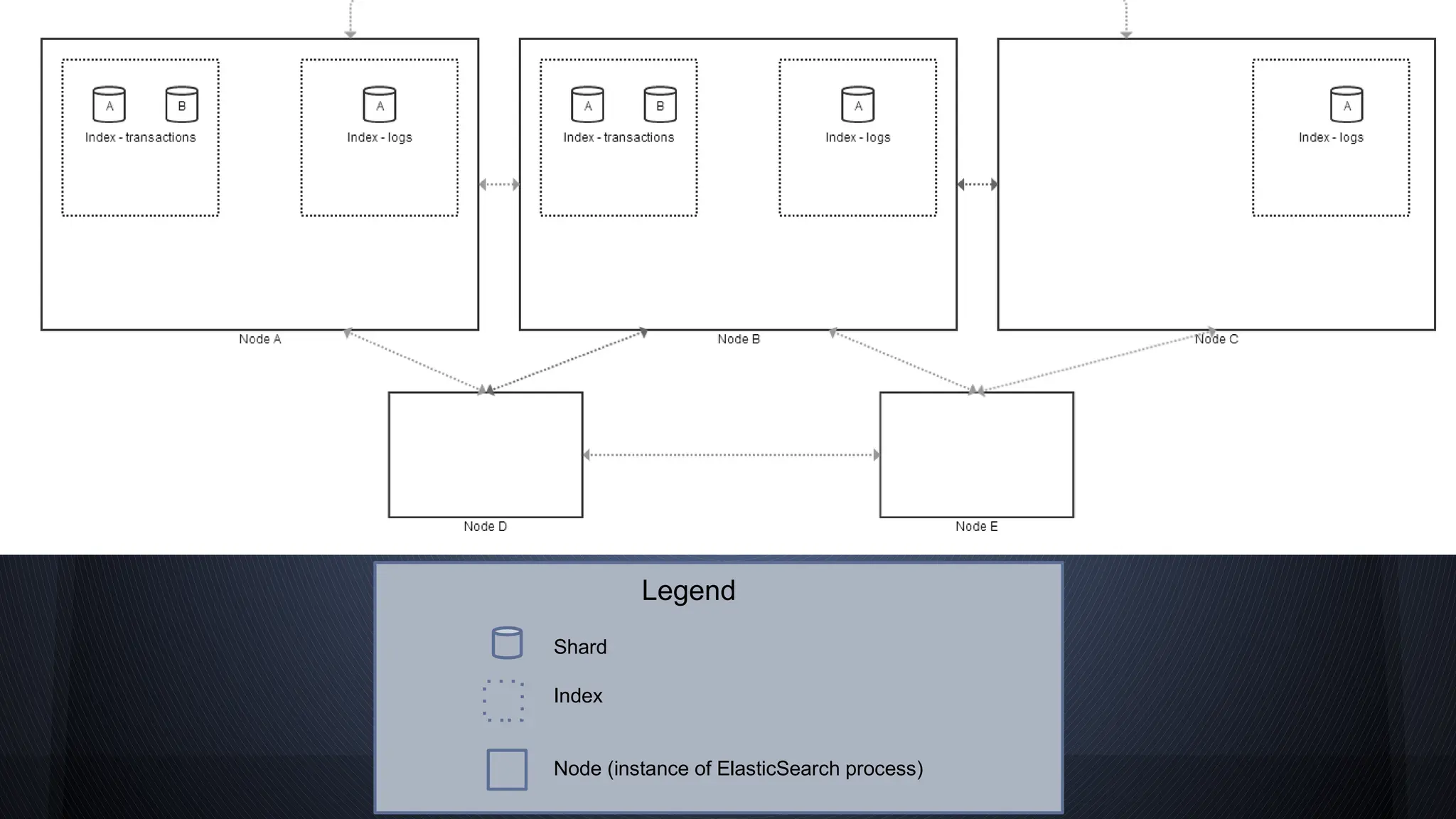
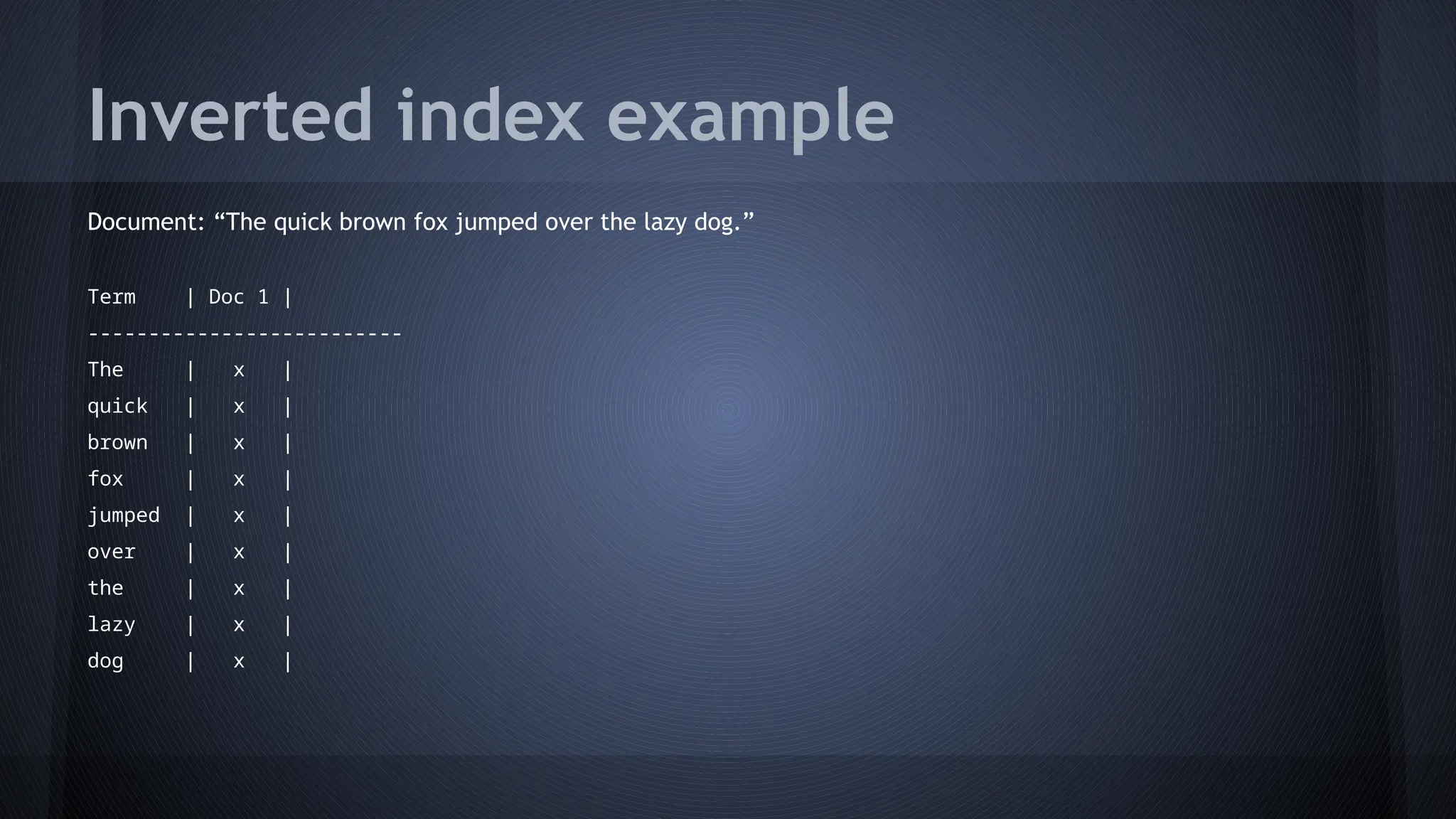
The document discusses the ELK stack, comprising Elasticsearch, Logstash, and Kibana, which serves for searching, analyzing, and visualizing data in real time. Elasticsearch is a distributed, schema-less document-oriented database that supports complex searching and data analytics. Logstash is a data processing tool for importing and exporting log data, while Kibana is a customizable dashboard for visualizing data stored in Elasticsearch.
















