





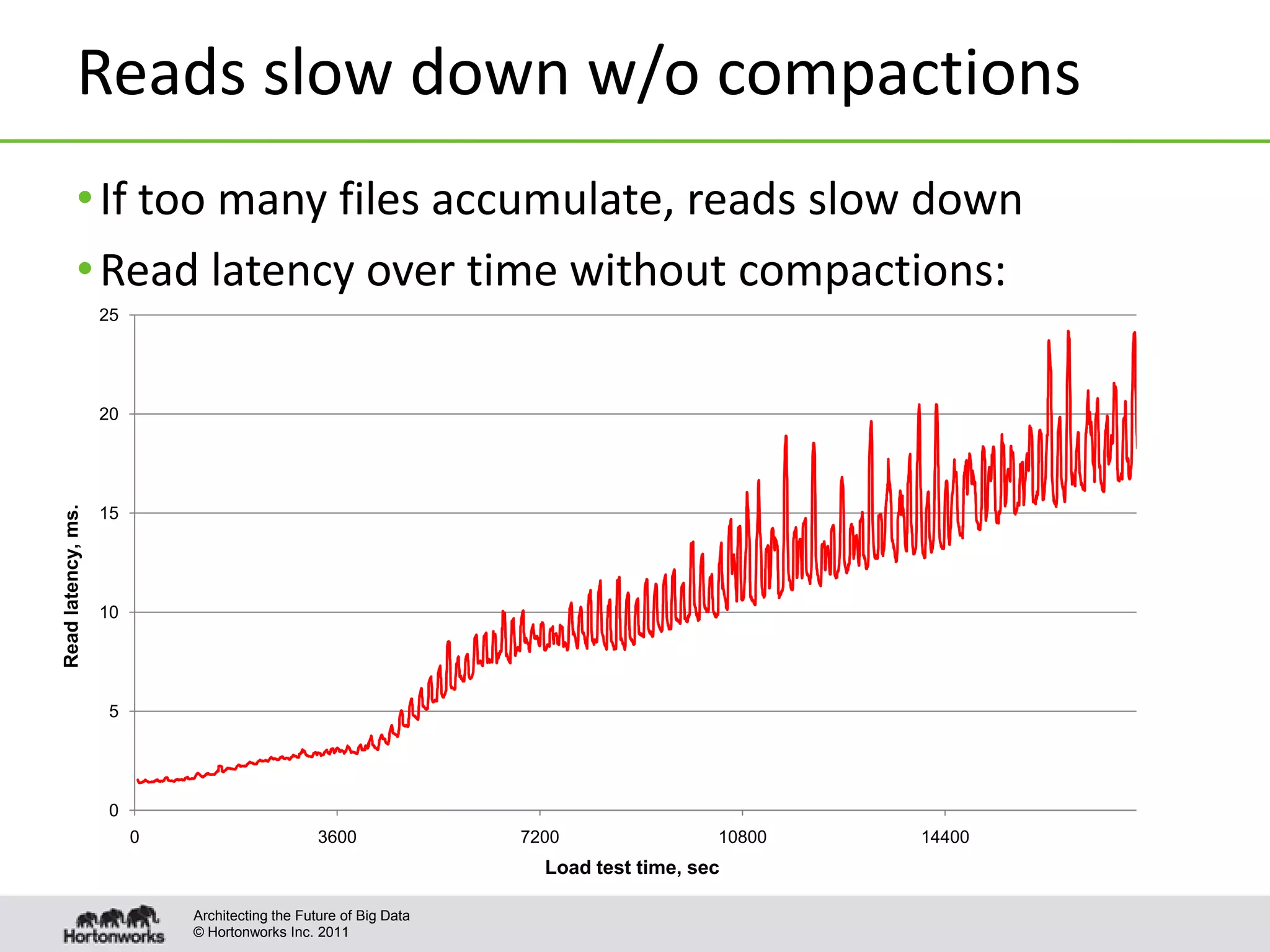
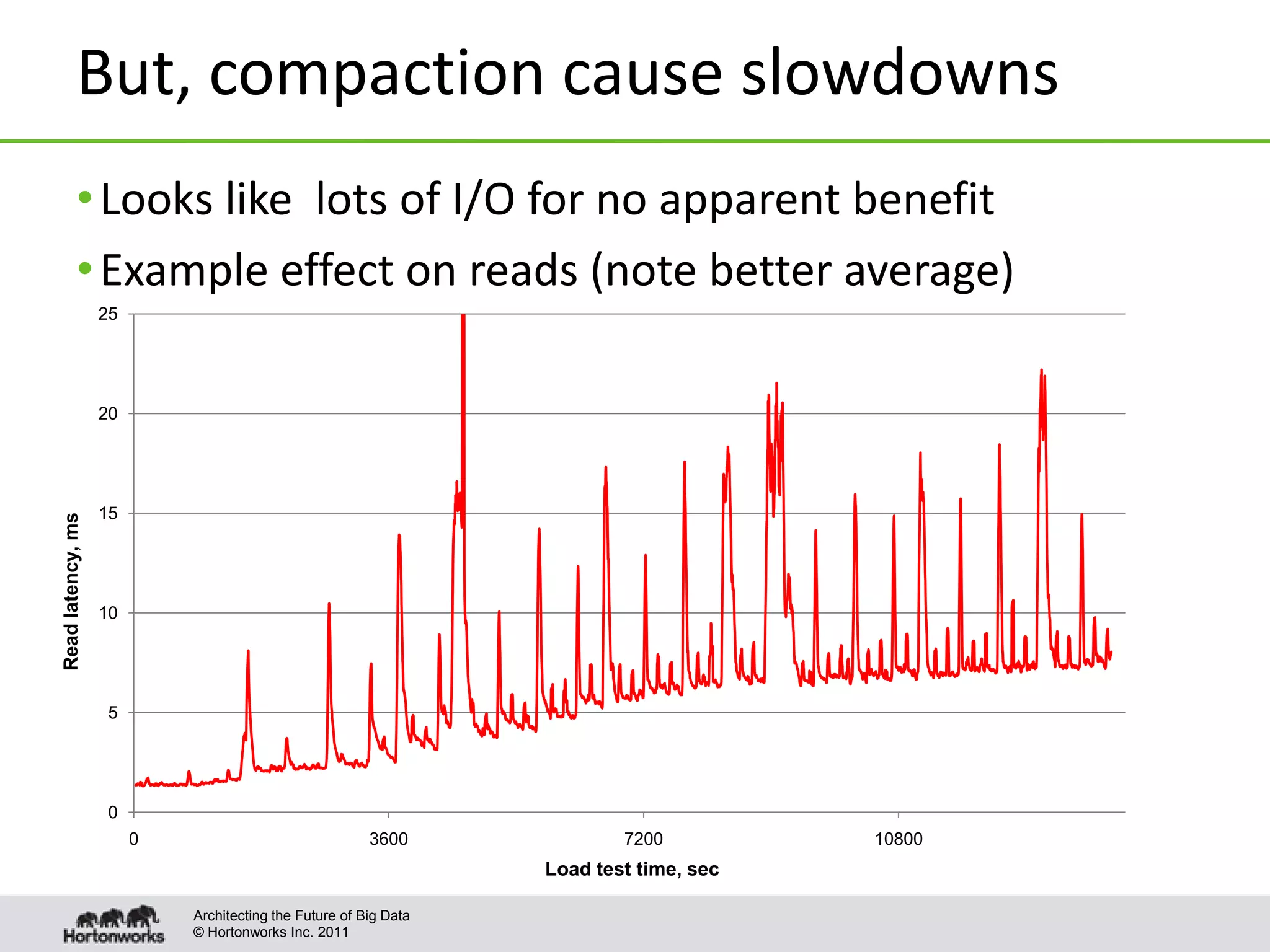

















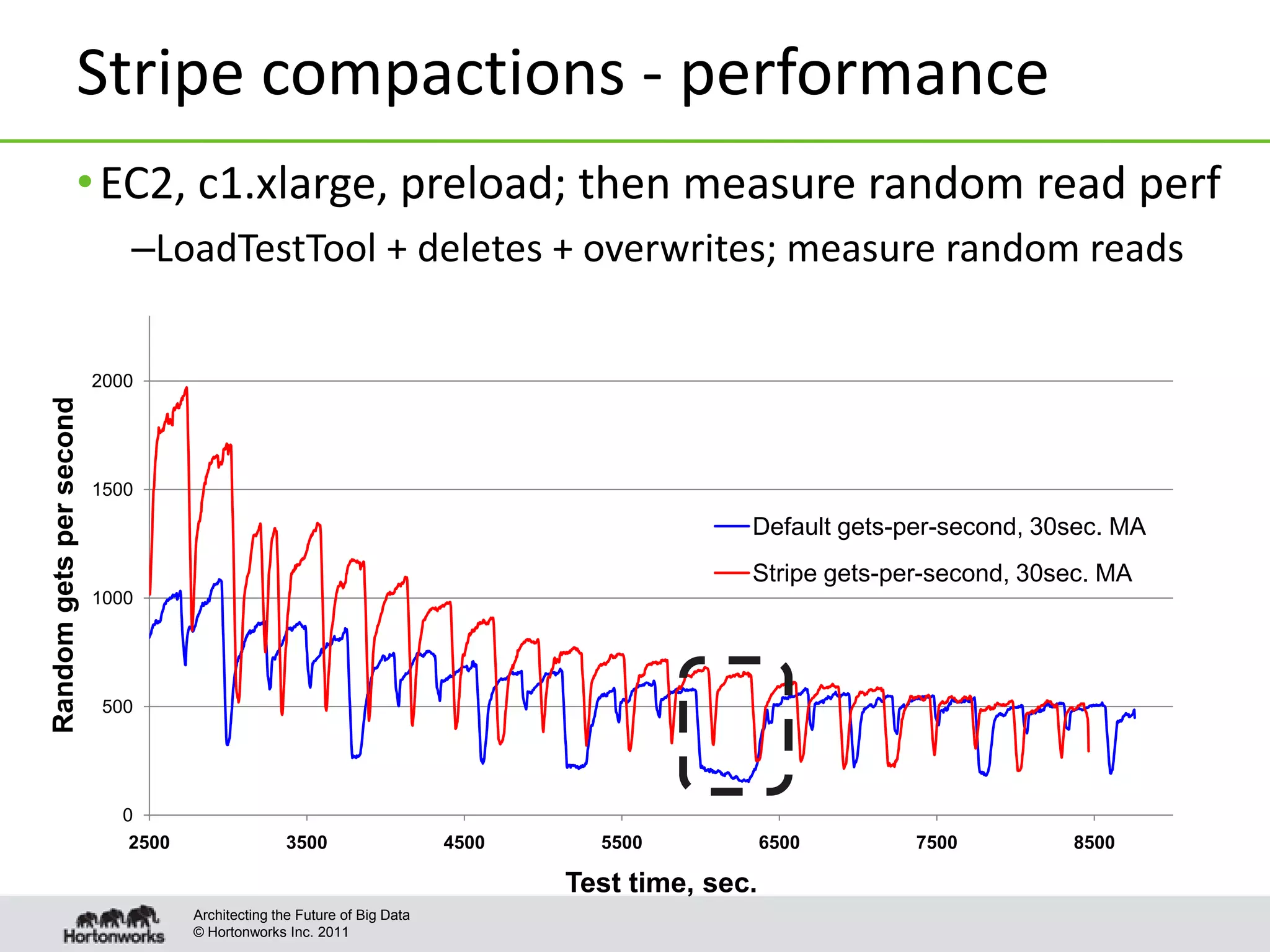
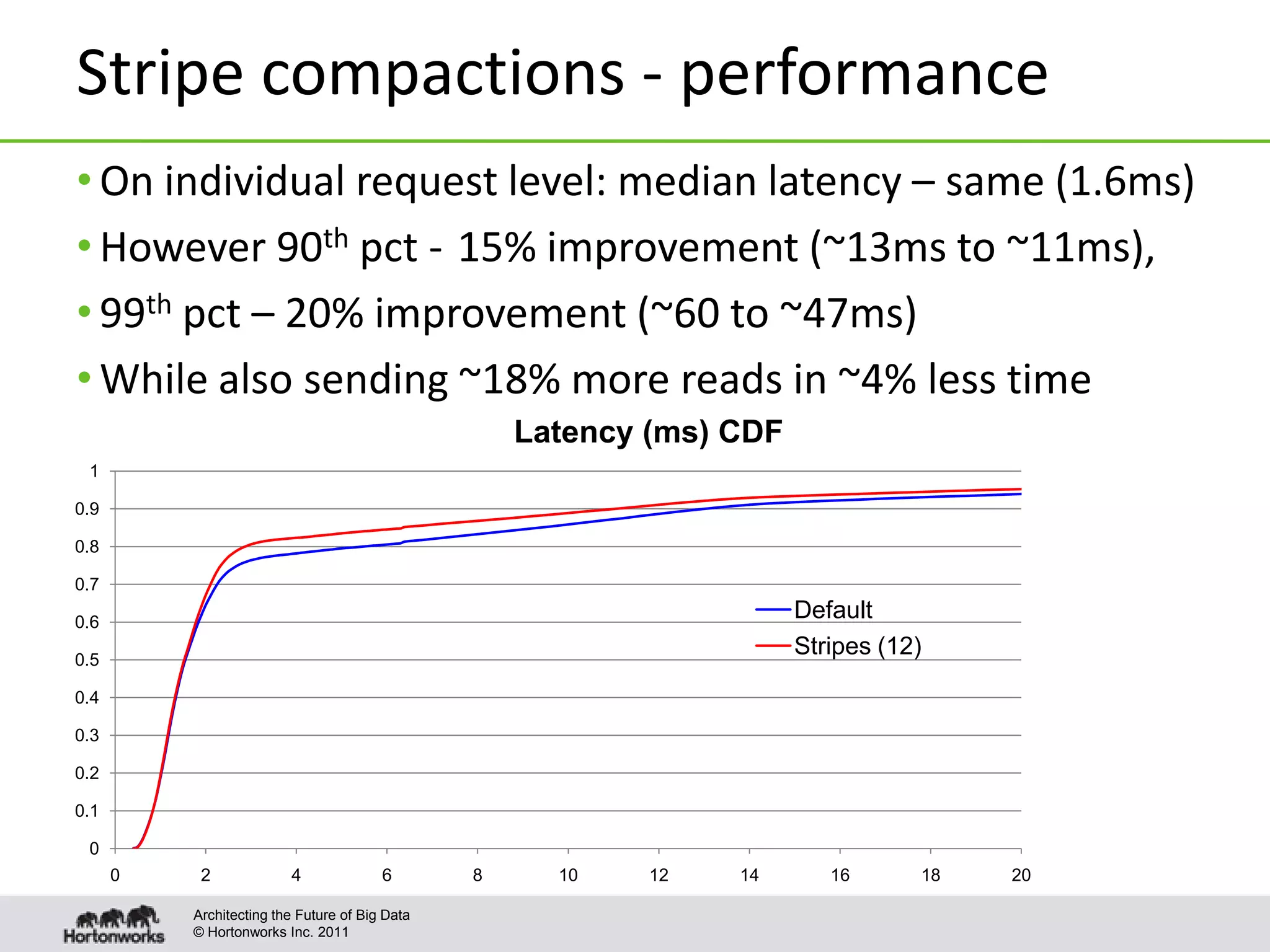








































This document discusses improvements to compaction in Apache HBase. It begins with an overview of what compactions are and how they improve read performance in HBase. It then describes the default compaction algorithm and improvements made, including exploring selection and off-peak compactions. The document also covers making compactions more pluggable and enabling tuning on a per-table/column family basis. Finally, it proposes algorithms for different scenarios, such as level and stripe compactions, to improve compaction performance.










































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)












