Download to read offline
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
Rachit Jain1, Samarth Joshi2
1,2B.Tech students, Department of Computer Science
Bharati Vidyapeeth’s College of Engineering, New Delhi, India
---------------------------------------------------------------------***---------------------------------------------------------------------
Abstract
Image captioning still remains a conundrum as it not only
focuses on extraction of the visual semantics of a given image
but also on combination techniques from the domain of
natural language processing. Various models capable of
captioning an image using the semantic features and the style
of the text corpus are unable to combine the visual semantics
of two different images being fed simultaneously. We propose
a novel methodology wherein multiple images sharingsimilar
context can be used to generate a single story/caption. Our
alignment model is based on a novel combination of
Convolutional Neural Networks over image regions,
bidirectional RecurrentNeuralNetworksoversentences, anda
structured objective that aligns the two modalities through
multimodal embedding. We, then describe a Multimodal
Recurrent Neural Network architecture that uses the inferred
alignments to learn to generate novel descriptions of image
regions. The paper encompasses on extracting the visual
semantics using existing deep learning architecture followed
by a pipeline of NLP model of skip thought vectors. This can be
further used along with a matrix of TF-IDFvaluesbasedonthe
text corpus extracted from various books. After training our
model, we extract and evaluate our vectors on semantic
readiness with linear models. The results compare two
different models- one based on TF-IDFmatrixvaluesandother
being skip thought vector representationof bagofwords, each
considering 2 grams at a time.
Key Words: visual semantics, natural language
processing,convolutionneural networks,imageregions,
recurrent neuralnetwork, multimodal embedding,deep
learning architecture, skip thought vectors, TF-IDF
values
1. INTRODUCTION
Describing an image is probably the easiest task for a human
being. This remarkable ability of humans to describe an
image just by looking at it canserve as a motivationforvisual
recognitionmodels.However,achievingremarkablyaccurate
results has proven to be an elusive task for a machine
learning model. The vocabularies of visual concept are more
convoluted as compared to the impeccable descriptions by
humans. The field of visual recognition has shown various
models that achieve feature extraction.
Ever since the starting of ImageNet challenge, there has
been an exponential increase in the Convolution
architecture that has beckoned the task of image
recognition as well as object detection. Plenty of work has
been done in visual recognition which focuses on labeling
of images with a fixed set of visual categories. The main
focus of these works has been to describe a compound
multiplex visual scenario in a single line sentence/caption.
These models can therefore be of immense significance in
describing the visualsemantics ofanimageinformofshort
sentences. Some pioneering approaches that address the
challenge of generating image descriptions have been
developed [1, 2]. However,thesemodelsoftenrelyonhard-
coded visual concepts and sentence templates, which
imposes limits on their variety. In this paper, we aim at
taking this task to the next level by combining the visual
descriptions into a single story (which shares the context
similar to the images it has seenattheinput).Wecombined
the two well-known architectures namely NeuralTalk2by
Andrej Karpathy for extracting image captions and Skip
thoughts, which is an unsupervised learning algorithm to
encode these captions. Neural talk 2 is trained on
Flicker8K,Flicker30Kand MSCOCO datasets whiletheskip
thoughts has a dataset of 16 different genres like romance,
fantasy, science fiction, teen, etc. The rest of the paper
includes a description of these architectures followed by
the approach used by us to combine the captions. We use
two approaches- TF-IDF matrix representation and Skip
thought vector representation and then compare the
results achieved.
2. INDIVIDUAL MODELS
We have used the hybrid model of two existing
architectures to generate and combine the annotations to
generatemeaningfulsentences.Inthefollowingsection,we
describe these two architectures followed by theapproach
used by us to combine these annotations in form of dense
vectors.
Image Captioning using Multimodal Embedding
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2504](https://image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-1-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
2.1 Neural Talk 2 [7]
There are two main contributions that this architecture has
provided. Firstly, development of a deep neural network
model that infers the latent alignment between segments of
sentences and the region of the image that they describe.
Secondly, introduction of a multimodal Recurrent Neural
Network architecture that takes an input image and
generates its description in text format.
