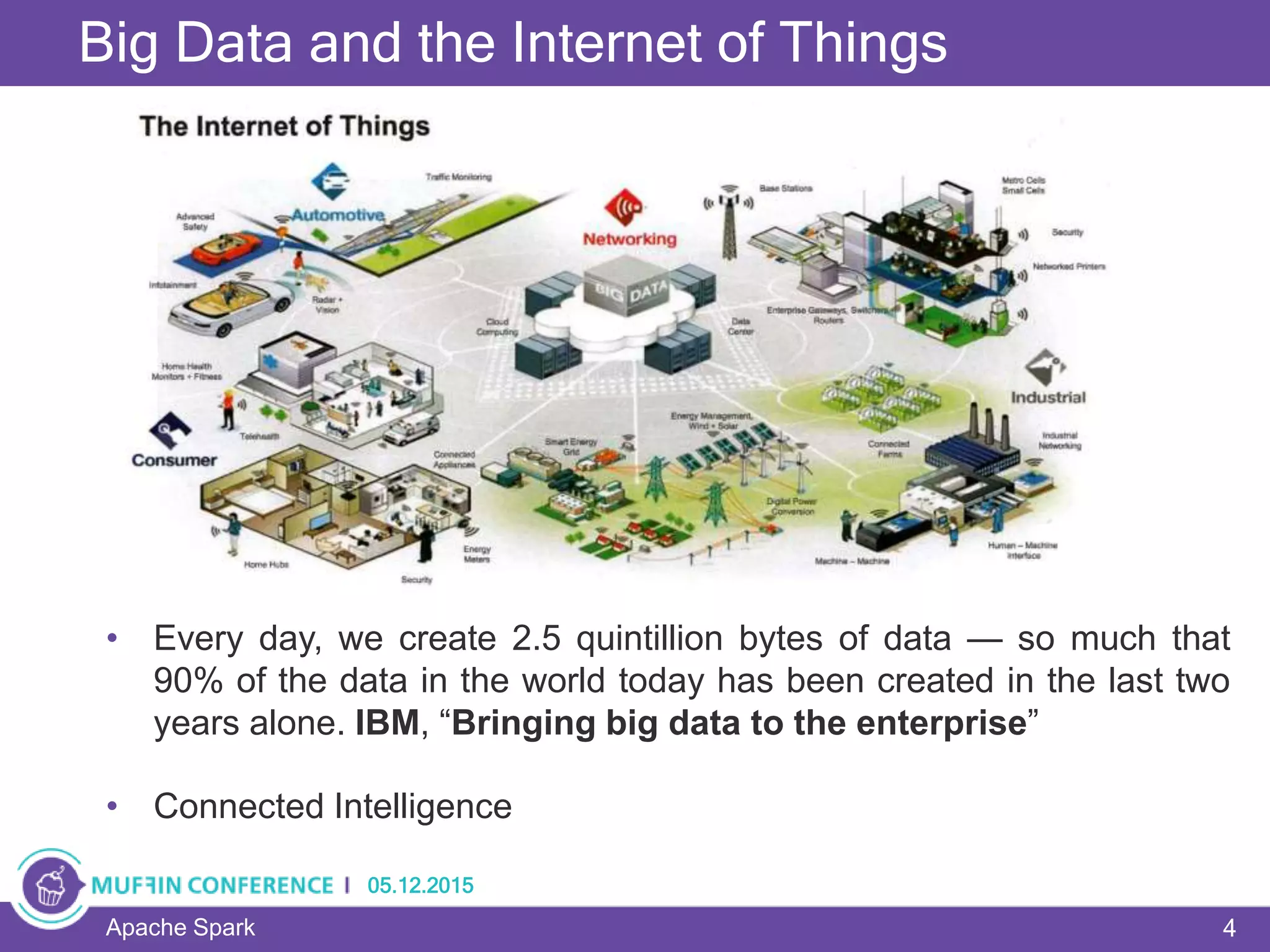
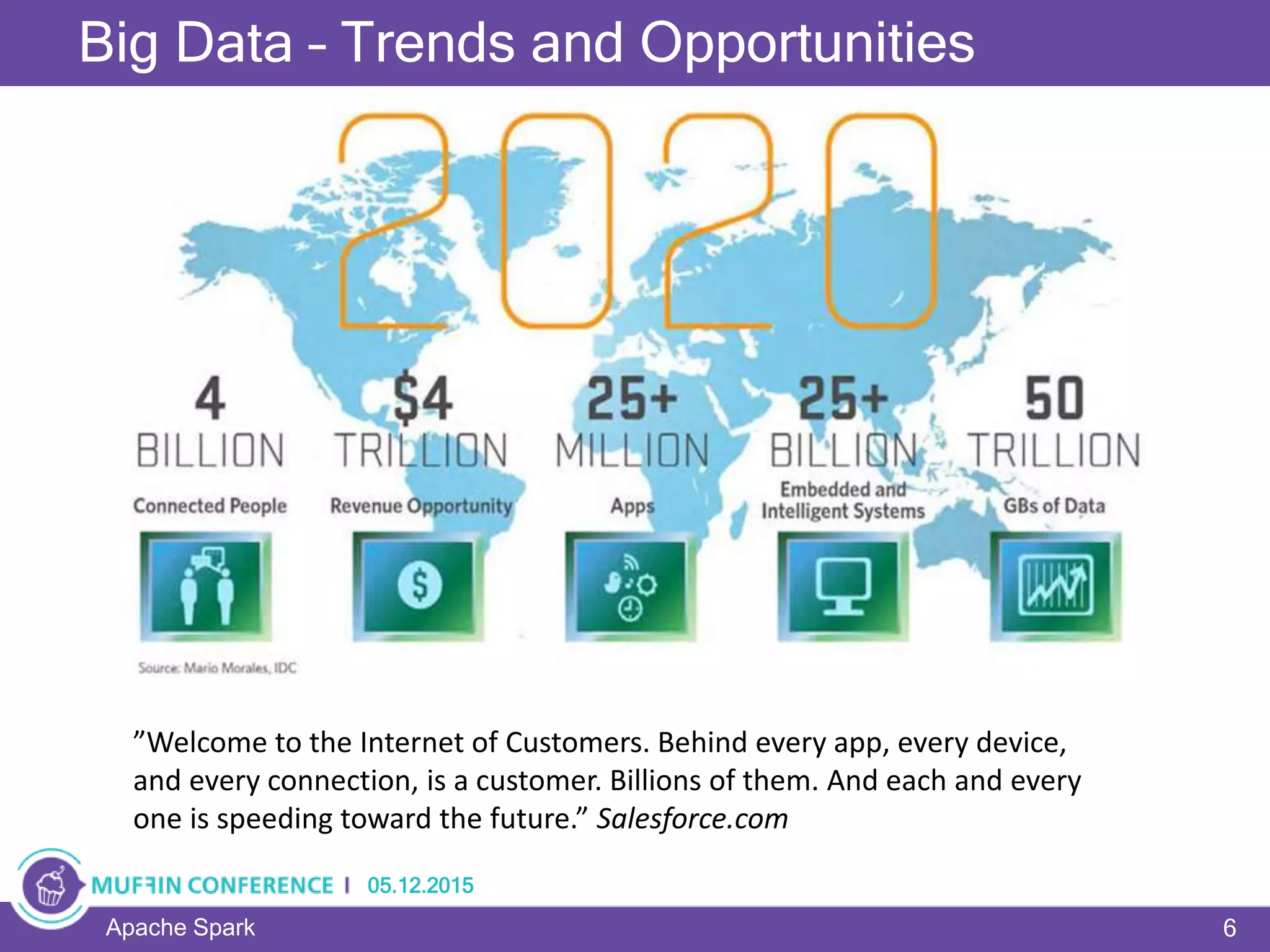
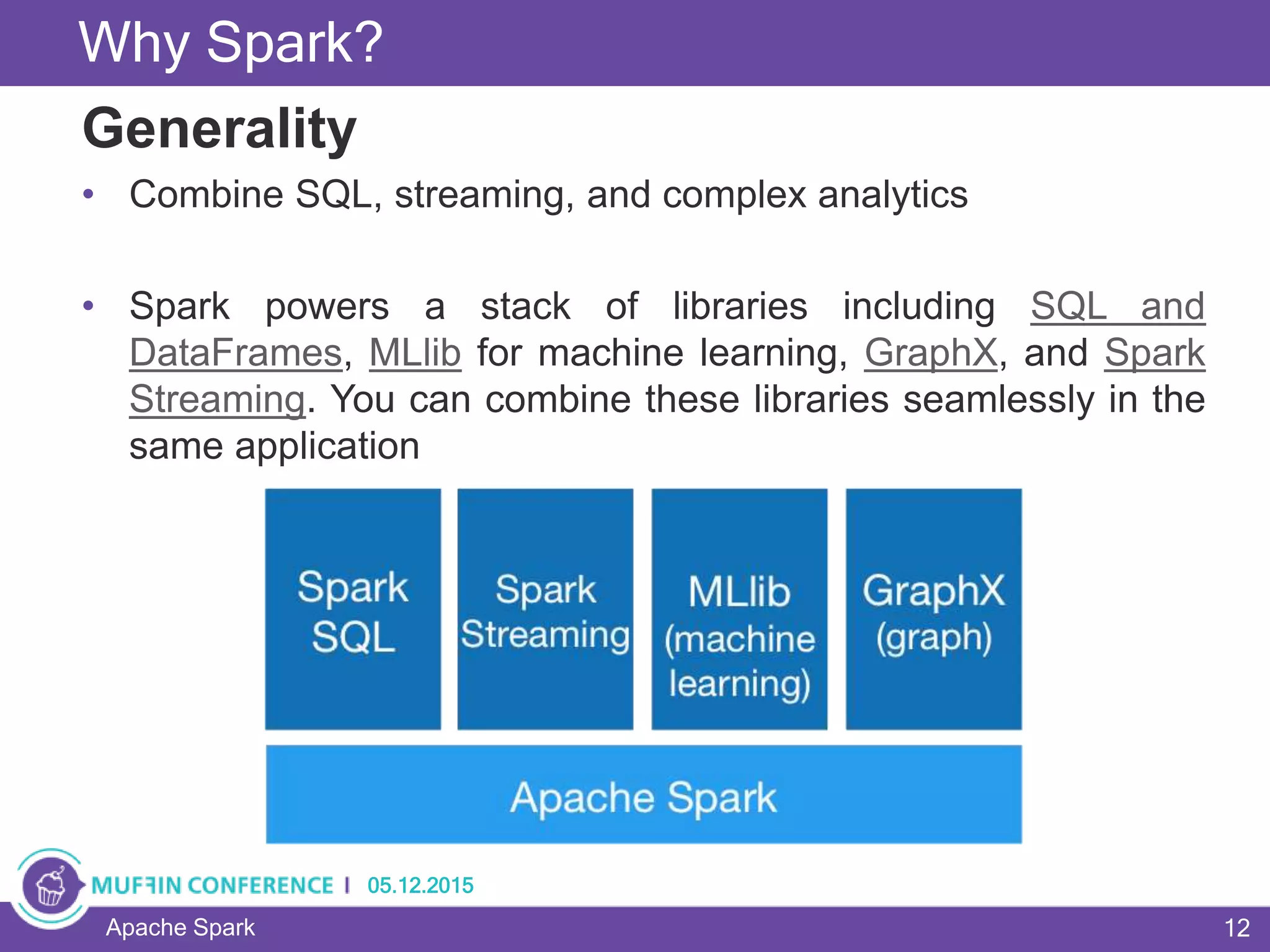
