Download to read offline











![Django Documentation, Release 1.5.1
manage.py syncdb
The syncdb command looks at all your available models and creates tables in your database for whichever tables
don’t already exist.
2.1.3 Enjoy the free API
With that, you’ve got a free, and rich, Python API to access your data. The API is created on the fly, no code generation
necessary:
# Import the models we created from our "news" app
>>> from news.models import Reporter, Article
# No reporters are in the system yet.
>>> Reporter.objects.all()
[]
# Create a new Reporter.
>>> r = Reporter(full_name=’John Smith’)
# Save the object into the database. You have to call save() explicitly.
>>> r.save()
# Now it has an ID.
>>> r.id
1
# Now the new reporter is in the database.
>>> Reporter.objects.all()
[<Reporter: John Smith>]
# Fields are represented as attributes on the Python object.
>>> r.full_name
’John Smith’
# Django provides a rich database lookup API.
>>> Reporter.objects.get(id=1)
<Reporter: John Smith>
>>> Reporter.objects.get(full_name__startswith=’John’)
<Reporter: John Smith>
>>> Reporter.objects.get(full_name__contains=’mith’)
<Reporter: John Smith>
>>> Reporter.objects.get(id=2)
Traceback (most recent call last):
...
DoesNotExist: Reporter matching query does not exist. Lookup parameters were {’id’: 2}
# Create an article.
>>> from datetime import date
>>> a = Article(pub_date=date.today(), headline=’Django is cool’,
... content=’Yeah.’, reporter=r)
>>> a.save()
# Now the article is in the database.
>>> Article.objects.all()
[<Article: Django is cool>]
8 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-12-2048.jpg)
![Django Documentation, Release 1.5.1
# Article objects get API access to related Reporter objects.
>>> r = a.reporter
>>> r.full_name
’John Smith’
# And vice versa: Reporter objects get API access to Article objects.
>>> r.article_set.all()
[<Article: Django is cool>]
# The API follows relationships as far as you need, performing efficient
# JOINs for you behind the scenes.
# This finds all articles by a reporter whose name starts with "John".
>>> Article.objects.filter(reporter__full_name__startswith="John")
[<Article: Django is cool>]
# Change an object by altering its attributes and calling save().
>>> r.full_name = ’Billy Goat’
>>> r.save()
# Delete an object with delete().
>>> r.delete()
2.1.4 A dynamic admin interface: it’s not just scaffolding – it’s the whole house
Once your models are defined, Django can automatically create a professional, production ready administrative inter-face
– a Web site that lets authenticated users add, change and delete objects. It’s as easy as registering your model in
the admin site:
# In models.py...
from django.db import models
class Article(models.Model):
pub_date = models.DateField()
headline = models.CharField(max_length=200)
content = models.TextField()
reporter = models.ForeignKey(Reporter)
# In admin.py in the same directory...
import models
from django.contrib import admin
admin.site.register(models.Article)
The philosophy here is that your site is edited by a staff, or a client, or maybe just you – and you don’t want to have to
deal with creating backend interfaces just to manage content.
One typical workflow in creating Django apps is to create models and get the admin sites up and running as fast as
possible, so your staff (or clients) can start populating data. Then, develop the way data is presented to the public.
2.1.5 Design your URLs
A clean, elegant URL scheme is an important detail in a high-quality Web application. Django encourages beautiful
URL design and doesn’t put any cruft in URLs, like .php or .asp.
2.1. Django at a glance 9](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-13-2048.jpg)


![Django Documentation, Release 1.5.1
The next obvious steps are for you to download Django, read the tutorial and join the community. Thanks for your
interest!
2.2 Quick install guide
Before you can use Django, you’ll need to get it installed. We have a complete installation guide that covers all
the possibilities; this guide will guide you to a simple, minimal installation that’ll work while you walk through the
introduction.
2.2.1 Install Python
Being a Python Web framework, Django requires Python. It works with any Python version from 2.6.5 to 2.7. It also
features experimental support for versions 3.2 and 3.3. All these versions of Python include a lightweight database
called SQLite so you won’t need to set up a database just yet.
Get Python at http://www.python.org. If you’re running Linux or Mac OS X, you probably already have it installed.
Django on Jython
If you use Jython (a Python implementation for the Java platform), you’ll need to follow a few additional steps. See
Running Django on Jython for details.
You can verify that Python is installed by typing python from your shell; you should see something like:
Python 2.6.6 (r266:84292, Dec 26 2010, 22:31:48)
[GCC 4.4.5] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
2.2.2 Set up a database
This step is only necessary if you’d like to work with a “large” database engine like PostgreSQL, MySQL, or Oracle.
To install such a database, consult the database installation information.
2.2.3 Remove any old versions of Django
If you are upgrading your installation of Django from a previous version, you will need to uninstall the old Django
version before installing the new version.
2.2.4 Install Django
You’ve got three easy options to install Django:
• Install a version of Django provided by your operating system distribution. This is the quickest option for those
who have operating systems that distribute Django.
• Install an official release. This is the best approach for users who want a stable version number and aren’t
concerned about running a slightly older version of Django.
• Install the latest development version. This is best for users who want the latest-and-greatest features and aren’t
afraid of running brand-new code.
12 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-16-2048.jpg)







![Django Documentation, Release 1.5.1
project since the last time you ran syncdb. syncdb can be called as often as you like, and it will only ever create the
tables that don’t exist.
Read the django-admin.py documentation for full information on what the manage.py utility can do.
2.3.4 Playing with the API
Now, let’s hop into the interactive Python shell and play around with the free API Django gives you. To invoke the
Python shell, use this command:
python manage.py shell
We’re using this instead of simply typing “python”, because manage.py sets the DJANGO_SETTINGS_MODULE
environment variable, which gives Django the Python import path to your mysite/settings.py file.
Bypassing manage.py
If you’d rather not use manage.py, no problem. Just set the DJANGO_SETTINGS_MODULE environment variable
to mysite.settings and run python from the same directory manage.py is in (or ensure that directory is on
the Python path, so that import mysite works).
For more information on all of this, see the django-admin.py documentation.
Once you’re in the shell, explore the database API:
>>> from polls.models import Poll, Choice # Import the model classes we just wrote.
# No polls are in the system yet.
>>> Poll.objects.all()
[]
# Create a new Poll.
# Support for time zones is enabled in the default settings file, so
# Django expects a datetime with tzinfo for pub_date. Use timezone.now()
# instead of datetime.datetime.now() and it will do the right thing.
>>> from django.utils import timezone
>>> p = Poll(question="What’s new?", pub_date=timezone.now())
# Save the object into the database. You have to call save() explicitly.
>>> p.save()
# Now it has an ID. Note that this might say "1L" instead of "1", depending
# on which database you’re using. That’s no biggie; it just means your
# database backend prefers to return integers as Python long integer
# objects.
>>> p.id
1
# Access database columns via Python attributes.
>>> p.question
"What’s new?"
>>> p.pub_date
datetime.datetime(2012, 2, 26, 13, 0, 0, 775217, tzinfo=<UTC>)
# Change values by changing the attributes, then calling save().
>>> p.question = "What’s up?"
>>> p.save()
20 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-24-2048.jpg)
![Django Documentation, Release 1.5.1
# objects.all() displays all the polls in the database.
>>> Poll.objects.all()
[<Poll: Poll object>]
Wait a minute. <Poll: Poll object> is, utterly, an unhelpful representation of this object. Let’s fix that by
editing the polls model (in the polls/models.py file) and adding a __unicode__() method to both Poll and
Choice:
class Poll(models.Model):
# ...
def __unicode__(self):
return self.question
class Choice(models.Model):
# ...
def __unicode__(self):
return self.choice_text
It’s important to add __unicode__() methods to your models, not only for your own sanity when dealing with the
interactive prompt, but also because objects’ representations are used throughout Django’s automatically-generated
admin.
Why __unicode__() and not __str__()?
If you’re familiar with Python, you might be in the habit of adding __str__() methods to your classes, not
__unicode__() methods. We use __unicode__() here because Django models deal with Unicode by default.
All data stored in your database is converted to Unicode when it’s returned.
Django models have a default __str__() method that calls __unicode__() and converts the result to a UTF-8
bytestring. This means that unicode(p) will return a Unicode string, and str(p) will return a normal string, with
characters encoded as UTF-8.
If all of this is gibberish to you, just remember to add __unicode__() methods to your models. With any luck,
things should Just Work for you.
Note these are normal Python methods. Let’s add a custom method, just for demonstration:
import datetime
from django.utils import timezone
# ...
class Poll(models.Model):
# ...
def was_published_recently(self):
return self.pub_date >= timezone.now() - datetime.timedelta(days=1)
Note the addition of import datetime and from django.utils import timezone, to reference
Python’s standard datetime module and Django’s time-zone-related utilities in django.utils.timezone,
respectively. If you aren’t familiar with time zone handling in Python, you can learn more in the time zone support
docs.
Save these changes and start a new Python interactive shell by running python manage.py shell again:
>>> from polls.models import Poll, Choice
# Make sure our __unicode__() addition worked.
>>> Poll.objects.all()
[<Poll: What’s up?>]
2.3. Writing your first Django app, part 1 21](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-25-2048.jpg)
![Django Documentation, Release 1.5.1
# Django provides a rich database lookup API that’s entirely driven by
# keyword arguments.
>>> Poll.objects.filter(id=1)
[<Poll: What’s up?>]
>>> Poll.objects.filter(question__startswith=’What’)
[<Poll: What’s up?>]
# Get the poll that was published this year.
>>> from django.utils import timezone
>>> current_year = timezone.now().year
>>> Poll.objects.get(pub_date__year=current_year)
<Poll: What’s up?>
# Request an ID that doesn’t exist, this will raise an exception.
>>> Poll.objects.get(id=2)
Traceback (most recent call last):
...
DoesNotExist: Poll matching query does not exist. Lookup parameters were {’id’: 2}
# Lookup by a primary key is the most common case, so Django provides a
# shortcut for primary-key exact lookups.
# The following is identical to Poll.objects.get(id=1).
>>> Poll.objects.get(pk=1)
<Poll: What’s up?>
# Make sure our custom method worked.
>>> p = Poll.objects.get(pk=1)
>>> p.was_published_recently()
True
# Give the Poll a couple of Choices. The create call constructs a new
# Choice object, does the INSERT statement, adds the choice to the set
# of available choices and returns the new Choice object. Django creates
# a set to hold the "other side" of a ForeignKey relation
# (e.g. a poll’s choices) which can be accessed via the API.
>>> p = Poll.objects.get(pk=1)
# Display any choices from the related object set -- none so far.
>>> p.choice_set.all()
[]
# Create three choices.
>>> p.choice_set.create(choice_text=’Not much’, votes=0)
<Choice: Not much>
>>> p.choice_set.create(choice_text=’The sky’, votes=0)
<Choice: The sky>
>>> c = p.choice_set.create(choice_text=’Just hacking again’, votes=0)
# Choice objects have API access to their related Poll objects.
>>> c.poll
<Poll: What’s up?>
# And vice versa: Poll objects get access to Choice objects.
>>> p.choice_set.all()
[<Choice: Not much>, <Choice: The sky>, <Choice: Just hacking again>]
>>> p.choice_set.count()
3
22 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-26-2048.jpg)
![Django Documentation, Release 1.5.1
# The API automatically follows relationships as far as you need.
# Use double underscores to separate relationships.
# This works as many levels deep as you want; there’s no limit.
# Find all Choices for any poll whose pub_date is in this year
# (reusing the ’current_year’ variable we created above).
>>> Choice.objects.filter(poll__pub_date__year=current_year)
[<Choice: Not much>, <Choice: The sky>, <Choice: Just hacking again>]
# Let’s delete one of the choices. Use delete() for that.
>>> c = p.choice_set.filter(choice_text__startswith=’Just hacking’)
>>> c.delete()
For more information on model relations, see Accessing related objects. For more on how to use double underscores
to perform field lookups via the API, see Field lookups. For full details on the database API, see our Database API
reference.
When you’re comfortable with the API, read part 2 of this tutorial to get Django’s automatic admin working.
2.4 Writing your first Django app, part 2
This tutorial begins where Tutorial 1 left off. We’re continuing the Web-poll application and will focus on Django’s
automatically-generated admin site.
Philosophy
Generating admin sites for your staff or clients to add, change and delete content is tedious work that doesn’t require
much creativity. For that reason, Django entirely automates creation of admin interfaces for models.
Django was written in a newsroom environment, with a very clear separation between “content publishers” and the
“public” site. Site managers use the system to add news stories, events, sports scores, etc., and that content is displayed
on the public site. Django solves the problem of creating a unified interface for site administrators to edit content.
The admin isn’t intended to be used by site visitors. It’s for site managers.
2.4.1 Activate the admin site
The Django admin site is not activated by default – it’s an opt-in thing. To activate the admin site for your installation,
do these three things:
• Uncomment "django.contrib.admin" in the INSTALLED_APPS setting.
• Run python manage.py syncdb. Since you have added a new application to INSTALLED_APPS, the
database tables need to be updated.
• Edit your mysite/urls.py file and uncomment the lines that reference the admin – there are three lines in
total to uncomment. This file is a URLconf; we’ll dig into URLconfs in the next tutorial. For now, all you need
to know is that it maps URL roots to applications. In the end, you should have a urls.py file that looks like
this:
from django.conf.urls import patterns, include, url
# Uncomment the next two lines to enable the admin:
from django.contrib import admin
admin.autodiscover()
2.4. Writing your first Django app, part 2 23](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-27-2048.jpg)
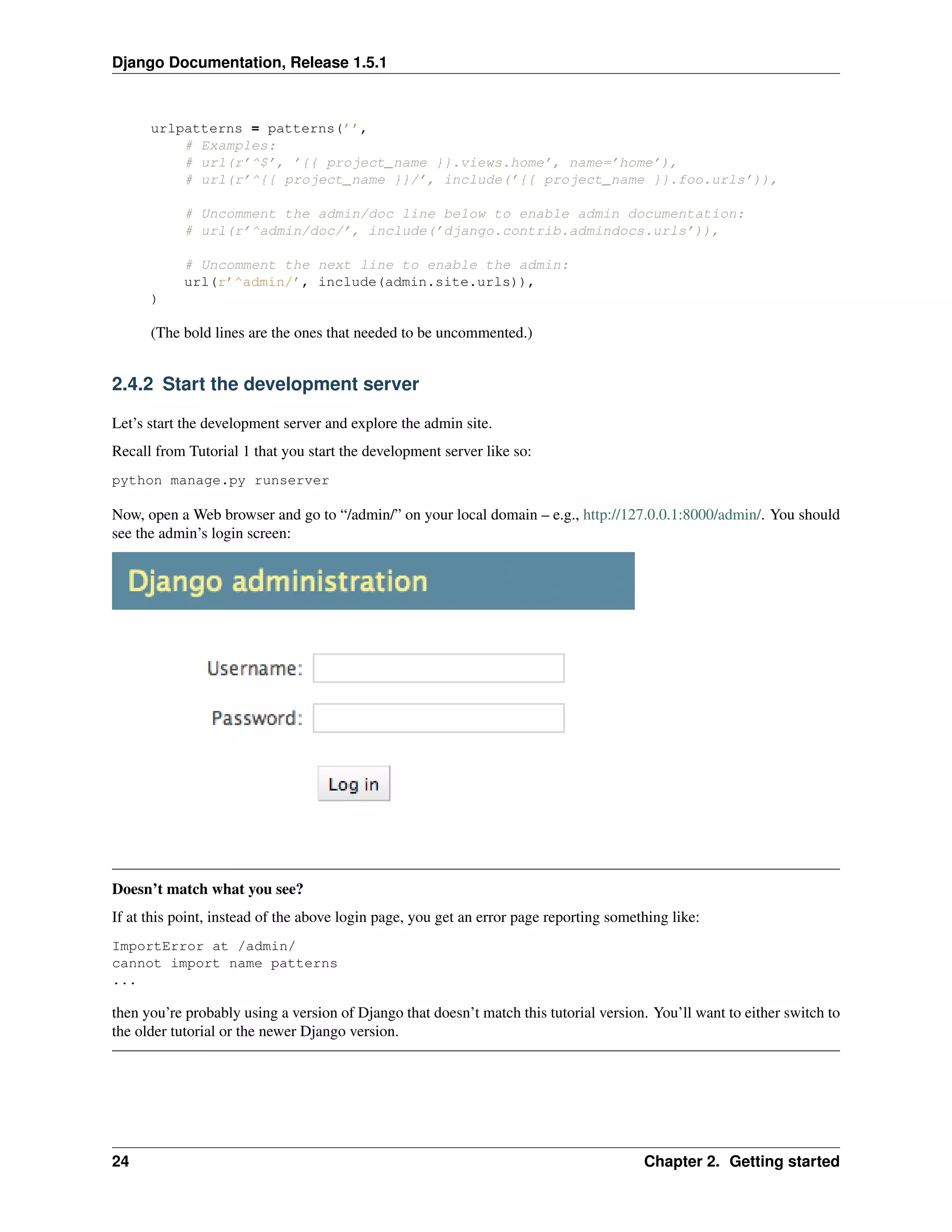

![Django Documentation, Release 1.5.1
2.4.6 Customize the admin form
Take a few minutes to marvel at all the code you didn’t have to write. By registering the Poll model with
admin.site.register(Poll), Django was able to construct a default form representation. Often, you’ll want
to customize how the admin form looks and works. You’ll do this by telling Django the options you want when you
register the object.
Let’s see how this works by re-ordering the fields on the edit form. Replace the admin.site.register(Poll)
line with:
class PollAdmin(admin.ModelAdmin):
fields = [’pub_date’, ’question’]
admin.site.register(Poll, PollAdmin)
You’ll follow this pattern – create a model admin object, then pass it as the second argument to
admin.site.register() – any time you need to change the admin options for an object.
This particular change above makes the “Publication date” come before the “Question” field:
This isn’t impressive with only two fields, but for admin forms with dozens of fields, choosing an intuitive order is an
important usability detail.
And speaking of forms with dozens of fields, you might want to split the form up into fieldsets:
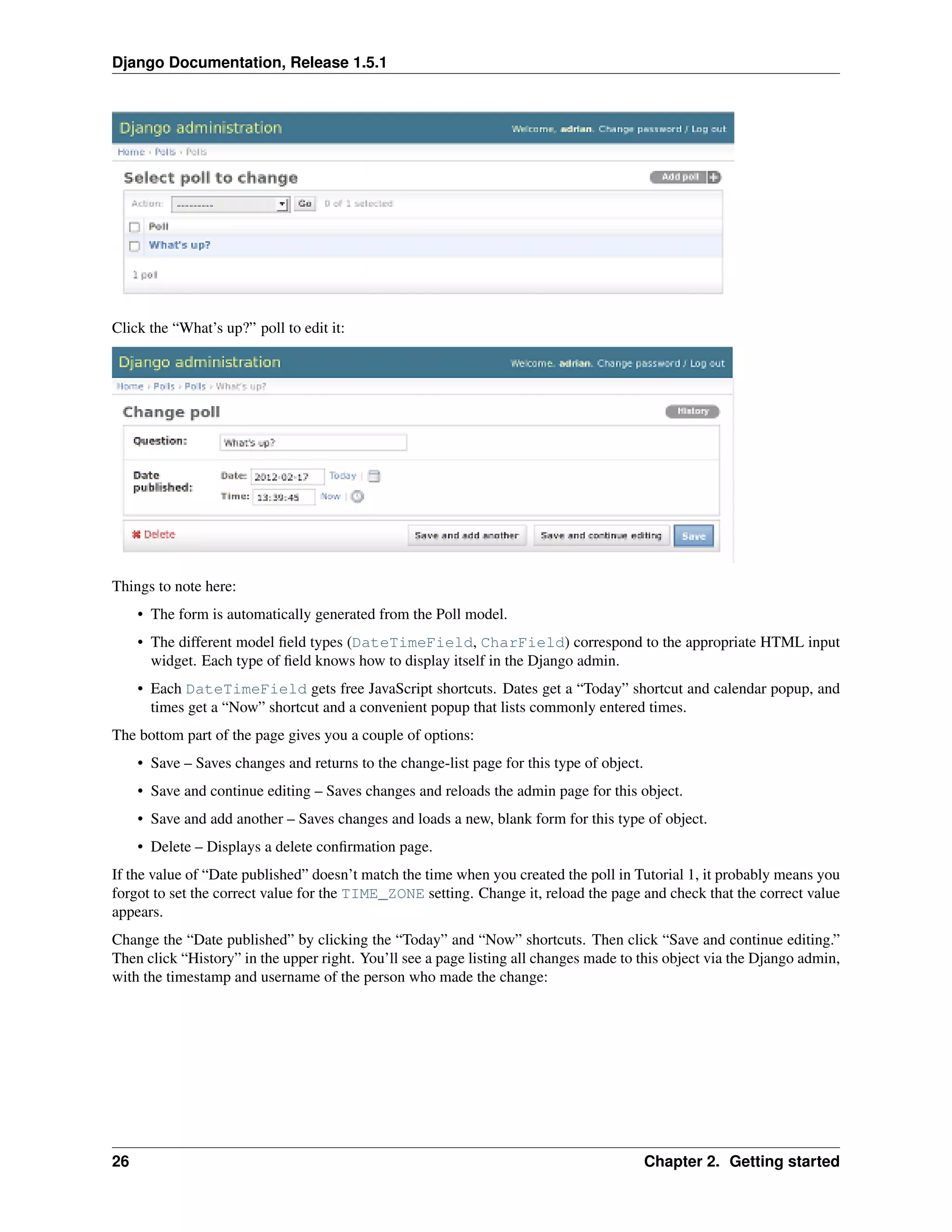
2.4. Writing your first Django app, part 2 27](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-31-2048.jpg)
![Django Documentation, Release 1.5.1
class PollAdmin(admin.ModelAdmin):
fieldsets = [
(None, {’fields’: [’question’]}),
(’Date information’, {’fields’: [’pub_date’]}),
]
admin.site.register(Poll, PollAdmin)
The first element of each tuple in fieldsets is the title of the fieldset. Here’s what our form looks like now:
You can assign arbitrary HTML classes to each fieldset. Django provides a "collapse" class that displays a
particular fieldset initially collapsed. This is useful when you have a long form that contains a number of fields that
aren’t commonly used:
class PollAdmin(admin.ModelAdmin):
fieldsets = [
(None, {’fields’: [’question’]}),
(’Date information’, {’fields’: [’pub_date’], ’classes’: [’collapse’]}),
]
28 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-32-2048.jpg)
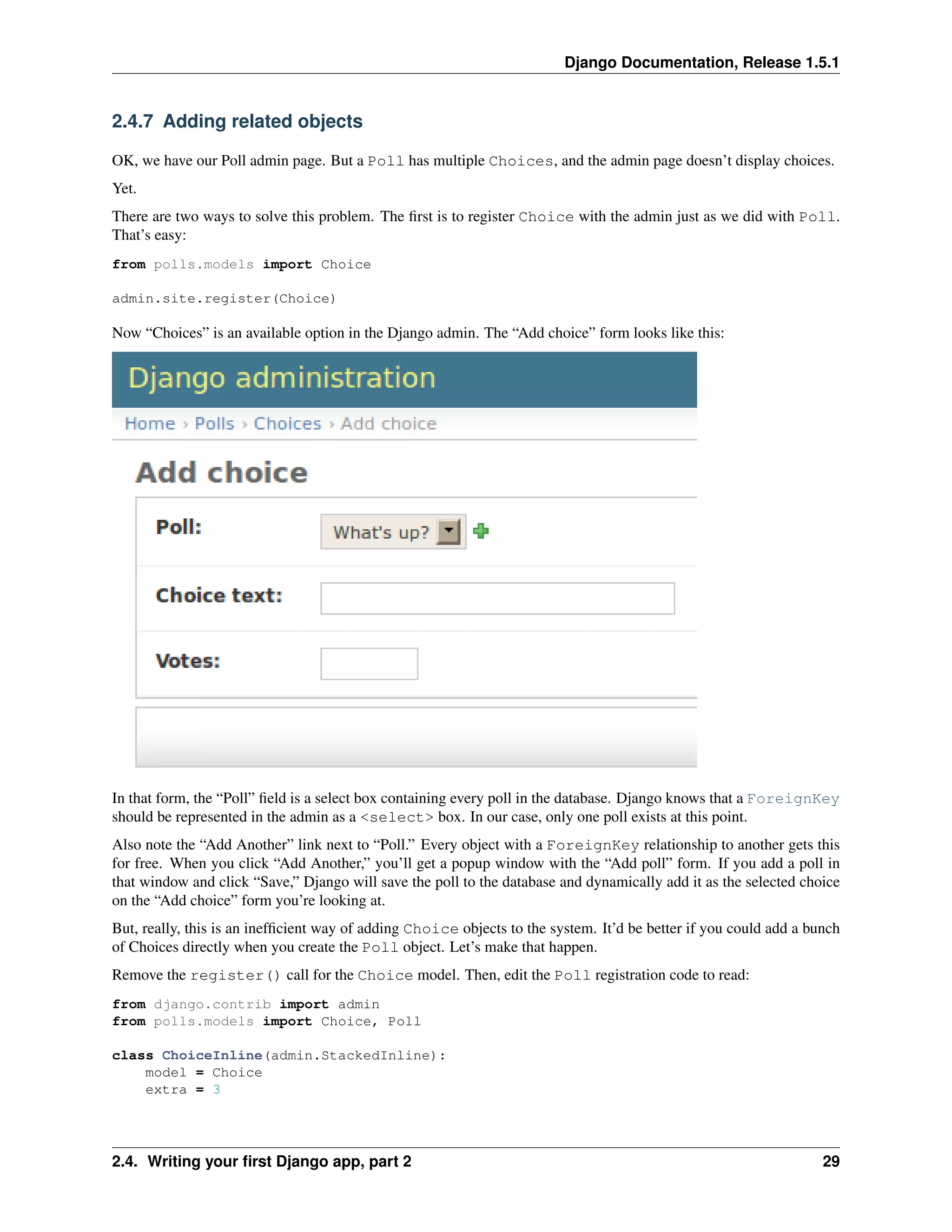
![Django Documentation, Release 1.5.1
class PollAdmin(admin.ModelAdmin):
fieldsets = [
(None, {’fields’: [’question’]}),
(’Date information’, {’fields’: [’pub_date’], ’classes’: [’collapse’]}),
]
inlines = [ChoiceInline]
admin.site.register(Poll, PollAdmin)
This tells Django: “Choice objects are edited on the Poll admin page. By default, provide enough fields for 3
choices.”
Load the “Add poll” page to see how that looks, you may need to restart your development server:
It works like this: There are three slots for related Choices – as specified by extra – and each time you come back
to the “Change” page for an already-created object, you get another three extra slots.
At the end of the three current slots you will find an “Add another Choice” link. If you click on it, a new slot will be
added. If you want to remove the added slot, you can click on the X to the top right of the added slot. Note that you
can’t remove the original three slots. This image shows an added slot:
30 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-34-2048.jpg)
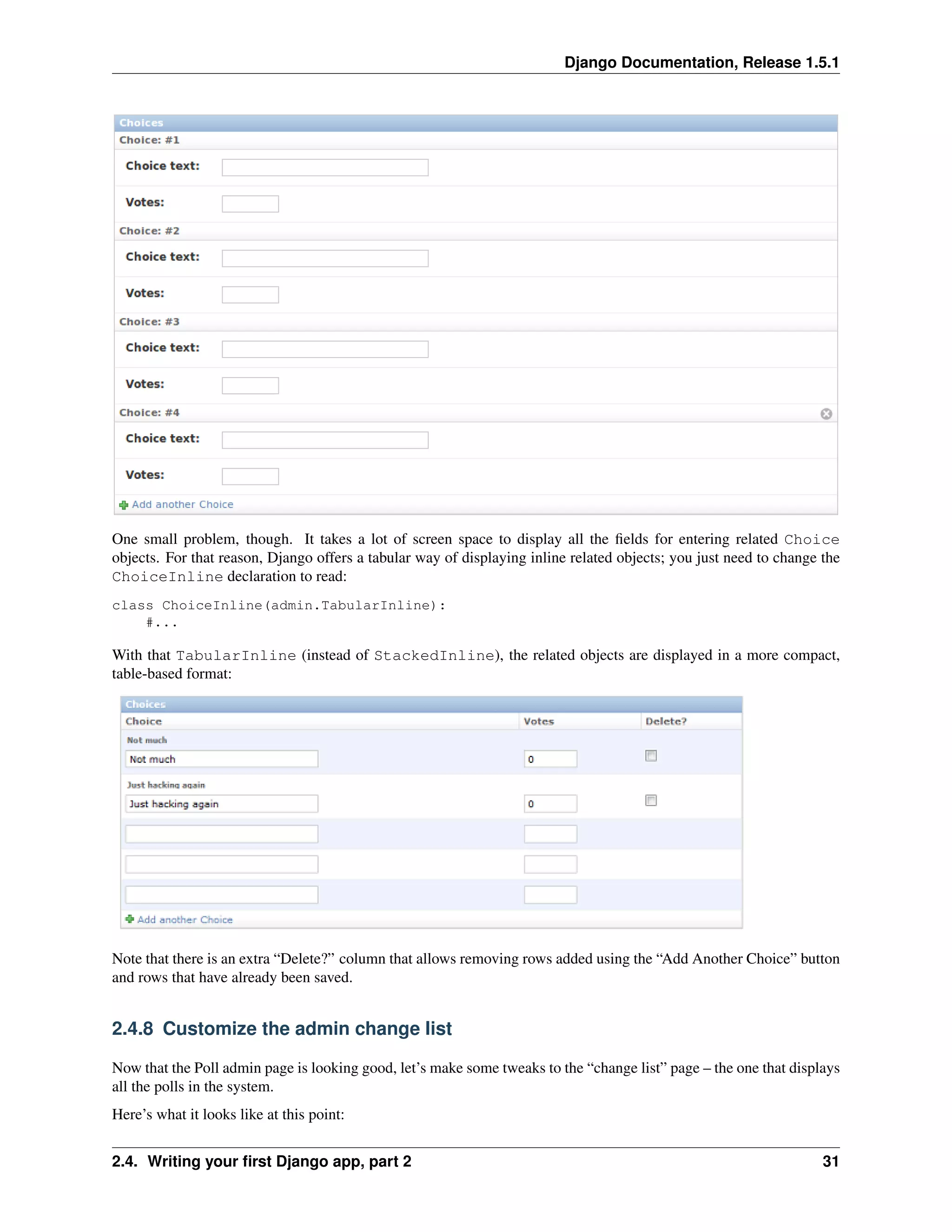
![Django Documentation, Release 1.5.1
By default, Django displays the str() of each object. But sometimes it’d be more helpful if we could display
individual fields. To do that, use the list_display admin option, which is a tuple of field names to display, as
columns, on the change list page for the object:
class PollAdmin(admin.ModelAdmin):
# ...
list_display = (’question’, ’pub_date’)
Just for good measure, let’s also include the was_published_recently custom method from Tutorial 1:
class PollAdmin(admin.ModelAdmin):
# ...
list_display = (’question’, ’pub_date’, ’was_published_recently’)
Now the poll change list page looks like this:
You can click on the column headers to sort by those values – except in the case of the was_published_recently
header, because sorting by the output of an arbitrary method is not supported. Also note that the column header for
was_published_recently is, by default, the name of the method (with underscores replaced with spaces), and
that each line contains the string representation of the output.
You can improve that by giving that method (in polls/models.py) a few attributes, as follows:
class Poll(models.Model):
# ...
def was_published_recently(self):
return self.pub_date >= timezone.now() - datetime.timedelta(days=1)
was_published_recently.admin_order_field = ’pub_date’
was_published_recently.boolean = True
was_published_recently.short_description = ’Published recently?’
Edit your polls/admin.py file again and add an improvement to the Poll change list page: Filters. Add the
following line to PollAdmin:
list_filter = [’pub_date’]
32 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-36-2048.jpg)
![Django Documentation, Release 1.5.1
That adds a “Filter” sidebar that lets people filter the change list by the pub_date field:
The type of filter displayed depends on the type of field you’re filtering on. Because pub_date is a
DateTimeField, Django knows to give appropriate filter options: “Any date,” “Today,” “Past 7 days,” “This
month,” “This year.”
This is shaping up well. Let’s add some search capability:
search_fields = [’question’]
That adds a search box at the top of the change list. When somebody enters search terms, Django will search the
question field. You can use as many fields as you’d like – although because it uses a LIKE query behind the
scenes, keep it reasonable, to keep your database happy.
Finally, because Poll objects have dates, it’d be convenient to be able to drill down by date. Add this line:
date_hierarchy = ’pub_date’
That adds hierarchical navigation, by date, to the top of the change list page. At top level, it displays all available
years. Then it drills down to months and, ultimately, days.
Now’s also a good time to note that change lists give you free pagination. The default is to display 100 items per page.
Change-list pagination, search boxes, filters, date-hierarchies and column-header-ordering all work together like you
think they should.
2.4.9 Customize the admin look and feel
Clearly, having “Django administration” at the top of each admin page is ridiculous. It’s just placeholder text.
That’s easy to change, though, using Django’s template system. The Django admin is powered by Django itself, and
its interfaces use Django’s own template system.
Customizing your project’s templates
Create a templates directory in your project directory. Templates can live anywhere on your filesystem that Django
can access. (Django runs as whatever user your server runs.) However, keeping your templates within the project is a
good convention to follow.
Open your settings file (mysite/settings.py, remember) and add a TEMPLATE_DIRS setting:
TEMPLATE_DIRS = (
’/path/to/mysite/templates’, # Change this to your own directory.
)
Now copy the template admin/base_site.html from within the default Django admin tem-plate
directory in the source code of Django itself (django/contrib/admin/templates)
2.4. Writing your first Django app, part 2 33](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-37-2048.jpg)
![Django Documentation, Release 1.5.1
into an admin subdirectory of whichever directory you’re using in TEMPLATE_DIRS.
For example, if your TEMPLATE_DIRS includes ’/path/to/mysite/templates’, as
above, then copy django/contrib/admin/templates/admin/base_site.html to
/path/to/mysite/templates/admin/base_site.html. Don’t forget that admin subdirectory.
Where are the Django source files?
If you have difficulty finding where the Django source files are located on your system, run the following command:
python -c "
import sys
sys.path = sys.path[1:]
import django
print(django.__path__)"
Then, just edit the file and replace the generic Django text with your own site’s name as you see fit.
This template file contains lots of text like {% block branding %} and {{ title }}. The {% and {{ tags
are part of Django’s template language. When Django renders admin/base_site.html, this template language
will be evaluated to produce the final HTML page. Don’t worry if you can’t make any sense of the template right now
– we’ll delve into Django’s templating language in Tutorial 3.
Note that any of Django’s default admin templates can be overridden. To override a template, just do the same thing
you did with base_site.html – copy it from the default directory into your custom directory, and make changes.
Customizing your application’s templates
Astute readers will ask: But if TEMPLATE_DIRS was empty by default, how was Django finding the default admin
templates? The answer is that, by default, Django automatically looks for a templates/ subdirectory within each
application package, for use as a fallback (don’t forget that django.contrib.admin is an application).
Our poll application is not very complex and doesn’t need custom admin templates. But if it grew more sophisticated
and required modification of Django’s standard admin templates for some of its functionality, it would be more sensible
to modify the application’s templates, rather than those in the project. That way, you could include the polls application
in any new project and be assured that it would find the custom templates it needed.
See the template loader documentation for more information about how Django finds its templates.
2.4.10 Customize the admin index page
On a similar note, you might want to customize the look and feel of the Django admin index page.
By default, it displays all the apps in INSTALLED_APPS that have been registered with the admin application, in
alphabetical order. You may want to make significant changes to the layout. After all, the index is probably the most
important page of the admin, and it should be easy to use.
The template to customize is admin/index.html. (Do the same as with admin/base_site.html in the
previous section – copy it from the default directory to your custom template directory.) Edit the file, and you’ll see it
uses a template variable called app_list. That variable contains every installed Django app. Instead of using that,
you can hard-code links to object-specific admin pages in whatever way you think is best. Again, don’t worry if you
can’t understand the template language – we’ll cover that in more detail in Tutorial 3.
When you’re comfortable with the admin site, read part 3 of this tutorial to start working on public poll views.
34 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-38-2048.jpg)



![Django Documentation, Release 1.5.1
Note that the regular expressions for the include() functions don’t have a $ (end-of-string match character) but
rather a trailing slash. Whenever Django encounters include(), it chops off whatever part of the URL matched up
to that point and sends the remaining string to the included URLconf for further processing.
The idea behind include() is to make it easy to plug-and-play URLs. Since polls are in their own URLconf
(polls/urls.py), they can be placed under “/polls/”, or under “/fun_polls/”, or under “/content/polls/”, or any
other path root, and the app will still work.
Here’s what happens if a user goes to “/polls/34/” in this system:
• Django will find the match at ’^polls/’
• Then, Django will strip off the matching text ("polls/") and send the remaining text – "34/" – to the
‘polls.urls’ URLconf for further processing which matches r’^(?P<poll_id>d+)/$’ resulting in a call
to the detail() view like so:
detail(request=<HttpRequest object>, poll_id=’34’)
The poll_id=’34’ part comes from (?P<poll_id>d+). Using parentheses around a pattern “captures” the
text matched by that pattern and sends it as an argument to the view function; ?P<poll_id> defines the name that
will be used to identify the matched pattern; and d+ is a regular expression to match a sequence of digits (i.e., a
number).
Because the URL patterns are regular expressions, there really is no limit on what you can do with them. And there’s
no need to add URL cruft such as .html – unless you want to, in which case you can do something like this:
(r’^polls/latest.html$’, ’polls.views.index’),
But, don’t do that. It’s silly.
2.5.4 Write views that actually do something
Each view is responsible for doing one of two things: returning an HttpResponse object containing the content for
the requested page, or raising an exception such as Http404. The rest is up to you.
Your view can read records from a database, or not. It can use a template system such as Django’s – or a third-party
Python template system – or not. It can generate a PDF file, output XML, create a ZIP file on the fly, anything you
want, using whatever Python libraries you want.
All Django wants is that HttpResponse. Or an exception.
Because it’s convenient, let’s use Django’s own database API, which we covered in Tutorial 1. Here’s one stab at
the index() view, which displays the latest 5 poll questions in the system, separated by commas, according to
publication date:
from django.http import HttpResponse
from polls.models import Poll
def index(request):
latest_poll_list = Poll.objects.order_by(’-pub_date’)[:5]
output = ’, ’.join([p.question for p in latest_poll_list])
return HttpResponse(output)
There’s a problem here, though: the page’s design is hard-coded in the view. If you want to change the way the page
looks, you’ll have to edit this Python code. So let’s use Django’s template system to separate the design from Python
by creating a template that the view can use.
First, create a directory called templates in your polls directory. Django will look for templates in there.
38 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-42-2048.jpg)
![Django Documentation, Release 1.5.1
Django’s TEMPLATE_LOADERS setting contains a list of callables that know how to import templates from various
sources. One of the defaults is django.template.loaders.app_directories.Loader which looks for
a “templates” subdirectory in each of the INSTALLED_APPS - this is how Django knows to find the polls templates
even though we didn’t modify TEMPLATE_DIRS, as we did in Tutorial 2.
Organizing templates
We could have all our templates together, in one big templates directory, and it would work perfectly well. However,
this template belongs to the polls application, so unlike the admin template we created in the previous tutorial, we’ll
put this one in the application’s template directory (polls/templates) rather than the project’s (templates).
We’ll discuss in more detail in the reusable apps tutorial why we do this.
Within the templates directory you have just created, create another directory called polls,
and within that create a file called index.html. In other words, your template should be at
polls/templates/polls/index.html. Because of how the app_directories template loader
works as described above, you can refer to this template within Django simply as polls/index.html.
Template namespacing
Now we might be able to get away with putting our templates directly in polls/templates (rather than creating
another polls subdirectory), but it would actually be a bad idea. Django will choose the first template it finds whose
name matches, and if you had a template with the same name in a different application, Django would be unable to
distinguish between them. We need to be able to point Django at the right one, and the easiest way to ensure this is by
namespacing them. That is, by putting those templates inside another directory named for the application itself.
Put the following code in that template:
{% if latest_poll_list %}
<ul>
{% for poll in latest_poll_list %}
<li><a href="/polls/{{ poll.id }}/">{{ poll.question }}</a></li>
{% endfor %}
</ul>
{% else %}
<p>No polls are available.</p>
{% endif %}
Now let’s use that html template in our index view:
from django.http import HttpResponse
from django.template import Context, loader
from polls.models import Poll
def index(request):
latest_poll_list = Poll.objects.order_by(’-pub_date’)[:5]
template = loader.get_template(’polls/index.html’)
context = Context({
’latest_poll_list’: latest_poll_list,
})
return HttpResponse(template.render(context))
That code loads the template called polls/index.html and passes it a context. The context is a dictionary
mapping template variable names to Python objects.
Load the page by pointing your browser at “/polls/”, and you should see a bulleted-list containing the “What’s up” poll
from Tutorial 1. The link points to the poll’s detail page.
2.5. Writing your first Django app, part 3 39](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-43-2048.jpg)
![Django Documentation, Release 1.5.1
A shortcut: render()
It’s a very common idiom to load a template, fill a context and return an HttpResponse object with the result of the
rendered template. Django provides a shortcut. Here’s the full index() view, rewritten:
from django.shortcuts import render
from polls.models import Poll
def index(request):
latest_poll_list = Poll.objects.all().order_by(’-pub_date’)[:5]
context = {’latest_poll_list’: latest_poll_list}
return render(request, ’polls/index.html’, context)
Note that once we’ve done this in all these views, we no longer need to import loader, Context and
HttpResponse (you’ll want to keep HttpResponse if you still have the stub methods for detail, results,
and vote).
The render() function takes the request object as its first argument, a template name as its second argument and a
dictionary as its optional third argument. It returns an HttpResponse object of the given template rendered with
the given context.
2.5.5 Raising a 404 error
Now, let’s tackle the poll detail view – the page that displays the question for a given poll. Here’s the view:
from django.http import Http404
# ...
def detail(request, poll_id):
try:
poll = Poll.objects.get(pk=poll_id)
except Poll.DoesNotExist:
raise Http404
return render(request, ’polls/detail.html’, {’poll’: poll})
The new concept here: The view raises the Http404 exception if a poll with the requested ID doesn’t exist.
We’ll discuss what you could put in that polls/detail.html template a bit later, but if you’d like to quickly get
the above example working, a file containing just:
{{ poll }}
will get you started for now.
A shortcut: get_object_or_404()
It’s a very common idiom to use get() and raise Http404 if the object doesn’t exist. Django provides a shortcut.
Here’s the detail() view, rewritten:
from django.shortcuts import render, get_object_or_404
# ...
def detail(request, poll_id):
poll = get_object_or_404(Poll, pk=poll_id)
return render(request, ’polls/detail.html’, {’poll’: poll})
40 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-44-2048.jpg)



![Django Documentation, Release 1.5.1
form will alter data server-side. Whenever you create a form that alters data server-side, use method="post".
This tip isn’t specific to Django; it’s just good Web development practice.
• forloop.counter indicates how many times the for tag has gone through its loop
• Since we’re creating a POST form (which can have the effect of modifying data), we need to worry about Cross
Site Request Forgeries. Thankfully, you don’t have to worry too hard, because Django comes with a very easy-to-
use system for protecting against it. In short, all POST forms that are targeted at internal URLs should use
the {% csrf_token %} template tag.
Now, let’s create a Django view that handles the submitted data and does something with it. Remember, in Tutorial 3,
we created a URLconf for the polls application that includes this line:
url(r’^(?P<poll_id>d+)/vote/$’, views.vote, name=’vote’),
We also created a dummy implementation of the vote() function. Let’s create a real version. Add the following to
polls/views.py:
from django.shortcuts import get_object_or_404, render
from django.http import HttpResponseRedirect, HttpResponse
from django.core.urlresolvers import reverse
from polls.models import Choice, Poll
# ...
def vote(request, poll_id):
p = get_object_or_404(Poll, pk=poll_id)
try:
selected_choice = p.choice_set.get(pk=request.POST[’choice’])
except (KeyError, Choice.DoesNotExist):
# Redisplay the poll voting form.
return render(request, ’polls/detail.html’, {
’poll’: p,
’error_message’: "You didn’t select a choice.",
})
else:
selected_choice.votes += 1
selected_choice.save()
# Always return an HttpResponseRedirect after successfully dealing
# with POST data. This prevents data from being posted twice if a
# user hits the Back button.
return HttpResponseRedirect(reverse(’polls:results’, args=(p.id,)))
This code includes a few things we haven’t covered yet in this tutorial:
• request.POST is a dictionary-like object that lets you access submitted data by key name. In this case,
request.POST[’choice’] returns the ID of the selected choice, as a string. request.POST values are
always strings.
Note that Django also provides request.GET for accessing GET data in the same way – but we’re explicitly
using request.POST in our code, to ensure that data is only altered via a POST call.
• request.POST[’choice’] will raise KeyError if choice wasn’t provided in POST data. The above
code checks for KeyError and redisplays the poll form with an error message if choice isn’t given.
• After incrementing the choice count, the code returns an HttpResponseRedirect rather than a normal
HttpResponse. HttpResponseRedirect takes a single argument: the URL to which the user will be
redirected (see the following point for how we construct the URL in this case).
As the Python comment above points out, you should always return an HttpResponseRedirect after
successfully dealing with POST data. This tip isn’t specific to Django; it’s just goodWeb development practice.
44 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-48-2048.jpg)

![Django Documentation, Release 1.5.1
Generally, when writing a Django app, you’ll evaluate whether generic views are a good fit for your problem, and
you’ll use them from the beginning, rather than refactoring your code halfway through. But this tutorial intentionally
has focused on writing the views “the hard way” until now, to focus on core concepts.
You should know basic math before you start using a calculator.
Amend URLconf
First, open the polls/urls.py URLconf and change it like so:
from django.conf.urls import patterns, url
from django.views.generic import DetailView, ListView
from polls.models import Poll
urlpatterns = patterns(’’,
url(r’^$’,
ListView.as_view(
queryset=Poll.objects.order_by(’-pub_date’)[:5],
context_object_name=’latest_poll_list’,
template_name=’polls/index.html’),
name=’index’),
url(r’^(?P<pk>d+)/$’,
DetailView.as_view(
model=Poll,
template_name=’polls/detail.html’),
name=’detail’),
url(r’^(?P<pk>d+)/results/$’,
DetailView.as_view(
model=Poll,
template_name=’polls/results.html’),
name=’results’),
url(r’^(?P<poll_id>d+)/vote/$’, ’polls.views.vote’, name=’vote’),
)
Amend views
We’re using two generic views here: ListView and DetailView. Respectively, those two views abstract the
concepts of “display a list of objects” and “display a detail page for a particular type of object.”
• Each generic view needs to know what model it will be acting upon. This is provided using the model param-eter.
• The DetailView generic view expects the primary key value captured from the URL to be called "pk", so
we’ve changed poll_id to pk for the generic views.
By default, the DetailView generic view uses a template called <app name>/<model
name>_detail.html. In our case, it’ll use the template "polls/poll_detail.html". The
template_name argument is used to tell Django to use a specific template name instead of the autogener-ated
default template name. We also specify the template_name for the results list view – this ensures that the
results view and the detail view have a different appearance when rendered, even though they’re both a DetailView
behind the scenes.
Similarly, the ListView generic view uses a default template called <app name>/<model
name>_list.html; we use template_name to tell ListView to use our existing "polls/index.html"
template.
46 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-50-2048.jpg)





![Django Documentation, Release 1.5.1
We will start again with the shell, where we need to do a couple of things that won’t be necessary in tests.py. The
first is to set up the test environment in the shell:
>>> from django.test.utils import setup_test_environment
>>> setup_test_environment()
Next we need to import the test client class (later in tests.py we will use the django.test.TestCase class,
which comes with its own client, so this won’t be required):
>>> from django.test.client import Client
>>> # create an instance of the client for our use
>>> client = Client()
With that ready, we can ask the client to do some work for us:
>>> # get a response from ’/’
>>> response = client.get(’/’)
>>> # we should expect a 404 from that address
>>> response.status_code
404
>>> # on the other hand we should expect to find something at ’/polls/’
>>> # we’ll use ’reverse()’ rather than a harcoded URL
>>> from django.core.urlresolvers import reverse
>>> response = client.get(reverse(’polls:index’))
>>> response.status_code
200
>>> response.content
’nnn <p>No polls are available.</p>nn’
>>> # note - you might get unexpected results if your ‘‘TIME_ZONE‘‘
>>> # in ‘‘settings.py‘‘ is not correct. If you need to change it,
>>> # you will also need to restart your shell session
>>> from polls.models import Poll
>>> from django.utils import timezone
>>> # create a Poll and save it
>>> p = Poll(question="Who is your favorite Beatle?", pub_date=timezone.now())
>>> p.save()
>>> # check the response once again
>>> response = client.get(’/polls/’)
>>> response.content
’nnn <ul>n n <li><a href="/polls/1/">Who is your favorite Beatle?</a></li>n n >>> response.context[’latest_poll_list’]
[<Poll: Who is your favorite Beatle?>]
Improving our view
The list of polls shows polls that aren’t published yet (i.e. those that have a pub_date in the future). Let’s fix that.
In Tutorial 4 we deleted the view functions from views.py in favor of a ListView in urls.py:
url(r’^$’,
ListView.as_view(
queryset=Poll.objects.order_by(’-pub_date’)[:5],
context_object_name=’latest_poll_list’,
template_name=’polls/index.html’),
name=’index’),
response.context_data[’latest_poll_list’] extracts the data this view places into the context.
We need to amend the line that gives us the queryset:
52 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-56-2048.jpg)
![Django Documentation, Release 1.5.1
queryset=Poll.objects.order_by(’-pub_date’)[:5],
Let’s change the queryset so that it also checks the date by comparing it with timezone.now(). First we need to
add an import:
from django.utils import timezone
and then we must amend the existing url function to:
url(r’^$’,
ListView.as_view(
queryset=Poll.objects.filter(pub_date__lte=timezone.now)
.order_by(’-pub_date’)[:5],
context_object_name=’latest_poll_list’,
template_name=’polls/index.html’),
name=’index’),
Poll.objects.filter(pub_date__lte=timezone.now) returns a queryset containing Polls whose
pub_date is less than or equal to - that is, earlier than or equal to - timezone.now. Notice that we use a callable
queryset argument, timezone.now, which will be evaluated at request time. If we had included the parentheses,
timezone.now() would be evaluated just once when the web server is started.
Testing our new view
Now you can satisfy yourself that this behaves as expected by firing up the runserver, loading the site in your browser,
creating Polls with dates in the past and future, and checking that only those that have been published are listed.
You don’t want to have to do that every single time you make any change that might affect this - so let’s also create a
test, based on our shell session above.
Add the following to polls/tests.py:
from django.core.urlresolvers import reverse
and we’ll create a factory method to create polls as well as a new test class:
def create_poll(question, days):
"""
Creates a poll with the given ‘question‘ published the given number of
‘days‘ offset to now (negative for polls published in the past,
positive for polls that have yet to be published).
"""
return Poll.objects.create(question=question,
pub_date=timezone.now() + datetime.timedelta(days=days))
class PollViewTests(TestCase):
def test_index_view_with_no_polls(self):
"""
If no polls exist, an appropriate message should be displayed.
"""
response = self.client.get(reverse(’polls:index’))
self.assertEqual(response.status_code, 200)
self.assertContains(response, "No polls are available.")
self.assertQuerysetEqual(response.context[’latest_poll_list’], [])
def test_index_view_with_a_past_poll(self):
"""
Polls with a pub_date in the past should be displayed on the index page.
"""
2.7. Writing your first Django app, part 5 53](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-57-2048.jpg)
![Django Documentation, Release 1.5.1
create_poll(question="Past poll.", days=-30)
response = self.client.get(reverse(’polls:index’))
self.assertQuerysetEqual(
response.context[’latest_poll_list’],
[’<Poll: Past poll.>’]
)
def test_index_view_with_a_future_poll(self):
"""
Polls with a pub_date in the future should not be displayed on the
index page.
"""
create_poll(question="Future poll.", days=30)
response = self.client.get(reverse(’polls:index’))
self.assertContains(response, "No polls are available.", status_code=200)
self.assertQuerysetEqual(response.context[’latest_poll_list’], [])
def test_index_view_with_future_poll_and_past_poll(self):
"""
Even if both past and future polls exist, only past polls should be
displayed.
"""
create_poll(question="Past poll.", days=-30)
create_poll(question="Future poll.", days=30)
response = self.client.get(reverse(’polls:index’))
self.assertQuerysetEqual(
response.context[’latest_poll_list’],
[’<Poll: Past poll.>’]
)
def test_index_view_with_two_past_polls(self):
"""
The polls index page may display multiple polls.
"""
create_poll(question="Past poll 1.", days=-30)
create_poll(question="Past poll 2.", days=-5)
response = self.client.get(reverse(’polls:index’))
self.assertQuerysetEqual(
response.context[’latest_poll_list’],
[’<Poll: Past poll 2.>’, ’<Poll: Past poll 1.>’]
)
Let’s look at some of these more closely.
First is a poll factory method, create_poll, to take some repetition out of the process of creating polls.
test_index_view_with_no_polls doesn’t create any polls, but checks the message: “No polls are available.”
and verifies the latest_poll_list is empty. Note that the django.test.TestCase class provides some
additional assertion methods. In these examples, we use assertContains() and assertQuerysetEqual().
In test_index_view_with_a_past_poll, we create a poll and verify that it appears in the list.
In test_index_view_with_a_future_poll, we create a poll with a pub_date in the future. The database
is reset for each test method, so the first poll is no longer there, and so again the index shouldn’t have any polls in it.
And so on. In effect, we are using the tests to tell a story of admin input and user experience on the site, and checking
that at every state and for every new change in the state of the system, the expected results are published.
54 Chapter 2. Getting started](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-58-2048.jpg)






![Django Documentation, Release 1.5.1
README = open(os.path.join(os.path.dirname(__file__), ’README.rst’)).read()
# allow setup.py to be run from any path
os.chdir(os.path.normpath(os.path.join(os.path.abspath(__file__), os.pardir)))
setup(
name=’django-polls’,
version=’0.1’,
packages=[’polls’],
include_package_data=True,
license=’BSD License’, # example license
description=’A simple Django app to conduct Web-based polls.’,
long_description=README,
url=’http://www.example.com/’,
author=’Your Name’,
author_email=’yourname@example.com’,
classifiers=[
’Environment :: Web Environment’,
’Framework :: Django’,
’Intended Audience :: Developers’,
’License :: OSI Approved :: BSD License’, # example license
’Operating System :: OS Independent’,
’Programming Language :: Python’,
’Programming Language :: Python :: 2.6’,
’Programming Language :: Python :: 2.7’,
’Topic :: Internet :: WWW/HTTP’,
’Topic :: Internet :: WWW/HTTP :: Dynamic Content’,
],
)
I thought you said we were going to use distribute?
Distribute is a drop-in replacement for setuptools. Even though we appear to import from setuptools, since
we have distribute installed, it will override the import.
6. Only Python modules and packages are included in the package by default. To include additional files,
we’ll need to create a MANIFEST.in file. The distribute docs referred to in the previous step discuss
this file in more details. To include the templates, the README.rst and our LICENSE file, create a file
django-polls/MANIFEST.in with the following contents:
include LICENSE
include README.rst
recursive-include polls/templates *
7. It’s optional, but recommended, to include detailed documentation with your app. Create an
empty directory django-polls/docs for future documentation. Add an additional line to
django-polls/MANIFEST.in:
recursive-include docs *
Note that the docs directory won’t be included in your package unless you add some files to it. Many Django
apps also provide their documentation online through sites like readthedocs.org.
8. Try building your package with python setup.py sdist (run from inside django-polls). This cre-ates
a directory called dist and builds your new package, django-polls-0.1.tar.gz.
For more information on packaging, see The Hitchhiker’s Guide to Packaging.
2.9. Advanced tutorial: How to write reusable apps 61](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-65-2048.jpg)















![Django Documentation, Release 1.5.1
a database user with these permissions, you’ll specify the details in your project’s settings file, see DATABASES for
details.
If you’re using Django’s testing framework to test database queries, Django will need permission to create a test
database.
3.1.4 Remove any old versions of Django
If you are upgrading your installation of Django from a previous version, you will need to uninstall the old Django
version before installing the new version.
If you installed Django using pip or easy_install previously, installing with pip or easy_install again will
automatically take care of the old version, so you don’t need to do it yourself.
If you previously installed Django using python setup.py install, uninstalling is as simple as deleting the
django directory from your Python site-packages. To find the directory you need to remove, you can run the
following at your shell prompt (not the interactive Python prompt):
python -c "import sys; sys.path = sys.path[1:]; import django; print(django.__path__)"
3.1.5 Install the Django code
Installation instructions are slightly different depending on whether you’re installing a distribution-specific package,
downloading the latest official release, or fetching the latest development version.
It’s easy, no matter which way you choose.
Installing a distribution-specific package
Check the distribution specific notes to see if your platform/distribution provides official Django packages/installers.
Distribution-provided packages will typically allow for automatic installation of dependencies and easy upgrade paths.
Installing an official release with pip
This is the recommended way to install Django.
1. Install pip. The easiest is to use the standalone pip installer. If your distribution already has pip installed, you
might need to update it if it’s outdated. (If it’s outdated, you’ll know because installation won’t work.)
2. (optional) Take a look at virtualenv and virtualenvwrapper. These tools provide isolated Python environments,
which are more practical than installing packages systemwide. They also allow installing packages without
administrator privileges. It’s up to you to decide if you want to learn and use them.
3. If you’re using Linux, Mac OS X or some other flavor of Unix, enter the command sudo pip install
Django at the shell prompt. If you’re using Windows, start a command shell with administrator privi-leges
and run the command pip install Django. This will install Django in your Python installation’s
site-packages directory.
If you’re using a virtualenv, you don’t need sudo or administrator privileges, and this will install Django in the
virtualenv’s site-packages directory.
3.1. How to install Django 77](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-81-2048.jpg)




![Django Documentation, Release 1.5.1
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(Person, through=’Membership’)
def __unicode__(self):
return self.name
class Membership(models.Model):
person = models.ForeignKey(Person)
group = models.ForeignKey(Group)
date_joined = models.DateField()
invite_reason = models.CharField(max_length=64)
When you set up the intermediary model, you explicitly specify foreign keys to the models that are involved in the
ManyToMany relation. This explicit declaration defines how the two models are related.
There are a few restrictions on the intermediate model:
• Your intermediate model must contain one - and only one - foreign key to the target model (this would be
Person in our example). If you have more than one foreign key, a validation error will be raised.
• Your intermediate model must contain one - and only one - foreign key to the source model (this would be
Group in our example). If you have more than one foreign key, a validation error will be raised.
• The only exception to this is a model which has a many-to-many relationship to itself, through an intermediary
model. In this case, two foreign keys to the same model are permitted, but they will be treated as the two
(different) sides of the many-to-many relation.
• When defining a many-to-many relationship from a model to itself, using an intermediary model, you must use
symmetrical=False (see the model field reference).
Now that you have set up your ManyToManyField to use your intermediary model (Membership, in this case),
you’re ready to start creating some many-to-many relationships. You do this by creating instances of the intermediate
model:
>>> ringo = Person.objects.create(name="Ringo Starr")
>>> paul = Person.objects.create(name="Paul McCartney")
>>> beatles = Group.objects.create(name="The Beatles")
>>> m1 = Membership(person=ringo, group=beatles,
... date_joined=date(1962, 8, 16),
... invite_reason= "Needed a new drummer.")
>>> m1.save()
>>> beatles.members.all()
[<Person: Ringo Starr>]
>>> ringo.group_set.all()
[<Group: The Beatles>]
>>> m2 = Membership.objects.create(person=paul, group=beatles,
... date_joined=date(1960, 8, 1),
... invite_reason= "Wanted to form a band.")
>>> beatles.members.all()
[<Person: Ringo Starr>, <Person: Paul McCartney>]
Unlike normal many-to-many fields, you can’t use add, create, or assignment (i.e., beatles.members =
[...]) to create relationships:
# THIS WILL NOT WORK
>>> beatles.members.add(john)
# NEITHER WILL THIS
>>> beatles.members.create(name="George Harrison")
3.2. Models and databases 85](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-89-2048.jpg)
![Django Documentation, Release 1.5.1
# AND NEITHER WILL THIS
>>> beatles.members = [john, paul, ringo, george]
Why? You can’t just create a relationship between a Person and a Group - you need to specify all the detail for the
relationship required by the Membership model. The simple add, create and assignment calls don’t provide a
way to specify this extra detail. As a result, they are disabled for many-to-many relationships that use an intermediate
model. The only way to create this type of relationship is to create instances of the intermediate model.
The remove() method is disabled for similar reasons. However, the clear() method can be used to remove all
many-to-many relationships for an instance:
# Beatles have broken up
>>> beatles.members.clear()
Once you have established the many-to-many relationships by creating instances of your intermediate model, you can
issue queries. Just as with normal many-to-many relationships, you can query using the attributes of the many-to-many-
related model:
# Find all the groups with a member whose name starts with ’Paul’
>>> Group.objects.filter(members__name__startswith=’Paul’)
[<Group: The Beatles>]
As you are using an intermediate model, you can also query on its attributes:
# Find all the members of the Beatles that joined after 1 Jan 1961
>>> Person.objects.filter(
... group__name=’The Beatles’,
... membership__date_joined__gt=date(1961,1,1))
[<Person: Ringo Starr]
If you need to access a membership’s information you may do so by directly querying the Membership model:
>>> ringos_membership = Membership.objects.get(group=beatles, person=ringo)
>>> ringos_membership.date_joined
datetime.date(1962, 8, 16)
>>> ringos_membership.invite_reason
u’Needed a new drummer.’
Another way to access the same information is by querying the many-to-many reverse relationship from a Person
object:
>>> ringos_membership = ringo.membership_set.get(group=beatles)
>>> ringos_membership.date_joined
datetime.date(1962, 8, 16)
>>> ringos_membership.invite_reason
u’Needed a new drummer.’
One-to-one relationships To define a one-to-one relationship, use OneToOneField. You use it just like any other
Field type: by including it as a class attribute of your model.
This is most useful on the primary key of an object when that object “extends” another object in some way.
OneToOneField requires a positional argument: the class to which the model is related.
For example, if you were building a database of “places”, you would build pretty standard stuff such as address, phone
number, etc. in the database. Then, if you wanted to build a database of restaurants on top of the places, instead of
repeating yourself and replicating those fields in the Restaurant model, you could make Restaurant have a
OneToOneField to Place (because a restaurant “is a” place; in fact, to handle this you’d typically use inheritance,
which involves an implicit one-to-one relation).
86 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-90-2048.jpg)

![Django Documentation, Release 1.5.1
Meta options
Give your model metadata by using an inner class Meta, like so:
class Ox(models.Model):
horn_length = models.IntegerField()
class Meta:
ordering = ["horn_length"]
verbose_name_plural = "oxen"
Model metadata is “anything that’s not a field”, such as ordering options (ordering), database table name
(db_table), or human-readable singular and plural names (verbose_name and verbose_name_plural).
None are required, and adding class Meta to a model is completely optional.
A complete list of all possible Meta options can be found in the model option reference.
Model methods
Define custom methods on a model to add custom “row-level” functionality to your objects. Whereas Manager
methods are intended to do “table-wide” things, model methods should act on a particular model instance.
This is a valuable technique for keeping business logic in one place – the model.
For example, this model has a few custom methods:
from django.contrib.localflavor.us.models import USStateField
class Person(models.Model):
first_name = models.CharField(max_length=50)
last_name = models.CharField(max_length=50)
birth_date = models.DateField()
address = models.CharField(max_length=100)
city = models.CharField(max_length=50)
state = USStateField() # Yes, this is America-centric...
def baby_boomer_status(self):
"Returns the person’s baby-boomer status."
import datetime
if self.birth_date < datetime.date(1945, 8, 1):
return "Pre-boomer"
elif self.birth_date < datetime.date(1965, 1, 1):
return "Baby boomer"
else:
return "Post-boomer"
def is_midwestern(self):
"Returns True if this person is from the Midwest."
return self.state in (’IL’, ’WI’, ’MI’, ’IN’, ’OH’, ’IA’, ’MO’)
def _get_full_name(self):
"Returns the person’s full name."
return ’%s %s’ % (self.first_name, self.last_name)
full_name = property(_get_full_name)
The last method in this example is a property.
The model instance reference has a complete list of methods automatically given to each model. You can override
most of these – see overriding predefined model methods, below – but there are a couple that you’ll almost always
88 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-92-2048.jpg)


![Django Documentation, Release 1.5.1
Meta inheritance When an abstract base class is created, Django makes any Meta inner class you declared in the
base class available as an attribute. If a child class does not declare its own Meta class, it will inherit the parent’s Meta.
If the child wants to extend the parent’s Meta class, it can subclass it. For example:
class CommonInfo(models.Model):
...
class Meta:
abstract = True
ordering = [’name’]
class Student(CommonInfo):
...
class Meta(CommonInfo.Meta):
db_table = ’student_info’
Django does make one adjustment to the Meta class of an abstract base class: before installing the Meta attribute,
it sets abstract=False. This means that children of abstract base classes don’t automatically become abstract
classes themselves. Of course, you can make an abstract base class that inherits from another abstract base class. You
just need to remember to explicitly set abstract=True each time.
Some attributes won’t make sense to include in the Meta class of an abstract base class. For example, including
db_table would mean that all the child classes (the ones that don’t specify their own Meta) would use the same
database table, which is almost certainly not what you want.
Be careful with related_name If you are using the related_name attribute on a ForeignKey or
ManyToManyField, you must always specify a unique reverse name for the field. This would normally cause a
problem in abstract base classes, since the fields on this class are included into each of the child classes, with exactly
the same values for the attributes (including related_name) each time.
To work around this problem, when you are using related_name in an abstract base class (only), part of the name
should contain ’%(app_label)s’ and ’%(class)s’.
• ’%(class)s’ is replaced by the lower-cased name of the child class that the field is used in.
• ’%(app_label)s’ is replaced by the lower-cased name of the app the child class is contained within. Each
installed application name must be unique and the model class names within each app must also be unique,
therefore the resulting name will end up being different.
For example, given an app common/models.py:
class Base(models.Model):
m2m = models.ManyToManyField(OtherModel, related_name="%(app_label)s_%(class)s_related")
class Meta:
abstract = True
class ChildA(Base):
pass
class ChildB(Base):
pass
Along with another app rare/models.py:
from common.models import Base
class ChildB(Base):
pass
3.2. Models and databases 91](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-95-2048.jpg)

![Django Documentation, Release 1.5.1
# Remove parent’s ordering effect
ordering = []
Inheritance and reverse relations Because multi-table inheritance uses an implicit OneToOneField to link the
child and the parent, it’s possible to move from the parent down to the child, as in the above example. However, this
uses up the name that is the default related_name value for ForeignKey and ManyToManyField relations.
If you are putting those types of relations on a subclass of another model, you must specify the related_name
attribute on each such field. If you forget, Django will raise an error when you run validate or syncdb.
For example, using the above Place class again, let’s create another subclass with a ManyToManyField:
class Supplier(Place):
# Must specify related_name on all relations.
customers = models.ManyToManyField(Restaurant, related_name=’provider’)
Specifying the parent link field As mentioned, Django will automatically create a OneToOneField linking your
child class back any non-abstract parent models. If you want to control the name of the attribute linking back to the
parent, you can create your own OneToOneField and set parent_link=True to indicate that your field is the
link back to the parent class.
Proxy models
When using multi-table inheritance, a new database table is created for each subclass of a model. This is usually the
desired behavior, since the subclass needs a place to store any additional data fields that are not present on the base
class. Sometimes, however, you only want to change the Python behavior of a model – perhaps to change the default
manager, or add a new method.
This is what proxy model inheritance is for: creating a proxy for the original model. You can create, delete and update
instances of the proxy model and all the data will be saved as if you were using the original (non-proxied) model. The
difference is that you can change things like the default model ordering or the default manager in the proxy, without
having to alter the original.
Proxy models are declared like normal models. You tell Django that it’s a proxy model by setting the proxy attribute
of the Meta class to True.
For example, suppose you want to add a method to the Person model described above. You can do it like this:
class MyPerson(Person):
class Meta:
proxy = True
def do_something(self):
...
The MyPerson class operates on the same database table as its parent Person class. In particular, any new instances
of Person will also be accessible through MyPerson, and vice-versa:
>>> p = Person.objects.create(first_name="foobar")
>>> MyPerson.objects.get(first_name="foobar")
<MyPerson: foobar>
You could also use a proxy model to define a different default ordering on a model. You might not always want to
order the Person model, but regularly order by the last_name attribute when you use the proxy. This is easy:
3.2. Models and databases 93](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-97-2048.jpg)
![Django Documentation, Release 1.5.1
class OrderedPerson(Person):
class Meta:
ordering = ["last_name"]
proxy = True
Now normal Person queries will be unordered and OrderedPerson queries will be ordered by last_name.
QuerySets still return the model that was requested There is no way to have Django return, say, a MyPerson
object whenever you query for Person objects. A queryset for Person objects will return those types of objects.
The whole point of proxy objects is that code relying on the original Person will use those and your own code can
use the extensions you included (that no other code is relying on anyway). It is not a way to replace the Person (or
any other) model everywhere with something of your own creation.
Base class restrictions A proxy model must inherit from exactly one non-abstract model class. You can’t inherit
from multiple non-abstract models as the proxy model doesn’t provide any connection between the rows in the different
database tables. A proxy model can inherit from any number of abstract model classes, providing they do not define
any model fields.
Proxy models inherit any Meta options that they don’t define from their non-abstract model parent (the model they
are proxying for).
Proxy model managers If you don’t specify any model managers on a proxy model, it inherits the managers from
its model parents. If you define a manager on the proxy model, it will become the default, although any managers
defined on the parent classes will still be available.
Continuing our example from above, you could change the default manager used when you query the Person model
like this:
class NewManager(models.Manager):
...
class MyPerson(Person):
objects = NewManager()
class Meta:
proxy = True
If you wanted to add a new manager to the Proxy, without replacing the existing default, you can use the techniques
described in the custom manager documentation: create a base class containing the new managers and inherit that
after the primary base class:
# Create an abstract class for the new manager.
class ExtraManagers(models.Model):
secondary = NewManager()
class Meta:
abstract = True
class MyPerson(Person, ExtraManagers):
class Meta:
proxy = True
You probably won’t need to do this very often, but, when you do, it’s possible.
94 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-98-2048.jpg)




![Django Documentation, Release 1.5.1
>>> Entry.objects.filter(
... headline__startswith=’What’
... ).exclude(
... pub_date__gte=datetime.date.today()
... ).filter(
... pub_date__gte=datetime(2005, 1, 30)
... )
This takes the initial QuerySet of all entries in the database, adds a filter, then an exclusion, then another filter. The
final result is a QuerySet containing all entries with a headline that starts with “What”, that were published between
January 30, 2005, and the current day.
Filtered QuerySets are unique Each time you refine a QuerySet, you get a brand-new QuerySet that is in no
way bound to the previous QuerySet. Each refinement creates a separate and distinct QuerySet that can be stored,
used and reused.
Example:
>> q1 = Entry.objects.filter(headline__startswith="What")
>> q2 = q1.exclude(pub_date__gte=datetime.date.today())
>> q3 = q1.filter(pub_date__gte=datetime.date.today())
These three QuerySets are separate. The first is a base QuerySet containing all entries that contain a headline
starting with “What”. The second is a subset of the first, with an additional criteria that excludes records whose
pub_date is greater than now. The third is a subset of the first, with an additional criteria that selects only the
records whose pub_date is greater than now. The initial QuerySet (q1) is unaffected by the refinement process.
QuerySets are lazy QuerySets are lazy – the act of creating a QuerySet doesn’t involve any database activity.
You can stack filters together all day long, and Django won’t actually run the query until the QuerySet is evaluated.
Take a look at this example:
>>> q = Entry.objects.filter(headline__startswith="What")
>>> q = q.filter(pub_date__lte=datetime.date.today())
>>> q = q.exclude(body_text__icontains="food")
>>> print(q)
Though this looks like three database hits, in fact it hits the database only once, at the last line (print(q)). In
general, the results of a QuerySet aren’t fetched from the database until you “ask” for them. When you do, the
QuerySet is evaluated by accessing the database. For more details on exactly when evaluation takes place, see
When QuerySets are evaluated.
Retrieving a single object with get
filter() will always give you a QuerySet, even if only a single object matches the query - in this case, it will be
a QuerySet containing a single element.
If you know there is only one object that matches your query, you can use the get() method on a Manager which
returns the object directly:
>>> one_entry = Entry.objects.get(pk=1)
You can use any query expression with get(), just like with filter() - again, see Field lookups below.
Note that there is a difference between using get(), and using filter() with a slice of [0]. If there are no results
that match the query, get() will raise a DoesNotExist exception. This exception is an attribute of the model
3.2. Models and databases 99](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-103-2048.jpg)
![Django Documentation, Release 1.5.1
class that the query is being performed on - so in the code above, if there is no Entry object with a primary key of 1,
Django will raise Entry.DoesNotExist.
Similarly, Django will complain if more than one item matches the get() query. In this case, it will raise
MultipleObjectsReturned, which again is an attribute of the model class itself.
Other QuerySet methods
Most of the time you’ll use all(), get(), filter() and exclude() when you need to look up objects from
the database. However, that’s far from all there is; see the QuerySet API Reference for a complete list of all the various
QuerySet methods.
Limiting QuerySets
Use a subset of Python’s array-slicing syntax to limit your QuerySet to a certain number of results. This is the
equivalent of SQL’s LIMIT and OFFSET clauses.
For example, this returns the first 5 objects (LIMIT 5):
>>> Entry.objects.all()[:5]
This returns the sixth through tenth objects (OFFSET 5 LIMIT 5):
>>> Entry.objects.all()[5:10]
Negative indexing (i.e. Entry.objects.all()[-1]) is not supported.
Generally, slicing a QuerySet returns a new QuerySet – it doesn’t evaluate the query. An exception is if you use
the “step” parameter of Python slice syntax. For example, this would actually execute the query in order to return a
list of every second object of the first 10:
>>> Entry.objects.all()[:10:2]
To retrieve a single object rather than a list (e.g. SELECT foo FROM bar LIMIT 1), use a simple index instead
of a slice. For example, this returns the first Entry in the database, after ordering entries alphabetically by headline:
>>> Entry.objects.order_by(’headline’)[0]
This is roughly equivalent to:
>>> Entry.objects.order_by(’headline’)[0:1].get()
Note, however, that the first of these will raise IndexError while the second will raise DoesNotExist if no
objects match the given criteria. See get() for more details.
Field lookups
Field lookups are how you specify the meat of an SQL WHERE clause. They’re specified as keyword arguments to the
QuerySet methods filter(), exclude() and get().
Basic lookups keyword arguments take the form field__lookuptype=value. (That’s a double-underscore).
For example:
>>> Entry.objects.filter(pub_date__lte=’2006-01-01’)
translates (roughly) into the following SQL:
100 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-104-2048.jpg)


![Django Documentation, Release 1.5.1
New in version 1.5: .bitand() and .bitor() The F() objects now support bitwise operations by .bitand()
and .bitor(), for example:
>>> F(’somefield’).bitand(16)
Changed in version 1.5: The previously undocumented operators & and | no longer produce bitwise operations, use
.bitand() and .bitor() instead.
The pk lookup shortcut
For convenience, Django provides a pk lookup shortcut, which stands for “primary key”.
In the example Blog model, the primary key is the id field, so these three statements are equivalent:
>>> Blog.objects.get(id__exact=14) # Explicit form
>>> Blog.objects.get(id=14) # __exact is implied
>>> Blog.objects.get(pk=14) # pk implies id__exact
The use of pk isn’t limited to __exact queries – any query term can be combined with pk to perform a query on the
primary key of a model:
# Get blogs entries with id 1, 4 and 7
>>> Blog.objects.filter(pk__in=[1,4,7])
# Get all blog entries with id > 14
>>> Blog.objects.filter(pk__gt=14)
pk lookups also work across joins. For example, these three statements are equivalent:
>>> Entry.objects.filter(blog__id__exact=3) # Explicit form
>>> Entry.objects.filter(blog__id=3) # __exact is implied
>>> Entry.objects.filter(blog__pk=3) # __pk implies __id__exact
Escaping percent signs and underscores in LIKE statements
The field lookups that equate to LIKE SQL statements (iexact, contains, icontains, startswith,
istartswith, endswith and iendswith) will automatically escape the two special characters used in LIKE
statements – the percent sign and the underscore. (In a LIKE statement, the percent sign signifies a multiple-character
wildcard and the underscore signifies a single-character wildcard.)
This means things should work intuitively, so the abstraction doesn’t leak. For example, to retrieve all the entries that
contain a percent sign, just use the percent sign as any other character:
>>> Entry.objects.filter(headline__contains=’%’)
Django takes care of the quoting for you; the resulting SQL will look something like this:
SELECT ... WHERE headline LIKE ’%%%’;
Same goes for underscores. Both percentage signs and underscores are handled for you transparently.
Caching and QuerySets
Each QuerySet contains a cache, to minimize database access. It’s important to understand how it works, in order
to write the most efficient code.
104 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-108-2048.jpg)
![Django Documentation, Release 1.5.1
In a newly created QuerySet, the cache is empty. The first time a QuerySet is evaluated – and, hence, a database
query happens – Django saves the query results in the QuerySet‘s cache and returns the results that have been
explicitly requested (e.g., the next element, if the QuerySet is being iterated over). Subsequent evaluations of the
QuerySet reuse the cached results.
Keep this caching behavior in mind, because it may bite you if you don’t use your QuerySets correctly. For example,
the following will create two QuerySets, evaluate them, and throw them away:
>>> print([e.headline for e in Entry.objects.all()])
>>> print([e.pub_date for e in Entry.objects.all()])
That means the same database query will be executed twice, effectively doubling your database load. Also, there’s
a possibility the two lists may not include the same database records, because an Entry may have been added or
deleted in the split second between the two requests.
To avoid this problem, simply save the QuerySet and reuse it:
>>> queryset = Entry.objects.all()
>>> print([p.headline for p in queryset]) # Evaluate the query set.
>>> print([p.pub_date for p in queryset]) # Re-use the cache from the evaluation.
Complex lookups with Q objects
class Q
Keyword argument queries – in filter(), etc. – are “AND”ed together. If you need to execute more complex
queries (for example, queries with OR statements), you can use Q objects.
A Q object (django.db.models.Q) is an object used to encapsulate a collection of keyword arguments. These
keyword arguments are specified as in “Field lookups” above.
For example, this Q object encapsulates a single LIKE query:
from django.db.models import Q
Q(question__startswith=’What’)
Q objects can be combined using the & and | operators. When an operator is used on two Q objects, it yields a new Q
object.
For example, this statement yields a single Q object that represents the “OR” of two "question__startswith"
queries:
Q(question__startswith=’Who’) | Q(question__startswith=’What’)
This is equivalent to the following SQL WHERE clause:
WHERE question LIKE ’Who%’ OR question LIKE ’What%’
You can compose statements of arbitrary complexity by combining Q objects with the & and | operators and use
parenthetical grouping. Also, Q objects can be negated using the ~ operator, allowing for combined lookups that
combine both a normal query and a negated (NOT) query:
Q(question__startswith=’Who’) | ~Q(pub_date__year=2005)
Each lookup function that takes keyword-arguments (e.g. filter(), exclude(), get()) can also be passed
one or more Q objects as positional (not-named) arguments. If you provide multiple Q object arguments to a lookup
function, the arguments will be “AND”ed together. For example:
3.2. Models and databases 105](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-109-2048.jpg)

