Mean Tests &X2
Parametric vs Nonparametric
Errors
Selection of a Statistical Test
SW242
2.
4 Levelsof Measurement
Nominal, ordinal, interval, ratio
Variable Types
Independent Variables, Dependent Variables
Moderator variables
Discrete Variables
Finite answers, limited by measurement e.g. test scores,
Continuous variables
All values possible (GPA not exceed 5.0)
Dichotomous variable
Only 2 values, yes or no, male or female
Binary variable
Assign a 0 (yes) or 1 (no) to indicate presence or absence of something
Dummy variable
Assign a binary value to a dichotomous value for analytic purposes
(e.g. male = ‘0’, female = ‘1’).
Creation & Description of a Data Set
3.
Variable Types
Independent Variables, Dependent Variables
Moderator variables
Discrete Variables
Finite answers, limited by measurement e.g. test scores,
Continuous variables
All values possible (GPA not exceed 5.0)
Dichotomous variable
Only 2 values, yes or no, male or female
Binary variable
Assign a ‘0’ or ‘1’ to indicate presence or absence of
something
Dummy variable
Assign a binary value to a dichotomous value for analytic
purposes (e.g. male = ‘0’, female = ‘1’).
Creation & Description of a Data Set
4.
Number of VariablesAnalyzed
Univariate analyses
Examine the distribution of value categories
(nominal/ordinal) or values (interval or ratio)
Bivariate analyses
Examine relationship between 2 variables
Multivariate analyses
Simultaneously examine the relationship
among 3 or more variables
Categories of Analysis
5.
Descriptive
Summaries ofpopulation studied
(parameters)
Preliminary to further analysis
Inferential
Used with sample from total
population and how well can results be
generalized to total population
Purpose of Analysis
6.
Parametric Testsrequire:
One variable (usually the DV) is at the interval or ratio
level of measurement
DV is normally distributed in the population;
independent samples should have equal or near equal
variances
Cases selected independently (random selection or
random assignment)
Robustness how many and which assumptions above
can be violated without affecting the result (delineated
in advanced texts).
Parametric vs. Non-parametric
7.
Nonparametric Testsrequire nominal or ordinal level
data
Samples complied form different populations and we
want to compare the distribution of a single variable
within each of them
Variables are nominal or can only be rank ordered
Very small samples: 6 or 7 are available
Statistical power is low, increases with sample size (as
with parametric tests)
Parametric vs. Non-parametric
8.
Frequency Distributions
Array is an arrangement of data from smallest to highest
Absolute/simple frequency distribution displays number of times a
value occurs (all levels of measurement)
Cumulative frequency distribution adds cases together so that it last
number in distribution is the total number of cases observed
Percentage distribution adds the percent of occurrence in the table
Cumulative Percentage
Creation & Description of a Data Set
9.
