Downloaded 927 times






















































































Big Data technologies represent a major shift that is here to stay. Big Data enables the use of all types of data, including unstructured data like clinical notes and medical images, for new insights. Advanced analytics like predictive modeling and text mining will become more prevalent and intelligent with Big Data. Big Data will impact application development and require changes to data management approaches. Technologies like Hadoop, NoSQL databases, and semantic modeling will be important for healthcare Big Data.
Overview of Big Data in healthcare; presenters introduce the topic and outline the agenda.
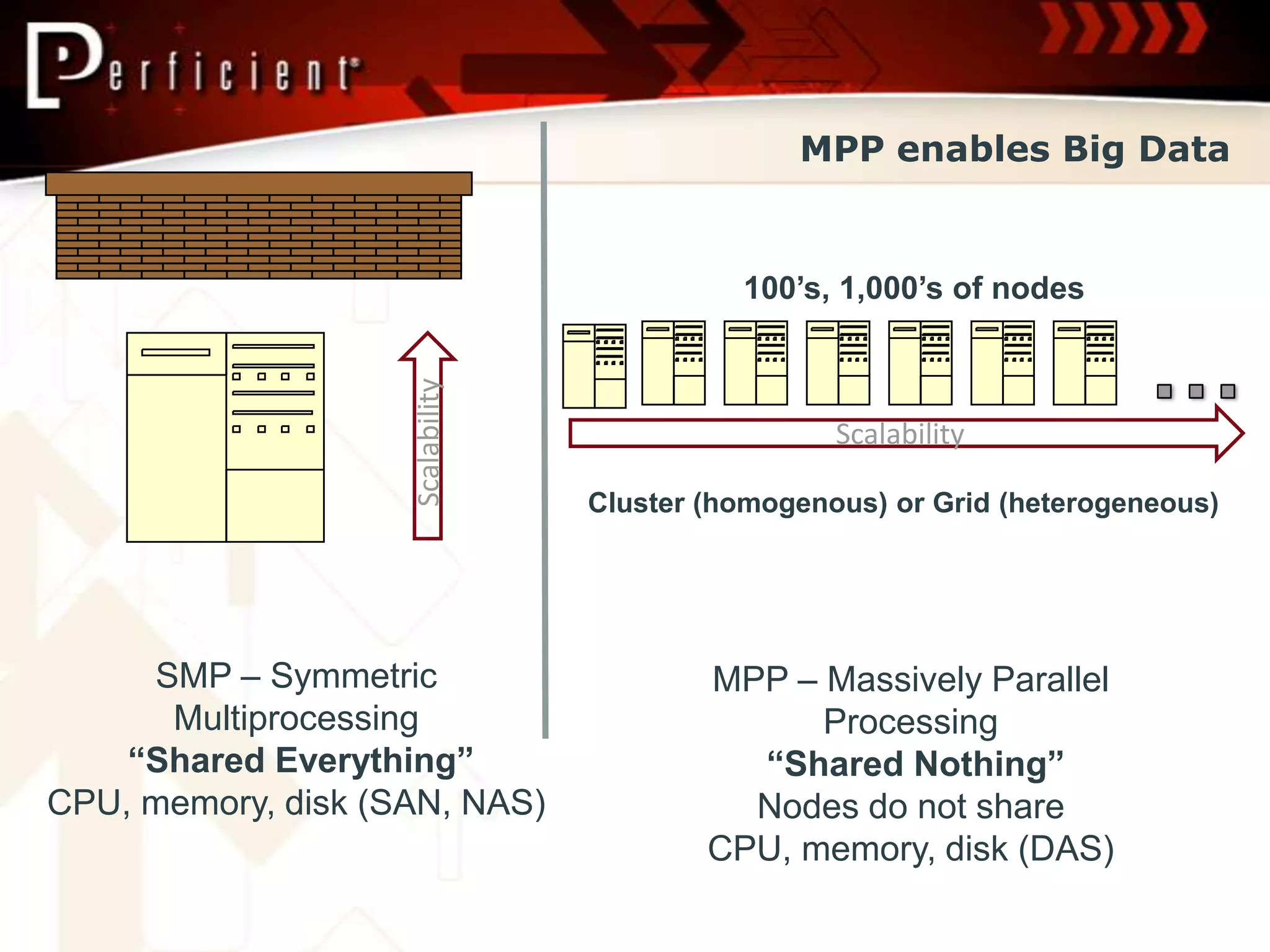
Explains Big Data's characteristics: Volume, Velocity, Variety; discusses MPP and cost factors in Big Data processing.
