Downloaded 19 times










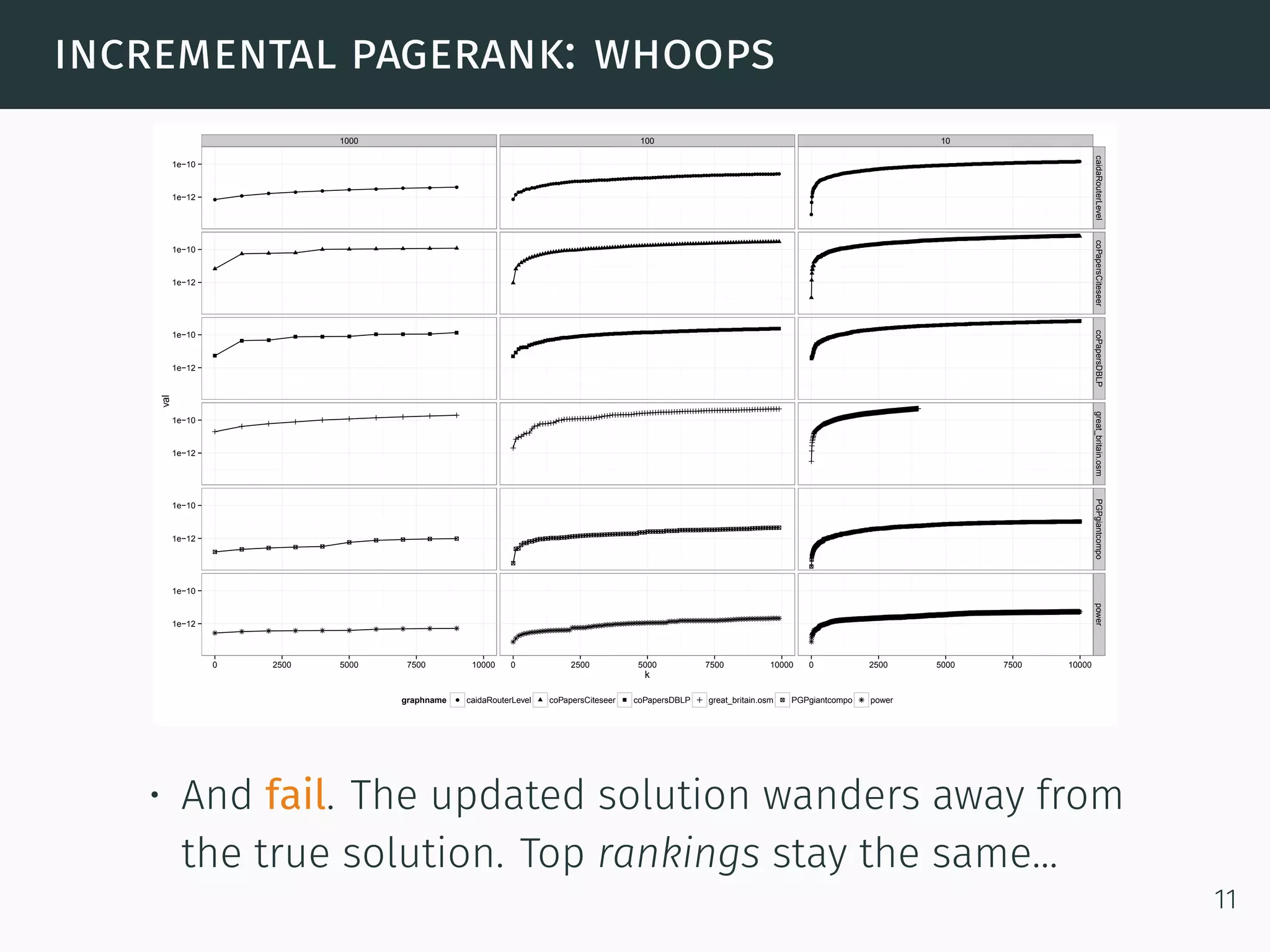

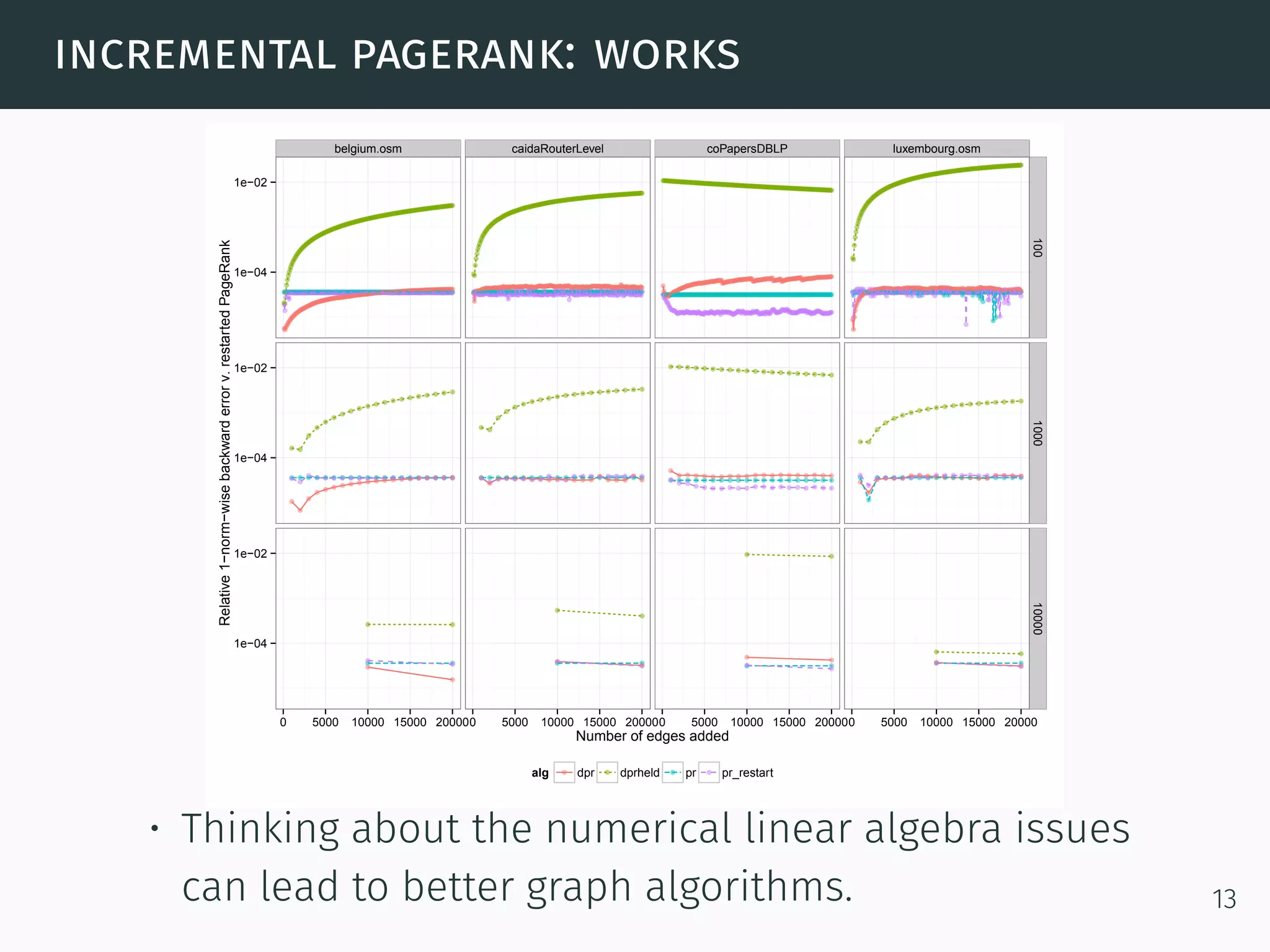

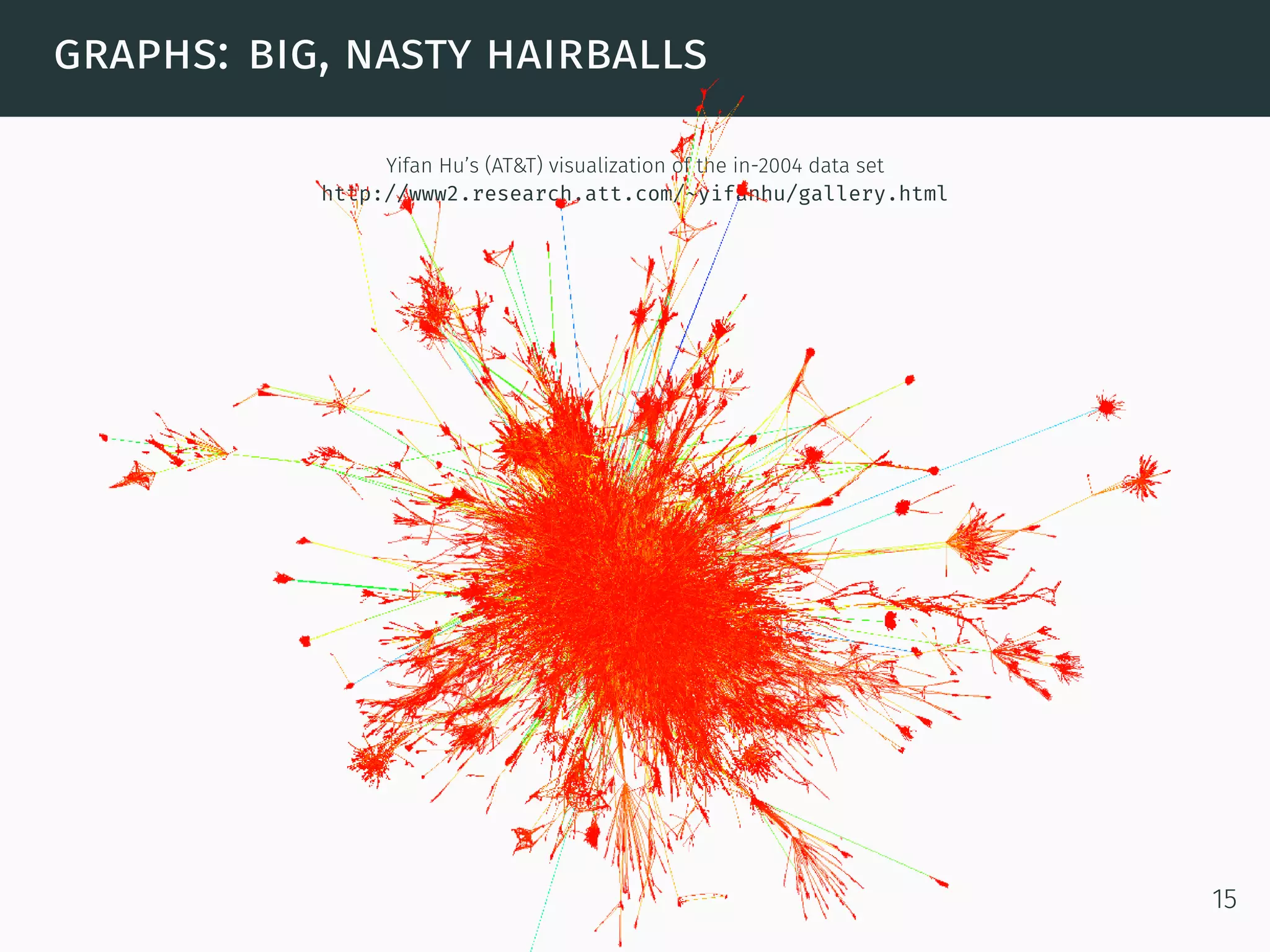
