Download as PDF, PPTX







![ASimpleWordCountprogram
text_file = spark.textFile("hdfs://...")
text_file.flatMap(lambda line:
line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a+b)
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCount extends
Configured implements Tool{
public int run(String[] args)
throws Exception
{
//creating a JobConf
object and assigning a job name for
identification purposes
JobConf conf = new
JobConf(getConf(), WordCount.class);
conf.setJobName("WordCount");
//Setting configuration
object with the Data Type of output
Key and Value
conf.setOutputKeyClass(Text.class);](https://image.slidesharecdn.com/spark-161216055316/75/An-Introduction-to-Apache-Spark-10-2048.jpg)











![ASimpleWordCountprogram
text_file = spark.textFile("hdfs://...")
text_file.flatMap(lambda line:
line.split())
.map(lambda word: (word, 1))
.reduceByKey(lambda a, b: a+b)
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class WordCount extends
Configured implements Tool{
public int run(String[] args)
throws Exception
{
//creating a JobConf
object and assigning a job name for
identification purposes
JobConf conf = new
JobConf(getConf(), WordCount.class);
conf.setJobName("WordCount");
//Setting configuration
object with the Data Type of output
Key and Value
conf.setOutputKeyClass(Text.class);](https://crownmelresort.com/image.slidesharecdn.com/spark-161216055316/75/An-Introduction-to-Apache-Spark-10-2048.jpg)



