Download to read offline

















































The document discusses the limitations of traditional core banking systems and the challenges in product personalization due to data silos. It highlights the advantages of using event-driven architectures and tools like Apache Pinot and Trino for real-time analytics and improved product offerings. The takeaway emphasizes the benefits of microservices and domain-driven design while addressing the complexities of managing data across these domains.
Introduction by Stuart Coleman discussing the need for product personalization in banking using Kafka, Pinot, and Trino.
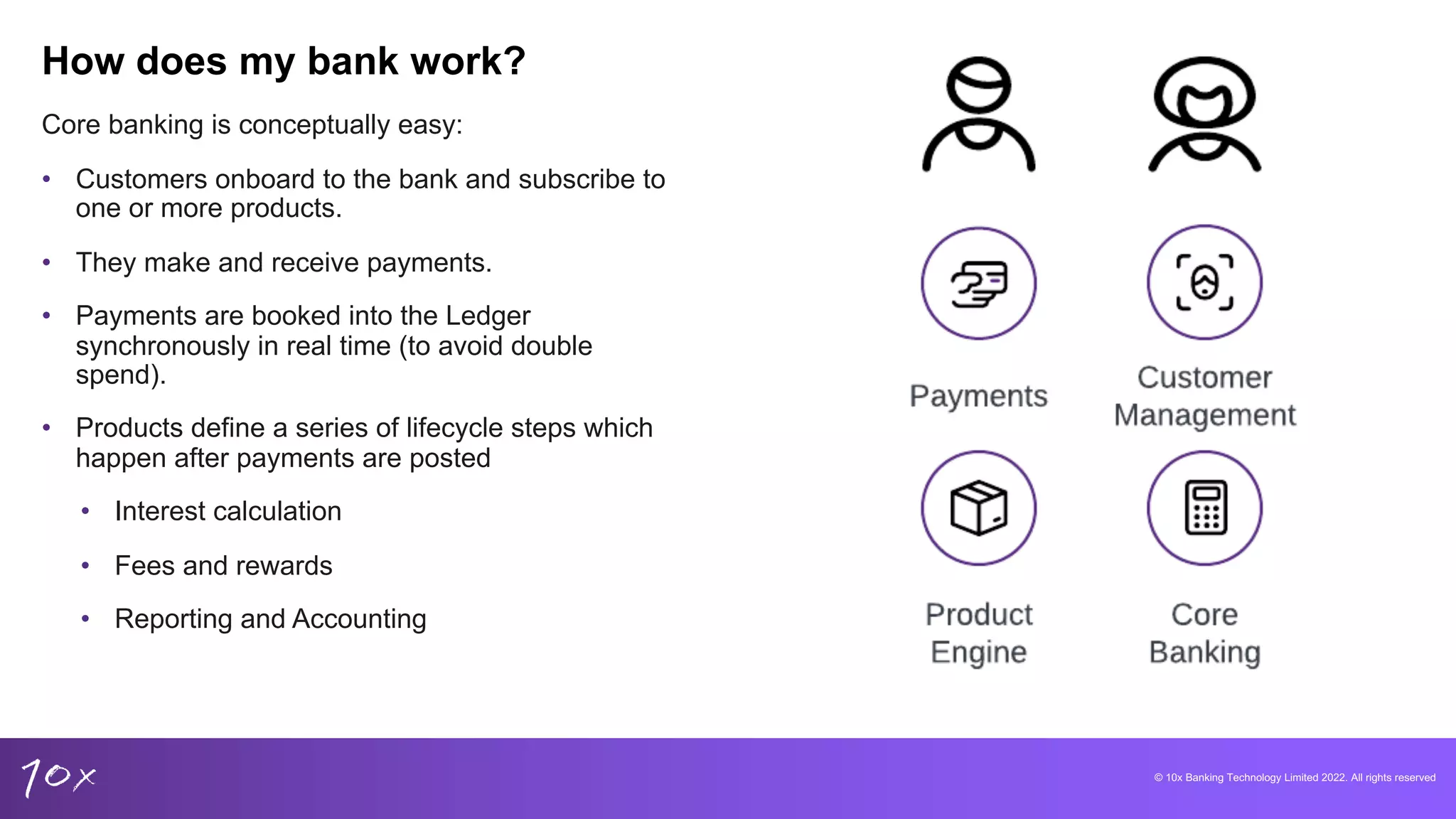
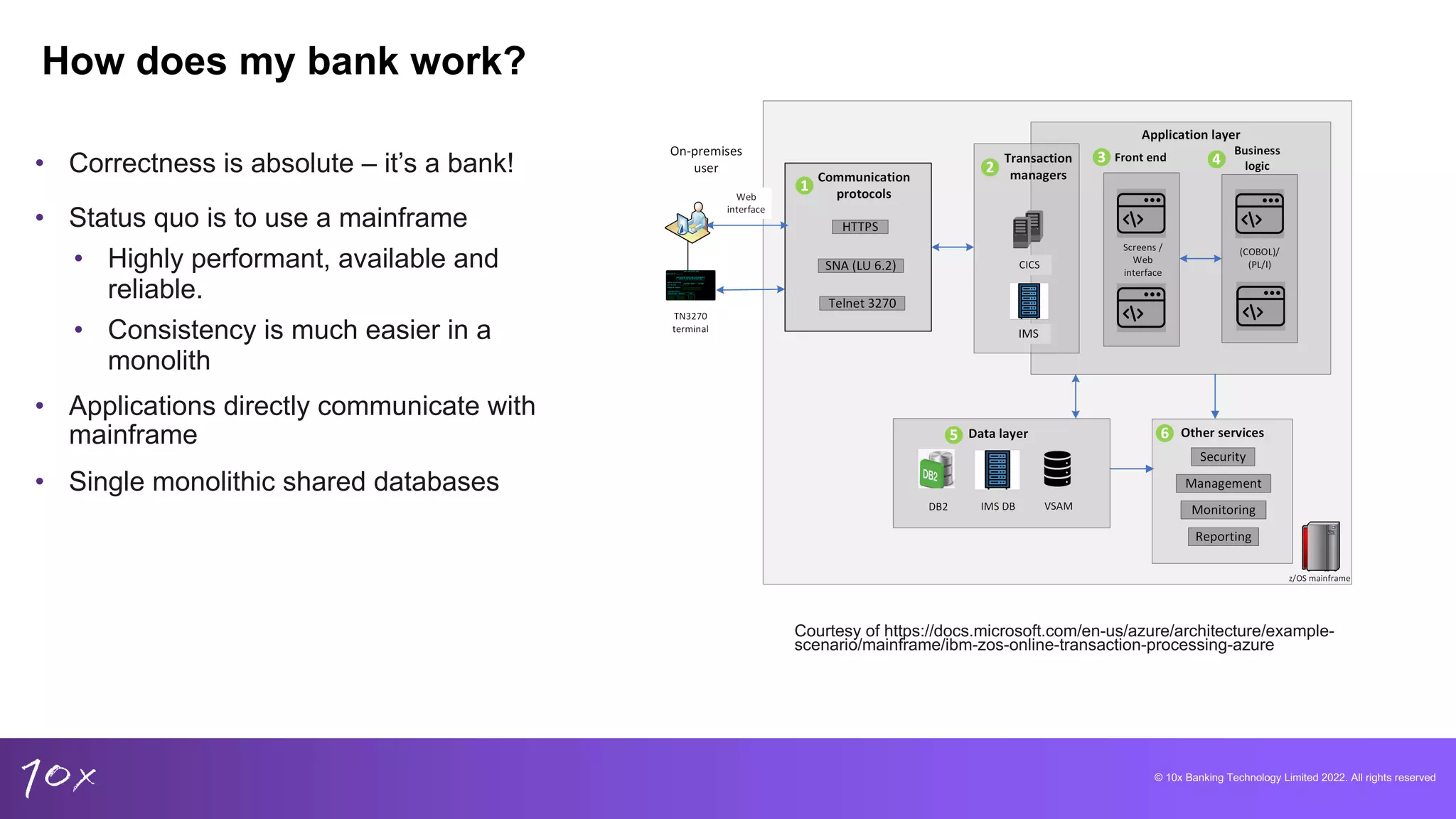
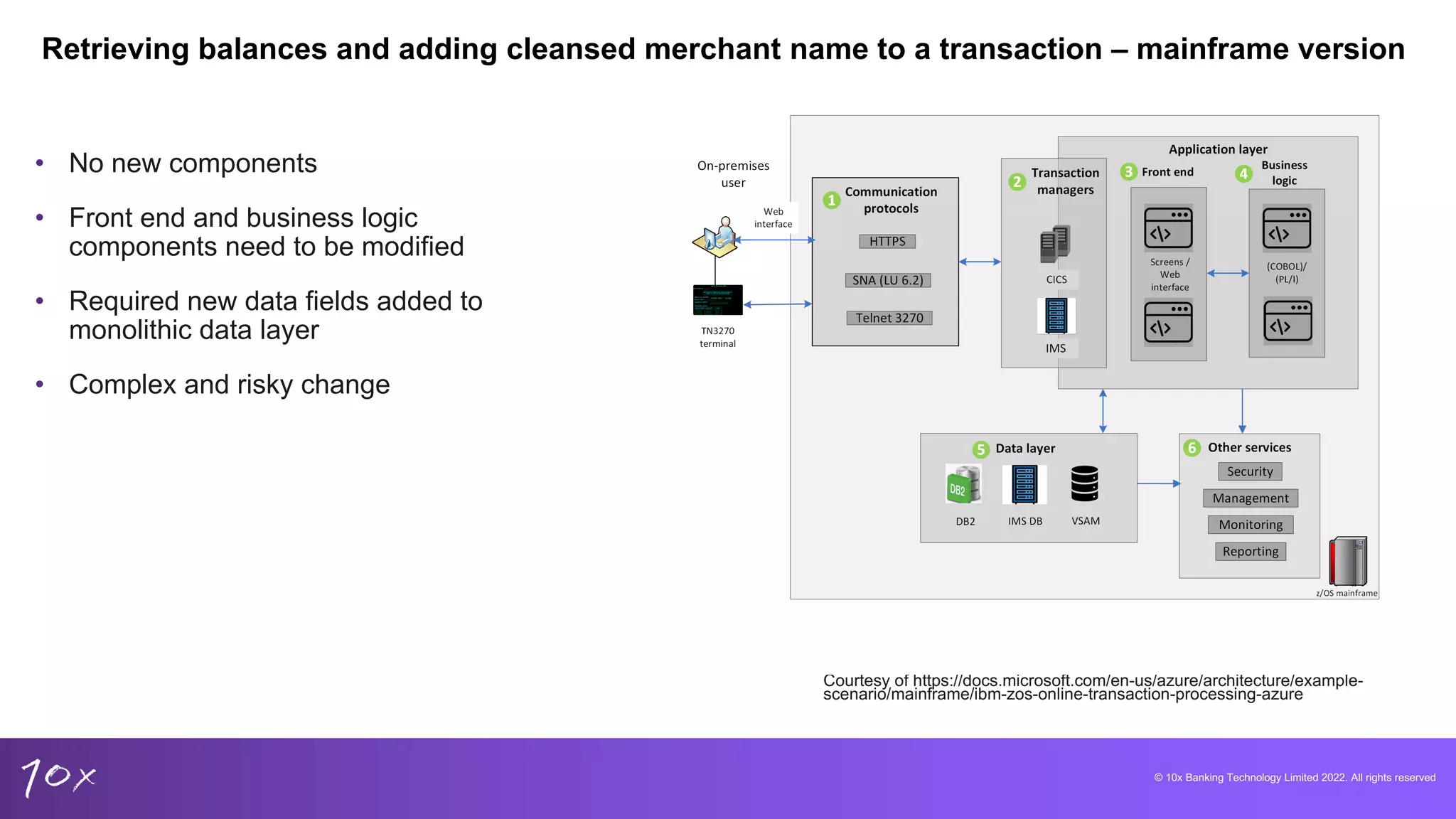
Core banking explained: customer onboarding, product lifecycle, and the reliance on mainframe architecture.
