
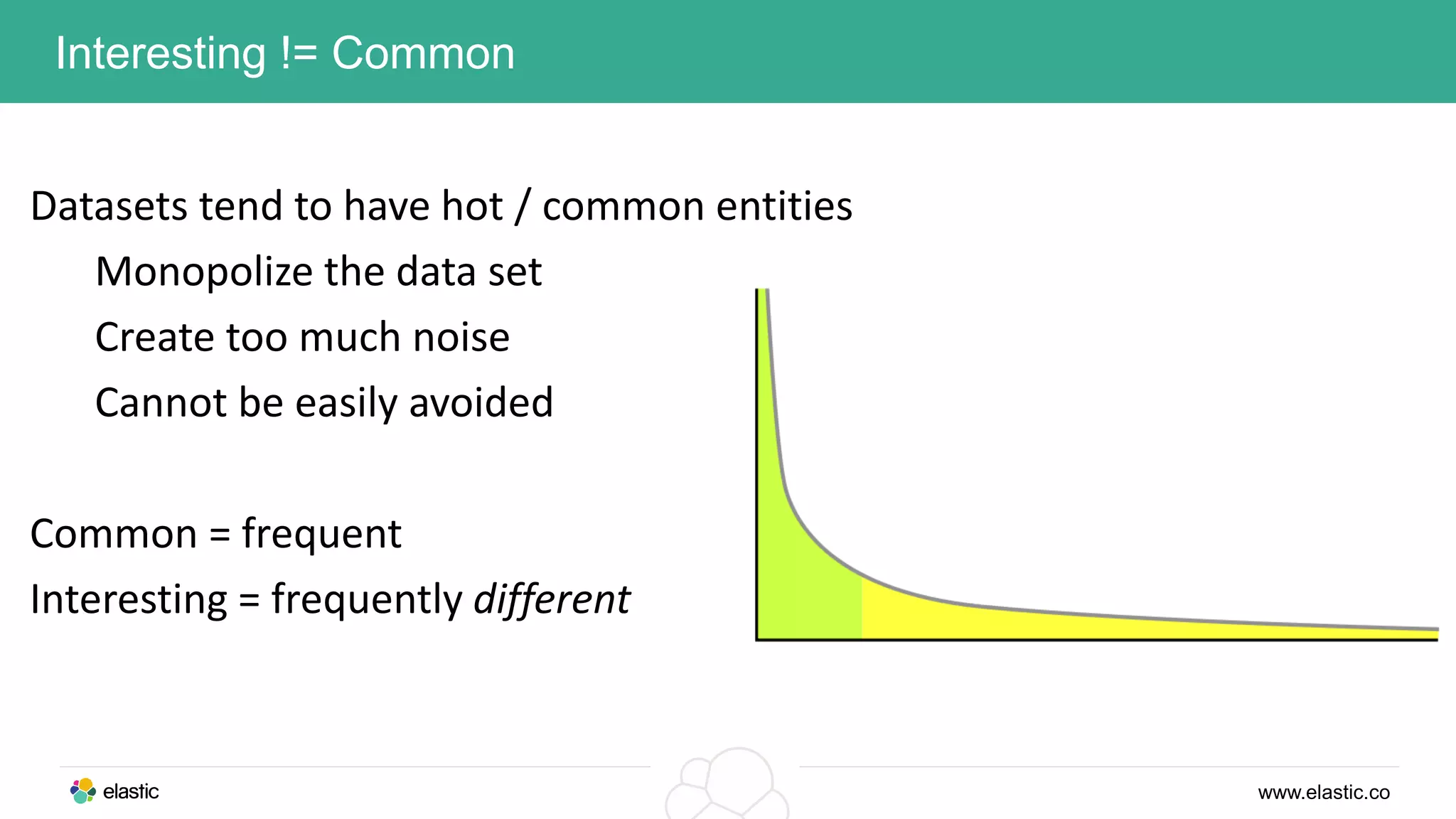
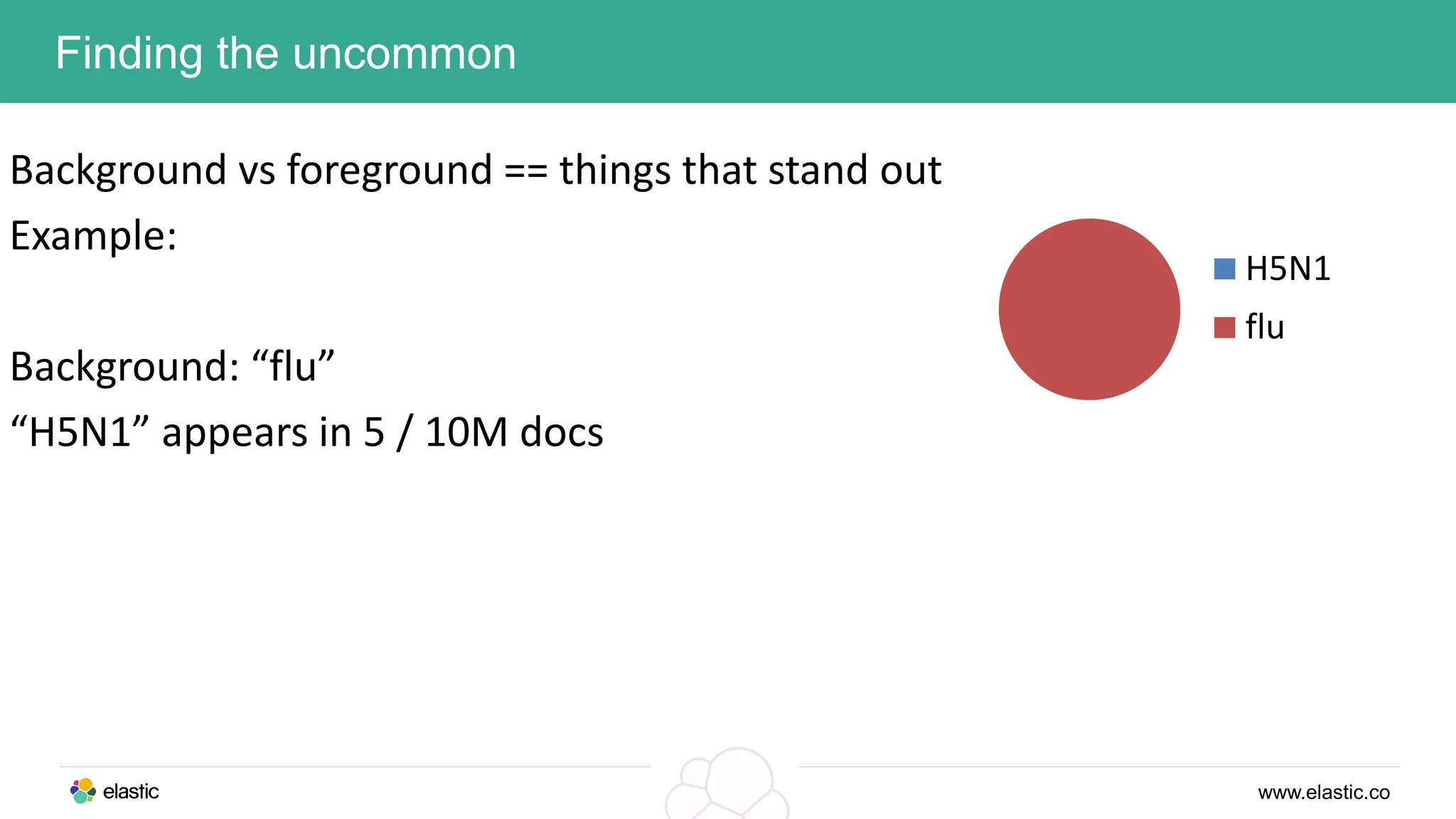



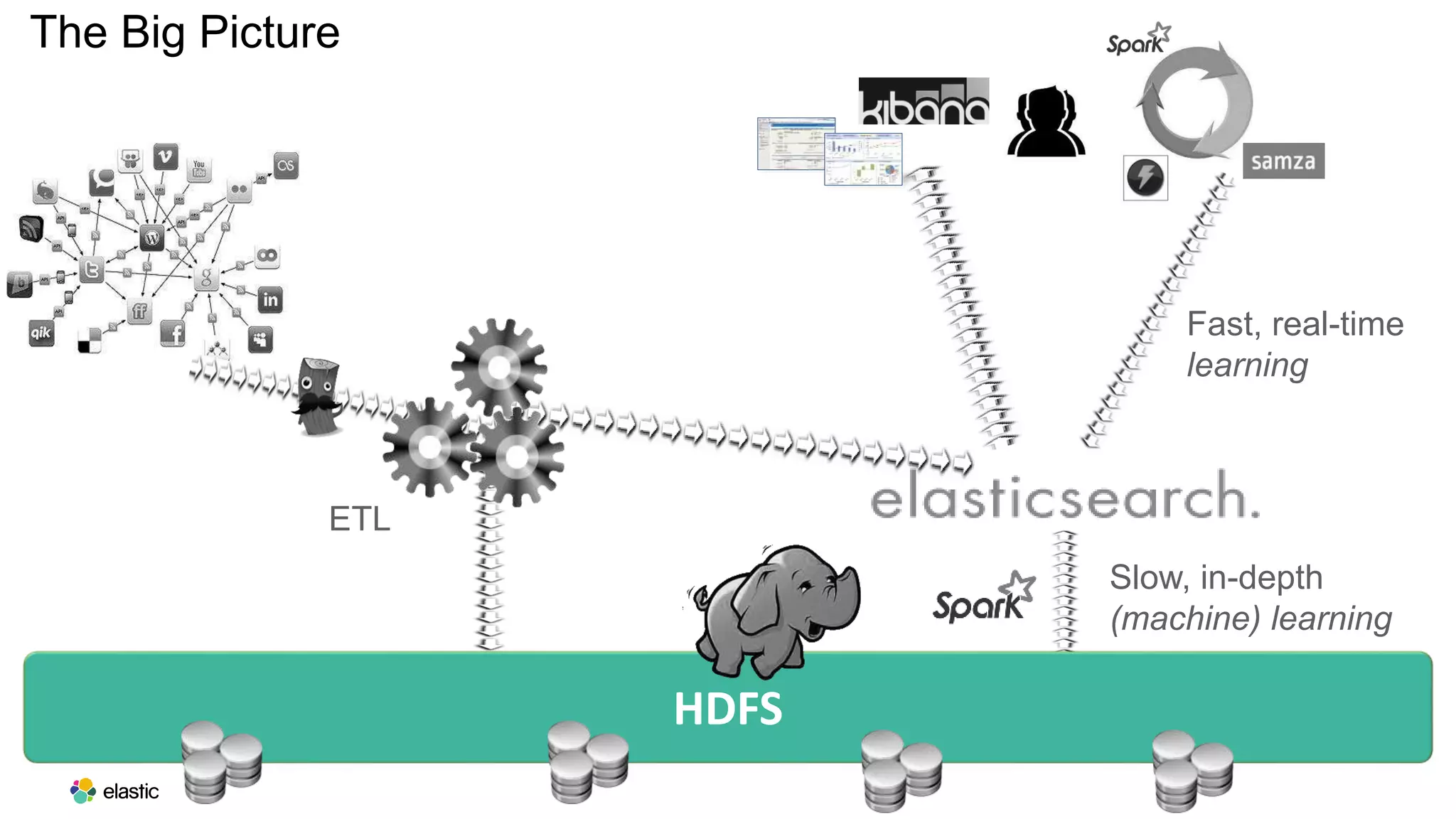




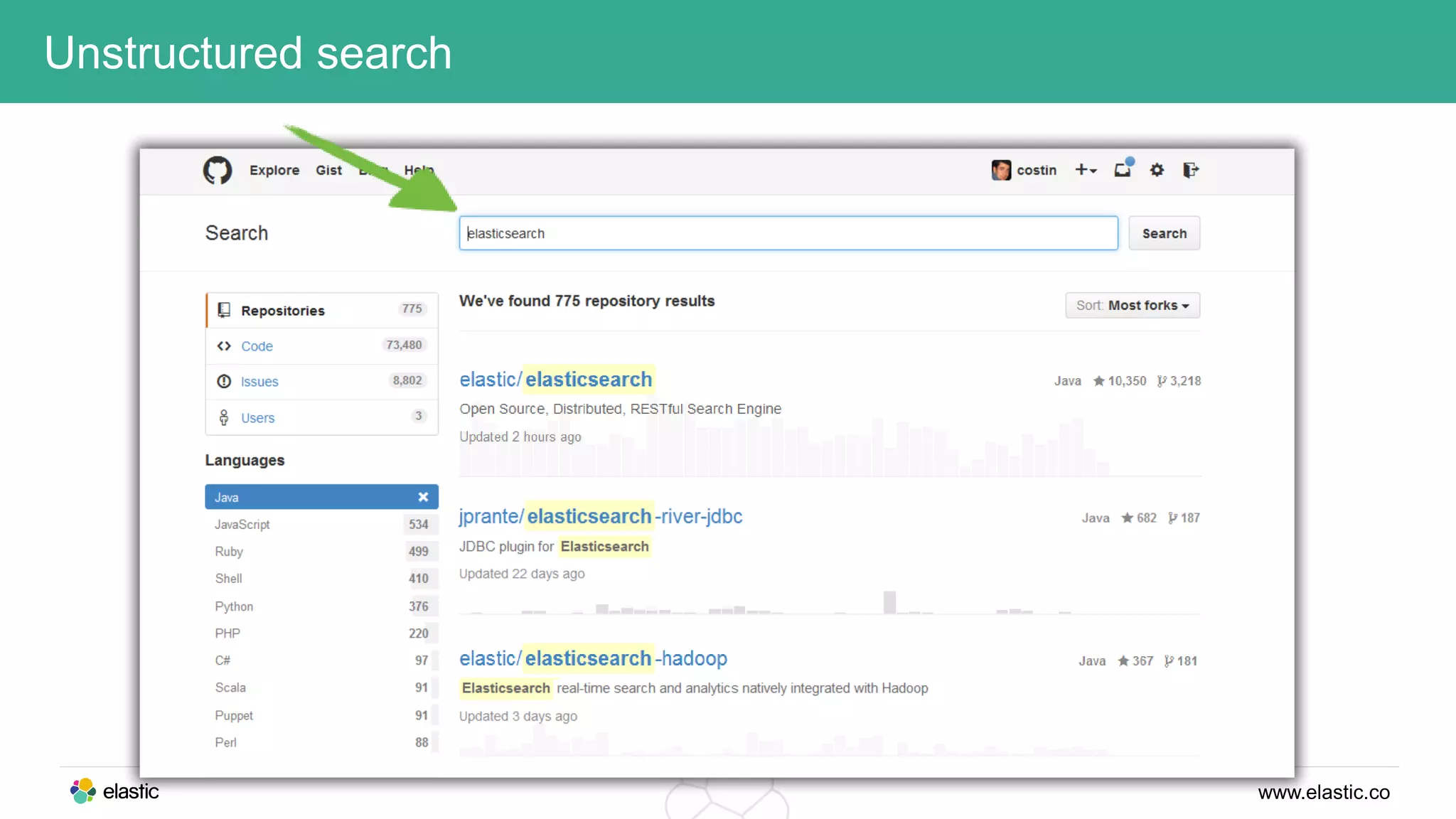
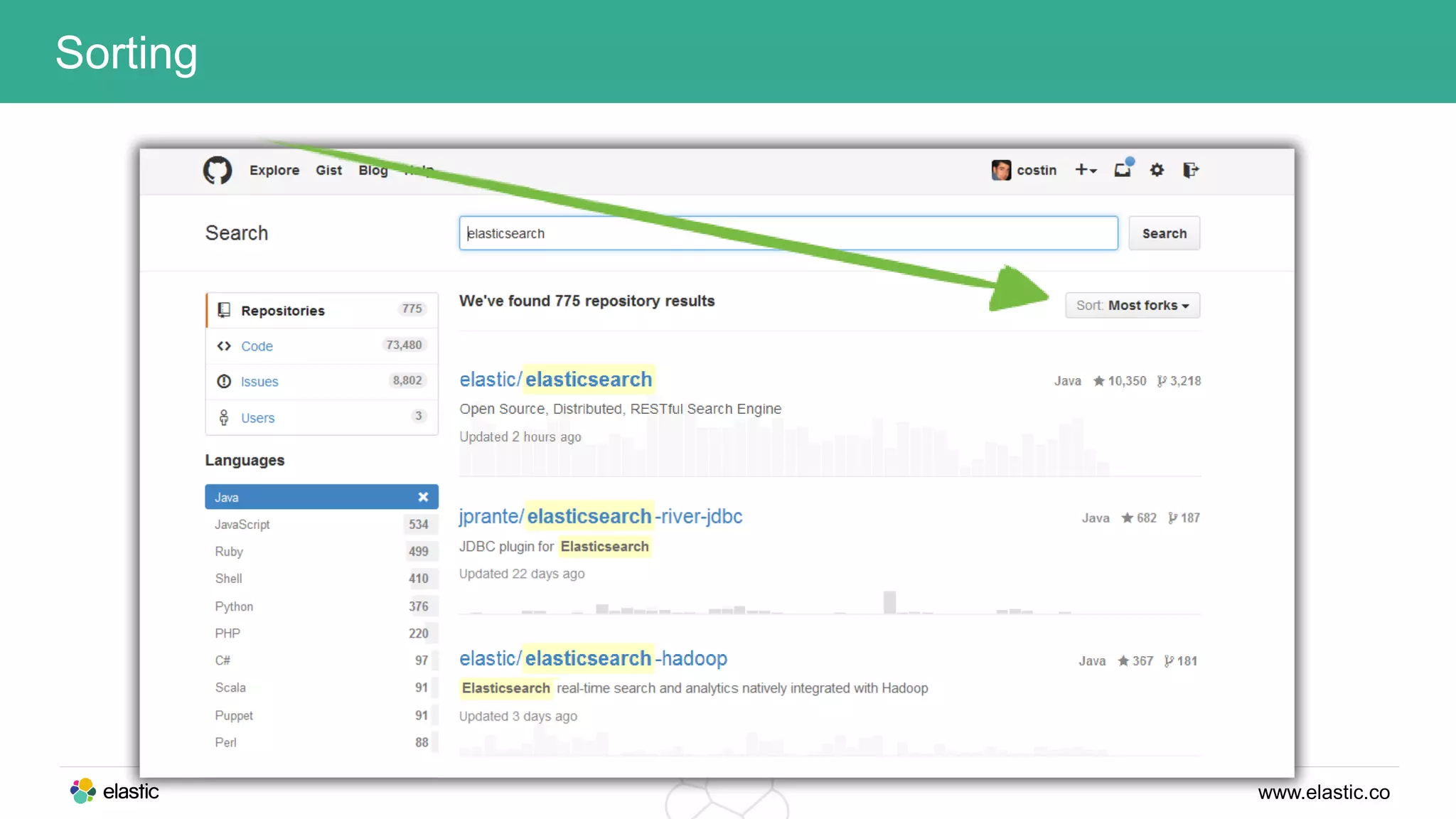
