“Data” refers toanything that can be recorded or
measured.
• Data can be
• raw numbers (like stock prices on successive days, the mass of different
planets, the heights of people visiting a county fair).
• sounds (the words someone speaks into their cell phone),
• pictures (photographs of flowers or cats),
• words (the text of a newspaper article or a novel),
• or anything else that we want to investigate.
• “Meaningful information” is whatever we can extract from the data
that will be useful to us in some way.
• We decide what’s meaningful to us, and then we design an algorithm
to find as much of it as possible from our data.
4.
What’s machine learning?
•The phrase “machine learning” describes a wide diversity of
algorithms and techniques.
• It’s used by so many people in so many different ways that it’s best to
consider it as:
A big, expanding collection of algorithms and principles that
analyze vast quantities of training data in order to extract
meaning from it.
5.
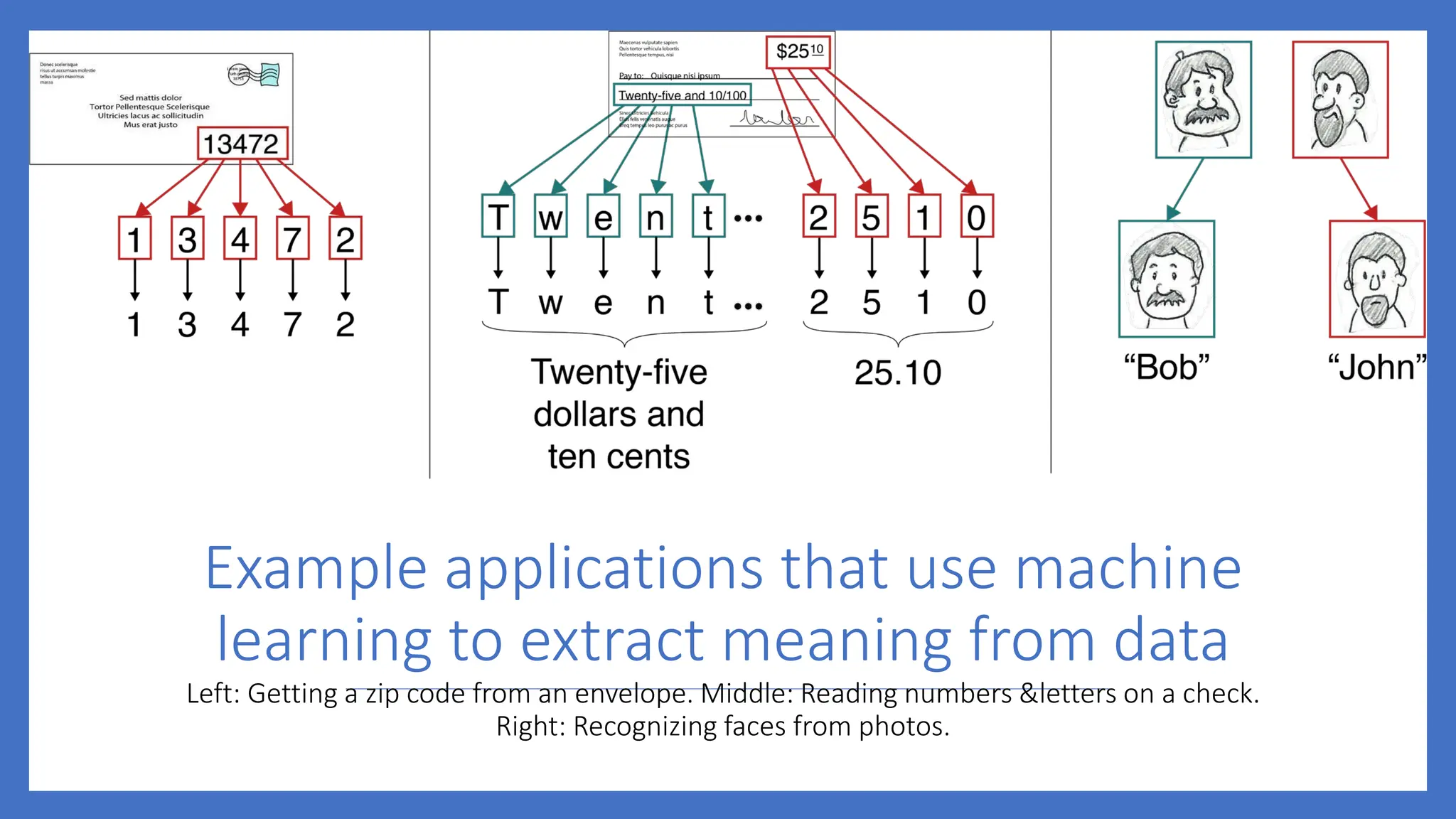
Example applications thatuse machine
learning to extract meaning from data
Left: Getting a zip code from an envelope. Middle: Reading numbers &letters on a check.
Right: Recognizing faces from photos.
6.
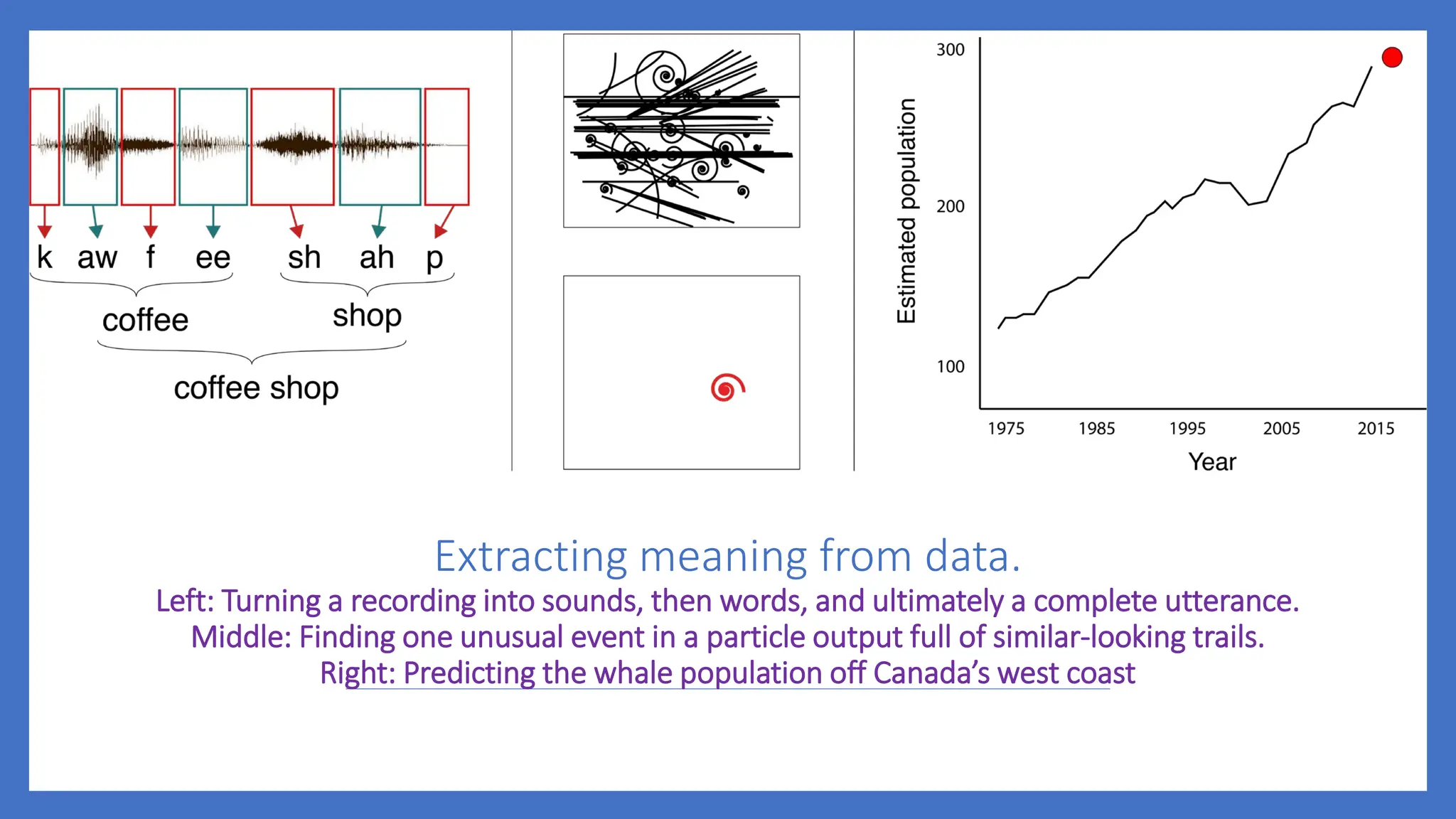
Extracting meaning fromdata.
