Download to read offline




![PSUDEO CODE - REDUCER
Class REDUCER
method INITIALIZE
TOTALFREQ = 0
method REDUCE (Pair p, counts [c1, c2, c3, … ])
sum = 0
for all count c in counts [c1, c2, c3, … ]) do
sum = sum + c
if ( p.getNeighbor() == “*”)) then //Neighbor is second element of the pair
TOTALFREQ = sum
else
EMIT ( Pair p, sum / TOTALFREQ)](https://image.slidesharecdn.com/crystalballeventpredictionmapreduce-160619040352/75/Crystal-Ball-Event-Prediction-and-Log-Analysis-with-Hadoop-MapReduce-and-Spark-5-2048.jpg)







![PSUDEO CODE - REDUCER
Class REDUCER
method INITIALIZE
TOTALFREQ = 0
Hf = new Associative Array
method REDUCE (term t, stripes [H1, H2, H3, … ])
for all stripe H in stripes [H1, H2, H3, … ]) do
for all term w in stripe H do
Hf { w } = Hf { w } + H { w } // Hf = Hf + H ; Element-wise addition
TOTALFREQ = TOTALFREQ + count H { w }
for all term w in stripe Hf do
Hf { w } = Hf { w } / TOTALFREQ
EMIT ( term t, stripe Hf )](https://image.slidesharecdn.com/crystalballeventpredictionmapreduce-160619040352/75/Crystal-Ball-Event-Prediction-and-Log-Analysis-with-Hadoop-MapReduce-and-Spark-13-2048.jpg)