![Django Documentation, Release 1.5.1
Entry.objects.filter(pub_date__year=2005).delete()
Keep in mind that this will, whenever possible, be executed purely in SQL, and so the delete() methods of in-dividual
object instances will not necessarily be called during the process. If you’ve provided a custom delete()
method on a model class and want to ensure that it is called, you will need to “manually” delete instances of that model
(e.g., by iterating over a QuerySet and calling delete() on each object individually) rather than using the bulk
delete() method of a QuerySet.
When Django deletes an object, by default it emulates the behavior of the SQL constraint ON DELETE CASCADE –
in other words, any objects which had foreign keys pointing at the object to be deleted will be deleted along with it.
For example:
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
This cascade behavior is customizable via the on_delete argument to the ForeignKey.
Note that delete() is the only QuerySet method that is not exposed on a Manager itself. This is a safety
mechanism to prevent you from accidentally requesting Entry.objects.delete(), and deleting all the entries.
If you do want to delete all the objects, then you have to explicitly request a complete query set:
Entry.objects.all().delete()
Copying model instances
Although there is no built-in method for copying model instances, it is possible to easily create new instance with all
fields’ values copied. In the simplest case, you can just set pk to None. Using our blog example:
blog = Blog(name=’My blog’, tagline=’Blogging is easy’)
blog.save() # blog.pk == 1
blog.pk = None
blog.save() # blog.pk == 2
Things get more complicated if you use inheritance. Consider a subclass of Blog:
class ThemeBlog(Blog):
theme = models.CharField(max_length=200)
django_blog = ThemeBlog(name=’Django’, tagline=’Django is easy’, theme=’python’)
django_blog.save() # django_blog.pk == 3
Due to how inheritance works, you have to set both pk and id to None:
django_blog.pk = None
django_blog.id = None
django_blog.save() # django_blog.pk == 4
This process does not copy related objects. If you want to copy relations, you have to write a little bit more code. In
our example, Entry has a many to many field to Author:
entry = Entry.objects.all()[0] # some previous entry
old_authors = entry.authors.all()
entry.pk = None
entry.save()
entry.authors = old_authors # saves new many2many relations
3.2. Models and databases 107](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-111-2048.jpg)
![Django Documentation, Release 1.5.1
You can override the FOO_set name by setting the related_name parameter in the ForeignKey()
definition. For example, if the Entry model was altered to blog = ForeignKey(Blog,
related_name=’entries’), the above example code would look like this:
>>> b = Blog.objects.get(id=1)
>>> b.entries.all() # Returns all Entry objects related to Blog.
# b.entries is a Manager that returns QuerySets.
>>> b.entries.filter(headline__contains=’Lennon’)
>>> b.entries.count()
You cannot access a reverse ForeignKey Manager from the class; it must be accessed from an instance:
>>> Blog.entry_set
Traceback:
...
AttributeError: "Manager must be accessed via instance".
In addition to the QuerySet methods defined in “Retrieving objects” above, the ForeignKey Manager has ad-ditional
methods used to handle the set of related objects. A synopsis of each is below, and complete details can be
found in the related objects reference.
add(obj1, obj2, ...) Adds the specified model objects to the related object set.
create(**kwargs) Creates a new object, saves it and puts it in the related object set. Returns the newly created
object.
remove(obj1, obj2, ...) Removes the specified model objects from the related object set.
clear() Removes all objects from the related object set.
To assign the members of a related set in one fell swoop, just assign to it from any iterable object. The iterable can
contain object instances, or just a list of primary key values. For example:
b = Blog.objects.get(id=1)
b.entry_set = [e1, e2]
In this example, e1 and e2 can be full Entry instances, or integer primary key values.
If the clear() method is available, any pre-existing objects will be removed from the entry_set before all
objects in the iterable (in this case, a list) are added to the set. If the clear() method is not available, all objects in
the iterable will be added without removing any existing elements.
Each “reverse” operation described in this section has an immediate effect on the database. Every addition, creation
and deletion is immediately and automatically saved to the database.
Many-to-many relationships
Both ends of a many-to-many relationship get automatic API access to the other end. The API works just as a
“backward” one-to-many relationship, above.
The only difference is in the attribute naming: The model that defines the ManyToManyField uses the attribute
name of that field itself, whereas the “reverse” model uses the lowercased model name of the original model, plus
’_set’ (just like reverse one-to-many relationships).
An example makes this easier to understand:
e = Entry.objects.get(id=3)
e.authors.all() # Returns all Author objects for this Entry.
e.authors.count()
e.authors.filter(name__contains=’John’)
110 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-114-2048.jpg)

![Django Documentation, Release 1.5.1
>>> Book.objects.all().aggregate(Avg(’price’))
{’price__avg’: 34.35}
# Max price across all books.
>>> from django.db.models import Max
>>> Book.objects.all().aggregate(Max(’price’))
{’price__max’: Decimal(’81.20’)}
# All the following queries involve traversing the Book<->Publisher
# many-to-many relationship backward
# Each publisher, each with a count of books as a "num_books" attribute.
>>> from django.db.models import Count
>>> pubs = Publisher.objects.annotate(num_books=Count(’book’))
>>> pubs
[<Publisher BaloneyPress>, <Publisher SalamiPress>, ...]
>>> pubs[0].num_books
73
# The top 5 publishers, in order by number of books.
>>> pubs = Publisher.objects.annotate(num_books=Count(’book’)).order_by(’-num_books’)[:5]
>>> pubs[0].num_books
1323
Generating aggregates over a QuerySet
Django provides two ways to generate aggregates. The first way is to generate summary values over an entire
QuerySet. For example, say you wanted to calculate the average price of all books available for sale. Django’s
query syntax provides a means for describing the set of all books:
>>> Book.objects.all()
What we need is a way to calculate summary values over the objects that belong to this QuerySet. This is done by
appending an aggregate() clause onto the QuerySet:
>>> from django.db.models import Avg
>>> Book.objects.all().aggregate(Avg(’price’))
{’price__avg’: 34.35}
The all() is redundant in this example, so this could be simplified to:
>>> Book.objects.aggregate(Avg(’price’))
{’price__avg’: 34.35}
The argument to the aggregate() clause describes the aggregate value that we want to compute - in this case, the
average of the price field on the Book model. A list of the aggregate functions that are available can be found in the
QuerySet reference.
aggregate() is a terminal clause for a QuerySet that, when invoked, returns a dictionary of name-value pairs.
The name is an identifier for the aggregate value; the value is the computed aggregate. The name is automatically
generated from the name of the field and the aggregate function. If you want to manually specify a name for the
aggregate value, you can do so by providing that name when you specify the aggregate clause:
>>> Book.objects.aggregate(average_price=Avg(’price’))
{’average_price’: 34.35}
If you want to generate more than one aggregate, you just add another argument to the aggregate() clause. So, if
we also wanted to know the maximum and minimum price of all books, we would issue the query:
3.2. Models and databases 113](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-117-2048.jpg)
![Django Documentation, Release 1.5.1
>>> from django.db.models import Avg, Max, Min, Count
>>> Book.objects.aggregate(Avg(’price’), Max(’price’), Min(’price’))
{’price__avg’: 34.35, ’price__max’: Decimal(’81.20’), ’price__min’: Decimal(’12.99’)}
Generating aggregates for each item in a QuerySet
The second way to generate summary values is to generate an independent summary for each object in a QuerySet.
For example, if you are retrieving a list of books, you may want to know how many authors contributed to each book.
Each Book has a many-to-many relationship with the Author; we want to summarize this relationship for each book
in the QuerySet.
Per-object summaries can be generated using the annotate() clause. When an annotate() clause is specified,
each object in the QuerySet will be annotated with the specified values.
The syntax for these annotations is identical to that used for the aggregate() clause. Each argument to
annotate() describes an aggregate that is to be calculated. For example, to annotate books with the number of
authors:
# Build an annotated queryset
>>> q = Book.objects.annotate(Count(’authors’))
# Interrogate the first object in the queryset
>>> q[0]
<Book: The Definitive Guide to Django>
>>> q[0].authors__count
2
# Interrogate the second object in the queryset
>>> q[1]
<Book: Practical Django Projects>
>>> q[1].authors__count
1
As with aggregate(), the name for the annotation is automatically derived from the name of the aggregate function
and the name of the field being aggregated. You can override this default name by providing an alias when you specify
the annotation:
>>> q = Book.objects.annotate(num_authors=Count(’authors’))
>>> q[0].num_authors
2
>>> q[1].num_authors
1
Unlike aggregate(), annotate() is not a terminal clause. The output of the annotate() clause is
a QuerySet; this QuerySet can be modified using any other QuerySet operation, including filter(),
order_by(), or even additional calls to annotate().
Joins and aggregates
So far, we have dealt with aggregates over fields that belong to the model being queried. However, sometimes the
value you want to aggregate will belong to a model that is related to the model you are querying.
When specifying the field to be aggregated in an aggregate function, Django will allow you to use the same double
underscore notation that is used when referring to related fields in filters. Django will then handle any table joins that
are required to retrieve and aggregate the related value.
For example, to find the price range of books offered in each store, you could use the annotation:
114 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-118-2048.jpg)


![Django Documentation, Release 1.5.1
returned in the result set, the method for evaluating annotations is slightly different. Instead of returning an annotated
result for each result in the original QuerySet, the original results are grouped according to the unique combinations
of the fields specified in the values() clause. An annotation is then provided for each unique group; the annotation
is computed over all members of the group.
For example, consider an author query that attempts to find out the average rating of books written by each author:
>>> Author.objects.annotate(average_rating=Avg(’book__rating’))
This will return one result for each author in the database, annotated with their average book rating.
However, the result will be slightly different if you use a values() clause:
>>> Author.objects.values(’name’).annotate(average_rating=Avg(’book__rating’))
In this example, the authors will be grouped by name, so you will only get an annotated result for each unique author
name. This means if you have two authors with the same name, their results will be merged into a single result in the
output of the query; the average will be computed as the average over the books written by both authors.
Order of annotate() and values() clauses As with the filter() clause, the order in which annotate()
and values() clauses are applied to a query is significant. If the values() clause precedes the annotate(),
the annotation will be computed using the grouping described by the values() clause.
However, if the annotate() clause precedes the values() clause, the annotations will be generated over the
entire query set. In this case, the values() clause only constrains the fields that are generated on output.
For example, if we reverse the order of the values() and annotate() clause from our previous example:
>>> Author.objects.annotate(average_rating=Avg(’book__rating’)).values(’name’, ’average_rating’)
This will now yield one unique result for each author; however, only the author’s name and the average_rating
annotation will be returned in the output data.
You should also note that average_rating has been explicitly included in the list of values to be returned. This is
required because of the ordering of the values() and annotate() clause.
If the values() clause precedes the annotate() clause, any annotations will be automatically added to the result
set. However, if the values() clause is applied after the annotate() clause, you need to explicitly include the
aggregate column.
Interaction with default ordering or order_by() Fields that are mentioned in the order_by() part of a
queryset (or which are used in the default ordering on a model) are used when selecting the output data, even if they
are not otherwise specified in the values() call. These extra fields are used to group “like” results together and they
can make otherwise identical result rows appear to be separate. This shows up, particularly, when counting things.
By way of example, suppose you have a model like this:
class Item(models.Model):
name = models.CharField(max_length=10)
data = models.IntegerField()
class Meta:
ordering = ["name"]
The important part here is the default ordering on the name field. If you want to count how many times each distinct
data value appears, you might try this:
# Warning: not quite correct!
Item.objects.values("data").annotate(Count("id"))
3.2. Models and databases 117](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-121-2048.jpg)

![Django Documentation, Release 1.5.1
Custom Managers
You can use a custom Manager in a particular model by extending the base Manager class and instantiating your
custom Manager in your model.
There are two reasons you might want to customize a Manager: to add extra Manager methods, and/or to modify
the initial QuerySet the Manager returns.
Adding extra Manager methods
Adding extra Manager methods is the preferred way to add “table-level” functionality to your models. (For “row-level”
functionality – i.e., functions that act on a single instance of a model object – use Model methods, not custom
Manager methods.)
A custom Manager method can return anything you want. It doesn’t have to return a QuerySet.
For example, this custom Manager offers a method with_counts(), which returns a list of all OpinionPoll
objects, each with an extra num_responses attribute that is the result of an aggregate query:
class PollManager(models.Manager):
def with_counts(self):
from django.db import connection
cursor = connection.cursor()
cursor.execute("""
SELECT p.id, p.question, p.poll_date, COUNT(*)
FROM polls_opinionpoll p, polls_response r
WHERE p.id = r.poll_id
GROUP BY p.id, p.question, p.poll_date
ORDER BY p.poll_date DESC""")
result_list = []
for row in cursor.fetchall():
p = self.model(id=row[0], question=row[1], poll_date=row[2])
p.num_responses = row[3]
result_list.append(p)
return result_list
class OpinionPoll(models.Model):
question = models.CharField(max_length=200)
poll_date = models.DateField()
objects = PollManager()
class Response(models.Model):
poll = models.ForeignKey(OpinionPoll)
person_name = models.CharField(max_length=50)
response = models.TextField()
With this example, you’d use OpinionPoll.objects.with_counts() to return that list of OpinionPoll
objects with num_responses attributes.
Another thing to note about this example is that Manager methods can access self.model to get the model class
to which they’re attached.
Modifying initial Manager QuerySets
A Manager‘s base QuerySet returns all objects in the system. For example, using this model:
3.2. Models and databases 119](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-123-2048.jpg)



![Django Documentation, Release 1.5.1
For more details check out the documentation for the db_table option, which also lets you manually set the database
table name.
Warning: No checking is done on the SQL statement that is passed in to .raw(). Django expects that the
statement will return a set of rows from the database, but does nothing to enforce that. If the query does not return
rows, a (possibly cryptic) error will result.
Mapping query fields to model fields
raw() automatically maps fields in the query to fields on the model.
The order of fields in your query doesn’t matter. In other words, both of the following queries work identically:
>>> Person.objects.raw(’SELECT id, first_name, last_name, birth_date FROM myapp_person’)
...
>>> Person.objects.raw(’SELECT last_name, birth_date, first_name, id FROM myapp_person’)
...
Matching is done by name. This means that you can use SQL’s AS clauses to map fields in the query to model fields.
So if you had some other table that had Person data in it, you could easily map it into Person instances:
>>> Person.objects.raw(’’’SELECT first AS first_name,
... last AS last_name,
... bd AS birth_date,
... pk as id,
... FROM some_other_table’’’)
As long as the names match, the model instances will be created correctly.
Alternatively, you can map fields in the query to model fields using the translations argument to raw(). This
is a dictionary mapping names of fields in the query to names of fields on the model. For example, the above query
could also be written:
>>> name_map = {’first’: ’first_name’, ’last’: ’last_name’, ’bd’: ’birth_date’, ’pk’: ’id’}
>>> Person.objects.raw(’SELECT * FROM some_other_table’, translations=name_map)
Index lookups
raw() supports indexing, so if you need only the first result you can write:
>>> first_person = Person.objects.raw(’SELECT * from myapp_person’)[0]
However, the indexing and slicing are not performed at the database level. If you have a big amount of Person
objects in your database, it is more efficient to limit the query at the SQL level:
>>> first_person = Person.objects.raw(’SELECT * from myapp_person LIMIT 1’)[0]
Deferring model fields
Fields may also be left out:
>>> people = Person.objects.raw(’SELECT id, first_name FROM myapp_person’)
3.2. Models and databases 125](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-129-2048.jpg)
![Django Documentation, Release 1.5.1
The Person objects returned by this query will be deferred model instances (see defer()). This means that the
fields that are omitted from the query will be loaded on demand. For example:
>>> for p in Person.objects.raw(’SELECT id, first_name FROM myapp_person’):
... print(p.first_name, # This will be retrieved by the original query
... p.last_name) # This will be retrieved on demand
...
John Smith
Jane Jones
From outward appearances, this looks like the query has retrieved both the first name and last name. However, this
example actually issued 3 queries. Only the first names were retrieved by the raw() query – the last names were both
retrieved on demand when they were printed.
There is only one field that you can’t leave out - the primary key field. Django uses the primary key to identify model
instances, so it must always be included in a raw query. An InvalidQuery exception will be raised if you forget to
include the primary key.
Adding annotations
You can also execute queries containing fields that aren’t defined on the model. For example, we could use Post-greSQL’s
age() function to get a list of people with their ages calculated by the database:
>>> people = Person.objects.raw(’SELECT *, age(birth_date) AS age FROM myapp_person’)
>>> for p in people:
... print("%s is %s." % (p.first_name, p.age))
John is 37.
Jane is 42.
...
Passing parameters into raw()
If you need to perform parameterized queries, you can use the params argument to raw():
>>> lname = ’Doe’
>>> Person.objects.raw(’SELECT * FROM myapp_person WHERE last_name = %s’, [lname])
params is a list of parameters. You’ll use %s placeholders in the query string (regardless of your database engine);
they’ll be replaced with parameters from the params list.
Warning: Do not use string formatting on raw queries!
It’s tempting to write the above query as:
>>> query = ’SELECT * FROM myapp_person WHERE last_name = %s’ % lname
>>> Person.objects.raw(query)
Don’t.
Using the params list completely protects you from SQL injection attacks, a common exploit where attackers
inject arbitrary SQL into your database. If you use string interpolation, sooner or later you’ll fall victim to SQL
injection. As long as you remember to always use the params list you’ll be protected.
126 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-130-2048.jpg)
![Django Documentation, Release 1.5.1
Executing custom SQL directly
Sometimes even Manager.raw() isn’t quite enough: you might need to perform queries that don’t map cleanly to
models, or directly execute UPDATE, INSERT, or DELETE queries.
In these cases, you can always access the database directly, routing around the model layer entirely.
The object django.db.connection represents the default database connection, and
django.db.transaction represents the default database transaction. To use the database connection,
call connection.cursor() to get a cursor object. Then, call cursor.execute(sql, [params]) to
execute the SQL and cursor.fetchone() or cursor.fetchall() to return the resulting rows. After
performing a data changing operation, you should then call transaction.commit_unless_managed() to
ensure your changes are committed to the database. If your query is purely a data retrieval operation, no commit is
required. For example:
def my_custom_sql():
from django.db import connection, transaction
cursor = connection.cursor()
# Data modifying operation - commit required
cursor.execute("UPDATE bar SET foo = 1 WHERE baz = %s", [self.baz])
transaction.commit_unless_managed()
# Data retrieval operation - no commit required
cursor.execute("SELECT foo FROM bar WHERE baz = %s", [self.baz])
row = cursor.fetchone()
return row
If you are using more than one database, you can use django.db.connections to obtain the connection (and
cursor) for a specific database. django.db.connections is a dictionary-like object that allows you to retrieve a
specific connection using its alias:
from django.db import connections
cursor = connections[’my_db_alias’].cursor()
# Your code here...
transaction.commit_unless_managed(using=’my_db_alias’)
By default, the Python DB API will return results without their field names, which means you end up with a list of
values, rather than a dict. At a small performance cost, you can return results as a dict by using something like
this:
def dictfetchall(cursor):
"Returns all rows from a cursor as a dict"
desc = cursor.description
return [
dict(zip([col[0] for col in desc], row))
for row in cursor.fetchall()
]
Here is an example of the difference between the two:
>>> cursor.execute("SELECT id, parent_id from test LIMIT 2");
>>> cursor.fetchall()
((54360982L, None), (54360880L, None))
>>> cursor.execute("SELECT id, parent_id from test LIMIT 2");
>>> dictfetchall(cursor)
[{’parent_id’: None, ’id’: 54360982L}, {’parent_id’: None, ’id’: 54360880L}]
3.2. Models and databases 127](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-131-2048.jpg)








![Django Documentation, Release 1.5.1
Now we’ll need to handle routing. First we want a router that knows to send queries for the auth app to auth_db:
class AuthRouter(object):
"""
A router to control all database operations on models in the
auth application.
"""
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.app_label == ’auth’:
return ’auth_db’
return None
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
if model._meta.app_label == ’auth’:
return ’auth_db’
return None
def allow_relation(self, obj1, obj2, **hints):
"""
Allow relations if a model in the auth app is involved.
"""
if obj1._meta.app_label == ’auth’ or
obj2._meta.app_label == ’auth’:
return True
return None
def allow_syncdb(self, db, model):
"""
Make sure the auth app only appears in the ’auth_db’
database.
"""
if db == ’auth_db’:
return model._meta.app_label == ’auth’
elif model._meta.app_label == ’auth’:
return False
return None
And we also want a router that sends all other apps to the master/slave configuration, and randomly chooses a slave to
read from:
import random
class MasterSlaveRouter(object):
def db_for_read(self, model, **hints):
"""
Reads go to a randomly-chosen slave.
"""
return random.choice([’slave1’, ’slave2’])
def db_for_write(self, model, **hints):
"""
Writes always go to master.
"""
3.2. Models and databases 137](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-141-2048.jpg)
![Django Documentation, Release 1.5.1
return ’master’
def allow_relation(self, obj1, obj2, **hints):
"""
Relations between objects are allowed if both objects are
in the master/slave pool.
"""
db_list = (’master’, ’slave1’, ’slave2’)
if obj1.state.db in db_list and obj2.state.db in db_list:
return True
return None
def allow_syncdb(self, db, model):
"""
All non-auth models end up in this pool.
"""
return True
Finally, in the settings file, we add the following (substituting path.to. with the actual python path to the module(s)
where the routers are defined):
DATABASE_ROUTERS = [’path.to.AuthRouter’, ’path.to.MasterSlaveRouter’]
The order in which routers are processed is significant. Routers will be queried in the order the are
listed in the DATABASE_ROUTERS setting . In this example, the AuthRouter is processed before the
MasterSlaveRouter, and as a result, decisions concerning the models in auth are processed before
any other decision is made. If the DATABASE_ROUTERS setting listed the two routers in the other order,
MasterSlaveRouter.allow_syncdb() would be processed first. The catch-all nature of the MasterSlaveR-outer
implementation would mean that all models would be available on all databases.
With this setup installed, lets run some Django code:
>>> # This retrieval will be performed on the ’auth_db’ database
>>> fred = User.objects.get(username=’fred’)
>>> fred.first_name = ’Frederick’
>>> # This save will also be directed to ’auth_db’
>>> fred.save()
>>> # These retrieval will be randomly allocated to a slave database
>>> dna = Person.objects.get(name=’Douglas Adams’)
>>> # A new object has no database allocation when created
>>> mh = Book(title=’Mostly Harmless’)
>>> # This assignment will consult the router, and set mh onto
>>> # the same database as the author object
>>> mh.author = dna
>>> # This save will force the ’mh’ instance onto the master database...
>>> mh.save()
>>> # ... but if we re-retrieve the object, it will come back on a slave
>>> mh = Book.objects.get(title=’Mostly Harmless’)
138 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-142-2048.jpg)

![Django Documentation, Release 1.5.1
# on the ’other’ database.
return super(MultiDBTabularInline, self).formfield_for_manytomany(db_field, request=request, Once you’ve written your model admin definitions, they can be registered with any Admin instance:
from django.contrib import admin
# Specialize the multi-db admin objects for use with specific models.
class BookInline(MultiDBTabularInline):
model = Book
class PublisherAdmin(MultiDBModelAdmin):
inlines = [BookInline]
admin.site.register(Author, MultiDBModelAdmin)
admin.site.register(Publisher, PublisherAdmin)
othersite = admin.AdminSite(’othersite’)
othersite.register(Publisher, MultiDBModelAdmin)
This example sets up two admin sites. On the first site, the Author and Publisher objects are exposed;
Publisher objects have an tabular inline showing books published by that publisher. The second site exposes
just publishers, without the inlines.
Using raw cursors with multiple databases
If you are using more than one database you can use django.db.connections to obtain the connection (and
cursor) for a specific database. django.db.connections is a dictionary-like object that allows you to retrieve a
specific connection using its alias:
from django.db import connections
cursor = connections[’my_db_alias’].cursor()
Limitations of multiple databases
Cross-database relations
Django doesn’t currently provide any support for foreign key or many-to-many relationships spanning multiple
databases. If you have used a router to partition models to different databases, any foreign key and many-to-many
relationships defined by those models must be internal to a single database.
This is because of referential integrity. In order to maintain a relationship between two objects, Django needs to know
that the primary key of the related object is valid. If the primary key is stored on a separate database, it’s not possible
to easily evaluate the validity of a primary key.
If you’re using Postgres, Oracle, or MySQL with InnoDB, this is enforced at the database integrity level – database
level key constraints prevent the creation of relations that can’t be validated.
However, if you’re using SQLite or MySQL with MyISAM tables, there is no enforced referential integrity; as a
result, you may be able to ‘fake’ cross database foreign keys. However, this configuration is not officially supported
by Django.
142 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-146-2048.jpg)




![Django Documentation, Release 1.5.1
{% endfor %}
{% else %}
<p>No messages today.</p>
{% endif %}
{% endwith %}
{% endif %}
It is optimal because:
1. Since QuerySets are lazy, this does no database queries if ‘display_inbox’ is False.
2. Use of with means that we store user.emails.all in a variable for later use, allowing its cache to be
re-used.
3. The line {% if emails %} causes QuerySet.__bool__() to be called, which causes the
user.emails.all() query to be run on the database, and at the least the first line to be turned into an
ORM object. If there aren’t any results, it will return False, otherwise True.
4. The use of {{ emails|length }} calls QuerySet.__len__(), filling out the rest of the cache without
doing another query.
5. The for loop iterates over the already filled cache.
In total, this code does either one or zero database queries. The only deliberate optimization performed is the use of the
with tag. Using QuerySet.exists() or QuerySet.count() at any point would cause additional queries.
Use QuerySet.update() and delete()
Rather than retrieve a load of objects, set some values, and save them individual, use a bulk SQL UPDATE statement,
via QuerySet.update(). Similarly, do bulk deletes where possible.
Note, however, that these bulk update methods cannot call the save() or delete() methods of individual instances,
which means that any custom behavior you have added for these methods will not be executed, including anything
driven from the normal database object signals.
Use foreign key values directly
If you only need a foreign key value, use the foreign key value that is already on the object you’ve got, rather than
getting the whole related object and taking its primary key. i.e. do:
entry.blog_id
instead of:
entry.blog.id
Insert in bulk
When creating objects, where possible, use the bulk_create() method to reduce the number of SQL queries. For
example:
Entry.objects.bulk_create([
Entry(headline="Python 3.0 Released"),
Entry(headline="Python 3.1 Planned")
])
148 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-152-2048.jpg)

![Django Documentation, Release 1.5.1
Create an Article:
>>> a1 = Article(headline=’Django lets you build Web apps easily’)
You can’t associate it with a Publication until it’s been saved:
>>> a1.publications.add(p1)
Traceback (most recent call last):
...
ValueError: ’Article’ instance needs to have a primary key value before a many-to-many relationship can Save it!
>>> a1.save()
Associate the Article with a Publication:
>>> a1.publications.add(p1)
Create another Article, and set it to appear in both Publications:
>>> a2 = Article(headline=’NASA uses Python’)
>>> a2.save()
>>> a2.publications.add(p1, p2)
>>> a2.publications.add(p3)
Adding a second time is OK:
>>> a2.publications.add(p3)
Adding an object of the wrong type raises TypeError:
>>> a2.publications.add(a1)
Traceback (most recent call last):
...
TypeError: ’Publication’ instance expected
Create and add a Publication to an Article in one step using create():
>>> new_publication = a2.publications.create(title=’Highlights for Children’)
Article objects have access to their related Publication objects:
>>> a1.publications.all()
[<Publication: The Python Journal>]
>>> a2.publications.all()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, Publication objects have access to their related Article objects:
>>> p2.article_set.all()
[<Article: NASA uses Python>]
>>> p1.article_set.all()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Publication.objects.get(id=4).article_set.all()
[<Article: NASA uses Python>]
Many-to-many relationships can be queried using lookups across relationships:
>>> Article.objects.filter(publications__id__exact=1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__pk=1)
150 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-154-2048.jpg)
![Django Documentation, Release 1.5.1
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications=1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications=p1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__title__startswith="Science")
[<Article: NASA uses Python>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__title__startswith="Science").distinct()
[<Article: NASA uses Python>]
The count() function respects distinct() as well:
>>> Article.objects.filter(publications__title__startswith="Science").count()
2
>>> Article.objects.filter(publications__title__startswith="Science").distinct().count()
1
>>> Article.objects.filter(publications__in=[1,2]).distinct()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__in=[p1,p2]).distinct()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
Reverse m2m queries are supported (i.e., starting at the table that doesn’t have a ManyToManyField):
>>> Publication.objects.filter(id__exact=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(pk=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__headline__startswith="NASA")
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, >>> Publication.objects.filter(article__id__exact=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__pk=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article=a1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__in=[1,2]).distinct()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, >>> Publication.objects.filter(article__in=[a1,a2]).distinct()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, Excluding a related item works as you would expect, too (although the SQL involved is a little complex):
>>> Article.objects.exclude(publications=p2)
[<Article: Django lets you build Web apps easily>]
If we delete a Publication, its Articles won’t be able to access it:
>>> p1.delete()
>>> Publication.objects.all()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>]
3.2. Models and databases 151](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-155-2048.jpg)
![Django Documentation, Release 1.5.1
>>> a1 = Article.objects.get(pk=1)
>>> a1.publications.all()
[]
If we delete an Article, its Publications won’t be able to access it:
>>> a2.delete()
>>> Article.objects.all()
[<Article: Django lets you build Web apps easily>]
>>> p2.article_set.all()
[]
Adding via the ‘other’ end of an m2m:
>>> a4 = Article(headline=’NASA finds intelligent life on Earth’)
>>> a4.save()
>>> p2.article_set.add(a4)
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>]
>>> a4.publications.all()
[<Publication: Science News>]
Adding via the other end using keywords:
>>> new_article = p2.article_set.create(headline=’Oxygen-free diet works wonders’)
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>, <Article: Oxygen-free diet works wonders>]
>>> a5 = p2.article_set.all()[1]
>>> a5.publications.all()
[<Publication: Science News>]
Removing Publication from an Article:
>>> a4.publications.remove(p2)
>>> p2.article_set.all()
[<Article: Oxygen-free diet works wonders>]
>>> a4.publications.all()
[]
And from the other end:
>>> p2.article_set.remove(a5)
>>> p2.article_set.all()
[]
>>> a5.publications.all()
[]
Relation sets can be assigned. Assignment clears any existing set members:
>>> a4.publications.all()
[<Publication: Science News>]
>>> a4.publications = [p3]
>>> a4.publications.all()
[<Publication: Science Weekly>]
Relation sets can be cleared:
>>> p2.article_set.clear()
>>> p2.article_set.all()
[]
152 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-156-2048.jpg)
![Django Documentation, Release 1.5.1
And you can clear from the other end:
>>> p2.article_set.add(a4, a5)
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>, <Article: Oxygen-free diet works wonders>]
>>> a4.publications.all()
[<Publication: Science News>, <Publication: Science Weekly>]
>>> a4.publications.clear()
>>> a4.publications.all()
[]
>>> p2.article_set.all()
[<Article: Oxygen-free diet works wonders>]
Recreate the Article and Publication we have deleted:
>>> p1 = Publication(title=’The Python Journal’)
>>> p1.save()
>>> a2 = Article(headline=’NASA uses Python’)
>>> a2.save()
>>> a2.publications.add(p1, p2, p3)
Bulk delete some Publications - references to deleted publications should go:
>>> Publication.objects.filter(title__startswith=’Science’).delete()
>>> Publication.objects.all()
[<Publication: Highlights for Children>, <Publication: The Python Journal>]
>>> Article.objects.all()
[<Article: Django lets you build Web apps easily>, <Article: NASA finds intelligent life on Earth>, <>>> a2.publications.all()
[<Publication: The Python Journal>]
Bulk delete some articles - references to deleted objects should go:
>>> q = Article.objects.filter(headline__startswith=’Django’)
>>> print(q)
[<Article: Django lets you build Web apps easily>]
>>> q.delete()
After the delete(), the QuerySet cache needs to be cleared, and the referenced objects should be gone:
>>> print(q)
[]
>>> p1.article_set.all()
[<Article: NASA uses Python>]
An alternate to calling clear() is to assign the empty set:
>>> p1.article_set = []
>>> p1.article_set.all()
[]
>>> a2.publications = [p1, new_publication]
>>> a2.publications.all()
[<Publication: Highlights for Children>, <Publication: The Python Journal>]
>>> a2.publications = []
>>> a2.publications.all()
[]
3.2. Models and databases 153](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-157-2048.jpg)

![Django Documentation, Release 1.5.1
>>> new_article = r.article_set.create(headline="John’s second story", pub_date=date(2005, 7, 29))
>>> new_article
<Article: John’s second story>
>>> new_article.reporter
<Reporter: John Smith>
>>> new_article.reporter.id
1
Create a new article, and add it to the article set:
>>> new_article2 = Article(headline="Paul’s story", pub_date=date(2006, 1, 17))
>>> r.article_set.add(new_article2)
>>> new_article2.reporter
<Reporter: John Smith>
>>> new_article2.reporter.id
1
>>> r.article_set.all()
[<Article: John’s second story>, <Article: Paul’s story>, <Article: This is a test>]
Add the same article to a different article set - check that it moves:
>>> r2.article_set.add(new_article2)
>>> new_article2.reporter.id
2
>>> new_article2.reporter
<Reporter: Paul Jones>
Adding an object of the wrong type raises TypeError:
>>> r.article_set.add(r2)
Traceback (most recent call last):
...
TypeError: ’Article’ instance expected
>>> r.article_set.all()
[<Article: John’s second story>, <Article: This is a test>]
>>> r2.article_set.all()
[<Article: Paul’s story>]
>>> r.article_set.count()
2
>>> r2.article_set.count()
1
Note that in the last example the article has moved from John to Paul.
Related managers support field lookups as well. The API automatically follows relationships as far as you need. Use
double underscores to separate relationships. This works as many levels deep as you want. There’s no limit. For
example:
>>> r.article_set.filter(headline__startswith=’This’)
[<Article: This is a test>]
# Find all Articles for any Reporter whose first name is "John".
>>> Article.objects.filter(reporter__first_name__exact=’John’)
[<Article: John’s second story>, <Article: This is a test>]
Exact match is implied here:
3.2. Models and databases 155](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-159-2048.jpg)
![Django Documentation, Release 1.5.1
>>> Article.objects.filter(reporter__first_name=’John’)
[<Article: John’s second story>, <Article: This is a test>]
Query twice over the related field. This translates to an AND condition in the WHERE clause:
>>> Article.objects.filter(reporter__first_name__exact=’John’, reporter__last_name__exact=’Smith’)
[<Article: John’s second story>, <Article: This is a test>]
For the related lookup you can supply a primary key value or pass the related object explicitly:
>>> Article.objects.filter(reporter__pk=1)
[<Article: John’s second story>, <Article: This is a test>]
>>> Article.objects.filter(reporter=1)
[<Article: John’s second story>, <Article: This is a test>]
>>> Article.objects.filter(reporter=r)
[<Article: John’s second story>, <Article: This is a test>]
>>> Article.objects.filter(reporter__in=[1,2]).distinct()
[<Article: John’s second story>, <Article: Paul’s story>, <Article: This is a test>]
>>> Article.objects.filter(reporter__in=[r,r2]).distinct()
[<Article: John’s second story>, <Article: Paul’s story>, <Article: This is a test>]
You can also use a queryset instead of a literal list of instances:
>>> Article.objects.filter(reporter__in=Reporter.objects.filter(first_name=’John’)).distinct()
[<Article: John’s second story>, <Article: This is a test>]
Querying in the opposite direction:
>>> Reporter.objects.filter(article__pk=1)
[<Reporter: John Smith>]
>>> Reporter.objects.filter(article=1)
[<Reporter: John Smith>]
>>> Reporter.objects.filter(article=a)
[<Reporter: John Smith>]
>>> Reporter.objects.filter(article__headline__startswith=’This’)
[<Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>]
>>> Reporter.objects.filter(article__headline__startswith=’This’).distinct()
[<Reporter: John Smith>]
Counting in the opposite direction works in conjunction with distinct():
>>> Reporter.objects.filter(article__headline__startswith=’This’).count()
3
>>> Reporter.objects.filter(article__headline__startswith=’This’).distinct().count()
1
Queries can go round in circles:
>>> Reporter.objects.filter(article__reporter__first_name__startswith=’John’)
[<Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>]
>>> Reporter.objects.filter(article__reporter__first_name__startswith=’John’).distinct()
[<Reporter: John Smith>]
>>> Reporter.objects.filter(article__reporter__exact=r).distinct()
[<Reporter: John Smith>]
If you delete a reporter, his articles will be deleted (assuming that the ForeignKey was defined with
django.db.models.ForeignKey.on_delete set to CASCADE, which is the default):
156 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-160-2048.jpg)
![Django Documentation, Release 1.5.1
>>> Article.objects.all()
[<Article: John’s second story>, <Article: Paul’s story>, <Article: This is a test>]
>>> Reporter.objects.order_by(’first_name’)
[<Reporter: John Smith>, <Reporter: Paul Jones>]
>>> r2.delete()
>>> Article.objects.all()
[<Article: John’s second story>, <Article: This is a test>]
>>> Reporter.objects.order_by(’first_name’)
[<Reporter: John Smith>]
You can delete using a JOIN in the query:
>>> Reporter.objects.filter(article__headline__startswith=’This’).delete()
>>> Reporter.objects.all()
[]
>>> Article.objects.all()
[]
One-to-one relationships
To define a one-to-one relationship, use OneToOneField.
In this example, a Place optionally can be a Restaurant:
from django.db import models, transaction, IntegrityError
class Place(models.Model):
name = models.CharField(max_length=50)
address = models.CharField(max_length=80)
def __unicode__(self):
return u"%s the place" % self.name
class Restaurant(models.Model):
place = models.OneToOneField(Place, primary_key=True)
serves_hot_dogs = models.BooleanField()
serves_pizza = models.BooleanField()
def __unicode__(self):
return u"%s the restaurant" % self.place.name
class Waiter(models.Model):
restaurant = models.ForeignKey(Restaurant)
name = models.CharField(max_length=50)
def __unicode__(self):
return u"%s the waiter at %s" % (self.name, self.restaurant)
What follows are examples of operations that can be performed using the Python API facilities.
Create a couple of Places:
>>> p1 = Place(name=’Demon Dogs’, address=’944 W. Fullerton’)
>>> p1.save()
>>> p2 = Place(name=’Ace Hardware’, address=’1013 N. Ashland’)
>>> p2.save()
Create a Restaurant. Pass the ID of the “parent” object as this object’s ID:
3.2. Models and databases 157](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-161-2048.jpg)
![Django Documentation, Release 1.5.1
>>> r = Restaurant(place=p1, serves_hot_dogs=True, serves_pizza=False)
>>> r.save()
A Restaurant can access its place:
>>> r.place
<Place: Demon Dogs the place>
A Place can access its restaurant, if available:
>>> p1.restaurant
<Restaurant: Demon Dogs the restaurant>
p2 doesn’t have an associated restaurant:
>>> p2.restaurant
Traceback (most recent call last):
...
DoesNotExist: Restaurant matching query does not exist.
Set the place using assignment notation. Because place is the primary key on Restaurant, the save will create a new
restaurant:
>>> r.place = p2
>>> r.save()
>>> p2.restaurant
<Restaurant: Ace Hardware the restaurant>
>>> r.place
<Place: Ace Hardware the place>
Set the place back again, using assignment in the reverse direction:
>>> p1.restaurant = r
>>> p1.restaurant
<Restaurant: Demon Dogs the restaurant>
Restaurant.objects.all() just returns the Restaurants, not the Places. Note that there are two restaurants - Ace Hardware
the Restaurant was created in the call to r.place = p2:
>>> Restaurant.objects.all()
[<Restaurant: Demon Dogs the restaurant>, <Restaurant: Ace Hardware the restaurant>]
Place.objects.all() returns all Places, regardless of whether they have Restaurants:
>>> Place.objects.order_by(’name’)
[<Place: Ace Hardware the place>, <Place: Demon Dogs the place>]
You can query the models using lookups across relationships:
>>> Restaurant.objects.get(place=p1)
<Restaurant: Demon Dogs the restaurant>
>>> Restaurant.objects.get(place__pk=1)
<Restaurant: Demon Dogs the restaurant>
>>> Restaurant.objects.filter(place__name__startswith="Demon")
[<Restaurant: Demon Dogs the restaurant>]
>>> Restaurant.objects.exclude(place__address__contains="Ashland")
[<Restaurant: Demon Dogs the restaurant>]
This of course works in reverse:
158 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-162-2048.jpg)
![Django Documentation, Release 1.5.1
>>> Place.objects.get(pk=1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant__place__exact=p1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant=r)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant__place__name__startswith="Demon")
<Place: Demon Dogs the place>
Add a Waiter to the Restaurant:
>>> w = r.waiter_set.create(name=’Joe’)
>>> w.save()
>>> w
<Waiter: Joe the waiter at Demon Dogs the restaurant>
Query the waiters:
>>> Waiter.objects.filter(restaurant__place=p1)
[<Waiter: Joe the waiter at Demon Dogs the restaurant>]
>>> Waiter.objects.filter(restaurant__place__name__startswith="Demon")
[<Waiter: Joe the waiter at Demon Dogs the restaurant>]
3.3 Handling HTTP requests
Information on handling HTTP requests in Django:
3.3.1 URL dispatcher
A clean, elegant URL scheme is an important detail in a high-quality Web application. Django lets you design URLs
however you want, with no framework limitations.
There’s no .php or .cgi required, and certainly none of that 0,2097,1-1-1928,00 nonsense.
See Cool URIs don’t change, by World Wide Web creator Tim Berners-Lee, for excellent arguments on why URLs
should be clean and usable.
Overview
To design URLs for an app, you create a Python module informally called a URLconf (URL configuration). This
module is pure Python code and is a simple mapping between URL patterns (simple regular expressions) to Python
functions (your views).
This mapping can be as short or as long as needed. It can reference other mappings. And, because it’s pure Python
code, it can be constructed dynamically. New in version 1.4: Django also provides a way to translate URLs according
to the active language. See the internationalization documentation for more information.
How Django processes a request
When a user requests a page from your Django-powered site, this is the algorithm the system follows to determine
which Python code to execute:
3.3. Handling HTTP requests 159](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-163-2048.jpg)


![Django Documentation, Release 1.5.1
• handler403 – See django.conf.urls.handler403.
New in version 1.4: handler403 is new in Django 1.4.
The view prefix
You can specify a common prefix in your patterns() call, to cut down on code duplication.
Here’s the example URLconf from the Django overview:
from django.conf.urls import patterns, url
urlpatterns = patterns(’’,
url(r’^articles/(d{4})/$’, ’news.views.year_archive’),
url(r’^articles/(d{4})/(d{2})/$’, ’news.views.month_archive’),
url(r’^articles/(d{4})/(d{2})/(d+)/$’, ’news.views.article_detail’),
)
In this example, each view has a common prefix – ’news.views’. Instead of typing that out for each entry in
urlpatterns, you can use the first argument to the patterns() function to specify a prefix to apply to each
view function.
With this in mind, the above example can be written more concisely as:
from django.conf.urls import patterns, url
urlpatterns = patterns(’news.views’,
url(r’^articles/(d{4})/$’, ’year_archive’),
url(r’^articles/(d{4})/(d{2})/$’, ’month_archive’),
url(r’^articles/(d{4})/(d{2})/(d+)/$’, ’article_detail’),
)
Note that you don’t put a trailing dot (".") in the prefix. Django puts that in automatically.
Multiple view prefixes
In practice, you’ll probably end up mixing and matching views to the point where the views in your urlpatterns
won’t have a common prefix. However, you can still take advantage of the view prefix shortcut to remove duplication.
Just add multiple patterns() objects together, like this:
Old:
from django.conf.urls import patterns, url
urlpatterns = patterns(’’,
url(r’^$’, ’myapp.views.app_index’),
url(r’^(?P<year>d{4})/(?P<month>[a-z]{3})/$’, ’myapp.views.month_display’),
url(r’^tag/(?P<tag>w+)/$’, ’weblog.views.tag’),
)
New:
from django.conf.urls import patterns, url
urlpatterns = patterns(’myapp.views’,
url(r’^$’, ’app_index’),
url(r’^(?P<year>d{4})/(?P<month>[a-z]{3})/$’,’month_display’),
)
3.3. Handling HTTP requests 163](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-167-2048.jpg)









![Django Documentation, Release 1.5.1
from django.core.exceptions import PermissionDenied
def edit(request, pk):
if not request.user.is_staff:
raise PermissionDenied
# ...
It is possible to override django.views.defaults.permission_denied in the same way you can for the
404 and 500 views by specifying a handler403 in your URLconf:
handler403 = ’mysite.views.my_custom_permission_denied_view’
3.3.3 View decorators
Django provides several decorators that can be applied to views to support various HTTP features.
Allowed HTTP methods
The decorators in django.views.decorators.http can be used to restrict access to views based on the request
method. These decorators will return a django.http.HttpResponseNotAllowed if the conditions are not
met.
require_http_methods(request_method_list)
Decorator to require that a view only accept particular request methods. Usage:
from django.views.decorators.http import require_http_methods
@require_http_methods(["GET", "POST"])
def my_view(request):
# I can assume now that only GET or POST requests make it this far
# ...
pass
Note that request methods should be in uppercase.
require_GET()
Decorator to require that a view only accept the GET method.
require_POST()
Decorator to require that a view only accept the POST method.
require_safe()
New in version 1.4. Decorator to require that a view only accept the GET and HEAD methods. These methods
are commonly considered “safe” because they should not have the significance of taking an action other than
retrieving the requested resource.
Note: Django will automatically strip the content of responses to HEAD requests while leaving the headers un-changed,
so you may handle HEAD requests exactly like GET requests in your views. Since some software, such
as link checkers, rely on HEAD requests, you might prefer using require_safe instead of require_GET.
Conditional view processing
The following decorators in django.views.decorators.http can be used to control caching behavior on
particular views.
174 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-178-2048.jpg)
![Django Documentation, Release 1.5.1
condition(etag_func=None, last_modified_func=None)
etag(etag_func)
last_modified(last_modified_func)
These decorators can be used to generate ETag and Last-Modified headers; see conditional view process-ing.
GZip compression
The decorators in django.views.decorators.gzip control content compression on a per-view basis.
gzip_page()
This decorator compresses content if the browser allows gzip compression. It sets the Vary header accordingly,
so that caches will base their storage on the Accept-Encoding header.
Vary headers
The decorators in django.views.decorators.vary can be used to control caching based on specific request
headers.
vary_on_cookie(func)
vary_on_headers(*headers)
The Vary header defines which request headers a cache mechanism should take into account when building its
cache key.
See using vary headers.
3.3.4 File Uploads
When Django handles a file upload, the file data ends up placed in request.FILES (for more on the request
object see the documentation for request and response objects). This document explains how files are stored on disk
and in memory, and how to customize the default behavior.
Basic file uploads
Consider a simple form containing a FileField:
from django import forms
class UploadFileForm(forms.Form):
title = forms.CharField(max_length=50)
file = forms.FileField()
A view handling this form will receive the file data in request.FILES, which is a dictionary containing a key for
each FileField (or ImageField, or other FileField subclass) in the form. So the data from the above form
would be accessible as request.FILES[’file’].
Note that request.FILES will only contain data if the request method was POST and the <form> that posted the
request has the attribute enctype="multipart/form-data". Otherwise, request.FILES will be empty.
Most of the time, you’ll simply pass the file data from request into the form as described in Binding uploaded files
to a form. This would look something like:
3.3. Handling HTTP requests 175](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-179-2048.jpg)
![Django Documentation, Release 1.5.1
from django.http import HttpResponseRedirect
from django.shortcuts import render_to_response
# Imaginary function to handle an uploaded file.
from somewhere import handle_uploaded_file
def upload_file(request):
if request.method == ’POST’:
form = UploadFileForm(request.POST, request.FILES)
if form.is_valid():
handle_uploaded_file(request.FILES[’file’])
return HttpResponseRedirect(’/success/url/’)
else:
form = UploadFileForm()
return render_to_response(’upload.html’, {’form’: form})
Notice that we have to pass request.FILES into the form’s constructor; this is how file data gets bound into a
form.
Handling uploaded files
class UploadedFile
The final piece of the puzzle is handling the actual file data from request.FILES. Each entry in this dictio-nary
is an UploadedFile object – a simple wrapper around an uploaded file. You’ll usually use one of these
methods to access the uploaded content:
read()
Read the entire uploaded data from the file. Be careful with this method: if the uploaded file is huge it can
overwhelm your system if you try to read it into memory. You’ll probably want to use chunks() instead;
see below.
multiple_chunks()
Returns True if the uploaded file is big enough to require reading in multiple chunks. By default this will
be any file larger than 2.5 megabytes, but that’s configurable; see below.
chunks()
A generator returning chunks of the file. If multiple_chunks() is True, you should use this method
in a loop instead of read().
In practice, it’s often easiest simply to use chunks() all the time; see the example below.
name
The name of the uploaded file (e.g. my_file.txt).
size
The size, in bytes, of the uploaded file.
There are a few other methods and attributes available on UploadedFile objects; see UploadedFile objects for a
complete reference.
Putting it all together, here’s a common way you might handle an uploaded file:
def handle_uploaded_file(f):
with open(’some/file/name.txt’, ’wb+’) as destination:
for chunk in f.chunks():
destination.write(chunk)
Looping over UploadedFile.chunks() instead of using read() ensures that large files don’t overwhelm your
system’s memory.
176 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-180-2048.jpg)

![Django Documentation, Release 1.5.1
from django.http import HttpResponseRedirect
from django.shortcuts import render
from .forms import ModelFormWithFileField
def upload_file(request):
if request.method == ’POST’:
form = ModelFormWithFileField(request.POST, request.FILES)
if form.is_valid():
# file is saved
form.save()
return HttpResponseRedirect(’/success/url/’)
else:
form = ModelFormWithFileField()
return render(request, ’upload.html’, {’form’: form})
If you are constructing an object manually, you can simply assign the file object from request.FILES to the file
field in the model:
from django.http import HttpResponseRedirect
from django.shortcuts import render
from .forms import UploadFileForm
from .models import ModelWithFileField
def upload_file(request):
if request.method == ’POST’:
form = UploadFileForm(request.POST, request.FILES)
if form.is_valid():
instance = ModelWithFileField(file_field=request.FILES[’file’])
instance.save()
return HttpResponseRedirect(’/success/url/’)
else:
form = UploadFileForm()
return render(request, ’upload.html’, {’form’: form})
UploadedFile objects
In addition to those inherited from File, all UploadedFile objects define the following methods/attributes:
UploadedFile.content_type
The content-type header uploaded with the file (e.g. text/plain or application/pdf). Like any data
supplied by the user, you shouldn’t trust that the uploaded file is actually this type. You’ll still need to validate
that the file contains the content that the content-type header claims – “trust but verify.”
UploadedFile.charset
For text/* content-types, the character set (i.e. utf8) supplied by the browser. Again, “trust but verify” is
the best policy here.
UploadedFile.temporary_file_path
Only files uploaded onto disk will have this method; it returns the full path to the temporary uploaded file.
Note: Like regular Python files, you can read the file line-by-line simply by iterating over the uploaded file:
for line in uploadedfile:
do_something_with(line)
However, unlike standard Python files, UploadedFile only understands n (also known as “Unix-style”) line
endings. If you know that you need to handle uploaded files with different line endings, you’ll need to do so in your
178 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-182-2048.jpg)
![Django Documentation, Release 1.5.1
view.
Upload Handlers
When a user uploads a file, Django passes off the file data to an upload handler – a small class that handles file data as
it gets uploaded. Upload handlers are initially defined in the FILE_UPLOAD_HANDLERS setting, which defaults to:
("django.core.files.uploadhandler.MemoryFileUploadHandler",
"django.core.files.uploadhandler.TemporaryFileUploadHandler",)
Together the MemoryFileUploadHandler and TemporaryFileUploadHandler provide Django’s default
file upload behavior of reading small files into memory and large ones onto disk.
You can write custom handlers that customize how Django handles files. You could, for example, use custom handlers
to enforce user-level quotas, compress data on the fly, render progress bars, and even send data to another storage
location directly without storing it locally.
Modifying upload handlers on the fly
Sometimes particular views require different upload behavior. In these cases, you can override upload handlers on a
per-request basis by modifying request.upload_handlers. By default, this list will contain the upload handlers
given by FILE_UPLOAD_HANDLERS, but you can modify the list as you would any other list.
For instance, suppose you’ve written a ProgressBarUploadHandler that provides feedback on upload progress
to some sort of AJAX widget. You’d add this handler to your upload handlers like this:
request.upload_handlers.insert(0, ProgressBarUploadHandler())
You’d probably want to use list.insert() in this case (instead of append()) because a progress bar handler
would need to run before any other handlers. Remember, the upload handlers are processed in order.
If you want to replace the upload handlers completely, you can just assign a new list:
request.upload_handlers = [ProgressBarUploadHandler()]
Note: You can only modify upload handlers before accessing request.POST or request.FILES – it
doesn’t make sense to change upload handlers after upload handling has already started. If you try to modify
request.upload_handlers after reading from request.POST or request.FILES Django will throw an
error.
Thus, you should always modify uploading handlers as early in your view as possible.
Also, request.POST is accessed by CsrfViewMiddleware which is enabled by default. This means you will
need to use csrf_exempt() on your view to allow you to change the upload handlers. You will then need to use
csrf_protect() on the function that actually processes the request. Note that this means that the handlers may
start receiving the file upload before the CSRF checks have been done. Example code:
from django.views.decorators.csrf import csrf_exempt, csrf_protect
@csrf_exempt
def upload_file_view(request):
request.upload_handlers.insert(0, ProgressBarUploadHandler())
return _upload_file_view(request)
@csrf_protect
3.3. Handling HTTP requests 179](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-183-2048.jpg)

![Django Documentation, Release 1.5.1
This method may raise a StopFutureHandlers exception to prevent future handlers from handling this file.
FileUploadHandler.upload_complete(self) Callback signaling that the entire upload (all files) has
completed.
FileUploadHandler.handle_raw_input(self, input_data, META, content_length, boundary, encoding)
Allows the handler to completely override the parsing of the raw HTTP input.
input_data is a file-like object that supports read()-ing.
META is the same object as request.META.
content_length is the length of the data in input_data. Don’t read more than content_length
bytes from input_data.
boundary is the MIME boundary for this request.
encoding is the encoding of the request.
Return None if you want upload handling to continue, or a tuple of (POST, FILES) if you want to return
the new data structures suitable for the request directly.
3.3.5 Django shortcut functions
The package django.shortcuts collects helper functions and classes that “span” multiple levels of MVC. In
other words, these functions/classes introduce controlled coupling for convenience’s sake.
render
render(request, template_name[, dictionary][, context_instance][, content_type][, status][, current_app])
Combines a given template with a given context dictionary and returns an HttpResponse object with that
rendered text.
render() is the same as a call to render_to_response() with a context_instance argument that forces
the use of a RequestContext.
Required arguments
request The request object used to generate this response.
template_name The full name of a template to use or sequence of template names.
Optional arguments
dictionary A dictionary of values to add to the template context. By default, this is an empty dictionary. If a
value in the dictionary is callable, the view will call it just before rendering the template.
context_instance The context instance to render the template with. By default, the template will be rendered
with a RequestContext instance (filled with values from request and dictionary).
content_type The MIME type to use for the resulting document. Defaults to the value of the
DEFAULT_CONTENT_TYPE setting. Changed in version 1.5: This parameter used to be called mimetype.
status The status code for the response. Defaults to 200.
current_app A hint indicating which application contains the current view. See the namespaced URL resolution
strategy for more information.
3.3. Handling HTTP requests 181](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-185-2048.jpg)
![Django Documentation, Release 1.5.1
Example
The following example renders the template myapp/index.html with the MIME type
application/xhtml+xml:
from django.shortcuts import render
def my_view(request):
# View code here...
return render(request, ’myapp/index.html’, {"foo": "bar"},
content_type="application/xhtml+xml")
This example is equivalent to:
from django.http import HttpResponse
from django.template import RequestContext, loader
def my_view(request):
# View code here...
t = loader.get_template(’myapp/template.html’)
c = RequestContext(request, {’foo’: ’bar’})
return HttpResponse(t.render(c),
content_type="application/xhtml+xml")
render_to_response
render_to_response(template_name[, dictionary][, context_instance][, content_type])
Renders a given template with a given context dictionary and returns an HttpResponse object with that
rendered text.
Required arguments
template_name The full name of a template to use or sequence of template names. If a sequence is given, the first
template that exists will be used. See the template loader documentation for more information on how templates
are found.
Optional arguments
dictionary A dictionary of values to add to the template context. By default, this is an empty dictionary. If a
value in the dictionary is callable, the view will call it just before rendering the template.
context_instance The context instance to render the template with. By default, the template will be rendered
with a Context instance (filled with values from dictionary). If you need to use context processors, render
the template with a RequestContext instance instead. Your code might look something like this:
return render_to_response(’my_template.html’,
my_data_dictionary,
context_instance=RequestContext(request))
content_type The MIME type to use for the resulting document. Defaults to the value of the
DEFAULT_CONTENT_TYPE setting. Changed in version 1.5: This parameter used to be called mimetype.
182 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-186-2048.jpg)
![Django Documentation, Release 1.5.1
Example
The following example renders the template myapp/index.html with the MIME type
application/xhtml+xml:
from django.shortcuts import render_to_response
def my_view(request):
# View code here...
return render_to_response(’myapp/index.html’, {"foo": "bar"},
mimetype="application/xhtml+xml")
This example is equivalent to:
from django.http import HttpResponse
from django.template import Context, loader
def my_view(request):
# View code here...
t = loader.get_template(’myapp/template.html’)
c = Context({’foo’: ’bar’})
return HttpResponse(t.render(c),
content_type="application/xhtml+xml")
redirect
redirect(to[, permanent=False ], *args, **kwargs)
Returns an HttpResponseRedirect to the appropriate URL for the arguments passed.
The arguments could be:
•A model: the model’s get_absolute_url() function will be called.
•A view name, possibly with arguments: urlresolvers.reverse will be used to reverse-resolve the
name.
•A URL, which will be used as-is for the redirect location.
By default issues a temporary redirect; pass permanent=True to issue a permanent redirect
Examples
You can use the redirect() function in a number of ways.
1. By passing some object; that object’s get_absolute_url() method will be called to figure out the redirect
URL:
from django.shortcuts import redirect
def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object)
2. By passing the name of a view and optionally some positional or keyword arguments; the URL will be reverse
resolved using the reverse() method:
3.3. Handling HTTP requests 183](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-187-2048.jpg)






![Django Documentation, Release 1.5.1
Warning: The session data is signed but not encrypted
When using the cookies backend the session data can be read by the client.
A MAC (Message Authentication Code) is used to protect the data against changes by the client, so that the session
data will be invalidated when being tampered with. The same invalidation happens if the client storing the cookie
(e.g. your user’s browser) can’t store all of the session cookie and drops data. Even though Django compresses the
data, it’s still entirely possible to exceed the common limit of 4096 bytes per cookie.
No freshness guarantee
Note also that while the MAC can guarantee the authenticity of the data (that it was generated by your site, and
not someone else), and the integrity of the data (that it is all there and correct), it cannot guarantee freshness i.e.
that you are being sent back the last thing you sent to the client. This means that for some uses of session data, the
cookie backend might open you up to replay attacks. Cookies will only be detected as ‘stale’ if they are older than
your SESSION_COOKIE_AGE.
Performance
Finally, the size of a cookie can have an impact on the speed of your site.
Using sessions in views
When SessionMiddleware is activated, each HttpRequest object – the first argument to any Django view
function – will have a session attribute, which is a dictionary-like object.
You can read it and write to request.session at any point in your view. You can edit it multiple times.
class backends.base.SessionBase
This is the base class for all session objects. It has the following standard dictionary methods:
__getitem__(key)
Example: fav_color = request.session[’fav_color’]
__setitem__(key, value)
Example: request.session[’fav_color’] = ’blue’
__delitem__(key)
Example: del request.session[’fav_color’]. This raises KeyError if the given key isn’t
already in the session.
__contains__(key)
Example: ’fav_color’ in request.session
get(key, default=None)
Example: fav_color = request.session.get(’fav_color’, ’red’)
pop(key)
Example: fav_color = request.session.pop(’fav_color’)
keys()
items()
setdefault()
clear()
It also has these methods:
flush()
Delete the current session data from the session and regenerate the session key value that is sent back to
the user in the cookie. This is used if you want to ensure that the previous session data can’t be accessed
again from the user’s browser (for example, the django.contrib.auth.logout() function calls
it).
3.3. Handling HTTP requests 191](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-195-2048.jpg)

![Django Documentation, Release 1.5.1
• Don’t override request.session with a new object, and don’t access or set its attributes. Use it like a
Python dictionary.
Examples
This simplistic view sets a has_commented variable to True after a user posts a comment. It doesn’t let a user post
a comment more than once:
def post_comment(request, new_comment):
if request.session.get(’has_commented’, False):
return HttpResponse("You’ve already commented.")
c = comments.Comment(comment=new_comment)
c.save()
request.session[’has_commented’] = True
return HttpResponse(’Thanks for your comment!’)
This simplistic view logs in a “member” of the site:
def login(request):
m = Member.objects.get(username=request.POST[’username’])
if m.password == request.POST[’password’]:
request.session[’member_id’] = m.id
return HttpResponse("You’re logged in.")
else:
return HttpResponse("Your username and password didn’t match.")
...And this one logs a member out, according to login() above:
def logout(request):
try:
del request.session[’member_id’]
except KeyError:
pass
return HttpResponse("You’re logged out.")
The standard django.contrib.auth.logout() function actually does a bit more than this to prevent inadver-tent
data leakage. It calls the flush() method of request.session. We are using this example as a demonstra-tion
of how to work with session objects, not as a full logout() implementation.
Setting test cookies
As a convenience, Django provides an easy way to test whether the user’s browser accepts cookies. Just call the
set_test_cookie() method of request.session in a view, and call test_cookie_worked() in a sub-sequent
view – not in the same view call.
This awkward split between set_test_cookie() and test_cookie_worked() is necessary due to the way
cookies work. When you set a cookie, you can’t actually tell whether a browser accepted it until the browser’s next
request.
It’s good practice to use delete_test_cookie() to clean up after yourself. Do this after you’ve verified that the
test cookie worked.
Here’s a typical usage example:
def login(request):
if request.method == ’POST’:
if request.session.test_cookie_worked():
3.3. Handling HTTP requests 193](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-197-2048.jpg)
![Django Documentation, Release 1.5.1
request.session.delete_test_cookie()
return HttpResponse("You’re logged in.")
else:
return HttpResponse("Please enable cookies and try again.")
request.session.set_test_cookie()
return render_to_response(’foo/login_form.html’)
Using sessions out of views
An API is available to manipulate session data outside of a view:
>>> from django.contrib.sessions.backends.db import SessionStore
>>> import datetime
>>> s = SessionStore()
>>> s[’last_login’] = datetime.datetime(2005, 8, 20, 13, 35, 10)
>>> s.save()
>>> s.session_key
’2b1189a188b44ad18c35e113ac6ceead’
>>> s = SessionStore(session_key=’2b1189a188b44ad18c35e113ac6ceead’)
>>> s[’last_login’]
datetime.datetime(2005, 8, 20, 13, 35, 0)
In order to prevent session fixation attacks, sessions keys that don’t exist are regenerated:
>>> from django.contrib.sessions.backends.db import SessionStore
>>> s = SessionStore(session_key=’no-such-session-here’)
>>> s.save()
>>> s.session_key
’ff882814010ccbc3c870523934fee5a2’
If you’re using the django.contrib.sessions.backends.db backend, each session is just a normal Django
model. The Session model is defined in django/contrib/sessions/models.py. Because it’s a normal
model, you can access sessions using the normal Django database API:
>>> from django.contrib.sessions.models import Session
>>> s = Session.objects.get(pk=’2b1189a188b44ad18c35e113ac6ceead’)
>>> s.expire_date
datetime.datetime(2005, 8, 20, 13, 35, 12)
Note that you’ll need to call get_decoded() to get the session dictionary. This is necessary because the dictionary
is stored in an encoded format:
>>> s.session_data
’KGRwMQpTJ19hdXRoX3VzZXJfaWQnCnAyCkkxCnMuMTExY2ZjODI2Yj...’
>>> s.get_decoded()
{’user_id’: 42}
When sessions are saved
By default, Django only saves to the session database when the session has been modified – that is if any of its
dictionary values have been assigned or deleted:
# Session is modified.
request.session[’foo’] = ’bar’
194 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-198-2048.jpg)
![Django Documentation, Release 1.5.1
# Session is modified.
del request.session[’foo’]
# Session is modified.
request.session[’foo’] = {}
# Gotcha: Session is NOT modified, because this alters
# request.session[’foo’] instead of request.session.
request.session[’foo’][’bar’] = ’baz’
In the last case of the above example, we can tell the session object explicitly that it has been modified by setting the
modified attribute on the session object:
request.session.modified = True
To change this default behavior, set the SESSION_SAVE_EVERY_REQUEST setting to True. When set to True,
Django will save the session to the database on every single request.
Note that the session cookie is only sent when a session has been created or modified. If
SESSION_SAVE_EVERY_REQUEST is True, the session cookie will be sent on every request.
Similarly, the expires part of a session cookie is updated each time the session cookie is sent. Changed in version
1.5: The session is not saved if the response’s status code is 500.
Browser-length sessions vs. persistent sessions
You can control whether the session framework uses browser-length sessions vs. persistent sessions with the
SESSION_EXPIRE_AT_BROWSER_CLOSE setting.
By default, SESSION_EXPIRE_AT_BROWSER_CLOSE is set to False, which means session cookies will be stored
in users’ browsers for as long as SESSION_COOKIE_AGE. Use this if you don’t want people to have to log in every
time they open a browser.
If SESSION_EXPIRE_AT_BROWSER_CLOSE is set to True, Django will use browser-length cookies – cookies
that expire as soon as the user closes his or her browser. Use this if you want people to have to log in every time they
open a browser.
This setting is a global default and can be overwritten at a per-session level by explicitly calling the set_expiry()
method of request.session as described above in using sessions in views.
Note: Some browsers (Chrome, for example) provide settings that allow users to continue brows-ing
sessions after closing and re-opening the browser. In some cases, this can interfere with the
SESSION_EXPIRE_AT_BROWSER_CLOSE setting and prevent sessions from expiring on browser close. Please
be aware of this while testing Django applications which have the SESSION_EXPIRE_AT_BROWSER_CLOSE set-ting
enabled.
Clearing the session store
As users create new sessions on your website, session data can accumulate in your session store. If you’re using the
database backend, the django_session database table will grow. If you’re using the file backend, your temporary
directory will contain an increasing number of files.
To understand this problem, consider what happens with the database backend. When a user logs in, Django adds a
row to the django_session database table. Django updates this row each time the session data changes. If the
user logs out manually, Django deletes the row. But if the user does not log out, the row never gets deleted. A similar
process happens with the file backend.
3.3. Handling HTTP requests 195](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-199-2048.jpg)




![Django Documentation, Release 1.5.1
Note: You can still access the unvalidated data directly from request.POST at this point, but the validated data is
better.
In the above example, cc_myself will be a boolean value. Likewise, fields such as IntegerField and
FloatField convert values to a Python int and float respectively.
Read-only fields are not available in form.cleaned_data (and setting a value in a custom clean() method
won’t have any effect). These fields are displayed as text rather than as input elements, and thus are not posted back
to the server.
Extending the earlier example, here’s how the form data could be processed:
if form.is_valid():
subject = form.cleaned_data[’subject’]
message = form.cleaned_data[’message’]
sender = form.cleaned_data[’sender’]
cc_myself = form.cleaned_data[’cc_myself’]
recipients = [’info@example.com’]
if cc_myself:
recipients.append(sender)
from django.core.mail import send_mail
send_mail(subject, message, sender, recipients)
return HttpResponseRedirect(’/thanks/’) # Redirect after POST
Tip: For more on sending email from Django, see Sending email.
Displaying a form using a template
Forms are designed to work with the Django template language. In the above example, we passed our ContactForm
instance to the template using the context variable form. Here’s a simple example template:
<form action="/contact/" method="post">{% csrf_token %}
{{ form.as_p }}
<input type="submit" value="Submit" />
</form>
The form only outputs its own fields; it is up to you to provide the surrounding <form> tags and the submit button.
If your form includes uploaded files, be sure to include enctype="multipart/form-data" in the form el-ement.
If you wish to write a generic template that will work whether or not the form has files, you can use the
is_multipart() attribute on the form:
<form action="/contact/" method="post"
{% if form.is_multipart %}enctype="multipart/form-data"{% endif %}>
Forms and Cross Site Request Forgery protection
Django ships with an easy-to-use protection against Cross Site Request Forgeries. When submitting a form via POST
with CSRF protection enabled you must use the csrf_token template tag as in the preceding example. However,
since CSRF protection is not directly tied to forms in templates, this tag is omitted from the following examples in this
document.
form.as_p will output the form with each form field and accompanying label wrapped in a paragraph. Here’s the
output for our example template:
200 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-204-2048.jpg)



![Django Documentation, Release 1.5.1
3.4.3 Further topics
This covers the basics, but forms can do a whole lot more:
Formsets
class django.forms.formset.BaseFormSet
A formset is a layer of abstraction to work with multiple forms on the same page. It can be best compared to a data
grid. Let’s say you have the following form:
>>> from django import forms
>>> class ArticleForm(forms.Form):
... title = forms.CharField()
... pub_date = forms.DateField()
You might want to allow the user to create several articles at once. To create a formset out of an ArticleForm you
would do:
>>> from django.forms.formsets import formset_factory
>>> ArticleFormSet = formset_factory(ArticleForm)
You now have created a formset named ArticleFormSet. The formset gives you the ability to iterate over the
forms in the formset and display them as you would with a regular form:
>>> formset = ArticleFormSet()
>>> for form in formset:
... print(form.as_table())
<tr><th><label for="id_form-0-title">Title:</label></th><td><input type="text" name="form-0-title" id="<tr><th><label for="id_form-0-pub_date">Pub date:</label></th><td><input type="text" name="form-0-pub_As you can see it only displayed one empty form. The number of empty forms that is displayed is controlled by the
extra parameter. By default, formset_factory defines one extra form; the following example will display two
blank forms:
>>> ArticleFormSet = formset_factory(ArticleForm, extra=2)
Iterating over the formset will render the forms in the order they were created. You can change this order by
providing an alternate implementation for the __iter__() method.
Formsets can also be indexed into, which returns the corresponding form. If you override __iter__, you will need
to also override __getitem__ to have matching behavior.
Using initial data with a formset
Initial data is what drives the main usability of a formset. As shown above you can define the number of extra forms.
What this means is that you are telling the formset how many additional forms to show in addition to the number of
forms it generates from the initial data. Lets take a look at an example:
>>> ArticleFormSet = formset_factory(ArticleForm, extra=2)
>>> formset = ArticleFormSet(initial=[
... {’title’: u’Django is now open source’,
... ’pub_date’: datetime.date.today(),}
... ])
>>> for form in formset:
... print(form.as_table())
204 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-208-2048.jpg)

