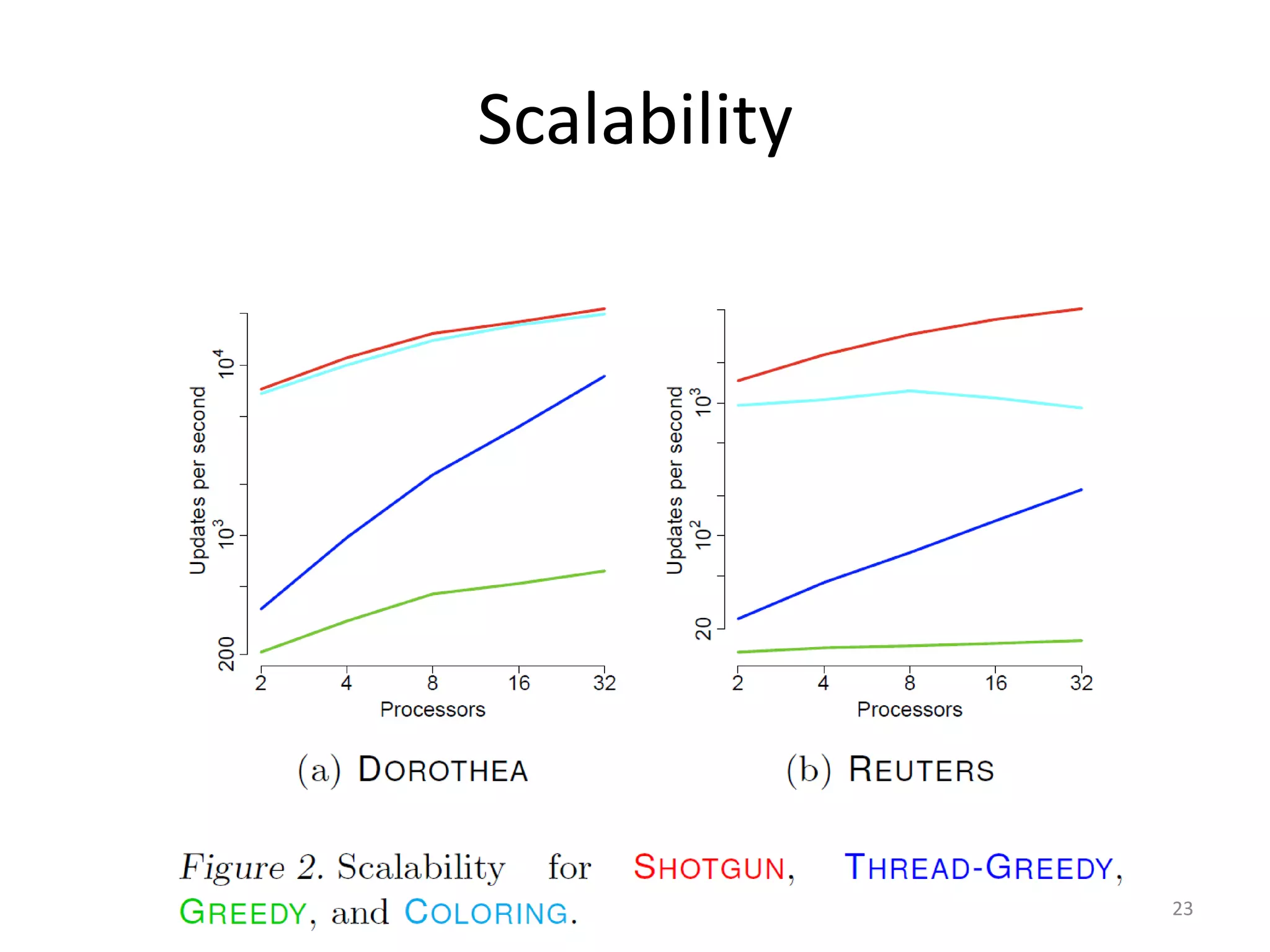
The document discusses a framework for parallel coordinate descent algorithms aimed at optimizing large L1 regularization problems, introducing two methods: thread-greedy and coloring-based coordinate descent. Experiments comparing four coordinate descent methods demonstrate their performance in shared memory multi-core environments, concluding that no single method is definitively superior. The authors also highlight that the convergence condition for the thread-greedy algorithm remains an open question.

