Downloaded 55 times







![Peer-to-peermiddleware
• The third generation is characterized by the emergence of middleware
layers for the application-independent management of distributed resources
on a global scale.
•Peer-to-peer middleware systems are designed specifically to meet the
need for the automatic placement and subsequent location of the
distributed objects managed by peer-to-peer systems and applications.
• The best-known and most fully developed examples include Pastry
[Rowstron and Druschel 2001], Tapestry [Zhao et al. 2004], CAN
[Ratnasamy et al. 2001], Chord [Stoica et al. 2001] and Kademlia
[Maymounkov and Mazieres 2002].](https://image.slidesharecdn.com/unit-3cs6601-180223090838/75/Unit-3-cs6601-Distributed-Systems-8-2048.jpg)



![Figure (e): Basic programming interface for distributed object
location and routing (DOLR) as implemented by Tapestry
publish(GUID )
GUID can be computed from the object (or some part of it, e.g. its
name). This function makes the node performing a publish operation
the host for the object corresponding to GUID.
unpublish(GUID)
Makes the object corresponding to GUID inaccessible.
sendToObj(msg, GUID, [n])
Following the object-oriented paradigm, an invocation message is sent
to an object in order to access it. This might be a request to open a TCP
connection for data transfer or to return a message containing all or
part of the object’s state. The final optional parameter [n], if present,
requests the delivery of the same message to n replicas of the object.](https://image.slidesharecdn.com/unit-3cs6601-180223090838/75/Unit-3-cs6601-Distributed-Systems-13-2048.jpg)
![OVERLAY CASE STUDIES: PASTRY, TAPESTRY
• Pastry is the message routing infrastructure deployed in several applications
including PAST [Druschel and Rowstron 2001], an archival (immutable) file
storage system implemented as a distributed hash table with the API in Figure
(d).
• Pastry has a straightforward but effective design.
• Tapestry is the basis for the OceanStore storage system.
• It has a more complex architecture than Pastry because it aims to support a
wider range of locality approaches.](https://image.slidesharecdn.com/unit-3cs6601-180223090838/75/Unit-3-cs6601-Distributed-Systems-14-2048.jpg)








![Peer-to-peermiddleware
• The third generation is characterized by the emergence of middleware
layers for the application-independent management of distributed resources
on a global scale.
•Peer-to-peer middleware systems are designed specifically to meet the
need for the automatic placement and subsequent location of the
distributed objects managed by peer-to-peer systems and applications.
• The best-known and most fully developed examples include Pastry
[Rowstron and Druschel 2001], Tapestry [Zhao et al. 2004], CAN
[Ratnasamy et al. 2001], Chord [Stoica et al. 2001] and Kademlia
[Maymounkov and Mazieres 2002].](https://crownmelresort.com/image.slidesharecdn.com/unit-3cs6601-180223090838/75/Unit-3-cs6601-Distributed-Systems-8-2048.jpg)




![Figure (e): Basic programming interface for distributed object
location and routing (DOLR) as implemented by Tapestry
publish(GUID )
GUID can be computed from the object (or some part of it, e.g. its
name). This function makes the node performing a publish operation
the host for the object corresponding to GUID.
unpublish(GUID)
Makes the object corresponding to GUID inaccessible.
sendToObj(msg, GUID, [n])
Following the object-oriented paradigm, an invocation message is sent
to an object in order to access it. This might be a request to open a TCP
connection for data transfer or to return a message containing all or
part of the object’s state. The final optional parameter [n], if present,
requests the delivery of the same message to n replicas of the object.](https://crownmelresort.com/image.slidesharecdn.com/unit-3cs6601-180223090838/75/Unit-3-cs6601-Distributed-Systems-13-2048.jpg)
![OVERLAY CASE STUDIES: PASTRY, TAPESTRY
• Pastry is the message routing infrastructure deployed in several applications
including PAST [Druschel and Rowstron 2001], an archival (immutable) file
storage system implemented as a distributed hash table with the API in Figure
(d).
• Pastry has a straightforward but effective design.
• Tapestry is the basis for the OceanStore storage system.
• It has a more complex architecture than Pastry because it aims to support a
wider range of locality approaches.](https://crownmelresort.com/image.slidesharecdn.com/unit-3cs6601-180223090838/75/Unit-3-cs6601-Distributed-Systems-14-2048.jpg)


