Download as PDF, PPTX




































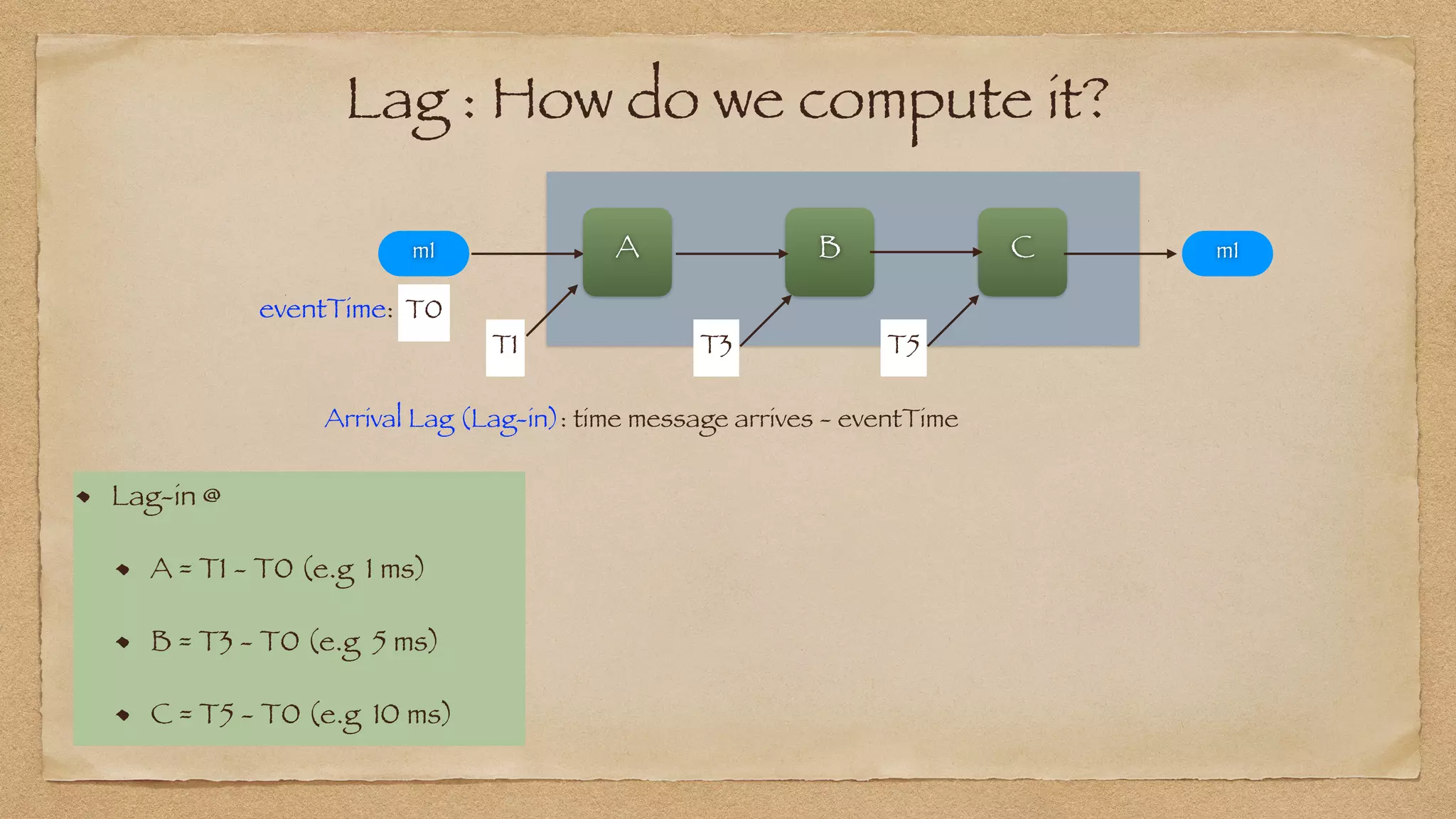
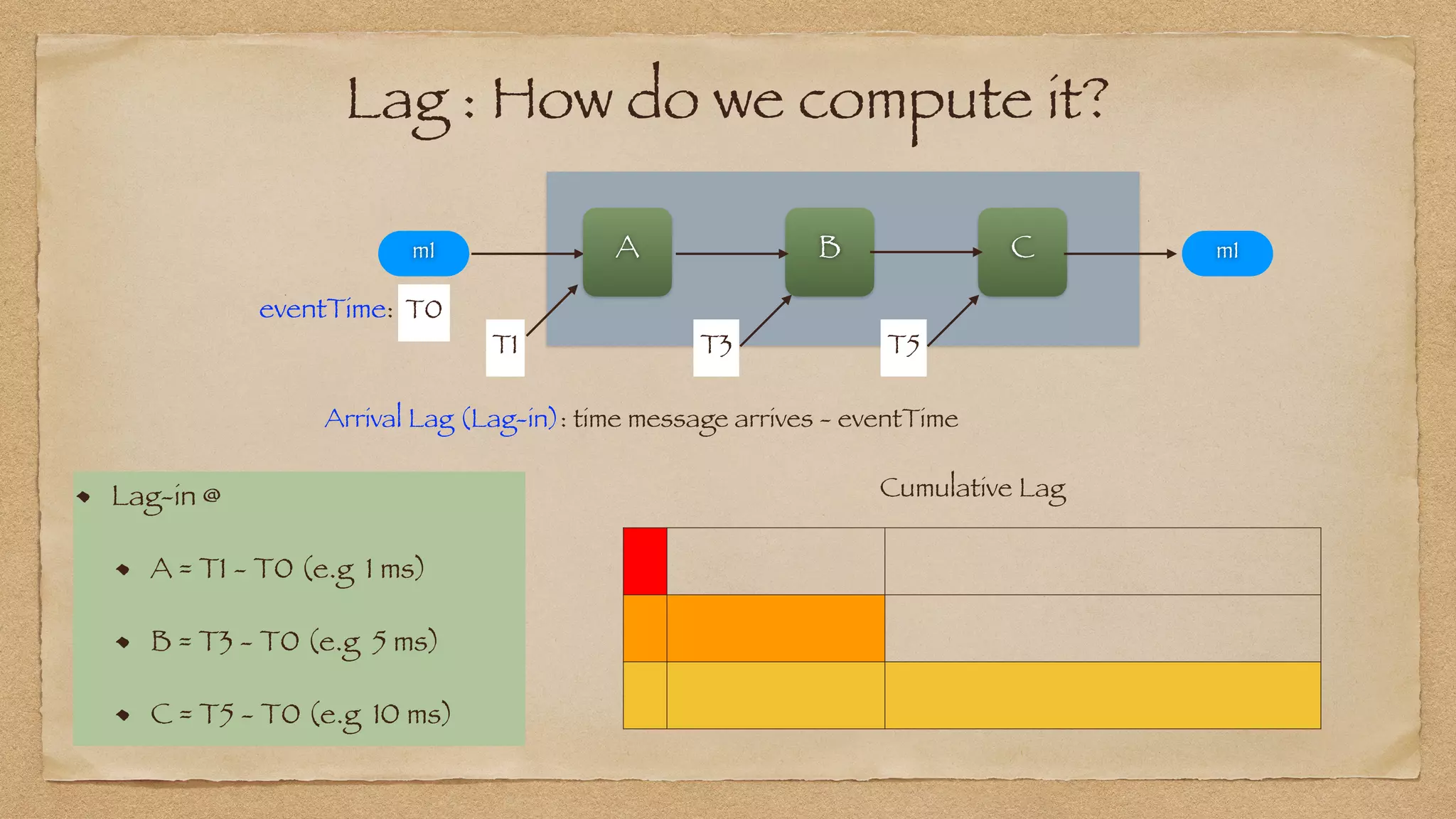


: P95 Lag_in or Lag_out at any Node N](https://image.slidesharecdn.com/yowdatakeynote2021final-210513004018/75/YOW-Data-Keynote-2021-73-2048.jpg)
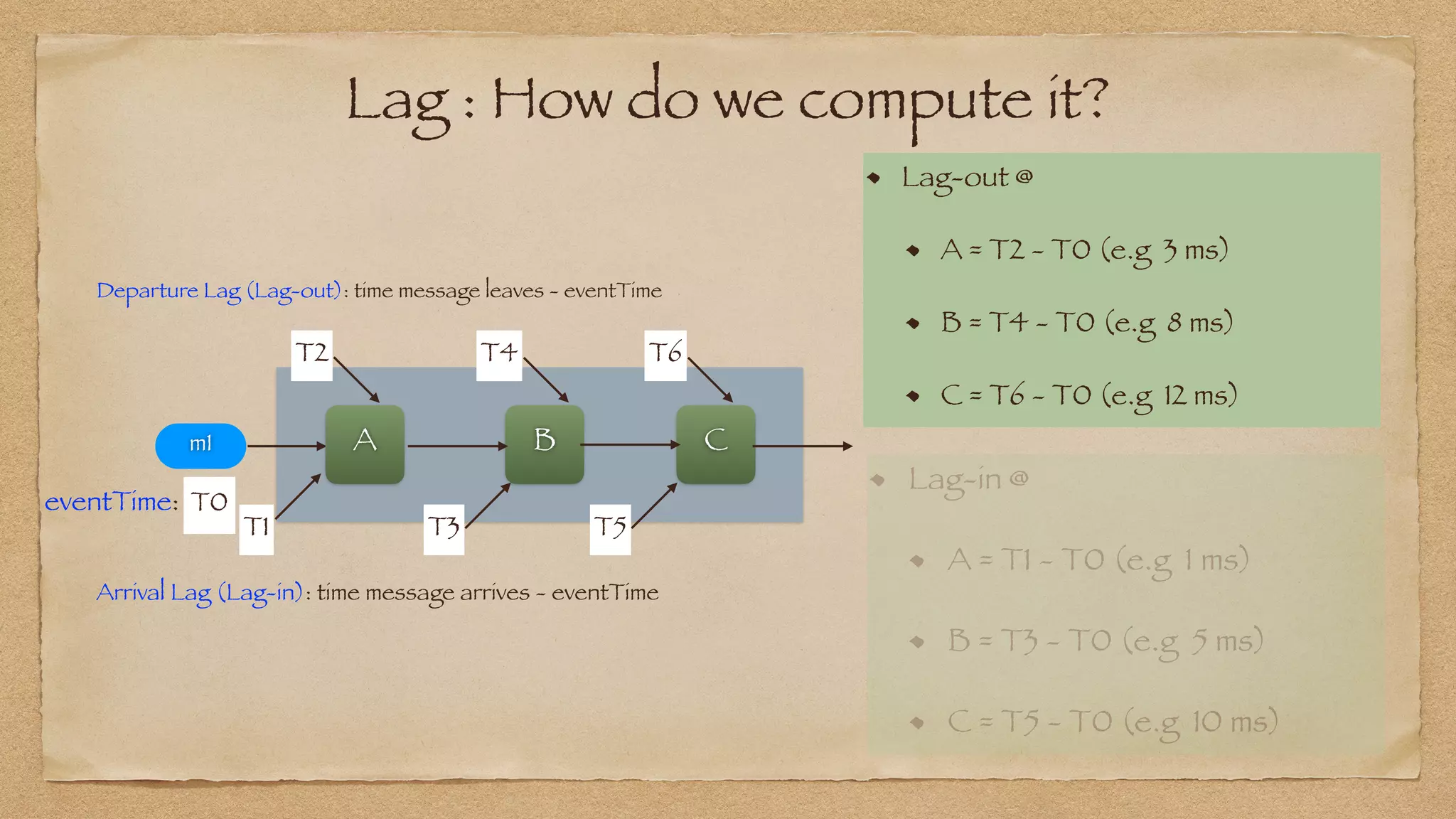
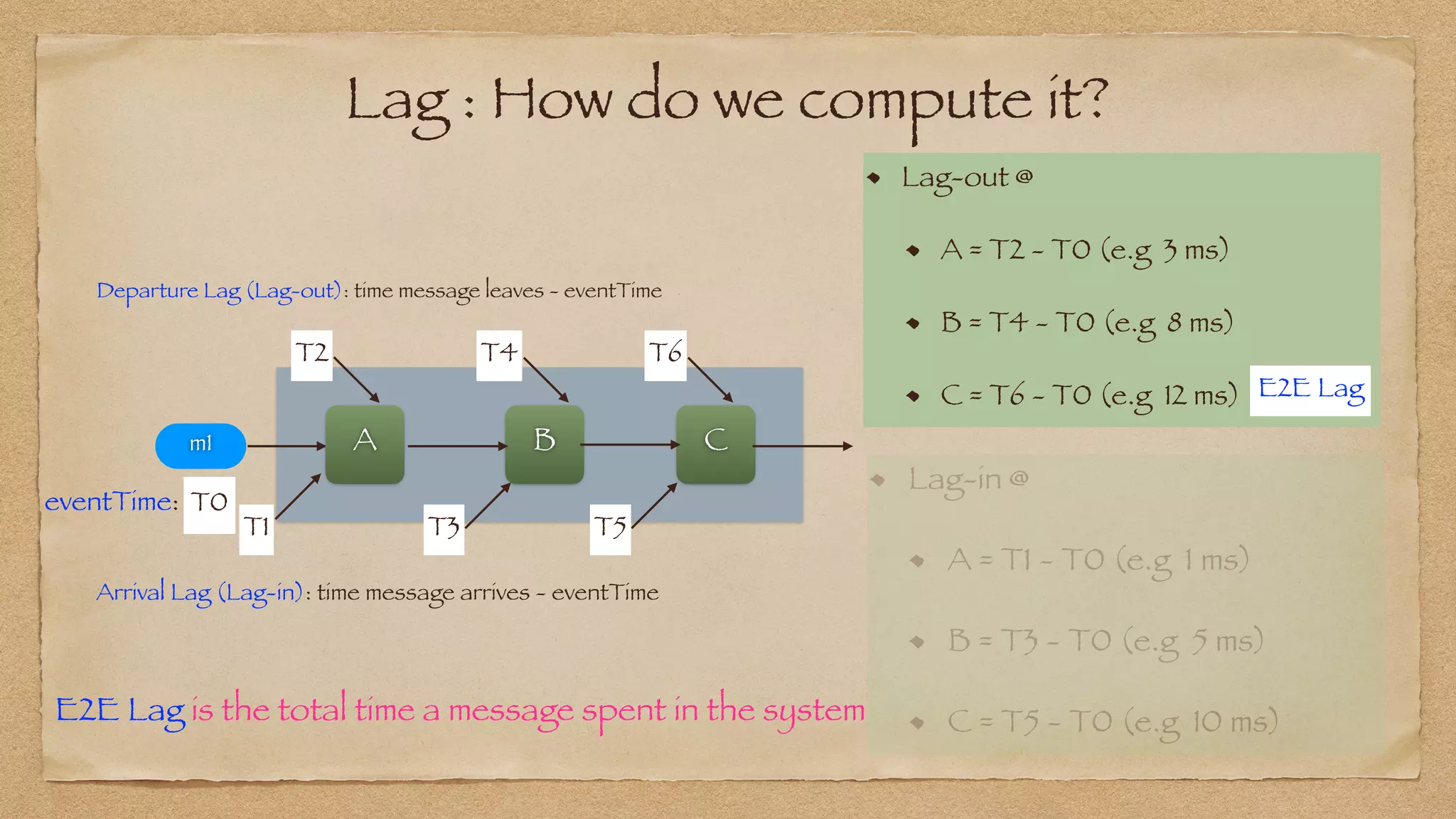
: P95 Lag_in or Lag_out at any Node N
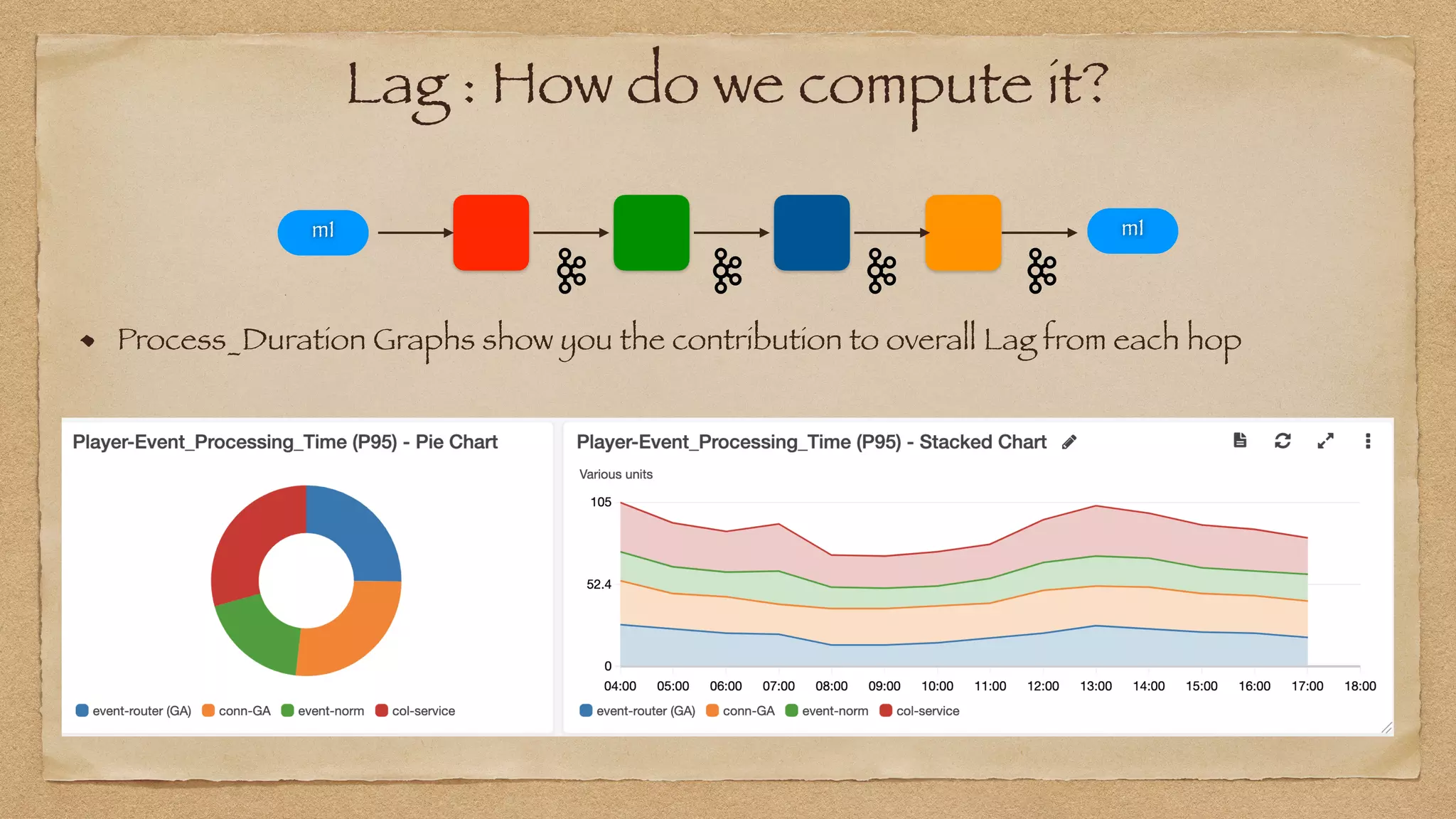