This model takes a set of images as input and their
corresponding sentence descriptions (Figure 2). Firstly, it
presents an approach that aligns the sentence snippets to
the visual regions through a multimodal embedding. It
then treats these correspondences as training data for a
second multimodal Recurrent Neural Network model that
learns to generate the snippets.
As it is known that sentence descriptions make frequent
references to objectsand their attributes. Thus, it followsthe
method of Girshick et al. [5] to detect objects in every image
with a Region Convolutional Neural Network (RCNN). The
CNN is pre-trained on ImageNet [6] and fine-tuned on the
200 classes of the ImageNet Detection Challenge [4].
Following Karpathy et al. [3], we use the top 19 detected
locations in addition to the whole image and compute the
representations based on the pixels Ib inside each bounding
box as follows:
The above approach is simply a multilayer perceptron with
CNN layer consisting of nearly 60 million parameters. The
matrix Wm has dimensions h × 4096, where histhesizeofthe
multimodal embedding space (h ranges from 1000-1600 in
our experiments). Every image is thus represented as a setof
h-dimensional vectors {vi | i = 1 . . . 20}.
To address the part of intermodal relationship, it proposes a
Bidirectional Recurrent Neural Network (BRNN).
Using a sequence of N words (encoded in a 1-of-k
representation) it transformseachoneintoanh-dimensional
vector.
However, the representation of each word is enriched by a
variably-sizedcontextaroundthatword.Themathematical
representation of BRNN is as follows:
The BRNN consists of two independent streams of
processing, one moving left to right(ht
f )andtheotherright
to left (ht
b) (see Figure 3 for diagram). The final h-
dimensional representation st for the tth word is a function
of both the word at that location and its surrounding
context in the sentence. Now the objective is to focus at the
level of entire images and sentences to formulate an image-
sentence score as a function of the individual region-word
scores. Intuitively, a sentence-image pair should have a high
matching score if its words have a confident support in the
image. The model of Karpathy et a. [3] interprets the dot
product vi
T
* st between the ith
region and the tth word as a
measure of similarity and uses it to define the score
between image k and sentence l as follows:
Fig 1. A dataset of images andtheir sentencedescriptionsisgivenasinputandthemodelinferscorrespondencesand
learns to generate novel descriptions.
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2505](https://image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-2-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
It then computes a sequence of hidden states (h1…ht) anda
sequence of outputs (y1…yt) by iterating the following
recurrence relation for t = 1 to T:
Fig 2. Old Neural Talk2 Model
We can interpret the quantity * as the vi
T * st un-normalized
log probability of the tth worddescribing any of the bounding
boxes in the image. As the purpose is to annotate each
bounding box withasequenceofwordsitactuallyrepresents,
so it uses true alignment of these words asalatentvariablein
Markov Random Field (MRF). The MRF considers the binary
interaction between two neighboring words to be aligned in
the same region. Thus, it takes a sentence with N words and
an image with M bounding boxes and defines latent
alignment variables aj ∈ {1 . . . M} for j = 1 . . . N and formulate
an MRF in a chain structure along with the sentence.
Here, weuse β as a hyper-parameterthatcontrolstheaffinity
towards longer word phrases.
For captioning duringtraining,theMultimodalRNNtakesthe
image pixels I and a sequence of input vectors (x1 . . . xT). This
can be described as follows:
2.2 Skip-Thoughts
Skip-thoughts is basically an encoder-decoder framework
whose aim is to represent every sentenceasaskip-thought
vector in which encoder accepts a middle sentence and
then one decoder generates the previous sentence while
the other one generates the future (next) sentence for the
given middle sentence. Skip-thought vectors are used to
generate vectors for every sentence to know which
sentences are semantically similar. Once the model has
been trained, the vectorrepresentationofasentencecanbe
extracted from the learned encoder by inputting the
sequence of tokens that makes up the sentence. The
encoder-decoder model is composed of gated recurrent
units (GRUs) [9]. In order to get vector representation of
sentences, we have employed the already trained model
provided by kiros et al (2015) [8].