Left: Turning a recording into sounds, then words, and ultimately a complete utterance.
Middle: Finding one unusual event in a particle output full of similar-looking trails.
Right: Predicting the whale population off Canada’s west coast
7.
Common threads inML applications
• Sheer volume of work involved, and its painstaking detail.
• We have millions of data to examine, and we want to extract some meaning from
every one of them.
• Why can’t humans do it ?
• Humans get tired, bored, and distracted,
• What about Computers?
• computers just plow on steadily and reliably.
ML has ability to extract meaningful information quickly, so are
used in many fields.
8.
Expert systems canalso find meaning from data
• Expert systems was an early approach to finding the meaning that’s hiding
inside of data.
• Idea:
• Study what human experts know and automate that.
• Make a computer mimic the human experts it was based on.
• Create a rule-based system: a large number of rules for the computer to
imitate human experts.
• Example: Recognize zip codes. 7’s have a horizontal line at the top, and a
diagonal line that starts at the right edge of the horizontal line and moves
left and down. Some people put a bar through the middle of their 7’s. So
now we add another rule for that special case.
9.
But handcrafting rulesis a tough job!
• This process of hand-crafting the rules to understand data is called
feature engineering
• term is also used to describe when we use the computer to find these
features for us.
• It’s easy to overlook one rule, or even lots of them. It's a tough job !
10.
How does MLcompare with Expert systems?
• Expert Systems: Difficult to manually find right set of rules, & make
sure they work properly across a wide variety of data. This difficulties
have doomed expert systems.
• ML Systems: Beauty is they learn a dataset’s characteristics
automatically.
• Don’t have to tell an algorithm how to recognize a cat or dog, because system
figures that out for itself.
• Flip side of ML: To do its job well, ML system often needs a lot of
data. Enormous amounts of data.
11.
Why recent explosionin ML ?
• Why has machine learning has exploded in popularity and
applications in the last few years?
• Couple of big reasons:
A. Flood of data: provided by the Internet has let these tools extract a
lot of meaning from a lot of data.
Example: Online companies make use of every interaction with every customer to
accumulate more data. Then they use it as input to ML algorithms, getting more
information about customers.
B. Increased Computing power - GPUs
12.
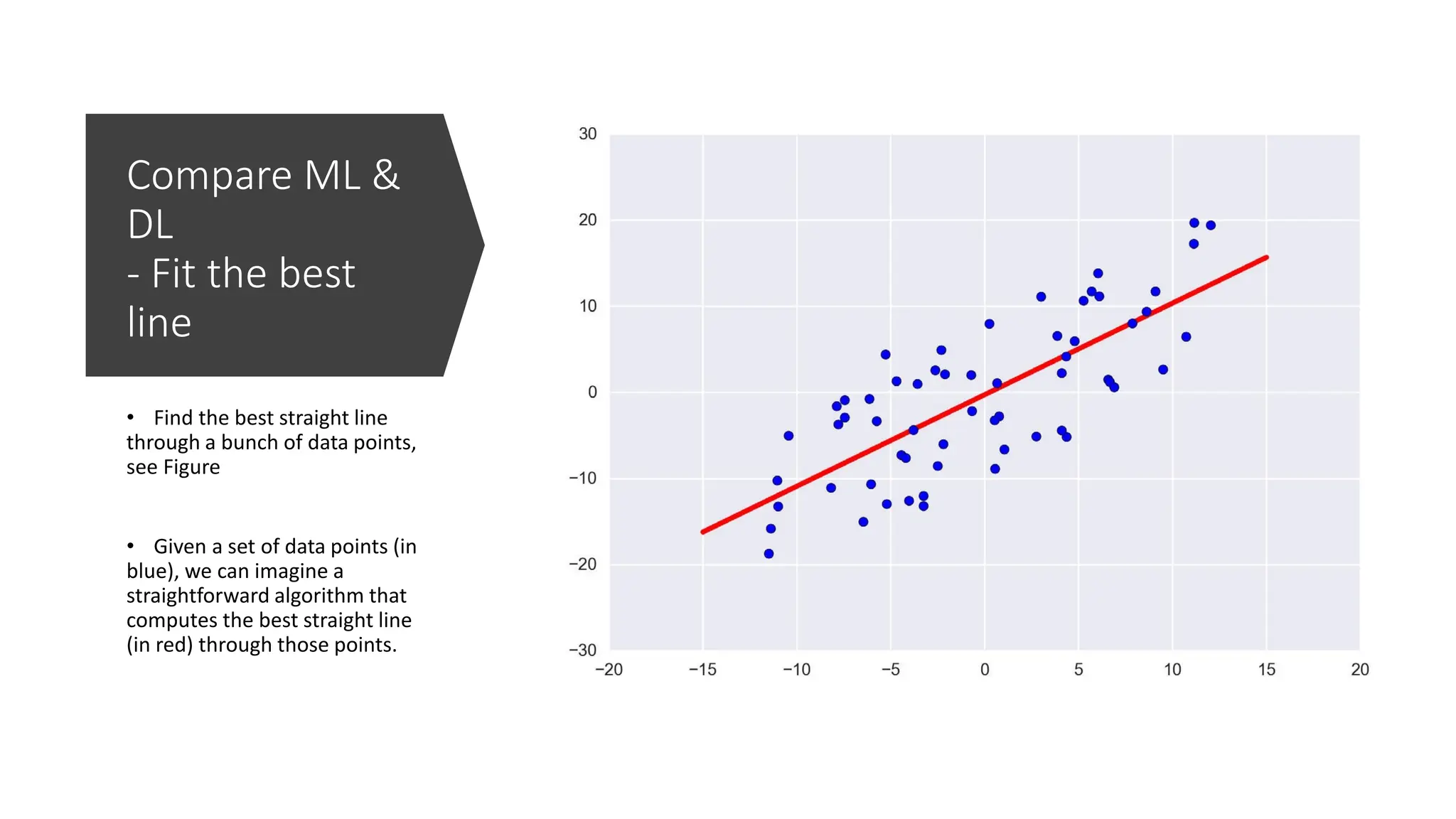
Compare ML &
DL
-Fit the best
line
• Find the best straight line
through a bunch of data points,
see Figure
• Given a set of data points (in
blue), we can imagine a
straightforward algorithm that
computes the best straight line
(in red) through those points.