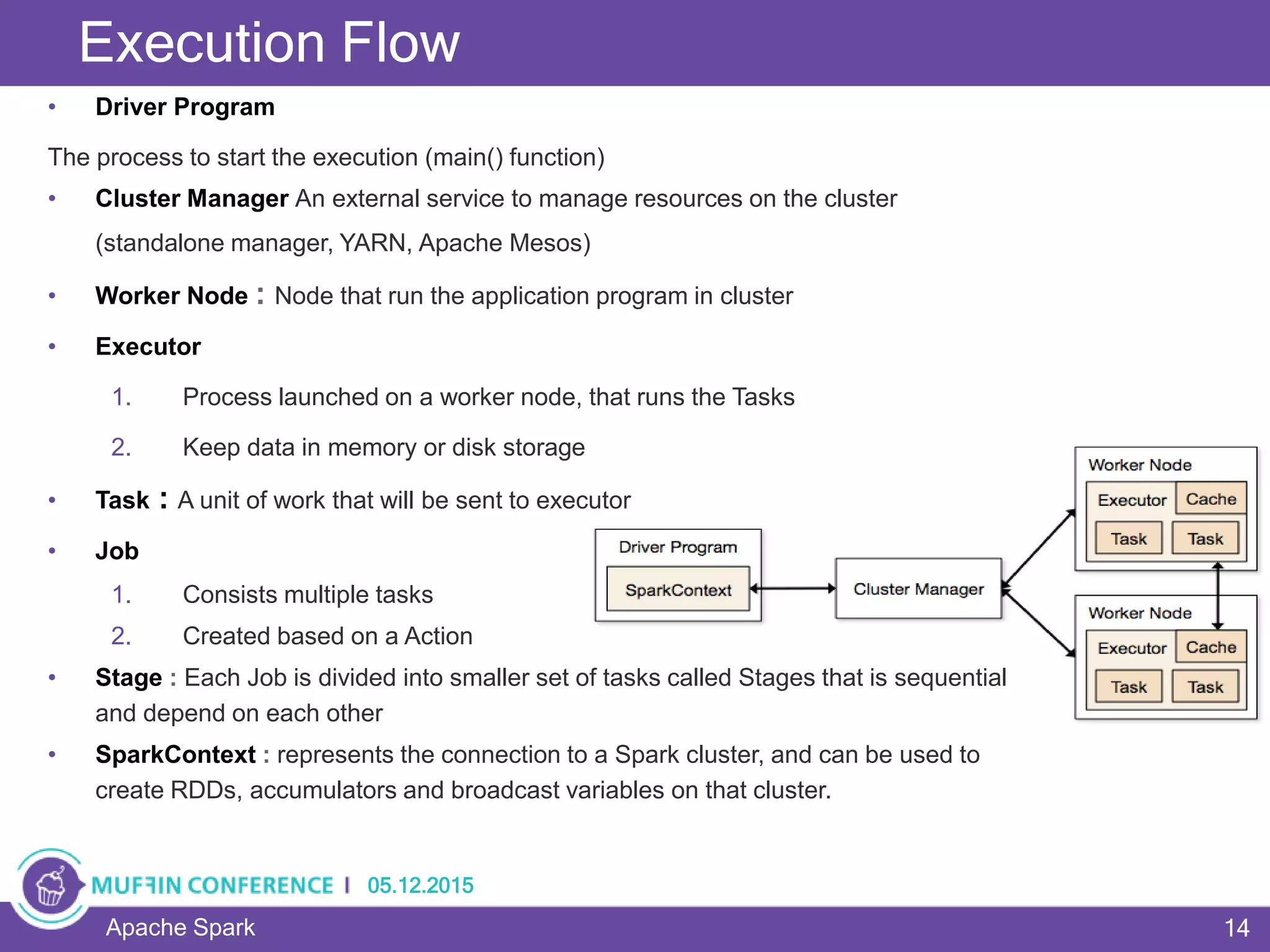
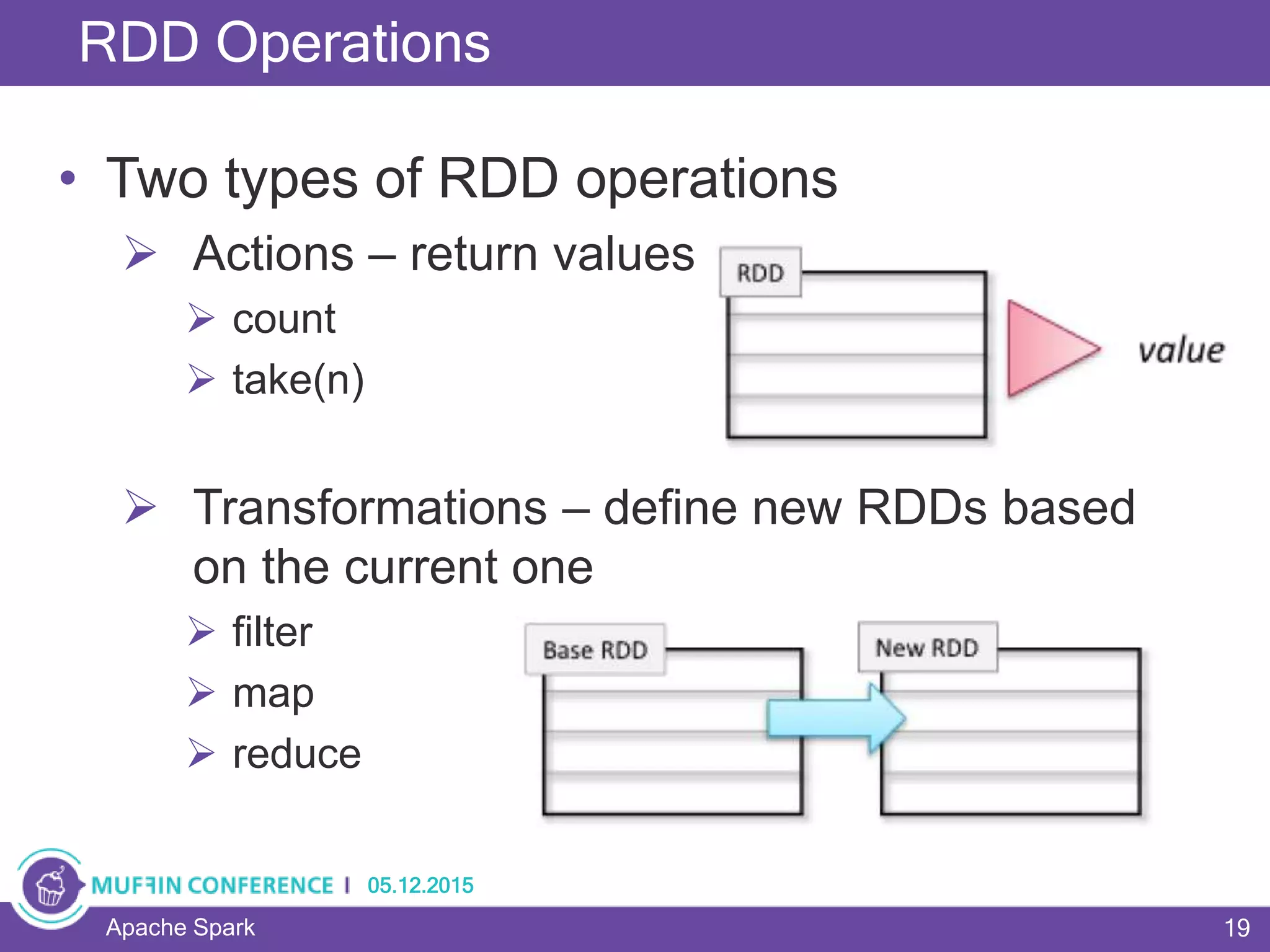
