Downloaded 32 times

![1/3 business leaders frequently make
decisions with data they don’t trust
Bad data costs the economy $100s BN / year
[IBM]
[TDWI]](https://image.slidesharecdn.com/bigdatatorontocarl-190618024848/75/Data-Quality-principles-approaches-and-best-practices-2-2048.jpg)







![1/3 business leaders frequently make
decisions with data they don’t trust
Bad data costs the economy $100s BN / year
[IBM]
[TDWI]](https://crownmelresort.com/image.slidesharecdn.com/bigdatatorontocarl-190618024848/75/Data-Quality-principles-approaches-and-best-practices-2-2048.jpg)





















The document discusses principles and best practices for data quality. It outlines key facets of data quality including accuracy, coherence, completeness, consistency, being defined and timely. It provides examples of how to measure these facets through metrics like percentage of records quarantined or missing fields. The document advocates establishing data governance practices like publishing schemas, adhering to definitions, and integrating data quality checks and monitoring into normal workflows. It promotes a culture where data quality is a shared responsibility across teams.
A presentation by Carl Anderson on data quality principles, approaches, and best practices.
1/3 business leaders distrust data; bad data costs the economy hundreds of billions annually.
Overview of data science, business intelligence, and engineering alongside data strategy.
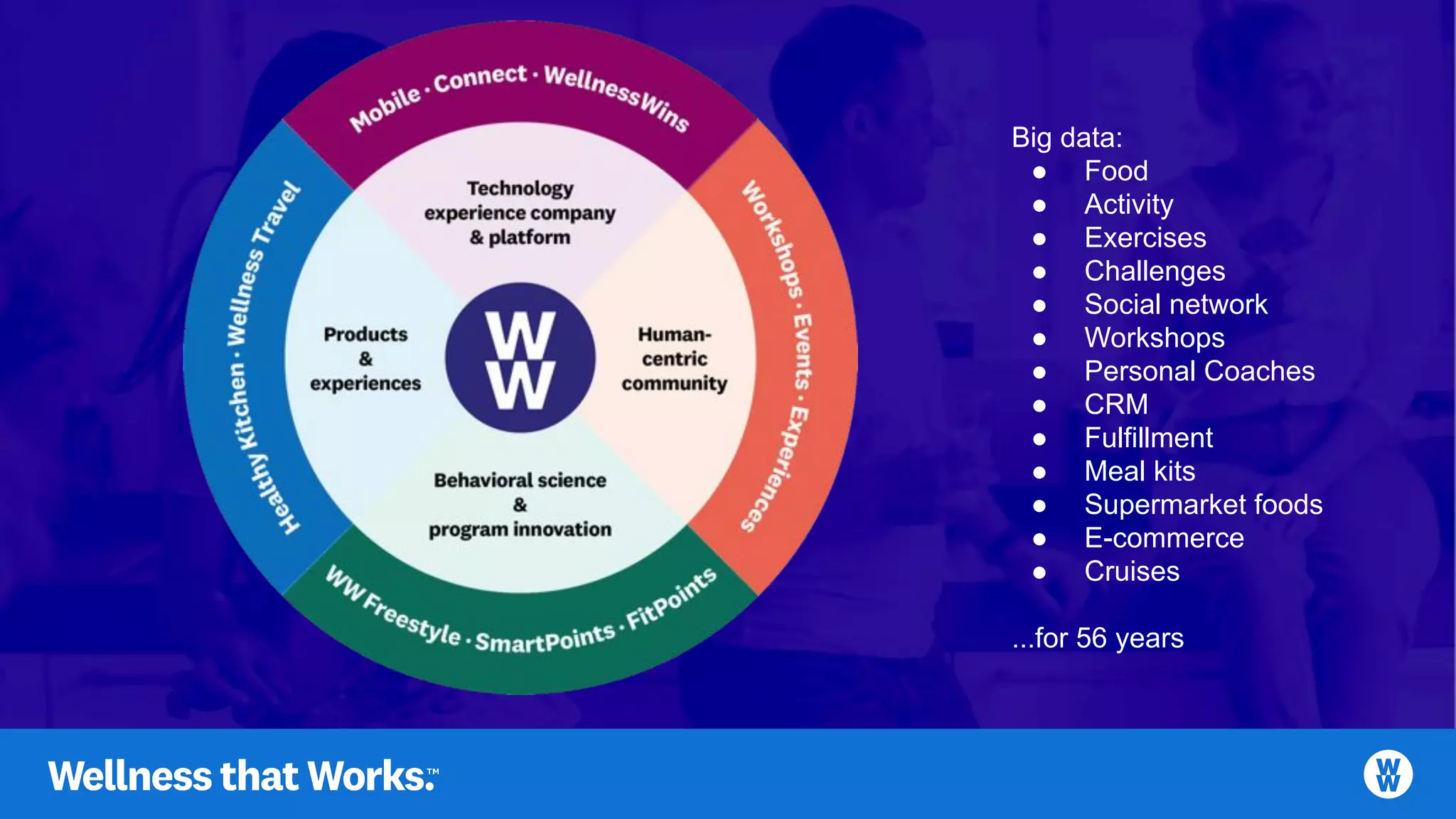
Elements of big data including food, activity, exercises, personal coaching, and e-commerce.
In 2017, initiated data lake; by 2019, established upstream control and governance frameworks.