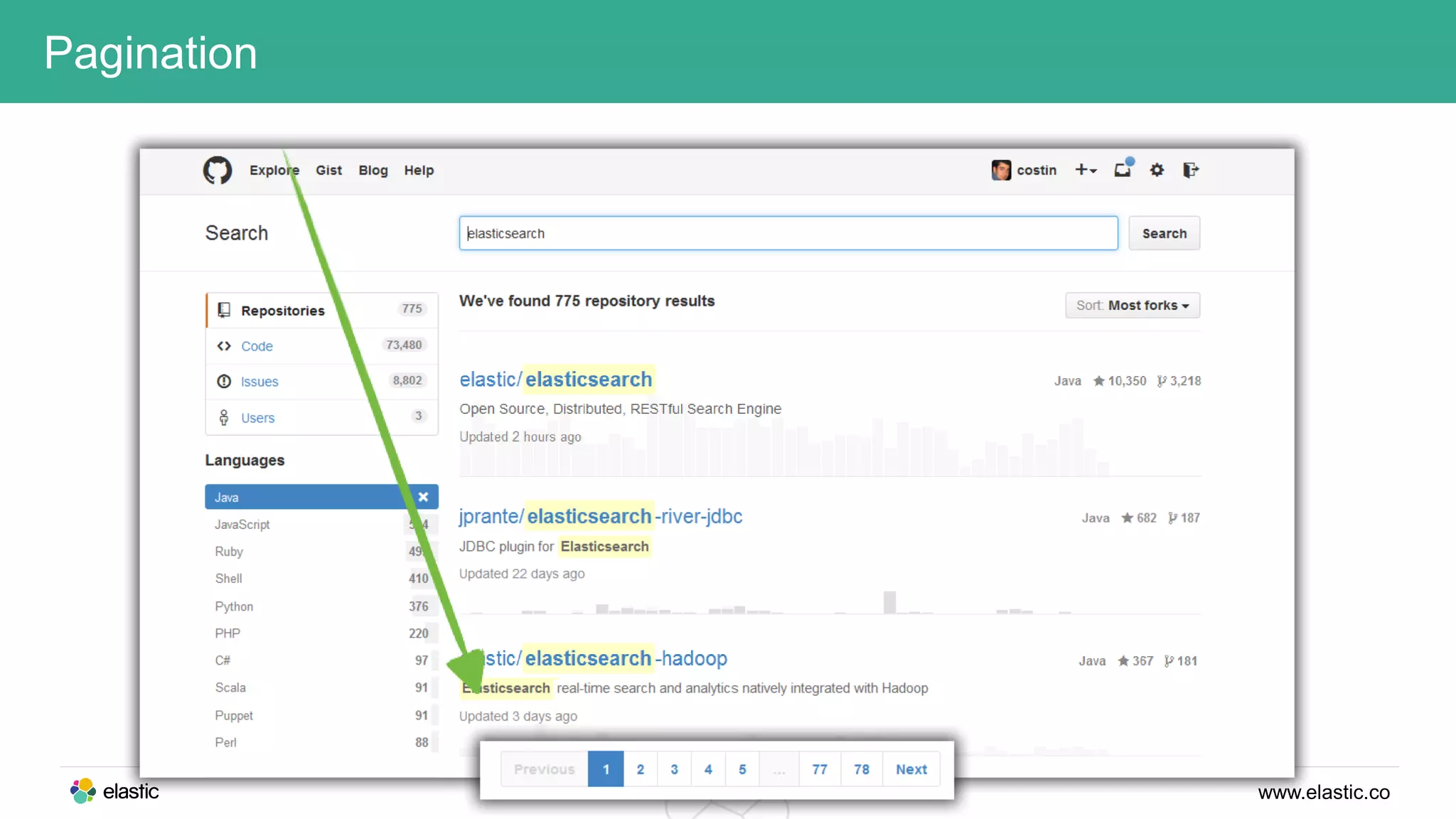
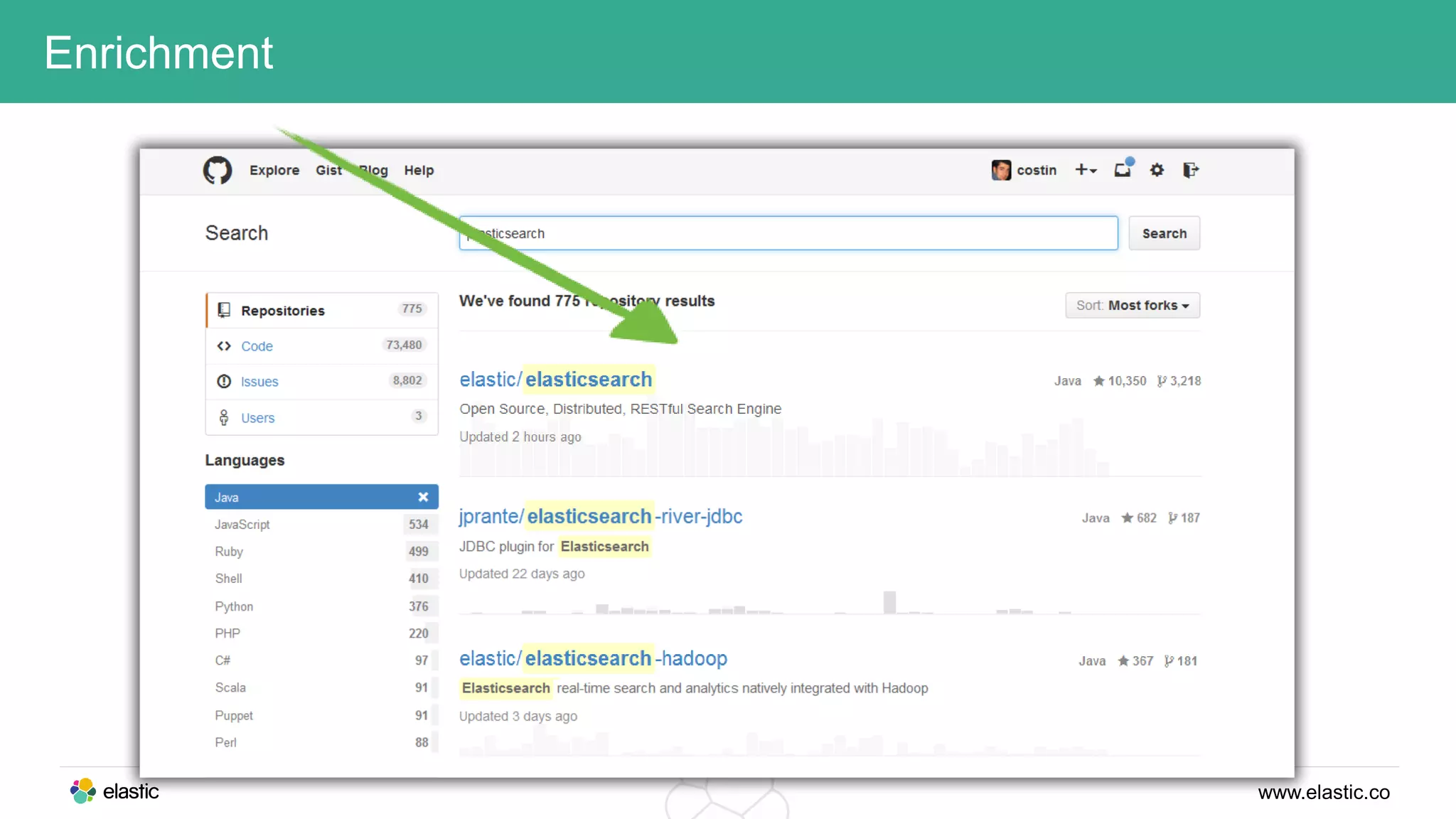
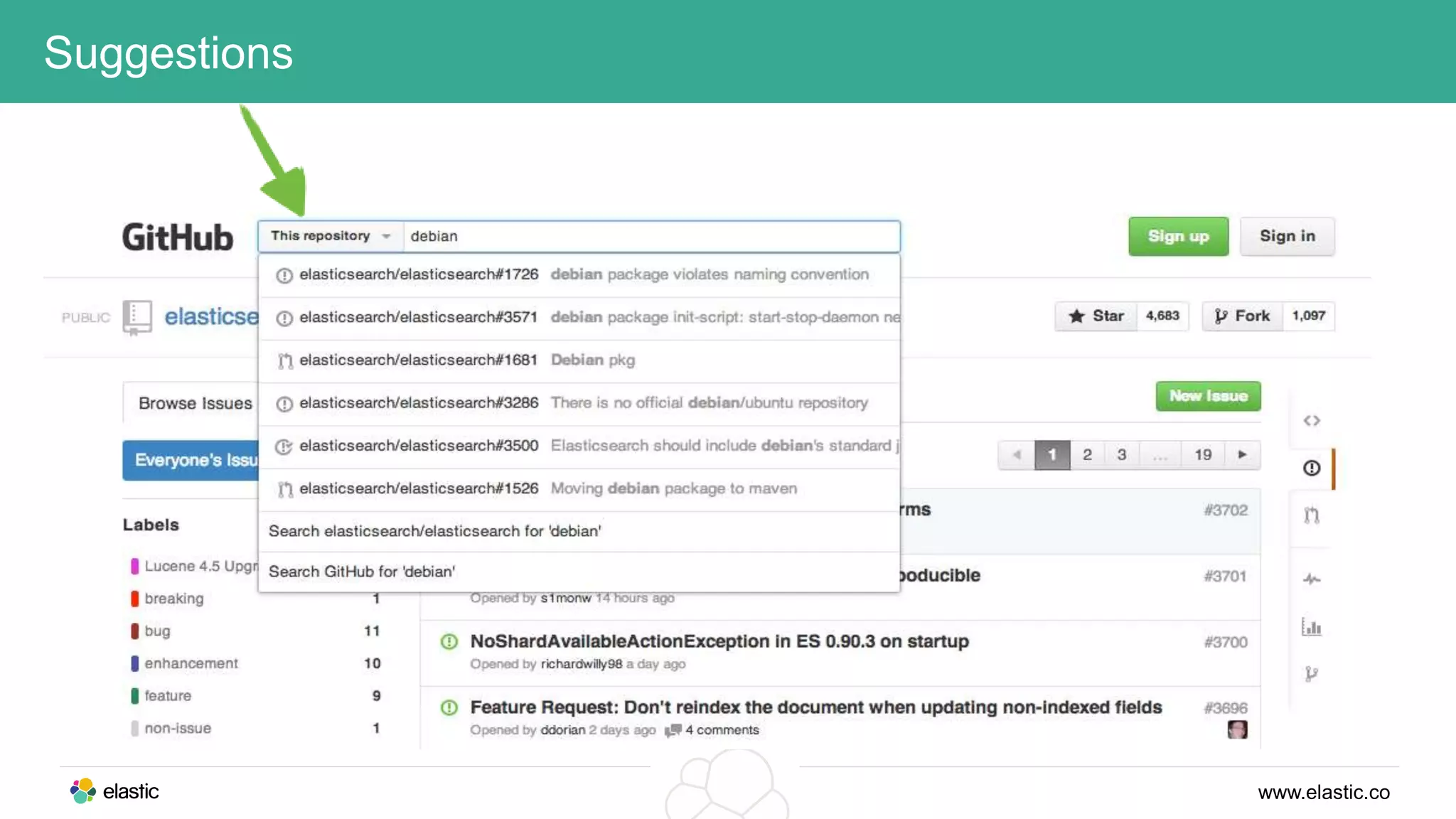
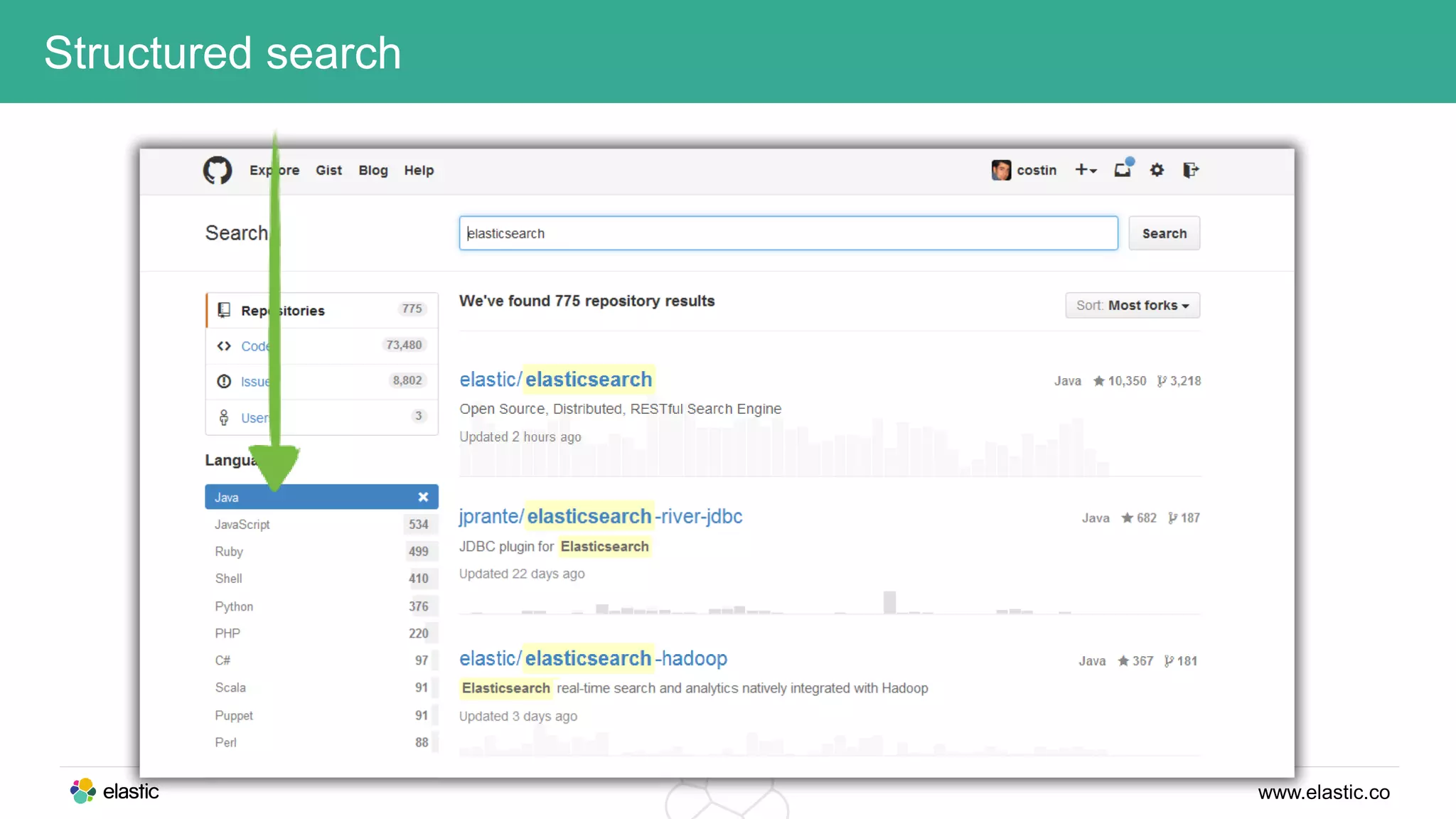
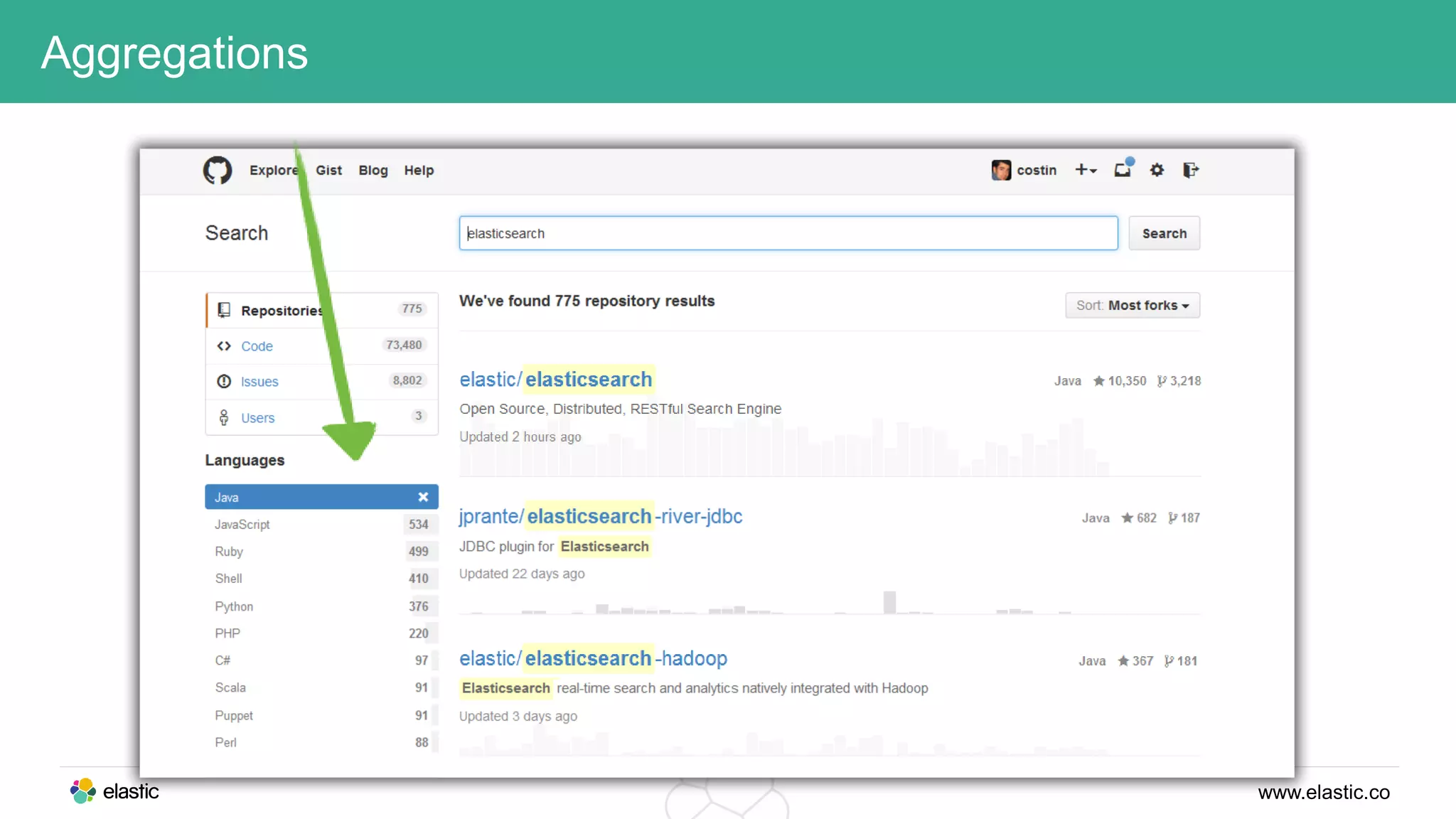
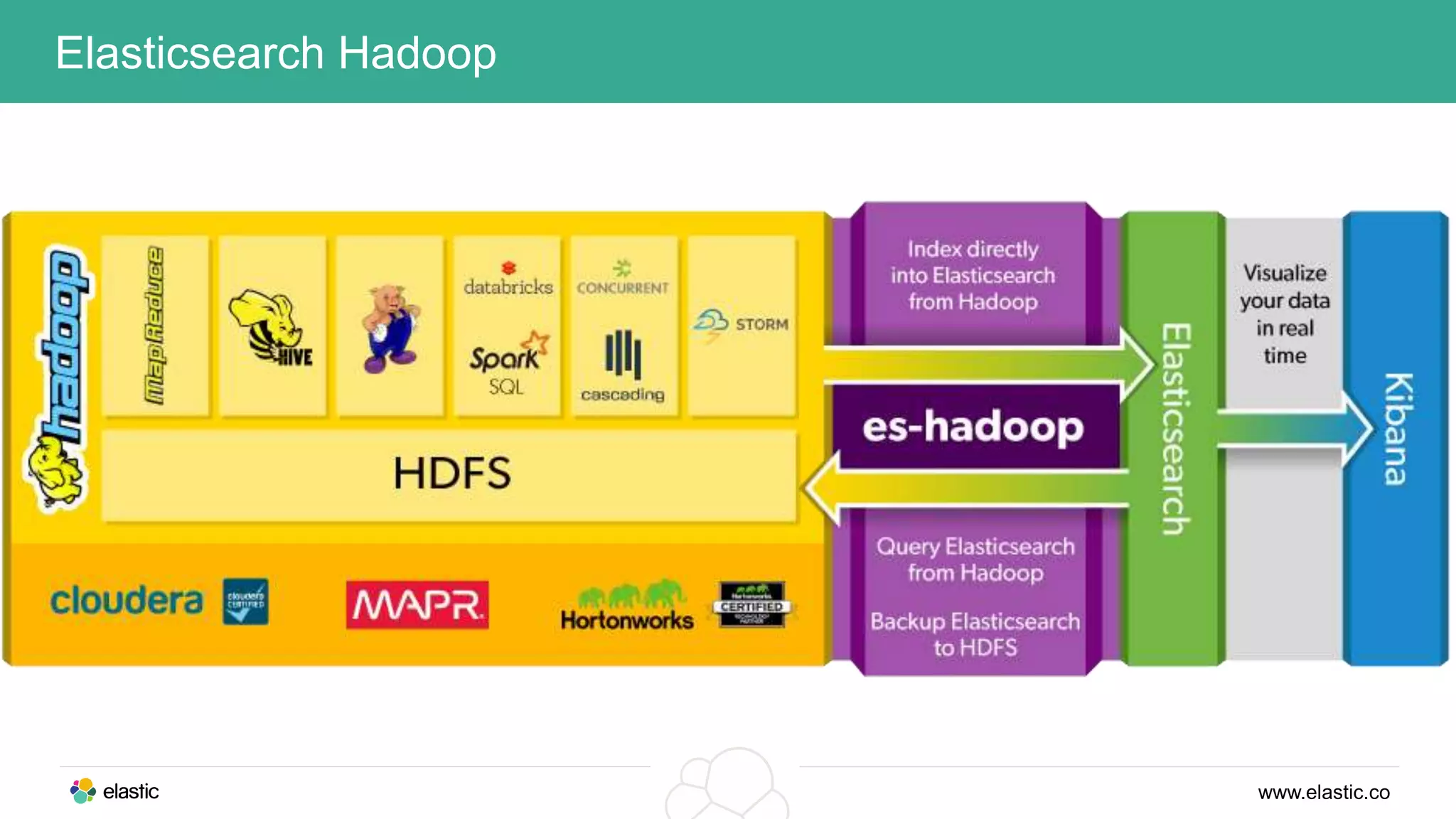