Process_Duration(N, p95) : Lag_out(N, p95) - Lag_in(N, p95)](https://image.slidesharecdn.com/yowdatakeynote2021final-210513004018/75/YOW-Data-Keynote-2021-74-2048.jpg)






























































































































: P95 Lag_in or Lag_out at any Node N](https://crownmelresort.com/image.slidesharecdn.com/yowdatakeynote2021final-210513004018/75/YOW-Data-Keynote-2021-73-2048.jpg)
: P95 Lag_in or Lag_out at any Node N
Process_Duration(N, p95) : Lag_out(N, p95) - Lag_in(N, p95)](https://crownmelresort.com/image.slidesharecdn.com/yowdatakeynote2021final-210513004018/75/YOW-Data-Keynote-2021-74-2048.jpg)












































































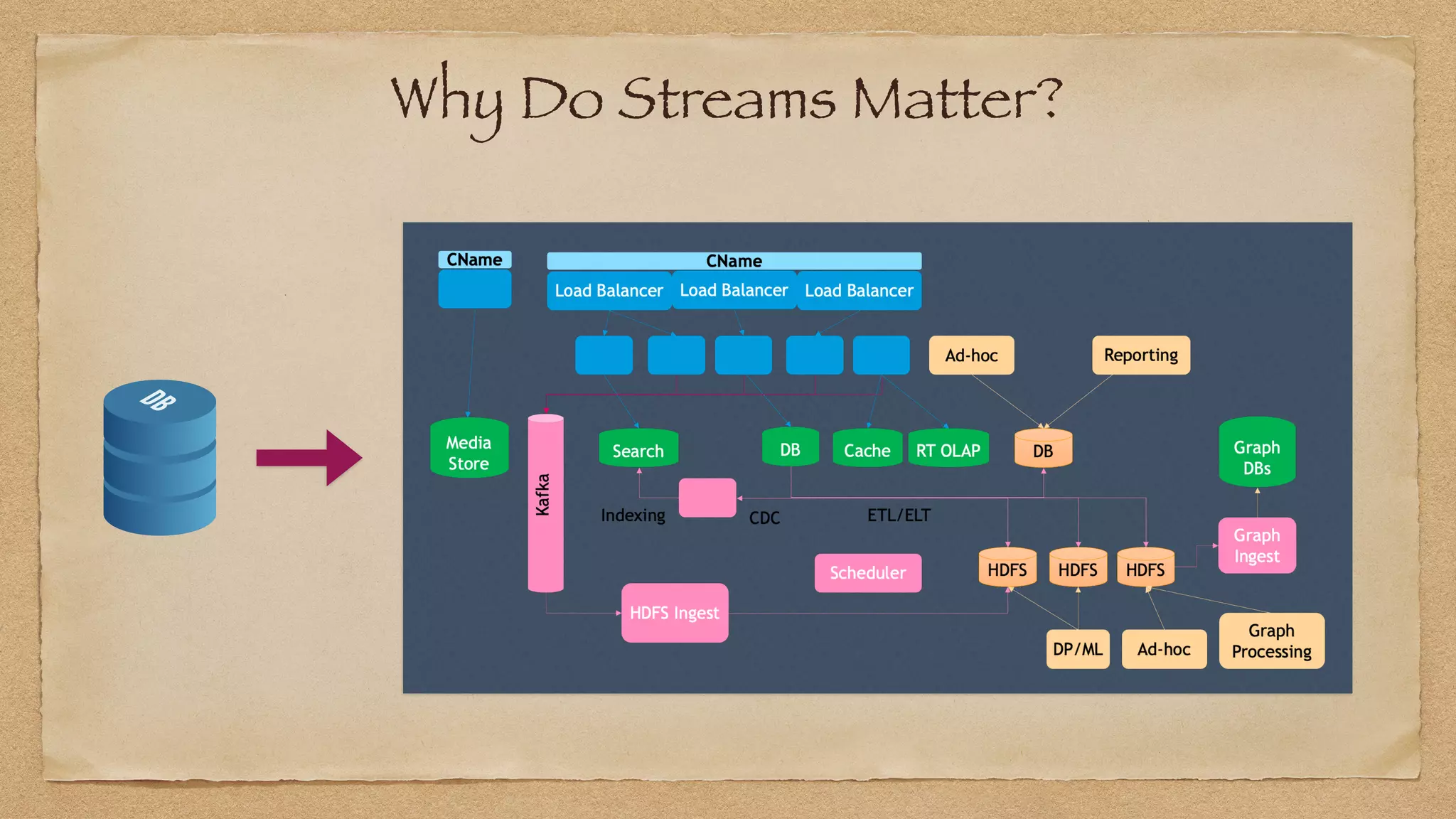
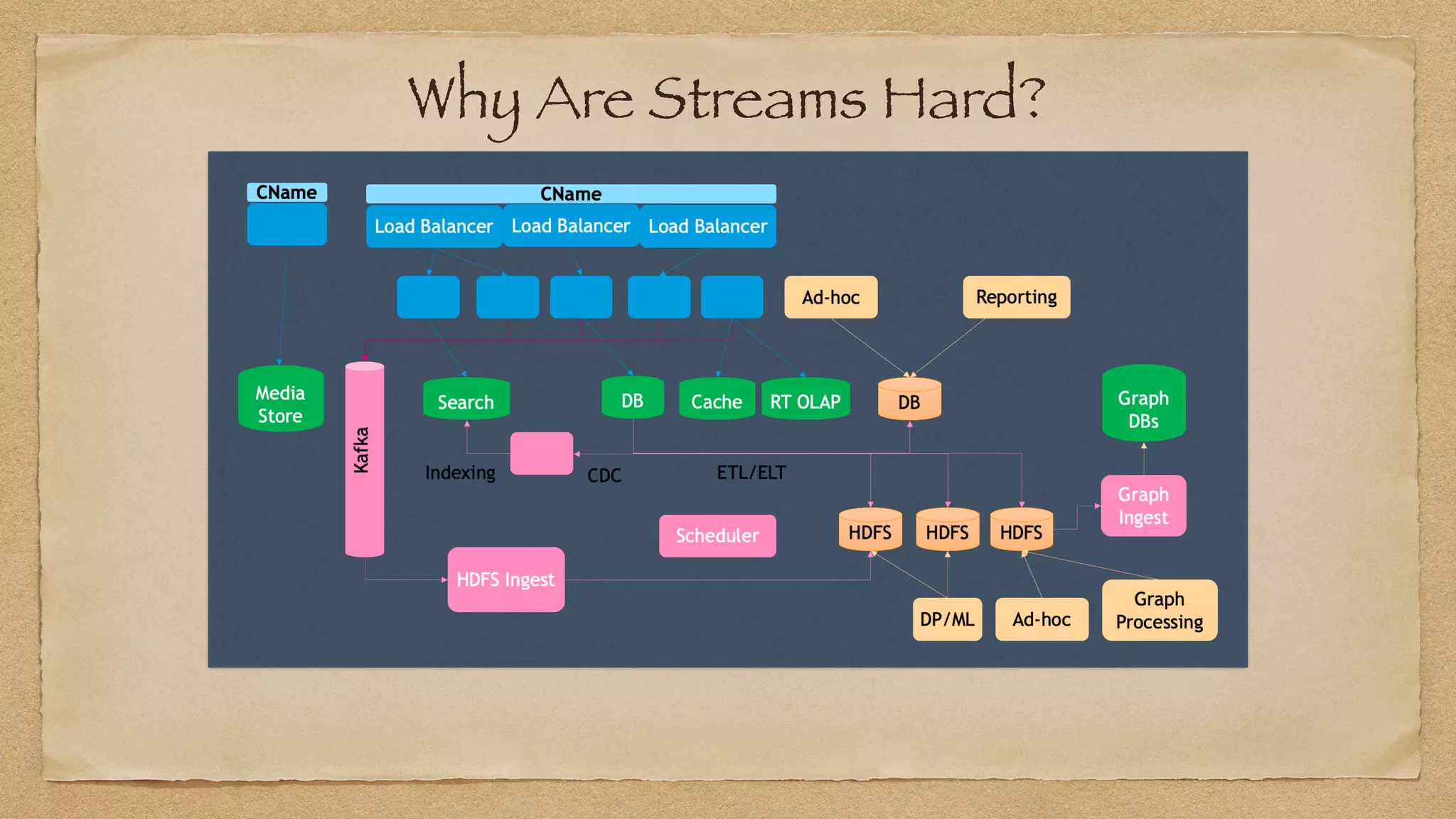
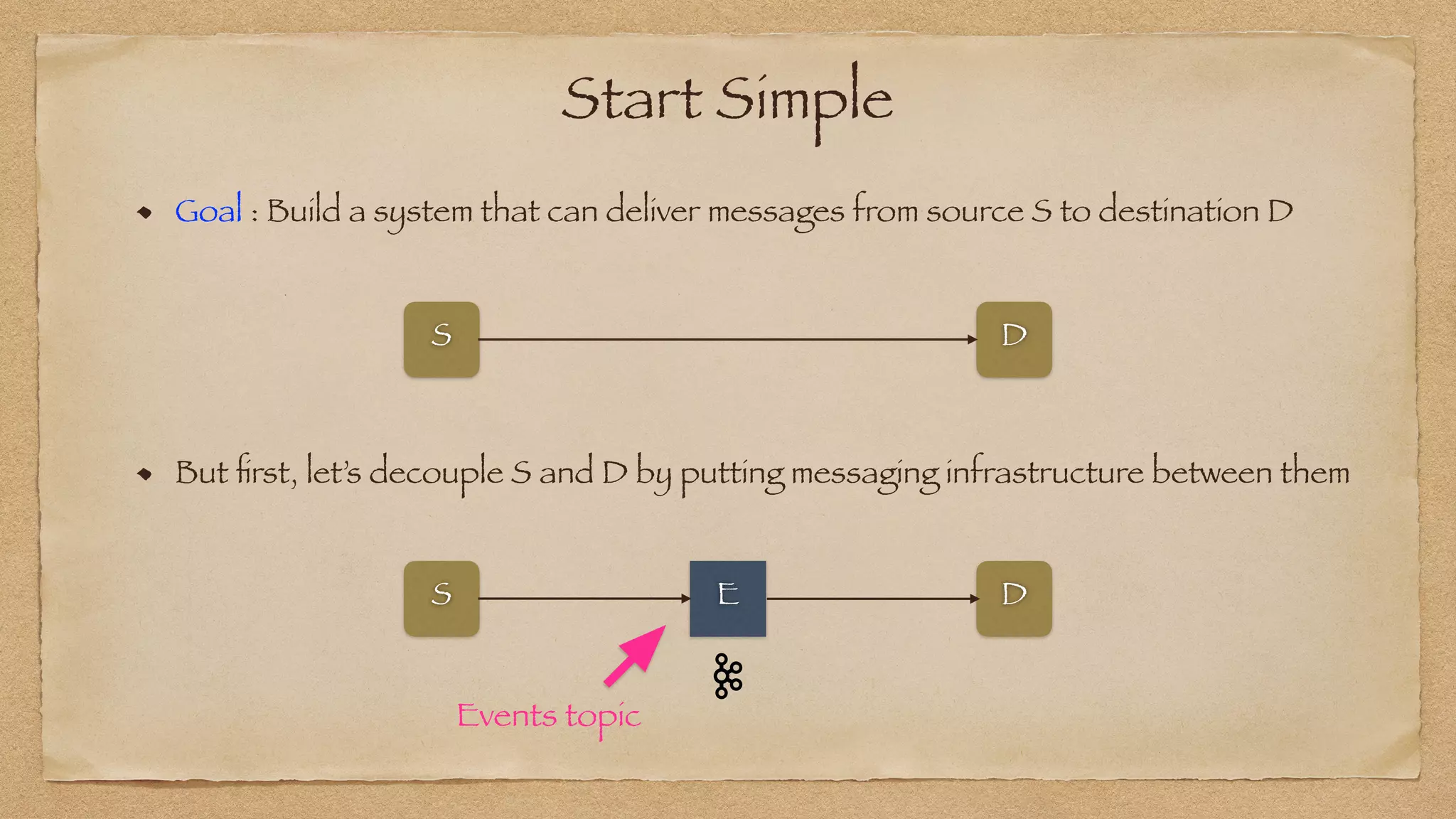
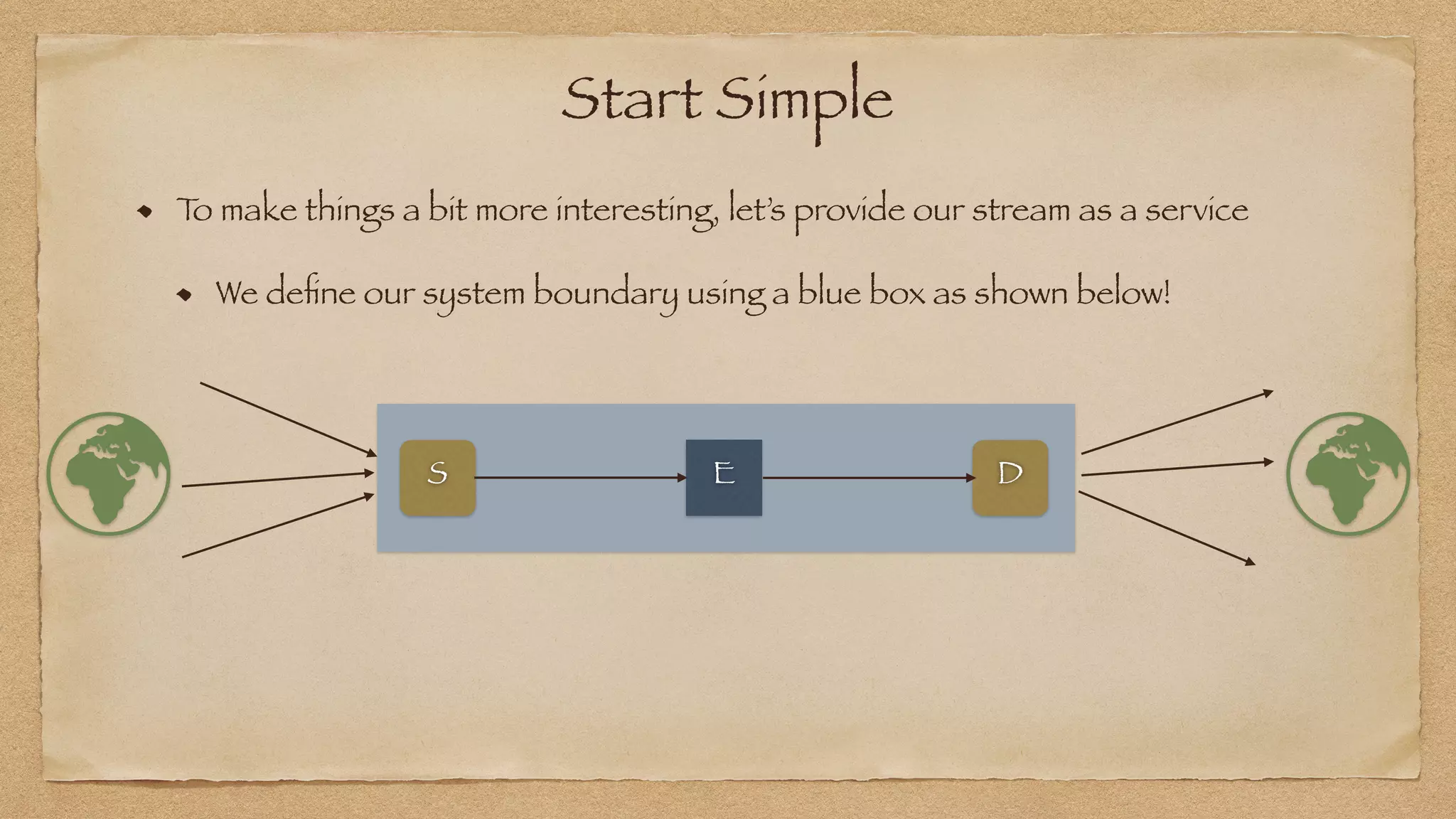
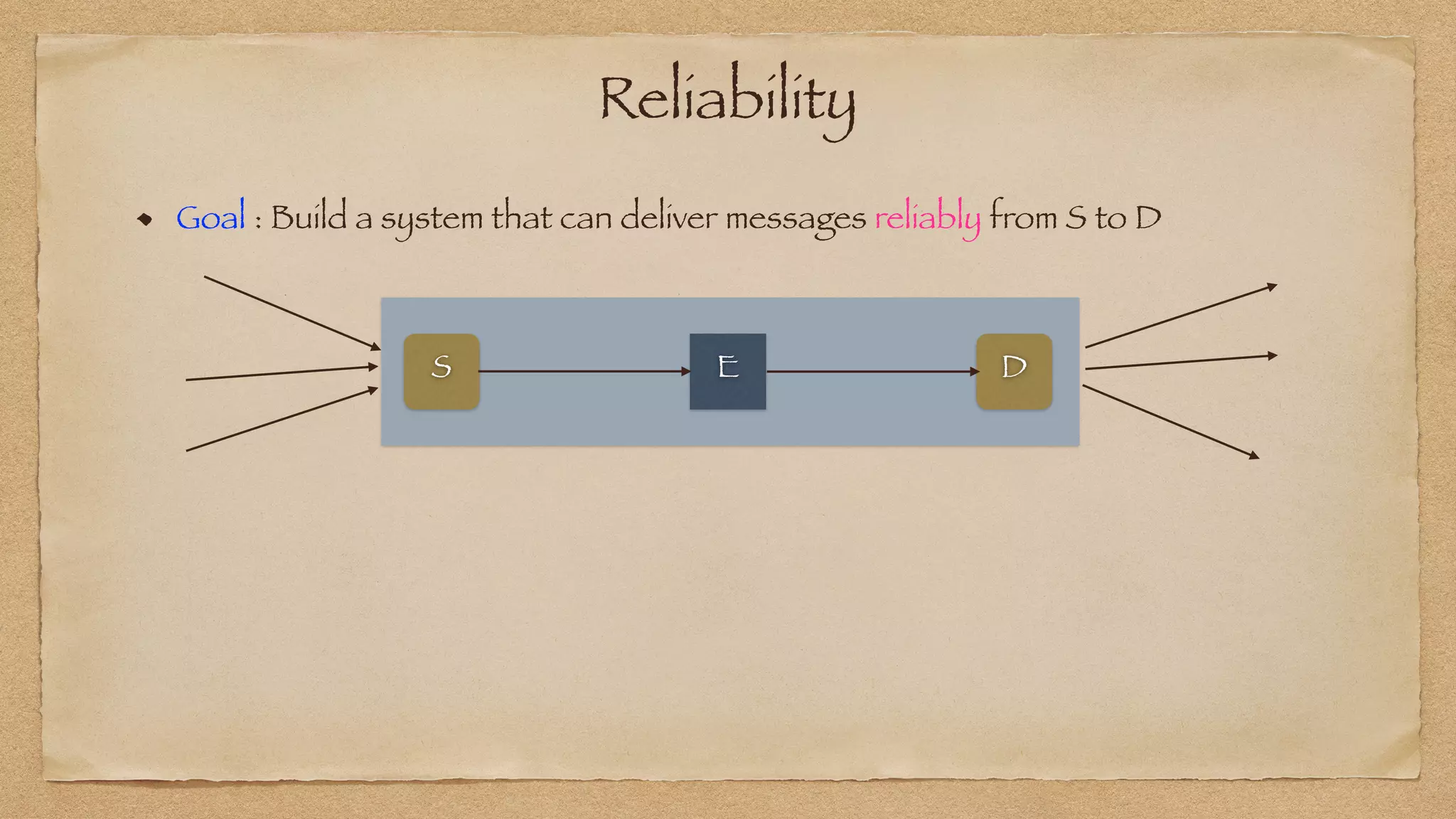
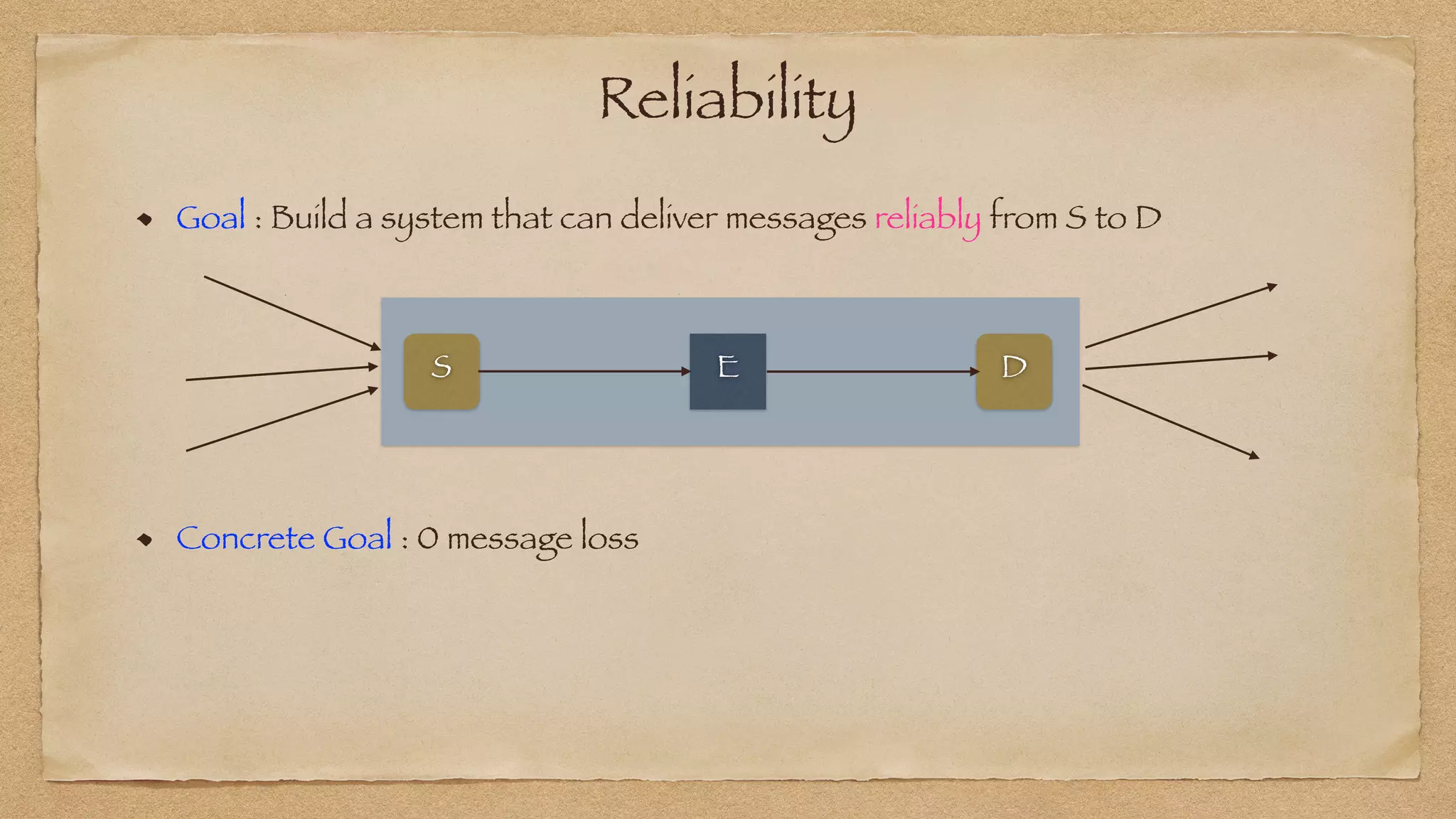