Focus on domain-driven design, microservices in banking, and challenges with data retrieval from monolithic systems.
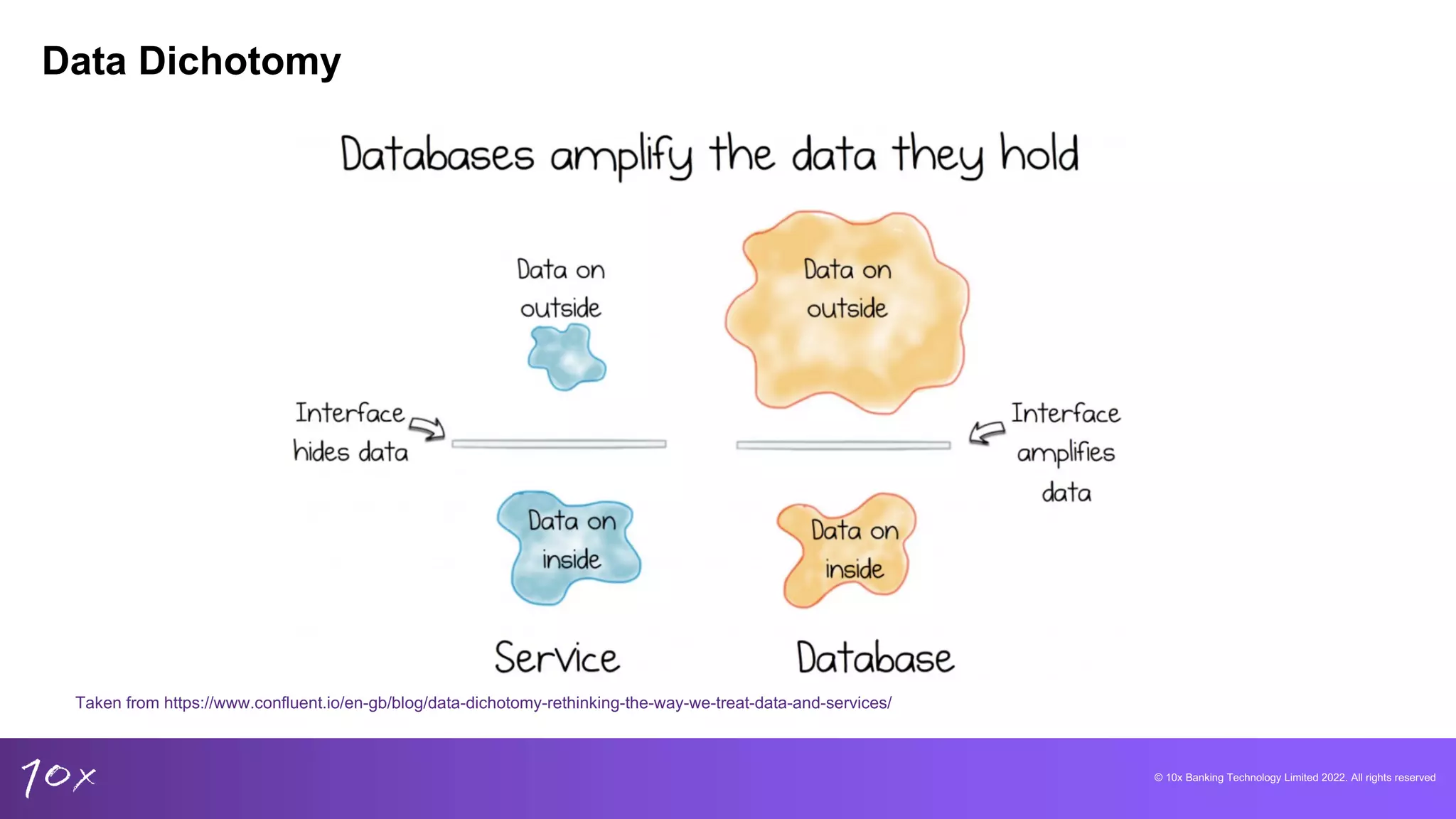
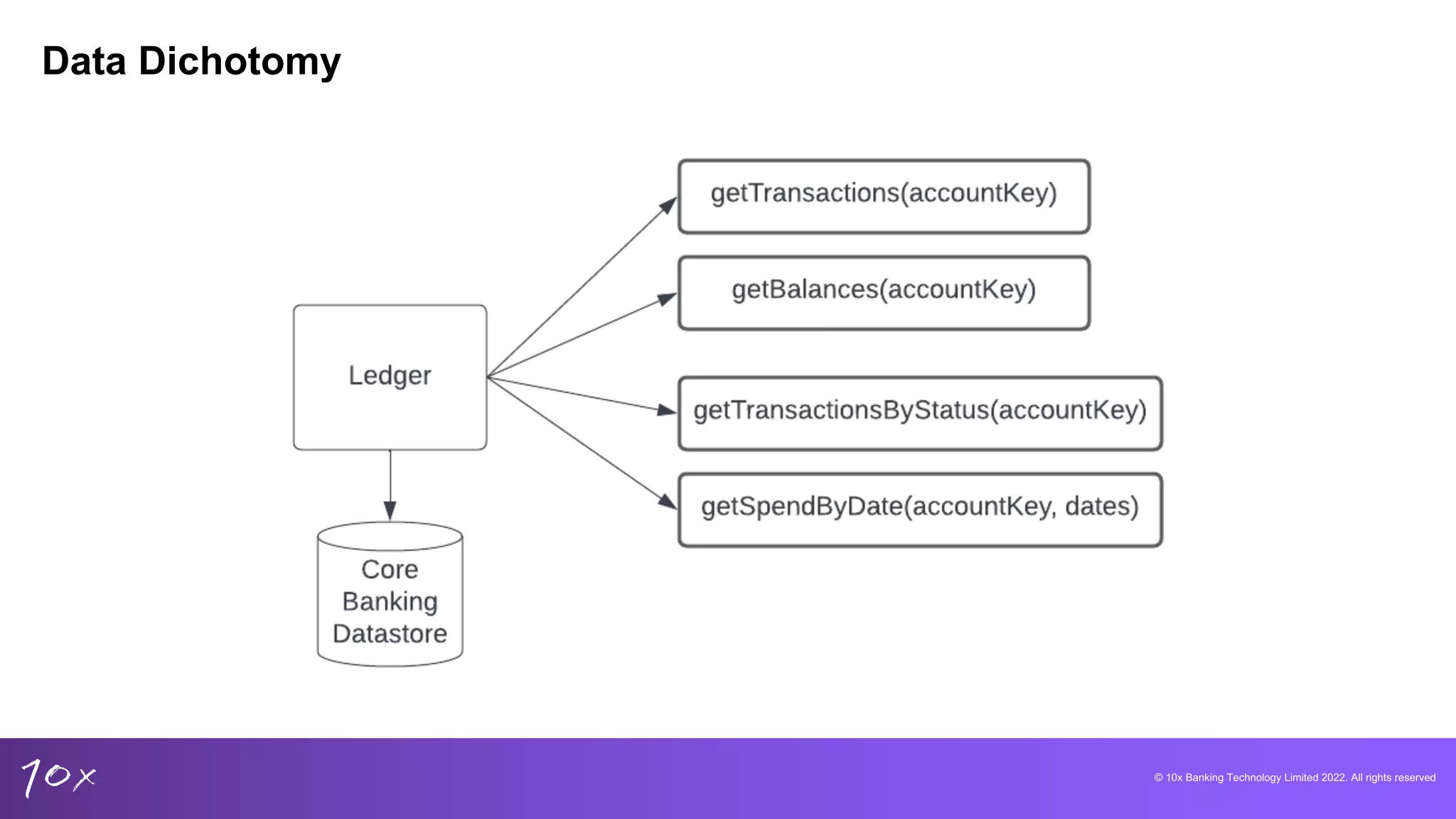
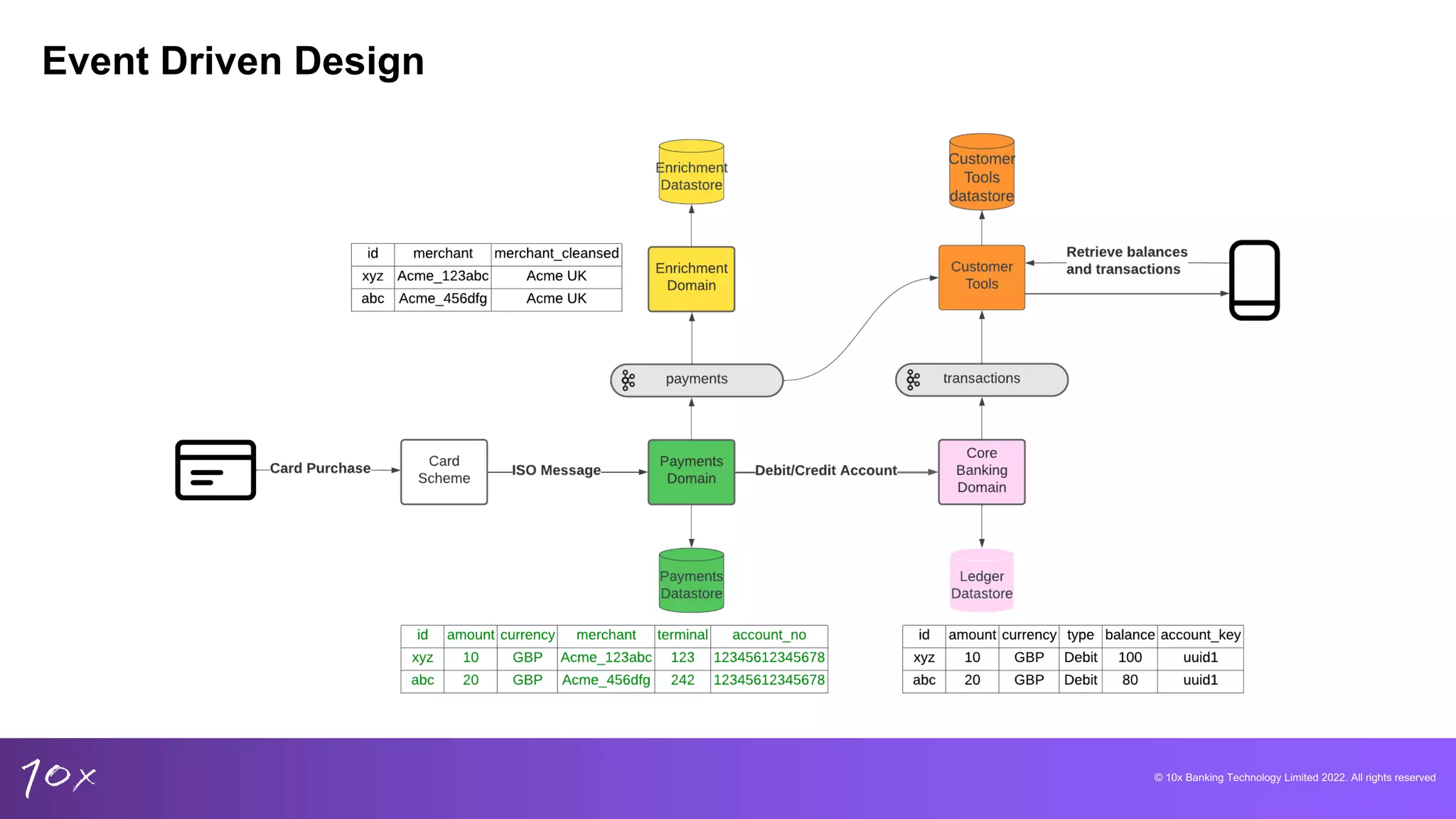
Exploring data dichotomy and event-driven design principles to enhance data utilization in banking.
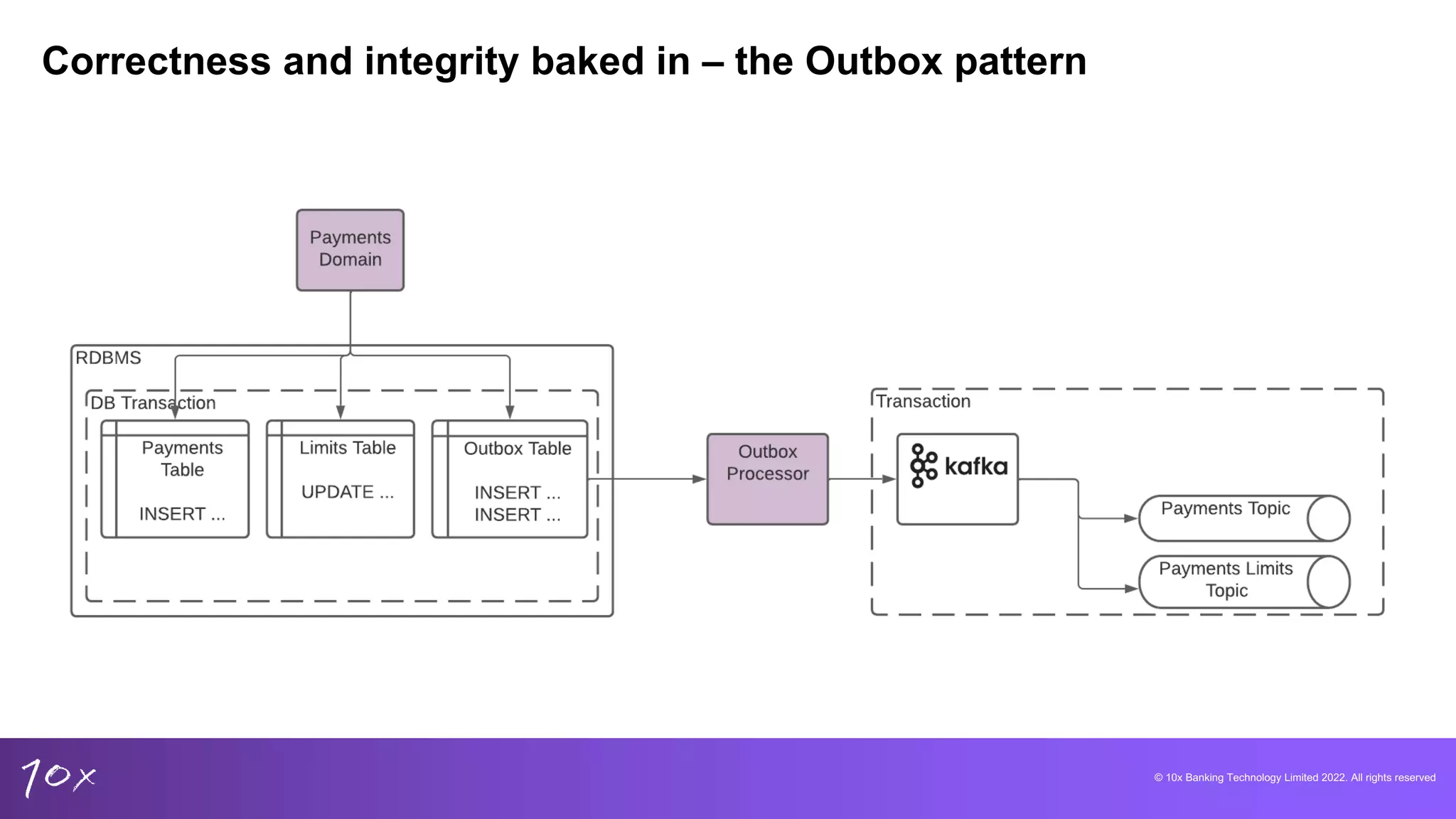
Importance of maintaining correctness in banking data and how it affects customer accounts.
