Download to read offline


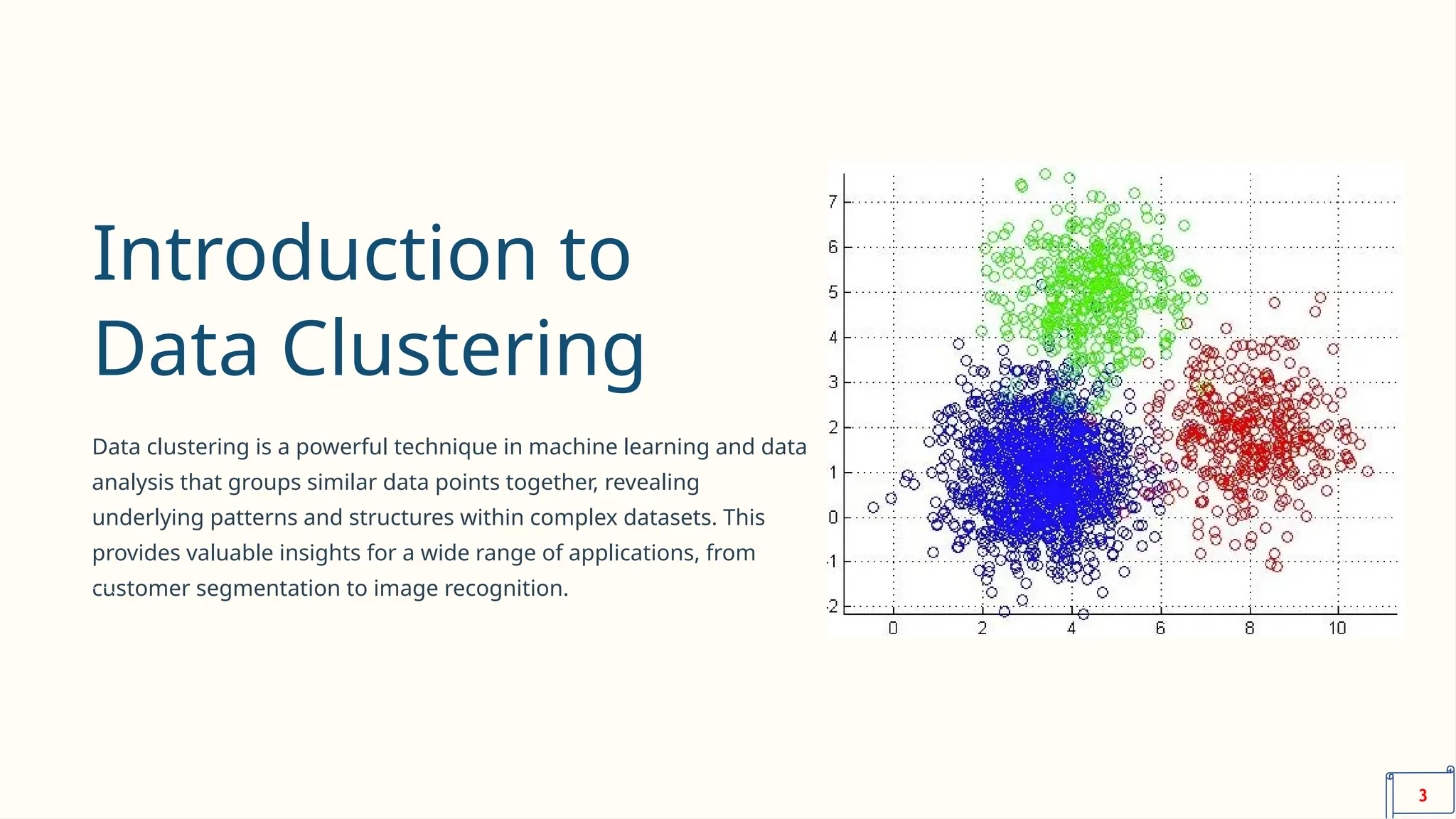


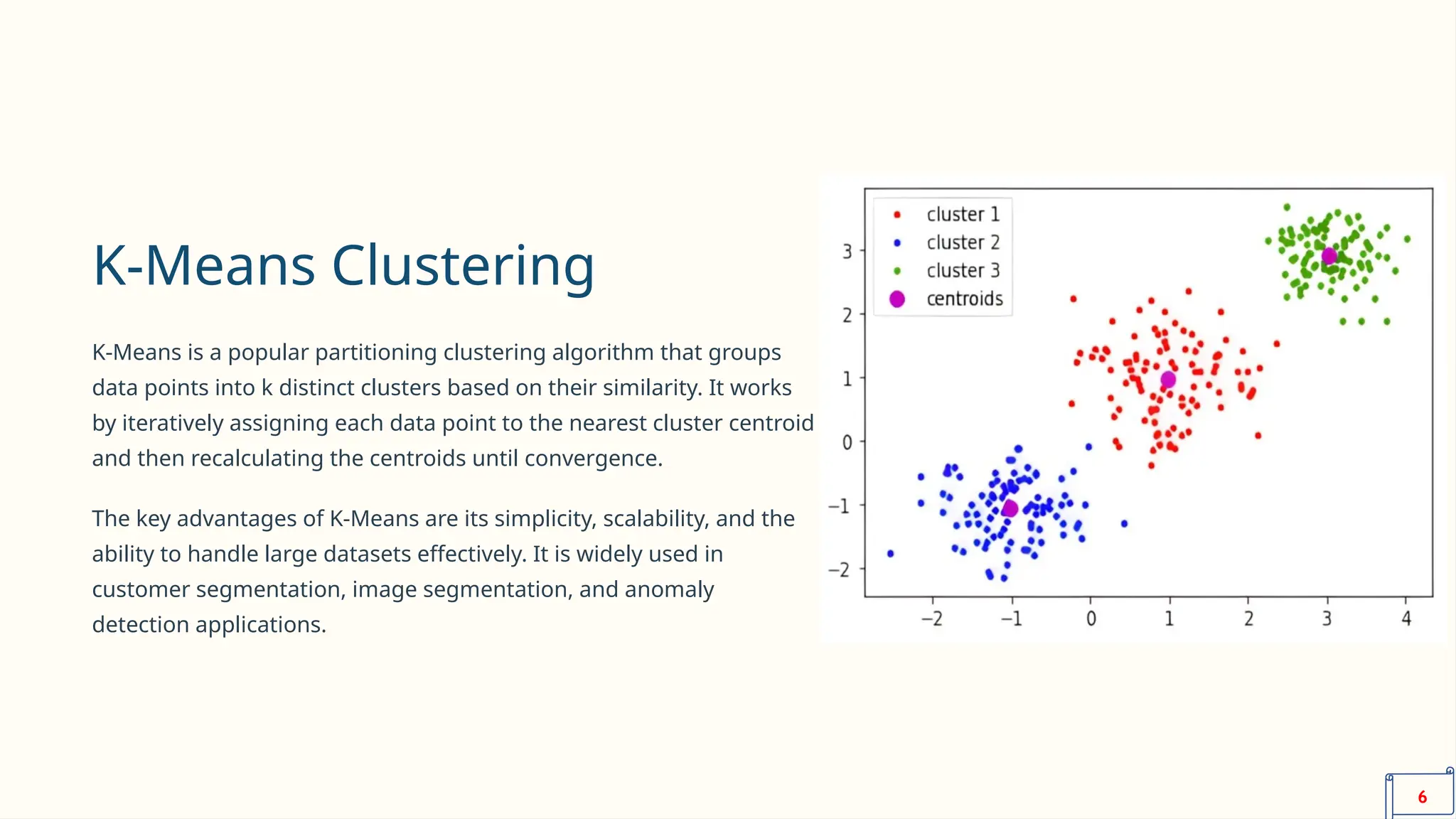
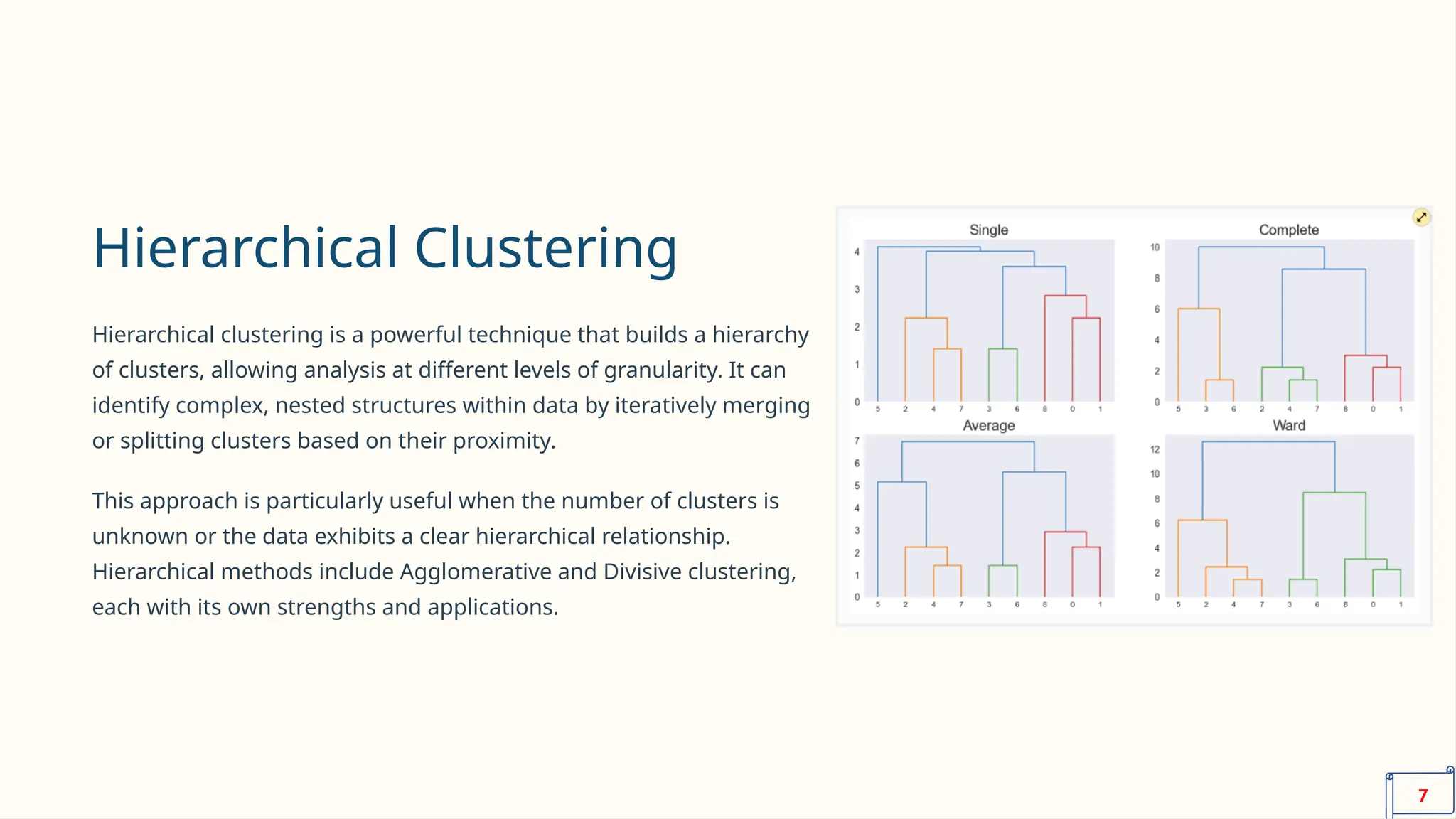




















The document discusses the seminar on data clustering within the context of artificial intelligence and robotics, covering various clustering algorithms like k-means, hierarchical, and DBSCAN. It emphasizes the significance of clustering in analyzing complex datasets to extract insights applicable in fields like customer segmentation and biomedical research. Additionally, it highlights the importance of selecting the appropriate clustering algorithm based on data characteristics and evaluating their performance to ensure effective decision-making.












![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)