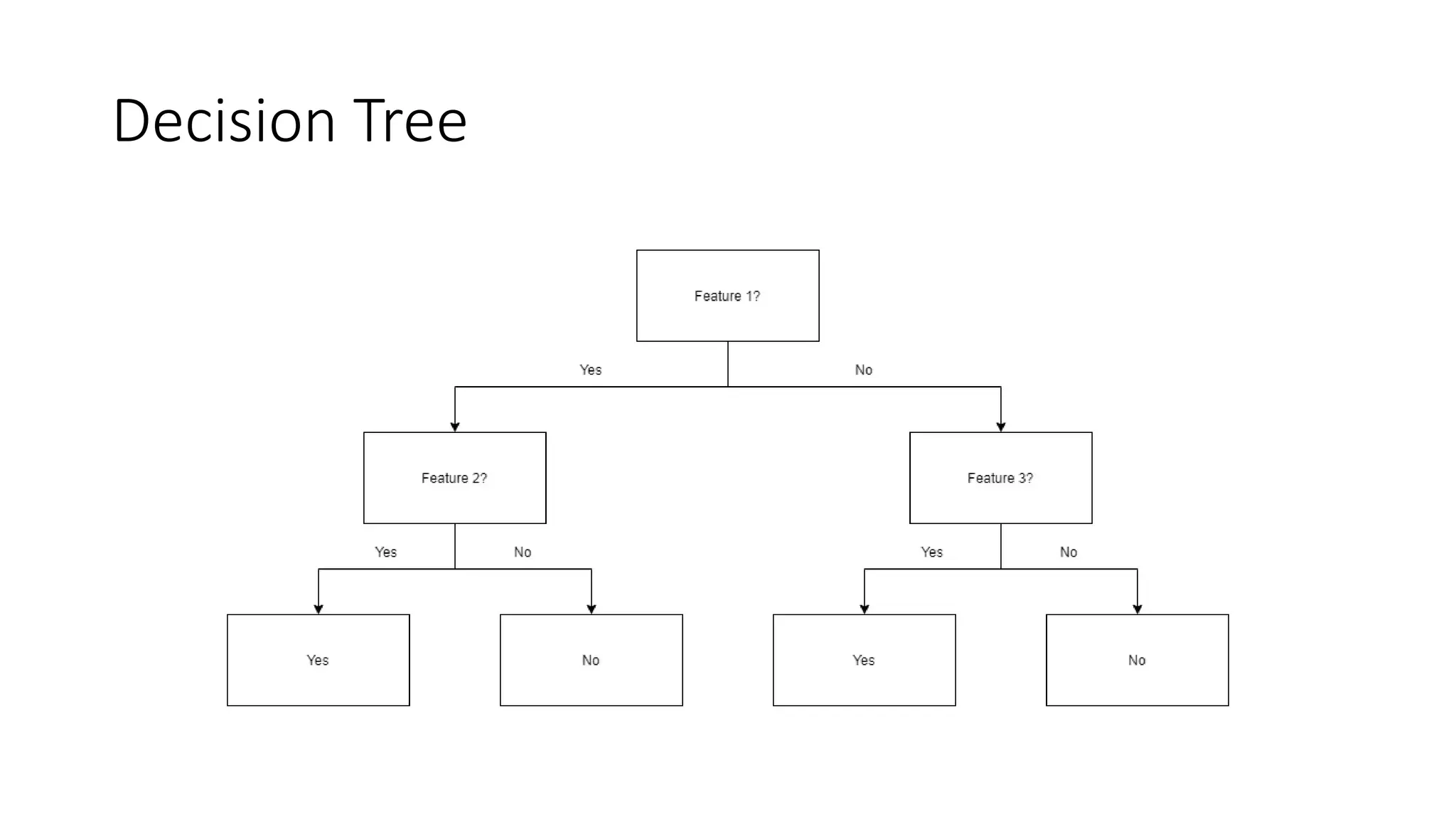
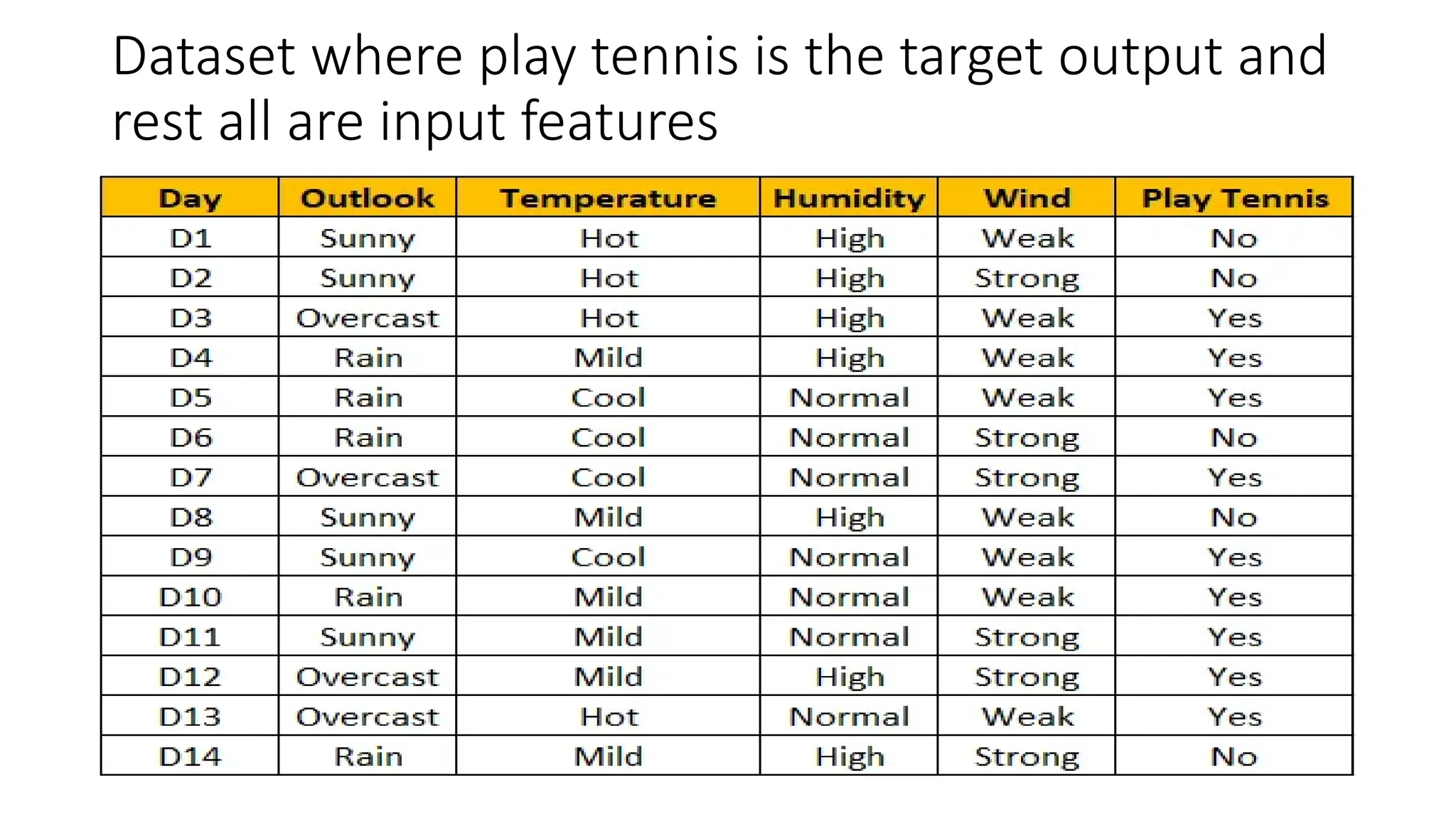
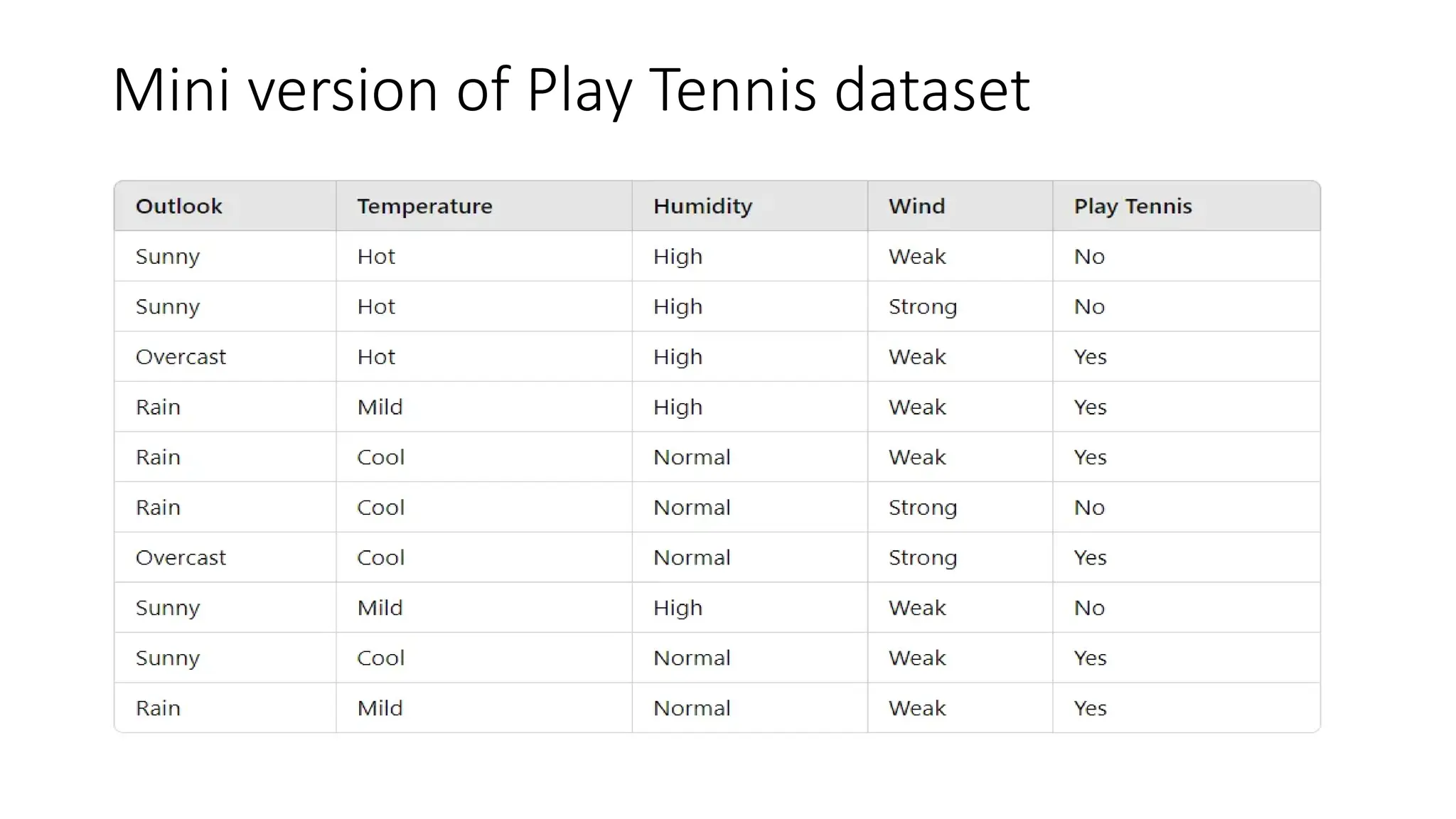
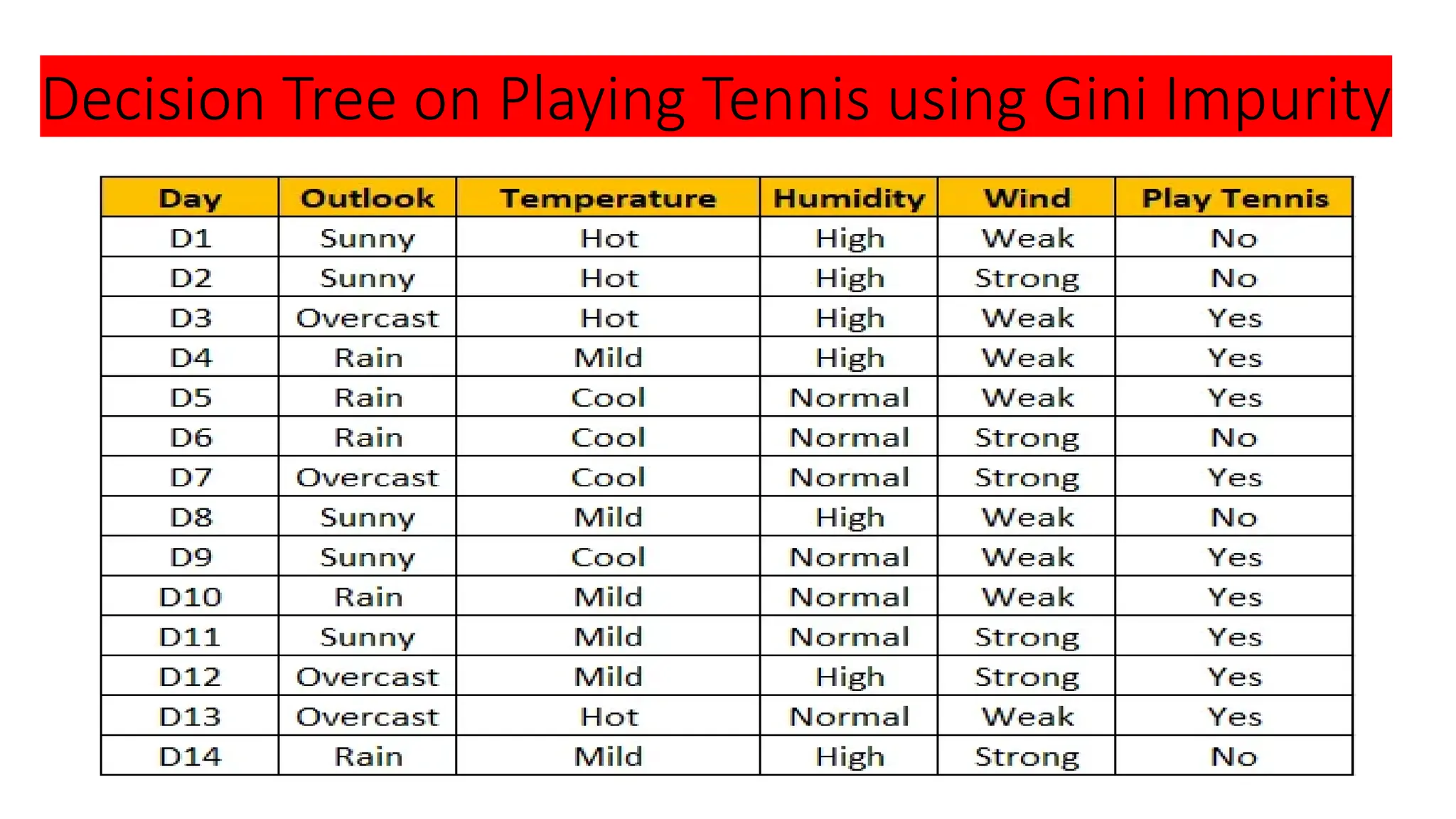
