Download to read offline











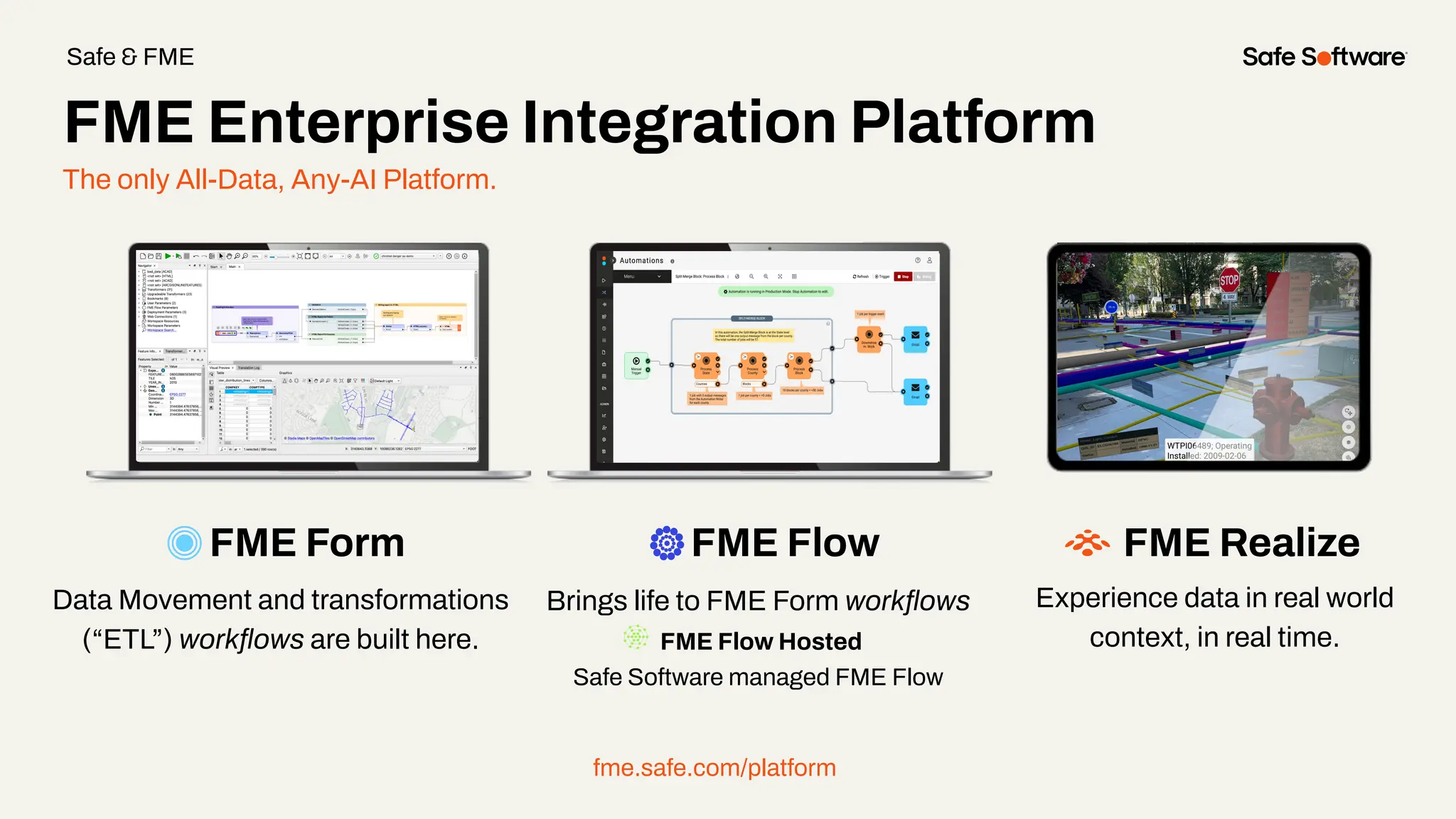







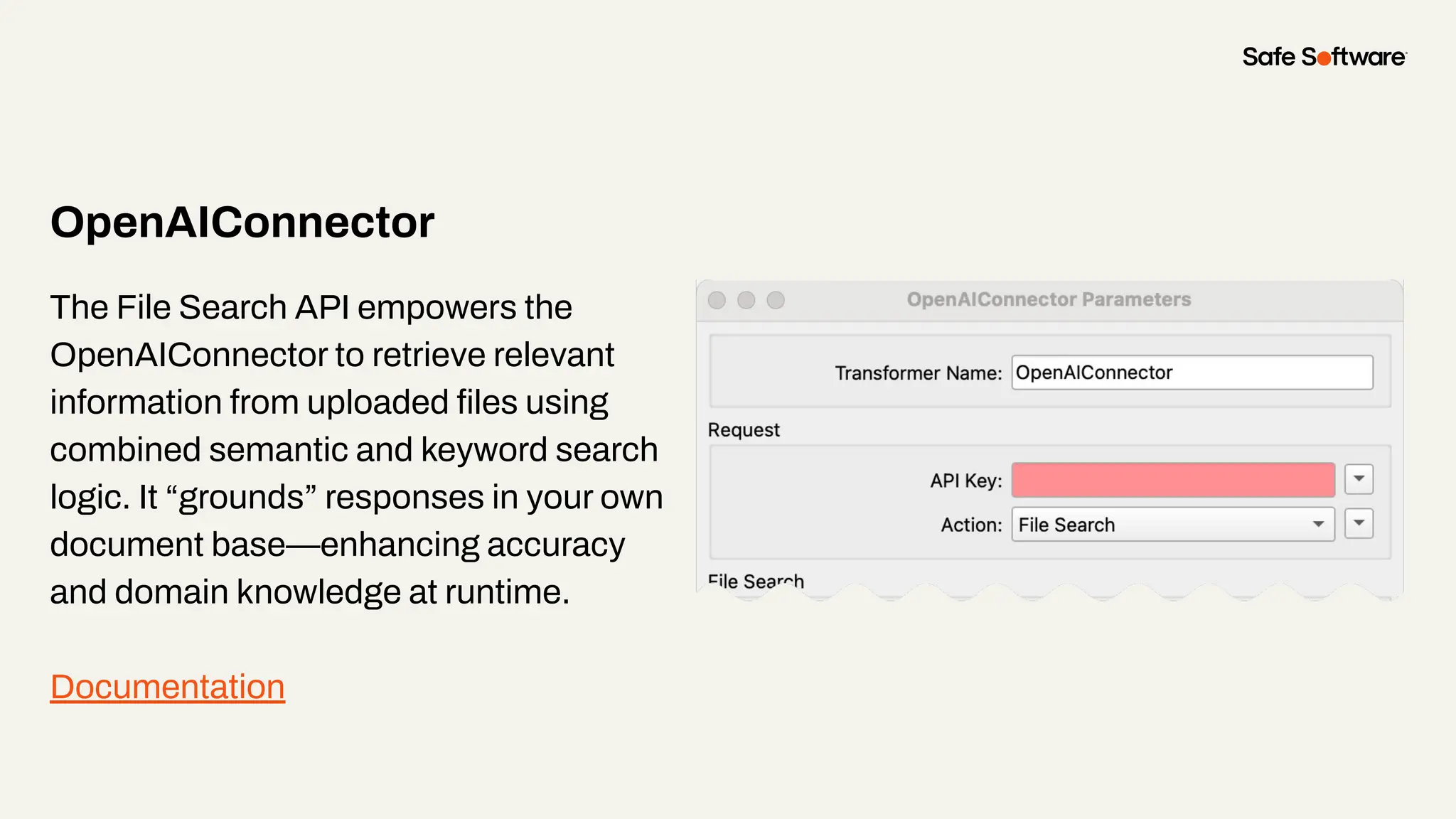

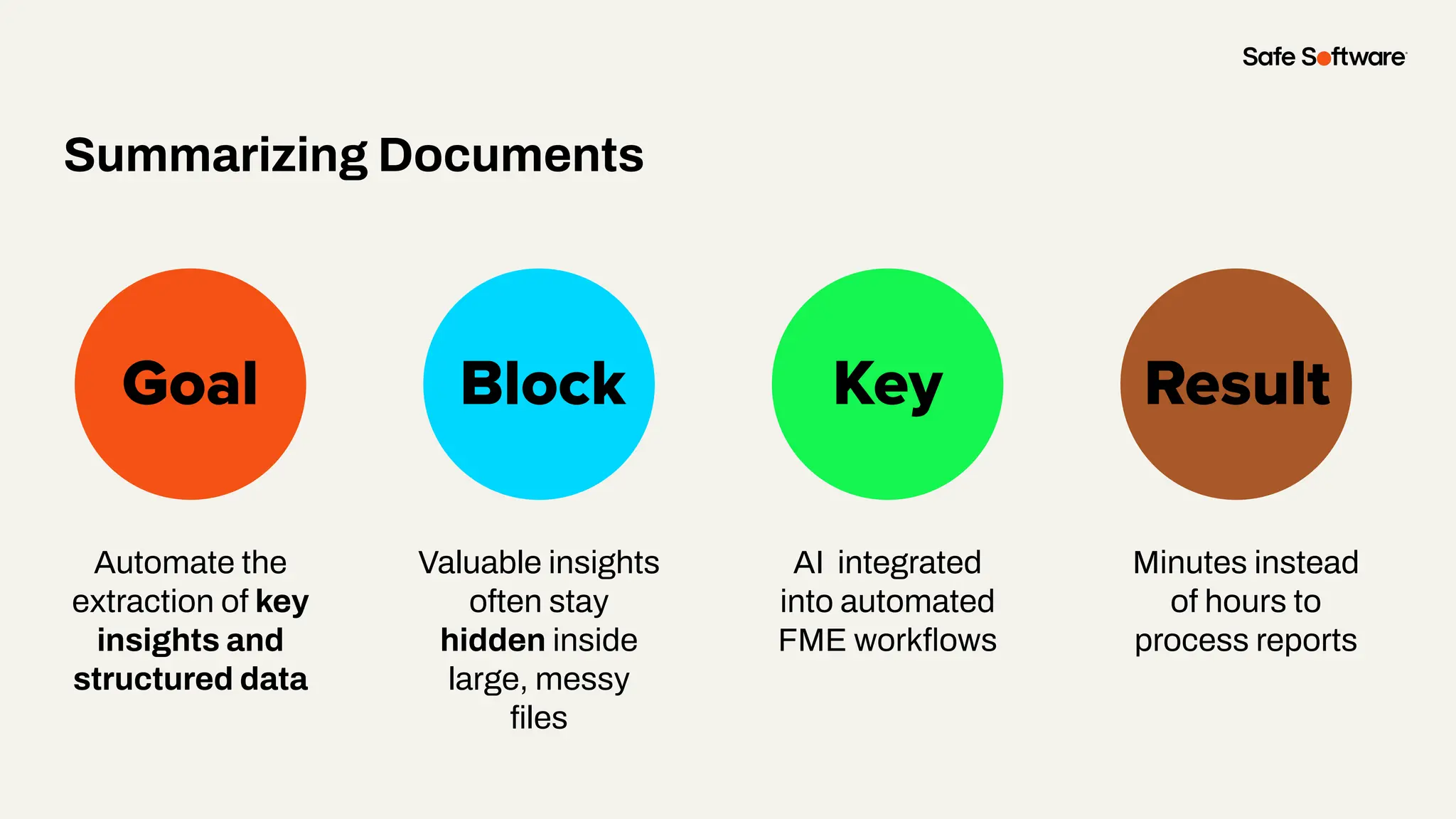

