




![Productivity Optimization Lab Shao-Yen Hung
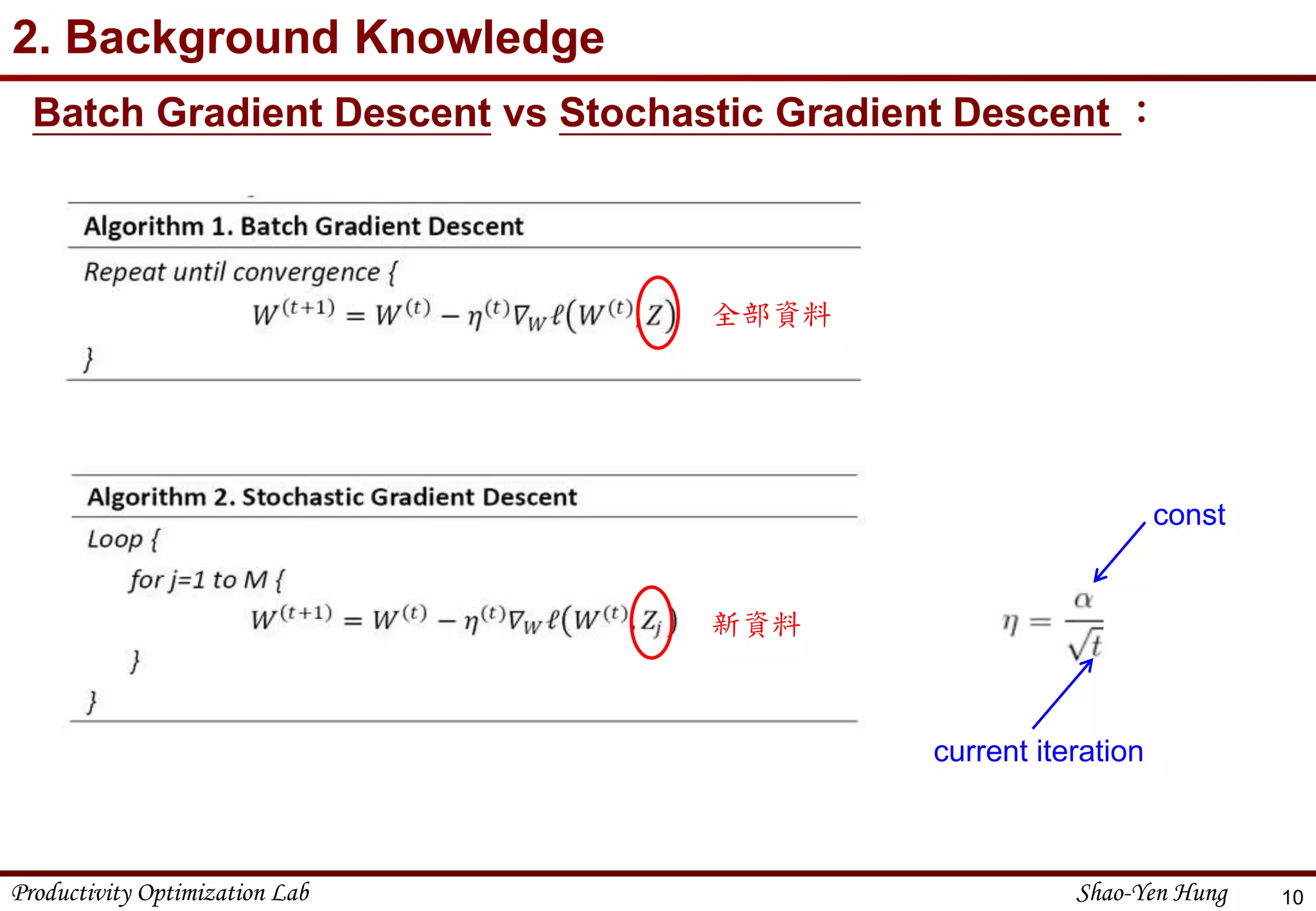
2. Background Knowledge
Convex Function
𝜕2 𝑓
𝜕𝑥2 ≥ 0
Gradient and Subgradient
6
(Gradient)
x
y y=f(x)=|x|
At x=0, subgradient ∂f ∈ [-1, 1]](https://image.slidesharecdn.com/2016-05-160723150429/75/Online-Optimization-Problem-1-Online-machine-learning-6-2048.jpg)