![Django Documentation, Release 1.5.1
... ’form-1-pub_date’: u’’, # <-- this date is missing but required
... }
>>> formset = ArticleFormSet(data)
>>> formset.is_valid()
False
>>> formset.errors
[{}, {’pub_date’: [u’This field is required.’]}]
As we can see, formset.errors is a list whose entries correspond to the forms in the formset. Validation was
performed for each of the two forms, and the expected error message appears for the second item. New in version 1.4.
We can also check if form data differs from the initial data (i.e. the form was sent without any data):
>>> data = {
... ’form-TOTAL_FORMS’: u’1’,
... ’form-INITIAL_FORMS’: u’0’,
... ’form-MAX_NUM_FORMS’: u’’,
... ’form-0-title’: u’’,
... ’form-0-pub_date’: u’’,
... }
>>> formset = ArticleFormSet(data)
>>> formset.has_changed()
False
Understanding the ManagementForm You may have noticed the additional data (form-TOTAL_FORMS,
form-INITIAL_FORMS and form-MAX_NUM_FORMS) that was required in the formset’s data above. This data is
required for the ManagementForm. This form is used by the formset to manage the collection of forms contained
in the formset. If you don’t provide this management data, an exception will be raised:
>>> data = {
... ’form-0-title’: u’Test’,
... ’form-0-pub_date’: u’’,
... }
>>> formset = ArticleFormSet(data)
Traceback (most recent call last):
...
django.forms.util.ValidationError: [u’ManagementForm data is missing or has been tampered with’]
It is used to keep track of how many form instances are being displayed. If you are adding new forms via JavaScript,
you should increment the count fields in this form as well. On the other hand, if you are using JavaScript to allow
deletion of existing objects, then you need to ensure the ones being removed are properly marked for deletion by
including form-#-DELETE in the POST data. It is expected that all forms are present in the POST data regardless.
The management form is available as an attribute of the formset itself. When rendering a formset in a template, you
can include all the management data by rendering {{ my_formset.management_form }} (substituting the
name of your formset as appropriate).
total_form_count and initial_form_count BaseFormSet has a couple of methods that are closely
related to the ManagementForm, total_form_count and initial_form_count.
total_form_count returns the total number of forms in this formset. initial_form_count returns the
number of forms in the formset that were pre-filled, and is also used to determine how many forms are required. You
will probably never need to override either of these methods, so please be sure you understand what they do before
doing so.
empty_form BaseFormSet provides an additional attribute empty_form which returns a form instance with
a prefix of __prefix__ for easier use in dynamic forms with JavaScript.
206 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-210-2048.jpg)
![Django Documentation, Release 1.5.1
Custom formset validation A formset has a clean method similar to the one on a Form class. This is where you
define your own validation that works at the formset level:
>>> from django.forms.formsets import BaseFormSet
>>> class BaseArticleFormSet(BaseFormSet):
... def clean(self):
... """Checks that no two articles have the same title."""
... if any(self.errors):
... # Don’t bother validating the formset unless each form is valid on its own
... return
... titles = []
... for i in range(0, self.total_form_count()):
... form = self.forms[i]
... title = form.cleaned_data[’title’]
... if title in titles:
... raise forms.ValidationError("Articles in a set must have distinct titles.")
... titles.append(title)
>>> ArticleFormSet = formset_factory(ArticleForm, formset=BaseArticleFormSet)
>>> data = {
... ’form-TOTAL_FORMS’: u’2’,
... ’form-INITIAL_FORMS’: u’0’,
... ’form-MAX_NUM_FORMS’: u’’,
... ’form-0-title’: u’Test’,
... ’form-0-pub_date’: u’1904-06-16’,
... ’form-1-title’: u’Test’,
... ’form-1-pub_date’: u’1912-06-23’,
... }
>>> formset = ArticleFormSet(data)
>>> formset.is_valid()
False
>>> formset.errors
[{}, {}]
>>> formset.non_form_errors()
[u’Articles in a set must have distinct titles.’]
The formset clean method is called after all the Form.clean methods have been called. The errors will be found
using the non_form_errors() method on the formset.
Dealing with ordering and deletion of forms
Common use cases with a formset is dealing with ordering and deletion of the form instances. This has been dealt
with for you. The formset_factory provides two optional parameters can_order and can_delete that will
do the extra work of adding the extra fields and providing simpler ways of getting to that data.
can_order Default: False
Lets you create a formset with the ability to order:
>>> ArticleFormSet = formset_factory(ArticleForm, can_order=True)
>>> formset = ArticleFormSet(initial=[
... {’title’: u’Article #1’, ’pub_date’: datetime.date(2008, 5, 10)},
... {’title’: u’Article #2’, ’pub_date’: datetime.date(2008, 5, 11)},
... ])
>>> for form in formset:
... print(form.as_table())
3.4. Working with forms 207](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-211-2048.jpg)
![Django Documentation, Release 1.5.1
<tr><th><label for="id_form-0-title">Title:</label></th><td><input type="text" name="form-0-title" value="<tr><th><label for="id_form-0-pub_date">Pub date:</label></th><td><input type="text" name="form-0-pub_<tr><th><label for="id_form-0-ORDER">Order:</label></th><td><input type="text" name="form-0-ORDER" value="<tr><th><label for="id_form-1-title">Title:</label></th><td><input type="text" name="form-1-title" value="<tr><th><label for="id_form-1-pub_date">Pub date:</label></th><td><input type="text" name="form-1-pub_<tr><th><label for="id_form-1-ORDER">Order:</label></th><td><input type="text" name="form-1-ORDER" value="<tr><th><label for="id_form-2-title">Title:</label></th><td><input type="text" name="form-2-title" id="<tr><th><label for="id_form-2-pub_date">Pub date:</label></th><td><input type="text" name="form-2-pub_<tr><th><label for="id_form-2-ORDER">Order:</label></th><td><input type="text" name="form-2-ORDER" id="This adds an additional field to each form. This new field is named ORDER and is an forms.IntegerField.
For the forms that came from the initial data it automatically assigned them a numeric value. Let’s look at what will
happen when the user changes these values:
>>> data = {
... ’form-TOTAL_FORMS’: u’3’,
... ’form-INITIAL_FORMS’: u’2’,
... ’form-MAX_NUM_FORMS’: u’’,
... ’form-0-title’: u’Article #1’,
... ’form-0-pub_date’: u’2008-05-10’,
... ’form-0-ORDER’: u’2’,
... ’form-1-title’: u’Article #2’,
... ’form-1-pub_date’: u’2008-05-11’,
... ’form-1-ORDER’: u’1’,
... ’form-2-title’: u’Article #3’,
... ’form-2-pub_date’: u’2008-05-01’,
... ’form-2-ORDER’: u’0’,
... }
>>> formset = ArticleFormSet(data, initial=[
... {’title’: u’Article #1’, ’pub_date’: datetime.date(2008, 5, 10)},
... {’title’: u’Article #2’, ’pub_date’: datetime.date(2008, 5, 11)},
... ])
>>> formset.is_valid()
True
>>> for form in formset.ordered_forms:
... print(form.cleaned_data)
{’pub_date’: datetime.date(2008, 5, 1), ’ORDER’: 0, ’title’: u’Article #3’}
{’pub_date’: datetime.date(2008, 5, 11), ’ORDER’: 1, ’title’: u’Article #2’}
{’pub_date’: datetime.date(2008, 5, 10), ’ORDER’: 2, ’title’: u’Article #1’}
can_delete Default: False
Lets you create a formset with the ability to delete:
>>> ArticleFormSet = formset_factory(ArticleForm, can_delete=True)
>>> formset = ArticleFormSet(initial=[
... {’title’: u’Article #1’, ’pub_date’: datetime.date(2008, 5, 10)},
... {’title’: u’Article #2’, ’pub_date’: datetime.date(2008, 5, 11)},
... ])
>>> for form in formset:
.... print(form.as_table())
<input type="hidden" name="form-TOTAL_FORMS" value="3" id="id_form-TOTAL_FORMS" /><input type="hidden" <tr><th><label for="id_form-0-title">Title:</label></th><td><input type="text" name="form-0-title" value="<tr><th><label for="id_form-0-pub_date">Pub date:</label></th><td><input type="text" name="form-0-pub_<tr><th><label for="id_form-0-DELETE">Delete:</label></th><td><input type="checkbox" name="form-0-DELETE" <tr><th><label for="id_form-1-title">Title:</label></th><td><input type="text" name="form-1-title" value="<tr><th><label for="id_form-1-pub_date">Pub date:</label></th><td><input type="text" name="form-1-pub_208 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-212-2048.jpg)
![Django Documentation, Release 1.5.1
<tr><th><label for="id_form-1-DELETE">Delete:</label></th><td><input type="checkbox" name="form-1-DELETE" <tr><th><label for="id_form-2-title">Title:</label></th><td><input type="text" name="form-2-title" id="<tr><th><label for="id_form-2-pub_date">Pub date:</label></th><td><input type="text" name="form-2-pub_<tr><th><label for="id_form-2-DELETE">Delete:</label></th><td><input type="checkbox" name="form-2-DELETE" Similar to can_order this adds a new field to each form named DELETE and is a forms.BooleanField. When
data comes through marking any of the delete fields you can access them with deleted_forms:
>>> data = {
... ’form-TOTAL_FORMS’: u’3’,
... ’form-INITIAL_FORMS’: u’2’,
... ’form-MAX_NUM_FORMS’: u’’,
... ’form-0-title’: u’Article #1’,
... ’form-0-pub_date’: u’2008-05-10’,
... ’form-0-DELETE’: u’on’,
... ’form-1-title’: u’Article #2’,
... ’form-1-pub_date’: u’2008-05-11’,
... ’form-1-DELETE’: u’’,
... ’form-2-title’: u’’,
... ’form-2-pub_date’: u’’,
... ’form-2-DELETE’: u’’,
... }
>>> formset = ArticleFormSet(data, initial=[
... {’title’: u’Article #1’, ’pub_date’: datetime.date(2008, 5, 10)},
... {’title’: u’Article #2’, ’pub_date’: datetime.date(2008, 5, 11)},
... ])
>>> [form.cleaned_data for form in formset.deleted_forms]
[{’DELETE’: True, ’pub_date’: datetime.date(2008, 5, 10), ’title’: u’Article #1’}]
Adding additional fields to a formset
If you need to add additional fields to the formset this can be easily accomplished. The formset base class provides
an add_fields method. You can simply override this method to add your own fields or even redefine the default
fields/attributes of the order and deletion fields:
>>> class BaseArticleFormSet(BaseFormSet):
... def add_fields(self, form, index):
... super(BaseArticleFormSet, self).add_fields(form, index)
... form.fields["my_field"] = forms.CharField()
>>> ArticleFormSet = formset_factory(ArticleForm, formset=BaseArticleFormSet)
>>> formset = ArticleFormSet()
>>> for form in formset:
... print(form.as_table())
<tr><th><label for="id_form-0-title">Title:</label></th><td><input type="text" name="form-0-title" id="<tr><th><label for="id_form-0-pub_date">Pub date:</label></th><td><input type="text" name="form-0-pub_<tr><th><label for="id_form-0-my_field">My field:</label></th><td><input type="text" name="form-0-my_Using a formset in views and templates
Using a formset inside a view is as easy as using a regular Form class. The only thing you will want to be aware of is
making sure to use the management form inside the template. Let’s look at a sample view:
3.4. Working with forms 209](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-213-2048.jpg)







![Django Documentation, Release 1.5.1
The save() method returns the instances that have been saved to the database. If a given instance’s data didn’t change
in the bound data, the instance won’t be saved to the database and won’t be included in the return value (instances,
in the above example).
When fields are missing from the form (for example because they have been excluded), these fields will not be
set by the save() method. You can find more information about this restriction, which also holds for regular
ModelForms, in Using a subset of fields on the form.
Pass commit=False to return the unsaved model instances:
# don’t save to the database
>>> instances = formset.save(commit=False)
>>> for instance in instances:
... # do something with instance
... instance.save()
This gives you the ability to attach data to the instances before saving them to the database. If your formset contains
a ManyToManyField, you’ll also need to call formset.save_m2m() to ensure the many-to-many relationships
are saved properly.
Limiting the number of editable objects As with regular formsets, you can use the max_num and extra param-eters
to modelformset_factory() to limit the number of extra forms displayed.
max_num does not prevent existing objects from being displayed:
>>> Author.objects.order_by(’name’)
[<Author: Charles Baudelaire>, <Author: Paul Verlaine>, <Author: Walt Whitman>]
>>> AuthorFormSet = modelformset_factory(Author, max_num=1)
>>> formset = AuthorFormSet(queryset=Author.objects.order_by(’name’))
>>> [x.name for x in formset.get_queryset()]
[u’Charles Baudelaire’, u’Paul Verlaine’, u’Walt Whitman’]
If the value of max_num is greater than the number of existing related objects, up to extra additional blank forms
will be added to the formset, so long as the total number of forms does not exceed max_num:
>>> AuthorFormSet = modelformset_factory(Author, max_num=4, extra=2)
>>> formset = AuthorFormSet(queryset=Author.objects.order_by(’name’))
>>> for form in formset:
... print(form.as_table())
<tr><th><label for="id_form-0-name">Name:</label></th><td><input id="id_form-0-name" type="text" name="<tr><th><label for="id_form-1-name">Name:</label></th><td><input id="id_form-1-name" type="text" name="<tr><th><label for="id_form-2-name">Name:</label></th><td><input id="id_form-2-name" type="text" name="<tr><th><label for="id_form-3-name">Name:</label></th><td><input id="id_form-3-name" type="text" name="A max_num value of None (the default) puts a high limit on the number of forms displayed (1000). In practice this
is equivalent to no limit.
Using a model formset in a view Model formsets are very similar to formsets. Let’s say we want to present a
formset to edit Author model instances:
def manage_authors(request):
AuthorFormSet = modelformset_factory(Author)
if request.method == ’POST’:
formset = AuthorFormSet(request.POST, request.FILES)
if formset.is_valid():
formset.save()
# do something.
220 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-224-2048.jpg)





![Django Documentation, Release 1.5.1
However, Media objects have some other interesting properties.
Media subsets If you only want media of a particular type, you can use the subscript operator to filter out a medium
of interest. For example:
>>> w = CalendarWidget()
>>> print(w.media)
<link href="http://static.example.com/pretty.css" type="text/css" media="all" rel="stylesheet" />
<script type="text/javascript" src="http://static.example.com/animations.js"></script>
<script type="text/javascript" src="http://static.example.com/actions.js"></script>
>>> print(w.media)[’css’]
<link href="http://static.example.com/pretty.css" type="text/css" media="all" rel="stylesheet" />
When you use the subscript operator, the value that is returned is a new Media object – but one that only contains the
media of interest.
Combining media objects Media objects can also be added together. When two media objects are added, the
resulting Media object contains the union of the media from both files:
>>> class CalendarWidget(forms.TextInput):
... class Media:
... css = {
... ’all’: (’pretty.css’,)
... }
... js = (’animations.js’, ’actions.js’)
>>> class OtherWidget(forms.TextInput):
... class Media:
... js = (’whizbang.js’,)
>>> w1 = CalendarWidget()
>>> w2 = OtherWidget()
>>> print(w1.media + w2.media)
<link href="http://static.example.com/pretty.css" type="text/css" media="all" rel="stylesheet" />
<script type="text/javascript" src="http://static.example.com/animations.js"></script>
<script type="text/javascript" src="http://static.example.com/actions.js"></script>
<script type="text/javascript" src="http://static.example.com/whizbang.js"></script>
Media on Forms
Widgets aren’t the only objects that can have media definitions – forms can also define media. The rules for media
definitions on forms are the same as the rules for widgets: declarations can be static or dynamic; path and inheritance
rules for those declarations are exactly the same.
Regardless of whether you define a media declaration, all Form objects have a media property. The default value for
this property is the result of adding the media definitions for all widgets that are part of the form:
>>> class ContactForm(forms.Form):
... date = DateField(widget=CalendarWidget)
... name = CharField(max_length=40, widget=OtherWidget)
>>> f = ContactForm()
>>> f.media
<link href="http://static.example.com/pretty.css" type="text/css" media="all" rel="stylesheet" />
<script type="text/javascript" src="http://static.example.com/animations.js"></script>
3.4. Working with forms 227](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-231-2048.jpg)


![Django Documentation, Release 1.5.1
Because dictionary lookup happens first, that behavior kicks in and provides a default value instead of using the
intended .iteritems() method. In this case, consider converting to a dictionary first.
In the above example, {{ section.title }} will be replaced with the title attribute of the section object.
If you use a variable that doesn’t exist, the template system will insert the value of the
TEMPLATE_STRING_IF_INVALID setting, which is set to ” (the empty string) by default.
Note that “bar” in a template expression like {{ foo.bar }} will be interpreted as a literal string and not using the
value of the variable “bar”, if one exists in the template context.
3.5.3 Filters
You can modify variables for display by using filters.
Filters look like this: {{ name|lower }}. This displays the value of the {{ name }} variable after being
filtered through the lower filter, which converts text to lowercase. Use a pipe (|) to apply a filter.
Filters can be “chained.” The output of one filter is applied to the next. {{ text|escape|linebreaks }} is a
common idiom for escaping text contents, then converting line breaks to <p> tags.
Some filters take arguments. A filter argument looks like this: {{ bio|truncatewords:30 }}. This will
display the first 30 words of the bio variable.
Filter arguments that contain spaces must be quoted; for example, to join a list with commas and spaced you’d use {{
list|join:", " }}.
Django provides about thirty built-in template filters. You can read all about them in the built-in filter reference. To
give you a taste of what’s available, here are some of the more commonly used template filters:
default If a variable is false or empty, use given default. Otherwise, use the value of the variable
For example:
{{ value|default:"nothing" }}
If value isn’t provided or is empty, the above will display “nothing”.
length Returns the length of the value. This works for both strings and lists; for example:
{{ value|length }}
If value is [’a’, ’b’, ’c’, ’d’], the output will be 4.
striptags Strips all [X]HTML tags. For example:
{{ value|striptags }}
If value is "<b>Joel</b> <button>is</button> a <span>slug</span>", the output will be
"Joel is a slug".
Again, these are just a few examples; see the built-in filter reference for the complete list.
You can also create your own custom template filters; see Custom template tags and filters.
See Also:
Django’s admin interface can include a complete reference of all template tags and filters available for a given site.
See The Django admin documentation generator.
230 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-234-2048.jpg)










![Django Documentation, Release 1.5.1
Let’s start by looking at some examples of showing a list of objects or an individual object.
We’ll be using these models:
# models.py
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
class Meta:
ordering = ["-name"]
def __unicode__(self):
return self.name
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(’Author’)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
Now we need to define a view:
# views.py
from django.views.generic import ListView
from books.models import Publisher
class PublisherList(ListView):
model = Publisher
Finally hook that view into your urls:
# urls.py
from django.conf.urls import patterns, url
from books.views import PublisherList
urlpatterns = patterns(’’,
url(r’^publishers/$’, PublisherList.as_view()),
)
That’s all the Python code we need to write. We still need to write a template, however. We could explicitly
tell the view which template to use by adding a template_name attribute to the view, but in the absence of
an explicit template Django will infer one from the object’s name. In this case, the inferred template will be
"books/publisher_list.html" – the “books” part comes from the name of the app that defines the model,
while the “publisher” bit is just the lowercased version of the model’s name.
Note: Thus, when (for example) the django.template.loaders.app_directories.Loader
template loader is enabled in TEMPLATE_LOADERS, a template location could be:
/path/to/project/books/templates/books/publisher_list.html
This template will be rendered against a context containing a variable called object_list that contains all the
publisher objects. A very simple template might look like the following:
3.6. Class-based views 243](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-247-2048.jpg)
![Django Documentation, Release 1.5.1
def get_context_data(self, **kwargs):
# Call the base implementation first to get a context
context = super(PublisherDetail, self).get_context_data(**kwargs)
# Add in a QuerySet of all the books
context[’book_list’] = Book.objects.all()
return context
Note: Generally, get_context_data will merge the context data of all parent classes with those of the current class.
To preserve this behavior in your own classes where you want to alter the context, you should be sure to call
get_context_data on the super class. When no two classes try to define the same key, this will give the expected
results. However if any class attempts to override a key after parent classes have set it (after the call to super), any
children of that class will also need to explictly set it after super if they want to be sure to override all parents. If you’re
having trouble, review the method resolution order of your view.
Viewing subsets of objects
Now let’s take a closer look at the model argument we’ve been using all along. The model argument, which specifies
the database model that the view will operate upon, is available on all the generic views that operate on a single object
or a collection of objects. However, the model argument is not the only way to specify the objects that the view will
operate upon – you can also specify the list of objects using the queryset argument:
from django.views.generic import DetailView
from books.models import Publisher, Book
class PublisherDetail(DetailView):
context_object_name = ’publisher’
queryset = Publisher.objects.all()
Specifying model = Publisher is really just shorthand for saying queryset =
Publisher.objects.all(). However, by using queryset to define a filtered list of objects you can
be more specific about the objects that will be visible in the view (see Making queries for more information about
QuerySet objects, and see the class-based views reference for the complete details).
To pick a simple example, we might want to order a list of books by publication date, with the most recent first:
from django.views.generic import ListView
from books.models import Book
class BookList(ListView):
queryset = Book.objects.order_by(’-publication_date’)
context_object_name = ’book_list’
That’s a pretty simple example, but it illustrates the idea nicely. Of course, you’ll usually want to do more than just
reorder objects. If you want to present a list of books by a particular publisher, you can use the same technique:
from django.views.generic import ListView
from books.models import Book
class AcmeBookList(ListView):
context_object_name = ’book_list’
queryset = Book.objects.filter(publisher__name=’Acme Publishing’)
template_name = ’books/acme_list.html’
3.6. Class-based views 245](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-249-2048.jpg)
![Django Documentation, Release 1.5.1
Notice that along with a filtered queryset, we’re also using a custom template name. If we didn’t, the generic view
would use the same template as the “vanilla” object list, which might not be what we want.
Also notice that this isn’t a very elegant way of doing publisher-specific books. If we want to add another publisher
page, we’d need another handful of lines in the URLconf, and more than a few publishers would get unreasonable.
We’ll deal with this problem in the next section.
Note: If you get a 404 when requesting /books/acme/, check to ensure you actually have a Publisher with the
name ‘ACME Publishing’. Generic views have an allow_empty parameter for this case. See the class-based-views
reference for more details.
Dynamic filtering
Another common need is to filter down the objects given in a list page by some key in the URL. Earlier we hard-coded
the publisher’s name in the URLconf, but what if we wanted to write a view that displayed all the books by some
arbitrary publisher?
Handily, the ListView has a get_queryset() method we can override. Previously, it has just been returning the
value of the queryset attribute, but now we can add more logic.
The key part to making this work is that when class-based views are called, various useful things are stored on self; as
well as the request (self.request) this includes the positional (self.args) and name-based (self.kwargs)
arguments captured according to the URLconf.
Here, we have a URLconf with a single captured group:
# urls.py
from books.views import PublisherBookList
urlpatterns = patterns(’’,
(r’^books/([w-]+)/$’, PublisherBookList.as_view()),
)
Next, we’ll write the PublisherBookList view itself:
# views.py
from django.shortcuts import get_object_or_404
from django.views.generic import ListView
from books.models import Book, Publisher
class PublisherBookList(ListView):
template_name = ’books/books_by_publisher.html’
def get_queryset(self):
self.publisher = get_object_or_404(Publisher, name=self.args[0])
return Book.objects.filter(publisher=self.publisher)
As you can see, it’s quite easy to add more logic to the queryset selection; if we wanted, we could use
self.request.user to filter using the current user, or other more complex logic.
We can also add the publisher into the context at the same time, so we can use it in the template:
# ...
def get_context_data(self, **kwargs):
# Call the base implementation first to get a context
context = super(PublisherBookList, self).get_context_data(**kwargs)
246 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-250-2048.jpg)
![Django Documentation, Release 1.5.1
# Add in the publisher
context[’publisher’] = self.publisher
return context
Performing extra work
The last common pattern we’ll look at involves doing some extra work before or after calling the generic view.
Imagine we had a last_accessed field on our Author object that we were using to keep track of the last time
anybody looked at that author:
# models.py
class Author(models.Model):
salutation = models.CharField(max_length=10)
name = models.CharField(max_length=200)
email = models.EmailField()
headshot = models.ImageField(upload_to=’/tmp’)
last_accessed = models.DateTimeField()
The generic DetailView class, of course, wouldn’t know anything about this field, but once again we could easily
write a custom view to keep that field updated.
First, we’d need to add an author detail bit in the URLconf to point to a custom view:
from books.views import AuthorDetailView
urlpatterns = patterns(’’,
#...
url(r’^authors/(?P<pk>d+)/$’, AuthorDetailView.as_view(), name=’author-detail’),
)
Then we’d write our new view – get_object is the method that retrieves the object – so we simply override it and
wrap the call:
from django.views.generic import DetailView
from django.shortcuts import get_object_or_404
from django.utils import timezone
from books.models import Author
class AuthorDetailView(DetailView):
queryset = Author.objects.all()
def get_object(self):
# Call the superclass
object = super(AuthorDetailView, self).get_object()
# Record the last accessed date
object.last_accessed = timezone.now()
object.save()
# Return the object
return object
Note: The URLconf here uses the named group pk - this name is the default name that DetailView uses to find
the value of the primary key used to filter the queryset.
If you want to call the group something else, you can set pk_url_kwarg on the view. More details can be found in
the reference for DetailView
3.6. Class-based views 247](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-251-2048.jpg)


![Django Documentation, Release 1.5.1
Note that you’ll need to decorate this view using login_required(), or alternatively handle unauthorized users
in the form_valid().
AJAX example
Here is a simple example showing how you might go about implementing a form that works for AJAX requests as
well as ‘normal’ form POSTs:
import json
from django.http import HttpResponse
from django.views.generic.edit import CreateView
class AjaxableResponseMixin(object):
"""
Mixin to add AJAX support to a form.
Must be used with an object-based FormView (e.g. CreateView)
"""
def render_to_json_response(self, context, **response_kwargs):
data = json.dumps(context)
response_kwargs[’content_type’] = ’application/json’
return HttpResponse(data, **response_kwargs)
def form_invalid(self, form):
response = super(AjaxableResponseMixin, self).form_invalid(form)
if self.request.is_ajax():
return self.render_to_json_response(form.errors, status=400)
else:
return response
def form_valid(self, form):
# We make sure to call the parent’s form_valid() method because
# it might do some processing (in the case of CreateView, it will
# call form.save() for example).
response = super(AjaxableResponseMixin, self).form_valid(form)
if self.request.is_ajax():
data = {
’pk’: self.object.pk,
}
return self.render_to_json_response(data)
else:
return response
class AuthorCreate(AjaxableResponseMixin, CreateView):
model = Author
3.6.4 Using mixins with class-based views
Caution: This is an advanced topic. A working knowledge of Django’s class-based views is advised before
exploring these techniques.
Django’s built-in class-based views provide a lot of functionality, but some of it you may want to use separately.
For instance, you may want to write a view that renders a template to make the HTTP response, but you can’t use
TemplateView; perhaps you need to render a template only on POST, with GET doing something else entirely.
While you could use TemplateResponse directly, this will likely result in duplicate code.
3.6. Class-based views 251](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-255-2048.jpg)



![Django Documentation, Release 1.5.1
explictly ensure the Publisher is in the context data. ListView will add in the suitable page_obj and paginator
for us providing we remember to call super().
Now we can write a new PublisherDetail:
from django.views.generic import ListView
from django.views.generic.detail import SingleObjectMixin
from books.models import Publisher
class PublisherDetail(SingleObjectMixin, ListView):
paginate_by = 2
template_name = "books/publisher_detail.html"
def get_context_data(self, **kwargs):
kwargs[’publisher’] = self.object
return super(PublisherDetail, self).get_context_data(**kwargs)
def get_queryset(self):
self.object = self.get_object(Publisher.objects.all())
return self.object.book_set.all()
Notice how we set self.object within get_queryset() so we can use it again later in
get_context_data(). If you don’t set template_name, the template will default to the normal ListView
choice, which in this case would be "books/book_list.html" because it’s a list of books; ListView knows
nothing about SingleObjectMixin, so it doesn’t have any clue this view is anything to do with a Publisher.
The paginate_by is deliberately small in the example so you don’t have to create lots of books to see the pagination
working! Here’s the template you’d want to use:
{% extends "base.html" %}
{% block content %}
<h2>Publisher {{ publisher.name }}</h2>
<ol>
{% for book in page_obj %}
<li>{{ book.title }}</li>
{% endfor %}
</ol>
<div class="pagination">
<span class="step-links">
{% if page_obj.has_previous %}
<a href="?page={{ page_obj.previous_page_number }}">previous</a>
{% endif %}
<span class="current">
Page {{ page_obj.number }} of {{ paginator.num_pages }}.
</span>
{% if page_obj.has_next %}
<a href="?page={{ page_obj.next_page_number }}">next</a>
{% endif %}
</span>
</div>
{% endblock %}
3.6. Class-based views 255](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-259-2048.jpg)



![Django Documentation, Release 1.5.1
def get(self, request, *args, **kwargs):
view = AuthorDisplay.as_view()
return view(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
view = AuthorInterest.as_view()
return view(request, *args, **kwargs)
This approach can also be used with any other generic class-based views or your own class-based views inheriting
directly from View or TemplateView, as it keeps the different views as separate as possible.
More than just HTML
Where class based views shine is when you want to do the same thing many times. Suppose you’re writing an API,
and every view should return JSON instead of rendered HTML.
We can create a mixin class to use in all of our views, handling the conversion to JSON once.
For example, a simple JSON mixin might look something like this:
import json
from django.http import HttpResponse
class JSONResponseMixin(object):
"""
A mixin that can be used to render a JSON response.
"""
response_class = HttpResponse
def render_to_response(self, context, **response_kwargs):
"""
Returns a JSON response, transforming ’context’ to make the payload.
"""
response_kwargs[’content_type’] = ’application/json’
return self.response_class(
self.convert_context_to_json(context),
**response_kwargs
)
def convert_context_to_json(self, context):
"Convert the context dictionary into a JSON object"
# Note: This is *EXTREMELY* naive; in reality, you’ll need
# to do much more complex handling to ensure that arbitrary
# objects -- such as Django model instances or querysets
# -- can be serialized as JSON.
return json.dumps(context)
Now we mix this into the base TemplateView:
from django.views.generic import TemplateView
class JSONView(JSONResponseMixin, TemplateView):
pass
Equally we could use our mixin with one of the generic views. We can make our own version of DetailView
by mixing JSONResponseMixin with the django.views.generic.detail.BaseDetailView – (the
DetailView before template rendering behavior has been mixed in):
3.6. Class-based views 259](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-263-2048.jpg)

![Django Documentation, Release 1.5.1
# some_app/views.py
from django.views.generic import TemplateView
class AboutView(TemplateView):
template_name = "about.html"
Then we just need to add this new view into our URLconf. ~django.views.generic.base.TemplateView is a class, not
a function, so we point the URL to the as_view() class method instead, which provides a function-like entry to
class-based views:
# urls.py
from django.conf.urls import patterns
from some_app.views import AboutView
urlpatterns = patterns(’’,
(r’^about/’, AboutView.as_view()),
)
For more information on how to use the built in generic views, consult the next topic on generic class based views.
Supporting other HTTP methods
Suppose somebody wants to access our book library over HTTP using the views as an API. The API client would
connect every now and then and download book data for the books published since last visit. But if no new books
appeared since then, it is a waste of CPU time and bandwidth to fetch the books from the database, render a full
response and send it to the client. It might be preferable to ask the API when the most recent book was published.
We map the URL to book list view in the URLconf:
from django.conf.urls import patterns
from books.views import BookListView
urlpatterns = patterns(’’,
(r’^books/$’, BookListView.as_view()),
)
And the view:
from django.http import HttpResponse
from django.views.generic import ListView
from books.models import Book
class BookListView(ListView):
model = Book
def head(self, *args, **kwargs):
last_book = self.get_queryset().latest(’publication_date’)
response = HttpResponse(’’)
# RFC 1123 date format
response[’Last-Modified’] = last_book.publication_date.strftime(’%a, %d %b %Y %H:%M:%S GMT’)
return response
If the view is accessed from a GET request, a plain-and-simple object list is returned in the response (using
book_list.html template). But if the client issues a HEAD request, the response has an empty body and the
Last-Modified header indicates when the most recent book was published. Based on this information, the client
may or may not download the full object list.
3.6. Class-based views 261](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-265-2048.jpg)

![Django Documentation, Release 1.5.1
Now you can use any of the documented attributes and methods of the File class.
Be aware that files created in this way are not automatically closed. The following approach may be used to close files
automatically:
>>> from django.core.files import File
# Create a Python file object using open() and the with statement
>>> with open(’/tmp/hello.world’, ’w’) as f:
>>> myfile = File(f)
>>> for line in myfile:
>>> print line
>>> myfile.closed
True
>>> f.closed
True
Closing files is especially important when accessing file fields in a loop over a large number of objects:: If files are
not manually closed after accessing them, the risk of running out of file descriptors may arise. This may lead to the
following error:
IOError: [Errno 24] Too many open files
3.7.3 File storage
Behind the scenes, Django delegates decisions about how and where to store files to a file storage system. This is the
object that actually understands things like file systems, opening and reading files, etc.
Django’s default file storage is given by the DEFAULT_FILE_STORAGE setting; if you don’t explicitly provide a
storage system, this is the one that will be used.
See below for details of the built-in default file storage system, and see Writing a custom storage system for information
on writing your own file storage system.
Storage objects
Though most of the time you’ll want to use a File object (which delegates to the proper storage for that file), you can
use file storage systems directly. You can create an instance of some custom file storage class, or – often more useful
– you can use the global default storage system:
>>> from django.core.files.storage import default_storage
>>> from django.core.files.base import ContentFile
>>> path = default_storage.save(’/path/to/file’, ContentFile(’new content’))
>>> path
u’/path/to/file’
>>> default_storage.size(path)
11
>>> default_storage.open(path).read()
’new content’
>>> default_storage.delete(path)
>>> default_storage.exists(path)
False
See File storage API for the file storage API.
3.7. Managing files 263](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-267-2048.jpg)







![Django Documentation, Release 1.5.1
The headers sent via **extra should follow CGI specification. For example, emulating a different
“Host” header as sent in the HTTP request from the browser to the server should be passed as HTTP_HOST.
If you already have the GET arguments in URL-encoded form, you can use that encoding instead of using
the data argument. For example, the previous GET request could also be posed as:
>>> c = Client()
>>> c.get(’/customers/details/?name=fred&age=7’)
If you provide a URL with both an encoded GET data and a data argument, the data argument will take
precedence.
If you set follow to True the client will follow any redirects and a redirect_chain attribute will
be set in the response object containing tuples of the intermediate urls and status codes.
If you had a URL /redirect_me/ that redirected to /next/, that redirected to /final/, this is what
you’d see:
>>> response = c.get(’/redirect_me/’, follow=True)
>>> response.redirect_chain
[(u’http://testserver/next/’, 302), (u’http://testserver/final/’, 302)]
post(path, data={}, content_type=MULTIPART_CONTENT, follow=False, **extra)
Makes a POST request on the provided path and returns a Response object, which is documented
below.
The key-value pairs in the data dictionary are used to submit POST data. For example:
>>> c = Client()
>>> c.post(’/login/’, {’name’: ’fred’, ’passwd’: ’secret’})
...will result in the evaluation of a POST request to this URL:
/login/
...with this POST data:
name=fred&passwd=secret
If you provide content_type (e.g. text/xml for an XML payload), the contents of data will be
sent as-is in the POST request, using content_type in the HTTP Content-Type header.
If you don’t provide a value for content_type, the values in data will be transmitted with a con-tent
type of multipart/form-data. In this case, the key-value pairs in data will be encoded as a
multipart message and used to create the POST data payload.
To submit multiple values for a given key – for example, to specify the selections for a <select
multiple> – provide the values as a list or tuple for the required key. For example, this value of data
would submit three selected values for the field named choices:
{’choices’: (’a’, ’b’, ’d’)}
Submitting files is a special case. To POST a file, you need only provide the file field name as a key, and a
file handle to the file you wish to upload as a value. For example:
>>> c = Client()
>>> with open(’wishlist.doc’) as fp:
... c.post(’/customers/wishes/’, {’name’: ’fred’, ’attachment’: fp})
(The name attachment here is not relevant; use whatever name your file-processing code expects.)
3.8. Testing in Django 271](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-275-2048.jpg)

![Django Documentation, Release 1.5.1
>>> c = Client()
>>> c.login(username=’fred’, password=’secret’)
# Now you can access a view that’s only available to logged-in users.
If you’re using a different authentication backend, this method may require different credentials. It requires
whichever credentials are required by your backend’s authenticate() method.
login() returns True if it the credentials were accepted and login was successful.
Finally, you’ll need to remember to create user accounts before you can use this method. As we explained
above, the test runner is executed using a test database, which contains no users by default. As a result,
user accounts that are valid on your production site will not work under test conditions. You’ll need to
create users as part of the test suite – either manually (using the Django model API) or with a test fixture.
Remember that if you want your test user to have a password, you can’t set the user’s password by setting
the password attribute directly – you must use the set_password() function to store a correctly hashed
password. Alternatively, you can use the create_user() helper method to create a new user with a
correctly hashed password.
logout()
If your site uses Django’s authentication system, the logout() method can be used to simulate the effect
of a user logging out of your site.
After you call this method, the test client will have all the cookies and session data cleared to defaults.
Subsequent requests will appear to come from an AnonymousUser.
Testing responses The get() and post() methods both return a Response object. This Response object is
not the same as the HttpResponse object returned Django views; the test response object has some additional data
useful for test code to verify.
Specifically, a Response object has the following attributes:
class Response
client
The test client that was used to make the request that resulted in the response.
content
The body of the response, as a string. This is the final page content as rendered by the view, or any error
message.
context
The template Context instance that was used to render the template that produced the response content.
If the rendered page used multiple templates, then context will be a list of Context objects, in the
order in which they were rendered.
Regardless of the number of templates used during rendering, you can retrieve context values using the []
operator. For example, the context variable name could be retrieved using:
>>> response = client.get(’/foo/’)
>>> response.context[’name’]
’Arthur’
request
The request data that stimulated the response.
status_code
The HTTP status of the response, as an integer. See RFC 2616 for a full list of HTTP status codes.
3.8. Testing in Django 273](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-277-2048.jpg)
![Django Documentation, Release 1.5.1
templates
A list of Template instances used to render the final content, in the order they were rendered. For each
template in the list, use template.name to get the template’s file name, if the template was loaded from
a file. (The name is a string such as ’admin/index.html’.)
You can also use dictionary syntax on the response object to query the value of any settings in the HTTP headers. For
example, you could determine the content type of a response using response[’Content-Type’].
Exceptions If you point the test client at a view that raises an exception, that exception will be visible in the test
case. You can then use a standard try ... except block or assertRaises() to test for exceptions.
The only exceptions that are not visible to the test client are Http404, PermissionDenied and SystemExit.
Django catches these exceptions internally and converts them into the appropriate HTTP response codes. In these
cases, you can check response.status_code in your test.
Persistent state The test client is stateful. If a response returns a cookie, then that cookie will be stored in the test
client and sent with all subsequent get() and post() requests.
Expiration policies for these cookies are not followed. If you want a cookie to expire, either delete it manually or
create a new Client instance (which will effectively delete all cookies).
A test client has two attributes that store persistent state information. You can access these properties as part of a test
condition.
Client.cookies
A Python SimpleCookie object, containing the current values of all the client cookies. See the documentation
of the Cookie module for more.
Client.session
A dictionary-like object containing session information. See the session documentation for full details.
To modify the session and then save it, it must be stored in a variable first (because a new SessionStore is
created every time this property is accessed):
def test_something(self):
session = self.client.session
session[’somekey’] = ’test’
session.save()
Example The following is a simple unit test using the test client:
from django.utils import unittest
from django.test.client import Client
class SimpleTest(unittest.TestCase):
def setUp(self):
# Every test needs a client.
self.client = Client()
def test_details(self):
# Issue a GET request.
response = self.client.get(’/customer/details/’)
# Check that the response is 200 OK.
self.assertEqual(response.status_code, 200)
# Check that the rendered context contains 5 customers.
self.assertEqual(len(response.context[’customers’]), 5)
274 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-278-2048.jpg)

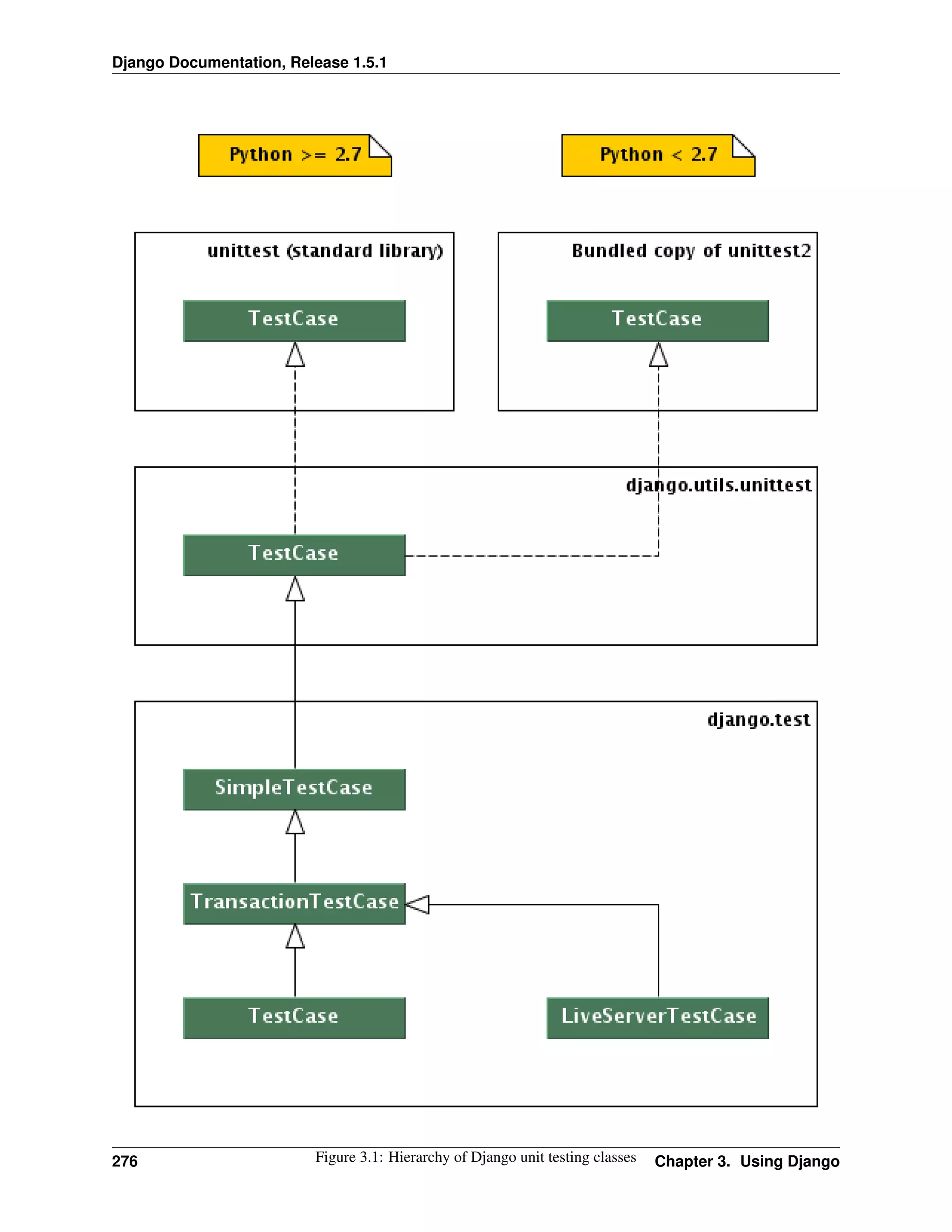

![Django Documentation, Release 1.5.1
LiveServerTestCase New in version 1.4.
class LiveServerTestCase
LiveServerTestCase does basically the same as TransactionTestCase with one extra feature: it launches
a live Django server in the background on setup, and shuts it down on teardown. This allows the use of automated test
clients other than the Django dummy client such as, for example, the Selenium client, to execute a series of functional
tests inside a browser and simulate a real user’s actions.
By default the live server’s address is ’localhost:8081’ and the full URL can be accessed during the tests with
self.live_server_url. If you’d like to change the default address (in the case, for example, where the 8081
port is already taken) then you may pass a different one to the test command via the --liveserver option, for
example:
./manage.py test --liveserver=localhost:8082
Another way of changing the default server address is by setting the DJANGO_LIVE_TEST_SERVER_ADDRESS
environment variable somewhere in your code (for example, in a custom test runner):
import os
os.environ[’DJANGO_LIVE_TEST_SERVER_ADDRESS’] = ’localhost:8082’
In the case where the tests are run by multiple processes in parallel (for example, in the context of several simulta-neous
continuous integration builds), the processes will compete for the same address, and therefore your tests might
randomly fail with an “Address already in use” error. To avoid this problem, you can pass a comma-separated list of
ports or ranges of ports (at least as many as the number of potential parallel processes). For example:
./manage.py test --liveserver=localhost:8082,8090-8100,9000-9200,7041
Then, during test execution, each new live test server will try every specified port until it finds one that is free and
takes it.
To demonstrate how to use LiveServerTestCase, let’s write a simple Selenium test. First of all, you need to
install the selenium package into your Python path:
pip install selenium
Then, add a LiveServerTestCase-based test to your app’s tests module (for example: myapp/tests.py).
The code for this test may look as follows:
from django.test import LiveServerTestCase
from selenium.webdriver.firefox.webdriver import WebDriver
class MySeleniumTests(LiveServerTestCase):
fixtures = [’user-data.json’]
@classmethod
def setUpClass(cls):
cls.selenium = WebDriver()
super(MySeleniumTests, cls).setUpClass()
@classmethod
def tearDownClass(cls):
cls.selenium.quit()
super(MySeleniumTests, cls).tearDownClass()
def test_login(self):
self.selenium.get(’%s%s’ % (self.live_server_url, ’/login/’))
username_input = self.selenium.find_element_by_name("username")
username_input.send_keys(’myuser’)
278 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-282-2048.jpg)
![Django Documentation, Release 1.5.1
password_input = self.selenium.find_element_by_name("password")
password_input.send_keys(’secret’)
self.selenium.find_element_by_xpath(’//input[@value="Log in"]’).click()
Finally, you may run the test as follows:
./manage.py test myapp.MySeleniumTests.test_login
This example will automatically open Firefox then go to the login page, enter the credentials and press the “Log in”
button. Selenium offers other drivers in case you do not have Firefox installed or wish to use another browser. The
example above is just a tiny fraction of what the Selenium client can do; check out the full reference for more details.
Note: LiveServerTestCase makes use of the staticfiles contrib app so you’ll need to have your project config-ured
accordingly (in particular by setting STATIC_URL).
Note: When using an in-memory SQLite database to run the tests, the same database connection will be shared
by two threads in parallel: the thread in which the live server is run and the thread in which the test case is run.
It’s important to prevent simultaneous database queries via this shared connection by the two threads, as that may
sometimes randomly cause the tests to fail. So you need to ensure that the two threads don’t access the database at the
same time. In particular, this means that in some cases (for example, just after clicking a link or submitting a form),
you might need to check that a response is received by Selenium and that the next page is loaded before proceeding
with further test execution. Do this, for example, by making Selenium wait until the <body> HTML tag is found in
the response (requires Selenium > 2.13):
def test_login(self):
from selenium.webdriver.support.wait import WebDriverWait
timeout = 2
...
self.selenium.find_element_by_xpath(’//input[@value="Log in"]’).click()
# Wait until the response is received
WebDriverWait(self.selenium, timeout).until(
lambda driver: driver.find_element_by_tag_name(’body’))
The tricky thing here is that there’s really no such thing as a “page load,” especially in modern Web apps that generate
HTML dynamically after the server generates the initial document. So, simply checking for the presence of <body>
in the response might not necessarily be appropriate for all use cases. Please refer to the Selenium FAQ and Selenium
documentation for more information.
Test cases features
Default test client
TestCase.client
Every test case in a django.test.TestCase instance has access to an instance of a Django test client. This client
can be accessed as self.client. This client is recreated for each test, so you don’t have to worry about state (such
as cookies) carrying over from one test to another.
This means, instead of instantiating a Client in each test:
from django.utils import unittest
from django.test.client import Client
class SimpleTest(unittest.TestCase):
def test_details(self):
client = Client()
3.8. Testing in Django 279](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-283-2048.jpg)

![Django Documentation, Release 1.5.1
Initial SQL data and testing
Django provides a second way to insert initial data into models – the custom SQL hook. However, this technique
cannot be used to provide initial data for testing purposes. Django’s test framework flushes the contents of the test
database after each test; as a result, any data added using the custom SQL hook will be lost.
Once you’ve created a fixture and placed it in a fixtures directory in one of your INSTALLED_APPS, you can
use it in your unit tests by specifying a fixtures class attribute on your django.test.TestCase subclass:
from django.test import TestCase
from myapp.models import Animal
class AnimalTestCase(TestCase):
fixtures = [’mammals.json’, ’birds’]
def setUp(self):
# Test definitions as before.
call_setup_methods()
def testFluffyAnimals(self):
# A test that uses the fixtures.
call_some_test_code()
Here’s specifically what will happen:
• At the start of each test case, before setUp() is run, Django will flush the database, returning the database to
the state it was in directly after syncdb was called.
• Then, all the named fixtures are installed. In this example, Django will install any JSON fixture named
mammals, followed by any fixture named birds. See the loaddata documentation for more details on
defining and installing fixtures.
This flush/load procedure is repeated for each test in the test case, so you can be certain that the outcome of a test will
not be affected by another test, or by the order of test execution.
URLconf configuration
TestCase.urls
If your application provides views, you may want to include tests that use the test client to exercise those views.
However, an end user is free to deploy the views in your application at any URL of their choosing. This means that
your tests can’t rely upon the fact that your views will be available at a particular URL.
In order to provide a reliable URL space for your test, django.test.TestCase provides the ability to customize
the URLconf configuration for the duration of the execution of a test suite. If your TestCase instance defines an
urls attribute, the TestCase will use the value of that attribute as the ROOT_URLCONF for the duration of that
test.
For example:
from django.test import TestCase
class TestMyViews(TestCase):
urls = ’myapp.test_urls’
def testIndexPageView(self):
# Here you’d test your view using ‘‘Client‘‘.
call_some_test_code()
This test case will use the contents of myapp.test_urls as the URLconf for the duration of the test case.
3.8. Testing in Django 281](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-285-2048.jpg)


![Django Documentation, Release 1.5.1
SimpleTestCase.assertFieldOutput(self, fieldclass, valid, invalid, field_args=None,
field_kwargs=None, empty_value=u’‘)
New in version 1.4. Asserts that a form field behaves correctly with various inputs.
Parameters
• fieldclass – the class of the field to be tested.
• valid – a dictionary mapping valid inputs to their expected cleaned values.
• invalid – a dictionary mapping invalid inputs to one or more raised error messages.
• field_args – the args passed to instantiate the field.
• field_kwargs – the kwargs passed to instantiate the field.
• empty_value – the expected clean output for inputs in EMPTY_VALUES.
For example, the following code tests that an EmailField accepts “a@a.com” as a valid email address, but
rejects “aaa” with a reasonable error message:
self.assertFieldOutput(EmailField, {’a@a.com’: ’a@a.com’}, {’aaa’: [u’Enter a valid email address.’]})
TestCase.assertContains(response, text, count=None, status_code=200, msg_prefix=’‘, html=False)
Asserts that a Response instance produced the given status_code and that text appears in the content
of the response. If count is provided, text must occur exactly count times in the response. New in version
1.4. Set html to True to handle text as HTML. The comparison with the response content will be based
on HTML semantics instead of character-by-character equality. Whitespace is ignored in most cases, attribute
ordering is not significant. See assertHTMLEqual() for more details.
TestCase.assertNotContains(response, text, status_code=200, msg_prefix=’‘, html=False)
Asserts that a Response instance produced the given status_code and that text does not appears in the
content of the response. New in version 1.4. Set html to True to handle text as HTML. The comparison with
the response content will be based on HTML semantics instead of character-by-character equality. Whitespace
is ignored in most cases, attribute ordering is not significant. See assertHTMLEqual() for more details.
TestCase.assertFormError(response, form, field, errors, msg_prefix=’‘)
Asserts that a field on a form raises the provided list of errors when rendered on the form.
form is the name the Form instance was given in the template context.
field is the name of the field on the form to check. If field has a value of None, non-field errors (errors
you can access via form.non_field_errors()) will be checked.
errors is an error string, or a list of error strings, that are expected as a result of form validation.
TestCase.assertTemplateUsed(response, template_name, msg_prefix=’‘)
Asserts that the template with the given name was used in rendering the response.
The name is a string such as ’admin/index.html’. New in version 1.4. You can use this as a context
manager, like this:
with self.assertTemplateUsed(’index.html’):
render_to_string(’index.html’)
with self.assertTemplateUsed(template_name=’index.html’):
render_to_string(’index.html’)
TestCase.assertTemplateNotUsed(response, template_name, msg_prefix=’‘)
Asserts that the template with the given name was not used in rendering the response. New in version 1.4. You
can use this as a context manager in the same way as assertTemplateUsed().
284 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-288-2048.jpg)

![Django Documentation, Release 1.5.1
SimpleTestCase.assertHTMLNotEqual(html1, html2, msg=None)
New in version 1.4. Asserts that the strings html1 and html2 are not equal. The comparison is based on
HTML semantics. See assertHTMLEqual() for details.
html1 and html2 must be valid HTML. An AssertionError will be raised if one of them cannot be
parsed.
SimpleTestCase.assertXMLEqual(xml1, xml2, msg=None)
New in version 1.5. Asserts that the strings xml1 and xml2 are equal. The comparison is based on XML
semantics. Similarily to assertHTMLEqual(), the comparison is made on parsed content, hence only se-mantic
differences are considered, not syntax differences. When unvalid XML is passed in any parameter, an
AssertionError is always raised, even if both string are identical.
SimpleTestCase.assertXMLNotEqual(xml1, xml2, msg=None)
New in version 1.5. Asserts that the strings xml1 and xml2 are not equal. The comparison is based on XML
semantics. See assertXMLEqual() for details.
Email services
If any of your Django views send email using Django’s email functionality, you probably don’t want to send email
each time you run a test using that view. For this reason, Django’s test runner automatically redirects all Django-sent
email to a dummy outbox. This lets you test every aspect of sending email – from the number of messages sent to the
contents of each message – without actually sending the messages.
The test runner accomplishes this by transparently replacing the normal email backend with a testing backend. (Don’t
worry – this has no effect on any other email senders outside of Django, such as your machine’s mail server, if you’re
running one.)
django.core.mail.outbox
During test running, each outgoing email is saved in django.core.mail.outbox. This is a simple list of all
EmailMessage instances that have been sent. The outbox attribute is a special attribute that is created only when
the locmem email backend is used. It doesn’t normally exist as part of the django.core.mail module and you
can’t import it directly. The code below shows how to access this attribute correctly.
Here’s an example test that examines django.core.mail.outbox for length and contents:
from django.core import mail
from django.test import TestCase
class EmailTest(TestCase):
def test_send_email(self):
# Send message.
mail.send_mail(’Subject here’, ’Here is the message.’,
’from@example.com’, [’to@example.com’],
fail_silently=False)
# Test that one message has been sent.
self.assertEqual(len(mail.outbox), 1)
# Verify that the subject of the first message is correct.
self.assertEqual(mail.outbox[0].subject, ’Subject here’)
As noted previously, the test outbox is emptied at the start of every test in a Django TestCase. To empty the outbox
manually, assign the empty list to mail.outbox:
from django.core import mail
286 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-290-2048.jpg)
![Django Documentation, Release 1.5.1
# Empty the test outbox
mail.outbox = []
Skipping tests
The unittest library provides the @skipIf and @skipUnless decorators to allow you to skip tests if you know
ahead of time that those tests are going to fail under certain conditions.
For example, if your test requires a particular optional library in order to succeed, you could decorate the test case
with @skipIf. Then, the test runner will report that the test wasn’t executed and why, instead of failing the test or
omitting the test altogether.
To supplement these test skipping behaviors, Django provides two additional skip decorators. Instead of testing a
generic boolean, these decorators check the capabilities of the database, and skip the test if the database doesn’t
support a specific named feature.
The decorators use a string identifier to describe database features. This string corresponds to attributes of the
database connection features class. See django.db.backends.BaseDatabaseFeatures class for a full list
of database features that can be used as a basis for skipping tests.
skipIfDBFeature(feature_name_string)
Skip the decorated test if the named database feature is supported.
For example, the following test will not be executed if the database supports transactions (e.g., it would not run under
PostgreSQL, but it would under MySQL with MyISAM tables):
class MyTests(TestCase):
@skipIfDBFeature(’supports_transactions’)
def test_transaction_behavior(self):
# ... conditional test code
skipUnlessDBFeature(feature_name_string)
Skip the decorated test if the named database feature is not supported.
For example, the following test will only be executed if the database supports transactions (e.g., it would run under
PostgreSQL, but not under MySQL with MyISAM tables):
class MyTests(TestCase):
@skipUnlessDBFeature(’supports_transactions’)
def test_transaction_behavior(self):
# ... conditional test code
3.8.2 Django and doctests
Doctests use Python’s standard doctest module, which searches your docstrings for statements that resemble a
session of the Python interactive interpreter. A full explanation of how doctest works is out of the scope of this
document; read Python’s official documentation for the details.
What’s a docstring?
A good explanation of docstrings (and some guidelines for using them effectively) can be found in PEP 257:
A docstring is a string literal that occurs as the first statement in a module, function, class, or method
definition. Such a docstring becomes the __doc__ special attribute of that object.
For example, this function has a docstring that describes what it does:
3.8. Testing in Django 287](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-291-2048.jpg)


![Django Documentation, Release 1.5.1
’TEST_MIRROR’: ’default’
# ... plus some other settings
}
}
In this setup, we have two database servers: dbmaster, described by the database alias default, and dbslave
described by the alias slave. As you might expect, dbslave has been configured by the database administrator as
a read slave of dbmaster, so in normal activity, any write to default will appear on slave.
If Django created two independent test databases, this would break any tests that expected replication to occur. How-ever,
the slave database has been configured as a test mirror (using the TEST_MIRROR setting), indicating that
under testing, slave should be treated as a mirror of default.
When the test environment is configured, a test version of slave will not be created. Instead the connection to slave
will be redirected to point at default. As a result, writes to default will appear on slave – but because they are
actually the same database, not because there is data replication between the two databases.
Controlling creation order for test databases
By default, Django will always create the default database first. However, no guarantees are made on the creation
order of any other databases in your test setup.
If your database configuration requires a specific creation order, you can specify the dependencies that exist using the
TEST_DEPENDENCIES setting. Consider the following (simplified) example database configuration:
DATABASES = {
’default’: {
# ... db settings
’TEST_DEPENDENCIES’: [’diamonds’]
},
’diamonds’: {
# ... db settings
},
’clubs’: {
# ... db settings
’TEST_DEPENDENCIES’: [’diamonds’]
},
’spades’: {
# ... db settings
’TEST_DEPENDENCIES’: [’diamonds’,’hearts’]
},
’hearts’: {
# ... db settings
’TEST_DEPENDENCIES’: [’diamonds’,’clubs’]
}
}
Under this configuration, the diamonds database will be created first, as it is the only database alias without de-pendencies.
The default and clubs alias will be created next (although the order of creation of this pair is not
guaranteed); then hearts; and finally spades.
If there are any circular dependencies in the TEST_DEPENDENCIES definition, an ImproperlyConfigured
exception will be raised.
290 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-294-2048.jpg)


![Django Documentation, Release 1.5.1
Returns the result produced by the running the test suite.
DjangoTestSuiteRunner.teardown_databases(old_config, **kwargs)
Destroys the test databases, restoring pre-test conditions.
old_config is a data structure defining the changes in the database configuration that need to be reversed. It
is the return value of the setup_databases() method.
DjangoTestSuiteRunner.teardown_test_environment(**kwargs)
Restores the pre-test environment.
DjangoTestSuiteRunner.suite_result(suite, result, **kwargs)
Computes and returns a return code based on a test suite, and the result from that test suite.
Testing utilities
To assist in the creation of your own test runner, Django provides a number of utility methods in the
django.test.utils module.
setup_test_environment()
Performs any global pre-test setup, such as the installing the instrumentation of the template rendering system
and setting up the dummy email outbox.
teardown_test_environment()
Performs any global post-test teardown, such as removing the black magic hooks into the template system and
restoring normal email services.
The creation module of the database backend (connection.creation) also provides some utilities that can be
useful during testing.
create_test_db([verbosity=1, autoclobber=False ])
Creates a new test database and runs syncdb against it.
verbosity has the same behavior as in run_tests().
autoclobber describes the behavior that will occur if a database with the same name as the test database is
discovered:
•If autoclobber is False, the user will be asked to approve destroying the existing database.
sys.exit is called if the user does not approve.
•If autoclobber is True, the database will be destroyed without consulting the user.
Returns the name of the test database that it created.
create_test_db() has the side effect of modifying the value of NAME in DATABASES to match the name
of the test database.
destroy_test_db(old_database_name[, verbosity=1 ])
Destroys the database whose name is the value of NAME in DATABASES, and sets NAME to the value of
old_database_name.
The verbosity argument has the same behavior as for DjangoTestSuiteRunner.
Integration with coverage.py
Code coverage describes how much source code has been tested. It shows which parts of your code are being exercised
by tests and which are not. It’s an important part of testing applications, so it’s strongly recommended to check the
coverage of your tests.
3.8. Testing in Django 293](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-297-2048.jpg)
![Django Documentation, Release 1.5.1
Django can be easily integrated with coverage.py, a tool for measuring code coverage of Python programs. First,
install coverage.py. Next, run the following from your project folder containing manage.py:
coverage run --source=’.’ manage.py test myapp
This runs your tests and collects coverage data of the executed files in your project. You can see a report of this data
by typing following command:
coverage report
Note that some Django code was executed while running tests, but it is not listed here because of the source flag
passed to the previous command.
For more options like annotated HTML listings detailing missed lines, see the coverage.py docs.
Automated testing is an extremely useful bug-killing tool for the modern Web developer. You can use a collection of
tests – a test suite – to solve, or avoid, a number of problems:
• When you’re writing new code, you can use tests to validate your code works as expected.
• When you’re refactoring or modifying old code, you can use tests to ensure your changes haven’t affected your
application’s behavior unexpectedly.
Testing a Web application is a complex task, because a Web application is made of several layers of logic – from
HTTP-level request handling, to form validation and processing, to template rendering. With Django’s test-execution
framework and assorted utilities, you can simulate requests, insert test data, inspect your application’s output and
generally verify your code is doing what it should be doing.
The best part is, it’s really easy.
3.8.4 Unit tests v. doctests
There are two primary ways to write tests with Django, corresponding to the two test frameworks that ship in the
Python standard library. The two frameworks are:
• Unit tests – tests that are expressed as methods on a Python class that subclasses unittest.TestCase or
Django’s customized TestCase. For example:
import unittest
class MyFuncTestCase(unittest.TestCase):
def testBasic(self):
a = [’larry’, ’curly’, ’moe’]
self.assertEqual(my_func(a, 0), ’larry’)
self.assertEqual(my_func(a, 1), ’curly’)
• Doctests – tests that are embedded in your functions’ docstrings and are written in a way that emulates a session
of the Python interactive interpreter. For example:
def my_func(a_list, idx):
"""
>>> a = [’larry’, ’curly’, ’moe’]
>>> my_func(a, 0)
’larry’
>>> my_func(a, 1)
’curly’
"""
return a_list[idx]
294 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-298-2048.jpg)


![Django Documentation, Release 1.5.1
If you have the Django admin installed, you can also change user’s passwords on the authentication system’s admin
pages.
Django also provides views and forms that may be used to allow users to change their own passwords.
Authenticating Users
authenticate(**credentials)
To authenticate a given username and password, use authenticate(). It takes credentials in the form of
keyword arguments, for the default configuration this is username and password, and it returns a User
object if the password is valid for the given username. If the password is invalid, authenticate() returns
None. Example:
from django.contrib.auth import authenticate
user = authenticate(username=’john’, password=’secret’)
if user is not None:
# the password verified for the user
if user.is_active:
print("User is valid, active and authenticated")
else:
print("The password is valid, but the account has been disabled!")
else:
# the authentication system was unable to verify the username and password
print("The username and password were incorrect.")
Permissions and Authorization
Django comes with a simple permissions system. It provides a way to assign permissions to specific users and groups
of users.
It’s used by the Django admin site, but you’re welcome to use it in your own code.
The Django admin site uses permissions as follows:
• Access to view the “add” form and add an object is limited to users with the “add” permission for that type of
object.
• Access to view the change list, view the “change” form and change an object is limited to users with the “change”
permission for that type of object.
• Access to delete an object is limited to users with the “delete” permission for that type of object.
Permissions can be set not only per type of object, but also per specific object instance. By using the
has_add_permission(), has_change_permission() and has_delete_permission() methods
provided by the ModelAdmin class, it is possible to customize permissions for different object instances of the
same type.
User objects have two many-to-many fields: groups and user_permissions. User objects can access their
related objects in the same way as any other Django model:
myuser.groups = [group_list]
myuser.groups.add(group, group, ...)
myuser.groups.remove(group, group, ...)
myuser.groups.clear()
myuser.user_permissions = [permission_list]
myuser.user_permissions.add(permission, permission, ...)
myuser.user_permissions.remove(permission, permission, ...)
myuser.user_permissions.clear()
3.9. User authentication in Django 297](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-301-2048.jpg)

![Django Documentation, Release 1.5.1
if request.user.is_authenticated():
# Do something for authenticated users.
else:
# Do something for anonymous users.
How to log a user in
If you have an authenticated user you want to attach to the current session - this is done with a login() function.
login()
To log a user in, from a view, use login(). It takes an HttpRequest object and a User object. login()
saves the user’s ID in the session, using Django’s session framework.
Note that any data set during the anonymous session is retained in the session after a user logs in.
This example shows how you might use both authenticate() and login():
from django.contrib.auth import authenticate, login
def my_view(request):
username = request.POST[’username’]
password = request.POST[’password’]
user = authenticate(username=username, password=password)
if user is not None:
if user.is_active:
login(request, user)
# Redirect to a success page.
else:
# Return a ’disabled account’ error message
else:
# Return an ’invalid login’ error message.
Calling authenticate() first
When you’re manually logging a user in, you must call authenticate() before you call login().
authenticate() sets an attribute on the User noting which authentication backend successfully authenticated
that user (see the backends documentation for details), and this information is needed later during the login process.
An error will be raise if you try to login a user object retrieved from the database directly.
How to log a user out
logout()
To log out a user who has been logged in via django.contrib.auth.login(), use
django.contrib.auth.logout() within your view. It takes an HttpRequest object and has
no return value. Example:
from django.contrib.auth import logout
def logout_view(request):
logout(request)
# Redirect to a success page.
Note that logout() doesn’t throw any errors if the user wasn’t logged in.
3.9. User authentication in Django 299](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-303-2048.jpg)
![Django Documentation, Release 1.5.1
When you call logout(), the session data for the current request is completely cleaned out. All existing data
is removed. This is to prevent another person from using the same Web browser to log in and have access to
the previous user’s session data. If you want to put anything into the session that will be available to the user
immediately after logging out, do that after calling django.contrib.auth.logout().
Limiting access to logged-in users
The raw way The simple, raw way to limit access to pages is to check
request.user.is_authenticated() and either redirect to a login page:
from django.shortcuts import redirect
def my_view(request):
if not request.user.is_authenticated():
return redirect(’/login/?next=%s’ % request.path)
# ...
...or display an error message:
from django.shortcuts import render
def my_view(request):
if not request.user.is_authenticated():
return render(request, ’myapp/login_error.html’)
# ...
The login_required decorator
login_required([redirect_field_name=REDIRECT_FIELD_NAME, login_url=None ])
As a shortcut, you can use the convenient login_required() decorator:
from django.contrib.auth.decorators import login_required
@login_required
def my_view(request):
...
login_required() does the following:
•If the user isn’t logged in, redirect to settings.LOGIN_URL, passing the current absolute path in the
query string. Example: /accounts/login/?next=/polls/3/.
•If the user is logged in, execute the view normally. The view code is free to assume the user is logged in.
By default, the path that the user should be redirected to upon successful authentication is stored in a
query string parameter called "next". If you would prefer to use a different name for this parameter,
login_required() takes an optional redirect_field_name parameter:
from django.contrib.auth.decorators import login_required
@login_required(redirect_field_name=’my_redirect_field’)
def my_view(request):
...
Note that if you provide a value to redirect_field_name, you will most likely need to customize your
login template as well, since the template context variable which stores the redirect path will use the value of
redirect_field_name as its key rather than "next" (the default).
login_required() also takes an optional login_url parameter. Example:
300 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-304-2048.jpg)
![Django Documentation, Release 1.5.1
from django.contrib.auth.decorators import login_required
@login_required(login_url=’/accounts/login/’)
def my_view(request):
...
Note that if you don’t specify the login_url parameter, you’ll need to ensure that the
settings.LOGIN_URL and your login view are properly associated. For example, using the defaults, add
the following line to your URLconf:
(r’^accounts/login/$’, ’django.contrib.auth.views.login’),
Changed in version 1.5. The settings.LOGIN_URL also accepts view function names and named URL
patterns. This allows you to freely remap your login view within your URLconf without having to update the
setting.
Note: The login_required decorator does NOT check the is_active flag on a user.
Limiting access to logged-in users that pass a test To limit access based on certain permissions or some other test,
you’d do essentially the same thing as described in the previous section.
The simple way is to run your test on request.user in the view directly. For example, this view checks to make
sure the user has an email in the desired domain:
def my_view(request):
if not ’@example.com’ in request.user.email:
return HttpResponse("You can’t vote in this poll.")
# ...
user_passes_test(func[, login_url=None ])
As a shortcut, you can use the convenient user_passes_test decorator:
from django.contrib.auth.decorators import user_passes_test
def email_check(user):
return ’@example.com’ in user.email
@user_passes_test(email_check)
def my_view(request):
...
user_passes_test() takes a required argument: a callable that takes a User object and returns True if
the user is allowed to view the page. Note that user_passes_test() does not automatically check that the
User is not anonymous.
user_passes_test() takes an optional login_url argument, which lets you specify the URL for your
login page (settings.LOGIN_URL by default).
For example:
@user_passes_test(email_check, login_url=’/login/’)
def my_view(request):
...
The permission_required decorator
3.9. User authentication in Django 301](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-305-2048.jpg)
![Django Documentation, Release 1.5.1
permission_required([login_url=None, raise_exception=False ])
It’s a relatively common task to check whether a user has a particular permission. For that reason, Django
provides a shortcut for that case: the permission_required() decorator.:
from django.contrib.auth.decorators import permission_required
@permission_required(’polls.can_vote’)
def my_view(request):
...
As for the has_perm() method, permission names take the form "<app label>.<permission
codename>" (i.e. polls.can_vote for a permission on a model in the polls application).
Note that permission_required() also takes an optional login_url parameter. Example:
from django.contrib.auth.decorators import permission_required
@permission_required(’polls.can_vote’, login_url=’/loginpage/’)
def my_view(request):
...
As in the login_required() decorator, login_url defaults to settings.LOGIN_URL. Changed in
version 1.4. Added raise_exception parameter. If given, the decorator will raise PermissionDenied,
prompting the 403 (HTTP Forbidden) view instead of redirecting to the login page.
Applying permissions to generic views To apply a permission to a class-based generic view, decorate the
View.dispatch method on the class. See Decorating the class for details.
Authentication Views
Django provides several views that you can use for handling login, logout, and password management. These make
use of the stock auth forms but you can pass in your own forms as well.
Django provides no default template for the authentication views - however the template context is documented for
each view below. New in version 1.4. The built-in views all return a TemplateResponse instance, which allows
you to easily customize the response data before rendering. For more details, see the TemplateResponse documenta-tion.
Most built-in authentication views provide a URL name for easier reference. See the URL documentation for details
on using named URL patterns.
login(request[, template_name, redirect_field_name, authentication_form ])
URL name: login
See the URL documentation for details on using named URL patterns.
Here’s what django.contrib.auth.views.login does:
•If called via GET, it displays a login form that POSTs to the same URL. More on this in a bit.
•If called via POST with user submitted credentials, it tries to log the user in. If login is suc-cessful,
the view redirects to the URL specified in next. If next isn’t provided, it redirects to
settings.LOGIN_REDIRECT_URL (which defaults to /accounts/profile/). If login isn’t suc-cessful,
it redisplays the login form.
It’s your responsibility to provide the html for the login template , called registration/login.html by
default. This template gets passed four template context variables:
•form: A Form object representing the AuthenticationForm.
302 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-306-2048.jpg)
![Django Documentation, Release 1.5.1
•next: The URL to redirect to after successful login. This may contain a query string, too.
•site: The current Site, according to the SITE_ID setting. If you don’t have the site framework
installed, this will be set to an instance of RequestSite, which derives the site name and domain from
the current HttpRequest.
•site_name: An alias for site.name. If you don’t have the site framework installed, this will be set to
the value of request.META[’SERVER_NAME’]. For more on sites, see The “sites” framework.
If you’d prefer not to call the template registration/login.html, you can pass the template_name
parameter via the extra arguments to the view in your URLconf. For example, this URLconf line would use
myapp/login.html instead:
(r’^accounts/login/$’, ’django.contrib.auth.views.login’, {’template_name’: ’myapp/login.html’}),
You can also specify the name of the GET field which contains the URL to redirect to after login by passing
redirect_field_name to the view. By default, the field is called next.
Here’s a sample registration/login.html template you can use as a starting point. It assumes you
have a base.html template that defines a content block:
{% extends "base.html" %}
{% block content %}
{% if form.errors %}
<p>Your username and password didn’t match. Please try again.</p>
{% endif %}
<form method="post" action="{% url ’django.contrib.auth.views.login’ %}">
{% csrf_token %}
<table>
<tr>
<td>{{ form.username.label_tag }}</td>
<td>{{ form.username }}</td>
</tr>
<tr>
<td>{{ form.password.label_tag }}</td>
<td>{{ form.password }}</td>
</tr>
</table>
<input type="submit" value="login" />
<input type="hidden" name="next" value="{{ next }}" />
</form>
{% endblock %}
If you have customized authentication (see Customizing Authentication) you can pass a custom authentication
form to the login view via the authentication_form parameter. This form must accept a request
keyword argument in its __init__ method, and provide a get_user method which returns the authenticated
user object (this method is only ever called after successful form validation).
logout(request[, next_page, template_name, redirect_field_name ])
Logs a user out.
URL name: logout
Optional arguments:
•next_page: The URL to redirect to after logout.
3.9. User authentication in Django 303](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-307-2048.jpg)
![Django Documentation, Release 1.5.1
•template_name: The full name of a template to display after logging the user out. Defaults to
registration/logged_out.html if no argument is supplied.
•redirect_field_name: The name of a GET field containing the URL to redirect to after log out.
Overrides next_page if the given GET parameter is passed.
Template context:
•title: The string “Logged out”, localized.
•site: The current Site, according to the SITE_ID setting. If you don’t have the site framework
installed, this will be set to an instance of RequestSite, which derives the site name and domain from
the current HttpRequest.
•site_name: An alias for site.name. If you don’t have the site framework installed, this will be set to
the value of request.META[’SERVER_NAME’]. For more on sites, see The “sites” framework.
logout_then_login(request[, login_url ])
Logs a user out, then redirects to the login page.
URL name: No default URL provided
Optional arguments:
•login_url: The URL of the login page to redirect to. Defaults to settings.LOGIN_URL if not
supplied.
password_change(request[, template_name, post_change_redirect, password_change_form ])
Allows a user to change their password.
URL name: password_change
Optional arguments:
•template_name: The full name of a template to use for displaying the password change form. Defaults
to registration/password_change_form.html if not supplied.
•post_change_redirect: The URL to redirect to after a successful password change.
•password_change_form: A custom “change password” form which must accept a user key-word
argument. The form is responsible for actually changing the user’s password. Defaults to
PasswordChangeForm.
Template context:
•form: The password change form (see password_change_form above).
password_change_done(request[, template_name ])
The page shown after a user has changed their password.
URL name: password_change_done
Optional arguments:
•template_name: The full name of a template to use. Defaults to
registration/password_change_done.html if not supplied.
password_reset(request[, is_admin_site, template_name, email_template_name, password_reset_form,
token_generator, post_reset_redirect, from_email ])
Allows a user to reset their password by generating a one-time use link that can be used to reset the password, and
sending that link to the user’s registered email address. Changed in version 1.4: Users flagged with an unusable
password (see set_unusable_password() will not be able to request a password reset to prevent misuse
when using an external authentication source like LDAP. URL name: password_reset
Optional arguments:
304 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-308-2048.jpg)
![Django Documentation, Release 1.5.1
•template_name: The full name of a template to use for displaying the password reset form. Defaults
to registration/password_reset_form.html if not supplied.
•email_template_name: The full name of a template to use for generating the email with the reset
password link. Defaults to registration/password_reset_email.html if not supplied.
•subject_template_name: The full name of a template to use for the subject of the email with the
reset password link. Defaults to registration/password_reset_subject.txt if not supplied.
New in version 1.4.
•password_reset_form: Form that will be used to get the email of the user to reset the password for.
Defaults to PasswordResetForm.
•token_generator: Instance of the class to check the one time link.
This will default to default_token_generator, it’s an instance of
django.contrib.auth.tokens.PasswordResetTokenGenerator.
•post_reset_redirect: The URL to redirect to after a successful password reset request.
•from_email: A valid email address. By default Django uses the DEFAULT_FROM_EMAIL.
Template context:
•form: The form (see password_reset_form above) for resetting the user’s password.
Email template context:
•email: An alias for user.email
•user: The current User, according to the email form field. Only active users are able to reset their
passwords (User.is_active is True).
•site_name: An alias for site.name. If you don’t have the site framework installed, this will be set to
the value of request.META[’SERVER_NAME’]. For more on sites, see The “sites” framework.
•domain: An alias for site.domain. If you don’t have the site framework installed, this will be set to
the value of request.get_host().
•protocol: http or https
•uid: The user’s id encoded in base 36.
•token: Token to check that the reset link is valid.
Sample registration/password_reset_email.html (email body template):
Someone asked for password reset for email {{ email }}. Follow the link below:
{{ protocol}}://{{ domain }}{% url ’password_reset_confirm’ uidb36=uid token=token %}
The same template context is used for subject template. Subject must be single line plain text string.
password_reset_done(request[, template_name ])
The page shown after a user has been emailed a link to reset their password. This view is called by default if the
password_reset() view doesn’t have an explicit post_reset_redirect URL set.
URL name: password_reset_done
Optional arguments:
•template_name: The full name of a template to use. Defaults to
registration/password_reset_done.html if not supplied.
password_reset_confirm(request[, uidb36, token, template_name, token_generator,
set_password_form, post_reset_redirect ])
Presents a form for entering a new password.
3.9. User authentication in Django 305](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-309-2048.jpg)
![Django Documentation, Release 1.5.1
URL name: password_reset_confirm
Optional arguments:
•uidb36: The user’s id encoded in base 36. Defaults to None.
•token: Token to check that the password is valid. Defaults to None.
•template_name: The full name of a template to display the confirm password view. Default value is
registration/password_reset_confirm.html.
•token_generator: Instance of the class to check the password.
This will default to default_token_generator, it’s an instance of
django.contrib.auth.tokens.PasswordResetTokenGenerator.
•set_password_form: Form that will be used to set the password. Defaults to SetPasswordForm
•post_reset_redirect: URL to redirect after the password reset done. Defaults to None.
Template context:
•form: The form (see set_password_form above) for setting the new user’s password.
•validlink: Boolean, True if the link (combination of uidb36 and token) is valid or unused yet.
password_reset_complete(request[, template_name ])
Presents a view which informs the user that the password has been successfully changed.
URL name: password_reset_complete
Optional arguments:
•template_name: The full name of a template to display the view. Defaults to
registration/password_reset_complete.html.
Helper functions
redirect_to_login(next[, login_url, redirect_field_name ])
Redirects to the login page, and then back to another URL after a successful login.
Required arguments:
•next: The URL to redirect to after a successful login.
Optional arguments:
•login_url: The URL of the login page to redirect to. Defaults to settings.LOGIN_URL if not
supplied.
•redirect_field_name: The name of a GET field containing the URL to redirect to after log out.
Overrides next if the given GET parameter is passed.
Built-in forms
If you don’t want to use the built-in views, but want the convenience of not having to write forms for this functionality,
the authentication system provides several built-in forms located in django.contrib.auth.forms:
Note: The built-in authentication forms make certain assumptions about the user model that they are working with.
If you’re using a custom User model, it may be necessary to define your own forms for the authentication system. For
more information, refer to the documentation about using the built-in authentication forms with custom user models.
306 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-310-2048.jpg)