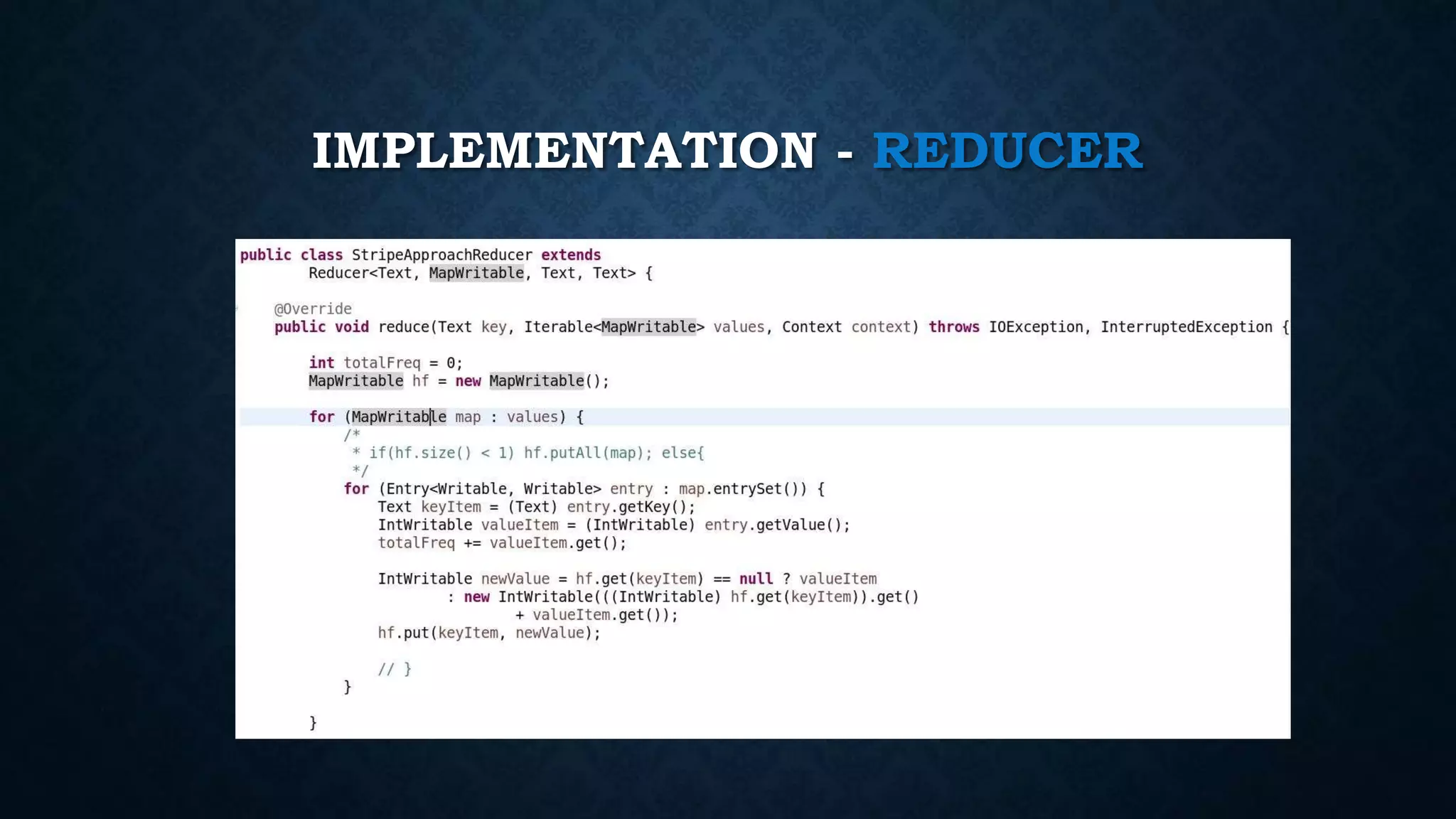





![PSUDEO CODE - REDUCER
Class REDUCER
method INITIALIZE
TOTALFREQ = 0
Hf = new Associative Array
PREVKEY = “”
method REDUCE (Pair p, counts [C1, C2, C3, … ])
sum = 0
for all count c in counts [ C1, C2, C3, … ] do
sum = sum + c
if ( PREVKEY <> p.getKey( )) then
EMIT ( PREVKEY, Hf / TOTALFREQ ) // Element-wise divide
Hf = new Associative Array
TOTALFREQ = 0](https://image.slidesharecdn.com/crystalballeventpredictionmapreduce-160619040352/75/Crystal-Ball-Event-Prediction-and-Log-Analysis-with-Hadoop-MapReduce-and-Spark-22-2048.jpg)


























![PSUDEO CODE - REDUCER
Class REDUCER
method INITIALIZE
TOTALFREQ = 0
method REDUCE (Pair p, counts [c1, c2, c3, … ])
sum = 0
for all count c in counts [c1, c2, c3, … ]) do
sum = sum + c
if ( p.getNeighbor() == “*”)) then //Neighbor is second element of the pair
TOTALFREQ = sum
else
EMIT ( Pair p, sum / TOTALFREQ)](https://crownmelresort.com/image.slidesharecdn.com/crystalballeventpredictionmapreduce-160619040352/75/Crystal-Ball-Event-Prediction-and-Log-Analysis-with-Hadoop-MapReduce-and-Spark-5-2048.jpg)







![PSUDEO CODE - REDUCER
Class REDUCER
method INITIALIZE
TOTALFREQ = 0
Hf = new Associative Array
method REDUCE (term t, stripes [H1, H2, H3, … ])
for all stripe H in stripes [H1, H2, H3, … ]) do
for all term w in stripe H do
Hf { w } = Hf { w } + H { w } // Hf = Hf + H ; Element-wise addition
TOTALFREQ = TOTALFREQ + count H { w }
for all term w in stripe Hf do
Hf { w } = Hf { w } / TOTALFREQ
EMIT ( term t, stripe Hf )](https://crownmelresort.com/image.slidesharecdn.com/crystalballeventpredictionmapreduce-160619040352/75/Crystal-Ball-Event-Prediction-and-Log-Analysis-with-Hadoop-MapReduce-and-Spark-13-2048.jpg)








![PSUDEO CODE - REDUCER
Class REDUCER
method INITIALIZE
TOTALFREQ = 0
Hf = new Associative Array
PREVKEY = “”
method REDUCE (Pair p, counts [C1, C2, C3, … ])
sum = 0
for all count c in counts [ C1, C2, C3, … ] do
sum = sum + c
if ( PREVKEY <> p.getKey( )) then
EMIT ( PREVKEY, Hf / TOTALFREQ ) // Element-wise divide
Hf = new Associative Array
TOTALFREQ = 0](https://crownmelresort.com/image.slidesharecdn.com/crystalballeventpredictionmapreduce-160619040352/75/Crystal-Ball-Event-Prediction-and-Log-Analysis-with-Hadoop-MapReduce-and-Spark-22-2048.jpg)

























