Download to read offline


























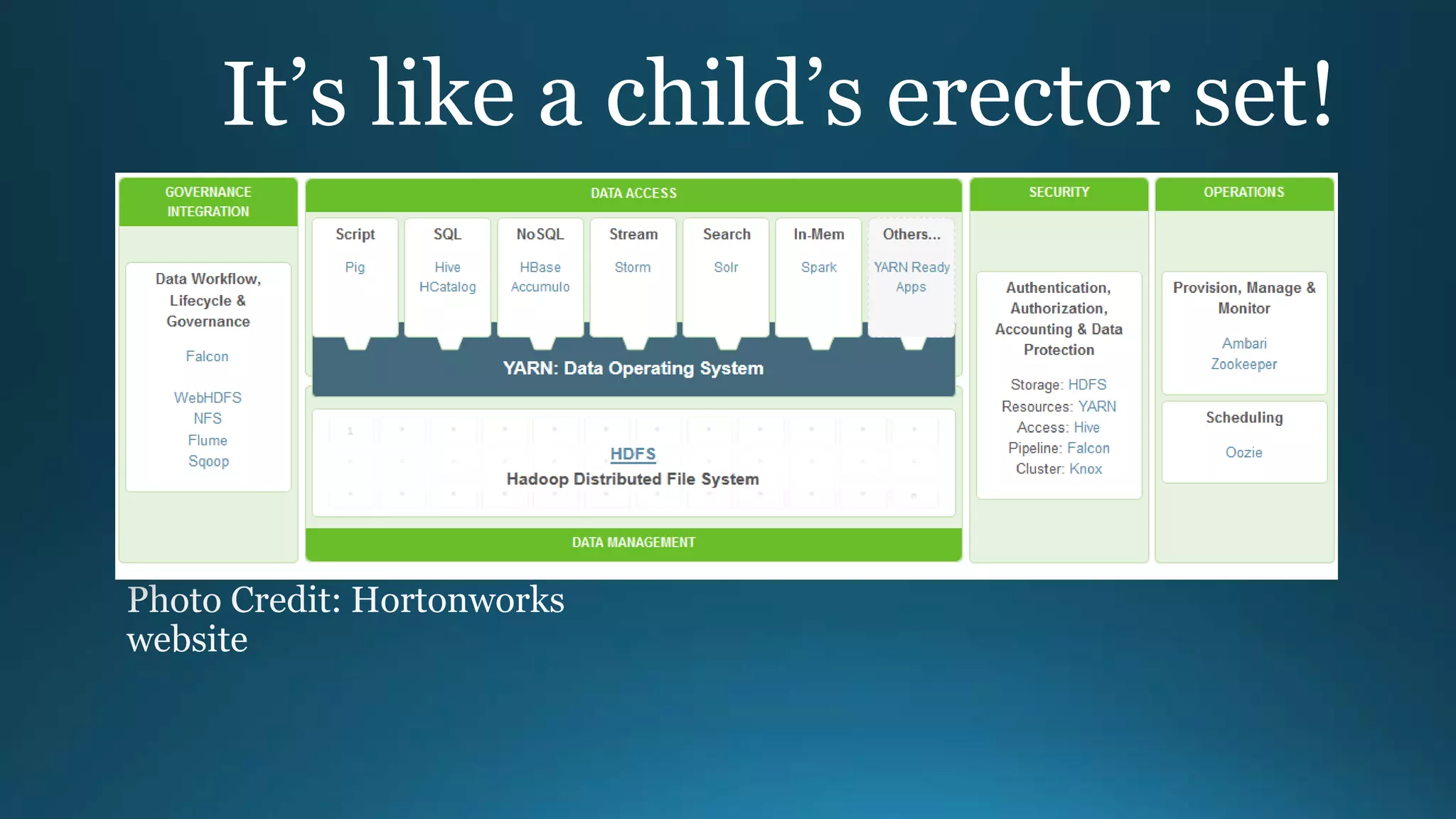
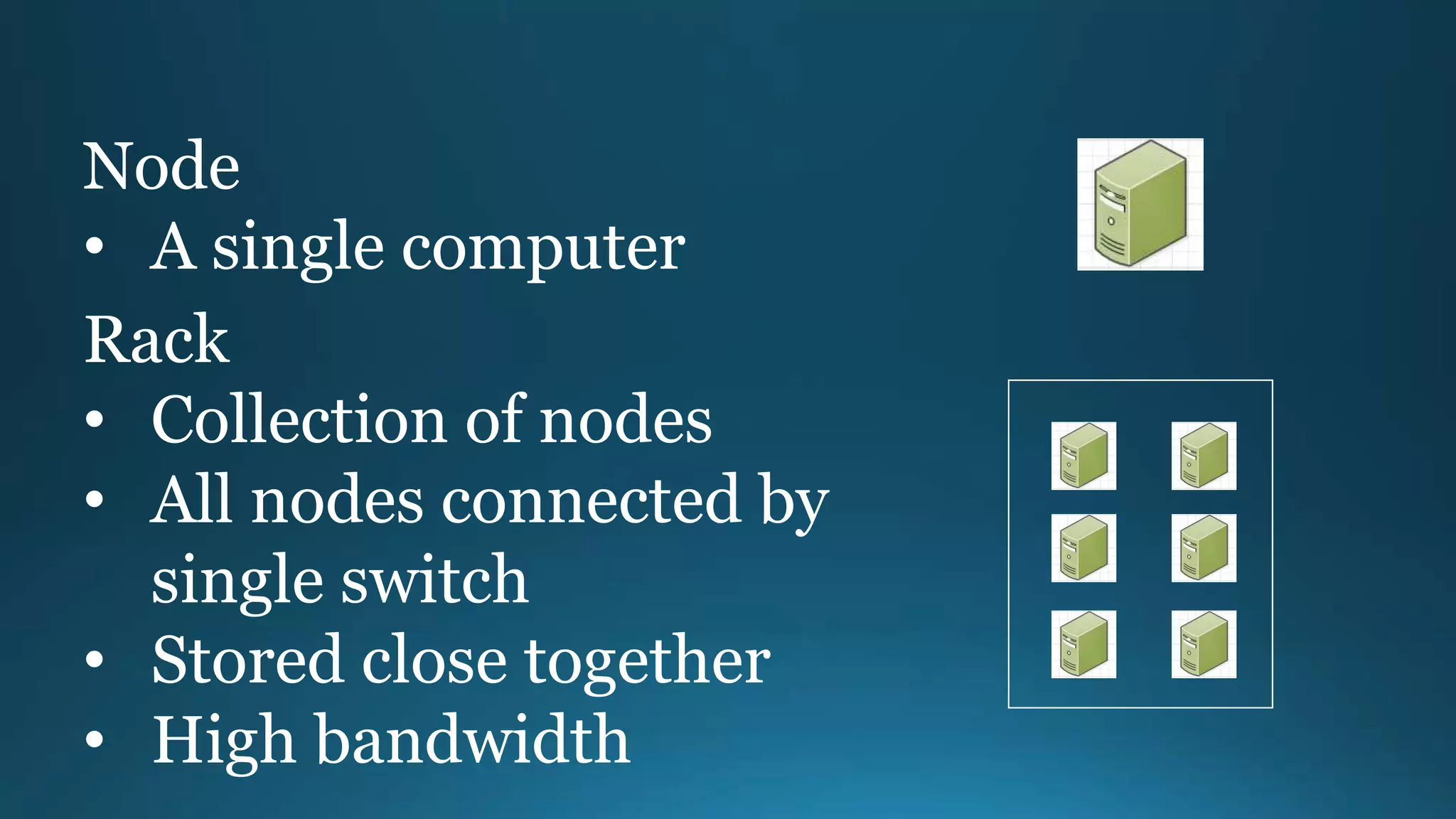





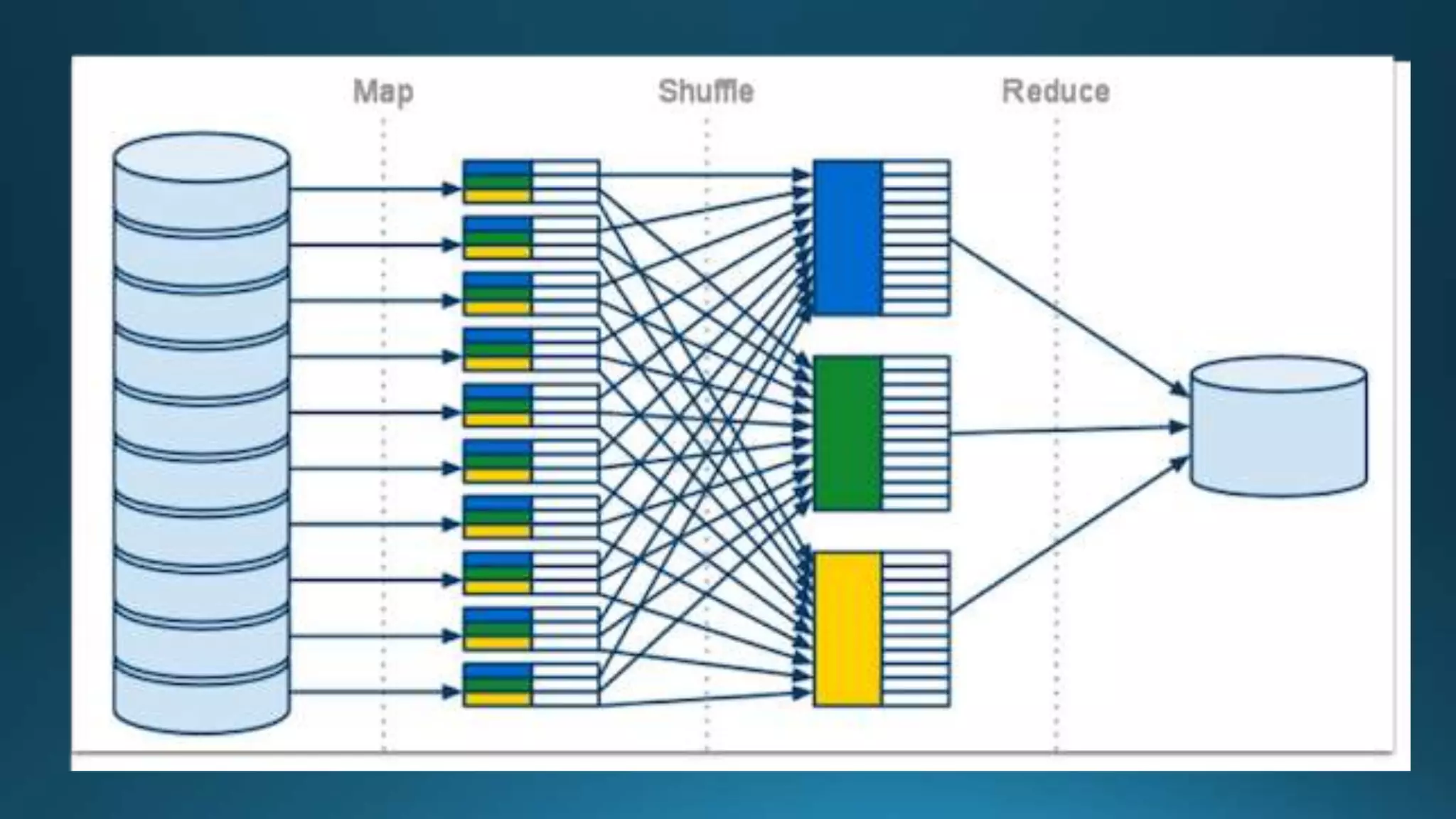





