Downloaded 48 times



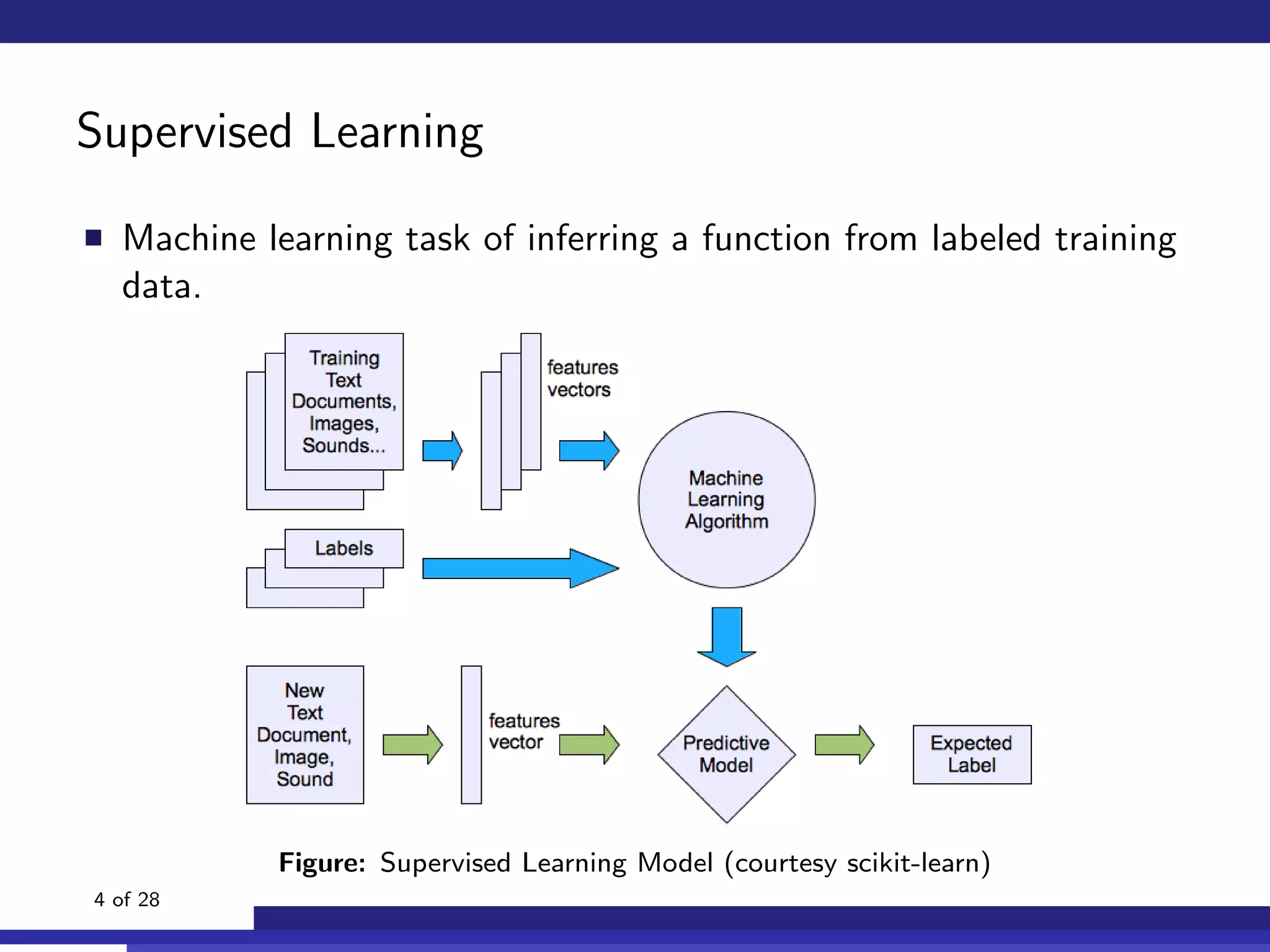
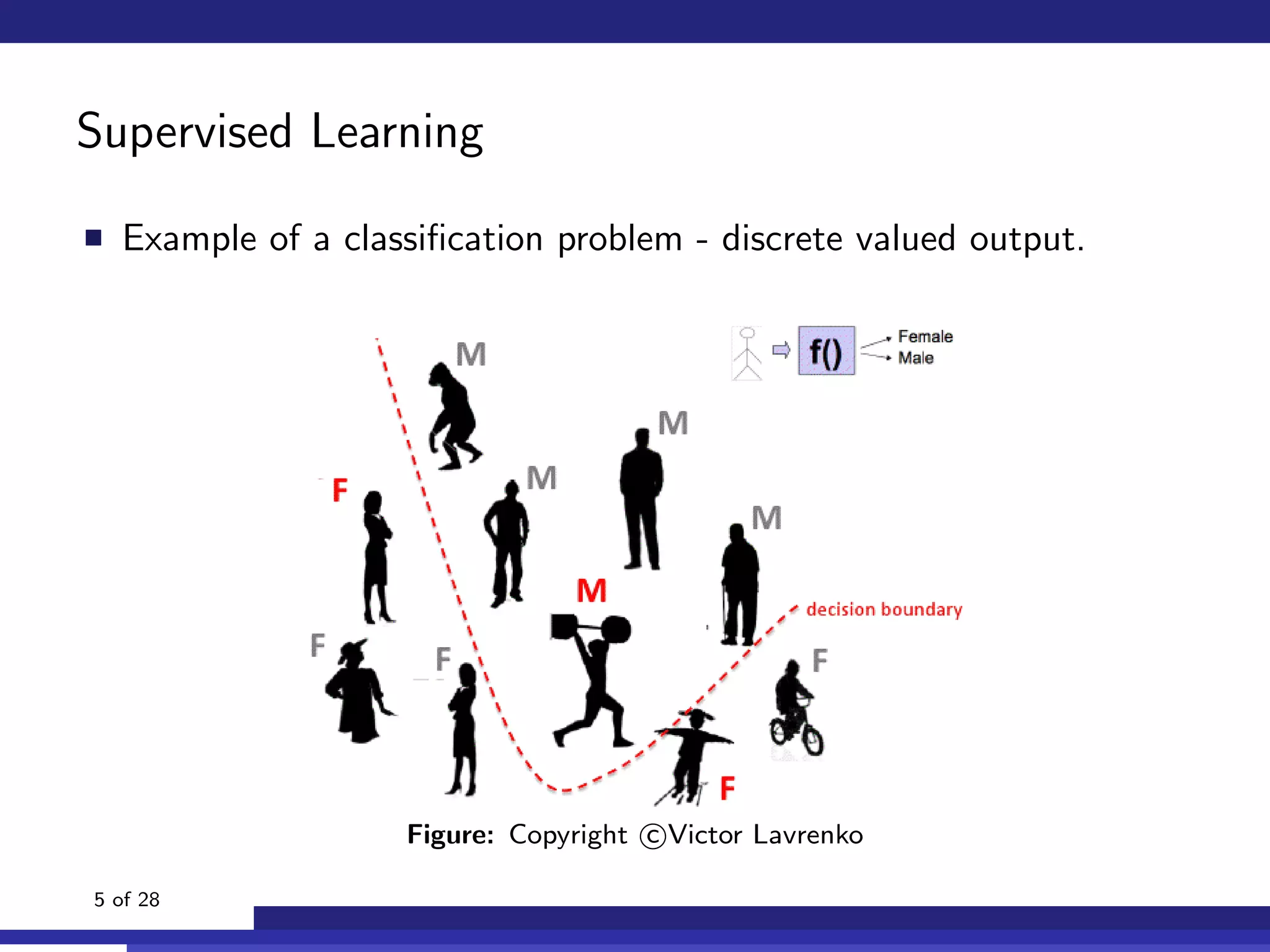
