Downloaded 16 times




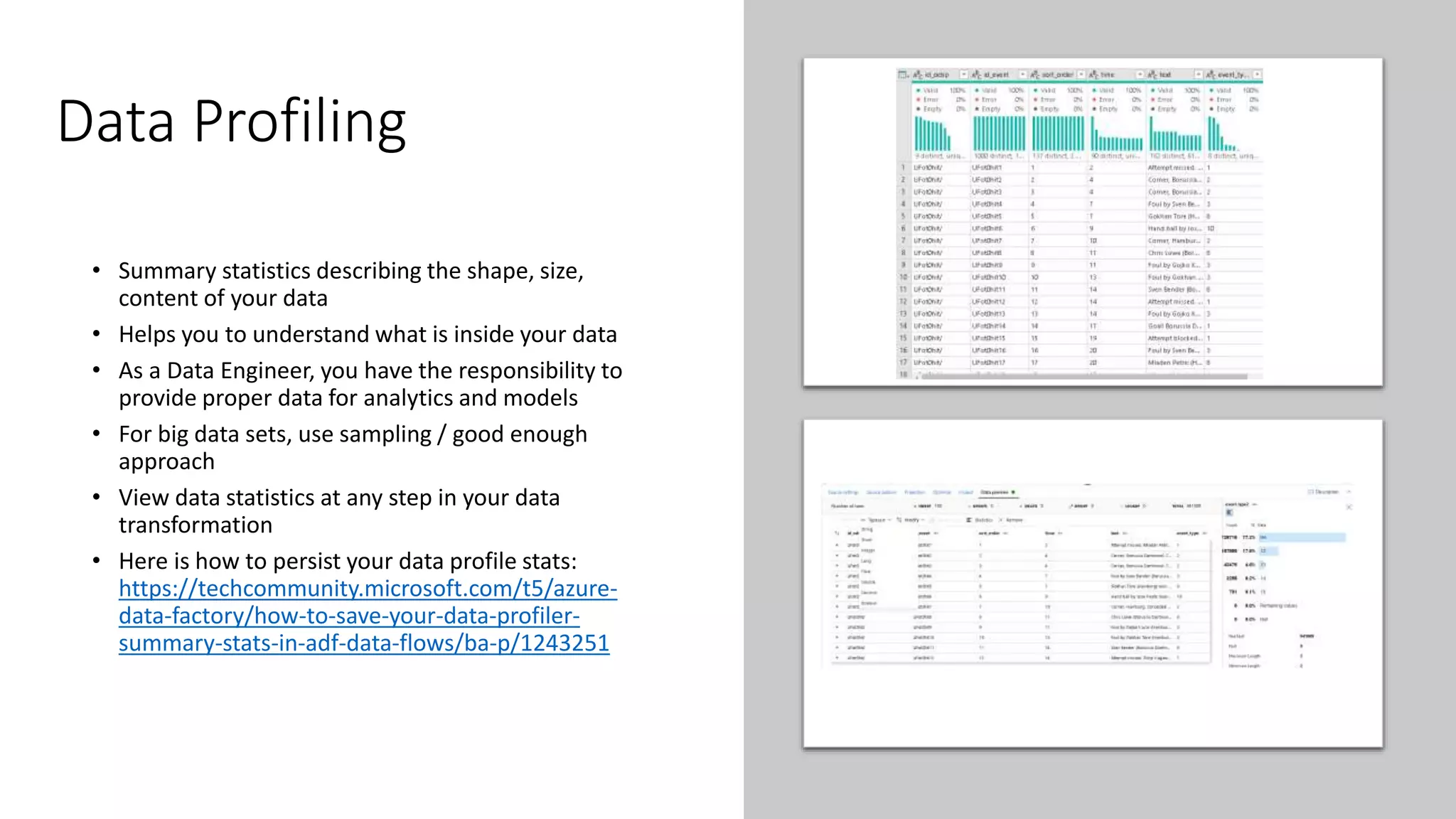
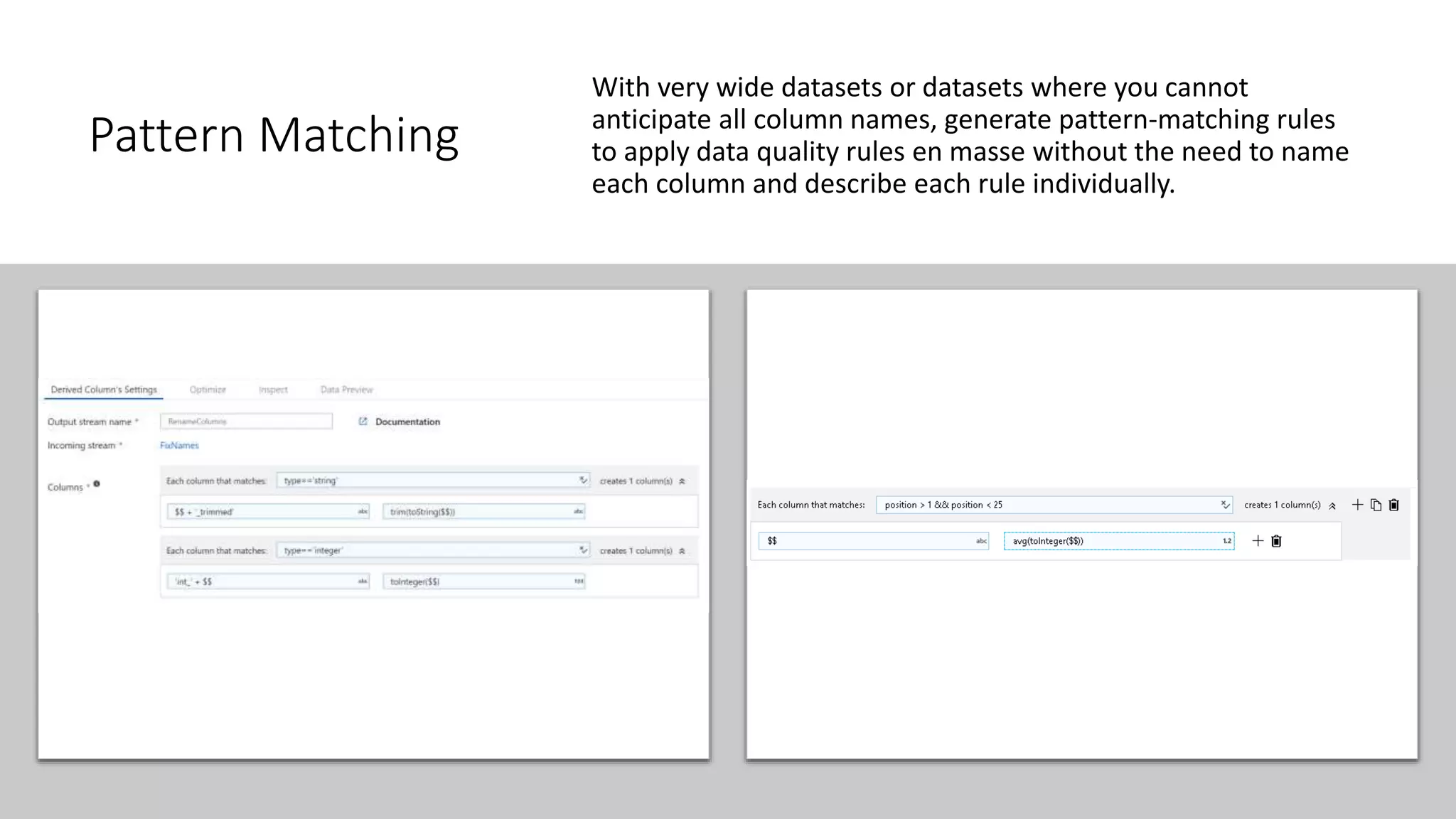


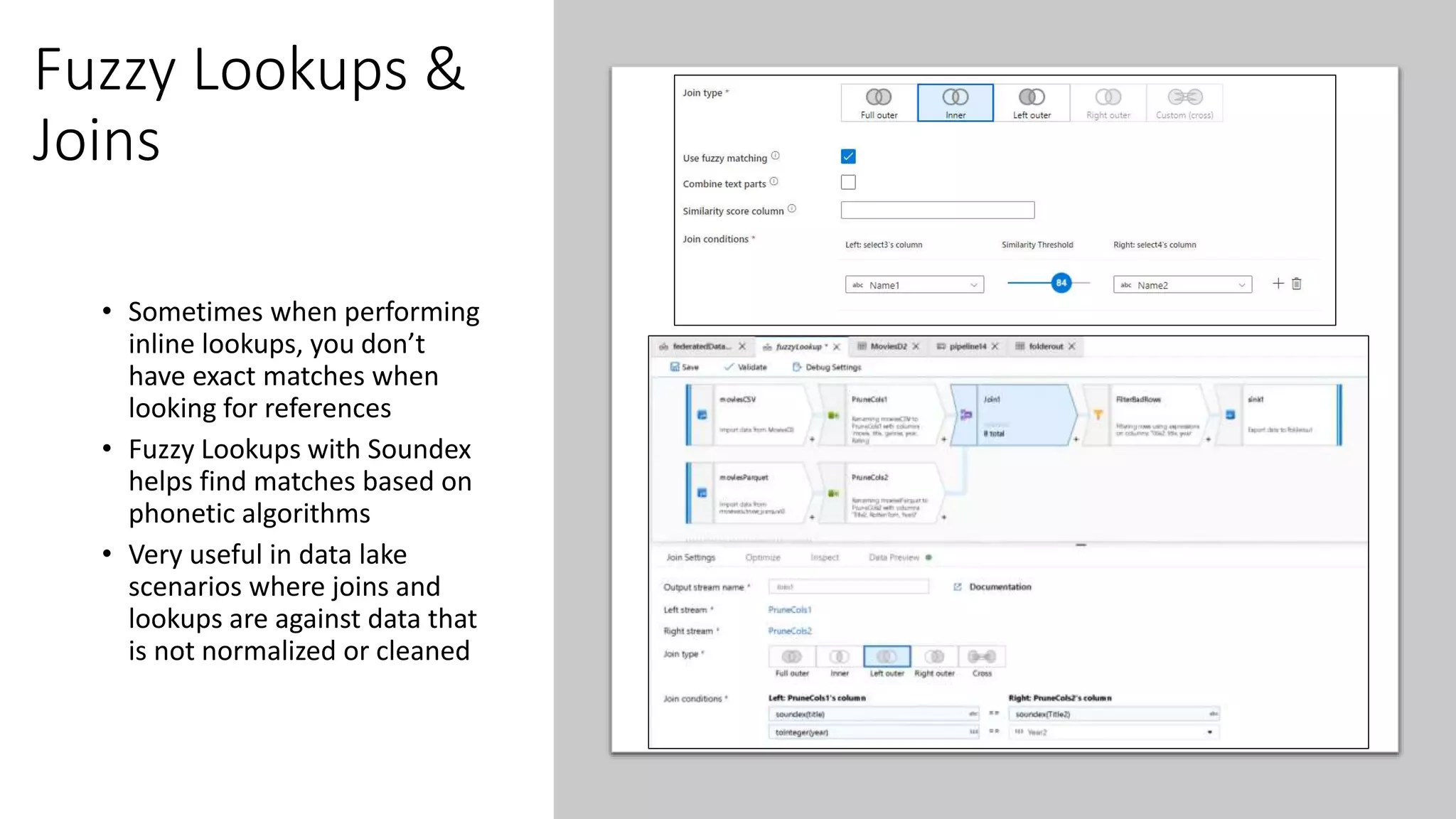
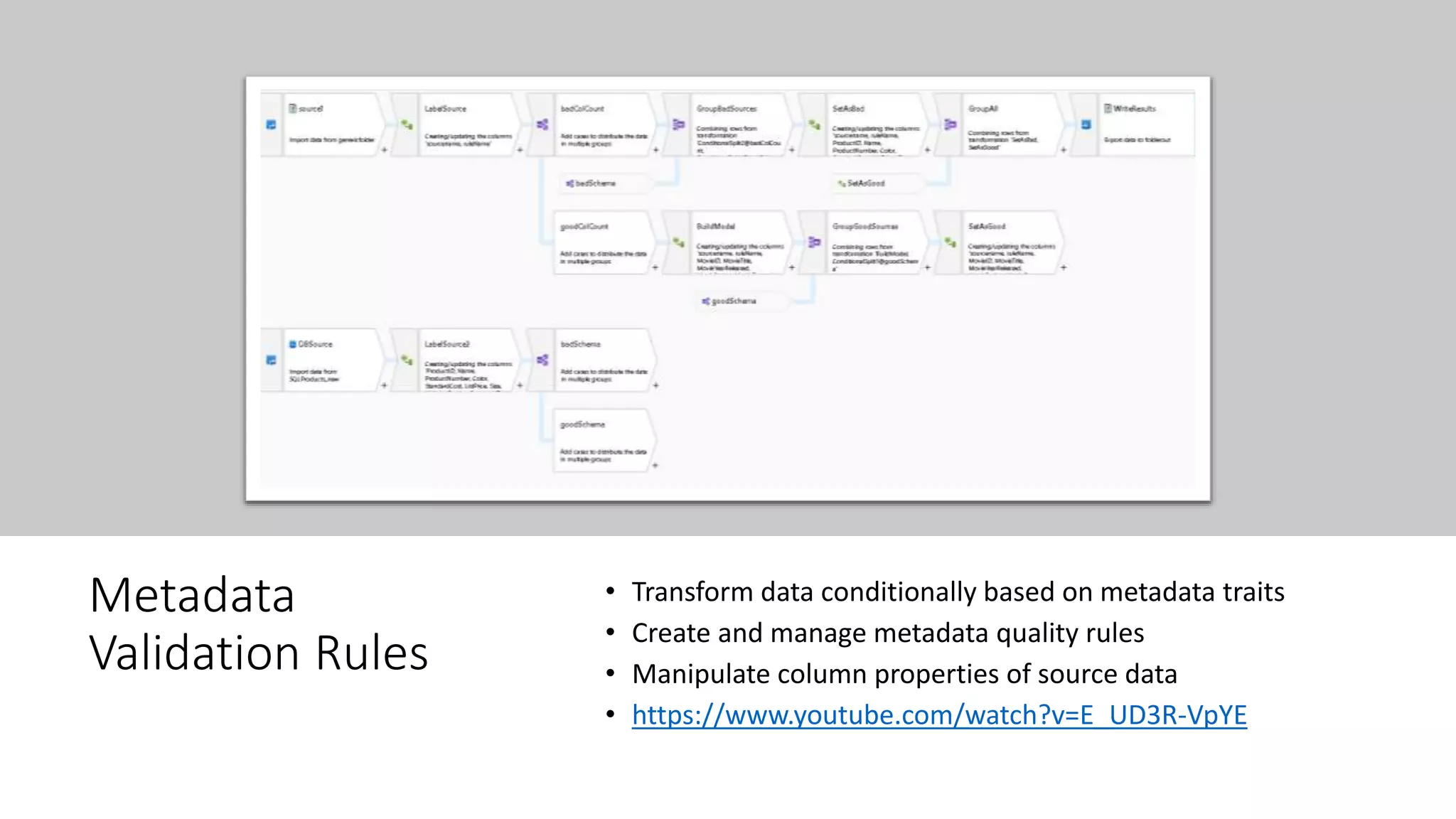