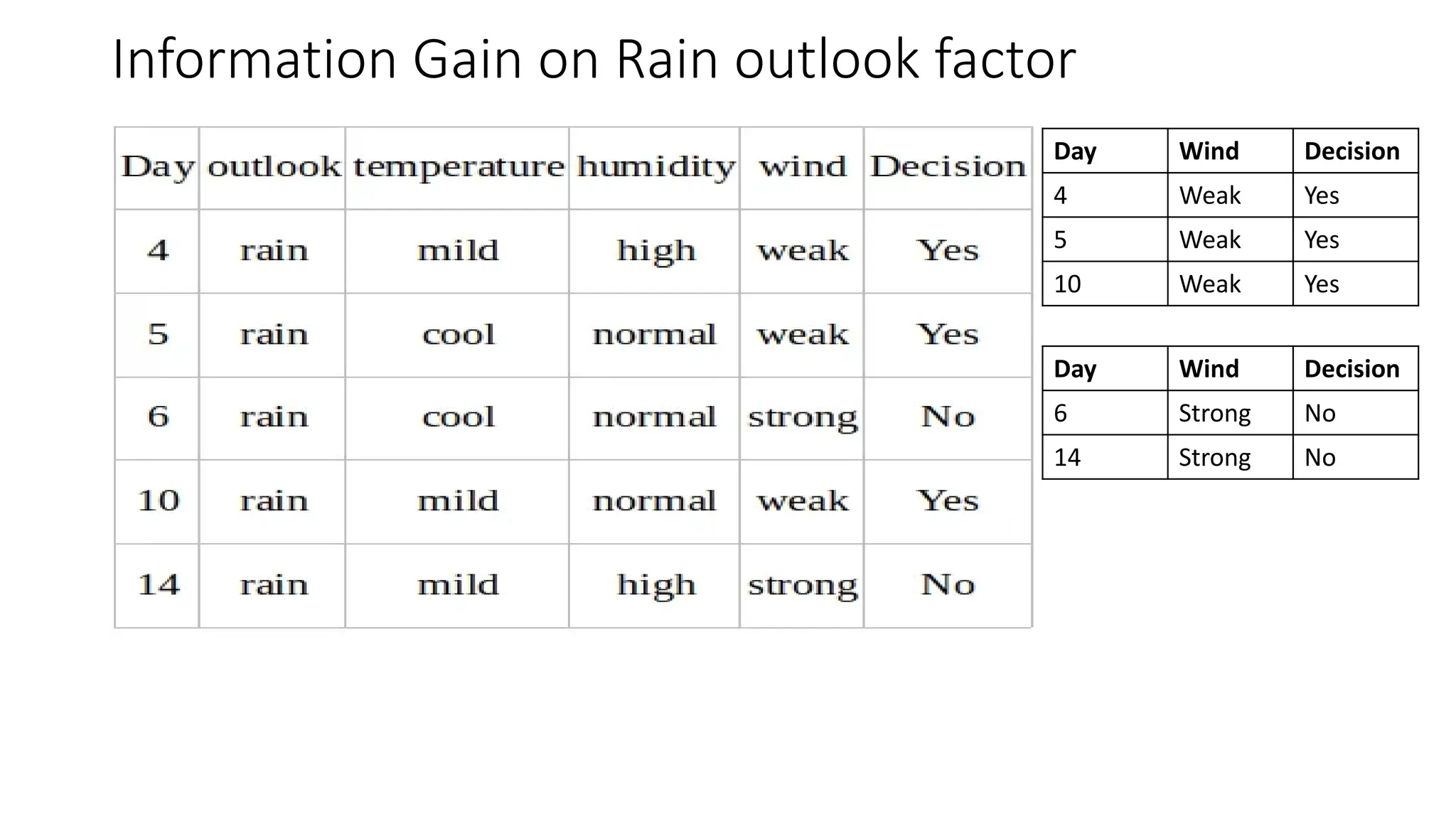
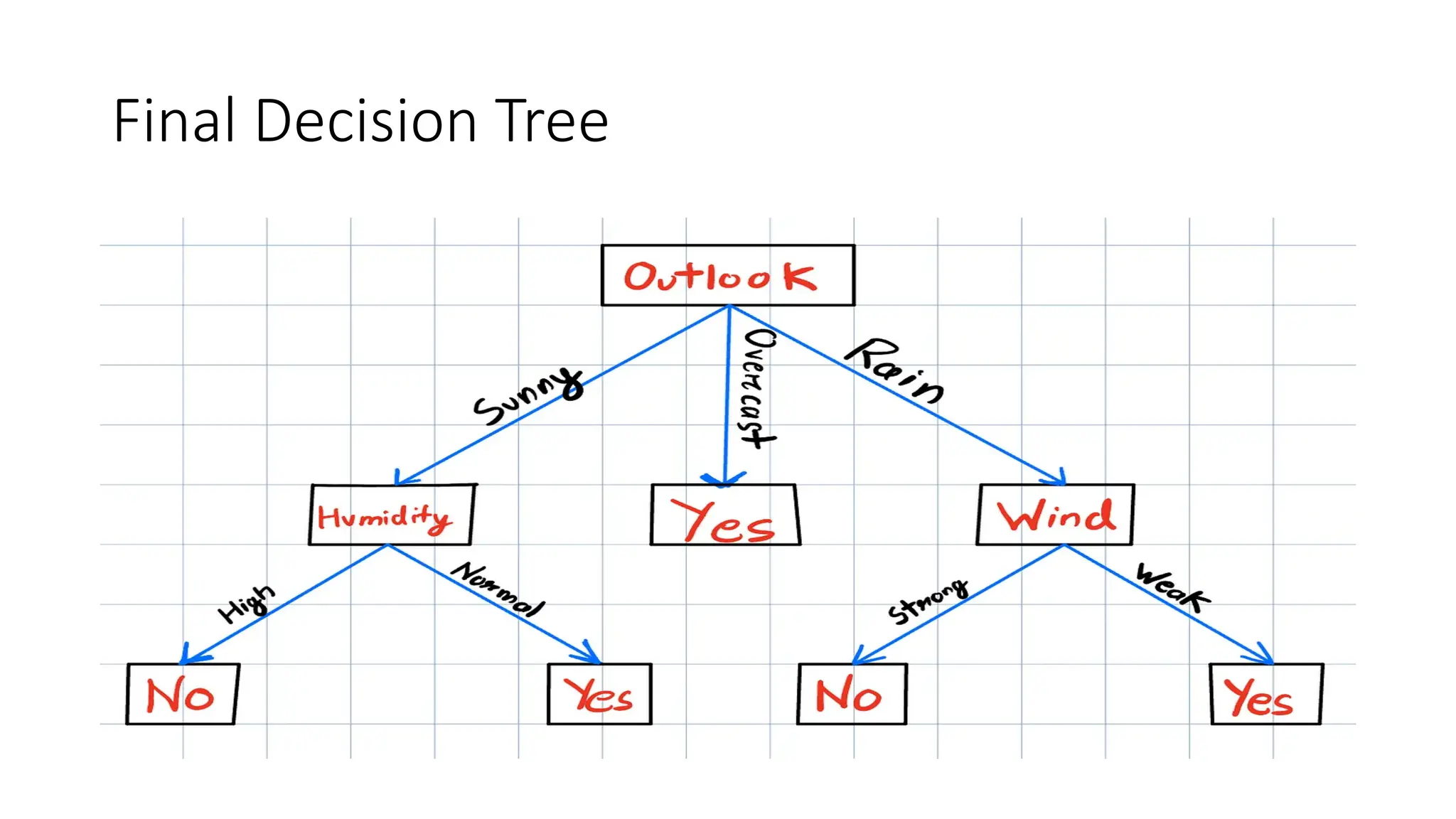
A **Decision Tree** is a supervised machine learning algorithm used for classification and regression tasks. It models decisions as a tree-like structure, where each internal node represents a feature-based decision, each branch represents an outcome, and each leaf node represents a final prediction. Decision Trees are widely used due to their simplicity, interpretability, and ability to handle both numerical and categorical data.
