Downloaded 75 times


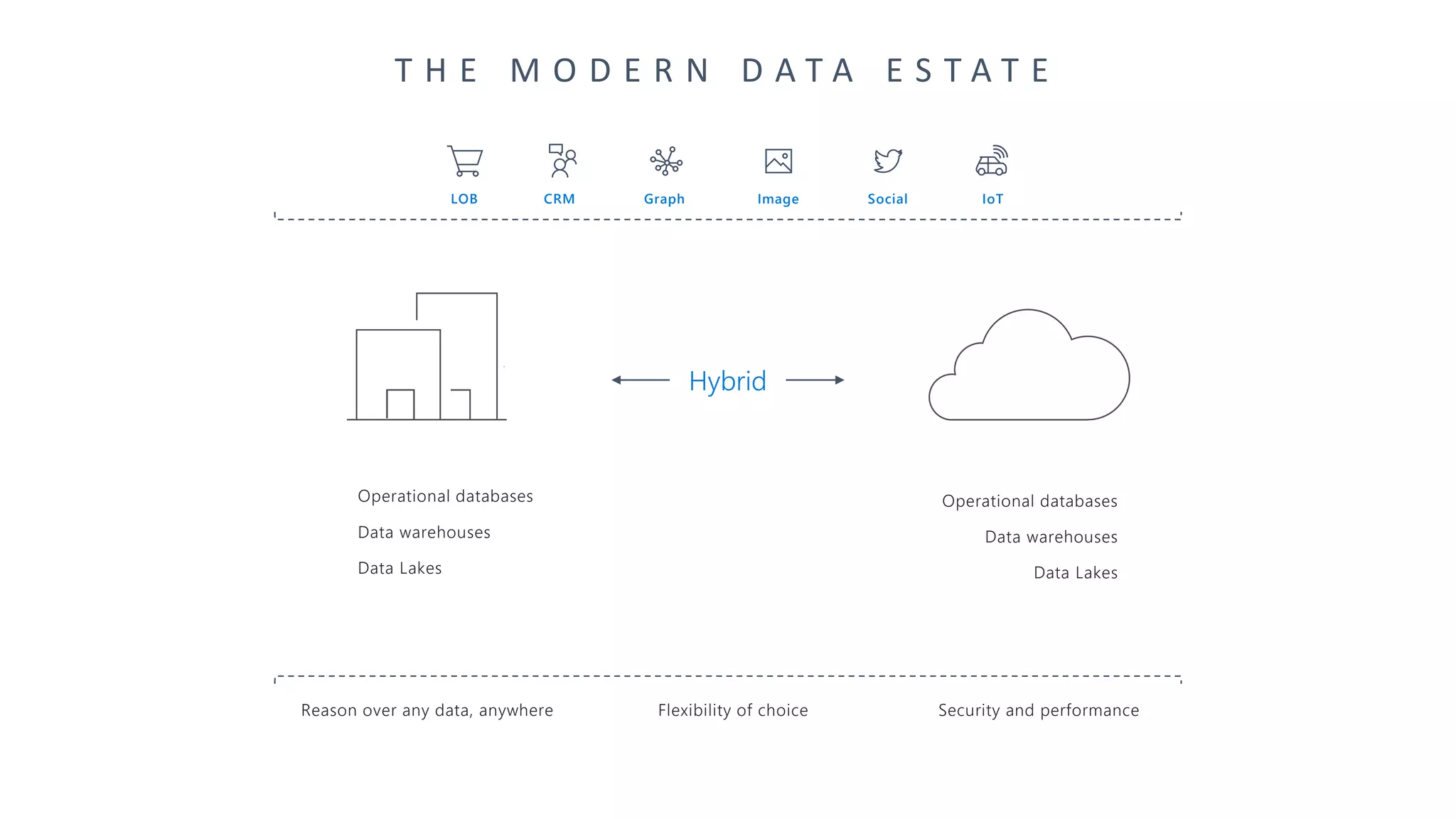
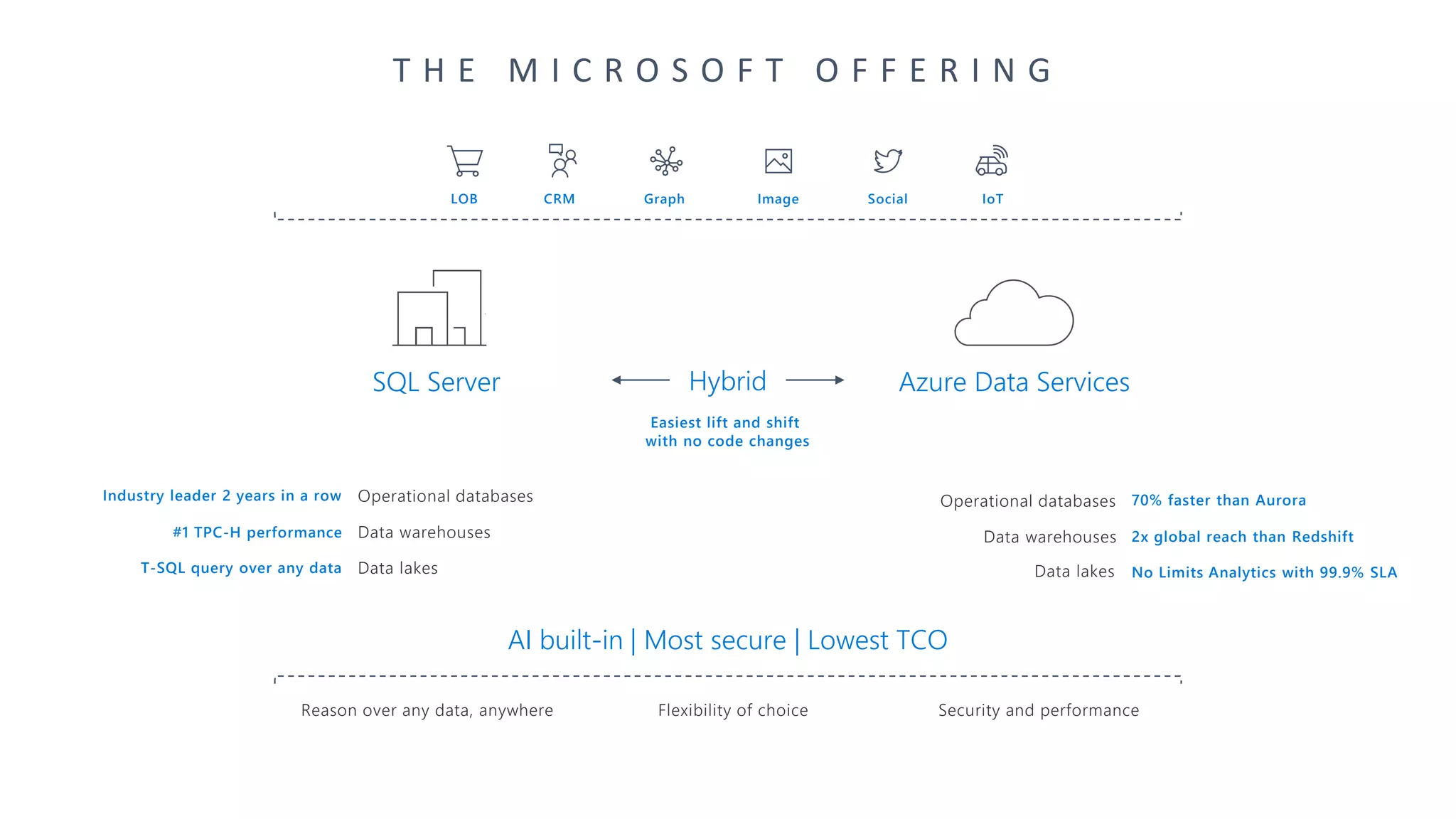

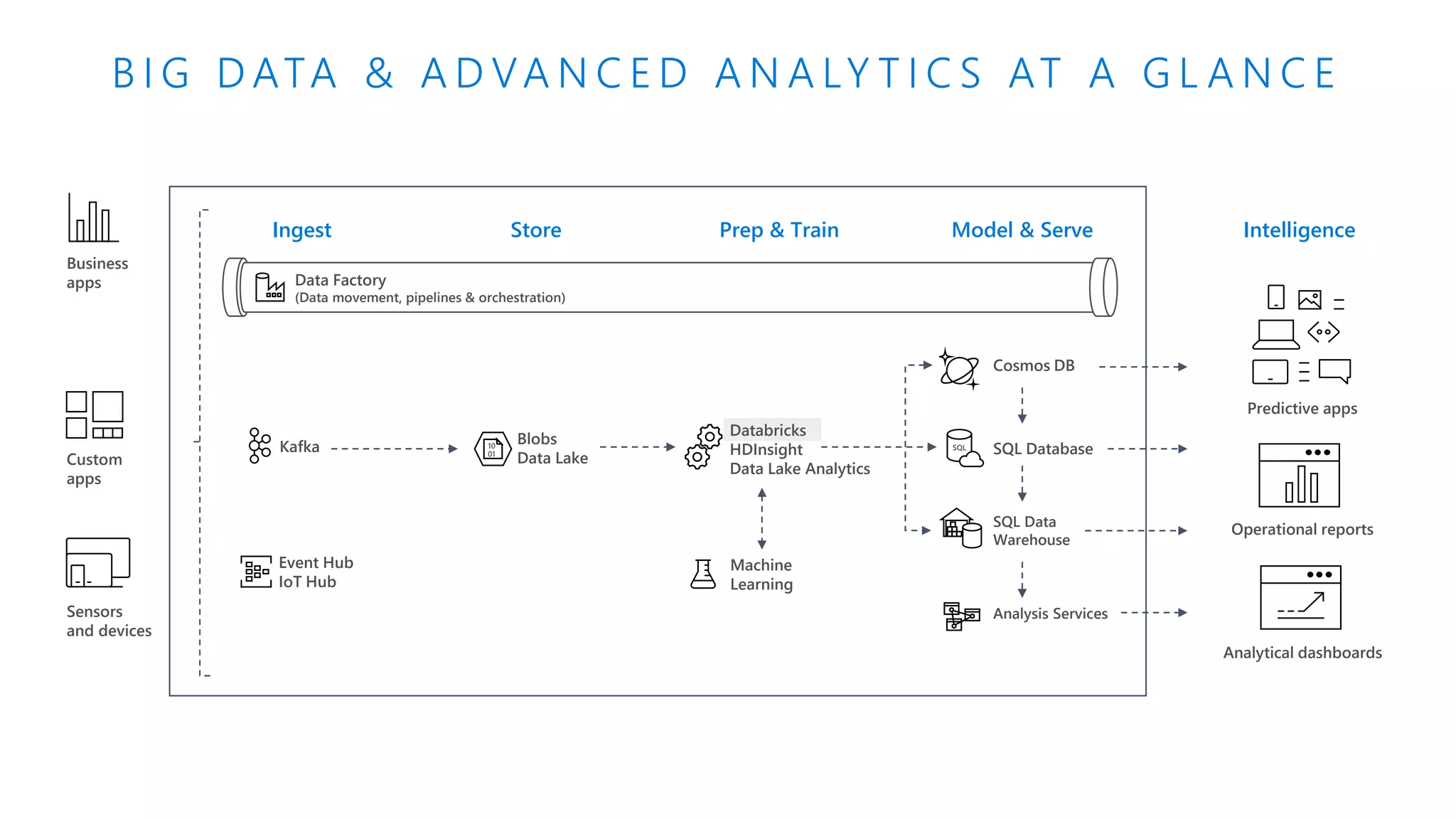


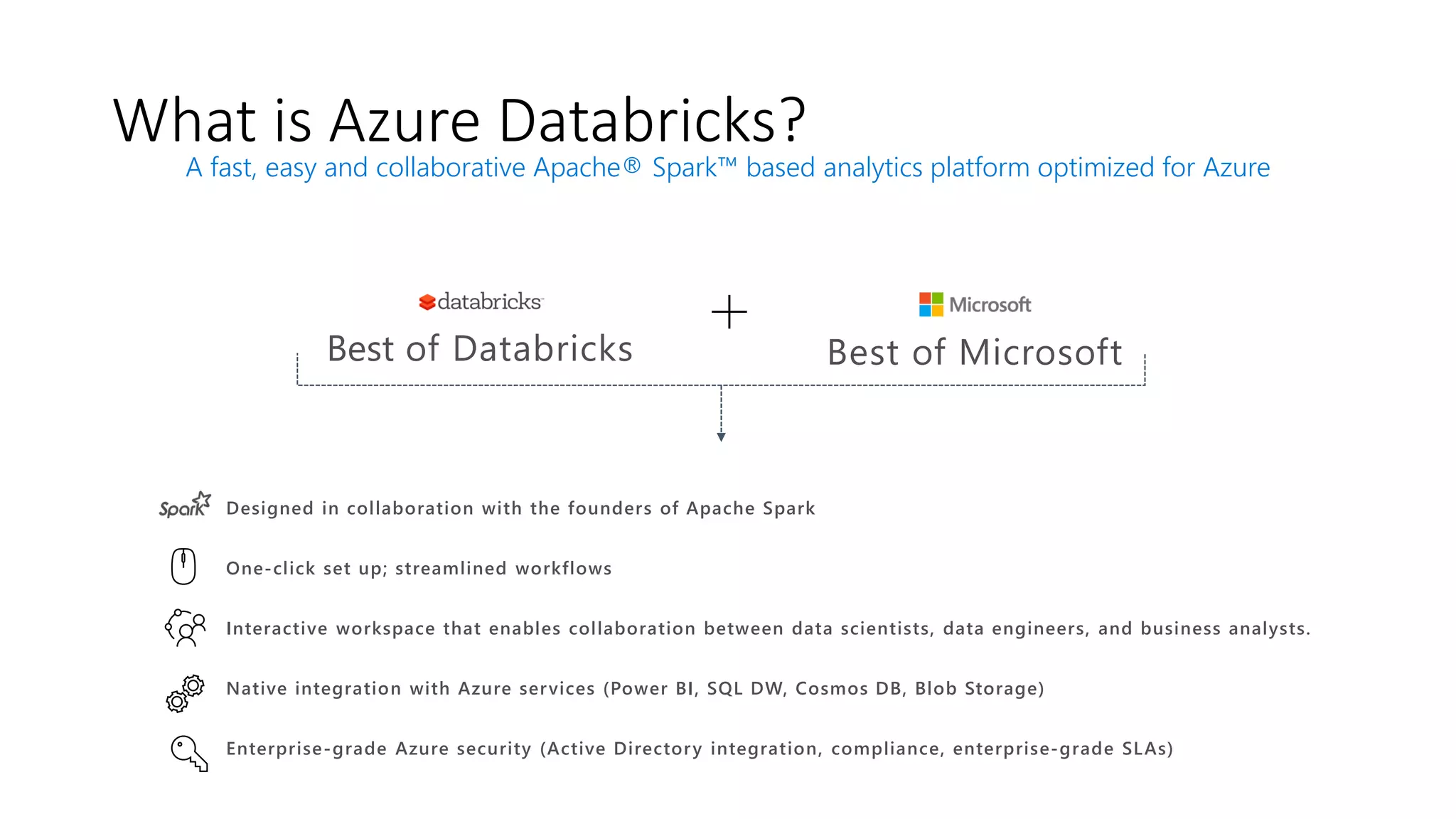