![Productivity Optimization Lab Shao-Yen Hung
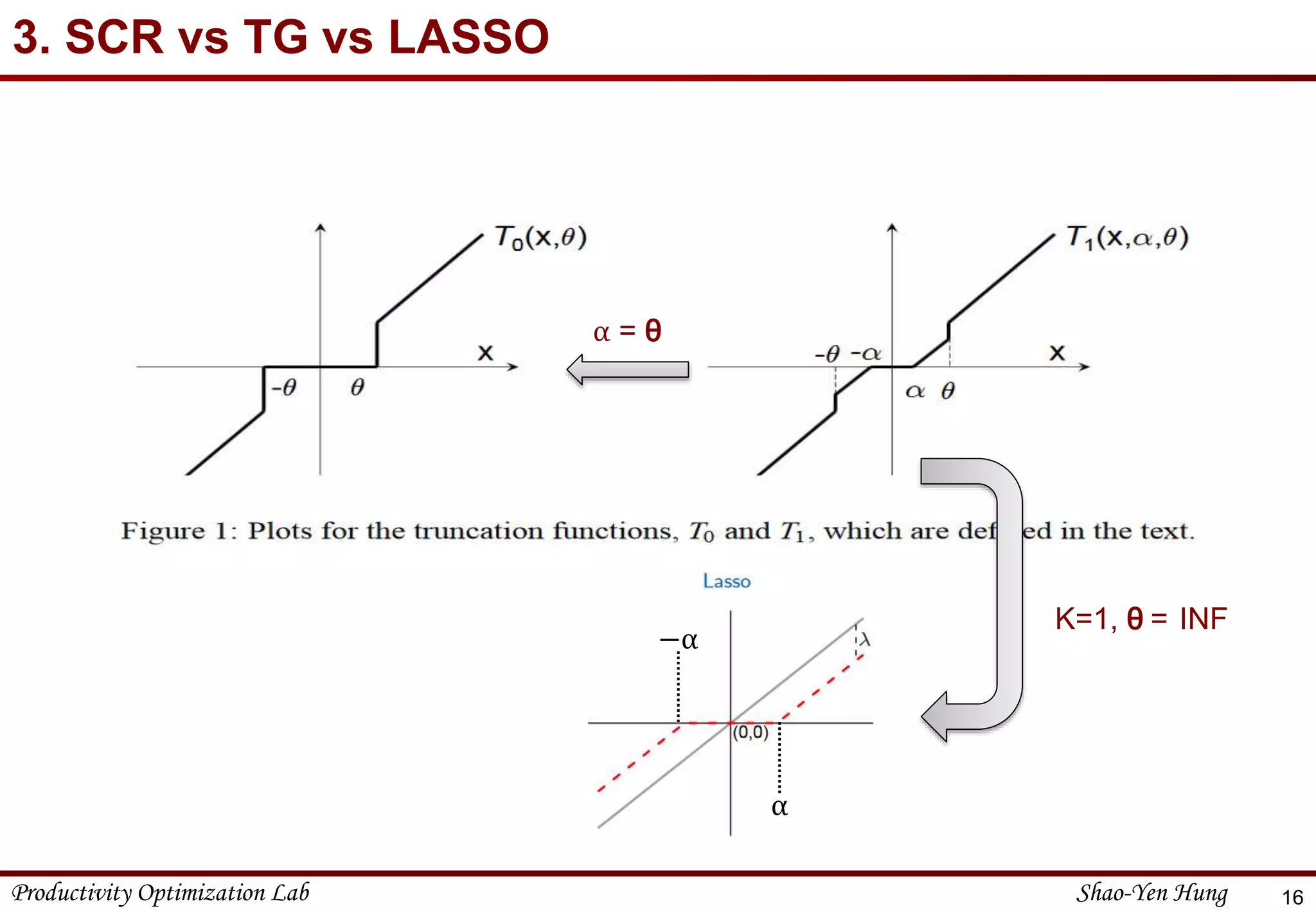
3. TG (Truncated Gradient)
14
𝑇1(𝑣𝑖, α, θ) =
max 0, 𝑣𝑖 − α , 𝑖𝑓 𝑣𝑖∈ [0, θ]
min 0, 𝑣𝑖 + α , 𝑖𝑓 𝑣𝑖∈ [−θ, 0]
𝑣𝑖 , 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
𝑊𝑡+1 = 𝑇1(𝑊𝑡 − η
𝜕 𝑙 𝑊𝑡,𝑍
𝜕𝑊𝑡
, η𝒈𝒊, θ)
𝒈𝒊 =
0 , 𝑖𝑓 𝑚𝑜𝑑 𝑡, 𝐾 ≠ 0
𝐾𝑔 , 𝑖𝑓 𝑚𝑜𝑑 𝑡, 𝐾 = 0
• 4 parameters:
θ : threshold for deciding whether coefficient is 0 or not
K : doing truncating after k online steps
η : learning rate
g:gravity parameter](https://image.slidesharecdn.com/2016-05-160723150429/75/Online-Optimization-Problem-1-Online-machine-learning-14-2048.jpg)