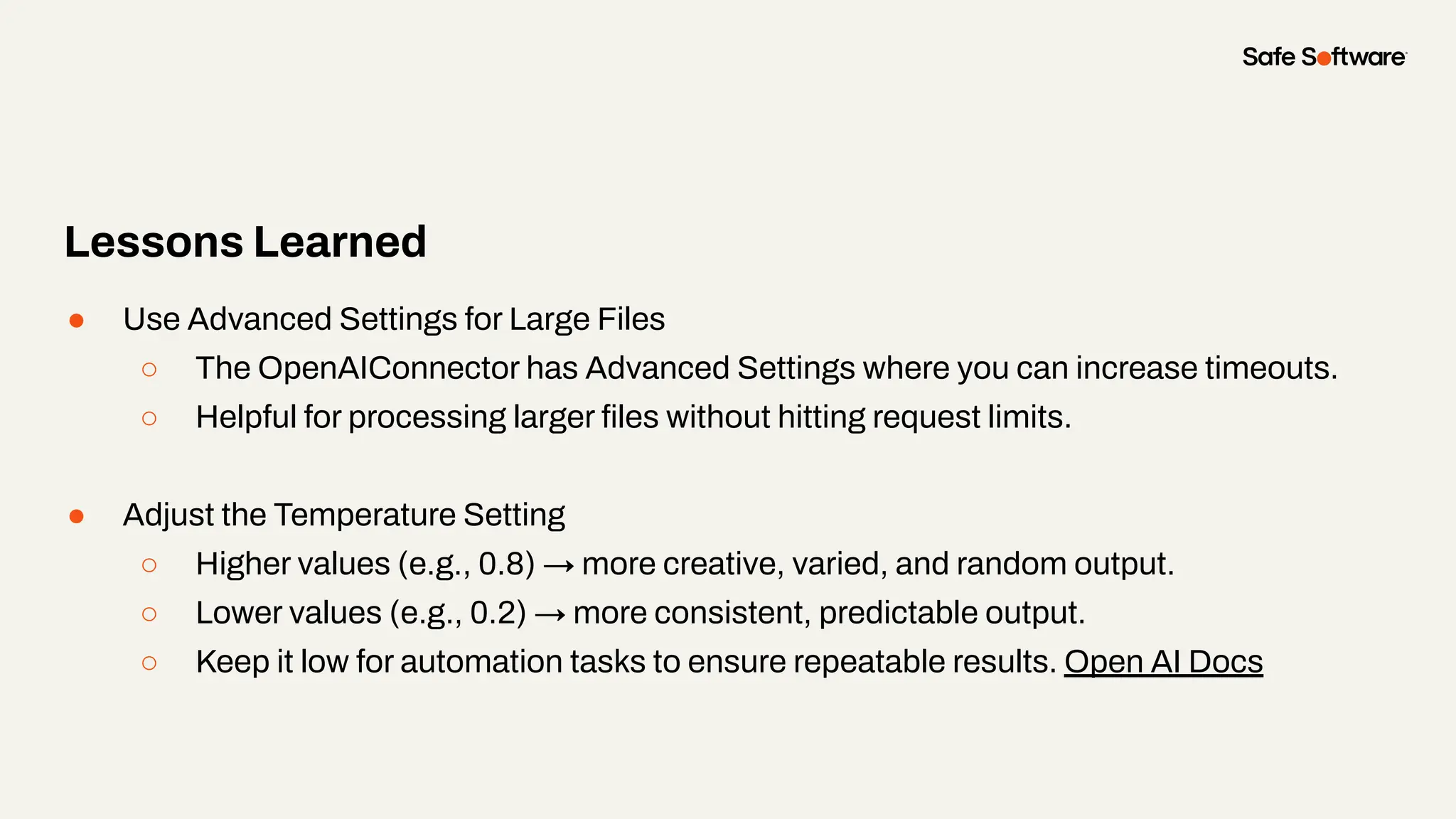

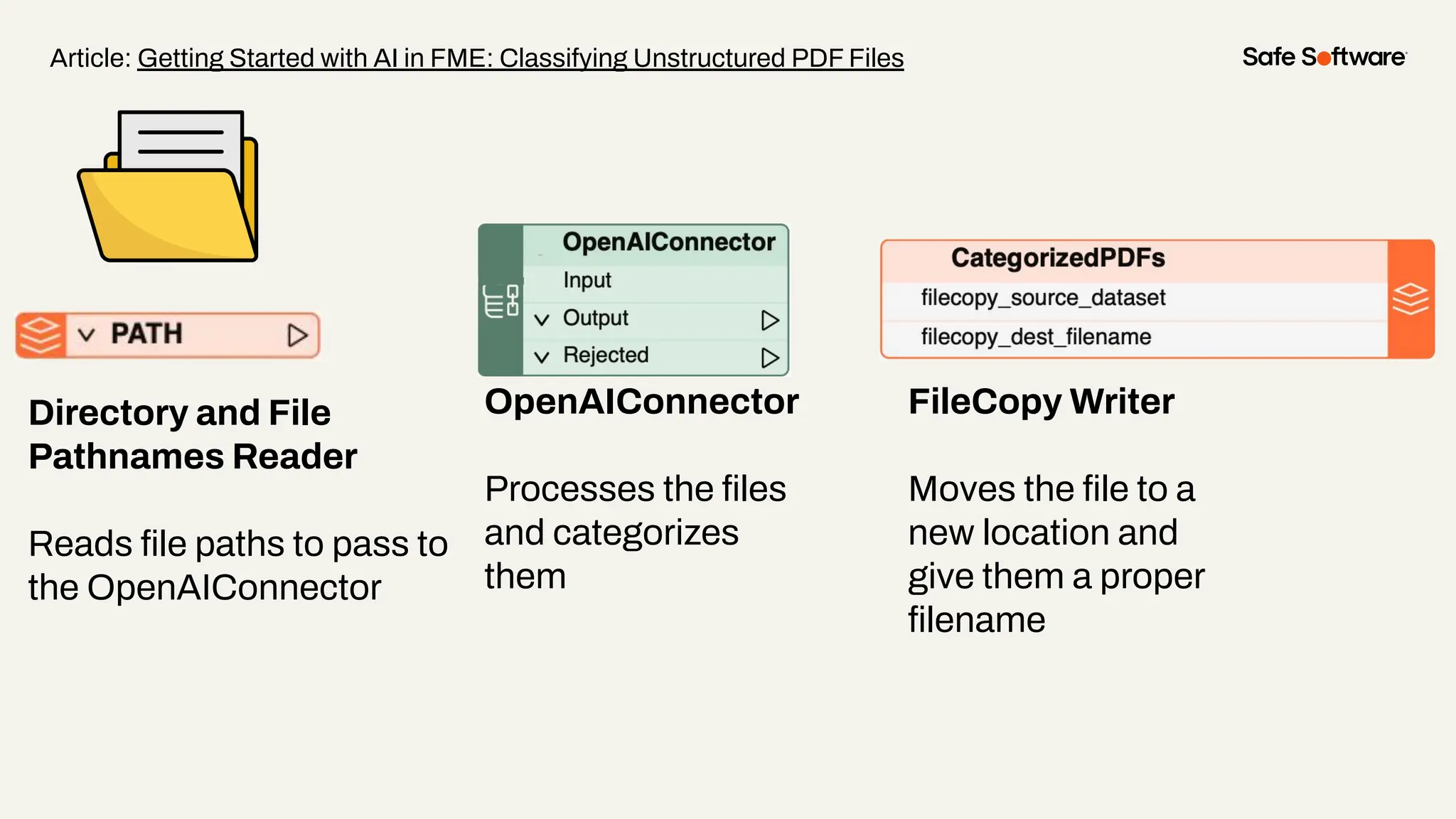
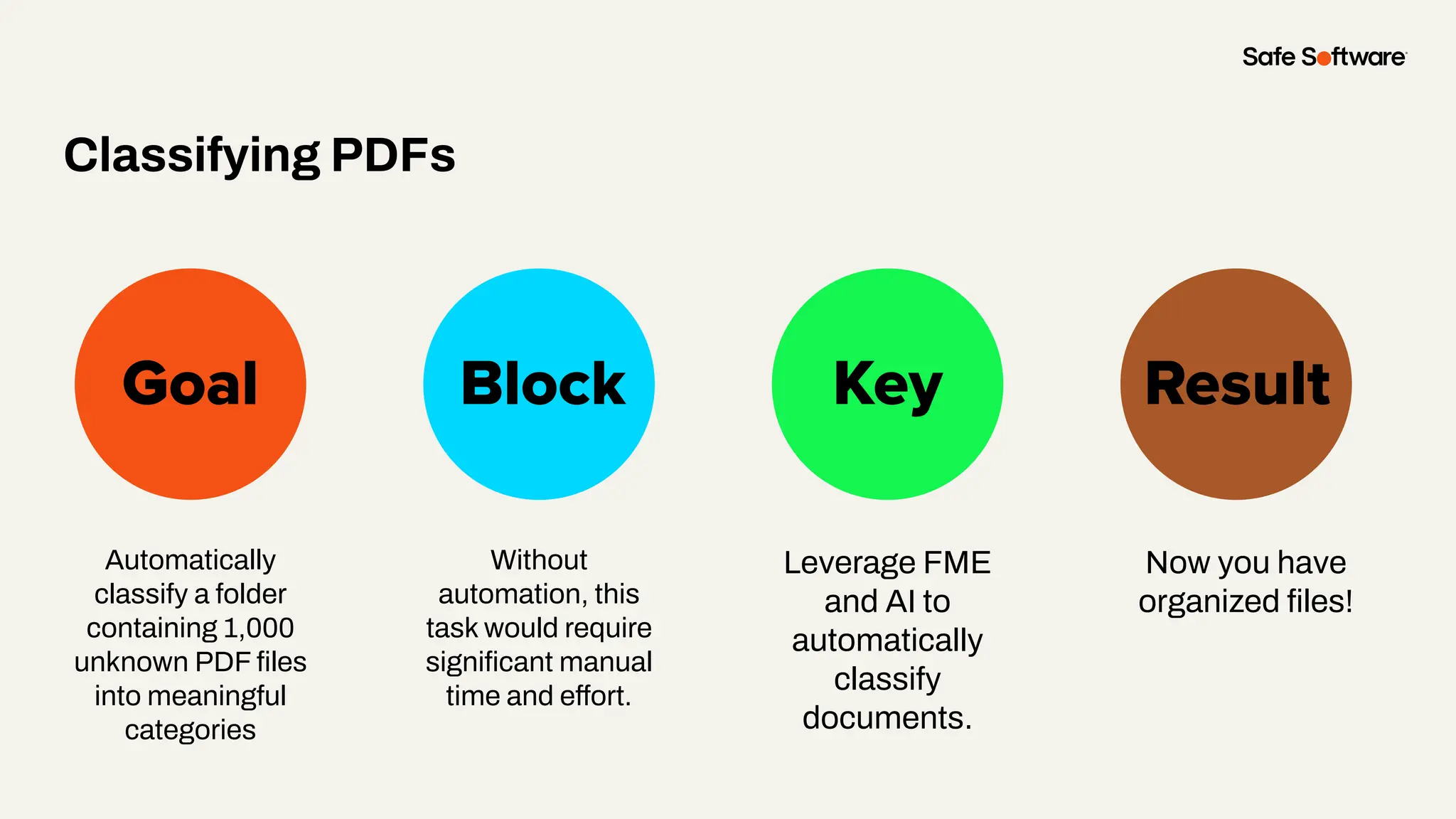






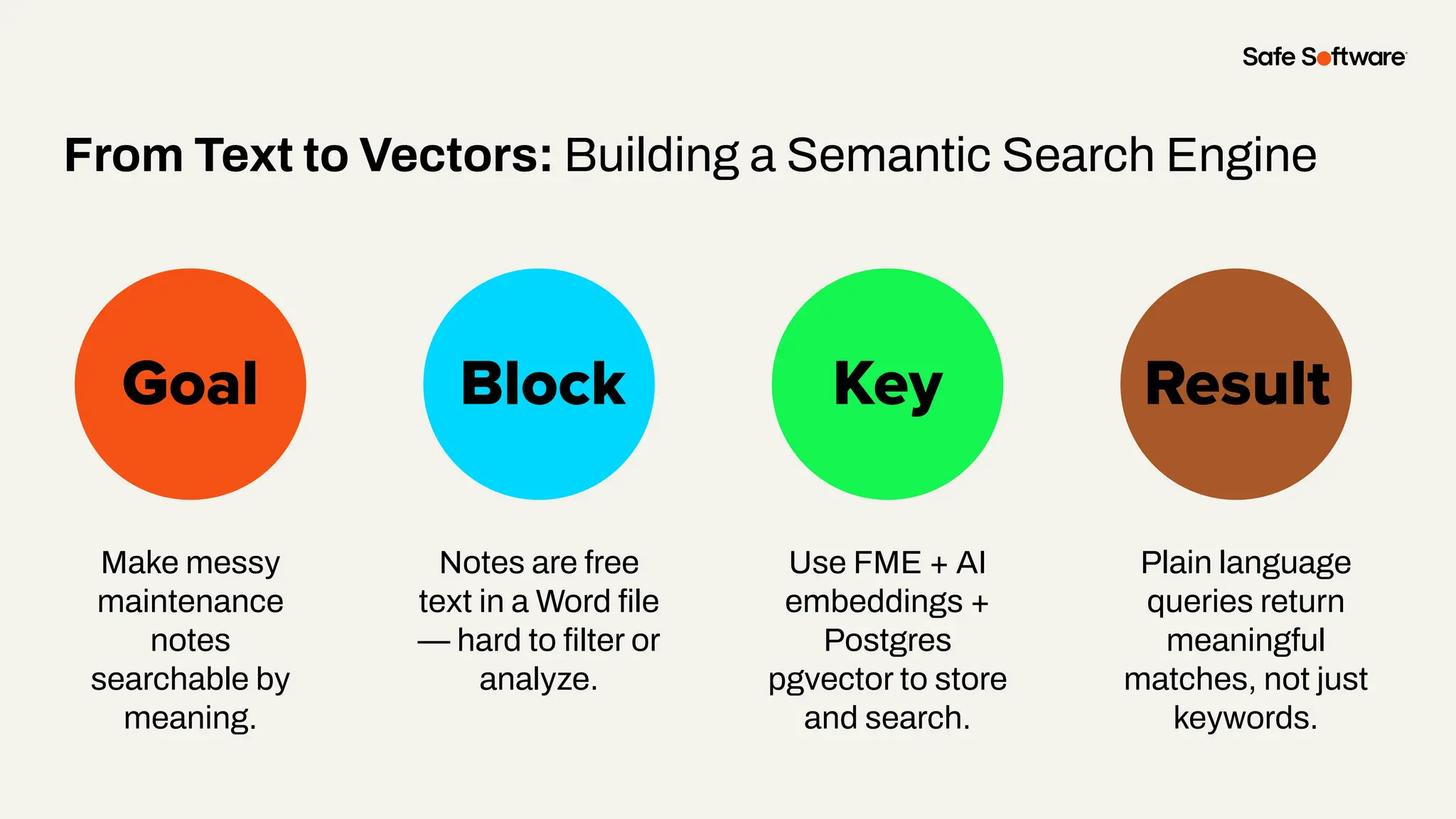