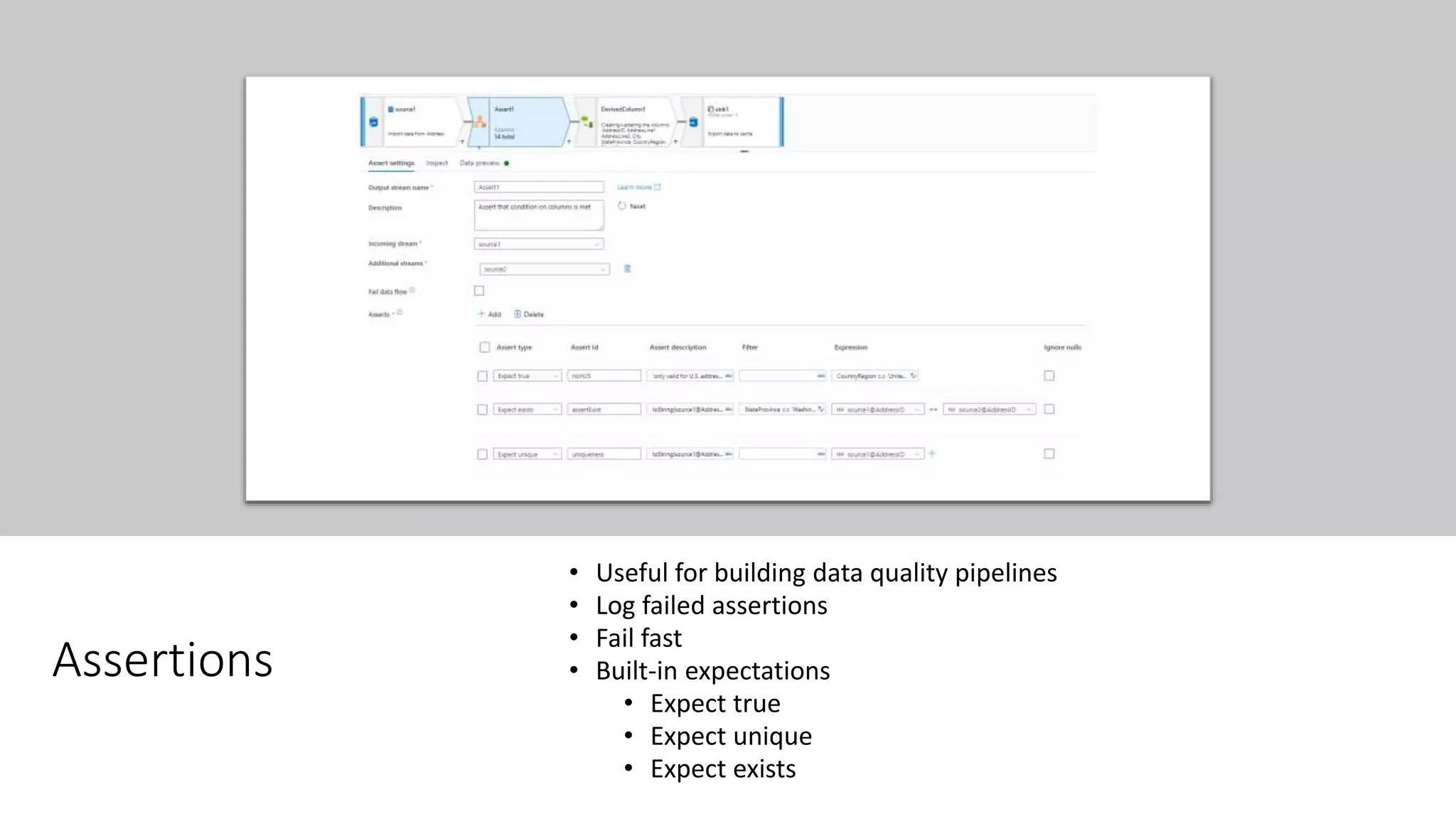













This document provides guidance on building data quality rules and data cleansing into data pipelines. It discusses considerations for data quality in data warehouse and data science scenarios, including verifying data types and lengths, handling null values, domain value constraints, and reference data lookups. It also provides examples of techniques for replacing values, splitting data based on values, data profiling, pattern matching, enumerations/lookups, de-duplicating data, fuzzy joins, validating metadata rules, and using assertions.









































![Informatica data quality[IDQ] 9](https://cdn.slidesharecdn.com/ss_thumbnails/informaticadataquality9-121217045711-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)













