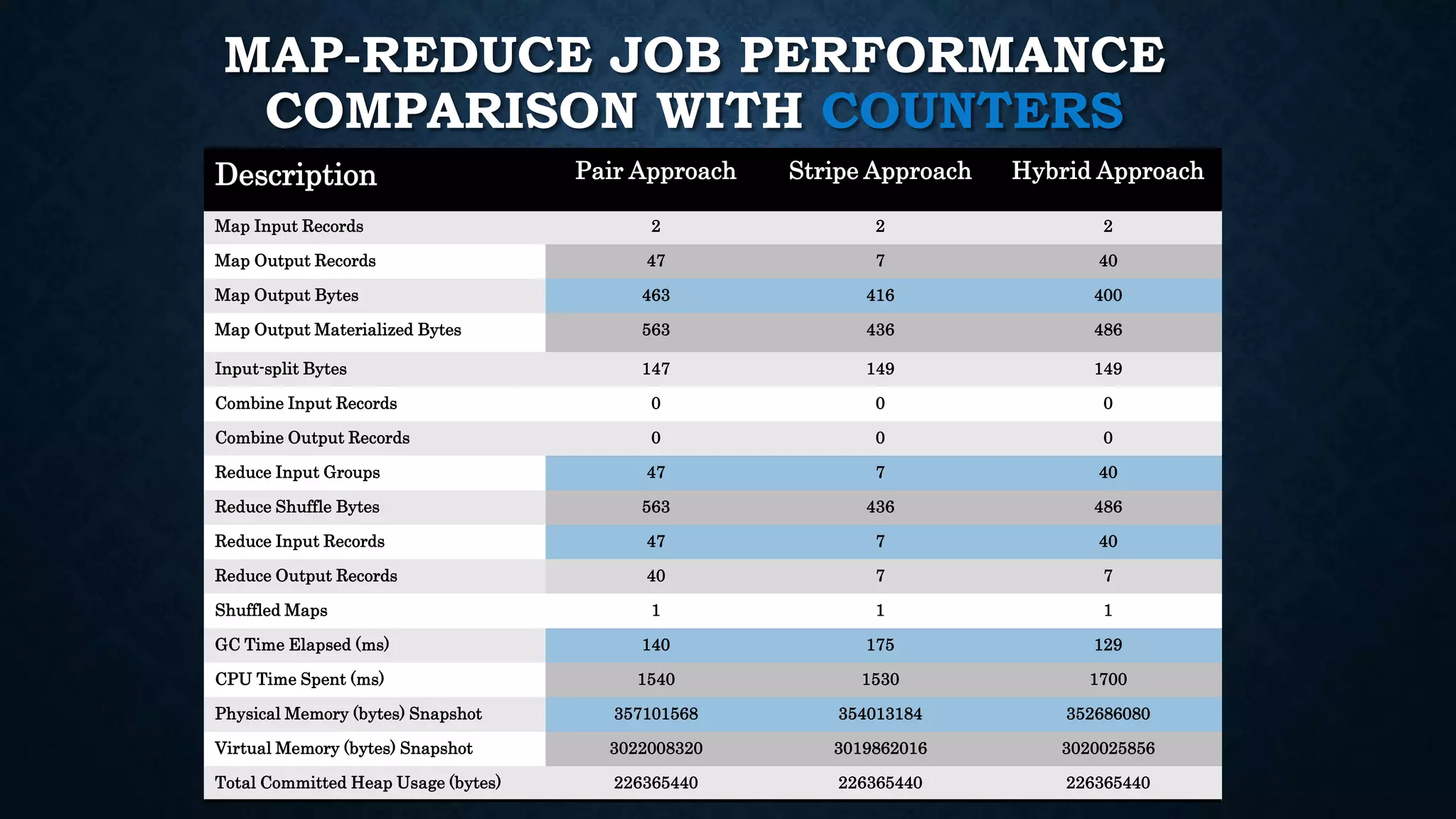
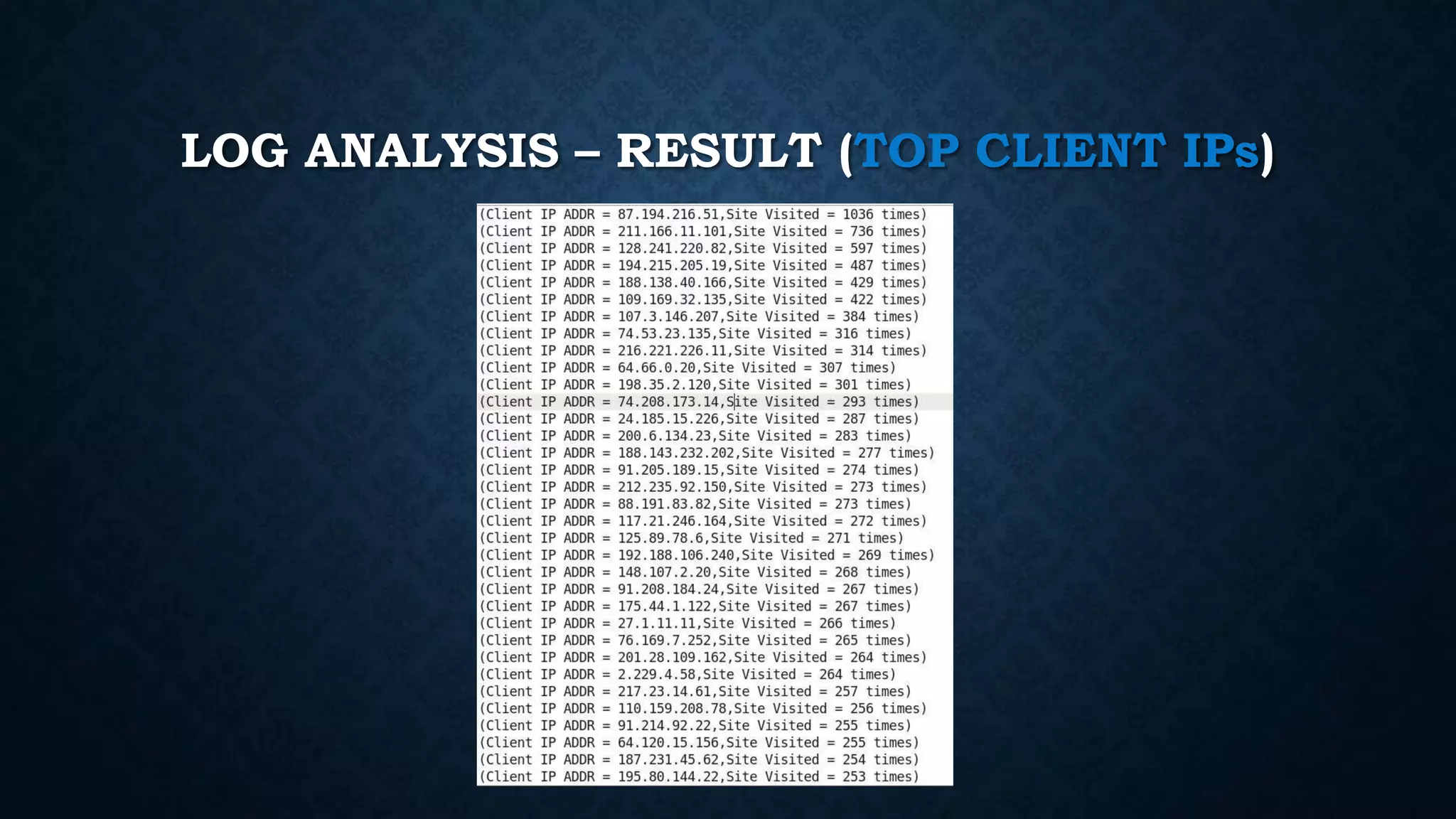
This document summarizes a student's Big Data project using MapReduce (Hadoop) and Spark that analyzes log data. It describes implementations of three approaches (pair, stripe, hybrid) to predict event co-occurrence relationships. It also describes using Spark and Scala to analyze web server log files to find top products, categories, and client IPs. Pseudocode and results are shown for each technique.








![[Paper Reading] Generalized Sub-Query Fusion for Eliminating Redundant I/O fr...](https://cdn.slidesharecdn.com/ss_thumbnails/resin-210920113222-thumbnail.jpg?width=640&height=640&fit=bounds)




























































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)