![Productivity Optimization Lab Shao-Yen Hung
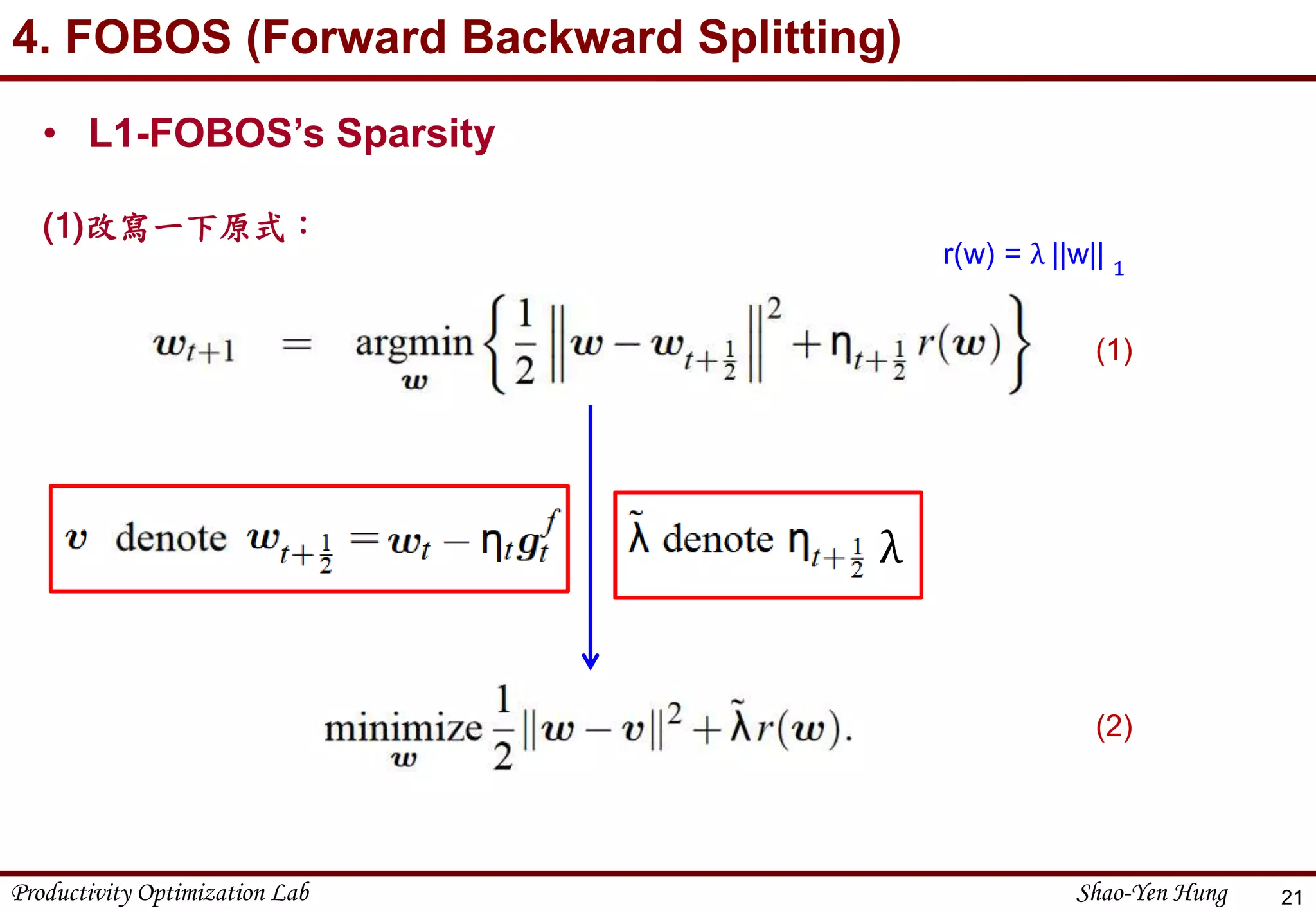
4. FOBOS (Forward Backward Splitting)
24
• L1-FOBOS’s Sparsity
(4)當𝒘𝒋‧𝒗𝒋 ≥ 0:
If 𝐯𝐣 ≥ 0:
a) 𝒘∗ > 0:Since βw*=0, β=0 w* = v - 𝜆
b) 𝒘∗
= 0:Since β≥ 0, 𝑣𝑖 - 𝜆 ≤ 0
That is, w* = max(0, 𝑣𝑖 - 𝜆)
s.t −𝒘𝒋 ≤ 𝟎
]=0 and βw=0
𝜕
𝜕𝑤
[
KKT
𝑤∗
(5) Same as 𝒗𝒋 < 0: w* = -max(0, −𝑣𝑖 - 𝜆)](https://image.slidesharecdn.com/2016-05-160723150429/75/Online-Optimization-Problem-1-Online-machine-learning-24-2048.jpg)