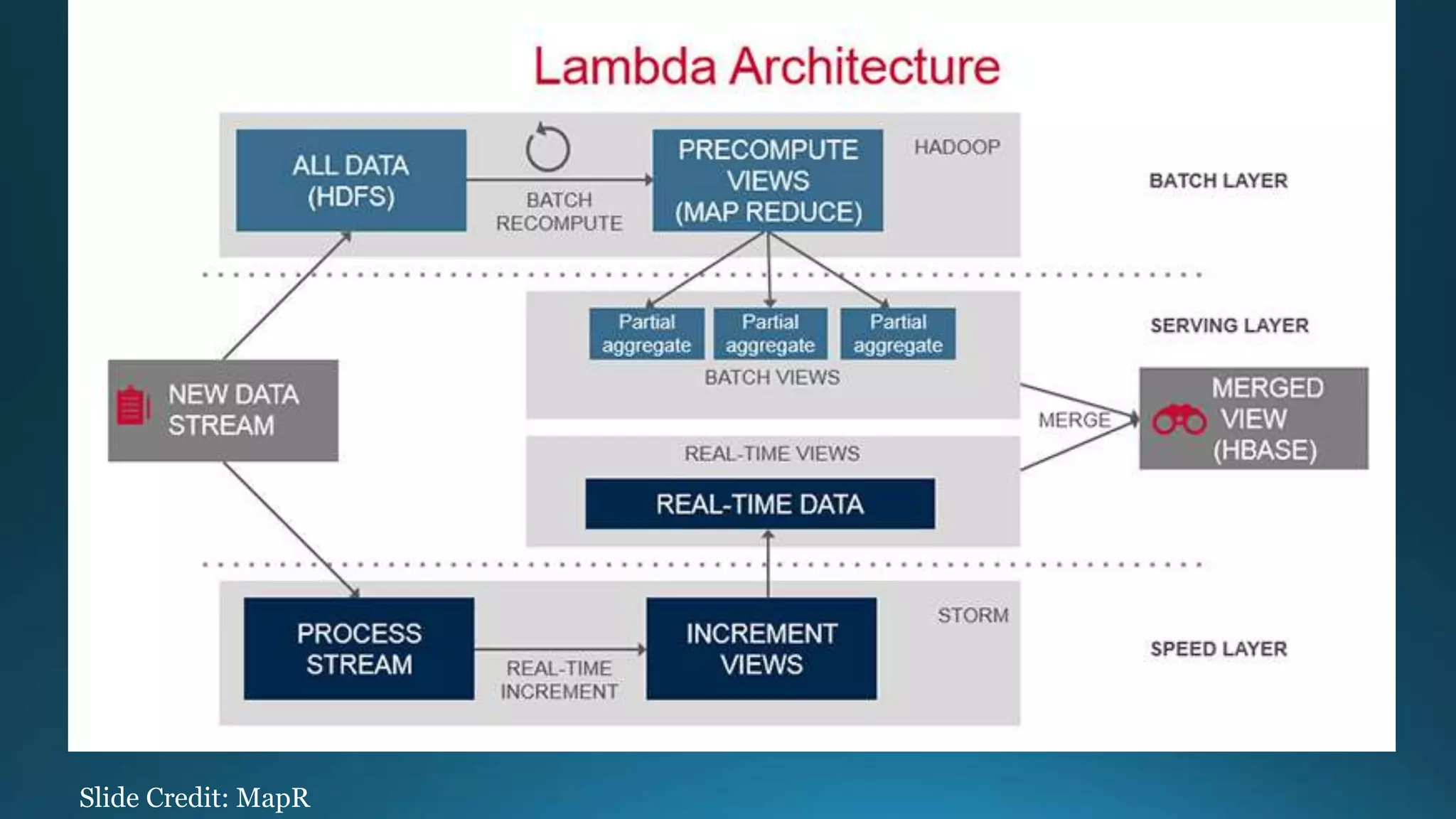
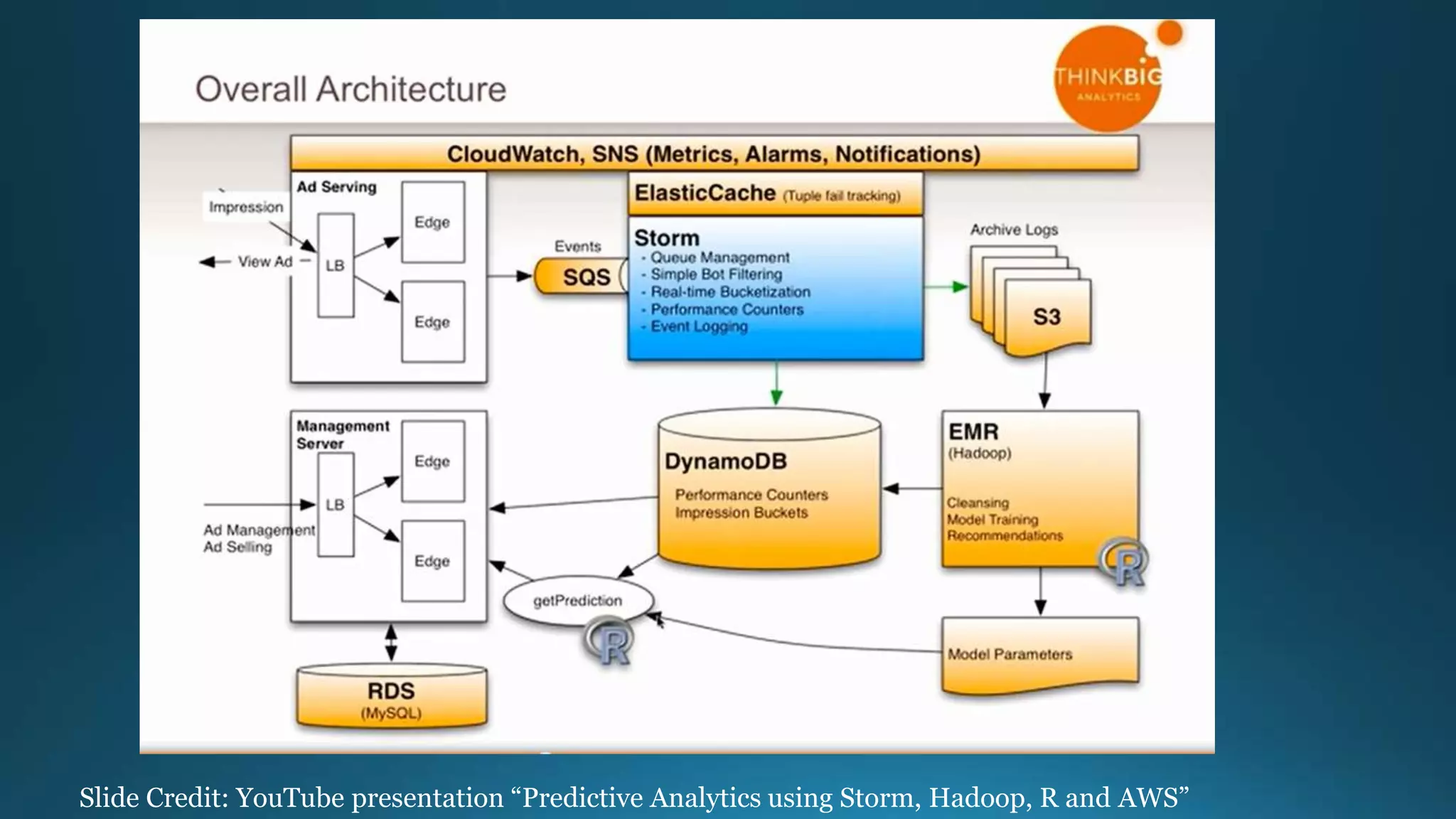



















































The document outlines the importance and benefits of Apache Hadoop for organizations dealing with large amounts of data. It emphasizes Hadoop's cost-effectiveness, scalability, and ability to handle unstructured data while providing a framework for distributed data storage and analysis. The document also highlights various Hadoop components and technologies, including HDFS, MapReduce, and Hive, and suggests resources for getting started with Hadoop.

















































