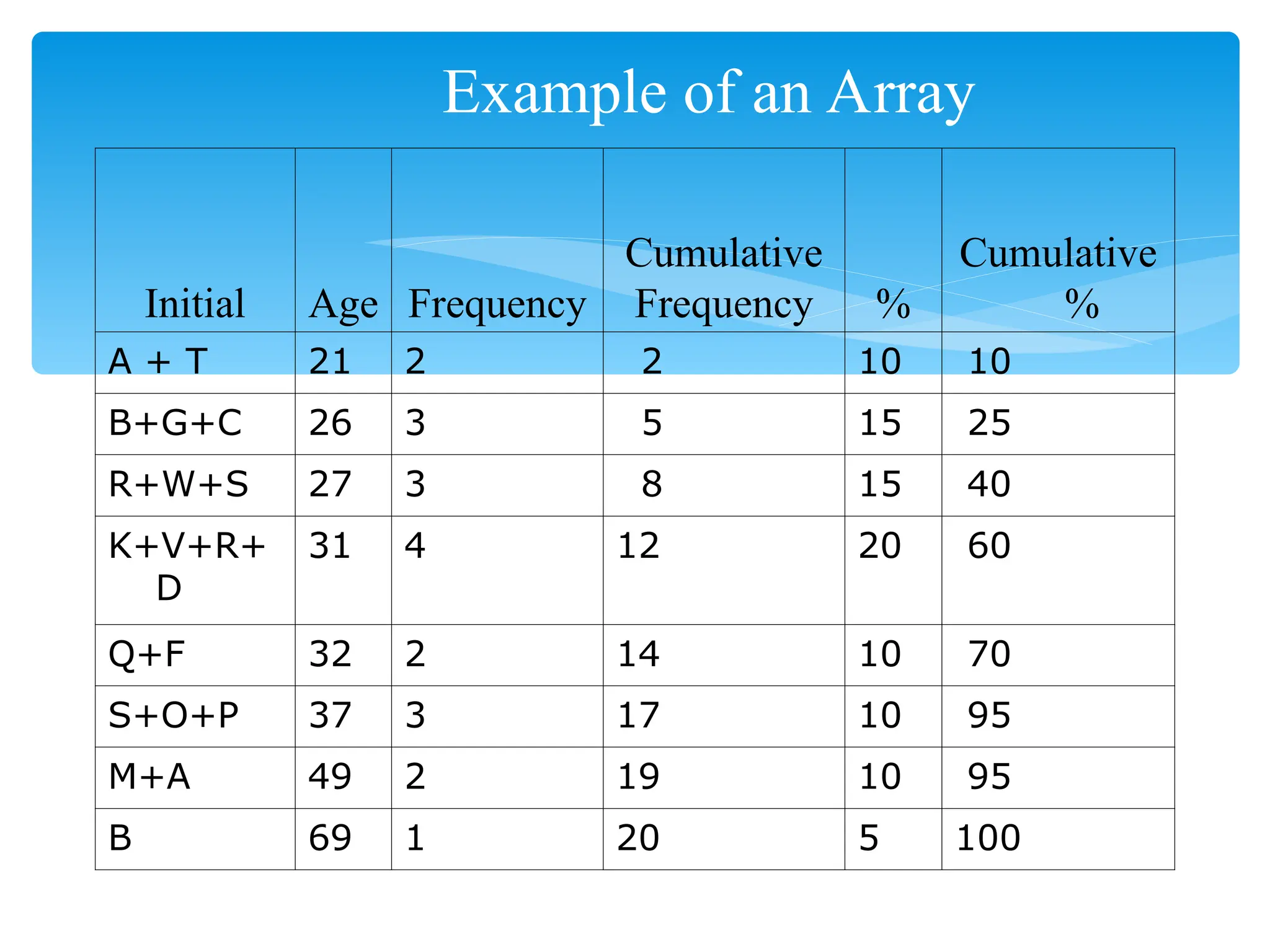
Example of anArray
Initial Age Frequency
Cumulative
Frequency %
Cumulative
%
A + T 21 2 2 10 10
B+G+C 26 3 5 15 25
R+W+S 27 3 8 15 40
K+V+R+
D
31 4 12 20 60
Q+F 32 2 14 10 70
S+O+P 37 3 17 10 95
M+A 49 2 19 10 95
B 69 1 20 5 100
10.
Bar Graph/Histogram (barstouch)
Line Graph/Frequency Polygon
Pie Chart
Keep graphs simple.
Limit to only salient information.
Collapse categories/distributions when possible.
Graphical Representations
11.
Typical representationof data, e.g. find a number or
groups of numbers that is most representative of a dataset
Mode
Values within a dataset that occur most frequently, if two occur
equally then bimodal distribution, etc.
Median
The value in the exact middle of a linear array, mean between 2
values if even number of values.
Mean: arithmetic mean
Trimmed mean (outliers removed) minimize effect of extreme
outliers
Weighted mean: compute an average for values that are not
equally weighted (proportionate / disproportionate sampling)
Measures of Central Tendency
12.