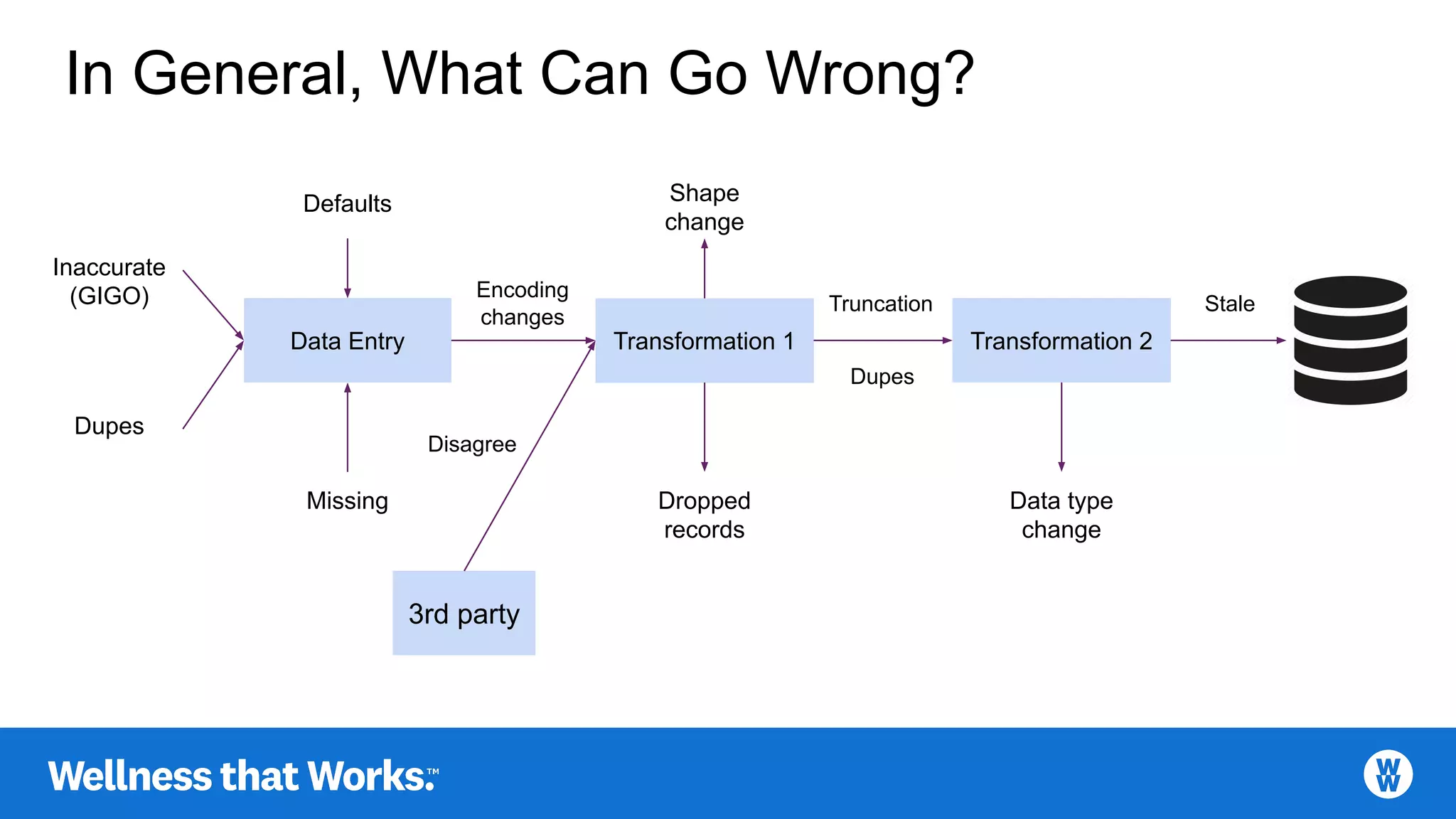
Common issues in data entry transformation such as inaccuracies, missing records, and encoding changes.
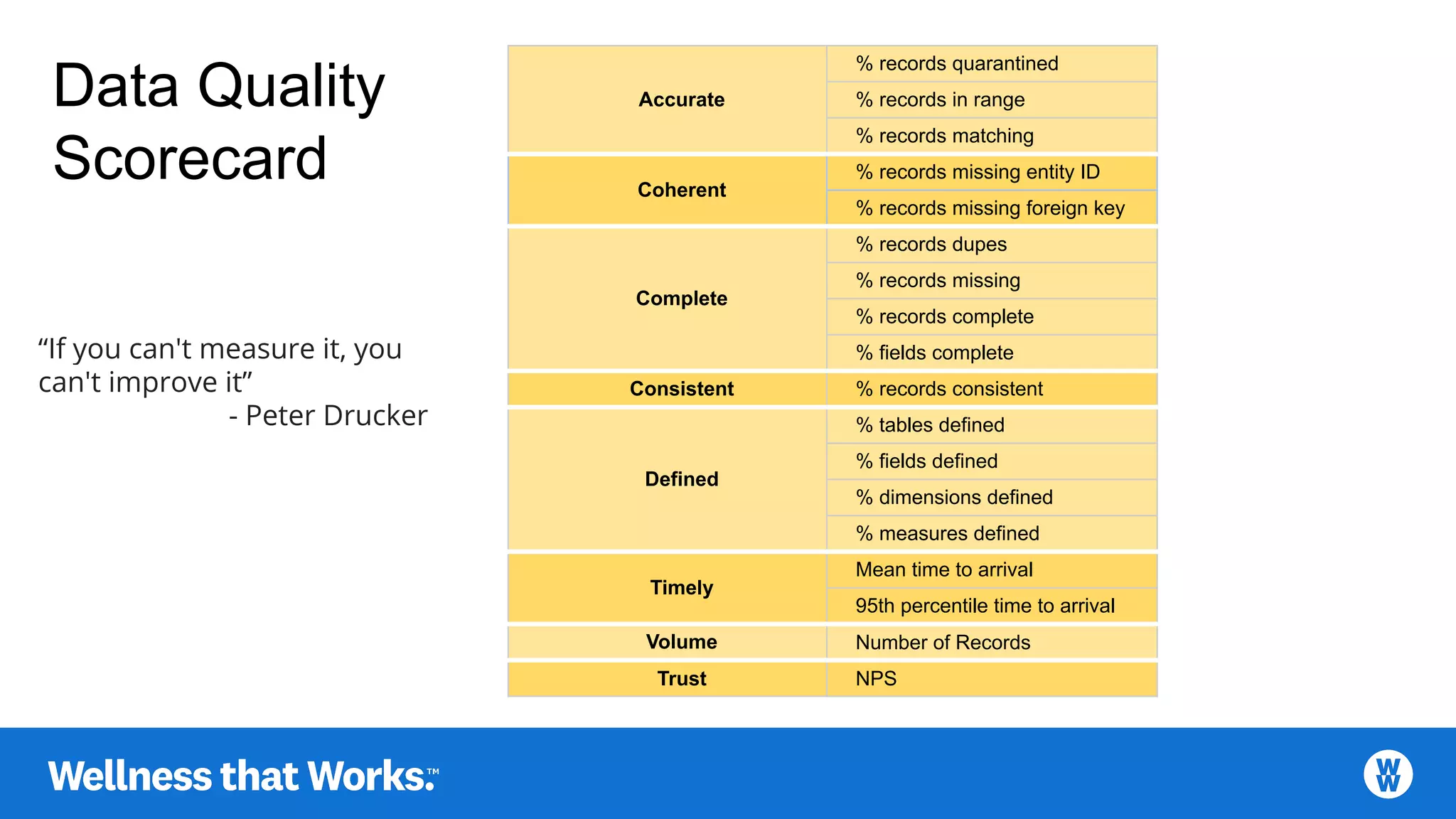