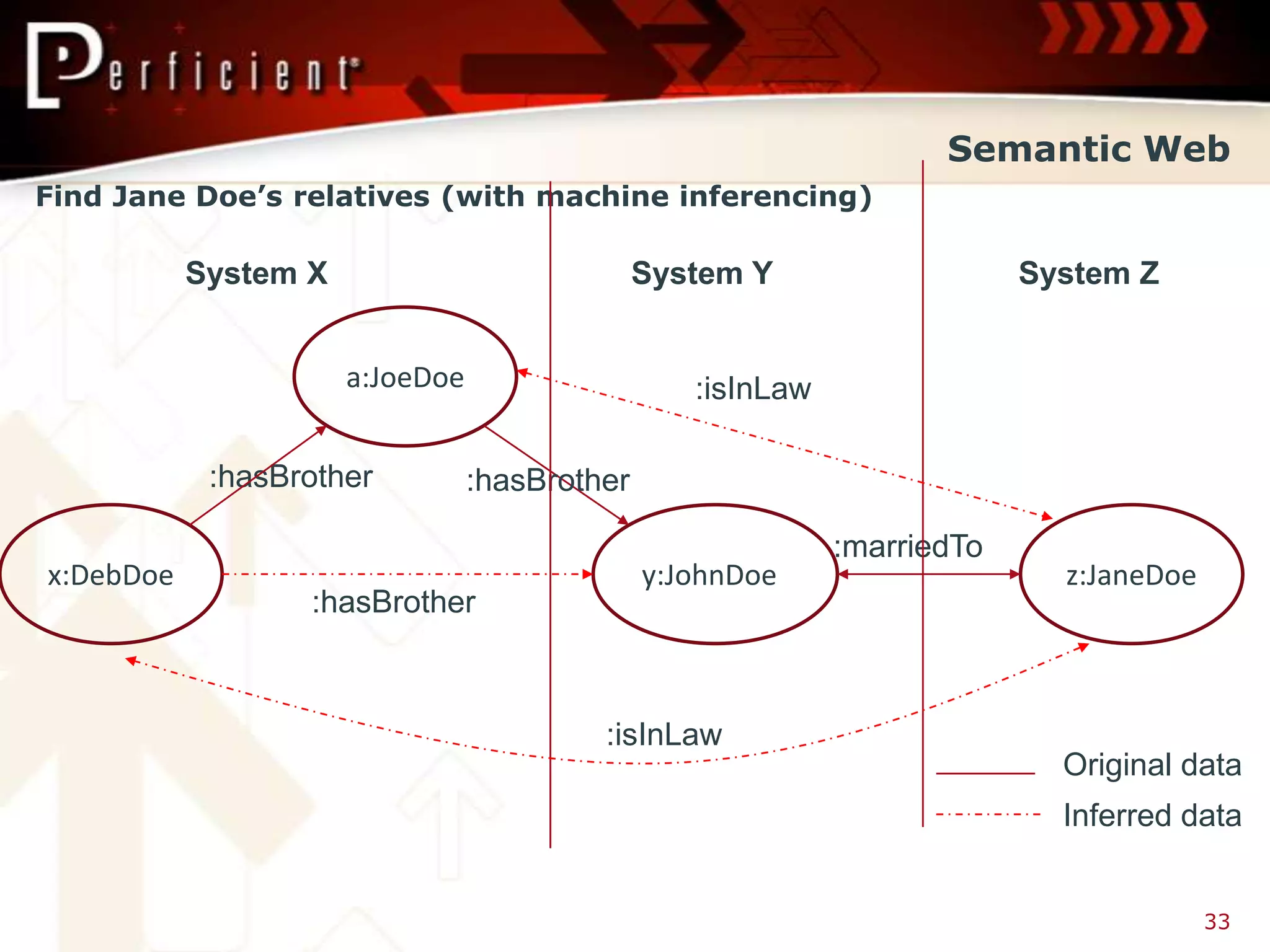
Introduction to Hadoop, MapReduce, and NoSQL; discusses their relevance in Big Data solutions.