Variability/Dispersion
Nominalor Ordinal use a frequency distribution or graph (bar
chart)
Interval or ratio use range
Range = maximum value – minimum value +1
Informs about the number of values that exist between
the ends of the distribution e.g. 31 to 46 there are
potentially 16 values possible. The larger the range, the
greater the variability. However, outliers make the range
misleading. Therefore use median, or mean and standard
deviation whenever possible for interval & ratio data.
Measures of Central Tendency
13.
Statistical significanceof the Chi Square only tells us
that the result is not due to sampling error.
Nominal variables only
Small group use
Chi Square Test of Independence
14.
1. Test therelationship of nominal Variables.
Not a statistic that can infer causality.
Tells us the difference between Observed and Expected
frequencies.
Pre-Experimental research designs, limited practice
issues.
- Use for one direction hypothesis testing
(directionality).
- Chi Square only tells us that the result is not due to
sampling error.
Purpose of X2 --- Chi-Square
15.
Implying causerather than association
Overestimating the importance of a finding,
especially with large sample sizes
Failure to recognize spurious relationships
Nominal variables only (both IV and DV)
Limitations & Common Problems
16.
One Samplet-test
You have the test scores for one population only.
Compare to a known value e.g. average non-clinical
population test score = 30
Analyze
Research design for this type of comparison
Pre-experimental
Other uses: establish external validity of the sample not
significantly different from the general population
parameter (what is a population parameter?)
Mean Comparison Tests
17.
Independent Samplest-Test
2 different samples/populations are tested for
comparison
not matched, receive same treatment (if matched they
would be paired sample t-test
Prepare dataset all scores in one column, tx_time = 2.
Paired T-Test
Same populations is tested for comparison
Mean Comparison Tests (cont.)
18.
Squared Pearsonproduct moment correlation
tells the strength of a relationship which
represents the amount of variation explained by
the DV about the IV.