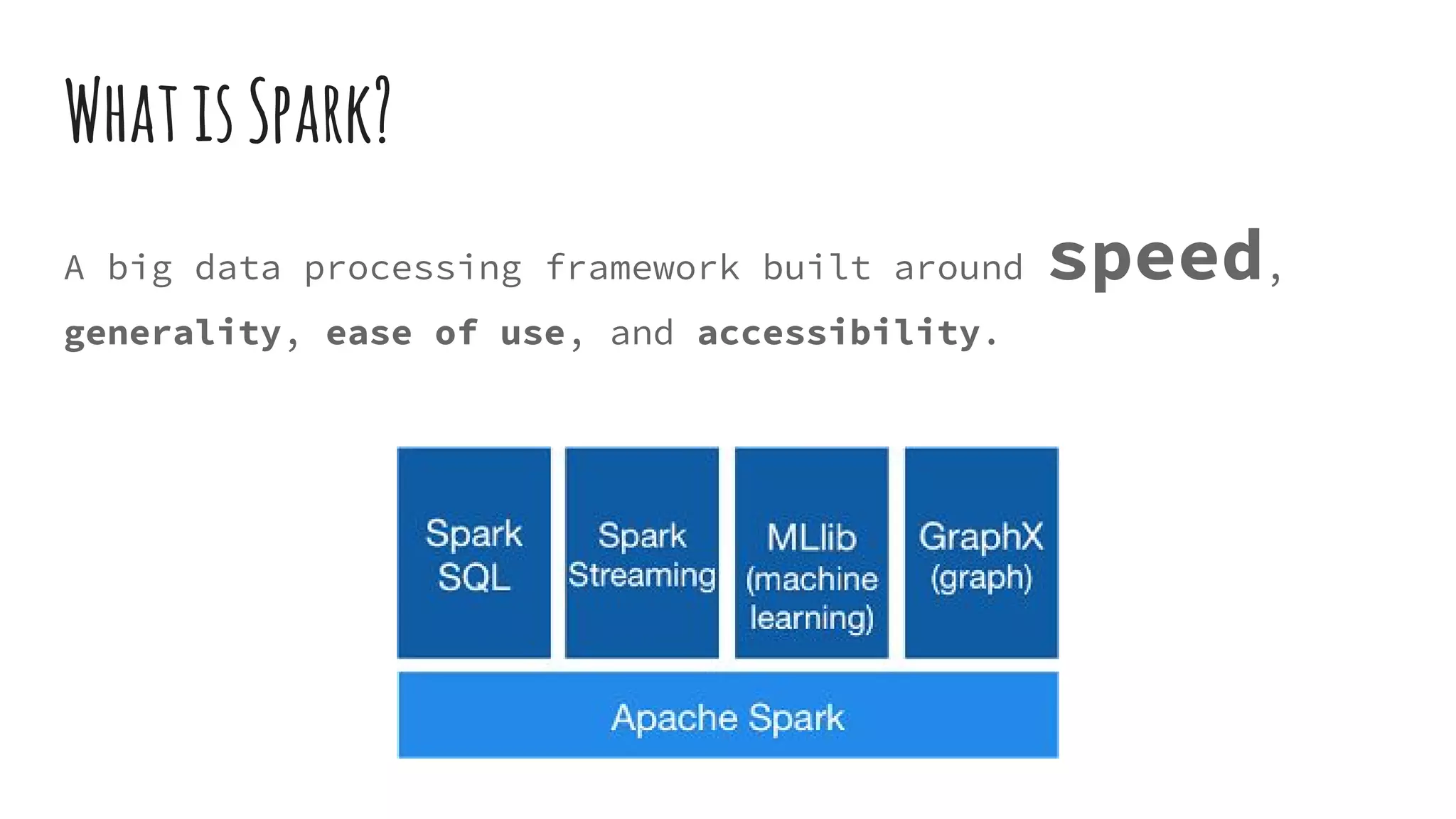
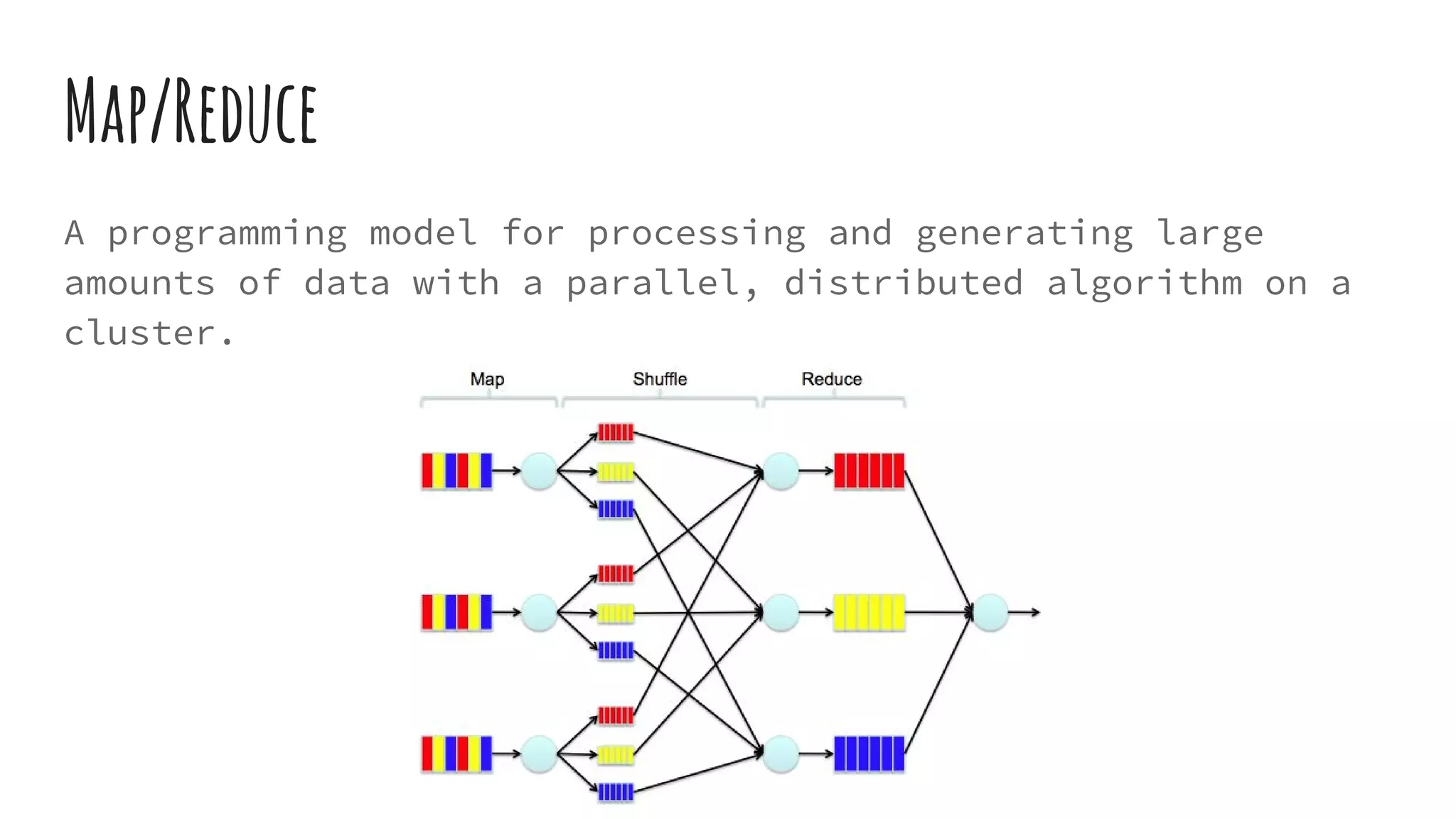
Spark is a big data processing framework built in Scala that runs on the JVM. It provides speed, generality, ease of use, and accessibility for processing large datasets. Spark features include working directly on memory for speed, supporting MapReduce, lazy evaluation of queries for optimization, and APIs for Scala, R and Python. It includes Spark Streaming for real-time data, Spark SQL for SQL queries, and MLlib for machine learning. Resilient Distributed Datasets (RDDs) are Spark's fundamental data structure, and MapReduce is a programming model used for processing large amounts of data in parallel.













































![[@NaukriEngineering] Apache Spark](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkppt-170105054406-thumbnail.jpg?width=640&height=640&fit=bounds)






