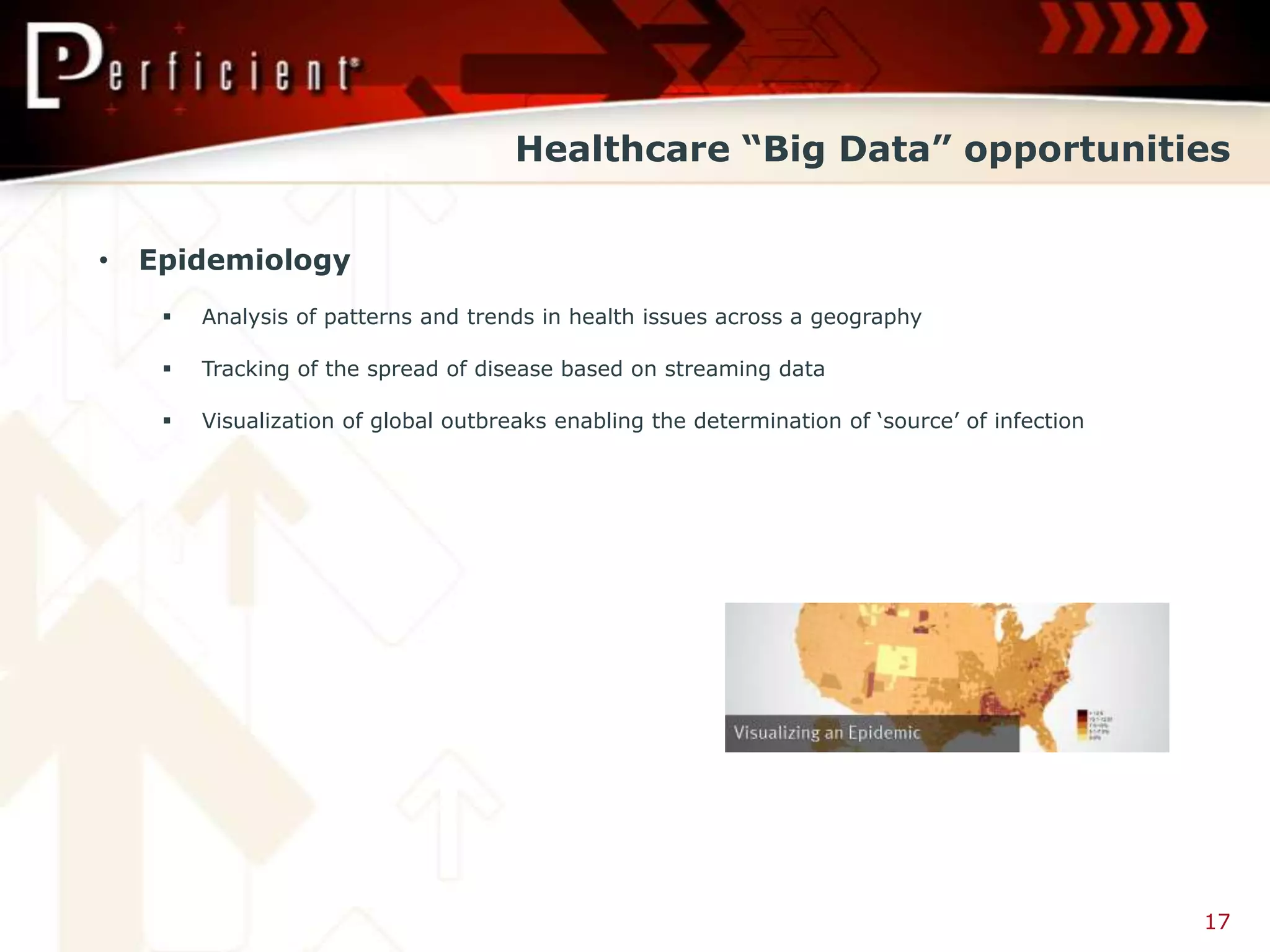
Explores various healthcare applications including patient monitoring, personalized medicine, and epidemiology.