![読む論文
• Scaling Up Coordinate Descent Algorithms for
Large L1 regularization Problems
– by C. Scherrer, M. Halappanavar, A. Tewari, D.
Haglin
• Coordinate Descent の並列計算
– [Bradley+ 11] Parallel Coordinate Descent for L1-
Regularized Loss Minimization (ICML2011) とか
2](https://image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-2-2048.jpg)



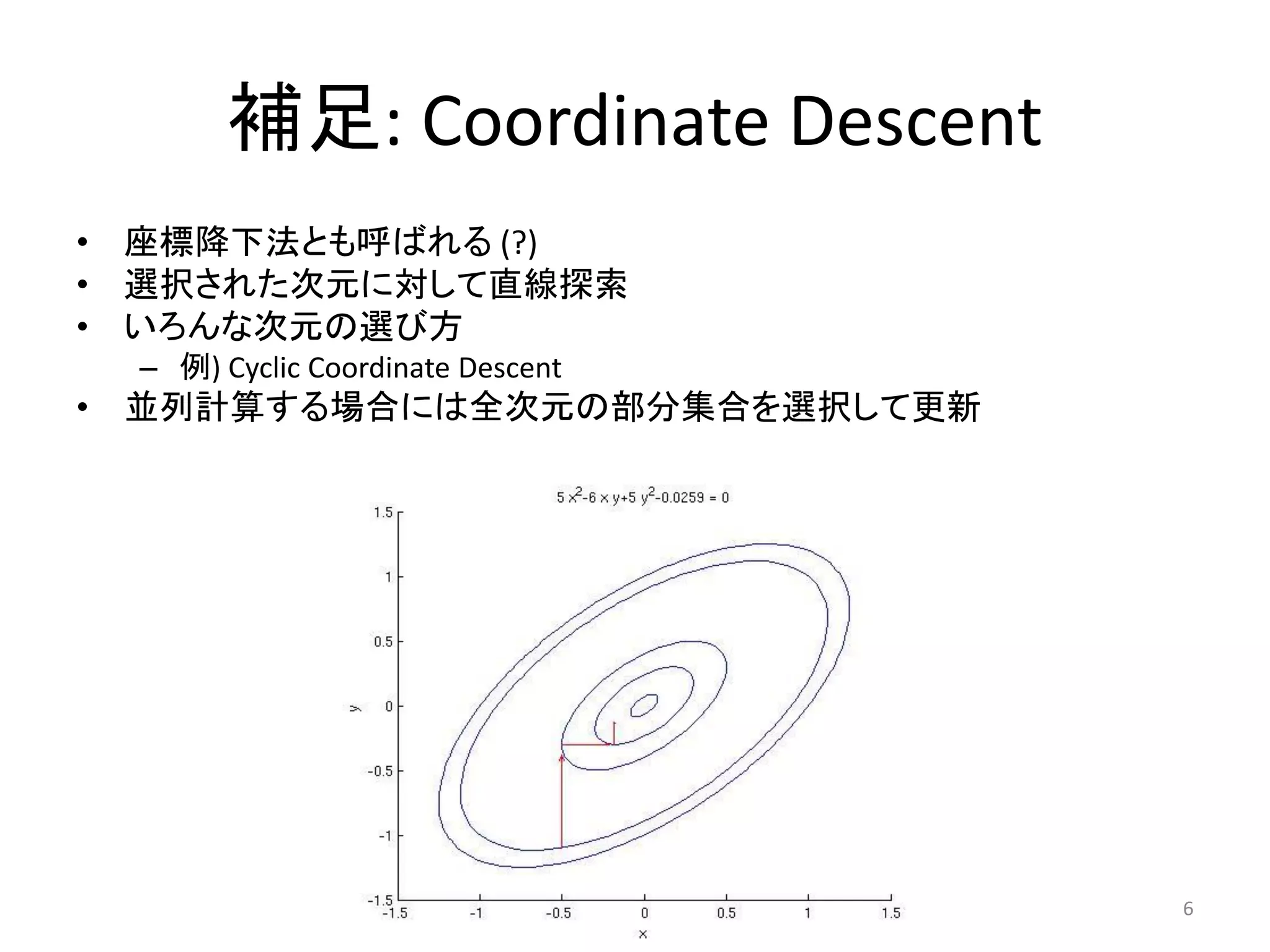


![Step 1: Select
• Selecting 𝐽 coordinates
• The selection criteria differs for variations of CD
techniques
– cyclic CD (CCD)
– stochastic CD (SCD)
• selection of a singlton
– fully greedy CD
• 𝐽 = {1, … , 𝑘}
– Shotgun [Bradley+ 11]
• selects a random subset of a given size
9](https://image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-9-2048.jpg)

