Download to read offline




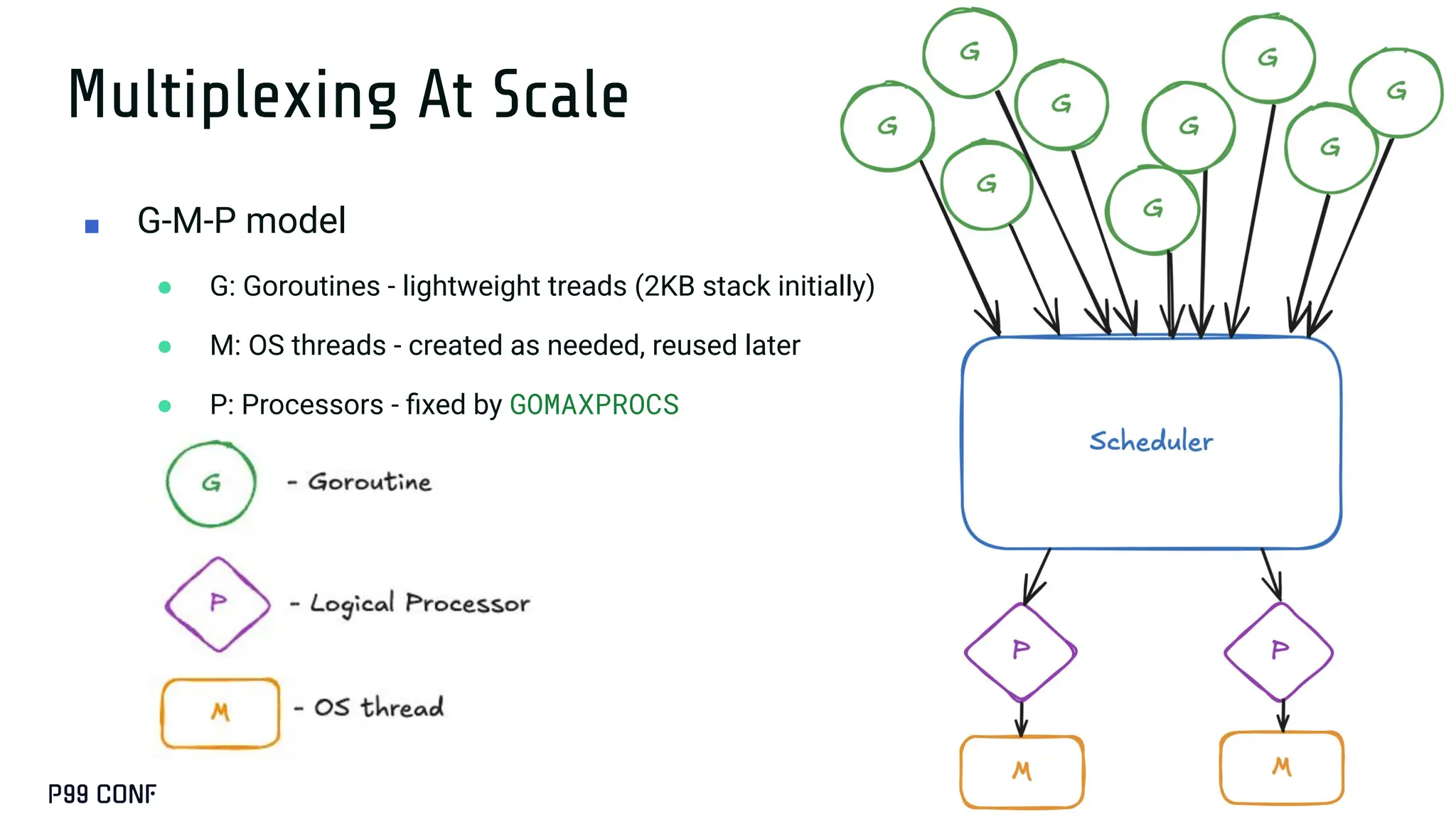
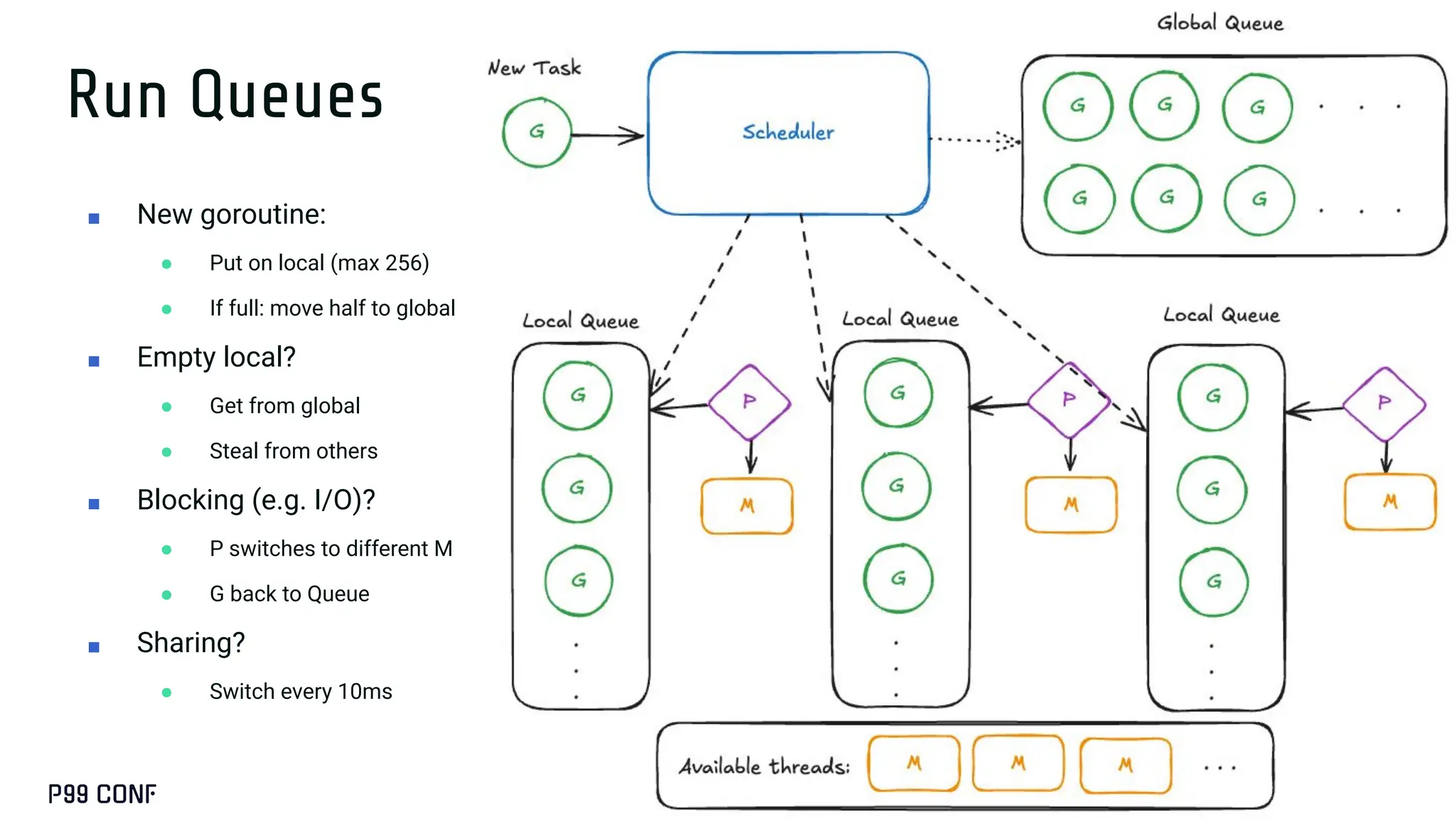





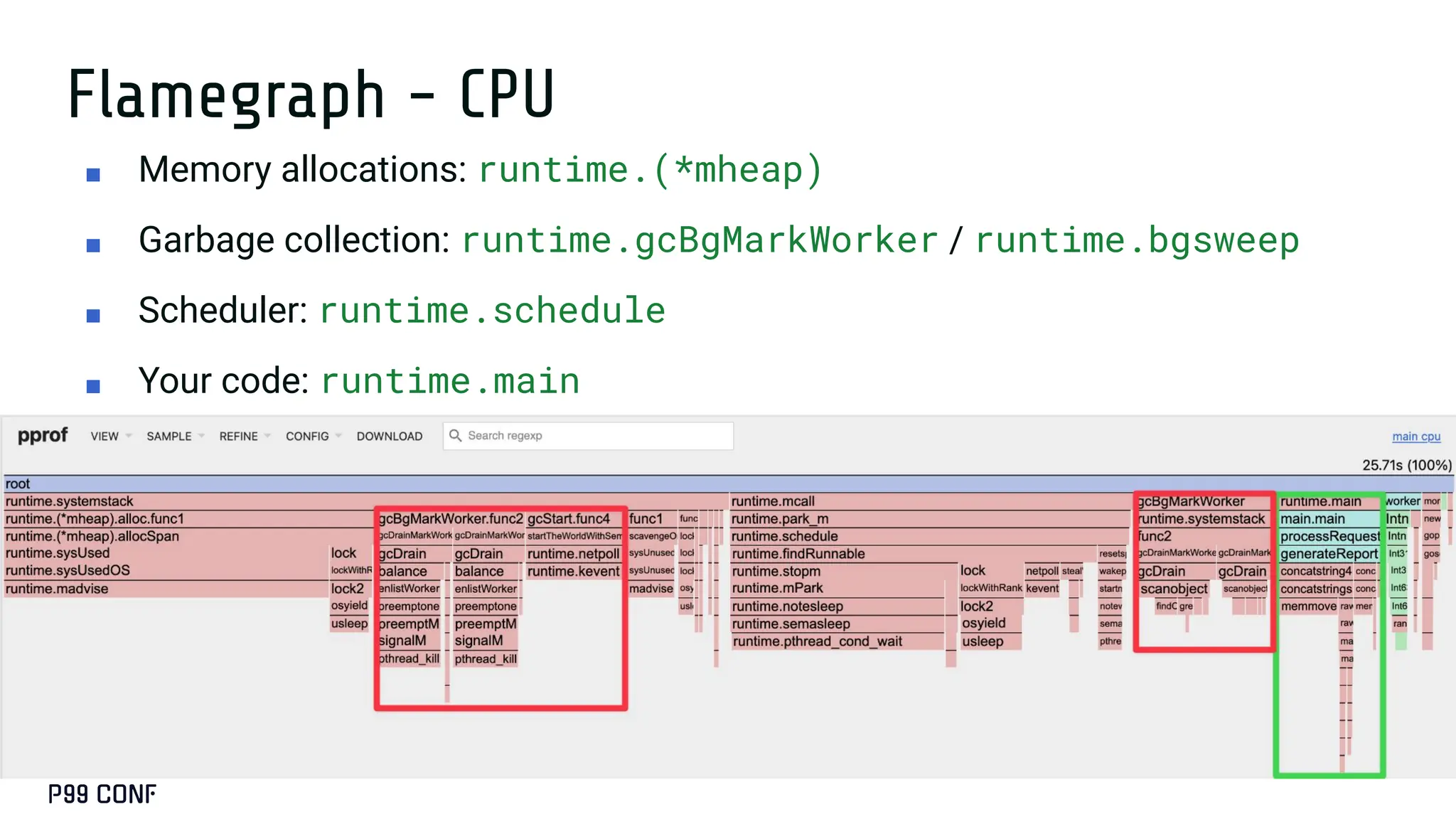