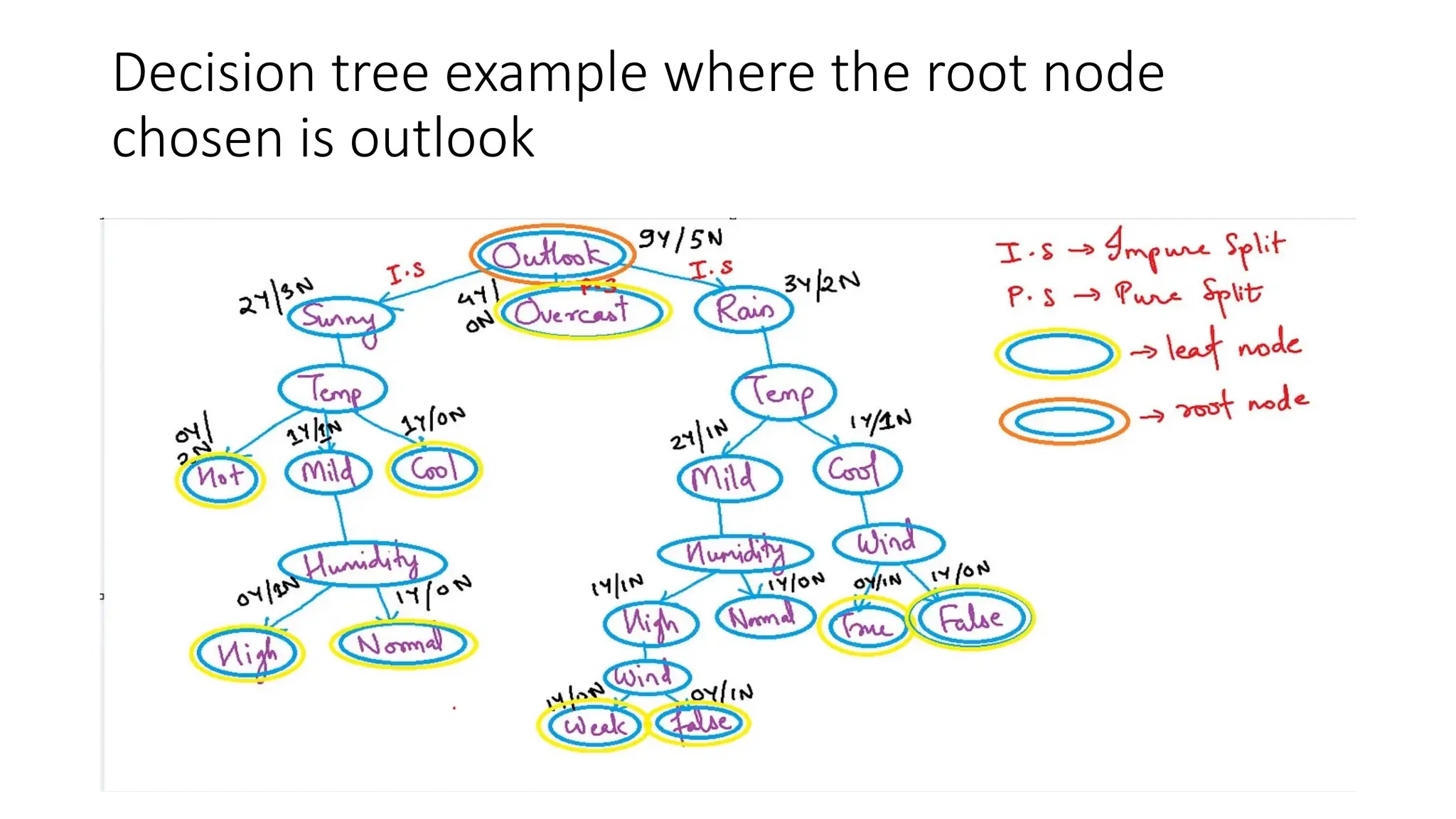
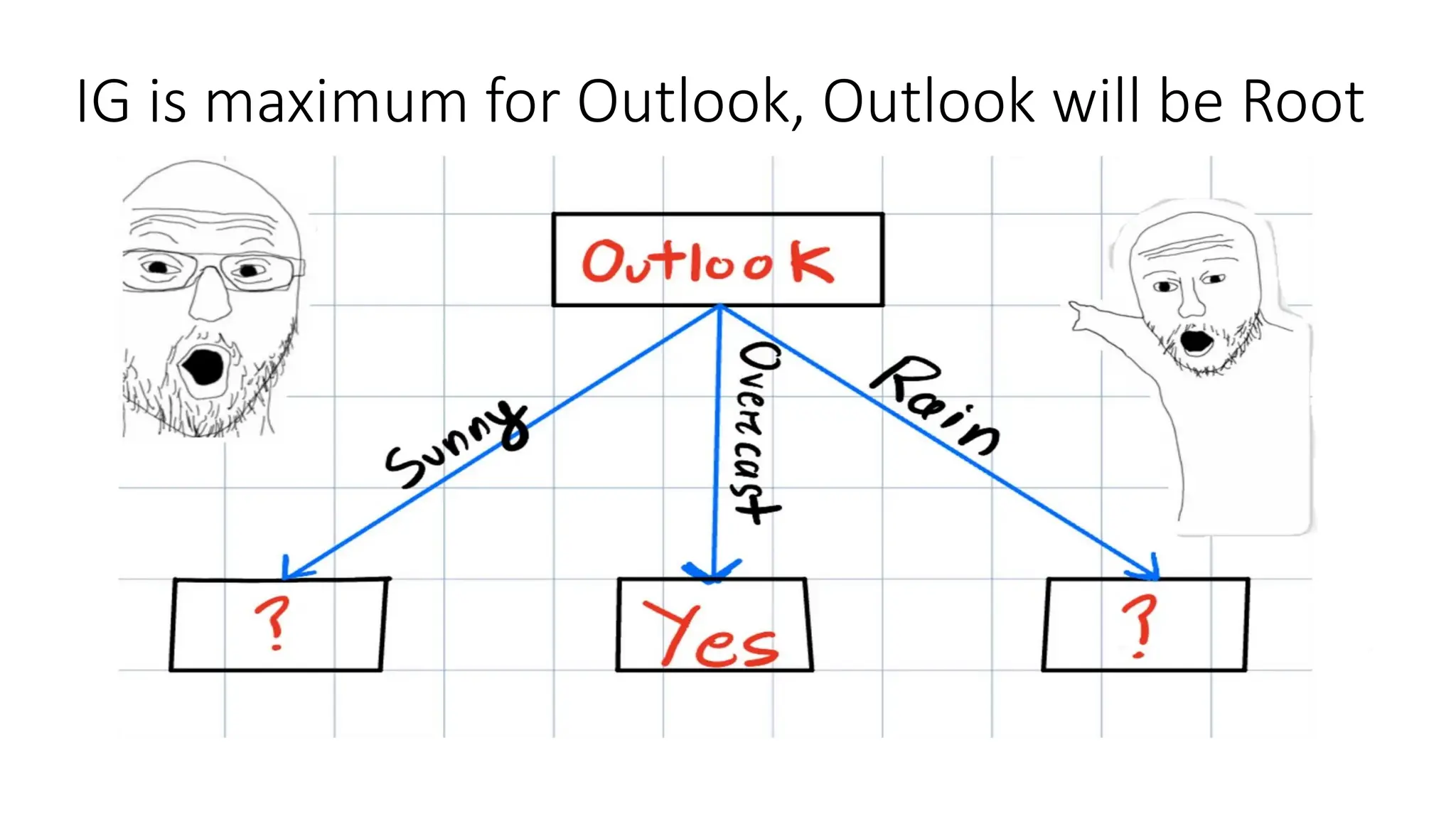
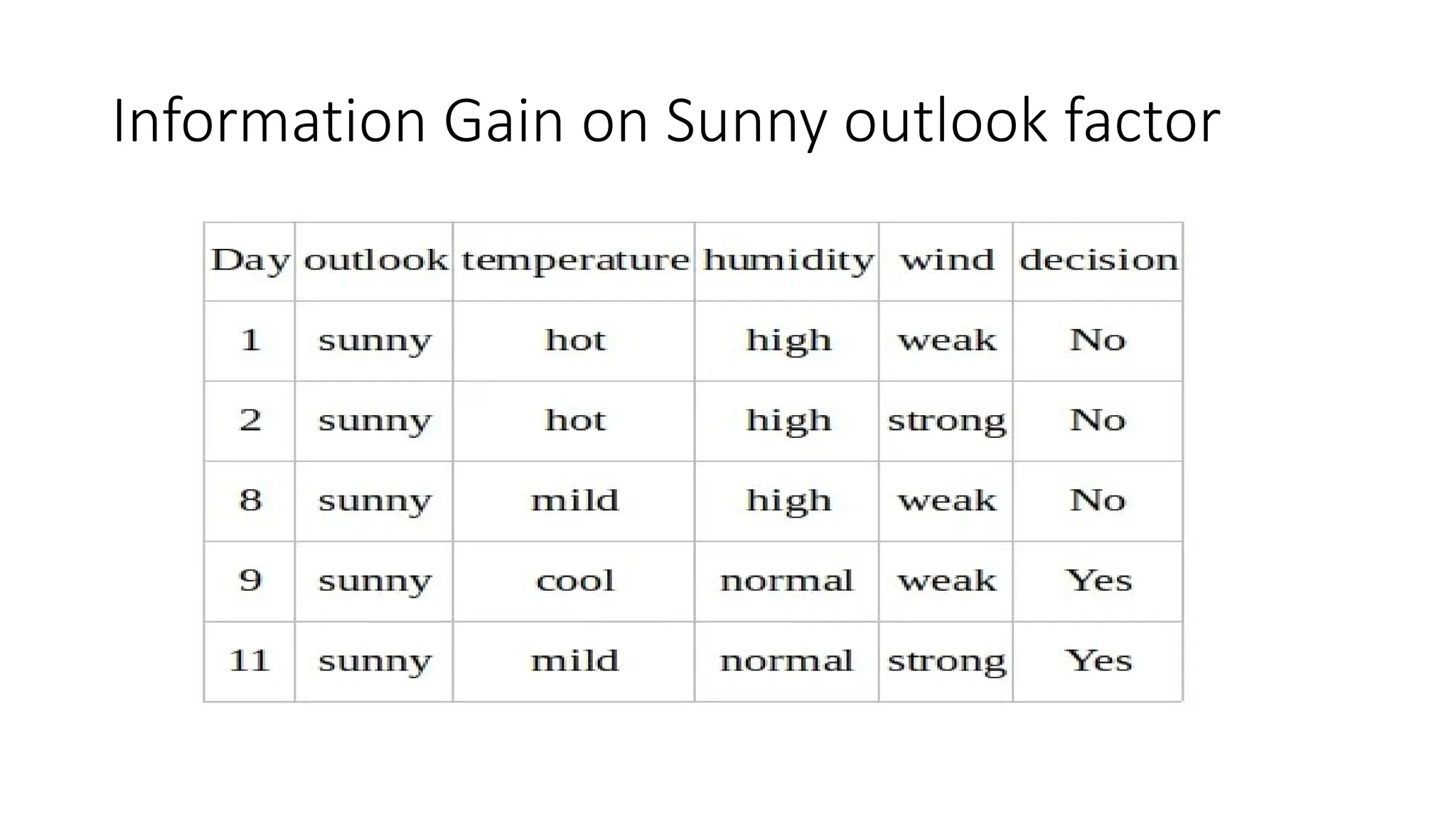
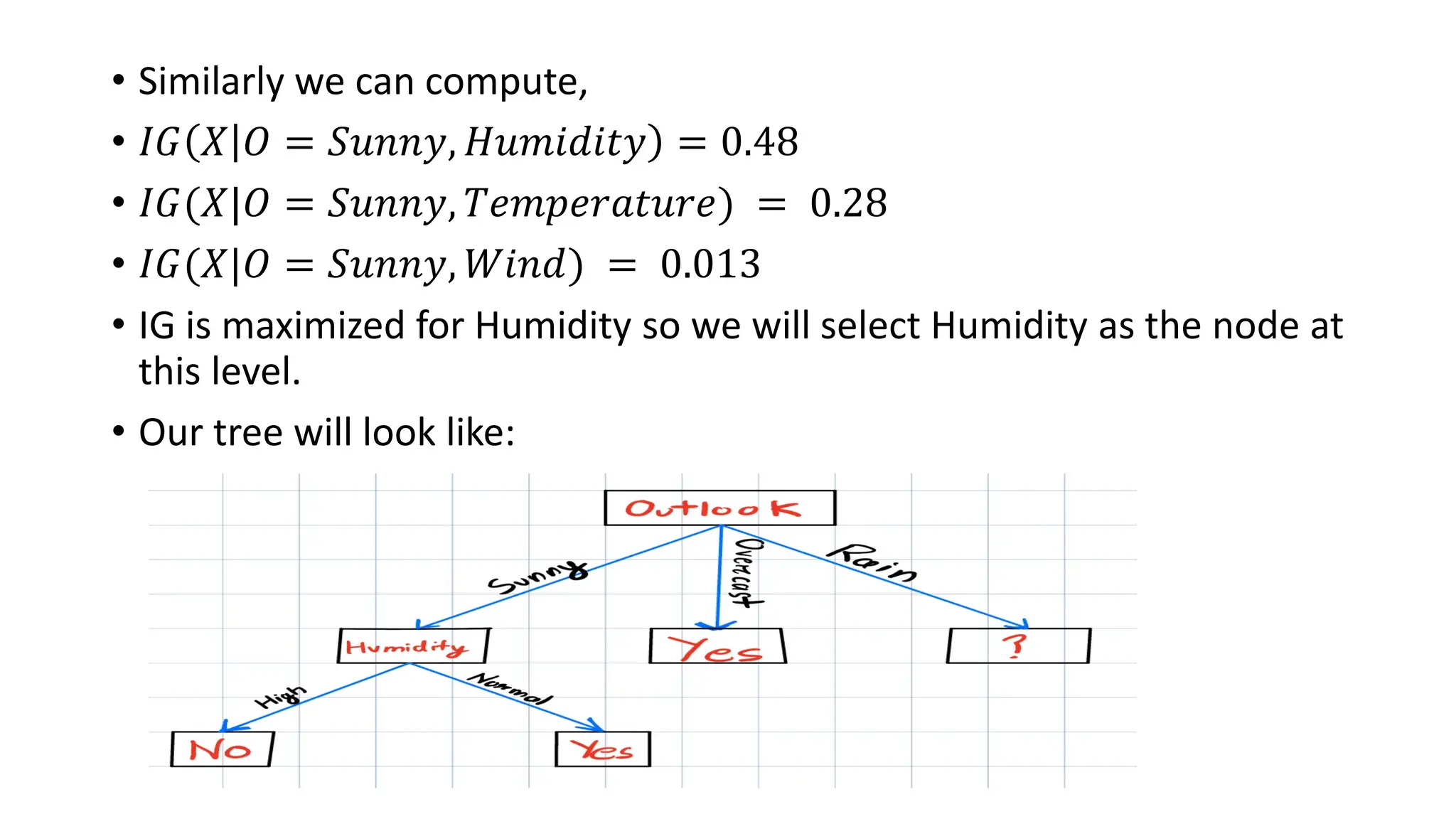
The algorithm works by recursively splitting the dataset based on feature values to maximize information gain. Common splitting criteria include **Gini Impurity**, **Entropy (Information Gain)** for classification, and **Mean Squared Error (MSE)** for regression. The process continues until a stopping condition is met, such as reaching a maximum depth, having too few samples in a node, or achieving pure class labels.