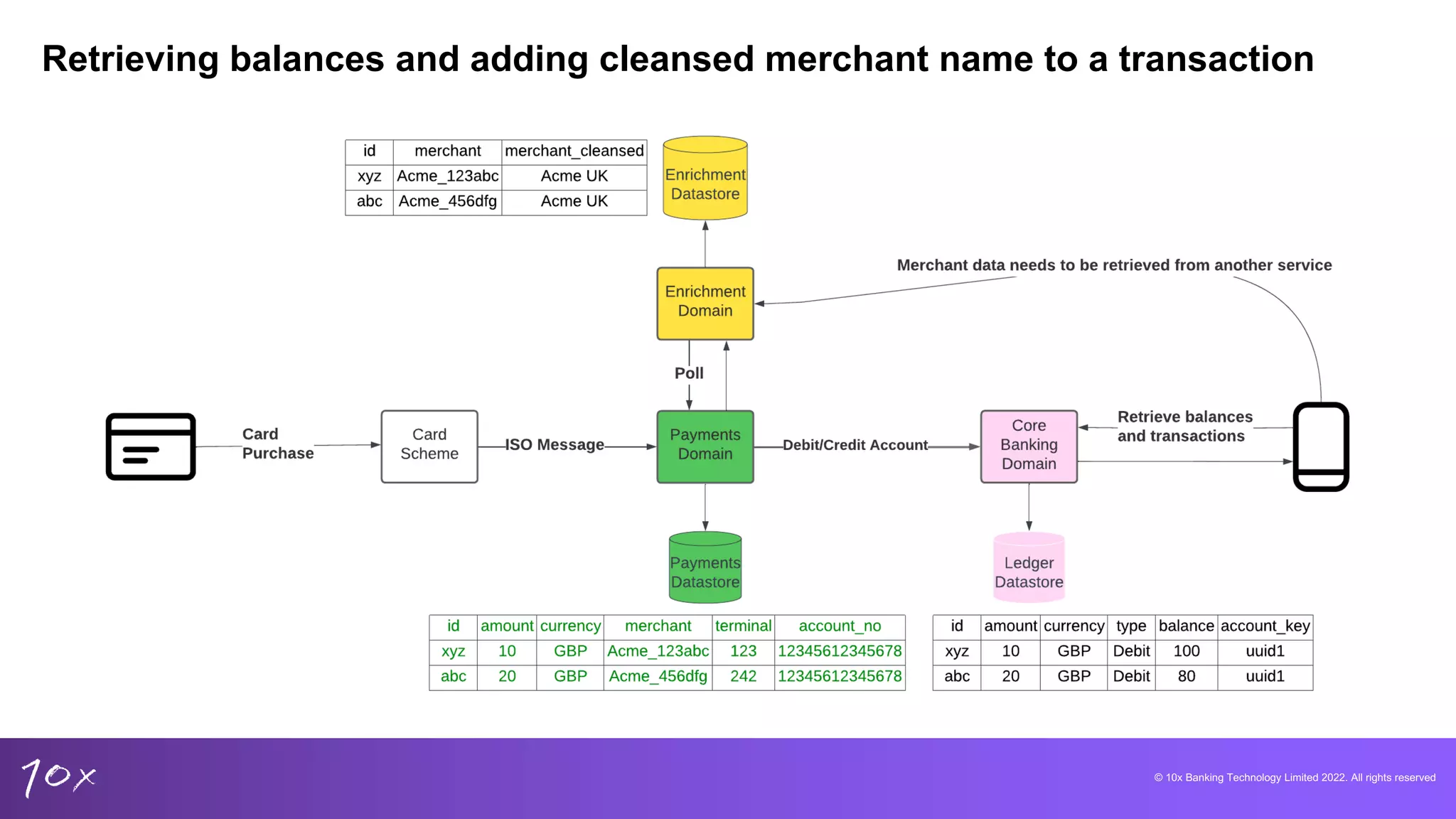
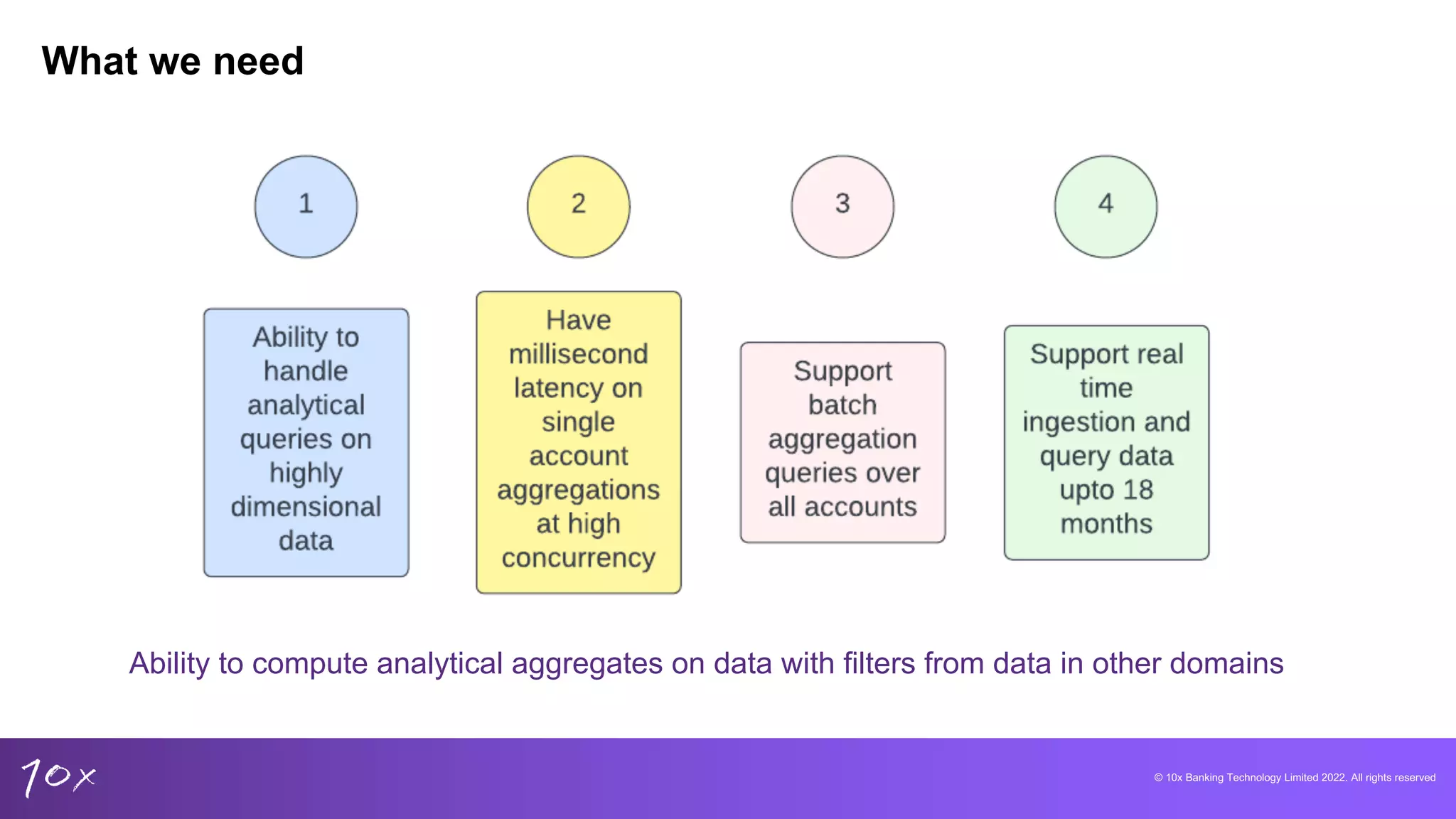
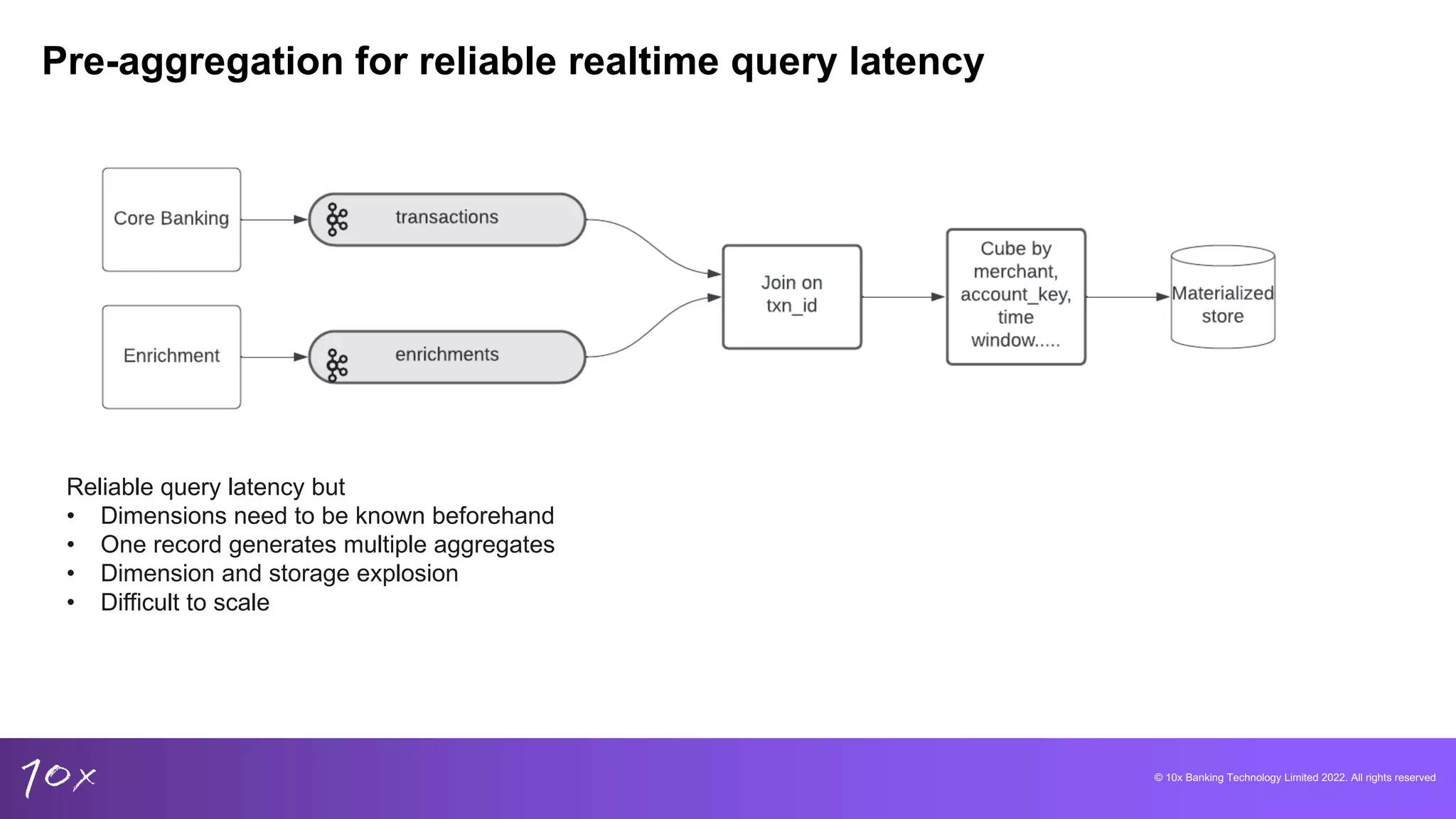
Strategies for building new banking