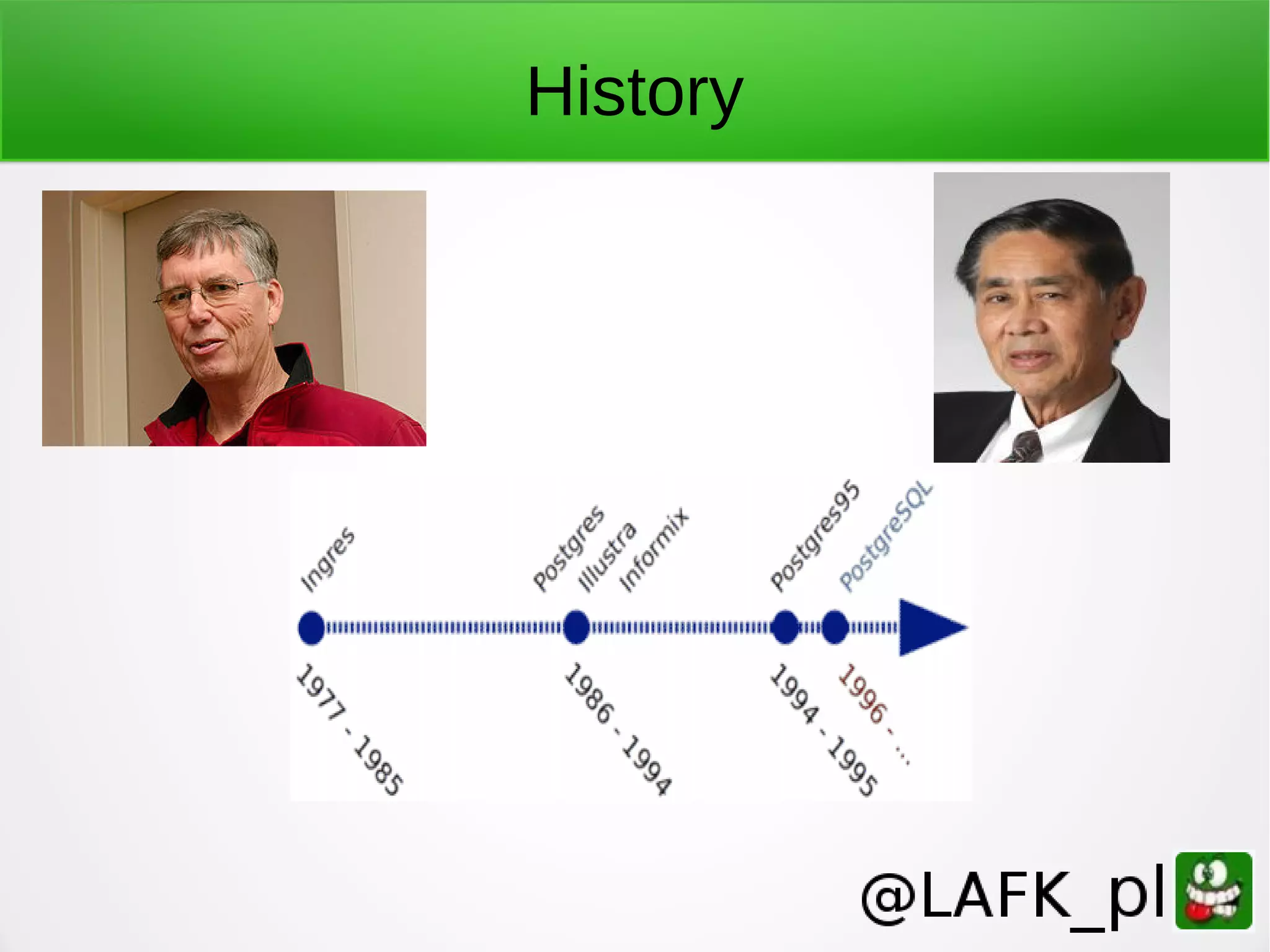
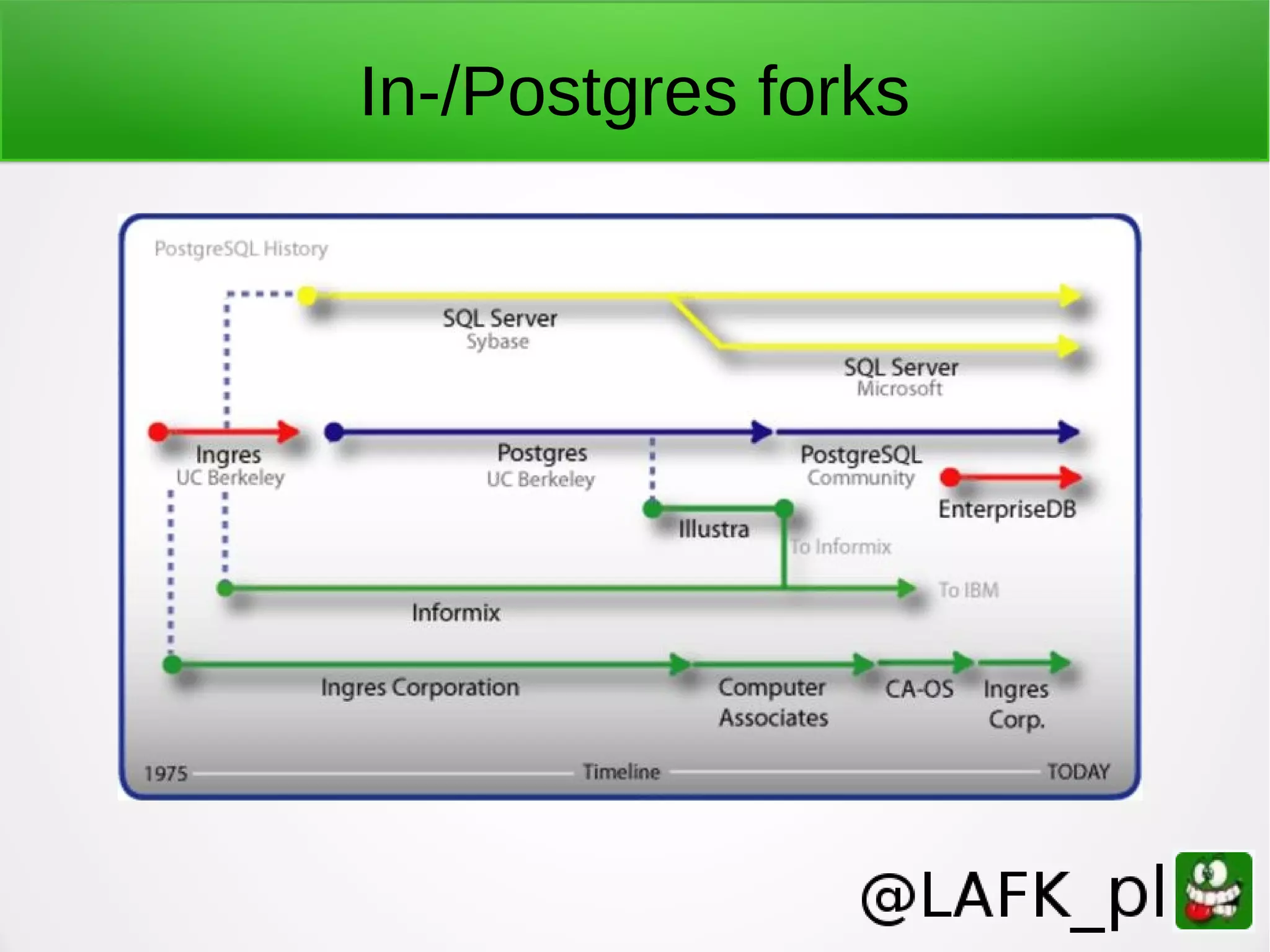
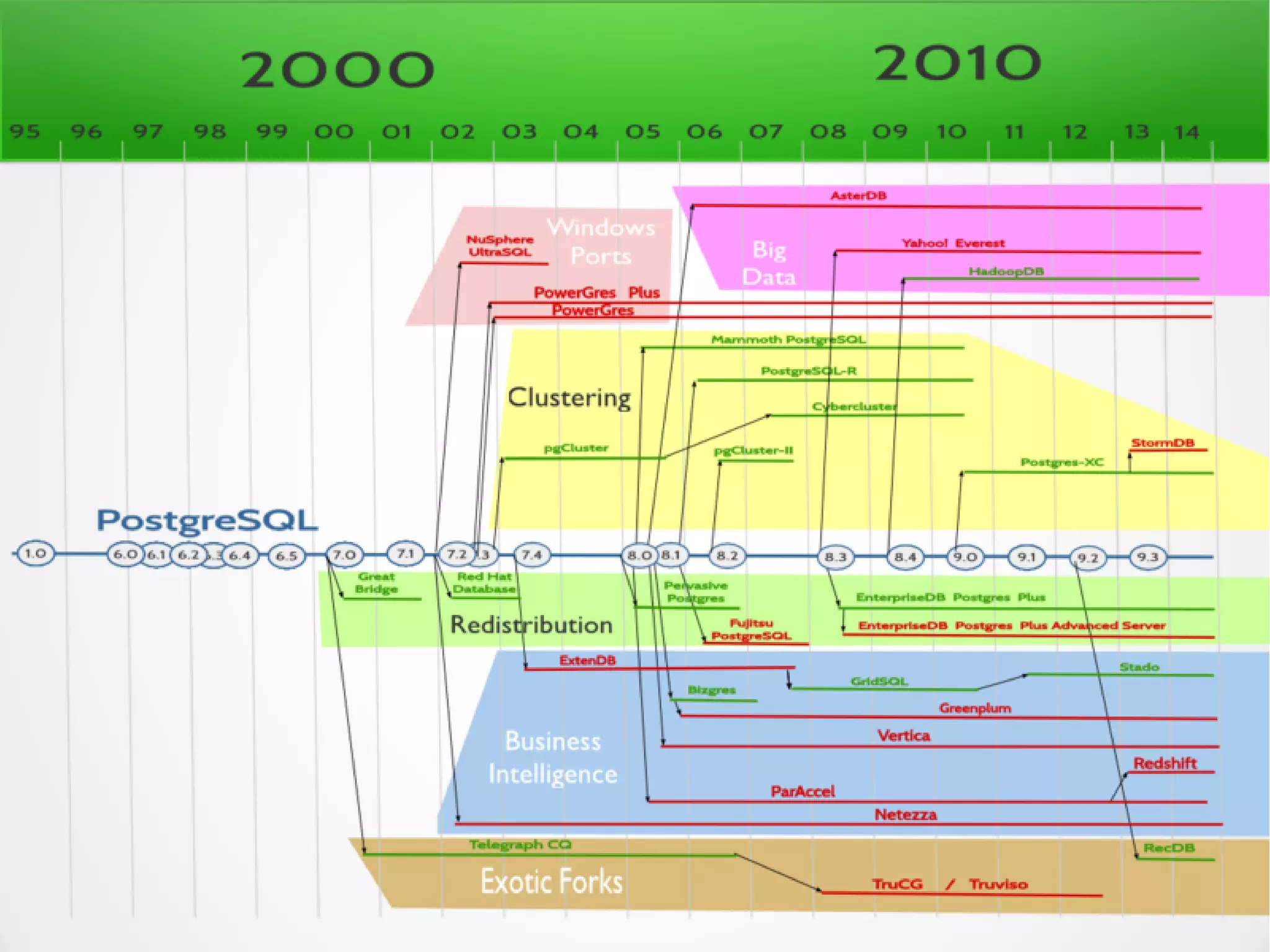
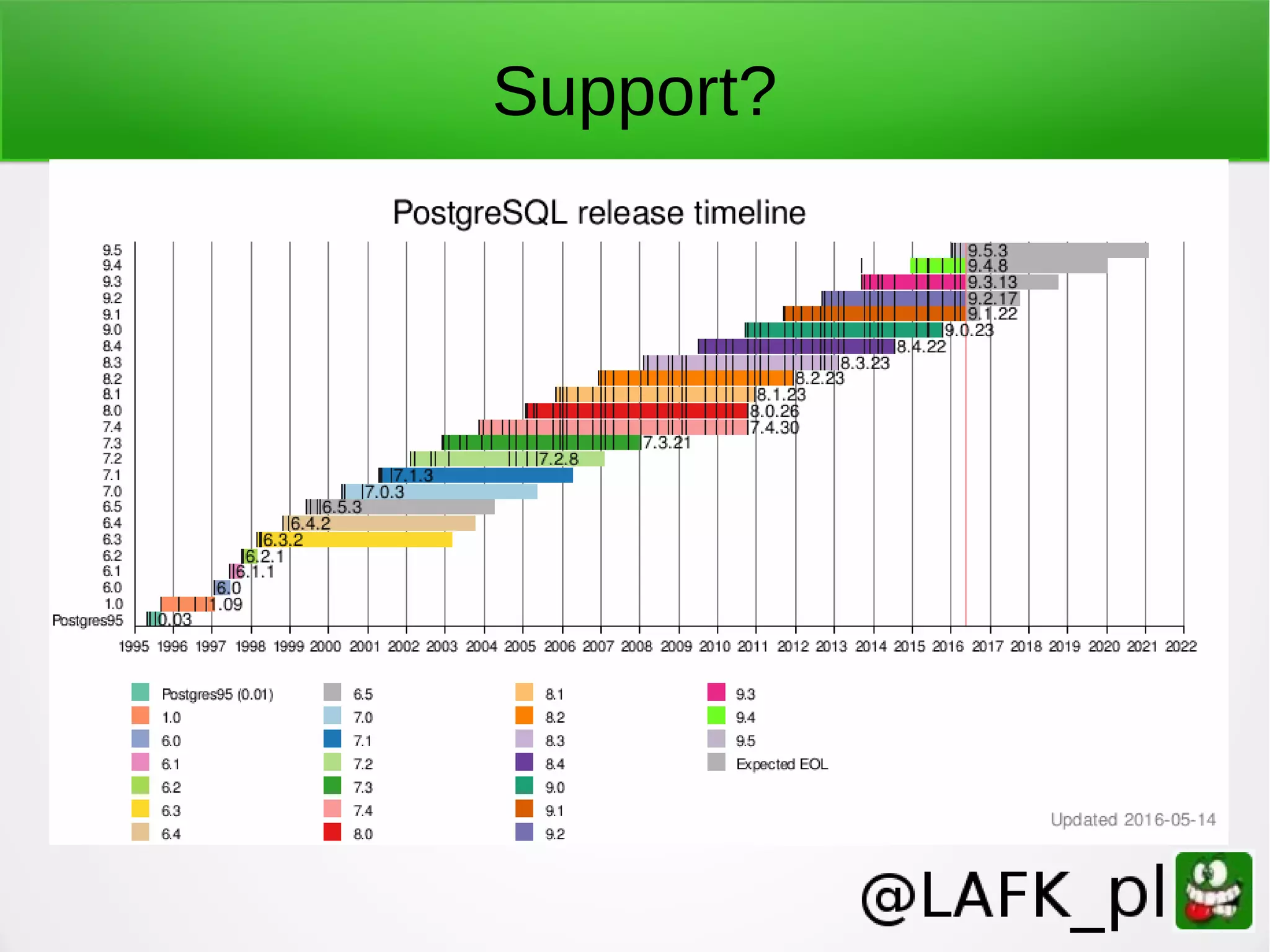