One of the key advantages of Decision Trees is their transparency, as they mimic human decision-making and allow for easy interpretation. They also require minimal data preprocessing, as they can handle missing values and irrelevant features well. However, they are prone to overfitting, especially when the tree grows too deep. To mitigate this, **pruning** techniques (such as pre-pruning and post-pruning) are used to reduce complexity and improve generalization.
Decision Trees form the foundation of powerful ensemble methods like **Random Forest** and **Gradient Boosted Trees**, which enhance predictive accuracy and robustness. They are widely applied in fields like medical diagnosis, customer segmentation, fraud detection, and recommendation systems. Despite their limitations, Decision Trees remain a fundamental tool in machine learning due to their efficiency, ease of understanding, and adaptability to various types of data.






















![• import pandas as pd
• from sklearn.tree import DecisionTreeClassifier
• from sklearn.model_selection import train_test_split
• from sklearn.metrics import accuracy_score
• # Load the dataset
• data = {
• "Outlook": ["Sunny", "Sunny", "Overcast", "Rain", "Rain", "Rain", "Overcast", "Sunny", "Sunny",
"Rain", "Sunny", "Overcast", "Overcast", "Rain"],
• "Temperature": ["Hot", "Hot", "Hot", "Mild", "Cool", "Cool", "Cool", "Mild", "Cool", "Mild",
"Mild", "Mild", "Hot", "Mild"],
• "Humidity": ["High", "High", "High", "High", "Normal", "Normal", "Normal", "High", "Normal",
"Normal", "Normal", "High", "Normal", "High"],
• "Wind": ["Weak", "Strong", "Weak", "Weak", "Weak", "Strong", "Strong", "Weak", "Weak",
"Weak", "Strong", "Strong", "Weak", "Strong"],
• "Play Tennis": ["No", "No", "Yes", "Yes", "Yes", "No", "Yes", "No", "Yes", "Yes", "Yes", "Yes", "Yes",
"No"]
• }
• df = pd.DataFrame(data)](https://image.slidesharecdn.com/decisiontree-250401102546-f73591d6/75/Decision-Tree-in-classification-problems-in-ML-33-2048.jpg)
![• # Encode categorical variables
• df_encoded = pd.get_dummies(df, columns=["Outlook", "Temperature", "Humidity", "Wind"], drop_first=True)
• X = df_encoded.drop("Play Tennis", axis=1)
• y = df["Play Tennis"]
• # Split the data into training and testing sets
• X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
• # Train Decision Tree Classifier
• clf = DecisionTreeClassifier(criterion="gini", random_state=42)
• clf.fit(X_train, y_train)
• # Make predictions on the test set
• y_pred = clf.predict(X_test)
• # Compute accuracy
• accuracy = accuracy_score(y_test, y_pred)
• print("Accuracy of the Decision Tree: {:.2f}%".format(accuracy * 100))](https://image.slidesharecdn.com/decisiontree-250401102546-f73591d6/75/Decision-Tree-in-classification-problems-in-ML-34-2048.jpg)
































![• import pandas as pd
• from sklearn.tree import DecisionTreeClassifier
• from sklearn.model_selection import train_test_split
• from sklearn.metrics import accuracy_score
• # Load the dataset
• data = {
• "Outlook": ["Sunny", "Sunny", "Overcast", "Rain", "Rain", "Rain", "Overcast", "Sunny", "Sunny",
"Rain", "Sunny", "Overcast", "Overcast", "Rain"],
• "Temperature": ["Hot", "Hot", "Hot", "Mild", "Cool", "Cool", "Cool", "Mild", "Cool", "Mild",
"Mild", "Mild", "Hot", "Mild"],
• "Humidity": ["High", "High", "High", "High", "Normal", "Normal", "Normal", "High", "Normal",
"Normal", "Normal", "High", "Normal", "High"],
• "Wind": ["Weak", "Strong", "Weak", "Weak", "Weak", "Strong", "Strong", "Weak", "Weak",
"Weak", "Strong", "Strong", "Weak", "Strong"],
• "Play Tennis": ["No", "No", "Yes", "Yes", "Yes", "No", "Yes", "No", "Yes", "Yes", "Yes", "Yes", "Yes",
"No"]
• }
• df = pd.DataFrame(data)](https://crownmelresort.com/image.slidesharecdn.com/decisiontree-250401102546-f73591d6/75/Decision-Tree-in-classification-problems-in-ML-33-2048.jpg)
![• # Encode categorical variables
• df_encoded = pd.get_dummies(df, columns=["Outlook", "Temperature", "Humidity", "Wind"], drop_first=True)
• X = df_encoded.drop("Play Tennis", axis=1)
• y = df["Play Tennis"]
• # Split the data into training and testing sets
• X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
• # Train Decision Tree Classifier
• clf = DecisionTreeClassifier(criterion="gini", random_state=42)
• clf.fit(X_train, y_train)
• # Make predictions on the test set
• y_pred = clf.predict(X_test)
• # Compute accuracy
• accuracy = accuracy_score(y_test, y_pred)
• print("Accuracy of the Decision Tree: {:.2f}%".format(accuracy * 100))](https://crownmelresort.com/image.slidesharecdn.com/decisiontree-250401102546-f73591d6/75/Decision-Tree-in-classification-problems-in-ML-34-2048.jpg)






![[Women in Data Science Meetup ATX] Decision Trees](https://cdn.slidesharecdn.com/ss_thumbnails/decisiontrees-161118165341-thumbnail.jpg?width=640&height=640&fit=bounds)








