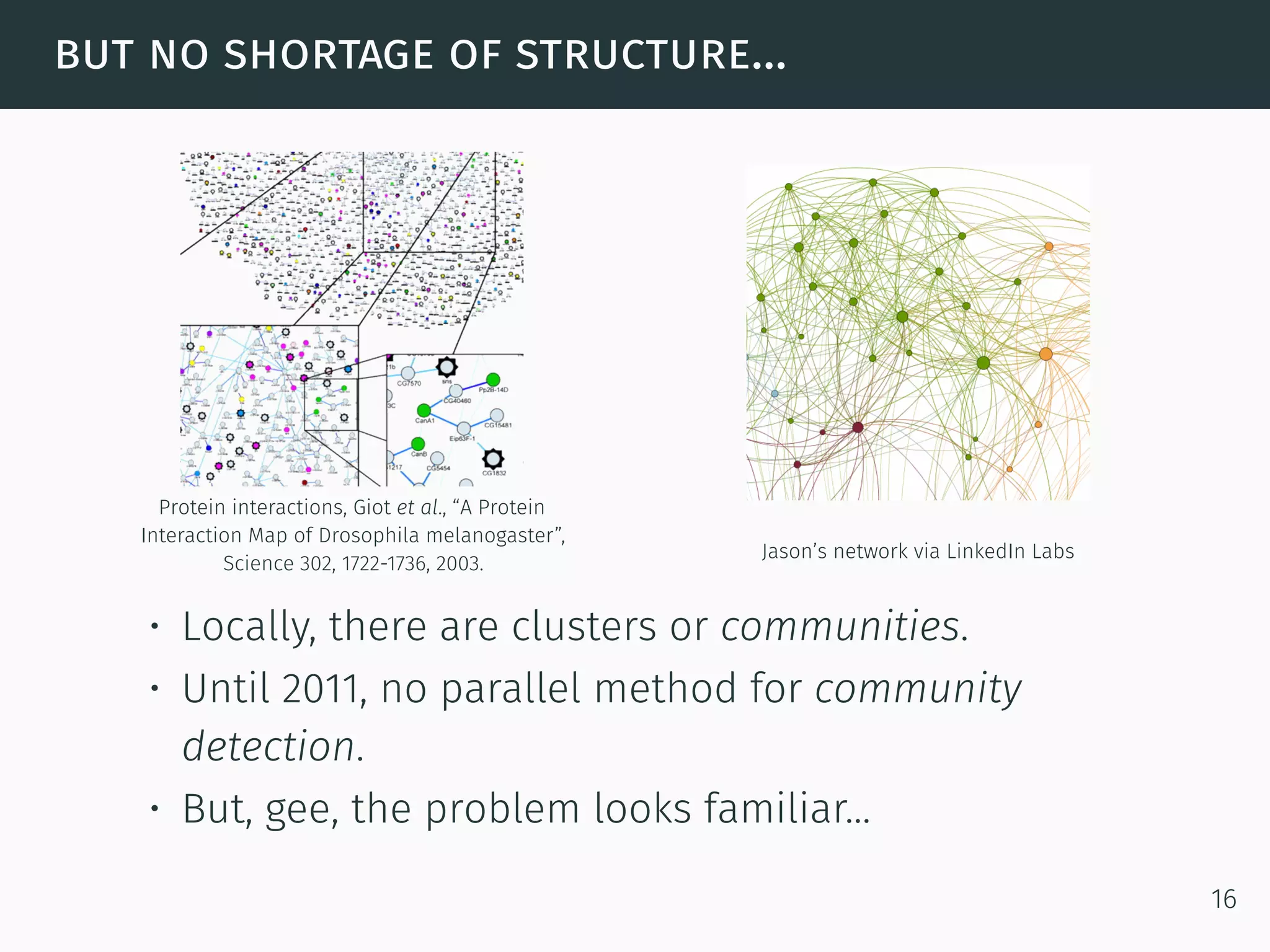









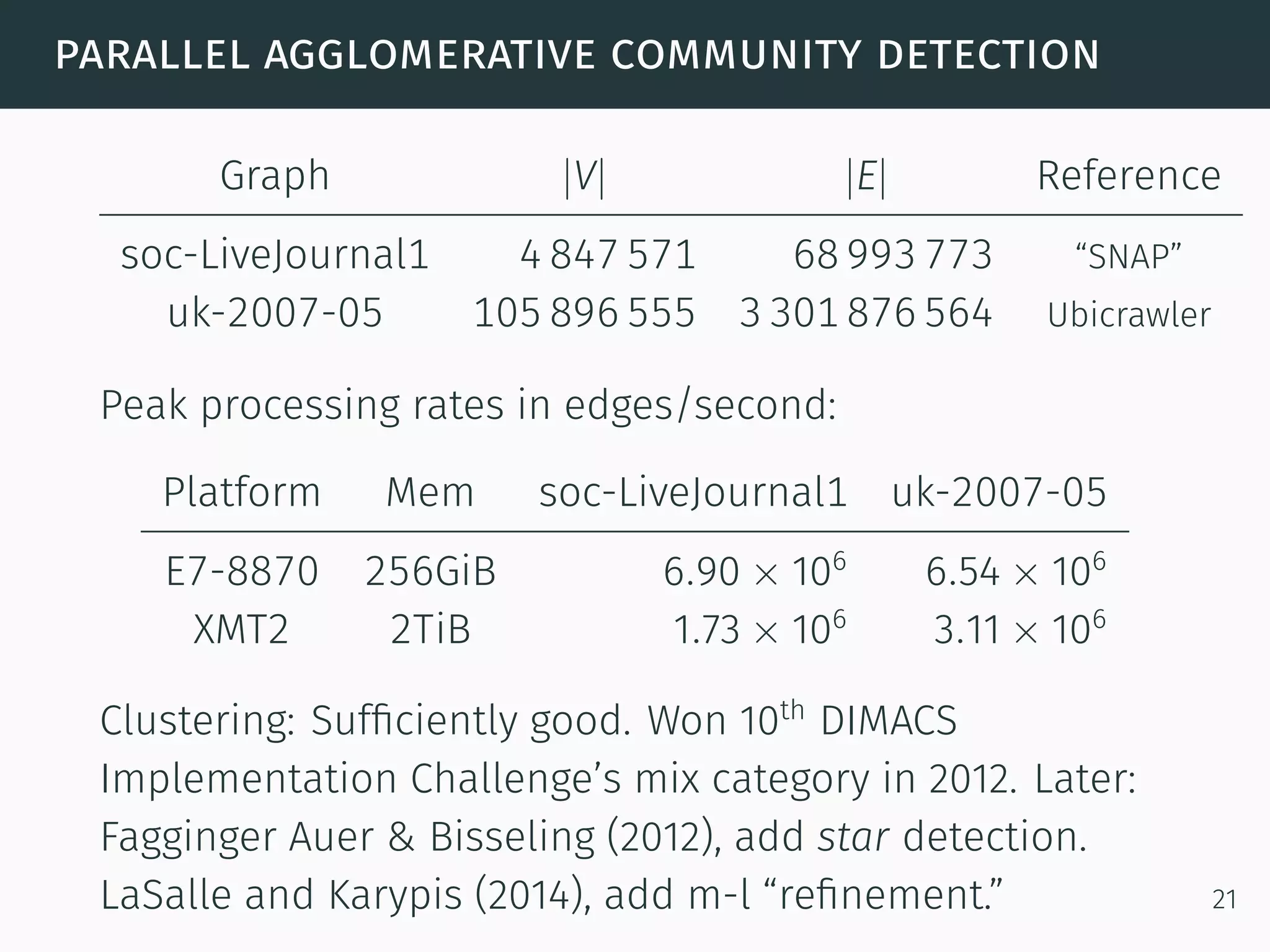
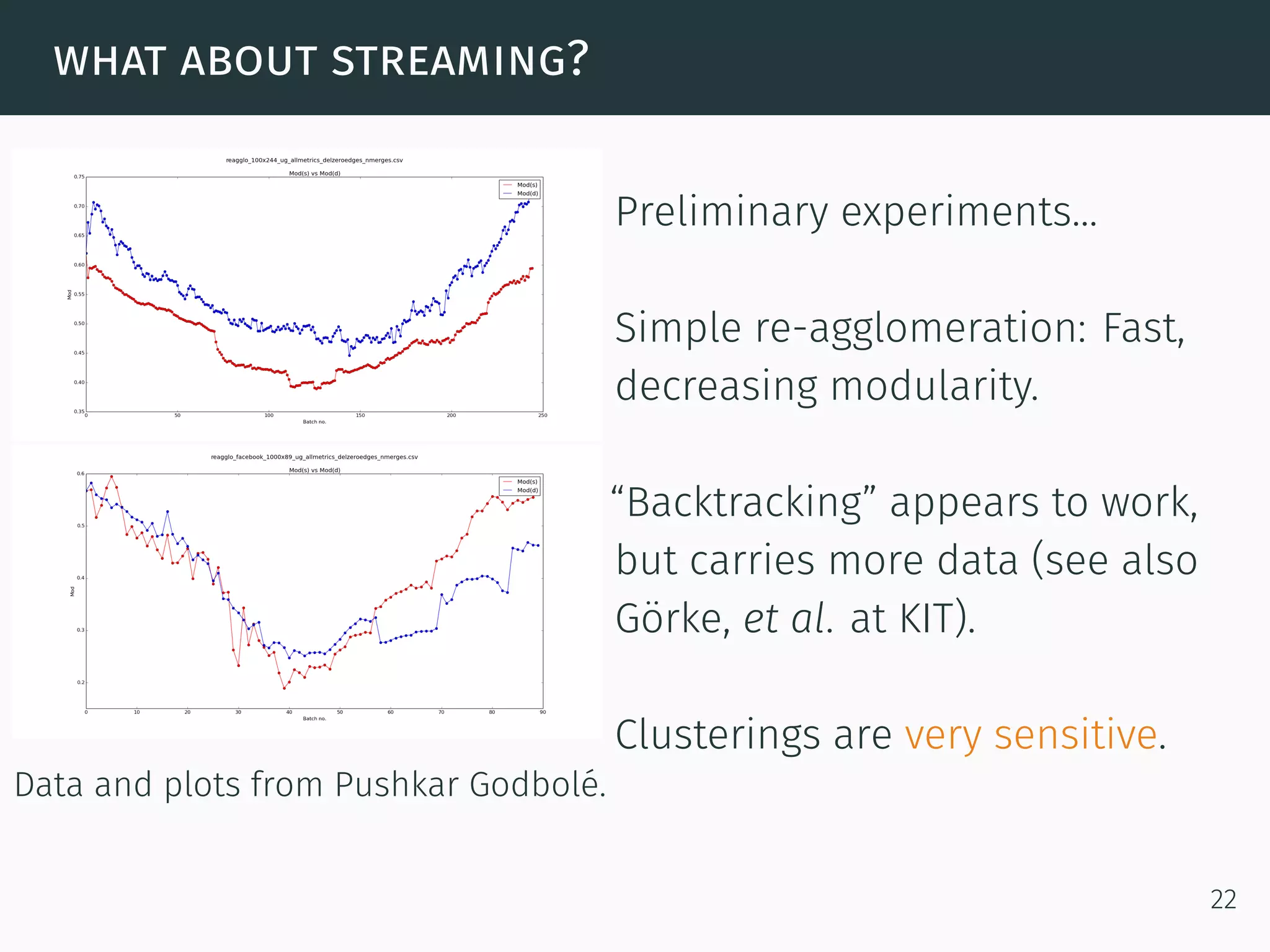