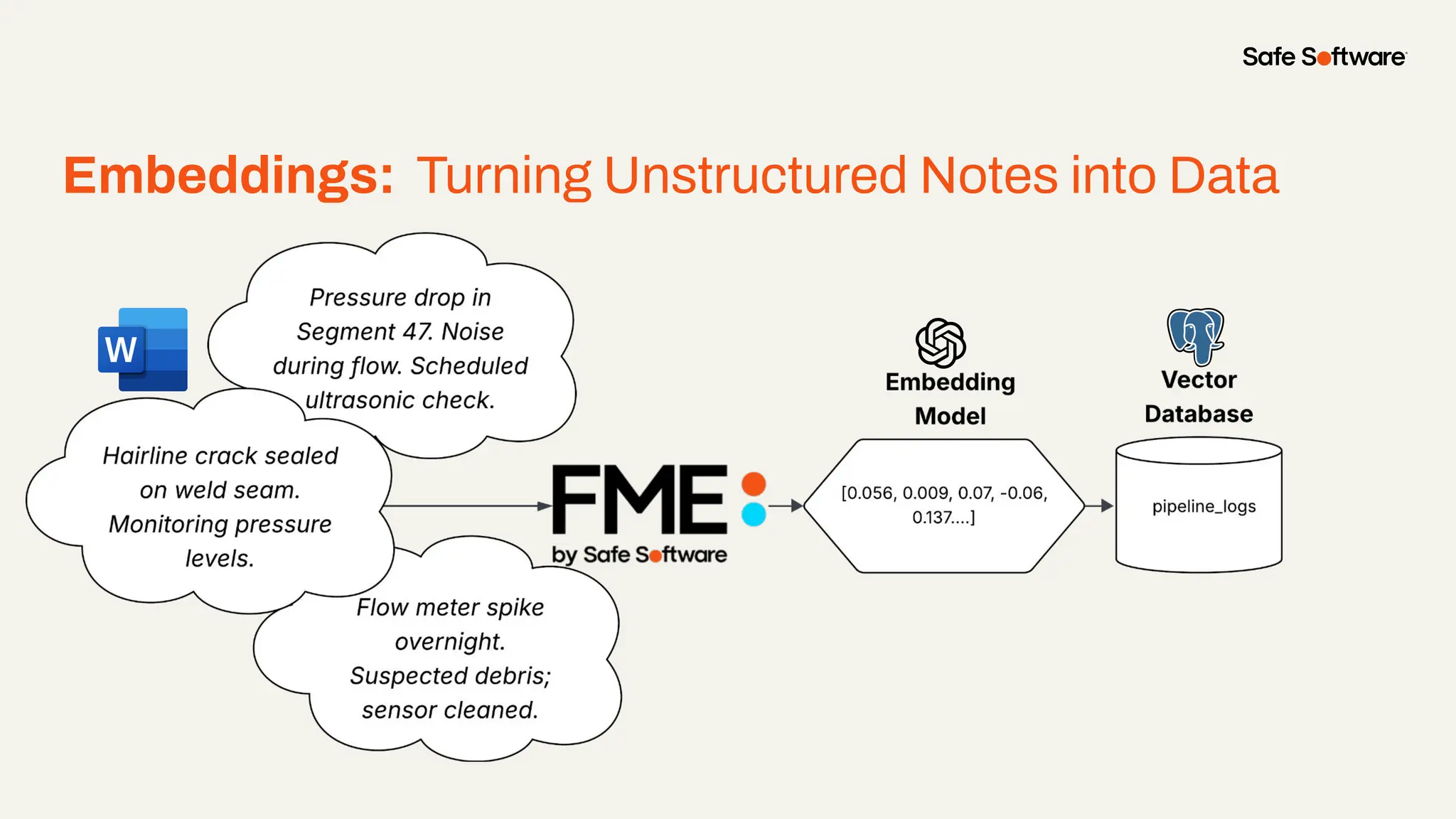





















































































Unstructured data is everywhere: buried in reports, scattered across image folders, or hidden in scanned documents. But with the right tools, it’s possible to extract meaning and turn chaos into clarity. In this webinar, you’ll discover how to use FME to process unstructured data types and unlock new insights. From document summarization and metadata extraction to AI-powered semantic search, we’ll walk through four practical demos that make your data work harder. You’ll learn how to: -Categorize a series of documents using transformers and workflows -Extract and structure key fields from messy PDFs or forms -Use OpenAI embeddings with FME to enable powerful semantic search -Map photo metadata and enrich it with GPS validation Whether you’re wrangling PDFs, images, or forms: this session will show how to streamline your unstructured data strategy.


































