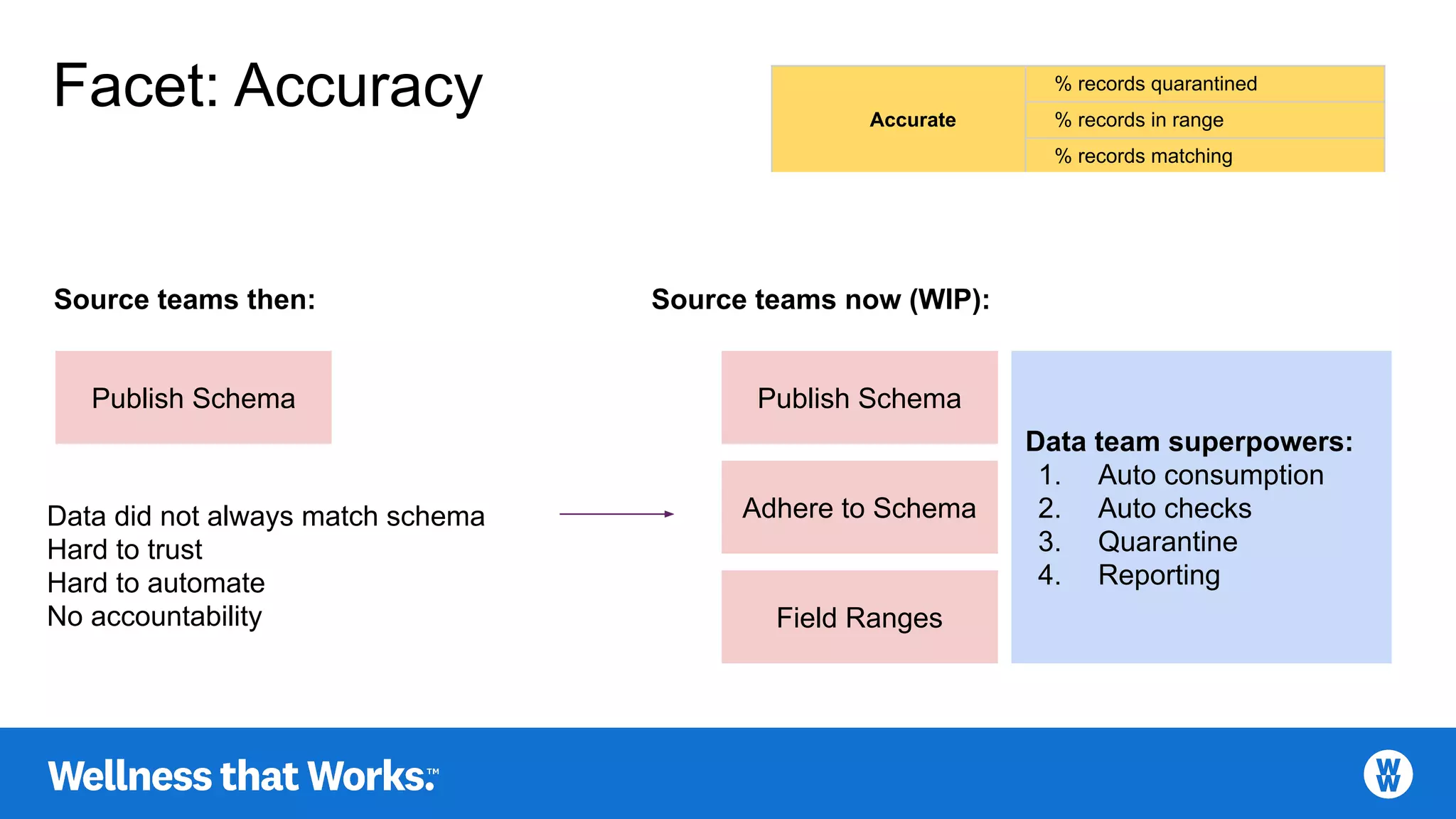
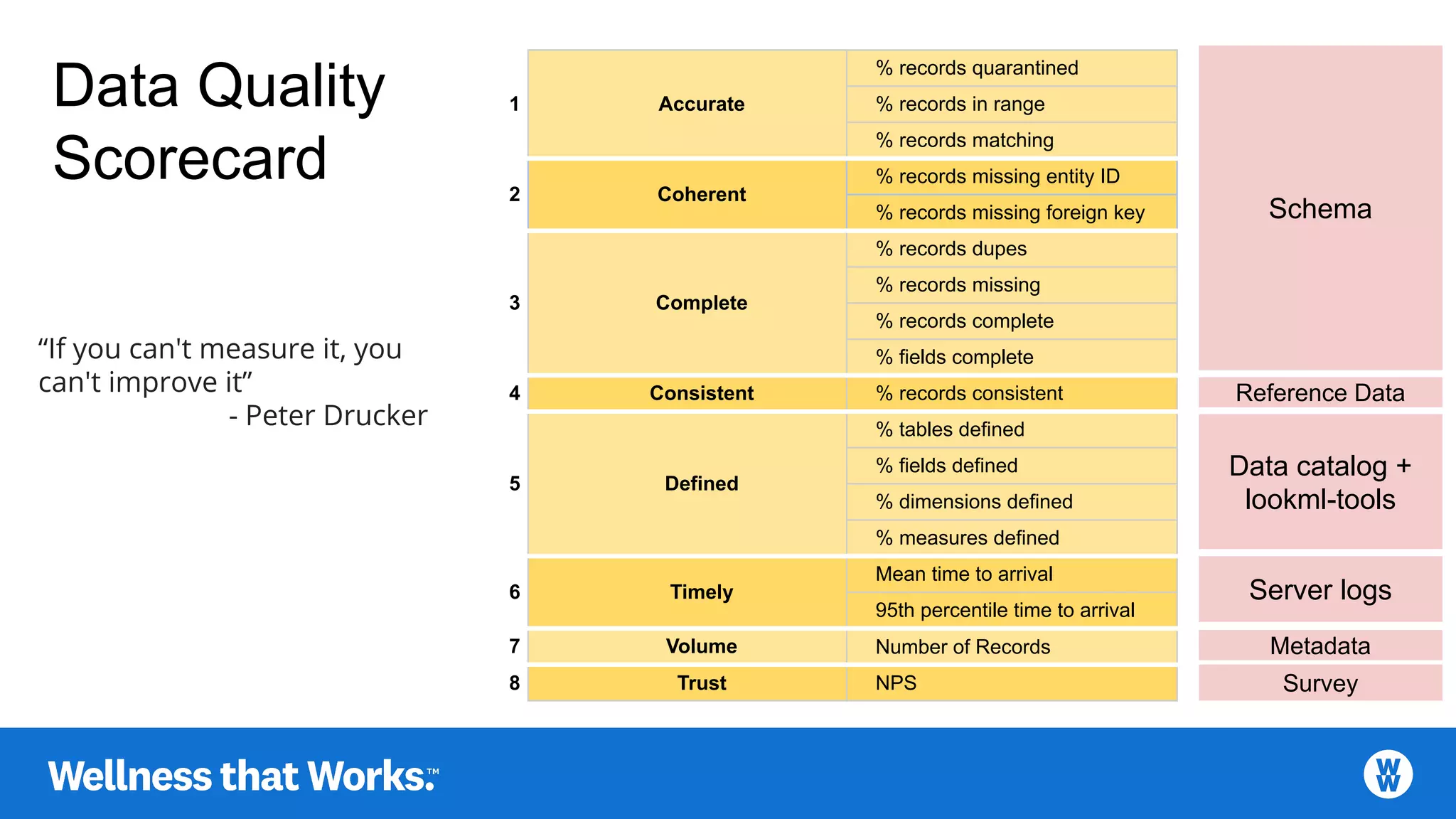
Discusses characteristics like accuracy, coherence, completeness, consistency, definition, and timeliness.