A poll for audience to identify which Big Data use cases they find most significant in healthcare.
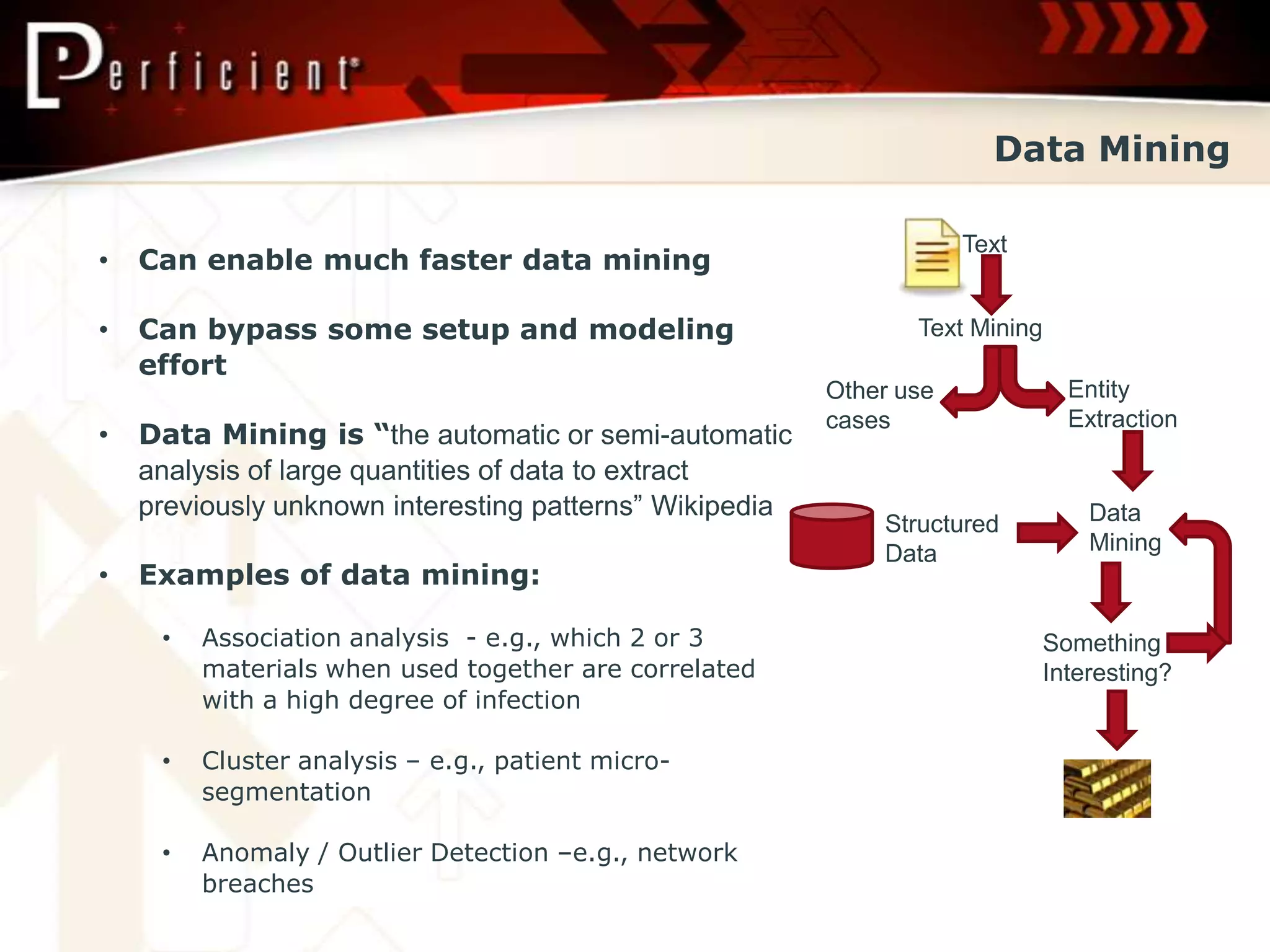