![Django Documentation, Release 1.5.1
3.9.2 Password management in Django
Password management is something that should generally not be reinvented unnecessarily, and Django endeavors to
provide a secure and flexible set of tools for managing user passwords. This document describes how Django stores
passwords, how the storage hashing can be configured, and some utilities to work with hashed passwords.
How Django stores passwords
New in version 1.4: Django 1.4 introduces a new flexible password storage system and uses PBKDF2 by default.
Previous versions of Django used SHA1, and other algorithms couldn’t be chosen. The password attribute of a
User object is a string in this format:
<algorithm>$<iterations>$<salt>$<hash>
Those are the components used for storing a User’s password, separated by the dollar-sign character and consist of: the
hashing algorithm, the number of algorithm iterations (work factor), the random salt, and the resulting password hash.
The algorithm is one of a number of one-way hashing or password storage algorithms Django can use; see below.
Iterations describe the number of times the algorithm is run over the hash. Salt is the random seed used and the hash
is the result of the one-way function.
By default, Django uses the PBKDF2 algorithm with a SHA256 hash, a password stretching mechanism recommended
by NIST. This should be sufficient for most users: it’s quite secure, requiring massive amounts of computing time to
break.
However, depending on your requirements, you may choose a different algorithm, or even use a custom algorithm to
match your specific security situation. Again, most users shouldn’t need to do this – if you’re not sure, you probably
don’t. If you do, please read on:
Django chooses the algorithm to use by consulting the PASSWORD_HASHERS setting. This is a list
of hashing algorithm classes that this Django installation supports. The first entry in this list (that is,
settings.PASSWORD_HASHERS[0]) will be used to store passwords, and all the other entries are valid hash-ers
that can be used to check existing passwords. This means that if you want to use a different algorithm, you’ll need
to modify PASSWORD_HASHERS to list your preferred algorithm first in the list.
The default for PASSWORD_HASHERS is:
PASSWORD_HASHERS = (
’django.contrib.auth.hashers.PBKDF2PasswordHasher’,
’django.contrib.auth.hashers.PBKDF2SHA1PasswordHasher’,
’django.contrib.auth.hashers.BCryptPasswordHasher’,
’django.contrib.auth.hashers.SHA1PasswordHasher’,
’django.contrib.auth.hashers.MD5PasswordHasher’,
’django.contrib.auth.hashers.CryptPasswordHasher’,
)
This means that Django will use PBKDF2 to store all passwords, but will support checking passwords stored with
PBKDF2SHA1, bcrypt, SHA1, etc. The next few sections describe a couple of common ways advanced users may
want to modify this setting.
Using bcrypt with Django
Bcrypt is a popular password storage algorithm that’s specifically designed for long-term password storage. It’s not
the default used by Django since it requires the use of third-party libraries, but since many people may want to use it
Django supports bcrypt with minimal effort.
To use Bcrypt as your default storage algorithm, do the following:
3.9. User authentication in Django 309](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-313-2048.jpg)
![Django Documentation, Release 1.5.1
1. Install the py-bcrypt library (probably by running sudo pip install py-bcrypt, or downloading the
library and installing it with python setup.py install).
2. Modify PASSWORD_HASHERS to list BCryptPasswordHasher first. That is, in your settings file, you’d
put:
PASSWORD_HASHERS = (
’django.contrib.auth.hashers.BCryptPasswordHasher’,
’django.contrib.auth.hashers.PBKDF2PasswordHasher’,
’django.contrib.auth.hashers.PBKDF2SHA1PasswordHasher’,
’django.contrib.auth.hashers.SHA1PasswordHasher’,
’django.contrib.auth.hashers.MD5PasswordHasher’,
’django.contrib.auth.hashers.CryptPasswordHasher’,
)
(You need to keep the other entries in this list, or else Django won’t be able to upgrade passwords; see below).
That’s it – now your Django install will use Bcrypt as the default storage algorithm.
Password truncation with BCryptPasswordHasher
The designers of bcrypt truncate all passwords at 72 characters which means that
bcrypt(password_with_100_chars) == bcrypt(password_with_100_chars[:72]).
BCryptPasswordHasher does not have any special handling and thus is also subject to this hidden pass-word
length limit. The practical ramification of this truncation is pretty marginal as the average user does not have a
password greater than 72 characters in length and even being truncated at 72 the compute powered required to brute
force bcrypt in any useful amount of time is still astronomical.
Other bcrypt implementations
There are several other implementations that allow bcrypt to be used with Django. Django’s
bcrypt support is NOT directly compatible with these. To upgrade, you will need to modify the
hashes in your database to be in the form bcrypt$(raw bcrypt output). For example:
bcrypt$$2a$12$NT0I31Sa7ihGEWpka9ASYrEFkhuTNeBQ2xfZskIiiJeyFXhRgS.Sy.
Increasing the work factor
The PBKDF2 and bcrypt algorithms use a number of iterations or rounds of hashing. This deliberately slows down
attackers, making attacks against hashed passwords harder. However, as computing power increases, the number of
iterations needs to be increased. We’ve chosen a reasonable default (and will increase it with each release of Django),
but you may wish to tune it up or down, depending on your security needs and available processing power. To do so,
you’ll subclass the appropriate algorithm and override the iterations parameters. For example, to increase the
number of iterations used by the default PBKDF2 algorithm:
1. Create a subclass of django.contrib.auth.hashers.PBKDF2PasswordHasher:
from django.contrib.auth.hashers import PBKDF2PasswordHasher
class MyPBKDF2PasswordHasher(PBKDF2PasswordHasher):
"""
A subclass of PBKDF2PasswordHasher that uses 100 times more iterations.
"""
iterations = PBKDF2PasswordHasher.iterations * 100
Save this somewhere in your project. For example, you might put this in a file like myproject/hashers.py.
310 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-314-2048.jpg)
![Django Documentation, Release 1.5.1
2. Add your new hasher as the first entry in PASSWORD_HASHERS:
PASSWORD_HASHERS = (
’myproject.hashers.MyPBKDF2PasswordHasher’,
’django.contrib.auth.hashers.PBKDF2PasswordHasher’,
’django.contrib.auth.hashers.PBKDF2SHA1PasswordHasher’,
’django.contrib.auth.hashers.BCryptPasswordHasher’,
’django.contrib.auth.hashers.SHA1PasswordHasher’,
’django.contrib.auth.hashers.MD5PasswordHasher’,
’django.contrib.auth.hashers.CryptPasswordHasher’,
)
That’s it – now your Django install will use more iterations when it stores passwords using PBKDF2.
Password upgrading
When users log in, if their passwords are stored with anything other than the preferred algorithm, Django will auto-matically
upgrade the algorithm to the preferred one. This means that old installs of Django will get automatically
more secure as users log in, and it also means that you can switch to new (and better) storage algorithms as they get
invented.
However, Django can only upgrade passwords that use algorithms mentioned in PASSWORD_HASHERS, so as you
upgrade to new systems you should make sure never to remove entries from this list. If you do, users using un-mentioned
algorithms won’t be able to upgrade.
Manually managing a user’s password
New in version 1.4: The django.contrib.auth.hashers module provides a set of functions to create and
validate hashed password. You can use them independently from the User model.
check_password(password, encoded)
New in version 1.4. If you’d like to manually authenticate a user by comparing a plain-text password to the
hashed password in the database, use the convenience function check_password(). It takes two arguments:
the plain-text password to check, and the full value of a user’s password field in the database to check against,
and returns True if they match, False otherwise.
make_password(password[, salt, hashers ])
New in version 1.4. Creates a hashed password in the format used by this application. It takes one mandatory
argument: the password in plain-text. Optionally, you can provide a salt and a hashing algorithm to use, if you
don’t want to use the defaults (first entry of PASSWORD_HASHERS setting). Currently supported algorithms are:
’pbkdf2_sha256’, ’pbkdf2_sha1’, ’bcrypt’ (see Using bcrypt with Django), ’sha1’, ’md5’,
’unsalted_md5’ (only for backward compatibility) and ’crypt’ if you have the crypt library installed.
If the password argument is None, an unusable password is returned (a one that will be never accepted by
check_password()).
is_password_usable(encoded_password)
New in version 1.4. Checks if the given string is a hashed password that has a chance of being verified against
check_password().
3.9.3 Customizing authentication in Django
The authentication that comes with Django is good enough for most common cases, but you may have needs not met
by the out-of-the-box defaults. To customize authentication to your projects needs involves understanding what points
of the provided system are extendible or replaceable. This document provides details about how the auth system can
be customized.
3.9. User authentication in Django 311](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-315-2048.jpg)






![Django Documentation, Release 1.5.1
The easiest way to construct a compliant custom User model is to inherit from AbstractBaseUser.
AbstractBaseUser provides the core implementation of a User model, including hashed passwords and tok-enized
password resets. You must then provide some key implementation details:
class models.CustomUser
USERNAME_FIELD
A string describing the name of the field on the User model that is used as the unique identifier. This will
usually be a username of some kind, but it can also be an email address, or any other unique identifier. The
field must be unique (i.e., have unique=True set in its definition).
In the following example, the field identifier is used as the identifying field:
class MyUser(AbstractBaseUser):
identifier = models.CharField(max_length=40, unique=True, db_index=True)
...
USERNAME_FIELD = ’identifier’
REQUIRED_FIELDS
A list of the field names that must be provided when creating a user via the createsuperuser man-agement
command. The user will be prompted to supply a value for each of these fields. It should include
any field for which blank is False or undefined, but may include additional fields you want prompted
for when a user is created interactively. However, it will not work for ForeignKey fields.
For example, here is the partial definition for a User model that defines two required fields - a date of
birth and height:
class MyUser(AbstractBaseUser):
...
date_of_birth = models.DateField()
height = models.FloatField()
...
REQUIRED_FIELDS = [’date_of_birth’, ’height’]
Note: REQUIRED_FIELDS must contain all required fields on your User model, but should not contain
the USERNAME_FIELD.
is_active
A boolean attribute that indicates whether the user is considered “active”. This attribute is provided as
an attribute on AbstractBaseUser defaulting to True. How you choose to implement it will de-pend
on the details of your chosen auth backends. See the documentation of the attribute on the
builtin user model for details.
get_full_name()
A longer formal identifier for the user. A common interpretation would be the full name name of the user,
but it can be any string that identifies the user.
get_short_name()
A short, informal identifier for the user. A common interpretation would be the first name of the user,
but it can be any string that identifies the user in an informal way. It may also return the same value as
django.contrib.auth.models.User.get_full_name().
The following methods are available on any subclass of AbstractBaseUser:
class models.AbstractBaseUser
318 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-322-2048.jpg)




![Django Documentation, Release 1.5.1
Creates and saves a superuser with the given email, date of
birth and password.
"""
user = self.create_user(email,
password=password,
date_of_birth=date_of_birth
)
user.is_admin = True
user.save(using=self._db)
return user
class MyUser(AbstractBaseUser):
email = models.EmailField(
verbose_name=’email address’,
max_length=255,
unique=True,
db_index=True,
)
date_of_birth = models.DateField()
is_active = models.BooleanField(default=True)
is_admin = models.BooleanField(default=False)
objects = MyUserManager()
USERNAME_FIELD = ’email’
REQUIRED_FIELDS = [’date_of_birth’]
def get_full_name(self):
# The user is identified by their email address
return self.email
def get_short_name(self):
# The user is identified by their email address
return self.email
def __unicode__(self):
return self.email
def has_perm(self, perm, obj=None):
"Does the user have a specific permission?"
# Simplest possible answer: Yes, always
return True
def has_module_perms(self, app_label):
"Does the user have permissions to view the app ‘app_label‘?"
# Simplest possible answer: Yes, always
return True
@property
def is_staff(self):
"Is the user a member of staff?"
# Simplest possible answer: All admins are staff
return self.is_admin
Then, to register this custom User model with Django’s admin, the following code would be required in the app’s
admin.py file:
324 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-328-2048.jpg)
![Django Documentation, Release 1.5.1
from django import forms
from django.contrib import admin
from django.contrib.auth.models import Group
from django.contrib.auth.admin import UserAdmin
from django.contrib.auth.forms import ReadOnlyPasswordHashField
from customauth.models import MyUser
class UserCreationForm(forms.ModelForm):
"""A form for creating new users. Includes all the required
fields, plus a repeated password."""
password1 = forms.CharField(label=’Password’, widget=forms.PasswordInput)
password2 = forms.CharField(label=’Password confirmation’, widget=forms.PasswordInput)
class Meta:
model = MyUser
fields = (’email’, ’date_of_birth’)
def clean_password2(self):
# Check that the two password entries match
password1 = self.cleaned_data.get("password1")
password2 = self.cleaned_data.get("password2")
if password1 and password2 and password1 != password2:
raise forms.ValidationError("Passwords don’t match")
return password2
def save(self, commit=True):
# Save the provided password in hashed format
user = super(UserCreationForm, self).save(commit=False)
user.set_password(self.cleaned_data["password1"])
if commit:
user.save()
return user
class UserChangeForm(forms.ModelForm):
"""A form for updating users. Includes all the fields on
the user, but replaces the password field with admin’s
password hash display field.
"""
password = ReadOnlyPasswordHashField()
class Meta:
model = MyUser
def clean_password(self):
# Regardless of what the user provides, return the initial value.
# This is done here, rather than on the field, because the
# field does not have access to the initial value
return self.initial["password"]
class MyUserAdmin(UserAdmin):
# The forms to add and change user instances
form = UserChangeForm
add_form = UserCreationForm
3.9. User authentication in Django 325](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-329-2048.jpg)



![Django Documentation, Release 1.5.1
CACHES = {
’default’: {
’BACKEND’: ’django.core.cache.backends.memcached.MemcachedCache’,
’LOCATION’: ’unix:/tmp/memcached.sock’,
}
}
One excellent feature of Memcached is its ability to share cache over multiple servers. This means you can run
Memcached daemons on multiple machines, and the program will treat the group of machines as a single cache,
without the need to duplicate cache values on each machine. To take advantage of this feature, include all server
addresses in LOCATION, either separated by semicolons or as a list.
In this example, the cache is shared over Memcached instances running on IP address 172.19.26.240 and
172.19.26.242, both on port 11211:
CACHES = {
’default’: {
’BACKEND’: ’django.core.cache.backends.memcached.MemcachedCache’,
’LOCATION’: [
’172.19.26.240:11211’,
’172.19.26.242:11211’,
]
}
}
In the following example, the cache is shared over Memcached instances running on the IP addresses 172.19.26.240
(port 11211), 172.19.26.242 (port 11212), and 172.19.26.244 (port 11213):
CACHES = {
’default’: {
’BACKEND’: ’django.core.cache.backends.memcached.MemcachedCache’,
’LOCATION’: [
’172.19.26.240:11211’,
’172.19.26.242:11212’,
’172.19.26.244:11213’,
]
}
}
A final point about Memcached is that memory-based caching has one disadvantage: Because the cached data is stored
in memory, the data will be lost if your server crashes. Clearly, memory isn’t intended for permanent data storage, so
don’t rely on memory-based caching as your only data storage. Without a doubt, none of the Django caching backends
should be used for permanent storage – they’re all intended to be solutions for caching, not storage – but we point this
out here because memory-based caching is particularly temporary.
Database caching
To use a database table as your cache backend, first create a cache table in your database by running this command:
python manage.py createcachetable [cache_table_name]
...where [cache_table_name] is the name of the database table to create. (This name can be whatever you want,
as long as it’s a valid table name that’s not already being used in your database.) This command creates a single table
in your database that is in the proper format that Django’s database-cache system expects.
Once you’ve created that database table, set your BACKEND setting to
"django.core.cache.backends.db.DatabaseCache", and LOCATION to tablename – the name of
the database table. In this example, the cache table’s name is my_cache_table:
3.10. Django’s cache framework 329](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-333-2048.jpg)





![Django Documentation, Release 1.5.1
>>> cache.set(’my_key’, ’hello, world!’, 30)
>>> cache.get(’my_key’)
’hello, world!’
The timeout argument is optional and defaults to the timeout argument of the appropriate backend in the CACHES
setting (explained above). It’s the number of seconds the value should be stored in the cache.
If the object doesn’t exist in the cache, cache.get() returns None:
# Wait 30 seconds for ’my_key’ to expire...
>>> cache.get(’my_key’)
None
We advise against storing the literal value None in the cache, because you won’t be able to distinguish between your
stored None value and a cache miss signified by a return value of None.
cache.get() can take a default argument. This specifies which value to return if the object doesn’t exist in the
cache:
>>> cache.get(’my_key’, ’has expired’)
’has expired’
To add a key only if it doesn’t already exist, use the add() method. It takes the same parameters as set(), but it
will not attempt to update the cache if the key specified is already present:
>>> cache.set(’add_key’, ’Initial value’)
>>> cache.add(’add_key’, ’New value’)
>>> cache.get(’add_key’)
’Initial value’
If you need to know whether add() stored a value in the cache, you can check the return value. It will return True
if the value was stored, False otherwise.
There’s also a get_many() interface that only hits the cache once. get_many() returns a dictionary with all the
keys you asked for that actually exist in the cache (and haven’t expired):
>>> cache.set(’a’, 1)
>>> cache.set(’b’, 2)
>>> cache.set(’c’, 3)
>>> cache.get_many([’a’, ’b’, ’c’])
{’a’: 1, ’b’: 2, ’c’: 3}
To set multiple values more efficiently, use set_many() to pass a dictionary of key-value pairs:
>>> cache.set_many({’a’: 1, ’b’: 2, ’c’: 3})
>>> cache.get_many([’a’, ’b’, ’c’])
{’a’: 1, ’b’: 2, ’c’: 3}
Like cache.set(), set_many() takes an optional timeout parameter.
You can delete keys explicitly with delete(). This is an easy way of clearing the cache for a particular object:
>>> cache.delete(’a’)
If you want to clear a bunch of keys at once, delete_many() can take a list of keys to be cleared:
>>> cache.delete_many([’a’, ’b’, ’c’])
Finally, if you want to delete all the keys in the cache, use cache.clear(). Be careful with this; clear() will
remove everything from the cache, not just the keys set by your application.
3.10. Django’s cache framework 337](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-341-2048.jpg)

![Django Documentation, Release 1.5.1
>>> cache.get(’my_key’, version=2)
’hello world!’
The version of a specific key can be incremented and decremented using the incr_version() and
decr_version() methods. This enables specific keys to be bumped to a new version, leaving other keys unaf-fected.
Continuing our previous example:
# Increment the version of ’my_key’
>>> cache.incr_version(’my_key’)
# The default version still isn’t available
>>> cache.get(’my_key’)
None
# Version 2 isn’t available, either
>>> cache.get(’my_key’, version=2)
None
# But version 3 *is* available
>>> cache.get(’my_key’, version=3)
’hello world!’
Cache key transformation
As described in the previous two sections, the cache key provided by a user is not used verbatim – it is combined with
the cache prefix and key version to provide a final cache key. By default, the three parts are joined using colons to
produce a final string:
def make_key(key, key_prefix, version):
return ’:’.join([key_prefix, str(version), key])
If you want to combine the parts in different ways, or apply other processing to the final key (e.g., taking a hash digest
of the key parts), you can provide a custom key function.
The KEY_FUNCTION cache setting specifies a dotted-path to a function matching the prototype of make_key()
above. If provided, this custom key function will be used instead of the default key combining function.
Cache key warnings
Memcached, the most commonly-used production cache backend, does not allow cache keys longer than 250 char-acters
or containing whitespace or control characters, and using such keys will cause an exception. To encour-age
cache-portable code and minimize unpleasant surprises, the other built-in cache backends issue a warning
(django.core.cache.backends.base.CacheKeyWarning) if a key is used that would cause an error on
memcached.
If you are using a production backend that can accept a wider range of keys (a custom backend, or one of
the non-memcached built-in backends), and want to use this wider range without warnings, you can silence
CacheKeyWarning with this code in the management module of one of your INSTALLED_APPS:
import warnings
from django.core.cache import CacheKeyWarning
warnings.simplefilter("ignore", CacheKeyWarning)
If you want to instead provide custom key validation logic for one of the built-in backends, you can subclass it, override
just the validate_key method, and follow the instructions for using a custom cache backend. For instance, to do
this for the locmem backend, put this code in a module:
3.10. Django’s cache framework 339](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-343-2048.jpg)

![Django Documentation, Release 1.5.1
from django.views.decorators.vary import vary_on_headers
@vary_on_headers(’User-Agent’)
def my_view(request):
# ...
In this case, a caching mechanism (such as Django’s own cache middleware) will cache a separate version of the page
for each unique user-agent.
The advantage to using the vary_on_headers decorator rather than manually setting the Vary header (using
something like response[’Vary’] = ’user-agent’) is that the decorator adds to the Vary header (which
may already exist), rather than setting it from scratch and potentially overriding anything that was already in there.
You can pass multiple headers to vary_on_headers():
@vary_on_headers(’User-Agent’, ’Cookie’)
def my_view(request):
# ...
This tells upstream caches to vary on both, which means each combination of user-agent and cookie will get its own
cache value. For example, a request with the user-agent Mozilla and the cookie value foo=bar will be considered
different from a request with the user-agent Mozilla and the cookie value foo=ham.
Because varying on cookie is so common, there’s a vary_on_cookie decorator. These two views are equivalent:
@vary_on_cookie
def my_view(request):
# ...
@vary_on_headers(’Cookie’)
def my_view(request):
# ...
The headers you pass to vary_on_headers are not case sensitive; "User-Agent" is the same thing as
"user-agent".
You can also use a helper function, django.utils.cache.patch_vary_headers, directly. This function
sets, or adds to, the Vary header. For example:
from django.utils.cache import patch_vary_headers
def my_view(request):
# ...
response = render_to_response(’template_name’, context)
patch_vary_headers(response, [’Cookie’])
return response
patch_vary_headers takes an HttpResponse instance as its first argument and a list/tuple of case-insensitive
header names as its second argument.
For more on Vary headers, see the official Vary spec.
3.10.8 Controlling cache: Using other headers
Other problems with caching are the privacy of data and the question of where data should be stored in a cascade of
caches.
A user usually faces two kinds of caches: his or her own browser cache (a private cache) and his or her provider’s
cache (a public cache). A public cache is used by multiple users and controlled by someone else. This poses problems
3.10. Django’s cache framework 341](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-345-2048.jpg)







![Django Documentation, Release 1.5.1
The code lives in the django.core.mail module.
3.13.1 Quick example
In two lines:
from django.core.mail import send_mail
send_mail(’Subject here’, ’Here is the message.’, ’from@example.com’,
[’to@example.com’], fail_silently=False)
Mail is sent using the SMTP host and port specified in the EMAIL_HOST and EMAIL_PORT settings. The
EMAIL_HOST_USER and EMAIL_HOST_PASSWORD settings, if set, are used to authenticate to the SMTP server,
and the EMAIL_USE_TLS setting controls whether a secure connection is used.
Note: The character set of email sent with django.core.mail will be set to the value of your
DEFAULT_CHARSET setting.
3.13.2 send_mail()
send_mail(subject, message, from_email, recipient_list, fail_silently=False, auth_user=None,
auth_password=None, connection=None)
The simplest way to send email is using django.core.mail.send_mail().
The subject, message, from_email and recipient_list parameters are required.
• subject: A string.
• message: A string.
• from_email: A string.
• recipient_list: A list of strings, each an email address. Each member of recipient_list will see
the other recipients in the “To:” field of the email message.
• fail_silently: A boolean. If it’s False, send_mail will raise an smtplib.SMTPException. See
the smtplib docs for a list of possible exceptions, all of which are subclasses of SMTPException.
• auth_user: The optional username to use to authenticate to the SMTP server. If this isn’t provided, Django
will use the value of the EMAIL_HOST_USER setting.
• auth_password: The optional password to use to authenticate to the SMTP server. If this isn’t provided,
Django will use the value of the EMAIL_HOST_PASSWORD setting.
• connection: The optional email backend to use to send the mail. If unspecified, an instance of the default
backend will be used. See the documentation on Email backends for more details.
3.13.3 send_mass_mail()
send_mass_mail(datatuple, fail_silently=False, auth_user=None, auth_password=None, connec-tion=
None)
django.core.mail.send_mass_mail() is intended to handle mass emailing.
datatuple is a tuple in which each element is in this format:
3.13. Sending email 349](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-353-2048.jpg)
![Django Documentation, Release 1.5.1
(subject, message, from_email, recipient_list)
fail_silently, auth_user and auth_password have the same functions as in send_mail().
Each separate element of datatuple results in a separate email message. As in send_mail(), recipients in the
same recipient_list will all see the other addresses in the email messages’ “To:” field.
For example, the following code would send two different messages to two different sets of recipients; however, only
one connection to the mail server would be opened:
message1 = (’Subject here’, ’Here is the message’, ’from@example.com’, [’first@example.com’, ’other@example.message2 = (’Another Subject’, ’Here is another message’, ’from@example.com’, [’second@test.com’])
send_mass_mail((message1, message2), fail_silently=False)
send_mass_mail() vs. send_mail()
The main difference between send_mass_mail() and send_mail() is that send_mail() opens a connec-tion
to the mail server each time it’s executed, while send_mass_mail() uses a single connection for all of its
messages. This makes send_mass_mail() slightly more efficient.
3.13.4 mail_admins()
mail_admins(subject, message, fail_silently=False, connection=None, html_message=None)
django.core.mail.mail_admins() is a shortcut for sending an email to the site admins, as defined in the
ADMINS setting.
mail_admins() prefixes the subject with the value of the EMAIL_SUBJECT_PREFIX setting, which is
"[Django] " by default.
The “From:” header of the email will be the value of the SERVER_EMAIL setting.
This method exists for convenience and readability.
If html_message is provided, the resulting email will be a multipart/alternative email with message
as the text/plain content type and html_message as the text/html content type.
3.13.5 mail_managers()
mail_managers(subject, message, fail_silently=False, connection=None, html_message=None)
django.core.mail.mail_managers() is just like mail_admins(), except it sends an email to the site
managers, as defined in the MANAGERS setting.
3.13.6 Examples
This sends a single email to john@example.com and jane@example.com, with them both appearing in the “To:”:
send_mail(’Subject’, ’Message.’, ’from@example.com’,
[’john@example.com’, ’jane@example.com’])
This sends a message to john@example.com and jane@example.com, with them both receiving a separate email:
350 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-354-2048.jpg)
![Django Documentation, Release 1.5.1
datatuple = (
(’Subject’, ’Message.’, ’from@example.com’, [’john@example.com’]),
(’Subject’, ’Message.’, ’from@example.com’, [’jane@example.com’]),
)
send_mass_mail(datatuple)
3.13.7 Preventing header injection
Header injection is a security exploit in which an attacker inserts extra email headers to control the “To:” and “From:”
in email messages that your scripts generate.
The Django email functions outlined above all protect against header injection by forbidding newlines in header
values. If any subject, from_email or recipient_list contains a newline (in either Unix,Windows or Mac
style), the email function (e.g. send_mail()) will raise django.core.mail.BadHeaderError (a subclass
of ValueError) and, hence, will not send the email. It’s your responsibility to validate all data before passing it to
the email functions.
If a message contains headers at the start of the string, the headers will simply be printed as the first bit of the email
message.
Here’s an example view that takes a subject, message and from_email from the request’s POST data, sends
that to admin@example.com and redirects to “/contact/thanks/” when it’s done:
from django.core.mail import send_mail, BadHeaderError
def send_email(request):
subject = request.POST.get(’subject’, ’’)
message = request.POST.get(’message’, ’’)
from_email = request.POST.get(’from_email’, ’’)
if subject and message and from_email:
try:
send_mail(subject, message, from_email, [’admin@example.com’])
except BadHeaderError:
return HttpResponse(’Invalid header found.’)
return HttpResponseRedirect(’/contact/thanks/’)
else:
# In reality we’d use a form class
# to get proper validation errors.
return HttpResponse(’Make sure all fields are entered and valid.’)
3.13.8 The EmailMessage class
Django’s send_mail() and send_mass_mail() functions are actually thin wrappers that make use of the
EmailMessage class.
Not all features of the EmailMessage class are available through the send_mail() and related wrapper functions.
If you wish to use advanced features, such as BCC’ed recipients, file attachments, or multi-part email, you’ll need to
create EmailMessage instances directly.
Note: This is a design feature. send_mail() and related functions were originally the only interface Django
provided. However, the list of parameters they accepted was slowly growing over time. It made sense to move to a
more object-oriented design for email messages and retain the original functions only for backwards compatibility.
EmailMessage is responsible for creating the email message itself. The email backend is then responsible for
sending the email.
3.13. Sending email 351](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-355-2048.jpg)
![Django Documentation, Release 1.5.1
For convenience, EmailMessage provides a simple send() method for sending a single email. If you need to send
multiple messages, the email backend API provides an alternative.
EmailMessage Objects
class EmailMessage
The EmailMessage class is initialized with the following parameters (in the given order, if positional arguments are
used). All parameters are optional and can be set at any time prior to calling the send() method.
• subject: The subject line of the email.
• body: The body text. This should be a plain text message.
• from_email: The sender’s address. Both fred@example.com and Fred <fred@example.com>
forms are legal. If omitted, the DEFAULT_FROM_EMAIL setting is used.
• to: A list or tuple of recipient addresses.
• bcc: A list or tuple of addresses used in the “Bcc” header when sending the email.
• connection: An email backend instance. Use this parameter if you want to use the same connection for
multiple messages. If omitted, a new connection is created when send() is called.
• attachments: A list of attachments to put on the message. These can be either
email.MIMEBase.MIMEBase instances, or (filename, content, mimetype) triples.
• headers: A dictionary of extra headers to put on the message. The keys are the header name, values are the
header values. It’s up to the caller to ensure header names and values are in the correct format for an email
message.
• cc: A list or tuple of recipient addresses used in the “Cc” header when sending the email.
For example:
email = EmailMessage(’Hello’, ’Body goes here’, ’from@example.com’,
[’to1@example.com’, ’to2@example.com’], [’bcc@example.com’],
headers = {’Reply-To’: ’another@example.com’})
The class has the following methods:
• send(fail_silently=False) sends the message. If a connection was specified when the email was
constructed, that connection will be used. Otherwise, an instance of the default backend will be instantiated and
used. If the keyword argument fail_silently is True, exceptions raised while sending the message will
be quashed.
• message() constructs a django.core.mail.SafeMIMEText object (a subclass of Python’s
email.MIMEText.MIMEText class) or a django.core.mail.SafeMIMEMultipart object hold-ing
the message to be sent. If you ever need to extend the EmailMessage class, you’ll probably want to
override this method to put the content you want into the MIME object.
• recipients() returns a list of all the recipients of the message, whether they’re recorded in the to, cc or
bcc attributes. This is another method you might need to override when subclassing, because the SMTP server
needs to be told the full list of recipients when the message is sent. If you add another way to specify recipients
in your class, they need to be returned from this method as well.
• attach() creates a new file attachment and adds it to the message. There are two ways to call attach():
– You can pass it a single argument that is an email.MIMEBase.MIMEBase instance. This will be
inserted directly into the resulting message.
352 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-356-2048.jpg)
![Django Documentation, Release 1.5.1
– Alternatively, you can pass attach() three arguments: filename, content and mimetype.
filename is the name of the file attachment as it will appear in the email, content is the data that
will be contained inside the attachment and mimetype is the optional MIME type for the attachment. If
you omit mimetype, the MIME content type will be guessed from the filename of the attachment.
For example:
message.attach(’design.png’, img_data, ’image/png’)
• attach_file() creates a new attachment using a file from your filesystem. Call it with the path of the file to
attach and, optionally, the MIME type to use for the attachment. If the MIME type is omitted, it will be guessed
from the filename. The simplest use would be:
message.attach_file(’/images/weather_map.png’)
Sending alternative content types
It can be useful to include multiple versions of the content in an email; the classic example is to send both text and
HTML versions of a message. With Django’s email library, you can do this using the EmailMultiAlternatives
class. This subclass of EmailMessage has an attach_alternative() method for including extra versions of
the message body in the email. All the other methods (including the class initialization) are inherited directly from
EmailMessage.
To send a text and HTML combination, you could write:
from django.core.mail import EmailMultiAlternatives
subject, from_email, to = ’hello’, ’from@example.com’, ’to@example.com’
text_content = ’This is an important message.’
html_content = ’<p>This is an <strong>important</strong> message.</p>’
msg = EmailMultiAlternatives(subject, text_content, from_email, [to])
msg.attach_alternative(html_content, "text/html")
msg.send()
By default, the MIME type of the body parameter in an EmailMessage is "text/plain". It is good practice
to leave this alone, because it guarantees that any recipient will be able to read the email, regardless of their mail
client. However, if you are confident that your recipients can handle an alternative content type, you can use the
content_subtype attribute on the EmailMessage class to change the main content type. The major type will
always be "text", but you can change the subtype. For example:
msg = EmailMessage(subject, html_content, from_email, [to])
msg.content_subtype = "html" # Main content is now text/html
msg.send()
3.13.9 Email backends
The actual sending of an email is handled by the email backend.
The email backend class has the following methods:
• open() instantiates an long-lived email-sending connection.
• close() closes the current email-sending connection.
• send_messages(email_messages) sends a list of EmailMessage objects. If the connection is not
open, this call will implicitly open the connection, and close the connection afterwards. If the connection is
already open, it will be left open after mail has been sent.
3.13. Sending email 353](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-357-2048.jpg)


![Django Documentation, Release 1.5.1
In this example, the call to send_messages() opens a connection on the backend, sends the list of messages, and
then closes the connection again.
The second approach is to use the open() and close() methods on the email backend to manually control the
connection. send_messages() will not manually open or close the connection if it is already open, so if you
manually open the connection, you can control when it is closed. For example:
from django.core import mail
connection = mail.get_connection()
# Manually open the connection
connection.open()
# Construct an email message that uses the connection
email1 = mail.EmailMessage(’Hello’, ’Body goes here’, ’from@example.com’,
[’to1@example.com’], connection=connection)
email1.send() # Send the email
# Construct two more messages
email2 = mail.EmailMessage(’Hello’, ’Body goes here’, ’from@example.com’,
[’to2@example.com’])
email3 = mail.EmailMessage(’Hello’, ’Body goes here’, ’from@example.com’,
[’to3@example.com’])
# Send the two emails in a single call -
connection.send_messages([email2, email3])
# The connection was already open so send_messages() doesn’t close it.
# We need to manually close the connection.
connection.close()
3.13.10 Testing email sending
There are times when you do not want Django to send emails at all. For example, while developing a Web site, you
probably don’t want to send out thousands of emails – but you may want to validate that emails will be sent to the
right people under the right conditions, and that those emails will contain the correct content.
The easiest way to test your project’s use of email is to use the console email backend. This backend redirects all
email to stdout, allowing you to inspect the content of mail.
The file email backend can also be useful during development – this backend dumps the contents of every SMTP
connection to a file that can be inspected at your leisure.
Another approach is to use a “dumb” SMTP server that receives the emails locally and displays them to the terminal,
but does not actually send anything. Python has a built-in way to accomplish this with a single command:
python -m smtpd -n -c DebuggingServer localhost:1025
This command will start a simple SMTP server listening on port 1025 of localhost. This server simply prints to
standard output all email headers and the email body. You then only need to set the EMAIL_HOST and EMAIL_PORT
accordingly, and you are set.
For a more detailed discussion of testing and processing of emails locally, see the Python documentation for the
smtpd module.
356 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-360-2048.jpg)

![Django Documentation, Release 1.5.1
from django.utils.translation import ugettext as _
def my_view(request):
output = _("Welcome to my site.")
return HttpResponse(output)
Obviously, you could code this without using the alias. This example is identical to the previous one:
from django.utils.translation import ugettext
def my_view(request):
output = ugettext("Welcome to my site.")
return HttpResponse(output)
Translation works on computed values. This example is identical to the previous two:
def my_view(request):
words = [’Welcome’, ’to’, ’my’, ’site.’]
output = _(’ ’.join(words))
return HttpResponse(output)
Translation works on variables. Again, here’s an identical example:
def my_view(request):
sentence = ’Welcome to my site.’
output = _(sentence)
return HttpResponse(output)
(The caveat with using variables or computed values, as in the previous two examples, is that Django’s translation-string-
detecting utility, django-admin.py makemessages, won’t be able to find these strings. More on
makemessages later.)
The strings you pass to _() or ugettext() can take placeholders, specified with Python’s standard named-string
interpolation syntax. Example:
def my_view(request, m, d):
output = _(’Today is %(month)s %(day)s.’) % {’month’: m, ’day’: d}
return HttpResponse(output)
This technique lets language-specific translations reorder the placeholder text. For example, an English translation
may be "Today is November 26.", while a Spanish translation may be "Hoy es 26 de Noviembre."
– with the the month and the day placeholders swapped.
For this reason, you should use named-string interpolation (e.g., %(day)s) instead of positional interpolation (e.g.,
%s or %d) whenever you have more than a single parameter. If you used positional interpolation, translations wouldn’t
be able to reorder placeholder text.
Comments for translators
If you would like to give translators hints about a translatable string, you can add a comment prefixed with the
Translators keyword on the line preceding the string, e.g.:
def my_view(request):
# Translators: This message appears on the home page only
output = ugettext("Welcome to my site.")
The comment will then appear in the resulting .po file associated with the translatable contruct located below it and
should also be displayed by most translation tools.
358 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-362-2048.jpg)
![Django Documentation, Release 1.5.1
’There are %(count)d %(name)s available.’,
count
) % {
’count’: count,
’name’: name
}
Here we reuse localizable, hopefully already translated literals (contained in the verbose_name and
verbose_name_plural model Meta options) for other parts of the sentence so all of it is consistently based
on the cardinality of the elements at play.
Note: When using this technique, make sure you use a single name for every extrapolated variable included in the
literal. In the example above note how we used the name Python variable in both translation strings. This example
would fail:
from django.utils.translation import ungettext
from myapp.models import Report
count = Report.objects.count()
d = {
’count’: count,
’name’: Report._meta.verbose_name,
’plural_name’: Report._meta.verbose_name_plural
}
text = ungettext(
’There is %(count)d %(name)s available.’,
’There are %(count)d %(plural_name)s available.’,
count
) % d
You would get an error when running django-admin.py compilemessages:
a format specification for argument ’name’, as in ’msgstr[0]’, doesn’t exist in ’msgid’
Contextual markers
Sometimes words have several meanings, such as "May" in English, which refers to a month
name and to a verb. To enable translators to translate these words correctly in different
contexts, you can use the django.utils.translation.pgettext() function, or the
django.utils.translation.npgettext() function if the string needs pluralization. Both take a
context string as the first variable.
In the resulting .po file, the string will then appear as often as there are different contextual markers for the same
string (the context will appear on the msgctxt line), allowing the translator to give a different translation for each of
them.
For example:
from django.utils.translation import pgettext
month = pgettext("month name", "May")
or:
from django.utils.translation import pgettext_lazy
360 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-364-2048.jpg)
![Django Documentation, Release 1.5.1
verbose_name = _(’my thing’)
verbose_name_plural = _(’my things’)
Model methods short_description attribute values For model methods, you can provide translations to
Django and the admin site with the short_description attribute:
from django.utils.translation import ugettext_lazy as _
class MyThing(models.Model):
kind = models.ForeignKey(ThingKind, related_name=’kinds’,
verbose_name=_(’kind’))
def is_mouse(self):
return self.kind.type == MOUSE_TYPE
is_mouse.short_description = _(’Is it a mouse?’)
Working with lazy translation objects
The result of a ugettext_lazy() call can be used wherever you would use a unicode string (an object with type
unicode) in Python. If you try to use it where a bytestring (a str object) is expected, things will not work as
expected, since a ugettext_lazy() object doesn’t know how to convert itself to a bytestring. You can’t use a
unicode string inside a bytestring, either, so this is consistent with normal Python behavior. For example:
# This is fine: putting a unicode proxy into a unicode string.
u"Hello %s" % ugettext_lazy("people")
# This will not work, since you cannot insert a unicode object
# into a bytestring (nor can you insert our unicode proxy there)
"Hello %s" % ugettext_lazy("people")
If you ever see output that looks like "hello <django.utils.functional...>", you have tried to insert
the result of ugettext_lazy() into a bytestring. That’s a bug in your code.
If you don’t like the long ugettext_lazy name, you can just alias it as _ (underscore), like so:
from django.utils.translation import ugettext_lazy as _
class MyThing(models.Model):
name = models.CharField(help_text=_(’This is the help text’))
Using ugettext_lazy() and ungettext_lazy() to mark strings in models and utility functions is a common
operation. When you’re working with these objects elsewhere in your code, you should ensure that you don’t acci-dentally
convert them to strings, because they should be converted as late as possible (so that the correct locale is in
effect). This necessitates the use of the helper function described next.
Joining strings: string_concat() Standard Python string joins (”.join([...])) will not work on lists contain-ing
lazy translation objects. Instead, you can use django.utils.translation.string_concat(), which
creates a lazy object that concatenates its contents and converts them to strings only when the result is included in a
string. For example:
from django.utils.translation import string_concat
...
name = ugettext_lazy(’John Lennon’)
instrument = ugettext_lazy(’guitar’)
result = string_concat(name, ’: ’, instrument)
362 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-366-2048.jpg)
![Django Documentation, Release 1.5.1
In this case, the lazy translations in result will only be converted to strings when result itself is used in a string
(usually at template rendering time).
Other uses of lazy in delayed translations For any other case where you would like to delay the translation, but
have to pass the translatable string as argument to another function, you can wrap this function inside a lazy call
yourself. For example:
from django.utils import six # Python 3 compatibility
from django.utils.functional import lazy
from django.utils.safestring import mark_safe
from django.utils.translation import ugettext_lazy as _
mark_safe_lazy = lazy(mark_safe, six.text_type)
And then later:
lazy_string = mark_safe_lazy(_("<p>My <strong>string!</strong></p>"))
Localized names of languages
get_language_info()
The get_language_info() function provides detailed information about languages:
>>> from django.utils.translation import get_language_info
>>> li = get_language_info(’de’)
>>> print(li[’name’], li[’name_local’], li[’bidi’])
German Deutsch False
The name and name_local attributes of the dictionary contain the name of the language in English and in the
language itself, respectively. The bidi attribute is True only for bi-directional languages.
The source of the language information is the django.conf.locale module. Similar access to this information
is available for template code. See below.
Internationalization: in template code
Translations in Django templates uses two template tags and a slightly different syntax than in Python code. To give
your template access to these tags, put {% load i18n %} toward the top of your template. As with all template
tags, this tag needs to be loaded in all templates which use translations, even those templates that extend from other
templates which have already loaded the i18n tag.
trans template tag
The {% trans %} template tag translates either a constant string (enclosed in single or double quotes) or variable
content:
<title>{% trans "This is the title." %}</title>
<title>{% trans myvar %}</title>
If the noop option is present, variable lookup still takes place but the translation is skipped. This is useful when
“stubbing out” content that will require translation in the future:
<title>{% trans "myvar" noop %}</title>
3.14. Internationalization and localization 363](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-367-2048.jpg)



![Django Documentation, Release 1.5.1
{% some_special_tag _("Page not found") value|yesno:_("yes,no") %}
In this case, both the tag and the filter will see the already-translated string, so they don’t need to be aware of transla-tions.
Note: In this example, the translation infrastructure will be passed the string "yes,no", not the individual strings
"yes" and "no". The translated string will need to contain the comma so that the filter parsing code knows how
to split up the arguments. For example, a German translator might translate the string "yes,no" as "ja,nein"
(keeping the comma intact).
You can also retrieve information about any of the available languages using provided template tags and filters. To get
information about a single language, use the {% get_language_info %} tag:
{% get_language_info for LANGUAGE_CODE as lang %}
{% get_language_info for "pl" as lang %}
You can then access the information:
Language code: {{ lang.code }}<br />
Name of language: {{ lang.name_local }}<br />
Name in English: {{ lang.name }}<br />
Bi-directional: {{ lang.bidi }}
You can also use the {% get_language_info_list %} template tag to retrieve information for a list of lan-guages
(e.g. active languages as specified in LANGUAGES). See the section about the set_language redirect view for
an example of how to display a language selector using {% get_language_info_list %}.
In addition to LANGUAGES style nested tuples, {% get_language_info_list %} supports simple lists of
language codes. If you do this in your view:
return render_to_response(’mytemplate.html’, {
’available_languages’: [’en’, ’es’, ’fr’],
}, RequestContext(request))
you can iterate over those languages in the template:
{% get_language_info_list for available_languages as langs %}
{% for lang in langs %} ... {% endfor %}
There are also simple filters available for convenience:
• {{ LANGUAGE_CODE|language_name }} (“German”)
• {{ LANGUAGE_CODE|language_name_local }} (“Deutsch”)
• {{ LANGUAGE_CODE|bidi }} (False)
Internationalization: in JavaScript code
Adding translations to JavaScript poses some problems:
• JavaScript code doesn’t have access to a gettext implementation.
• JavaScript code doesn’t have access to .po or .mo files; they need to be delivered by the server.
• The translation catalogs for JavaScript should be kept as small as possible.
Django provides an integrated solution for these problems: It passes the translations into JavaScript, so you can call
gettext, etc., from within JavaScript.
3.14. Internationalization and localization 367](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-371-2048.jpg)
![Django Documentation, Release 1.5.1
var object_cnt = 1 // or 0, or 2, or 3, ...
s = ngettext(’literal for the singular case’,
’literal for the plural case’, object_cnt);
and even a string interpolation function:
function interpolate(fmt, obj, named);
The interpolation syntax is borrowed from Python, so the interpolate function supports both positional and named
interpolation:
• Positional interpolation: obj contains a JavaScript Array object whose elements values are then sequentially
interpolated in their corresponding fmt placeholders in the same order they appear. For example:
fmts = ngettext(’There is %s object. Remaining: %s’,
’There are %s objects. Remaining: %s’, 11);
s = interpolate(fmts, [11, 20]);
// s is ’There are 11 objects. Remaining: 20’
• Named interpolation: This mode is selected by passing the optional boolean named parameter as true. obj
contains a JavaScript object or associative array. For example:
d = {
count: 10,
total: 50
};
fmts = ngettext(’Total: %(total)s, there is %(count)s object’,
’there are %(count)s of a total of %(total)s objects’, d.count);
s = interpolate(fmts, d, true);
You shouldn’t go over the top with string interpolation, though: this is still JavaScript, so the code has to make repeated
regular-expression substitutions. This isn’t as fast as string interpolation in Python, so keep it to those cases where you
really need it (for example, in conjunction with ngettext to produce proper pluralizations).
Note on performance
The javascript_catalog() view generates the catalog from .mo files on every request. Since its output is
constant— at least for a given version of a site— it’s a good candidate for caching.
Server-side caching will reduce CPU load. It’s easily implemented with the cache_page() decorator. To trigger
cache invalidation when your translations change, provide a version-dependant key prefix, as shown in the example
below, or map the view at a version-dependant URL.
from django.views.decorators.cache import cache_page
from django.views.i18n import javascript_catalog
# The value returned by get_version() must change when translations change.
@cache_page(86400, key_prefix=’js18n-%s’ % get_version())
def cached_javascript_catalog(request, domain=’djangojs’, packages=None):
return javascript_catalog(request, domain, packages)
Client-side caching will save bandwidth and make your site load faster. If you’re using ETags (USE_ETAGS =
True), you’re already covered. Otherwise, you can apply conditional decorators. In the following example, the cache
is invalidated whenever your restart your application server.
from django.utils import timezone
from django.views.decorators.http import last_modified
3.14. Internationalization and localization 369](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-373-2048.jpg)
![Django Documentation, Release 1.5.1
from django.views.i18n import javascript_catalog
last_modified_date = timezone.now()
@last_modified(lambda req, **kw: last_modified_date)
def cached_javascript_catalog(request, domain=’djangojs’, packages=None):
return javascript_catalog(request, domain, packages)
You can even pre-generate the javascript catalog as part of your deployment procedure and serve it as a static file. This
radical technique is implemented in django-statici18n.
Internationalization: in URL patterns
New in version 1.4. Django provides two mechanisms to internationalize URL patterns:
• Adding the language prefix to the root of the URL patterns to make it possible for LocaleMiddleware to
detect the language to activate from the requested URL.
• Making URL patterns themselves translatable via the django.utils.translation.ugettext_lazy()
function.
Warning: Using either one of these features requires that an active language be set for each re-quest;
in other words, you need to have django.middleware.locale.LocaleMiddleware in your
MIDDLEWARE_CLASSES setting.
Language prefix in URL patterns
i18n_patterns(prefix, pattern_description, ...)
This function can be used in your root URLconf as a replacement for the normal
django.conf.urls.patterns() function. Django will automatically prepend the current active language
code to all url patterns defined within i18n_patterns(). Example URL patterns:
from django.conf.urls import patterns, include, url
from django.conf.urls.i18n import i18n_patterns
urlpatterns = patterns(’’,
url(r’^sitemap.xml$’, ’sitemap.view’, name=’sitemap_xml’),
)
news_patterns = patterns(’’,
url(r’^$’, ’news.views.index’, name=’index’),
url(r’^category/(?P<slug>[w-]+)/$’, ’news.views.category’, name=’category’),
url(r’^(?P<slug>[w-]+)/$’, ’news.views.details’, name=’detail’),
)
urlpatterns += i18n_patterns(’’,
url(r’^about/$’, ’about.view’, name=’about’),
url(r’^news/’, include(news_patterns, namespace=’news’)),
)
After defining these URL patterns, Django will automatically add the language prefix to the URL patterns that were
added by the i18n_patterns function. Example:
from django.core.urlresolvers import reverse
from django.utils.translation import activate
370 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-374-2048.jpg)
![Django Documentation, Release 1.5.1
>>> activate(’en’)
>>> reverse(’sitemap_xml’)
’/sitemap.xml’
>>> reverse(’news:index’)
’/en/news/’
>>> activate(’nl’)
>>> reverse(’news:detail’, kwargs={’slug’: ’news-slug’})
’/nl/news/news-slug/’
Warning: i18n_patterns() is only allowed in your root URLconf. Using it within an included URLconf
will throw an ImproperlyConfigured exception.
Warning: Ensure that you don’t have non-prefixed URL patterns that might collide with an automatically-added
language prefix.
Translating URL patterns
URL patterns can also be marked translatable using the ugettext_lazy() function. Example:
from django.conf.urls import patterns, include, url
from django.conf.urls.i18n import i18n_patterns
from django.utils.translation import ugettext_lazy as _
urlpatterns = patterns(’’
url(r’^sitemap.xml$’, ’sitemap.view’, name=’sitemap_xml’),
)
news_patterns = patterns(’’
url(r’^$’, ’news.views.index’, name=’index’),
url(_(r’^category/(?P<slug>[w-]+)/$’), ’news.views.category’, name=’category’),
url(r’^(?P<slug>[w-]+)/$’, ’news.views.details’, name=’detail’),
)
urlpatterns += i18n_patterns(’’,
url(_(r’^about/$’), ’about.view’, name=’about’),
url(_(r’^news/’), include(news_patterns, namespace=’news’)),
)
After you’ve created the translations, the reverse() function will return the URL in the active language. Example:
from django.core.urlresolvers import reverse
from django.utils.translation import activate
>>> activate(’en’)
>>> reverse(’news:category’, kwargs={’slug’: ’recent’})
’/en/news/category/recent/’
>>> activate(’nl’)
>>> reverse(’news:category’, kwargs={’slug’: ’recent’})
’/nl/nieuws/categorie/recent/’
Warning: In most cases, it’s best to use translated URLs only within a language-code-prefixed block of patterns
(using i18n_patterns()), to avoid the possibility that a carelessly translated URL causes a collision with a
non-translated URL pattern.
3.14. Internationalization and localization 371](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-375-2048.jpg)













![Django Documentation, Release 1.5.1
Create a view that can set the current timezone:
import pytz
from django.shortcuts import redirect, render
def set_timezone(request):
if request.method == ’POST’:
request.session[’django_timezone’] = pytz.timezone(request.POST[’timezone’])
return redirect(’/’)
else:
return render(request, ’template.html’, {’timezones’: pytz.common_timezones})
Include a form in template.html that will POST to this view:
{% load tz %}
<form action="{% url ’set_timezone’ %}" method="POST">
{% csrf_token %}
<label for="timezone">Time zone:</label>
<select name="timezone">
{% for tz in timezones %}
<option value="{{ tz }}"{% if tz == TIME_ZONE %} selected="selected"{% endif %}>{{ tz }}</option>
{% endfor %}
</select>
<input type="submit" value="Set" />
</form>
Time zone aware input in forms
When you enable time zone support, Django interprets datetimes entered in forms in the current time zone and returns
aware datetime objects in cleaned_data.
If the current time zone raises an exception for datetimes that don’t exist or are ambiguous because they fall in a DST
transition (the timezones provided by pytz do this), such datetimes will be reported as invalid values.
Time zone aware output in templates
When you enable time zone support, Django converts aware datetime objects to the current time zone when they’re
rendered in templates. This behaves very much like format localization.
Warning: Django doesn’t convert naive datetime objects, because they could be ambiguous, and because your
code should never produce naive datetimes when time zone support is enabled. However, you can force conversion
with the template filters described below.
Conversion to local time isn’t always appropriate – you may be generating output for computers rather than for humans.
The following filters and tags, provided by the tz template tag library, allow you to control the time zone conversions.
Template tags
localtime Enables or disables conversion of aware datetime objects to the current time zone in the contained block.
This tag has exactly the same effects as the USE_TZ setting as far as the template engine is concerned. It allows a
more fine grained control of conversion.
To activate or deactivate conversion for a template block, use:
3.14. Internationalization and localization 385](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-389-2048.jpg)










![Django Documentation, Release 1.5.1
’class’: ’django.utils.log.NullHandler’,
},
’console’:{
’level’: ’DEBUG’,
’class’: ’logging.StreamHandler’,
’formatter’: ’simple’
},
’mail_admins’: {
’level’: ’ERROR’,
’class’: ’django.utils.log.AdminEmailHandler’,
’filters’: [’special’]
}
},
’loggers’: {
’django’: {
’handlers’: [’null’],
’propagate’: True,
’level’: ’INFO’,
},
’django.request’: {
’handlers’: [’mail_admins’],
’level’: ’ERROR’,
’propagate’: False,
},
’myproject.custom’: {
’handlers’: [’console’, ’mail_admins’],
’level’: ’INFO’,
’filters’: [’special’]
}
}
}
This logging configuration does the following things:
• Identifies the configuration as being in ‘dictConfig version 1’ format. At present, this is the only dictConfig
format version.
• Disables all existing logging configurations.
• Defines two formatters:
– simple, that just outputs the log level name (e.g., DEBUG) and the log message.
The format string is a normal Python formatting string describing the details that are to be output on
each logging line. The full list of detail that can be output can be found in the formatter documentation.
– verbose, that outputs the log level name, the log message, plus the time, process, thread and module that
generate the log message.
• Defines one filter – project.logging.SpecialFilter, using the alias special. If this filter re-quired
additional arguments at time of construction, they can be provided as additional keys in the filter con-figuration
dictionary. In this case, the argument foo will be given a value of bar when instantiating the
SpecialFilter.
• Defines three handlers:
– null, a NullHandler, which will pass any DEBUG (or higher) message to /dev/null.
– console, a StreamHandler, which will print any DEBUG (or higher) message to stderr. This handler uses
the simple output format.
396 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-400-2048.jpg)

![Django Documentation, Release 1.5.1
django.request
Log messages related to the handling of requests. 5XX responses are raised as ERROR messages; 4XX responses are
raised as WARNING messages.
Messages to this logger have the following extra context:
• status_code: The HTTP response code associated with the request.
• request: The request object that generated the logging message.
django.db.backends
Messages relating to the interaction of code with the database. For example, every SQL statement executed by a
request is logged at the DEBUG level to this logger.
Messages to this logger have the following extra context:
• duration: The time taken to execute the SQL statement.
• sql: The SQL statement that was executed.
• params: The parameters that were used in the SQL call.
For performance reasons, SQL logging is only enabled when settings.DEBUG is set to True, regardless of the
logging level or handlers that are installed.
Handlers
Django provides one log handler in addition to those provided by the Python logging module.
class AdminEmailHandler([include_html=False ])
This handler sends an email to the site admins for each log message it receives.
If the log record contains a request attribute, the full details of the request will be included in the email.
If the log record contains stack trace information, that stack trace will be included in the email.
The include_html argument of AdminEmailHandler is used to control whether the traceback email
includes an HTML attachment containing the full content of the debug Web page that would have been pro-duced
if DEBUG were True. To set this value in your configuration, include it in the handler definition for
django.utils.log.AdminEmailHandler, like this:
’handlers’: {
’mail_admins’: {
’level’: ’ERROR’,
’class’: ’django.utils.log.AdminEmailHandler’,
’include_html’: True,
}
},
Note that this HTML version of the email contains a full traceback, with names and values of local variables at
each level of the stack, plus the values of your Django settings. This information is potentially very sensitive,
and you may not want to send it over email. Consider using something such as Sentry to get the best of both
worlds – the rich information of full tracebacks plus the security of not sending the information over email. You
may also explicitly designate certain sensitive information to be filtered out of error reports – learn more on
Filtering error reports.
398 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-402-2048.jpg)
![Django Documentation, Release 1.5.1
Filters
Django provides two log filters in addition to those provided by the Python logging module.
class CallbackFilter(callback)
New in version 1.4. This filter accepts a callback function (which should accept a single argument, the record to
be logged), and calls it for each record that passes through the filter. Handling of that record will not proceed if
the callback returns False.
For instance, to filter out UnreadablePostError (raised when a user cancels an upload) from the admin
emails, you would create a filter function:
from django.http import UnreadablePostError
def skip_unreadable_post(record):
if record.exc_info:
exc_type, exc_value = record.exc_info[:2]
if isinstance(exc_value, UnreadablePostError):
return False
return True
and then add it to your logging config:
’filters’: {
’skip_unreadable_posts’: {
’()’: ’django.utils.log.CallbackFilter’,
’callback’: skip_unreadable_post,
}
},
’handlers’: {
’mail_admins’: {
’level’: ’ERROR’,
’filters’: [’skip_unreadable_posts’],
’class’: ’django.utils.log.AdminEmailHandler’
}
},
class RequireDebugFalse
New in version 1.4. This filter will only pass on records when settings.DEBUG is False.
This filter is used as follows in the default LOGGING configuration to ensure that the AdminEmailHandler
only sends error emails to admins when DEBUG is False:
’filters’: {
’require_debug_false’: {
’()’: ’django.utils.log.RequireDebugFalse’,
}
},
’handlers’: {
’mail_admins’: {
’level’: ’ERROR’,
’filters’: [’require_debug_false’],
’class’: ’django.utils.log.AdminEmailHandler’
}
},
class RequireDebugTrue
New in version 1.5. This filter is similar to RequireDebugFalse, except that records are passed only when
DEBUG is True.
3.15. Logging 399](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-403-2048.jpg)
![Django Documentation, Release 1.5.1
3.15.5 Django’s default logging configuration
By default, Django configures the django.request logger so that all messages with ERROR or CRITICAL level
are sent to AdminEmailHandler, as long as the DEBUG setting is set to False.
All messages reaching the django catch-all logger when DEBUG is True are sent to the console. They are simply
discarded (sent to NullHandler) when DEBUG is False. Changed in version 1.5. See also Configuring logging to
learn how you can complement or replace this default logging configuration.
3.16 Pagination
Django provides a few classes that help you manage paginated data – that is, data that’s split across several pages, with
“Previous/Next” links. These classes live in django/core/paginator.py.
3.16.1 Example
Give Paginator a list of objects, plus the number of items you’d like to have on each page, and it gives you methods
for accessing the items for each page:
>>> from django.core.paginator import Paginator
>>> objects = [’john’, ’paul’, ’george’, ’ringo’]
>>> p = Paginator(objects, 2)
>>> p.count
4
>>> p.num_pages
2
>>> p.page_range
[1, 2]
>>> page1 = p.page(1)
>>> page1
<Page 1 of 2>
>>> page1.object_list
[’john’, ’paul’]
>>> page2 = p.page(2)
>>> page2.object_list
[’george’, ’ringo’]
>>> page2.has_next()
False
>>> page2.has_previous()
True
>>> page2.has_other_pages()
True
>>> page2.next_page_number()
Traceback (most recent call last):
...
EmptyPage: That page contains no results
>>> page2.previous_page_number()
1
>>> page2.start_index() # The 1-based index of the first item on this page
3
>>> page2.end_index() # The 1-based index of the last item on this page
4
400 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-404-2048.jpg)


![Django Documentation, Release 1.5.1
Paginator.num_pages
The total number of pages.
Paginator.page_range
A 1-based range of page numbers, e.g., [1, 2, 3, 4].
3.16.4 InvalidPage exceptions
exception InvalidPage
A base class for exceptions raised when a paginator is passed an invalid page number.
The Paginator.page() method raises an exception if the requested page is invalid (i.e., not an integer) or contains
no objects. Generally, it’s enough to trap the InvalidPage exception, but if you’d like more granularity, you can
trap either of the following exceptions:
exception PageNotAnInteger
Raised when page() is given a value that isn’t an integer.
exception EmptyPage
Raised when page() is given a valid value but no objects exist on that page.
Both of the exceptions are subclasses of InvalidPage, so you can handle them both with a simple except
InvalidPage.
3.16.5 Page objects
You usually won’t construct Page objects by hand – you’ll get them using Paginator.page().
class Page(object_list, number, paginator)
New in version 1.4: A page acts like a sequence of Page.object_list when using len() or iterating it directly.
Methods
Page.has_next()
Returns True if there’s a next page.
Page.has_previous()
Returns True if there’s a previous page.
Page.has_other_pages()
Returns True if there’s a next or previous page.
Page.next_page_number()
Returns the next page number. Changed in version 1.5. Raises InvalidPage if next page doesn’t exist.
Page.previous_page_number()
Returns the previous page number. Changed in version 1.5. Raises InvalidPage if previous page doesn’t
exist.
Page.start_index()
Returns the 1-based index of the first object on the page, relative to all of the objects in the paginator’s list.
For example, when paginating a list of 5 objects with 2 objects per page, the second page’s start_index()
would return 3.
3.16. Pagination 403](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-407-2048.jpg)












![Django Documentation, Release 1.5.1
name = models.CharField(max_length=100)
author = models.ForeignKey(Person)
Ordinarily, serialized data for Book would use an integer to refer to the author. For example, in JSON, a Book might
be serialized as:
...
{
pk: 1,
model: store.book,
fields: {
name: Mostly Harmless,
author: 42
}
}
...
This isn’t a particularly natural way to refer to an author. It requires that you know the primary key value for the
author; it also requires that this primary key value is stable and predictable.
However, if we add natural key handling to Person, the fixture becomes much more humane. To add natural key
handling, you define a default Manager for Person with a get_by_natural_key() method. In the case of a
Person, a good natural key might be the pair of first and last name:
from django.db import models
class PersonManager(models.Manager):
def get_by_natural_key(self, first_name, last_name):
return self.get(first_name=first_name, last_name=last_name)
class Person(models.Model):
objects = PersonManager()
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
birthdate = models.DateField()
class Meta:
unique_together = ((’first_name’, ’last_name’),)
Now books can use that natural key to refer to Person objects:
...
{
pk: 1,
model: store.book,
fields: {
name: Mostly Harmless,
author: [Douglas, Adams]
}
}
...
When you try to load this serialized data, Django will use the get_by_natural_key() method to resolve
[Douglas, Adams] into the primary key of an actual Person object.
Note: Whatever fields you use for a natural key must be able to uniquely identify an object. This will usually mean
that your model will have a uniqueness clause (either unique=True on a single field, or unique_together over
multiple fields) for the field or fields in your natural key. However, uniqueness doesn’t need to be enforced at the
416 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-420-2048.jpg)
![Django Documentation, Release 1.5.1
database level. If you are certain that a set of fields will be effectively unique, you can still use those fields as a natural
key.
Serialization of natural keys
So how do you get Django to emit a natural key when serializing an object? Firstly, you need to add another method
– this time to the model itself:
class Person(models.Model):
objects = PersonManager()
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
birthdate = models.DateField()
def natural_key(self):
return (self.first_name, self.last_name)
class Meta:
unique_together = ((’first_name’, ’last_name’),)
That method should always return a natural key tuple – in this example, (first name, last name). Then,
when you call serializers.serialize(), you provide a use_natural_keys=True argument:
serializers.serialize(’json’, [book1, book2], indent=2, use_natural_keys=True)
When use_natural_keys=True is specified, Django will use the natural_key() method to serialize any
reference to objects of the type that defines the method.
If you are using dumpdata to generate serialized data, you use the --natural command line flag to generate
natural keys.
Note: You don’t need to define both natural_key() and get_by_natural_key(). If you don’t want Django
to output natural keys during serialization, but you want to retain the ability to load natural keys, then you can opt to
not implement the natural_key() method.
Conversely, if (for some strange reason) you want Django to output natural keys during serialization, but not be able
to load those key values, just don’t define the get_by_natural_key() method.
Dependencies during serialization
Since natural keys rely on database lookups to resolve references, it is important that the data exists before it is
referenced. You can’t make a “forward reference” with natural keys – the data you’re referencing must exist before
you include a natural key reference to that data.
To accommodate this limitation, calls to dumpdata that use the --natural option will serialize any model with a
natural_key() method before serializing standard primary key objects.
However, this may not always be enough. If your natural key refers to another object (by using a foreign key or natural
key to another object as part of a natural key), then you need to be able to ensure that the objects on which a natural
key depends occur in the serialized data before the natural key requires them.
To control this ordering, you can define dependencies on your natural_key() methods. You do this by setting a
dependencies attribute on the natural_key() method itself.
3.19. Serializing Django objects 417](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-421-2048.jpg)
![Django Documentation, Release 1.5.1
For example, let’s add a natural key to the Book model from the example above:
class Book(models.Model):
name = models.CharField(max_length=100)
author = models.ForeignKey(Person)
def natural_key(self):
return (self.name,) + self.author.natural_key()
The natural key for a Book is a combination of its name and its author. This means that Person must be serialized
before Book. To define this dependency, we add one extra line:
def natural_key(self):
return (self.name,) + self.author.natural_key()
natural_key.dependencies = [’example_app.person’]
This definition ensures that all Person objects are serialized before any Book objects. In turn, any object referencing
Book will be serialized after both Person and Book have been serialized.
3.20 Django settings
A Django settings file contains all the configuration of your Django installation. This document explains how settings
work and which settings are available.
3.20.1 The basics
A settings file is just a Python module with module-level variables.
Here are a couple of example settings:
DEBUG = False
DEFAULT_FROM_EMAIL = ’webmaster@example.com’
TEMPLATE_DIRS = (’/home/templates/mike’, ’/home/templates/john’)
Because a settings file is a Python module, the following apply:
• It doesn’t allow for Python syntax errors.
• It can assign settings dynamically using normal Python syntax. For example:
MY_SETTING = [str(i) for i in range(30)]
• It can import values from other settings files.
3.20.2 Designating the settings
DJANGO_SETTINGS_MODULE
When you use Django, you have to tell it which settings you’re using. Do this by using an environment variable,
DJANGO_SETTINGS_MODULE.
The value of DJANGO_SETTINGS_MODULE should be in Python path syntax, e.g. mysite.settings. Note that
the settings module should be on the Python import search path.
418 Chapter 3. Using Django](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-422-2048.jpg)
![Django Documentation, Release 1.5.1
The django-admin.py utility
When using django-admin.py, you can either set the environment variable once, or explicitly pass in the settings
module each time you run the utility.
Example (Unix Bash shell):
export DJANGO_SETTINGS_MODULE=mysite.settings
django-admin.py runserver
Example (Windows shell):
set DJANGO_SETTINGS_MODULE=mysite.settings
django-admin.py runserver
Use the --settings command-line argument to specify the settings manually:
django-admin.py runserver --settings=mysite.settings
On the server (mod_wsgi)
In your live server environment, you’ll need to tell your WSGI application what settings file to use. Do that with
os.environ:
import os
os.environ[’DJANGO_SETTINGS_MODULE’] = ’mysite.settings’
Read the Django mod_wsgi documentation for more information and other common elements to a Django WSGI
application.
3.20.3 Default settings
A Django settings file doesn’t have to define any settings if it doesn’t need to. Each setting has a sensible default value.
These defaults live in the module django/conf/global_settings.py.
Here’s the algorithm Django uses in compiling settings:
• Load settings from global_settings.py.
• Load settings from the specified settings file, overriding the global settings as necessary.
Note that a settings file should not import from global_settings, because that’s redundant.
Seeing which settings you’ve changed
There’s an easy way to view which of your settings deviate from the default settings. The command python
manage.py diffsettings displays differences between the current settings file and Django’s default settings.
For more, see the diffsettings documentation.
3.20.4 Using settings in Python code
In your Django apps, use settings by importing the object django.conf.settings. Example:
3.20. Django settings 419](https://image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-423-2048.jpg)






























































































































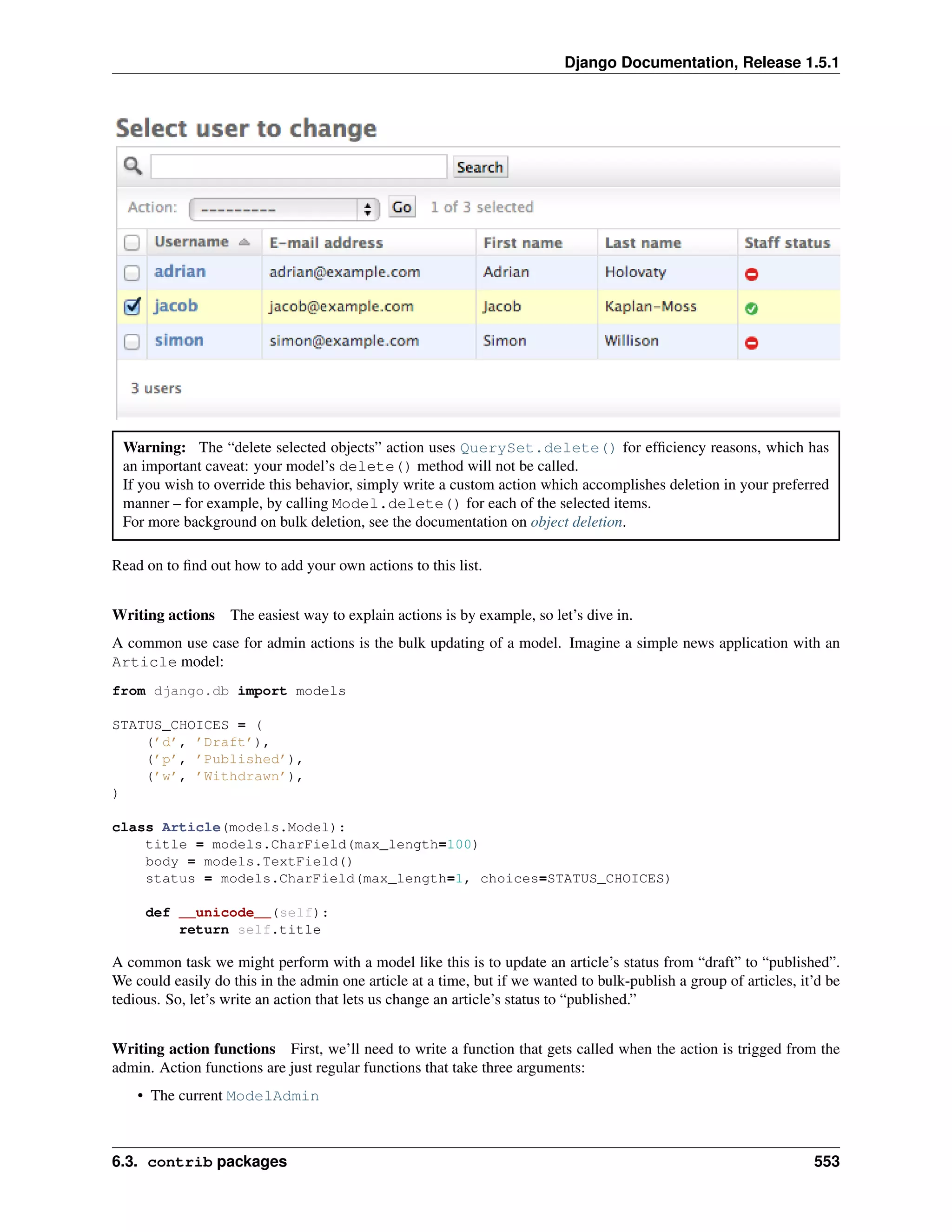

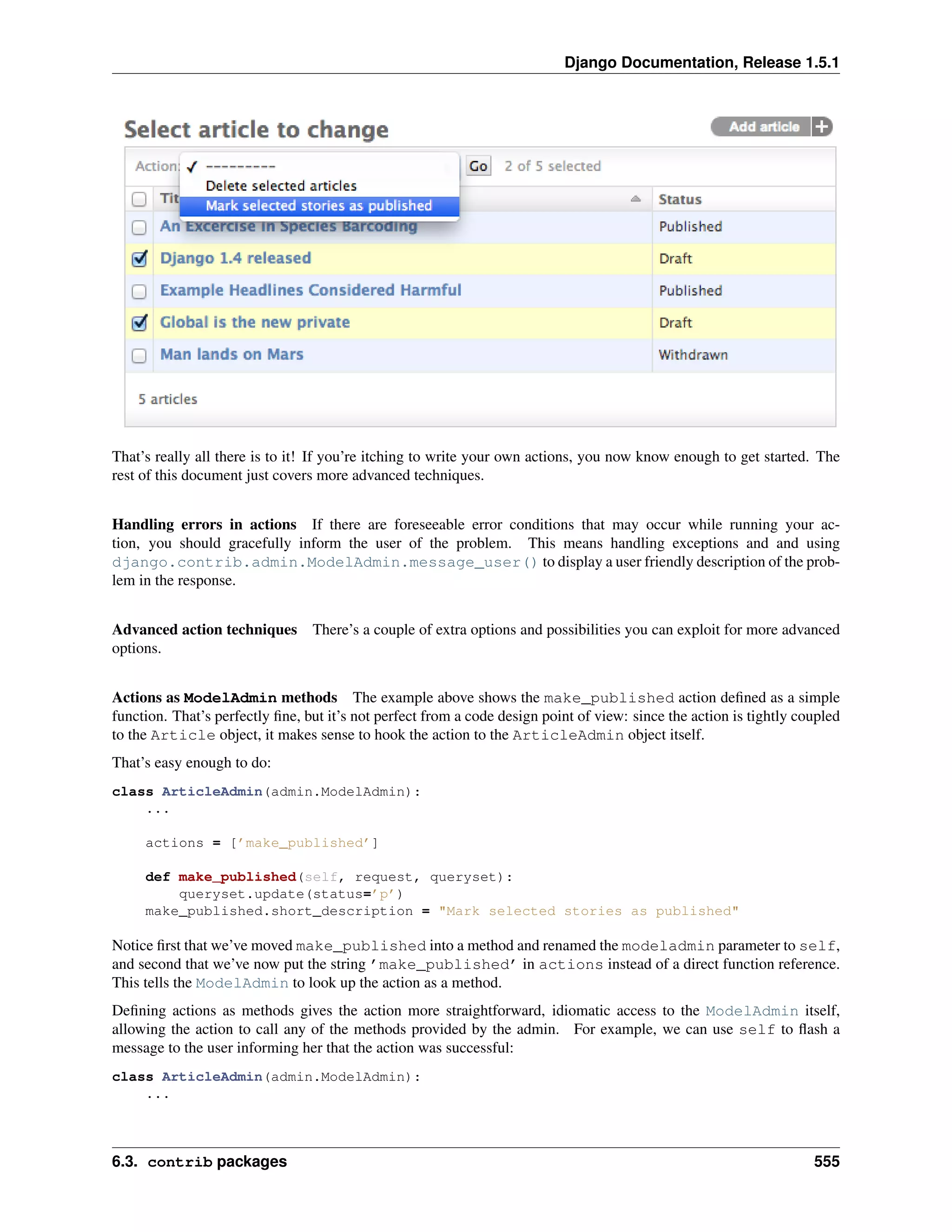
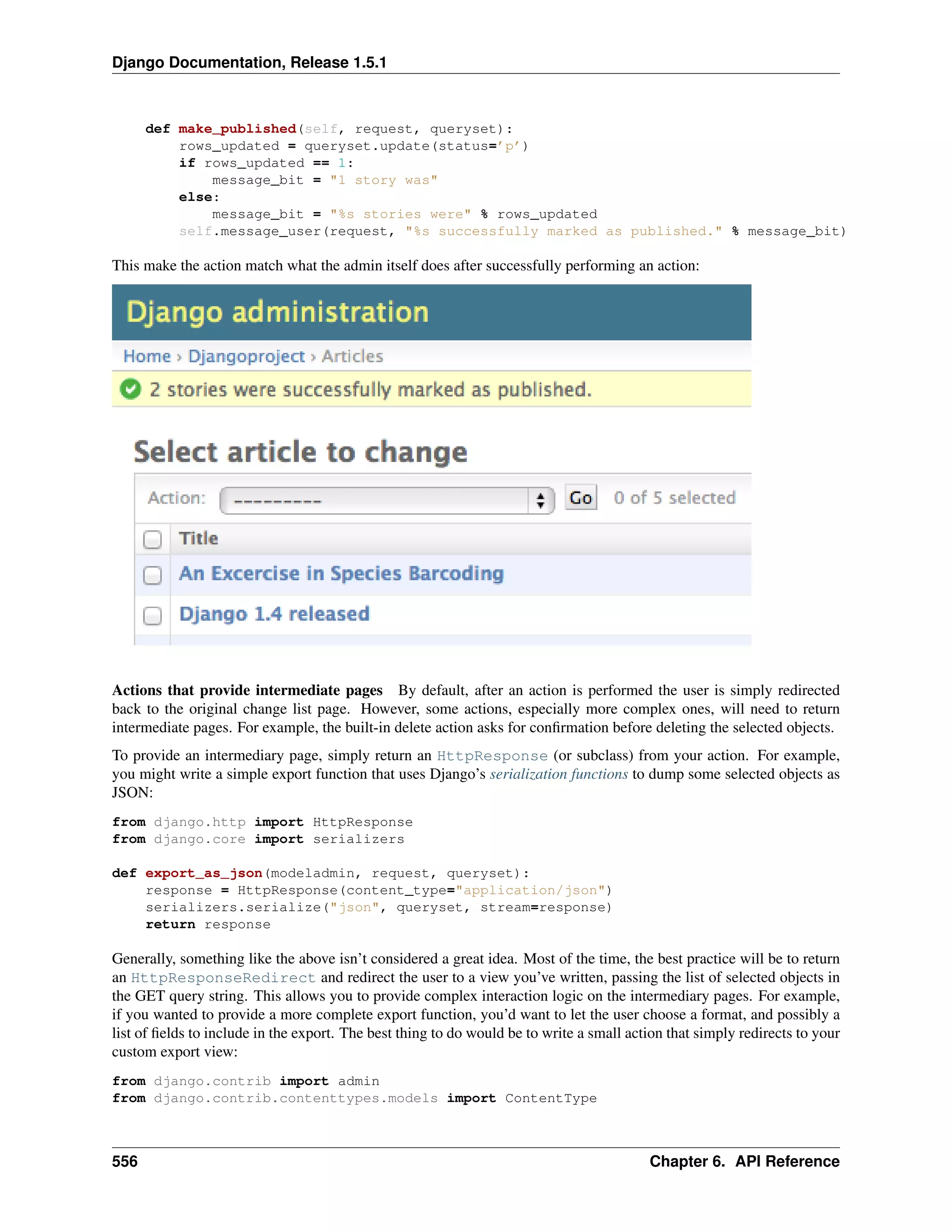