Metrics for assessing data quality, including record quarantine percentage and timeliness measures.
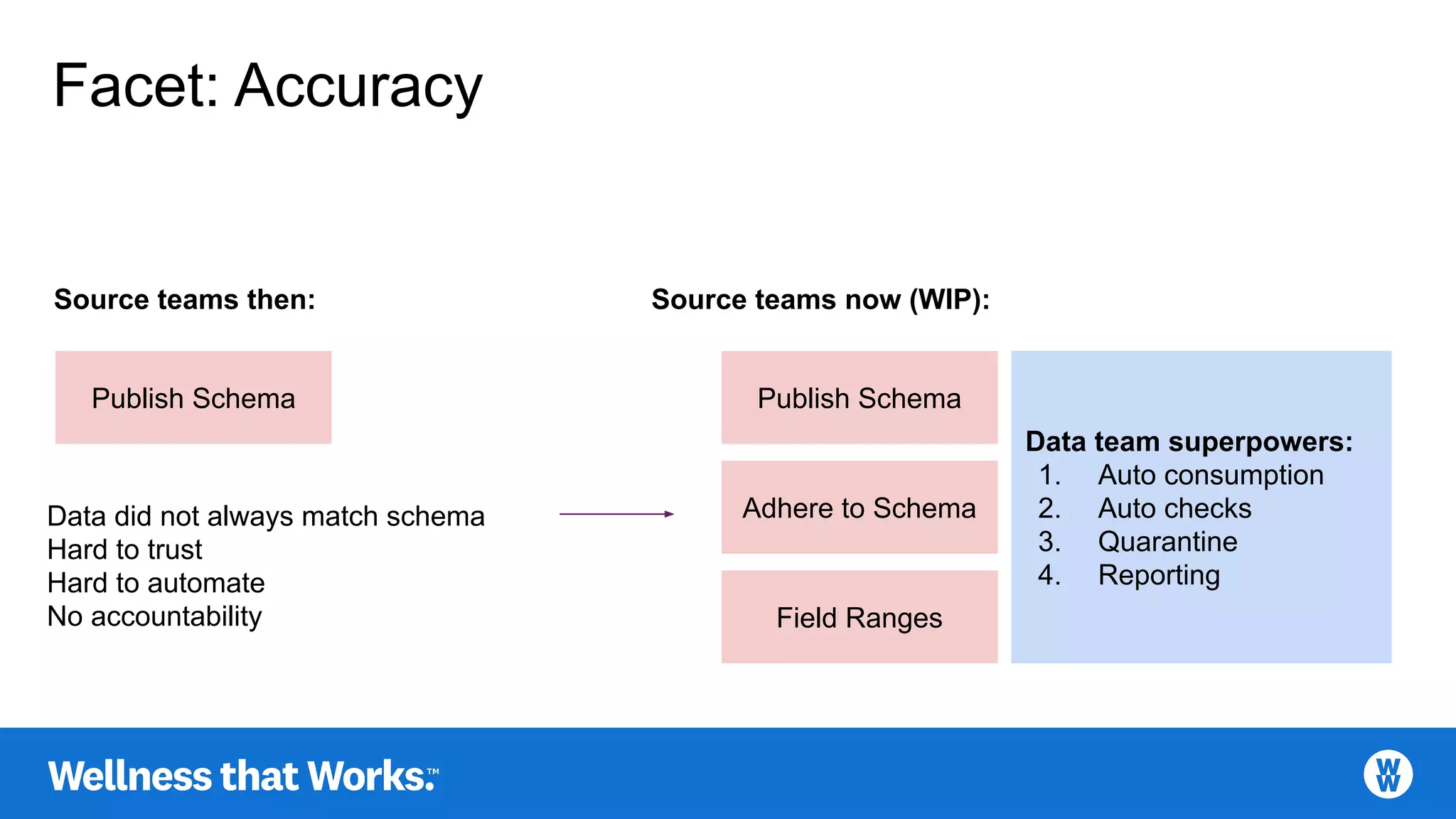
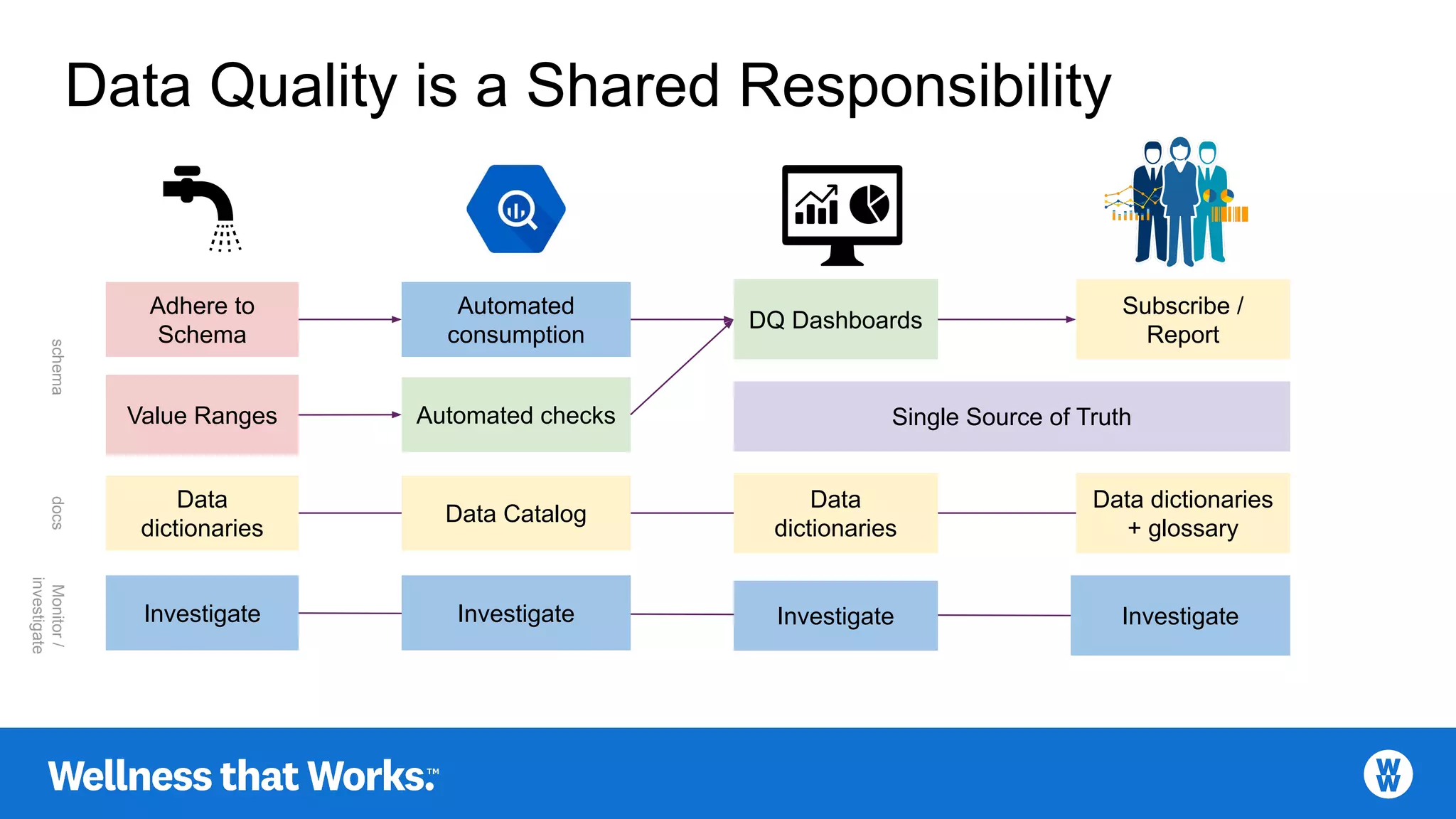