13.
What’s a classifier?
• A classifier assigns a label to each sample describing which category or class, that
sample belongs to.
14.
Example of Classifiers
•If the input is a song, classifier assigns the label as the genre (e.g., rock
or classical).
• If it’s a photo of an animal, the classifier assigns the label as the name
of the animal shown (e.g., a tiger or an elephant).
• In mountain weather for hiking, classifier may label the hiking
experience into 3 categories: Lousy, Good, and Great.
15.
Simple example ofML Systems
Example: Online
companies (Amazon,
Flipkart etc.) make use of
every interaction with
every customer to
accumulate more data.
They use it as input to
machine learning
algorithms, getting more
information about
customers.
16.
Example of Samples,Features, Labels
• Weather measurements on a mountain for hiking
• Sample is weather at a given moment.
• Features are measurements: temperature, wind speed, humidity, etc.
• Hand over each sample (with a value for each feature) to a human expert.
• Expert examines features and provides a label for that sample.
• Expert’s opinion, using a score from 0 to 100, tells how the day’s weather would be for
good hiking.
• Labels can be “Lousy”, “Good”, “Excellent” (weather for hiking)
• The idea is shown in next Figure .
17.
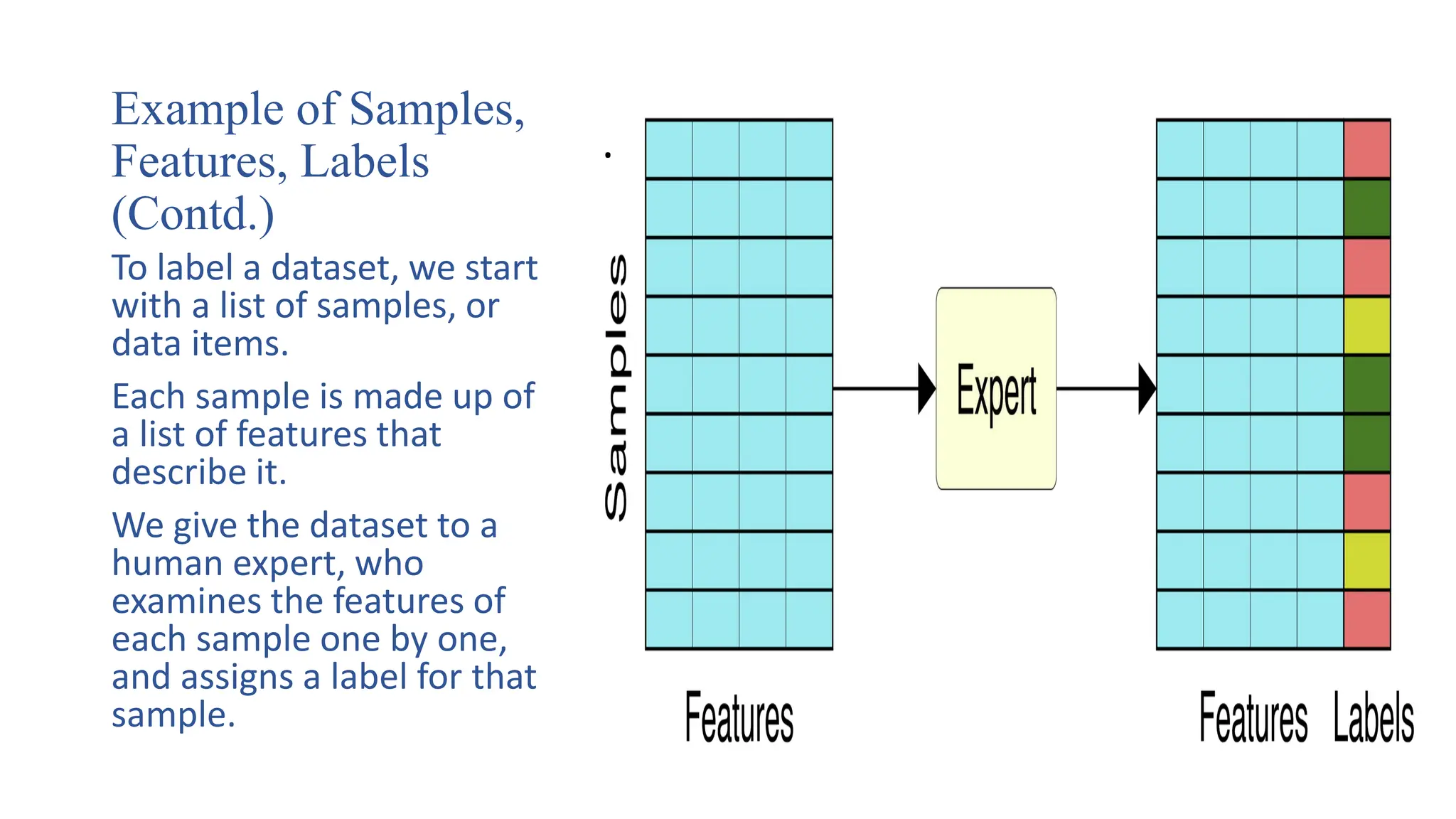
Example of Samples,
Features,Labels
(Contd.)
To label a dataset, we start
with a list of samples, or
data items.
Each sample is made up of
a list of features that
describe it.
We give the dataset to a
human expert, who
examines the features of
each sample one by one,
and assigns a label for that
sample.
.
18.
A Computerized LearningStrategy
• First, collect as much data as possible.
• Call each piece of observed data (say, the weather at a given
moment) as sample,
• Call the names of the measurements that make it up (the
temperature, wind speed, humidity, etc.) as features.
• Hand over each sample (with a value for each feature) to a human
expert.
• Expert examines features and provides a label for that sample.
• Example: if our sample is a photo, the label might be the name of
the person or the type of animal in the photo.
19.