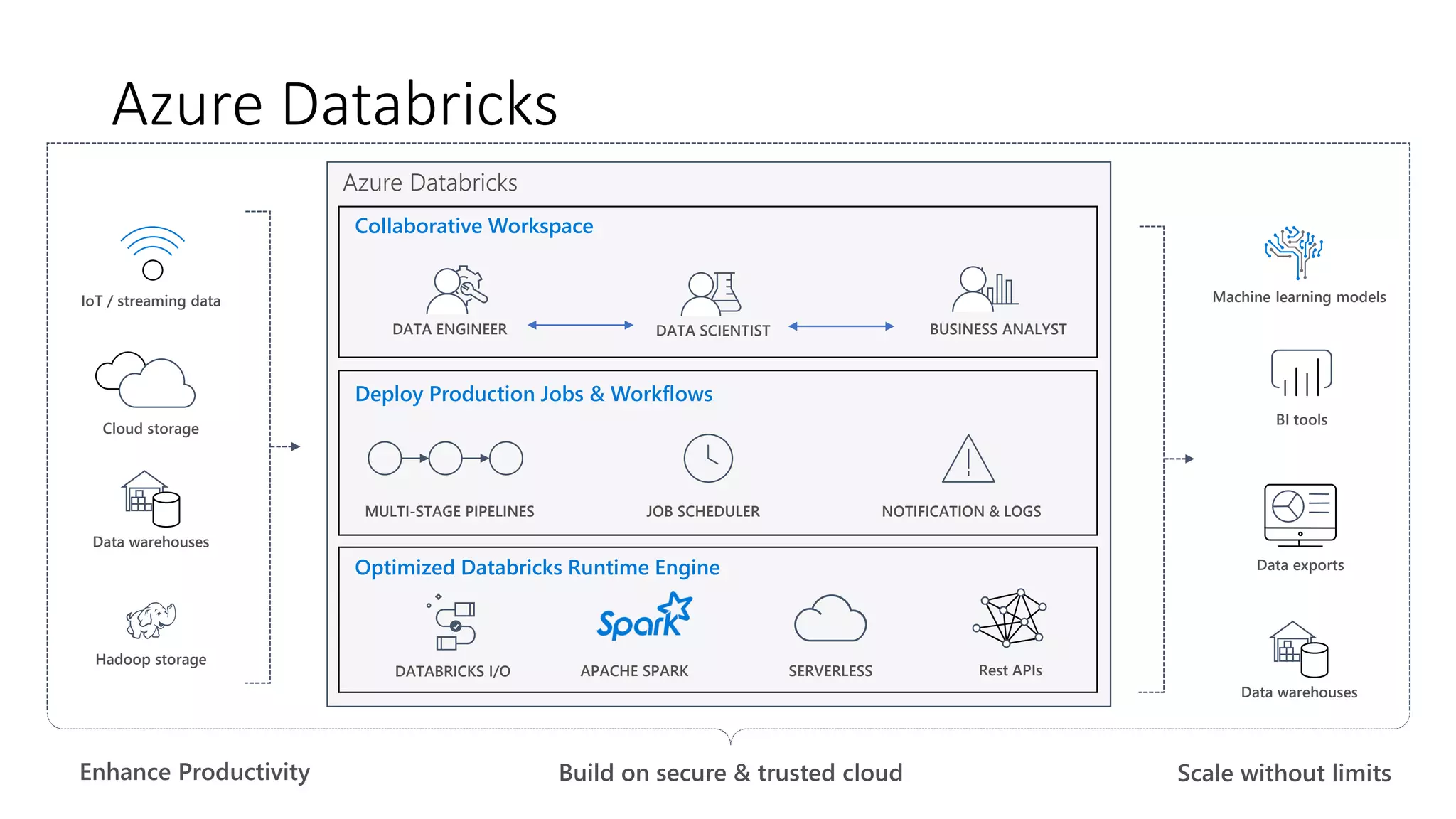
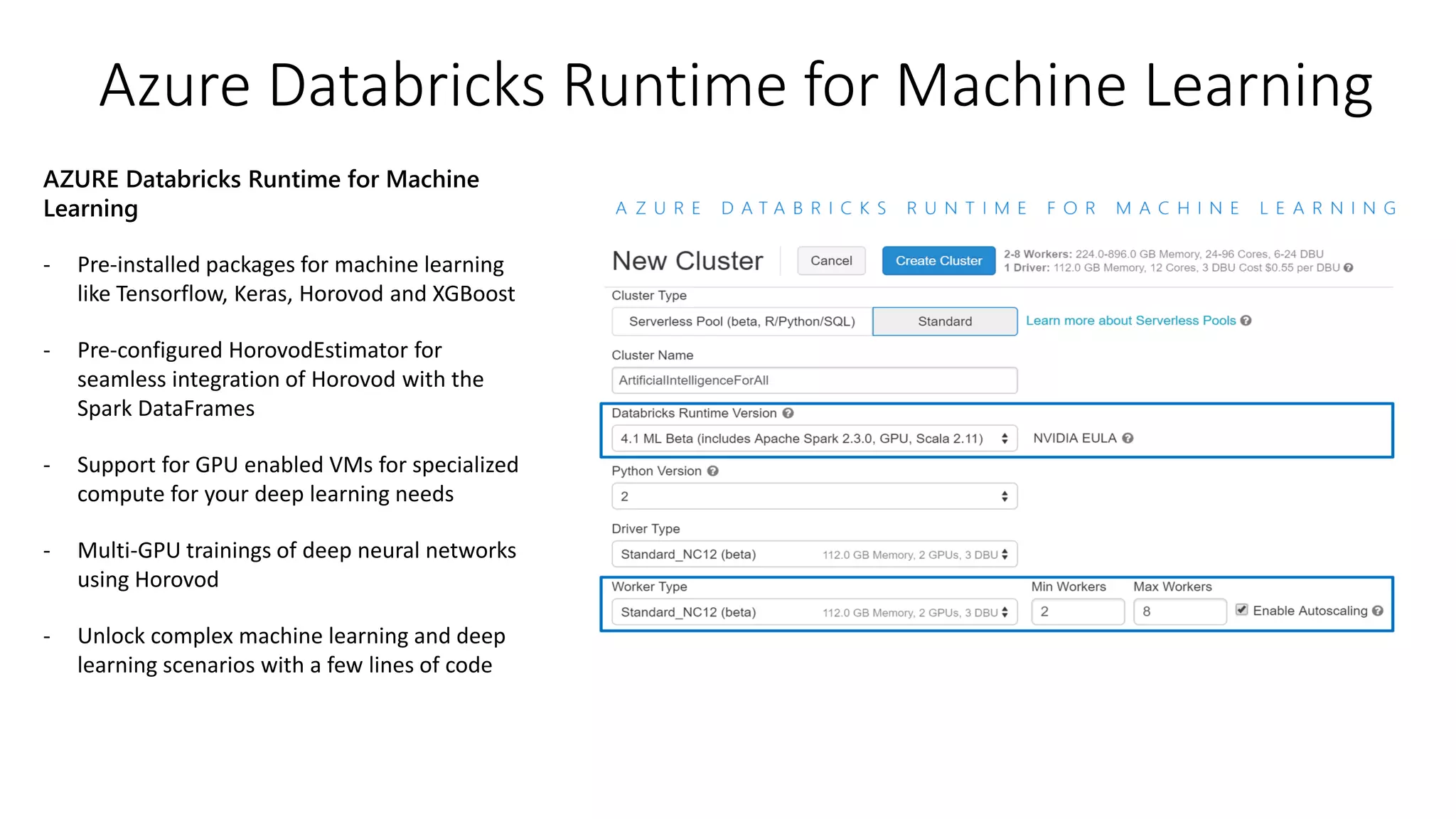





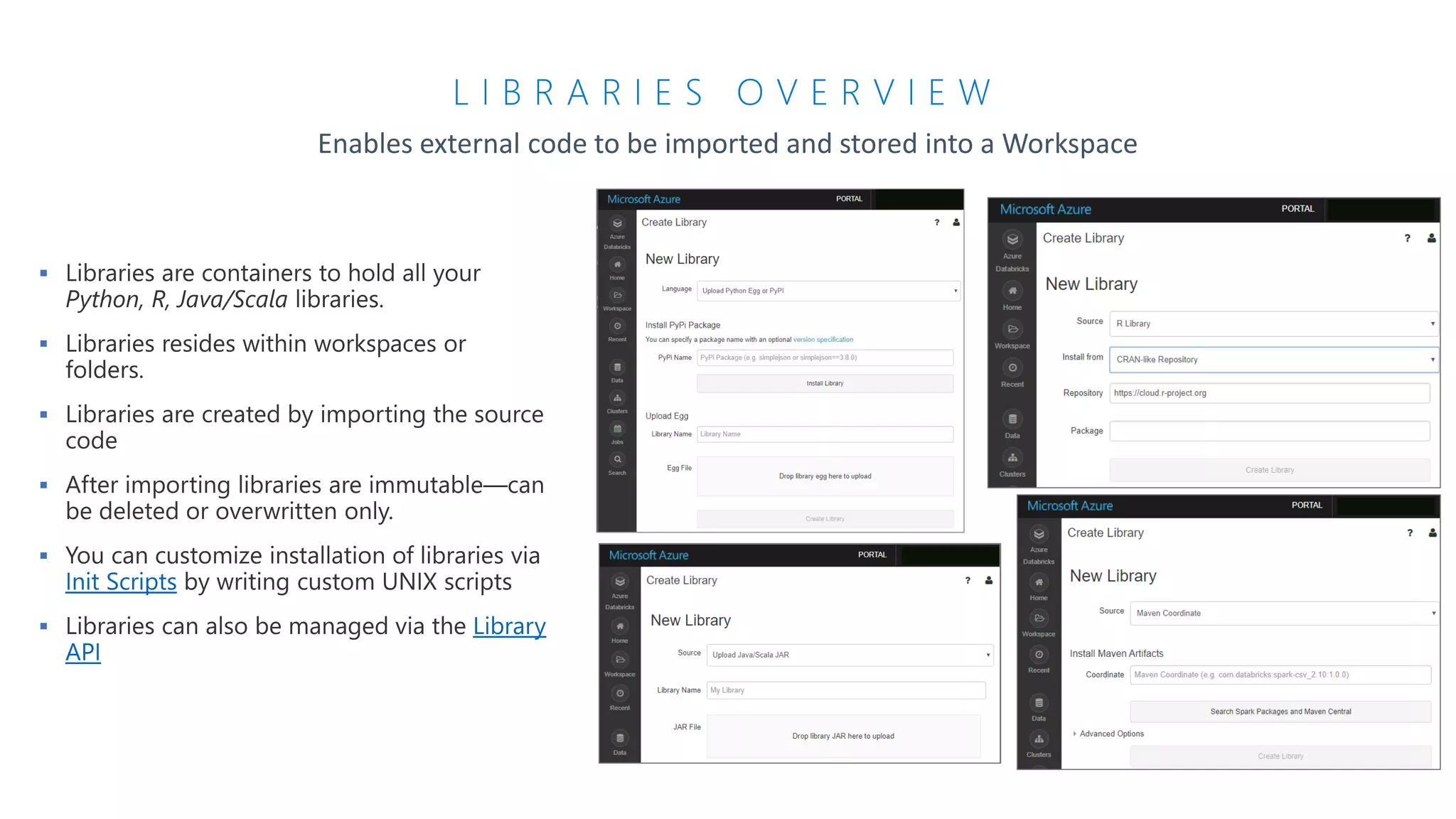
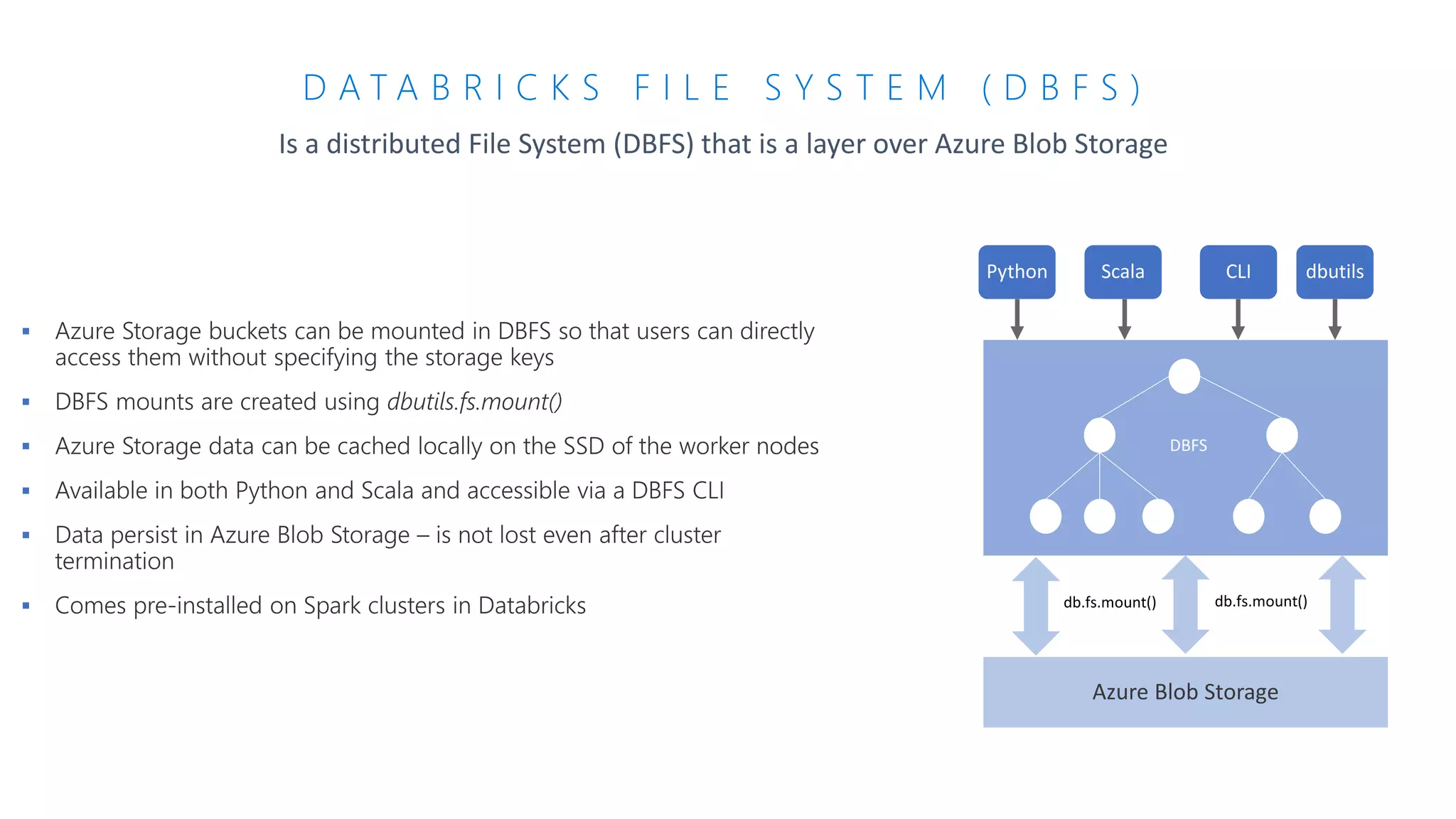