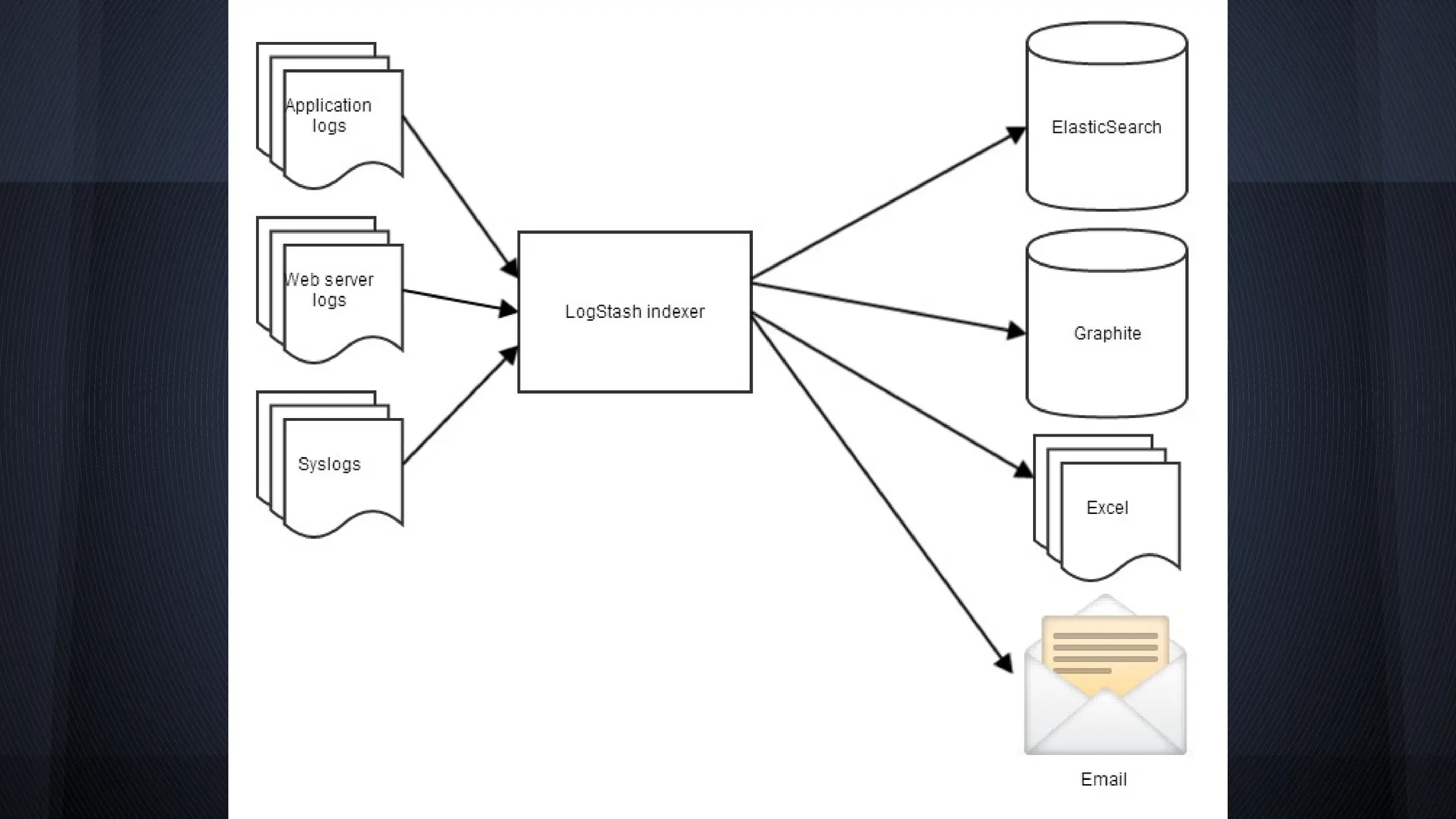
![What problem does it solve?
● How to parse and analyze log data from
many sources?