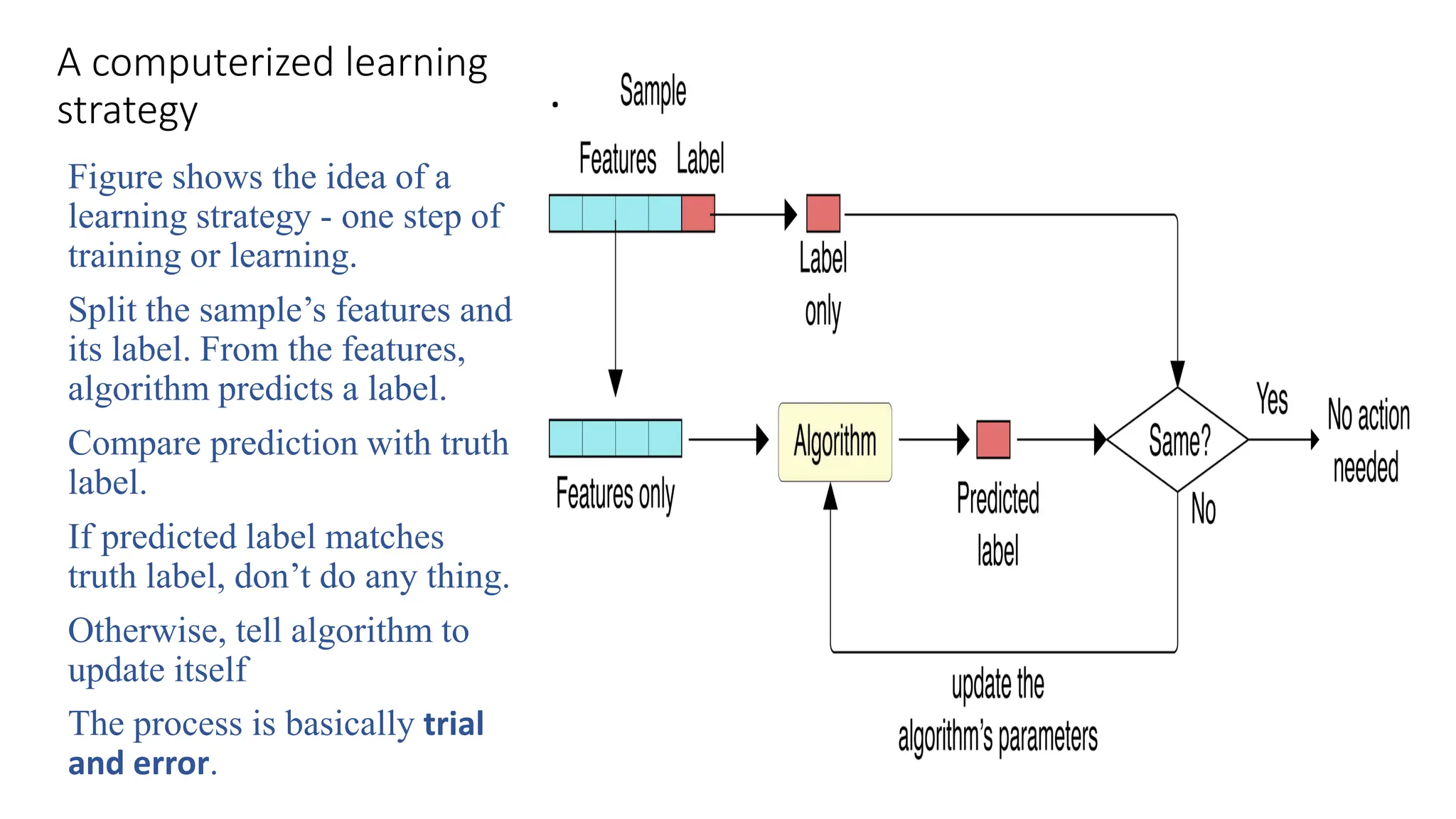
A computerized learning
strategy
Figureshows the idea of a
learning strategy - one step of
training or learning.
Split the sample’s features and
its label. From the features,
algorithm predicts a label.
Compare prediction with truth
label.
If predicted label matches
truth label, don’t do any thing.
Otherwise, tell algorithm to
update itself
The process is basically trial
and error.
.
20.
First, split Datafor Training & Validation
• First, set aside some of these labeled samples for time being (use them
later for validation).
• Give remaining labeled data to our computer, and ask it to find a way
to come up with the right label for each input.
• We do not tell it how to do this.
• Instead, we give labelled data to an algorithm with a large number of
parameters it can adjust (perhaps even millions of them).
• Different types of learning will use different algorithms.
21.
Training step andLearning rate
• Each algorithm learns by changing the internal parameters it uses to create its
predictions.
• Big change: risk of changing them so much that it makes other predictions
worse.
• Small change: Cause learning to run slower.
• We have to find by trial and error for each type of algorithm the right trade-off
between these extremes.
• We call the amount of updating the learning rate,
• A small learning rate is cautious and slow,
• A large learning rate speeds things up but could backfire.
22.
Testing or Validationstep
• We now return to the labeled data kept aside in the last section.
• This is called as test data.
• We evaluate how the system can generalize what it learned, by
showing these samples that it’s never seen before.
• This test set shows how the system performs on new data.
23.
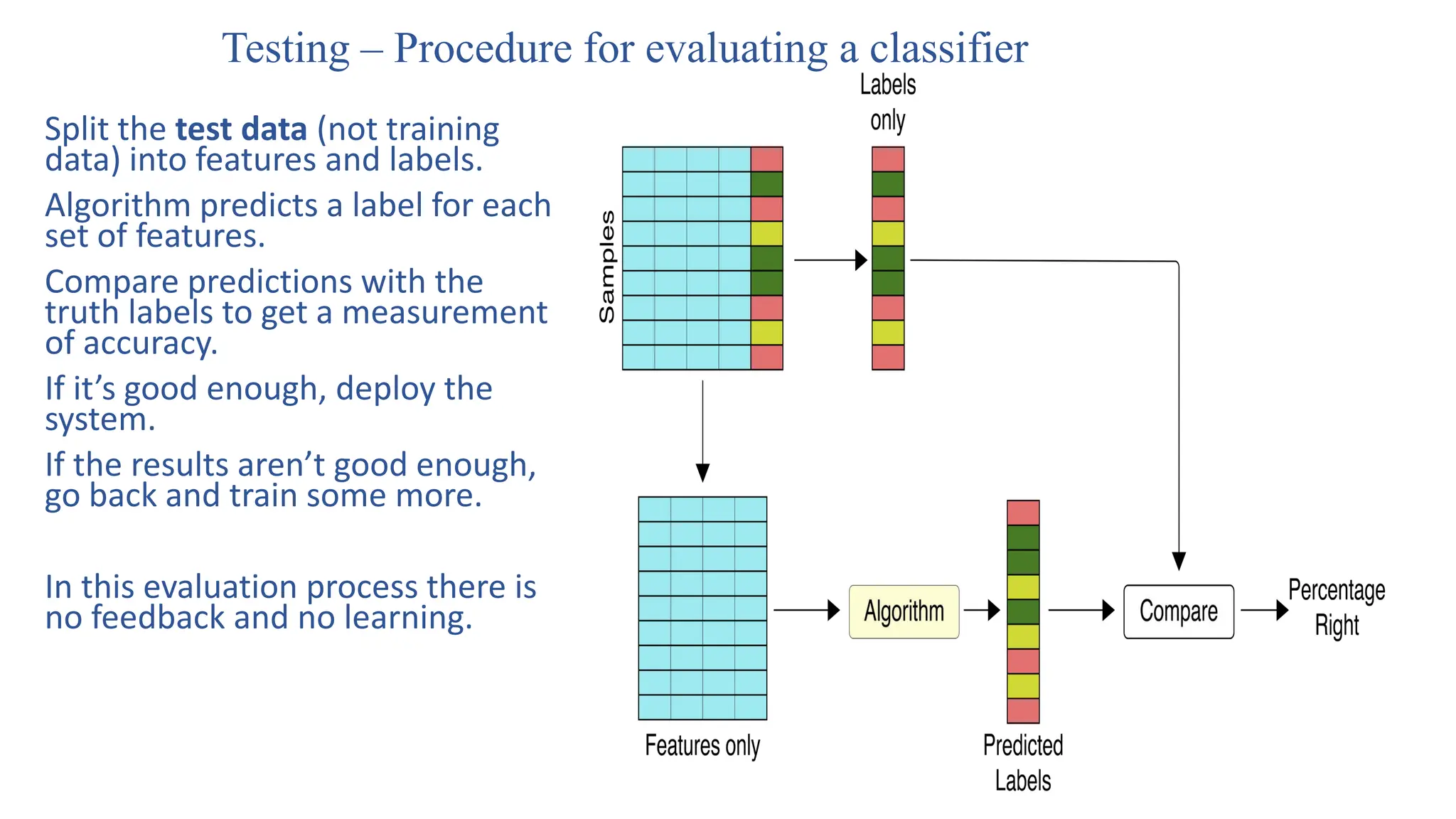
Testing – Procedurefor evaluating a classifier
Split the test data (not training
data) into features and labels.
