The document outlines Gaurav Marwaha's experience in data science over 15 years, focusing on product development in various domains such as GIS, health, and e-governance. It describes experiments conducted in text analysis, public data scoring, and cross-sell opportunities, emphasizing the importance of data quality and machine learning techniques. The conclusions highlight challenges in data management and integration, emphasizing that quality data entry is crucial for effective machine learning applications.










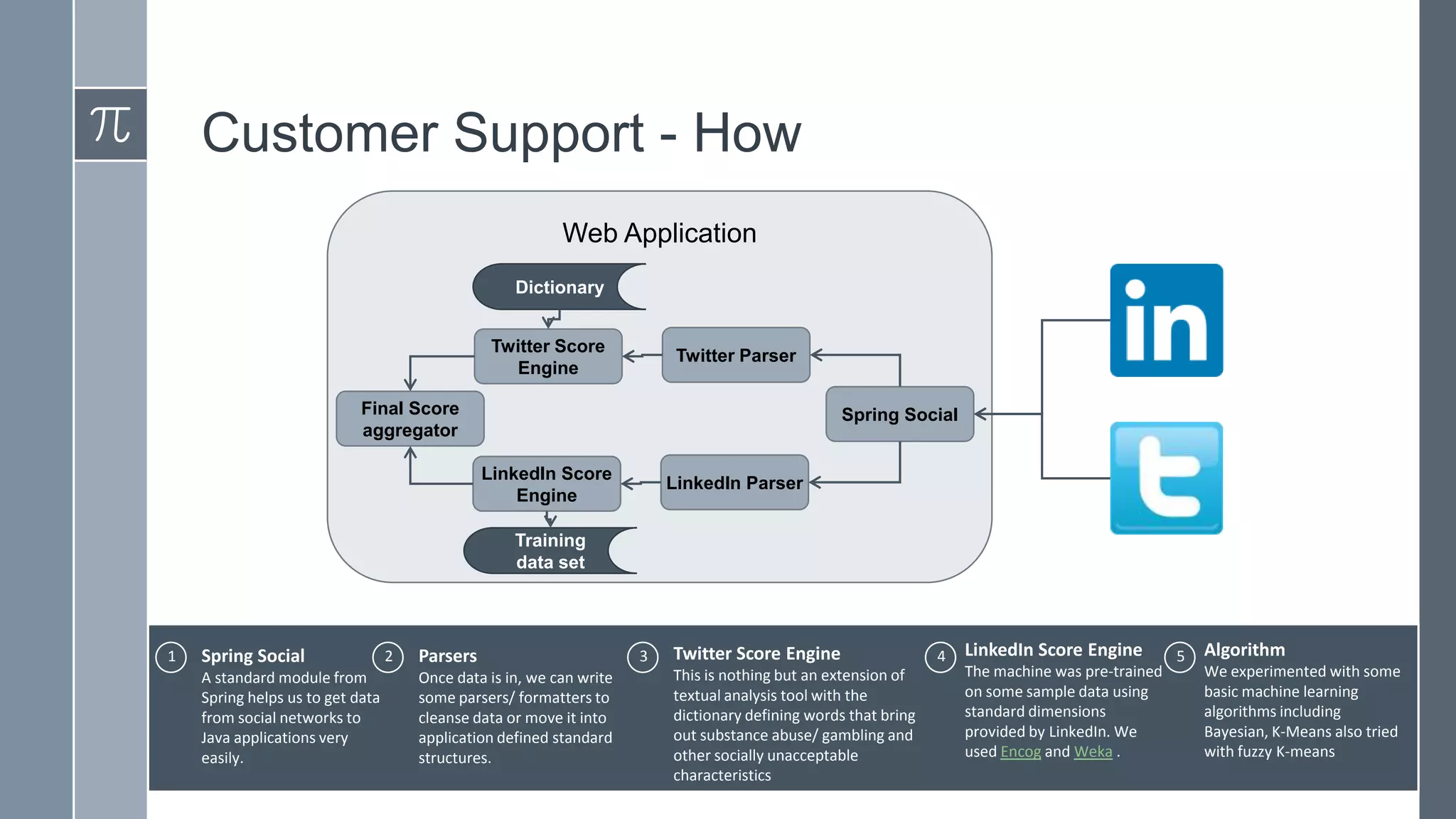


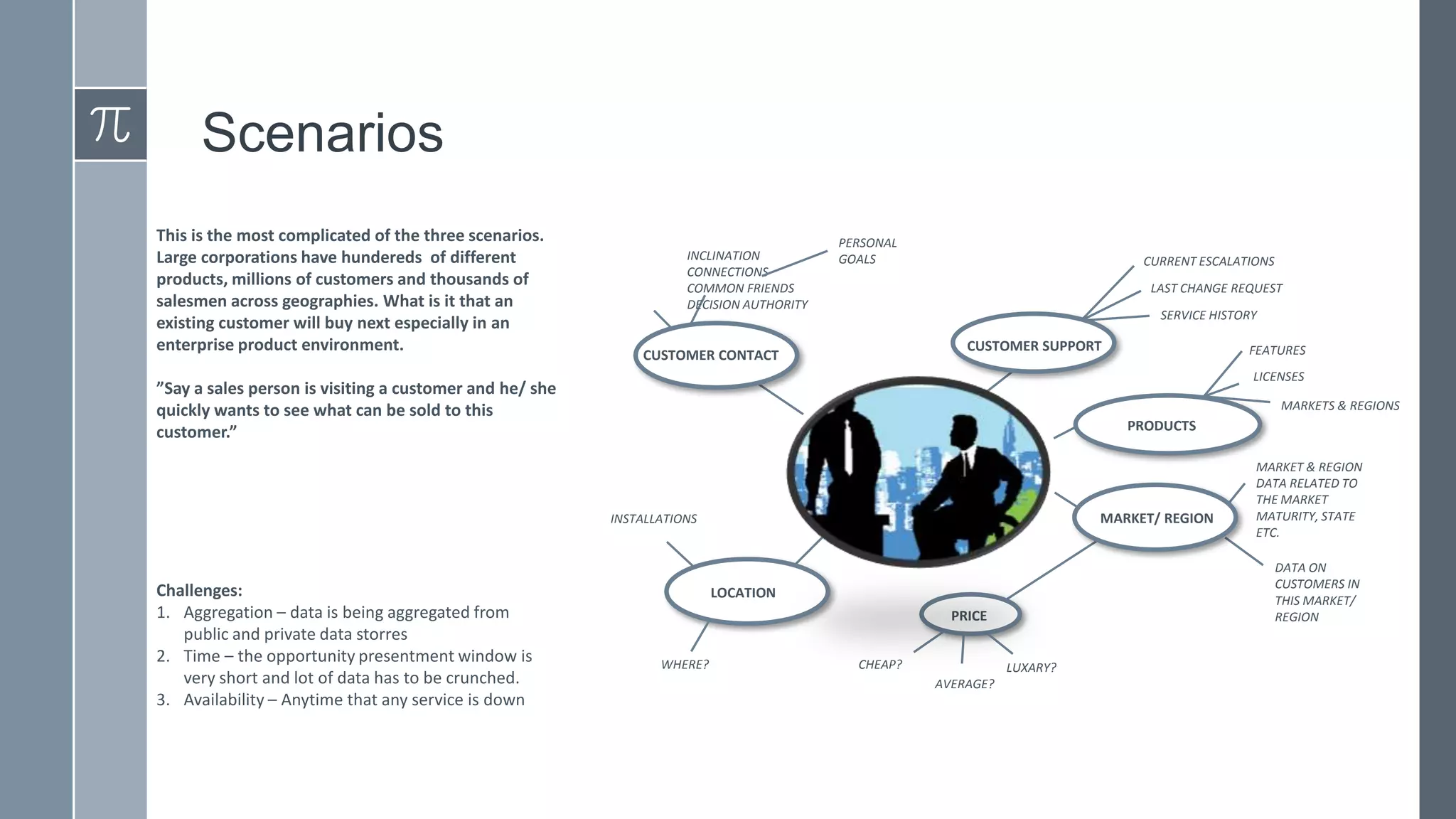

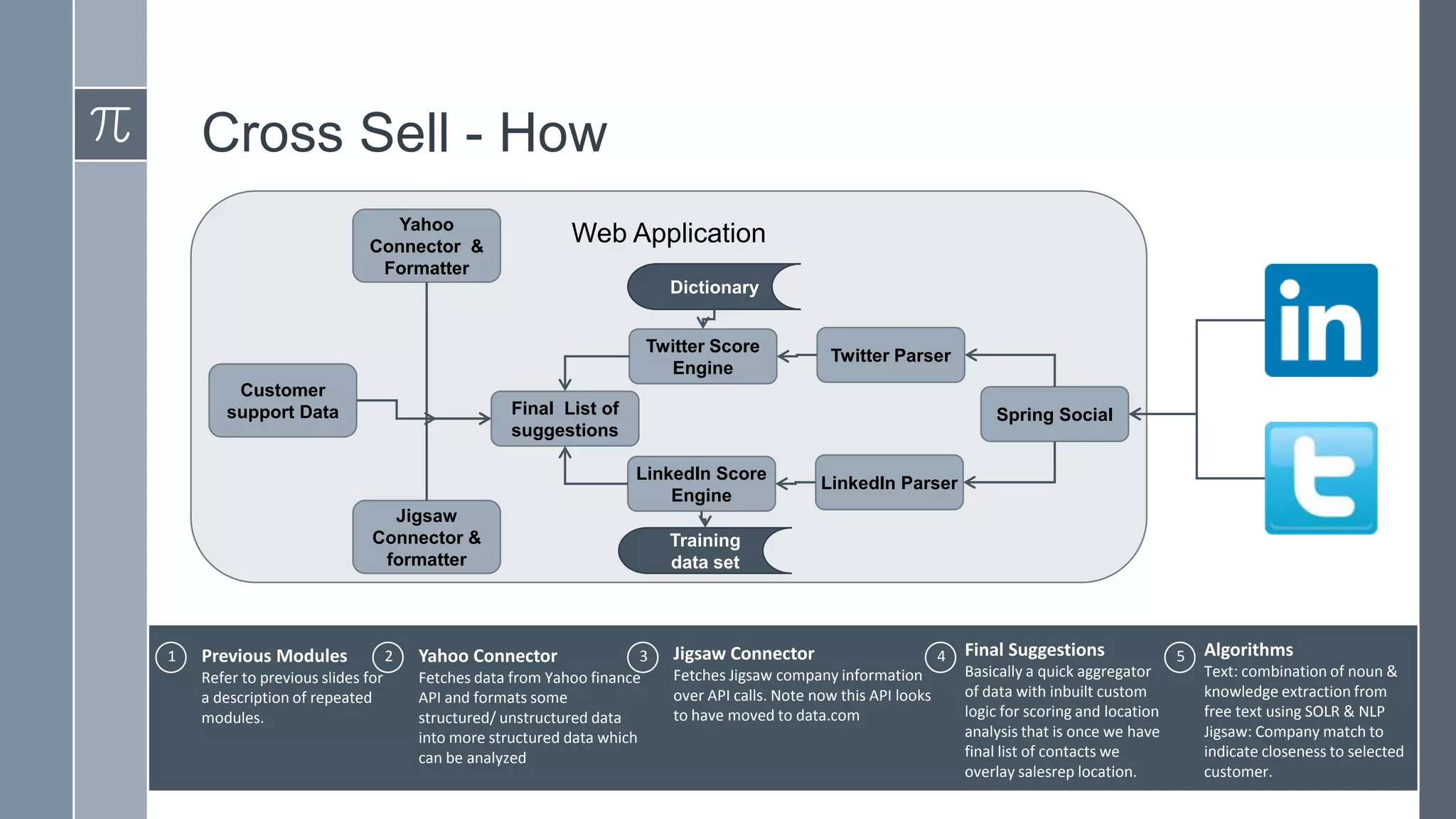












































































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
