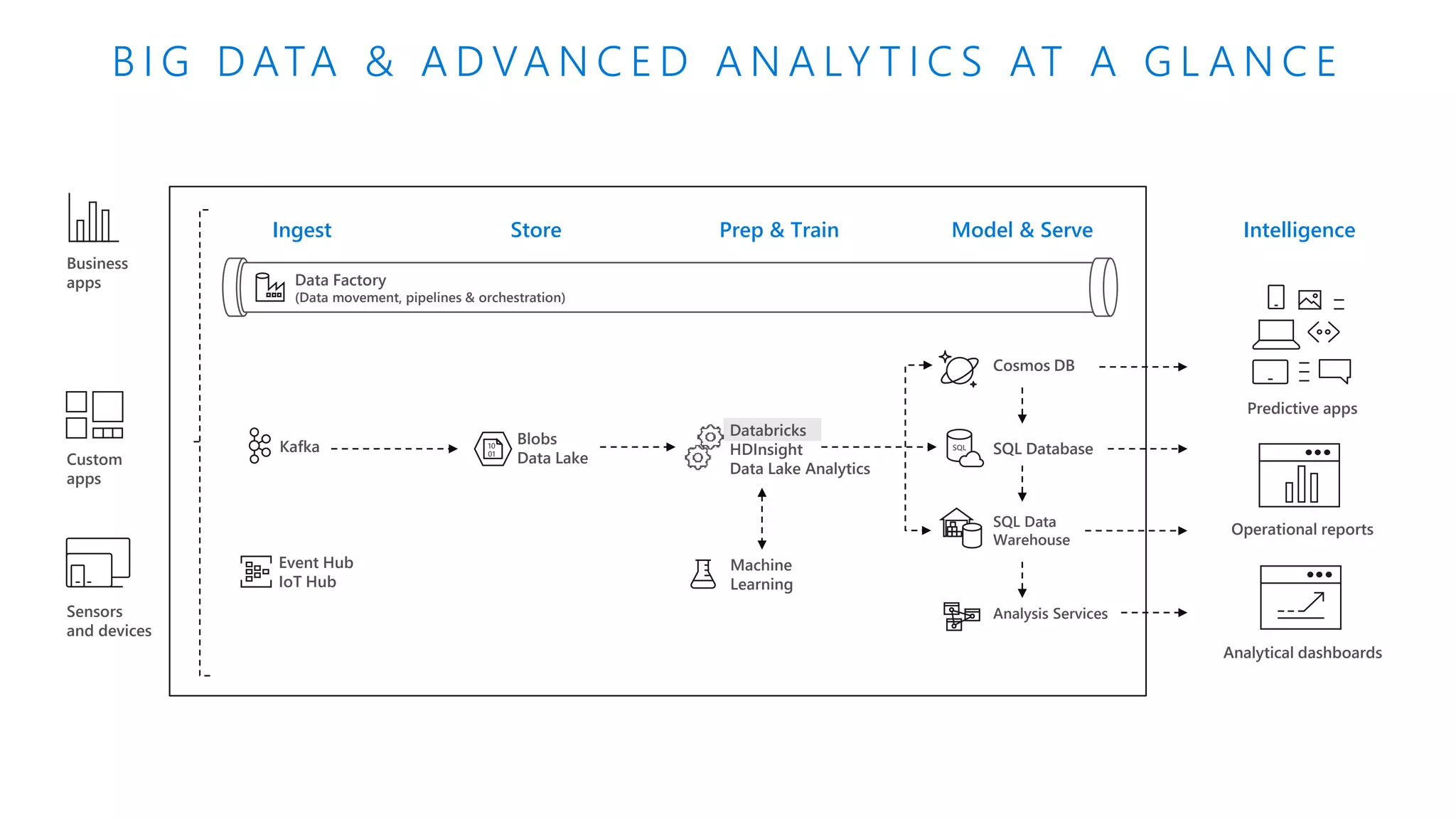
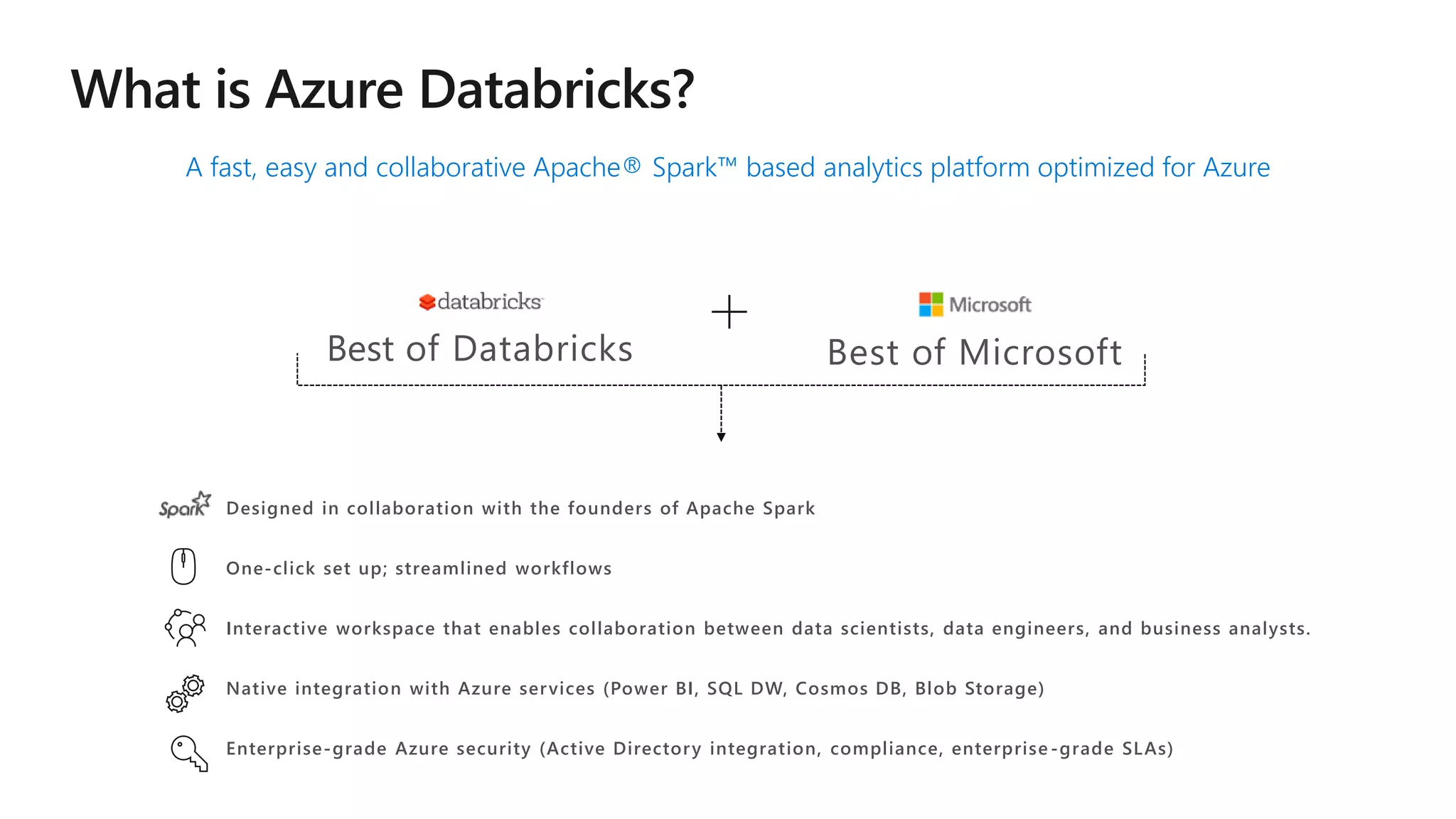
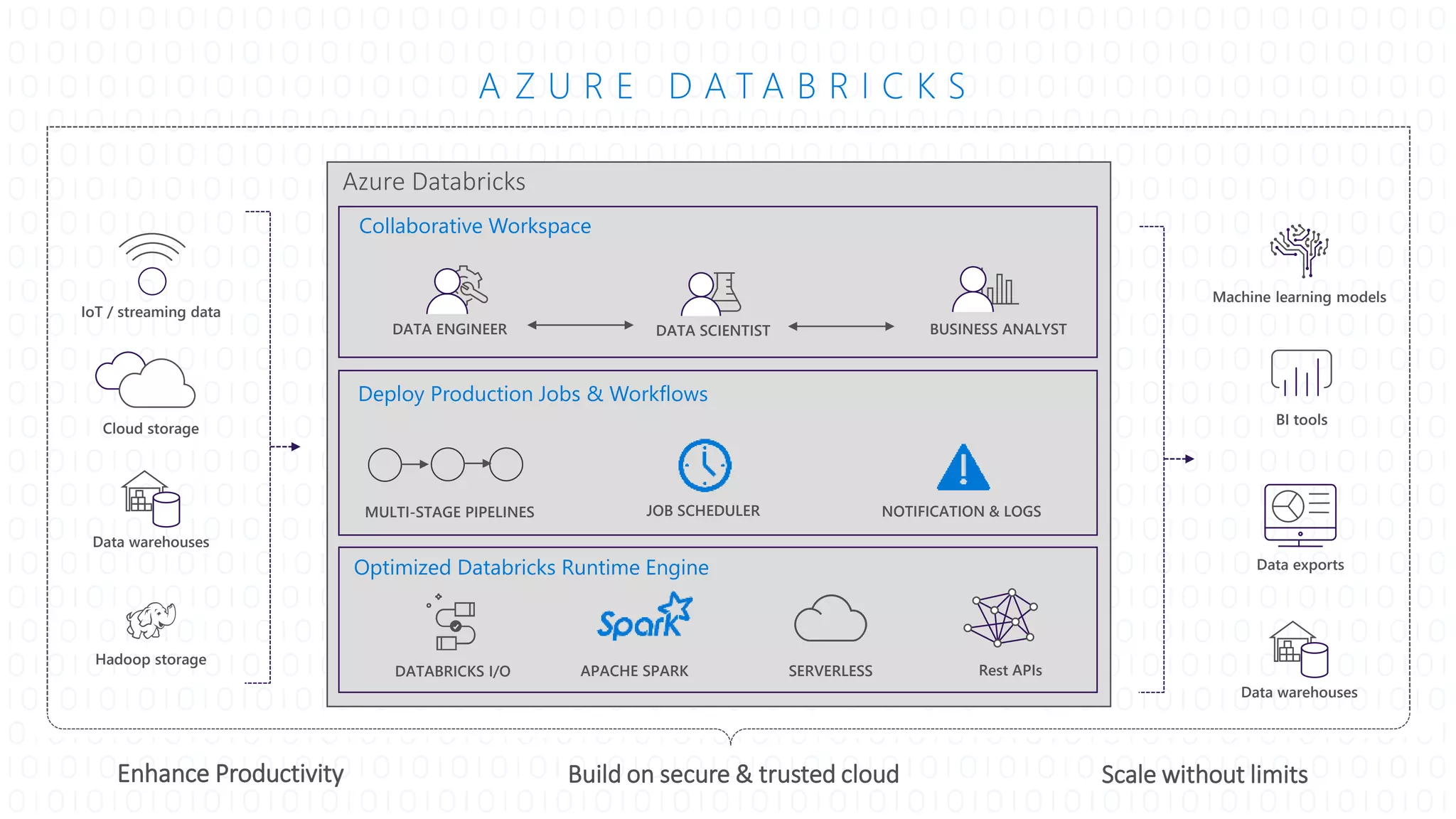
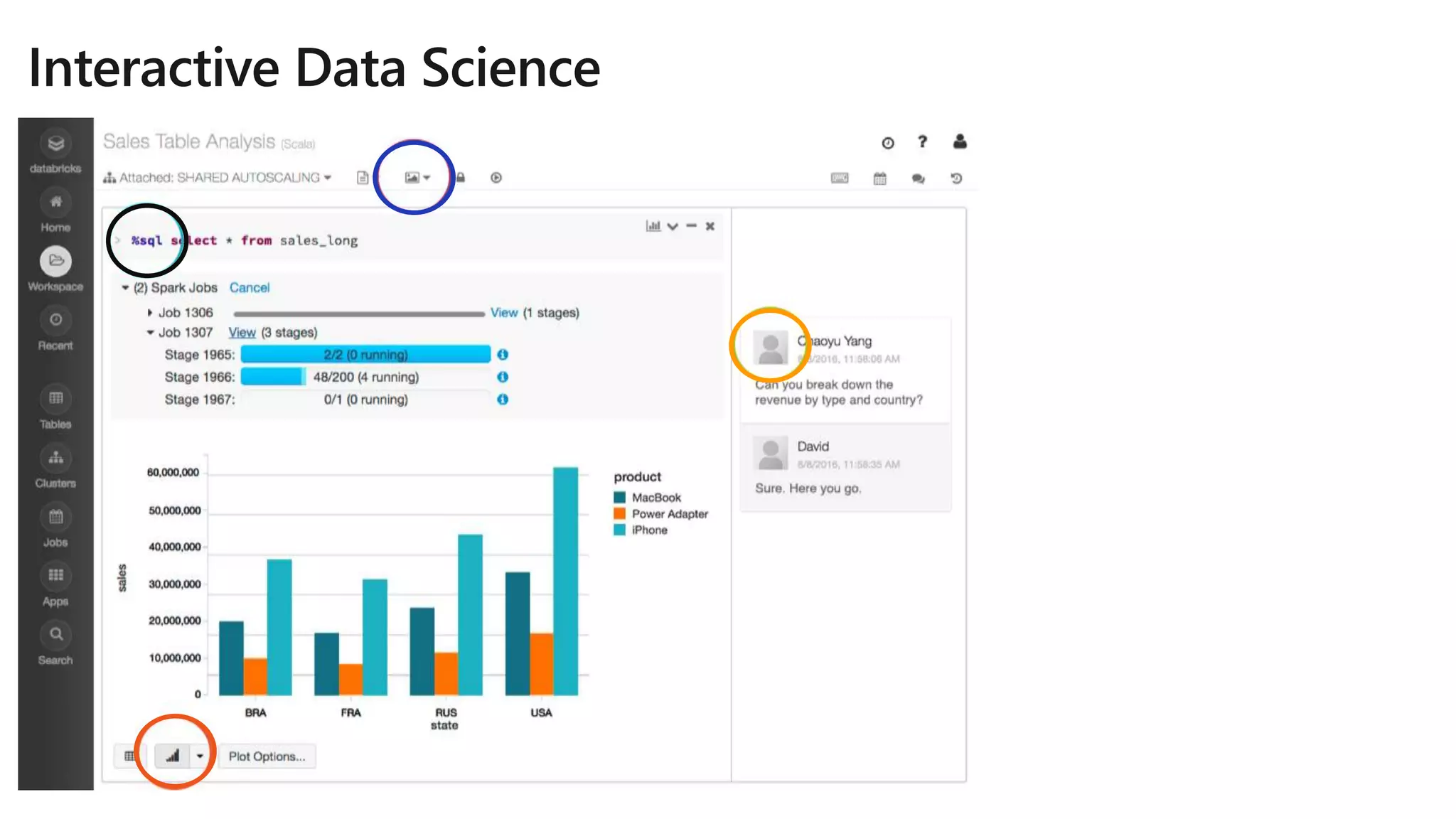