Mar 12 12:00:08 server2 rcd[308]: Loaded 12 packages in 'ximian-red-carpet|351'
(0.01878 seconds)
[2014-05-06 08:04:00.333] [ERROR] - core - bad thing happened
[Wed Oct 11 14:32:52 2000] [error] [client 127.0.0.1] client denied by server
configuration: /export/home/live/ap/htdocs/test](https://image.slidesharecdn.com/theelkstack-lunchandlearn-240808101813-ec027b13/75/The-ELK-Stack-Launch-and-Learn-presentation-19-2048.jpg)

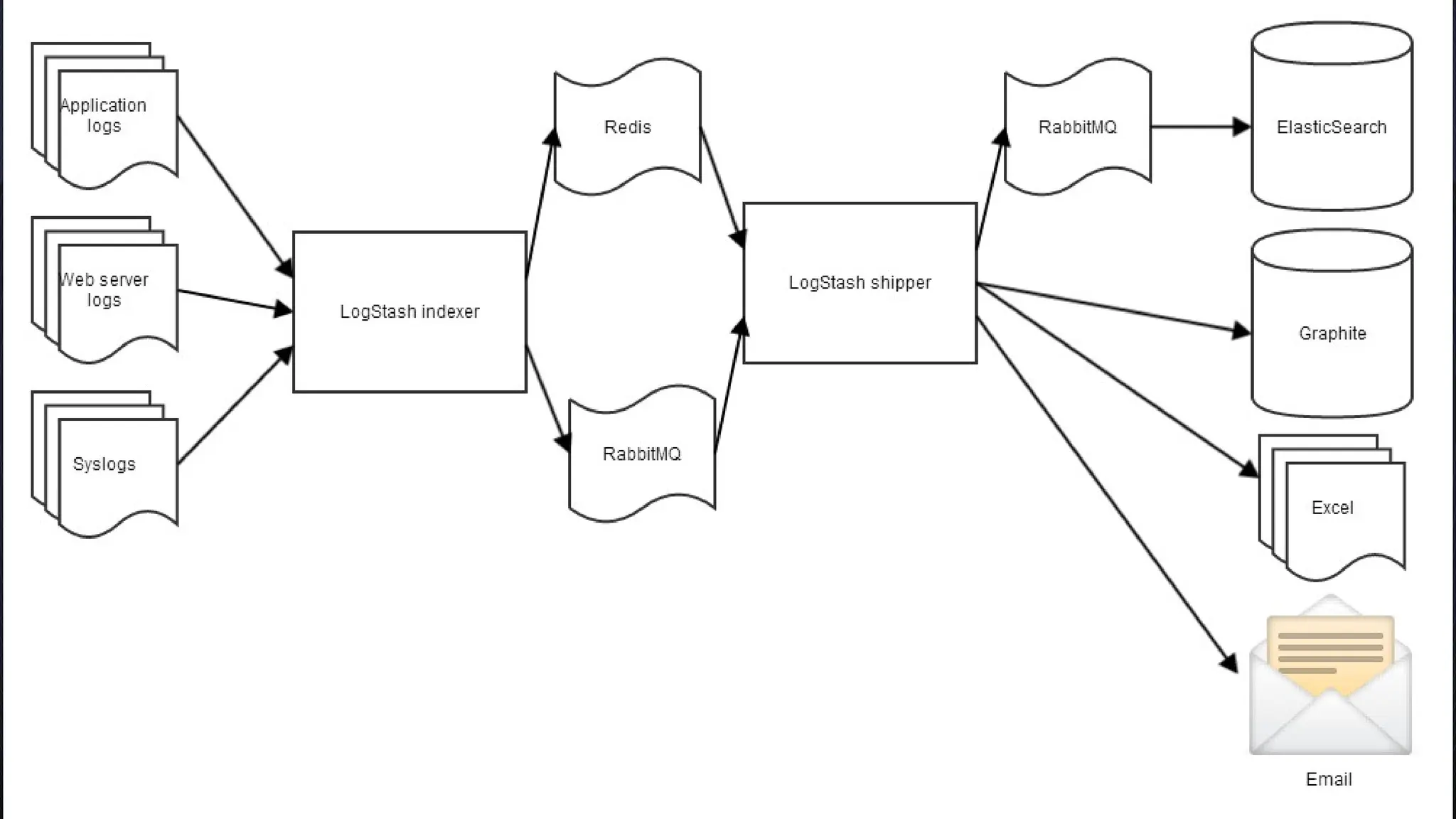























![What problem does it solve?
● How to parse and analyze log data from
many sources?
Mar 12 12:00:08 server2 rcd[308]: Loaded 12 packages in 'ximian-red-carpet|351'
(0.01878 seconds)
[2014-05-06 08:04:00.333] [ERROR] - core - bad thing happened
[Wed Oct 11 14:32:52 2000] [error] [client 127.0.0.1] client denied by server
configuration: /export/home/live/ap/htdocs/test](https://crownmelresort.com/image.slidesharecdn.com/theelkstack-lunchandlearn-240808101813-ec027b13/75/The-ELK-Stack-Launch-and-Learn-presentation-19-2048.jpg)
























