products and the necessity for analytical capabilities across domains.
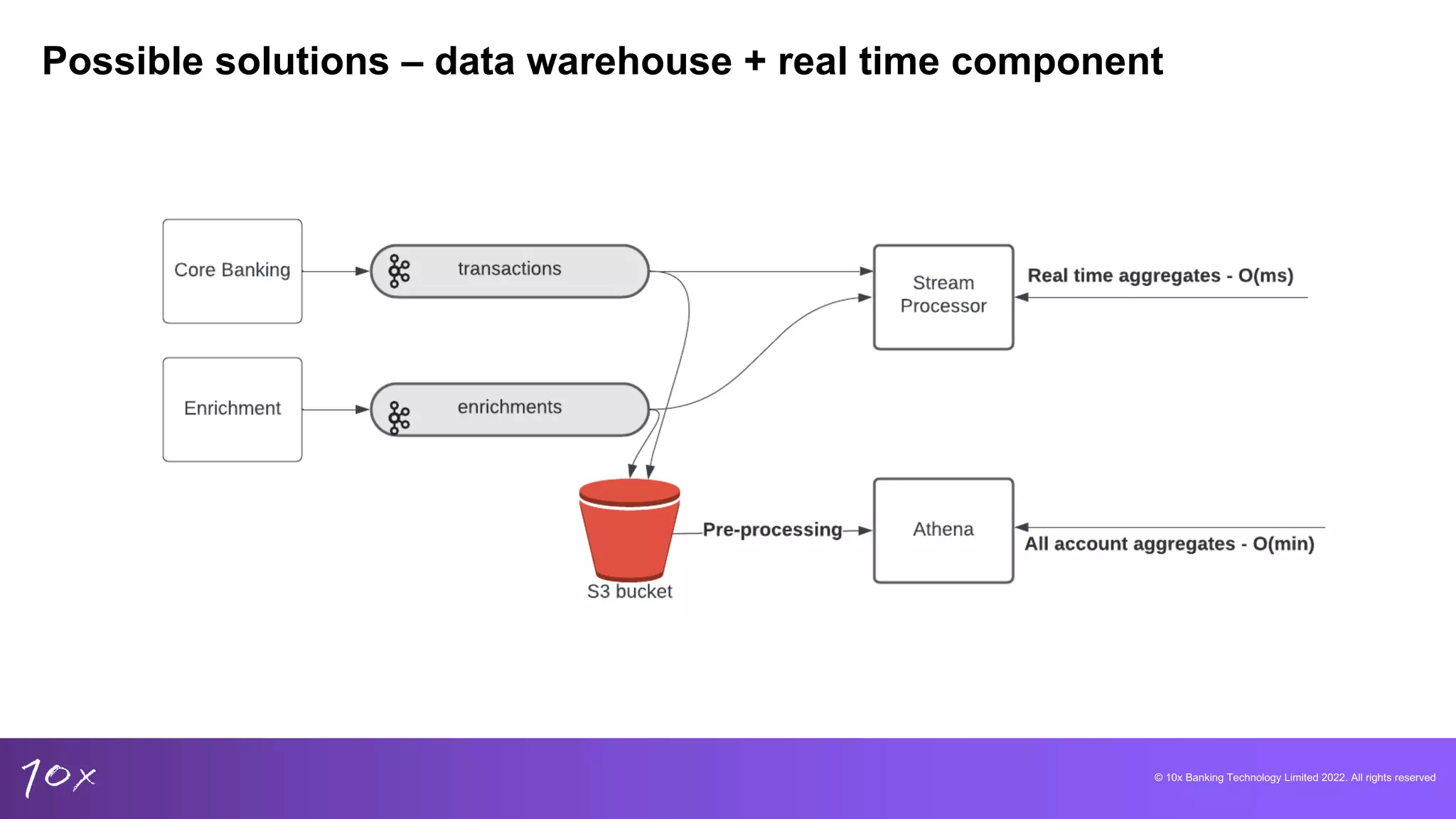
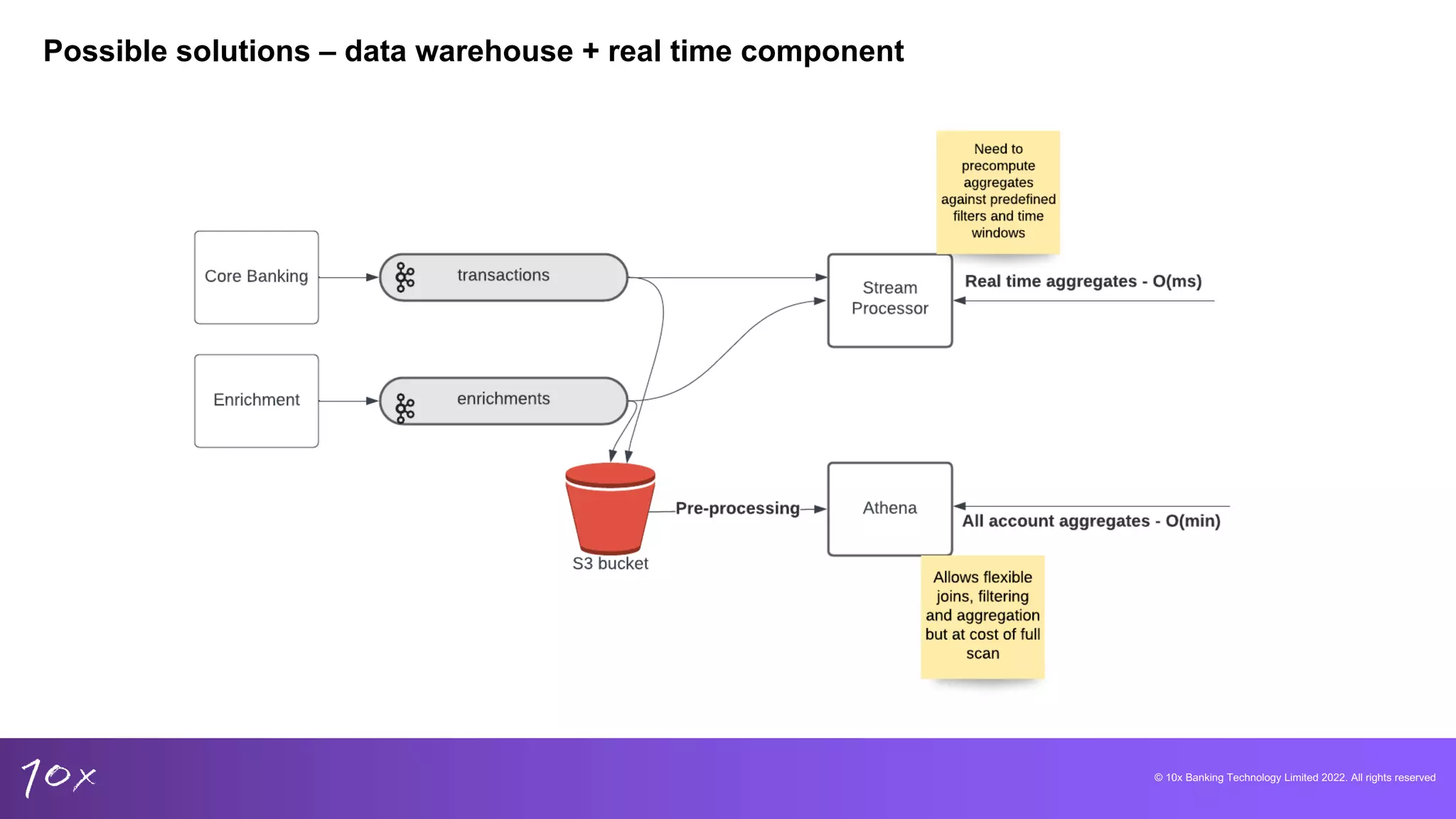
