Downloaded 20 times



![Data Explosion
• Exponential growth of information
[IDC, 2012] Information Data Corporation, a market research company](https://image.slidesharecdn.com/stormr-150504180859-conversion-gate01/75/Data-Stream-Algorithms-in-Storm-and-R-4-2048.jpg)
![Data, data everywhere [Economist]
• “In 2013, the available storage capacity could hold 33% of all
data. By 2020, it will be able to store less than 15%” [IDC, 2014]](https://image.slidesharecdn.com/stormr-150504180859-conversion-gate01/75/Data-Stream-Algorithms-in-Storm-and-R-5-2048.jpg)







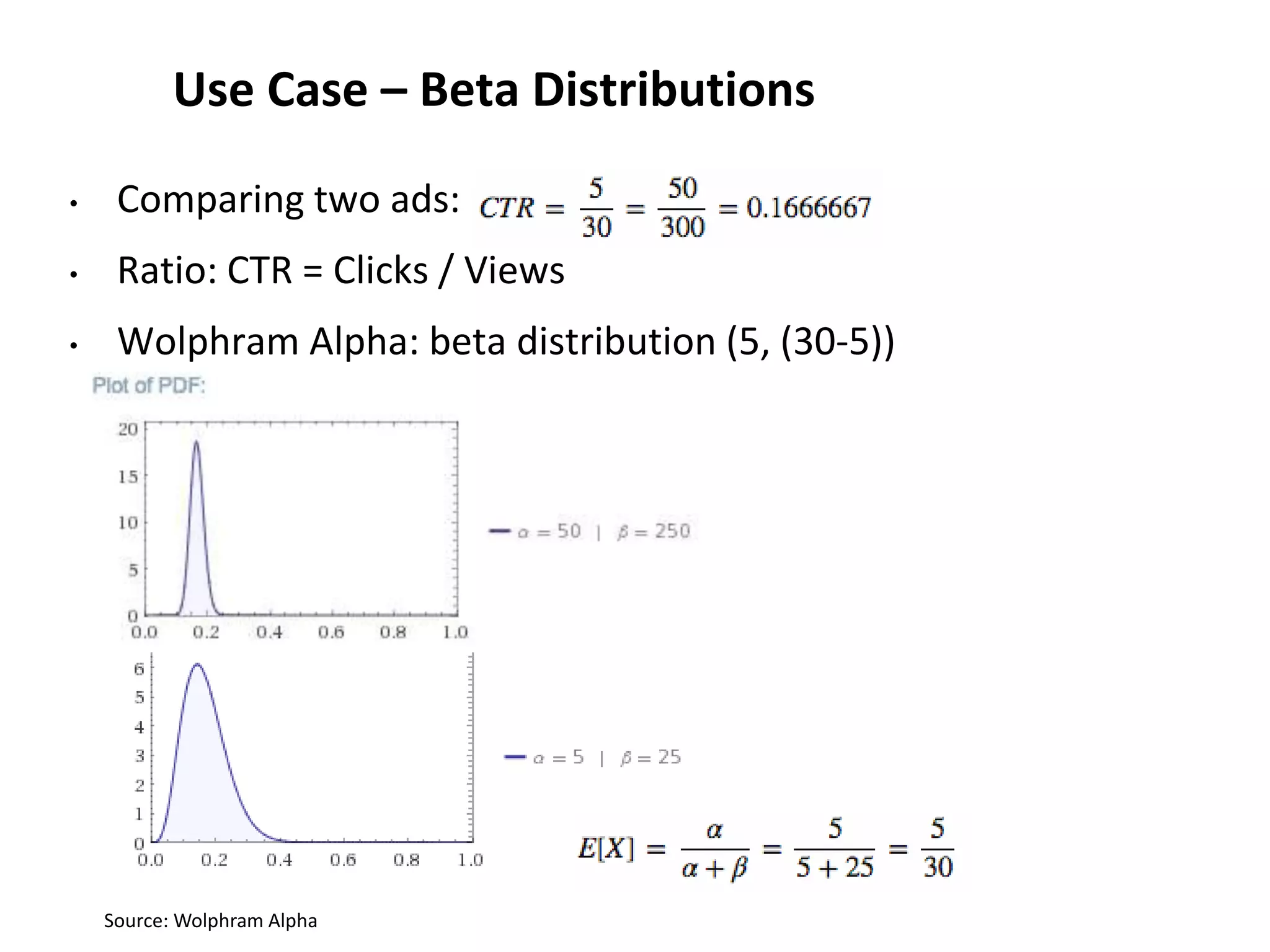
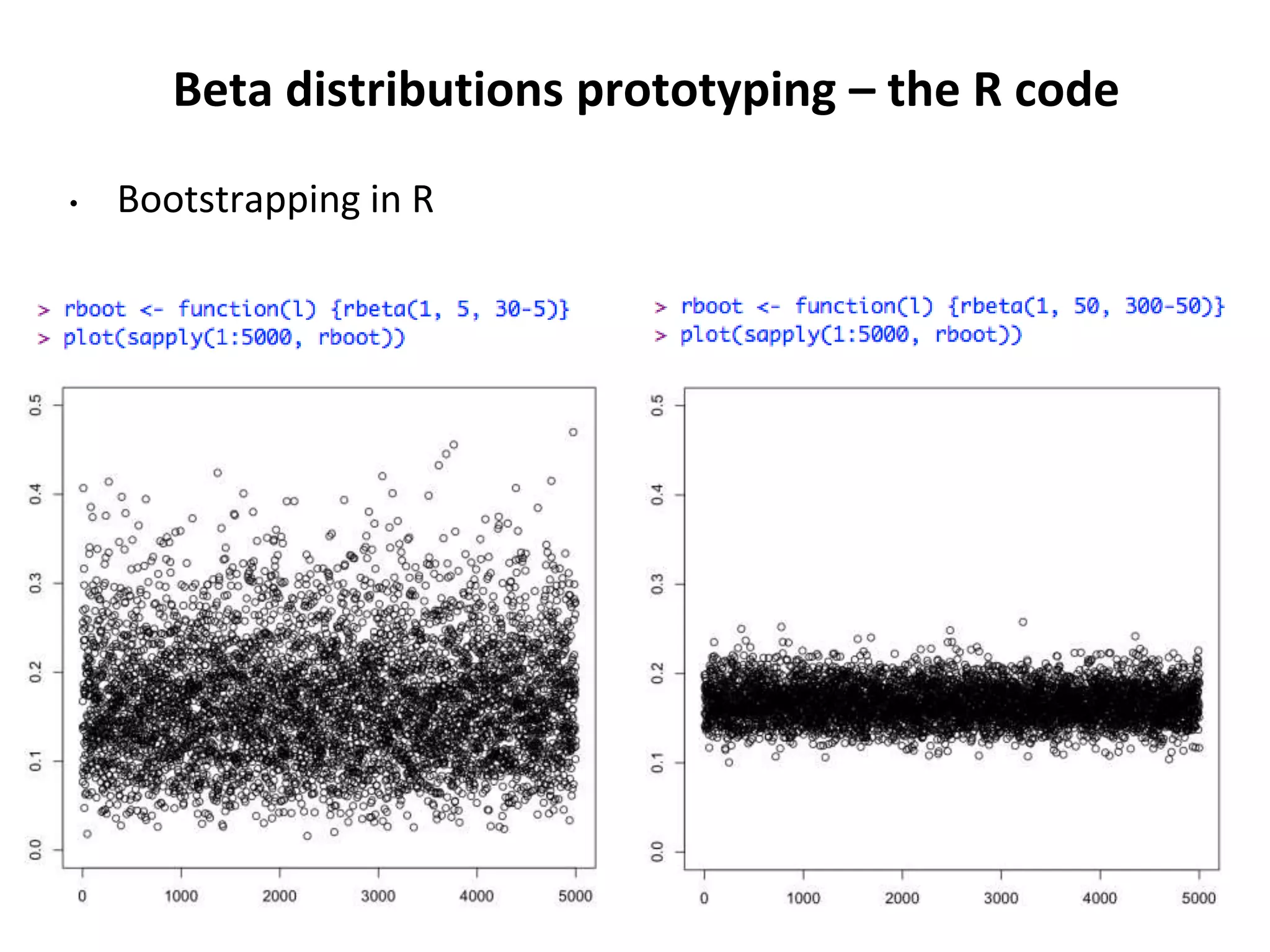

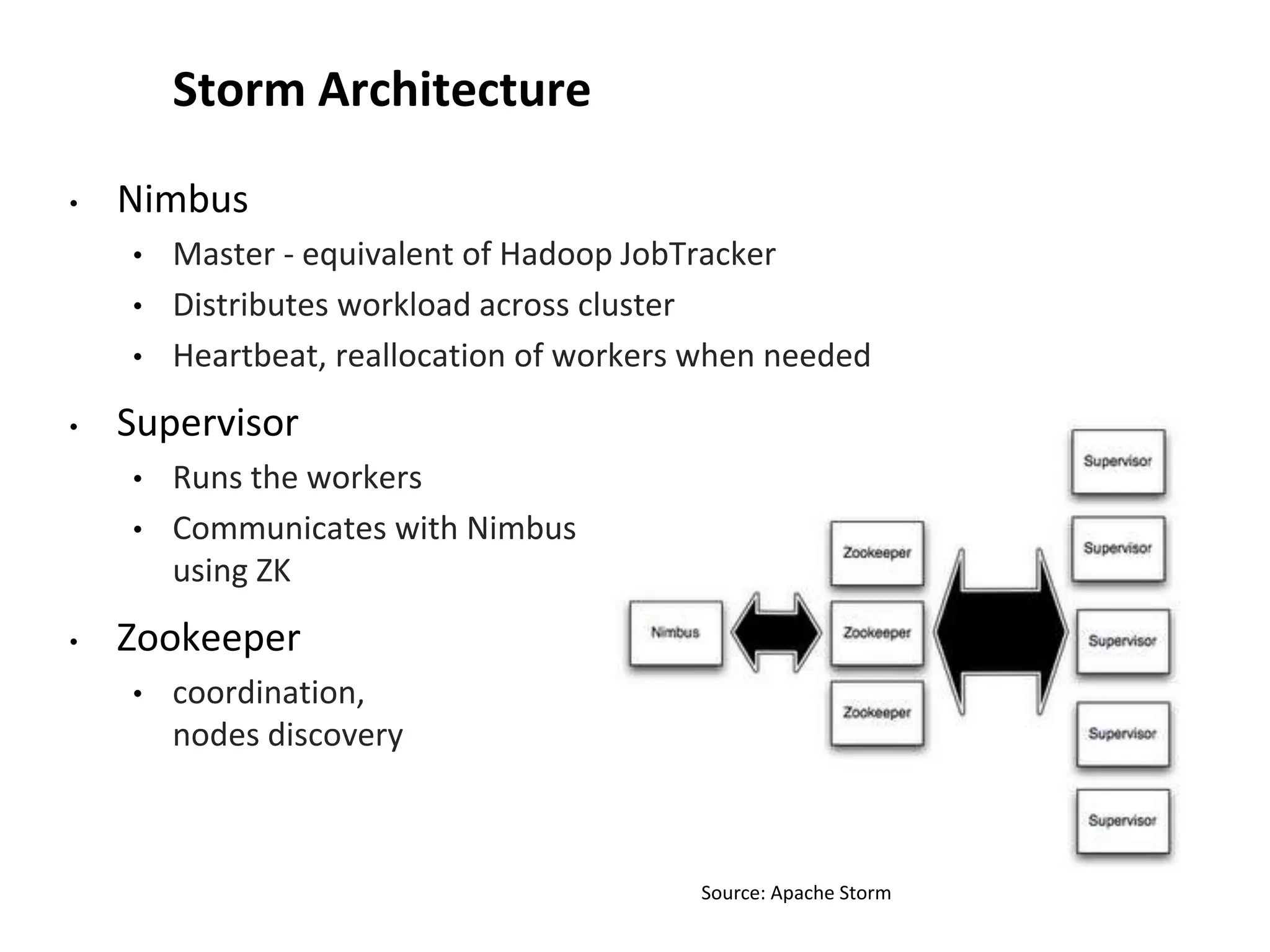
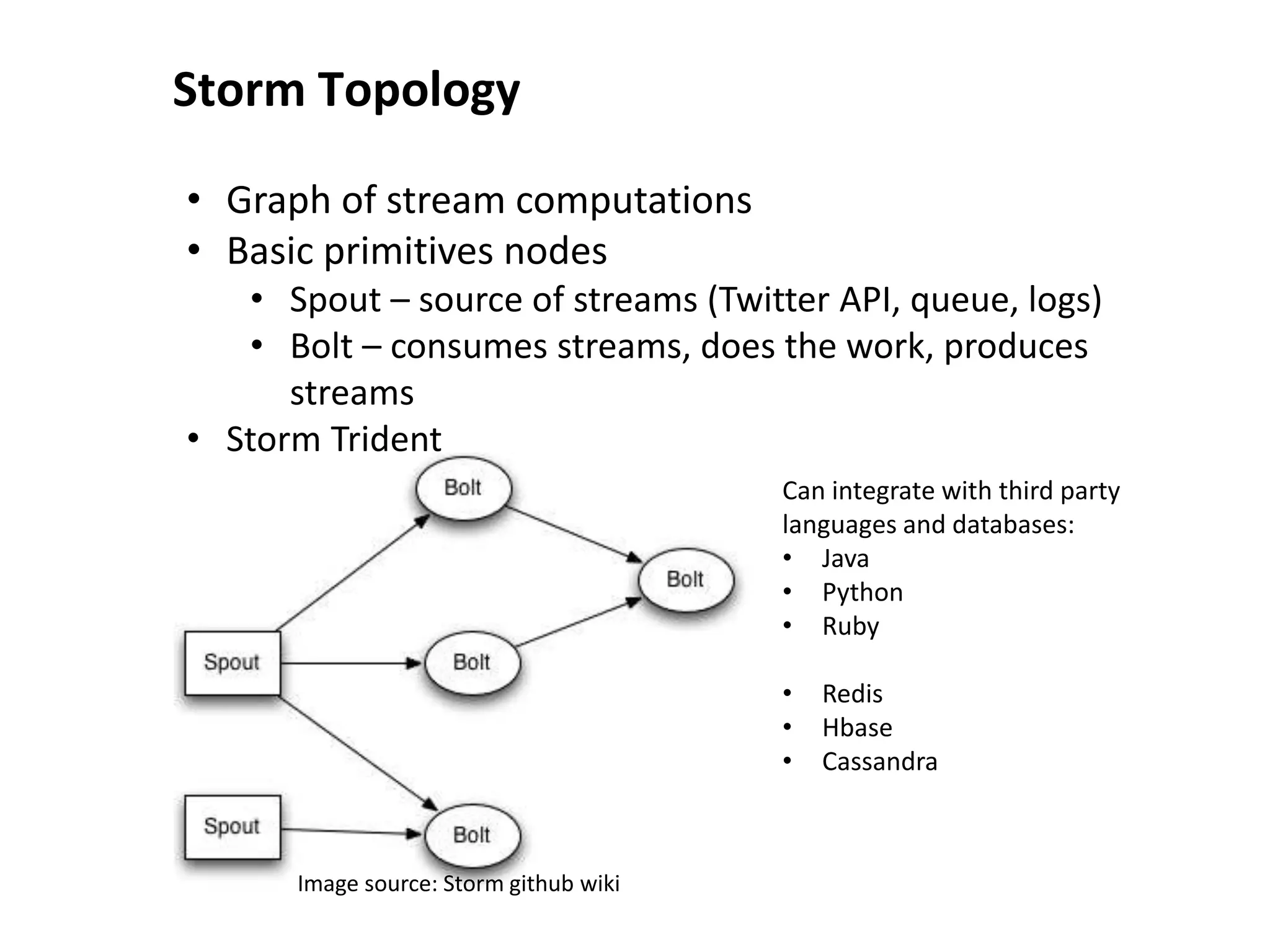

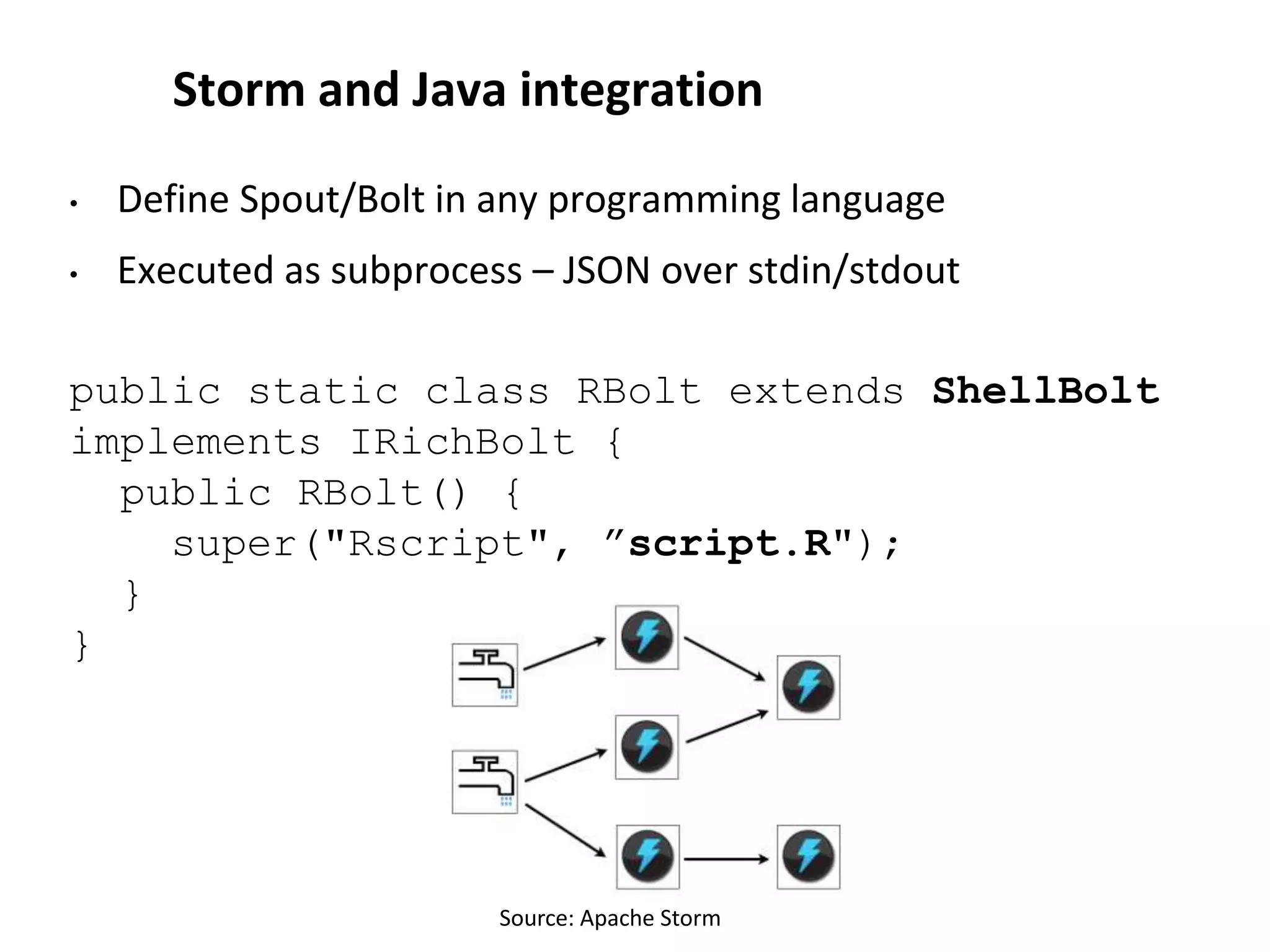
![Storm and R
storm = Storm$new();
storm$lambda = function(s) {