Used for Comparing Two Interval/Ratio Groups
Obtain a Correlation Coefficient that Ranges
from -1 (perfect inverse relationship) 0 (no
relationship) or +1 (perfect positive relationship)
Measures of Association
19.
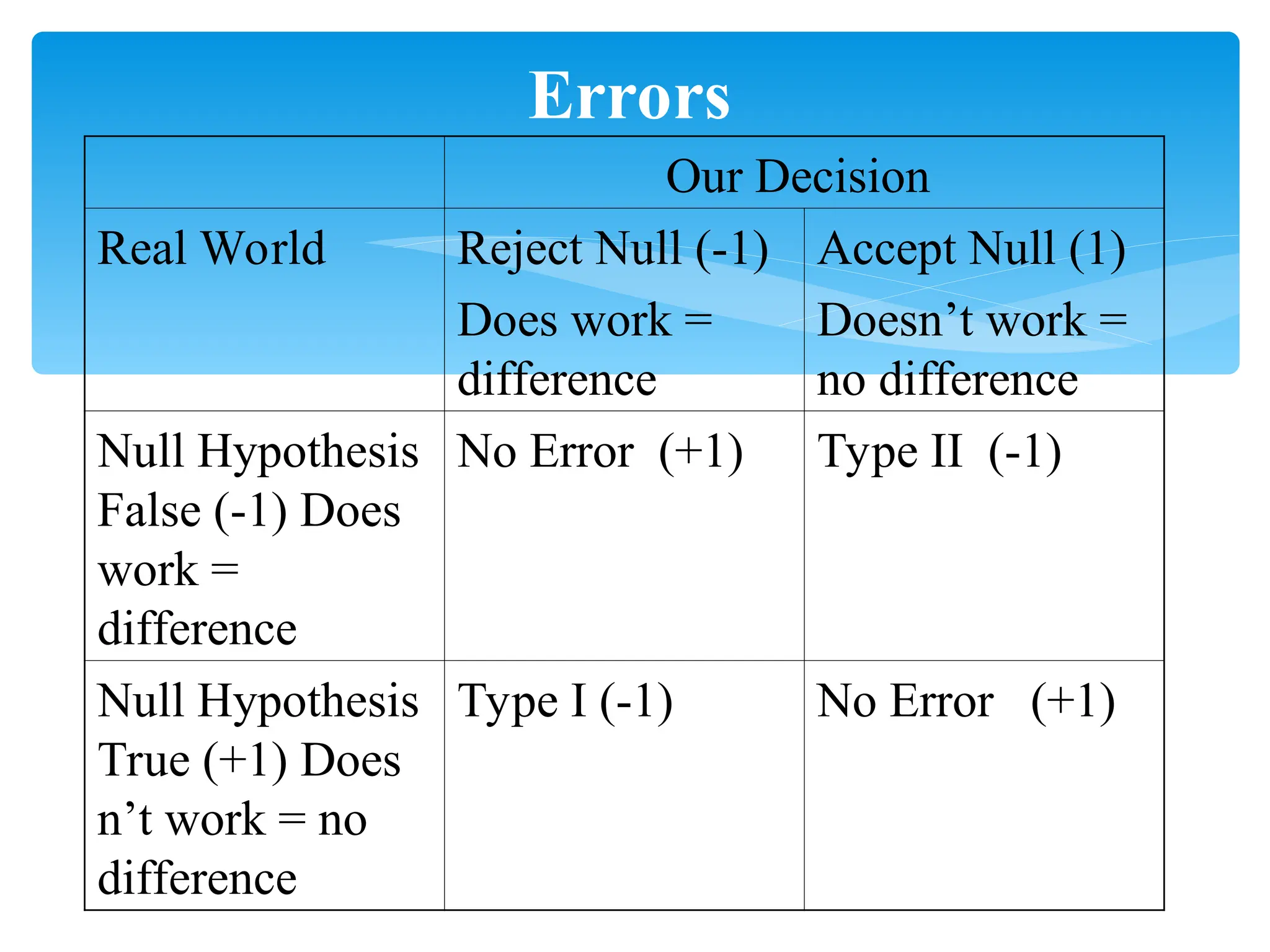
Errors
Our Decision
Real WorldReject Null (-1)
Does work =
difference
Accept Null (1)
Doesn’t work =
no difference
Null Hypothesis
False (-1) Does
work =
difference
No Error (+1) Type II (-1)
Null Hypothesis
True (+1) Does
n’t work = no
difference
Type I (-1) No Error (+1)
20.
The smallerthe p value, the less likelihood of committing a
type I, the greater the p value, the greater the chance of a
type II error. p values range from 0 (total significance) to
1.0 (least significance).
Generally p values less than .05 are considered significant,
while those more than .05 are not.
Errors (continued)
21.
Sampling MethodUsed
How was sample selected?
What is the size of the sample?
Were the samples related?
Was probability sampling used? Disproportionate selection?
What type of variables were used
Variable Distribution among Population
Evenly distributed?
Judgement call
How to Select a Statistical Test
22.
Level ofMeasurement of the Independent & Dependent
Variables
Inclusionary/ exclusionary criteria (screening mechanisms)
Variable measurement levels (nominal, ordinal, etc.)
Measurement precision (best measurement level used) Use
of low level measurement reduces the availability of
stronger statistical techniques.
How to Select a Statistical Test
23.
Statistical Power(Reduction in Type II error)
True relationship between variables is strong not weak
Variability of variables is small rather than large
A higher p value is used (e.g. .1 vs .05) thereby increases
risk of Type I error
Directional hypothesis used (one tailed)
Large sample versus a small sample (power analysis)
Cost effective sample just right for analysis
Avoid too small a sample since even if the IV is effective, it
would not yield a statistically significant relationship
How to Select a Statistical Test
























































































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)