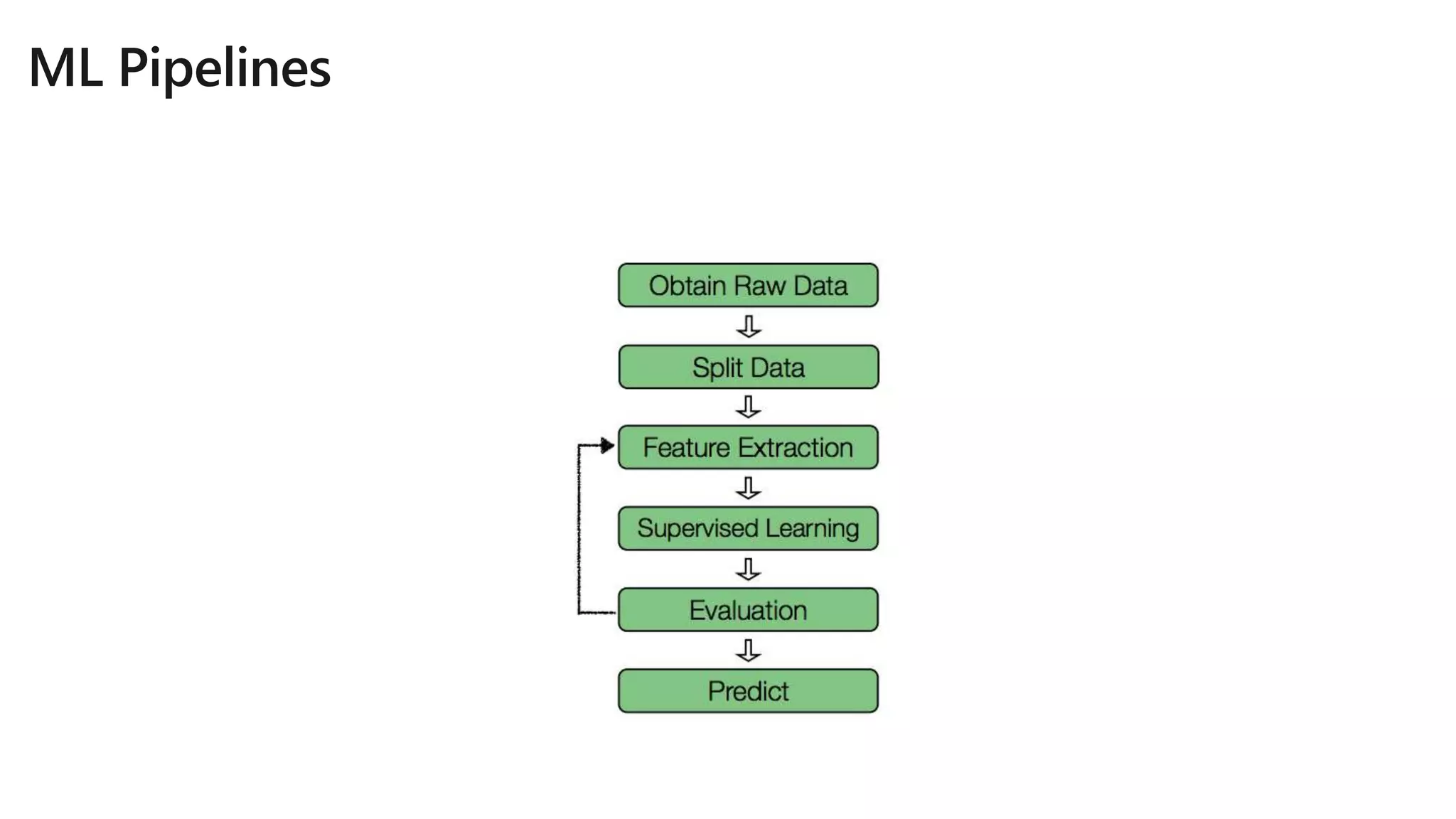
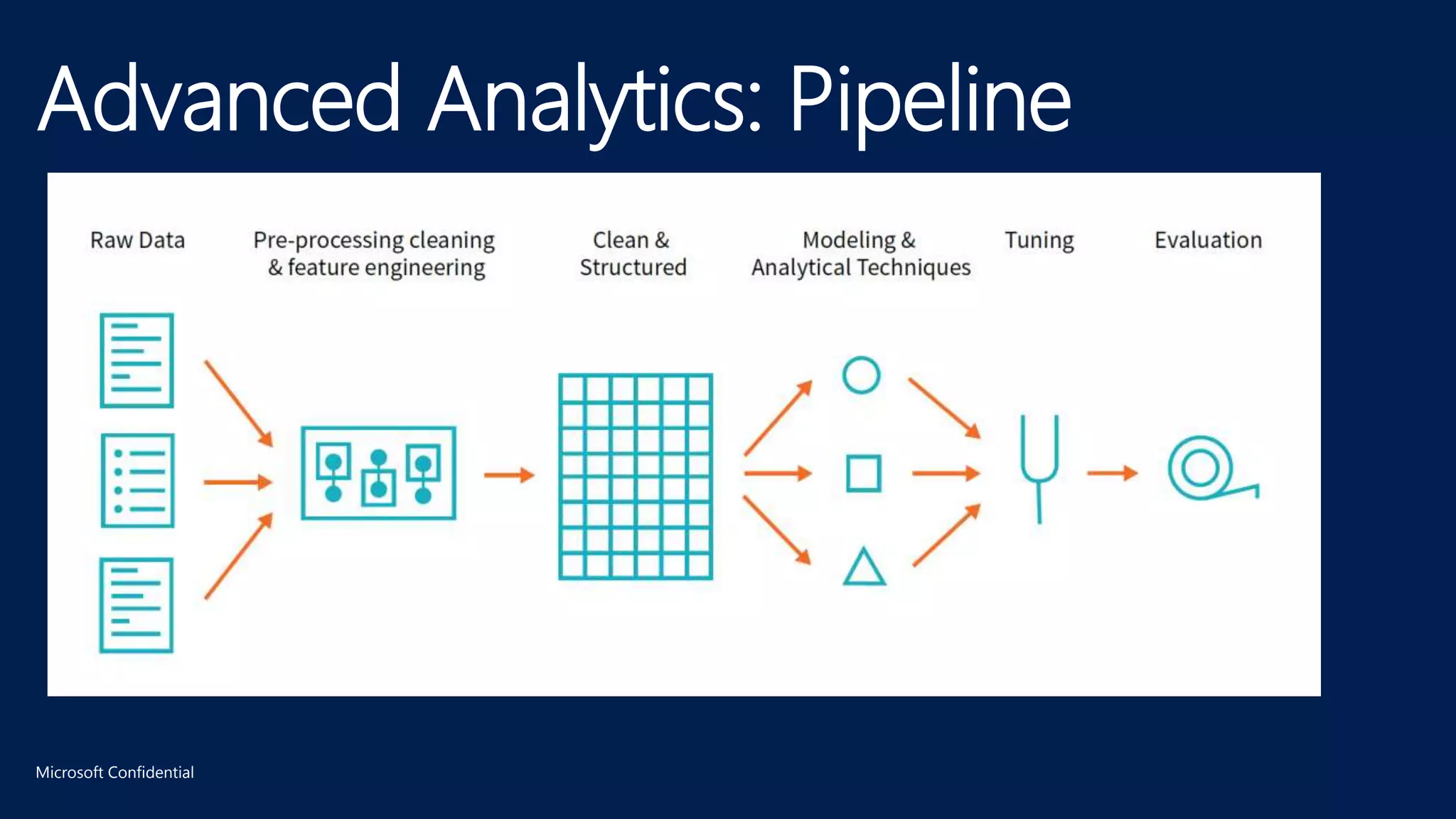
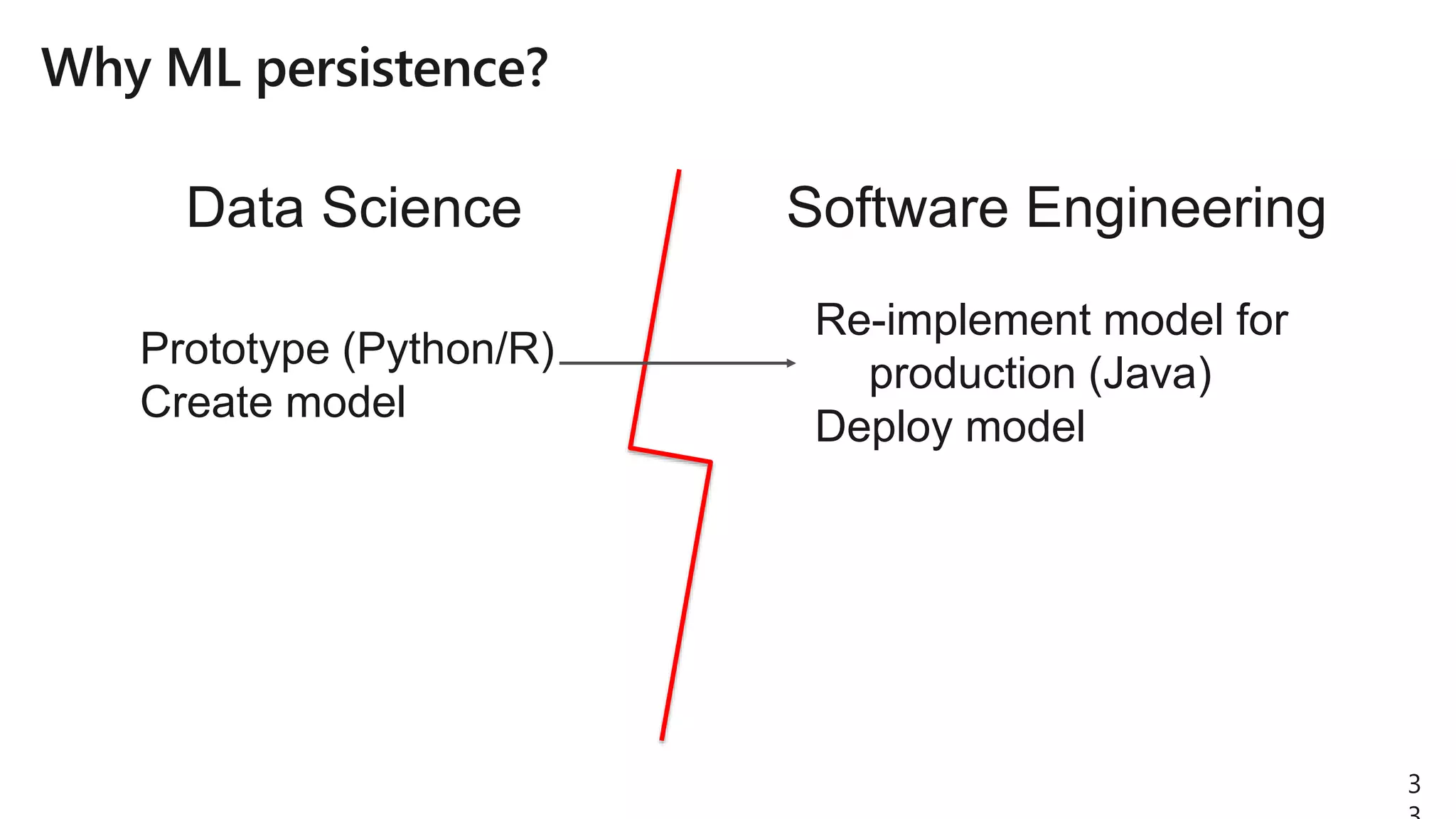
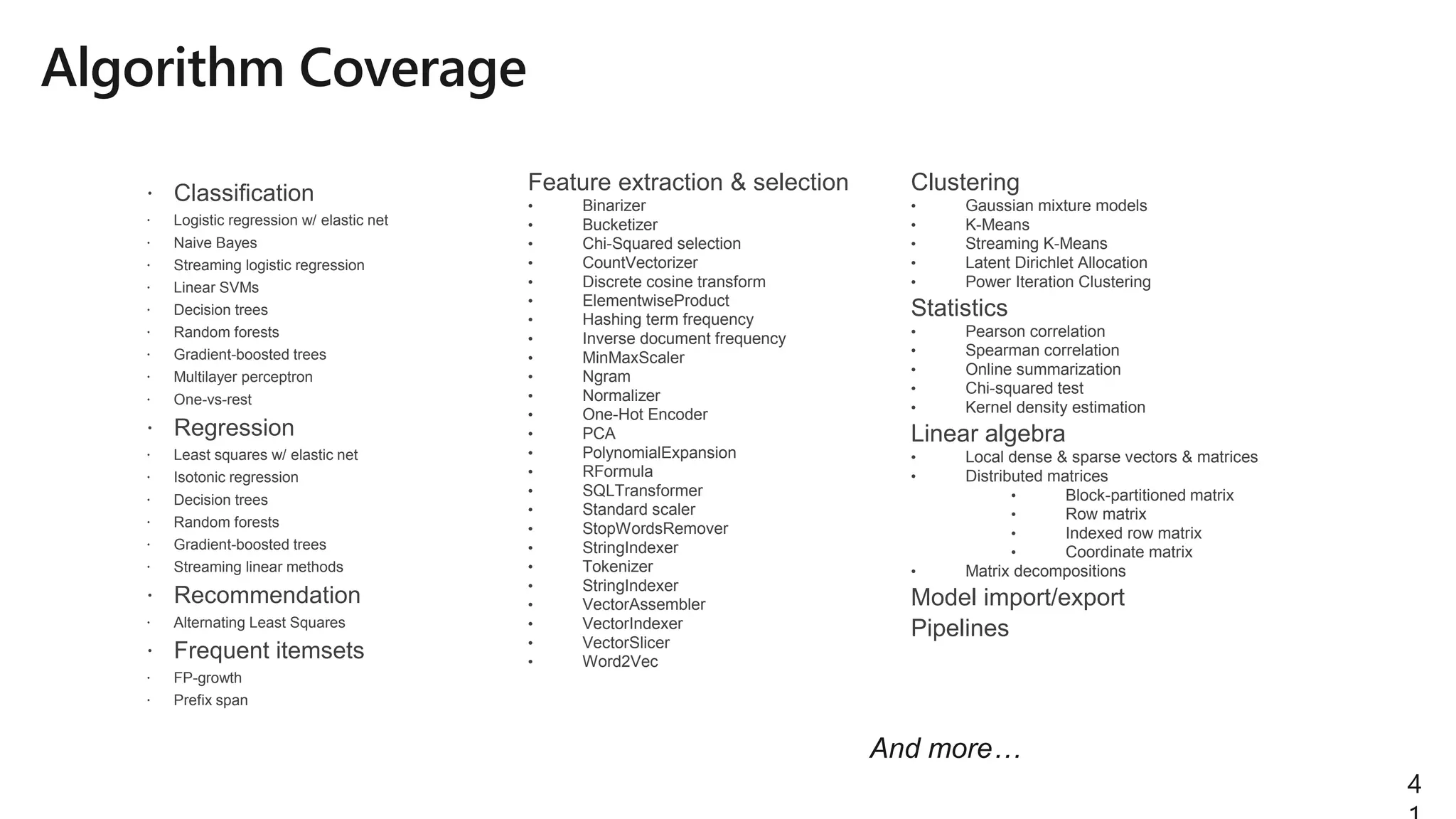
The document details Azure Databricks, an analytics platform optimized for Azure that leverages Apache Spark for data processing and analytics. It highlights features such as collaboration tools for data scientists and engineers, support for machine learning, data exploration and visualization, and integration with various Azure services. Key functionalities include model training pipelines, scalable compute clusters, and advanced analytics tools for deep learning and data management.