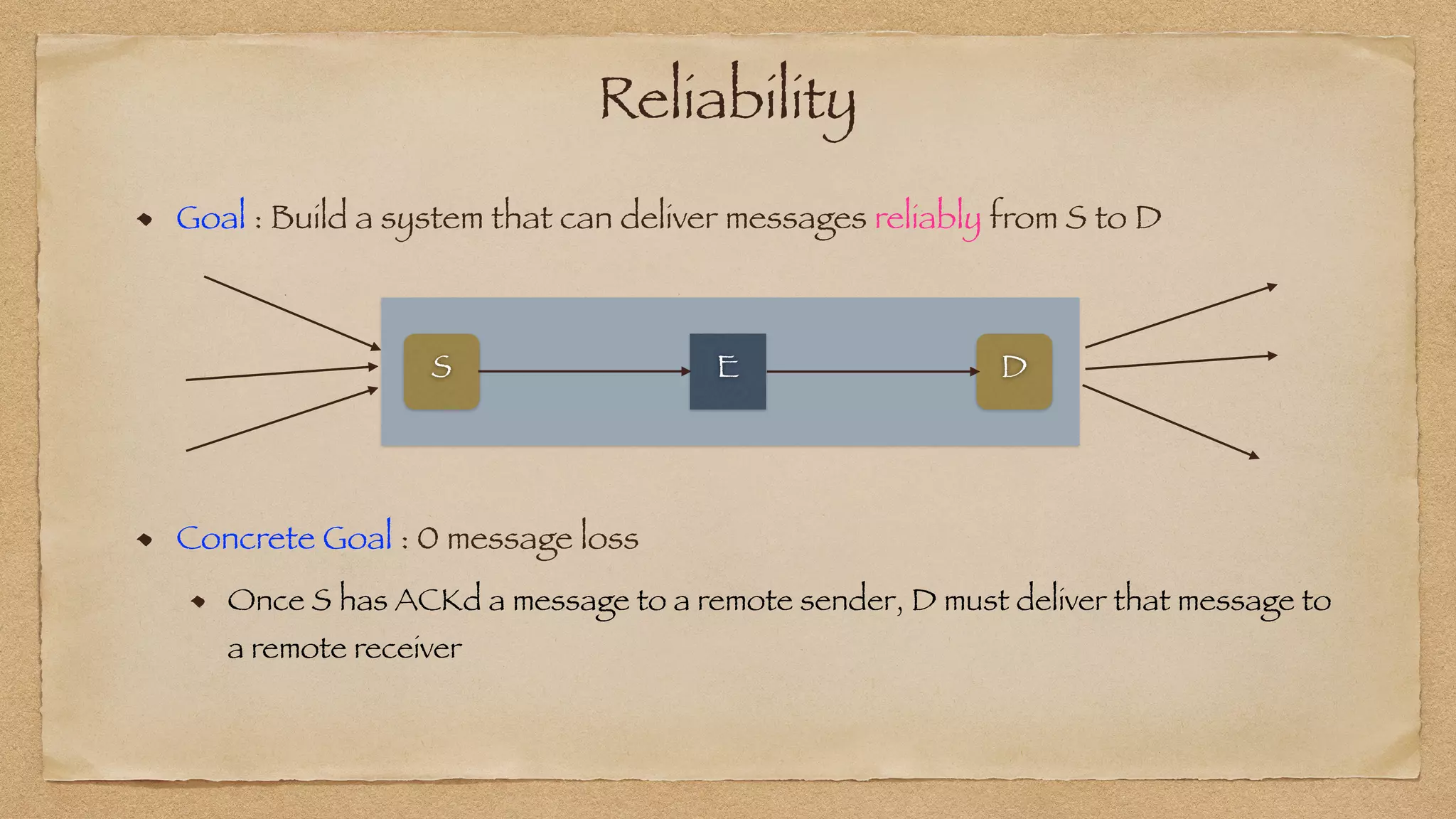
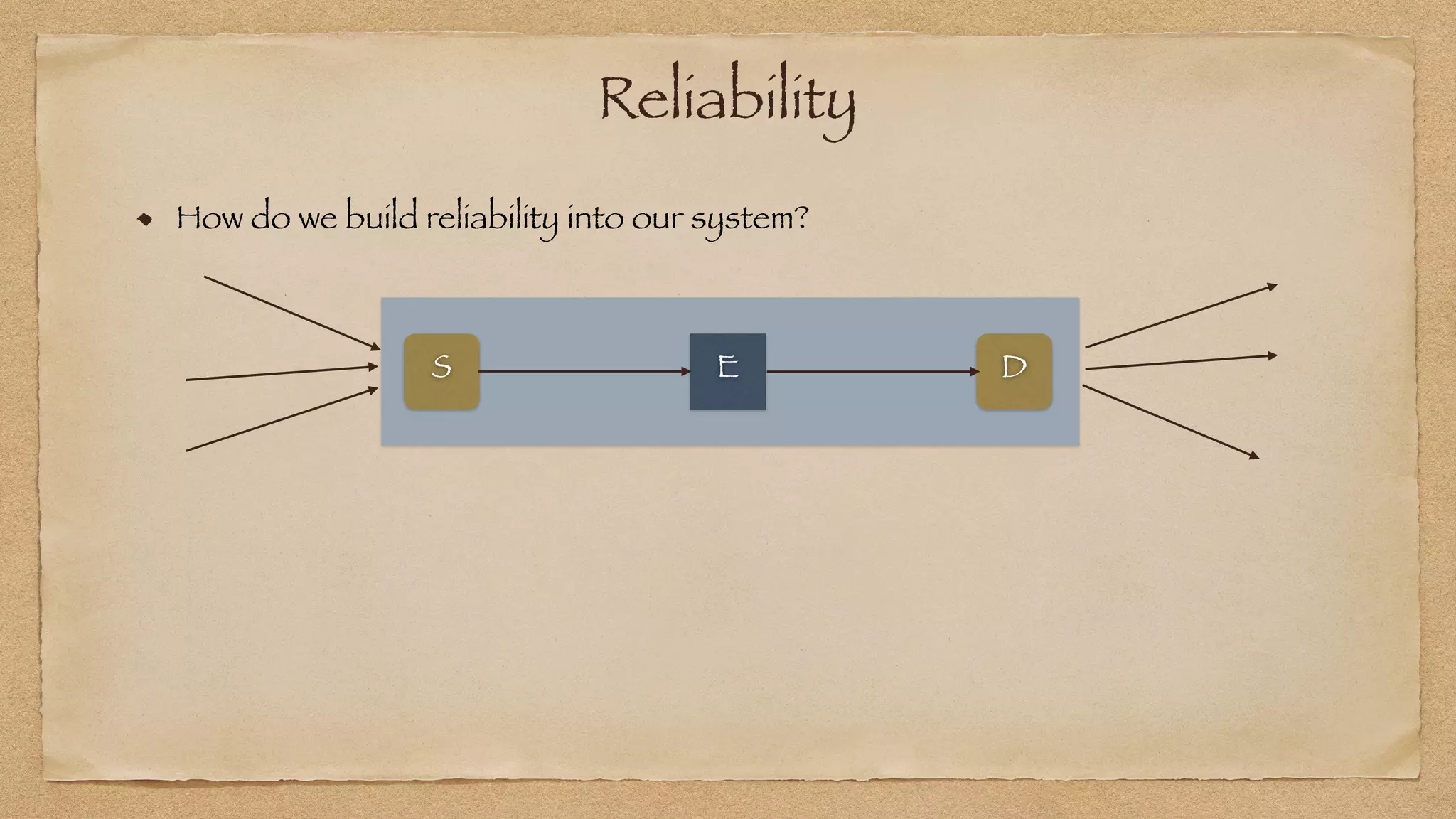
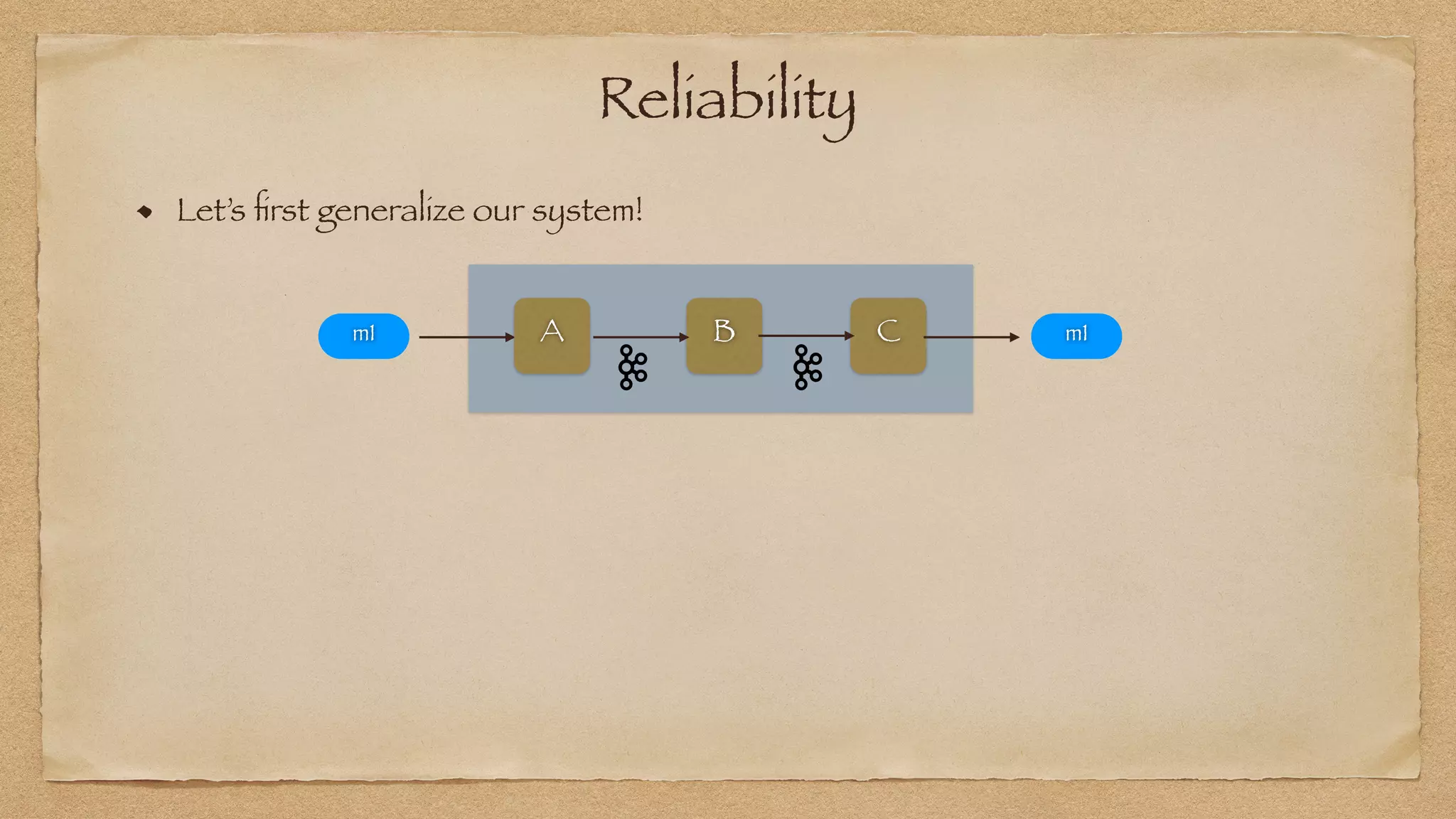
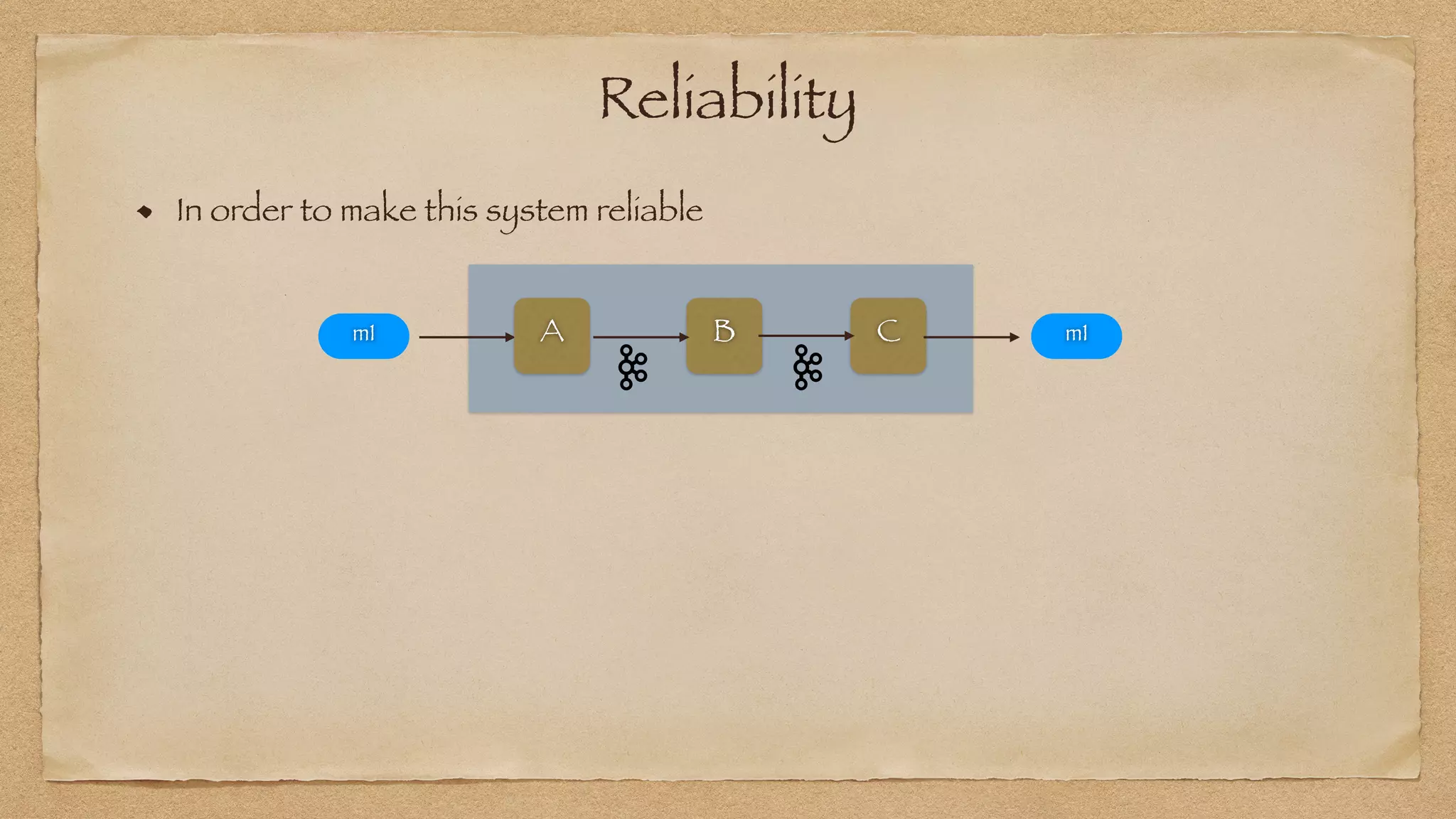
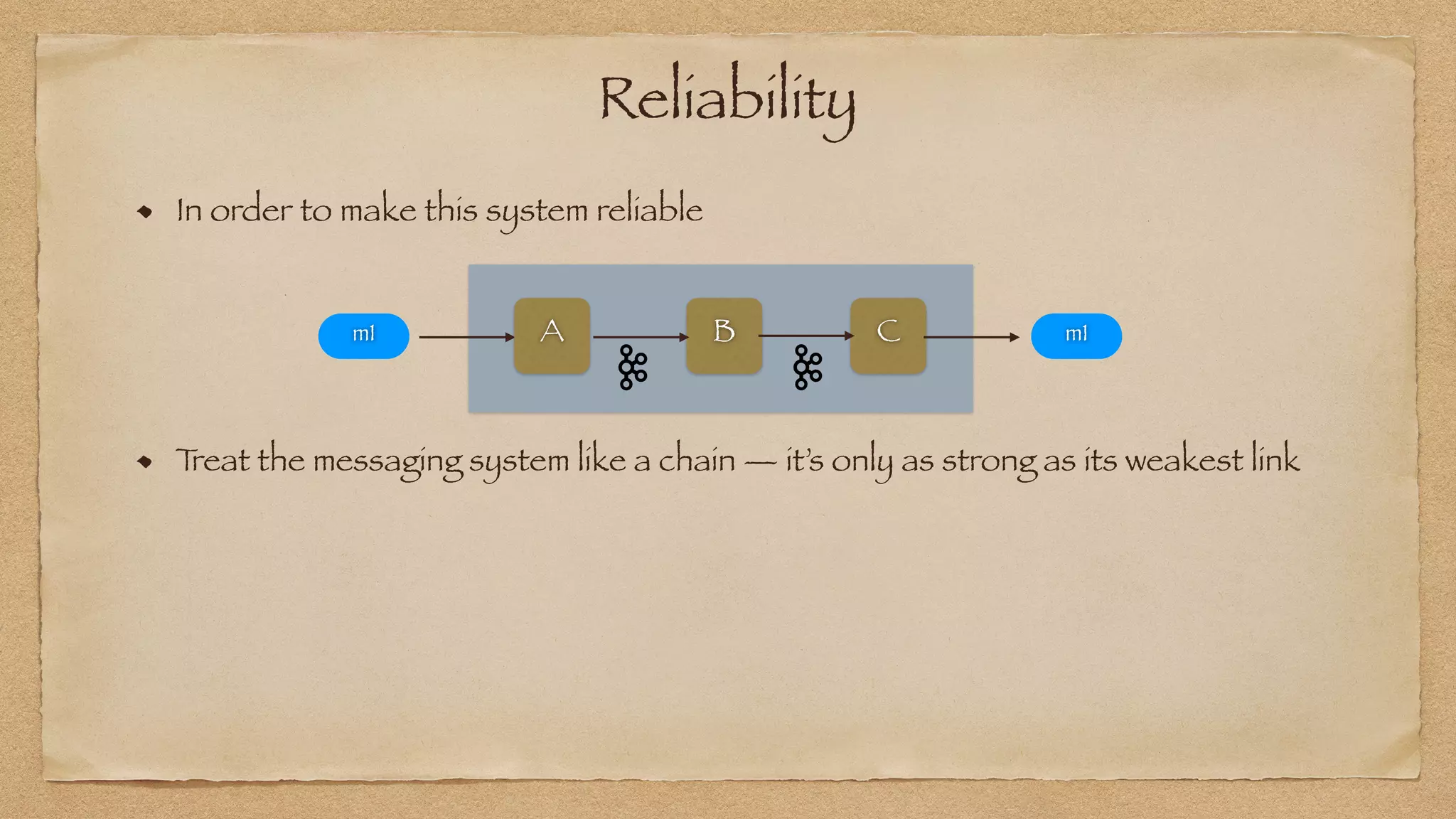
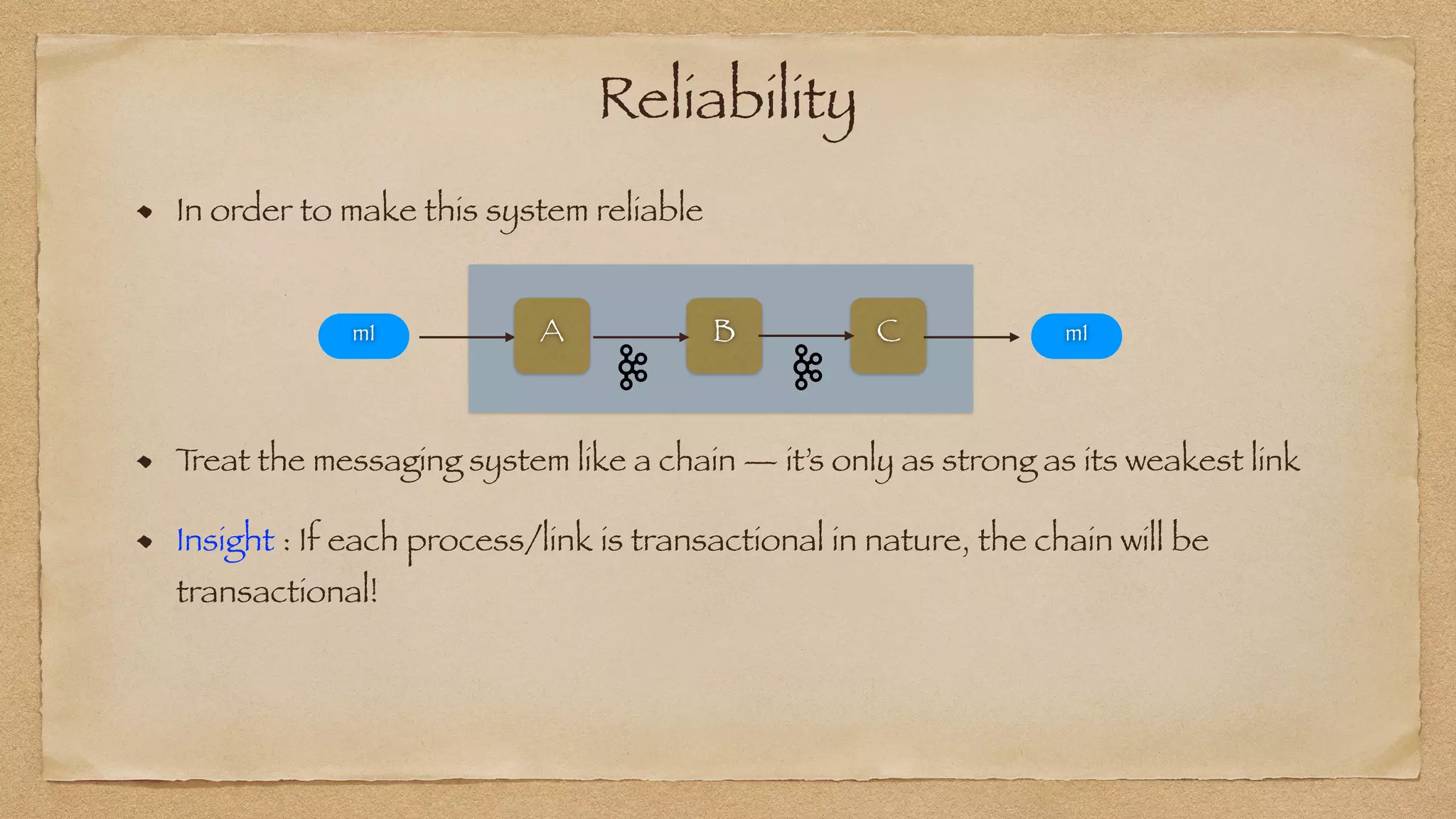
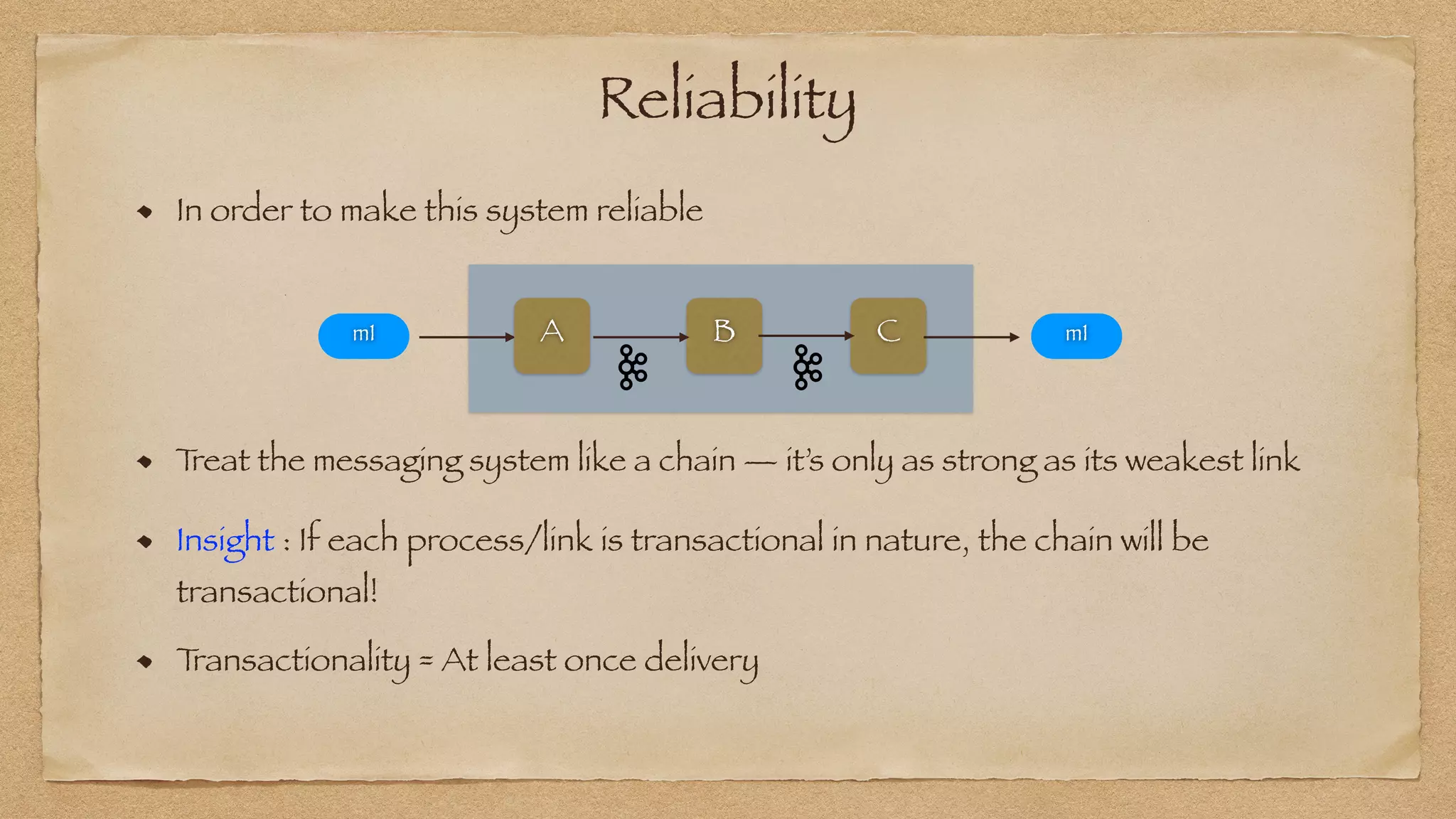
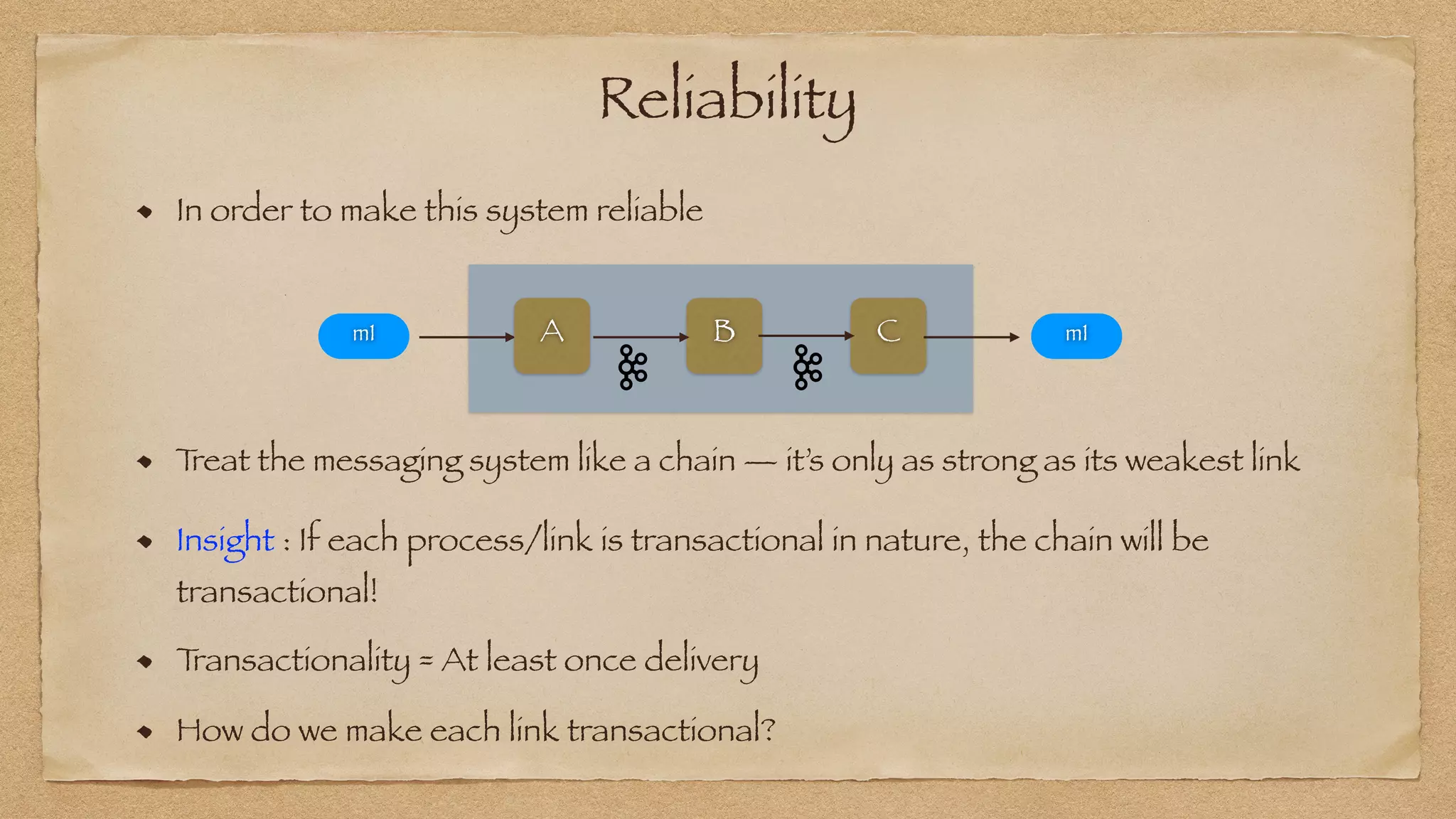
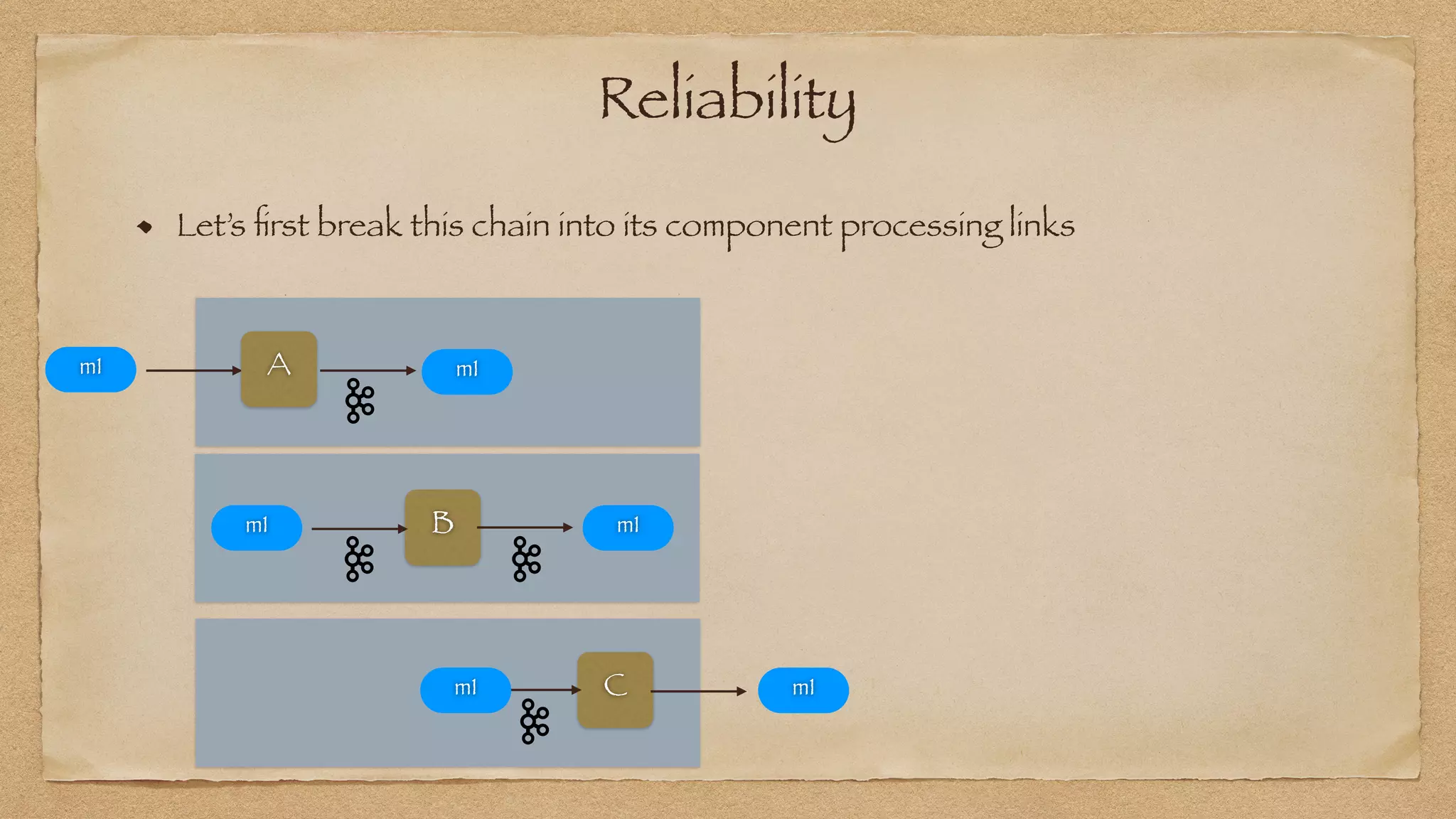
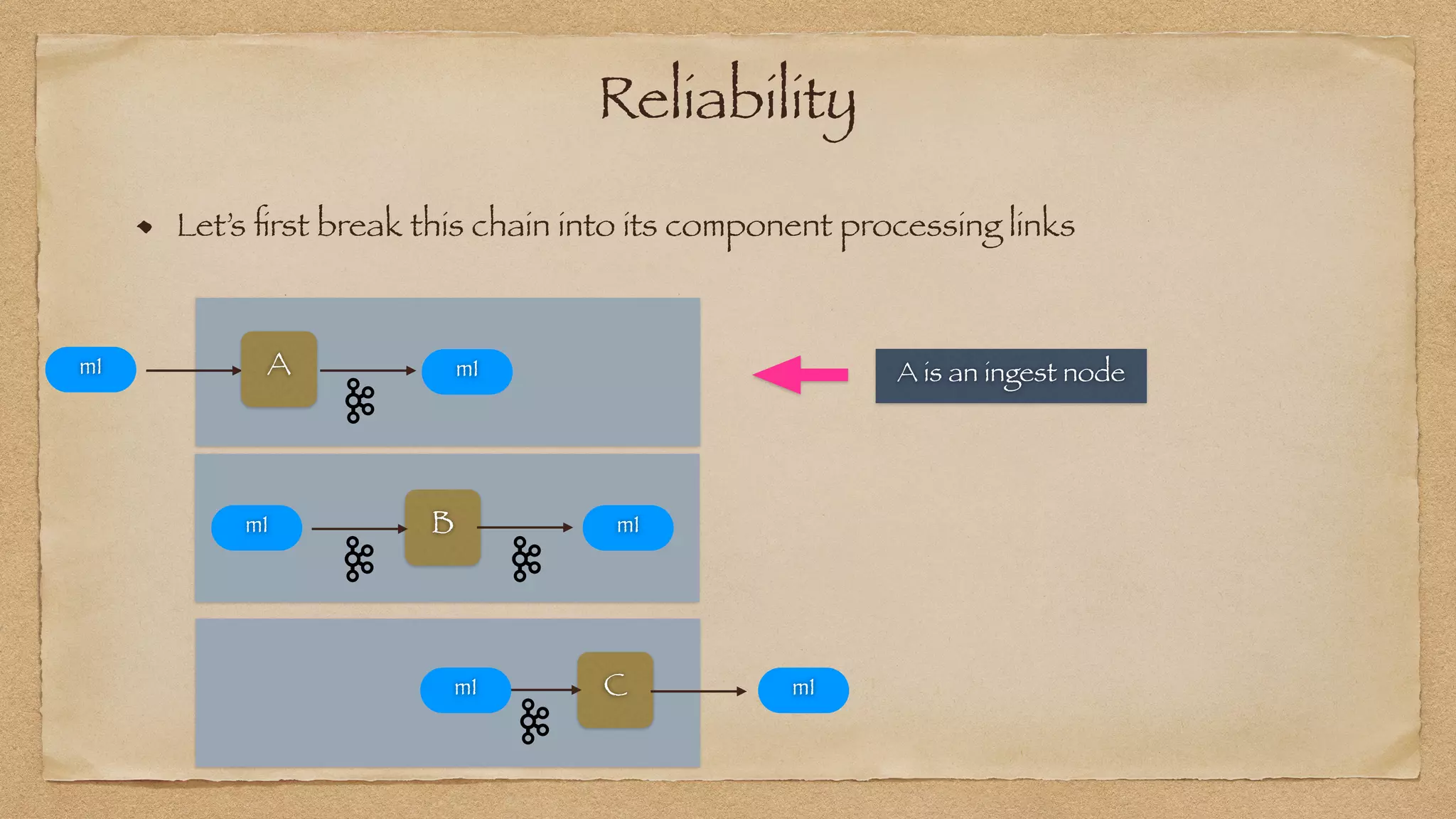
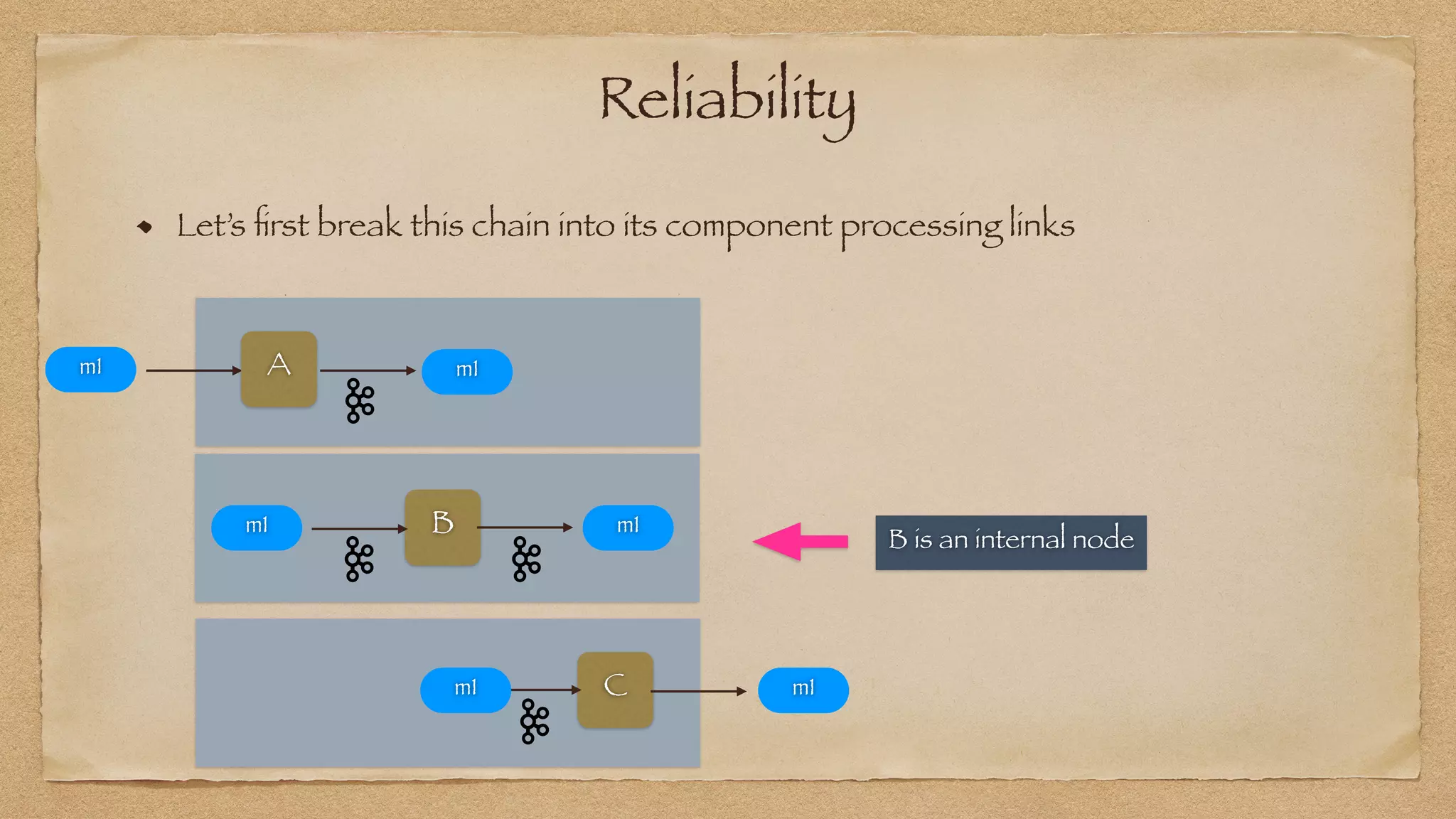
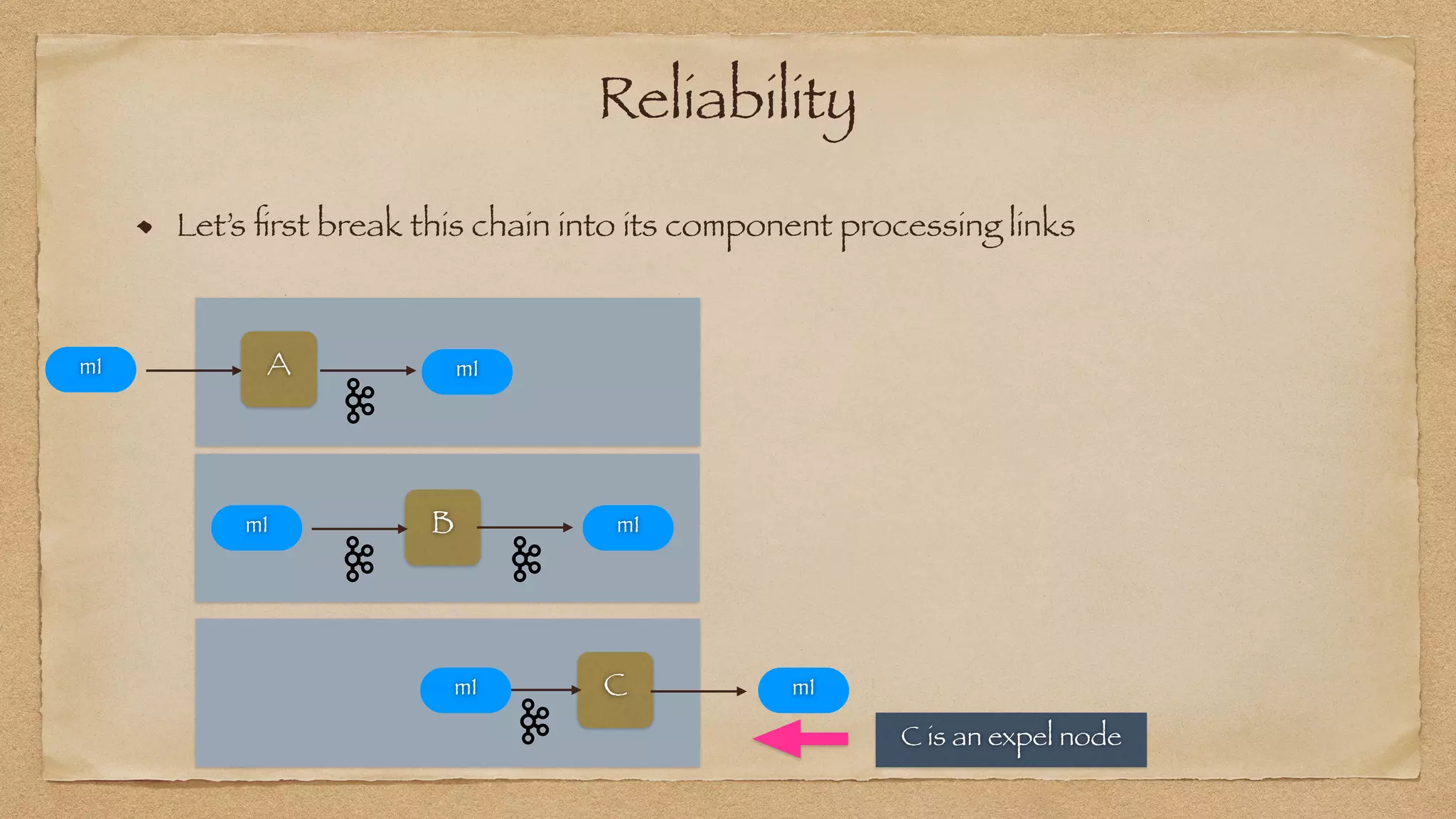