Focus on accuracy: schema adherence, automatic checks, quarantining poor data, and reporting.
Continues discussion on data accuracy and operations to enhance data trust and automation.
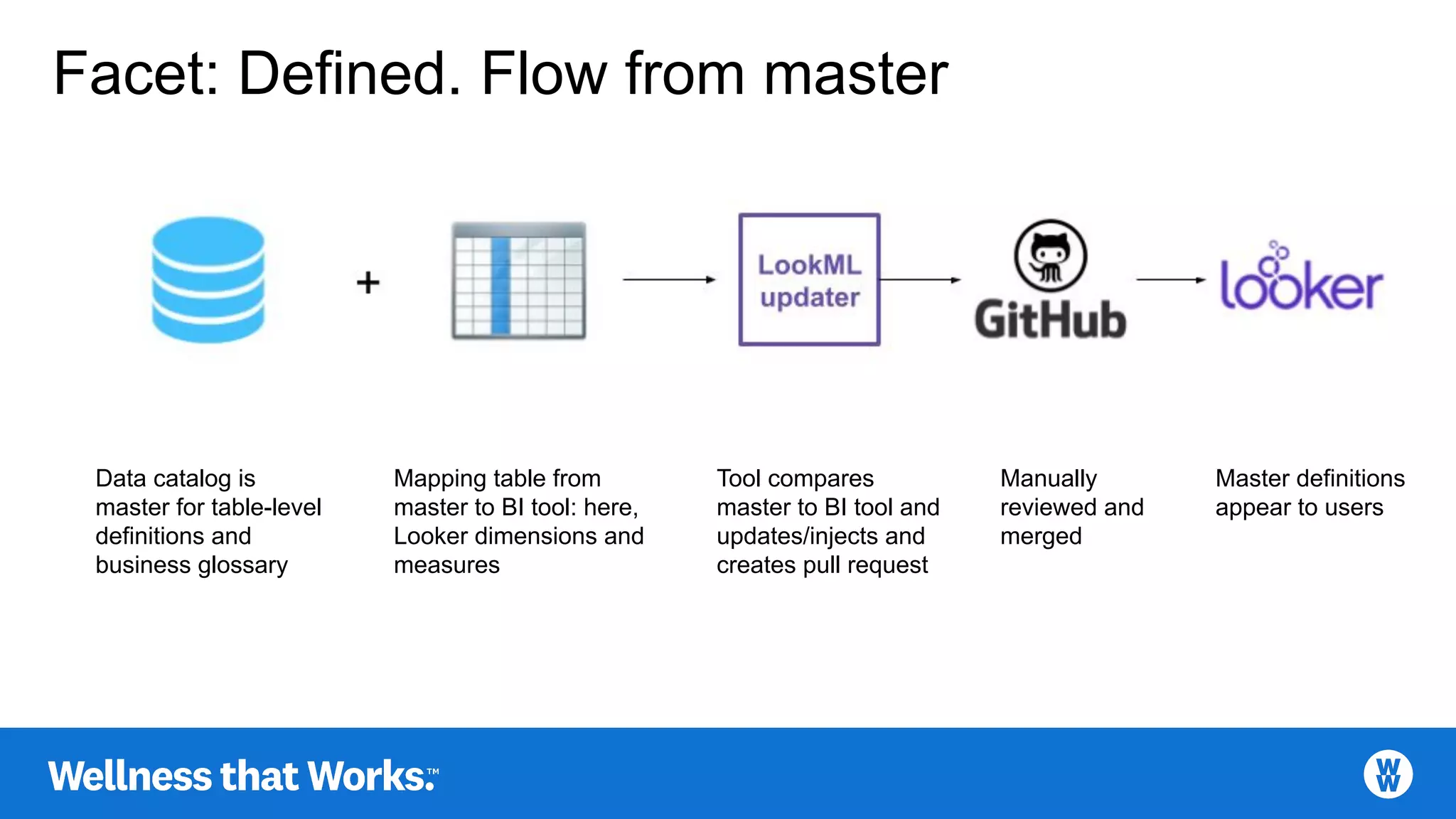