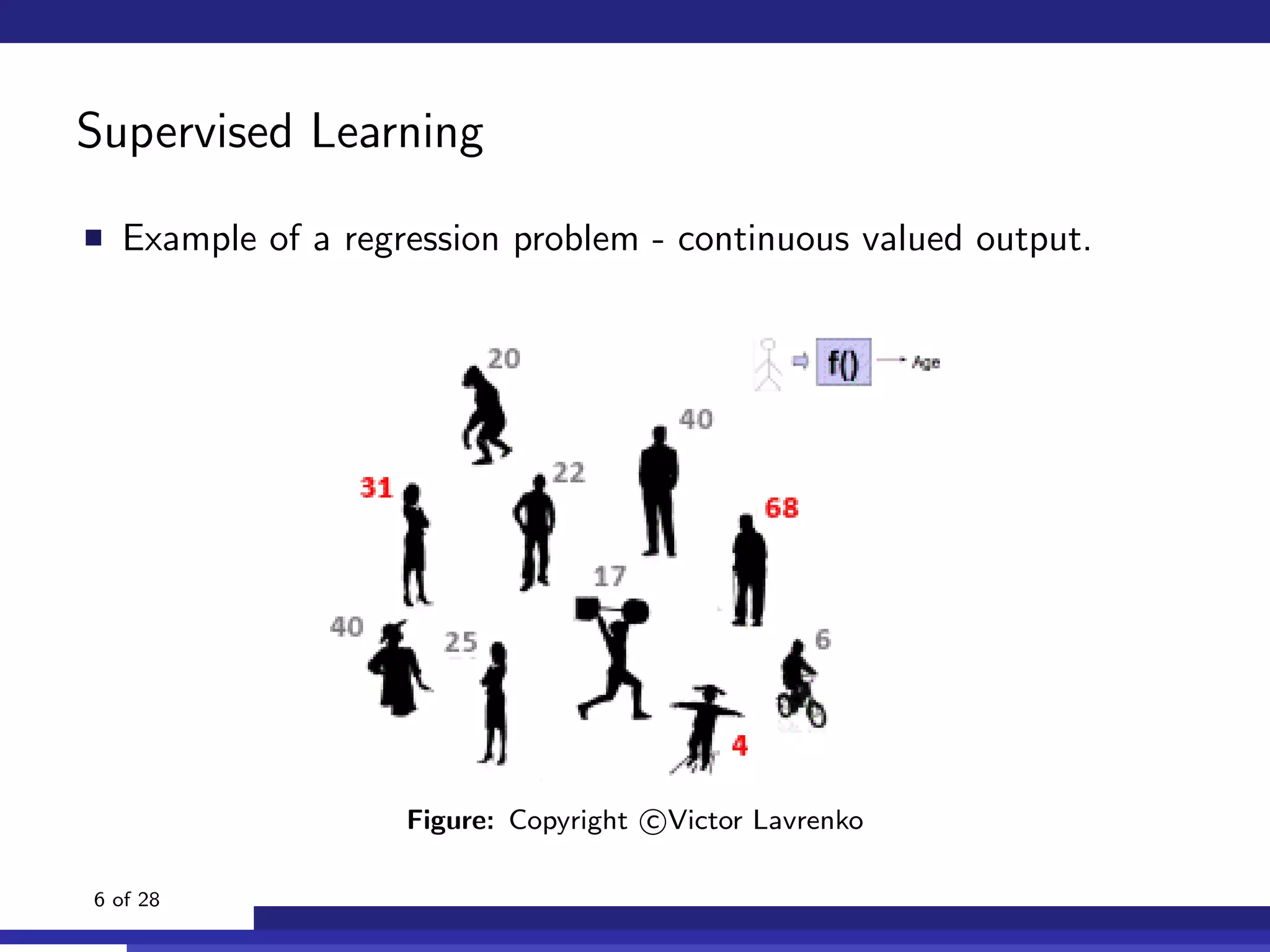
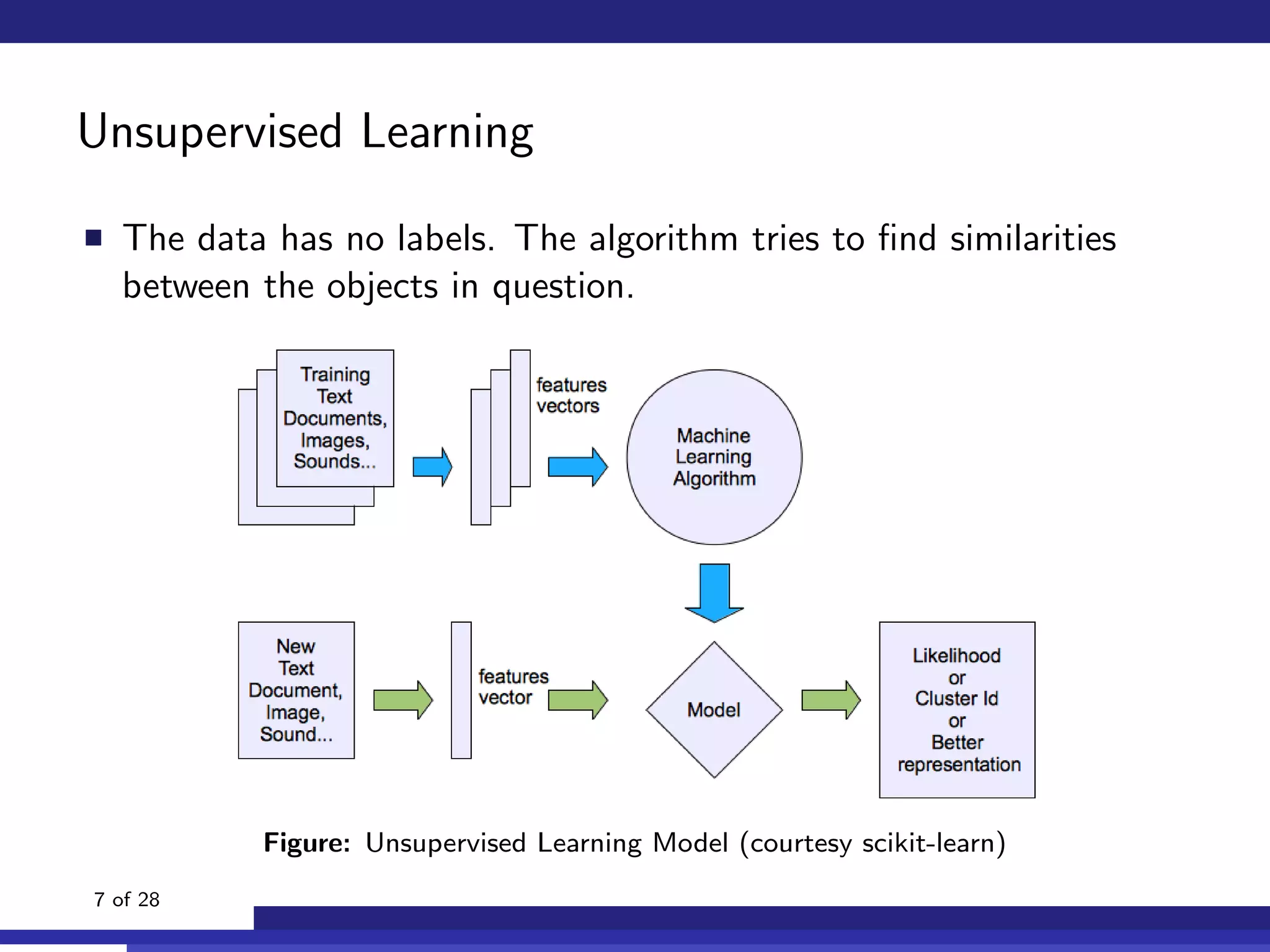
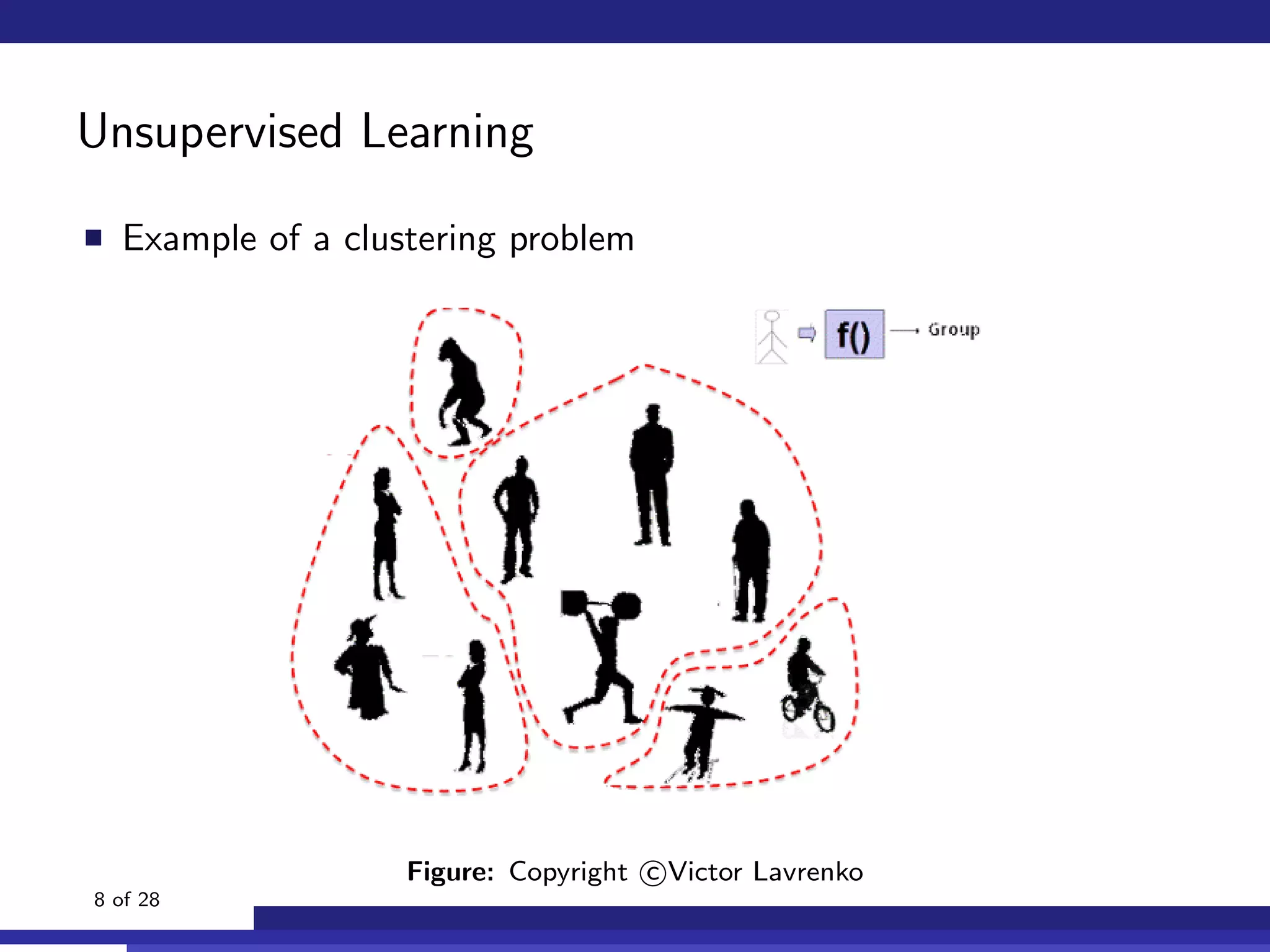