t = s$tuple;
t$output =
vector(mode="character",length=1);
clicks = as.numeric(t$input[1]);
views = as.numeric(t$input[2]);
t$output[1] = rbeta(1, clicks, views -
clicks);
s$emit(t);
#alternative: mark the tuple as failed.
s$fail(t);
}
storm$run();](https://image.slidesharecdn.com/stormr-150504180859-conversion-gate01/75/Data-Stream-Algorithms-in-Storm-and-R-22-2048.jpg)





![Data Explosion
• Exponential growth of information
[IDC, 2012] Information Data Corporation, a market research company](https://crownmelresort.com/image.slidesharecdn.com/stormr-150504180859-conversion-gate01/75/Data-Stream-Algorithms-in-Storm-and-R-4-2048.jpg)
![Data, data everywhere [Economist]
• “In 2013, the available storage capacity could hold 33% of all
data. By 2020, it will be able to store less than 15%” [IDC, 2014]](https://crownmelresort.com/image.slidesharecdn.com/stormr-150504180859-conversion-gate01/75/Data-Stream-Algorithms-in-Storm-and-R-5-2048.jpg)
















![Storm and R
storm = Storm$new();
storm$lambda = function(s) {
t = s$tuple;
t$output =
vector(mode="character",length=1);
clicks = as.numeric(t$input[1]);
views = as.numeric(t$input[2]);
t$output[1] = rbeta(1, clicks, views -
clicks);
s$emit(t);
#alternative: mark the tuple as failed.