Algorithm predicts a label for each
set of features.
Compare predictions with the
truth labels to get a measurement
of accuracy.
If it’s good enough, deploy the
system.
If the results aren’t good enough,
go back and train some more.
In this evaluation process there is
no feedback and no learning.
24.
How to Retrain,if testing results are not good
• Use again original training set data. Note that these are the same samples.
• Shuffle this data first - but no new information.
• Show every sample again, letting it learn along the way again.
• Computer learns over and over again from the very same data.
• Now, show test data set .
• Ask algorithm to predict labels for the test set again.
• If the performance isn’t good enough, go back to original training set again,
and then test again.
• Repeat this process often hundreds of times. Let it learn just a little more each
time.
• Computer doesn’t get bored or cranky seeing the same data over and over.
25.
Learning – Goodand Bad News
• Bad News:
• No guarantee that there’s a successful learning algorithm for every
set of data,
• No guarantee that if there is one, we’ll find it.
• May not have enough computational resources to find the
relationship between the samples and their labels.
• Good news:
• Even without a mathematical guarantee, in practice we can often
find solutions that generalize very well, sometimes doing even
better than human experts.
26.
Parameters and
hyperparameters
• Learningalgorithm modifies itself its own
parameter values, over time.
• Learning algorithm are also controlled by values
that we set (such as the learning rate we saw
above).
• These are called hyperparameters.
• What’s the difference between between
parameters and hyperparameters ?
• Computer adjusts its own parameter values
during the learning process, while we specify
the hyperparameters when we write and run
our program.
27.
When do we
deploythe
System ?
• When the algorithm has learned enough to
perform well enough on the test set that we’re
satisfied, we’re ready to deploy, or release, our
algorithm to the world.
• Users submit data and our system returns the
label it predicts.
• That’s how pictures of faces are turned into
names, sounds are turned into words, and
weather measurements are turned into
forecasts.
28.
Machine Learning –major categories
Let’s now get a big
picture for the field
of machine learning.
See the major
categories that make
up the majority of
today’s ML tools.
29.
Supervised
Learning (ML)
• Supervisedlearning (SL) is done for
samples with pre-assigned labels.
• Supervision comes from the labels.
• Labels guide the comparison step
• There are two general types of
supervised learning, called
classification and regression.
30.
Two Types ofSL
Classification: look through a
given collection of categories
to find the one that best
describes a particular input.
Regression: take a set of
measurements and predict
some other value
31.
SL – Classification
•Start training by providing a list of all the labels (or classes, or categories) that we
want it to learn.
• Make the list so that it has all the labels for all the samples in the training set,
with the duplicates removed.
• Train the system with lots of photos and their labels, until it does a good job of
predicting the correct label for each photo.
• Now, turn the system loose on new photos it hasn’t seen before.
• For those objects it saw during training, It should properly label images.
• Caution: For those objects it did not see during training, the system will try to
pick the best category from those it knows about.
• Next Figure shows the idea.
32.
SL – ClassificationExample
• Example: Sort and label photos of everyday objects.
• We want to sort them : an apple peeler, a salamander, a piano, and so
on.
• We want to classify or categorize these photos.
• The process is called classification or categorization.
33.
SL – ClassificationExample
In Figure, we used a trained
classifier to identify four
images never seen before.
The system had not been
trained on metal spoons or
headphones,
In both cases it found best
match it could.
To correctly identify those
objects, the system needs to
see multiple examples of
them during training.
34.
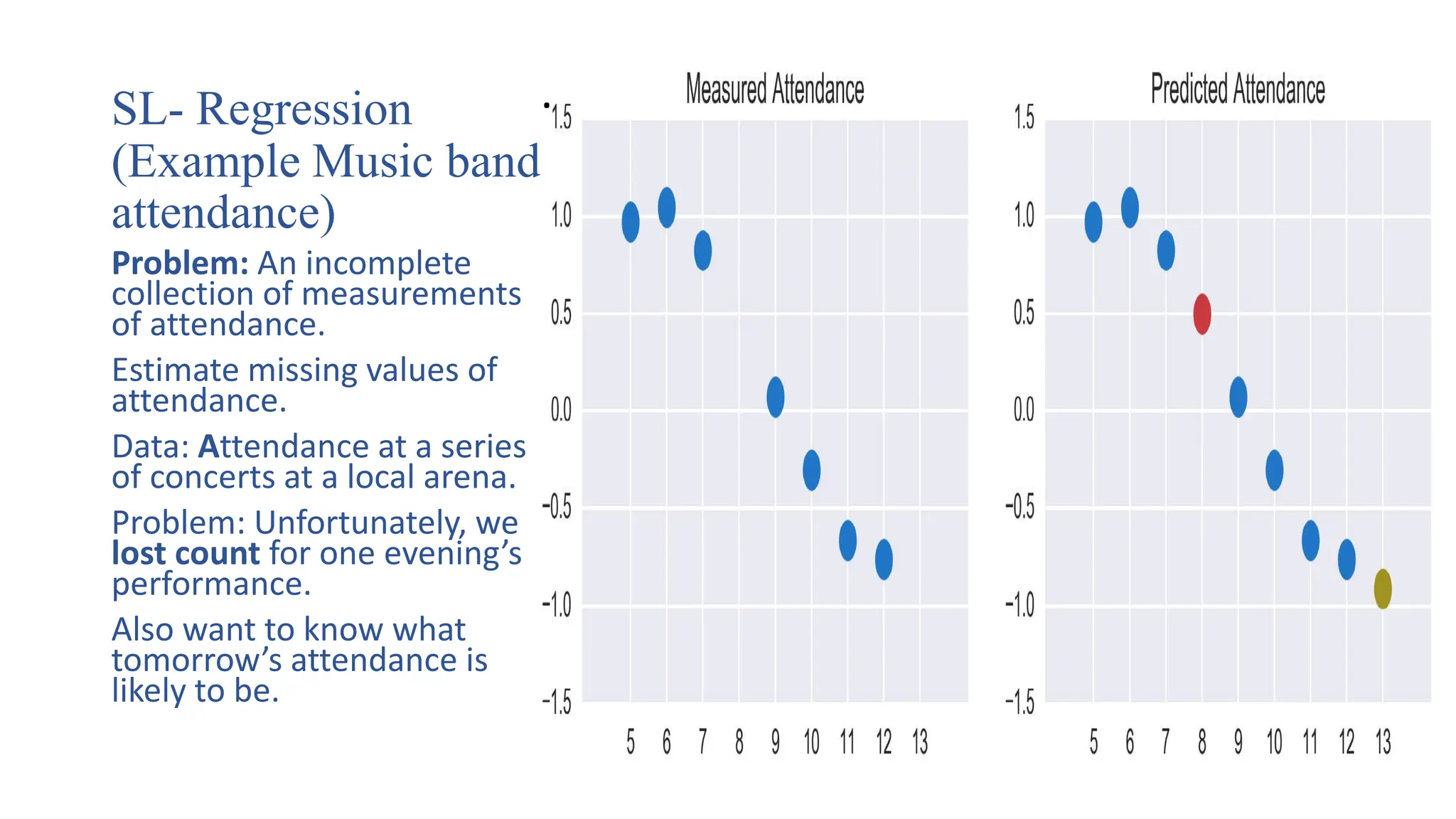
SL- Regression
(Example Musicband
attendance)
Problem: An incomplete
collection of measurements
of attendance.