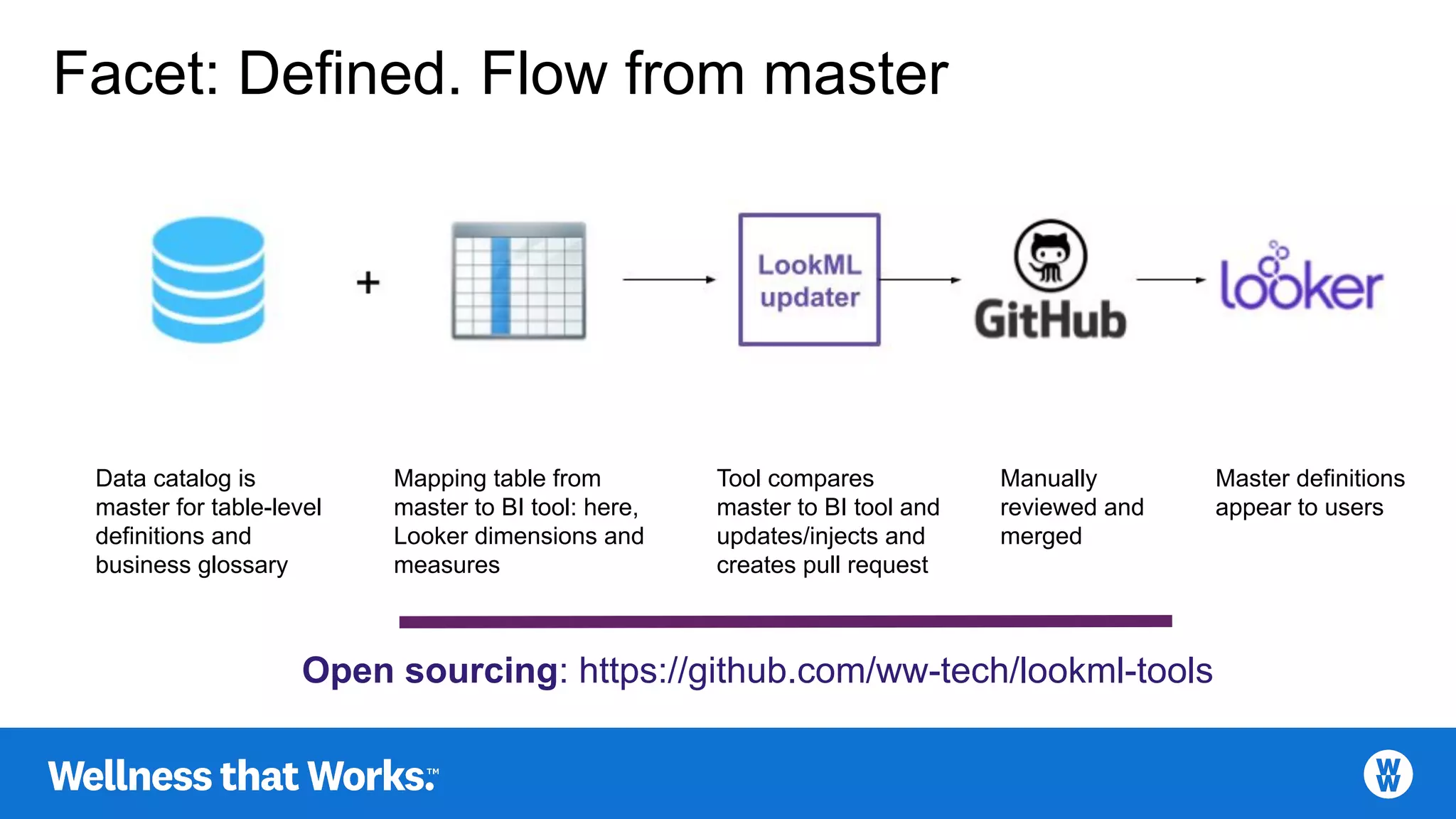
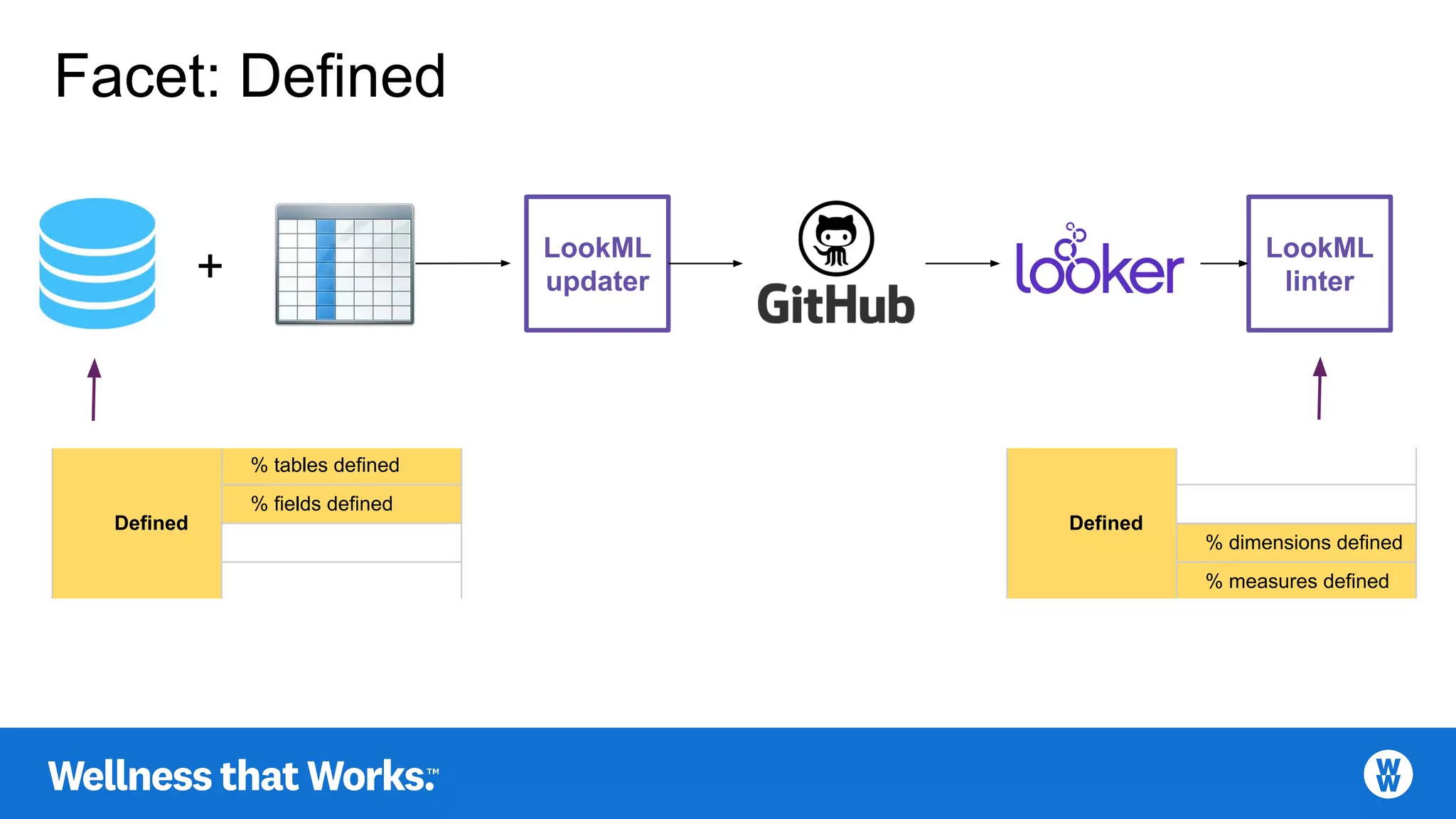
Essential components for defining data, emphasizing data dictionaries and business glossaries.