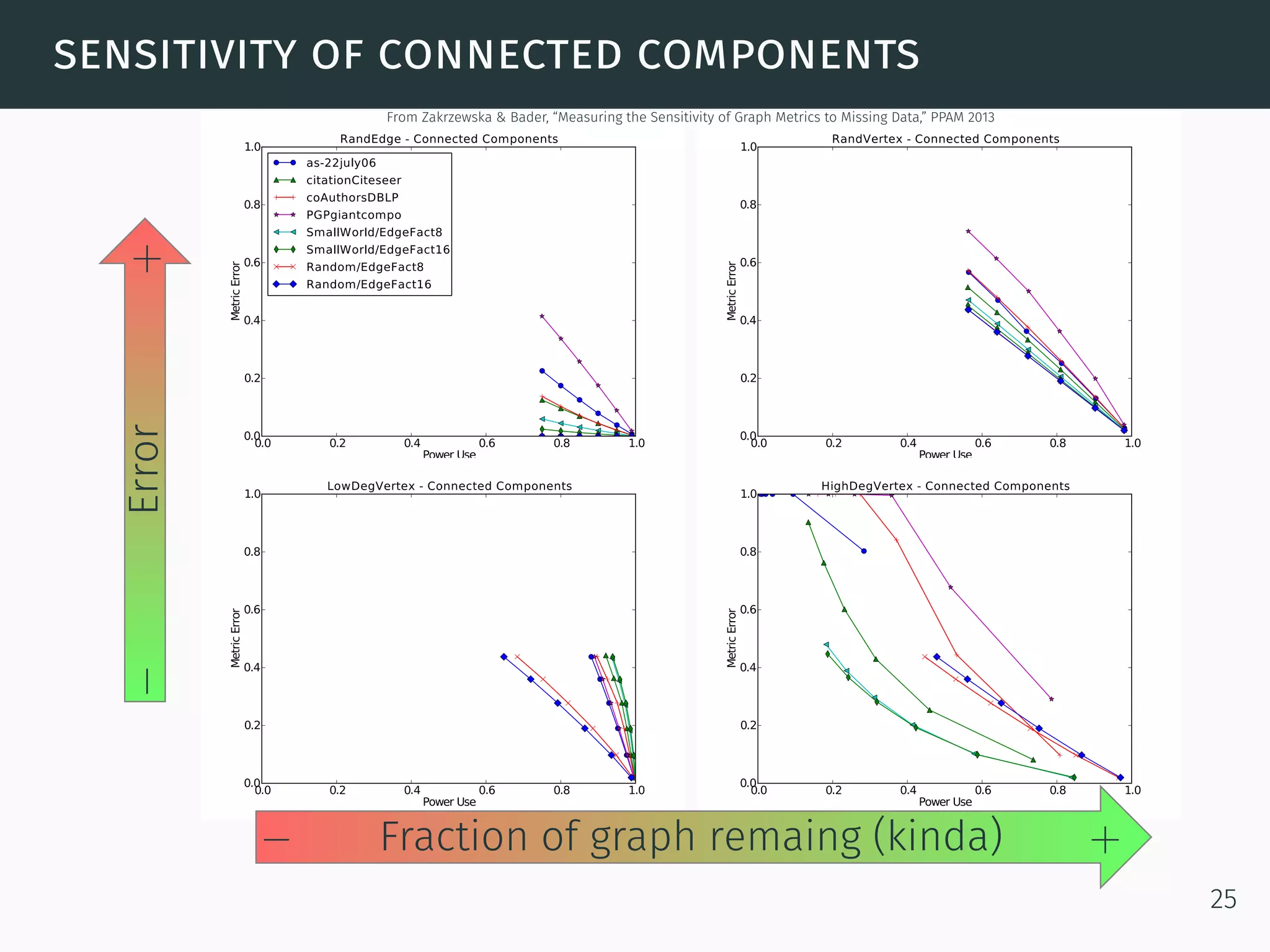







































The document discusses advanced graph analysis techniques beyond linear algebra, highlighting applications in areas such as cybersecurity, healthcare, and social networks. It explains methods like incremental pagerank and community detection, emphasizing the need for efficient algorithms in the context of dynamic and large-scale data environments. The document concludes with considerations for future research in integrating graph analysis with linear algebra and numerical analysis.

























































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)