This document discusses peer-to-peer systems and middleware for managing distributed resources at a large scale. It describes key characteristics of peer-to-peer systems like nodes contributing equal resources and decentralized operation. Middleware systems like Pastry and Tapestry are overlay networks that route requests to distributed objects across nodes through knowledge at each node. They provide simple APIs and support scalability, load balancing, and dynamic node availability.
Overview of the presentation introduced by Nandakumar P, covering peer-to-peer systems, middleware, and notable case studies.
Peer-to-peer systems aim to share data without centralized servers, utilizing edge resources.
Key characteristics include user contribution of resources, equal node capabilities, and algorithm choice for efficient data management.
Comparison between IP routing and overlay routing highlighting scalability, load balancing, fault tolerance, and security.
Napster was a pioneering P2P network for sharing music but faced legal challenges leading to its shutdown.
Third generation middleware enables distributed resource management; emphasizes scalability and user-friendly interfaces.
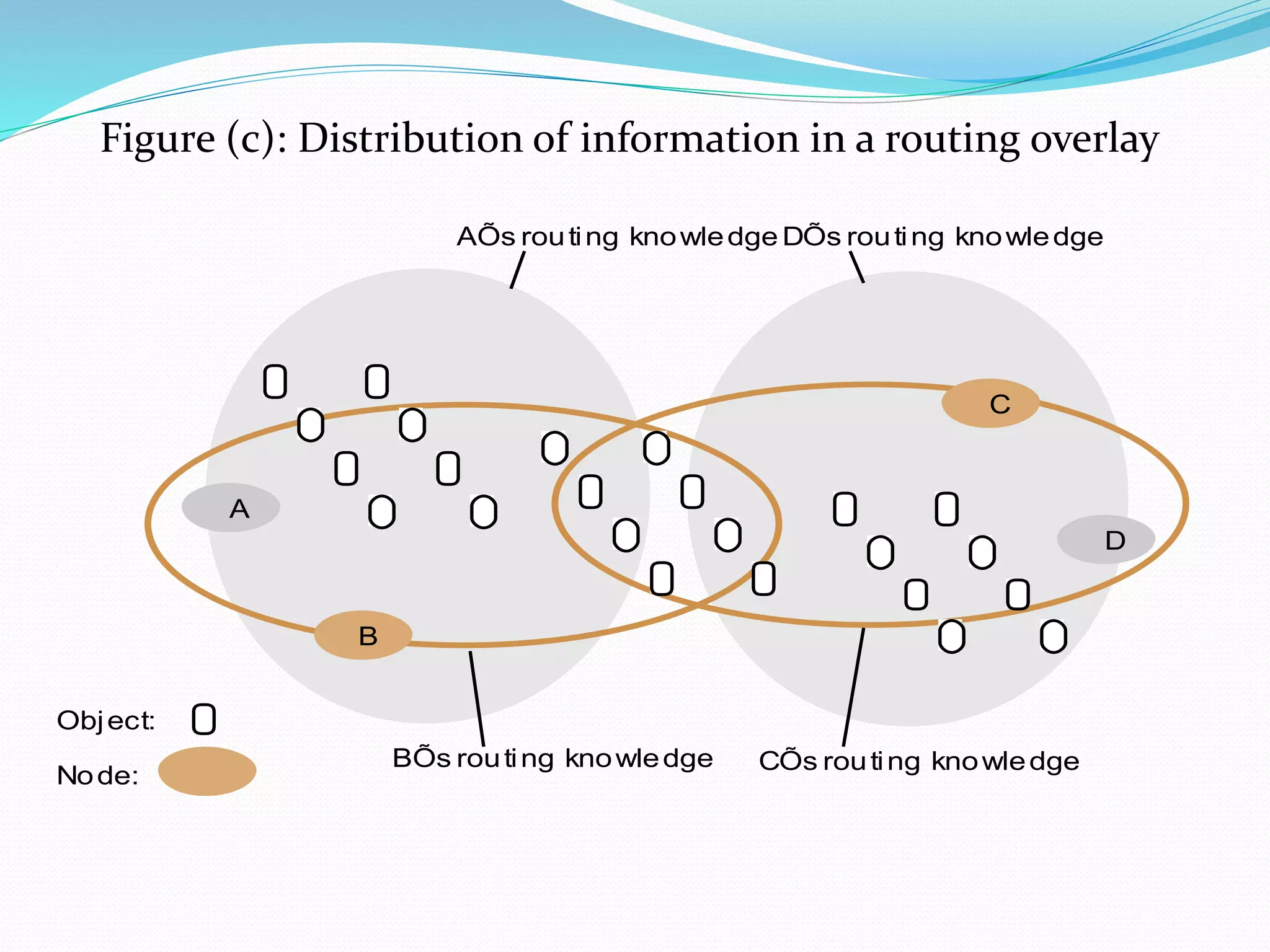
Routing overlays help locate objects in P2P networks, ensuring accessibility and managing object distribution.
Illustrate programming interfaces for managing objects in distributed systems implemented by Pastry and Tapestry.
Case studies on Pastry and Tapestry showcasing their architecture and applications in decentralized storage solutions.



































































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)