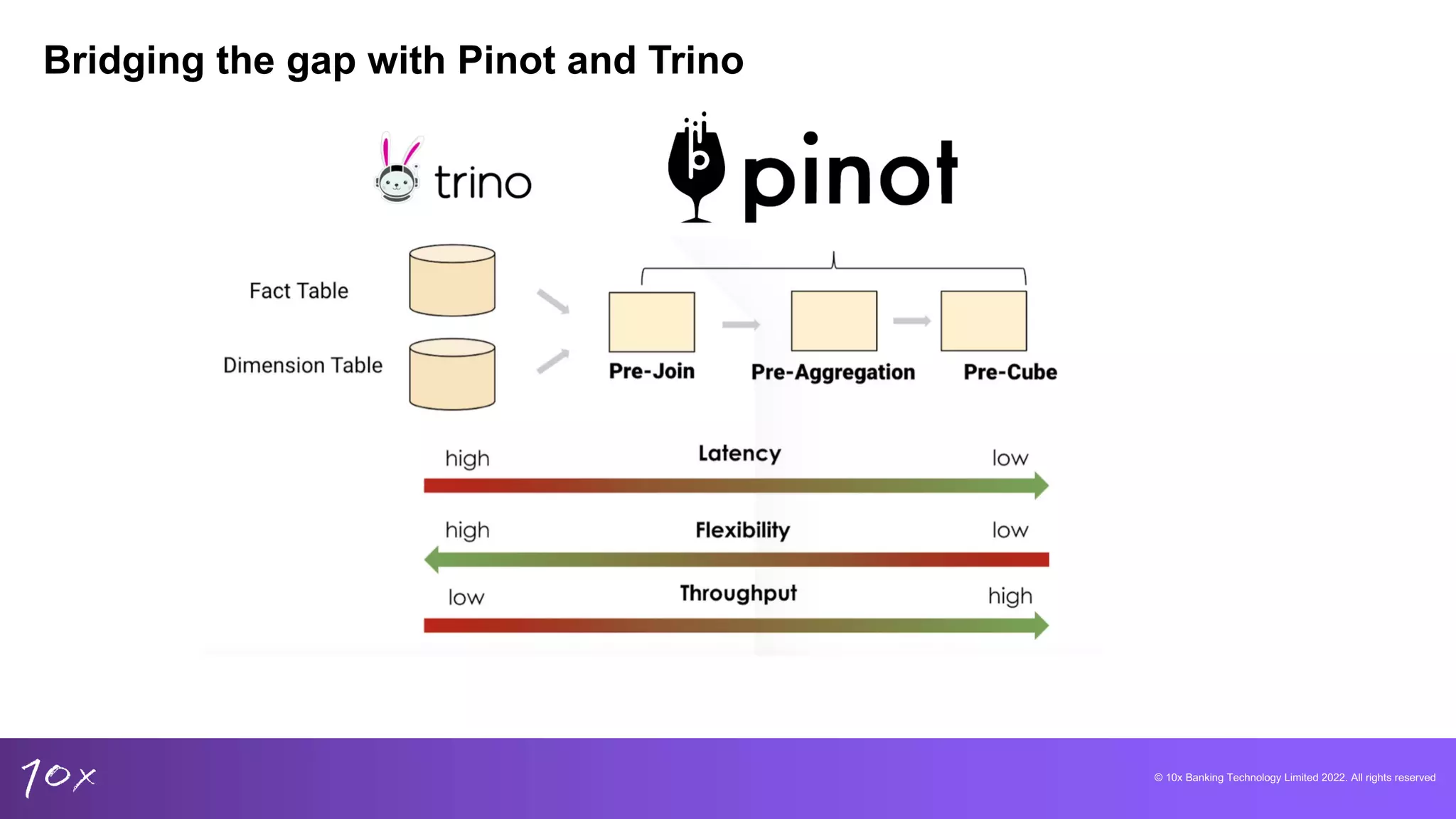
Proposed solutions include using data warehouses with real-time features, addressing reliability and scalability.