![Step 3: Accept
• In Accept step, the algorithm accepts 𝐽′ ⊆ 𝐽
– [Bradley+ 11] show correlations among features can
lead to divergence if too many coordinates are updated at
once (see below figure)
• In CCD, SCD, Shotgun, the algorithm allows all
proposals to be accepted
– No need to calculate 𝝋
11](https://image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-11-2048.jpg)


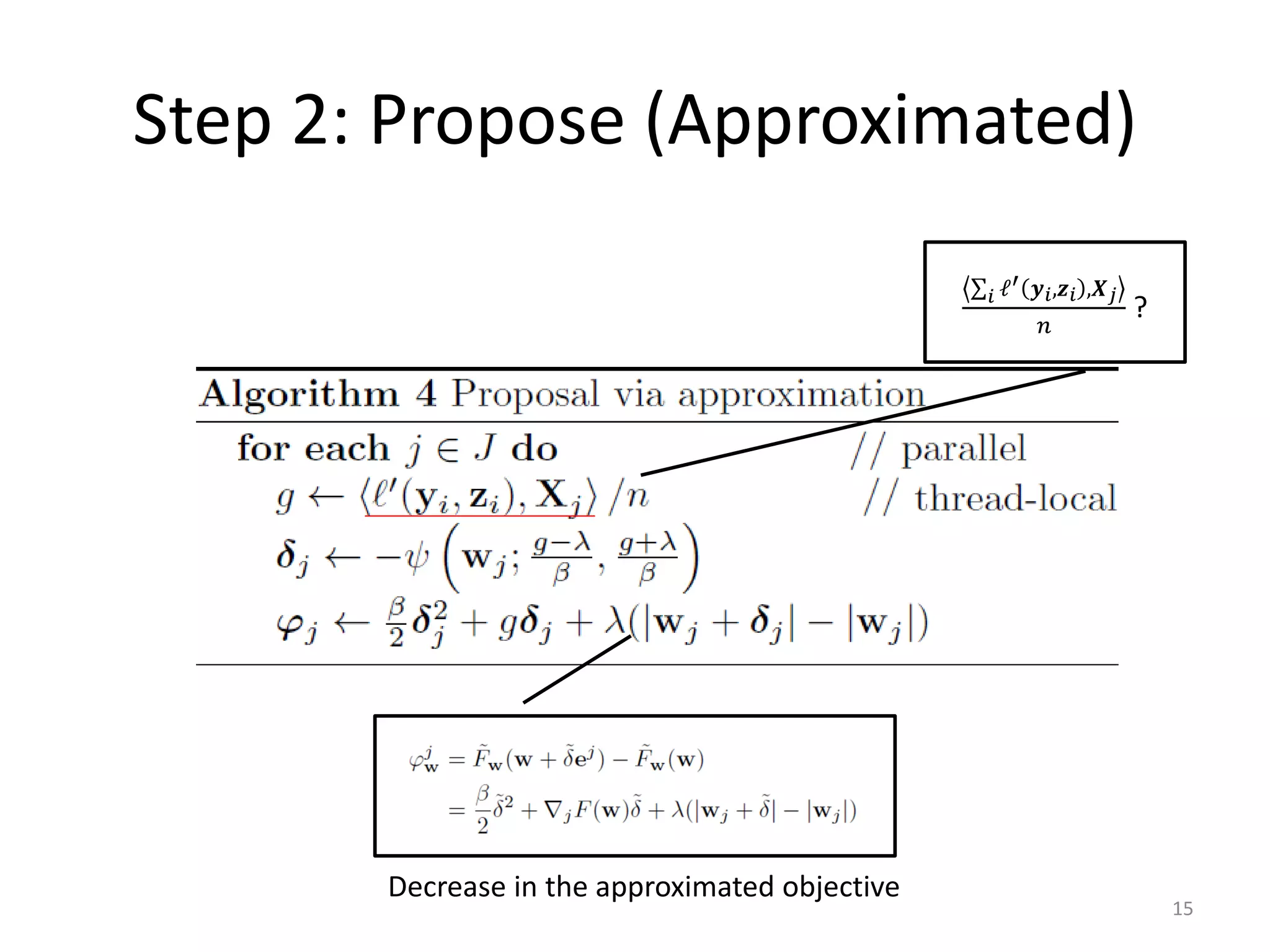
![Approximate Minimization (2/2)
• Well known minimizer (e.g., [Yuan and Lin 10])
𝛻𝑗 𝐹 𝒘 − 𝜆 𝛻𝑗 𝐹 𝒘 + 𝜆
𝛿 = −𝜓 𝒘𝑗; ,
𝛽 𝛽
𝑎 if 𝑥 < 𝑎
where, 𝜓 𝑥; 𝑎, 𝑏 = 𝑏 if 𝑥 > 𝑏
𝑥 otherwise
for squared loss 𝛽 = 1, logistic loss 𝛽 = 1/4.
14](https://image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-14-2048.jpg)