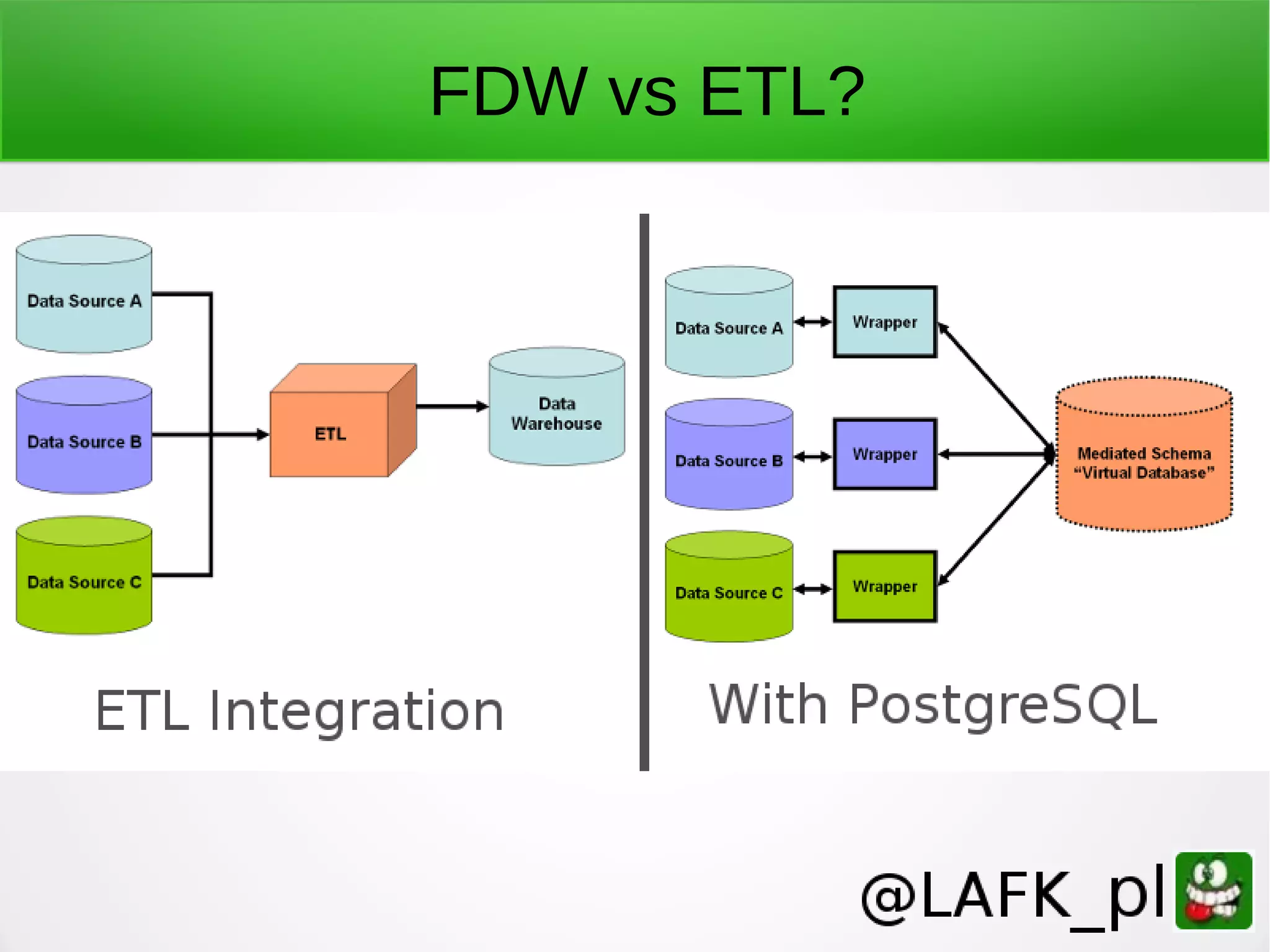
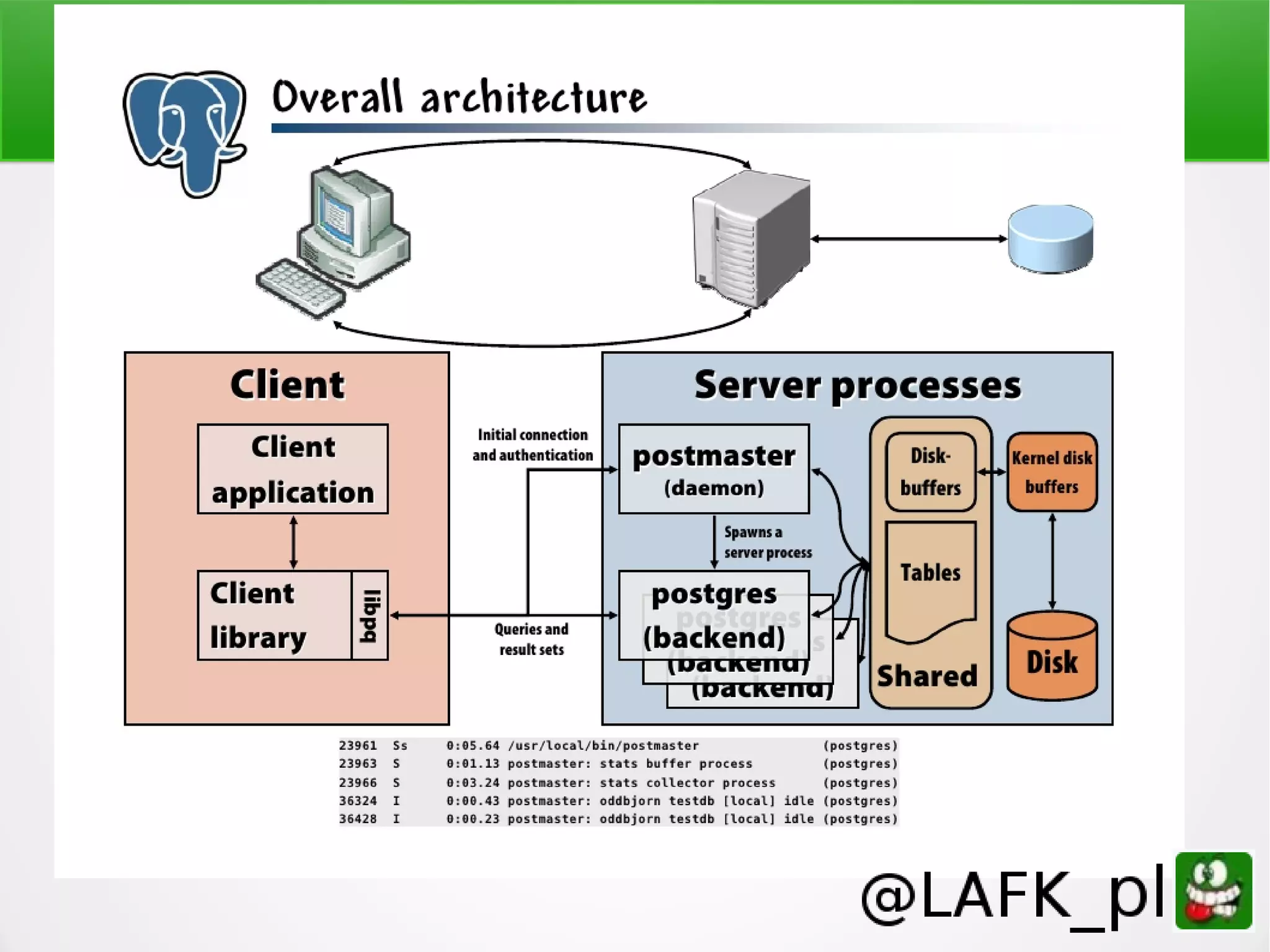
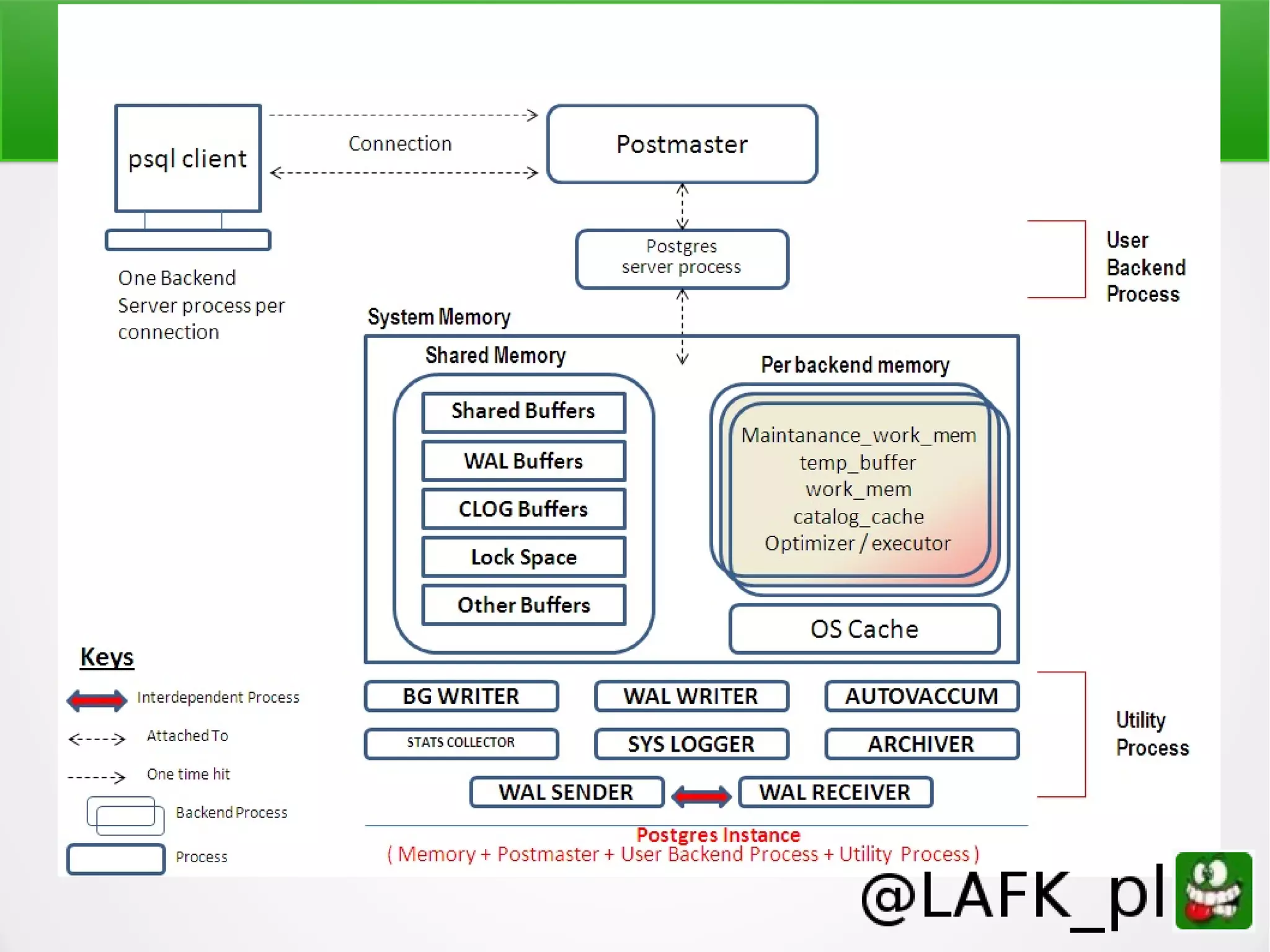