![Productivity Optimization Lab Shao-Yen Hung
Reference
[1] John Langford, Lihong Li & Tong Zhang. Sparse Online Learning via
Truncated Gradient. Journal of Machine Learning Research, 2009.
[2] John Duchi & Yoram Singer. Efficient Online and Batch Learning using
Forward Backward Splitting. Journal of Machine Learning Research, 2009.
[3] Lin Xiao. Dual Averaging Methods for Regularized Stochastic Learning
and Online Optimization. Journal of Machine Learning Research, 2010.
[4] H. B. McMahan. Follow-the-regularized-leader and mirror descent:
Equivalence theorems and L1 regularization. In AISTATS, 2011.
[5] H. Brendan McMahan,Gary Holt, D. Sculley et al. Ad Click Prediction: a
View from the Trenches. In KDD , 2013.
29](https://image.slidesharecdn.com/2016-05-160723150429/75/Online-Optimization-Problem-1-Online-machine-learning-29-2048.jpg)





![Productivity Optimization Lab Shao-Yen Hung
2. Background Knowledge
Convex Function
𝜕2 𝑓
𝜕𝑥2 ≥ 0
Gradient and Subgradient
6
(Gradient)
x
y y=f(x)=|x|
At x=0, subgradient ∂f ∈ [-1, 1]](https://crownmelresort.com/image.slidesharecdn.com/2016-05-160723150429/75/Online-Optimization-Problem-1-Online-machine-learning-6-2048.jpg)