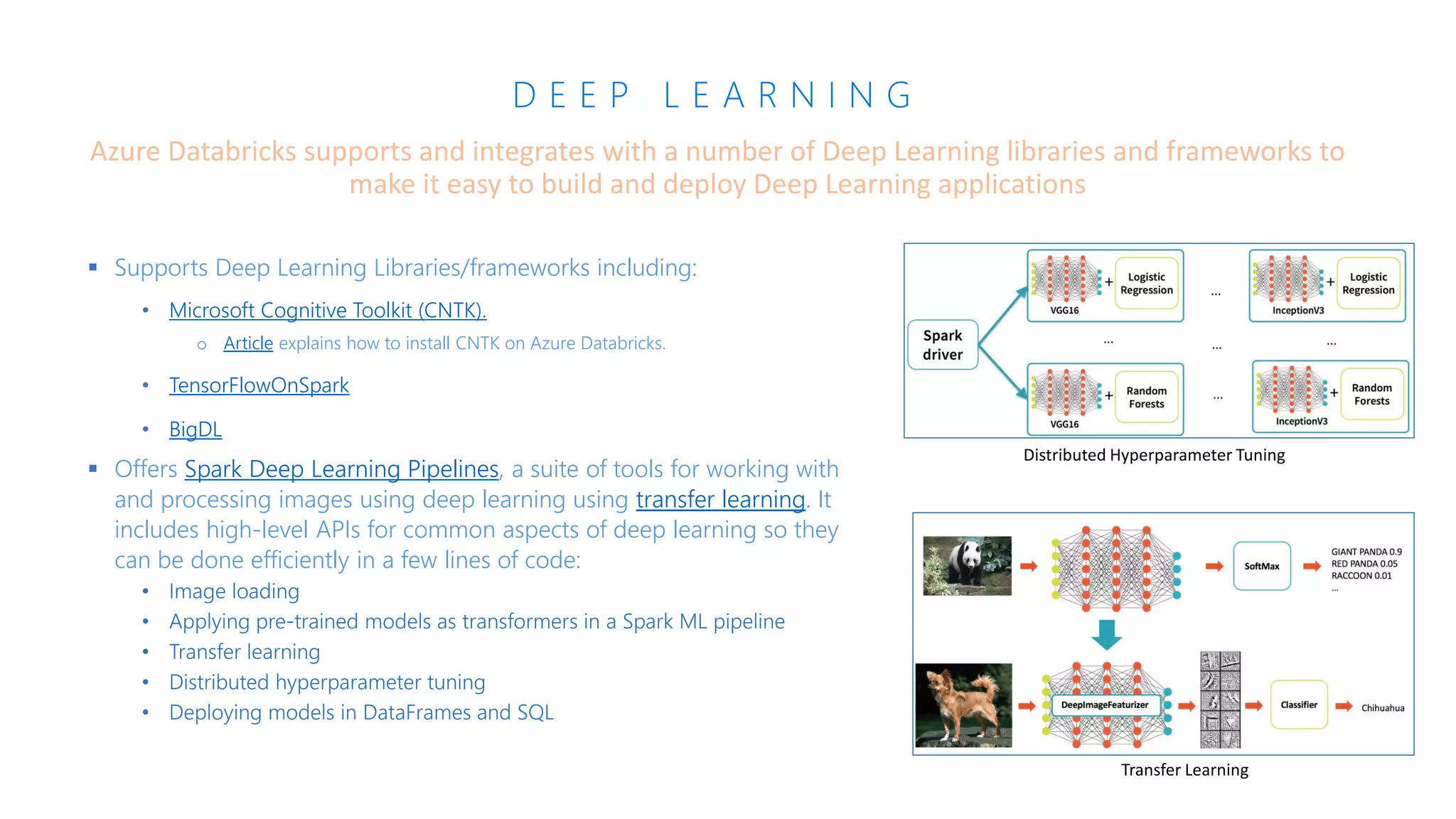
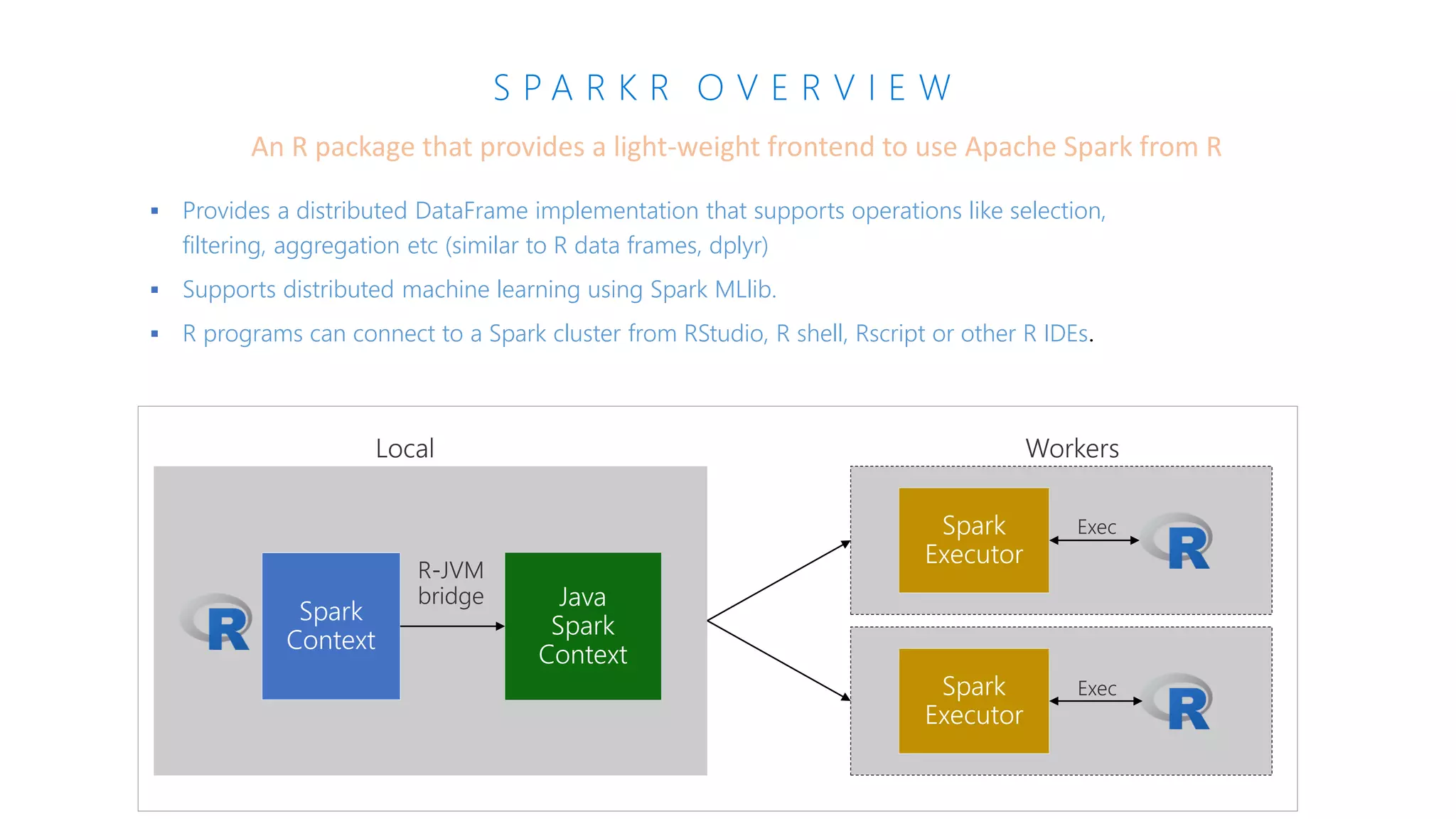

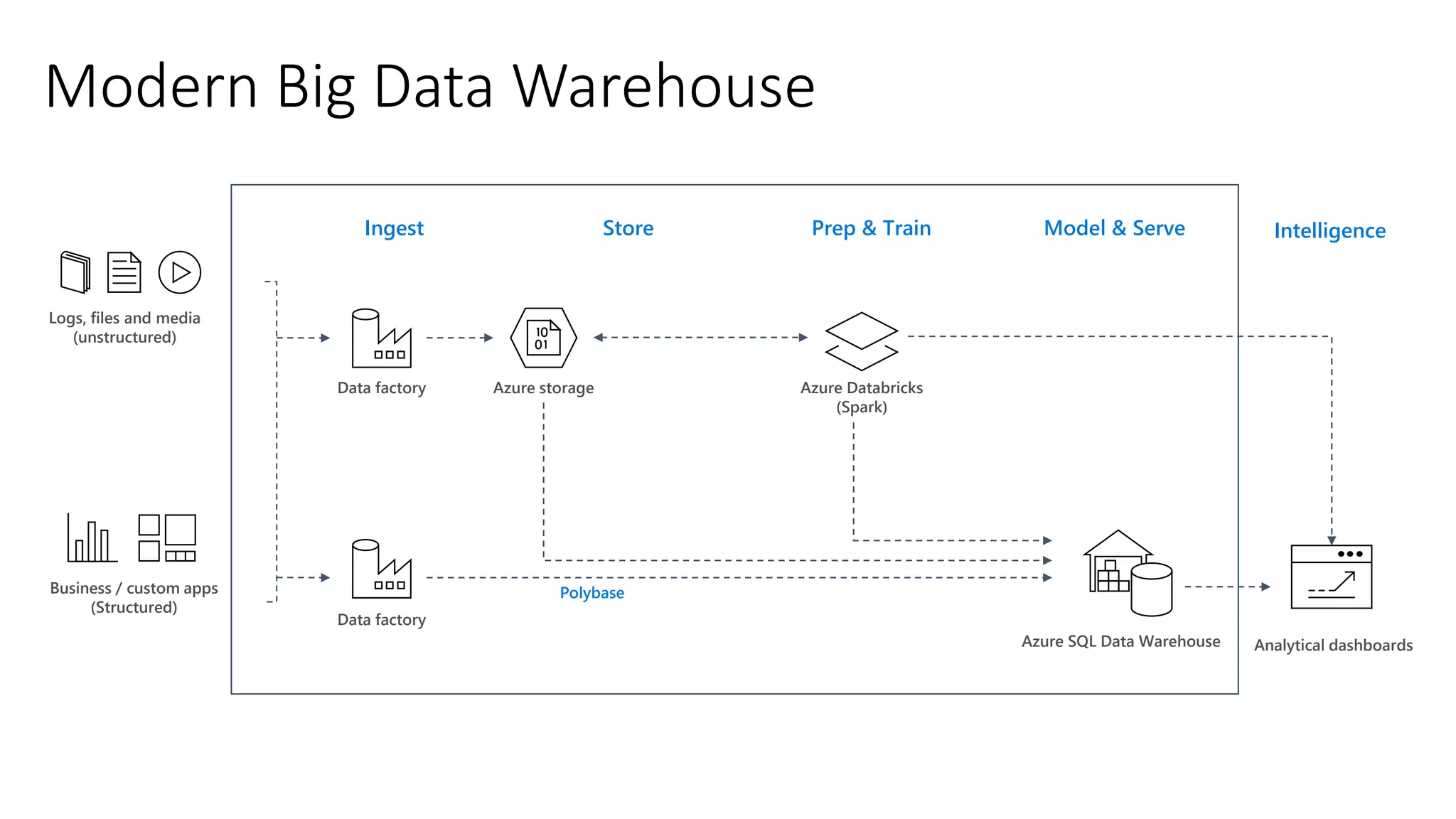
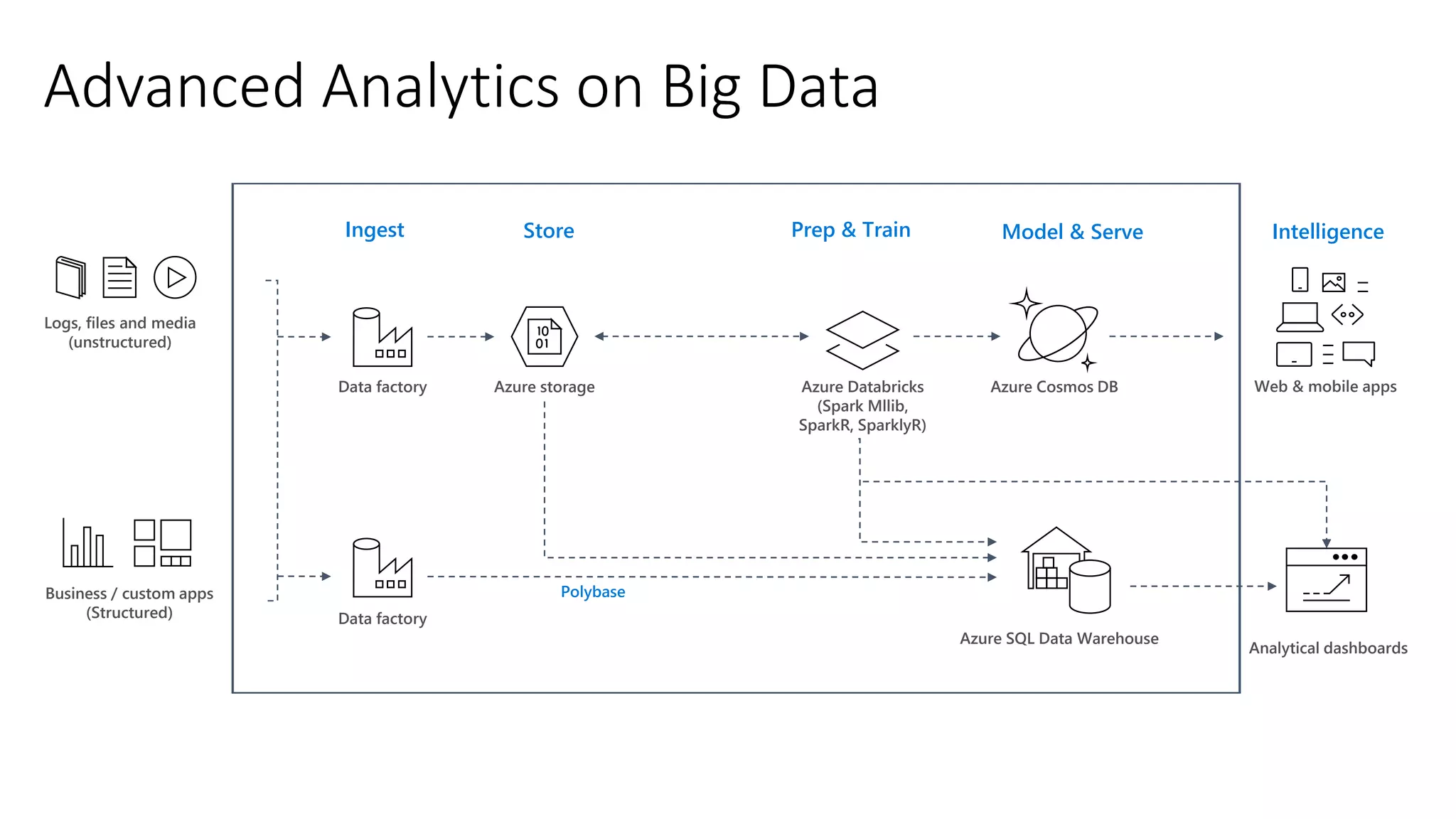
