Downloaded 16 times





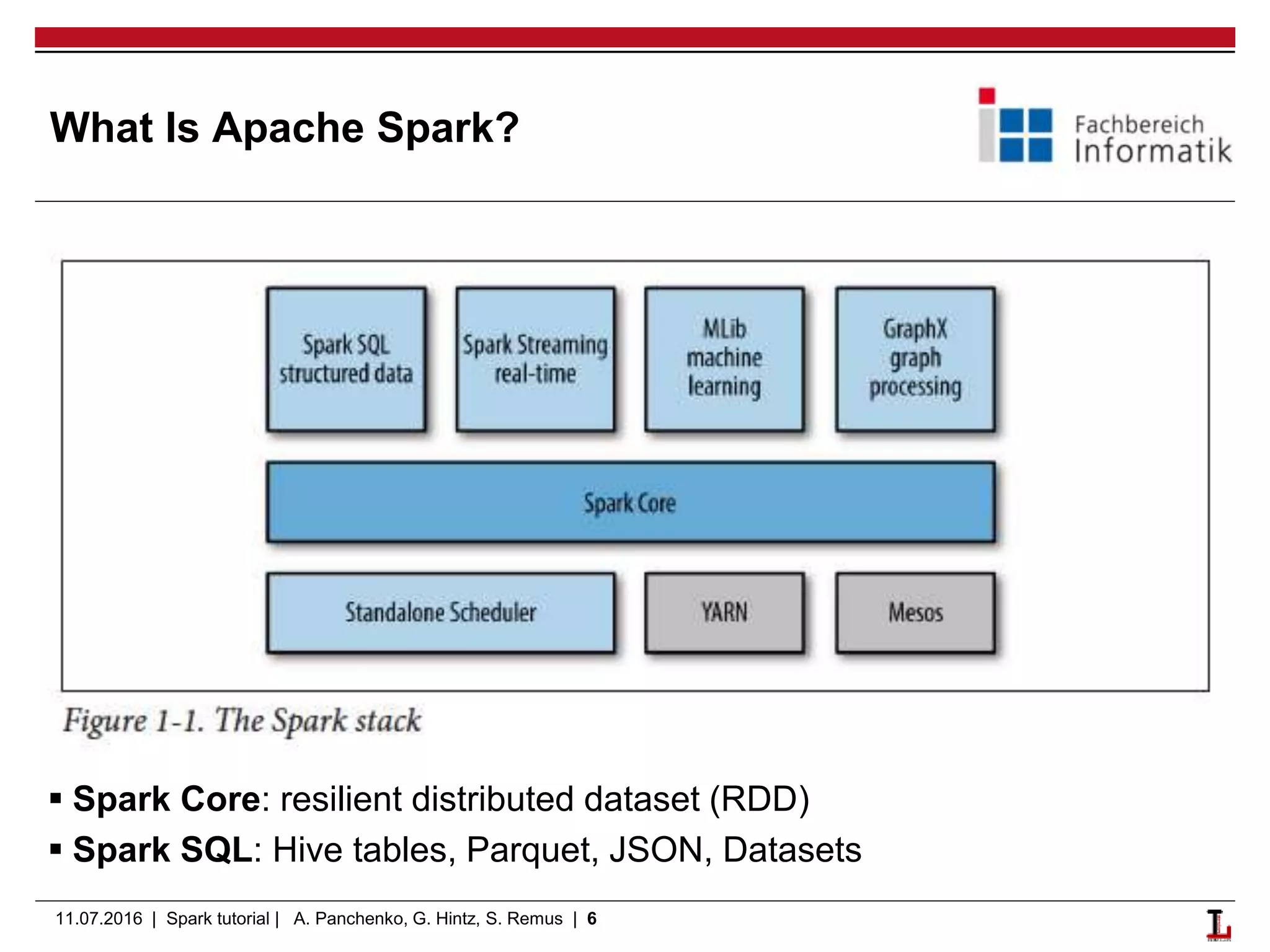
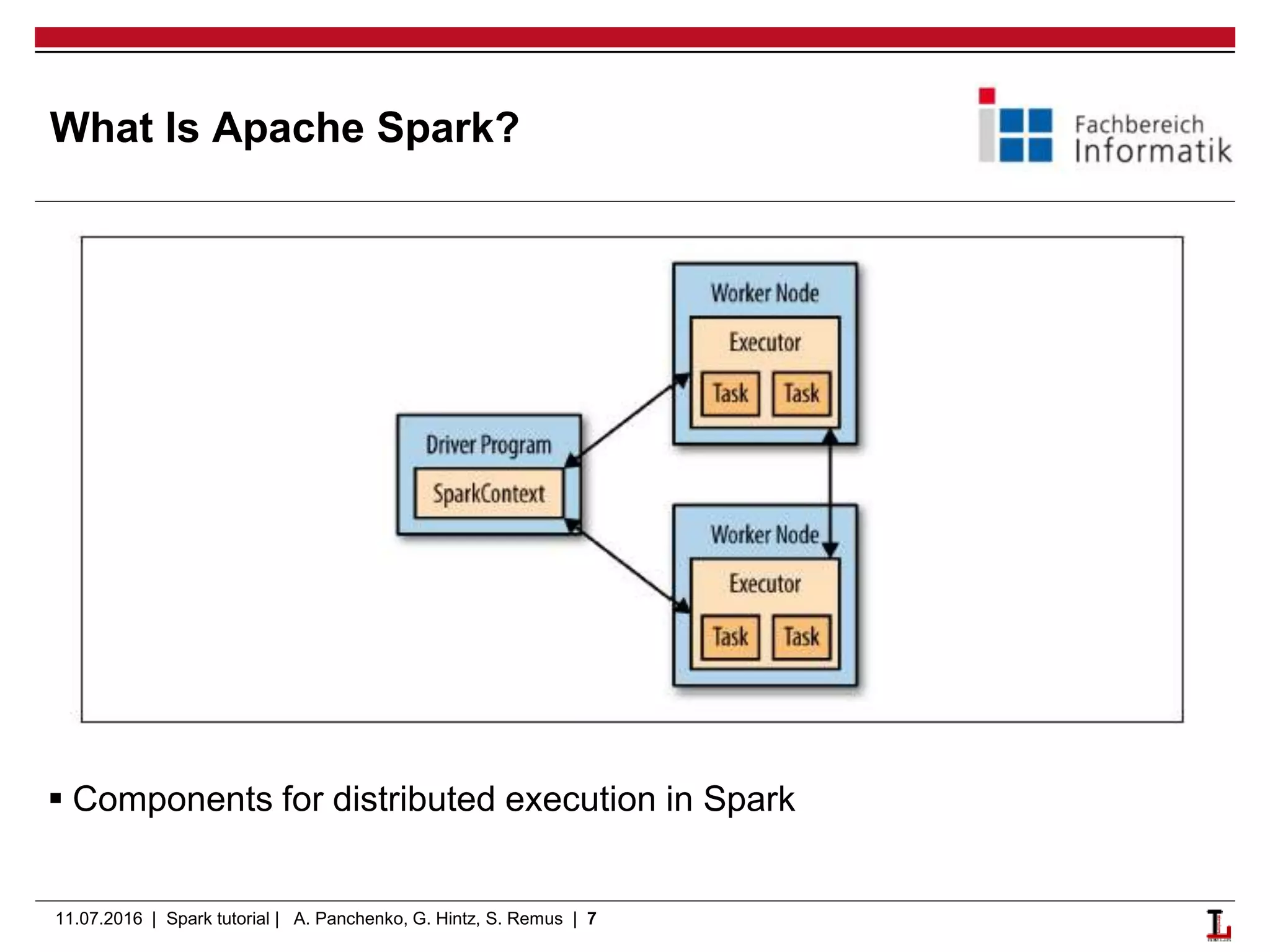




















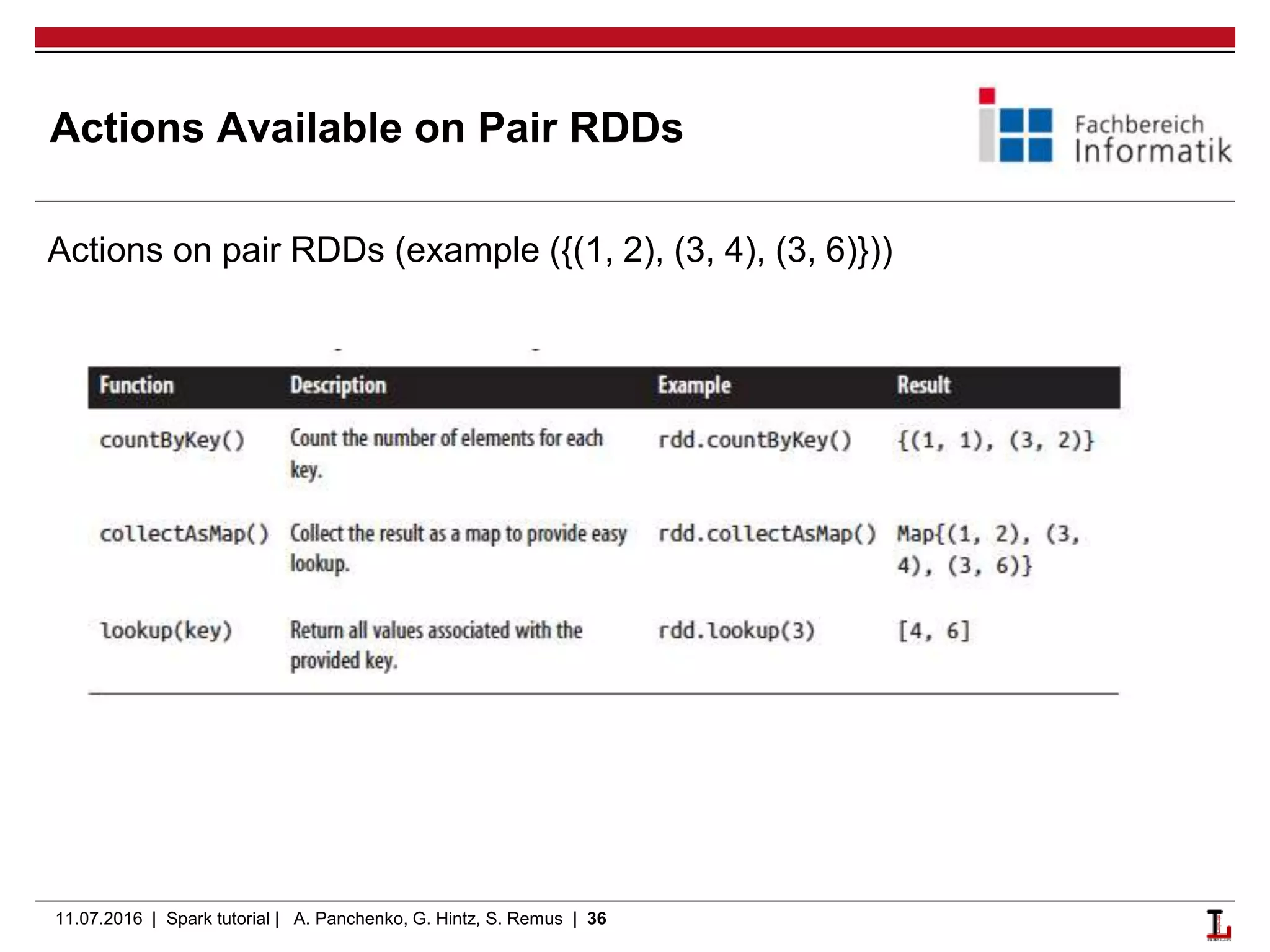









































This document provides an outline and overview of a Spark and Flink tutorial presented by Alexander Panchenko, Gerold Hintz, and Steffen Remus on 11.07.2016. The tutorial covers Scala basics, Spark fundamentals including RDDs and transformations/actions, running Spark applications, and key differences between Spark and Flink. It aims to help users get started with Apache Spark and Flink for distributed data processing and machine learning.