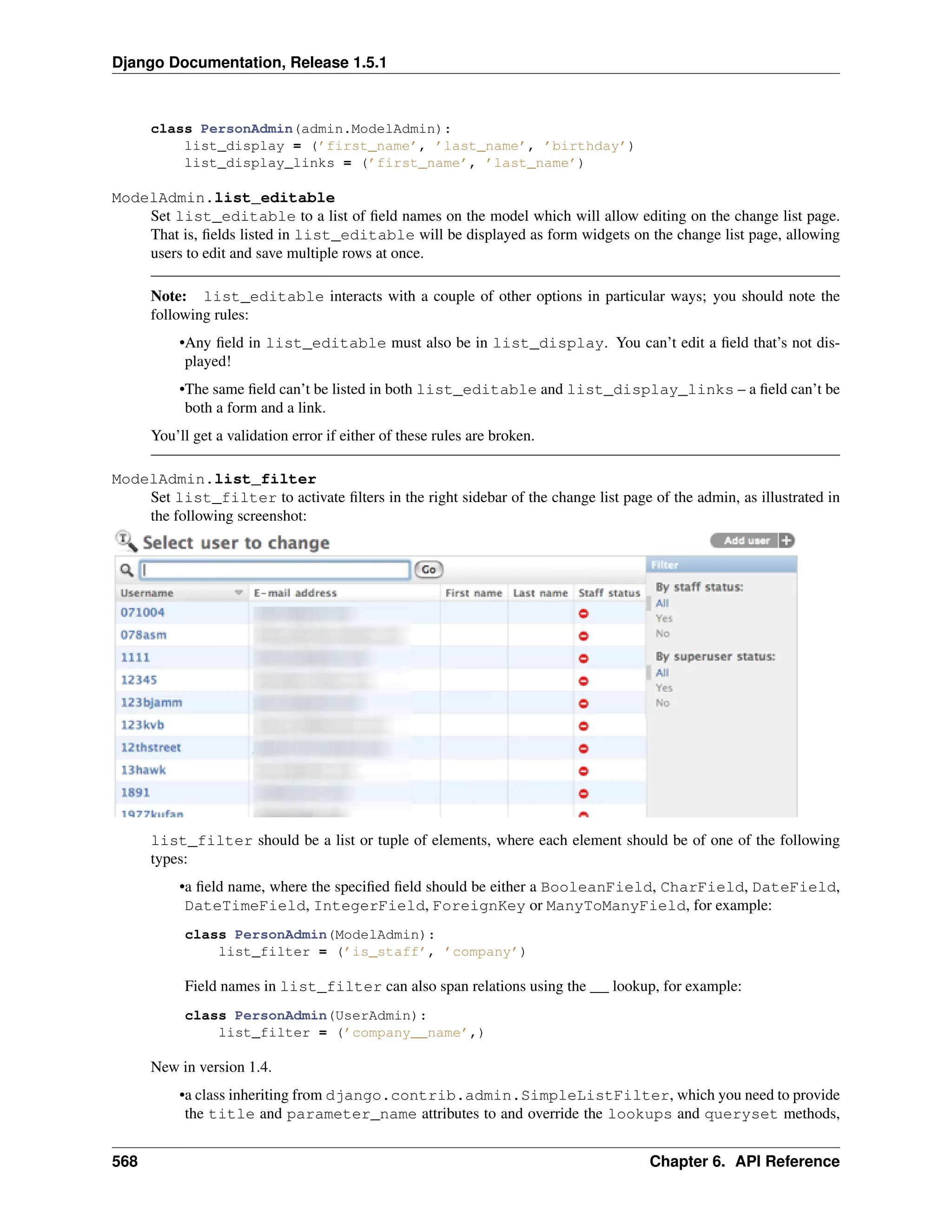










































































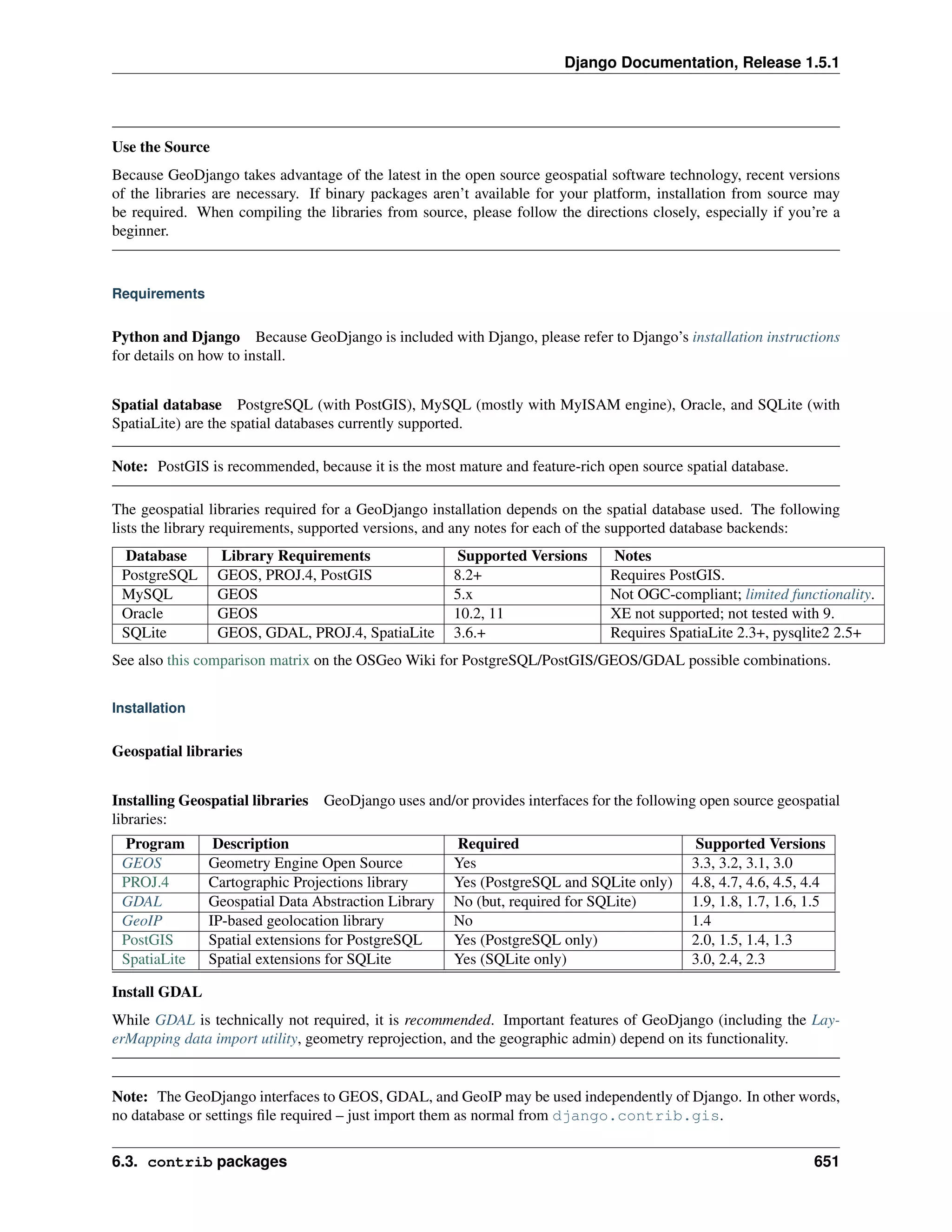
















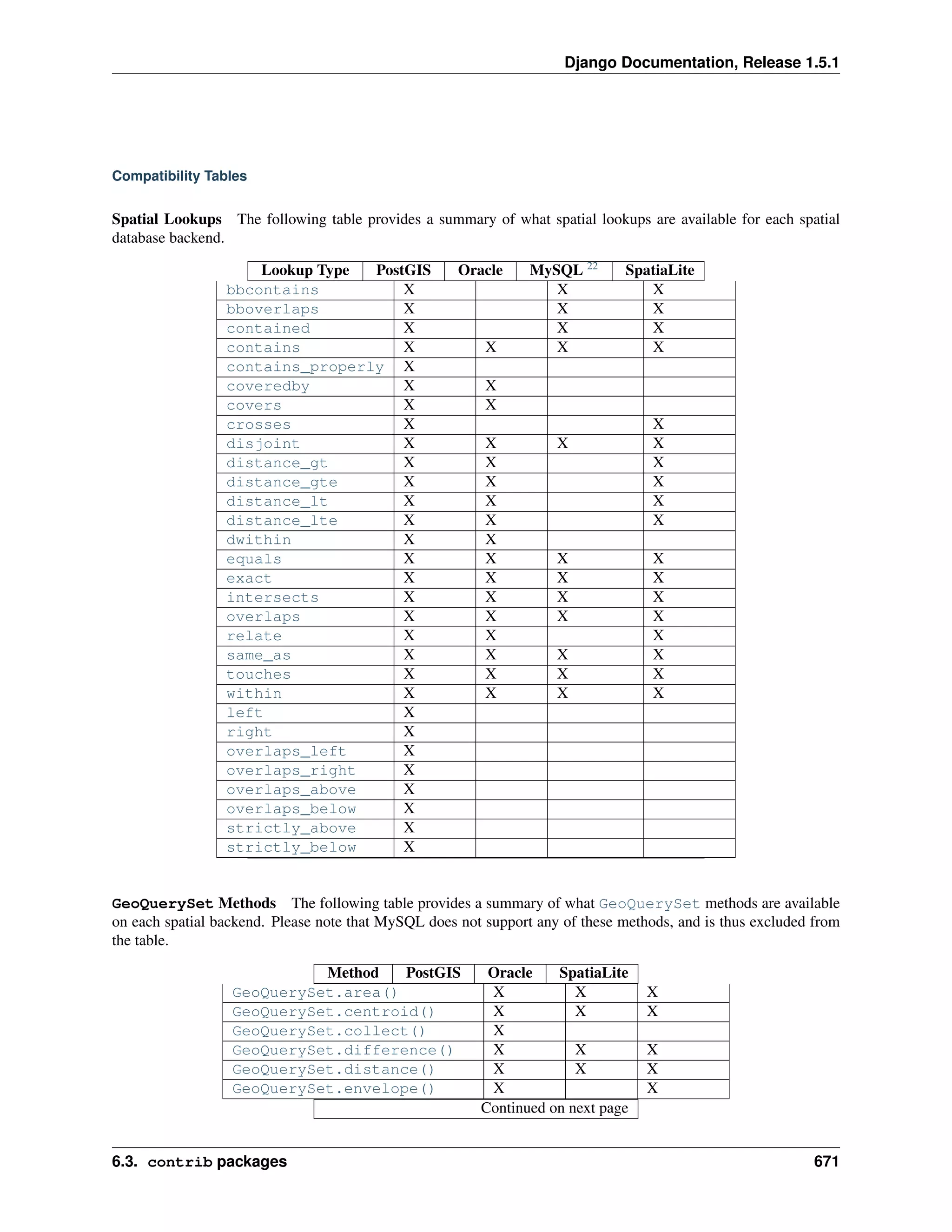
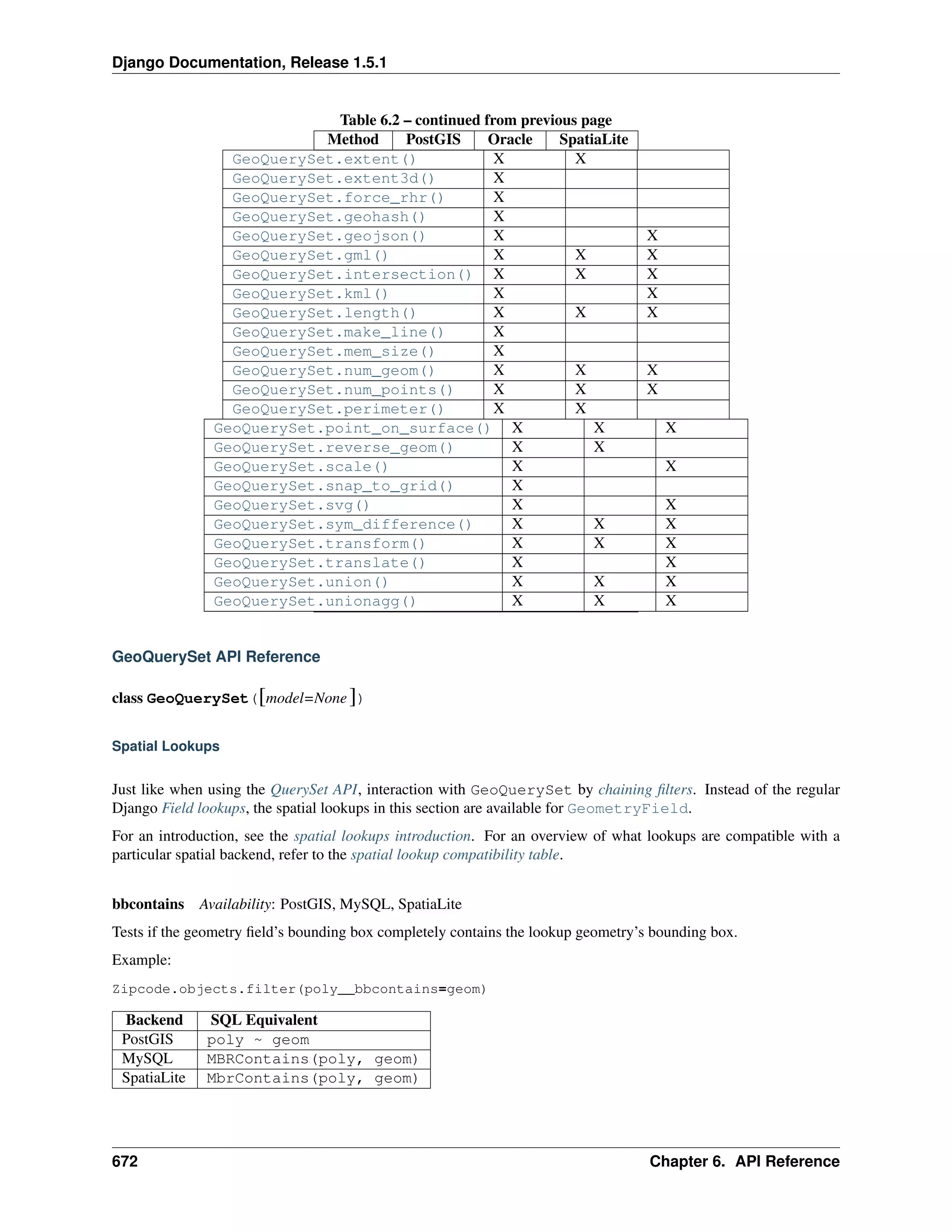








































































































































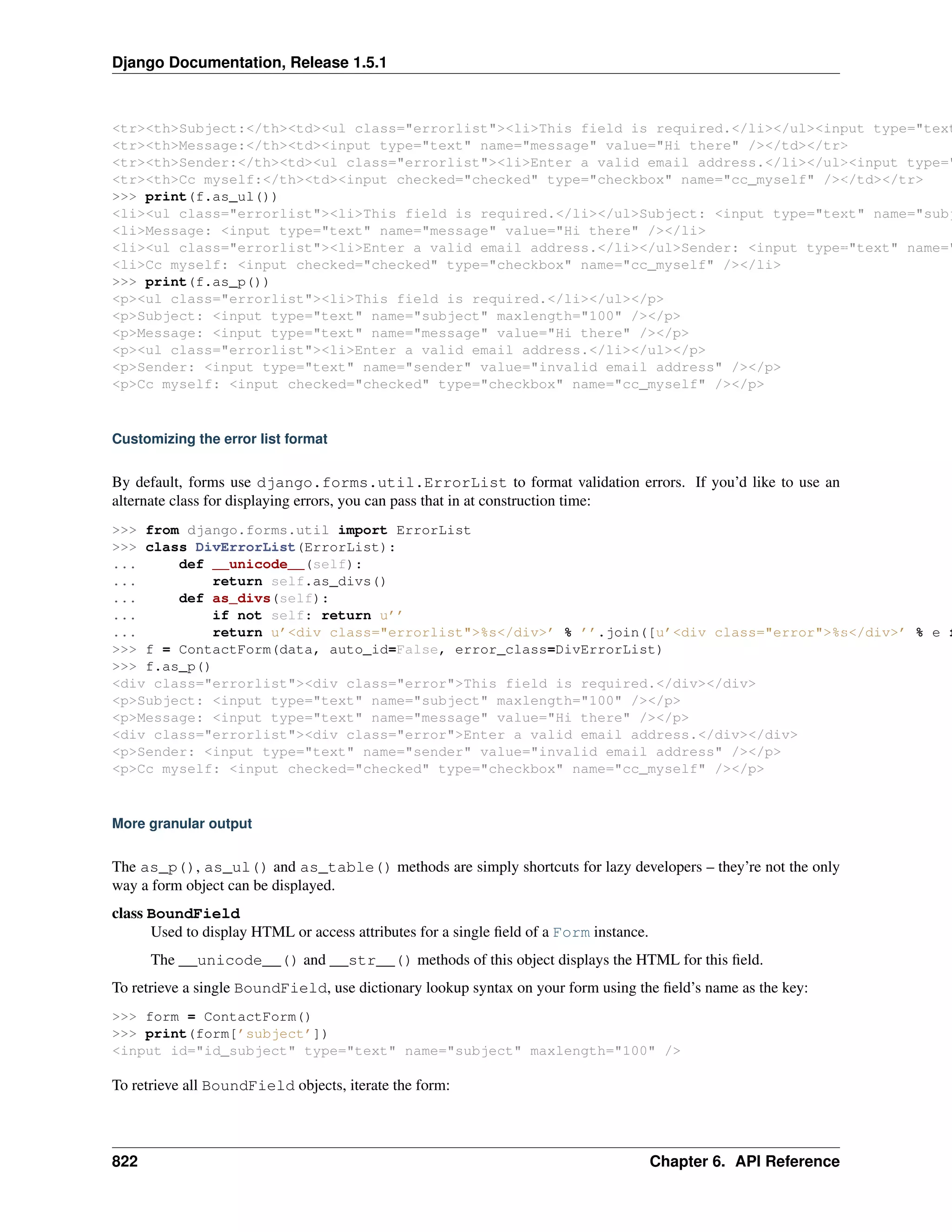























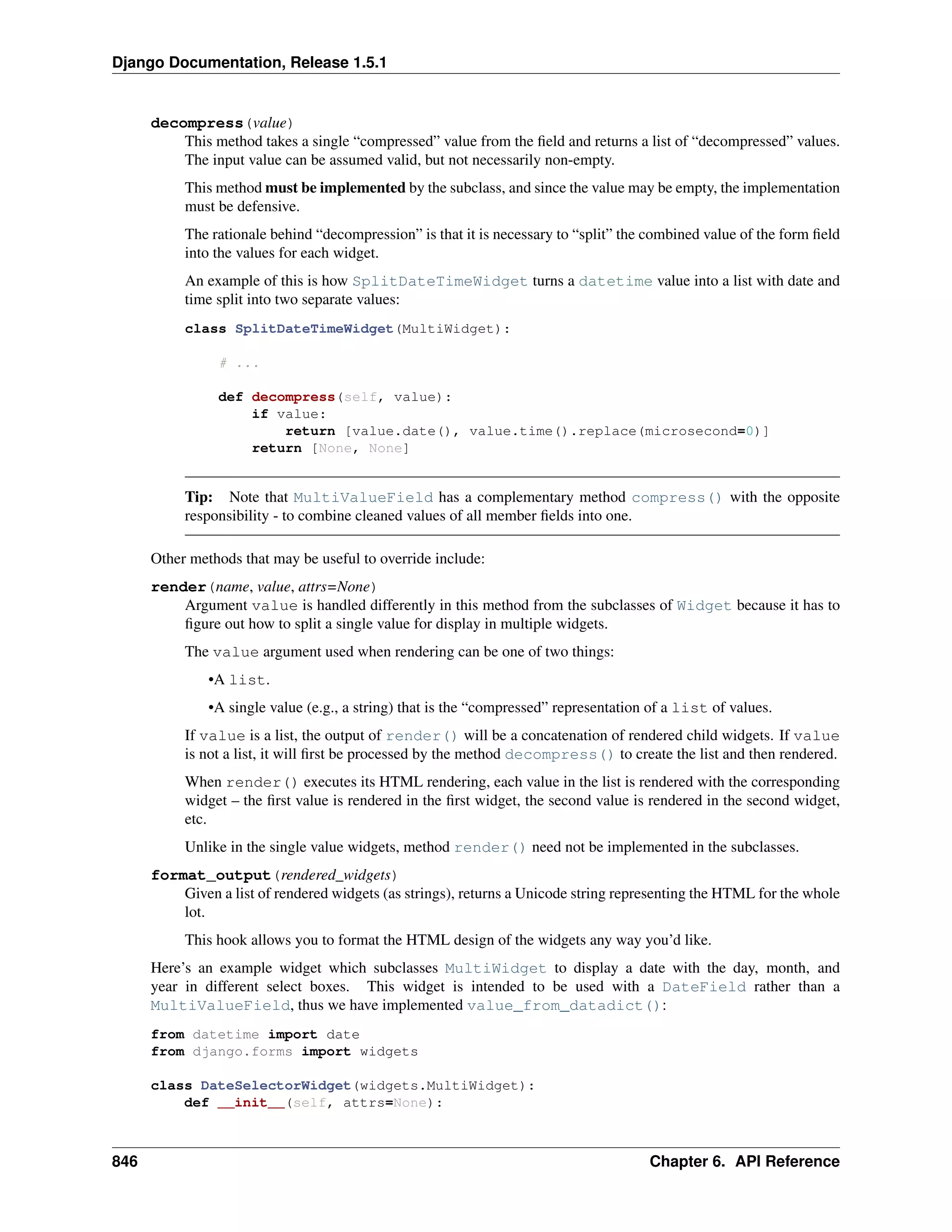














































































































































































































































































































































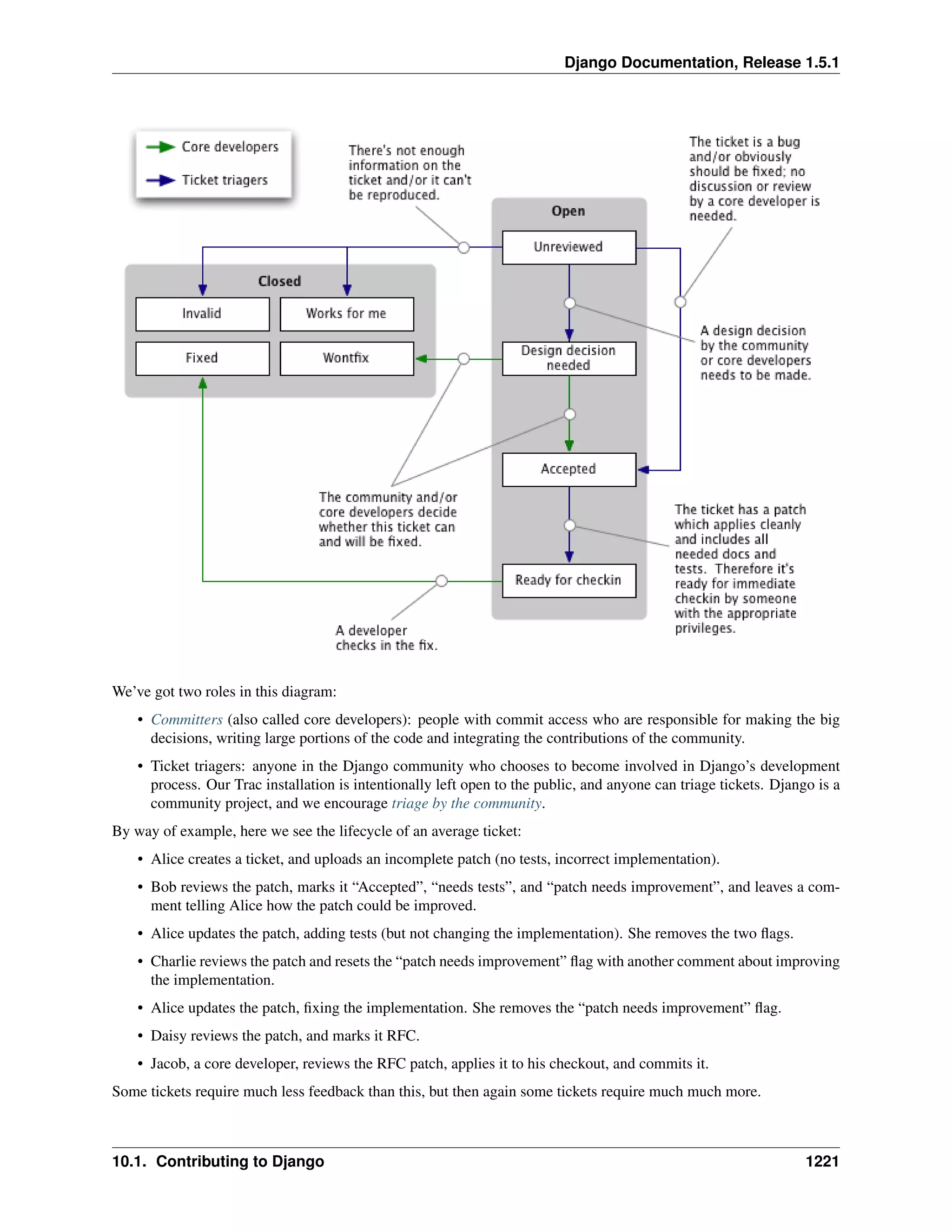























































![Django Documentation, Release 1.5.1
manage.py syncdb
The syncdb command looks at all your available models and creates tables in your database for whichever tables
don’t already exist.
2.1.3 Enjoy the free API
With that, you’ve got a free, and rich, Python API to access your data. The API is created on the fly, no code generation
necessary:
# Import the models we created from our "news" app
>>> from news.models import Reporter, Article
# No reporters are in the system yet.
>>> Reporter.objects.all()
[]
# Create a new Reporter.
>>> r = Reporter(full_name=’John Smith’)
# Save the object into the database. You have to call save() explicitly.
>>> r.save()
# Now it has an ID.
>>> r.id
1
# Now the new reporter is in the database.
>>> Reporter.objects.all()
[<Reporter: John Smith>]
# Fields are represented as attributes on the Python object.
>>> r.full_name
’John Smith’
# Django provides a rich database lookup API.
>>> Reporter.objects.get(id=1)
<Reporter: John Smith>
>>> Reporter.objects.get(full_name__startswith=’John’)
<Reporter: John Smith>
>>> Reporter.objects.get(full_name__contains=’mith’)
<Reporter: John Smith>
>>> Reporter.objects.get(id=2)
Traceback (most recent call last):
...
DoesNotExist: Reporter matching query does not exist. Lookup parameters were {’id’: 2}
# Create an article.
>>> from datetime import date
>>> a = Article(pub_date=date.today(), headline=’Django is cool’,
... content=’Yeah.’, reporter=r)
>>> a.save()
# Now the article is in the database.
>>> Article.objects.all()
[<Article: Django is cool>]
8 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-12-2048.jpg)
![Django Documentation, Release 1.5.1
# Article objects get API access to related Reporter objects.
>>> r = a.reporter
>>> r.full_name
’John Smith’
# And vice versa: Reporter objects get API access to Article objects.
>>> r.article_set.all()
[<Article: Django is cool>]
# The API follows relationships as far as you need, performing efficient
# JOINs for you behind the scenes.
# This finds all articles by a reporter whose name starts with "John".
>>> Article.objects.filter(reporter__full_name__startswith="John")
[<Article: Django is cool>]
# Change an object by altering its attributes and calling save().
>>> r.full_name = ’Billy Goat’
>>> r.save()
# Delete an object with delete().
>>> r.delete()
2.1.4 A dynamic admin interface: it’s not just scaffolding – it’s the whole house
Once your models are defined, Django can automatically create a professional, production ready administrative inter-face
– a Web site that lets authenticated users add, change and delete objects. It’s as easy as registering your model in
the admin site:
# In models.py...
from django.db import models
class Article(models.Model):
pub_date = models.DateField()
headline = models.CharField(max_length=200)
content = models.TextField()
reporter = models.ForeignKey(Reporter)
# In admin.py in the same directory...
import models
from django.contrib import admin
admin.site.register(models.Article)
The philosophy here is that your site is edited by a staff, or a client, or maybe just you – and you don’t want to have to
deal with creating backend interfaces just to manage content.
One typical workflow in creating Django apps is to create models and get the admin sites up and running as fast as
possible, so your staff (or clients) can start populating data. Then, develop the way data is presented to the public.
2.1.5 Design your URLs
A clean, elegant URL scheme is an important detail in a high-quality Web application. Django encourages beautiful
URL design and doesn’t put any cruft in URLs, like .php or .asp.
2.1. Django at a glance 9](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-13-2048.jpg)


![Django Documentation, Release 1.5.1
The next obvious steps are for you to download Django, read the tutorial and join the community. Thanks for your
interest!
2.2 Quick install guide
Before you can use Django, you’ll need to get it installed. We have a complete installation guide that covers all
the possibilities; this guide will guide you to a simple, minimal installation that’ll work while you walk through the
introduction.
2.2.1 Install Python
Being a Python Web framework, Django requires Python. It works with any Python version from 2.6.5 to 2.7. It also
features experimental support for versions 3.2 and 3.3. All these versions of Python include a lightweight database
called SQLite so you won’t need to set up a database just yet.
Get Python at http://www.python.org. If you’re running Linux or Mac OS X, you probably already have it installed.
Django on Jython
If you use Jython (a Python implementation for the Java platform), you’ll need to follow a few additional steps. See
Running Django on Jython for details.
You can verify that Python is installed by typing python from your shell; you should see something like:
Python 2.6.6 (r266:84292, Dec 26 2010, 22:31:48)
[GCC 4.4.5] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>>
2.2.2 Set up a database
This step is only necessary if you’d like to work with a “large” database engine like PostgreSQL, MySQL, or Oracle.
To install such a database, consult the database installation information.
2.2.3 Remove any old versions of Django
If you are upgrading your installation of Django from a previous version, you will need to uninstall the old Django
version before installing the new version.
2.2.4 Install Django
You’ve got three easy options to install Django:
• Install a version of Django provided by your operating system distribution. This is the quickest option for those
who have operating systems that distribute Django.
• Install an official release. This is the best approach for users who want a stable version number and aren’t
concerned about running a slightly older version of Django.
• Install the latest development version. This is best for users who want the latest-and-greatest features and aren’t
afraid of running brand-new code.
12 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-16-2048.jpg)







![Django Documentation, Release 1.5.1
project since the last time you ran syncdb. syncdb can be called as often as you like, and it will only ever create the
tables that don’t exist.
Read the django-admin.py documentation for full information on what the manage.py utility can do.
2.3.4 Playing with the API
Now, let’s hop into the interactive Python shell and play around with the free API Django gives you. To invoke the
Python shell, use this command:
python manage.py shell
We’re using this instead of simply typing “python”, because manage.py sets the DJANGO_SETTINGS_MODULE
environment variable, which gives Django the Python import path to your mysite/settings.py file.
Bypassing manage.py
If you’d rather not use manage.py, no problem. Just set the DJANGO_SETTINGS_MODULE environment variable
to mysite.settings and run python from the same directory manage.py is in (or ensure that directory is on
the Python path, so that import mysite works).
For more information on all of this, see the django-admin.py documentation.
Once you’re in the shell, explore the database API:
>>> from polls.models import Poll, Choice # Import the model classes we just wrote.
# No polls are in the system yet.
>>> Poll.objects.all()
[]
# Create a new Poll.
# Support for time zones is enabled in the default settings file, so
# Django expects a datetime with tzinfo for pub_date. Use timezone.now()
# instead of datetime.datetime.now() and it will do the right thing.
>>> from django.utils import timezone
>>> p = Poll(question="What’s new?", pub_date=timezone.now())
# Save the object into the database. You have to call save() explicitly.
>>> p.save()
# Now it has an ID. Note that this might say "1L" instead of "1", depending
# on which database you’re using. That’s no biggie; it just means your
# database backend prefers to return integers as Python long integer
# objects.
>>> p.id
1
# Access database columns via Python attributes.
>>> p.question
"What’s new?"
>>> p.pub_date
datetime.datetime(2012, 2, 26, 13, 0, 0, 775217, tzinfo=<UTC>)
# Change values by changing the attributes, then calling save().
>>> p.question = "What’s up?"
>>> p.save()
20 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-24-2048.jpg)
![Django Documentation, Release 1.5.1
# objects.all() displays all the polls in the database.
>>> Poll.objects.all()
[<Poll: Poll object>]
Wait a minute. <Poll: Poll object> is, utterly, an unhelpful representation of this object. Let’s fix that by
editing the polls model (in the polls/models.py file) and adding a __unicode__() method to both Poll and
Choice:
class Poll(models.Model):
# ...
def __unicode__(self):
return self.question
class Choice(models.Model):
# ...
def __unicode__(self):
return self.choice_text
It’s important to add __unicode__() methods to your models, not only for your own sanity when dealing with the
interactive prompt, but also because objects’ representations are used throughout Django’s automatically-generated
admin.
Why __unicode__() and not __str__()?
If you’re familiar with Python, you might be in the habit of adding __str__() methods to your classes, not
__unicode__() methods. We use __unicode__() here because Django models deal with Unicode by default.
All data stored in your database is converted to Unicode when it’s returned.
Django models have a default __str__() method that calls __unicode__() and converts the result to a UTF-8
bytestring. This means that unicode(p) will return a Unicode string, and str(p) will return a normal string, with
characters encoded as UTF-8.
If all of this is gibberish to you, just remember to add __unicode__() methods to your models. With any luck,
things should Just Work for you.
Note these are normal Python methods. Let’s add a custom method, just for demonstration:
import datetime
from django.utils import timezone
# ...
class Poll(models.Model):
# ...
def was_published_recently(self):
return self.pub_date >= timezone.now() - datetime.timedelta(days=1)
Note the addition of import datetime and from django.utils import timezone, to reference
Python’s standard datetime module and Django’s time-zone-related utilities in django.utils.timezone,
respectively. If you aren’t familiar with time zone handling in Python, you can learn more in the time zone support
docs.
Save these changes and start a new Python interactive shell by running python manage.py shell again:
>>> from polls.models import Poll, Choice
# Make sure our __unicode__() addition worked.
>>> Poll.objects.all()
[<Poll: What’s up?>]
2.3. Writing your first Django app, part 1 21](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-25-2048.jpg)
![Django Documentation, Release 1.5.1
# Django provides a rich database lookup API that’s entirely driven by
# keyword arguments.
>>> Poll.objects.filter(id=1)
[<Poll: What’s up?>]
>>> Poll.objects.filter(question__startswith=’What’)
[<Poll: What’s up?>]
# Get the poll that was published this year.
>>> from django.utils import timezone
>>> current_year = timezone.now().year
>>> Poll.objects.get(pub_date__year=current_year)
<Poll: What’s up?>
# Request an ID that doesn’t exist, this will raise an exception.
>>> Poll.objects.get(id=2)
Traceback (most recent call last):
...
DoesNotExist: Poll matching query does not exist. Lookup parameters were {’id’: 2}
# Lookup by a primary key is the most common case, so Django provides a
# shortcut for primary-key exact lookups.
# The following is identical to Poll.objects.get(id=1).
>>> Poll.objects.get(pk=1)
<Poll: What’s up?>
# Make sure our custom method worked.
>>> p = Poll.objects.get(pk=1)
>>> p.was_published_recently()
True
# Give the Poll a couple of Choices. The create call constructs a new
# Choice object, does the INSERT statement, adds the choice to the set
# of available choices and returns the new Choice object. Django creates
# a set to hold the "other side" of a ForeignKey relation
# (e.g. a poll’s choices) which can be accessed via the API.
>>> p = Poll.objects.get(pk=1)
# Display any choices from the related object set -- none so far.
>>> p.choice_set.all()
[]
# Create three choices.
>>> p.choice_set.create(choice_text=’Not much’, votes=0)
<Choice: Not much>
>>> p.choice_set.create(choice_text=’The sky’, votes=0)
<Choice: The sky>
>>> c = p.choice_set.create(choice_text=’Just hacking again’, votes=0)
# Choice objects have API access to their related Poll objects.
>>> c.poll
<Poll: What’s up?>
# And vice versa: Poll objects get access to Choice objects.
>>> p.choice_set.all()
[<Choice: Not much>, <Choice: The sky>, <Choice: Just hacking again>]
>>> p.choice_set.count()
3
22 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-26-2048.jpg)
![Django Documentation, Release 1.5.1
# The API automatically follows relationships as far as you need.
# Use double underscores to separate relationships.
# This works as many levels deep as you want; there’s no limit.
# Find all Choices for any poll whose pub_date is in this year
# (reusing the ’current_year’ variable we created above).
>>> Choice.objects.filter(poll__pub_date__year=current_year)
[<Choice: Not much>, <Choice: The sky>, <Choice: Just hacking again>]
# Let’s delete one of the choices. Use delete() for that.
>>> c = p.choice_set.filter(choice_text__startswith=’Just hacking’)
>>> c.delete()
For more information on model relations, see Accessing related objects. For more on how to use double underscores
to perform field lookups via the API, see Field lookups. For full details on the database API, see our Database API
reference.
When you’re comfortable with the API, read part 2 of this tutorial to get Django’s automatic admin working.
2.4 Writing your first Django app, part 2
This tutorial begins where Tutorial 1 left off. We’re continuing the Web-poll application and will focus on Django’s
automatically-generated admin site.
Philosophy
Generating admin sites for your staff or clients to add, change and delete content is tedious work that doesn’t require
much creativity. For that reason, Django entirely automates creation of admin interfaces for models.
Django was written in a newsroom environment, with a very clear separation between “content publishers” and the
“public” site. Site managers use the system to add news stories, events, sports scores, etc., and that content is displayed
on the public site. Django solves the problem of creating a unified interface for site administrators to edit content.
The admin isn’t intended to be used by site visitors. It’s for site managers.
2.4.1 Activate the admin site
The Django admin site is not activated by default – it’s an opt-in thing. To activate the admin site for your installation,
do these three things:
• Uncomment "django.contrib.admin" in the INSTALLED_APPS setting.
• Run python manage.py syncdb. Since you have added a new application to INSTALLED_APPS, the
database tables need to be updated.
• Edit your mysite/urls.py file and uncomment the lines that reference the admin – there are three lines in
total to uncomment. This file is a URLconf; we’ll dig into URLconfs in the next tutorial. For now, all you need
to know is that it maps URL roots to applications. In the end, you should have a urls.py file that looks like
this:
from django.conf.urls import patterns, include, url
# Uncomment the next two lines to enable the admin:
from django.contrib import admin
admin.autodiscover()
2.4. Writing your first Django app, part 2 23](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-27-2048.jpg)



![Django Documentation, Release 1.5.1
2.4.6 Customize the admin form
Take a few minutes to marvel at all the code you didn’t have to write. By registering the Poll model with
admin.site.register(Poll), Django was able to construct a default form representation. Often, you’ll want
to customize how the admin form looks and works. You’ll do this by telling Django the options you want when you
register the object.
Let’s see how this works by re-ordering the fields on the edit form. Replace the admin.site.register(Poll)
line with:
class PollAdmin(admin.ModelAdmin):
fields = [’pub_date’, ’question’]
admin.site.register(Poll, PollAdmin)
You’ll follow this pattern – create a model admin object, then pass it as the second argument to
admin.site.register() – any time you need to change the admin options for an object.
This particular change above makes the “Publication date” come before the “Question” field:
This isn’t impressive with only two fields, but for admin forms with dozens of fields, choosing an intuitive order is an
important usability detail.
And speaking of forms with dozens of fields, you might want to split the form up into fieldsets:
2.4. Writing your first Django app, part 2 27](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-31-2048.jpg)
![Django Documentation, Release 1.5.1
class PollAdmin(admin.ModelAdmin):
fieldsets = [
(None, {’fields’: [’question’]}),
(’Date information’, {’fields’: [’pub_date’]}),
]
admin.site.register(Poll, PollAdmin)
The first element of each tuple in fieldsets is the title of the fieldset. Here’s what our form looks like now:
You can assign arbitrary HTML classes to each fieldset. Django provides a "collapse" class that displays a
particular fieldset initially collapsed. This is useful when you have a long form that contains a number of fields that
aren’t commonly used:
class PollAdmin(admin.ModelAdmin):
fieldsets = [
(None, {’fields’: [’question’]}),
(’Date information’, {’fields’: [’pub_date’], ’classes’: [’collapse’]}),
]
28 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-32-2048.jpg)

![Django Documentation, Release 1.5.1
class PollAdmin(admin.ModelAdmin):
fieldsets = [
(None, {’fields’: [’question’]}),
(’Date information’, {’fields’: [’pub_date’], ’classes’: [’collapse’]}),
]
inlines = [ChoiceInline]
admin.site.register(Poll, PollAdmin)
This tells Django: “Choice objects are edited on the Poll admin page. By default, provide enough fields for 3
choices.”
Load the “Add poll” page to see how that looks, you may need to restart your development server:
It works like this: There are three slots for related Choices – as specified by extra – and each time you come back
to the “Change” page for an already-created object, you get another three extra slots.
At the end of the three current slots you will find an “Add another Choice” link. If you click on it, a new slot will be
added. If you want to remove the added slot, you can click on the X to the top right of the added slot. Note that you
can’t remove the original three slots. This image shows an added slot:
30 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-34-2048.jpg)

![Django Documentation, Release 1.5.1
By default, Django displays the str() of each object. But sometimes it’d be more helpful if we could display
individual fields. To do that, use the list_display admin option, which is a tuple of field names to display, as
columns, on the change list page for the object:
class PollAdmin(admin.ModelAdmin):
# ...
list_display = (’question’, ’pub_date’)
Just for good measure, let’s also include the was_published_recently custom method from Tutorial 1:
class PollAdmin(admin.ModelAdmin):
# ...
list_display = (’question’, ’pub_date’, ’was_published_recently’)
Now the poll change list page looks like this:
You can click on the column headers to sort by those values – except in the case of the was_published_recently
header, because sorting by the output of an arbitrary method is not supported. Also note that the column header for
was_published_recently is, by default, the name of the method (with underscores replaced with spaces), and
that each line contains the string representation of the output.
You can improve that by giving that method (in polls/models.py) a few attributes, as follows:
class Poll(models.Model):
# ...
def was_published_recently(self):
return self.pub_date >= timezone.now() - datetime.timedelta(days=1)
was_published_recently.admin_order_field = ’pub_date’
was_published_recently.boolean = True
was_published_recently.short_description = ’Published recently?’
Edit your polls/admin.py file again and add an improvement to the Poll change list page: Filters. Add the
following line to PollAdmin:
list_filter = [’pub_date’]
32 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-36-2048.jpg)
![Django Documentation, Release 1.5.1
That adds a “Filter” sidebar that lets people filter the change list by the pub_date field:
The type of filter displayed depends on the type of field you’re filtering on. Because pub_date is a
DateTimeField, Django knows to give appropriate filter options: “Any date,” “Today,” “Past 7 days,” “This
month,” “This year.”
This is shaping up well. Let’s add some search capability:
search_fields = [’question’]
That adds a search box at the top of the change list. When somebody enters search terms, Django will search the
question field. You can use as many fields as you’d like – although because it uses a LIKE query behind the
scenes, keep it reasonable, to keep your database happy.
Finally, because Poll objects have dates, it’d be convenient to be able to drill down by date. Add this line:
date_hierarchy = ’pub_date’
That adds hierarchical navigation, by date, to the top of the change list page. At top level, it displays all available
years. Then it drills down to months and, ultimately, days.
Now’s also a good time to note that change lists give you free pagination. The default is to display 100 items per page.
Change-list pagination, search boxes, filters, date-hierarchies and column-header-ordering all work together like you
think they should.
2.4.9 Customize the admin look and feel
Clearly, having “Django administration” at the top of each admin page is ridiculous. It’s just placeholder text.
That’s easy to change, though, using Django’s template system. The Django admin is powered by Django itself, and
its interfaces use Django’s own template system.
Customizing your project’s templates
Create a templates directory in your project directory. Templates can live anywhere on your filesystem that Django
can access. (Django runs as whatever user your server runs.) However, keeping your templates within the project is a
good convention to follow.
Open your settings file (mysite/settings.py, remember) and add a TEMPLATE_DIRS setting:
TEMPLATE_DIRS = (
’/path/to/mysite/templates’, # Change this to your own directory.
)
Now copy the template admin/base_site.html from within the default Django admin tem-plate
directory in the source code of Django itself (django/contrib/admin/templates)
2.4. Writing your first Django app, part 2 33](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-37-2048.jpg)
![Django Documentation, Release 1.5.1
into an admin subdirectory of whichever directory you’re using in TEMPLATE_DIRS.
For example, if your TEMPLATE_DIRS includes ’/path/to/mysite/templates’, as
above, then copy django/contrib/admin/templates/admin/base_site.html to
/path/to/mysite/templates/admin/base_site.html. Don’t forget that admin subdirectory.
Where are the Django source files?
If you have difficulty finding where the Django source files are located on your system, run the following command:
python -c "
import sys
sys.path = sys.path[1:]
import django
print(django.__path__)"
Then, just edit the file and replace the generic Django text with your own site’s name as you see fit.
This template file contains lots of text like {% block branding %} and {{ title }}. The {% and {{ tags
are part of Django’s template language. When Django renders admin/base_site.html, this template language
will be evaluated to produce the final HTML page. Don’t worry if you can’t make any sense of the template right now
– we’ll delve into Django’s templating language in Tutorial 3.
Note that any of Django’s default admin templates can be overridden. To override a template, just do the same thing
you did with base_site.html – copy it from the default directory into your custom directory, and make changes.
Customizing your application’s templates
Astute readers will ask: But if TEMPLATE_DIRS was empty by default, how was Django finding the default admin
templates? The answer is that, by default, Django automatically looks for a templates/ subdirectory within each
application package, for use as a fallback (don’t forget that django.contrib.admin is an application).
Our poll application is not very complex and doesn’t need custom admin templates. But if it grew more sophisticated
and required modification of Django’s standard admin templates for some of its functionality, it would be more sensible
to modify the application’s templates, rather than those in the project. That way, you could include the polls application
in any new project and be assured that it would find the custom templates it needed.
See the template loader documentation for more information about how Django finds its templates.
2.4.10 Customize the admin index page
On a similar note, you might want to customize the look and feel of the Django admin index page.
By default, it displays all the apps in INSTALLED_APPS that have been registered with the admin application, in
alphabetical order. You may want to make significant changes to the layout. After all, the index is probably the most
important page of the admin, and it should be easy to use.
The template to customize is admin/index.html. (Do the same as with admin/base_site.html in the
previous section – copy it from the default directory to your custom template directory.) Edit the file, and you’ll see it
uses a template variable called app_list. That variable contains every installed Django app. Instead of using that,
you can hard-code links to object-specific admin pages in whatever way you think is best. Again, don’t worry if you
can’t understand the template language – we’ll cover that in more detail in Tutorial 3.
When you’re comfortable with the admin site, read part 3 of this tutorial to start working on public poll views.
34 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-38-2048.jpg)



![Django Documentation, Release 1.5.1
Note that the regular expressions for the include() functions don’t have a $ (end-of-string match character) but
rather a trailing slash. Whenever Django encounters include(), it chops off whatever part of the URL matched up
to that point and sends the remaining string to the included URLconf for further processing.
The idea behind include() is to make it easy to plug-and-play URLs. Since polls are in their own URLconf
(polls/urls.py), they can be placed under “/polls/”, or under “/fun_polls/”, or under “/content/polls/”, or any
other path root, and the app will still work.
Here’s what happens if a user goes to “/polls/34/” in this system:
• Django will find the match at ’^polls/’
• Then, Django will strip off the matching text ("polls/") and send the remaining text – "34/" – to the
‘polls.urls’ URLconf for further processing which matches r’^(?P<poll_id>d+)/$’ resulting in a call
to the detail() view like so:
detail(request=<HttpRequest object>, poll_id=’34’)
The poll_id=’34’ part comes from (?P<poll_id>d+). Using parentheses around a pattern “captures” the
text matched by that pattern and sends it as an argument to the view function; ?P<poll_id> defines the name that
will be used to identify the matched pattern; and d+ is a regular expression to match a sequence of digits (i.e., a
number).
Because the URL patterns are regular expressions, there really is no limit on what you can do with them. And there’s
no need to add URL cruft such as .html – unless you want to, in which case you can do something like this:
(r’^polls/latest.html$’, ’polls.views.index’),
But, don’t do that. It’s silly.
2.5.4 Write views that actually do something
Each view is responsible for doing one of two things: returning an HttpResponse object containing the content for
the requested page, or raising an exception such as Http404. The rest is up to you.
Your view can read records from a database, or not. It can use a template system such as Django’s – or a third-party
Python template system – or not. It can generate a PDF file, output XML, create a ZIP file on the fly, anything you
want, using whatever Python libraries you want.
All Django wants is that HttpResponse. Or an exception.
Because it’s convenient, let’s use Django’s own database API, which we covered in Tutorial 1. Here’s one stab at
the index() view, which displays the latest 5 poll questions in the system, separated by commas, according to
publication date:
from django.http import HttpResponse
from polls.models import Poll
def index(request):
latest_poll_list = Poll.objects.order_by(’-pub_date’)[:5]
output = ’, ’.join([p.question for p in latest_poll_list])
return HttpResponse(output)
There’s a problem here, though: the page’s design is hard-coded in the view. If you want to change the way the page
looks, you’ll have to edit this Python code. So let’s use Django’s template system to separate the design from Python
by creating a template that the view can use.
First, create a directory called templates in your polls directory. Django will look for templates in there.
38 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-42-2048.jpg)
![Django Documentation, Release 1.5.1
Django’s TEMPLATE_LOADERS setting contains a list of callables that know how to import templates from various
sources. One of the defaults is django.template.loaders.app_directories.Loader which looks for
a “templates” subdirectory in each of the INSTALLED_APPS - this is how Django knows to find the polls templates
even though we didn’t modify TEMPLATE_DIRS, as we did in Tutorial 2.
Organizing templates
We could have all our templates together, in one big templates directory, and it would work perfectly well. However,
this template belongs to the polls application, so unlike the admin template we created in the previous tutorial, we’ll
put this one in the application’s template directory (polls/templates) rather than the project’s (templates).
We’ll discuss in more detail in the reusable apps tutorial why we do this.
Within the templates directory you have just created, create another directory called polls,
and within that create a file called index.html. In other words, your template should be at
polls/templates/polls/index.html. Because of how the app_directories template loader
works as described above, you can refer to this template within Django simply as polls/index.html.
Template namespacing
Now we might be able to get away with putting our templates directly in polls/templates (rather than creating
another polls subdirectory), but it would actually be a bad idea. Django will choose the first template it finds whose
name matches, and if you had a template with the same name in a different application, Django would be unable to
distinguish between them. We need to be able to point Django at the right one, and the easiest way to ensure this is by
namespacing them. That is, by putting those templates inside another directory named for the application itself.
Put the following code in that template:
{% if latest_poll_list %}
<ul>
{% for poll in latest_poll_list %}
<li><a href="/polls/{{ poll.id }}/">{{ poll.question }}</a></li>
{% endfor %}
</ul>
{% else %}
<p>No polls are available.</p>
{% endif %}
Now let’s use that html template in our index view:
from django.http import HttpResponse
from django.template import Context, loader
from polls.models import Poll
def index(request):
latest_poll_list = Poll.objects.order_by(’-pub_date’)[:5]
template = loader.get_template(’polls/index.html’)
context = Context({
’latest_poll_list’: latest_poll_list,
})
return HttpResponse(template.render(context))
That code loads the template called polls/index.html and passes it a context. The context is a dictionary
mapping template variable names to Python objects.
Load the page by pointing your browser at “/polls/”, and you should see a bulleted-list containing the “What’s up” poll
from Tutorial 1. The link points to the poll’s detail page.
2.5. Writing your first Django app, part 3 39](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-43-2048.jpg)
![Django Documentation, Release 1.5.1
A shortcut: render()
It’s a very common idiom to load a template, fill a context and return an HttpResponse object with the result of the
rendered template. Django provides a shortcut. Here’s the full index() view, rewritten:
from django.shortcuts import render
from polls.models import Poll
def index(request):
latest_poll_list = Poll.objects.all().order_by(’-pub_date’)[:5]
context = {’latest_poll_list’: latest_poll_list}
return render(request, ’polls/index.html’, context)
Note that once we’ve done this in all these views, we no longer need to import loader, Context and
HttpResponse (you’ll want to keep HttpResponse if you still have the stub methods for detail, results,
and vote).
The render() function takes the request object as its first argument, a template name as its second argument and a
dictionary as its optional third argument. It returns an HttpResponse object of the given template rendered with
the given context.
2.5.5 Raising a 404 error
Now, let’s tackle the poll detail view – the page that displays the question for a given poll. Here’s the view:
from django.http import Http404
# ...
def detail(request, poll_id):
try:
poll = Poll.objects.get(pk=poll_id)
except Poll.DoesNotExist:
raise Http404
return render(request, ’polls/detail.html’, {’poll’: poll})
The new concept here: The view raises the Http404 exception if a poll with the requested ID doesn’t exist.
We’ll discuss what you could put in that polls/detail.html template a bit later, but if you’d like to quickly get
the above example working, a file containing just:
{{ poll }}
will get you started for now.
A shortcut: get_object_or_404()
It’s a very common idiom to use get() and raise Http404 if the object doesn’t exist. Django provides a shortcut.
Here’s the detail() view, rewritten:
from django.shortcuts import render, get_object_or_404
# ...
def detail(request, poll_id):
poll = get_object_or_404(Poll, pk=poll_id)
return render(request, ’polls/detail.html’, {’poll’: poll})
40 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-44-2048.jpg)



![Django Documentation, Release 1.5.1
form will alter data server-side. Whenever you create a form that alters data server-side, use method="post".
This tip isn’t specific to Django; it’s just good Web development practice.
• forloop.counter indicates how many times the for tag has gone through its loop
• Since we’re creating a POST form (which can have the effect of modifying data), we need to worry about Cross
Site Request Forgeries. Thankfully, you don’t have to worry too hard, because Django comes with a very easy-to-
use system for protecting against it. In short, all POST forms that are targeted at internal URLs should use
the {% csrf_token %} template tag.
Now, let’s create a Django view that handles the submitted data and does something with it. Remember, in Tutorial 3,
we created a URLconf for the polls application that includes this line:
url(r’^(?P<poll_id>d+)/vote/$’, views.vote, name=’vote’),
We also created a dummy implementation of the vote() function. Let’s create a real version. Add the following to
polls/views.py:
from django.shortcuts import get_object_or_404, render
from django.http import HttpResponseRedirect, HttpResponse
from django.core.urlresolvers import reverse
from polls.models import Choice, Poll
# ...
def vote(request, poll_id):
p = get_object_or_404(Poll, pk=poll_id)
try:
selected_choice = p.choice_set.get(pk=request.POST[’choice’])
except (KeyError, Choice.DoesNotExist):
# Redisplay the poll voting form.
return render(request, ’polls/detail.html’, {
’poll’: p,
’error_message’: "You didn’t select a choice.",
})
else:
selected_choice.votes += 1
selected_choice.save()
# Always return an HttpResponseRedirect after successfully dealing
# with POST data. This prevents data from being posted twice if a
# user hits the Back button.
return HttpResponseRedirect(reverse(’polls:results’, args=(p.id,)))
This code includes a few things we haven’t covered yet in this tutorial:
• request.POST is a dictionary-like object that lets you access submitted data by key name. In this case,
request.POST[’choice’] returns the ID of the selected choice, as a string. request.POST values are
always strings.
Note that Django also provides request.GET for accessing GET data in the same way – but we’re explicitly
using request.POST in our code, to ensure that data is only altered via a POST call.
• request.POST[’choice’] will raise KeyError if choice wasn’t provided in POST data. The above
code checks for KeyError and redisplays the poll form with an error message if choice isn’t given.
• After incrementing the choice count, the code returns an HttpResponseRedirect rather than a normal
HttpResponse. HttpResponseRedirect takes a single argument: the URL to which the user will be
redirected (see the following point for how we construct the URL in this case).
As the Python comment above points out, you should always return an HttpResponseRedirect after
successfully dealing with POST data. This tip isn’t specific to Django; it’s just goodWeb development practice.
44 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-48-2048.jpg)

![Django Documentation, Release 1.5.1
Generally, when writing a Django app, you’ll evaluate whether generic views are a good fit for your problem, and
you’ll use them from the beginning, rather than refactoring your code halfway through. But this tutorial intentionally
has focused on writing the views “the hard way” until now, to focus on core concepts.
You should know basic math before you start using a calculator.
Amend URLconf
First, open the polls/urls.py URLconf and change it like so:
from django.conf.urls import patterns, url
from django.views.generic import DetailView, ListView
from polls.models import Poll
urlpatterns = patterns(’’,
url(r’^$’,
ListView.as_view(
queryset=Poll.objects.order_by(’-pub_date’)[:5],
context_object_name=’latest_poll_list’,
template_name=’polls/index.html’),
name=’index’),
url(r’^(?P<pk>d+)/$’,
DetailView.as_view(
model=Poll,
template_name=’polls/detail.html’),
name=’detail’),
url(r’^(?P<pk>d+)/results/$’,
DetailView.as_view(
model=Poll,
template_name=’polls/results.html’),
name=’results’),
url(r’^(?P<poll_id>d+)/vote/$’, ’polls.views.vote’, name=’vote’),
)
Amend views
We’re using two generic views here: ListView and DetailView. Respectively, those two views abstract the
concepts of “display a list of objects” and “display a detail page for a particular type of object.”
• Each generic view needs to know what model it will be acting upon. This is provided using the model param-eter.
• The DetailView generic view expects the primary key value captured from the URL to be called "pk", so
we’ve changed poll_id to pk for the generic views.
By default, the DetailView generic view uses a template called <app name>/<model
name>_detail.html. In our case, it’ll use the template "polls/poll_detail.html". The
template_name argument is used to tell Django to use a specific template name instead of the autogener-ated
default template name. We also specify the template_name for the results list view – this ensures that the
results view and the detail view have a different appearance when rendered, even though they’re both a DetailView
behind the scenes.
Similarly, the ListView generic view uses a default template called <app name>/<model
name>_list.html; we use template_name to tell ListView to use our existing "polls/index.html"
template.
46 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-50-2048.jpg)





![Django Documentation, Release 1.5.1
We will start again with the shell, where we need to do a couple of things that won’t be necessary in tests.py. The
first is to set up the test environment in the shell:
>>> from django.test.utils import setup_test_environment
>>> setup_test_environment()
Next we need to import the test client class (later in tests.py we will use the django.test.TestCase class,
which comes with its own client, so this won’t be required):
>>> from django.test.client import Client
>>> # create an instance of the client for our use
>>> client = Client()
With that ready, we can ask the client to do some work for us:
>>> # get a response from ’/’
>>> response = client.get(’/’)
>>> # we should expect a 404 from that address
>>> response.status_code
404
>>> # on the other hand we should expect to find something at ’/polls/’
>>> # we’ll use ’reverse()’ rather than a harcoded URL
>>> from django.core.urlresolvers import reverse
>>> response = client.get(reverse(’polls:index’))
>>> response.status_code
200
>>> response.content
’nnn <p>No polls are available.</p>nn’
>>> # note - you might get unexpected results if your ‘‘TIME_ZONE‘‘
>>> # in ‘‘settings.py‘‘ is not correct. If you need to change it,
>>> # you will also need to restart your shell session
>>> from polls.models import Poll
>>> from django.utils import timezone
>>> # create a Poll and save it
>>> p = Poll(question="Who is your favorite Beatle?", pub_date=timezone.now())
>>> p.save()
>>> # check the response once again
>>> response = client.get(’/polls/’)
>>> response.content
’nnn <ul>n n <li><a href="/polls/1/">Who is your favorite Beatle?</a></li>n n >>> response.context[’latest_poll_list’]
[<Poll: Who is your favorite Beatle?>]
Improving our view
The list of polls shows polls that aren’t published yet (i.e. those that have a pub_date in the future). Let’s fix that.
In Tutorial 4 we deleted the view functions from views.py in favor of a ListView in urls.py:
url(r’^$’,
ListView.as_view(
queryset=Poll.objects.order_by(’-pub_date’)[:5],
context_object_name=’latest_poll_list’,
template_name=’polls/index.html’),
name=’index’),
response.context_data[’latest_poll_list’] extracts the data this view places into the context.
We need to amend the line that gives us the queryset:
52 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-56-2048.jpg)
![Django Documentation, Release 1.5.1
queryset=Poll.objects.order_by(’-pub_date’)[:5],
Let’s change the queryset so that it also checks the date by comparing it with timezone.now(). First we need to
add an import:
from django.utils import timezone
and then we must amend the existing url function to:
url(r’^$’,
ListView.as_view(
queryset=Poll.objects.filter(pub_date__lte=timezone.now)
.order_by(’-pub_date’)[:5],
context_object_name=’latest_poll_list’,
template_name=’polls/index.html’),
name=’index’),
Poll.objects.filter(pub_date__lte=timezone.now) returns a queryset containing Polls whose
pub_date is less than or equal to - that is, earlier than or equal to - timezone.now. Notice that we use a callable
queryset argument, timezone.now, which will be evaluated at request time. If we had included the parentheses,
timezone.now() would be evaluated just once when the web server is started.
Testing our new view
Now you can satisfy yourself that this behaves as expected by firing up the runserver, loading the site in your browser,
creating Polls with dates in the past and future, and checking that only those that have been published are listed.
You don’t want to have to do that every single time you make any change that might affect this - so let’s also create a
test, based on our shell session above.
Add the following to polls/tests.py:
from django.core.urlresolvers import reverse
and we’ll create a factory method to create polls as well as a new test class:
def create_poll(question, days):
"""
Creates a poll with the given ‘question‘ published the given number of
‘days‘ offset to now (negative for polls published in the past,
positive for polls that have yet to be published).
"""
return Poll.objects.create(question=question,
pub_date=timezone.now() + datetime.timedelta(days=days))
class PollViewTests(TestCase):
def test_index_view_with_no_polls(self):
"""
If no polls exist, an appropriate message should be displayed.
"""
response = self.client.get(reverse(’polls:index’))
self.assertEqual(response.status_code, 200)
self.assertContains(response, "No polls are available.")
self.assertQuerysetEqual(response.context[’latest_poll_list’], [])
def test_index_view_with_a_past_poll(self):
"""
Polls with a pub_date in the past should be displayed on the index page.
"""
2.7. Writing your first Django app, part 5 53](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-57-2048.jpg)
![Django Documentation, Release 1.5.1
create_poll(question="Past poll.", days=-30)
response = self.client.get(reverse(’polls:index’))
self.assertQuerysetEqual(
response.context[’latest_poll_list’],
[’<Poll: Past poll.>’]
)
def test_index_view_with_a_future_poll(self):
"""
Polls with a pub_date in the future should not be displayed on the
index page.
"""
create_poll(question="Future poll.", days=30)
response = self.client.get(reverse(’polls:index’))
self.assertContains(response, "No polls are available.", status_code=200)
self.assertQuerysetEqual(response.context[’latest_poll_list’], [])
def test_index_view_with_future_poll_and_past_poll(self):
"""
Even if both past and future polls exist, only past polls should be
displayed.
"""
create_poll(question="Past poll.", days=-30)
create_poll(question="Future poll.", days=30)
response = self.client.get(reverse(’polls:index’))
self.assertQuerysetEqual(
response.context[’latest_poll_list’],
[’<Poll: Past poll.>’]
)
def test_index_view_with_two_past_polls(self):
"""
The polls index page may display multiple polls.
"""
create_poll(question="Past poll 1.", days=-30)
create_poll(question="Past poll 2.", days=-5)
response = self.client.get(reverse(’polls:index’))
self.assertQuerysetEqual(
response.context[’latest_poll_list’],
[’<Poll: Past poll 2.>’, ’<Poll: Past poll 1.>’]
)
Let’s look at some of these more closely.
First is a poll factory method, create_poll, to take some repetition out of the process of creating polls.
test_index_view_with_no_polls doesn’t create any polls, but checks the message: “No polls are available.”
and verifies the latest_poll_list is empty. Note that the django.test.TestCase class provides some
additional assertion methods. In these examples, we use assertContains() and assertQuerysetEqual().
In test_index_view_with_a_past_poll, we create a poll and verify that it appears in the list.
In test_index_view_with_a_future_poll, we create a poll with a pub_date in the future. The database
is reset for each test method, so the first poll is no longer there, and so again the index shouldn’t have any polls in it.
And so on. In effect, we are using the tests to tell a story of admin input and user experience on the site, and checking
that at every state and for every new change in the state of the system, the expected results are published.
54 Chapter 2. Getting started](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-58-2048.jpg)






![Django Documentation, Release 1.5.1
README = open(os.path.join(os.path.dirname(__file__), ’README.rst’)).read()
# allow setup.py to be run from any path
os.chdir(os.path.normpath(os.path.join(os.path.abspath(__file__), os.pardir)))
setup(
name=’django-polls’,
version=’0.1’,
packages=[’polls’],
include_package_data=True,
license=’BSD License’, # example license
description=’A simple Django app to conduct Web-based polls.’,
long_description=README,
url=’http://www.example.com/’,
author=’Your Name’,
author_email=’yourname@example.com’,
classifiers=[
’Environment :: Web Environment’,
’Framework :: Django’,
’Intended Audience :: Developers’,
’License :: OSI Approved :: BSD License’, # example license
’Operating System :: OS Independent’,
’Programming Language :: Python’,
’Programming Language :: Python :: 2.6’,
’Programming Language :: Python :: 2.7’,
’Topic :: Internet :: WWW/HTTP’,
’Topic :: Internet :: WWW/HTTP :: Dynamic Content’,
],
)
I thought you said we were going to use distribute?
Distribute is a drop-in replacement for setuptools. Even though we appear to import from setuptools, since
we have distribute installed, it will override the import.
6. Only Python modules and packages are included in the package by default. To include additional files,
we’ll need to create a MANIFEST.in file. The distribute docs referred to in the previous step discuss
this file in more details. To include the templates, the README.rst and our LICENSE file, create a file
django-polls/MANIFEST.in with the following contents:
include LICENSE
include README.rst
recursive-include polls/templates *
7. It’s optional, but recommended, to include detailed documentation with your app. Create an
empty directory django-polls/docs for future documentation. Add an additional line to
django-polls/MANIFEST.in:
recursive-include docs *
Note that the docs directory won’t be included in your package unless you add some files to it. Many Django
apps also provide their documentation online through sites like readthedocs.org.
8. Try building your package with python setup.py sdist (run from inside django-polls). This cre-ates
a directory called dist and builds your new package, django-polls-0.1.tar.gz.
For more information on packaging, see The Hitchhiker’s Guide to Packaging.
2.9. Advanced tutorial: How to write reusable apps 61](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-65-2048.jpg)















![Django Documentation, Release 1.5.1
a database user with these permissions, you’ll specify the details in your project’s settings file, see DATABASES for
details.
If you’re using Django’s testing framework to test database queries, Django will need permission to create a test
database.
3.1.4 Remove any old versions of Django
If you are upgrading your installation of Django from a previous version, you will need to uninstall the old Django
version before installing the new version.
If you installed Django using pip or easy_install previously, installing with pip or easy_install again will
automatically take care of the old version, so you don’t need to do it yourself.
If you previously installed Django using python setup.py install, uninstalling is as simple as deleting the
django directory from your Python site-packages. To find the directory you need to remove, you can run the
following at your shell prompt (not the interactive Python prompt):
python -c "import sys; sys.path = sys.path[1:]; import django; print(django.__path__)"
3.1.5 Install the Django code
Installation instructions are slightly different depending on whether you’re installing a distribution-specific package,
downloading the latest official release, or fetching the latest development version.
It’s easy, no matter which way you choose.
Installing a distribution-specific package
Check the distribution specific notes to see if your platform/distribution provides official Django packages/installers.
Distribution-provided packages will typically allow for automatic installation of dependencies and easy upgrade paths.
Installing an official release with pip
This is the recommended way to install Django.
1. Install pip. The easiest is to use the standalone pip installer. If your distribution already has pip installed, you
might need to update it if it’s outdated. (If it’s outdated, you’ll know because installation won’t work.)
2. (optional) Take a look at virtualenv and virtualenvwrapper. These tools provide isolated Python environments,
which are more practical than installing packages systemwide. They also allow installing packages without
administrator privileges. It’s up to you to decide if you want to learn and use them.
3. If you’re using Linux, Mac OS X or some other flavor of Unix, enter the command sudo pip install
Django at the shell prompt. If you’re using Windows, start a command shell with administrator privi-leges
and run the command pip install Django. This will install Django in your Python installation’s
site-packages directory.
If you’re using a virtualenv, you don’t need sudo or administrator privileges, and this will install Django in the
virtualenv’s site-packages directory.
3.1. How to install Django 77](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-81-2048.jpg)







![Django Documentation, Release 1.5.1
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(Person, through=’Membership’)
def __unicode__(self):
return self.name
class Membership(models.Model):
person = models.ForeignKey(Person)
group = models.ForeignKey(Group)
date_joined = models.DateField()
invite_reason = models.CharField(max_length=64)
When you set up the intermediary model, you explicitly specify foreign keys to the models that are involved in the
ManyToMany relation. This explicit declaration defines how the two models are related.
There are a few restrictions on the intermediate model:
• Your intermediate model must contain one - and only one - foreign key to the target model (this would be
Person in our example). If you have more than one foreign key, a validation error will be raised.
• Your intermediate model must contain one - and only one - foreign key to the source model (this would be
Group in our example). If you have more than one foreign key, a validation error will be raised.
• The only exception to this is a model which has a many-to-many relationship to itself, through an intermediary
model. In this case, two foreign keys to the same model are permitted, but they will be treated as the two
(different) sides of the many-to-many relation.
• When defining a many-to-many relationship from a model to itself, using an intermediary model, you must use
symmetrical=False (see the model field reference).
Now that you have set up your ManyToManyField to use your intermediary model (Membership, in this case),
you’re ready to start creating some many-to-many relationships. You do this by creating instances of the intermediate
model:
>>> ringo = Person.objects.create(name="Ringo Starr")
>>> paul = Person.objects.create(name="Paul McCartney")
>>> beatles = Group.objects.create(name="The Beatles")
>>> m1 = Membership(person=ringo, group=beatles,
... date_joined=date(1962, 8, 16),
... invite_reason= "Needed a new drummer.")
>>> m1.save()
>>> beatles.members.all()
[<Person: Ringo Starr>]
>>> ringo.group_set.all()
[<Group: The Beatles>]
>>> m2 = Membership.objects.create(person=paul, group=beatles,
... date_joined=date(1960, 8, 1),
... invite_reason= "Wanted to form a band.")
>>> beatles.members.all()
[<Person: Ringo Starr>, <Person: Paul McCartney>]
Unlike normal many-to-many fields, you can’t use add, create, or assignment (i.e., beatles.members =
[...]) to create relationships:
# THIS WILL NOT WORK
>>> beatles.members.add(john)
# NEITHER WILL THIS
>>> beatles.members.create(name="George Harrison")
3.2. Models and databases 85](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-89-2048.jpg)
![Django Documentation, Release 1.5.1
# AND NEITHER WILL THIS
>>> beatles.members = [john, paul, ringo, george]
Why? You can’t just create a relationship between a Person and a Group - you need to specify all the detail for the
relationship required by the Membership model. The simple add, create and assignment calls don’t provide a
way to specify this extra detail. As a result, they are disabled for many-to-many relationships that use an intermediate
model. The only way to create this type of relationship is to create instances of the intermediate model.
The remove() method is disabled for similar reasons. However, the clear() method can be used to remove all
many-to-many relationships for an instance:
# Beatles have broken up
>>> beatles.members.clear()
Once you have established the many-to-many relationships by creating instances of your intermediate model, you can
issue queries. Just as with normal many-to-many relationships, you can query using the attributes of the many-to-many-
related model:
# Find all the groups with a member whose name starts with ’Paul’
>>> Group.objects.filter(members__name__startswith=’Paul’)
[<Group: The Beatles>]
As you are using an intermediate model, you can also query on its attributes:
# Find all the members of the Beatles that joined after 1 Jan 1961
>>> Person.objects.filter(
... group__name=’The Beatles’,
... membership__date_joined__gt=date(1961,1,1))
[<Person: Ringo Starr]
If you need to access a membership’s information you may do so by directly querying the Membership model:
>>> ringos_membership = Membership.objects.get(group=beatles, person=ringo)
>>> ringos_membership.date_joined
datetime.date(1962, 8, 16)
>>> ringos_membership.invite_reason
u’Needed a new drummer.’
Another way to access the same information is by querying the many-to-many reverse relationship from a Person
object:
>>> ringos_membership = ringo.membership_set.get(group=beatles)
>>> ringos_membership.date_joined
datetime.date(1962, 8, 16)
>>> ringos_membership.invite_reason
u’Needed a new drummer.’
One-to-one relationships To define a one-to-one relationship, use OneToOneField. You use it just like any other
Field type: by including it as a class attribute of your model.
This is most useful on the primary key of an object when that object “extends” another object in some way.
OneToOneField requires a positional argument: the class to which the model is related.
For example, if you were building a database of “places”, you would build pretty standard stuff such as address, phone
number, etc. in the database. Then, if you wanted to build a database of restaurants on top of the places, instead of
repeating yourself and replicating those fields in the Restaurant model, you could make Restaurant have a
OneToOneField to Place (because a restaurant “is a” place; in fact, to handle this you’d typically use inheritance,
which involves an implicit one-to-one relation).
86 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-90-2048.jpg)

![Django Documentation, Release 1.5.1
Meta options
Give your model metadata by using an inner class Meta, like so:
class Ox(models.Model):
horn_length = models.IntegerField()
class Meta:
ordering = ["horn_length"]
verbose_name_plural = "oxen"
Model metadata is “anything that’s not a field”, such as ordering options (ordering), database table name
(db_table), or human-readable singular and plural names (verbose_name and verbose_name_plural).
None are required, and adding class Meta to a model is completely optional.
A complete list of all possible Meta options can be found in the model option reference.
Model methods
Define custom methods on a model to add custom “row-level” functionality to your objects. Whereas Manager
methods are intended to do “table-wide” things, model methods should act on a particular model instance.
This is a valuable technique for keeping business logic in one place – the model.
For example, this model has a few custom methods:
from django.contrib.localflavor.us.models import USStateField
class Person(models.Model):
first_name = models.CharField(max_length=50)
last_name = models.CharField(max_length=50)
birth_date = models.DateField()
address = models.CharField(max_length=100)
city = models.CharField(max_length=50)
state = USStateField() # Yes, this is America-centric...
def baby_boomer_status(self):
"Returns the person’s baby-boomer status."
import datetime
if self.birth_date < datetime.date(1945, 8, 1):
return "Pre-boomer"
elif self.birth_date < datetime.date(1965, 1, 1):
return "Baby boomer"
else:
return "Post-boomer"
def is_midwestern(self):
"Returns True if this person is from the Midwest."
return self.state in (’IL’, ’WI’, ’MI’, ’IN’, ’OH’, ’IA’, ’MO’)
def _get_full_name(self):
"Returns the person’s full name."
return ’%s %s’ % (self.first_name, self.last_name)
full_name = property(_get_full_name)
The last method in this example is a property.
The model instance reference has a complete list of methods automatically given to each model. You can override
most of these – see overriding predefined model methods, below – but there are a couple that you’ll almost always
88 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-92-2048.jpg)