Estimate missing values of
attendance.
Data: Attendance at a series
of concerts at a local arena.
Problem: Unfortunately, we
lost count for one evening’s
performance.
Also want to know what
tomorrow’s attendance is
likely to be.
.
35.
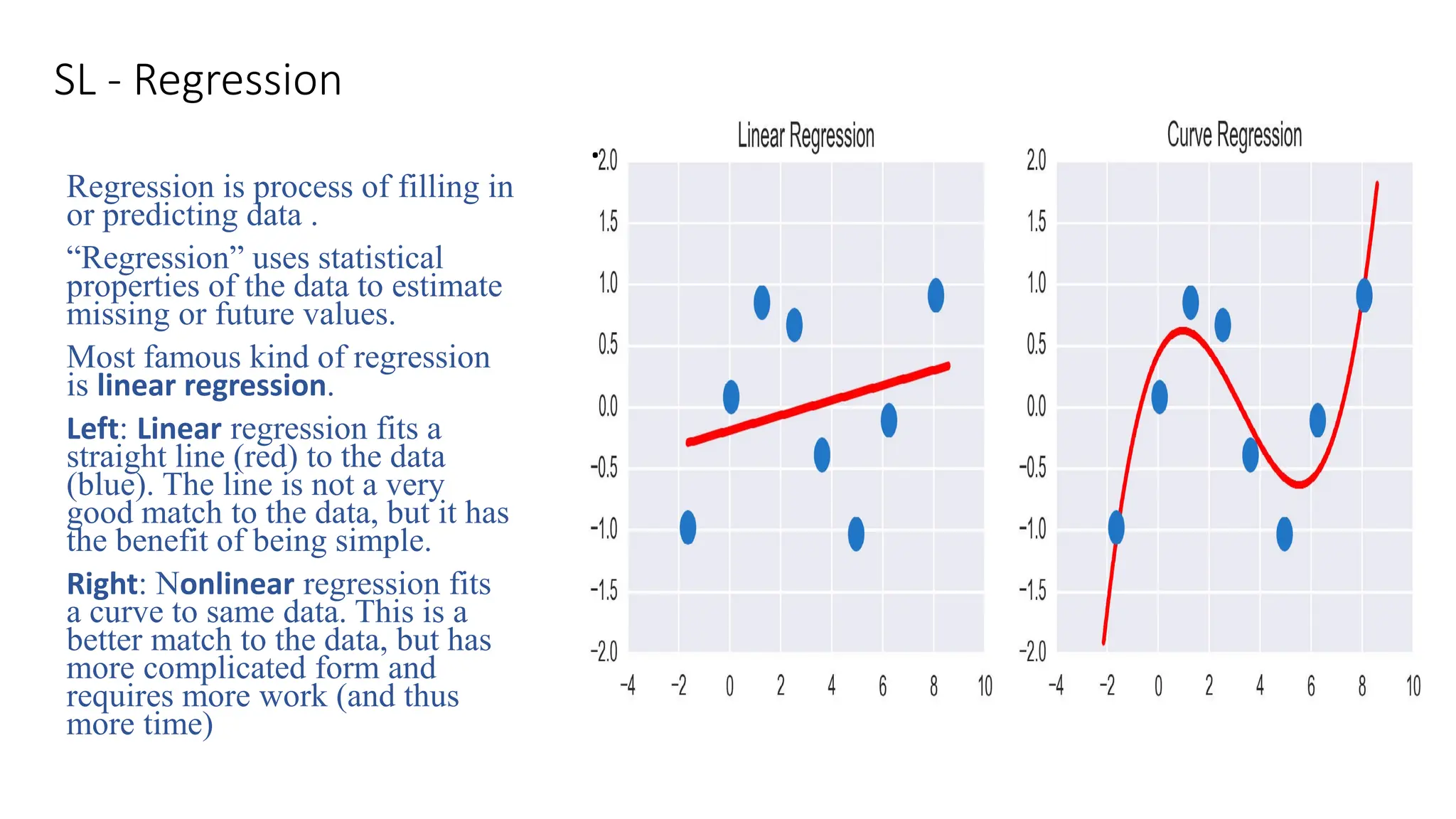
SL - Regression
Regressionis process of filling in
or predicting data .
“Regression” uses statistical
properties of the data to estimate
missing or future values.
Most famous kind of regression
is linear regression.
Left: Linear regression fits a
straight line (red) to the data
(blue). The line is not a very
good match to the data, but it has
the benefit of being simple.
Right: Nonlinear regression fits
a curve to same data. This is a
better match to the data, but has
more complicated form and
requires more work (and thus
more time)
.
36.
Unsupervised
Learning (USL)
– aform of ML
• What’s USL?
• When input data does not have labels, any
algorithm that learns from the data belongs to
USL.
• We are not “supervising” the learning process
by offering labels.
• The system has to figure everything out on its
own, with no help from us.
• USL used for clustering, noise reduction, and
dimension reduction.
• Let’s look at these in turn.
37.