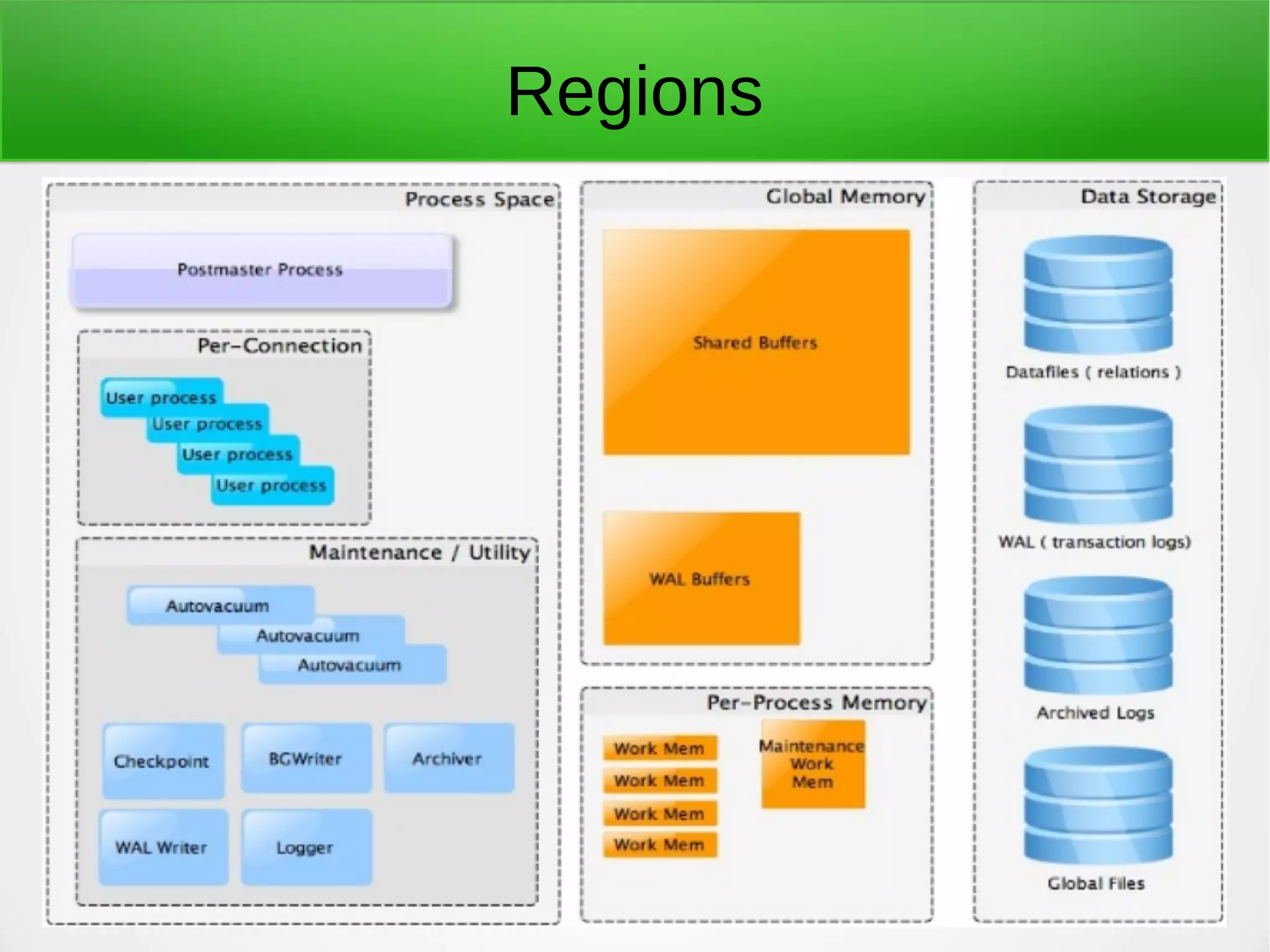
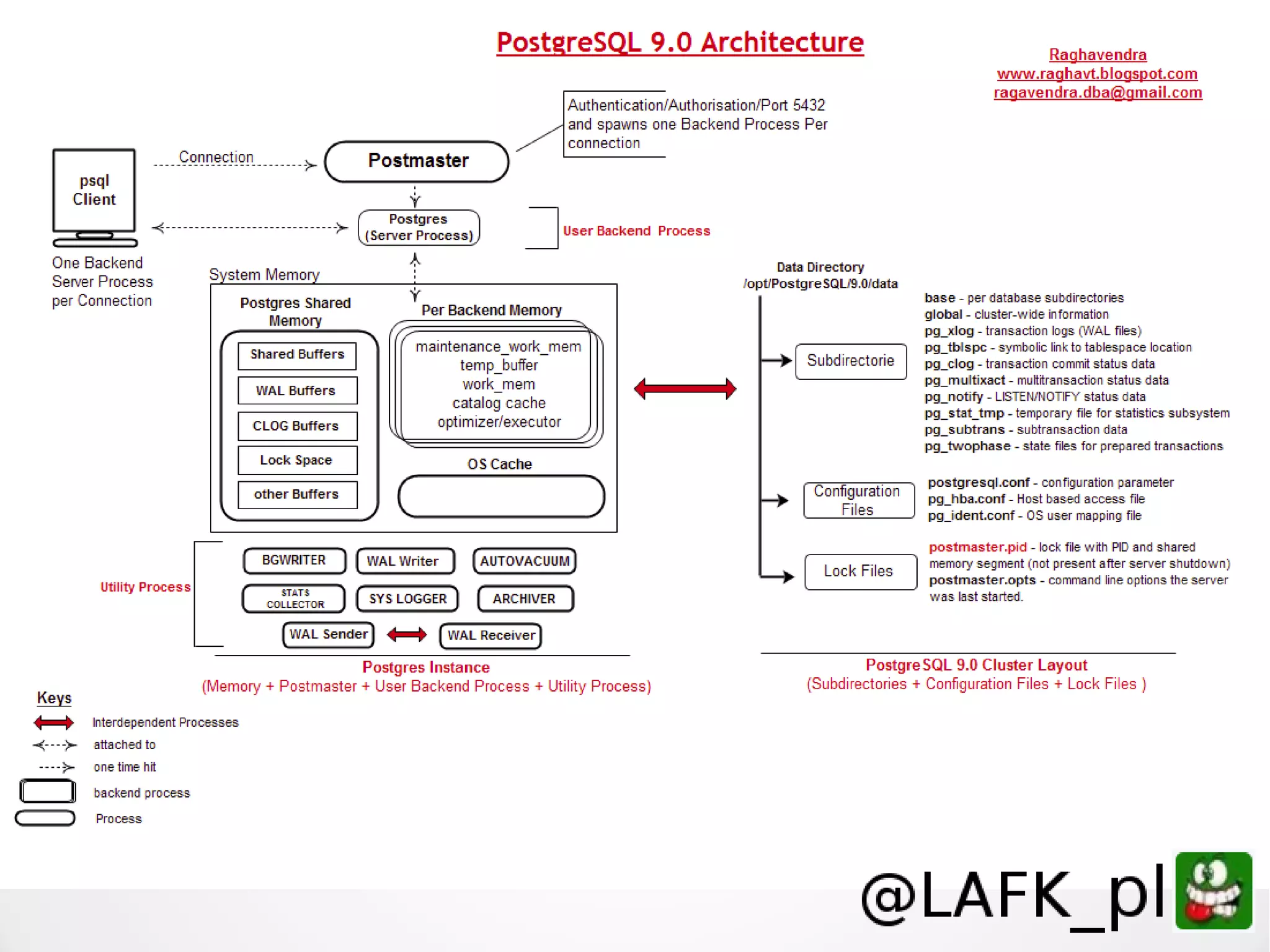
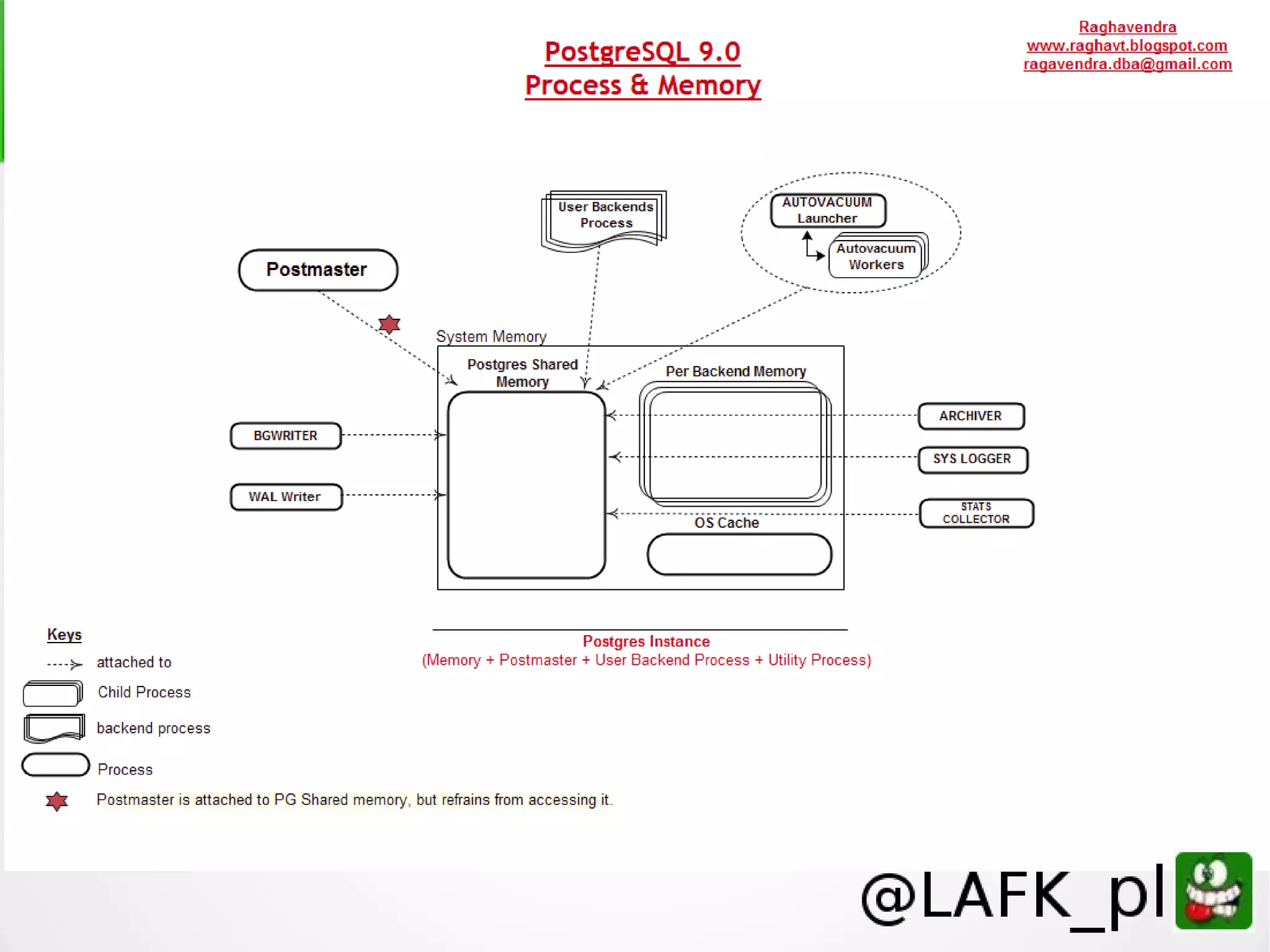
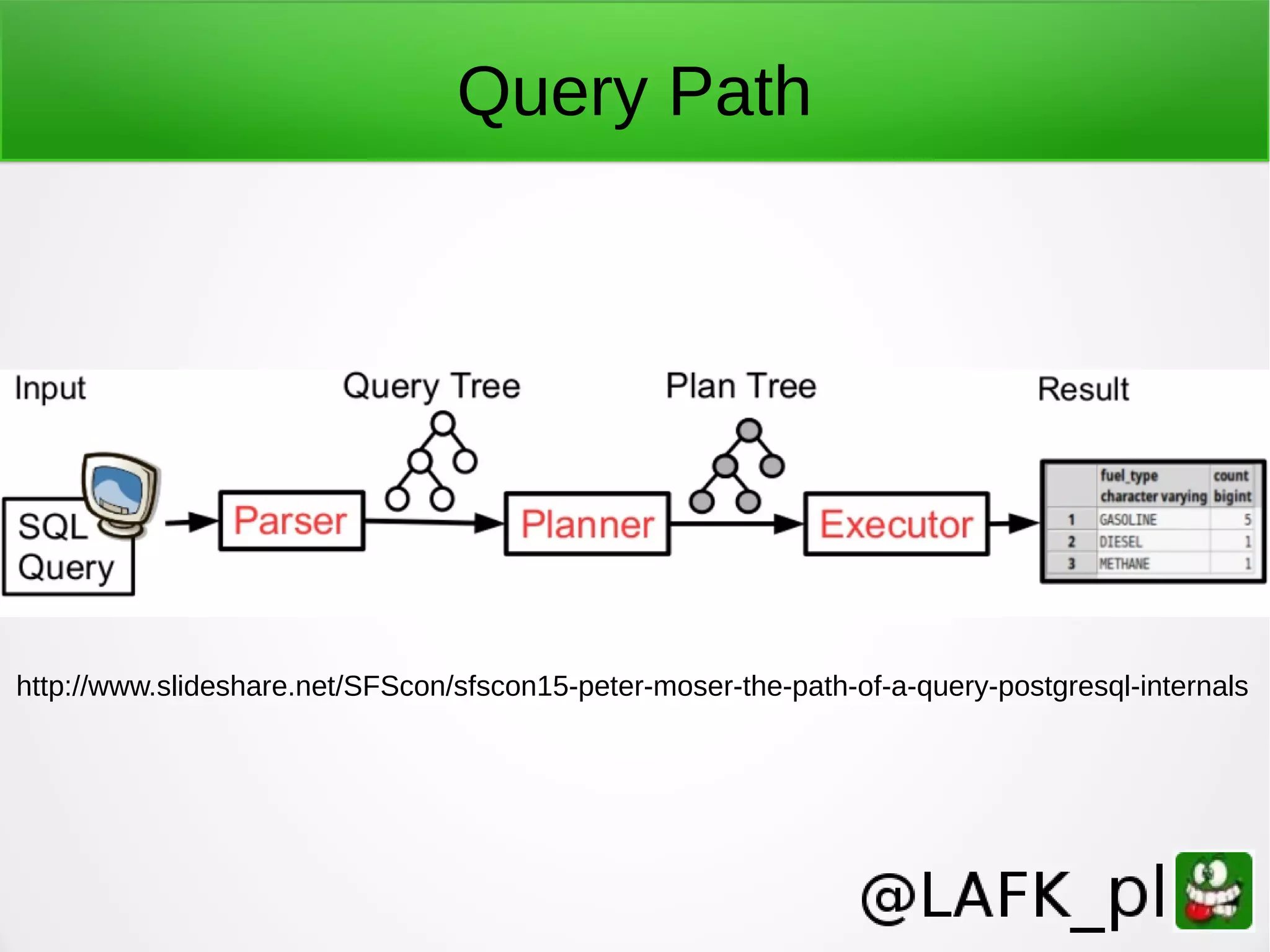