![Django Documentation, Release 1.5.1
Meta inheritance When an abstract base class is created, Django makes any Meta inner class you declared in the
base class available as an attribute. If a child class does not declare its own Meta class, it will inherit the parent’s Meta.
If the child wants to extend the parent’s Meta class, it can subclass it. For example:
class CommonInfo(models.Model):
...
class Meta:
abstract = True
ordering = [’name’]
class Student(CommonInfo):
...
class Meta(CommonInfo.Meta):
db_table = ’student_info’
Django does make one adjustment to the Meta class of an abstract base class: before installing the Meta attribute,
it sets abstract=False. This means that children of abstract base classes don’t automatically become abstract
classes themselves. Of course, you can make an abstract base class that inherits from another abstract base class. You
just need to remember to explicitly set abstract=True each time.
Some attributes won’t make sense to include in the Meta class of an abstract base class. For example, including
db_table would mean that all the child classes (the ones that don’t specify their own Meta) would use the same
database table, which is almost certainly not what you want.
Be careful with related_name If you are using the related_name attribute on a ForeignKey or
ManyToManyField, you must always specify a unique reverse name for the field. This would normally cause a
problem in abstract base classes, since the fields on this class are included into each of the child classes, with exactly
the same values for the attributes (including related_name) each time.
To work around this problem, when you are using related_name in an abstract base class (only), part of the name
should contain ’%(app_label)s’ and ’%(class)s’.
• ’%(class)s’ is replaced by the lower-cased name of the child class that the field is used in.
• ’%(app_label)s’ is replaced by the lower-cased name of the app the child class is contained within. Each
installed application name must be unique and the model class names within each app must also be unique,
therefore the resulting name will end up being different.
For example, given an app common/models.py:
class Base(models.Model):
m2m = models.ManyToManyField(OtherModel, related_name="%(app_label)s_%(class)s_related")
class Meta:
abstract = True
class ChildA(Base):
pass
class ChildB(Base):
pass
Along with another app rare/models.py:
from common.models import Base
class ChildB(Base):
pass
3.2. Models and databases 91](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-95-2048.jpg)

![Django Documentation, Release 1.5.1
# Remove parent’s ordering effect
ordering = []
Inheritance and reverse relations Because multi-table inheritance uses an implicit OneToOneField to link the
child and the parent, it’s possible to move from the parent down to the child, as in the above example. However, this
uses up the name that is the default related_name value for ForeignKey and ManyToManyField relations.
If you are putting those types of relations on a subclass of another model, you must specify the related_name
attribute on each such field. If you forget, Django will raise an error when you run validate or syncdb.
For example, using the above Place class again, let’s create another subclass with a ManyToManyField:
class Supplier(Place):
# Must specify related_name on all relations.
customers = models.ManyToManyField(Restaurant, related_name=’provider’)
Specifying the parent link field As mentioned, Django will automatically create a OneToOneField linking your
child class back any non-abstract parent models. If you want to control the name of the attribute linking back to the
parent, you can create your own OneToOneField and set parent_link=True to indicate that your field is the
link back to the parent class.
Proxy models
When using multi-table inheritance, a new database table is created for each subclass of a model. This is usually the
desired behavior, since the subclass needs a place to store any additional data fields that are not present on the base
class. Sometimes, however, you only want to change the Python behavior of a model – perhaps to change the default
manager, or add a new method.
This is what proxy model inheritance is for: creating a proxy for the original model. You can create, delete and update
instances of the proxy model and all the data will be saved as if you were using the original (non-proxied) model. The
difference is that you can change things like the default model ordering or the default manager in the proxy, without
having to alter the original.
Proxy models are declared like normal models. You tell Django that it’s a proxy model by setting the proxy attribute
of the Meta class to True.
For example, suppose you want to add a method to the Person model described above. You can do it like this:
class MyPerson(Person):
class Meta:
proxy = True
def do_something(self):
...
The MyPerson class operates on the same database table as its parent Person class. In particular, any new instances
of Person will also be accessible through MyPerson, and vice-versa:
>>> p = Person.objects.create(first_name="foobar")
>>> MyPerson.objects.get(first_name="foobar")
<MyPerson: foobar>
You could also use a proxy model to define a different default ordering on a model. You might not always want to
order the Person model, but regularly order by the last_name attribute when you use the proxy. This is easy:
3.2. Models and databases 93](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-97-2048.jpg)
![Django Documentation, Release 1.5.1
class OrderedPerson(Person):
class Meta:
ordering = ["last_name"]
proxy = True
Now normal Person queries will be unordered and OrderedPerson queries will be ordered by last_name.
QuerySets still return the model that was requested There is no way to have Django return, say, a MyPerson
object whenever you query for Person objects. A queryset for Person objects will return those types of objects.
The whole point of proxy objects is that code relying on the original Person will use those and your own code can
use the extensions you included (that no other code is relying on anyway). It is not a way to replace the Person (or
any other) model everywhere with something of your own creation.
Base class restrictions A proxy model must inherit from exactly one non-abstract model class. You can’t inherit
from multiple non-abstract models as the proxy model doesn’t provide any connection between the rows in the different
database tables. A proxy model can inherit from any number of abstract model classes, providing they do not define
any model fields.
Proxy models inherit any Meta options that they don’t define from their non-abstract model parent (the model they
are proxying for).
Proxy model managers If you don’t specify any model managers on a proxy model, it inherits the managers from
its model parents. If you define a manager on the proxy model, it will become the default, although any managers
defined on the parent classes will still be available.
Continuing our example from above, you could change the default manager used when you query the Person model
like this:
class NewManager(models.Manager):
...
class MyPerson(Person):
objects = NewManager()
class Meta:
proxy = True
If you wanted to add a new manager to the Proxy, without replacing the existing default, you can use the techniques
described in the custom manager documentation: create a base class containing the new managers and inherit that
after the primary base class:
# Create an abstract class for the new manager.
class ExtraManagers(models.Model):
secondary = NewManager()
class Meta:
abstract = True
class MyPerson(Person, ExtraManagers):
class Meta:
proxy = True
You probably won’t need to do this very often, but, when you do, it’s possible.
94 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-98-2048.jpg)




![Django Documentation, Release 1.5.1
>>> Entry.objects.filter(
... headline__startswith=’What’
... ).exclude(
... pub_date__gte=datetime.date.today()
... ).filter(
... pub_date__gte=datetime(2005, 1, 30)
... )
This takes the initial QuerySet of all entries in the database, adds a filter, then an exclusion, then another filter. The
final result is a QuerySet containing all entries with a headline that starts with “What”, that were published between
January 30, 2005, and the current day.
Filtered QuerySets are unique Each time you refine a QuerySet, you get a brand-new QuerySet that is in no
way bound to the previous QuerySet. Each refinement creates a separate and distinct QuerySet that can be stored,
used and reused.
Example:
>> q1 = Entry.objects.filter(headline__startswith="What")
>> q2 = q1.exclude(pub_date__gte=datetime.date.today())
>> q3 = q1.filter(pub_date__gte=datetime.date.today())
These three QuerySets are separate. The first is a base QuerySet containing all entries that contain a headline
starting with “What”. The second is a subset of the first, with an additional criteria that excludes records whose
pub_date is greater than now. The third is a subset of the first, with an additional criteria that selects only the
records whose pub_date is greater than now. The initial QuerySet (q1) is unaffected by the refinement process.
QuerySets are lazy QuerySets are lazy – the act of creating a QuerySet doesn’t involve any database activity.
You can stack filters together all day long, and Django won’t actually run the query until the QuerySet is evaluated.
Take a look at this example:
>>> q = Entry.objects.filter(headline__startswith="What")
>>> q = q.filter(pub_date__lte=datetime.date.today())
>>> q = q.exclude(body_text__icontains="food")
>>> print(q)
Though this looks like three database hits, in fact it hits the database only once, at the last line (print(q)). In
general, the results of a QuerySet aren’t fetched from the database until you “ask” for them. When you do, the
QuerySet is evaluated by accessing the database. For more details on exactly when evaluation takes place, see
When QuerySets are evaluated.
Retrieving a single object with get
filter() will always give you a QuerySet, even if only a single object matches the query - in this case, it will be
a QuerySet containing a single element.
If you know there is only one object that matches your query, you can use the get() method on a Manager which
returns the object directly:
>>> one_entry = Entry.objects.get(pk=1)
You can use any query expression with get(), just like with filter() - again, see Field lookups below.
Note that there is a difference between using get(), and using filter() with a slice of [0]. If there are no results
that match the query, get() will raise a DoesNotExist exception. This exception is an attribute of the model
3.2. Models and databases 99](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-103-2048.jpg)
![Django Documentation, Release 1.5.1
class that the query is being performed on - so in the code above, if there is no Entry object with a primary key of 1,
Django will raise Entry.DoesNotExist.
Similarly, Django will complain if more than one item matches the get() query. In this case, it will raise
MultipleObjectsReturned, which again is an attribute of the model class itself.
Other QuerySet methods
Most of the time you’ll use all(), get(), filter() and exclude() when you need to look up objects from
the database. However, that’s far from all there is; see the QuerySet API Reference for a complete list of all the various
QuerySet methods.
Limiting QuerySets
Use a subset of Python’s array-slicing syntax to limit your QuerySet to a certain number of results. This is the
equivalent of SQL’s LIMIT and OFFSET clauses.
For example, this returns the first 5 objects (LIMIT 5):
>>> Entry.objects.all()[:5]
This returns the sixth through tenth objects (OFFSET 5 LIMIT 5):
>>> Entry.objects.all()[5:10]
Negative indexing (i.e. Entry.objects.all()[-1]) is not supported.
Generally, slicing a QuerySet returns a new QuerySet – it doesn’t evaluate the query. An exception is if you use
the “step” parameter of Python slice syntax. For example, this would actually execute the query in order to return a
list of every second object of the first 10:
>>> Entry.objects.all()[:10:2]
To retrieve a single object rather than a list (e.g. SELECT foo FROM bar LIMIT 1), use a simple index instead
of a slice. For example, this returns the first Entry in the database, after ordering entries alphabetically by headline:
>>> Entry.objects.order_by(’headline’)[0]
This is roughly equivalent to:
>>> Entry.objects.order_by(’headline’)[0:1].get()
Note, however, that the first of these will raise IndexError while the second will raise DoesNotExist if no
objects match the given criteria. See get() for more details.
Field lookups
Field lookups are how you specify the meat of an SQL WHERE clause. They’re specified as keyword arguments to the
QuerySet methods filter(), exclude() and get().
Basic lookups keyword arguments take the form field__lookuptype=value. (That’s a double-underscore).
For example:
>>> Entry.objects.filter(pub_date__lte=’2006-01-01’)
translates (roughly) into the following SQL:
100 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-104-2048.jpg)



![Django Documentation, Release 1.5.1
New in version 1.5: .bitand() and .bitor() The F() objects now support bitwise operations by .bitand()
and .bitor(), for example:
>>> F(’somefield’).bitand(16)
Changed in version 1.5: The previously undocumented operators & and | no longer produce bitwise operations, use
.bitand() and .bitor() instead.
The pk lookup shortcut
For convenience, Django provides a pk lookup shortcut, which stands for “primary key”.
In the example Blog model, the primary key is the id field, so these three statements are equivalent:
>>> Blog.objects.get(id__exact=14) # Explicit form
>>> Blog.objects.get(id=14) # __exact is implied
>>> Blog.objects.get(pk=14) # pk implies id__exact
The use of pk isn’t limited to __exact queries – any query term can be combined with pk to perform a query on the
primary key of a model:
# Get blogs entries with id 1, 4 and 7
>>> Blog.objects.filter(pk__in=[1,4,7])
# Get all blog entries with id > 14
>>> Blog.objects.filter(pk__gt=14)
pk lookups also work across joins. For example, these three statements are equivalent:
>>> Entry.objects.filter(blog__id__exact=3) # Explicit form
>>> Entry.objects.filter(blog__id=3) # __exact is implied
>>> Entry.objects.filter(blog__pk=3) # __pk implies __id__exact
Escaping percent signs and underscores in LIKE statements
The field lookups that equate to LIKE SQL statements (iexact, contains, icontains, startswith,
istartswith, endswith and iendswith) will automatically escape the two special characters used in LIKE
statements – the percent sign and the underscore. (In a LIKE statement, the percent sign signifies a multiple-character
wildcard and the underscore signifies a single-character wildcard.)
This means things should work intuitively, so the abstraction doesn’t leak. For example, to retrieve all the entries that
contain a percent sign, just use the percent sign as any other character:
>>> Entry.objects.filter(headline__contains=’%’)
Django takes care of the quoting for you; the resulting SQL will look something like this:
SELECT ... WHERE headline LIKE ’%%%’;
Same goes for underscores. Both percentage signs and underscores are handled for you transparently.
Caching and QuerySets
Each QuerySet contains a cache, to minimize database access. It’s important to understand how it works, in order
to write the most efficient code.
104 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-108-2048.jpg)
![Django Documentation, Release 1.5.1
In a newly created QuerySet, the cache is empty. The first time a QuerySet is evaluated – and, hence, a database
query happens – Django saves the query results in the QuerySet‘s cache and returns the results that have been
explicitly requested (e.g., the next element, if the QuerySet is being iterated over). Subsequent evaluations of the
QuerySet reuse the cached results.
Keep this caching behavior in mind, because it may bite you if you don’t use your QuerySets correctly. For example,
the following will create two QuerySets, evaluate them, and throw them away:
>>> print([e.headline for e in Entry.objects.all()])
>>> print([e.pub_date for e in Entry.objects.all()])
That means the same database query will be executed twice, effectively doubling your database load. Also, there’s
a possibility the two lists may not include the same database records, because an Entry may have been added or
deleted in the split second between the two requests.
To avoid this problem, simply save the QuerySet and reuse it:
>>> queryset = Entry.objects.all()
>>> print([p.headline for p in queryset]) # Evaluate the query set.
>>> print([p.pub_date for p in queryset]) # Re-use the cache from the evaluation.
Complex lookups with Q objects
class Q
Keyword argument queries – in filter(), etc. – are “AND”ed together. If you need to execute more complex
queries (for example, queries with OR statements), you can use Q objects.
A Q object (django.db.models.Q) is an object used to encapsulate a collection of keyword arguments. These
keyword arguments are specified as in “Field lookups” above.
For example, this Q object encapsulates a single LIKE query:
from django.db.models import Q
Q(question__startswith=’What’)
Q objects can be combined using the & and | operators. When an operator is used on two Q objects, it yields a new Q
object.
For example, this statement yields a single Q object that represents the “OR” of two "question__startswith"
queries:
Q(question__startswith=’Who’) | Q(question__startswith=’What’)
This is equivalent to the following SQL WHERE clause:
WHERE question LIKE ’Who%’ OR question LIKE ’What%’
You can compose statements of arbitrary complexity by combining Q objects with the & and | operators and use
parenthetical grouping. Also, Q objects can be negated using the ~ operator, allowing for combined lookups that
combine both a normal query and a negated (NOT) query:
Q(question__startswith=’Who’) | ~Q(pub_date__year=2005)
Each lookup function that takes keyword-arguments (e.g. filter(), exclude(), get()) can also be passed
one or more Q objects as positional (not-named) arguments. If you provide multiple Q object arguments to a lookup
function, the arguments will be “AND”ed together. For example:
3.2. Models and databases 105](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-109-2048.jpg)

![Django Documentation, Release 1.5.1
Entry.objects.filter(pub_date__year=2005).delete()
Keep in mind that this will, whenever possible, be executed purely in SQL, and so the delete() methods of in-dividual
object instances will not necessarily be called during the process. If you’ve provided a custom delete()
method on a model class and want to ensure that it is called, you will need to “manually” delete instances of that model
(e.g., by iterating over a QuerySet and calling delete() on each object individually) rather than using the bulk
delete() method of a QuerySet.
When Django deletes an object, by default it emulates the behavior of the SQL constraint ON DELETE CASCADE –
in other words, any objects which had foreign keys pointing at the object to be deleted will be deleted along with it.
For example:
b = Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
This cascade behavior is customizable via the on_delete argument to the ForeignKey.
Note that delete() is the only QuerySet method that is not exposed on a Manager itself. This is a safety
mechanism to prevent you from accidentally requesting Entry.objects.delete(), and deleting all the entries.
If you do want to delete all the objects, then you have to explicitly request a complete query set:
Entry.objects.all().delete()
Copying model instances
Although there is no built-in method for copying model instances, it is possible to easily create new instance with all
fields’ values copied. In the simplest case, you can just set pk to None. Using our blog example:
blog = Blog(name=’My blog’, tagline=’Blogging is easy’)
blog.save() # blog.pk == 1
blog.pk = None
blog.save() # blog.pk == 2
Things get more complicated if you use inheritance. Consider a subclass of Blog:
class ThemeBlog(Blog):
theme = models.CharField(max_length=200)
django_blog = ThemeBlog(name=’Django’, tagline=’Django is easy’, theme=’python’)
django_blog.save() # django_blog.pk == 3
Due to how inheritance works, you have to set both pk and id to None:
django_blog.pk = None
django_blog.id = None
django_blog.save() # django_blog.pk == 4
This process does not copy related objects. If you want to copy relations, you have to write a little bit more code. In
our example, Entry has a many to many field to Author:
entry = Entry.objects.all()[0] # some previous entry
old_authors = entry.authors.all()
entry.pk = None
entry.save()
entry.authors = old_authors # saves new many2many relations
3.2. Models and databases 107](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-111-2048.jpg)


![Django Documentation, Release 1.5.1
You can override the FOO_set name by setting the related_name parameter in the ForeignKey()
definition. For example, if the Entry model was altered to blog = ForeignKey(Blog,
related_name=’entries’), the above example code would look like this:
>>> b = Blog.objects.get(id=1)
>>> b.entries.all() # Returns all Entry objects related to Blog.
# b.entries is a Manager that returns QuerySets.
>>> b.entries.filter(headline__contains=’Lennon’)
>>> b.entries.count()
You cannot access a reverse ForeignKey Manager from the class; it must be accessed from an instance:
>>> Blog.entry_set
Traceback:
...
AttributeError: "Manager must be accessed via instance".
In addition to the QuerySet methods defined in “Retrieving objects” above, the ForeignKey Manager has ad-ditional
methods used to handle the set of related objects. A synopsis of each is below, and complete details can be
found in the related objects reference.
add(obj1, obj2, ...) Adds the specified model objects to the related object set.
create(**kwargs) Creates a new object, saves it and puts it in the related object set. Returns the newly created
object.
remove(obj1, obj2, ...) Removes the specified model objects from the related object set.
clear() Removes all objects from the related object set.
To assign the members of a related set in one fell swoop, just assign to it from any iterable object. The iterable can
contain object instances, or just a list of primary key values. For example:
b = Blog.objects.get(id=1)
b.entry_set = [e1, e2]
In this example, e1 and e2 can be full Entry instances, or integer primary key values.
If the clear() method is available, any pre-existing objects will be removed from the entry_set before all
objects in the iterable (in this case, a list) are added to the set. If the clear() method is not available, all objects in
the iterable will be added without removing any existing elements.
Each “reverse” operation described in this section has an immediate effect on the database. Every addition, creation
and deletion is immediately and automatically saved to the database.
Many-to-many relationships
Both ends of a many-to-many relationship get automatic API access to the other end. The API works just as a
“backward” one-to-many relationship, above.
The only difference is in the attribute naming: The model that defines the ManyToManyField uses the attribute
name of that field itself, whereas the “reverse” model uses the lowercased model name of the original model, plus
’_set’ (just like reverse one-to-many relationships).
An example makes this easier to understand:
e = Entry.objects.get(id=3)
e.authors.all() # Returns all Author objects for this Entry.
e.authors.count()
e.authors.filter(name__contains=’John’)
110 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-114-2048.jpg)


![Django Documentation, Release 1.5.1
>>> Book.objects.all().aggregate(Avg(’price’))
{’price__avg’: 34.35}
# Max price across all books.
>>> from django.db.models import Max
>>> Book.objects.all().aggregate(Max(’price’))
{’price__max’: Decimal(’81.20’)}
# All the following queries involve traversing the Book<->Publisher
# many-to-many relationship backward
# Each publisher, each with a count of books as a "num_books" attribute.
>>> from django.db.models import Count
>>> pubs = Publisher.objects.annotate(num_books=Count(’book’))
>>> pubs
[<Publisher BaloneyPress>, <Publisher SalamiPress>, ...]
>>> pubs[0].num_books
73
# The top 5 publishers, in order by number of books.
>>> pubs = Publisher.objects.annotate(num_books=Count(’book’)).order_by(’-num_books’)[:5]
>>> pubs[0].num_books
1323
Generating aggregates over a QuerySet
Django provides two ways to generate aggregates. The first way is to generate summary values over an entire
QuerySet. For example, say you wanted to calculate the average price of all books available for sale. Django’s
query syntax provides a means for describing the set of all books:
>>> Book.objects.all()
What we need is a way to calculate summary values over the objects that belong to this QuerySet. This is done by
appending an aggregate() clause onto the QuerySet:
>>> from django.db.models import Avg
>>> Book.objects.all().aggregate(Avg(’price’))
{’price__avg’: 34.35}
The all() is redundant in this example, so this could be simplified to:
>>> Book.objects.aggregate(Avg(’price’))
{’price__avg’: 34.35}
The argument to the aggregate() clause describes the aggregate value that we want to compute - in this case, the
average of the price field on the Book model. A list of the aggregate functions that are available can be found in the
QuerySet reference.
aggregate() is a terminal clause for a QuerySet that, when invoked, returns a dictionary of name-value pairs.
The name is an identifier for the aggregate value; the value is the computed aggregate. The name is automatically
generated from the name of the field and the aggregate function. If you want to manually specify a name for the
aggregate value, you can do so by providing that name when you specify the aggregate clause:
>>> Book.objects.aggregate(average_price=Avg(’price’))
{’average_price’: 34.35}
If you want to generate more than one aggregate, you just add another argument to the aggregate() clause. So, if
we also wanted to know the maximum and minimum price of all books, we would issue the query:
3.2. Models and databases 113](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-117-2048.jpg)
![Django Documentation, Release 1.5.1
>>> from django.db.models import Avg, Max, Min, Count
>>> Book.objects.aggregate(Avg(’price’), Max(’price’), Min(’price’))
{’price__avg’: 34.35, ’price__max’: Decimal(’81.20’), ’price__min’: Decimal(’12.99’)}
Generating aggregates for each item in a QuerySet
The second way to generate summary values is to generate an independent summary for each object in a QuerySet.
For example, if you are retrieving a list of books, you may want to know how many authors contributed to each book.
Each Book has a many-to-many relationship with the Author; we want to summarize this relationship for each book
in the QuerySet.
Per-object summaries can be generated using the annotate() clause. When an annotate() clause is specified,
each object in the QuerySet will be annotated with the specified values.
The syntax for these annotations is identical to that used for the aggregate() clause. Each argument to
annotate() describes an aggregate that is to be calculated. For example, to annotate books with the number of
authors:
# Build an annotated queryset
>>> q = Book.objects.annotate(Count(’authors’))
# Interrogate the first object in the queryset
>>> q[0]
<Book: The Definitive Guide to Django>
>>> q[0].authors__count
2
# Interrogate the second object in the queryset
>>> q[1]
<Book: Practical Django Projects>
>>> q[1].authors__count
1
As with aggregate(), the name for the annotation is automatically derived from the name of the aggregate function
and the name of the field being aggregated. You can override this default name by providing an alias when you specify
the annotation:
>>> q = Book.objects.annotate(num_authors=Count(’authors’))
>>> q[0].num_authors
2
>>> q[1].num_authors
1
Unlike aggregate(), annotate() is not a terminal clause. The output of the annotate() clause is
a QuerySet; this QuerySet can be modified using any other QuerySet operation, including filter(),
order_by(), or even additional calls to annotate().
Joins and aggregates
So far, we have dealt with aggregates over fields that belong to the model being queried. However, sometimes the
value you want to aggregate will belong to a model that is related to the model you are querying.
When specifying the field to be aggregated in an aggregate function, Django will allow you to use the same double
underscore notation that is used when referring to related fields in filters. Django will then handle any table joins that
are required to retrieve and aggregate the related value.
For example, to find the price range of books offered in each store, you could use the annotation:
114 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-118-2048.jpg)


![Django Documentation, Release 1.5.1
returned in the result set, the method for evaluating annotations is slightly different. Instead of returning an annotated
result for each result in the original QuerySet, the original results are grouped according to the unique combinations
of the fields specified in the values() clause. An annotation is then provided for each unique group; the annotation
is computed over all members of the group.
For example, consider an author query that attempts to find out the average rating of books written by each author:
>>> Author.objects.annotate(average_rating=Avg(’book__rating’))
This will return one result for each author in the database, annotated with their average book rating.
However, the result will be slightly different if you use a values() clause:
>>> Author.objects.values(’name’).annotate(average_rating=Avg(’book__rating’))
In this example, the authors will be grouped by name, so you will only get an annotated result for each unique author
name. This means if you have two authors with the same name, their results will be merged into a single result in the
output of the query; the average will be computed as the average over the books written by both authors.
Order of annotate() and values() clauses As with the filter() clause, the order in which annotate()
and values() clauses are applied to a query is significant. If the values() clause precedes the annotate(),
the annotation will be computed using the grouping described by the values() clause.
However, if the annotate() clause precedes the values() clause, the annotations will be generated over the
entire query set. In this case, the values() clause only constrains the fields that are generated on output.
For example, if we reverse the order of the values() and annotate() clause from our previous example:
>>> Author.objects.annotate(average_rating=Avg(’book__rating’)).values(’name’, ’average_rating’)
This will now yield one unique result for each author; however, only the author’s name and the average_rating
annotation will be returned in the output data.
You should also note that average_rating has been explicitly included in the list of values to be returned. This is
required because of the ordering of the values() and annotate() clause.
If the values() clause precedes the annotate() clause, any annotations will be automatically added to the result
set. However, if the values() clause is applied after the annotate() clause, you need to explicitly include the
aggregate column.
Interaction with default ordering or order_by() Fields that are mentioned in the order_by() part of a
queryset (or which are used in the default ordering on a model) are used when selecting the output data, even if they
are not otherwise specified in the values() call. These extra fields are used to group “like” results together and they
can make otherwise identical result rows appear to be separate. This shows up, particularly, when counting things.
By way of example, suppose you have a model like this:
class Item(models.Model):
name = models.CharField(max_length=10)
data = models.IntegerField()
class Meta:
ordering = ["name"]
The important part here is the default ordering on the name field. If you want to count how many times each distinct
data value appears, you might try this:
# Warning: not quite correct!
Item.objects.values("data").annotate(Count("id"))
3.2. Models and databases 117](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-121-2048.jpg)

![Django Documentation, Release 1.5.1
Custom Managers
You can use a custom Manager in a particular model by extending the base Manager class and instantiating your
custom Manager in your model.
There are two reasons you might want to customize a Manager: to add extra Manager methods, and/or to modify
the initial QuerySet the Manager returns.
Adding extra Manager methods
Adding extra Manager methods is the preferred way to add “table-level” functionality to your models. (For “row-level”
functionality – i.e., functions that act on a single instance of a model object – use Model methods, not custom
Manager methods.)
A custom Manager method can return anything you want. It doesn’t have to return a QuerySet.
For example, this custom Manager offers a method with_counts(), which returns a list of all OpinionPoll
objects, each with an extra num_responses attribute that is the result of an aggregate query:
class PollManager(models.Manager):
def with_counts(self):
from django.db import connection
cursor = connection.cursor()
cursor.execute("""
SELECT p.id, p.question, p.poll_date, COUNT(*)
FROM polls_opinionpoll p, polls_response r
WHERE p.id = r.poll_id
GROUP BY p.id, p.question, p.poll_date
ORDER BY p.poll_date DESC""")
result_list = []
for row in cursor.fetchall():
p = self.model(id=row[0], question=row[1], poll_date=row[2])
p.num_responses = row[3]
result_list.append(p)
return result_list
class OpinionPoll(models.Model):
question = models.CharField(max_length=200)
poll_date = models.DateField()
objects = PollManager()
class Response(models.Model):
poll = models.ForeignKey(OpinionPoll)
person_name = models.CharField(max_length=50)
response = models.TextField()
With this example, you’d use OpinionPoll.objects.with_counts() to return that list of OpinionPoll
objects with num_responses attributes.
Another thing to note about this example is that Manager methods can access self.model to get the model class
to which they’re attached.
Modifying initial Manager QuerySets
A Manager‘s base QuerySet returns all objects in the system. For example, using this model:
3.2. Models and databases 119](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-123-2048.jpg)





![Django Documentation, Release 1.5.1
For more details check out the documentation for the db_table option, which also lets you manually set the database
table name.
Warning: No checking is done on the SQL statement that is passed in to .raw(). Django expects that the
statement will return a set of rows from the database, but does nothing to enforce that. If the query does not return
rows, a (possibly cryptic) error will result.
Mapping query fields to model fields
raw() automatically maps fields in the query to fields on the model.
The order of fields in your query doesn’t matter. In other words, both of the following queries work identically:
>>> Person.objects.raw(’SELECT id, first_name, last_name, birth_date FROM myapp_person’)
...
>>> Person.objects.raw(’SELECT last_name, birth_date, first_name, id FROM myapp_person’)
...
Matching is done by name. This means that you can use SQL’s AS clauses to map fields in the query to model fields.
So if you had some other table that had Person data in it, you could easily map it into Person instances:
>>> Person.objects.raw(’’’SELECT first AS first_name,
... last AS last_name,
... bd AS birth_date,
... pk as id,
... FROM some_other_table’’’)
As long as the names match, the model instances will be created correctly.
Alternatively, you can map fields in the query to model fields using the translations argument to raw(). This
is a dictionary mapping names of fields in the query to names of fields on the model. For example, the above query
could also be written:
>>> name_map = {’first’: ’first_name’, ’last’: ’last_name’, ’bd’: ’birth_date’, ’pk’: ’id’}
>>> Person.objects.raw(’SELECT * FROM some_other_table’, translations=name_map)
Index lookups
raw() supports indexing, so if you need only the first result you can write:
>>> first_person = Person.objects.raw(’SELECT * from myapp_person’)[0]
However, the indexing and slicing are not performed at the database level. If you have a big amount of Person
objects in your database, it is more efficient to limit the query at the SQL level:
>>> first_person = Person.objects.raw(’SELECT * from myapp_person LIMIT 1’)[0]
Deferring model fields
Fields may also be left out:
>>> people = Person.objects.raw(’SELECT id, first_name FROM myapp_person’)
3.2. Models and databases 125](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-129-2048.jpg)
![Django Documentation, Release 1.5.1
The Person objects returned by this query will be deferred model instances (see defer()). This means that the
fields that are omitted from the query will be loaded on demand. For example:
>>> for p in Person.objects.raw(’SELECT id, first_name FROM myapp_person’):
... print(p.first_name, # This will be retrieved by the original query
... p.last_name) # This will be retrieved on demand
...
John Smith
Jane Jones
From outward appearances, this looks like the query has retrieved both the first name and last name. However, this
example actually issued 3 queries. Only the first names were retrieved by the raw() query – the last names were both
retrieved on demand when they were printed.
There is only one field that you can’t leave out - the primary key field. Django uses the primary key to identify model
instances, so it must always be included in a raw query. An InvalidQuery exception will be raised if you forget to
include the primary key.
Adding annotations
You can also execute queries containing fields that aren’t defined on the model. For example, we could use Post-greSQL’s
age() function to get a list of people with their ages calculated by the database:
>>> people = Person.objects.raw(’SELECT *, age(birth_date) AS age FROM myapp_person’)
>>> for p in people:
... print("%s is %s." % (p.first_name, p.age))
John is 37.
Jane is 42.
...
Passing parameters into raw()
If you need to perform parameterized queries, you can use the params argument to raw():
>>> lname = ’Doe’
>>> Person.objects.raw(’SELECT * FROM myapp_person WHERE last_name = %s’, [lname])
params is a list of parameters. You’ll use %s placeholders in the query string (regardless of your database engine);
they’ll be replaced with parameters from the params list.
Warning: Do not use string formatting on raw queries!
It’s tempting to write the above query as:
>>> query = ’SELECT * FROM myapp_person WHERE last_name = %s’ % lname
>>> Person.objects.raw(query)
Don’t.
Using the params list completely protects you from SQL injection attacks, a common exploit where attackers
inject arbitrary SQL into your database. If you use string interpolation, sooner or later you’ll fall victim to SQL
injection. As long as you remember to always use the params list you’ll be protected.
126 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-130-2048.jpg)
![Django Documentation, Release 1.5.1
Executing custom SQL directly
Sometimes even Manager.raw() isn’t quite enough: you might need to perform queries that don’t map cleanly to
models, or directly execute UPDATE, INSERT, or DELETE queries.
In these cases, you can always access the database directly, routing around the model layer entirely.
The object django.db.connection represents the default database connection, and
django.db.transaction represents the default database transaction. To use the database connection,
call connection.cursor() to get a cursor object. Then, call cursor.execute(sql, [params]) to
execute the SQL and cursor.fetchone() or cursor.fetchall() to return the resulting rows. After
performing a data changing operation, you should then call transaction.commit_unless_managed() to
ensure your changes are committed to the database. If your query is purely a data retrieval operation, no commit is
required. For example:
def my_custom_sql():
from django.db import connection, transaction
cursor = connection.cursor()
# Data modifying operation - commit required
cursor.execute("UPDATE bar SET foo = 1 WHERE baz = %s", [self.baz])
transaction.commit_unless_managed()
# Data retrieval operation - no commit required
cursor.execute("SELECT foo FROM bar WHERE baz = %s", [self.baz])
row = cursor.fetchone()
return row
If you are using more than one database, you can use django.db.connections to obtain the connection (and
cursor) for a specific database. django.db.connections is a dictionary-like object that allows you to retrieve a
specific connection using its alias:
from django.db import connections
cursor = connections[’my_db_alias’].cursor()
# Your code here...
transaction.commit_unless_managed(using=’my_db_alias’)
By default, the Python DB API will return results without their field names, which means you end up with a list of
values, rather than a dict. At a small performance cost, you can return results as a dict by using something like
this:
def dictfetchall(cursor):
"Returns all rows from a cursor as a dict"
desc = cursor.description
return [
dict(zip([col[0] for col in desc], row))
for row in cursor.fetchall()
]
Here is an example of the difference between the two:
>>> cursor.execute("SELECT id, parent_id from test LIMIT 2");
>>> cursor.fetchall()
((54360982L, None), (54360880L, None))
>>> cursor.execute("SELECT id, parent_id from test LIMIT 2");
>>> dictfetchall(cursor)
[{’parent_id’: None, ’id’: 54360982L}, {’parent_id’: None, ’id’: 54360880L}]
3.2. Models and databases 127](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-131-2048.jpg)









![Django Documentation, Release 1.5.1
Now we’ll need to handle routing. First we want a router that knows to send queries for the auth app to auth_db:
class AuthRouter(object):
"""
A router to control all database operations on models in the
auth application.
"""
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.app_label == ’auth’:
return ’auth_db’
return None
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
if model._meta.app_label == ’auth’:
return ’auth_db’
return None
def allow_relation(self, obj1, obj2, **hints):
"""
Allow relations if a model in the auth app is involved.
"""
if obj1._meta.app_label == ’auth’ or
obj2._meta.app_label == ’auth’:
return True
return None
def allow_syncdb(self, db, model):
"""
Make sure the auth app only appears in the ’auth_db’
database.
"""
if db == ’auth_db’:
return model._meta.app_label == ’auth’
elif model._meta.app_label == ’auth’:
return False
return None
And we also want a router that sends all other apps to the master/slave configuration, and randomly chooses a slave to
read from:
import random
class MasterSlaveRouter(object):
def db_for_read(self, model, **hints):
"""
Reads go to a randomly-chosen slave.
"""
return random.choice([’slave1’, ’slave2’])
def db_for_write(self, model, **hints):
"""
Writes always go to master.
"""
3.2. Models and databases 137](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-141-2048.jpg)
![Django Documentation, Release 1.5.1
return ’master’
def allow_relation(self, obj1, obj2, **hints):
"""
Relations between objects are allowed if both objects are
in the master/slave pool.
"""
db_list = (’master’, ’slave1’, ’slave2’)
if obj1.state.db in db_list and obj2.state.db in db_list:
return True
return None
def allow_syncdb(self, db, model):
"""
All non-auth models end up in this pool.
"""
return True
Finally, in the settings file, we add the following (substituting path.to. with the actual python path to the module(s)
where the routers are defined):
DATABASE_ROUTERS = [’path.to.AuthRouter’, ’path.to.MasterSlaveRouter’]
The order in which routers are processed is significant. Routers will be queried in the order the are
listed in the DATABASE_ROUTERS setting . In this example, the AuthRouter is processed before the
MasterSlaveRouter, and as a result, decisions concerning the models in auth are processed before
any other decision is made. If the DATABASE_ROUTERS setting listed the two routers in the other order,
MasterSlaveRouter.allow_syncdb() would be processed first. The catch-all nature of the MasterSlaveR-outer
implementation would mean that all models would be available on all databases.
With this setup installed, lets run some Django code:
>>> # This retrieval will be performed on the ’auth_db’ database
>>> fred = User.objects.get(username=’fred’)
>>> fred.first_name = ’Frederick’
>>> # This save will also be directed to ’auth_db’
>>> fred.save()
>>> # These retrieval will be randomly allocated to a slave database
>>> dna = Person.objects.get(name=’Douglas Adams’)
>>> # A new object has no database allocation when created
>>> mh = Book(title=’Mostly Harmless’)
>>> # This assignment will consult the router, and set mh onto
>>> # the same database as the author object
>>> mh.author = dna
>>> # This save will force the ’mh’ instance onto the master database...
>>> mh.save()
>>> # ... but if we re-retrieve the object, it will come back on a slave
>>> mh = Book.objects.get(title=’Mostly Harmless’)
138 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-142-2048.jpg)



![Django Documentation, Release 1.5.1
# on the ’other’ database.
return super(MultiDBTabularInline, self).formfield_for_manytomany(db_field, request=request, Once you’ve written your model admin definitions, they can be registered with any Admin instance:
from django.contrib import admin
# Specialize the multi-db admin objects for use with specific models.
class BookInline(MultiDBTabularInline):
model = Book
class PublisherAdmin(MultiDBModelAdmin):
inlines = [BookInline]
admin.site.register(Author, MultiDBModelAdmin)
admin.site.register(Publisher, PublisherAdmin)
othersite = admin.AdminSite(’othersite’)
othersite.register(Publisher, MultiDBModelAdmin)
This example sets up two admin sites. On the first site, the Author and Publisher objects are exposed;
Publisher objects have an tabular inline showing books published by that publisher. The second site exposes
just publishers, without the inlines.
Using raw cursors with multiple databases
If you are using more than one database you can use django.db.connections to obtain the connection (and
cursor) for a specific database. django.db.connections is a dictionary-like object that allows you to retrieve a
specific connection using its alias:
from django.db import connections
cursor = connections[’my_db_alias’].cursor()
Limitations of multiple databases
Cross-database relations
Django doesn’t currently provide any support for foreign key or many-to-many relationships spanning multiple
databases. If you have used a router to partition models to different databases, any foreign key and many-to-many
relationships defined by those models must be internal to a single database.
This is because of referential integrity. In order to maintain a relationship between two objects, Django needs to know
that the primary key of the related object is valid. If the primary key is stored on a separate database, it’s not possible
to easily evaluate the validity of a primary key.
If you’re using Postgres, Oracle, or MySQL with InnoDB, this is enforced at the database integrity level – database
level key constraints prevent the creation of relations that can’t be validated.
However, if you’re using SQLite or MySQL with MyISAM tables, there is no enforced referential integrity; as a
result, you may be able to ‘fake’ cross database foreign keys. However, this configuration is not officially supported
by Django.
142 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-146-2048.jpg)





![Django Documentation, Release 1.5.1
{% endfor %}
{% else %}
<p>No messages today.</p>
{% endif %}
{% endwith %}
{% endif %}
It is optimal because:
1. Since QuerySets are lazy, this does no database queries if ‘display_inbox’ is False.
2. Use of with means that we store user.emails.all in a variable for later use, allowing its cache to be
re-used.
3. The line {% if emails %} causes QuerySet.__bool__() to be called, which causes the
user.emails.all() query to be run on the database, and at the least the first line to be turned into an
ORM object. If there aren’t any results, it will return False, otherwise True.
4. The use of {{ emails|length }} calls QuerySet.__len__(), filling out the rest of the cache without
doing another query.
5. The for loop iterates over the already filled cache.
In total, this code does either one or zero database queries. The only deliberate optimization performed is the use of the
with tag. Using QuerySet.exists() or QuerySet.count() at any point would cause additional queries.
Use QuerySet.update() and delete()
Rather than retrieve a load of objects, set some values, and save them individual, use a bulk SQL UPDATE statement,
via QuerySet.update(). Similarly, do bulk deletes where possible.
Note, however, that these bulk update methods cannot call the save() or delete() methods of individual instances,
which means that any custom behavior you have added for these methods will not be executed, including anything
driven from the normal database object signals.
Use foreign key values directly
If you only need a foreign key value, use the foreign key value that is already on the object you’ve got, rather than
getting the whole related object and taking its primary key. i.e. do:
entry.blog_id
instead of:
entry.blog.id
Insert in bulk
When creating objects, where possible, use the bulk_create() method to reduce the number of SQL queries. For
example:
Entry.objects.bulk_create([
Entry(headline="Python 3.0 Released"),
Entry(headline="Python 3.1 Planned")
])
148 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-152-2048.jpg)

![Django Documentation, Release 1.5.1
Create an Article:
>>> a1 = Article(headline=’Django lets you build Web apps easily’)
You can’t associate it with a Publication until it’s been saved:
>>> a1.publications.add(p1)
Traceback (most recent call last):
...
ValueError: ’Article’ instance needs to have a primary key value before a many-to-many relationship can Save it!
>>> a1.save()
Associate the Article with a Publication:
>>> a1.publications.add(p1)
Create another Article, and set it to appear in both Publications:
>>> a2 = Article(headline=’NASA uses Python’)
>>> a2.save()
>>> a2.publications.add(p1, p2)
>>> a2.publications.add(p3)
Adding a second time is OK:
>>> a2.publications.add(p3)
Adding an object of the wrong type raises TypeError:
>>> a2.publications.add(a1)
Traceback (most recent call last):
...
TypeError: ’Publication’ instance expected
Create and add a Publication to an Article in one step using create():
>>> new_publication = a2.publications.create(title=’Highlights for Children’)
Article objects have access to their related Publication objects:
>>> a1.publications.all()
[<Publication: The Python Journal>]
>>> a2.publications.all()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, Publication objects have access to their related Article objects:
>>> p2.article_set.all()
[<Article: NASA uses Python>]
>>> p1.article_set.all()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Publication.objects.get(id=4).article_set.all()
[<Article: NASA uses Python>]
Many-to-many relationships can be queried using lookups across relationships:
>>> Article.objects.filter(publications__id__exact=1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__pk=1)
150 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-154-2048.jpg)
![Django Documentation, Release 1.5.1
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications=1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications=p1)
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__title__startswith="Science")
[<Article: NASA uses Python>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__title__startswith="Science").distinct()
[<Article: NASA uses Python>]
The count() function respects distinct() as well:
>>> Article.objects.filter(publications__title__startswith="Science").count()
2
>>> Article.objects.filter(publications__title__startswith="Science").distinct().count()
1
>>> Article.objects.filter(publications__in=[1,2]).distinct()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
>>> Article.objects.filter(publications__in=[p1,p2]).distinct()
[<Article: Django lets you build Web apps easily>, <Article: NASA uses Python>]
Reverse m2m queries are supported (i.e., starting at the table that doesn’t have a ManyToManyField):
>>> Publication.objects.filter(id__exact=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(pk=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__headline__startswith="NASA")
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, >>> Publication.objects.filter(article__id__exact=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__pk=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article=1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article=a1)
[<Publication: The Python Journal>]
>>> Publication.objects.filter(article__in=[1,2]).distinct()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, >>> Publication.objects.filter(article__in=[a1,a2]).distinct()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, Excluding a related item works as you would expect, too (although the SQL involved is a little complex):
>>> Article.objects.exclude(publications=p2)
[<Article: Django lets you build Web apps easily>]
If we delete a Publication, its Articles won’t be able to access it:
>>> p1.delete()
>>> Publication.objects.all()
[<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>]
3.2. Models and databases 151](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-155-2048.jpg)
![Django Documentation, Release 1.5.1
>>> a1 = Article.objects.get(pk=1)
>>> a1.publications.all()
[]
If we delete an Article, its Publications won’t be able to access it:
>>> a2.delete()
>>> Article.objects.all()
[<Article: Django lets you build Web apps easily>]
>>> p2.article_set.all()
[]
Adding via the ‘other’ end of an m2m:
>>> a4 = Article(headline=’NASA finds intelligent life on Earth’)
>>> a4.save()
>>> p2.article_set.add(a4)
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>]
>>> a4.publications.all()
[<Publication: Science News>]
Adding via the other end using keywords:
>>> new_article = p2.article_set.create(headline=’Oxygen-free diet works wonders’)
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>, <Article: Oxygen-free diet works wonders>]
>>> a5 = p2.article_set.all()[1]
>>> a5.publications.all()
[<Publication: Science News>]
Removing Publication from an Article:
>>> a4.publications.remove(p2)
>>> p2.article_set.all()
[<Article: Oxygen-free diet works wonders>]
>>> a4.publications.all()
[]
And from the other end:
>>> p2.article_set.remove(a5)
>>> p2.article_set.all()
[]
>>> a5.publications.all()
[]
Relation sets can be assigned. Assignment clears any existing set members:
>>> a4.publications.all()
[<Publication: Science News>]
>>> a4.publications = [p3]
>>> a4.publications.all()
[<Publication: Science Weekly>]
Relation sets can be cleared:
>>> p2.article_set.clear()
>>> p2.article_set.all()
[]
152 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-156-2048.jpg)
![Django Documentation, Release 1.5.1
And you can clear from the other end:
>>> p2.article_set.add(a4, a5)
>>> p2.article_set.all()
[<Article: NASA finds intelligent life on Earth>, <Article: Oxygen-free diet works wonders>]
>>> a4.publications.all()
[<Publication: Science News>, <Publication: Science Weekly>]
>>> a4.publications.clear()
>>> a4.publications.all()
[]
>>> p2.article_set.all()
[<Article: Oxygen-free diet works wonders>]
Recreate the Article and Publication we have deleted:
>>> p1 = Publication(title=’The Python Journal’)
>>> p1.save()
>>> a2 = Article(headline=’NASA uses Python’)
>>> a2.save()
>>> a2.publications.add(p1, p2, p3)
Bulk delete some Publications - references to deleted publications should go:
>>> Publication.objects.filter(title__startswith=’Science’).delete()
>>> Publication.objects.all()
[<Publication: Highlights for Children>, <Publication: The Python Journal>]
>>> Article.objects.all()
[<Article: Django lets you build Web apps easily>, <Article: NASA finds intelligent life on Earth>, <>>> a2.publications.all()
[<Publication: The Python Journal>]
Bulk delete some articles - references to deleted objects should go:
>>> q = Article.objects.filter(headline__startswith=’Django’)
>>> print(q)
[<Article: Django lets you build Web apps easily>]
>>> q.delete()
After the delete(), the QuerySet cache needs to be cleared, and the referenced objects should be gone:
>>> print(q)
[]
>>> p1.article_set.all()
[<Article: NASA uses Python>]
An alternate to calling clear() is to assign the empty set:
>>> p1.article_set = []
>>> p1.article_set.all()
[]
>>> a2.publications = [p1, new_publication]
>>> a2.publications.all()
[<Publication: Highlights for Children>, <Publication: The Python Journal>]
>>> a2.publications = []
>>> a2.publications.all()
[]
3.2. Models and databases 153](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-157-2048.jpg)

![Django Documentation, Release 1.5.1
>>> new_article = r.article_set.create(headline="John’s second story", pub_date=date(2005, 7, 29))
>>> new_article
<Article: John’s second story>
>>> new_article.reporter
<Reporter: John Smith>
>>> new_article.reporter.id
1
Create a new article, and add it to the article set:
>>> new_article2 = Article(headline="Paul’s story", pub_date=date(2006, 1, 17))
>>> r.article_set.add(new_article2)
>>> new_article2.reporter
<Reporter: John Smith>
>>> new_article2.reporter.id
1
>>> r.article_set.all()
[<Article: John’s second story>, <Article: Paul’s story>, <Article: This is a test>]
Add the same article to a different article set - check that it moves:
>>> r2.article_set.add(new_article2)
>>> new_article2.reporter.id
2
>>> new_article2.reporter
<Reporter: Paul Jones>
Adding an object of the wrong type raises TypeError:
>>> r.article_set.add(r2)
Traceback (most recent call last):
...
TypeError: ’Article’ instance expected
>>> r.article_set.all()
[<Article: John’s second story>, <Article: This is a test>]
>>> r2.article_set.all()
[<Article: Paul’s story>]
>>> r.article_set.count()
2
>>> r2.article_set.count()
1
Note that in the last example the article has moved from John to Paul.
Related managers support field lookups as well. The API automatically follows relationships as far as you need. Use
double underscores to separate relationships. This works as many levels deep as you want. There’s no limit. For
example:
>>> r.article_set.filter(headline__startswith=’This’)
[<Article: This is a test>]
# Find all Articles for any Reporter whose first name is "John".
>>> Article.objects.filter(reporter__first_name__exact=’John’)
[<Article: John’s second story>, <Article: This is a test>]
Exact match is implied here:
3.2. Models and databases 155](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-159-2048.jpg)
![Django Documentation, Release 1.5.1
>>> Article.objects.filter(reporter__first_name=’John’)
[<Article: John’s second story>, <Article: This is a test>]
Query twice over the related field. This translates to an AND condition in the WHERE clause:
>>> Article.objects.filter(reporter__first_name__exact=’John’, reporter__last_name__exact=’Smith’)
[<Article: John’s second story>, <Article: This is a test>]
For the related lookup you can supply a primary key value or pass the related object explicitly:
>>> Article.objects.filter(reporter__pk=1)
[<Article: John’s second story>, <Article: This is a test>]
>>> Article.objects.filter(reporter=1)
[<Article: John’s second story>, <Article: This is a test>]
>>> Article.objects.filter(reporter=r)
[<Article: John’s second story>, <Article: This is a test>]
>>> Article.objects.filter(reporter__in=[1,2]).distinct()
[<Article: John’s second story>, <Article: Paul’s story>, <Article: This is a test>]
>>> Article.objects.filter(reporter__in=[r,r2]).distinct()
[<Article: John’s second story>, <Article: Paul’s story>, <Article: This is a test>]
You can also use a queryset instead of a literal list of instances:
>>> Article.objects.filter(reporter__in=Reporter.objects.filter(first_name=’John’)).distinct()
[<Article: John’s second story>, <Article: This is a test>]
Querying in the opposite direction:
>>> Reporter.objects.filter(article__pk=1)
[<Reporter: John Smith>]
>>> Reporter.objects.filter(article=1)
[<Reporter: John Smith>]
>>> Reporter.objects.filter(article=a)
[<Reporter: John Smith>]
>>> Reporter.objects.filter(article__headline__startswith=’This’)
[<Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>]
>>> Reporter.objects.filter(article__headline__startswith=’This’).distinct()
[<Reporter: John Smith>]
Counting in the opposite direction works in conjunction with distinct():
>>> Reporter.objects.filter(article__headline__startswith=’This’).count()
3
>>> Reporter.objects.filter(article__headline__startswith=’This’).distinct().count()
1
Queries can go round in circles:
>>> Reporter.objects.filter(article__reporter__first_name__startswith=’John’)
[<Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>, <Reporter: John Smith>]
>>> Reporter.objects.filter(article__reporter__first_name__startswith=’John’).distinct()
[<Reporter: John Smith>]
>>> Reporter.objects.filter(article__reporter__exact=r).distinct()
[<Reporter: John Smith>]
If you delete a reporter, his articles will be deleted (assuming that the ForeignKey was defined with
django.db.models.ForeignKey.on_delete set to CASCADE, which is the default):
156 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-160-2048.jpg)
![Django Documentation, Release 1.5.1
>>> Article.objects.all()
[<Article: John’s second story>, <Article: Paul’s story>, <Article: This is a test>]
>>> Reporter.objects.order_by(’first_name’)
[<Reporter: John Smith>, <Reporter: Paul Jones>]
>>> r2.delete()
>>> Article.objects.all()
[<Article: John’s second story>, <Article: This is a test>]
>>> Reporter.objects.order_by(’first_name’)
[<Reporter: John Smith>]
You can delete using a JOIN in the query:
>>> Reporter.objects.filter(article__headline__startswith=’This’).delete()
>>> Reporter.objects.all()
[]
>>> Article.objects.all()
[]
One-to-one relationships
To define a one-to-one relationship, use OneToOneField.
In this example, a Place optionally can be a Restaurant:
from django.db import models, transaction, IntegrityError
class Place(models.Model):
name = models.CharField(max_length=50)
address = models.CharField(max_length=80)
def __unicode__(self):
return u"%s the place" % self.name
class Restaurant(models.Model):
place = models.OneToOneField(Place, primary_key=True)
serves_hot_dogs = models.BooleanField()
serves_pizza = models.BooleanField()
def __unicode__(self):
return u"%s the restaurant" % self.place.name
class Waiter(models.Model):
restaurant = models.ForeignKey(Restaurant)
name = models.CharField(max_length=50)
def __unicode__(self):
return u"%s the waiter at %s" % (self.name, self.restaurant)
What follows are examples of operations that can be performed using the Python API facilities.
Create a couple of Places:
>>> p1 = Place(name=’Demon Dogs’, address=’944 W. Fullerton’)
>>> p1.save()
>>> p2 = Place(name=’Ace Hardware’, address=’1013 N. Ashland’)
>>> p2.save()
Create a Restaurant. Pass the ID of the “parent” object as this object’s ID:
3.2. Models and databases 157](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-161-2048.jpg)
![Django Documentation, Release 1.5.1
>>> r = Restaurant(place=p1, serves_hot_dogs=True, serves_pizza=False)
>>> r.save()
A Restaurant can access its place:
>>> r.place
<Place: Demon Dogs the place>
A Place can access its restaurant, if available:
>>> p1.restaurant
<Restaurant: Demon Dogs the restaurant>
p2 doesn’t have an associated restaurant:
>>> p2.restaurant
Traceback (most recent call last):
...
DoesNotExist: Restaurant matching query does not exist.
Set the place using assignment notation. Because place is the primary key on Restaurant, the save will create a new
restaurant:
>>> r.place = p2
>>> r.save()
>>> p2.restaurant
<Restaurant: Ace Hardware the restaurant>
>>> r.place
<Place: Ace Hardware the place>
Set the place back again, using assignment in the reverse direction:
>>> p1.restaurant = r
>>> p1.restaurant
<Restaurant: Demon Dogs the restaurant>
Restaurant.objects.all() just returns the Restaurants, not the Places. Note that there are two restaurants - Ace Hardware
the Restaurant was created in the call to r.place = p2:
>>> Restaurant.objects.all()
[<Restaurant: Demon Dogs the restaurant>, <Restaurant: Ace Hardware the restaurant>]
Place.objects.all() returns all Places, regardless of whether they have Restaurants:
>>> Place.objects.order_by(’name’)
[<Place: Ace Hardware the place>, <Place: Demon Dogs the place>]
You can query the models using lookups across relationships:
>>> Restaurant.objects.get(place=p1)
<Restaurant: Demon Dogs the restaurant>
>>> Restaurant.objects.get(place__pk=1)
<Restaurant: Demon Dogs the restaurant>
>>> Restaurant.objects.filter(place__name__startswith="Demon")
[<Restaurant: Demon Dogs the restaurant>]
>>> Restaurant.objects.exclude(place__address__contains="Ashland")
[<Restaurant: Demon Dogs the restaurant>]
This of course works in reverse:
158 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-162-2048.jpg)
![Django Documentation, Release 1.5.1
>>> Place.objects.get(pk=1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant__place__exact=p1)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant=r)
<Place: Demon Dogs the place>
>>> Place.objects.get(restaurant__place__name__startswith="Demon")
<Place: Demon Dogs the place>
Add a Waiter to the Restaurant:
>>> w = r.waiter_set.create(name=’Joe’)
>>> w.save()
>>> w
<Waiter: Joe the waiter at Demon Dogs the restaurant>
Query the waiters:
>>> Waiter.objects.filter(restaurant__place=p1)
[<Waiter: Joe the waiter at Demon Dogs the restaurant>]
>>> Waiter.objects.filter(restaurant__place__name__startswith="Demon")
[<Waiter: Joe the waiter at Demon Dogs the restaurant>]
3.3 Handling HTTP requests
Information on handling HTTP requests in Django:
3.3.1 URL dispatcher
A clean, elegant URL scheme is an important detail in a high-quality Web application. Django lets you design URLs
however you want, with no framework limitations.
There’s no .php or .cgi required, and certainly none of that 0,2097,1-1-1928,00 nonsense.
See Cool URIs don’t change, by World Wide Web creator Tim Berners-Lee, for excellent arguments on why URLs
should be clean and usable.
Overview
To design URLs for an app, you create a Python module informally called a URLconf (URL configuration). This
module is pure Python code and is a simple mapping between URL patterns (simple regular expressions) to Python
functions (your views).
This mapping can be as short or as long as needed. It can reference other mappings. And, because it’s pure Python
code, it can be constructed dynamically. New in version 1.4: Django also provides a way to translate URLs according
to the active language. See the internationalization documentation for more information.
How Django processes a request
When a user requests a page from your Django-powered site, this is the algorithm the system follows to determine
which Python code to execute:
3.3. Handling HTTP requests 159](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-163-2048.jpg)



![Django Documentation, Release 1.5.1
• handler403 – See django.conf.urls.handler403.
New in version 1.4: handler403 is new in Django 1.4.
The view prefix
You can specify a common prefix in your patterns() call, to cut down on code duplication.
Here’s the example URLconf from the Django overview:
from django.conf.urls import patterns, url
urlpatterns = patterns(’’,
url(r’^articles/(d{4})/$’, ’news.views.year_archive’),
url(r’^articles/(d{4})/(d{2})/$’, ’news.views.month_archive’),
url(r’^articles/(d{4})/(d{2})/(d+)/$’, ’news.views.article_detail’),
)
In this example, each view has a common prefix – ’news.views’. Instead of typing that out for each entry in
urlpatterns, you can use the first argument to the patterns() function to specify a prefix to apply to each
view function.
With this in mind, the above example can be written more concisely as:
from django.conf.urls import patterns, url
urlpatterns = patterns(’news.views’,
url(r’^articles/(d{4})/$’, ’year_archive’),
url(r’^articles/(d{4})/(d{2})/$’, ’month_archive’),
url(r’^articles/(d{4})/(d{2})/(d+)/$’, ’article_detail’),
)
Note that you don’t put a trailing dot (".") in the prefix. Django puts that in automatically.
Multiple view prefixes
In practice, you’ll probably end up mixing and matching views to the point where the views in your urlpatterns
won’t have a common prefix. However, you can still take advantage of the view prefix shortcut to remove duplication.
Just add multiple patterns() objects together, like this:
Old:
from django.conf.urls import patterns, url
urlpatterns = patterns(’’,
url(r’^$’, ’myapp.views.app_index’),
url(r’^(?P<year>d{4})/(?P<month>[a-z]{3})/$’, ’myapp.views.month_display’),
url(r’^tag/(?P<tag>w+)/$’, ’weblog.views.tag’),
)
New:
from django.conf.urls import patterns, url
urlpatterns = patterns(’myapp.views’,
url(r’^$’, ’app_index’),
url(r’^(?P<year>d{4})/(?P<month>[a-z]{3})/$’,’month_display’),
)
3.3. Handling HTTP requests 163](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-167-2048.jpg)










![Django Documentation, Release 1.5.1
from django.core.exceptions import PermissionDenied
def edit(request, pk):
if not request.user.is_staff:
raise PermissionDenied
# ...
It is possible to override django.views.defaults.permission_denied in the same way you can for the
404 and 500 views by specifying a handler403 in your URLconf:
handler403 = ’mysite.views.my_custom_permission_denied_view’
3.3.3 View decorators
Django provides several decorators that can be applied to views to support various HTTP features.
Allowed HTTP methods
The decorators in django.views.decorators.http can be used to restrict access to views based on the request
method. These decorators will return a django.http.HttpResponseNotAllowed if the conditions are not
met.
require_http_methods(request_method_list)
Decorator to require that a view only accept particular request methods. Usage:
from django.views.decorators.http import require_http_methods
@require_http_methods(["GET", "POST"])
def my_view(request):
# I can assume now that only GET or POST requests make it this far
# ...
pass
Note that request methods should be in uppercase.
require_GET()
Decorator to require that a view only accept the GET method.
require_POST()
Decorator to require that a view only accept the POST method.
require_safe()
New in version 1.4. Decorator to require that a view only accept the GET and HEAD methods. These methods
are commonly considered “safe” because they should not have the significance of taking an action other than
retrieving the requested resource.
Note: Django will automatically strip the content of responses to HEAD requests while leaving the headers un-changed,
so you may handle HEAD requests exactly like GET requests in your views. Since some software, such
as link checkers, rely on HEAD requests, you might prefer using require_safe instead of require_GET.
Conditional view processing
The following decorators in django.views.decorators.http can be used to control caching behavior on
particular views.
174 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-178-2048.jpg)
![Django Documentation, Release 1.5.1
condition(etag_func=None, last_modified_func=None)
etag(etag_func)
last_modified(last_modified_func)
These decorators can be used to generate ETag and Last-Modified headers; see conditional view process-ing.
GZip compression
The decorators in django.views.decorators.gzip control content compression on a per-view basis.
gzip_page()
This decorator compresses content if the browser allows gzip compression. It sets the Vary header accordingly,
so that caches will base their storage on the Accept-Encoding header.
Vary headers
The decorators in django.views.decorators.vary can be used to control caching based on specific request
headers.
vary_on_cookie(func)
vary_on_headers(*headers)
The Vary header defines which request headers a cache mechanism should take into account when building its
cache key.
See using vary headers.
3.3.4 File Uploads
When Django handles a file upload, the file data ends up placed in request.FILES (for more on the request
object see the documentation for request and response objects). This document explains how files are stored on disk
and in memory, and how to customize the default behavior.
Basic file uploads
Consider a simple form containing a FileField:
from django import forms
class UploadFileForm(forms.Form):
title = forms.CharField(max_length=50)
file = forms.FileField()
A view handling this form will receive the file data in request.FILES, which is a dictionary containing a key for
each FileField (or ImageField, or other FileField subclass) in the form. So the data from the above form
would be accessible as request.FILES[’file’].
Note that request.FILES will only contain data if the request method was POST and the <form> that posted the
request has the attribute enctype="multipart/form-data". Otherwise, request.FILES will be empty.
Most of the time, you’ll simply pass the file data from request into the form as described in Binding uploaded files
to a form. This would look something like:
3.3. Handling HTTP requests 175](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-179-2048.jpg)
![Django Documentation, Release 1.5.1
from django.http import HttpResponseRedirect
from django.shortcuts import render_to_response
# Imaginary function to handle an uploaded file.
from somewhere import handle_uploaded_file
def upload_file(request):
if request.method == ’POST’:
form = UploadFileForm(request.POST, request.FILES)
if form.is_valid():
handle_uploaded_file(request.FILES[’file’])
return HttpResponseRedirect(’/success/url/’)
else:
form = UploadFileForm()
return render_to_response(’upload.html’, {’form’: form})
Notice that we have to pass request.FILES into the form’s constructor; this is how file data gets bound into a
form.
Handling uploaded files
class UploadedFile
The final piece of the puzzle is handling the actual file data from request.FILES. Each entry in this dictio-nary
is an UploadedFile object – a simple wrapper around an uploaded file. You’ll usually use one of these
methods to access the uploaded content:
read()
Read the entire uploaded data from the file. Be careful with this method: if the uploaded file is huge it can
overwhelm your system if you try to read it into memory. You’ll probably want to use chunks() instead;
see below.
multiple_chunks()
Returns True if the uploaded file is big enough to require reading in multiple chunks. By default this will
be any file larger than 2.5 megabytes, but that’s configurable; see below.
chunks()
A generator returning chunks of the file. If multiple_chunks() is True, you should use this method
in a loop instead of read().
In practice, it’s often easiest simply to use chunks() all the time; see the example below.
name
The name of the uploaded file (e.g. my_file.txt).
size
The size, in bytes, of the uploaded file.
There are a few other methods and attributes available on UploadedFile objects; see UploadedFile objects for a
complete reference.
Putting it all together, here’s a common way you might handle an uploaded file:
def handle_uploaded_file(f):
with open(’some/file/name.txt’, ’wb+’) as destination:
for chunk in f.chunks():
destination.write(chunk)
Looping over UploadedFile.chunks() instead of using read() ensures that large files don’t overwhelm your
system’s memory.
176 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-180-2048.jpg)

![Django Documentation, Release 1.5.1
from django.http import HttpResponseRedirect
from django.shortcuts import render
from .forms import ModelFormWithFileField
def upload_file(request):
if request.method == ’POST’:
form = ModelFormWithFileField(request.POST, request.FILES)
if form.is_valid():
# file is saved
form.save()
return HttpResponseRedirect(’/success/url/’)
else:
form = ModelFormWithFileField()
return render(request, ’upload.html’, {’form’: form})
If you are constructing an object manually, you can simply assign the file object from request.FILES to the file
field in the model:
from django.http import HttpResponseRedirect
from django.shortcuts import render
from .forms import UploadFileForm
from .models import ModelWithFileField
def upload_file(request):
if request.method == ’POST’:
form = UploadFileForm(request.POST, request.FILES)
if form.is_valid():
instance = ModelWithFileField(file_field=request.FILES[’file’])
instance.save()
return HttpResponseRedirect(’/success/url/’)
else:
form = UploadFileForm()
return render(request, ’upload.html’, {’form’: form})
UploadedFile objects
In addition to those inherited from File, all UploadedFile objects define the following methods/attributes:
UploadedFile.content_type
The content-type header uploaded with the file (e.g. text/plain or application/pdf). Like any data
supplied by the user, you shouldn’t trust that the uploaded file is actually this type. You’ll still need to validate
that the file contains the content that the content-type header claims – “trust but verify.”
UploadedFile.charset
For text/* content-types, the character set (i.e. utf8) supplied by the browser. Again, “trust but verify” is
the best policy here.
UploadedFile.temporary_file_path
Only files uploaded onto disk will have this method; it returns the full path to the temporary uploaded file.
Note: Like regular Python files, you can read the file line-by-line simply by iterating over the uploaded file:
for line in uploadedfile:
do_something_with(line)
However, unlike standard Python files, UploadedFile only understands n (also known as “Unix-style”) line
endings. If you know that you need to handle uploaded files with different line endings, you’ll need to do so in your
178 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-182-2048.jpg)
![Django Documentation, Release 1.5.1
view.
Upload Handlers
When a user uploads a file, Django passes off the file data to an upload handler – a small class that handles file data as
it gets uploaded. Upload handlers are initially defined in the FILE_UPLOAD_HANDLERS setting, which defaults to:
("django.core.files.uploadhandler.MemoryFileUploadHandler",
"django.core.files.uploadhandler.TemporaryFileUploadHandler",)
Together the MemoryFileUploadHandler and TemporaryFileUploadHandler provide Django’s default
file upload behavior of reading small files into memory and large ones onto disk.
You can write custom handlers that customize how Django handles files. You could, for example, use custom handlers
to enforce user-level quotas, compress data on the fly, render progress bars, and even send data to another storage
location directly without storing it locally.
Modifying upload handlers on the fly
Sometimes particular views require different upload behavior. In these cases, you can override upload handlers on a
per-request basis by modifying request.upload_handlers. By default, this list will contain the upload handlers
given by FILE_UPLOAD_HANDLERS, but you can modify the list as you would any other list.
For instance, suppose you’ve written a ProgressBarUploadHandler that provides feedback on upload progress
to some sort of AJAX widget. You’d add this handler to your upload handlers like this:
request.upload_handlers.insert(0, ProgressBarUploadHandler())
You’d probably want to use list.insert() in this case (instead of append()) because a progress bar handler
would need to run before any other handlers. Remember, the upload handlers are processed in order.
If you want to replace the upload handlers completely, you can just assign a new list:
request.upload_handlers = [ProgressBarUploadHandler()]
Note: You can only modify upload handlers before accessing request.POST or request.FILES – it
doesn’t make sense to change upload handlers after upload handling has already started. If you try to modify
request.upload_handlers after reading from request.POST or request.FILES Django will throw an
error.
Thus, you should always modify uploading handlers as early in your view as possible.
Also, request.POST is accessed by CsrfViewMiddleware which is enabled by default. This means you will
need to use csrf_exempt() on your view to allow you to change the upload handlers. You will then need to use
csrf_protect() on the function that actually processes the request. Note that this means that the handlers may
start receiving the file upload before the CSRF checks have been done. Example code:
from django.views.decorators.csrf import csrf_exempt, csrf_protect
@csrf_exempt
def upload_file_view(request):
request.upload_handlers.insert(0, ProgressBarUploadHandler())
return _upload_file_view(request)
@csrf_protect
3.3. Handling HTTP requests 179](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-183-2048.jpg)

![Django Documentation, Release 1.5.1
This method may raise a StopFutureHandlers exception to prevent future handlers from handling this file.
FileUploadHandler.upload_complete(self) Callback signaling that the entire upload (all files) has
completed.
FileUploadHandler.handle_raw_input(self, input_data, META, content_length, boundary, encoding)
Allows the handler to completely override the parsing of the raw HTTP input.
input_data is a file-like object that supports read()-ing.
META is the same object as request.META.
content_length is the length of the data in input_data. Don’t read more than content_length
bytes from input_data.
boundary is the MIME boundary for this request.
encoding is the encoding of the request.
Return None if you want upload handling to continue, or a tuple of (POST, FILES) if you want to return
the new data structures suitable for the request directly.
3.3.5 Django shortcut functions
The package django.shortcuts collects helper functions and classes that “span” multiple levels of MVC. In
other words, these functions/classes introduce controlled coupling for convenience’s sake.
render
render(request, template_name[, dictionary][, context_instance][, content_type][, status][, current_app])
Combines a given template with a given context dictionary and returns an HttpResponse object with that
rendered text.
render() is the same as a call to render_to_response() with a context_instance argument that forces
the use of a RequestContext.
Required arguments
request The request object used to generate this response.
template_name The full name of a template to use or sequence of template names.
Optional arguments
dictionary A dictionary of values to add to the template context. By default, this is an empty dictionary. If a
value in the dictionary is callable, the view will call it just before rendering the template.
context_instance The context instance to render the template with. By default, the template will be rendered
with a RequestContext instance (filled with values from request and dictionary).
content_type The MIME type to use for the resulting document. Defaults to the value of the
DEFAULT_CONTENT_TYPE setting. Changed in version 1.5: This parameter used to be called mimetype.
status The status code for the response. Defaults to 200.
current_app A hint indicating which application contains the current view. See the namespaced URL resolution
strategy for more information.
3.3. Handling HTTP requests 181](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-185-2048.jpg)
![Django Documentation, Release 1.5.1
Example
The following example renders the template myapp/index.html with the MIME type
application/xhtml+xml:
from django.shortcuts import render
def my_view(request):
# View code here...
return render(request, ’myapp/index.html’, {"foo": "bar"},
content_type="application/xhtml+xml")
This example is equivalent to:
from django.http import HttpResponse
from django.template import RequestContext, loader
def my_view(request):
# View code here...
t = loader.get_template(’myapp/template.html’)
c = RequestContext(request, {’foo’: ’bar’})
return HttpResponse(t.render(c),
content_type="application/xhtml+xml")
render_to_response
render_to_response(template_name[, dictionary][, context_instance][, content_type])
Renders a given template with a given context dictionary and returns an HttpResponse object with that
rendered text.
Required arguments
template_name The full name of a template to use or sequence of template names. If a sequence is given, the first
template that exists will be used. See the template loader documentation for more information on how templates
are found.
Optional arguments
dictionary A dictionary of values to add to the template context. By default, this is an empty dictionary. If a
value in the dictionary is callable, the view will call it just before rendering the template.
context_instance The context instance to render the template with. By default, the template will be rendered
with a Context instance (filled with values from dictionary). If you need to use context processors, render
the template with a RequestContext instance instead. Your code might look something like this:
return render_to_response(’my_template.html’,
my_data_dictionary,
context_instance=RequestContext(request))
content_type The MIME type to use for the resulting document. Defaults to the value of the
DEFAULT_CONTENT_TYPE setting. Changed in version 1.5: This parameter used to be called mimetype.
182 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-186-2048.jpg)
![Django Documentation, Release 1.5.1
Example
The following example renders the template myapp/index.html with the MIME type
application/xhtml+xml:
from django.shortcuts import render_to_response
def my_view(request):
# View code here...
return render_to_response(’myapp/index.html’, {"foo": "bar"},
mimetype="application/xhtml+xml")
This example is equivalent to:
from django.http import HttpResponse
from django.template import Context, loader
def my_view(request):
# View code here...
t = loader.get_template(’myapp/template.html’)
c = Context({’foo’: ’bar’})
return HttpResponse(t.render(c),
content_type="application/xhtml+xml")
redirect
redirect(to[, permanent=False ], *args, **kwargs)
Returns an HttpResponseRedirect to the appropriate URL for the arguments passed.
The arguments could be:
•A model: the model’s get_absolute_url() function will be called.
•A view name, possibly with arguments: urlresolvers.reverse will be used to reverse-resolve the
name.
•A URL, which will be used as-is for the redirect location.
By default issues a temporary redirect; pass permanent=True to issue a permanent redirect
Examples
You can use the redirect() function in a number of ways.
1. By passing some object; that object’s get_absolute_url() method will be called to figure out the redirect
URL:
from django.shortcuts import redirect
def my_view(request):
...
object = MyModel.objects.get(...)
return redirect(object)
2. By passing the name of a view and optionally some positional or keyword arguments; the URL will be reverse
resolved using the reverse() method:
3.3. Handling HTTP requests 183](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-187-2048.jpg)







![Django Documentation, Release 1.5.1
Warning: The session data is signed but not encrypted
When using the cookies backend the session data can be read by the client.
A MAC (Message Authentication Code) is used to protect the data against changes by the client, so that the session
data will be invalidated when being tampered with. The same invalidation happens if the client storing the cookie
(e.g. your user’s browser) can’t store all of the session cookie and drops data. Even though Django compresses the
data, it’s still entirely possible to exceed the common limit of 4096 bytes per cookie.
No freshness guarantee
Note also that while the MAC can guarantee the authenticity of the data (that it was generated by your site, and
not someone else), and the integrity of the data (that it is all there and correct), it cannot guarantee freshness i.e.
that you are being sent back the last thing you sent to the client. This means that for some uses of session data, the
cookie backend might open you up to replay attacks. Cookies will only be detected as ‘stale’ if they are older than
your SESSION_COOKIE_AGE.
Performance
Finally, the size of a cookie can have an impact on the speed of your site.
Using sessions in views
When SessionMiddleware is activated, each HttpRequest object – the first argument to any Django view
function – will have a session attribute, which is a dictionary-like object.
You can read it and write to request.session at any point in your view. You can edit it multiple times.
class backends.base.SessionBase
This is the base class for all session objects. It has the following standard dictionary methods:
__getitem__(key)
Example: fav_color = request.session[’fav_color’]
__setitem__(key, value)
Example: request.session[’fav_color’] = ’blue’
__delitem__(key)
Example: del request.session[’fav_color’]. This raises KeyError if the given key isn’t
already in the session.
__contains__(key)
Example: ’fav_color’ in request.session
get(key, default=None)
Example: fav_color = request.session.get(’fav_color’, ’red’)
pop(key)
Example: fav_color = request.session.pop(’fav_color’)
keys()
items()
setdefault()
clear()
It also has these methods:
flush()
Delete the current session data from the session and regenerate the session key value that is sent back to
the user in the cookie. This is used if you want to ensure that the previous session data can’t be accessed
again from the user’s browser (for example, the django.contrib.auth.logout() function calls
it).
3.3. Handling HTTP requests 191](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-195-2048.jpg)