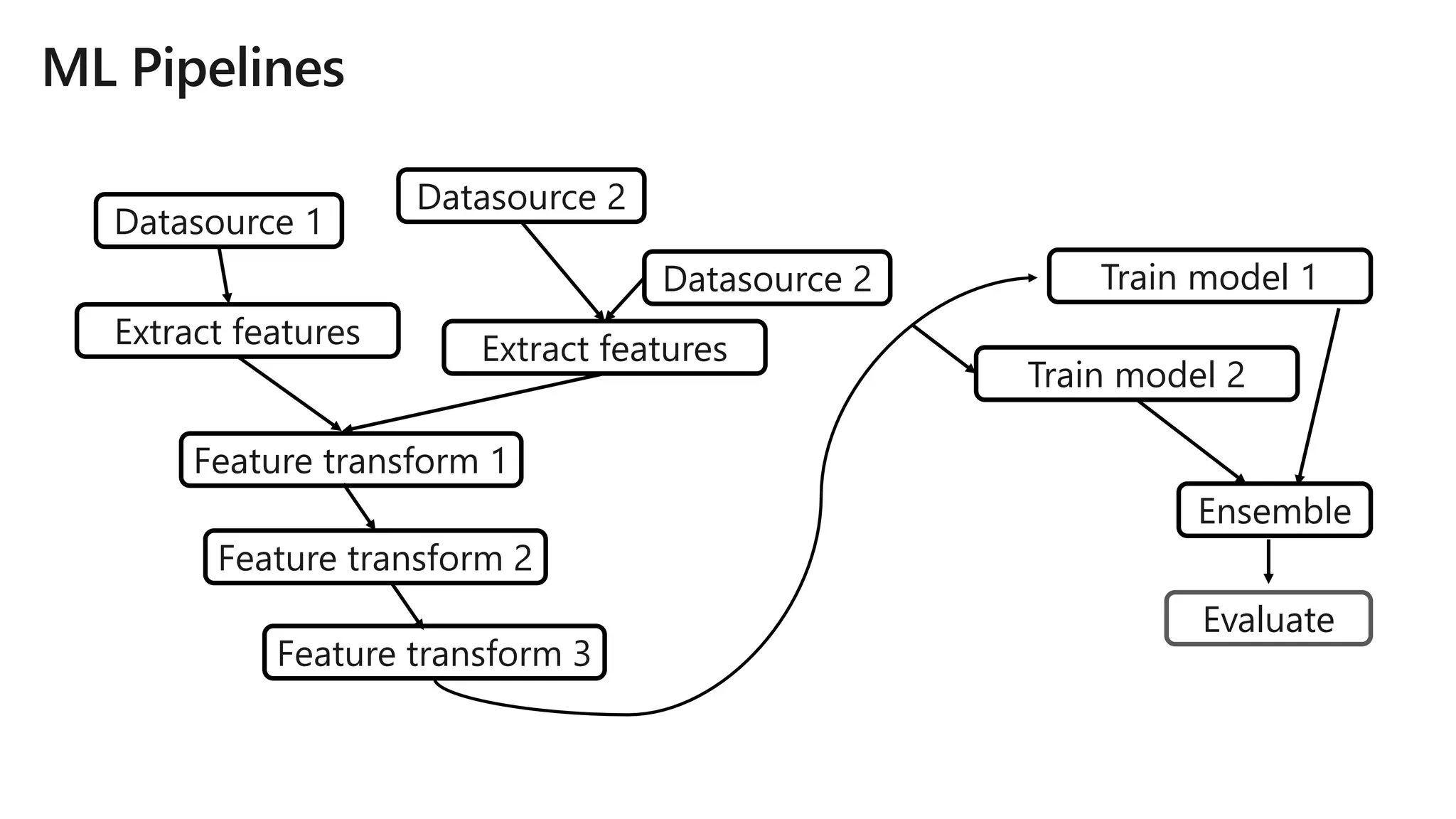



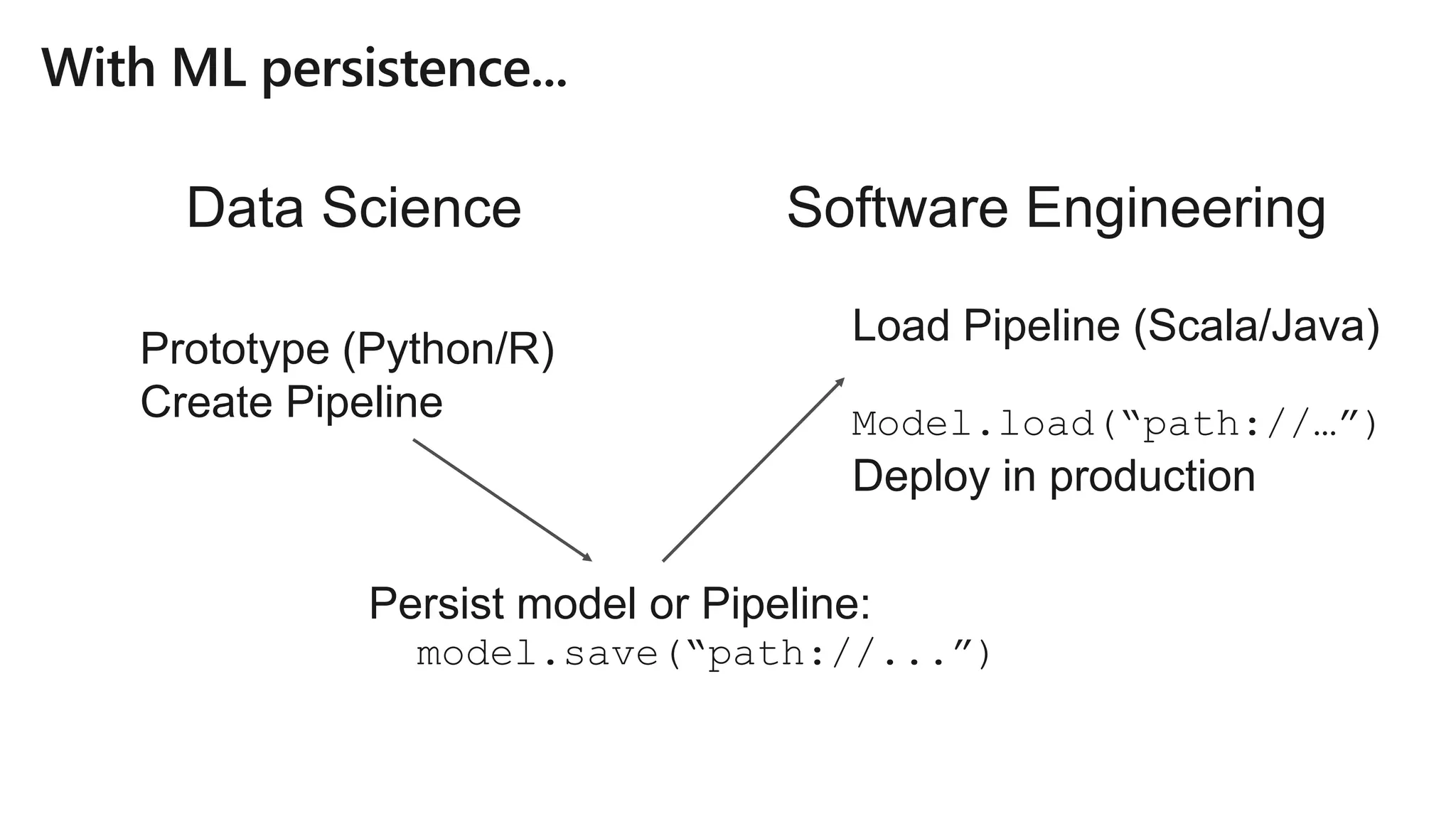
![model = est2.fit(est1.fit(
tf2.transform(tf1.transform(data)))
.transform(
tf2.transform(tf1.transform(data)))
)
model = Pipeline(stages=[tf1, tf2, est1, es2]).fit(data)](https://image.slidesharecdn.com/brk3320-180509201013/75/The-Developer-Data-Scientist-Creating-New-Analytics-Driven-Applications-using-Apache-Spark-with-Azure-Databricks-27-2048.jpg)

















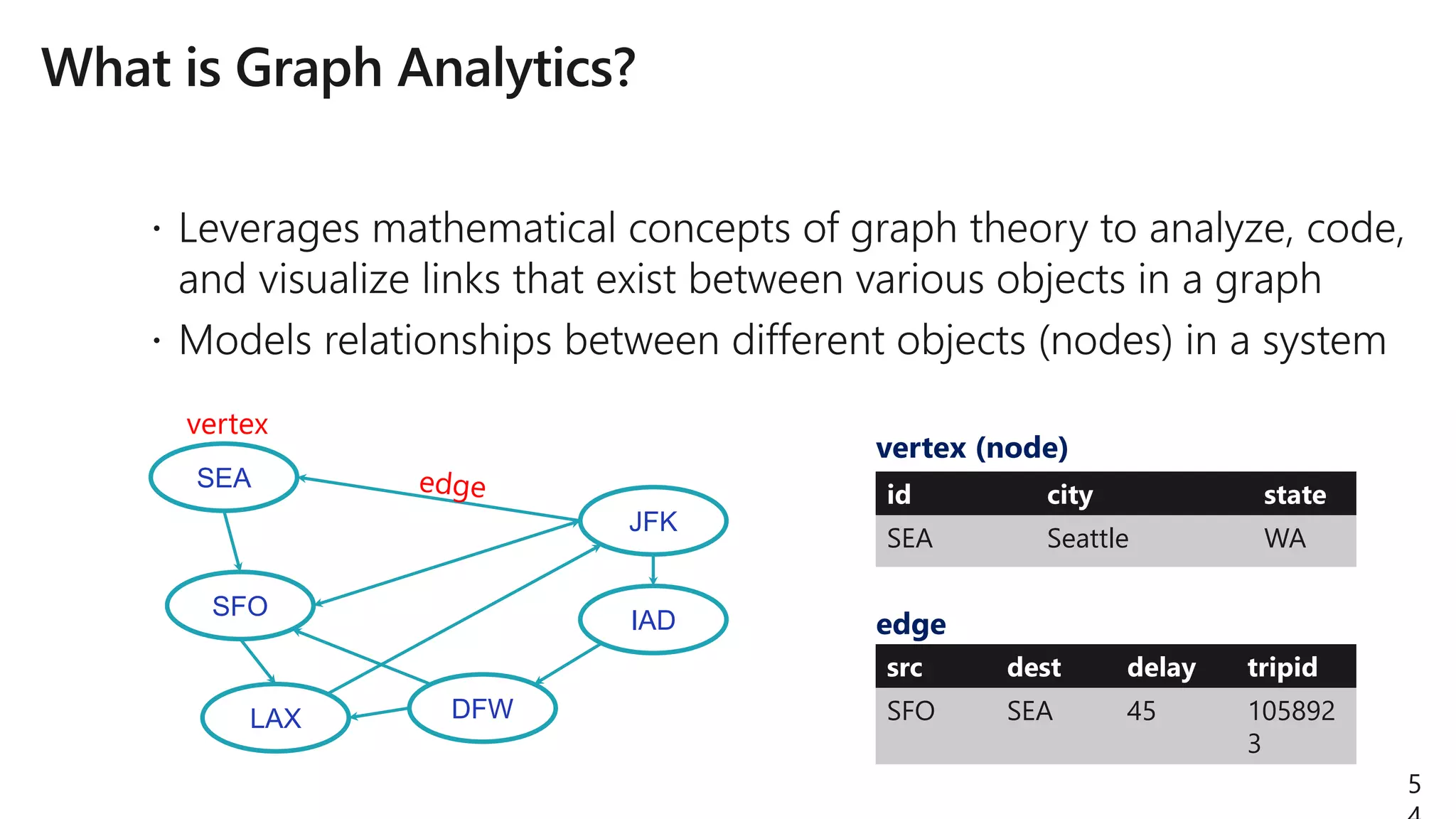



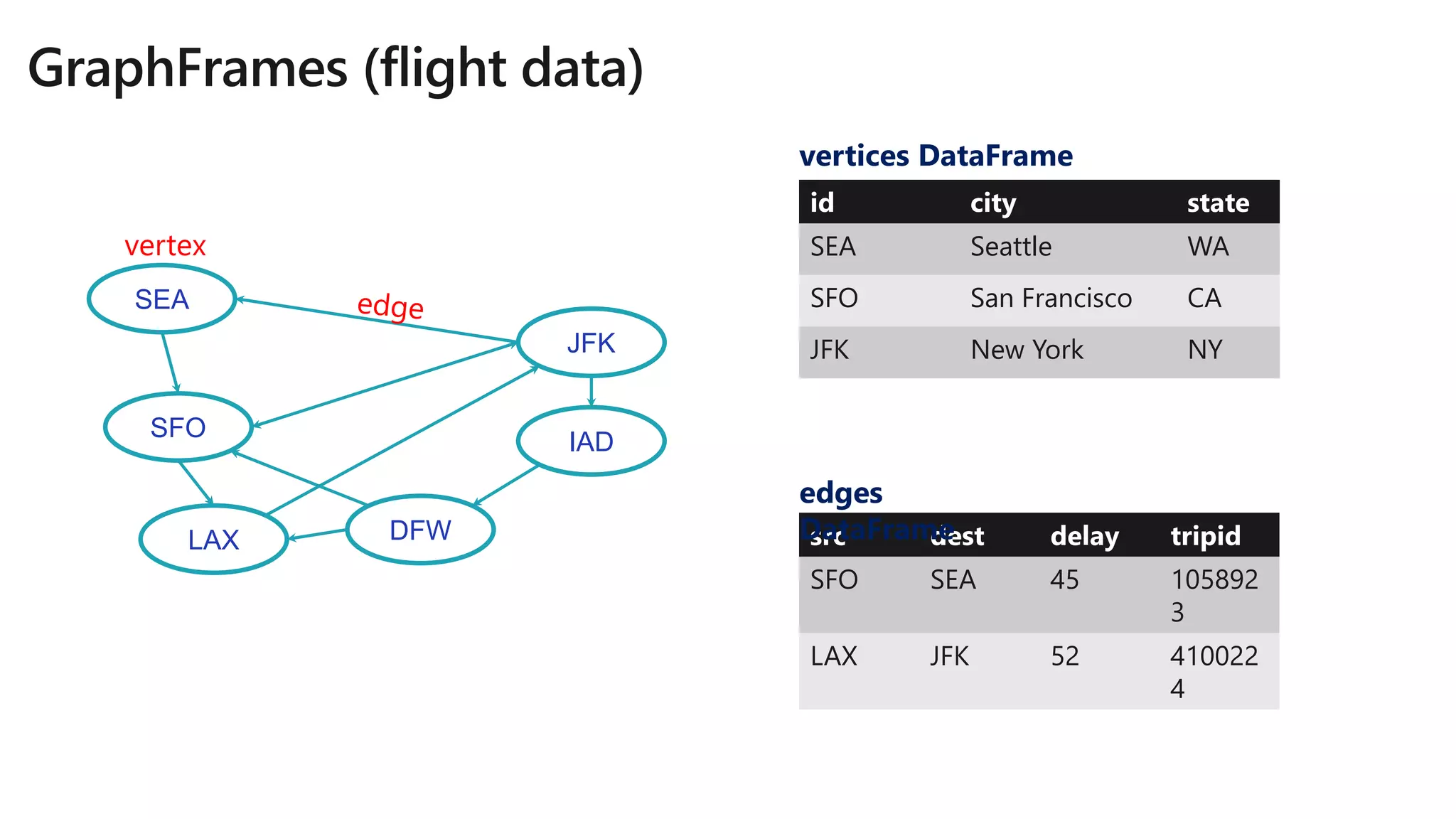


![JFK
IAD
LAX
SFO
SEA
DFW
(b)
(a)
(c)
Search for structural
patterns within a graph.