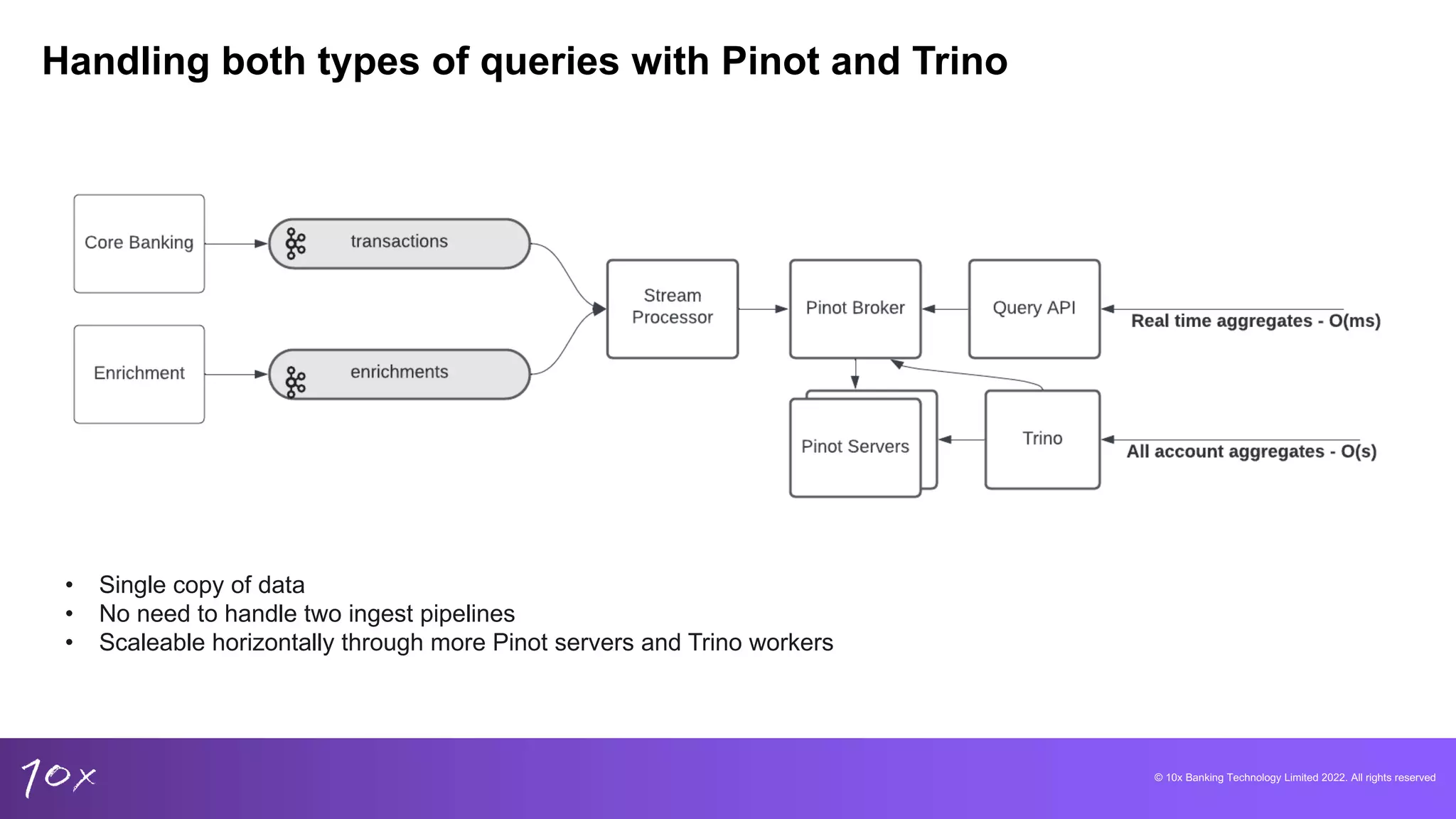
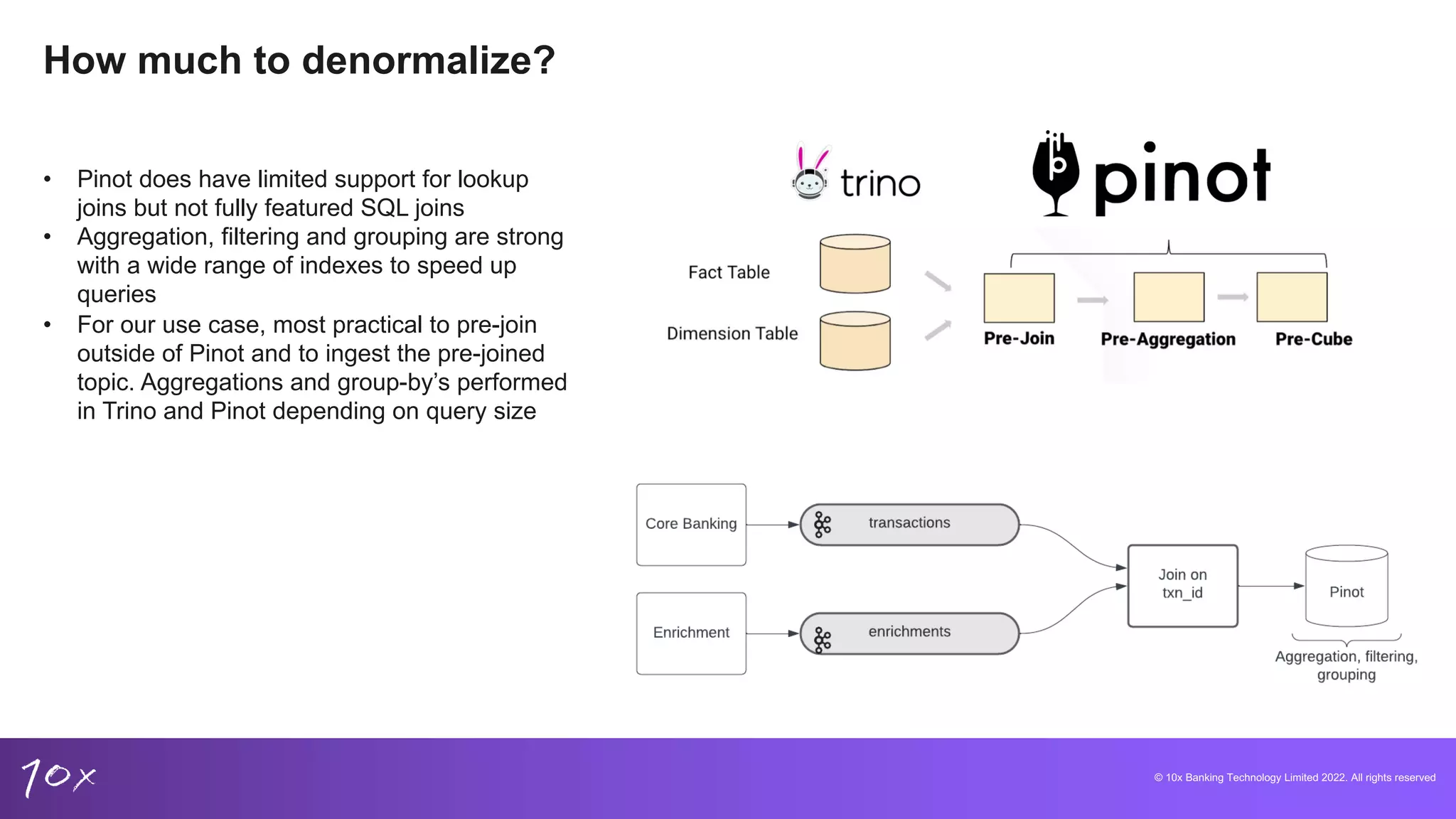
Overview of Pinot and Trino, focusing on capabilities for low-latency analytics and their integration advantages.
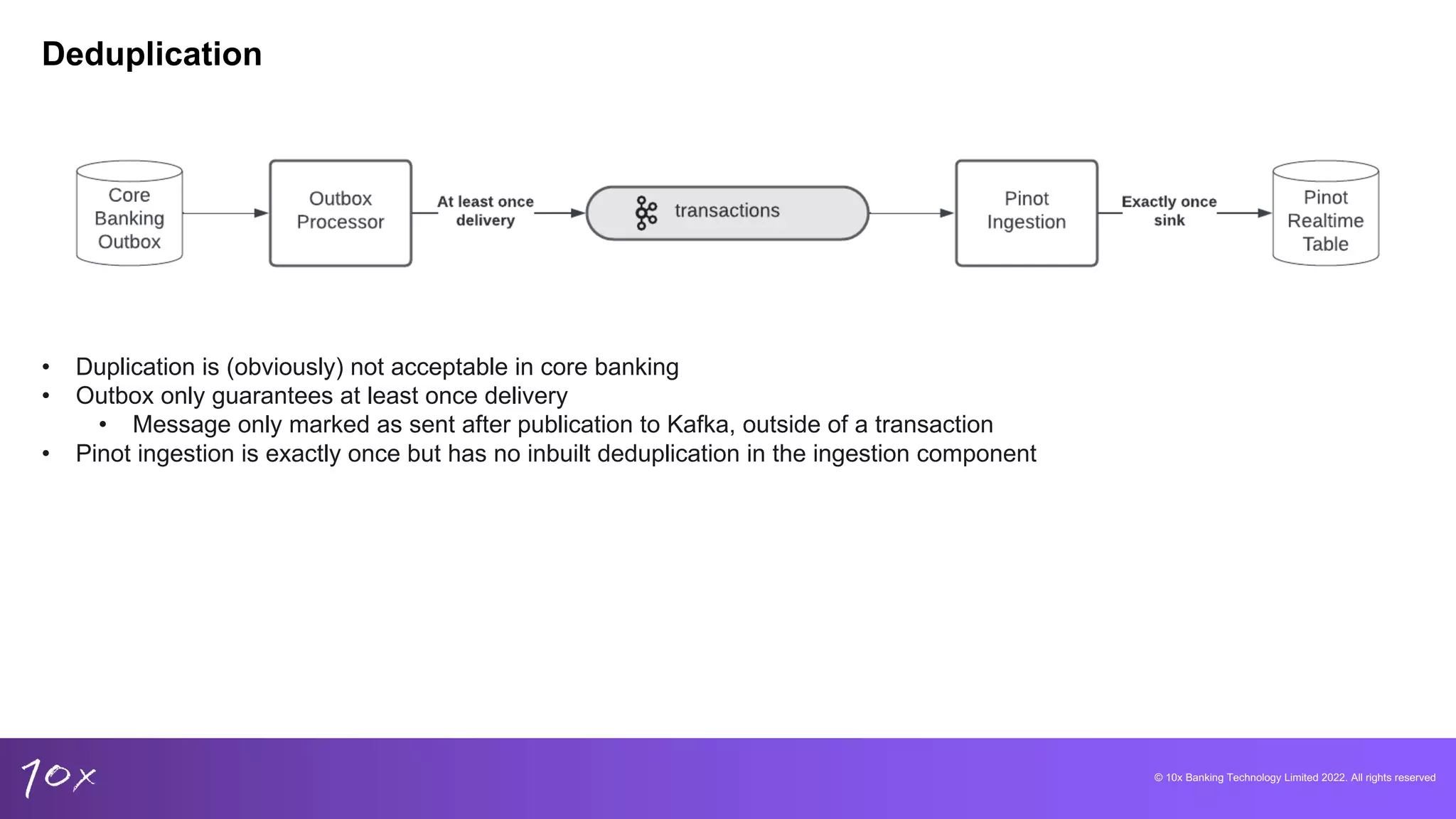
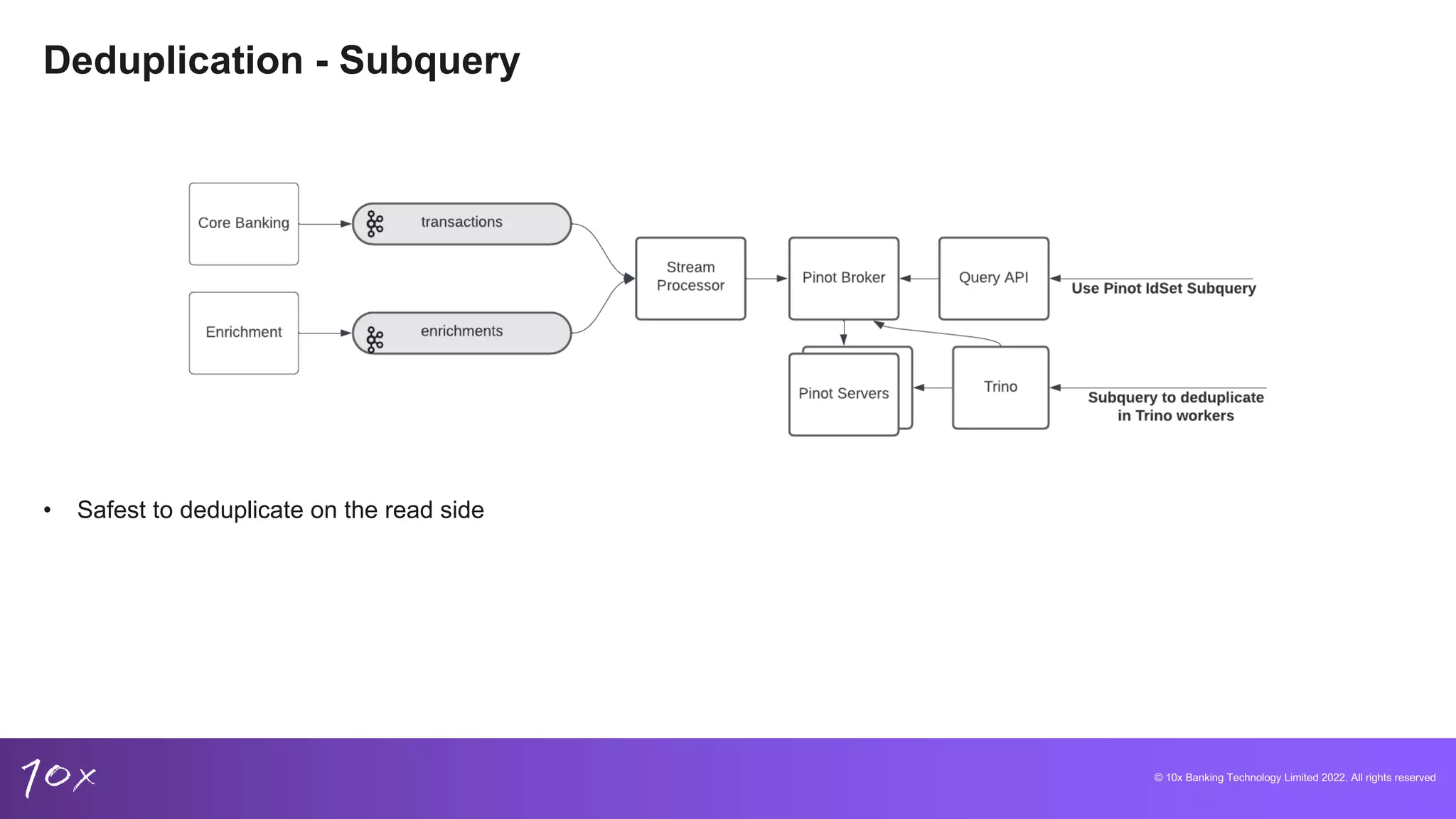