![Django Documentation, Release 1.5.1
• Don’t override request.session with a new object, and don’t access or set its attributes. Use it like a
Python dictionary.
Examples
This simplistic view sets a has_commented variable to True after a user posts a comment. It doesn’t let a user post
a comment more than once:
def post_comment(request, new_comment):
if request.session.get(’has_commented’, False):
return HttpResponse("You’ve already commented.")
c = comments.Comment(comment=new_comment)
c.save()
request.session[’has_commented’] = True
return HttpResponse(’Thanks for your comment!’)
This simplistic view logs in a “member” of the site:
def login(request):
m = Member.objects.get(username=request.POST[’username’])
if m.password == request.POST[’password’]:
request.session[’member_id’] = m.id
return HttpResponse("You’re logged in.")
else:
return HttpResponse("Your username and password didn’t match.")
...And this one logs a member out, according to login() above:
def logout(request):
try:
del request.session[’member_id’]
except KeyError:
pass
return HttpResponse("You’re logged out.")
The standard django.contrib.auth.logout() function actually does a bit more than this to prevent inadver-tent
data leakage. It calls the flush() method of request.session. We are using this example as a demonstra-tion
of how to work with session objects, not as a full logout() implementation.
Setting test cookies
As a convenience, Django provides an easy way to test whether the user’s browser accepts cookies. Just call the
set_test_cookie() method of request.session in a view, and call test_cookie_worked() in a sub-sequent
view – not in the same view call.
This awkward split between set_test_cookie() and test_cookie_worked() is necessary due to the way
cookies work. When you set a cookie, you can’t actually tell whether a browser accepted it until the browser’s next
request.
It’s good practice to use delete_test_cookie() to clean up after yourself. Do this after you’ve verified that the
test cookie worked.
Here’s a typical usage example:
def login(request):
if request.method == ’POST’:
if request.session.test_cookie_worked():
3.3. Handling HTTP requests 193](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-197-2048.jpg)
![Django Documentation, Release 1.5.1
request.session.delete_test_cookie()
return HttpResponse("You’re logged in.")
else:
return HttpResponse("Please enable cookies and try again.")
request.session.set_test_cookie()
return render_to_response(’foo/login_form.html’)
Using sessions out of views
An API is available to manipulate session data outside of a view:
>>> from django.contrib.sessions.backends.db import SessionStore
>>> import datetime
>>> s = SessionStore()
>>> s[’last_login’] = datetime.datetime(2005, 8, 20, 13, 35, 10)
>>> s.save()
>>> s.session_key
’2b1189a188b44ad18c35e113ac6ceead’
>>> s = SessionStore(session_key=’2b1189a188b44ad18c35e113ac6ceead’)
>>> s[’last_login’]
datetime.datetime(2005, 8, 20, 13, 35, 0)
In order to prevent session fixation attacks, sessions keys that don’t exist are regenerated:
>>> from django.contrib.sessions.backends.db import SessionStore
>>> s = SessionStore(session_key=’no-such-session-here’)
>>> s.save()
>>> s.session_key
’ff882814010ccbc3c870523934fee5a2’
If you’re using the django.contrib.sessions.backends.db backend, each session is just a normal Django
model. The Session model is defined in django/contrib/sessions/models.py. Because it’s a normal
model, you can access sessions using the normal Django database API:
>>> from django.contrib.sessions.models import Session
>>> s = Session.objects.get(pk=’2b1189a188b44ad18c35e113ac6ceead’)
>>> s.expire_date
datetime.datetime(2005, 8, 20, 13, 35, 12)
Note that you’ll need to call get_decoded() to get the session dictionary. This is necessary because the dictionary
is stored in an encoded format:
>>> s.session_data
’KGRwMQpTJ19hdXRoX3VzZXJfaWQnCnAyCkkxCnMuMTExY2ZjODI2Yj...’
>>> s.get_decoded()
{’user_id’: 42}
When sessions are saved
By default, Django only saves to the session database when the session has been modified – that is if any of its
dictionary values have been assigned or deleted:
# Session is modified.
request.session[’foo’] = ’bar’
194 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-198-2048.jpg)
![Django Documentation, Release 1.5.1
# Session is modified.
del request.session[’foo’]
# Session is modified.
request.session[’foo’] = {}
# Gotcha: Session is NOT modified, because this alters
# request.session[’foo’] instead of request.session.
request.session[’foo’][’bar’] = ’baz’
In the last case of the above example, we can tell the session object explicitly that it has been modified by setting the
modified attribute on the session object:
request.session.modified = True
To change this default behavior, set the SESSION_SAVE_EVERY_REQUEST setting to True. When set to True,
Django will save the session to the database on every single request.
Note that the session cookie is only sent when a session has been created or modified. If
SESSION_SAVE_EVERY_REQUEST is True, the session cookie will be sent on every request.
Similarly, the expires part of a session cookie is updated each time the session cookie is sent. Changed in version
1.5: The session is not saved if the response’s status code is 500.
Browser-length sessions vs. persistent sessions
You can control whether the session framework uses browser-length sessions vs. persistent sessions with the
SESSION_EXPIRE_AT_BROWSER_CLOSE setting.
By default, SESSION_EXPIRE_AT_BROWSER_CLOSE is set to False, which means session cookies will be stored
in users’ browsers for as long as SESSION_COOKIE_AGE. Use this if you don’t want people to have to log in every
time they open a browser.
If SESSION_EXPIRE_AT_BROWSER_CLOSE is set to True, Django will use browser-length cookies – cookies
that expire as soon as the user closes his or her browser. Use this if you want people to have to log in every time they
open a browser.
This setting is a global default and can be overwritten at a per-session level by explicitly calling the set_expiry()
method of request.session as described above in using sessions in views.
Note: Some browsers (Chrome, for example) provide settings that allow users to continue brows-ing
sessions after closing and re-opening the browser. In some cases, this can interfere with the
SESSION_EXPIRE_AT_BROWSER_CLOSE setting and prevent sessions from expiring on browser close. Please
be aware of this while testing Django applications which have the SESSION_EXPIRE_AT_BROWSER_CLOSE set-ting
enabled.
Clearing the session store
As users create new sessions on your website, session data can accumulate in your session store. If you’re using the
database backend, the django_session database table will grow. If you’re using the file backend, your temporary
directory will contain an increasing number of files.
To understand this problem, consider what happens with the database backend. When a user logs in, Django adds a
row to the django_session database table. Django updates this row each time the session data changes. If the
user logs out manually, Django deletes the row. But if the user does not log out, the row never gets deleted. A similar
process happens with the file backend.
3.3. Handling HTTP requests 195](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-199-2048.jpg)




![Django Documentation, Release 1.5.1
Note: You can still access the unvalidated data directly from request.POST at this point, but the validated data is
better.
In the above example, cc_myself will be a boolean value. Likewise, fields such as IntegerField and
FloatField convert values to a Python int and float respectively.
Read-only fields are not available in form.cleaned_data (and setting a value in a custom clean() method
won’t have any effect). These fields are displayed as text rather than as input elements, and thus are not posted back
to the server.
Extending the earlier example, here’s how the form data could be processed:
if form.is_valid():
subject = form.cleaned_data[’subject’]
message = form.cleaned_data[’message’]
sender = form.cleaned_data[’sender’]
cc_myself = form.cleaned_data[’cc_myself’]
recipients = [’info@example.com’]
if cc_myself:
recipients.append(sender)
from django.core.mail import send_mail
send_mail(subject, message, sender, recipients)
return HttpResponseRedirect(’/thanks/’) # Redirect after POST
Tip: For more on sending email from Django, see Sending email.
Displaying a form using a template
Forms are designed to work with the Django template language. In the above example, we passed our ContactForm
instance to the template using the context variable form. Here’s a simple example template:
<form action="/contact/" method="post">{% csrf_token %}
{{ form.as_p }}
<input type="submit" value="Submit" />
</form>
The form only outputs its own fields; it is up to you to provide the surrounding <form> tags and the submit button.
If your form includes uploaded files, be sure to include enctype="multipart/form-data" in the form el-ement.
If you wish to write a generic template that will work whether or not the form has files, you can use the
is_multipart() attribute on the form:
<form action="/contact/" method="post"
{% if form.is_multipart %}enctype="multipart/form-data"{% endif %}>
Forms and Cross Site Request Forgery protection
Django ships with an easy-to-use protection against Cross Site Request Forgeries. When submitting a form via POST
with CSRF protection enabled you must use the csrf_token template tag as in the preceding example. However,
since CSRF protection is not directly tied to forms in templates, this tag is omitted from the following examples in this
document.
form.as_p will output the form with each form field and accompanying label wrapped in a paragraph. Here’s the
output for our example template:
200 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-204-2048.jpg)



![Django Documentation, Release 1.5.1
3.4.3 Further topics
This covers the basics, but forms can do a whole lot more:
Formsets
class django.forms.formset.BaseFormSet
A formset is a layer of abstraction to work with multiple forms on the same page. It can be best compared to a data
grid. Let’s say you have the following form:
>>> from django import forms
>>> class ArticleForm(forms.Form):
... title = forms.CharField()
... pub_date = forms.DateField()
You might want to allow the user to create several articles at once. To create a formset out of an ArticleForm you
would do:
>>> from django.forms.formsets import formset_factory
>>> ArticleFormSet = formset_factory(ArticleForm)
You now have created a formset named ArticleFormSet. The formset gives you the ability to iterate over the
forms in the formset and display them as you would with a regular form:
>>> formset = ArticleFormSet()
>>> for form in formset:
... print(form.as_table())
<tr><th><label for="id_form-0-title">Title:</label></th><td><input type="text" name="form-0-title" id="<tr><th><label for="id_form-0-pub_date">Pub date:</label></th><td><input type="text" name="form-0-pub_As you can see it only displayed one empty form. The number of empty forms that is displayed is controlled by the
extra parameter. By default, formset_factory defines one extra form; the following example will display two
blank forms:
>>> ArticleFormSet = formset_factory(ArticleForm, extra=2)
Iterating over the formset will render the forms in the order they were created. You can change this order by
providing an alternate implementation for the __iter__() method.
Formsets can also be indexed into, which returns the corresponding form. If you override __iter__, you will need
to also override __getitem__ to have matching behavior.
Using initial data with a formset
Initial data is what drives the main usability of a formset. As shown above you can define the number of extra forms.
What this means is that you are telling the formset how many additional forms to show in addition to the number of
forms it generates from the initial data. Lets take a look at an example:
>>> ArticleFormSet = formset_factory(ArticleForm, extra=2)
>>> formset = ArticleFormSet(initial=[
... {’title’: u’Django is now open source’,
... ’pub_date’: datetime.date.today(),}
... ])
>>> for form in formset:
... print(form.as_table())
204 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-208-2048.jpg)

![Django Documentation, Release 1.5.1
... ’form-1-pub_date’: u’’, # <-- this date is missing but required
... }
>>> formset = ArticleFormSet(data)
>>> formset.is_valid()
False
>>> formset.errors
[{}, {’pub_date’: [u’This field is required.’]}]
As we can see, formset.errors is a list whose entries correspond to the forms in the formset. Validation was
performed for each of the two forms, and the expected error message appears for the second item. New in version 1.4.
We can also check if form data differs from the initial data (i.e. the form was sent without any data):
>>> data = {
... ’form-TOTAL_FORMS’: u’1’,
... ’form-INITIAL_FORMS’: u’0’,
... ’form-MAX_NUM_FORMS’: u’’,
... ’form-0-title’: u’’,
... ’form-0-pub_date’: u’’,
... }
>>> formset = ArticleFormSet(data)
>>> formset.has_changed()
False
Understanding the ManagementForm You may have noticed the additional data (form-TOTAL_FORMS,
form-INITIAL_FORMS and form-MAX_NUM_FORMS) that was required in the formset’s data above. This data is
required for the ManagementForm. This form is used by the formset to manage the collection of forms contained
in the formset. If you don’t provide this management data, an exception will be raised:
>>> data = {
... ’form-0-title’: u’Test’,
... ’form-0-pub_date’: u’’,
... }
>>> formset = ArticleFormSet(data)
Traceback (most recent call last):
...
django.forms.util.ValidationError: [u’ManagementForm data is missing or has been tampered with’]
It is used to keep track of how many form instances are being displayed. If you are adding new forms via JavaScript,
you should increment the count fields in this form as well. On the other hand, if you are using JavaScript to allow
deletion of existing objects, then you need to ensure the ones being removed are properly marked for deletion by
including form-#-DELETE in the POST data. It is expected that all forms are present in the POST data regardless.
The management form is available as an attribute of the formset itself. When rendering a formset in a template, you
can include all the management data by rendering {{ my_formset.management_form }} (substituting the
name of your formset as appropriate).
total_form_count and initial_form_count BaseFormSet has a couple of methods that are closely
related to the ManagementForm, total_form_count and initial_form_count.
total_form_count returns the total number of forms in this formset. initial_form_count returns the
number of forms in the formset that were pre-filled, and is also used to determine how many forms are required. You
will probably never need to override either of these methods, so please be sure you understand what they do before
doing so.
empty_form BaseFormSet provides an additional attribute empty_form which returns a form instance with
a prefix of __prefix__ for easier use in dynamic forms with JavaScript.
206 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-210-2048.jpg)
![Django Documentation, Release 1.5.1
Custom formset validation A formset has a clean method similar to the one on a Form class. This is where you
define your own validation that works at the formset level:
>>> from django.forms.formsets import BaseFormSet
>>> class BaseArticleFormSet(BaseFormSet):
... def clean(self):
... """Checks that no two articles have the same title."""
... if any(self.errors):
... # Don’t bother validating the formset unless each form is valid on its own
... return
... titles = []
... for i in range(0, self.total_form_count()):
... form = self.forms[i]
... title = form.cleaned_data[’title’]
... if title in titles:
... raise forms.ValidationError("Articles in a set must have distinct titles.")
... titles.append(title)
>>> ArticleFormSet = formset_factory(ArticleForm, formset=BaseArticleFormSet)
>>> data = {
... ’form-TOTAL_FORMS’: u’2’,
... ’form-INITIAL_FORMS’: u’0’,
... ’form-MAX_NUM_FORMS’: u’’,
... ’form-0-title’: u’Test’,
... ’form-0-pub_date’: u’1904-06-16’,
... ’form-1-title’: u’Test’,
... ’form-1-pub_date’: u’1912-06-23’,
... }
>>> formset = ArticleFormSet(data)
>>> formset.is_valid()
False
>>> formset.errors
[{}, {}]
>>> formset.non_form_errors()
[u’Articles in a set must have distinct titles.’]
The formset clean method is called after all the Form.clean methods have been called. The errors will be found
using the non_form_errors() method on the formset.
Dealing with ordering and deletion of forms
Common use cases with a formset is dealing with ordering and deletion of the form instances. This has been dealt
with for you. The formset_factory provides two optional parameters can_order and can_delete that will
do the extra work of adding the extra fields and providing simpler ways of getting to that data.
can_order Default: False
Lets you create a formset with the ability to order:
>>> ArticleFormSet = formset_factory(ArticleForm, can_order=True)
>>> formset = ArticleFormSet(initial=[
... {’title’: u’Article #1’, ’pub_date’: datetime.date(2008, 5, 10)},
... {’title’: u’Article #2’, ’pub_date’: datetime.date(2008, 5, 11)},
... ])
>>> for form in formset:
... print(form.as_table())
3.4. Working with forms 207](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-211-2048.jpg)
![Django Documentation, Release 1.5.1
<tr><th><label for="id_form-0-title">Title:</label></th><td><input type="text" name="form-0-title" value="<tr><th><label for="id_form-0-pub_date">Pub date:</label></th><td><input type="text" name="form-0-pub_<tr><th><label for="id_form-0-ORDER">Order:</label></th><td><input type="text" name="form-0-ORDER" value="<tr><th><label for="id_form-1-title">Title:</label></th><td><input type="text" name="form-1-title" value="<tr><th><label for="id_form-1-pub_date">Pub date:</label></th><td><input type="text" name="form-1-pub_<tr><th><label for="id_form-1-ORDER">Order:</label></th><td><input type="text" name="form-1-ORDER" value="<tr><th><label for="id_form-2-title">Title:</label></th><td><input type="text" name="form-2-title" id="<tr><th><label for="id_form-2-pub_date">Pub date:</label></th><td><input type="text" name="form-2-pub_<tr><th><label for="id_form-2-ORDER">Order:</label></th><td><input type="text" name="form-2-ORDER" id="This adds an additional field to each form. This new field is named ORDER and is an forms.IntegerField.
For the forms that came from the initial data it automatically assigned them a numeric value. Let’s look at what will
happen when the user changes these values:
>>> data = {
... ’form-TOTAL_FORMS’: u’3’,
... ’form-INITIAL_FORMS’: u’2’,
... ’form-MAX_NUM_FORMS’: u’’,
... ’form-0-title’: u’Article #1’,
... ’form-0-pub_date’: u’2008-05-10’,
... ’form-0-ORDER’: u’2’,
... ’form-1-title’: u’Article #2’,
... ’form-1-pub_date’: u’2008-05-11’,
... ’form-1-ORDER’: u’1’,
... ’form-2-title’: u’Article #3’,
... ’form-2-pub_date’: u’2008-05-01’,
... ’form-2-ORDER’: u’0’,
... }
>>> formset = ArticleFormSet(data, initial=[
... {’title’: u’Article #1’, ’pub_date’: datetime.date(2008, 5, 10)},
... {’title’: u’Article #2’, ’pub_date’: datetime.date(2008, 5, 11)},
... ])
>>> formset.is_valid()
True
>>> for form in formset.ordered_forms:
... print(form.cleaned_data)
{’pub_date’: datetime.date(2008, 5, 1), ’ORDER’: 0, ’title’: u’Article #3’}
{’pub_date’: datetime.date(2008, 5, 11), ’ORDER’: 1, ’title’: u’Article #2’}
{’pub_date’: datetime.date(2008, 5, 10), ’ORDER’: 2, ’title’: u’Article #1’}
can_delete Default: False
Lets you create a formset with the ability to delete:
>>> ArticleFormSet = formset_factory(ArticleForm, can_delete=True)
>>> formset = ArticleFormSet(initial=[
... {’title’: u’Article #1’, ’pub_date’: datetime.date(2008, 5, 10)},
... {’title’: u’Article #2’, ’pub_date’: datetime.date(2008, 5, 11)},
... ])
>>> for form in formset:
.... print(form.as_table())
<input type="hidden" name="form-TOTAL_FORMS" value="3" id="id_form-TOTAL_FORMS" /><input type="hidden" <tr><th><label for="id_form-0-title">Title:</label></th><td><input type="text" name="form-0-title" value="<tr><th><label for="id_form-0-pub_date">Pub date:</label></th><td><input type="text" name="form-0-pub_<tr><th><label for="id_form-0-DELETE">Delete:</label></th><td><input type="checkbox" name="form-0-DELETE" <tr><th><label for="id_form-1-title">Title:</label></th><td><input type="text" name="form-1-title" value="<tr><th><label for="id_form-1-pub_date">Pub date:</label></th><td><input type="text" name="form-1-pub_208 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-212-2048.jpg)
![Django Documentation, Release 1.5.1
<tr><th><label for="id_form-1-DELETE">Delete:</label></th><td><input type="checkbox" name="form-1-DELETE" <tr><th><label for="id_form-2-title">Title:</label></th><td><input type="text" name="form-2-title" id="<tr><th><label for="id_form-2-pub_date">Pub date:</label></th><td><input type="text" name="form-2-pub_<tr><th><label for="id_form-2-DELETE">Delete:</label></th><td><input type="checkbox" name="form-2-DELETE" Similar to can_order this adds a new field to each form named DELETE and is a forms.BooleanField. When
data comes through marking any of the delete fields you can access them with deleted_forms:
>>> data = {
... ’form-TOTAL_FORMS’: u’3’,
... ’form-INITIAL_FORMS’: u’2’,
... ’form-MAX_NUM_FORMS’: u’’,
... ’form-0-title’: u’Article #1’,
... ’form-0-pub_date’: u’2008-05-10’,
... ’form-0-DELETE’: u’on’,
... ’form-1-title’: u’Article #2’,
... ’form-1-pub_date’: u’2008-05-11’,
... ’form-1-DELETE’: u’’,
... ’form-2-title’: u’’,
... ’form-2-pub_date’: u’’,
... ’form-2-DELETE’: u’’,
... }
>>> formset = ArticleFormSet(data, initial=[
... {’title’: u’Article #1’, ’pub_date’: datetime.date(2008, 5, 10)},
... {’title’: u’Article #2’, ’pub_date’: datetime.date(2008, 5, 11)},
... ])
>>> [form.cleaned_data for form in formset.deleted_forms]
[{’DELETE’: True, ’pub_date’: datetime.date(2008, 5, 10), ’title’: u’Article #1’}]
Adding additional fields to a formset
If you need to add additional fields to the formset this can be easily accomplished. The formset base class provides
an add_fields method. You can simply override this method to add your own fields or even redefine the default
fields/attributes of the order and deletion fields:
>>> class BaseArticleFormSet(BaseFormSet):
... def add_fields(self, form, index):
... super(BaseArticleFormSet, self).add_fields(form, index)
... form.fields["my_field"] = forms.CharField()
>>> ArticleFormSet = formset_factory(ArticleForm, formset=BaseArticleFormSet)
>>> formset = ArticleFormSet()
>>> for form in formset:
... print(form.as_table())
<tr><th><label for="id_form-0-title">Title:</label></th><td><input type="text" name="form-0-title" id="<tr><th><label for="id_form-0-pub_date">Pub date:</label></th><td><input type="text" name="form-0-pub_<tr><th><label for="id_form-0-my_field">My field:</label></th><td><input type="text" name="form-0-my_Using a formset in views and templates
Using a formset inside a view is as easy as using a regular Form class. The only thing you will want to be aware of is
making sure to use the management form inside the template. Let’s look at a sample view:
3.4. Working with forms 209](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-213-2048.jpg)










![Django Documentation, Release 1.5.1
The save() method returns the instances that have been saved to the database. If a given instance’s data didn’t change
in the bound data, the instance won’t be saved to the database and won’t be included in the return value (instances,
in the above example).
When fields are missing from the form (for example because they have been excluded), these fields will not be
set by the save() method. You can find more information about this restriction, which also holds for regular
ModelForms, in Using a subset of fields on the form.
Pass commit=False to return the unsaved model instances:
# don’t save to the database
>>> instances = formset.save(commit=False)
>>> for instance in instances:
... # do something with instance
... instance.save()
This gives you the ability to attach data to the instances before saving them to the database. If your formset contains
a ManyToManyField, you’ll also need to call formset.save_m2m() to ensure the many-to-many relationships
are saved properly.
Limiting the number of editable objects As with regular formsets, you can use the max_num and extra param-eters
to modelformset_factory() to limit the number of extra forms displayed.
max_num does not prevent existing objects from being displayed:
>>> Author.objects.order_by(’name’)
[<Author: Charles Baudelaire>, <Author: Paul Verlaine>, <Author: Walt Whitman>]
>>> AuthorFormSet = modelformset_factory(Author, max_num=1)
>>> formset = AuthorFormSet(queryset=Author.objects.order_by(’name’))
>>> [x.name for x in formset.get_queryset()]
[u’Charles Baudelaire’, u’Paul Verlaine’, u’Walt Whitman’]
If the value of max_num is greater than the number of existing related objects, up to extra additional blank forms
will be added to the formset, so long as the total number of forms does not exceed max_num:
>>> AuthorFormSet = modelformset_factory(Author, max_num=4, extra=2)
>>> formset = AuthorFormSet(queryset=Author.objects.order_by(’name’))
>>> for form in formset:
... print(form.as_table())
<tr><th><label for="id_form-0-name">Name:</label></th><td><input id="id_form-0-name" type="text" name="<tr><th><label for="id_form-1-name">Name:</label></th><td><input id="id_form-1-name" type="text" name="<tr><th><label for="id_form-2-name">Name:</label></th><td><input id="id_form-2-name" type="text" name="<tr><th><label for="id_form-3-name">Name:</label></th><td><input id="id_form-3-name" type="text" name="A max_num value of None (the default) puts a high limit on the number of forms displayed (1000). In practice this
is equivalent to no limit.
Using a model formset in a view Model formsets are very similar to formsets. Let’s say we want to present a
formset to edit Author model instances:
def manage_authors(request):
AuthorFormSet = modelformset_factory(Author)
if request.method == ’POST’:
formset = AuthorFormSet(request.POST, request.FILES)
if formset.is_valid():
formset.save()
# do something.
220 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-224-2048.jpg)






![Django Documentation, Release 1.5.1
However, Media objects have some other interesting properties.
Media subsets If you only want media of a particular type, you can use the subscript operator to filter out a medium
of interest. For example:
>>> w = CalendarWidget()
>>> print(w.media)
<link href="http://static.example.com/pretty.css" type="text/css" media="all" rel="stylesheet" />
<script type="text/javascript" src="http://static.example.com/animations.js"></script>
<script type="text/javascript" src="http://static.example.com/actions.js"></script>
>>> print(w.media)[’css’]
<link href="http://static.example.com/pretty.css" type="text/css" media="all" rel="stylesheet" />
When you use the subscript operator, the value that is returned is a new Media object – but one that only contains the
media of interest.
Combining media objects Media objects can also be added together. When two media objects are added, the
resulting Media object contains the union of the media from both files:
>>> class CalendarWidget(forms.TextInput):
... class Media:
... css = {
... ’all’: (’pretty.css’,)
... }
... js = (’animations.js’, ’actions.js’)
>>> class OtherWidget(forms.TextInput):
... class Media:
... js = (’whizbang.js’,)
>>> w1 = CalendarWidget()
>>> w2 = OtherWidget()
>>> print(w1.media + w2.media)
<link href="http://static.example.com/pretty.css" type="text/css" media="all" rel="stylesheet" />
<script type="text/javascript" src="http://static.example.com/animations.js"></script>
<script type="text/javascript" src="http://static.example.com/actions.js"></script>
<script type="text/javascript" src="http://static.example.com/whizbang.js"></script>
Media on Forms
Widgets aren’t the only objects that can have media definitions – forms can also define media. The rules for media
definitions on forms are the same as the rules for widgets: declarations can be static or dynamic; path and inheritance
rules for those declarations are exactly the same.
Regardless of whether you define a media declaration, all Form objects have a media property. The default value for
this property is the result of adding the media definitions for all widgets that are part of the form:
>>> class ContactForm(forms.Form):
... date = DateField(widget=CalendarWidget)
... name = CharField(max_length=40, widget=OtherWidget)
>>> f = ContactForm()
>>> f.media
<link href="http://static.example.com/pretty.css" type="text/css" media="all" rel="stylesheet" />
<script type="text/javascript" src="http://static.example.com/animations.js"></script>
3.4. Working with forms 227](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-231-2048.jpg)


![Django Documentation, Release 1.5.1
Because dictionary lookup happens first, that behavior kicks in and provides a default value instead of using the
intended .iteritems() method. In this case, consider converting to a dictionary first.
In the above example, {{ section.title }} will be replaced with the title attribute of the section object.
If you use a variable that doesn’t exist, the template system will insert the value of the
TEMPLATE_STRING_IF_INVALID setting, which is set to ” (the empty string) by default.
Note that “bar” in a template expression like {{ foo.bar }} will be interpreted as a literal string and not using the
value of the variable “bar”, if one exists in the template context.
3.5.3 Filters
You can modify variables for display by using filters.
Filters look like this: {{ name|lower }}. This displays the value of the {{ name }} variable after being
filtered through the lower filter, which converts text to lowercase. Use a pipe (|) to apply a filter.
Filters can be “chained.” The output of one filter is applied to the next. {{ text|escape|linebreaks }} is a
common idiom for escaping text contents, then converting line breaks to <p> tags.
Some filters take arguments. A filter argument looks like this: {{ bio|truncatewords:30 }}. This will
display the first 30 words of the bio variable.
Filter arguments that contain spaces must be quoted; for example, to join a list with commas and spaced you’d use {{
list|join:", " }}.
Django provides about thirty built-in template filters. You can read all about them in the built-in filter reference. To
give you a taste of what’s available, here are some of the more commonly used template filters:
default If a variable is false or empty, use given default. Otherwise, use the value of the variable
For example:
{{ value|default:"nothing" }}
If value isn’t provided or is empty, the above will display “nothing”.
length Returns the length of the value. This works for both strings and lists; for example:
{{ value|length }}
If value is [’a’, ’b’, ’c’, ’d’], the output will be 4.
striptags Strips all [X]HTML tags. For example:
{{ value|striptags }}
If value is "<b>Joel</b> <button>is</button> a <span>slug</span>", the output will be
"Joel is a slug".
Again, these are just a few examples; see the built-in filter reference for the complete list.
You can also create your own custom template filters; see Custom template tags and filters.
See Also:
Django’s admin interface can include a complete reference of all template tags and filters available for a given site.
See The Django admin documentation generator.
230 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-234-2048.jpg)












![Django Documentation, Release 1.5.1
Let’s start by looking at some examples of showing a list of objects or an individual object.
We’ll be using these models:
# models.py
from django.db import models
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
class Meta:
ordering = ["-name"]
def __unicode__(self):
return self.name
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(’Author’)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
Now we need to define a view:
# views.py
from django.views.generic import ListView
from books.models import Publisher
class PublisherList(ListView):
model = Publisher
Finally hook that view into your urls:
# urls.py
from django.conf.urls import patterns, url
from books.views import PublisherList
urlpatterns = patterns(’’,
url(r’^publishers/$’, PublisherList.as_view()),
)
That’s all the Python code we need to write. We still need to write a template, however. We could explicitly
tell the view which template to use by adding a template_name attribute to the view, but in the absence of
an explicit template Django will infer one from the object’s name. In this case, the inferred template will be
"books/publisher_list.html" – the “books” part comes from the name of the app that defines the model,
while the “publisher” bit is just the lowercased version of the model’s name.
Note: Thus, when (for example) the django.template.loaders.app_directories.Loader
template loader is enabled in TEMPLATE_LOADERS, a template location could be:
/path/to/project/books/templates/books/publisher_list.html
This template will be rendered against a context containing a variable called object_list that contains all the
publisher objects. A very simple template might look like the following:
3.6. Class-based views 243](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-247-2048.jpg)

![Django Documentation, Release 1.5.1
def get_context_data(self, **kwargs):
# Call the base implementation first to get a context
context = super(PublisherDetail, self).get_context_data(**kwargs)
# Add in a QuerySet of all the books
context[’book_list’] = Book.objects.all()
return context
Note: Generally, get_context_data will merge the context data of all parent classes with those of the current class.
To preserve this behavior in your own classes where you want to alter the context, you should be sure to call
get_context_data on the super class. When no two classes try to define the same key, this will give the expected
results. However if any class attempts to override a key after parent classes have set it (after the call to super), any
children of that class will also need to explictly set it after super if they want to be sure to override all parents. If you’re
having trouble, review the method resolution order of your view.
Viewing subsets of objects
Now let’s take a closer look at the model argument we’ve been using all along. The model argument, which specifies
the database model that the view will operate upon, is available on all the generic views that operate on a single object
or a collection of objects. However, the model argument is not the only way to specify the objects that the view will
operate upon – you can also specify the list of objects using the queryset argument:
from django.views.generic import DetailView
from books.models import Publisher, Book
class PublisherDetail(DetailView):
context_object_name = ’publisher’
queryset = Publisher.objects.all()
Specifying model = Publisher is really just shorthand for saying queryset =
Publisher.objects.all(). However, by using queryset to define a filtered list of objects you can
be more specific about the objects that will be visible in the view (see Making queries for more information about
QuerySet objects, and see the class-based views reference for the complete details).
To pick a simple example, we might want to order a list of books by publication date, with the most recent first:
from django.views.generic import ListView
from books.models import Book
class BookList(ListView):
queryset = Book.objects.order_by(’-publication_date’)
context_object_name = ’book_list’
That’s a pretty simple example, but it illustrates the idea nicely. Of course, you’ll usually want to do more than just
reorder objects. If you want to present a list of books by a particular publisher, you can use the same technique:
from django.views.generic import ListView
from books.models import Book
class AcmeBookList(ListView):
context_object_name = ’book_list’
queryset = Book.objects.filter(publisher__name=’Acme Publishing’)
template_name = ’books/acme_list.html’
3.6. Class-based views 245](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-249-2048.jpg)
![Django Documentation, Release 1.5.1
Notice that along with a filtered queryset, we’re also using a custom template name. If we didn’t, the generic view
would use the same template as the “vanilla” object list, which might not be what we want.
Also notice that this isn’t a very elegant way of doing publisher-specific books. If we want to add another publisher
page, we’d need another handful of lines in the URLconf, and more than a few publishers would get unreasonable.
We’ll deal with this problem in the next section.
Note: If you get a 404 when requesting /books/acme/, check to ensure you actually have a Publisher with the
name ‘ACME Publishing’. Generic views have an allow_empty parameter for this case. See the class-based-views
reference for more details.
Dynamic filtering
Another common need is to filter down the objects given in a list page by some key in the URL. Earlier we hard-coded
the publisher’s name in the URLconf, but what if we wanted to write a view that displayed all the books by some
arbitrary publisher?
Handily, the ListView has a get_queryset() method we can override. Previously, it has just been returning the
value of the queryset attribute, but now we can add more logic.
The key part to making this work is that when class-based views are called, various useful things are stored on self; as
well as the request (self.request) this includes the positional (self.args) and name-based (self.kwargs)
arguments captured according to the URLconf.
Here, we have a URLconf with a single captured group:
# urls.py
from books.views import PublisherBookList
urlpatterns = patterns(’’,
(r’^books/([w-]+)/$’, PublisherBookList.as_view()),
)
Next, we’ll write the PublisherBookList view itself:
# views.py
from django.shortcuts import get_object_or_404
from django.views.generic import ListView
from books.models import Book, Publisher
class PublisherBookList(ListView):
template_name = ’books/books_by_publisher.html’
def get_queryset(self):
self.publisher = get_object_or_404(Publisher, name=self.args[0])
return Book.objects.filter(publisher=self.publisher)
As you can see, it’s quite easy to add more logic to the queryset selection; if we wanted, we could use
self.request.user to filter using the current user, or other more complex logic.
We can also add the publisher into the context at the same time, so we can use it in the template:
# ...
def get_context_data(self, **kwargs):
# Call the base implementation first to get a context
context = super(PublisherBookList, self).get_context_data(**kwargs)
246 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-250-2048.jpg)
![Django Documentation, Release 1.5.1
# Add in the publisher
context[’publisher’] = self.publisher
return context
Performing extra work
The last common pattern we’ll look at involves doing some extra work before or after calling the generic view.
Imagine we had a last_accessed field on our Author object that we were using to keep track of the last time
anybody looked at that author:
# models.py
class Author(models.Model):
salutation = models.CharField(max_length=10)
name = models.CharField(max_length=200)
email = models.EmailField()
headshot = models.ImageField(upload_to=’/tmp’)
last_accessed = models.DateTimeField()
The generic DetailView class, of course, wouldn’t know anything about this field, but once again we could easily
write a custom view to keep that field updated.
First, we’d need to add an author detail bit in the URLconf to point to a custom view:
from books.views import AuthorDetailView
urlpatterns = patterns(’’,
#...
url(r’^authors/(?P<pk>d+)/$’, AuthorDetailView.as_view(), name=’author-detail’),
)
Then we’d write our new view – get_object is the method that retrieves the object – so we simply override it and
wrap the call:
from django.views.generic import DetailView
from django.shortcuts import get_object_or_404
from django.utils import timezone
from books.models import Author
class AuthorDetailView(DetailView):
queryset = Author.objects.all()
def get_object(self):
# Call the superclass
object = super(AuthorDetailView, self).get_object()
# Record the last accessed date
object.last_accessed = timezone.now()
object.save()
# Return the object
return object
Note: The URLconf here uses the named group pk - this name is the default name that DetailView uses to find
the value of the primary key used to filter the queryset.
If you want to call the group something else, you can set pk_url_kwarg on the view. More details can be found in
the reference for DetailView
3.6. Class-based views 247](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-251-2048.jpg)



![Django Documentation, Release 1.5.1
Note that you’ll need to decorate this view using login_required(), or alternatively handle unauthorized users
in the form_valid().
AJAX example
Here is a simple example showing how you might go about implementing a form that works for AJAX requests as
well as ‘normal’ form POSTs:
import json
from django.http import HttpResponse
from django.views.generic.edit import CreateView
class AjaxableResponseMixin(object):
"""
Mixin to add AJAX support to a form.
Must be used with an object-based FormView (e.g. CreateView)
"""
def render_to_json_response(self, context, **response_kwargs):
data = json.dumps(context)
response_kwargs[’content_type’] = ’application/json’
return HttpResponse(data, **response_kwargs)
def form_invalid(self, form):
response = super(AjaxableResponseMixin, self).form_invalid(form)
if self.request.is_ajax():
return self.render_to_json_response(form.errors, status=400)
else:
return response
def form_valid(self, form):
# We make sure to call the parent’s form_valid() method because
# it might do some processing (in the case of CreateView, it will
# call form.save() for example).
response = super(AjaxableResponseMixin, self).form_valid(form)
if self.request.is_ajax():
data = {
’pk’: self.object.pk,
}
return self.render_to_json_response(data)
else:
return response
class AuthorCreate(AjaxableResponseMixin, CreateView):
model = Author
3.6.4 Using mixins with class-based views
Caution: This is an advanced topic. A working knowledge of Django’s class-based views is advised before
exploring these techniques.
Django’s built-in class-based views provide a lot of functionality, but some of it you may want to use separately.
For instance, you may want to write a view that renders a template to make the HTTP response, but you can’t use
TemplateView; perhaps you need to render a template only on POST, with GET doing something else entirely.
While you could use TemplateResponse directly, this will likely result in duplicate code.
3.6. Class-based views 251](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-255-2048.jpg)



![Django Documentation, Release 1.5.1
explictly ensure the Publisher is in the context data. ListView will add in the suitable page_obj and paginator
for us providing we remember to call super().
Now we can write a new PublisherDetail:
from django.views.generic import ListView
from django.views.generic.detail import SingleObjectMixin
from books.models import Publisher
class PublisherDetail(SingleObjectMixin, ListView):
paginate_by = 2
template_name = "books/publisher_detail.html"
def get_context_data(self, **kwargs):
kwargs[’publisher’] = self.object
return super(PublisherDetail, self).get_context_data(**kwargs)
def get_queryset(self):
self.object = self.get_object(Publisher.objects.all())
return self.object.book_set.all()
Notice how we set self.object within get_queryset() so we can use it again later in
get_context_data(). If you don’t set template_name, the template will default to the normal ListView
choice, which in this case would be "books/book_list.html" because it’s a list of books; ListView knows
nothing about SingleObjectMixin, so it doesn’t have any clue this view is anything to do with a Publisher.
The paginate_by is deliberately small in the example so you don’t have to create lots of books to see the pagination
working! Here’s the template you’d want to use:
{% extends "base.html" %}
{% block content %}
<h2>Publisher {{ publisher.name }}</h2>
<ol>
{% for book in page_obj %}
<li>{{ book.title }}</li>
{% endfor %}
</ol>
<div class="pagination">
<span class="step-links">
{% if page_obj.has_previous %}
<a href="?page={{ page_obj.previous_page_number }}">previous</a>
{% endif %}
<span class="current">
Page {{ page_obj.number }} of {{ paginator.num_pages }}.
</span>
{% if page_obj.has_next %}
<a href="?page={{ page_obj.next_page_number }}">next</a>
{% endif %}
</span>
</div>
{% endblock %}
3.6. Class-based views 255](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-259-2048.jpg)



![Django Documentation, Release 1.5.1
def get(self, request, *args, **kwargs):
view = AuthorDisplay.as_view()
return view(request, *args, **kwargs)
def post(self, request, *args, **kwargs):
view = AuthorInterest.as_view()
return view(request, *args, **kwargs)
This approach can also be used with any other generic class-based views or your own class-based views inheriting
directly from View or TemplateView, as it keeps the different views as separate as possible.
More than just HTML
Where class based views shine is when you want to do the same thing many times. Suppose you’re writing an API,
and every view should return JSON instead of rendered HTML.
We can create a mixin class to use in all of our views, handling the conversion to JSON once.
For example, a simple JSON mixin might look something like this:
import json
from django.http import HttpResponse
class JSONResponseMixin(object):
"""
A mixin that can be used to render a JSON response.
"""
response_class = HttpResponse
def render_to_response(self, context, **response_kwargs):
"""
Returns a JSON response, transforming ’context’ to make the payload.
"""
response_kwargs[’content_type’] = ’application/json’
return self.response_class(
self.convert_context_to_json(context),
**response_kwargs
)
def convert_context_to_json(self, context):
"Convert the context dictionary into a JSON object"
# Note: This is *EXTREMELY* naive; in reality, you’ll need
# to do much more complex handling to ensure that arbitrary
# objects -- such as Django model instances or querysets
# -- can be serialized as JSON.
return json.dumps(context)
Now we mix this into the base TemplateView:
from django.views.generic import TemplateView
class JSONView(JSONResponseMixin, TemplateView):
pass
Equally we could use our mixin with one of the generic views. We can make our own version of DetailView
by mixing JSONResponseMixin with the django.views.generic.detail.BaseDetailView – (the
DetailView before template rendering behavior has been mixed in):
3.6. Class-based views 259](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-263-2048.jpg)

![Django Documentation, Release 1.5.1
# some_app/views.py
from django.views.generic import TemplateView
class AboutView(TemplateView):
template_name = "about.html"
Then we just need to add this new view into our URLconf. ~django.views.generic.base.TemplateView is a class, not
a function, so we point the URL to the as_view() class method instead, which provides a function-like entry to
class-based views:
# urls.py
from django.conf.urls import patterns
from some_app.views import AboutView
urlpatterns = patterns(’’,
(r’^about/’, AboutView.as_view()),
)
For more information on how to use the built in generic views, consult the next topic on generic class based views.
Supporting other HTTP methods
Suppose somebody wants to access our book library over HTTP using the views as an API. The API client would
connect every now and then and download book data for the books published since last visit. But if no new books
appeared since then, it is a waste of CPU time and bandwidth to fetch the books from the database, render a full
response and send it to the client. It might be preferable to ask the API when the most recent book was published.
We map the URL to book list view in the URLconf:
from django.conf.urls import patterns
from books.views import BookListView
urlpatterns = patterns(’’,
(r’^books/$’, BookListView.as_view()),
)
And the view:
from django.http import HttpResponse
from django.views.generic import ListView
from books.models import Book
class BookListView(ListView):
model = Book
def head(self, *args, **kwargs):
last_book = self.get_queryset().latest(’publication_date’)
response = HttpResponse(’’)
# RFC 1123 date format
response[’Last-Modified’] = last_book.publication_date.strftime(’%a, %d %b %Y %H:%M:%S GMT’)
return response
If the view is accessed from a GET request, a plain-and-simple object list is returned in the response (using
book_list.html template). But if the client issues a HEAD request, the response has an empty body and the
Last-Modified header indicates when the most recent book was published. Based on this information, the client
may or may not download the full object list.
3.6. Class-based views 261](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-265-2048.jpg)

![Django Documentation, Release 1.5.1
Now you can use any of the documented attributes and methods of the File class.
Be aware that files created in this way are not automatically closed. The following approach may be used to close files
automatically:
>>> from django.core.files import File
# Create a Python file object using open() and the with statement
>>> with open(’/tmp/hello.world’, ’w’) as f:
>>> myfile = File(f)
>>> for line in myfile:
>>> print line
>>> myfile.closed
True
>>> f.closed
True
Closing files is especially important when accessing file fields in a loop over a large number of objects:: If files are
not manually closed after accessing them, the risk of running out of file descriptors may arise. This may lead to the
following error:
IOError: [Errno 24] Too many open files
3.7.3 File storage
Behind the scenes, Django delegates decisions about how and where to store files to a file storage system. This is the
object that actually understands things like file systems, opening and reading files, etc.
Django’s default file storage is given by the DEFAULT_FILE_STORAGE setting; if you don’t explicitly provide a
storage system, this is the one that will be used.
See below for details of the built-in default file storage system, and see Writing a custom storage system for information
on writing your own file storage system.
Storage objects
Though most of the time you’ll want to use a File object (which delegates to the proper storage for that file), you can
use file storage systems directly. You can create an instance of some custom file storage class, or – often more useful
– you can use the global default storage system:
>>> from django.core.files.storage import default_storage
>>> from django.core.files.base import ContentFile
>>> path = default_storage.save(’/path/to/file’, ContentFile(’new content’))
>>> path
u’/path/to/file’
>>> default_storage.size(path)
11
>>> default_storage.open(path).read()
’new content’
>>> default_storage.delete(path)
>>> default_storage.exists(path)
False
See File storage API for the file storage API.
3.7. Managing files 263](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-267-2048.jpg)







![Django Documentation, Release 1.5.1
The headers sent via **extra should follow CGI specification. For example, emulating a different
“Host” header as sent in the HTTP request from the browser to the server should be passed as HTTP_HOST.
If you already have the GET arguments in URL-encoded form, you can use that encoding instead of using
the data argument. For example, the previous GET request could also be posed as:
>>> c = Client()
>>> c.get(’/customers/details/?name=fred&age=7’)
If you provide a URL with both an encoded GET data and a data argument, the data argument will take
precedence.
If you set follow to True the client will follow any redirects and a redirect_chain attribute will
be set in the response object containing tuples of the intermediate urls and status codes.
If you had a URL /redirect_me/ that redirected to /next/, that redirected to /final/, this is what
you’d see:
>>> response = c.get(’/redirect_me/’, follow=True)
>>> response.redirect_chain
[(u’http://testserver/next/’, 302), (u’http://testserver/final/’, 302)]
post(path, data={}, content_type=MULTIPART_CONTENT, follow=False, **extra)
Makes a POST request on the provided path and returns a Response object, which is documented
below.
The key-value pairs in the data dictionary are used to submit POST data. For example:
>>> c = Client()
>>> c.post(’/login/’, {’name’: ’fred’, ’passwd’: ’secret’})
...will result in the evaluation of a POST request to this URL:
/login/
...with this POST data:
name=fred&passwd=secret
If you provide content_type (e.g. text/xml for an XML payload), the contents of data will be
sent as-is in the POST request, using content_type in the HTTP Content-Type header.
If you don’t provide a value for content_type, the values in data will be transmitted with a con-tent
type of multipart/form-data. In this case, the key-value pairs in data will be encoded as a
multipart message and used to create the POST data payload.
To submit multiple values for a given key – for example, to specify the selections for a <select
multiple> – provide the values as a list or tuple for the required key. For example, this value of data
would submit three selected values for the field named choices:
{’choices’: (’a’, ’b’, ’d’)}
Submitting files is a special case. To POST a file, you need only provide the file field name as a key, and a
file handle to the file you wish to upload as a value. For example:
>>> c = Client()
>>> with open(’wishlist.doc’) as fp:
... c.post(’/customers/wishes/’, {’name’: ’fred’, ’attachment’: fp})
(The name attachment here is not relevant; use whatever name your file-processing code expects.)
3.8. Testing in Django 271](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-275-2048.jpg)

![Django Documentation, Release 1.5.1
>>> c = Client()
>>> c.login(username=’fred’, password=’secret’)
# Now you can access a view that’s only available to logged-in users.
If you’re using a different authentication backend, this method may require different credentials. It requires
whichever credentials are required by your backend’s authenticate() method.
login() returns True if it the credentials were accepted and login was successful.
Finally, you’ll need to remember to create user accounts before you can use this method. As we explained
above, the test runner is executed using a test database, which contains no users by default. As a result,
user accounts that are valid on your production site will not work under test conditions. You’ll need to
create users as part of the test suite – either manually (using the Django model API) or with a test fixture.
Remember that if you want your test user to have a password, you can’t set the user’s password by setting
the password attribute directly – you must use the set_password() function to store a correctly hashed
password. Alternatively, you can use the create_user() helper method to create a new user with a
correctly hashed password.
logout()
If your site uses Django’s authentication system, the logout() method can be used to simulate the effect
of a user logging out of your site.
After you call this method, the test client will have all the cookies and session data cleared to defaults.
Subsequent requests will appear to come from an AnonymousUser.
Testing responses The get() and post() methods both return a Response object. This Response object is
not the same as the HttpResponse object returned Django views; the test response object has some additional data
useful for test code to verify.
Specifically, a Response object has the following attributes:
class Response
client
The test client that was used to make the request that resulted in the response.
content
The body of the response, as a string. This is the final page content as rendered by the view, or any error
message.
context
The template Context instance that was used to render the template that produced the response content.
If the rendered page used multiple templates, then context will be a list of Context objects, in the
order in which they were rendered.
Regardless of the number of templates used during rendering, you can retrieve context values using the []
operator. For example, the context variable name could be retrieved using:
>>> response = client.get(’/foo/’)
>>> response.context[’name’]
’Arthur’
request
The request data that stimulated the response.
status_code
The HTTP status of the response, as an integer. See RFC 2616 for a full list of HTTP status codes.
3.8. Testing in Django 273](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-277-2048.jpg)
![Django Documentation, Release 1.5.1
templates
A list of Template instances used to render the final content, in the order they were rendered. For each
template in the list, use template.name to get the template’s file name, if the template was loaded from
a file. (The name is a string such as ’admin/index.html’.)
You can also use dictionary syntax on the response object to query the value of any settings in the HTTP headers. For
example, you could determine the content type of a response using response[’Content-Type’].
Exceptions If you point the test client at a view that raises an exception, that exception will be visible in the test
case. You can then use a standard try ... except block or assertRaises() to test for exceptions.
The only exceptions that are not visible to the test client are Http404, PermissionDenied and SystemExit.
Django catches these exceptions internally and converts them into the appropriate HTTP response codes. In these
cases, you can check response.status_code in your test.
Persistent state The test client is stateful. If a response returns a cookie, then that cookie will be stored in the test
client and sent with all subsequent get() and post() requests.
Expiration policies for these cookies are not followed. If you want a cookie to expire, either delete it manually or
create a new Client instance (which will effectively delete all cookies).
A test client has two attributes that store persistent state information. You can access these properties as part of a test
condition.
Client.cookies
A Python SimpleCookie object, containing the current values of all the client cookies. See the documentation
of the Cookie module for more.
Client.session
A dictionary-like object containing session information. See the session documentation for full details.
To modify the session and then save it, it must be stored in a variable first (because a new SessionStore is
created every time this property is accessed):
def test_something(self):
session = self.client.session
session[’somekey’] = ’test’
session.save()
Example The following is a simple unit test using the test client:
from django.utils import unittest
from django.test.client import Client
class SimpleTest(unittest.TestCase):
def setUp(self):
# Every test needs a client.
self.client = Client()
def test_details(self):
# Issue a GET request.
response = self.client.get(’/customer/details/’)
# Check that the response is 200 OK.
self.assertEqual(response.status_code, 200)
# Check that the rendered context contains 5 customers.
self.assertEqual(len(response.context[’customers’]), 5)
274 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-278-2048.jpg)



![Django Documentation, Release 1.5.1
LiveServerTestCase New in version 1.4.
class LiveServerTestCase
LiveServerTestCase does basically the same as TransactionTestCase with one extra feature: it launches
a live Django server in the background on setup, and shuts it down on teardown. This allows the use of automated test
clients other than the Django dummy client such as, for example, the Selenium client, to execute a series of functional
tests inside a browser and simulate a real user’s actions.
By default the live server’s address is ’localhost:8081’ and the full URL can be accessed during the tests with
self.live_server_url. If you’d like to change the default address (in the case, for example, where the 8081
port is already taken) then you may pass a different one to the test command via the --liveserver option, for
example:
./manage.py test --liveserver=localhost:8082
Another way of changing the default server address is by setting the DJANGO_LIVE_TEST_SERVER_ADDRESS
environment variable somewhere in your code (for example, in a custom test runner):
import os
os.environ[’DJANGO_LIVE_TEST_SERVER_ADDRESS’] = ’localhost:8082’
In the case where the tests are run by multiple processes in parallel (for example, in the context of several simulta-neous
continuous integration builds), the processes will compete for the same address, and therefore your tests might
randomly fail with an “Address already in use” error. To avoid this problem, you can pass a comma-separated list of
ports or ranges of ports (at least as many as the number of potential parallel processes). For example:
./manage.py test --liveserver=localhost:8082,8090-8100,9000-9200,7041
Then, during test execution, each new live test server will try every specified port until it finds one that is free and
takes it.
To demonstrate how to use LiveServerTestCase, let’s write a simple Selenium test. First of all, you need to
install the selenium package into your Python path:
pip install selenium
Then, add a LiveServerTestCase-based test to your app’s tests module (for example: myapp/tests.py).
The code for this test may look as follows:
from django.test import LiveServerTestCase
from selenium.webdriver.firefox.webdriver import WebDriver
class MySeleniumTests(LiveServerTestCase):
fixtures = [’user-data.json’]
@classmethod
def setUpClass(cls):
cls.selenium = WebDriver()
super(MySeleniumTests, cls).setUpClass()
@classmethod
def tearDownClass(cls):
cls.selenium.quit()
super(MySeleniumTests, cls).tearDownClass()
def test_login(self):
self.selenium.get(’%s%s’ % (self.live_server_url, ’/login/’))
username_input = self.selenium.find_element_by_name("username")
username_input.send_keys(’myuser’)
278 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-282-2048.jpg)
![Django Documentation, Release 1.5.1
password_input = self.selenium.find_element_by_name("password")
password_input.send_keys(’secret’)
self.selenium.find_element_by_xpath(’//input[@value="Log in"]’).click()
Finally, you may run the test as follows:
./manage.py test myapp.MySeleniumTests.test_login
This example will automatically open Firefox then go to the login page, enter the credentials and press the “Log in”
button. Selenium offers other drivers in case you do not have Firefox installed or wish to use another browser. The
example above is just a tiny fraction of what the Selenium client can do; check out the full reference for more details.
Note: LiveServerTestCase makes use of the staticfiles contrib app so you’ll need to have your project config-ured
accordingly (in particular by setting STATIC_URL).
Note: When using an in-memory SQLite database to run the tests, the same database connection will be shared
by two threads in parallel: the thread in which the live server is run and the thread in which the test case is run.
It’s important to prevent simultaneous database queries via this shared connection by the two threads, as that may
sometimes randomly cause the tests to fail. So you need to ensure that the two threads don’t access the database at the
same time. In particular, this means that in some cases (for example, just after clicking a link or submitting a form),
you might need to check that a response is received by Selenium and that the next page is loaded before proceeding
with further test execution. Do this, for example, by making Selenium wait until the <body> HTML tag is found in
the response (requires Selenium > 2.13):
def test_login(self):
from selenium.webdriver.support.wait import WebDriverWait
timeout = 2
...
self.selenium.find_element_by_xpath(’//input[@value="Log in"]’).click()
# Wait until the response is received
WebDriverWait(self.selenium, timeout).until(
lambda driver: driver.find_element_by_tag_name(’body’))
The tricky thing here is that there’s really no such thing as a “page load,” especially in modern Web apps that generate
HTML dynamically after the server generates the initial document. So, simply checking for the presence of <body>
in the response might not necessarily be appropriate for all use cases. Please refer to the Selenium FAQ and Selenium
documentation for more information.
Test cases features
Default test client
TestCase.client
Every test case in a django.test.TestCase instance has access to an instance of a Django test client. This client
can be accessed as self.client. This client is recreated for each test, so you don’t have to worry about state (such
as cookies) carrying over from one test to another.
This means, instead of instantiating a Client in each test:
from django.utils import unittest
from django.test.client import Client
class SimpleTest(unittest.TestCase):
def test_details(self):
client = Client()
3.8. Testing in Django 279](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-283-2048.jpg)

![Django Documentation, Release 1.5.1
Initial SQL data and testing
Django provides a second way to insert initial data into models – the custom SQL hook. However, this technique
cannot be used to provide initial data for testing purposes. Django’s test framework flushes the contents of the test
database after each test; as a result, any data added using the custom SQL hook will be lost.
Once you’ve created a fixture and placed it in a fixtures directory in one of your INSTALLED_APPS, you can
use it in your unit tests by specifying a fixtures class attribute on your django.test.TestCase subclass:
from django.test import TestCase
from myapp.models import Animal
class AnimalTestCase(TestCase):
fixtures = [’mammals.json’, ’birds’]
def setUp(self):
# Test definitions as before.
call_setup_methods()
def testFluffyAnimals(self):
# A test that uses the fixtures.
call_some_test_code()
Here’s specifically what will happen:
• At the start of each test case, before setUp() is run, Django will flush the database, returning the database to
the state it was in directly after syncdb was called.
• Then, all the named fixtures are installed. In this example, Django will install any JSON fixture named
mammals, followed by any fixture named birds. See the loaddata documentation for more details on
defining and installing fixtures.
This flush/load procedure is repeated for each test in the test case, so you can be certain that the outcome of a test will
not be affected by another test, or by the order of test execution.
URLconf configuration
TestCase.urls
If your application provides views, you may want to include tests that use the test client to exercise those views.
However, an end user is free to deploy the views in your application at any URL of their choosing. This means that
your tests can’t rely upon the fact that your views will be available at a particular URL.
In order to provide a reliable URL space for your test, django.test.TestCase provides the ability to customize
the URLconf configuration for the duration of the execution of a test suite. If your TestCase instance defines an
urls attribute, the TestCase will use the value of that attribute as the ROOT_URLCONF for the duration of that
test.
For example:
from django.test import TestCase
class TestMyViews(TestCase):
urls = ’myapp.test_urls’
def testIndexPageView(self):
# Here you’d test your view using ‘‘Client‘‘.
call_some_test_code()
This test case will use the contents of myapp.test_urls as the URLconf for the duration of the test case.
3.8. Testing in Django 281](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-285-2048.jpg)


![Django Documentation, Release 1.5.1
SimpleTestCase.assertFieldOutput(self, fieldclass, valid, invalid, field_args=None,
field_kwargs=None, empty_value=u’‘)
New in version 1.4. Asserts that a form field behaves correctly with various inputs.
Parameters
• fieldclass – the class of the field to be tested.
• valid – a dictionary mapping valid inputs to their expected cleaned values.
• invalid – a dictionary mapping invalid inputs to one or more raised error messages.
• field_args – the args passed to instantiate the field.
• field_kwargs – the kwargs passed to instantiate the field.
• empty_value – the expected clean output for inputs in EMPTY_VALUES.
For example, the following code tests that an EmailField accepts “a@a.com” as a valid email address, but
rejects “aaa” with a reasonable error message:
self.assertFieldOutput(EmailField, {’a@a.com’: ’a@a.com’}, {’aaa’: [u’Enter a valid email address.’]})
TestCase.assertContains(response, text, count=None, status_code=200, msg_prefix=’‘, html=False)
Asserts that a Response instance produced the given status_code and that text appears in the content
of the response. If count is provided, text must occur exactly count times in the response. New in version
1.4. Set html to True to handle text as HTML. The comparison with the response content will be based
on HTML semantics instead of character-by-character equality. Whitespace is ignored in most cases, attribute
ordering is not significant. See assertHTMLEqual() for more details.
TestCase.assertNotContains(response, text, status_code=200, msg_prefix=’‘, html=False)
Asserts that a Response instance produced the given status_code and that text does not appears in the
content of the response. New in version 1.4. Set html to True to handle text as HTML. The comparison with
the response content will be based on HTML semantics instead of character-by-character equality. Whitespace
is ignored in most cases, attribute ordering is not significant. See assertHTMLEqual() for more details.
TestCase.assertFormError(response, form, field, errors, msg_prefix=’‘)
Asserts that a field on a form raises the provided list of errors when rendered on the form.
form is the name the Form instance was given in the template context.
field is the name of the field on the form to check. If field has a value of None, non-field errors (errors
you can access via form.non_field_errors()) will be checked.
errors is an error string, or a list of error strings, that are expected as a result of form validation.
TestCase.assertTemplateUsed(response, template_name, msg_prefix=’‘)
Asserts that the template with the given name was used in rendering the response.
The name is a string such as ’admin/index.html’. New in version 1.4. You can use this as a context
manager, like this:
with self.assertTemplateUsed(’index.html’):
render_to_string(’index.html’)
with self.assertTemplateUsed(template_name=’index.html’):
render_to_string(’index.html’)
TestCase.assertTemplateNotUsed(response, template_name, msg_prefix=’‘)
Asserts that the template with the given name was not used in rendering the response. New in version 1.4. You
can use this as a context manager in the same way as assertTemplateUsed().
284 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-288-2048.jpg)

![Django Documentation, Release 1.5.1
SimpleTestCase.assertHTMLNotEqual(html1, html2, msg=None)
New in version 1.4. Asserts that the strings html1 and html2 are not equal. The comparison is based on
HTML semantics. See assertHTMLEqual() for details.
html1 and html2 must be valid HTML. An AssertionError will be raised if one of them cannot be
parsed.
SimpleTestCase.assertXMLEqual(xml1, xml2, msg=None)
New in version 1.5. Asserts that the strings xml1 and xml2 are equal. The comparison is based on XML
semantics. Similarily to assertHTMLEqual(), the comparison is made on parsed content, hence only se-mantic
differences are considered, not syntax differences. When unvalid XML is passed in any parameter, an
AssertionError is always raised, even if both string are identical.
SimpleTestCase.assertXMLNotEqual(xml1, xml2, msg=None)
New in version 1.5. Asserts that the strings xml1 and xml2 are not equal. The comparison is based on XML
semantics. See assertXMLEqual() for details.
Email services
If any of your Django views send email using Django’s email functionality, you probably don’t want to send email
each time you run a test using that view. For this reason, Django’s test runner automatically redirects all Django-sent
email to a dummy outbox. This lets you test every aspect of sending email – from the number of messages sent to the
contents of each message – without actually sending the messages.
The test runner accomplishes this by transparently replacing the normal email backend with a testing backend. (Don’t
worry – this has no effect on any other email senders outside of Django, such as your machine’s mail server, if you’re
running one.)
django.core.mail.outbox
During test running, each outgoing email is saved in django.core.mail.outbox. This is a simple list of all
EmailMessage instances that have been sent. The outbox attribute is a special attribute that is created only when
the locmem email backend is used. It doesn’t normally exist as part of the django.core.mail module and you
can’t import it directly. The code below shows how to access this attribute correctly.
Here’s an example test that examines django.core.mail.outbox for length and contents:
from django.core import mail
from django.test import TestCase
class EmailTest(TestCase):
def test_send_email(self):
# Send message.
mail.send_mail(’Subject here’, ’Here is the message.’,
’from@example.com’, [’to@example.com’],
fail_silently=False)
# Test that one message has been sent.
self.assertEqual(len(mail.outbox), 1)
# Verify that the subject of the first message is correct.
self.assertEqual(mail.outbox[0].subject, ’Subject here’)
As noted previously, the test outbox is emptied at the start of every test in a Django TestCase. To empty the outbox
manually, assign the empty list to mail.outbox:
from django.core import mail
286 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-290-2048.jpg)
![Django Documentation, Release 1.5.1
# Empty the test outbox
mail.outbox = []
Skipping tests
The unittest library provides the @skipIf and @skipUnless decorators to allow you to skip tests if you know
ahead of time that those tests are going to fail under certain conditions.
For example, if your test requires a particular optional library in order to succeed, you could decorate the test case
with @skipIf. Then, the test runner will report that the test wasn’t executed and why, instead of failing the test or
omitting the test altogether.
To supplement these test skipping behaviors, Django provides two additional skip decorators. Instead of testing a
generic boolean, these decorators check the capabilities of the database, and skip the test if the database doesn’t
support a specific named feature.
The decorators use a string identifier to describe database features. This string corresponds to attributes of the
database connection features class. See django.db.backends.BaseDatabaseFeatures class for a full list
of database features that can be used as a basis for skipping tests.
skipIfDBFeature(feature_name_string)
Skip the decorated test if the named database feature is supported.
For example, the following test will not be executed if the database supports transactions (e.g., it would not run under
PostgreSQL, but it would under MySQL with MyISAM tables):
class MyTests(TestCase):
@skipIfDBFeature(’supports_transactions’)
def test_transaction_behavior(self):
# ... conditional test code
skipUnlessDBFeature(feature_name_string)
Skip the decorated test if the named database feature is not supported.
For example, the following test will only be executed if the database supports transactions (e.g., it would run under
PostgreSQL, but not under MySQL with MyISAM tables):
class MyTests(TestCase):
@skipUnlessDBFeature(’supports_transactions’)
def test_transaction_behavior(self):
# ... conditional test code
3.8.2 Django and doctests
Doctests use Python’s standard doctest module, which searches your docstrings for statements that resemble a
session of the Python interactive interpreter. A full explanation of how doctest works is out of the scope of this
document; read Python’s official documentation for the details.
What’s a docstring?
A good explanation of docstrings (and some guidelines for using them effectively) can be found in PEP 257:
A docstring is a string literal that occurs as the first statement in a module, function, class, or method
definition. Such a docstring becomes the __doc__ special attribute of that object.
For example, this function has a docstring that describes what it does:
3.8. Testing in Django 287](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-291-2048.jpg)


![Django Documentation, Release 1.5.1
’TEST_MIRROR’: ’default’
# ... plus some other settings
}
}
In this setup, we have two database servers: dbmaster, described by the database alias default, and dbslave
described by the alias slave. As you might expect, dbslave has been configured by the database administrator as
a read slave of dbmaster, so in normal activity, any write to default will appear on slave.
If Django created two independent test databases, this would break any tests that expected replication to occur. How-ever,
the slave database has been configured as a test mirror (using the TEST_MIRROR setting), indicating that
under testing, slave should be treated as a mirror of default.
When the test environment is configured, a test version of slave will not be created. Instead the connection to slave
will be redirected to point at default. As a result, writes to default will appear on slave – but because they are
actually the same database, not because there is data replication between the two databases.
Controlling creation order for test databases
By default, Django will always create the default database first. However, no guarantees are made on the creation
order of any other databases in your test setup.
If your database configuration requires a specific creation order, you can specify the dependencies that exist using the
TEST_DEPENDENCIES setting. Consider the following (simplified) example database configuration:
DATABASES = {
’default’: {
# ... db settings
’TEST_DEPENDENCIES’: [’diamonds’]
},
’diamonds’: {
# ... db settings
},
’clubs’: {
# ... db settings
’TEST_DEPENDENCIES’: [’diamonds’]
},
’spades’: {
# ... db settings
’TEST_DEPENDENCIES’: [’diamonds’,’hearts’]
},
’hearts’: {
# ... db settings
’TEST_DEPENDENCIES’: [’diamonds’,’clubs’]
}
}
Under this configuration, the diamonds database will be created first, as it is the only database alias without de-pendencies.
The default and clubs alias will be created next (although the order of creation of this pair is not
guaranteed); then hearts; and finally spades.
If there are any circular dependencies in the TEST_DEPENDENCIES definition, an ImproperlyConfigured
exception will be raised.
290 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-294-2048.jpg)


![Django Documentation, Release 1.5.1
Returns the result produced by the running the test suite.
DjangoTestSuiteRunner.teardown_databases(old_config, **kwargs)
Destroys the test databases, restoring pre-test conditions.
old_config is a data structure defining the changes in the database configuration that need to be reversed. It
is the return value of the setup_databases() method.
DjangoTestSuiteRunner.teardown_test_environment(**kwargs)
Restores the pre-test environment.
DjangoTestSuiteRunner.suite_result(suite, result, **kwargs)
Computes and returns a return code based on a test suite, and the result from that test suite.
Testing utilities
To assist in the creation of your own test runner, Django provides a number of utility methods in the
django.test.utils module.
setup_test_environment()
Performs any global pre-test setup, such as the installing the instrumentation of the template rendering system
and setting up the dummy email outbox.
teardown_test_environment()
Performs any global post-test teardown, such as removing the black magic hooks into the template system and
restoring normal email services.
The creation module of the database backend (connection.creation) also provides some utilities that can be
useful during testing.
create_test_db([verbosity=1, autoclobber=False ])
Creates a new test database and runs syncdb against it.
verbosity has the same behavior as in run_tests().
autoclobber describes the behavior that will occur if a database with the same name as the test database is
discovered:
•If autoclobber is False, the user will be asked to approve destroying the existing database.
sys.exit is called if the user does not approve.
•If autoclobber is True, the database will be destroyed without consulting the user.
Returns the name of the test database that it created.
create_test_db() has the side effect of modifying the value of NAME in DATABASES to match the name
of the test database.
destroy_test_db(old_database_name[, verbosity=1 ])
Destroys the database whose name is the value of NAME in DATABASES, and sets NAME to the value of
old_database_name.
The verbosity argument has the same behavior as for DjangoTestSuiteRunner.
Integration with coverage.py
Code coverage describes how much source code has been tested. It shows which parts of your code are being exercised
by tests and which are not. It’s an important part of testing applications, so it’s strongly recommended to check the
coverage of your tests.
3.8. Testing in Django 293](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-297-2048.jpg)
![Django Documentation, Release 1.5.1
Django can be easily integrated with coverage.py, a tool for measuring code coverage of Python programs. First,
install coverage.py. Next, run the following from your project folder containing manage.py:
coverage run --source=’.’ manage.py test myapp
This runs your tests and collects coverage data of the executed files in your project. You can see a report of this data
by typing following command:
coverage report
Note that some Django code was executed while running tests, but it is not listed here because of the source flag
passed to the previous command.
For more options like annotated HTML listings detailing missed lines, see the coverage.py docs.
Automated testing is an extremely useful bug-killing tool for the modern Web developer. You can use a collection of
tests – a test suite – to solve, or avoid, a number of problems:
• When you’re writing new code, you can use tests to validate your code works as expected.
• When you’re refactoring or modifying old code, you can use tests to ensure your changes haven’t affected your
application’s behavior unexpectedly.
Testing a Web application is a complex task, because a Web application is made of several layers of logic – from
HTTP-level request handling, to form validation and processing, to template rendering. With Django’s test-execution
framework and assorted utilities, you can simulate requests, insert test data, inspect your application’s output and
generally verify your code is doing what it should be doing.
The best part is, it’s really easy.
3.8.4 Unit tests v. doctests
There are two primary ways to write tests with Django, corresponding to the two test frameworks that ship in the
Python standard library. The two frameworks are:
• Unit tests – tests that are expressed as methods on a Python class that subclasses unittest.TestCase or
Django’s customized TestCase. For example:
import unittest
class MyFuncTestCase(unittest.TestCase):
def testBasic(self):
a = [’larry’, ’curly’, ’moe’]
self.assertEqual(my_func(a, 0), ’larry’)
self.assertEqual(my_func(a, 1), ’curly’)
• Doctests – tests that are embedded in your functions’ docstrings and are written in a way that emulates a session
of the Python interactive interpreter. For example:
def my_func(a_list, idx):
"""
>>> a = [’larry’, ’curly’, ’moe’]
>>> my_func(a, 0)
’larry’
>>> my_func(a, 1)
’curly’
"""
return a_list[idx]
294 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-298-2048.jpg)


![Django Documentation, Release 1.5.1
If you have the Django admin installed, you can also change user’s passwords on the authentication system’s admin
pages.
Django also provides views and forms that may be used to allow users to change their own passwords.
Authenticating Users
authenticate(**credentials)
To authenticate a given username and password, use authenticate(). It takes credentials in the form of
keyword arguments, for the default configuration this is username and password, and it returns a User
object if the password is valid for the given username. If the password is invalid, authenticate() returns
None. Example:
from django.contrib.auth import authenticate
user = authenticate(username=’john’, password=’secret’)
if user is not None:
# the password verified for the user
if user.is_active:
print("User is valid, active and authenticated")
else:
print("The password is valid, but the account has been disabled!")
else:
# the authentication system was unable to verify the username and password
print("The username and password were incorrect.")
Permissions and Authorization
Django comes with a simple permissions system. It provides a way to assign permissions to specific users and groups
of users.
It’s used by the Django admin site, but you’re welcome to use it in your own code.
The Django admin site uses permissions as follows:
• Access to view the “add” form and add an object is limited to users with the “add” permission for that type of
object.
• Access to view the change list, view the “change” form and change an object is limited to users with the “change”
permission for that type of object.
• Access to delete an object is limited to users with the “delete” permission for that type of object.
Permissions can be set not only per type of object, but also per specific object instance. By using the
has_add_permission(), has_change_permission() and has_delete_permission() methods
provided by the ModelAdmin class, it is possible to customize permissions for different object instances of the
same type.
User objects have two many-to-many fields: groups and user_permissions. User objects can access their
related objects in the same way as any other Django model:
myuser.groups = [group_list]
myuser.groups.add(group, group, ...)
myuser.groups.remove(group, group, ...)
myuser.groups.clear()
myuser.user_permissions = [permission_list]
myuser.user_permissions.add(permission, permission, ...)
myuser.user_permissions.remove(permission, permission, ...)
myuser.user_permissions.clear()
3.9. User authentication in Django 297](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-301-2048.jpg)