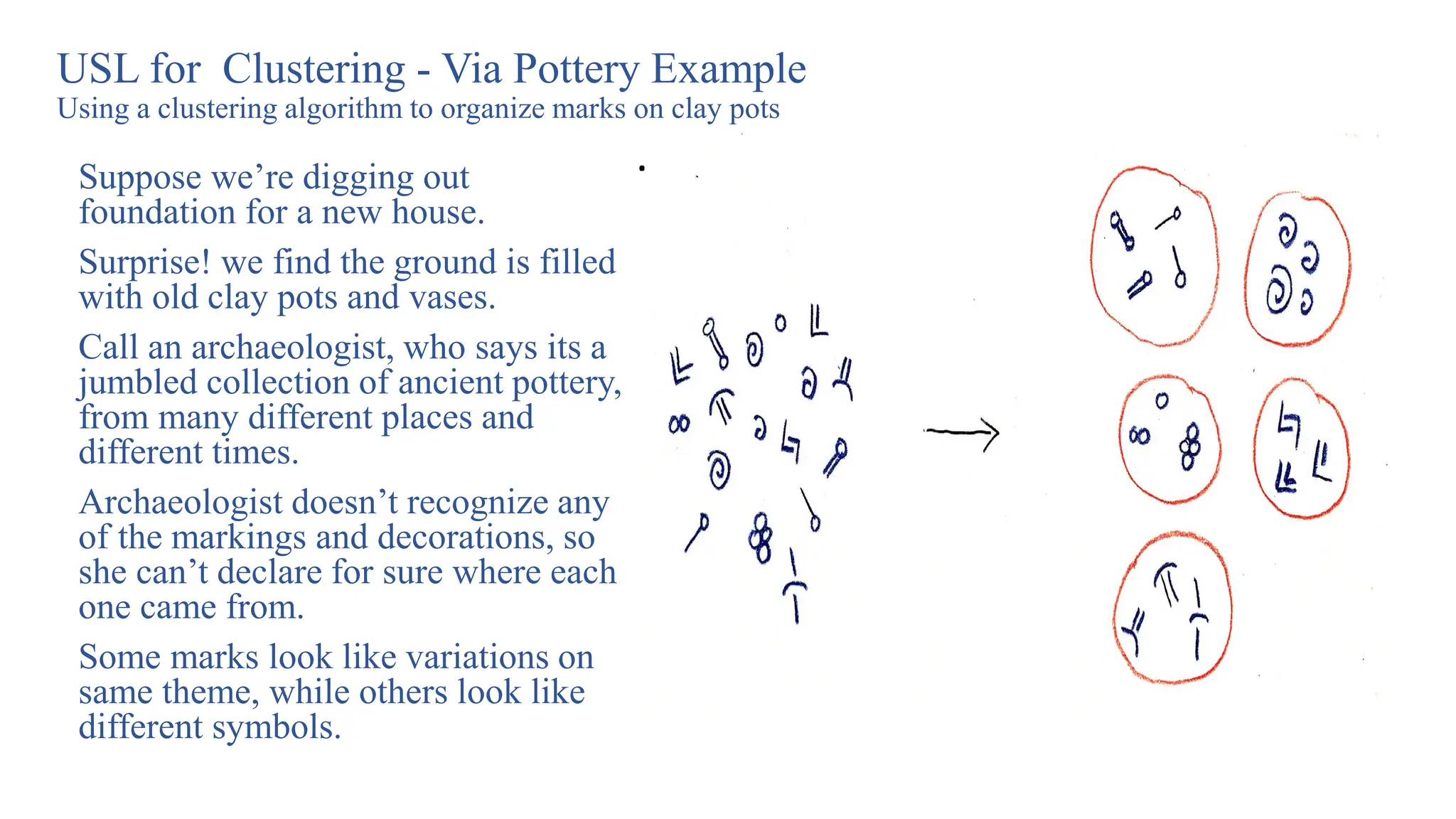
USL for Clustering- Via Pottery Example
Using a clustering algorithm to organize marks on clay pots
Suppose we’re digging out
foundation for a new house.
Surprise! we find the ground is filled
with old clay pots and vases.
Call an archaeologist, who says its a
jumbled collection of ancient pottery,
from many different places and
different times.
Archaeologist doesn’t recognize any
of the markings and decorations, so
she can’t declare for sure where each
one came from.
Some marks look like variations on
same theme, while others look like
different symbols.
.
38.
USL for
Clustering -
ViaPottery
Example
(Contd.)
• She takes rubbings of the markings, and then
tries to sort them into groups.
• But there are far too many of them for her to
manage.
• She turns to a machine learning algorithm.
• Why ML?
• To automatically group the markings together in
a sensible way.
• On the right of previous figure, we show her
captured marks, and the groupings that could
be found automatically by an algorithm.
39.
USL for Clustering
•This is a clustering problem
• The ML algorithm is a clustering
algorithm.
• There are many clustering algorithms to
choose from.
• Because our inputs are unlabeled, this
archaeologist is performing clustering,
using an unsupervised learning algorithm.
40.
USL for NoiseReduction – Noisy Image Example
Figure shows a noisy image, &
how a de-noising algorithm
cleans it up.
Why is de-noising a form of
unsupervised learning (USL)?
As we don’t have labels for our
data (for example, in a noisy
photo we just have pixels)
USL algorithm estimates what
part of sample is noise &
removes it.
By removing weird and missing
values from the input, learning
process happens more quickly
and smoothly.
.
41.
USL for DimensionalityReduction
Problem: Sometimes our samples have more features than they
need.
So, simplify data:
- Remove uninformative features,
- Combine redundant features, or
For these tasks, there are USL algorithms that can do the job.
USL finds a way to reduce the number of features of our data -
called as dimension reduction.
42.
USL for
Dimensionality
Reduction
Example#1 Weather
•Data: Weather samples in the desert at the height
of summer.
• Record daily wind speed, wind direction, and
rainfall.
• Given the season and locale, the rainfall value will
be 0 in every sample.
• If we use these samples in a machine learning
system, the computer will need to process and
interpret this useless, constant piece of
information with every sample.
• At best this would slow down the analysis.
• At worst it could affect the system’s accuracy,
because the computer would devote some of its
finite resources of time and memory to trying to
learn from this unchanging feature.
43.
USL for
Dimensionality
Reduction
Example#2 Health
Clinic
•Sometimes features contain redundant
data.
• A health clinic might take everyone’s weight
in kilograms when they walk into the door.
Then when a nurse takes them to an
examination room, she measures their
weight again but this time in pounds.
• Same information repeated twice, but it
might be hard to recognize that because
the values are different.
• Like the useless rainfall measurements, this
redundancy will not work to our benefit
44.
Semi-
Supervised
Learning
(Generators)
Example -
Persian Carpets
inMovie
Shooting a movie inside a Persian carpet warehouse.
Problem: Want hundreds of carpets, all over the warehouse.
Carpets on the floors, carpets on the walls, and carpets in
great racks in the middle of the space.
Each carpet to look real, but be different from all the others.
Our budget is nowhere near big enough to buy, or even
borrow, hundreds of unique carpets.
So instead, we buy just a few carpets, and then we give them
to our props department to make many fake carpets.
Semi-
Supervised
Learning
(Generators)
• This processof data generation is
implemented by ML algorithms called
generators.