val paths: DataFrame =
g.find(“(a)-[e1]->(b);
(b)-[e2]->(c);
!(c)-[]->(a)”)
Then filter using vertex
& edge data.
paths.filter(“e1.delay > 20”)](https://image.slidesharecdn.com/brk3320-180509201013/75/The-Developer-Data-Scientist-Creating-New-Analytics-Driven-Applications-using-Apache-Spark-with-Azure-Databricks-61-2048.jpg)































![model = est2.fit(est1.fit(
tf2.transform(tf1.transform(data)))
.transform(
tf2.transform(tf1.transform(data)))
)
model = Pipeline(stages=[tf1, tf2, est1, es2]).fit(data)](https://crownmelresort.com/image.slidesharecdn.com/brk3320-180509201013/75/The-Developer-Data-Scientist-Creating-New-Analytics-Driven-Applications-using-Apache-Spark-with-Azure-Databricks-27-2048.jpg)

































![JFK
IAD
LAX
SFO
SEA
DFW
(b)
(a)
(c)
Search for structural
patterns within a graph.
val paths: DataFrame =
g.find(“(a)-[e1]->(b);
(b)-[e2]->(c);
!(c)-[]->(a)”)
Then filter using vertex
& edge data.
paths.filter(“e1.delay > 20”)](https://crownmelresort.com/image.slidesharecdn.com/brk3320-180509201013/75/The-Developer-Data-Scientist-Creating-New-Analytics-Driven-Applications-using-Apache-Spark-with-Azure-Databricks-61-2048.jpg)



























































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