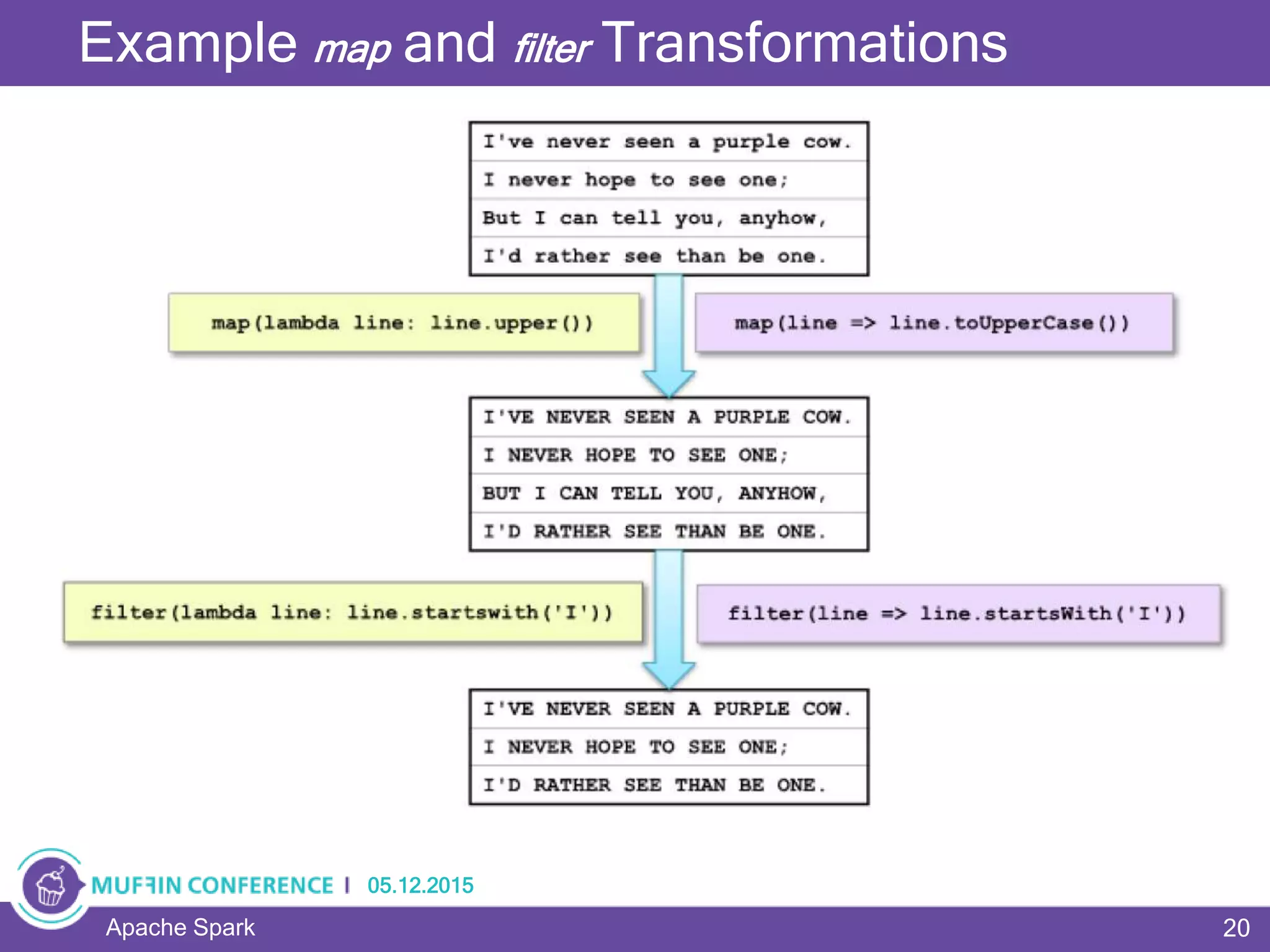
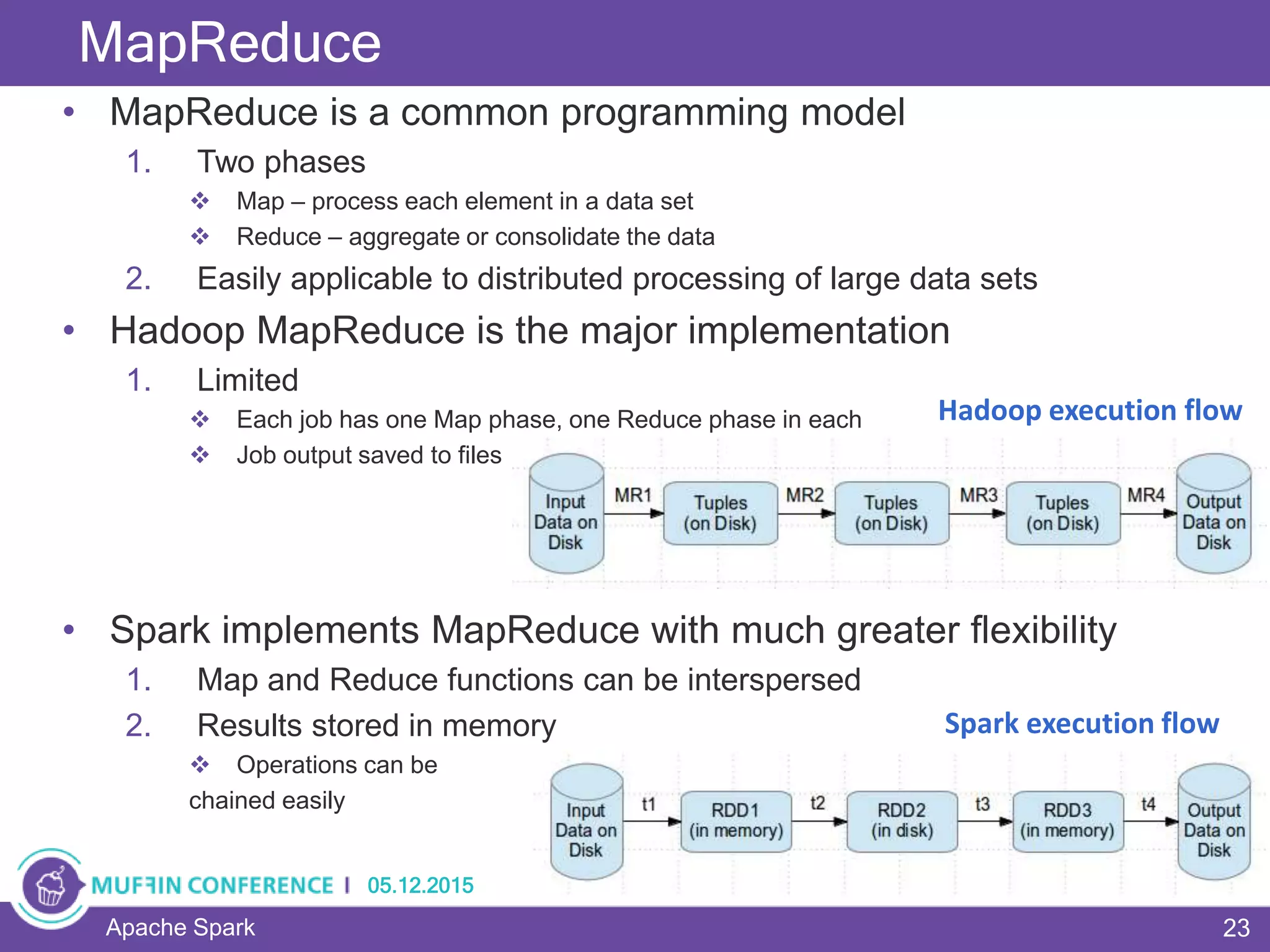
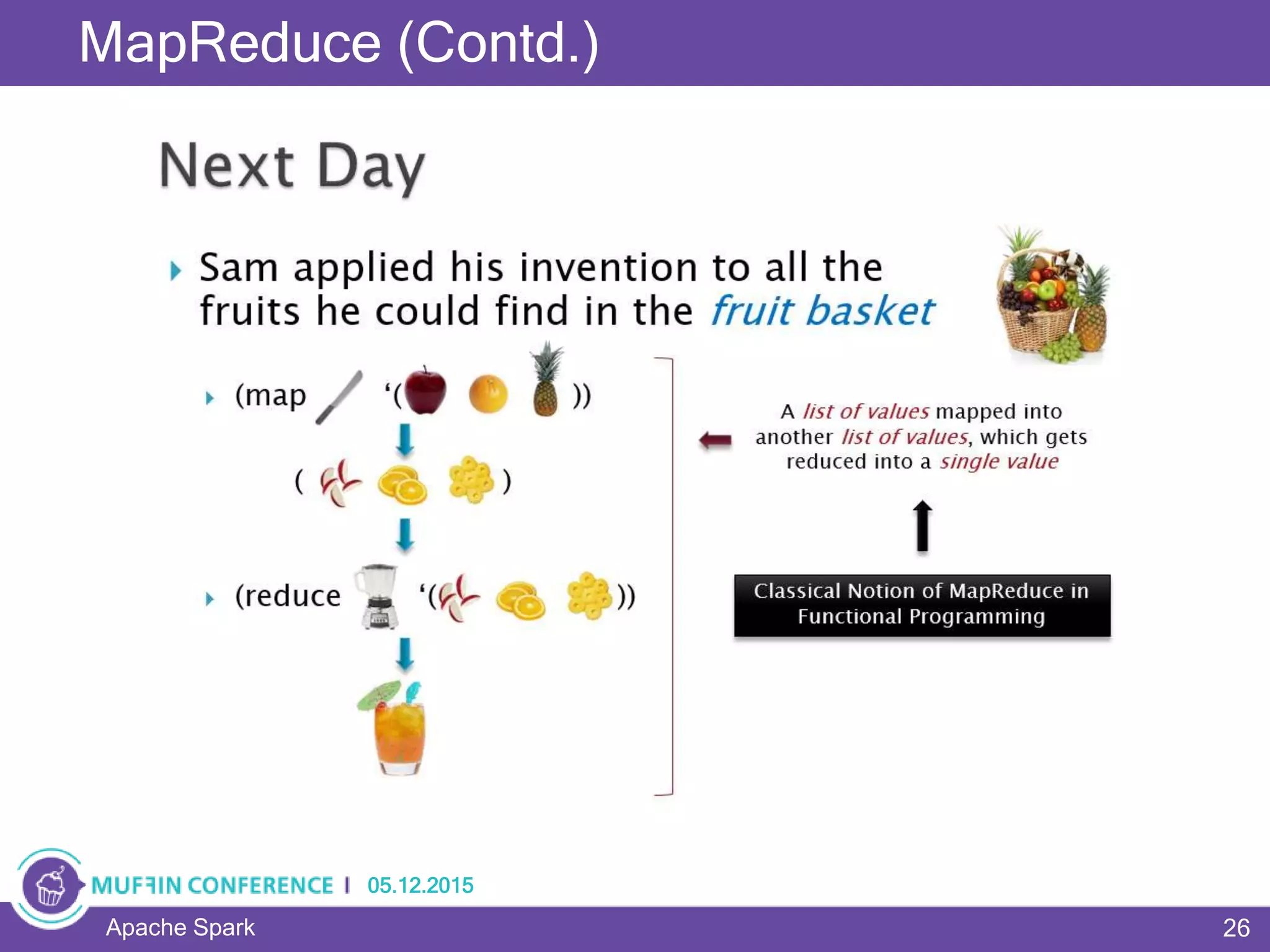