• Train generators with large numbers of
examples - so that they can produce new
• versions with lots of variation.
• We don’t need labels to train generators, so its
unsupervised learning techniques.
• But we do give generators some feedback as
they’re learning, so they know if they’re
making good enough fakes for us or not.
• A generator is in the middle ground. It doesn’t
have labels, but it is getting some feedback
from us. We call this middle ground semi-
supervised learning.
48.
Reinforcement
Learning -
Example#1
• Supposeyou are take care of a friend’s three-year old
daughter.
• You have no idea what the young girl likes to eat.
• First dinner: make Pasta with butter. She likes it!
• Repeat this dinner for a week. She gets bored.
• Week 2: Add some cheese, and she likes it.
• Repeat this dinner for week 2. She gets bored.
• Week 3: Try pesto sauce. But girl refuses to take a bite.
• So pasta + marinara sauce , and she rejects that too.
• Frustrated, you make a baked potato with cream. She
likes it!
• Weeks 3 & 4 : Try one recipe and one variation after
another, trying to develop a menu that the child will
enjoy.
• Only feedback: Little girl eats the meal, or she doesn’t.
• Approach to learning is Reinforcement Learning !
49.
RL Example #2:
•Agent: Autonomous car
• Environment: Traffic/people on the
street.
• Actions: Driving
• Feedback: Driving okay if following
traffic rules and keep everybody safe.
50.
RL Example #3:
•Agent: DJ at a dance club
• Environment : Dancers
• Feedback: Like or dislike the music.
51.
Reinforcement
Learning -
formally
• Agentmakes decisions and takes actions (the
chef).
• Environment is everything else in the universe
(the child).
• Environment gives feedback or a reward signal
to agent after every action
• Feedback tells how good or bad that action is.
• The reward signal is often just a single number,
where larger positive numbers mean the action
was considered better, while more negative
numbers can be seen as punishments.
• The reward signal is not a label, nor a pointer to
a specific kind of “correct answer.”
• Next figure shows the idea of RL
52.
Reinforcement
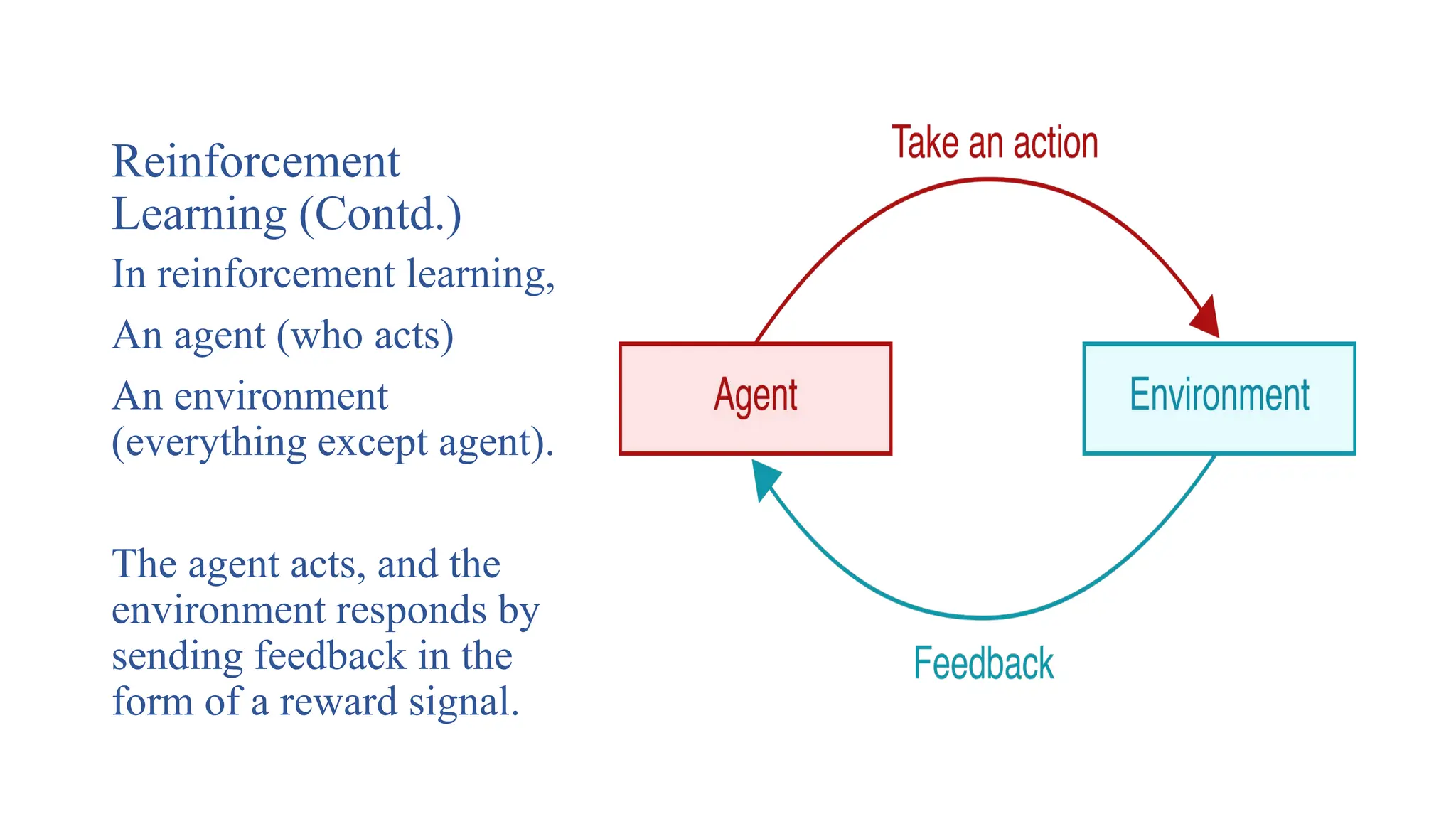
Learning (Contd.)
In reinforcementlearning,
An agent (who acts)
An environment
(everything except agent).
The agent acts, and the
environment responds by
sending feedback in the
form of a reward signal.
53.
How’s RL
different from
SL?
•The general plan of learning from mistakes
is the same, but the mechanism is
different.
• Supervised learning: system produces a
result (typically a category or a predicted
value), and then we compare it to the
correct result, which we provide.
• Reinforcement learning: There is no
correct result. The data has no label.
• There’s just feedback that tells us how well
we’re doing.
• Feedback tells that our action was “good”
or “bad.”
• In contrast to supervised learning
algorithms, the reward signal is not a label
and no idea/pointer to “correct answer.”











































































































![1_Introduction to Machine Learning [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/1introductiontomachinelearningautosaved-250910004933-3913b711-thumbnail.jpg?width=640&height=640&fit=bounds)


