This pre-trained model creates a 4800 dimensional vector
for each sentence by concatenating the vector
representations from the uni-skip model and the bi-skip
model. Uni-skip model encodes the input tokens of a
sentence in their original order, and outputs a 2400
dimensional vector. This uni-skip model is unidirectional
encoder. The bi-skip model is a bidirectional model that
encodes the input tokens of a sentence in their original
order and in their reversed order, outputting a 1200
dimensional vector for each direction.
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2506](https://image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-3-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
The resemblance between two sentences is then computed
with the help of cosine similarity. Cosine similarity of both
the sentences is taken in order to get their vector
representations. This whole process is described as skip
thoughts.
2.3 TF-IDF Matrix
In this approach each sentence in a pair of sentences is
depicted as vector, where each dimension corresponds to a
word type. In TF-IDF, each dimension holds the TF-IDF
weight forthe correspondingtype inthesentence.IDFvalues
are calculated over a 2015 dump of English Wikipediafrom1
September 2015, which waspre-processed using wp2txt1to
remove markup. Then, the similarity between the two
sentences is calculated as the cosine between vectors
depicting them. The documents are tokenized using an
approach provided by Speriosu et al. (2011) [11] — the text
is first split based on whitespace; for each token,ifitcontains
at least one alphanumeric character, then all leading and
trailing non-alphanumeric characters are stripped. Stop
words are removed based ona stopwordlistandcasefolding
is applied [10].
3. ALGORITHM AND FLOWCHART
We combined Neuraltalk2 architecture with the two
approaches mentioned above:
(i) Skip Thought Vector Matrix
(ii) TF-IDF Matrix
As each of the caption generated by the first model captures
the dense representation of the images, we can use the skip
thought vector of the corresponding sentences to generate
the context being used in them. Each of the vector
representing one sentence is converted to skip thought
vector and arranged along the rows of the matrices and
henceforth keeping the word values filled whereas keeping