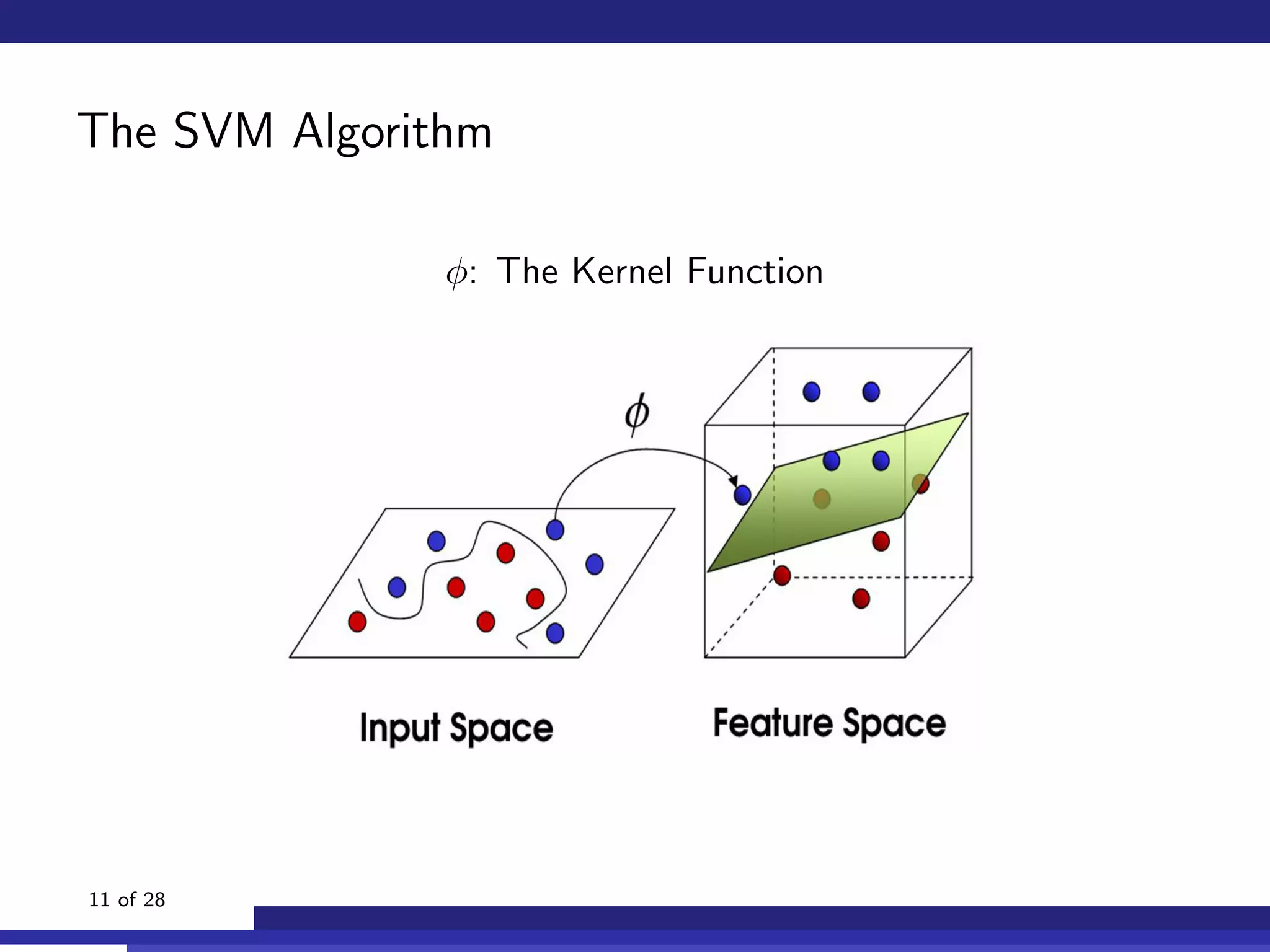

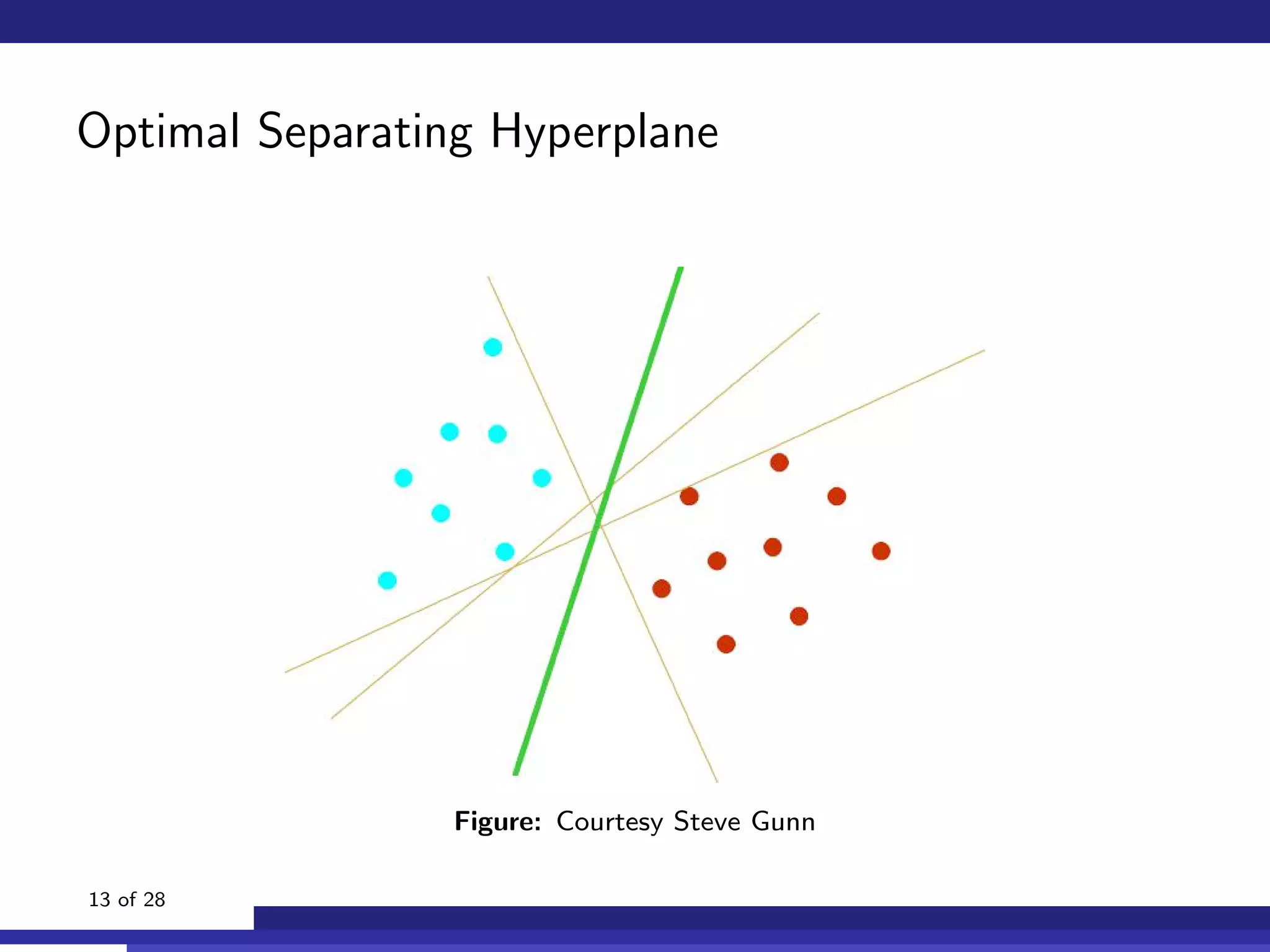
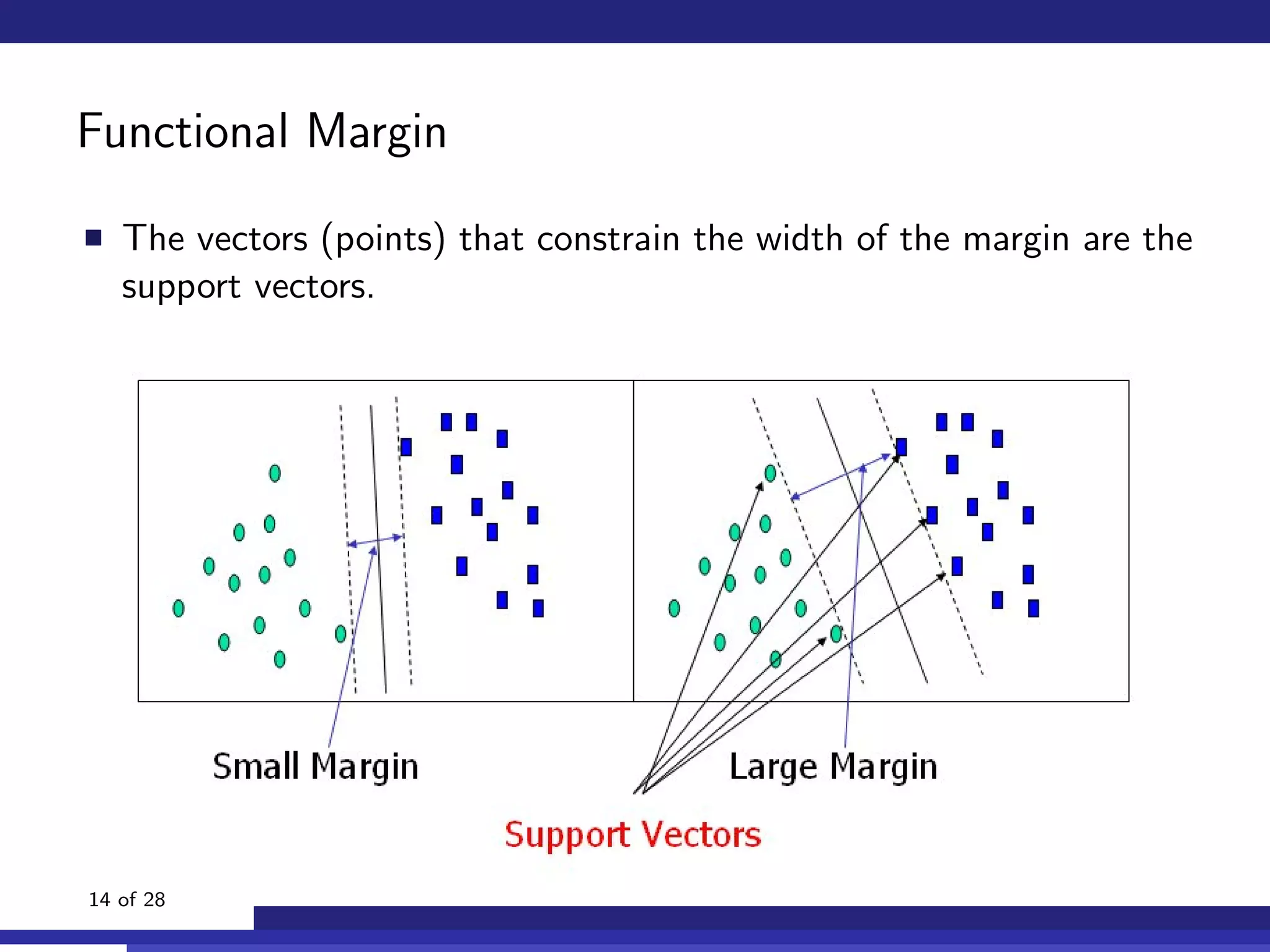