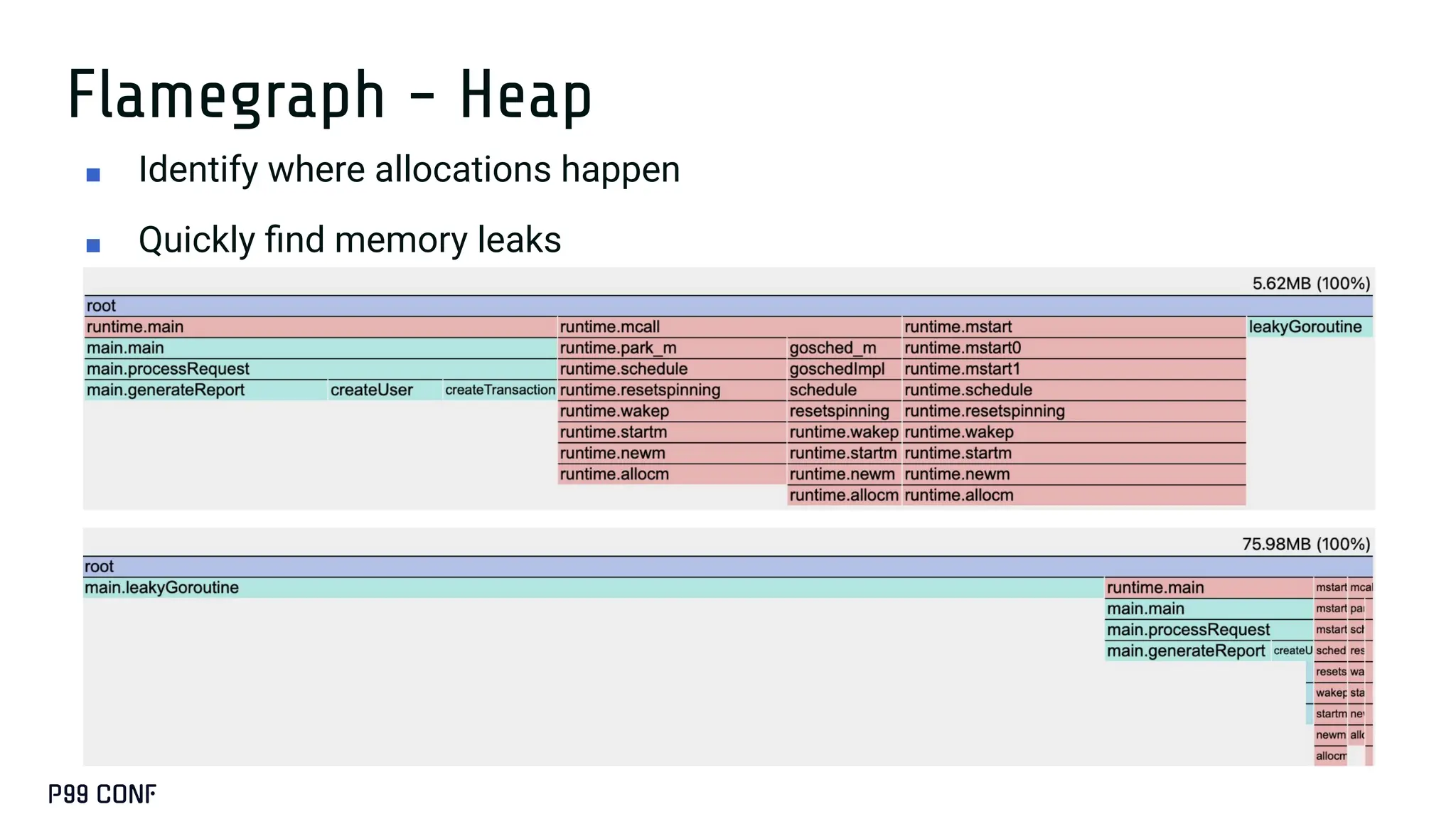


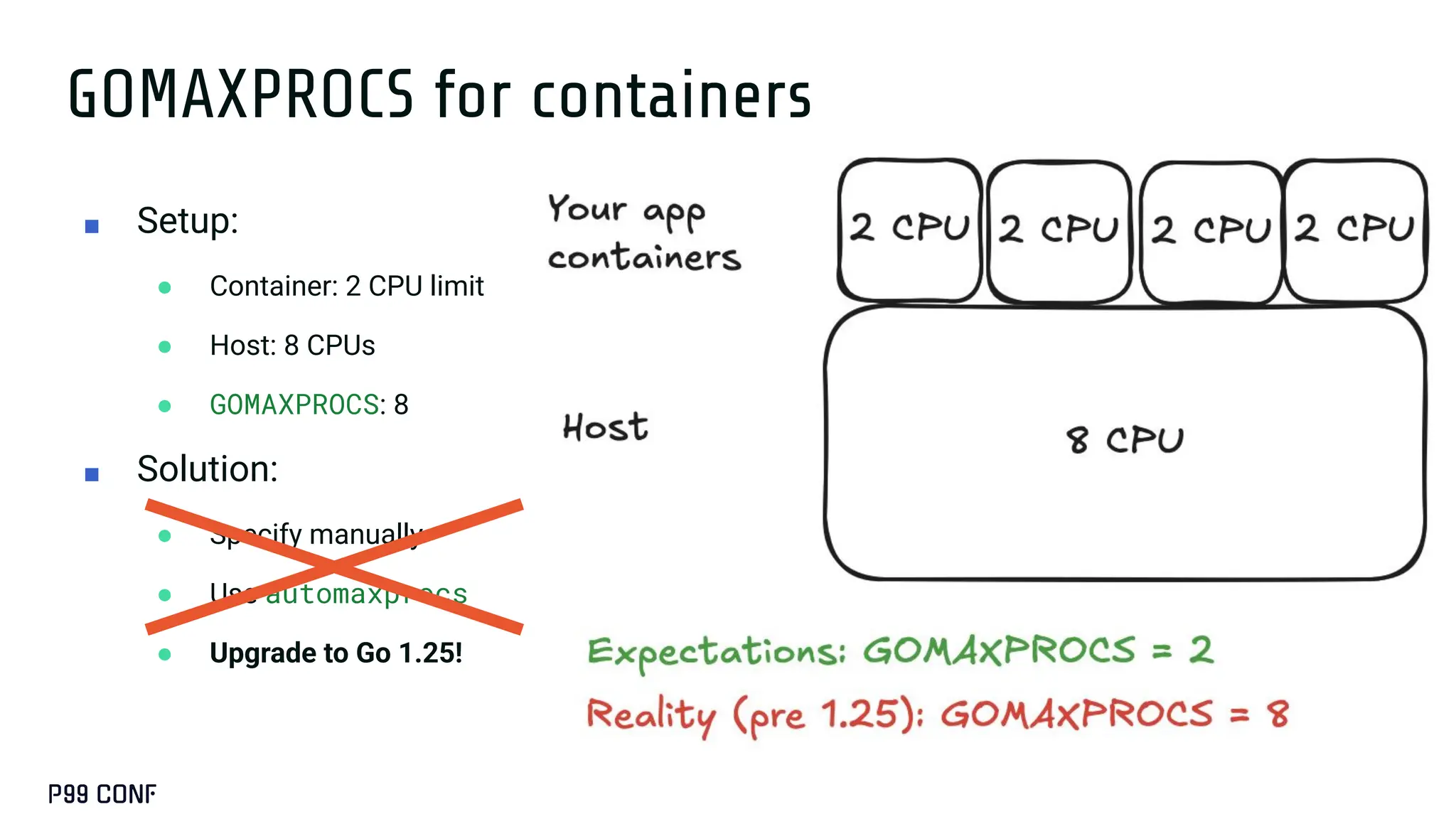

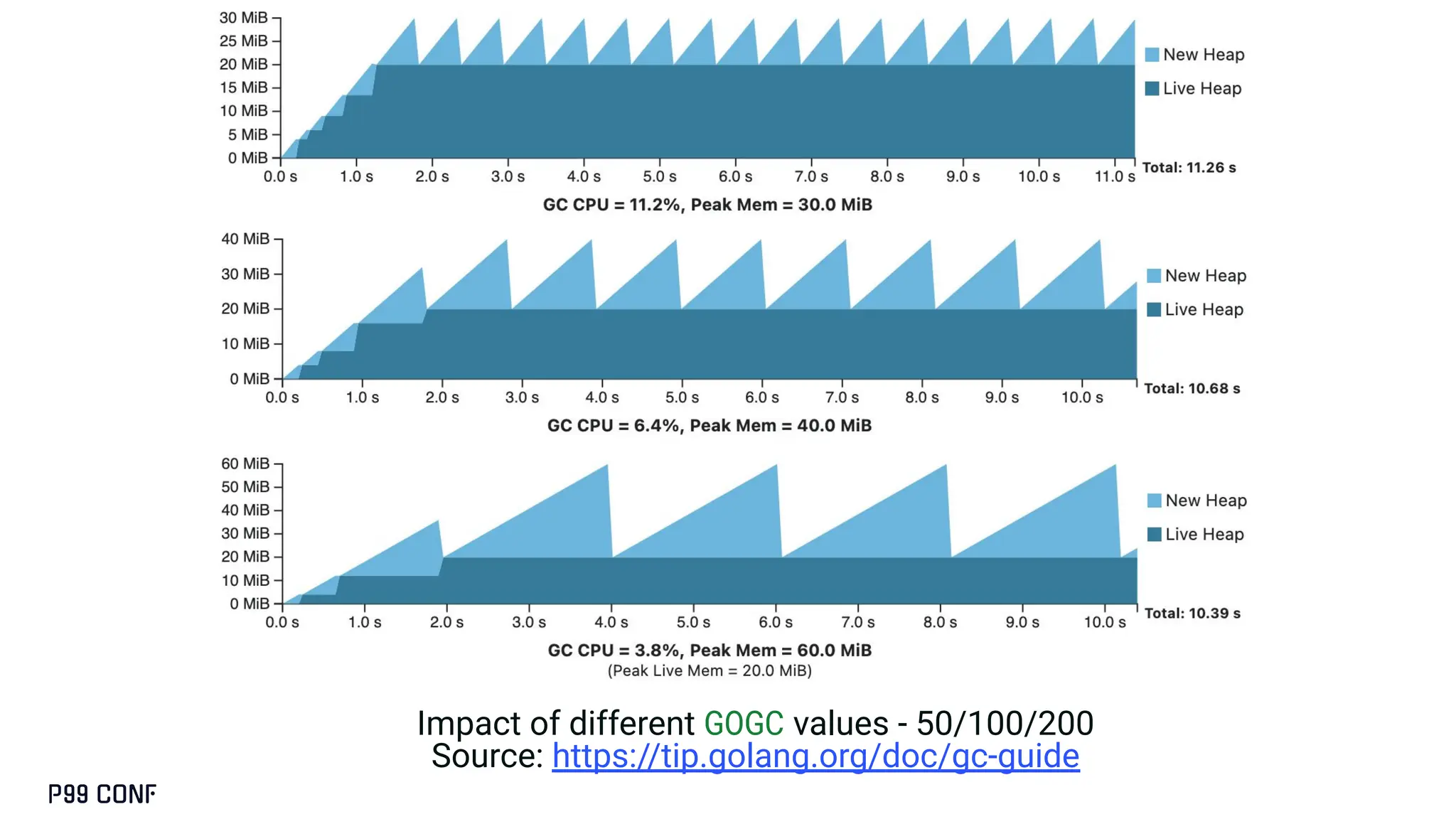

































Most Go services don’t need runtime tuning...until they do. At ShareChat, running hundreds of Go services across thousands of cores, we’ve seen real gains from understanding the scheduler and garbage collector under production load. This talk covers when tuning is worth it, how to use runtime variables like GOGC, GOMEMLIMIT, and GOMAXPROCS, and how to apply Profile-Guided Optimisation. We’ll also share lightweight monitoring strategies and the performance improvements we achieved in production.



































