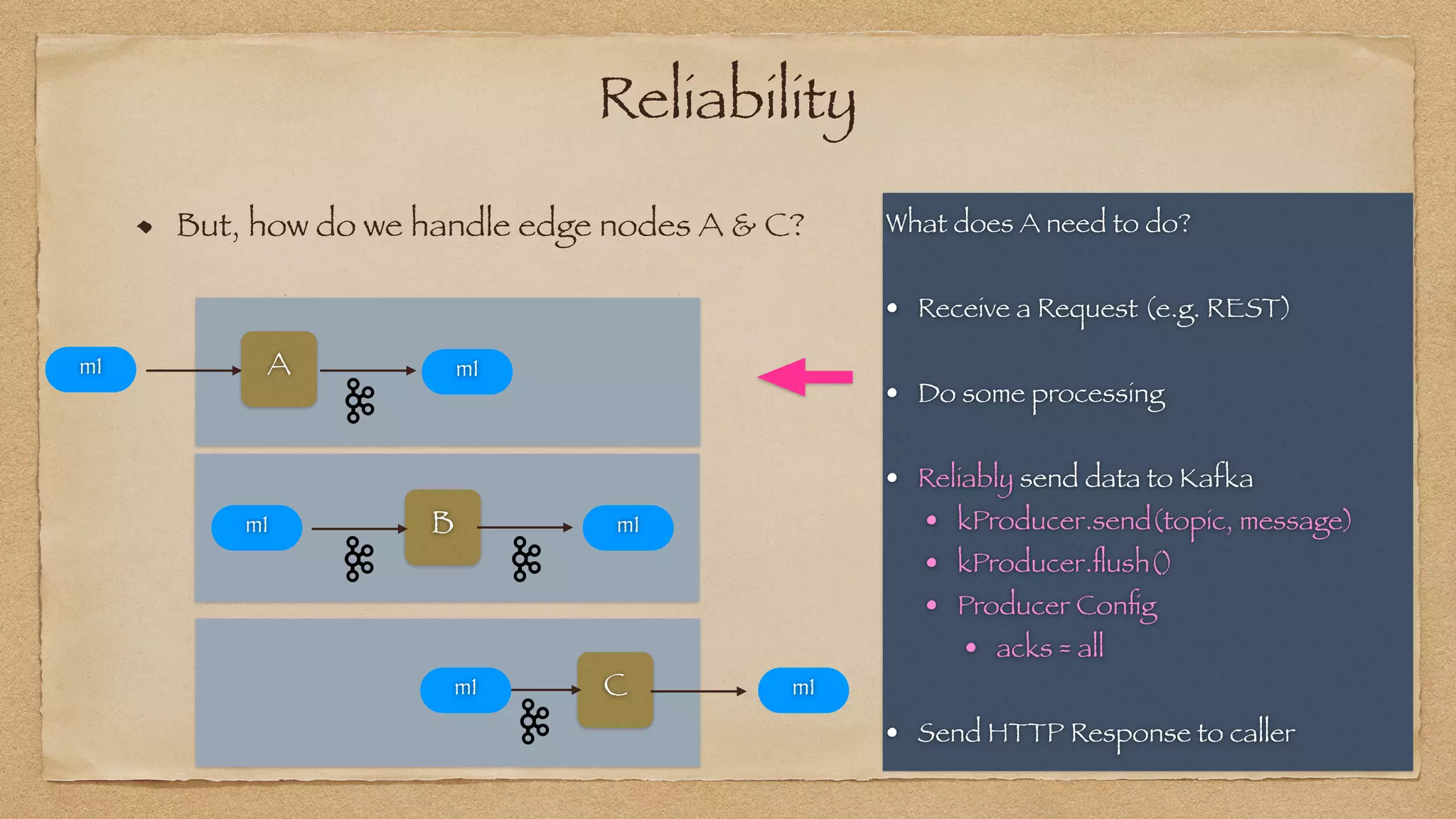
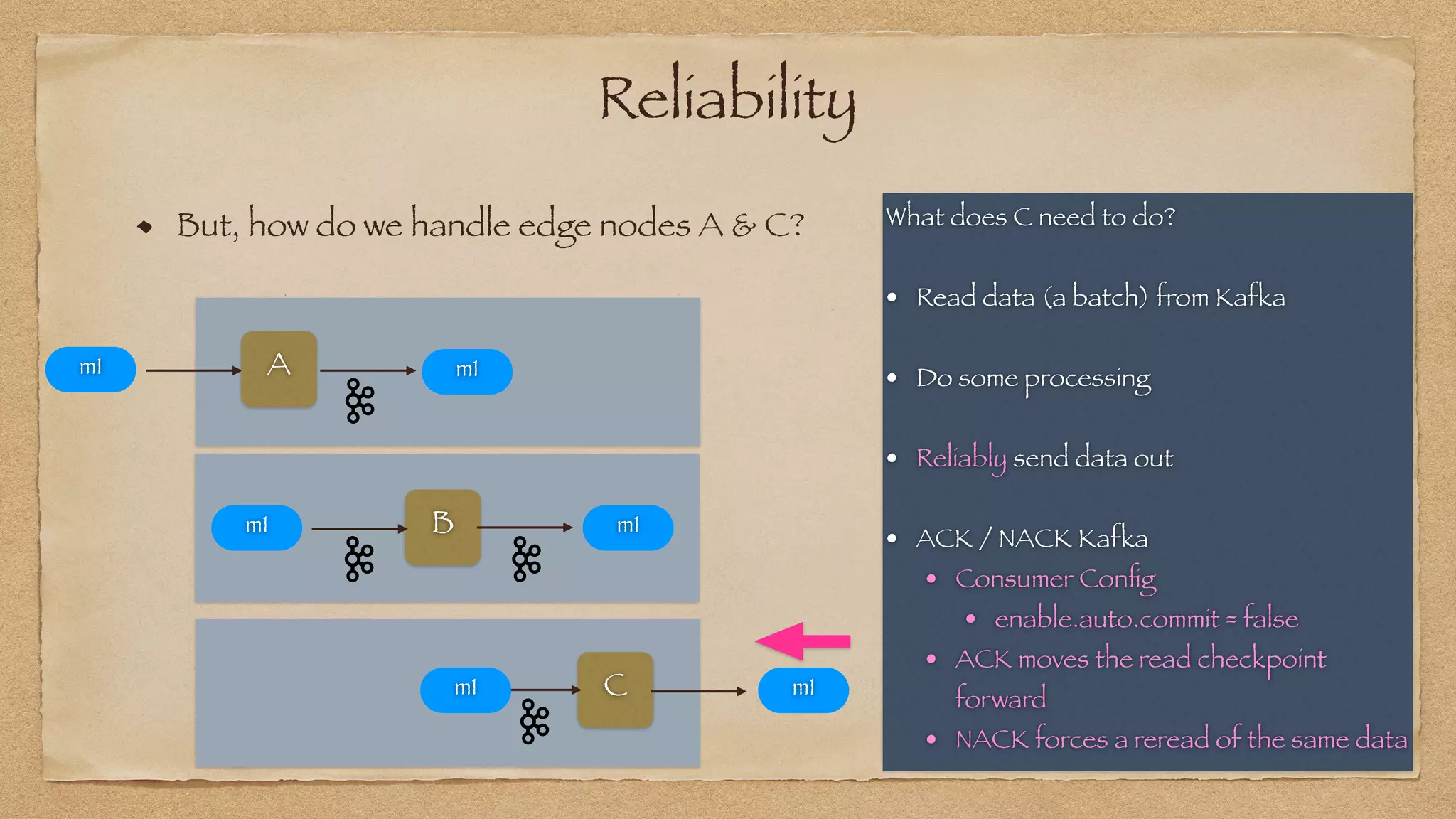
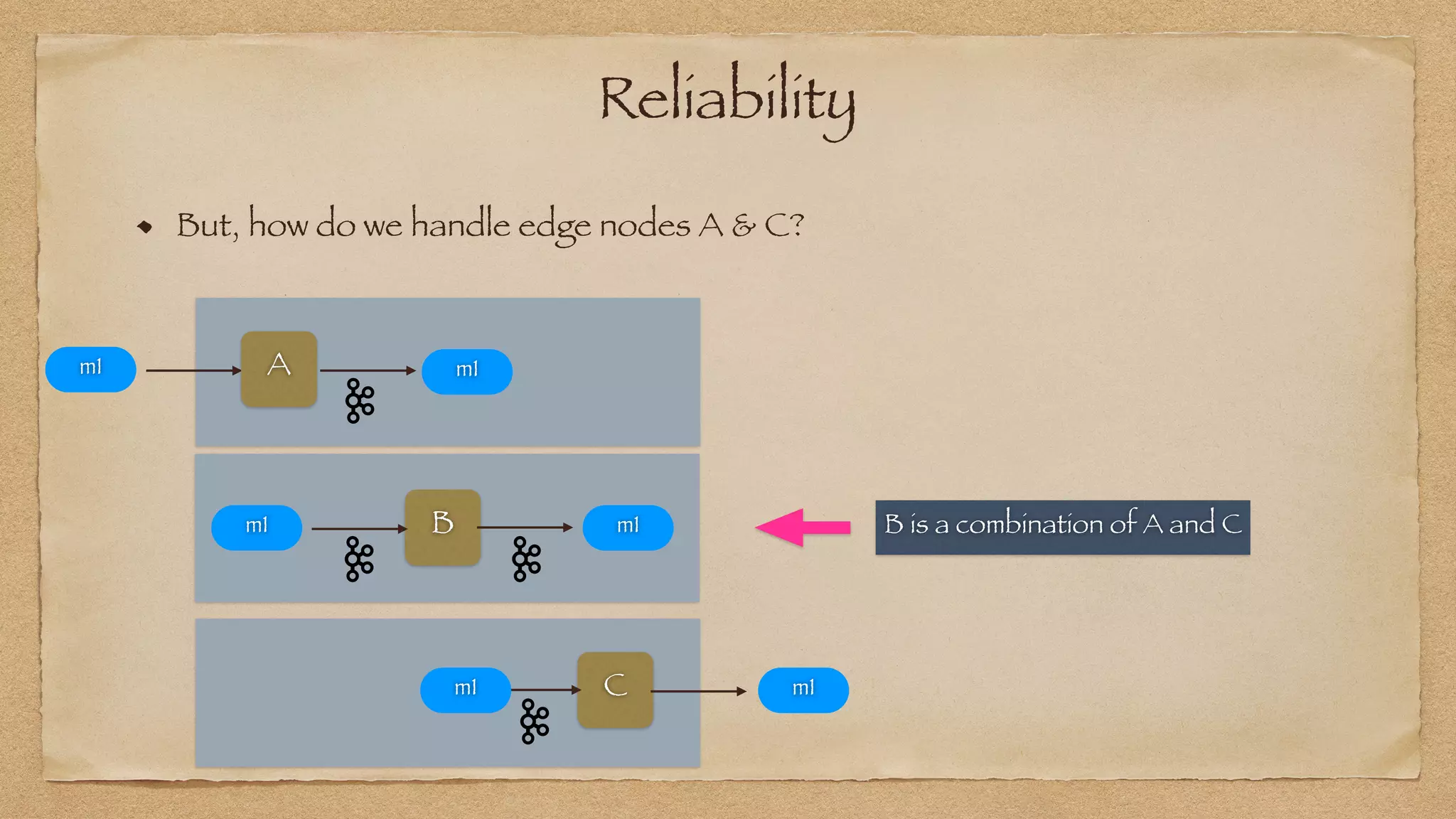
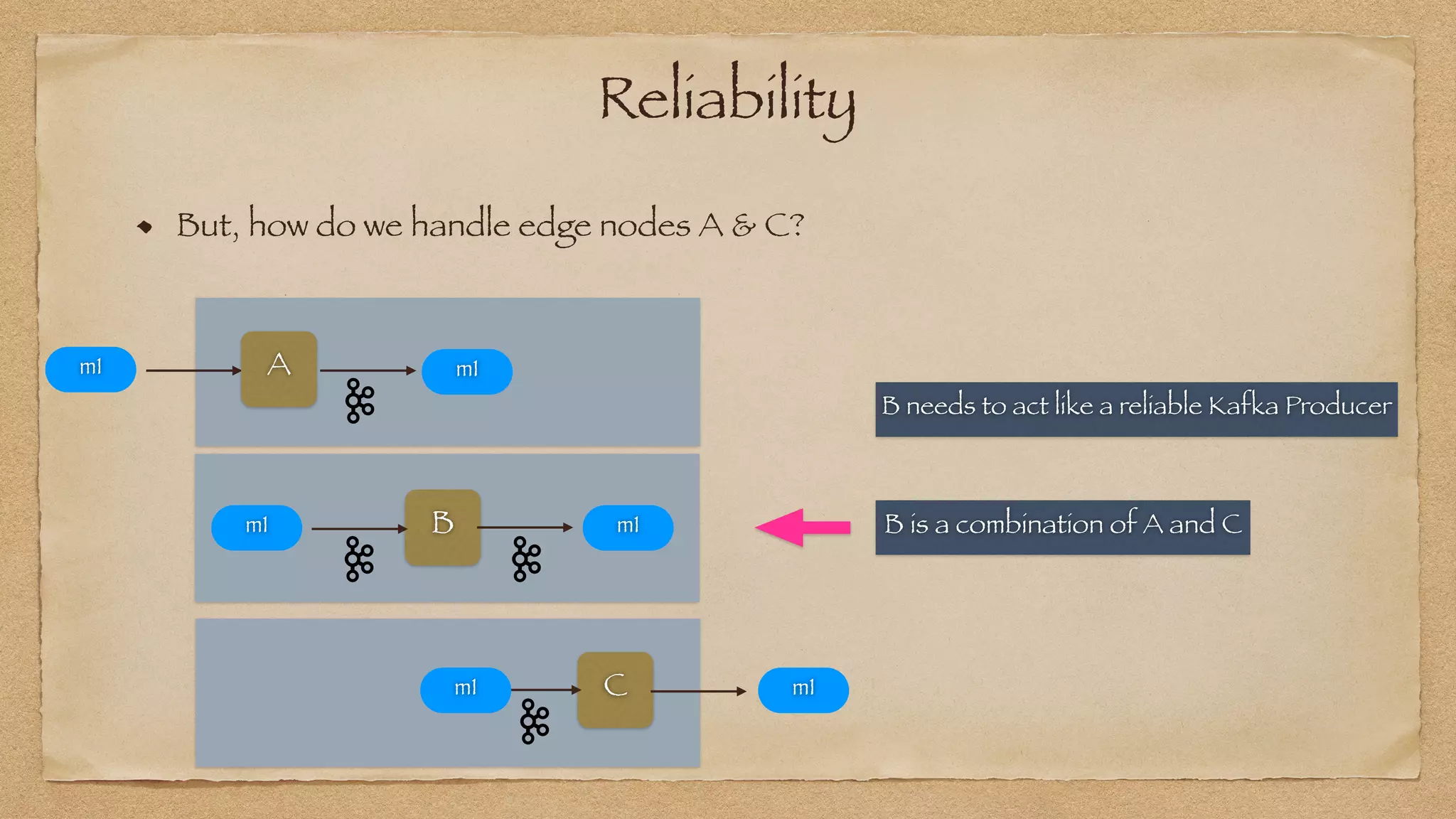
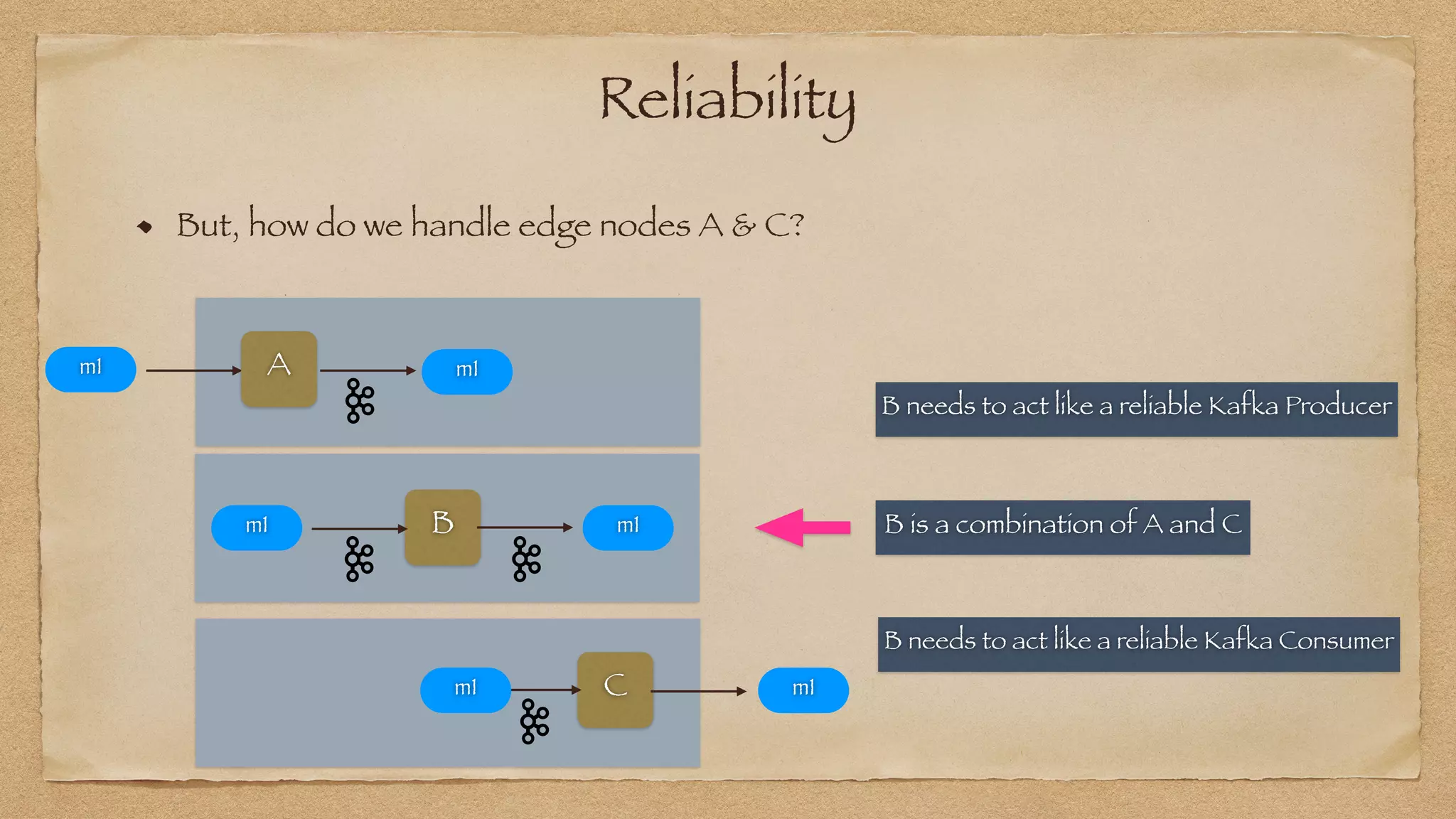
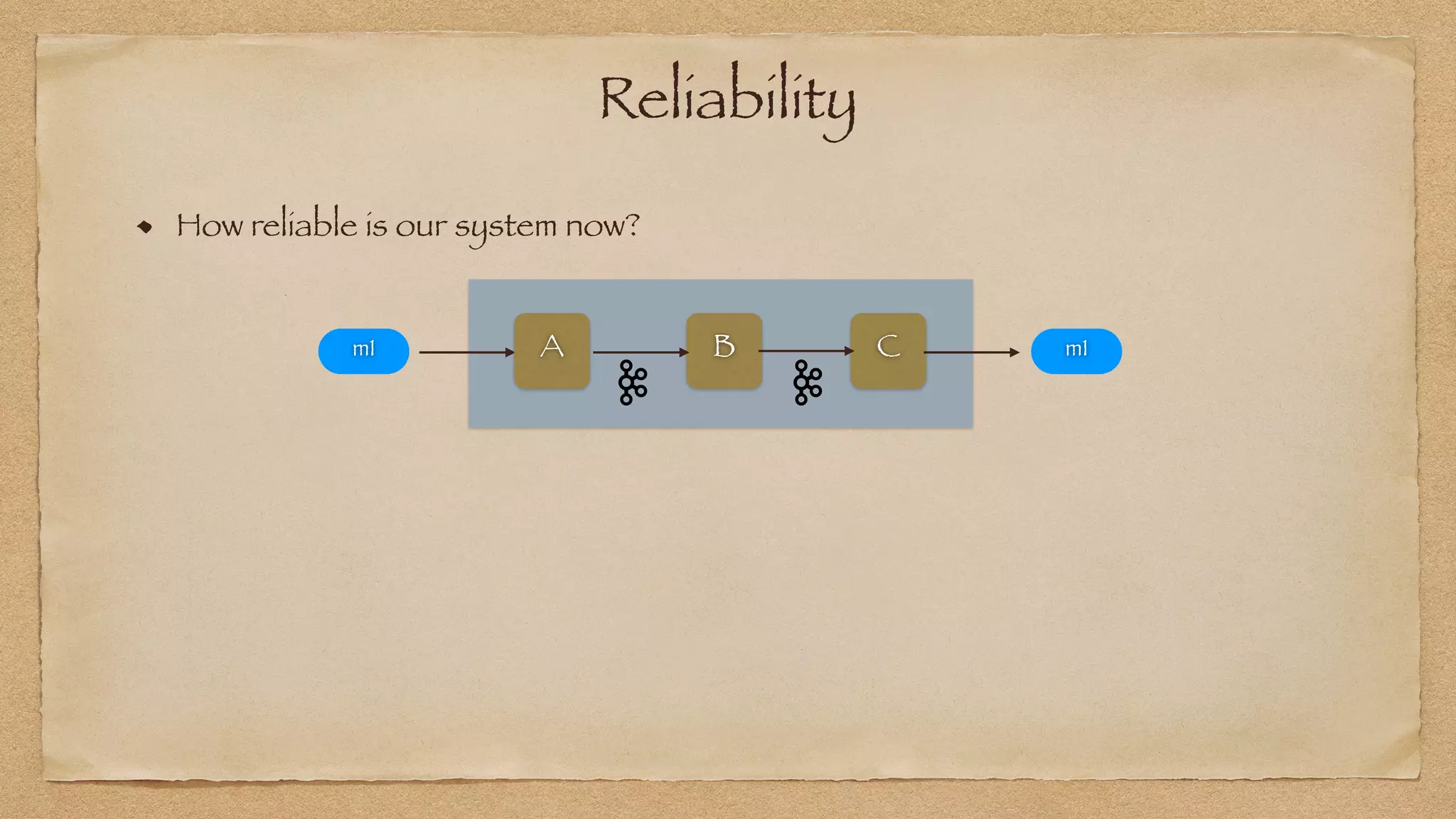
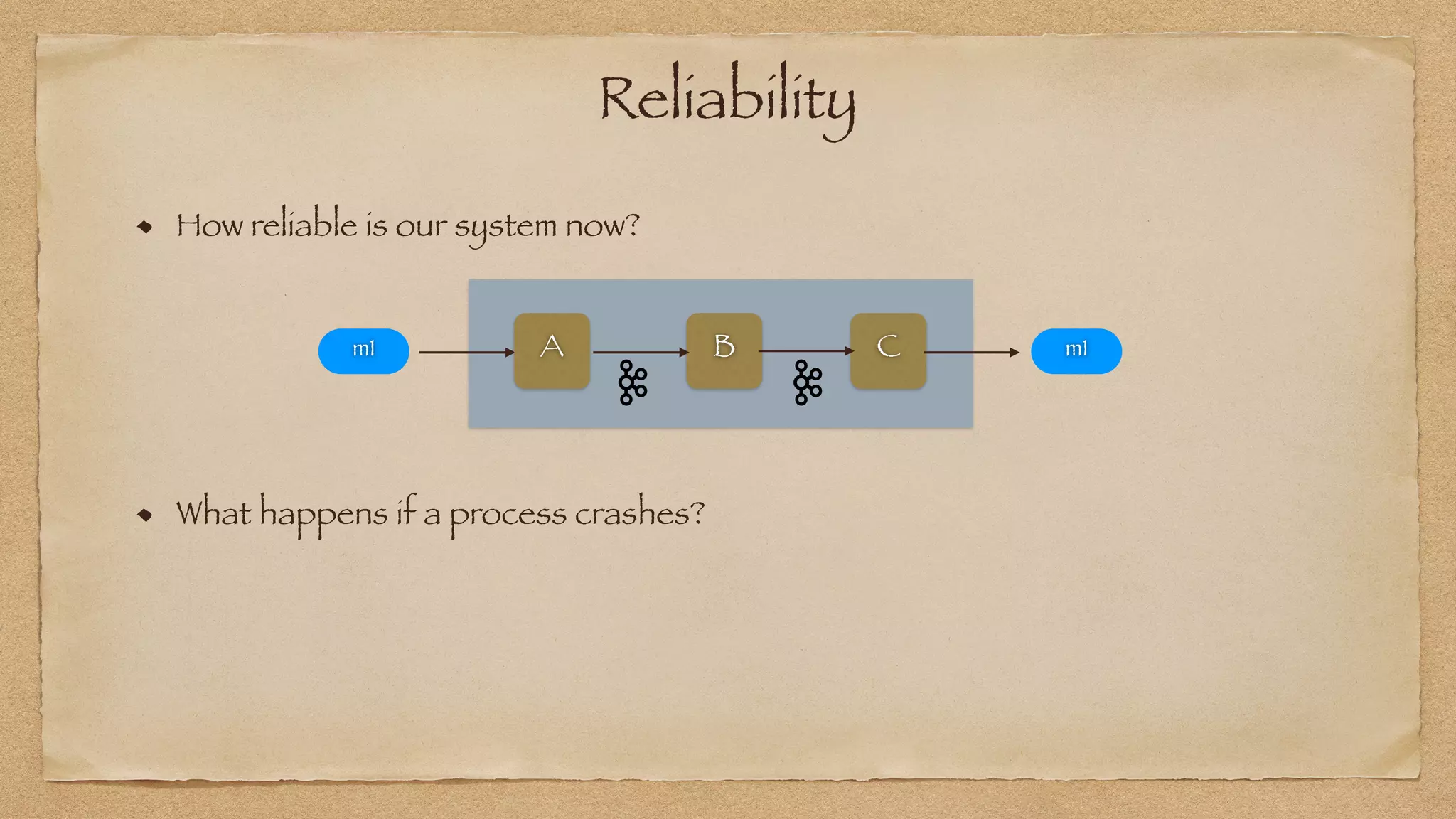
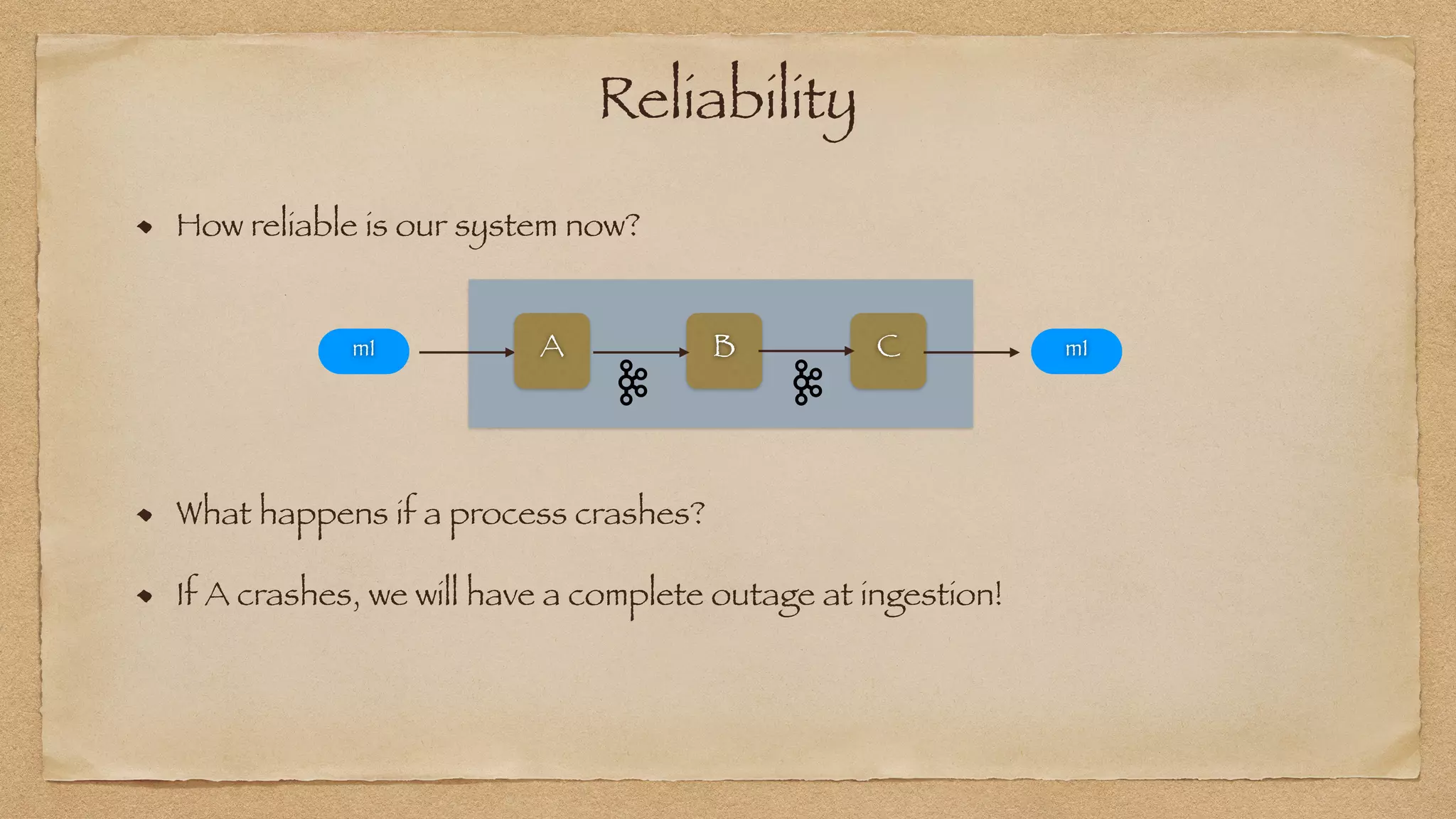
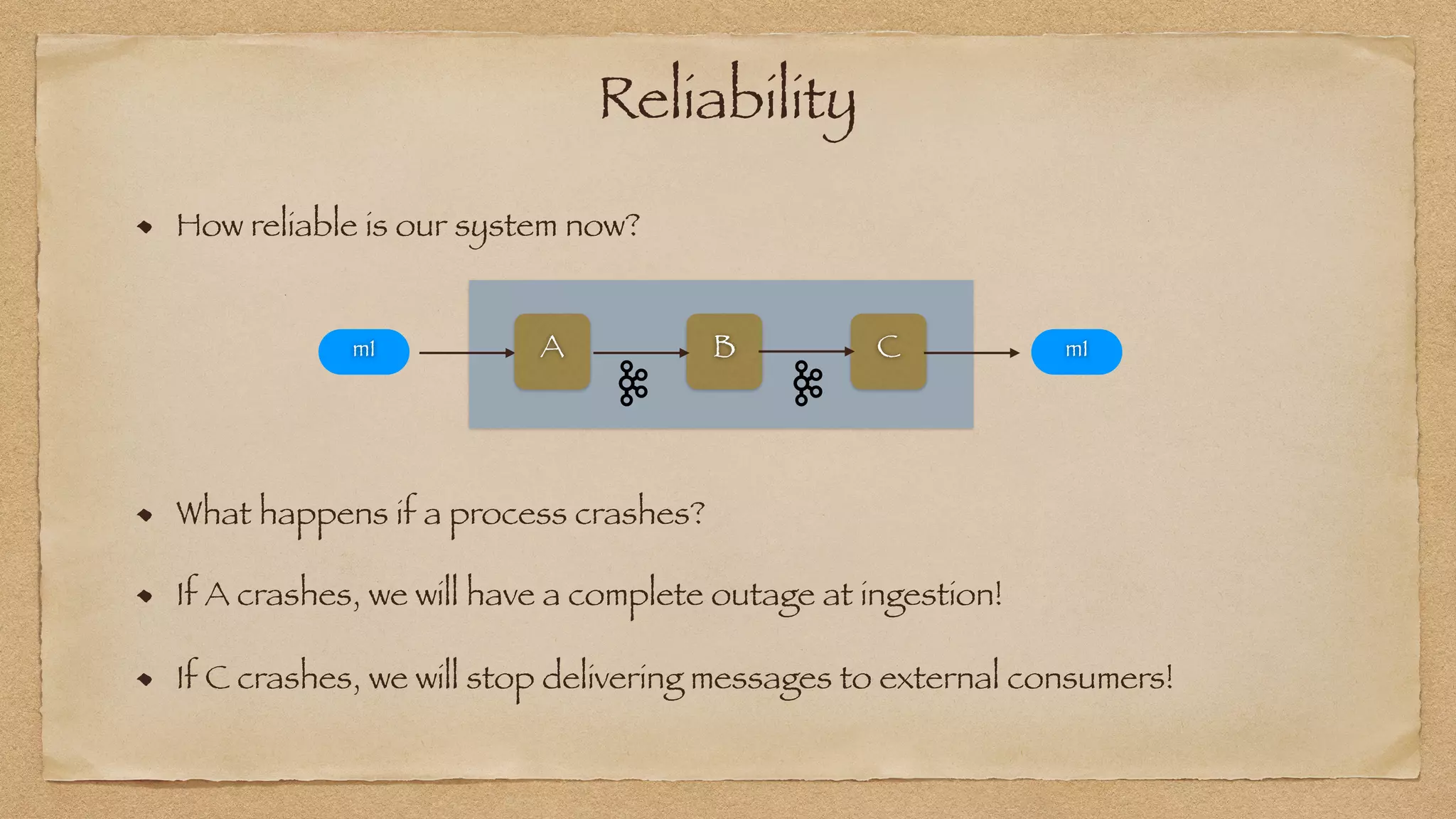
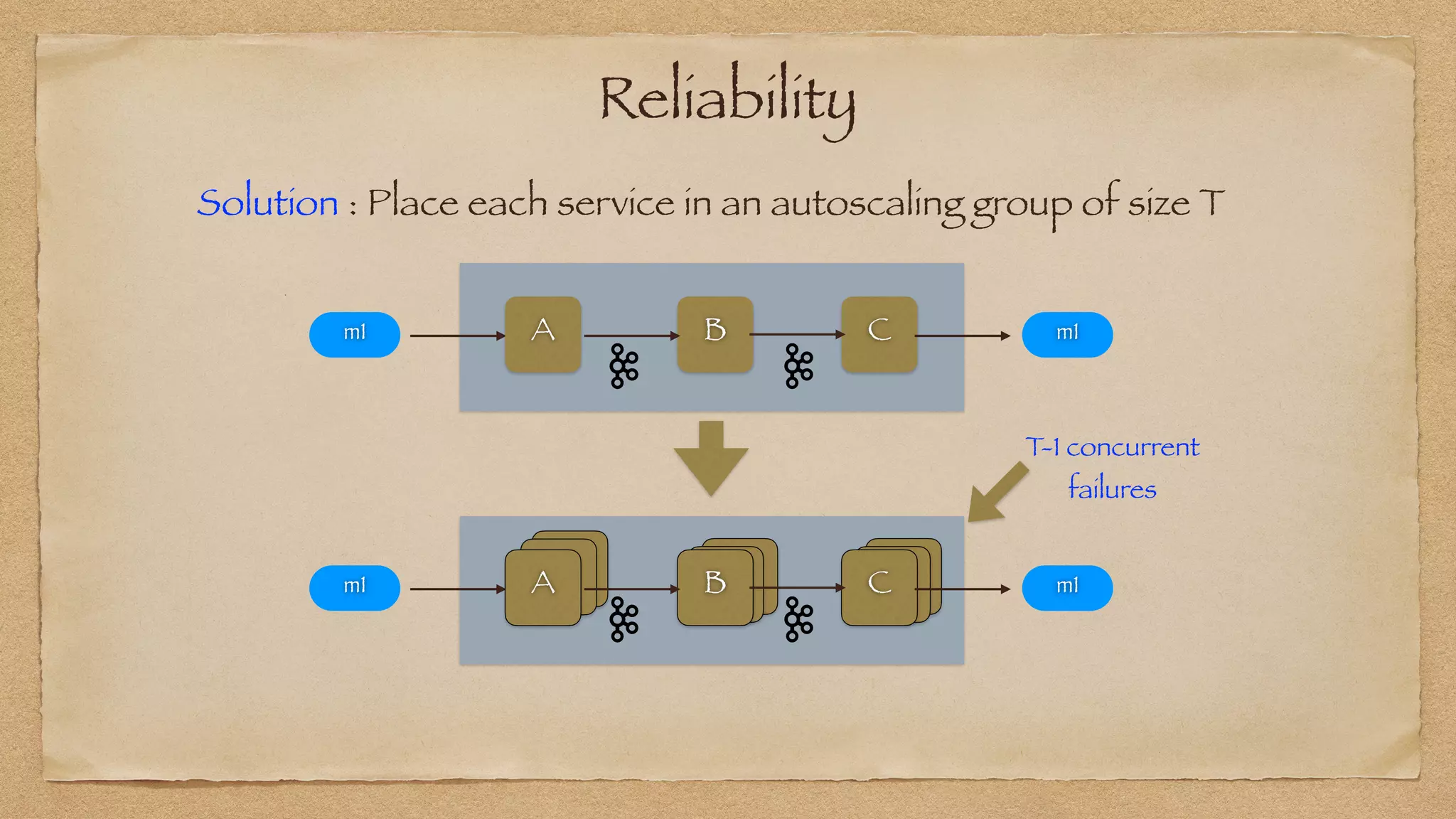
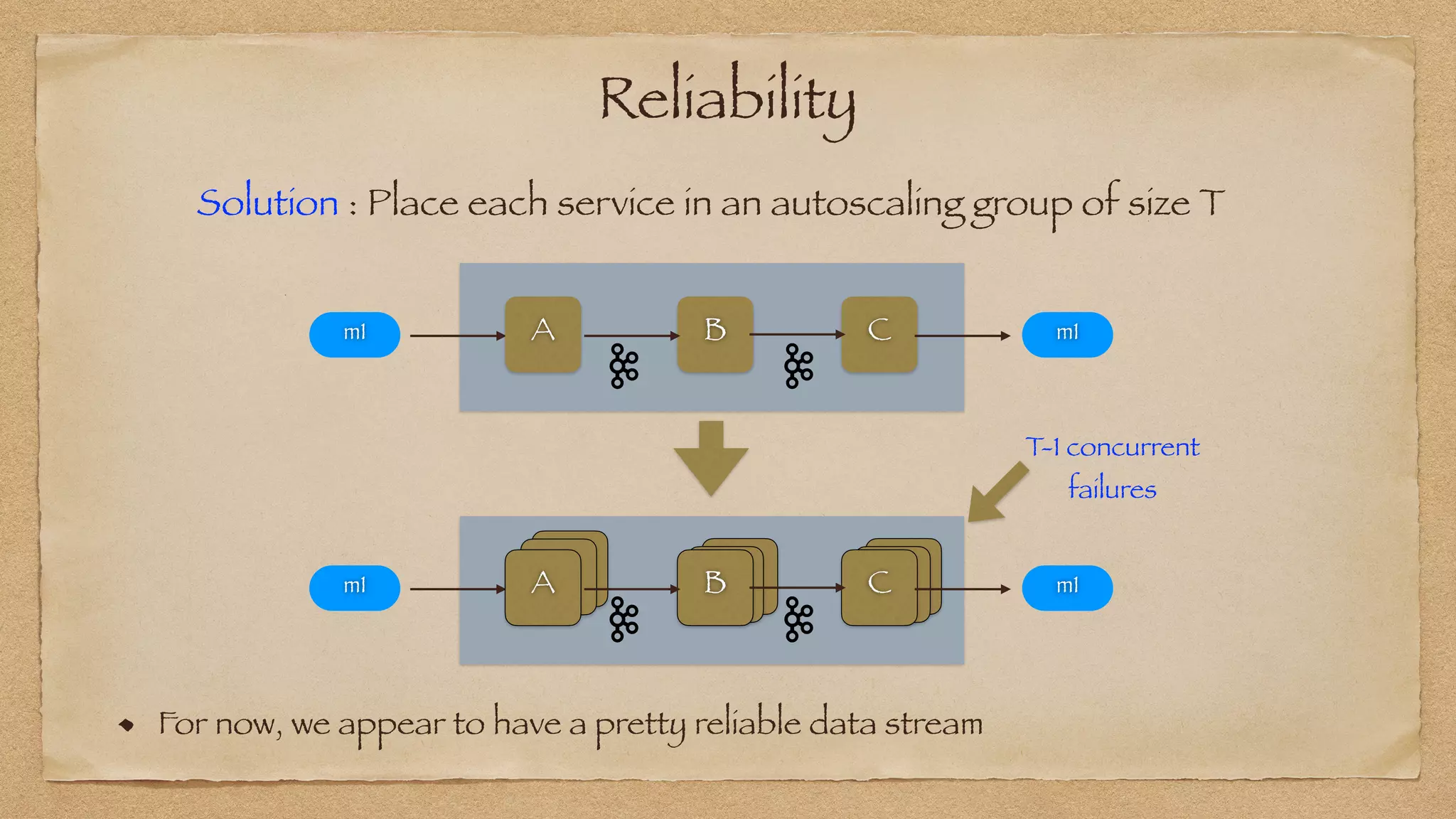
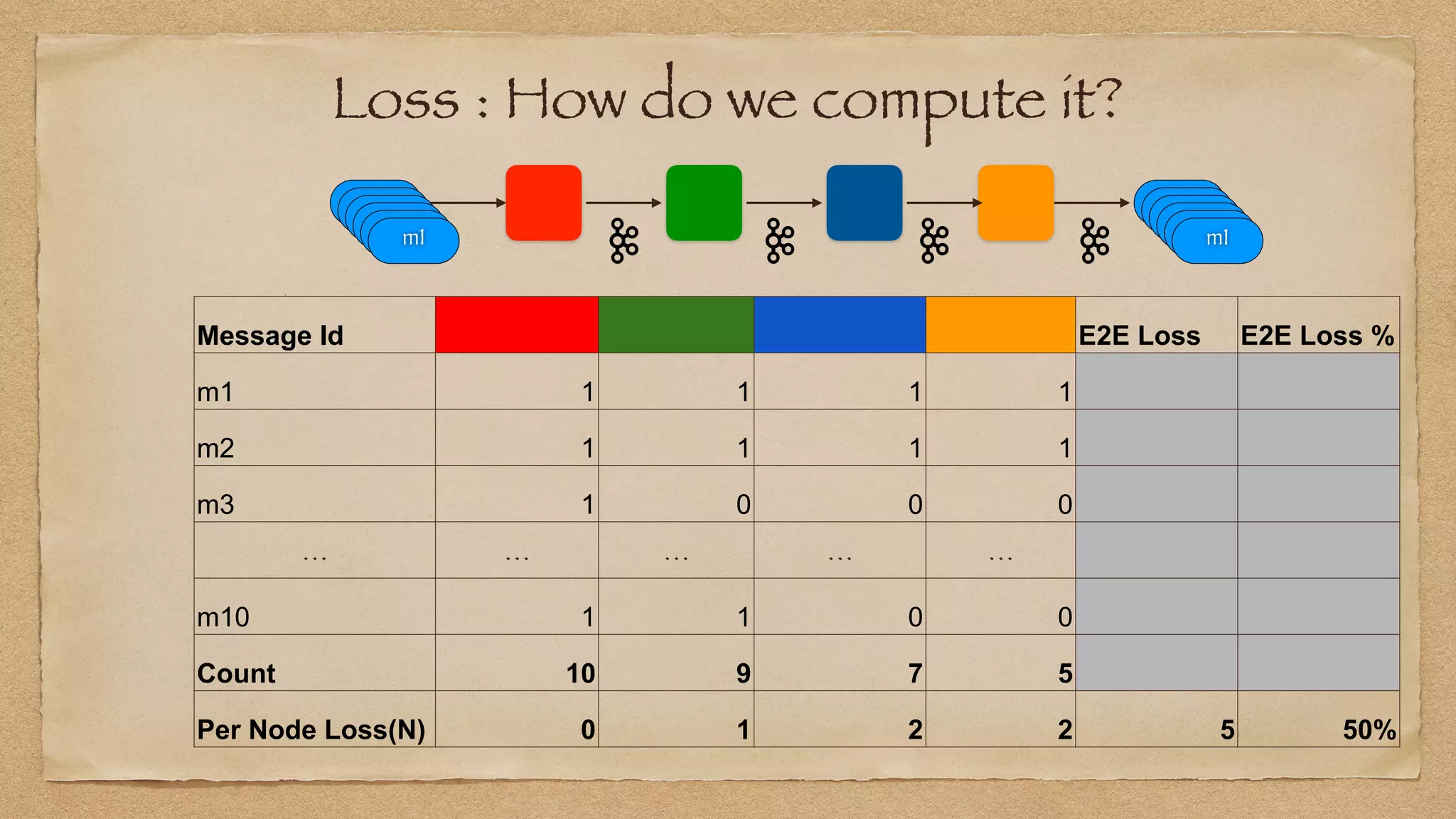