the other values as zeroes (Sparse matrix). The generated
matrix is then combined with the matrix generated using the
training phase of the language model. The dot product gives
the cosine similarity between the two and thusactivatingthe
words that are similar in context of the combined sentences.
Similarly we evaluate TF-IDF matrix with the language
model to get the resultant matrix. The finalsentenceisthus
accumulated using the log likelihood probability of each
words from the bag of wordsconsidering n-words(n=3)at
a time.
Fig 3. Flowchart of our model
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2507](https://image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-4-2048.jpg)
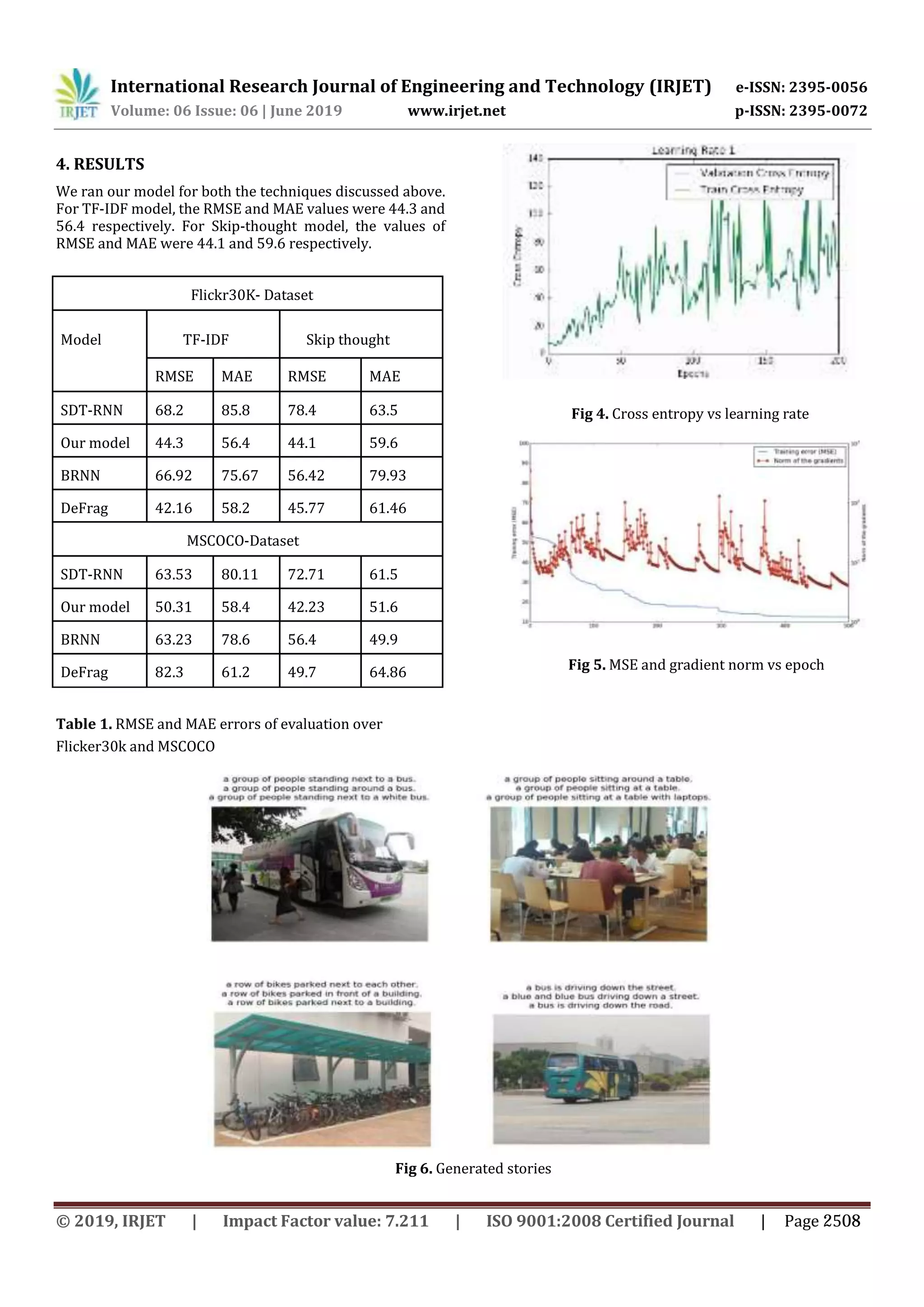
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
5. CONCLUSION
The best results were obtained using the skip thought vector
approach (to represent two sentencesandfurthercombining
them using semantic relatedness- Cosine similarity). We
further aim at improving our model by using the fluid
segmentation technique which is the current state-of-the-art
algorithm for image recognition. The applications of this
model are manifold. Itcan help in generatingreportsofcrime
investigations, automating notes generation from video
lectures, helping the patients of autism in medical diagnosis,
medical imaging and many more.
6. REFERENCES
[1] A. Farhadi, M. Hejrati, M. A. Sadeghi, P. Young, C.
Rashtchian, J. Hockenmaier, and D. Forsyth. Every picture
tells a story: Generating sentences from images. In ECCV.
2010.
[2] G. Kulkarni, V. Premraj, S.Dhar, S. Li, Y.Choi,A.C.Bergand
T. L. Berg. Baby talk: Understanding and generating simple
image descriptions. In CVPR, 2011.
[3] A. Karpathy, A. Joulin, and L. Fei-Fei. Deep fragment
embeddings forbidirectional image sentencemapping.arXiv
preprint arXiv:1406.5679, 2014.
[4] O. Russakovsky, J. Deng, H. Su, J. Krause,S.Satheesh,S.Ma,
Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg,
and L. Fei-Fei. Imagenet large scale visual recognition
challenge, 2014.
[5] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich
feature hierarchies for accurate object detection and
semantic segmentation. In CVPR, 2014.
[6] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei.
Imagenet: Alarge-scalehierarchicalimagedatabase.InCVPR,
2009.
[7] Karpathy, A., & Johnson, J. (2015). Neuraltalk2.