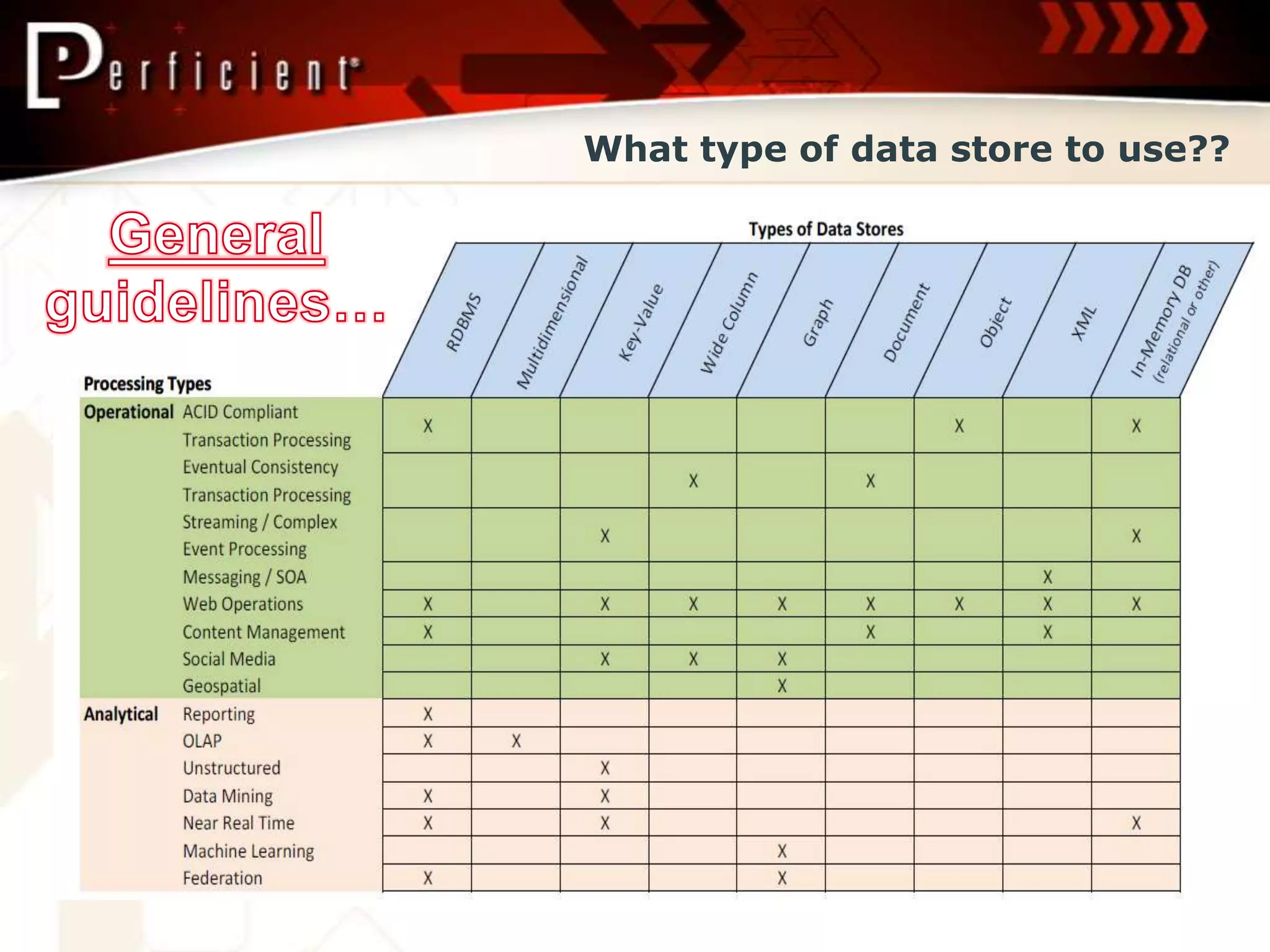
Discusses analytics, unstructured data mining, and transaction processing in Big Data contexts.