![Algorithms (conventional)
• SHOTGUN [Bradley+ 11]
– Select step: random subset of the columns
– Accept step: accepts every proposal
• No need to compute a proxy for the objective
– convergence is guaranteed only if the # of coordinates selected
is at most 𝑃 ∗ = 𝑘 (*1)
2𝜌
• GREEDY
– Select step: all coordinates
– Propose step: each thread generating proposals for some subset
of the coordinates using approximation
– Accept step: Only accepts the single best among the all threads.
(*1) 𝜌 is the matrix eigenvalue of 𝑿 𝑇 𝑿 17](https://image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-17-2048.jpg)




![References
• [Yuan and Lin 10] G. Yuan, C. Lin, “A Comparison of Opitmization Methods
and Software for Large-scale L1-regularized Linear Classification”, Journal
of Machine Learning Research, vol.11, pp.3183-3234, 2010.
• [Bradley+ 11] J. K. Bradley, A. Kyrola, D. Bickson, C. Guestrin, “Parallel
Coordinate Descent for L1-Regularized Loss Minimization”, In Proc. ICML
‘11, 2011.
25](https://image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-25-2048.jpg)


![読む論文
• Scaling Up Coordinate Descent Algorithms for
Large L1 regularization Problems
– by C. Scherrer, M. Halappanavar, A. Tewari, D.
Haglin
• Coordinate Descent の並列計算
– [Bradley+ 11] Parallel Coordinate Descent for L1-
Regularized Loss Minimization (ICML2011) とか
2](https://crownmelresort.com/image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-2-2048.jpg)






![Step 1: Select
• Selecting 𝐽 coordinates
• The selection criteria differs for variations of CD
techniques
– cyclic CD (CCD)
– stochastic CD (SCD)
• selection of a singlton
– fully greedy CD
• 𝐽 = {1, … , 𝑘}
– Shotgun [Bradley+ 11]
• selects a random subset of a given size
9](https://crownmelresort.com/image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-9-2048.jpg)

![Step 3: Accept
• In Accept step, the algorithm accepts 𝐽′ ⊆ 𝐽
– [Bradley+ 11] show correlations among features can
lead to divergence if too many coordinates are updated at
once (see below figure)
• In CCD, SCD, Shotgun, the algorithm allows all
proposals to be accepted
– No need to calculate 𝝋
11](https://crownmelresort.com/image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-11-2048.jpg)


![Approximate Minimization (2/2)
• Well known minimizer (e.g., [Yuan and Lin 10])
𝛻𝑗 𝐹 𝒘 − 𝜆 𝛻𝑗 𝐹 𝒘 + 𝜆
𝛿 = −𝜓 𝒘𝑗; ,
𝛽 𝛽
𝑎 if 𝑥 < 𝑎
where, 𝜓 𝑥; 𝑎, 𝑏 = 𝑏 if 𝑥 > 𝑏
𝑥 otherwise
for squared loss 𝛽 = 1, logistic loss 𝛽 = 1/4.
14](https://crownmelresort.com/image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-14-2048.jpg)


![Algorithms (conventional)
• SHOTGUN [Bradley+ 11]
– Select step: random subset of the columns
– Accept step: accepts every proposal
• No need to compute a proxy for the objective
– convergence is guaranteed only if the # of coordinates selected
is at most 𝑃 ∗ = 𝑘 (*1)
2𝜌
• GREEDY
– Select step: all coordinates
– Propose step: each thread generating proposals for some subset
of the coordinates using approximation
– Accept step: Only accepts the single best among the all threads.
(*1) 𝜌 is the matrix eigenvalue of 𝑿 𝑇 𝑿 17](https://crownmelresort.com/image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-17-2048.jpg)







![References
• [Yuan and Lin 10] G. Yuan, C. Lin, “A Comparison of Opitmization Methods
and Software for Large-scale L1-regularized Linear Classification”, Journal
of Machine Learning Research, vol.11, pp.3183-3234, 2010.
• [Bradley+ 11] J. K. Bradley, A. Kyrola, D. Bickson, C. Guestrin, “Parallel
Coordinate Descent for L1-Regularized Loss Minimization”, In Proc. ICML
‘11, 2011.
25](https://crownmelresort.com/image.slidesharecdn.com/20120728icmlreadingsuharav2-120728131204-phpapp02/75/ICML2012-Scaling-Up-Coordinate-Descent-Algorithms-for-Large-L1-regularization-Problems-25-2048.jpg)






























































