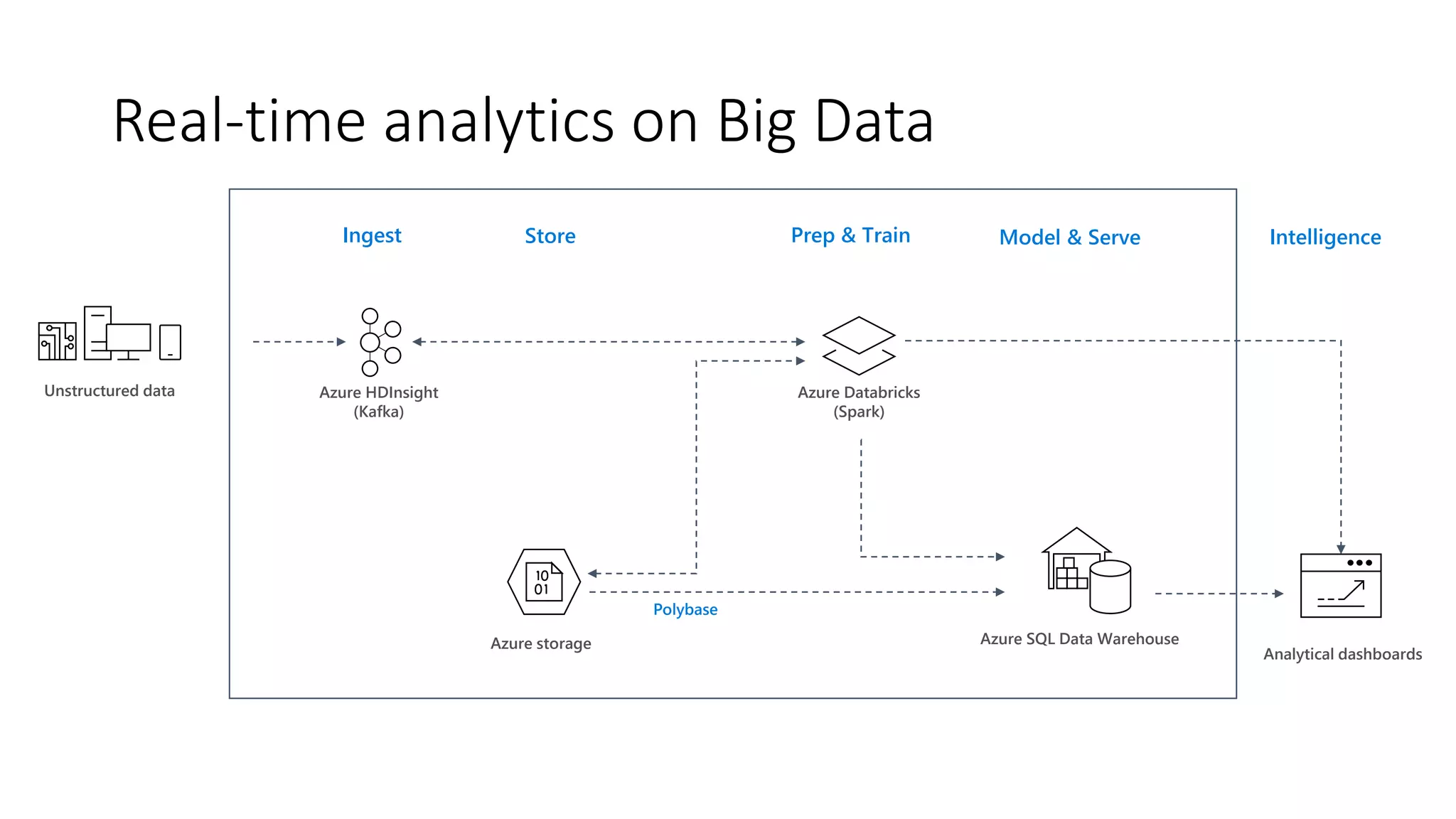




































The document presents an overview of Azure Databricks, emphasizing its capabilities for machine learning and data analytics, powered by Apache Spark. Key features include integration with Azure services, support for various programming languages in notebooks, and tools for deep learning and model training. It also highlights the platform's security, collaboration features, and scalability for large datasets, along with an invitation to engage with Microsoft for hands-on workshops.



























![[AKIBA.AWS] VGWのルーティング仕様](https://cdn.slidesharecdn.com/ss_thumbnails/akibaaws7-180524115259-thumbnail.jpg?width=640&height=640&fit=bounds)








































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