Master definitions streamlined via data catalogs and BI tools with updated mappings.
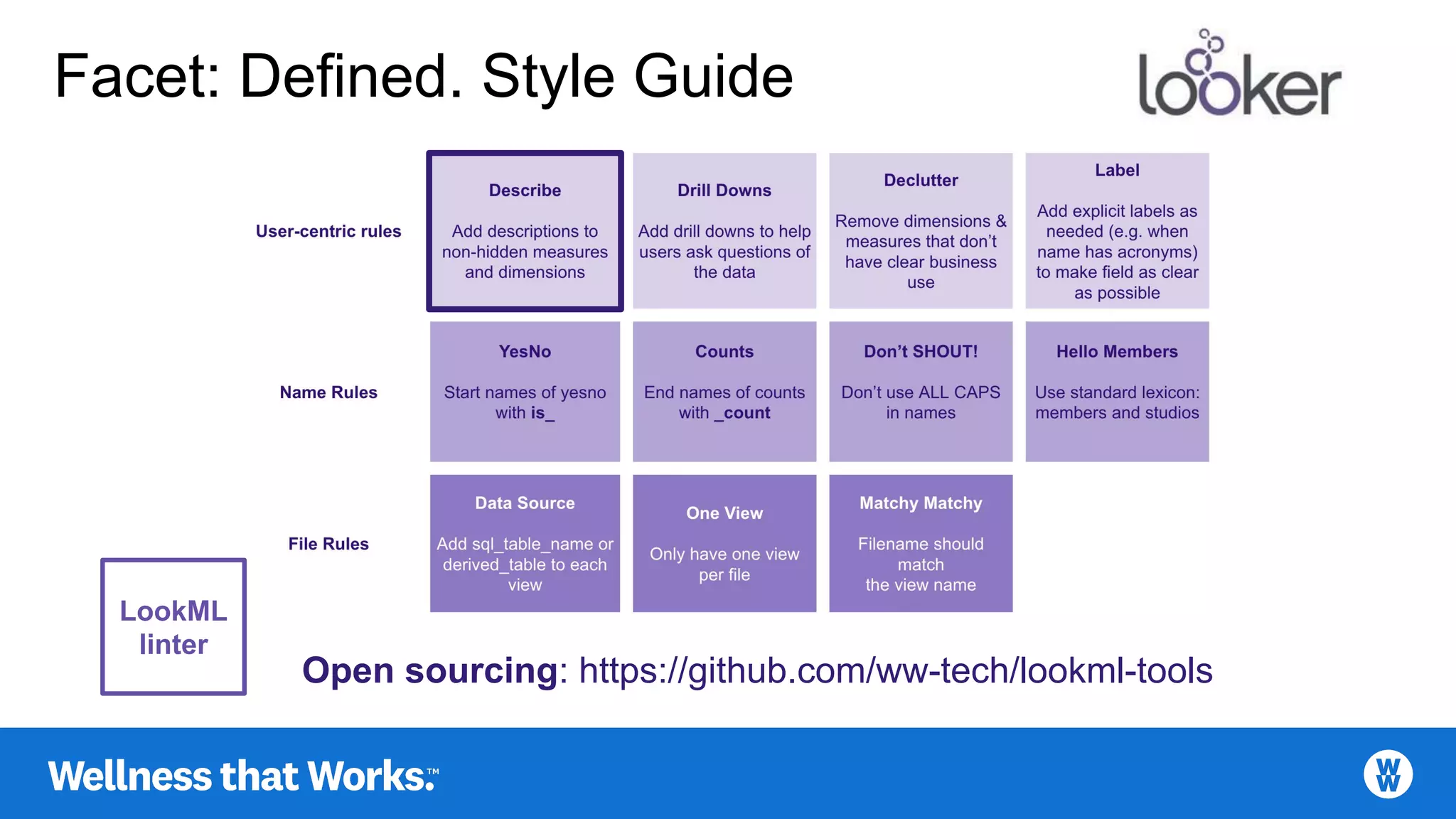
LookML linter tools open-sourced for maintaining data modeling standards.
Metrics for measuring table and field definitions in the context of data quality.