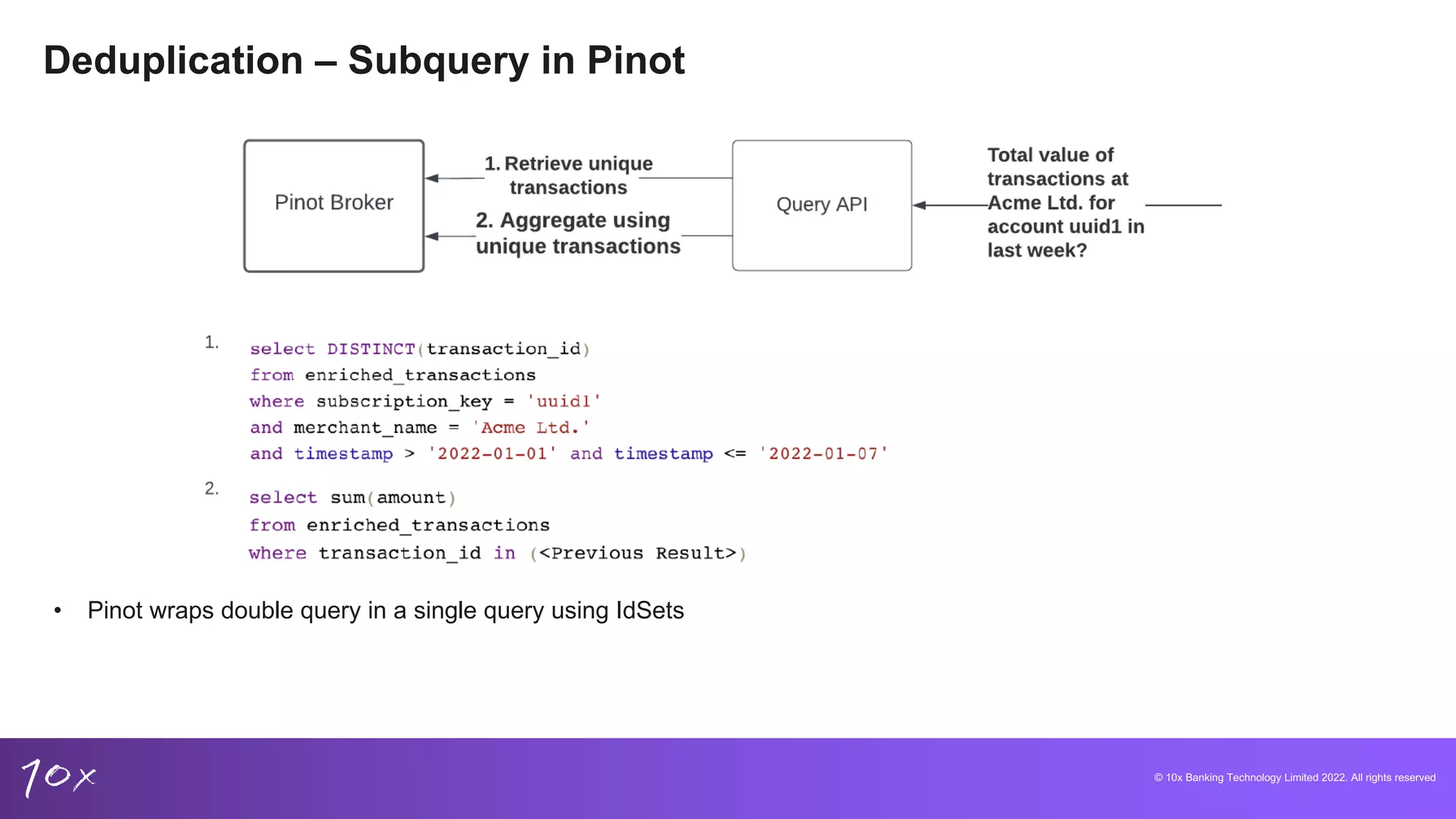
Techniques for managing data integrity, deduplication methods in core banking, and the challenges of real-time data.
Benefits of domain-driven design and microservices in banking, emphasizing the role of Apache Pinot in data analytics.