![Productivity Optimization Lab Shao-Yen Hung
3. TG (Truncated Gradient)
14
𝑇1(𝑣𝑖, α, θ) =
max 0, 𝑣𝑖 − α , 𝑖𝑓 𝑣𝑖∈ [0, θ]
min 0, 𝑣𝑖 + α , 𝑖𝑓 𝑣𝑖∈ [−θ, 0]
𝑣𝑖 , 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
𝑊𝑡+1 = 𝑇1(𝑊𝑡 − η
𝜕 𝑙 𝑊𝑡,𝑍
𝜕𝑊𝑡
, η𝒈𝒊, θ)
𝒈𝒊 =
0 , 𝑖𝑓 𝑚𝑜𝑑 𝑡, 𝐾 ≠ 0
𝐾𝑔 , 𝑖𝑓 𝑚𝑜𝑑 𝑡, 𝐾 = 0
• 4 parameters:
θ : threshold for deciding whether coefficient is 0 or not
K : doing truncating after k online steps
η : learning rate
g:gravity parameter](https://crownmelresort.com/image.slidesharecdn.com/2016-05-160723150429/75/Online-Optimization-Problem-1-Online-machine-learning-14-2048.jpg)









![Productivity Optimization Lab Shao-Yen Hung
4. FOBOS (Forward Backward Splitting)
24
• L1-FOBOS’s Sparsity
(4)當𝒘𝒋‧𝒗𝒋 ≥ 0:
If 𝐯𝐣 ≥ 0:
a) 𝒘∗ > 0:Since βw*=0, β=0 w* = v - 𝜆
b) 𝒘∗
= 0:Since β≥ 0, 𝑣𝑖 - 𝜆 ≤ 0
That is, w* = max(0, 𝑣𝑖 - 𝜆)
s.t −𝒘𝒋 ≤ 𝟎
]=0 and βw=0
𝜕
𝜕𝑤
[
KKT
𝑤∗
(5) Same as 𝒗𝒋 < 0: w* = -max(0, −𝑣𝑖 - 𝜆)](https://crownmelresort.com/image.slidesharecdn.com/2016-05-160723150429/75/Online-Optimization-Problem-1-Online-machine-learning-24-2048.jpg)




![Productivity Optimization Lab Shao-Yen Hung
Reference
[1] John Langford, Lihong Li & Tong Zhang. Sparse Online Learning via
Truncated Gradient. Journal of Machine Learning Research, 2009.
[2] John Duchi & Yoram Singer. Efficient Online and Batch Learning using
Forward Backward Splitting. Journal of Machine Learning Research, 2009.
[3] Lin Xiao. Dual Averaging Methods for Regularized Stochastic Learning
and Online Optimization. Journal of Machine Learning Research, 2010.
[4] H. B. McMahan. Follow-the-regularized-leader and mirror descent:
Equivalence theorems and L1 regularization. In AISTATS, 2011.
[5] H. Brendan McMahan,Gary Holt, D. Sculley et al. Ad Click Prediction: a
View from the Trenches. In KDD , 2013.
29](https://crownmelresort.com/image.slidesharecdn.com/2016-05-160723150429/75/Online-Optimization-Problem-1-Online-machine-learning-29-2048.jpg)

This document discusses online optimization algorithms. It begins with an introduction to online learning and its advantages over batch learning. It then provides background knowledge on relevant concepts like convex functions, gradients, loss functions, and regularization. It explains the differences between batch gradient descent and stochastic gradient descent. The document proceeds to describe several online optimization algorithms: Simple Coefficient Rounding (SCR), Truncated Gradient (TG), Forward-Backward Splitting (FOBOS), Regularized Dual Averaging (RDA), and Follow The Regularized Leader (FTRL). It provides detailed explanations of how SCR, TG, and FOBOS generate sparsity and their updating rules.





















































