




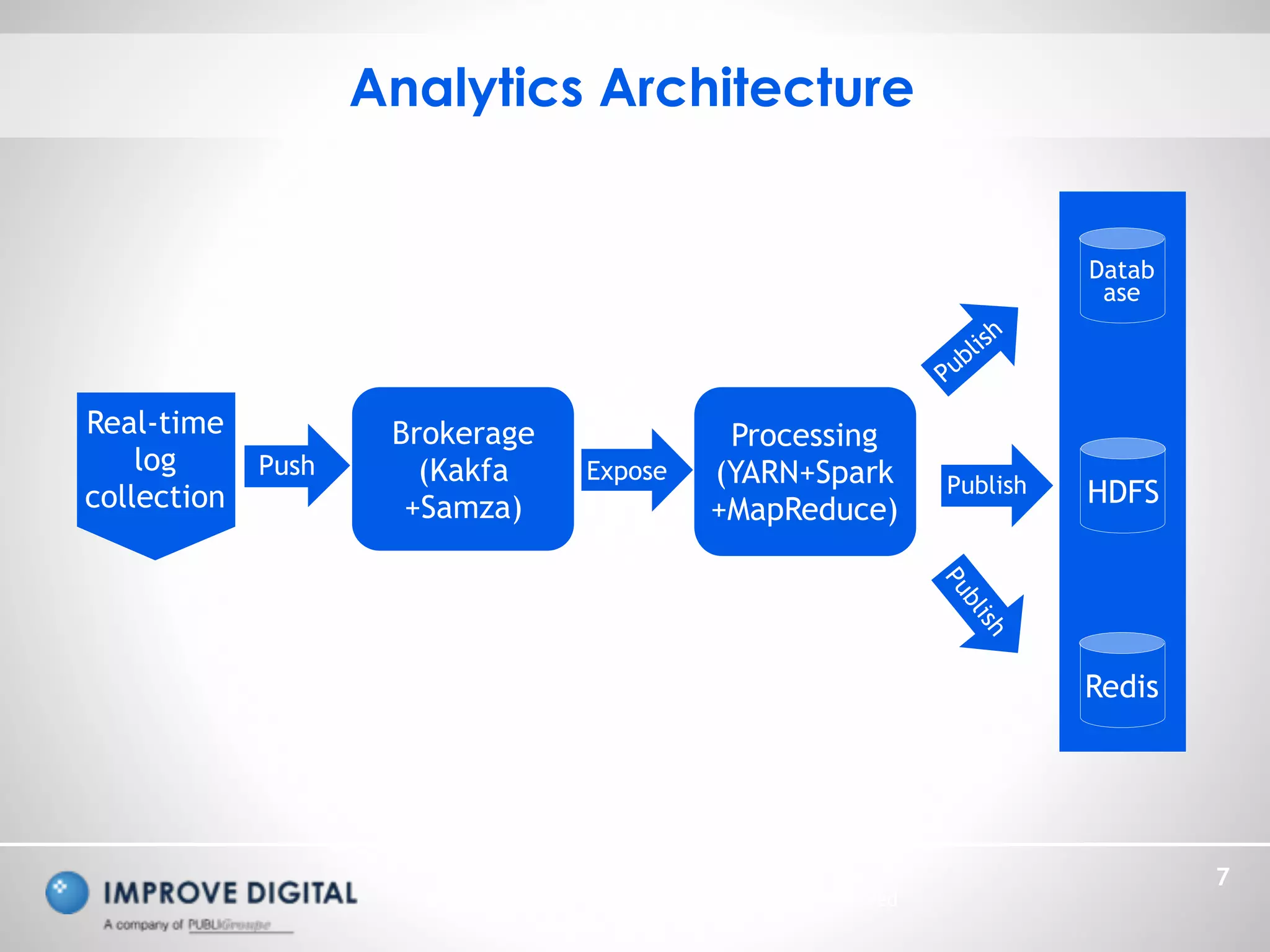

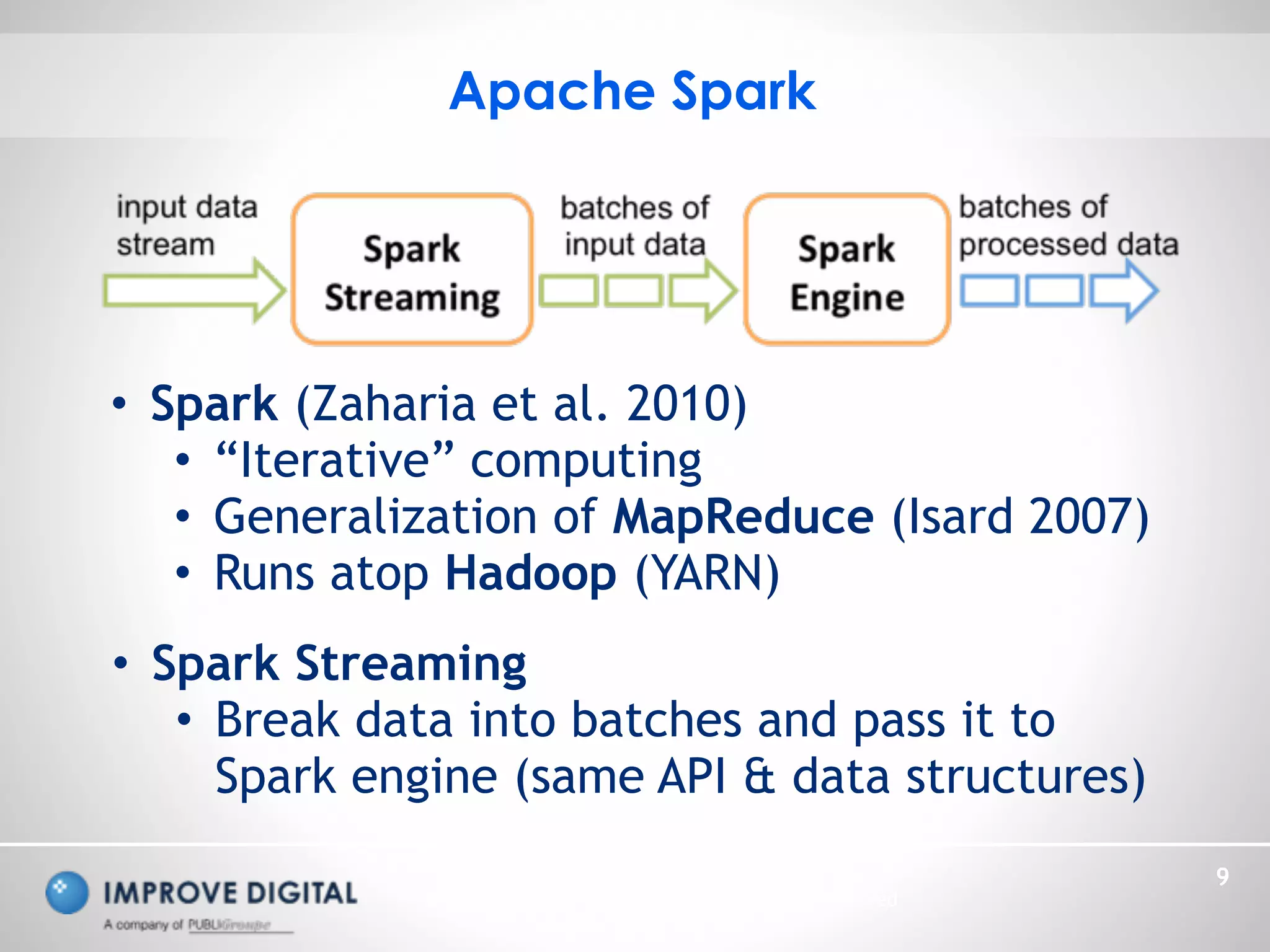







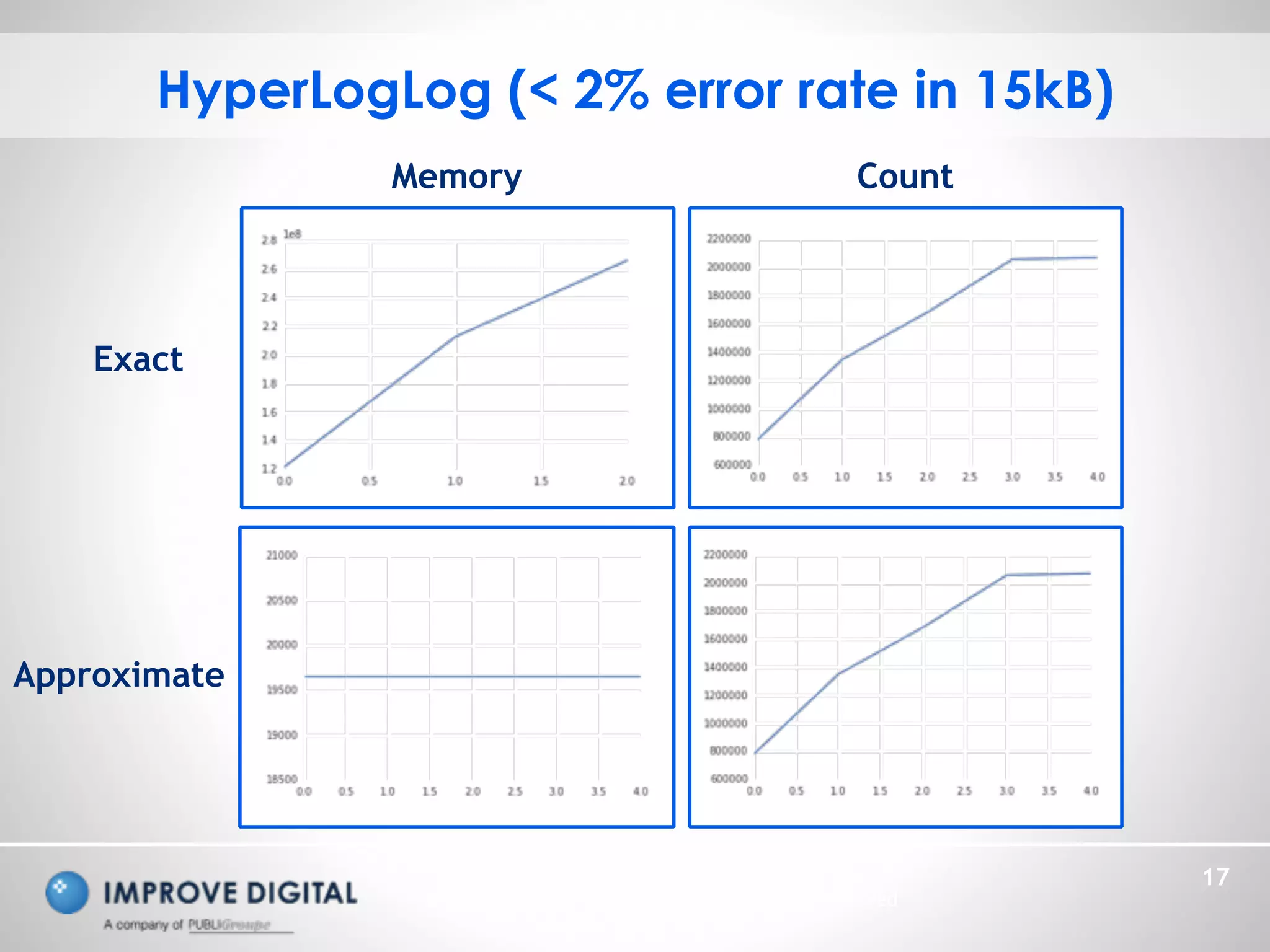



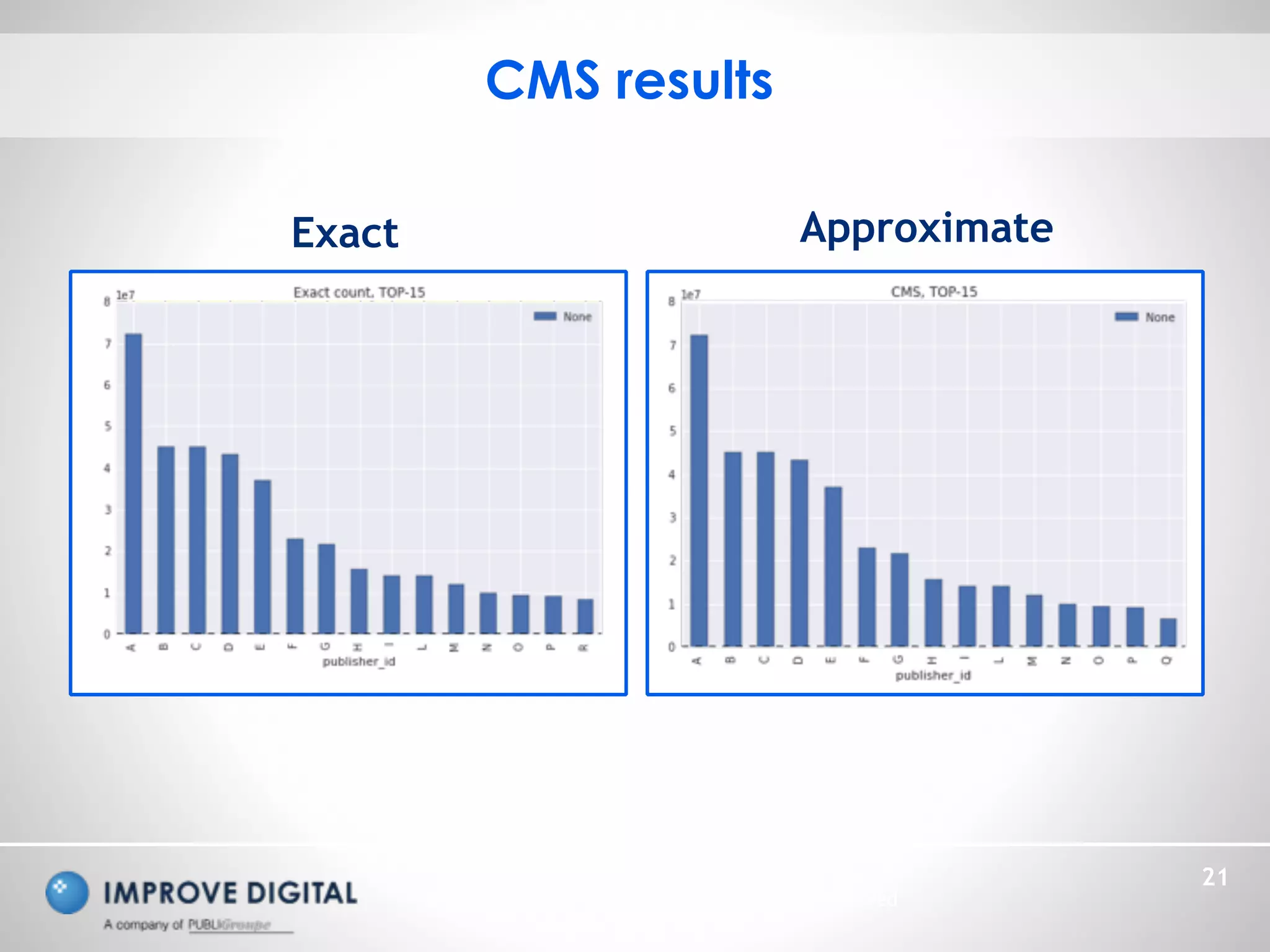































The document discusses the architecture and methodologies for processing large-scale data streams and batch analytics in real-time advertisement technology. Key topics include the use of Apache Kafka and Spark for data processing, various approximation algorithms for cardinality estimation, and challenges in managing infinite datasets. The emphasis is on unifying models, optimizing analytics, and efficiently managing big data through innovative algorithms.



































