s$fail(t);
}
storm$run();](https://crownmelresort.com/image.slidesharecdn.com/stormr-150504180859-conversion-gate01/75/Data-Stream-Algorithms-in-Storm-and-R-22-2048.jpg)





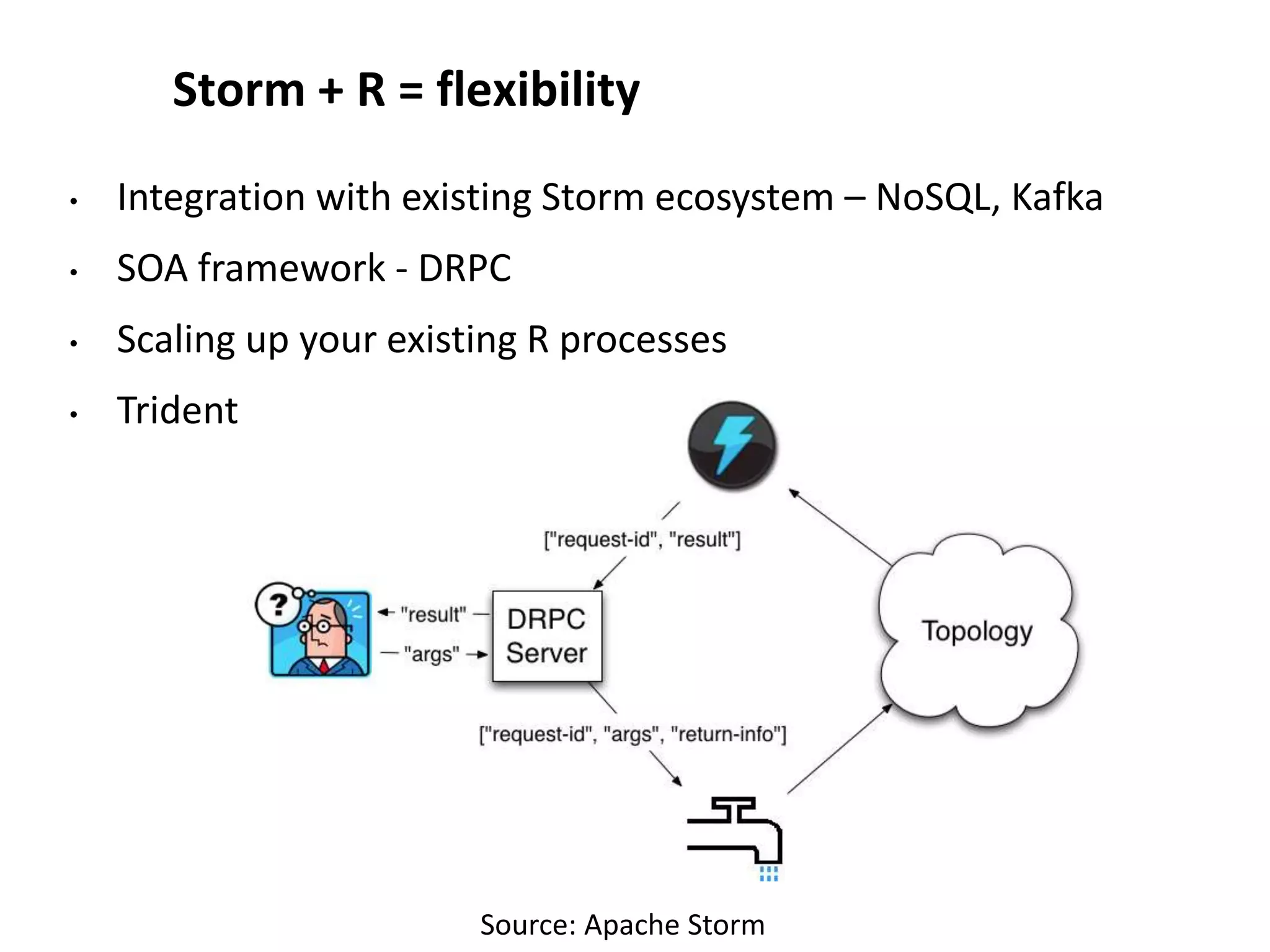
The document discusses data stream algorithms implemented in Apache Storm, focusing on their application in real-time data processing and statistical analysis. It outlines various use cases, such as dynamic sampling and unique user counting, while explaining algorithms like reservoir sampling and HyperLogLog. The integration of R with Storm for traditional statistics is also highlighted, showcasing its flexibility and scalability in big data environments.