[8] Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard
S. Zemel, Antonio Torralba, Raquel Urtasun, and Sanja
Fidler. 2015. Skip-thought vectors. In C. Cortes, N. D.
Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors,
Advances in Neural Information Processing Systems 28,
Curran Associates, Inc., pages 3276–3284.
[9] Kyunghyun Cho, Bart van Merrienboer, Dzmitry ¨
Bahdanau, and Yoshua Bengio. 2014. on the properties of
neural machinetranslation:Encoder–decoderapproaches.
In Proceedings of SSST-8, Eighth Workshop on Syntax,
Semantics and Structure in Statistical Translation. Doha,
Qatar, pages 103–111.
[10] King, M., Gharbieh, W., Park, S., & Cook, P. (2016).
UNBNLP at SemEval-2016 Task 1: Semantic Textual
Similarity: A Unified Framework for Semantic Processing
and Evaluation. In Proceedings of the 10th International
Workshop on Semantic Evaluation (SemEval-2016) (pp.
732-735).
[11] Michael Speriosu, Nikita Sudan, Sid Upadhyay, and
Jason Baldridge. 2011. Twitter polarity classification with
label propagation over lexical links and the followergraph.
In Proceedings of the First workshop on Unsupervised
Learning in NLP. Edinburgh, Scotland, pages 53–63.
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2509](https://image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-6-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
Rachit Jain1, Samarth Joshi2
1,2B.Tech students, Department of Computer Science
Bharati Vidyapeeth’s College of Engineering, New Delhi, India
---------------------------------------------------------------------***---------------------------------------------------------------------
Abstract
Image captioning still remains a conundrum as it not only
focuses on extraction of the visual semantics of a given image
but also on combination techniques from the domain of
natural language processing. Various models capable of
captioning an image using the semantic features and the style
of the text corpus are unable to combine the visual semantics
of two different images being fed simultaneously. We propose
a novel methodology wherein multiple images sharingsimilar
context can be used to generate a single story/caption. Our
alignment model is based on a novel combination of
Convolutional Neural Networks over image regions,
bidirectional RecurrentNeuralNetworksoversentences, anda
structured objective that aligns the two modalities through
multimodal embedding. We, then describe a Multimodal
Recurrent Neural Network architecture that uses the inferred
alignments to learn to generate novel descriptions of image
regions. The paper encompasses on extracting the visual
semantics using existing deep learning architecture followed
by a pipeline of NLP model of skip thought vectors. This can be
further used along with a matrix of TF-IDFvaluesbasedonthe
text corpus extracted from various books. After training our
model, we extract and evaluate our vectors on semantic
readiness with linear models. The results compare two
different models- one based on TF-IDFmatrixvaluesandother
being skip thought vector representationof bagofwords, each
considering 2 grams at a time.
Key Words: visual semantics, natural language
processing,convolutionneural networks,imageregions,
recurrent neuralnetwork, multimodal embedding,deep
learning architecture, skip thought vectors, TF-IDF
values
1. INTRODUCTION
Describing an image is probably the easiest task for a human
being. This remarkable ability of humans to describe an
image just by looking at it canserve as a motivationforvisual
recognitionmodels.However,achievingremarkablyaccurate
results has proven to be an elusive task for a machine
learning model. The vocabularies of visual concept are more
convoluted as compared to the impeccable descriptions by
humans. The field of visual recognition has shown various
models that achieve feature extraction.
Ever since the starting of ImageNet challenge, there has
been an exponential increase in the Convolution
architecture that has beckoned the task of image
recognition as well as object detection. Plenty of work has
been done in visual recognition which focuses on labeling
of images with a fixed set of visual categories. The main
focus of these works has been to describe a compound
multiplex visual scenario in a single line sentence/caption.