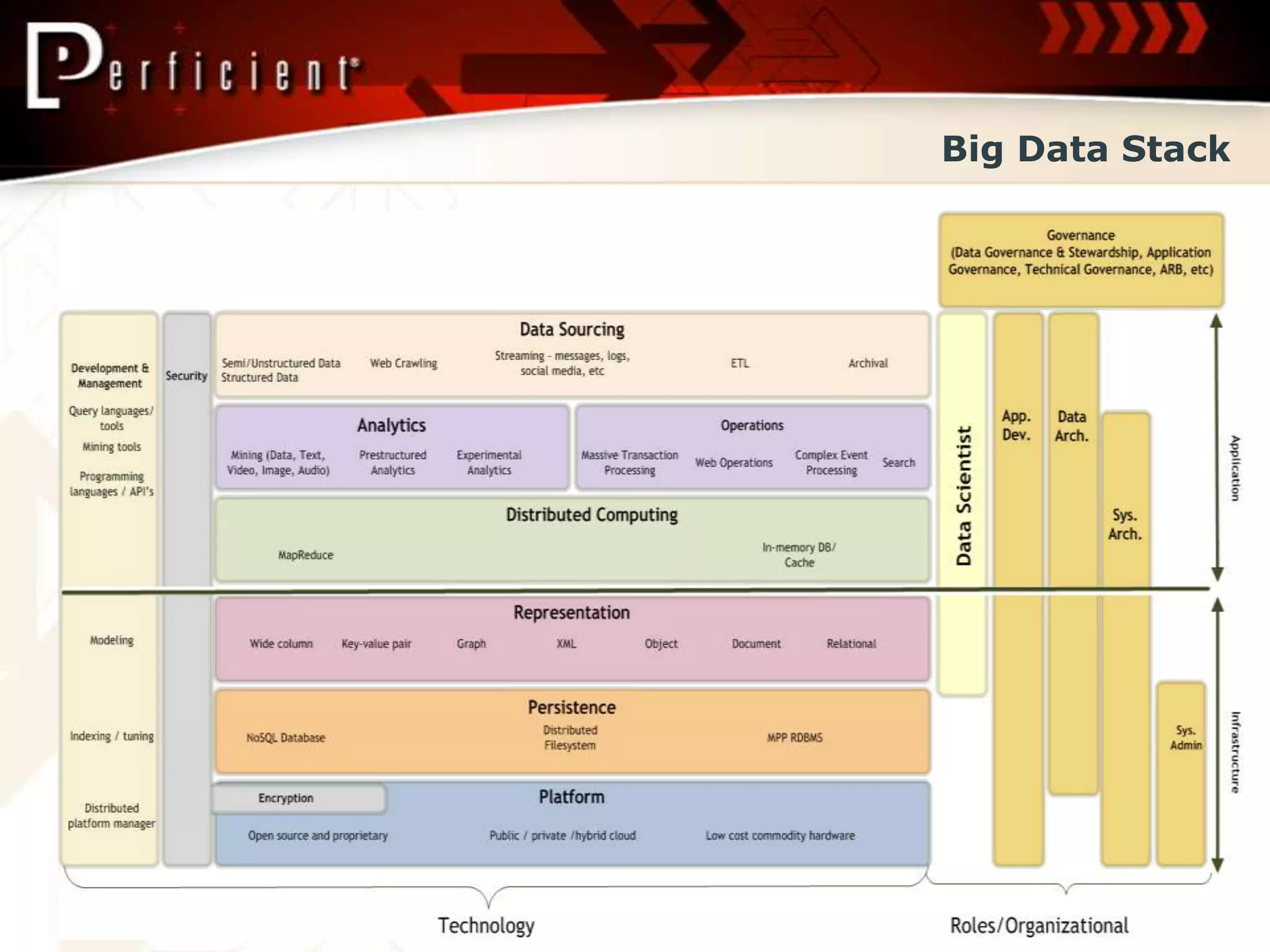
Overview of Big Data architecture, technologies (Hadoop, Cassandra, IMDB), and considerations for diverse data paradigms.
Impact of Big Data on application development and data management; emphasizes ACID vs. BASE transactions.
Recaps main points on Big Data opportunities, key technologies, costs, summarizing the learning curve and evolution.
Information about Perficient's services, history, market reach, and solutions expertise in technology consulting.































































![[IJET-V1I3P10] Authors : Kalaignanam.K, Aishwarya.M, Vasantharaj.K, Kumaresan...](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i3p10-150608055552-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)











