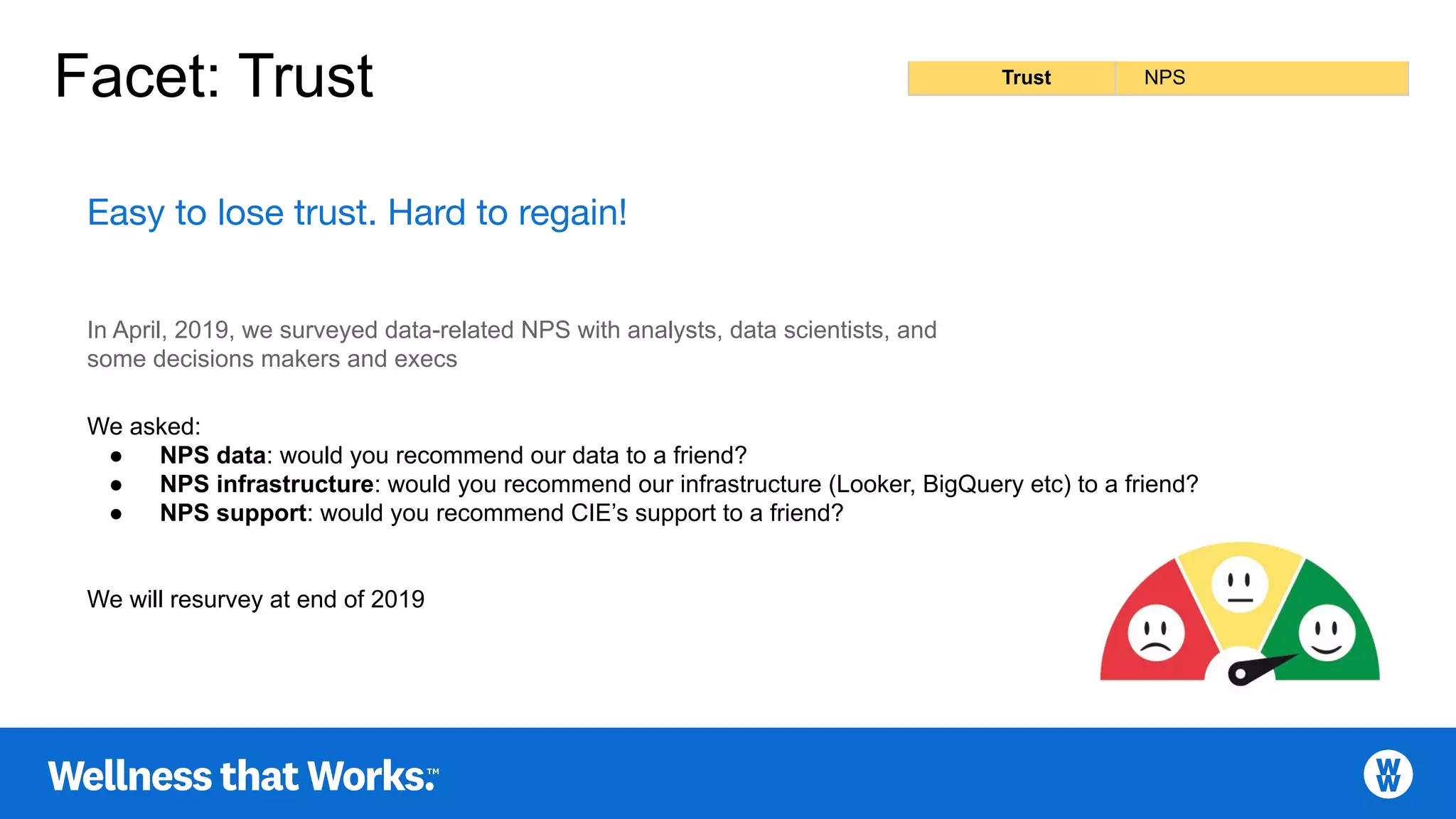
Surveyed NPS for data trust among analysts and infrastructure support recommendations.
Holistic scorecard encompassing all facets of data quality and their metrics for improvement.
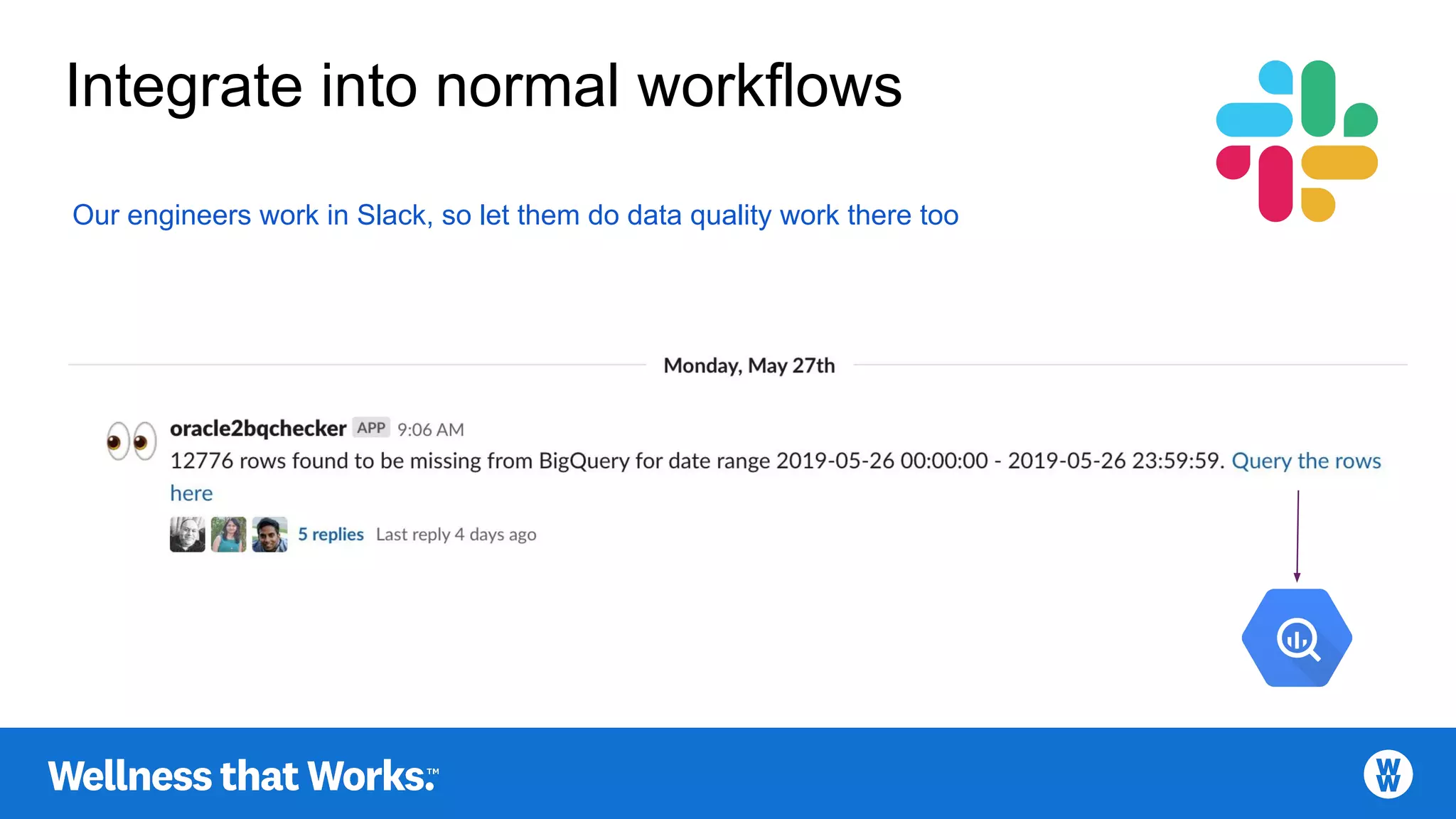
Integrating data quality checks into regular workflows, leveraging platforms like Slack.
Establishing a culture of data quality in BI teams, emphasizing proactive approaches.
Emphasizes collaborative responsibility for data quality with workflows to monitor and report.
Invitation for questions; presentation by Carl Anderson emphasizing recruitment for data roles.

























































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)

