These models can therefore be of immense significance in
describing the visualsemantics ofanimageinformofshort
sentences. Some pioneering approaches that address the
challenge of generating image descriptions have been
developed [1, 2]. However,thesemodelsoftenrelyonhard-
coded visual concepts and sentence templates, which
imposes limits on their variety. In this paper, we aim at
taking this task to the next level by combining the visual
descriptions into a single story (which shares the context
similar to the images it has seenattheinput).Wecombined
the two well-known architectures namely NeuralTalk2by
Andrej Karpathy for extracting image captions and Skip
thoughts, which is an unsupervised learning algorithm to
encode these captions. Neural talk 2 is trained on
Flicker8K,Flicker30Kand MSCOCO datasets whiletheskip
thoughts has a dataset of 16 different genres like romance,
fantasy, science fiction, teen, etc. The rest of the paper
includes a description of these architectures followed by
the approach used by us to combine the captions. We use
two approaches- TF-IDF matrix representation and Skip
thought vector representation and then compare the
results achieved.
2. INDIVIDUAL MODELS
We have used the hybrid model of two existing
architectures to generate and combine the annotations to
generatemeaningfulsentences.Inthefollowingsection,we
describe these two architectures followed by theapproach
used by us to combine these annotations in form of dense
vectors.
Image Captioning using Multimodal Embedding
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2504](https://crownmelresort.com/image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-1-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
2.1 Neural Talk 2 [7]
There are two main contributions that this architecture has
provided. Firstly, development of a deep neural network
model that infers the latent alignment between segments of
sentences and the region of the image that they describe.
Secondly, introduction of a multimodal Recurrent Neural
Network architecture that takes an input image and
generates its description in text format.
This model takes a set of images as input and their
corresponding sentence descriptions (Figure 2). Firstly, it
presents an approach that aligns the sentence snippets to
the visual regions through a multimodal embedding. It
then treats these correspondences as training data for a
second multimodal Recurrent Neural Network model that
learns to generate the snippets.
As it is known that sentence descriptions make frequent
references to objectsand their attributes. Thus, it followsthe
method of Girshick et al. [5] to detect objects in every image
with a Region Convolutional Neural Network (RCNN). The
CNN is pre-trained on ImageNet [6] and fine-tuned on the
200 classes of the ImageNet Detection Challenge [4].
Following Karpathy et al. [3], we use the top 19 detected
locations in addition to the whole image and compute the
representations based on the pixels Ib inside each bounding
box as follows:
The above approach is simply a multilayer perceptron with
CNN layer consisting of nearly 60 million parameters. The
matrix Wm has dimensions h × 4096, where histhesizeofthe
multimodal embedding space (h ranges from 1000-1600 in
our experiments). Every image is thus represented as a setof
h-dimensional vectors {vi | i = 1 . . . 20}.
To address the part of intermodal relationship, it proposes a
Bidirectional Recurrent Neural Network (BRNN).
Using a sequence of N words (encoded in a 1-of-k
representation) it transformseachoneintoanh-dimensional
vector.
However, the representation of each word is enriched by a
variably-sizedcontextaroundthatword.Themathematical
representation of BRNN is as follows:
The BRNN consists of two independent streams of
processing, one moving left to right(ht
f )andtheotherright
to left (ht
b) (see Figure 3 for diagram). The final h-
dimensional representation st for the tth word is a function
of both the word at that location and its surrounding
context in the sentence. Now the objective is to focus at the
level of entire images and sentences to formulate an image-
sentence score as a function of the individual region-word
scores. Intuitively, a sentence-image pair should have a high
matching score if its words have a confident support in the
image. The model of Karpathy et a. [3] interprets the dot
product vi
T
* st between the ith
region and the tth word as a
measure of similarity and uses it to define the score
between image k and sentence l as follows:
Fig 1. A dataset of images andtheir sentencedescriptionsisgivenasinputandthemodelinferscorrespondencesand
learns to generate novel descriptions.
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2505](https://crownmelresort.com/image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-2-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
It then computes a sequence of hidden states (h1…ht) anda
sequence of outputs (y1…yt) by iterating the following
recurrence relation for t = 1 to T:
Fig 2. Old Neural Talk2 Model
We can interpret the quantity * as the vi
T * st un-normalized
log probability of the tth worddescribing any of the bounding
boxes in the image. As the purpose is to annotate each
bounding box withasequenceofwordsitactuallyrepresents,
so it uses true alignment of these words asalatentvariablein
Markov Random Field (MRF). The MRF considers the binary
interaction between two neighboring words to be aligned in
the same region. Thus, it takes a sentence with N words and
an image with M bounding boxes and defines latent
alignment variables aj ∈ {1 . . . M} for j = 1 . . . N and formulate
an MRF in a chain structure along with the sentence.