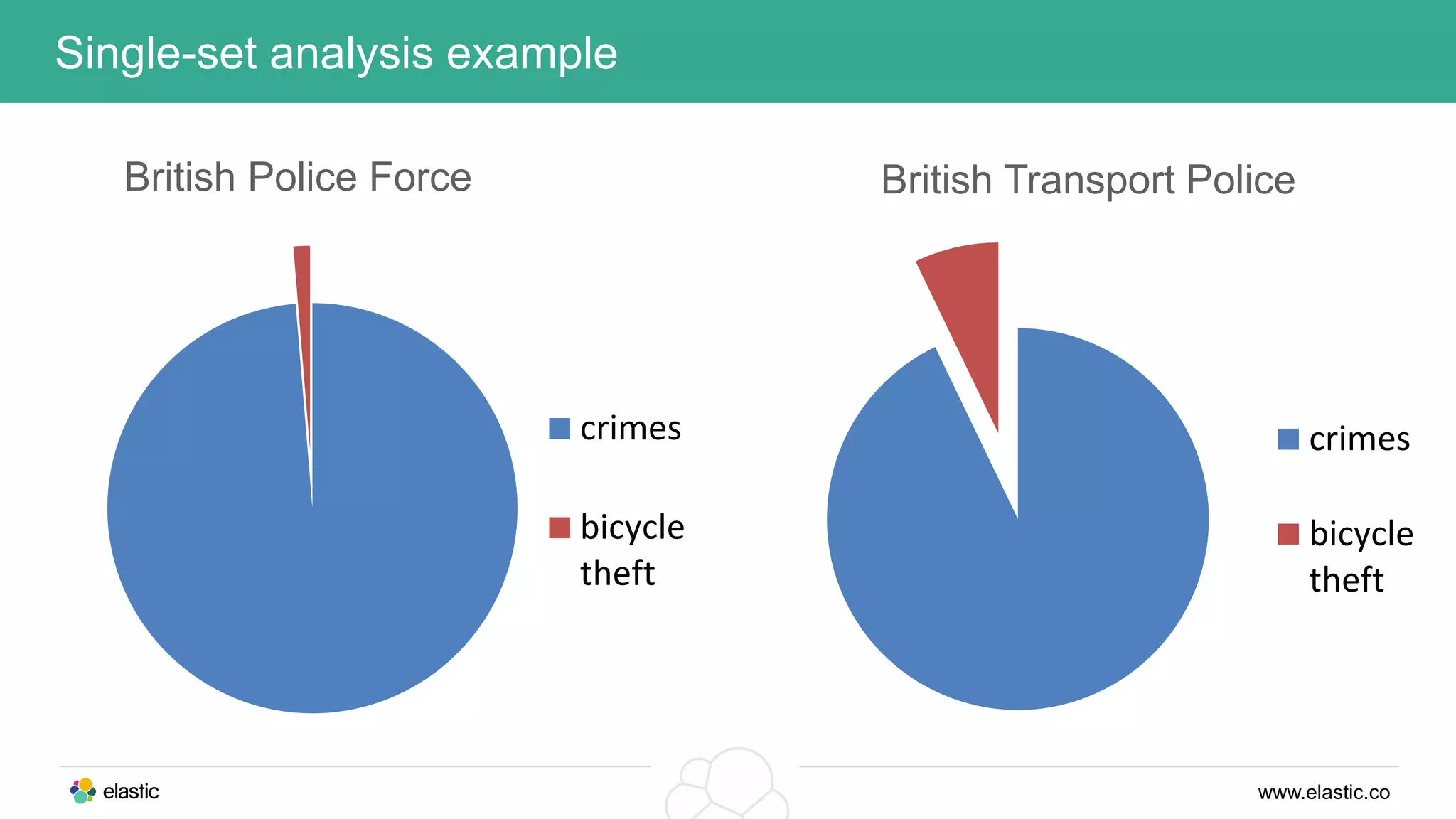
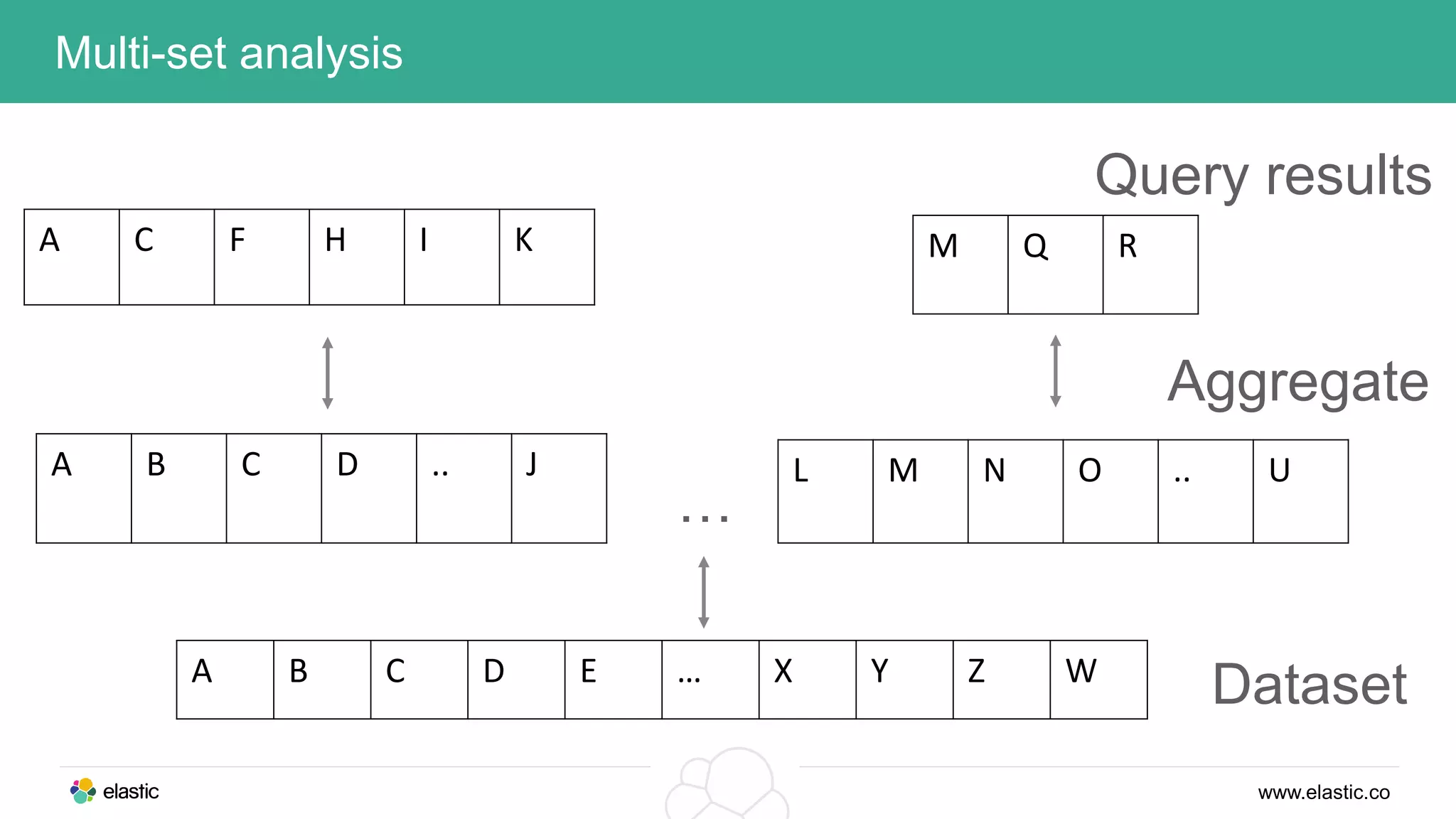
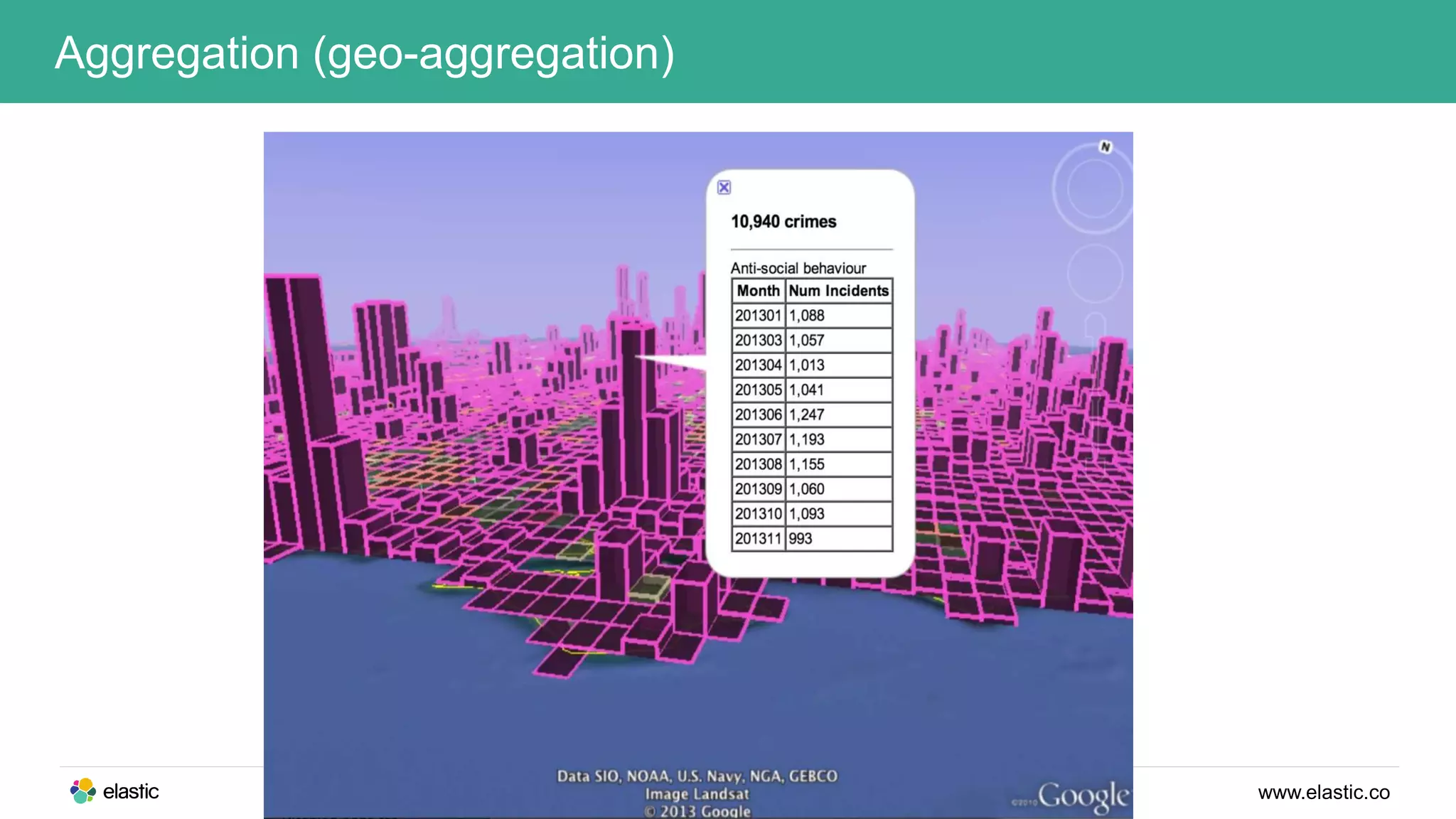
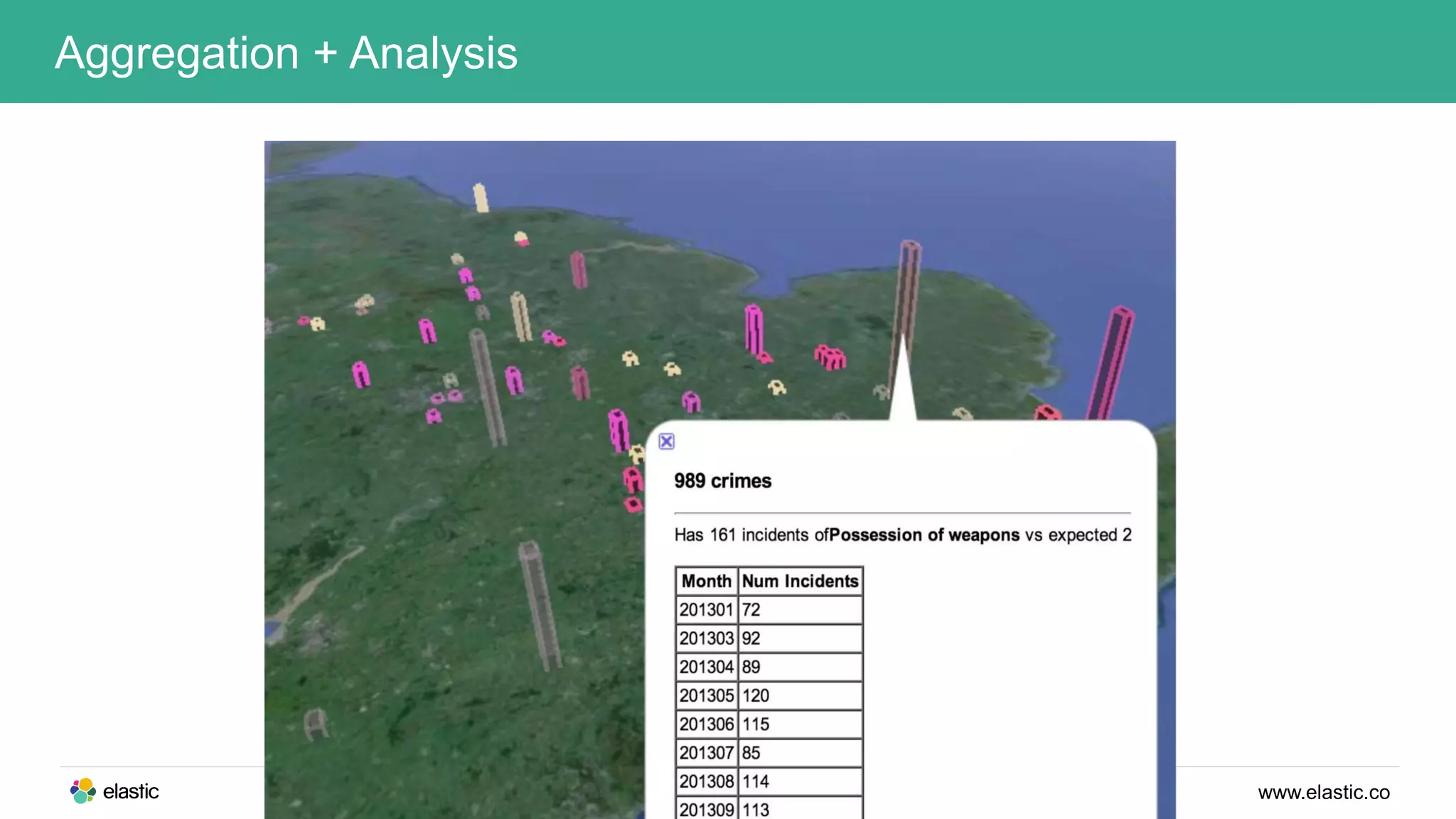




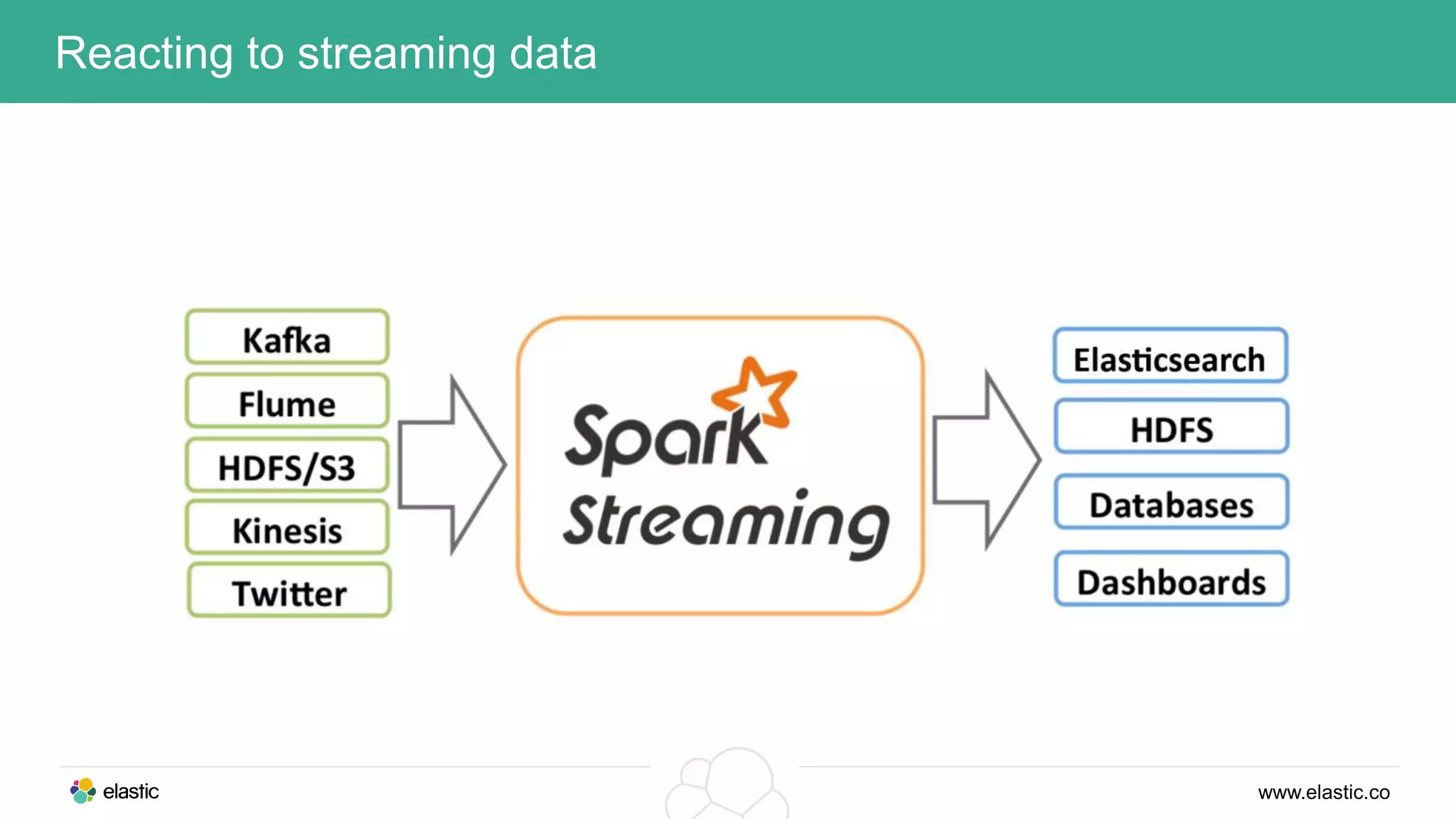