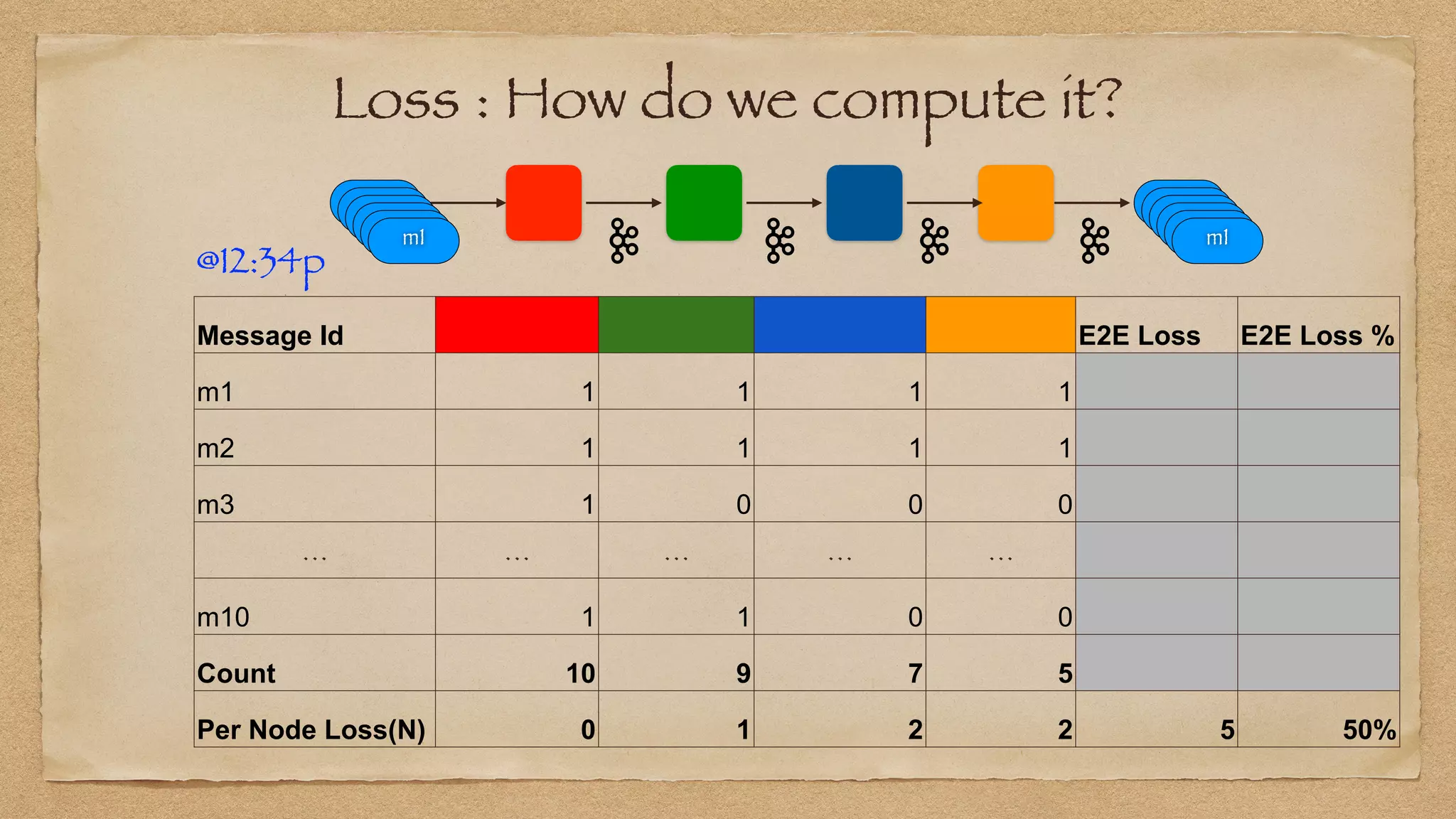
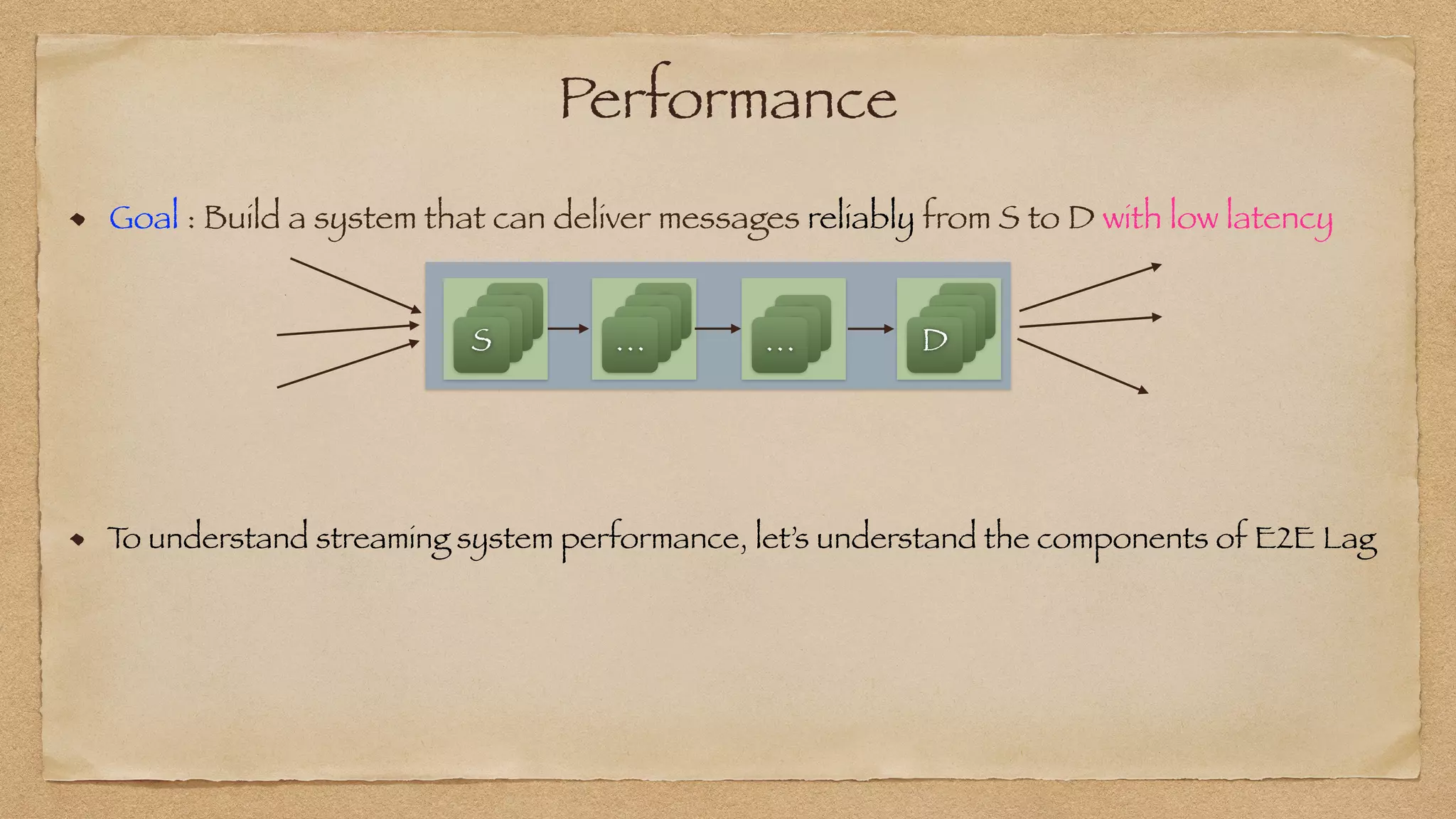
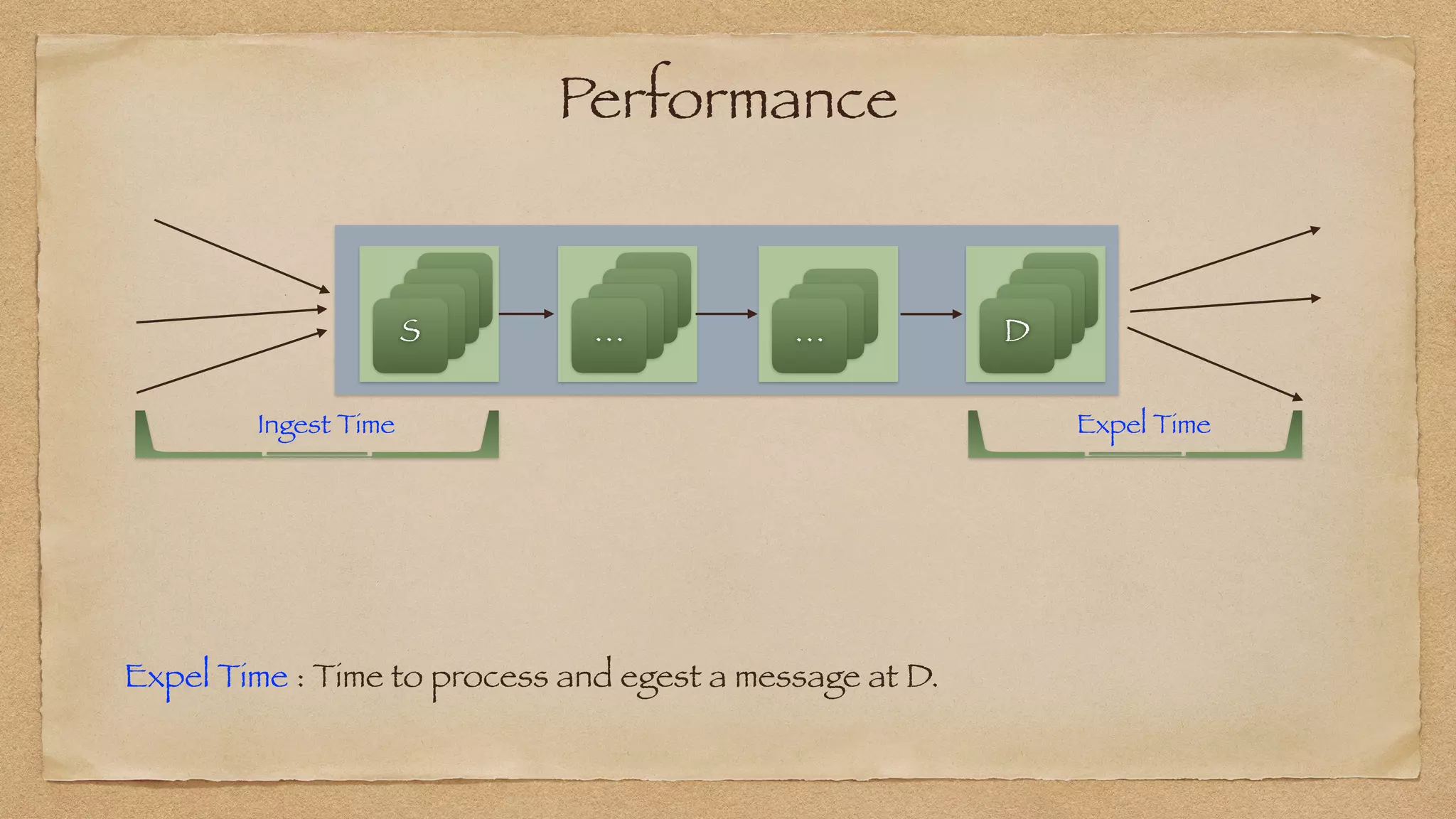
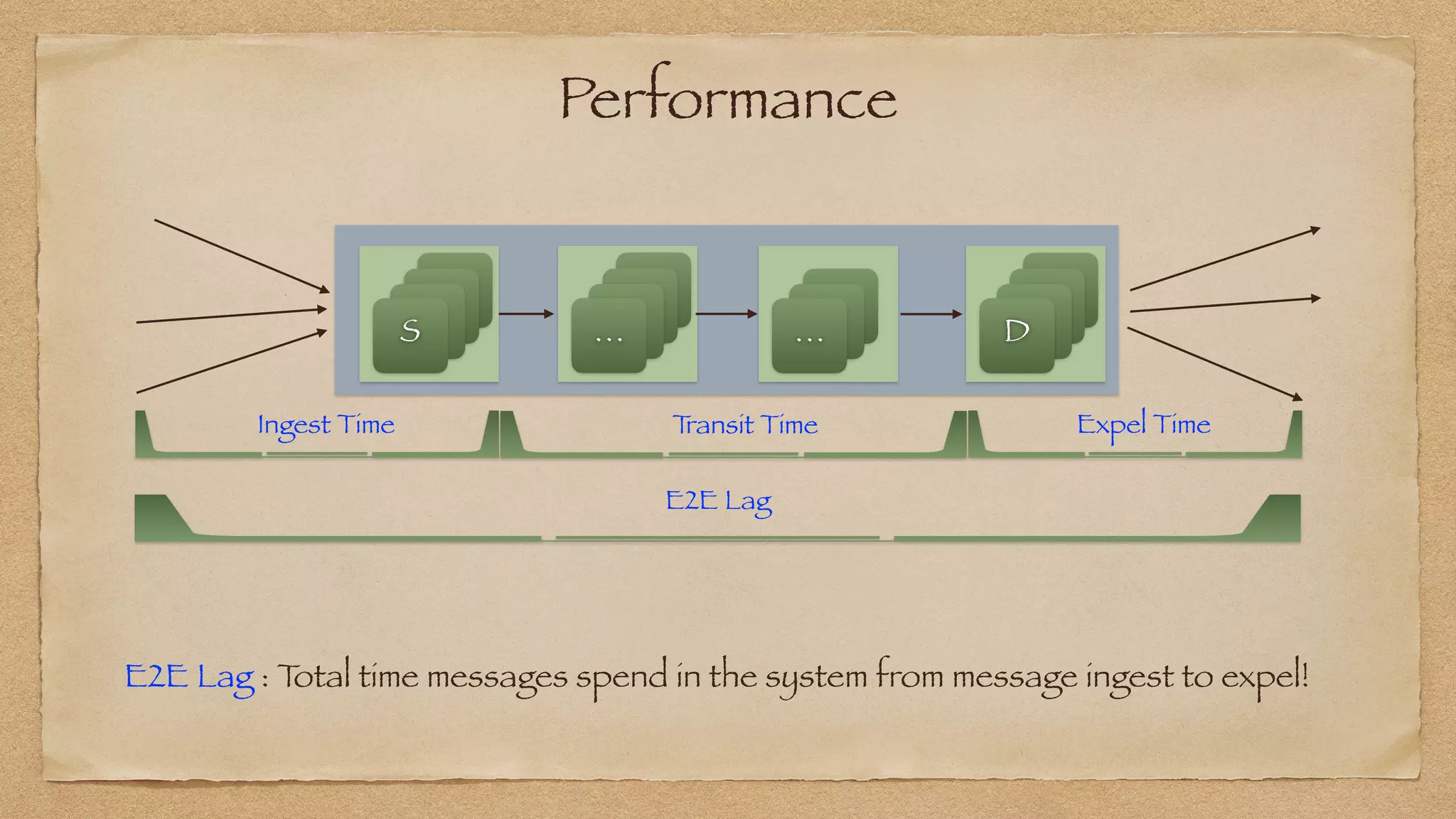
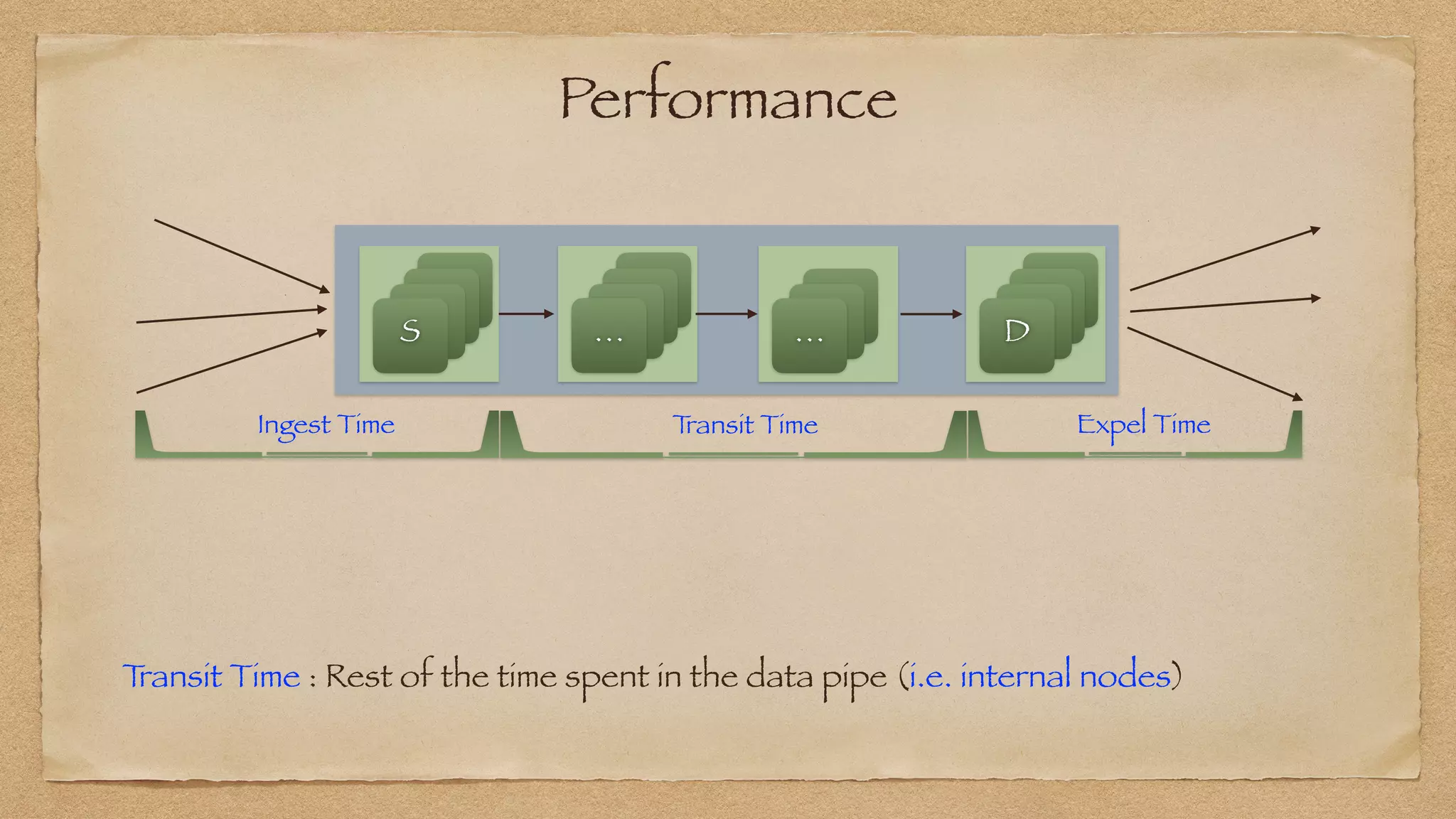
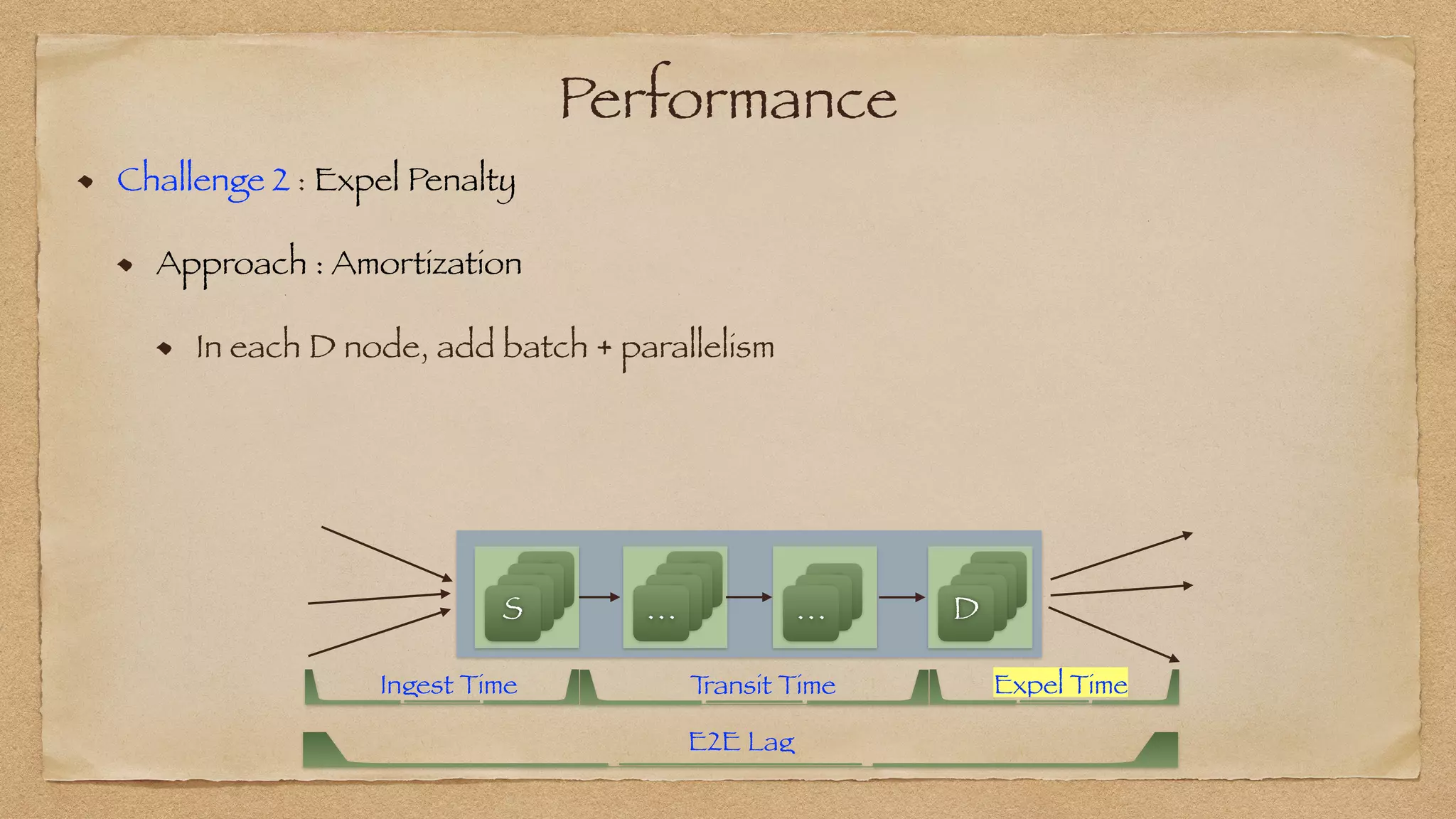
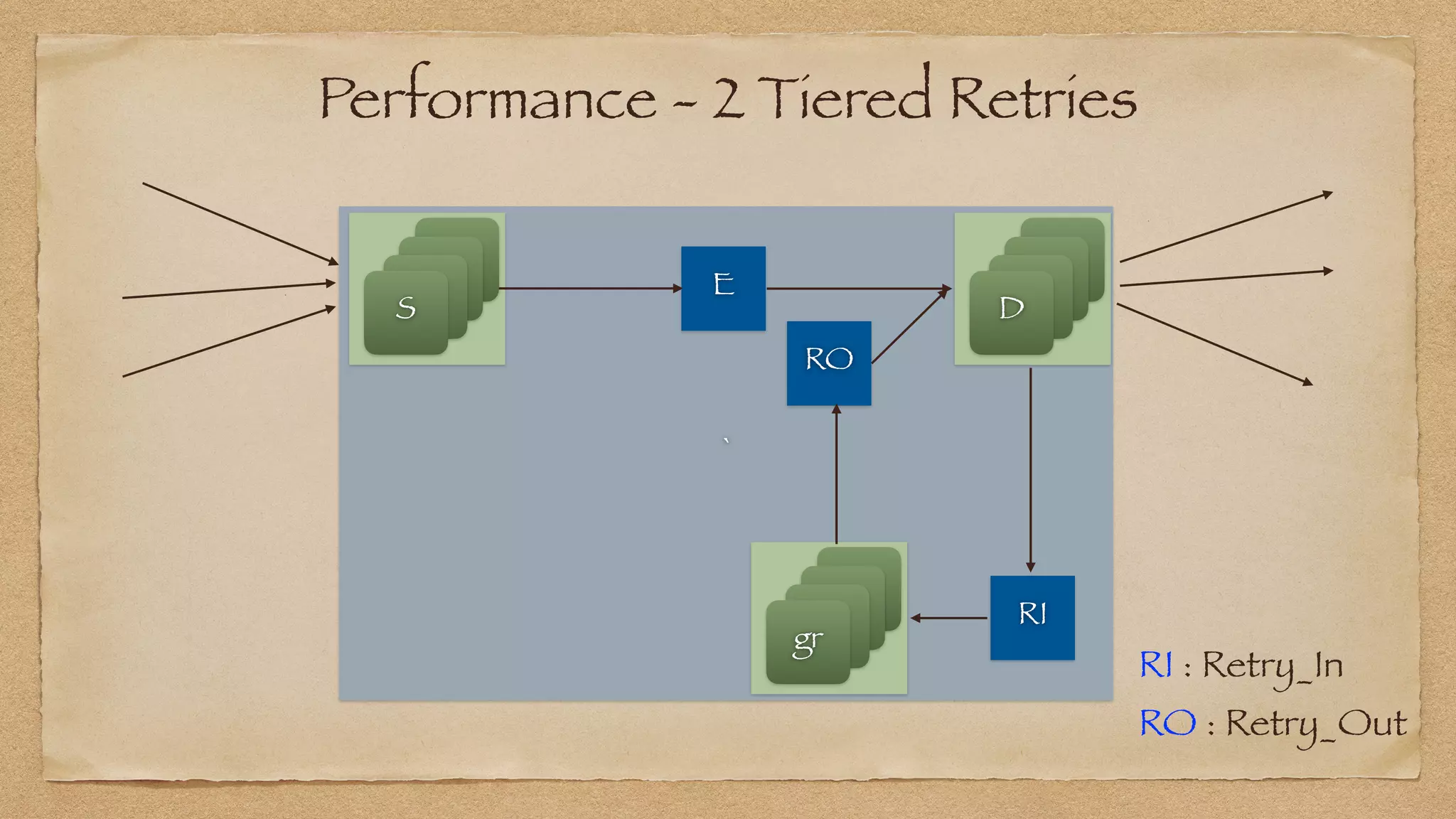
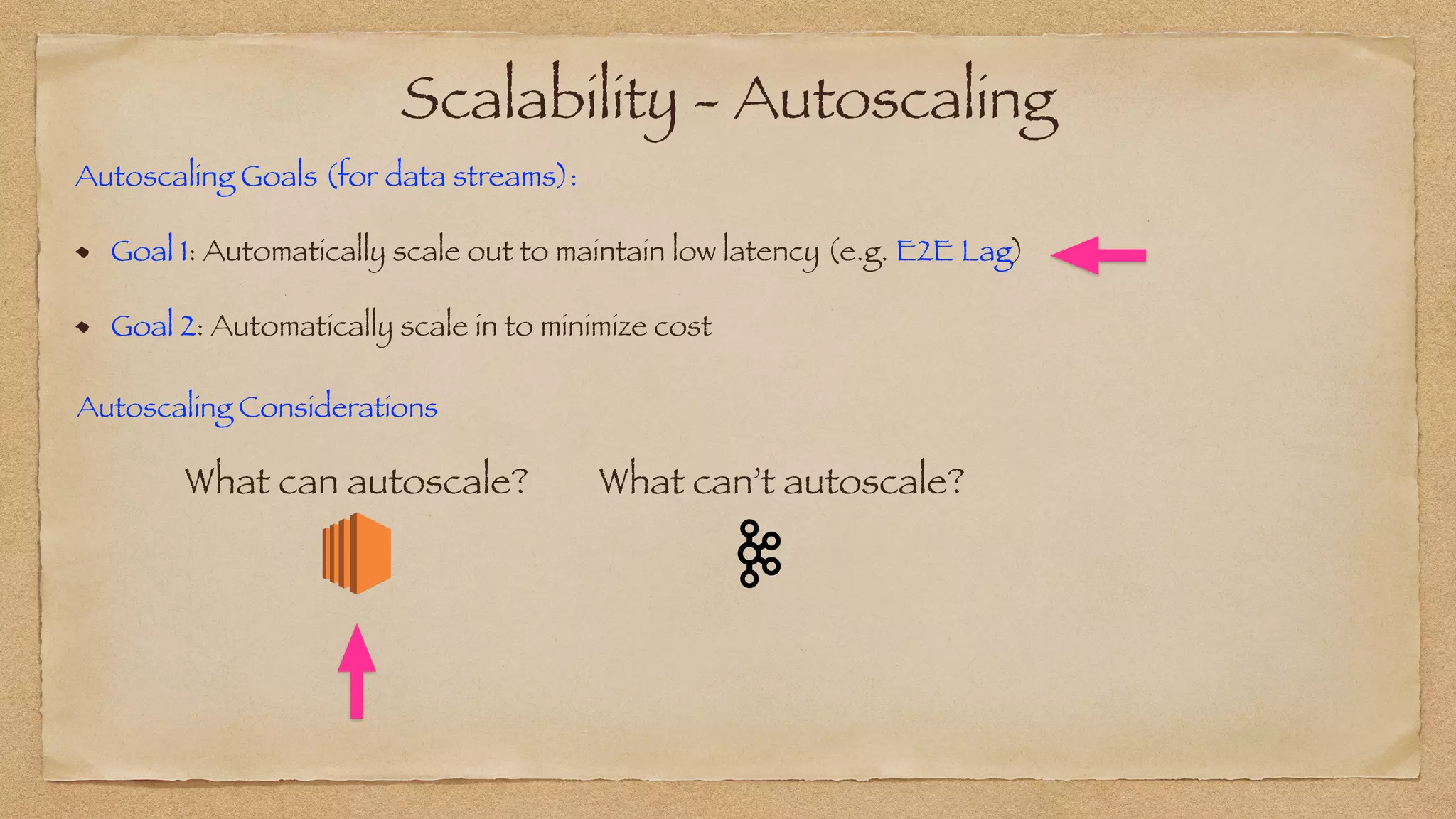
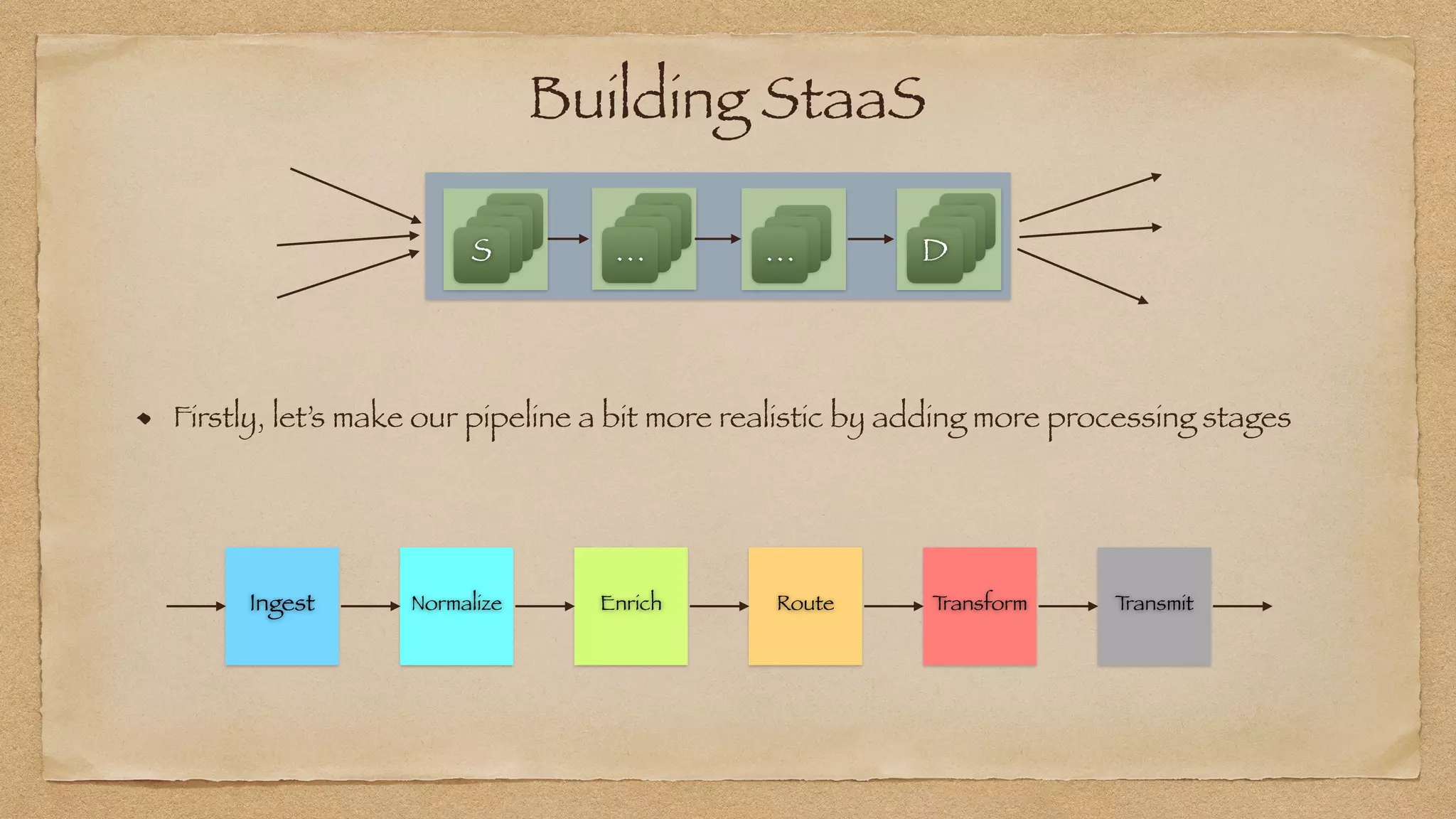
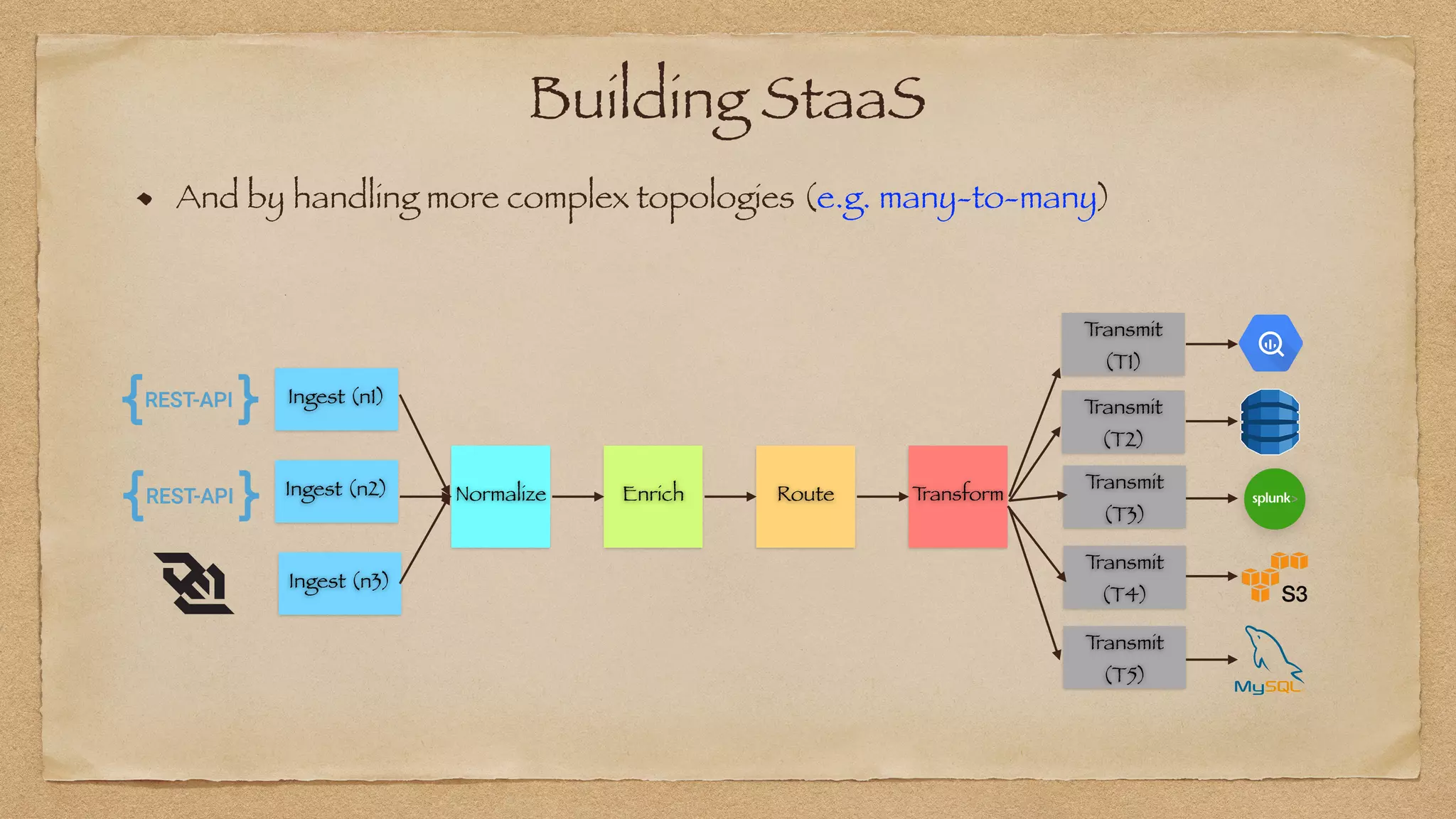
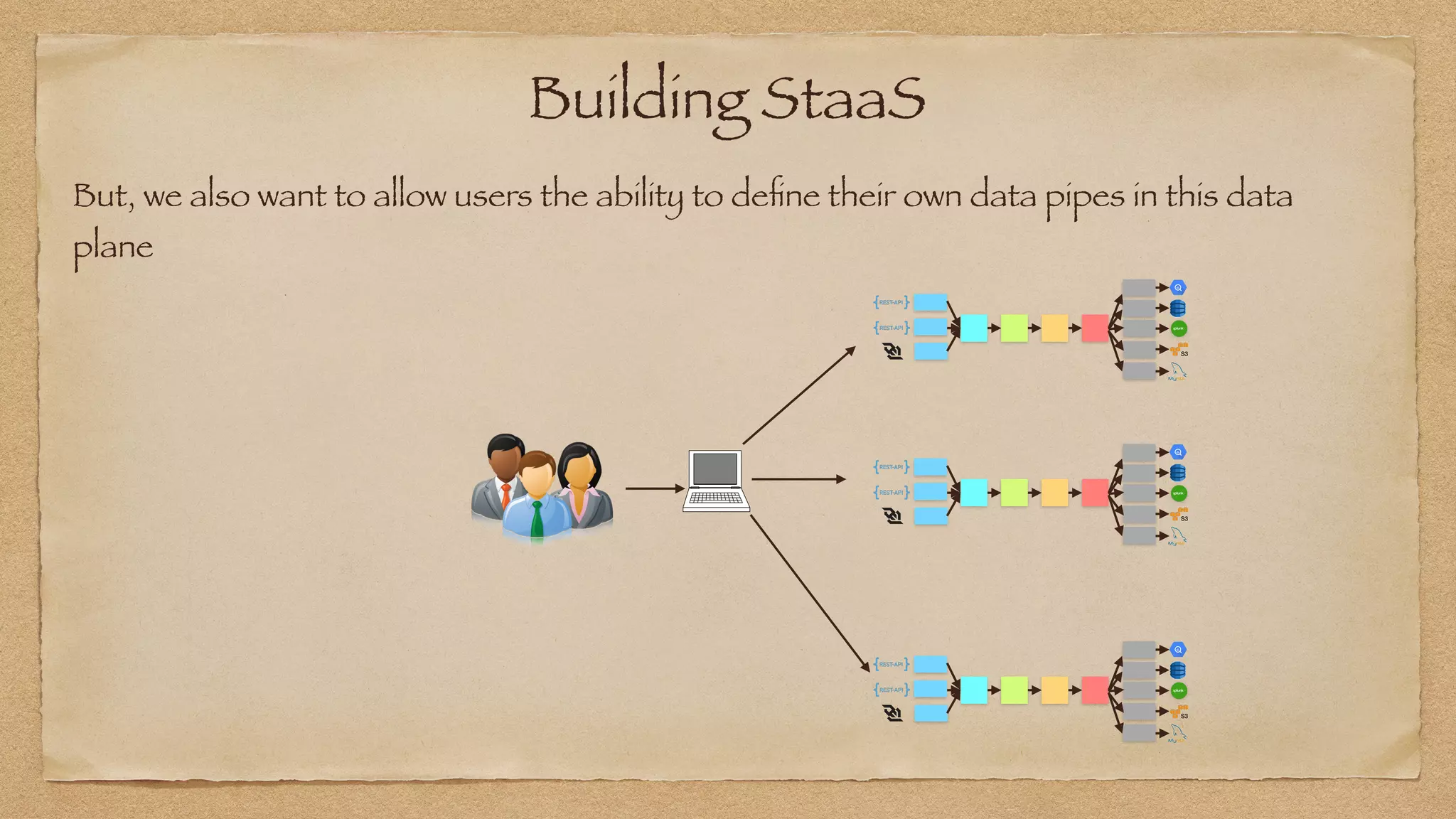
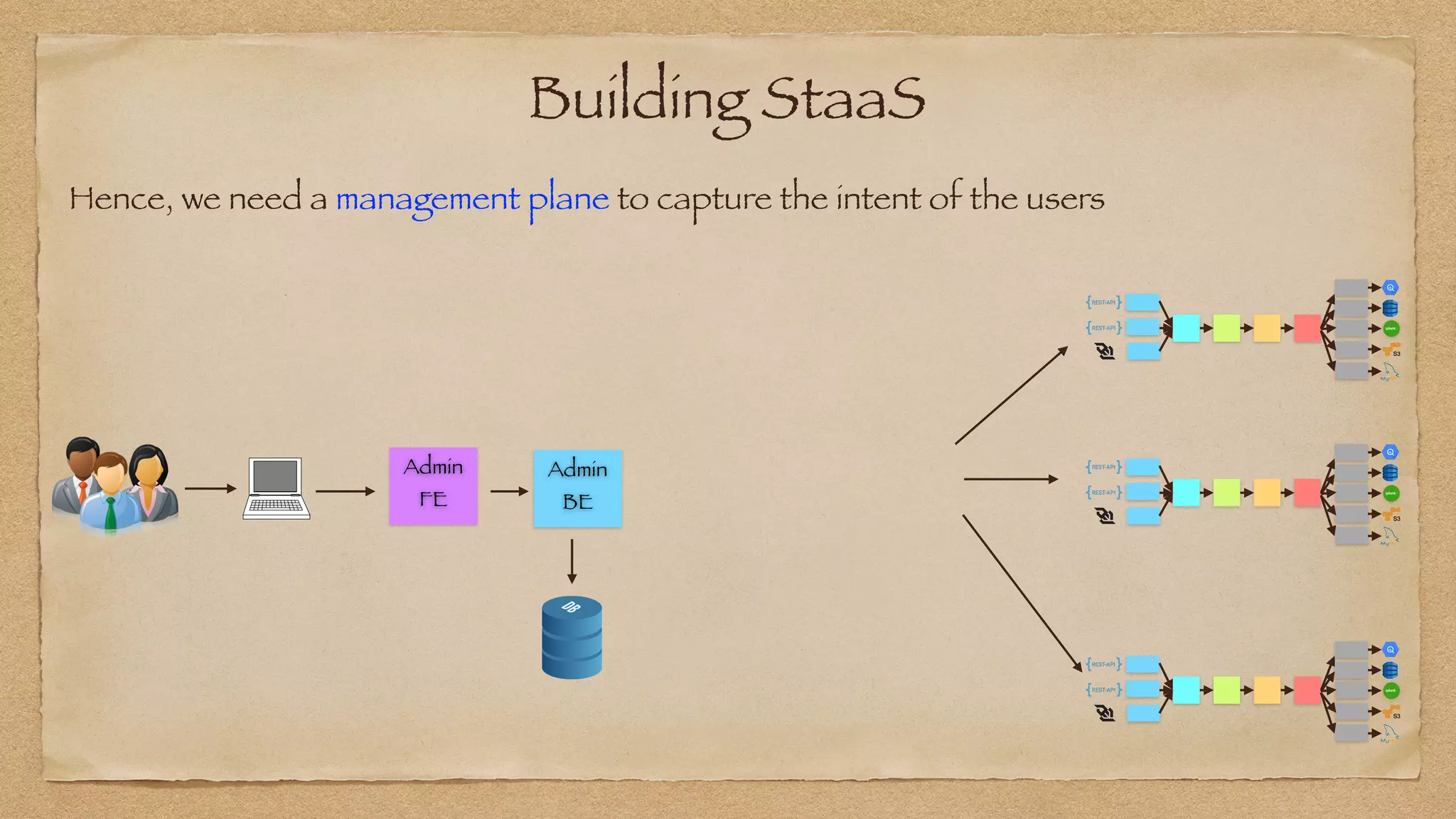