Here, weuse β as a hyper-parameterthatcontrolstheaffinity
towards longer word phrases.
For captioning duringtraining,theMultimodalRNNtakesthe
image pixels I and a sequence of input vectors (x1 . . . xT). This
can be described as follows:
2.2 Skip-Thoughts
Skip-thoughts is basically an encoder-decoder framework
whose aim is to represent every sentenceasaskip-thought
vector in which encoder accepts a middle sentence and
then one decoder generates the previous sentence while
the other one generates the future (next) sentence for the
given middle sentence. Skip-thought vectors are used to
generate vectors for every sentence to know which
sentences are semantically similar. Once the model has
been trained, the vectorrepresentationofasentencecanbe
extracted from the learned encoder by inputting the
sequence of tokens that makes up the sentence. The
encoder-decoder model is composed of gated recurrent
units (GRUs) [9]. In order to get vector representation of
sentences, we have employed the already trained model
provided by kiros et al (2015) [8].
This pre-trained model creates a 4800 dimensional vector
for each sentence by concatenating the vector
representations from the uni-skip model and the bi-skip
model. Uni-skip model encodes the input tokens of a
sentence in their original order, and outputs a 2400
dimensional vector. This uni-skip model is unidirectional
encoder. The bi-skip model is a bidirectional model that
encodes the input tokens of a sentence in their original
order and in their reversed order, outputting a 1200
dimensional vector for each direction.
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2506](https://crownmelresort.com/image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-3-2048.jpg)
![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
The resemblance between two sentences is then computed
with the help of cosine similarity. Cosine similarity of both
the sentences is taken in order to get their vector
representations. This whole process is described as skip
thoughts.
2.3 TF-IDF Matrix
In this approach each sentence in a pair of sentences is
depicted as vector, where each dimension corresponds to a
word type. In TF-IDF, each dimension holds the TF-IDF
weight forthe correspondingtype inthesentence.IDFvalues
are calculated over a 2015 dump of English Wikipediafrom1
September 2015, which waspre-processed using wp2txt1to
remove markup. Then, the similarity between the two
sentences is calculated as the cosine between vectors
depicting them. The documents are tokenized using an
approach provided by Speriosu et al. (2011) [11] — the text
is first split based on whitespace; for each token,ifitcontains
at least one alphanumeric character, then all leading and
trailing non-alphanumeric characters are stripped. Stop
words are removed based ona stopwordlistandcasefolding
is applied [10].
3. ALGORITHM AND FLOWCHART
We combined Neuraltalk2 architecture with the two
approaches mentioned above:
(i) Skip Thought Vector Matrix
(ii) TF-IDF Matrix
As each of the caption generated by the first model captures
the dense representation of the images, we can use the skip
thought vector of the corresponding sentences to generate
the context being used in them. Each of the vector
representing one sentence is converted to skip thought
vector and arranged along the rows of the matrices and
henceforth keeping the word values filled whereas keeping
the other values as zeroes (Sparse matrix). The generated
matrix is then combined with the matrix generated using the
training phase of the language model. The dot product gives
the cosine similarity between the two and thusactivatingthe
words that are similar in context of the combined sentences.
Similarly we evaluate TF-IDF matrix with the language
model to get the resultant matrix. The finalsentenceisthus
accumulated using the log likelihood probability of each
words from the bag of wordsconsidering n-words(n=3)at
a time.