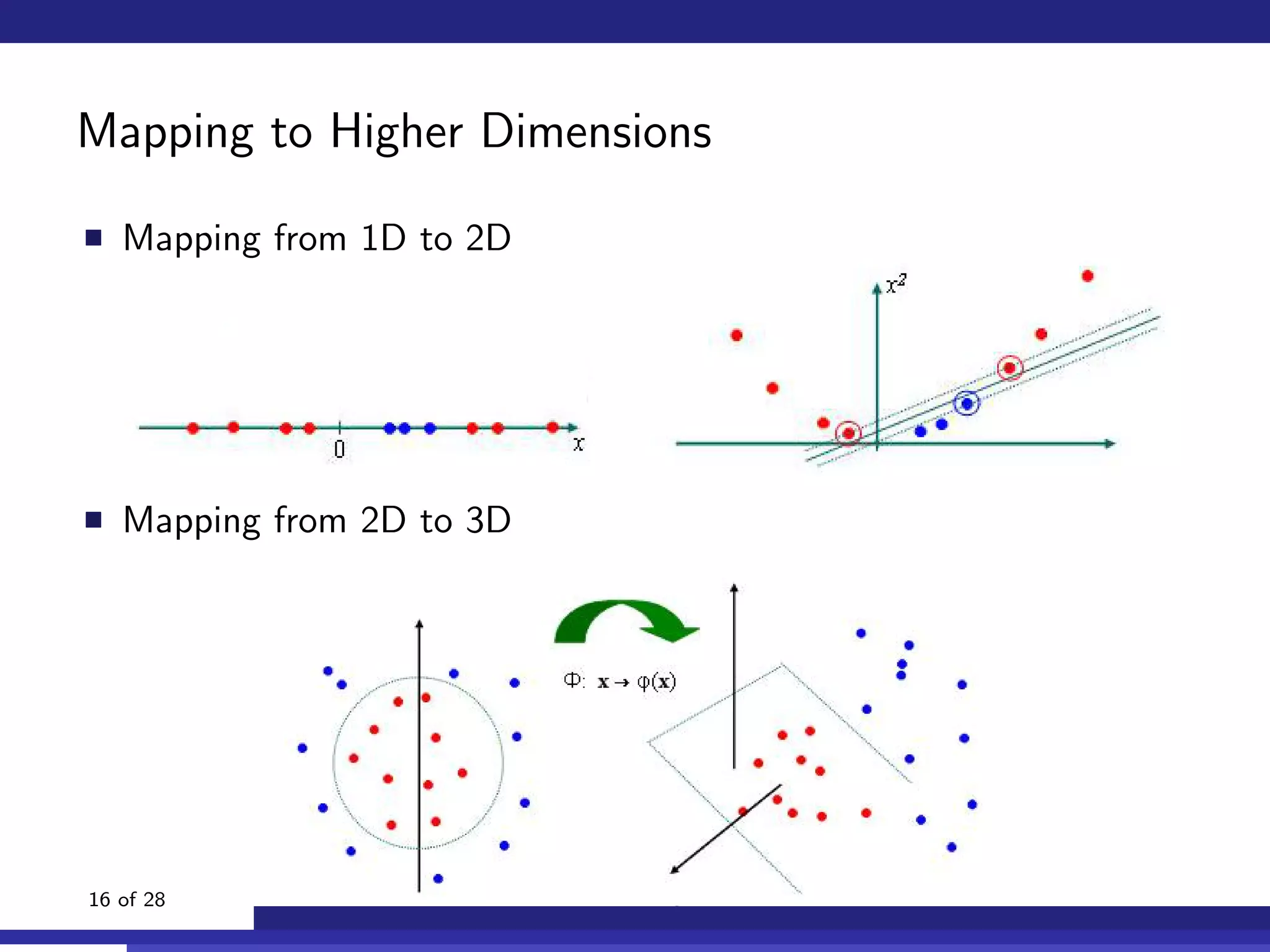

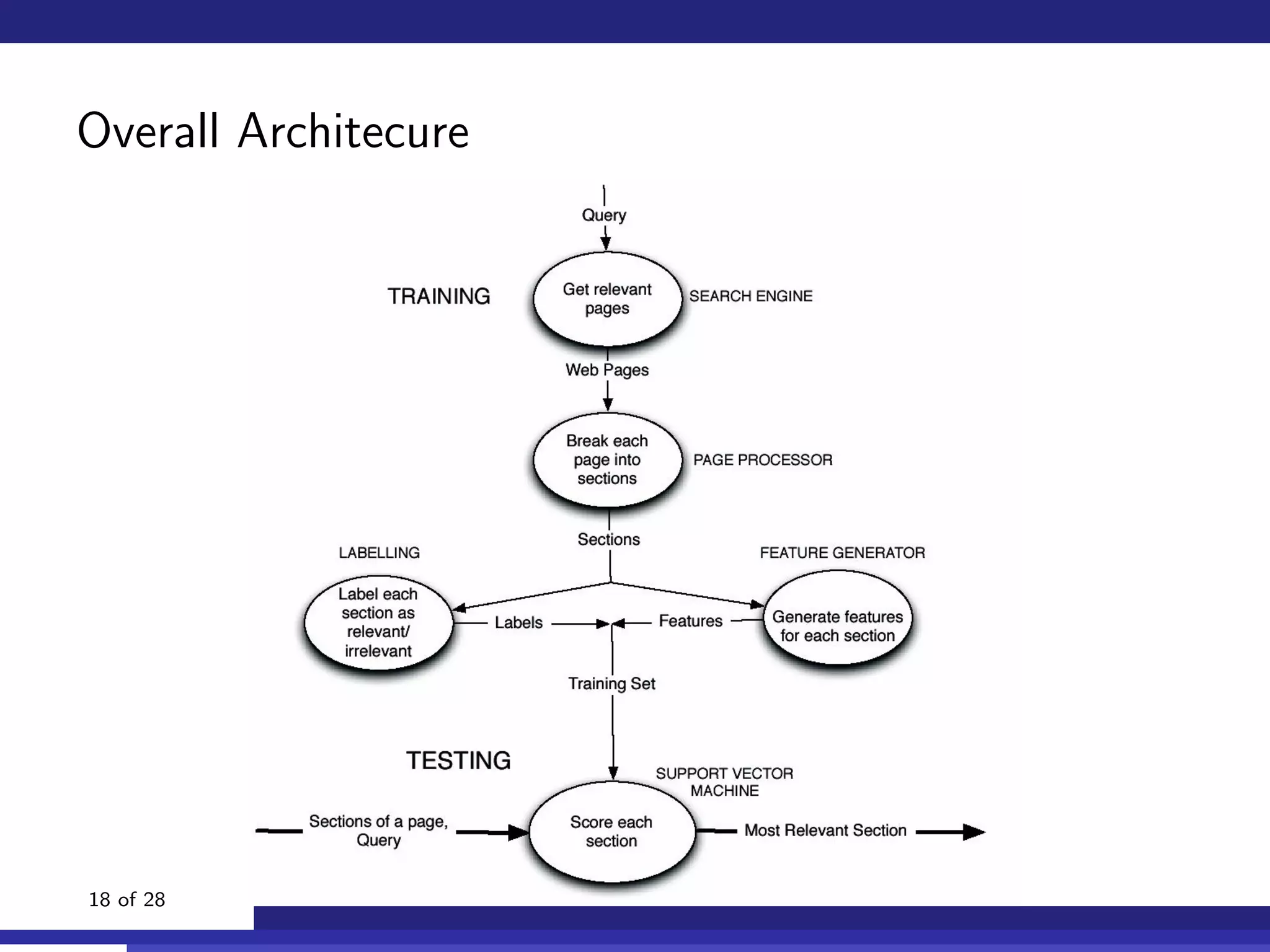







































The document discusses the use of machine learning, specifically Support Vector Machines (SVM), for identifying relevant sections of web pages in response to web searches. It highlights the limitations of keyword matching and proposes a method that leverages contextual features to improve search relevance. The findings suggest that SVMs, when combined with features from information retrieval, can significantly enhance user search experiences.



































