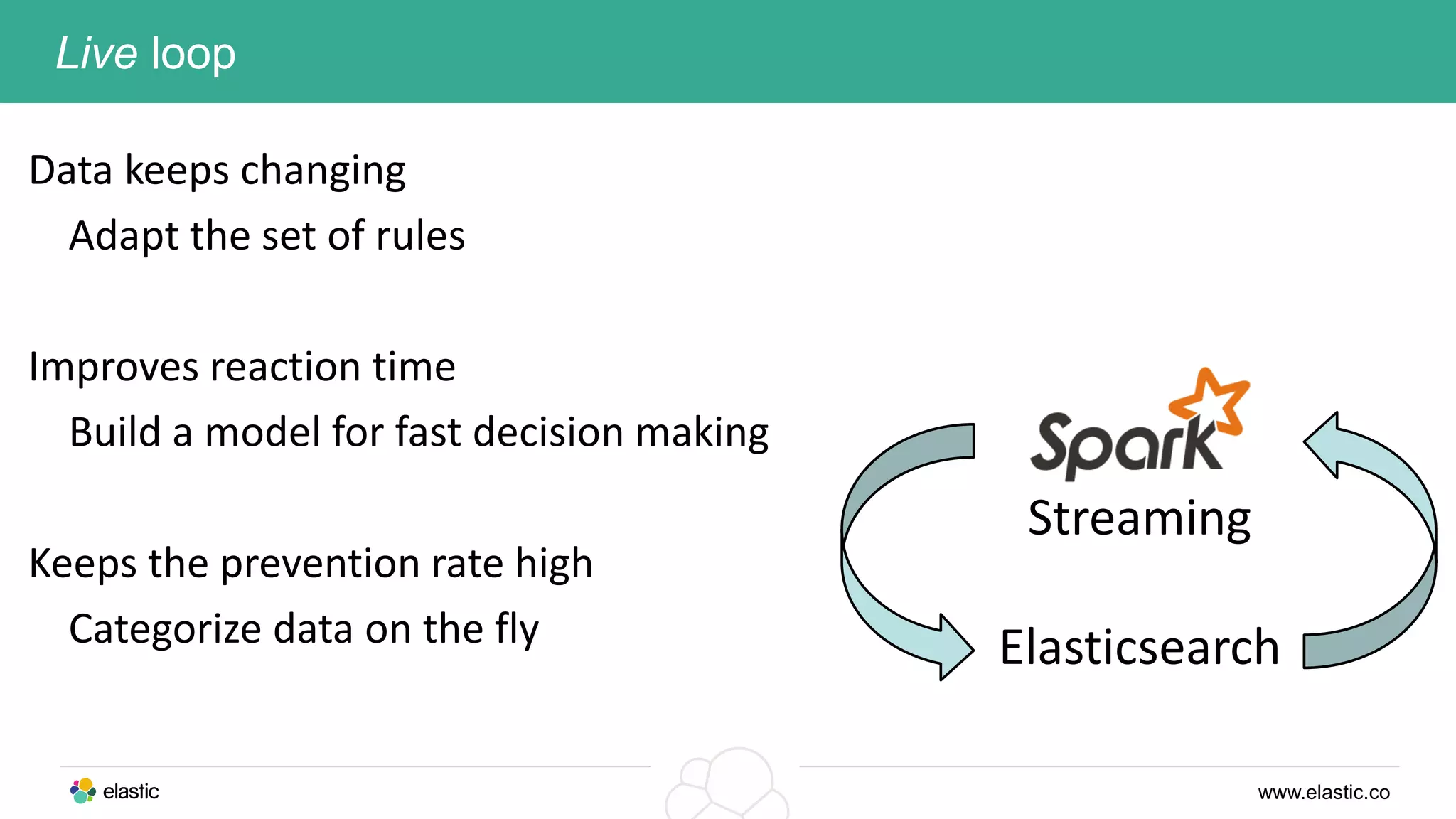
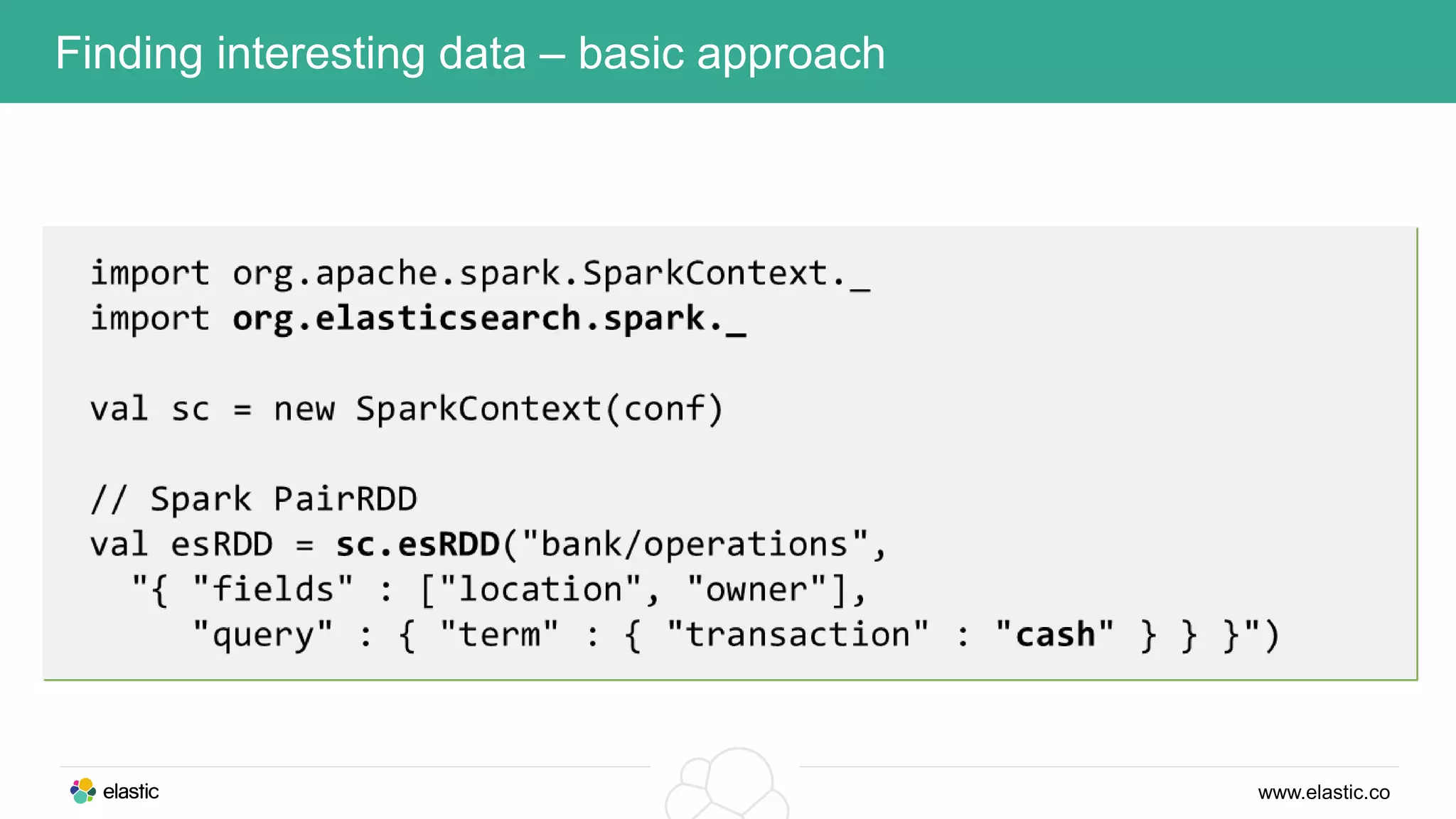
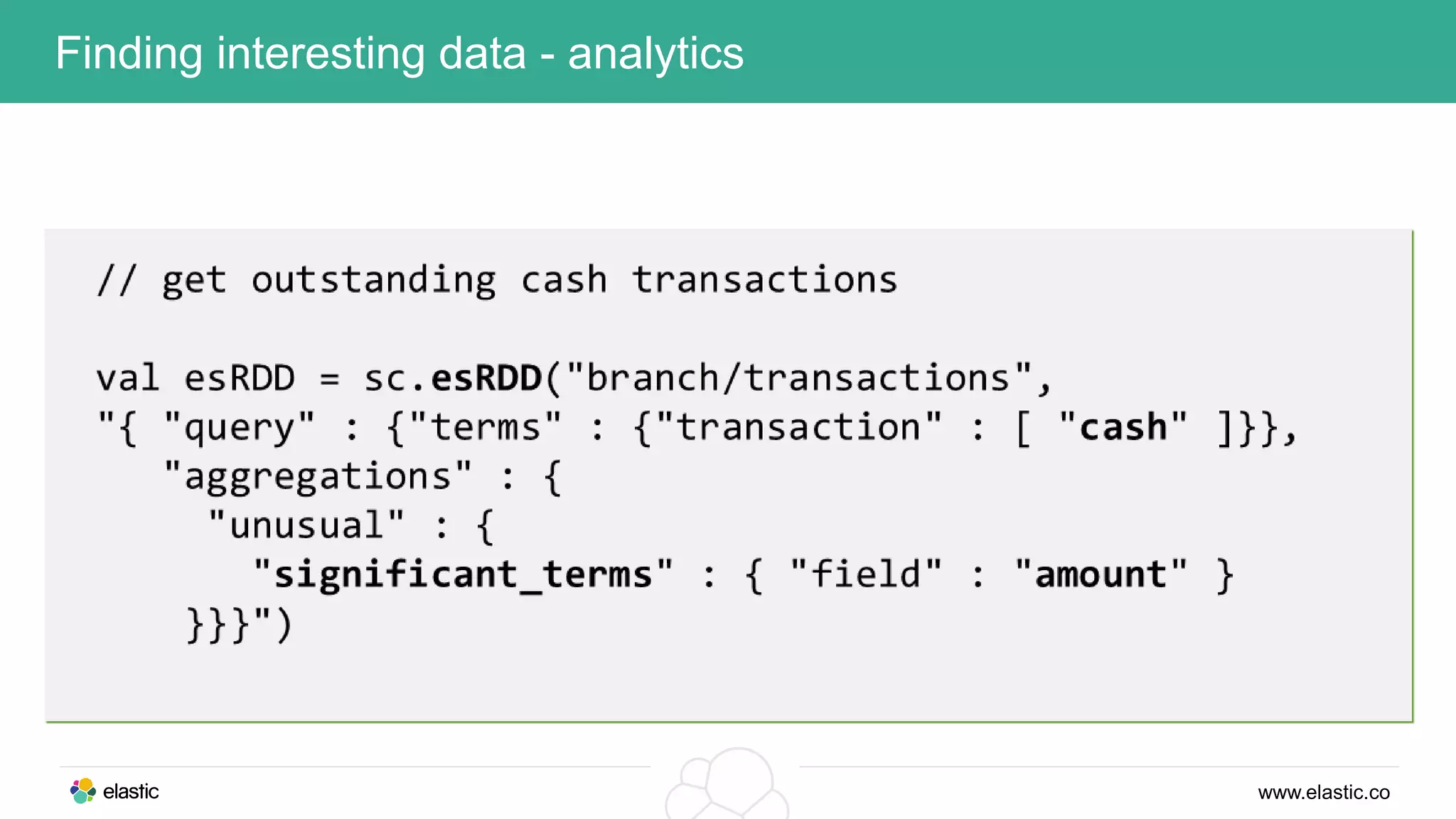















































This document discusses using a stack of Hadoop, Spark, and Elasticsearch to perform anomaly detection on large datasets in both batch and real-time. Hadoop is used for large-scale data storage and preprocessing. Spark is used to perform in-depth analysis to identify common entities and build models. Elasticsearch allows searching the data in real-time and performing aggregations to identify uncommon entities. A live loop continuously adapts the models to react to streaming data and improve anomaly detection over time.











































![[Vancouver] part 2 understanding the relevance of your search with elasticse...](https://cdn.slidesharecdn.com/ss_thumbnails/vancouverpart2understandingtherelevanceofyoursearchwithelasticsearchandkibana-210218165954-thumbnail.jpg?width=640&height=640&fit=bounds)







































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