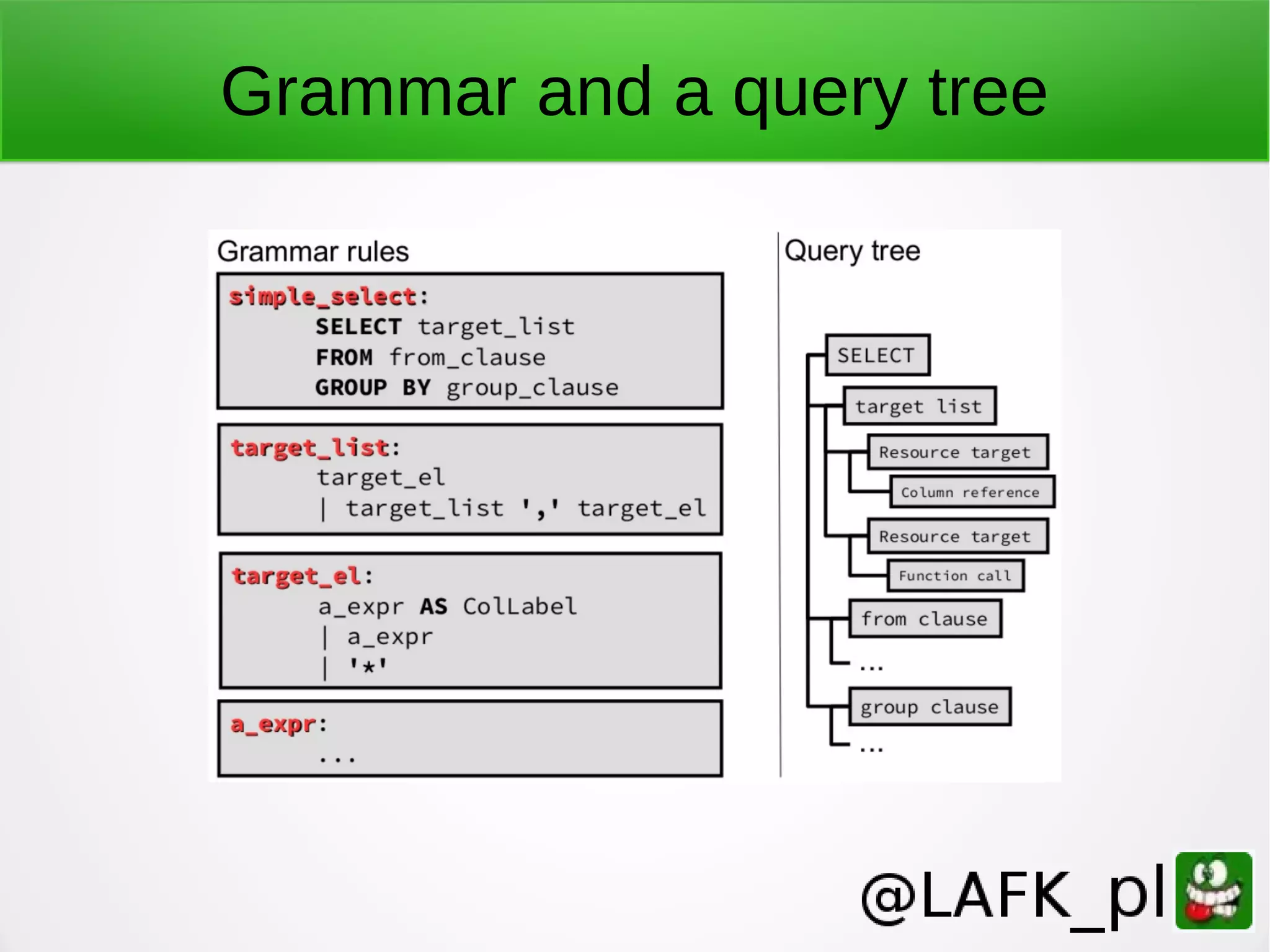
PostgreSQL is a battle-tested, open source database with a colorful history dating back to 1987. It has many advantages for a next project, including support for multiple programming languages for stored procedures, handling of XML and JSON, strong error reporting and logging, and window functions. It has a solid architecture with well-designed processes for handling write-ahead logs, statistics collection, and query optimization. While PostgreSQL has a learning curve, its longevity, stability, feature set and performance make it a great choice for many applications.




















































