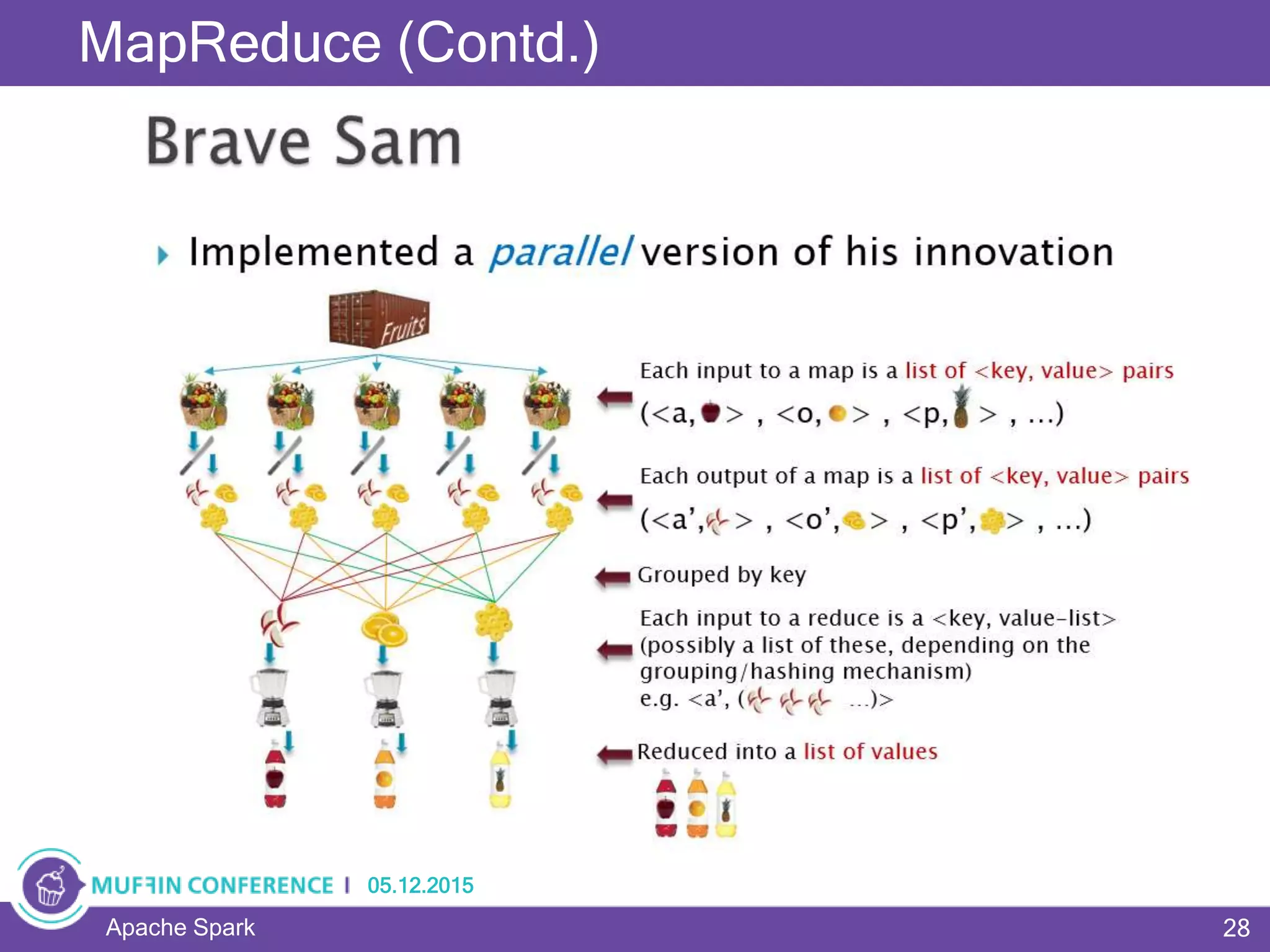
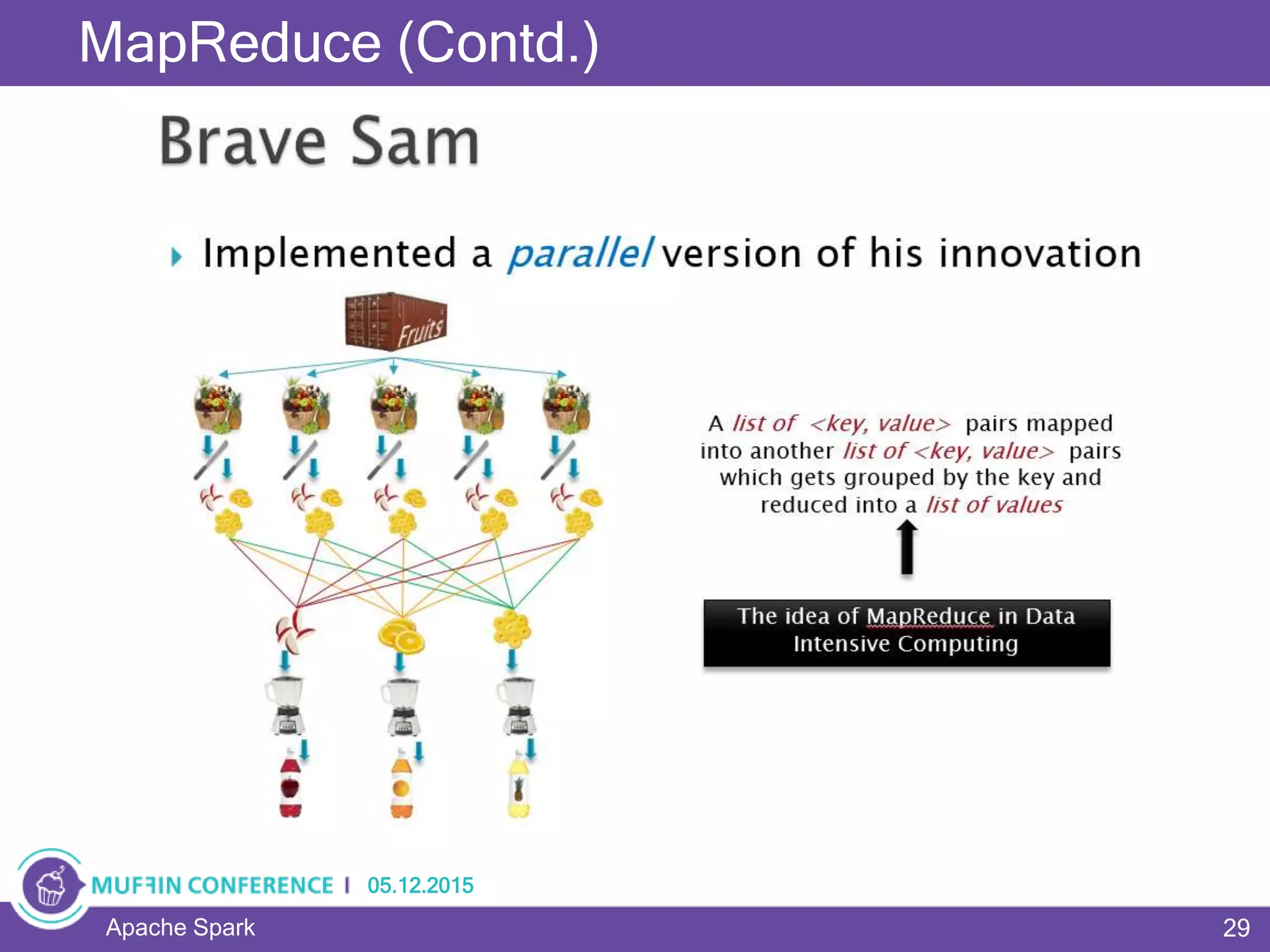
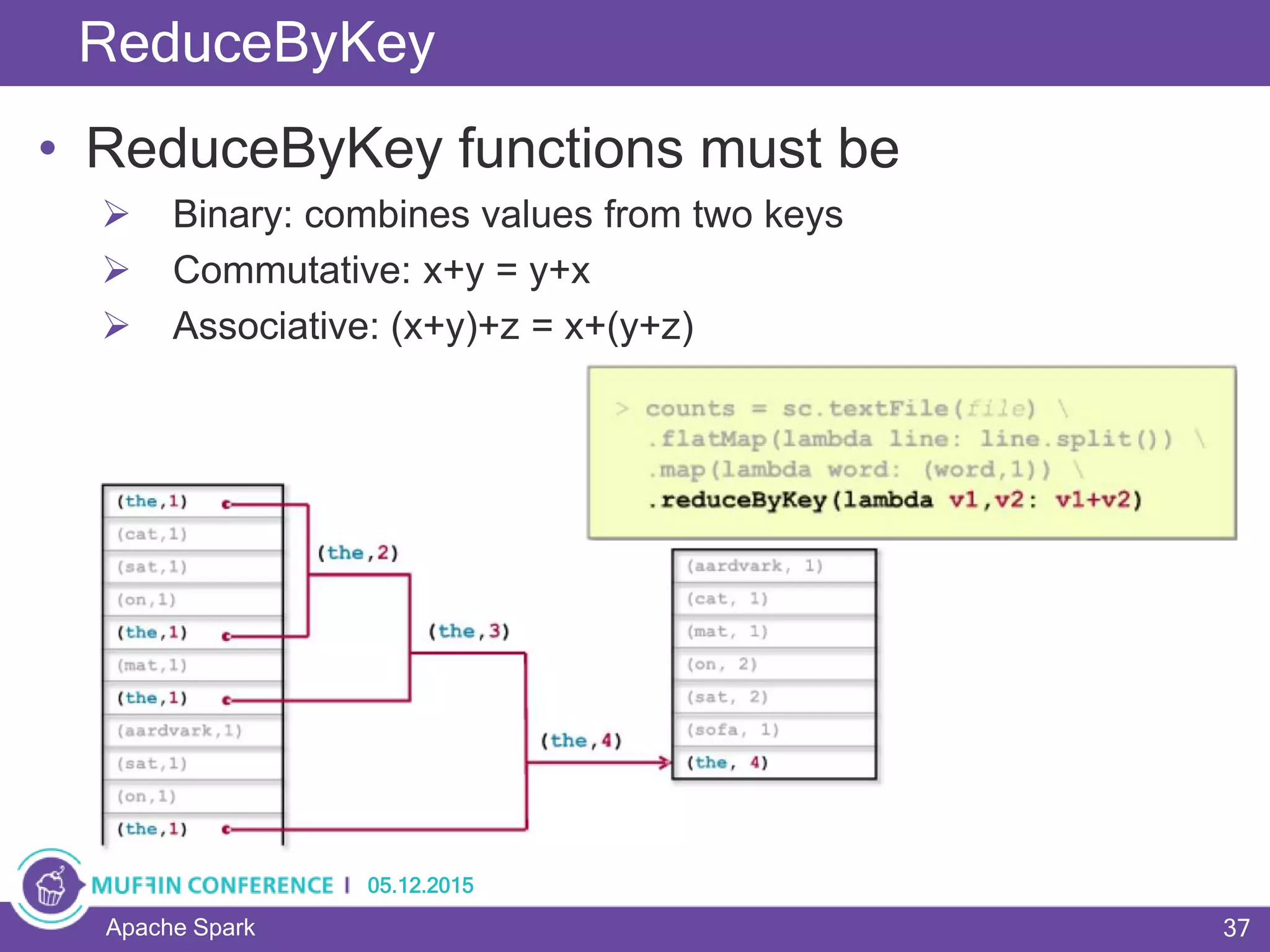
This document provides an overview of Apache Spark, a framework for large-scale data processing. It discusses what big data is, the history and advantages of Spark, and Spark's execution model. Key concepts explained include Resilient Distributed Datasets (RDDs), transformations, actions, and MapReduce algorithms like word count. Examples are provided to illustrate Spark's use of RDDs and how it can improve on Hadoop MapReduce.