Fig 3. Flowchart of our model
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2507](https://crownmelresort.com/image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-4-2048.jpg)

![International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056
Volume: 06 Issue: 06 | June 2019 www.irjet.net p-ISSN: 2395-0072
5. CONCLUSION
The best results were obtained using the skip thought vector
approach (to represent two sentencesandfurthercombining
them using semantic relatedness- Cosine similarity). We
further aim at improving our model by using the fluid
segmentation technique which is the current state-of-the-art
algorithm for image recognition. The applications of this
model are manifold. Itcan help in generatingreportsofcrime
investigations, automating notes generation from video
lectures, helping the patients of autism in medical diagnosis,
medical imaging and many more.
6. REFERENCES
[1] A. Farhadi, M. Hejrati, M. A. Sadeghi, P. Young, C.
Rashtchian, J. Hockenmaier, and D. Forsyth. Every picture
tells a story: Generating sentences from images. In ECCV.
2010.
[2] G. Kulkarni, V. Premraj, S.Dhar, S. Li, Y.Choi,A.C.Bergand
T. L. Berg. Baby talk: Understanding and generating simple
image descriptions. In CVPR, 2011.
[3] A. Karpathy, A. Joulin, and L. Fei-Fei. Deep fragment
embeddings forbidirectional image sentencemapping.arXiv
preprint arXiv:1406.5679, 2014.
[4] O. Russakovsky, J. Deng, H. Su, J. Krause,S.Satheesh,S.Ma,
Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg,
and L. Fei-Fei. Imagenet large scale visual recognition
challenge, 2014.
[5] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich
feature hierarchies for accurate object detection and
semantic segmentation. In CVPR, 2014.
[6] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei.
Imagenet: Alarge-scalehierarchicalimagedatabase.InCVPR,
2009.
[7] Karpathy, A., & Johnson, J. (2015). Neuraltalk2.
[8] Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard
S. Zemel, Antonio Torralba, Raquel Urtasun, and Sanja
Fidler. 2015. Skip-thought vectors. In C. Cortes, N. D.
Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors,
Advances in Neural Information Processing Systems 28,
Curran Associates, Inc., pages 3276–3284.
[9] Kyunghyun Cho, Bart van Merrienboer, Dzmitry ¨
Bahdanau, and Yoshua Bengio. 2014. on the properties of
neural machinetranslation:Encoder–decoderapproaches.
In Proceedings of SSST-8, Eighth Workshop on Syntax,
Semantics and Structure in Statistical Translation. Doha,
Qatar, pages 103–111.
[10] King, M., Gharbieh, W., Park, S., & Cook, P. (2016).
UNBNLP at SemEval-2016 Task 1: Semantic Textual
Similarity: A Unified Framework for Semantic Processing
and Evaluation. In Proceedings of the 10th International
Workshop on Semantic Evaluation (SemEval-2016) (pp.
732-735).
[11] Michael Speriosu, Nikita Sudan, Sid Upadhyay, and
Jason Baldridge. 2011. Twitter polarity classification with
label propagation over lexical links and the followergraph.
In Proceedings of the First workshop on Unsupervised
Learning in NLP. Edinburgh, Scotland, pages 53–63.
© 2019, IRJET | Impact Factor value: 7.211 | ISO 9001:2008 Certified Journal | Page 2509](https://crownmelresort.com/image.slidesharecdn.com/irjet-v6i6523-191209061109/75/IRJET-Image-Captioning-using-Multimodal-Embedding-6-2048.jpg)

This document proposes a novel methodology to generate a single story or caption from multiple images that share similar context. It combines existing image captioning and natural language processing models. Specifically, it uses a Convolutional Neural Network to extract visual semantics from images and generate captions. It then represents the captions as vectors using Skip Thought vectors or TF-IDF values. These vectors are combined into a matrix and used to generate a new story/caption that shares the context of the input images. The results show that the Skip Thought vector approach achieves better performance based on RMSE and MAE error metrics. The model could potentially be applied to applications like medical diagnosis, crime investigations, and lecture note generation.

















![[Ris cy business]](https://cdn.slidesharecdn.com/ss_thumbnails/riscybusiness-130329140828-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


























































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)