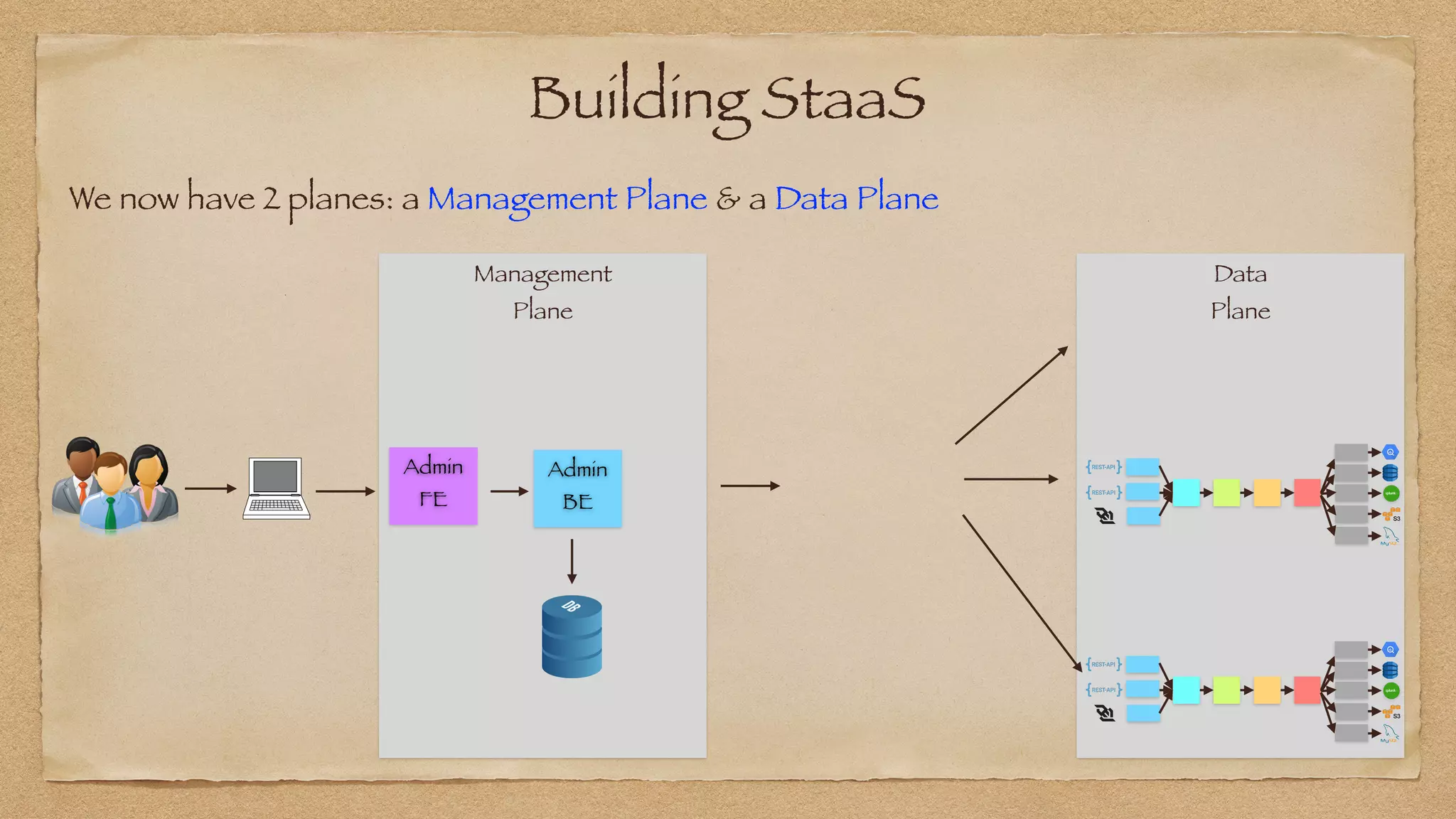
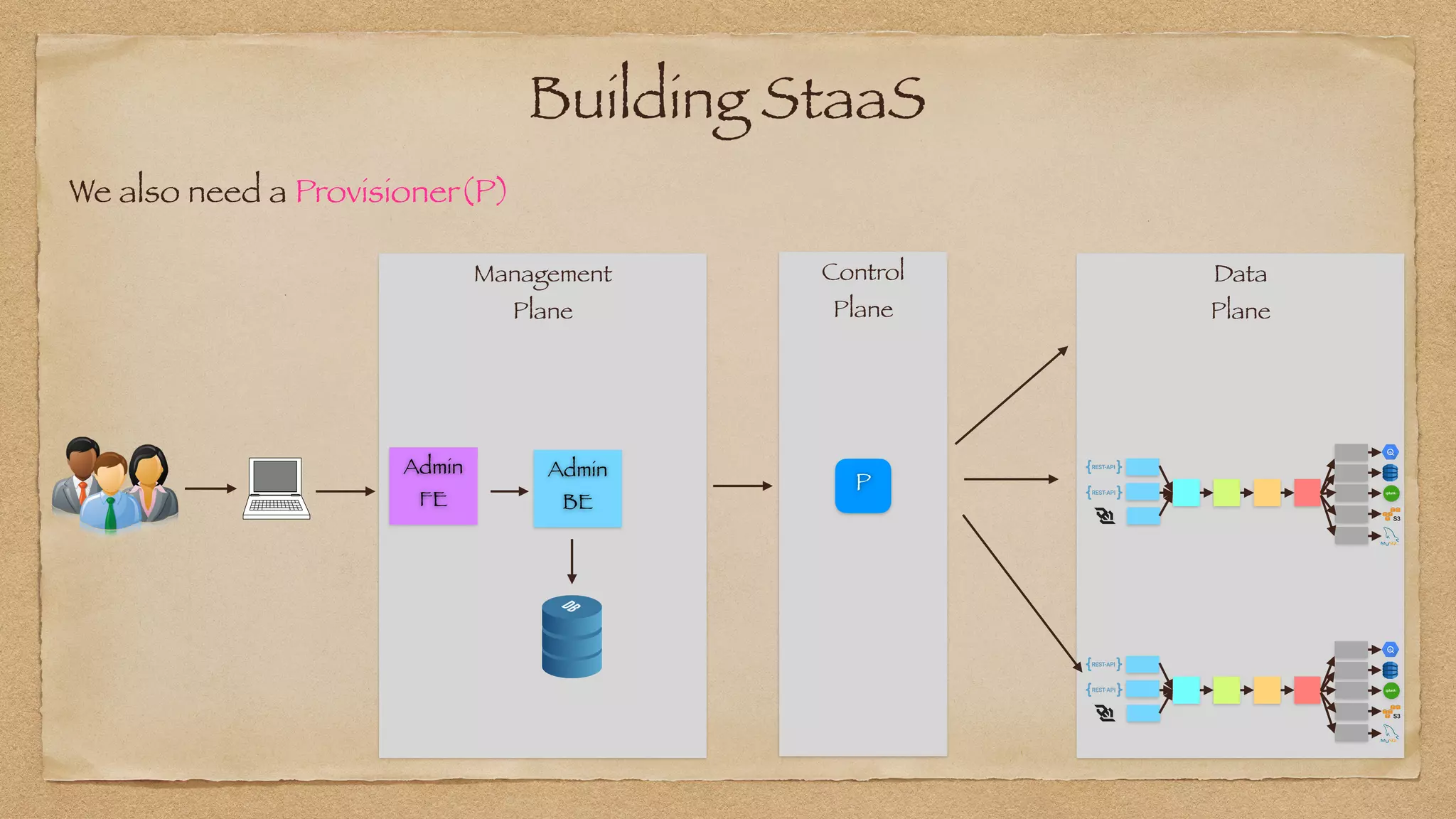
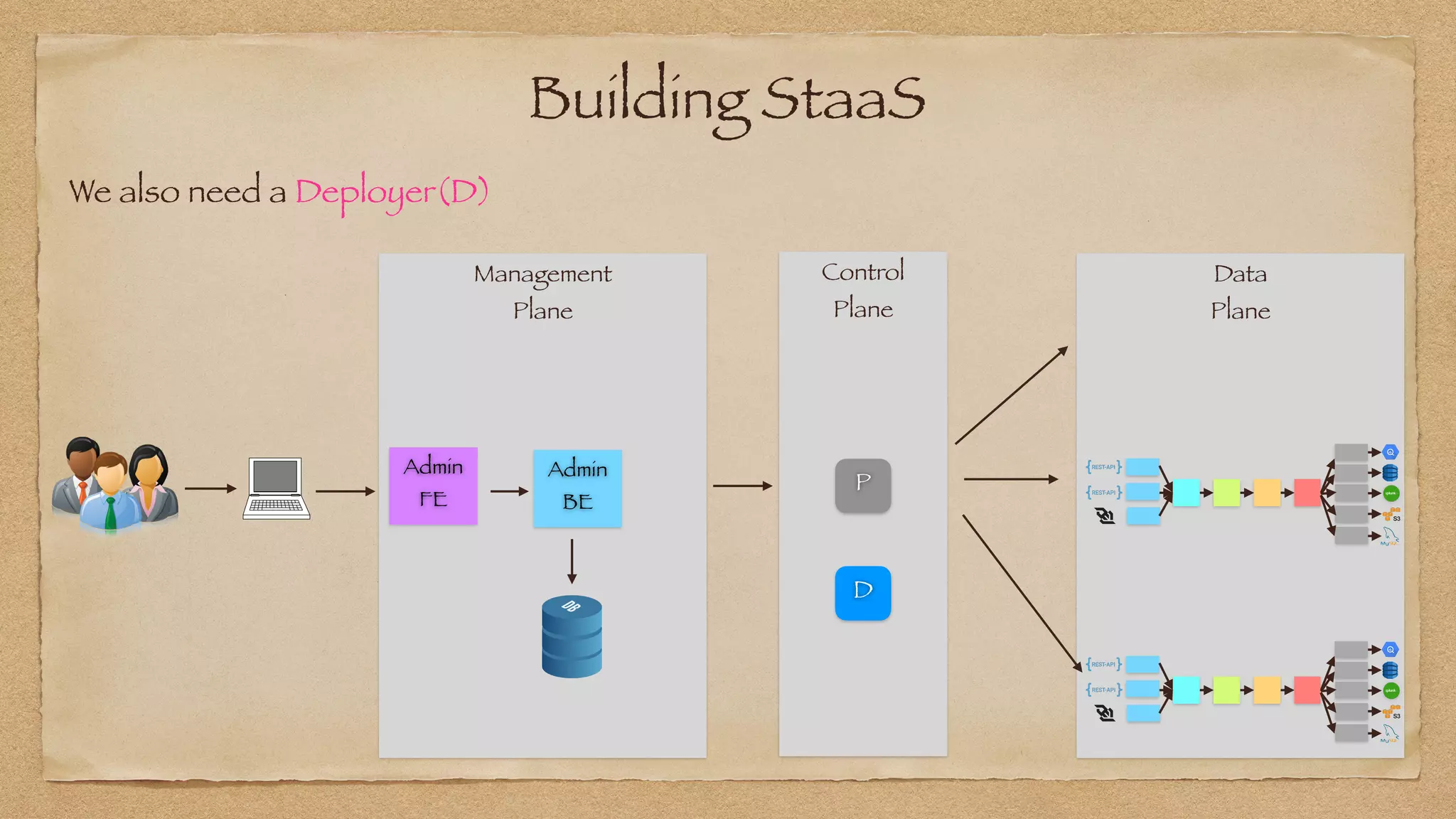
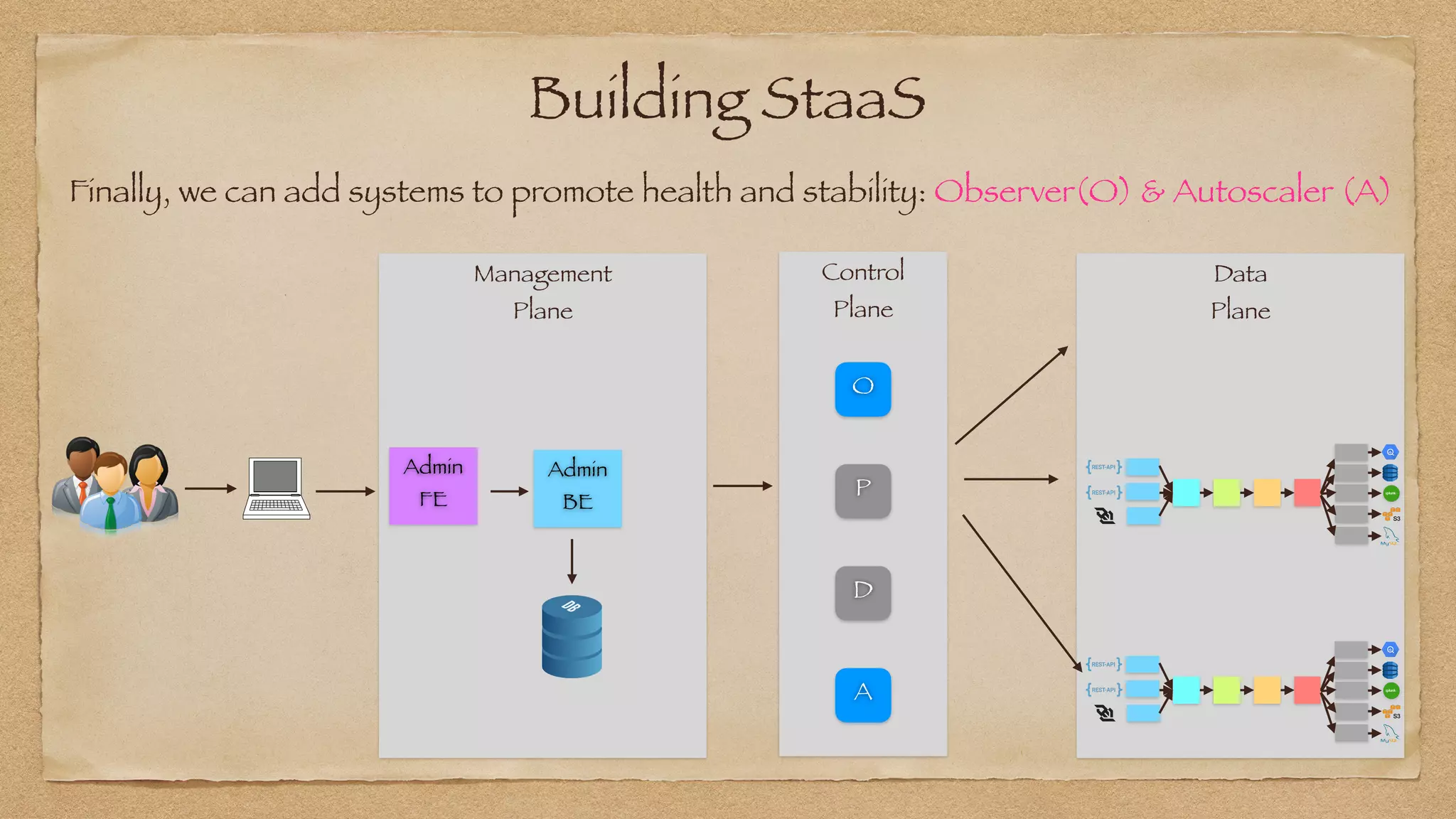
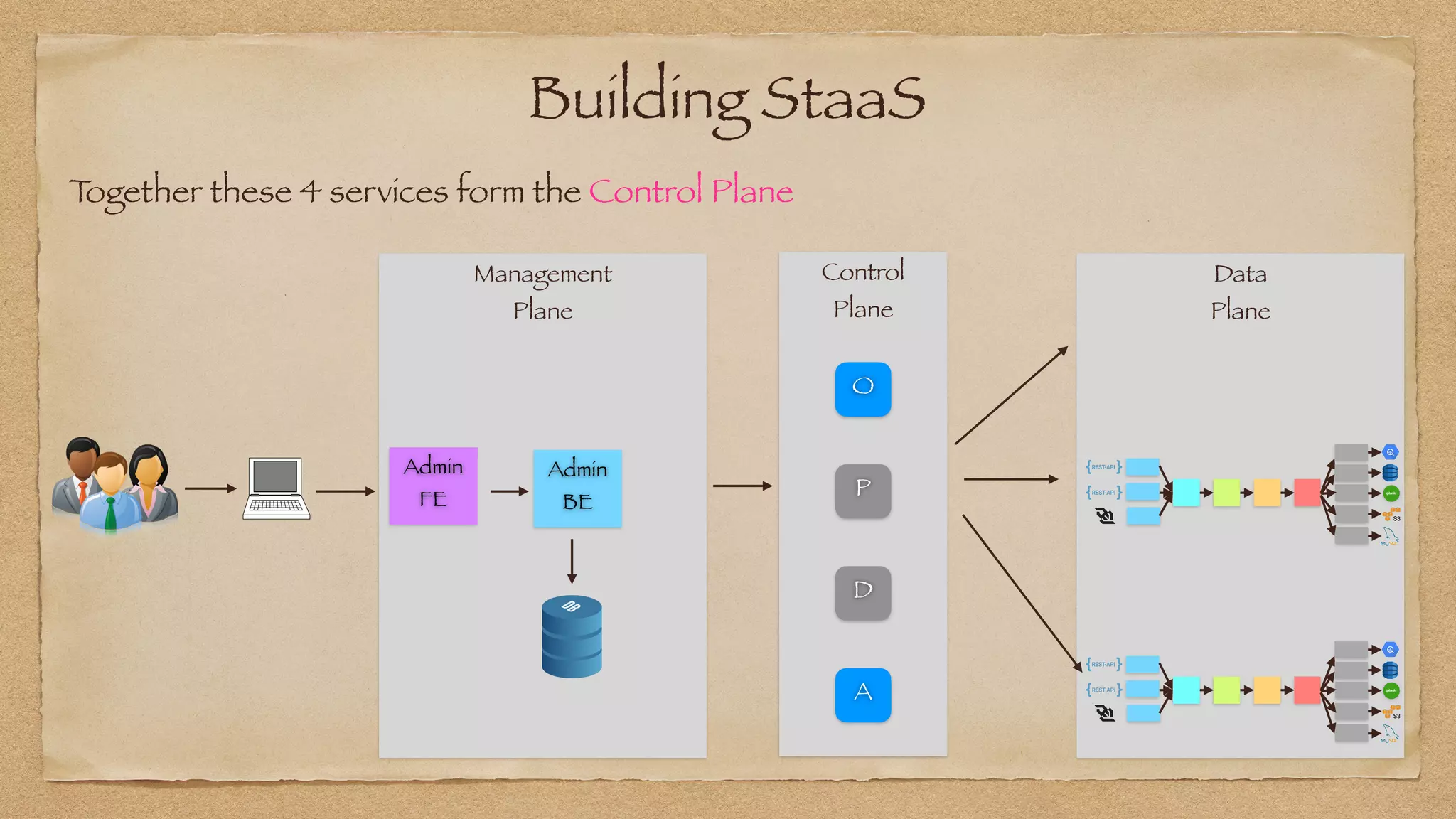
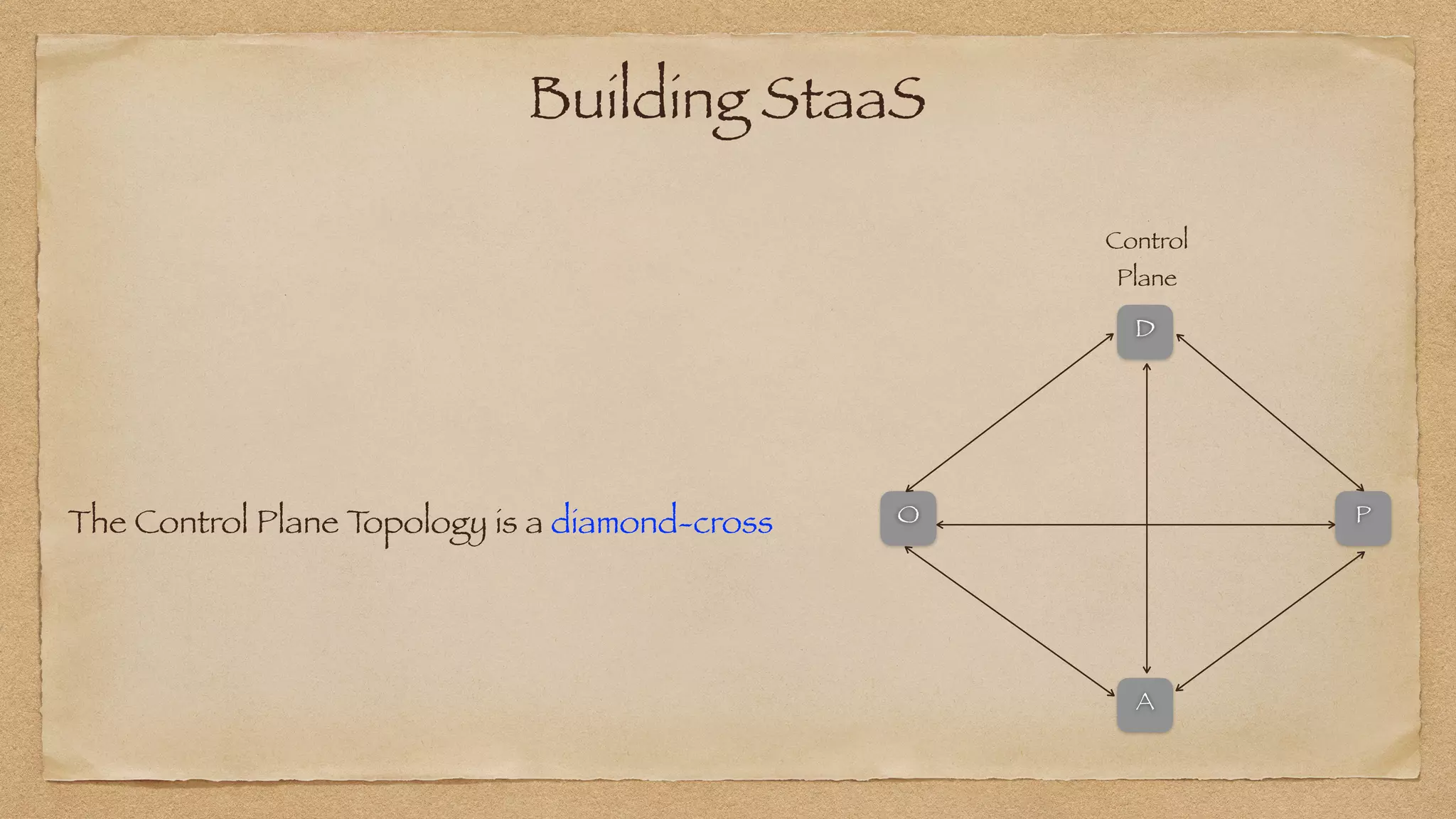
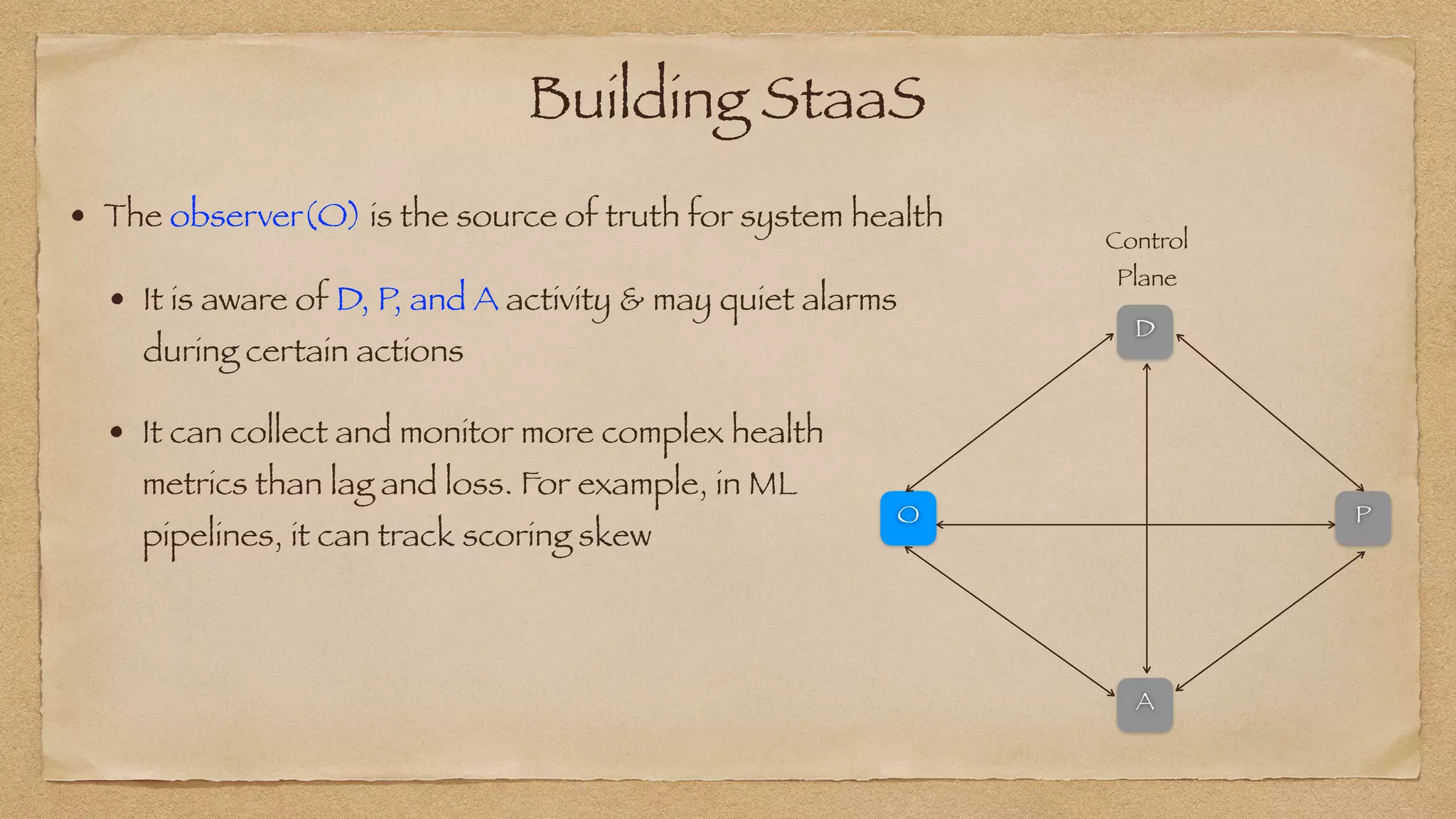
The document discusses the challenges of implementing reliable streaming architectures, emphasizing the importance of addressing non-functional requirements to avoid operational issues. It details the process of building a stream-as-a-service system, focusing on reliability through transactional messaging and the measurement of performance metrics such as lag and loss. The ultimate goal is to deliver messages with low latency while ensuring high quality and reliability for optimal customer satisfaction.



















![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)






















































![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)