![Django Documentation, Release 1.5.1
if request.user.is_authenticated():
# Do something for authenticated users.
else:
# Do something for anonymous users.
How to log a user in
If you have an authenticated user you want to attach to the current session - this is done with a login() function.
login()
To log a user in, from a view, use login(). It takes an HttpRequest object and a User object. login()
saves the user’s ID in the session, using Django’s session framework.
Note that any data set during the anonymous session is retained in the session after a user logs in.
This example shows how you might use both authenticate() and login():
from django.contrib.auth import authenticate, login
def my_view(request):
username = request.POST[’username’]
password = request.POST[’password’]
user = authenticate(username=username, password=password)
if user is not None:
if user.is_active:
login(request, user)
# Redirect to a success page.
else:
# Return a ’disabled account’ error message
else:
# Return an ’invalid login’ error message.
Calling authenticate() first
When you’re manually logging a user in, you must call authenticate() before you call login().
authenticate() sets an attribute on the User noting which authentication backend successfully authenticated
that user (see the backends documentation for details), and this information is needed later during the login process.
An error will be raise if you try to login a user object retrieved from the database directly.
How to log a user out
logout()
To log out a user who has been logged in via django.contrib.auth.login(), use
django.contrib.auth.logout() within your view. It takes an HttpRequest object and has
no return value. Example:
from django.contrib.auth import logout
def logout_view(request):
logout(request)
# Redirect to a success page.
Note that logout() doesn’t throw any errors if the user wasn’t logged in.
3.9. User authentication in Django 299](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-303-2048.jpg)
![Django Documentation, Release 1.5.1
When you call logout(), the session data for the current request is completely cleaned out. All existing data
is removed. This is to prevent another person from using the same Web browser to log in and have access to
the previous user’s session data. If you want to put anything into the session that will be available to the user
immediately after logging out, do that after calling django.contrib.auth.logout().
Limiting access to logged-in users
The raw way The simple, raw way to limit access to pages is to check
request.user.is_authenticated() and either redirect to a login page:
from django.shortcuts import redirect
def my_view(request):
if not request.user.is_authenticated():
return redirect(’/login/?next=%s’ % request.path)
# ...
...or display an error message:
from django.shortcuts import render
def my_view(request):
if not request.user.is_authenticated():
return render(request, ’myapp/login_error.html’)
# ...
The login_required decorator
login_required([redirect_field_name=REDIRECT_FIELD_NAME, login_url=None ])
As a shortcut, you can use the convenient login_required() decorator:
from django.contrib.auth.decorators import login_required
@login_required
def my_view(request):
...
login_required() does the following:
•If the user isn’t logged in, redirect to settings.LOGIN_URL, passing the current absolute path in the
query string. Example: /accounts/login/?next=/polls/3/.
•If the user is logged in, execute the view normally. The view code is free to assume the user is logged in.
By default, the path that the user should be redirected to upon successful authentication is stored in a
query string parameter called "next". If you would prefer to use a different name for this parameter,
login_required() takes an optional redirect_field_name parameter:
from django.contrib.auth.decorators import login_required
@login_required(redirect_field_name=’my_redirect_field’)
def my_view(request):
...
Note that if you provide a value to redirect_field_name, you will most likely need to customize your
login template as well, since the template context variable which stores the redirect path will use the value of
redirect_field_name as its key rather than "next" (the default).
login_required() also takes an optional login_url parameter. Example:
300 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-304-2048.jpg)
![Django Documentation, Release 1.5.1
from django.contrib.auth.decorators import login_required
@login_required(login_url=’/accounts/login/’)
def my_view(request):
...
Note that if you don’t specify the login_url parameter, you’ll need to ensure that the
settings.LOGIN_URL and your login view are properly associated. For example, using the defaults, add
the following line to your URLconf:
(r’^accounts/login/$’, ’django.contrib.auth.views.login’),
Changed in version 1.5. The settings.LOGIN_URL also accepts view function names and named URL
patterns. This allows you to freely remap your login view within your URLconf without having to update the
setting.
Note: The login_required decorator does NOT check the is_active flag on a user.
Limiting access to logged-in users that pass a test To limit access based on certain permissions or some other test,
you’d do essentially the same thing as described in the previous section.
The simple way is to run your test on request.user in the view directly. For example, this view checks to make
sure the user has an email in the desired domain:
def my_view(request):
if not ’@example.com’ in request.user.email:
return HttpResponse("You can’t vote in this poll.")
# ...
user_passes_test(func[, login_url=None ])
As a shortcut, you can use the convenient user_passes_test decorator:
from django.contrib.auth.decorators import user_passes_test
def email_check(user):
return ’@example.com’ in user.email
@user_passes_test(email_check)
def my_view(request):
...
user_passes_test() takes a required argument: a callable that takes a User object and returns True if
the user is allowed to view the page. Note that user_passes_test() does not automatically check that the
User is not anonymous.
user_passes_test() takes an optional login_url argument, which lets you specify the URL for your
login page (settings.LOGIN_URL by default).
For example:
@user_passes_test(email_check, login_url=’/login/’)
def my_view(request):
...
The permission_required decorator
3.9. User authentication in Django 301](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-305-2048.jpg)
![Django Documentation, Release 1.5.1
permission_required([login_url=None, raise_exception=False ])
It’s a relatively common task to check whether a user has a particular permission. For that reason, Django
provides a shortcut for that case: the permission_required() decorator.:
from django.contrib.auth.decorators import permission_required
@permission_required(’polls.can_vote’)
def my_view(request):
...
As for the has_perm() method, permission names take the form "<app label>.<permission
codename>" (i.e. polls.can_vote for a permission on a model in the polls application).
Note that permission_required() also takes an optional login_url parameter. Example:
from django.contrib.auth.decorators import permission_required
@permission_required(’polls.can_vote’, login_url=’/loginpage/’)
def my_view(request):
...
As in the login_required() decorator, login_url defaults to settings.LOGIN_URL. Changed in
version 1.4. Added raise_exception parameter. If given, the decorator will raise PermissionDenied,
prompting the 403 (HTTP Forbidden) view instead of redirecting to the login page.
Applying permissions to generic views To apply a permission to a class-based generic view, decorate the
View.dispatch method on the class. See Decorating the class for details.
Authentication Views
Django provides several views that you can use for handling login, logout, and password management. These make
use of the stock auth forms but you can pass in your own forms as well.
Django provides no default template for the authentication views - however the template context is documented for
each view below. New in version 1.4. The built-in views all return a TemplateResponse instance, which allows
you to easily customize the response data before rendering. For more details, see the TemplateResponse documenta-tion.
Most built-in authentication views provide a URL name for easier reference. See the URL documentation for details
on using named URL patterns.
login(request[, template_name, redirect_field_name, authentication_form ])
URL name: login
See the URL documentation for details on using named URL patterns.
Here’s what django.contrib.auth.views.login does:
•If called via GET, it displays a login form that POSTs to the same URL. More on this in a bit.
•If called via POST with user submitted credentials, it tries to log the user in. If login is suc-cessful,
the view redirects to the URL specified in next. If next isn’t provided, it redirects to
settings.LOGIN_REDIRECT_URL (which defaults to /accounts/profile/). If login isn’t suc-cessful,
it redisplays the login form.
It’s your responsibility to provide the html for the login template , called registration/login.html by
default. This template gets passed four template context variables:
•form: A Form object representing the AuthenticationForm.
302 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-306-2048.jpg)
![Django Documentation, Release 1.5.1
•next: The URL to redirect to after successful login. This may contain a query string, too.
•site: The current Site, according to the SITE_ID setting. If you don’t have the site framework
installed, this will be set to an instance of RequestSite, which derives the site name and domain from
the current HttpRequest.
•site_name: An alias for site.name. If you don’t have the site framework installed, this will be set to
the value of request.META[’SERVER_NAME’]. For more on sites, see The “sites” framework.
If you’d prefer not to call the template registration/login.html, you can pass the template_name
parameter via the extra arguments to the view in your URLconf. For example, this URLconf line would use
myapp/login.html instead:
(r’^accounts/login/$’, ’django.contrib.auth.views.login’, {’template_name’: ’myapp/login.html’}),
You can also specify the name of the GET field which contains the URL to redirect to after login by passing
redirect_field_name to the view. By default, the field is called next.
Here’s a sample registration/login.html template you can use as a starting point. It assumes you
have a base.html template that defines a content block:
{% extends "base.html" %}
{% block content %}
{% if form.errors %}
<p>Your username and password didn’t match. Please try again.</p>
{% endif %}
<form method="post" action="{% url ’django.contrib.auth.views.login’ %}">
{% csrf_token %}
<table>
<tr>
<td>{{ form.username.label_tag }}</td>
<td>{{ form.username }}</td>
</tr>
<tr>
<td>{{ form.password.label_tag }}</td>
<td>{{ form.password }}</td>
</tr>
</table>
<input type="submit" value="login" />
<input type="hidden" name="next" value="{{ next }}" />
</form>
{% endblock %}
If you have customized authentication (see Customizing Authentication) you can pass a custom authentication
form to the login view via the authentication_form parameter. This form must accept a request
keyword argument in its __init__ method, and provide a get_user method which returns the authenticated
user object (this method is only ever called after successful form validation).
logout(request[, next_page, template_name, redirect_field_name ])
Logs a user out.
URL name: logout
Optional arguments:
•next_page: The URL to redirect to after logout.
3.9. User authentication in Django 303](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-307-2048.jpg)
![Django Documentation, Release 1.5.1
•template_name: The full name of a template to display after logging the user out. Defaults to
registration/logged_out.html if no argument is supplied.
•redirect_field_name: The name of a GET field containing the URL to redirect to after log out.
Overrides next_page if the given GET parameter is passed.
Template context:
•title: The string “Logged out”, localized.
•site: The current Site, according to the SITE_ID setting. If you don’t have the site framework
installed, this will be set to an instance of RequestSite, which derives the site name and domain from
the current HttpRequest.
•site_name: An alias for site.name. If you don’t have the site framework installed, this will be set to
the value of request.META[’SERVER_NAME’]. For more on sites, see The “sites” framework.
logout_then_login(request[, login_url ])
Logs a user out, then redirects to the login page.
URL name: No default URL provided
Optional arguments:
•login_url: The URL of the login page to redirect to. Defaults to settings.LOGIN_URL if not
supplied.
password_change(request[, template_name, post_change_redirect, password_change_form ])
Allows a user to change their password.
URL name: password_change
Optional arguments:
•template_name: The full name of a template to use for displaying the password change form. Defaults
to registration/password_change_form.html if not supplied.
•post_change_redirect: The URL to redirect to after a successful password change.
•password_change_form: A custom “change password” form which must accept a user key-word
argument. The form is responsible for actually changing the user’s password. Defaults to
PasswordChangeForm.
Template context:
•form: The password change form (see password_change_form above).
password_change_done(request[, template_name ])
The page shown after a user has changed their password.
URL name: password_change_done
Optional arguments:
•template_name: The full name of a template to use. Defaults to
registration/password_change_done.html if not supplied.
password_reset(request[, is_admin_site, template_name, email_template_name, password_reset_form,
token_generator, post_reset_redirect, from_email ])
Allows a user to reset their password by generating a one-time use link that can be used to reset the password, and
sending that link to the user’s registered email address. Changed in version 1.4: Users flagged with an unusable
password (see set_unusable_password() will not be able to request a password reset to prevent misuse
when using an external authentication source like LDAP. URL name: password_reset
Optional arguments:
304 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-308-2048.jpg)
![Django Documentation, Release 1.5.1
•template_name: The full name of a template to use for displaying the password reset form. Defaults
to registration/password_reset_form.html if not supplied.
•email_template_name: The full name of a template to use for generating the email with the reset
password link. Defaults to registration/password_reset_email.html if not supplied.
•subject_template_name: The full name of a template to use for the subject of the email with the
reset password link. Defaults to registration/password_reset_subject.txt if not supplied.
New in version 1.4.
•password_reset_form: Form that will be used to get the email of the user to reset the password for.
Defaults to PasswordResetForm.
•token_generator: Instance of the class to check the one time link.
This will default to default_token_generator, it’s an instance of
django.contrib.auth.tokens.PasswordResetTokenGenerator.
•post_reset_redirect: The URL to redirect to after a successful password reset request.
•from_email: A valid email address. By default Django uses the DEFAULT_FROM_EMAIL.
Template context:
•form: The form (see password_reset_form above) for resetting the user’s password.
Email template context:
•email: An alias for user.email
•user: The current User, according to the email form field. Only active users are able to reset their
passwords (User.is_active is True).
•site_name: An alias for site.name. If you don’t have the site framework installed, this will be set to
the value of request.META[’SERVER_NAME’]. For more on sites, see The “sites” framework.
•domain: An alias for site.domain. If you don’t have the site framework installed, this will be set to
the value of request.get_host().
•protocol: http or https
•uid: The user’s id encoded in base 36.
•token: Token to check that the reset link is valid.
Sample registration/password_reset_email.html (email body template):
Someone asked for password reset for email {{ email }}. Follow the link below:
{{ protocol}}://{{ domain }}{% url ’password_reset_confirm’ uidb36=uid token=token %}
The same template context is used for subject template. Subject must be single line plain text string.
password_reset_done(request[, template_name ])
The page shown after a user has been emailed a link to reset their password. This view is called by default if the
password_reset() view doesn’t have an explicit post_reset_redirect URL set.
URL name: password_reset_done
Optional arguments:
•template_name: The full name of a template to use. Defaults to
registration/password_reset_done.html if not supplied.
password_reset_confirm(request[, uidb36, token, template_name, token_generator,
set_password_form, post_reset_redirect ])
Presents a form for entering a new password.
3.9. User authentication in Django 305](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-309-2048.jpg)
![Django Documentation, Release 1.5.1
URL name: password_reset_confirm
Optional arguments:
•uidb36: The user’s id encoded in base 36. Defaults to None.
•token: Token to check that the password is valid. Defaults to None.
•template_name: The full name of a template to display the confirm password view. Default value is
registration/password_reset_confirm.html.
•token_generator: Instance of the class to check the password.
This will default to default_token_generator, it’s an instance of
django.contrib.auth.tokens.PasswordResetTokenGenerator.
•set_password_form: Form that will be used to set the password. Defaults to SetPasswordForm
•post_reset_redirect: URL to redirect after the password reset done. Defaults to None.
Template context:
•form: The form (see set_password_form above) for setting the new user’s password.
•validlink: Boolean, True if the link (combination of uidb36 and token) is valid or unused yet.
password_reset_complete(request[, template_name ])
Presents a view which informs the user that the password has been successfully changed.
URL name: password_reset_complete
Optional arguments:
•template_name: The full name of a template to display the view. Defaults to
registration/password_reset_complete.html.
Helper functions
redirect_to_login(next[, login_url, redirect_field_name ])
Redirects to the login page, and then back to another URL after a successful login.
Required arguments:
•next: The URL to redirect to after a successful login.
Optional arguments:
•login_url: The URL of the login page to redirect to. Defaults to settings.LOGIN_URL if not
supplied.
•redirect_field_name: The name of a GET field containing the URL to redirect to after log out.
Overrides next if the given GET parameter is passed.
Built-in forms
If you don’t want to use the built-in views, but want the convenience of not having to write forms for this functionality,
the authentication system provides several built-in forms located in django.contrib.auth.forms:
Note: The built-in authentication forms make certain assumptions about the user model that they are working with.
If you’re using a custom User model, it may be necessary to define your own forms for the authentication system. For
more information, refer to the documentation about using the built-in authentication forms with custom user models.
306 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-310-2048.jpg)


![Django Documentation, Release 1.5.1
3.9.2 Password management in Django
Password management is something that should generally not be reinvented unnecessarily, and Django endeavors to
provide a secure and flexible set of tools for managing user passwords. This document describes how Django stores
passwords, how the storage hashing can be configured, and some utilities to work with hashed passwords.
How Django stores passwords
New in version 1.4: Django 1.4 introduces a new flexible password storage system and uses PBKDF2 by default.
Previous versions of Django used SHA1, and other algorithms couldn’t be chosen. The password attribute of a
User object is a string in this format:
<algorithm>$<iterations>$<salt>$<hash>
Those are the components used for storing a User’s password, separated by the dollar-sign character and consist of: the
hashing algorithm, the number of algorithm iterations (work factor), the random salt, and the resulting password hash.
The algorithm is one of a number of one-way hashing or password storage algorithms Django can use; see below.
Iterations describe the number of times the algorithm is run over the hash. Salt is the random seed used and the hash
is the result of the one-way function.
By default, Django uses the PBKDF2 algorithm with a SHA256 hash, a password stretching mechanism recommended
by NIST. This should be sufficient for most users: it’s quite secure, requiring massive amounts of computing time to
break.
However, depending on your requirements, you may choose a different algorithm, or even use a custom algorithm to
match your specific security situation. Again, most users shouldn’t need to do this – if you’re not sure, you probably
don’t. If you do, please read on:
Django chooses the algorithm to use by consulting the PASSWORD_HASHERS setting. This is a list
of hashing algorithm classes that this Django installation supports. The first entry in this list (that is,
settings.PASSWORD_HASHERS[0]) will be used to store passwords, and all the other entries are valid hash-ers
that can be used to check existing passwords. This means that if you want to use a different algorithm, you’ll need
to modify PASSWORD_HASHERS to list your preferred algorithm first in the list.
The default for PASSWORD_HASHERS is:
PASSWORD_HASHERS = (
’django.contrib.auth.hashers.PBKDF2PasswordHasher’,
’django.contrib.auth.hashers.PBKDF2SHA1PasswordHasher’,
’django.contrib.auth.hashers.BCryptPasswordHasher’,
’django.contrib.auth.hashers.SHA1PasswordHasher’,
’django.contrib.auth.hashers.MD5PasswordHasher’,
’django.contrib.auth.hashers.CryptPasswordHasher’,
)
This means that Django will use PBKDF2 to store all passwords, but will support checking passwords stored with
PBKDF2SHA1, bcrypt, SHA1, etc. The next few sections describe a couple of common ways advanced users may
want to modify this setting.
Using bcrypt with Django
Bcrypt is a popular password storage algorithm that’s specifically designed for long-term password storage. It’s not
the default used by Django since it requires the use of third-party libraries, but since many people may want to use it
Django supports bcrypt with minimal effort.
To use Bcrypt as your default storage algorithm, do the following:
3.9. User authentication in Django 309](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-313-2048.jpg)
![Django Documentation, Release 1.5.1
1. Install the py-bcrypt library (probably by running sudo pip install py-bcrypt, or downloading the
library and installing it with python setup.py install).
2. Modify PASSWORD_HASHERS to list BCryptPasswordHasher first. That is, in your settings file, you’d
put:
PASSWORD_HASHERS = (
’django.contrib.auth.hashers.BCryptPasswordHasher’,
’django.contrib.auth.hashers.PBKDF2PasswordHasher’,
’django.contrib.auth.hashers.PBKDF2SHA1PasswordHasher’,
’django.contrib.auth.hashers.SHA1PasswordHasher’,
’django.contrib.auth.hashers.MD5PasswordHasher’,
’django.contrib.auth.hashers.CryptPasswordHasher’,
)
(You need to keep the other entries in this list, or else Django won’t be able to upgrade passwords; see below).
That’s it – now your Django install will use Bcrypt as the default storage algorithm.
Password truncation with BCryptPasswordHasher
The designers of bcrypt truncate all passwords at 72 characters which means that
bcrypt(password_with_100_chars) == bcrypt(password_with_100_chars[:72]).
BCryptPasswordHasher does not have any special handling and thus is also subject to this hidden pass-word
length limit. The practical ramification of this truncation is pretty marginal as the average user does not have a
password greater than 72 characters in length and even being truncated at 72 the compute powered required to brute
force bcrypt in any useful amount of time is still astronomical.
Other bcrypt implementations
There are several other implementations that allow bcrypt to be used with Django. Django’s
bcrypt support is NOT directly compatible with these. To upgrade, you will need to modify the
hashes in your database to be in the form bcrypt$(raw bcrypt output). For example:
bcrypt$$2a$12$NT0I31Sa7ihGEWpka9ASYrEFkhuTNeBQ2xfZskIiiJeyFXhRgS.Sy.
Increasing the work factor
The PBKDF2 and bcrypt algorithms use a number of iterations or rounds of hashing. This deliberately slows down
attackers, making attacks against hashed passwords harder. However, as computing power increases, the number of
iterations needs to be increased. We’ve chosen a reasonable default (and will increase it with each release of Django),
but you may wish to tune it up or down, depending on your security needs and available processing power. To do so,
you’ll subclass the appropriate algorithm and override the iterations parameters. For example, to increase the
number of iterations used by the default PBKDF2 algorithm:
1. Create a subclass of django.contrib.auth.hashers.PBKDF2PasswordHasher:
from django.contrib.auth.hashers import PBKDF2PasswordHasher
class MyPBKDF2PasswordHasher(PBKDF2PasswordHasher):
"""
A subclass of PBKDF2PasswordHasher that uses 100 times more iterations.
"""
iterations = PBKDF2PasswordHasher.iterations * 100
Save this somewhere in your project. For example, you might put this in a file like myproject/hashers.py.
310 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-314-2048.jpg)
![Django Documentation, Release 1.5.1
2. Add your new hasher as the first entry in PASSWORD_HASHERS:
PASSWORD_HASHERS = (
’myproject.hashers.MyPBKDF2PasswordHasher’,
’django.contrib.auth.hashers.PBKDF2PasswordHasher’,
’django.contrib.auth.hashers.PBKDF2SHA1PasswordHasher’,
’django.contrib.auth.hashers.BCryptPasswordHasher’,
’django.contrib.auth.hashers.SHA1PasswordHasher’,
’django.contrib.auth.hashers.MD5PasswordHasher’,
’django.contrib.auth.hashers.CryptPasswordHasher’,
)
That’s it – now your Django install will use more iterations when it stores passwords using PBKDF2.
Password upgrading
When users log in, if their passwords are stored with anything other than the preferred algorithm, Django will auto-matically
upgrade the algorithm to the preferred one. This means that old installs of Django will get automatically
more secure as users log in, and it also means that you can switch to new (and better) storage algorithms as they get
invented.
However, Django can only upgrade passwords that use algorithms mentioned in PASSWORD_HASHERS, so as you
upgrade to new systems you should make sure never to remove entries from this list. If you do, users using un-mentioned
algorithms won’t be able to upgrade.
Manually managing a user’s password
New in version 1.4: The django.contrib.auth.hashers module provides a set of functions to create and
validate hashed password. You can use them independently from the User model.
check_password(password, encoded)
New in version 1.4. If you’d like to manually authenticate a user by comparing a plain-text password to the
hashed password in the database, use the convenience function check_password(). It takes two arguments:
the plain-text password to check, and the full value of a user’s password field in the database to check against,
and returns True if they match, False otherwise.
make_password(password[, salt, hashers ])
New in version 1.4. Creates a hashed password in the format used by this application. It takes one mandatory
argument: the password in plain-text. Optionally, you can provide a salt and a hashing algorithm to use, if you
don’t want to use the defaults (first entry of PASSWORD_HASHERS setting). Currently supported algorithms are:
’pbkdf2_sha256’, ’pbkdf2_sha1’, ’bcrypt’ (see Using bcrypt with Django), ’sha1’, ’md5’,
’unsalted_md5’ (only for backward compatibility) and ’crypt’ if you have the crypt library installed.
If the password argument is None, an unusable password is returned (a one that will be never accepted by
check_password()).
is_password_usable(encoded_password)
New in version 1.4. Checks if the given string is a hashed password that has a chance of being verified against
check_password().
3.9.3 Customizing authentication in Django
The authentication that comes with Django is good enough for most common cases, but you may have needs not met
by the out-of-the-box defaults. To customize authentication to your projects needs involves understanding what points
of the provided system are extendible or replaceable. This document provides details about how the auth system can
be customized.
3.9. User authentication in Django 311](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-315-2048.jpg)






![Django Documentation, Release 1.5.1
The easiest way to construct a compliant custom User model is to inherit from AbstractBaseUser.
AbstractBaseUser provides the core implementation of a User model, including hashed passwords and tok-enized
password resets. You must then provide some key implementation details:
class models.CustomUser
USERNAME_FIELD
A string describing the name of the field on the User model that is used as the unique identifier. This will
usually be a username of some kind, but it can also be an email address, or any other unique identifier. The
field must be unique (i.e., have unique=True set in its definition).
In the following example, the field identifier is used as the identifying field:
class MyUser(AbstractBaseUser):
identifier = models.CharField(max_length=40, unique=True, db_index=True)
...
USERNAME_FIELD = ’identifier’
REQUIRED_FIELDS
A list of the field names that must be provided when creating a user via the createsuperuser man-agement
command. The user will be prompted to supply a value for each of these fields. It should include
any field for which blank is False or undefined, but may include additional fields you want prompted
for when a user is created interactively. However, it will not work for ForeignKey fields.
For example, here is the partial definition for a User model that defines two required fields - a date of
birth and height:
class MyUser(AbstractBaseUser):
...
date_of_birth = models.DateField()
height = models.FloatField()
...
REQUIRED_FIELDS = [’date_of_birth’, ’height’]
Note: REQUIRED_FIELDS must contain all required fields on your User model, but should not contain
the USERNAME_FIELD.
is_active
A boolean attribute that indicates whether the user is considered “active”. This attribute is provided as
an attribute on AbstractBaseUser defaulting to True. How you choose to implement it will de-pend
on the details of your chosen auth backends. See the documentation of the attribute on the
builtin user model for details.
get_full_name()
A longer formal identifier for the user. A common interpretation would be the full name name of the user,
but it can be any string that identifies the user.
get_short_name()
A short, informal identifier for the user. A common interpretation would be the first name of the user,
but it can be any string that identifies the user in an informal way. It may also return the same value as
django.contrib.auth.models.User.get_full_name().
The following methods are available on any subclass of AbstractBaseUser:
class models.AbstractBaseUser
318 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-322-2048.jpg)





![Django Documentation, Release 1.5.1
Creates and saves a superuser with the given email, date of
birth and password.
"""
user = self.create_user(email,
password=password,
date_of_birth=date_of_birth
)
user.is_admin = True
user.save(using=self._db)
return user
class MyUser(AbstractBaseUser):
email = models.EmailField(
verbose_name=’email address’,
max_length=255,
unique=True,
db_index=True,
)
date_of_birth = models.DateField()
is_active = models.BooleanField(default=True)
is_admin = models.BooleanField(default=False)
objects = MyUserManager()
USERNAME_FIELD = ’email’
REQUIRED_FIELDS = [’date_of_birth’]
def get_full_name(self):
# The user is identified by their email address
return self.email
def get_short_name(self):
# The user is identified by their email address
return self.email
def __unicode__(self):
return self.email
def has_perm(self, perm, obj=None):
"Does the user have a specific permission?"
# Simplest possible answer: Yes, always
return True
def has_module_perms(self, app_label):
"Does the user have permissions to view the app ‘app_label‘?"
# Simplest possible answer: Yes, always
return True
@property
def is_staff(self):
"Is the user a member of staff?"
# Simplest possible answer: All admins are staff
return self.is_admin
Then, to register this custom User model with Django’s admin, the following code would be required in the app’s
admin.py file:
324 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-328-2048.jpg)
![Django Documentation, Release 1.5.1
from django import forms
from django.contrib import admin
from django.contrib.auth.models import Group
from django.contrib.auth.admin import UserAdmin
from django.contrib.auth.forms import ReadOnlyPasswordHashField
from customauth.models import MyUser
class UserCreationForm(forms.ModelForm):
"""A form for creating new users. Includes all the required
fields, plus a repeated password."""
password1 = forms.CharField(label=’Password’, widget=forms.PasswordInput)
password2 = forms.CharField(label=’Password confirmation’, widget=forms.PasswordInput)
class Meta:
model = MyUser
fields = (’email’, ’date_of_birth’)
def clean_password2(self):
# Check that the two password entries match
password1 = self.cleaned_data.get("password1")
password2 = self.cleaned_data.get("password2")
if password1 and password2 and password1 != password2:
raise forms.ValidationError("Passwords don’t match")
return password2
def save(self, commit=True):
# Save the provided password in hashed format
user = super(UserCreationForm, self).save(commit=False)
user.set_password(self.cleaned_data["password1"])
if commit:
user.save()
return user
class UserChangeForm(forms.ModelForm):
"""A form for updating users. Includes all the fields on
the user, but replaces the password field with admin’s
password hash display field.
"""
password = ReadOnlyPasswordHashField()
class Meta:
model = MyUser
def clean_password(self):
# Regardless of what the user provides, return the initial value.
# This is done here, rather than on the field, because the
# field does not have access to the initial value
return self.initial["password"]
class MyUserAdmin(UserAdmin):
# The forms to add and change user instances
form = UserChangeForm
add_form = UserCreationForm
3.9. User authentication in Django 325](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-329-2048.jpg)



![Django Documentation, Release 1.5.1
CACHES = {
’default’: {
’BACKEND’: ’django.core.cache.backends.memcached.MemcachedCache’,
’LOCATION’: ’unix:/tmp/memcached.sock’,
}
}
One excellent feature of Memcached is its ability to share cache over multiple servers. This means you can run
Memcached daemons on multiple machines, and the program will treat the group of machines as a single cache,
without the need to duplicate cache values on each machine. To take advantage of this feature, include all server
addresses in LOCATION, either separated by semicolons or as a list.
In this example, the cache is shared over Memcached instances running on IP address 172.19.26.240 and
172.19.26.242, both on port 11211:
CACHES = {
’default’: {
’BACKEND’: ’django.core.cache.backends.memcached.MemcachedCache’,
’LOCATION’: [
’172.19.26.240:11211’,
’172.19.26.242:11211’,
]
}
}
In the following example, the cache is shared over Memcached instances running on the IP addresses 172.19.26.240
(port 11211), 172.19.26.242 (port 11212), and 172.19.26.244 (port 11213):
CACHES = {
’default’: {
’BACKEND’: ’django.core.cache.backends.memcached.MemcachedCache’,
’LOCATION’: [
’172.19.26.240:11211’,
’172.19.26.242:11212’,
’172.19.26.244:11213’,
]
}
}
A final point about Memcached is that memory-based caching has one disadvantage: Because the cached data is stored
in memory, the data will be lost if your server crashes. Clearly, memory isn’t intended for permanent data storage, so
don’t rely on memory-based caching as your only data storage. Without a doubt, none of the Django caching backends
should be used for permanent storage – they’re all intended to be solutions for caching, not storage – but we point this
out here because memory-based caching is particularly temporary.
Database caching
To use a database table as your cache backend, first create a cache table in your database by running this command:
python manage.py createcachetable [cache_table_name]
...where [cache_table_name] is the name of the database table to create. (This name can be whatever you want,
as long as it’s a valid table name that’s not already being used in your database.) This command creates a single table
in your database that is in the proper format that Django’s database-cache system expects.
Once you’ve created that database table, set your BACKEND setting to
"django.core.cache.backends.db.DatabaseCache", and LOCATION to tablename – the name of
the database table. In this example, the cache table’s name is my_cache_table:
3.10. Django’s cache framework 329](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-333-2048.jpg)







![Django Documentation, Release 1.5.1
>>> cache.set(’my_key’, ’hello, world!’, 30)
>>> cache.get(’my_key’)
’hello, world!’
The timeout argument is optional and defaults to the timeout argument of the appropriate backend in the CACHES
setting (explained above). It’s the number of seconds the value should be stored in the cache.
If the object doesn’t exist in the cache, cache.get() returns None:
# Wait 30 seconds for ’my_key’ to expire...
>>> cache.get(’my_key’)
None
We advise against storing the literal value None in the cache, because you won’t be able to distinguish between your
stored None value and a cache miss signified by a return value of None.
cache.get() can take a default argument. This specifies which value to return if the object doesn’t exist in the
cache:
>>> cache.get(’my_key’, ’has expired’)
’has expired’
To add a key only if it doesn’t already exist, use the add() method. It takes the same parameters as set(), but it
will not attempt to update the cache if the key specified is already present:
>>> cache.set(’add_key’, ’Initial value’)
>>> cache.add(’add_key’, ’New value’)
>>> cache.get(’add_key’)
’Initial value’
If you need to know whether add() stored a value in the cache, you can check the return value. It will return True
if the value was stored, False otherwise.
There’s also a get_many() interface that only hits the cache once. get_many() returns a dictionary with all the
keys you asked for that actually exist in the cache (and haven’t expired):
>>> cache.set(’a’, 1)
>>> cache.set(’b’, 2)
>>> cache.set(’c’, 3)
>>> cache.get_many([’a’, ’b’, ’c’])
{’a’: 1, ’b’: 2, ’c’: 3}
To set multiple values more efficiently, use set_many() to pass a dictionary of key-value pairs:
>>> cache.set_many({’a’: 1, ’b’: 2, ’c’: 3})
>>> cache.get_many([’a’, ’b’, ’c’])
{’a’: 1, ’b’: 2, ’c’: 3}
Like cache.set(), set_many() takes an optional timeout parameter.
You can delete keys explicitly with delete(). This is an easy way of clearing the cache for a particular object:
>>> cache.delete(’a’)
If you want to clear a bunch of keys at once, delete_many() can take a list of keys to be cleared:
>>> cache.delete_many([’a’, ’b’, ’c’])
Finally, if you want to delete all the keys in the cache, use cache.clear(). Be careful with this; clear() will
remove everything from the cache, not just the keys set by your application.
3.10. Django’s cache framework 337](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-341-2048.jpg)

![Django Documentation, Release 1.5.1
>>> cache.get(’my_key’, version=2)
’hello world!’
The version of a specific key can be incremented and decremented using the incr_version() and
decr_version() methods. This enables specific keys to be bumped to a new version, leaving other keys unaf-fected.
Continuing our previous example:
# Increment the version of ’my_key’
>>> cache.incr_version(’my_key’)
# The default version still isn’t available
>>> cache.get(’my_key’)
None
# Version 2 isn’t available, either
>>> cache.get(’my_key’, version=2)
None
# But version 3 *is* available
>>> cache.get(’my_key’, version=3)
’hello world!’
Cache key transformation
As described in the previous two sections, the cache key provided by a user is not used verbatim – it is combined with
the cache prefix and key version to provide a final cache key. By default, the three parts are joined using colons to
produce a final string:
def make_key(key, key_prefix, version):
return ’:’.join([key_prefix, str(version), key])
If you want to combine the parts in different ways, or apply other processing to the final key (e.g., taking a hash digest
of the key parts), you can provide a custom key function.
The KEY_FUNCTION cache setting specifies a dotted-path to a function matching the prototype of make_key()
above. If provided, this custom key function will be used instead of the default key combining function.
Cache key warnings
Memcached, the most commonly-used production cache backend, does not allow cache keys longer than 250 char-acters
or containing whitespace or control characters, and using such keys will cause an exception. To encour-age
cache-portable code and minimize unpleasant surprises, the other built-in cache backends issue a warning
(django.core.cache.backends.base.CacheKeyWarning) if a key is used that would cause an error on
memcached.
If you are using a production backend that can accept a wider range of keys (a custom backend, or one of
the non-memcached built-in backends), and want to use this wider range without warnings, you can silence
CacheKeyWarning with this code in the management module of one of your INSTALLED_APPS:
import warnings
from django.core.cache import CacheKeyWarning
warnings.simplefilter("ignore", CacheKeyWarning)
If you want to instead provide custom key validation logic for one of the built-in backends, you can subclass it, override
just the validate_key method, and follow the instructions for using a custom cache backend. For instance, to do
this for the locmem backend, put this code in a module:
3.10. Django’s cache framework 339](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-343-2048.jpg)

![Django Documentation, Release 1.5.1
from django.views.decorators.vary import vary_on_headers
@vary_on_headers(’User-Agent’)
def my_view(request):
# ...
In this case, a caching mechanism (such as Django’s own cache middleware) will cache a separate version of the page
for each unique user-agent.
The advantage to using the vary_on_headers decorator rather than manually setting the Vary header (using
something like response[’Vary’] = ’user-agent’) is that the decorator adds to the Vary header (which
may already exist), rather than setting it from scratch and potentially overriding anything that was already in there.
You can pass multiple headers to vary_on_headers():
@vary_on_headers(’User-Agent’, ’Cookie’)
def my_view(request):
# ...
This tells upstream caches to vary on both, which means each combination of user-agent and cookie will get its own
cache value. For example, a request with the user-agent Mozilla and the cookie value foo=bar will be considered
different from a request with the user-agent Mozilla and the cookie value foo=ham.
Because varying on cookie is so common, there’s a vary_on_cookie decorator. These two views are equivalent:
@vary_on_cookie
def my_view(request):
# ...
@vary_on_headers(’Cookie’)
def my_view(request):
# ...
The headers you pass to vary_on_headers are not case sensitive; "User-Agent" is the same thing as
"user-agent".
You can also use a helper function, django.utils.cache.patch_vary_headers, directly. This function
sets, or adds to, the Vary header. For example:
from django.utils.cache import patch_vary_headers
def my_view(request):
# ...
response = render_to_response(’template_name’, context)
patch_vary_headers(response, [’Cookie’])
return response
patch_vary_headers takes an HttpResponse instance as its first argument and a list/tuple of case-insensitive
header names as its second argument.
For more on Vary headers, see the official Vary spec.
3.10.8 Controlling cache: Using other headers
Other problems with caching are the privacy of data and the question of where data should be stored in a cascade of
caches.
A user usually faces two kinds of caches: his or her own browser cache (a private cache) and his or her provider’s
cache (a public cache). A public cache is used by multiple users and controlled by someone else. This poses problems
3.10. Django’s cache framework 341](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-345-2048.jpg)







![Django Documentation, Release 1.5.1
The code lives in the django.core.mail module.
3.13.1 Quick example
In two lines:
from django.core.mail import send_mail
send_mail(’Subject here’, ’Here is the message.’, ’from@example.com’,
[’to@example.com’], fail_silently=False)
Mail is sent using the SMTP host and port specified in the EMAIL_HOST and EMAIL_PORT settings. The
EMAIL_HOST_USER and EMAIL_HOST_PASSWORD settings, if set, are used to authenticate to the SMTP server,
and the EMAIL_USE_TLS setting controls whether a secure connection is used.
Note: The character set of email sent with django.core.mail will be set to the value of your
DEFAULT_CHARSET setting.
3.13.2 send_mail()
send_mail(subject, message, from_email, recipient_list, fail_silently=False, auth_user=None,
auth_password=None, connection=None)
The simplest way to send email is using django.core.mail.send_mail().
The subject, message, from_email and recipient_list parameters are required.
• subject: A string.
• message: A string.
• from_email: A string.
• recipient_list: A list of strings, each an email address. Each member of recipient_list will see
the other recipients in the “To:” field of the email message.
• fail_silently: A boolean. If it’s False, send_mail will raise an smtplib.SMTPException. See
the smtplib docs for a list of possible exceptions, all of which are subclasses of SMTPException.
• auth_user: The optional username to use to authenticate to the SMTP server. If this isn’t provided, Django
will use the value of the EMAIL_HOST_USER setting.
• auth_password: The optional password to use to authenticate to the SMTP server. If this isn’t provided,
Django will use the value of the EMAIL_HOST_PASSWORD setting.
• connection: The optional email backend to use to send the mail. If unspecified, an instance of the default
backend will be used. See the documentation on Email backends for more details.
3.13.3 send_mass_mail()
send_mass_mail(datatuple, fail_silently=False, auth_user=None, auth_password=None, connec-tion=
None)
django.core.mail.send_mass_mail() is intended to handle mass emailing.
datatuple is a tuple in which each element is in this format:
3.13. Sending email 349](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-353-2048.jpg)
![Django Documentation, Release 1.5.1
(subject, message, from_email, recipient_list)
fail_silently, auth_user and auth_password have the same functions as in send_mail().
Each separate element of datatuple results in a separate email message. As in send_mail(), recipients in the
same recipient_list will all see the other addresses in the email messages’ “To:” field.
For example, the following code would send two different messages to two different sets of recipients; however, only
one connection to the mail server would be opened:
message1 = (’Subject here’, ’Here is the message’, ’from@example.com’, [’first@example.com’, ’other@example.message2 = (’Another Subject’, ’Here is another message’, ’from@example.com’, [’second@test.com’])
send_mass_mail((message1, message2), fail_silently=False)
send_mass_mail() vs. send_mail()
The main difference between send_mass_mail() and send_mail() is that send_mail() opens a connec-tion
to the mail server each time it’s executed, while send_mass_mail() uses a single connection for all of its
messages. This makes send_mass_mail() slightly more efficient.
3.13.4 mail_admins()
mail_admins(subject, message, fail_silently=False, connection=None, html_message=None)
django.core.mail.mail_admins() is a shortcut for sending an email to the site admins, as defined in the
ADMINS setting.
mail_admins() prefixes the subject with the value of the EMAIL_SUBJECT_PREFIX setting, which is
"[Django] " by default.
The “From:” header of the email will be the value of the SERVER_EMAIL setting.
This method exists for convenience and readability.
If html_message is provided, the resulting email will be a multipart/alternative email with message
as the text/plain content type and html_message as the text/html content type.
3.13.5 mail_managers()
mail_managers(subject, message, fail_silently=False, connection=None, html_message=None)
django.core.mail.mail_managers() is just like mail_admins(), except it sends an email to the site
managers, as defined in the MANAGERS setting.
3.13.6 Examples
This sends a single email to john@example.com and jane@example.com, with them both appearing in the “To:”:
send_mail(’Subject’, ’Message.’, ’from@example.com’,
[’john@example.com’, ’jane@example.com’])
This sends a message to john@example.com and jane@example.com, with them both receiving a separate email:
350 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-354-2048.jpg)
![Django Documentation, Release 1.5.1
datatuple = (
(’Subject’, ’Message.’, ’from@example.com’, [’john@example.com’]),
(’Subject’, ’Message.’, ’from@example.com’, [’jane@example.com’]),
)
send_mass_mail(datatuple)
3.13.7 Preventing header injection
Header injection is a security exploit in which an attacker inserts extra email headers to control the “To:” and “From:”
in email messages that your scripts generate.
The Django email functions outlined above all protect against header injection by forbidding newlines in header
values. If any subject, from_email or recipient_list contains a newline (in either Unix,Windows or Mac
style), the email function (e.g. send_mail()) will raise django.core.mail.BadHeaderError (a subclass
of ValueError) and, hence, will not send the email. It’s your responsibility to validate all data before passing it to
the email functions.
If a message contains headers at the start of the string, the headers will simply be printed as the first bit of the email
message.
Here’s an example view that takes a subject, message and from_email from the request’s POST data, sends
that to admin@example.com and redirects to “/contact/thanks/” when it’s done:
from django.core.mail import send_mail, BadHeaderError
def send_email(request):
subject = request.POST.get(’subject’, ’’)
message = request.POST.get(’message’, ’’)
from_email = request.POST.get(’from_email’, ’’)
if subject and message and from_email:
try:
send_mail(subject, message, from_email, [’admin@example.com’])
except BadHeaderError:
return HttpResponse(’Invalid header found.’)
return HttpResponseRedirect(’/contact/thanks/’)
else:
# In reality we’d use a form class
# to get proper validation errors.
return HttpResponse(’Make sure all fields are entered and valid.’)
3.13.8 The EmailMessage class
Django’s send_mail() and send_mass_mail() functions are actually thin wrappers that make use of the
EmailMessage class.
Not all features of the EmailMessage class are available through the send_mail() and related wrapper functions.
If you wish to use advanced features, such as BCC’ed recipients, file attachments, or multi-part email, you’ll need to
create EmailMessage instances directly.
Note: This is a design feature. send_mail() and related functions were originally the only interface Django
provided. However, the list of parameters they accepted was slowly growing over time. It made sense to move to a
more object-oriented design for email messages and retain the original functions only for backwards compatibility.
EmailMessage is responsible for creating the email message itself. The email backend is then responsible for
sending the email.
3.13. Sending email 351](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-355-2048.jpg)
![Django Documentation, Release 1.5.1
For convenience, EmailMessage provides a simple send() method for sending a single email. If you need to send
multiple messages, the email backend API provides an alternative.
EmailMessage Objects
class EmailMessage
The EmailMessage class is initialized with the following parameters (in the given order, if positional arguments are
used). All parameters are optional and can be set at any time prior to calling the send() method.
• subject: The subject line of the email.
• body: The body text. This should be a plain text message.
• from_email: The sender’s address. Both fred@example.com and Fred <fred@example.com>
forms are legal. If omitted, the DEFAULT_FROM_EMAIL setting is used.
• to: A list or tuple of recipient addresses.
• bcc: A list or tuple of addresses used in the “Bcc” header when sending the email.
• connection: An email backend instance. Use this parameter if you want to use the same connection for
multiple messages. If omitted, a new connection is created when send() is called.
• attachments: A list of attachments to put on the message. These can be either
email.MIMEBase.MIMEBase instances, or (filename, content, mimetype) triples.
• headers: A dictionary of extra headers to put on the message. The keys are the header name, values are the
header values. It’s up to the caller to ensure header names and values are in the correct format for an email
message.
• cc: A list or tuple of recipient addresses used in the “Cc” header when sending the email.
For example:
email = EmailMessage(’Hello’, ’Body goes here’, ’from@example.com’,
[’to1@example.com’, ’to2@example.com’], [’bcc@example.com’],
headers = {’Reply-To’: ’another@example.com’})
The class has the following methods:
• send(fail_silently=False) sends the message. If a connection was specified when the email was
constructed, that connection will be used. Otherwise, an instance of the default backend will be instantiated and
used. If the keyword argument fail_silently is True, exceptions raised while sending the message will
be quashed.
• message() constructs a django.core.mail.SafeMIMEText object (a subclass of Python’s
email.MIMEText.MIMEText class) or a django.core.mail.SafeMIMEMultipart object hold-ing
the message to be sent. If you ever need to extend the EmailMessage class, you’ll probably want to
override this method to put the content you want into the MIME object.
• recipients() returns a list of all the recipients of the message, whether they’re recorded in the to, cc or
bcc attributes. This is another method you might need to override when subclassing, because the SMTP server
needs to be told the full list of recipients when the message is sent. If you add another way to specify recipients
in your class, they need to be returned from this method as well.
• attach() creates a new file attachment and adds it to the message. There are two ways to call attach():
– You can pass it a single argument that is an email.MIMEBase.MIMEBase instance. This will be
inserted directly into the resulting message.
352 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-356-2048.jpg)
![Django Documentation, Release 1.5.1
– Alternatively, you can pass attach() three arguments: filename, content and mimetype.
filename is the name of the file attachment as it will appear in the email, content is the data that
will be contained inside the attachment and mimetype is the optional MIME type for the attachment. If
you omit mimetype, the MIME content type will be guessed from the filename of the attachment.
For example:
message.attach(’design.png’, img_data, ’image/png’)
• attach_file() creates a new attachment using a file from your filesystem. Call it with the path of the file to
attach and, optionally, the MIME type to use for the attachment. If the MIME type is omitted, it will be guessed
from the filename. The simplest use would be:
message.attach_file(’/images/weather_map.png’)
Sending alternative content types
It can be useful to include multiple versions of the content in an email; the classic example is to send both text and
HTML versions of a message. With Django’s email library, you can do this using the EmailMultiAlternatives
class. This subclass of EmailMessage has an attach_alternative() method for including extra versions of
the message body in the email. All the other methods (including the class initialization) are inherited directly from
EmailMessage.
To send a text and HTML combination, you could write:
from django.core.mail import EmailMultiAlternatives
subject, from_email, to = ’hello’, ’from@example.com’, ’to@example.com’
text_content = ’This is an important message.’
html_content = ’<p>This is an <strong>important</strong> message.</p>’
msg = EmailMultiAlternatives(subject, text_content, from_email, [to])
msg.attach_alternative(html_content, "text/html")
msg.send()
By default, the MIME type of the body parameter in an EmailMessage is "text/plain". It is good practice
to leave this alone, because it guarantees that any recipient will be able to read the email, regardless of their mail
client. However, if you are confident that your recipients can handle an alternative content type, you can use the
content_subtype attribute on the EmailMessage class to change the main content type. The major type will
always be "text", but you can change the subtype. For example:
msg = EmailMessage(subject, html_content, from_email, [to])
msg.content_subtype = "html" # Main content is now text/html
msg.send()
3.13.9 Email backends
The actual sending of an email is handled by the email backend.
The email backend class has the following methods:
• open() instantiates an long-lived email-sending connection.
• close() closes the current email-sending connection.
• send_messages(email_messages) sends a list of EmailMessage objects. If the connection is not
open, this call will implicitly open the connection, and close the connection afterwards. If the connection is
already open, it will be left open after mail has been sent.
3.13. Sending email 353](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-357-2048.jpg)


![Django Documentation, Release 1.5.1
In this example, the call to send_messages() opens a connection on the backend, sends the list of messages, and
then closes the connection again.
The second approach is to use the open() and close() methods on the email backend to manually control the
connection. send_messages() will not manually open or close the connection if it is already open, so if you
manually open the connection, you can control when it is closed. For example:
from django.core import mail
connection = mail.get_connection()
# Manually open the connection
connection.open()
# Construct an email message that uses the connection
email1 = mail.EmailMessage(’Hello’, ’Body goes here’, ’from@example.com’,
[’to1@example.com’], connection=connection)
email1.send() # Send the email
# Construct two more messages
email2 = mail.EmailMessage(’Hello’, ’Body goes here’, ’from@example.com’,
[’to2@example.com’])
email3 = mail.EmailMessage(’Hello’, ’Body goes here’, ’from@example.com’,
[’to3@example.com’])
# Send the two emails in a single call -
connection.send_messages([email2, email3])
# The connection was already open so send_messages() doesn’t close it.
# We need to manually close the connection.
connection.close()
3.13.10 Testing email sending
There are times when you do not want Django to send emails at all. For example, while developing a Web site, you
probably don’t want to send out thousands of emails – but you may want to validate that emails will be sent to the
right people under the right conditions, and that those emails will contain the correct content.
The easiest way to test your project’s use of email is to use the console email backend. This backend redirects all
email to stdout, allowing you to inspect the content of mail.
The file email backend can also be useful during development – this backend dumps the contents of every SMTP
connection to a file that can be inspected at your leisure.
Another approach is to use a “dumb” SMTP server that receives the emails locally and displays them to the terminal,
but does not actually send anything. Python has a built-in way to accomplish this with a single command:
python -m smtpd -n -c DebuggingServer localhost:1025
This command will start a simple SMTP server listening on port 1025 of localhost. This server simply prints to
standard output all email headers and the email body. You then only need to set the EMAIL_HOST and EMAIL_PORT
accordingly, and you are set.
For a more detailed discussion of testing and processing of emails locally, see the Python documentation for the
smtpd module.
356 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-360-2048.jpg)

![Django Documentation, Release 1.5.1
from django.utils.translation import ugettext as _
def my_view(request):
output = _("Welcome to my site.")
return HttpResponse(output)
Obviously, you could code this without using the alias. This example is identical to the previous one:
from django.utils.translation import ugettext
def my_view(request):
output = ugettext("Welcome to my site.")
return HttpResponse(output)
Translation works on computed values. This example is identical to the previous two:
def my_view(request):
words = [’Welcome’, ’to’, ’my’, ’site.’]
output = _(’ ’.join(words))
return HttpResponse(output)
Translation works on variables. Again, here’s an identical example:
def my_view(request):
sentence = ’Welcome to my site.’
output = _(sentence)
return HttpResponse(output)
(The caveat with using variables or computed values, as in the previous two examples, is that Django’s translation-string-
detecting utility, django-admin.py makemessages, won’t be able to find these strings. More on
makemessages later.)
The strings you pass to _() or ugettext() can take placeholders, specified with Python’s standard named-string
interpolation syntax. Example:
def my_view(request, m, d):
output = _(’Today is %(month)s %(day)s.’) % {’month’: m, ’day’: d}
return HttpResponse(output)
This technique lets language-specific translations reorder the placeholder text. For example, an English translation
may be "Today is November 26.", while a Spanish translation may be "Hoy es 26 de Noviembre."
– with the the month and the day placeholders swapped.
For this reason, you should use named-string interpolation (e.g., %(day)s) instead of positional interpolation (e.g.,
%s or %d) whenever you have more than a single parameter. If you used positional interpolation, translations wouldn’t
be able to reorder placeholder text.
Comments for translators
If you would like to give translators hints about a translatable string, you can add a comment prefixed with the
Translators keyword on the line preceding the string, e.g.:
def my_view(request):
# Translators: This message appears on the home page only
output = ugettext("Welcome to my site.")
The comment will then appear in the resulting .po file associated with the translatable contruct located below it and
should also be displayed by most translation tools.
358 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-362-2048.jpg)

![Django Documentation, Release 1.5.1
’There are %(count)d %(name)s available.’,
count
) % {
’count’: count,
’name’: name
}
Here we reuse localizable, hopefully already translated literals (contained in the verbose_name and
verbose_name_plural model Meta options) for other parts of the sentence so all of it is consistently based
on the cardinality of the elements at play.
Note: When using this technique, make sure you use a single name for every extrapolated variable included in the
literal. In the example above note how we used the name Python variable in both translation strings. This example
would fail:
from django.utils.translation import ungettext
from myapp.models import Report
count = Report.objects.count()
d = {
’count’: count,
’name’: Report._meta.verbose_name,
’plural_name’: Report._meta.verbose_name_plural
}
text = ungettext(
’There is %(count)d %(name)s available.’,
’There are %(count)d %(plural_name)s available.’,
count
) % d
You would get an error when running django-admin.py compilemessages:
a format specification for argument ’name’, as in ’msgstr[0]’, doesn’t exist in ’msgid’
Contextual markers
Sometimes words have several meanings, such as "May" in English, which refers to a month
name and to a verb. To enable translators to translate these words correctly in different
contexts, you can use the django.utils.translation.pgettext() function, or the
django.utils.translation.npgettext() function if the string needs pluralization. Both take a
context string as the first variable.
In the resulting .po file, the string will then appear as often as there are different contextual markers for the same
string (the context will appear on the msgctxt line), allowing the translator to give a different translation for each of
them.
For example:
from django.utils.translation import pgettext
month = pgettext("month name", "May")
or:
from django.utils.translation import pgettext_lazy
360 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-364-2048.jpg)

![Django Documentation, Release 1.5.1
verbose_name = _(’my thing’)
verbose_name_plural = _(’my things’)
Model methods short_description attribute values For model methods, you can provide translations to
Django and the admin site with the short_description attribute:
from django.utils.translation import ugettext_lazy as _
class MyThing(models.Model):
kind = models.ForeignKey(ThingKind, related_name=’kinds’,
verbose_name=_(’kind’))
def is_mouse(self):
return self.kind.type == MOUSE_TYPE
is_mouse.short_description = _(’Is it a mouse?’)
Working with lazy translation objects
The result of a ugettext_lazy() call can be used wherever you would use a unicode string (an object with type
unicode) in Python. If you try to use it where a bytestring (a str object) is expected, things will not work as
expected, since a ugettext_lazy() object doesn’t know how to convert itself to a bytestring. You can’t use a
unicode string inside a bytestring, either, so this is consistent with normal Python behavior. For example:
# This is fine: putting a unicode proxy into a unicode string.
u"Hello %s" % ugettext_lazy("people")
# This will not work, since you cannot insert a unicode object
# into a bytestring (nor can you insert our unicode proxy there)
"Hello %s" % ugettext_lazy("people")
If you ever see output that looks like "hello <django.utils.functional...>", you have tried to insert
the result of ugettext_lazy() into a bytestring. That’s a bug in your code.
If you don’t like the long ugettext_lazy name, you can just alias it as _ (underscore), like so:
from django.utils.translation import ugettext_lazy as _
class MyThing(models.Model):
name = models.CharField(help_text=_(’This is the help text’))
Using ugettext_lazy() and ungettext_lazy() to mark strings in models and utility functions is a common
operation. When you’re working with these objects elsewhere in your code, you should ensure that you don’t acci-dentally
convert them to strings, because they should be converted as late as possible (so that the correct locale is in
effect). This necessitates the use of the helper function described next.
Joining strings: string_concat() Standard Python string joins (”.join([...])) will not work on lists contain-ing
lazy translation objects. Instead, you can use django.utils.translation.string_concat(), which
creates a lazy object that concatenates its contents and converts them to strings only when the result is included in a
string. For example:
from django.utils.translation import string_concat
...
name = ugettext_lazy(’John Lennon’)
instrument = ugettext_lazy(’guitar’)
result = string_concat(name, ’: ’, instrument)
362 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-366-2048.jpg)
![Django Documentation, Release 1.5.1
In this case, the lazy translations in result will only be converted to strings when result itself is used in a string
(usually at template rendering time).
Other uses of lazy in delayed translations For any other case where you would like to delay the translation, but
have to pass the translatable string as argument to another function, you can wrap this function inside a lazy call
yourself. For example:
from django.utils import six # Python 3 compatibility
from django.utils.functional import lazy
from django.utils.safestring import mark_safe
from django.utils.translation import ugettext_lazy as _
mark_safe_lazy = lazy(mark_safe, six.text_type)
And then later:
lazy_string = mark_safe_lazy(_("<p>My <strong>string!</strong></p>"))
Localized names of languages
get_language_info()
The get_language_info() function provides detailed information about languages:
>>> from django.utils.translation import get_language_info
>>> li = get_language_info(’de’)
>>> print(li[’name’], li[’name_local’], li[’bidi’])
German Deutsch False
The name and name_local attributes of the dictionary contain the name of the language in English and in the
language itself, respectively. The bidi attribute is True only for bi-directional languages.
The source of the language information is the django.conf.locale module. Similar access to this information
is available for template code. See below.
Internationalization: in template code
Translations in Django templates uses two template tags and a slightly different syntax than in Python code. To give
your template access to these tags, put {% load i18n %} toward the top of your template. As with all template
tags, this tag needs to be loaded in all templates which use translations, even those templates that extend from other
templates which have already loaded the i18n tag.
trans template tag
The {% trans %} template tag translates either a constant string (enclosed in single or double quotes) or variable
content:
<title>{% trans "This is the title." %}</title>
<title>{% trans myvar %}</title>
If the noop option is present, variable lookup still takes place but the translation is skipped. This is useful when
“stubbing out” content that will require translation in the future:
<title>{% trans "myvar" noop %}</title>
3.14. Internationalization and localization 363](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-367-2048.jpg)



![Django Documentation, Release 1.5.1
{% some_special_tag _("Page not found") value|yesno:_("yes,no") %}
In this case, both the tag and the filter will see the already-translated string, so they don’t need to be aware of transla-tions.
Note: In this example, the translation infrastructure will be passed the string "yes,no", not the individual strings
"yes" and "no". The translated string will need to contain the comma so that the filter parsing code knows how
to split up the arguments. For example, a German translator might translate the string "yes,no" as "ja,nein"
(keeping the comma intact).
You can also retrieve information about any of the available languages using provided template tags and filters. To get
information about a single language, use the {% get_language_info %} tag:
{% get_language_info for LANGUAGE_CODE as lang %}
{% get_language_info for "pl" as lang %}
You can then access the information:
Language code: {{ lang.code }}<br />
Name of language: {{ lang.name_local }}<br />
Name in English: {{ lang.name }}<br />
Bi-directional: {{ lang.bidi }}
You can also use the {% get_language_info_list %} template tag to retrieve information for a list of lan-guages
(e.g. active languages as specified in LANGUAGES). See the section about the set_language redirect view for
an example of how to display a language selector using {% get_language_info_list %}.
In addition to LANGUAGES style nested tuples, {% get_language_info_list %} supports simple lists of
language codes. If you do this in your view:
return render_to_response(’mytemplate.html’, {
’available_languages’: [’en’, ’es’, ’fr’],
}, RequestContext(request))
you can iterate over those languages in the template:
{% get_language_info_list for available_languages as langs %}
{% for lang in langs %} ... {% endfor %}
There are also simple filters available for convenience:
• {{ LANGUAGE_CODE|language_name }} (“German”)
• {{ LANGUAGE_CODE|language_name_local }} (“Deutsch”)
• {{ LANGUAGE_CODE|bidi }} (False)
Internationalization: in JavaScript code
Adding translations to JavaScript poses some problems:
• JavaScript code doesn’t have access to a gettext implementation.
• JavaScript code doesn’t have access to .po or .mo files; they need to be delivered by the server.
• The translation catalogs for JavaScript should be kept as small as possible.
Django provides an integrated solution for these problems: It passes the translations into JavaScript, so you can call
gettext, etc., from within JavaScript.
3.14. Internationalization and localization 367](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-371-2048.jpg)

![Django Documentation, Release 1.5.1
var object_cnt = 1 // or 0, or 2, or 3, ...
s = ngettext(’literal for the singular case’,
’literal for the plural case’, object_cnt);
and even a string interpolation function:
function interpolate(fmt, obj, named);
The interpolation syntax is borrowed from Python, so the interpolate function supports both positional and named
interpolation:
• Positional interpolation: obj contains a JavaScript Array object whose elements values are then sequentially
interpolated in their corresponding fmt placeholders in the same order they appear. For example:
fmts = ngettext(’There is %s object. Remaining: %s’,
’There are %s objects. Remaining: %s’, 11);
s = interpolate(fmts, [11, 20]);
// s is ’There are 11 objects. Remaining: 20’
• Named interpolation: This mode is selected by passing the optional boolean named parameter as true. obj
contains a JavaScript object or associative array. For example:
d = {
count: 10,
total: 50
};
fmts = ngettext(’Total: %(total)s, there is %(count)s object’,
’there are %(count)s of a total of %(total)s objects’, d.count);
s = interpolate(fmts, d, true);
You shouldn’t go over the top with string interpolation, though: this is still JavaScript, so the code has to make repeated
regular-expression substitutions. This isn’t as fast as string interpolation in Python, so keep it to those cases where you
really need it (for example, in conjunction with ngettext to produce proper pluralizations).
Note on performance
The javascript_catalog() view generates the catalog from .mo files on every request. Since its output is
constant— at least for a given version of a site— it’s a good candidate for caching.
Server-side caching will reduce CPU load. It’s easily implemented with the cache_page() decorator. To trigger
cache invalidation when your translations change, provide a version-dependant key prefix, as shown in the example
below, or map the view at a version-dependant URL.
from django.views.decorators.cache import cache_page
from django.views.i18n import javascript_catalog
# The value returned by get_version() must change when translations change.
@cache_page(86400, key_prefix=’js18n-%s’ % get_version())
def cached_javascript_catalog(request, domain=’djangojs’, packages=None):
return javascript_catalog(request, domain, packages)
Client-side caching will save bandwidth and make your site load faster. If you’re using ETags (USE_ETAGS =
True), you’re already covered. Otherwise, you can apply conditional decorators. In the following example, the cache
is invalidated whenever your restart your application server.
from django.utils import timezone
from django.views.decorators.http import last_modified
3.14. Internationalization and localization 369](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-373-2048.jpg)
![Django Documentation, Release 1.5.1
from django.views.i18n import javascript_catalog
last_modified_date = timezone.now()
@last_modified(lambda req, **kw: last_modified_date)
def cached_javascript_catalog(request, domain=’djangojs’, packages=None):
return javascript_catalog(request, domain, packages)
You can even pre-generate the javascript catalog as part of your deployment procedure and serve it as a static file. This
radical technique is implemented in django-statici18n.
Internationalization: in URL patterns
New in version 1.4. Django provides two mechanisms to internationalize URL patterns:
• Adding the language prefix to the root of the URL patterns to make it possible for LocaleMiddleware to
detect the language to activate from the requested URL.
• Making URL patterns themselves translatable via the django.utils.translation.ugettext_lazy()
function.
Warning: Using either one of these features requires that an active language be set for each re-quest;
in other words, you need to have django.middleware.locale.LocaleMiddleware in your
MIDDLEWARE_CLASSES setting.
Language prefix in URL patterns
i18n_patterns(prefix, pattern_description, ...)
This function can be used in your root URLconf as a replacement for the normal
django.conf.urls.patterns() function. Django will automatically prepend the current active language
code to all url patterns defined within i18n_patterns(). Example URL patterns:
from django.conf.urls import patterns, include, url
from django.conf.urls.i18n import i18n_patterns
urlpatterns = patterns(’’,
url(r’^sitemap.xml$’, ’sitemap.view’, name=’sitemap_xml’),
)
news_patterns = patterns(’’,
url(r’^$’, ’news.views.index’, name=’index’),
url(r’^category/(?P<slug>[w-]+)/$’, ’news.views.category’, name=’category’),
url(r’^(?P<slug>[w-]+)/$’, ’news.views.details’, name=’detail’),
)
urlpatterns += i18n_patterns(’’,
url(r’^about/$’, ’about.view’, name=’about’),
url(r’^news/’, include(news_patterns, namespace=’news’)),
)
After defining these URL patterns, Django will automatically add the language prefix to the URL patterns that were
added by the i18n_patterns function. Example:
from django.core.urlresolvers import reverse
from django.utils.translation import activate
370 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-374-2048.jpg)
![Django Documentation, Release 1.5.1
>>> activate(’en’)
>>> reverse(’sitemap_xml’)
’/sitemap.xml’
>>> reverse(’news:index’)
’/en/news/’
>>> activate(’nl’)
>>> reverse(’news:detail’, kwargs={’slug’: ’news-slug’})
’/nl/news/news-slug/’
Warning: i18n_patterns() is only allowed in your root URLconf. Using it within an included URLconf
will throw an ImproperlyConfigured exception.
Warning: Ensure that you don’t have non-prefixed URL patterns that might collide with an automatically-added
language prefix.
Translating URL patterns
URL patterns can also be marked translatable using the ugettext_lazy() function. Example:
from django.conf.urls import patterns, include, url
from django.conf.urls.i18n import i18n_patterns
from django.utils.translation import ugettext_lazy as _
urlpatterns = patterns(’’
url(r’^sitemap.xml$’, ’sitemap.view’, name=’sitemap_xml’),
)
news_patterns = patterns(’’
url(r’^$’, ’news.views.index’, name=’index’),
url(_(r’^category/(?P<slug>[w-]+)/$’), ’news.views.category’, name=’category’),
url(r’^(?P<slug>[w-]+)/$’, ’news.views.details’, name=’detail’),
)
urlpatterns += i18n_patterns(’’,
url(_(r’^about/$’), ’about.view’, name=’about’),
url(_(r’^news/’), include(news_patterns, namespace=’news’)),
)
After you’ve created the translations, the reverse() function will return the URL in the active language. Example:
from django.core.urlresolvers import reverse
from django.utils.translation import activate
>>> activate(’en’)
>>> reverse(’news:category’, kwargs={’slug’: ’recent’})
’/en/news/category/recent/’
>>> activate(’nl’)
>>> reverse(’news:category’, kwargs={’slug’: ’recent’})
’/nl/nieuws/categorie/recent/’
Warning: In most cases, it’s best to use translated URLs only within a language-code-prefixed block of patterns
(using i18n_patterns()), to avoid the possibility that a carelessly translated URL causes a collision with a
non-translated URL pattern.
3.14. Internationalization and localization 371](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-375-2048.jpg)













![Django Documentation, Release 1.5.1
Create a view that can set the current timezone:
import pytz
from django.shortcuts import redirect, render
def set_timezone(request):
if request.method == ’POST’:
request.session[’django_timezone’] = pytz.timezone(request.POST[’timezone’])
return redirect(’/’)
else:
return render(request, ’template.html’, {’timezones’: pytz.common_timezones})
Include a form in template.html that will POST to this view:
{% load tz %}
<form action="{% url ’set_timezone’ %}" method="POST">
{% csrf_token %}
<label for="timezone">Time zone:</label>
<select name="timezone">
{% for tz in timezones %}
<option value="{{ tz }}"{% if tz == TIME_ZONE %} selected="selected"{% endif %}>{{ tz }}</option>
{% endfor %}
</select>
<input type="submit" value="Set" />
</form>
Time zone aware input in forms
When you enable time zone support, Django interprets datetimes entered in forms in the current time zone and returns
aware datetime objects in cleaned_data.
If the current time zone raises an exception for datetimes that don’t exist or are ambiguous because they fall in a DST
transition (the timezones provided by pytz do this), such datetimes will be reported as invalid values.
Time zone aware output in templates
When you enable time zone support, Django converts aware datetime objects to the current time zone when they’re
rendered in templates. This behaves very much like format localization.
Warning: Django doesn’t convert naive datetime objects, because they could be ambiguous, and because your
code should never produce naive datetimes when time zone support is enabled. However, you can force conversion
with the template filters described below.
Conversion to local time isn’t always appropriate – you may be generating output for computers rather than for humans.
The following filters and tags, provided by the tz template tag library, allow you to control the time zone conversions.
Template tags
localtime Enables or disables conversion of aware datetime objects to the current time zone in the contained block.
This tag has exactly the same effects as the USE_TZ setting as far as the template engine is concerned. It allows a
more fine grained control of conversion.
To activate or deactivate conversion for a template block, use:
3.14. Internationalization and localization 385](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-389-2048.jpg)










![Django Documentation, Release 1.5.1
’class’: ’django.utils.log.NullHandler’,
},
’console’:{
’level’: ’DEBUG’,
’class’: ’logging.StreamHandler’,
’formatter’: ’simple’
},
’mail_admins’: {
’level’: ’ERROR’,
’class’: ’django.utils.log.AdminEmailHandler’,
’filters’: [’special’]
}
},
’loggers’: {
’django’: {
’handlers’: [’null’],
’propagate’: True,
’level’: ’INFO’,
},
’django.request’: {
’handlers’: [’mail_admins’],
’level’: ’ERROR’,
’propagate’: False,
},
’myproject.custom’: {
’handlers’: [’console’, ’mail_admins’],
’level’: ’INFO’,
’filters’: [’special’]
}
}
}
This logging configuration does the following things:
• Identifies the configuration as being in ‘dictConfig version 1’ format. At present, this is the only dictConfig
format version.
• Disables all existing logging configurations.
• Defines two formatters:
– simple, that just outputs the log level name (e.g., DEBUG) and the log message.
The format string is a normal Python formatting string describing the details that are to be output on
each logging line. The full list of detail that can be output can be found in the formatter documentation.
– verbose, that outputs the log level name, the log message, plus the time, process, thread and module that
generate the log message.
• Defines one filter – project.logging.SpecialFilter, using the alias special. If this filter re-quired
additional arguments at time of construction, they can be provided as additional keys in the filter con-figuration
dictionary. In this case, the argument foo will be given a value of bar when instantiating the
SpecialFilter.
• Defines three handlers:
– null, a NullHandler, which will pass any DEBUG (or higher) message to /dev/null.
– console, a StreamHandler, which will print any DEBUG (or higher) message to stderr. This handler uses
the simple output format.
396 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-400-2048.jpg)

![Django Documentation, Release 1.5.1
django.request
Log messages related to the handling of requests. 5XX responses are raised as ERROR messages; 4XX responses are
raised as WARNING messages.
Messages to this logger have the following extra context:
• status_code: The HTTP response code associated with the request.
• request: The request object that generated the logging message.
django.db.backends
Messages relating to the interaction of code with the database. For example, every SQL statement executed by a
request is logged at the DEBUG level to this logger.
Messages to this logger have the following extra context:
• duration: The time taken to execute the SQL statement.
• sql: The SQL statement that was executed.
• params: The parameters that were used in the SQL call.
For performance reasons, SQL logging is only enabled when settings.DEBUG is set to True, regardless of the
logging level or handlers that are installed.
Handlers
Django provides one log handler in addition to those provided by the Python logging module.
class AdminEmailHandler([include_html=False ])
This handler sends an email to the site admins for each log message it receives.
If the log record contains a request attribute, the full details of the request will be included in the email.
If the log record contains stack trace information, that stack trace will be included in the email.
The include_html argument of AdminEmailHandler is used to control whether the traceback email
includes an HTML attachment containing the full content of the debug Web page that would have been pro-duced
if DEBUG were True. To set this value in your configuration, include it in the handler definition for
django.utils.log.AdminEmailHandler, like this:
’handlers’: {
’mail_admins’: {
’level’: ’ERROR’,
’class’: ’django.utils.log.AdminEmailHandler’,
’include_html’: True,
}
},
Note that this HTML version of the email contains a full traceback, with names and values of local variables at
each level of the stack, plus the values of your Django settings. This information is potentially very sensitive,
and you may not want to send it over email. Consider using something such as Sentry to get the best of both
worlds – the rich information of full tracebacks plus the security of not sending the information over email. You
may also explicitly designate certain sensitive information to be filtered out of error reports – learn more on
Filtering error reports.
398 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-402-2048.jpg)
![Django Documentation, Release 1.5.1
Filters
Django provides two log filters in addition to those provided by the Python logging module.
class CallbackFilter(callback)
New in version 1.4. This filter accepts a callback function (which should accept a single argument, the record to
be logged), and calls it for each record that passes through the filter. Handling of that record will not proceed if
the callback returns False.
For instance, to filter out UnreadablePostError (raised when a user cancels an upload) from the admin
emails, you would create a filter function:
from django.http import UnreadablePostError
def skip_unreadable_post(record):
if record.exc_info:
exc_type, exc_value = record.exc_info[:2]
if isinstance(exc_value, UnreadablePostError):
return False
return True
and then add it to your logging config:
’filters’: {
’skip_unreadable_posts’: {
’()’: ’django.utils.log.CallbackFilter’,
’callback’: skip_unreadable_post,
}
},
’handlers’: {
’mail_admins’: {
’level’: ’ERROR’,
’filters’: [’skip_unreadable_posts’],
’class’: ’django.utils.log.AdminEmailHandler’
}
},
class RequireDebugFalse
New in version 1.4. This filter will only pass on records when settings.DEBUG is False.
This filter is used as follows in the default LOGGING configuration to ensure that the AdminEmailHandler
only sends error emails to admins when DEBUG is False:
’filters’: {
’require_debug_false’: {
’()’: ’django.utils.log.RequireDebugFalse’,
}
},
’handlers’: {
’mail_admins’: {
’level’: ’ERROR’,
’filters’: [’require_debug_false’],
’class’: ’django.utils.log.AdminEmailHandler’
}
},
class RequireDebugTrue
New in version 1.5. This filter is similar to RequireDebugFalse, except that records are passed only when
DEBUG is True.
3.15. Logging 399](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-403-2048.jpg)
![Django Documentation, Release 1.5.1
3.15.5 Django’s default logging configuration
By default, Django configures the django.request logger so that all messages with ERROR or CRITICAL level
are sent to AdminEmailHandler, as long as the DEBUG setting is set to False.
All messages reaching the django catch-all logger when DEBUG is True are sent to the console. They are simply
discarded (sent to NullHandler) when DEBUG is False. Changed in version 1.5. See also Configuring logging to
learn how you can complement or replace this default logging configuration.
3.16 Pagination
Django provides a few classes that help you manage paginated data – that is, data that’s split across several pages, with
“Previous/Next” links. These classes live in django/core/paginator.py.
3.16.1 Example
Give Paginator a list of objects, plus the number of items you’d like to have on each page, and it gives you methods
for accessing the items for each page:
>>> from django.core.paginator import Paginator
>>> objects = [’john’, ’paul’, ’george’, ’ringo’]
>>> p = Paginator(objects, 2)
>>> p.count
4
>>> p.num_pages
2
>>> p.page_range
[1, 2]
>>> page1 = p.page(1)
>>> page1
<Page 1 of 2>
>>> page1.object_list
[’john’, ’paul’]
>>> page2 = p.page(2)
>>> page2.object_list
[’george’, ’ringo’]
>>> page2.has_next()
False
>>> page2.has_previous()
True
>>> page2.has_other_pages()
True
>>> page2.next_page_number()
Traceback (most recent call last):
...
EmptyPage: That page contains no results
>>> page2.previous_page_number()
1
>>> page2.start_index() # The 1-based index of the first item on this page
3
>>> page2.end_index() # The 1-based index of the last item on this page
4
400 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-404-2048.jpg)


![Django Documentation, Release 1.5.1
Paginator.num_pages
The total number of pages.
Paginator.page_range
A 1-based range of page numbers, e.g., [1, 2, 3, 4].
3.16.4 InvalidPage exceptions
exception InvalidPage
A base class for exceptions raised when a paginator is passed an invalid page number.
The Paginator.page() method raises an exception if the requested page is invalid (i.e., not an integer) or contains
no objects. Generally, it’s enough to trap the InvalidPage exception, but if you’d like more granularity, you can
trap either of the following exceptions:
exception PageNotAnInteger
Raised when page() is given a value that isn’t an integer.
exception EmptyPage
Raised when page() is given a valid value but no objects exist on that page.
Both of the exceptions are subclasses of InvalidPage, so you can handle them both with a simple except
InvalidPage.
3.16.5 Page objects
You usually won’t construct Page objects by hand – you’ll get them using Paginator.page().
class Page(object_list, number, paginator)
New in version 1.4: A page acts like a sequence of Page.object_list when using len() or iterating it directly.
Methods
Page.has_next()
Returns True if there’s a next page.
Page.has_previous()
Returns True if there’s a previous page.
Page.has_other_pages()
Returns True if there’s a next or previous page.
Page.next_page_number()
Returns the next page number. Changed in version 1.5. Raises InvalidPage if next page doesn’t exist.
Page.previous_page_number()
Returns the previous page number. Changed in version 1.5. Raises InvalidPage if previous page doesn’t
exist.
Page.start_index()
Returns the 1-based index of the first object on the page, relative to all of the objects in the paginator’s list.
For example, when paginating a list of 5 objects with 2 objects per page, the second page’s start_index()
would return 3.
3.16. Pagination 403](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-407-2048.jpg)












![Django Documentation, Release 1.5.1
name = models.CharField(max_length=100)
author = models.ForeignKey(Person)
Ordinarily, serialized data for Book would use an integer to refer to the author. For example, in JSON, a Book might
be serialized as:
...
{
pk: 1,
model: store.book,
fields: {
name: Mostly Harmless,
author: 42
}
}
...
This isn’t a particularly natural way to refer to an author. It requires that you know the primary key value for the
author; it also requires that this primary key value is stable and predictable.
However, if we add natural key handling to Person, the fixture becomes much more humane. To add natural key
handling, you define a default Manager for Person with a get_by_natural_key() method. In the case of a
Person, a good natural key might be the pair of first and last name:
from django.db import models
class PersonManager(models.Manager):
def get_by_natural_key(self, first_name, last_name):
return self.get(first_name=first_name, last_name=last_name)
class Person(models.Model):
objects = PersonManager()
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
birthdate = models.DateField()
class Meta:
unique_together = ((’first_name’, ’last_name’),)
Now books can use that natural key to refer to Person objects:
...
{
pk: 1,
model: store.book,
fields: {
name: Mostly Harmless,
author: [Douglas, Adams]
}
}
...
When you try to load this serialized data, Django will use the get_by_natural_key() method to resolve
[Douglas, Adams] into the primary key of an actual Person object.
Note: Whatever fields you use for a natural key must be able to uniquely identify an object. This will usually mean
that your model will have a uniqueness clause (either unique=True on a single field, or unique_together over
multiple fields) for the field or fields in your natural key. However, uniqueness doesn’t need to be enforced at the
416 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-420-2048.jpg)
![Django Documentation, Release 1.5.1
database level. If you are certain that a set of fields will be effectively unique, you can still use those fields as a natural
key.
Serialization of natural keys
So how do you get Django to emit a natural key when serializing an object? Firstly, you need to add another method
– this time to the model itself:
class Person(models.Model):
objects = PersonManager()
first_name = models.CharField(max_length=100)
last_name = models.CharField(max_length=100)
birthdate = models.DateField()
def natural_key(self):
return (self.first_name, self.last_name)
class Meta:
unique_together = ((’first_name’, ’last_name’),)
That method should always return a natural key tuple – in this example, (first name, last name). Then,
when you call serializers.serialize(), you provide a use_natural_keys=True argument:
serializers.serialize(’json’, [book1, book2], indent=2, use_natural_keys=True)
When use_natural_keys=True is specified, Django will use the natural_key() method to serialize any
reference to objects of the type that defines the method.
If you are using dumpdata to generate serialized data, you use the --natural command line flag to generate
natural keys.
Note: You don’t need to define both natural_key() and get_by_natural_key(). If you don’t want Django
to output natural keys during serialization, but you want to retain the ability to load natural keys, then you can opt to
not implement the natural_key() method.
Conversely, if (for some strange reason) you want Django to output natural keys during serialization, but not be able
to load those key values, just don’t define the get_by_natural_key() method.
Dependencies during serialization
Since natural keys rely on database lookups to resolve references, it is important that the data exists before it is
referenced. You can’t make a “forward reference” with natural keys – the data you’re referencing must exist before
you include a natural key reference to that data.
To accommodate this limitation, calls to dumpdata that use the --natural option will serialize any model with a
natural_key() method before serializing standard primary key objects.
However, this may not always be enough. If your natural key refers to another object (by using a foreign key or natural
key to another object as part of a natural key), then you need to be able to ensure that the objects on which a natural
key depends occur in the serialized data before the natural key requires them.
To control this ordering, you can define dependencies on your natural_key() methods. You do this by setting a
dependencies attribute on the natural_key() method itself.
3.19. Serializing Django objects 417](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-421-2048.jpg)
![Django Documentation, Release 1.5.1
For example, let’s add a natural key to the Book model from the example above:
class Book(models.Model):
name = models.CharField(max_length=100)
author = models.ForeignKey(Person)
def natural_key(self):
return (self.name,) + self.author.natural_key()
The natural key for a Book is a combination of its name and its author. This means that Person must be serialized
before Book. To define this dependency, we add one extra line:
def natural_key(self):
return (self.name,) + self.author.natural_key()
natural_key.dependencies = [’example_app.person’]
This definition ensures that all Person objects are serialized before any Book objects. In turn, any object referencing
Book will be serialized after both Person and Book have been serialized.
3.20 Django settings
A Django settings file contains all the configuration of your Django installation. This document explains how settings
work and which settings are available.
3.20.1 The basics
A settings file is just a Python module with module-level variables.
Here are a couple of example settings:
DEBUG = False
DEFAULT_FROM_EMAIL = ’webmaster@example.com’
TEMPLATE_DIRS = (’/home/templates/mike’, ’/home/templates/john’)
Because a settings file is a Python module, the following apply:
• It doesn’t allow for Python syntax errors.
• It can assign settings dynamically using normal Python syntax. For example:
MY_SETTING = [str(i) for i in range(30)]
• It can import values from other settings files.
3.20.2 Designating the settings
DJANGO_SETTINGS_MODULE
When you use Django, you have to tell it which settings you’re using. Do this by using an environment variable,
DJANGO_SETTINGS_MODULE.
The value of DJANGO_SETTINGS_MODULE should be in Python path syntax, e.g. mysite.settings. Note that
the settings module should be on the Python import search path.
418 Chapter 3. Using Django](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-422-2048.jpg)
![Django Documentation, Release 1.5.1
The django-admin.py utility
When using django-admin.py, you can either set the environment variable once, or explicitly pass in the settings
module each time you run the utility.
Example (Unix Bash shell):
export DJANGO_SETTINGS_MODULE=mysite.settings
django-admin.py runserver
Example (Windows shell):
set DJANGO_SETTINGS_MODULE=mysite.settings
django-admin.py runserver
Use the --settings command-line argument to specify the settings manually:
django-admin.py runserver --settings=mysite.settings
On the server (mod_wsgi)
In your live server environment, you’ll need to tell your WSGI application what settings file to use. Do that with
os.environ:
import os
os.environ[’DJANGO_SETTINGS_MODULE’] = ’mysite.settings’
Read the Django mod_wsgi documentation for more information and other common elements to a Django WSGI
application.
3.20.3 Default settings
A Django settings file doesn’t have to define any settings if it doesn’t need to. Each setting has a sensible default value.
These defaults live in the module django/conf/global_settings.py.
Here’s the algorithm Django uses in compiling settings:
• Load settings from global_settings.py.
• Load settings from the specified settings file, overriding the global settings as necessary.
Note that a settings file should not import from global_settings, because that’s redundant.
Seeing which settings you’ve changed
There’s an easy way to view which of your settings deviate from the default settings. The command python
manage.py diffsettings displays differences between the current settings file and Django’s default settings.
For more, see the diffsettings documentation.
3.20.4 Using settings in Python code
In your Django apps, use settings by importing the object django.conf.settings. Example:
3.20. Django settings 419](https://crownmelresort.com/image.slidesharecdn.com/django-141201081021-conversion-gate02/75/Django-423-2048.jpg)
















































































































































































































































































































































































































































































































































































































































































































































































































































































This document provides an overview of the key components of Django, including designing models, installing Django, accessing the model API, creating an admin interface, designing URLs and views, writing templates, and more. It explains these concepts at a high level and provides examples to illustrate how each component works and fits together. The goal is to help new users understand the basics of how to build a database-driven web application with Django.





















































